ZFS 学习笔记
- 格式:doc
- 大小:430.50 KB
- 文档页数:51

ZFS学习笔记ZFS 学习笔记第一章zpool的管理 (2)1.1 创建zpool (3)1.1.1 创建单边zpool (3)1.1.2 创建mirror pool (4)1.1.3 创建raidz zpool (6)1.2 删除zpool (7)1.3 对zpool进行管理 (8)1.3.1 镜像和拆镜像 (8)1.3.2 添加zpool空间 (9)1.3.3 spare盘的添加和删除 (10)1.4 zpool的维护/故障盘的更换 (12) 1.5 zpool的迁移 (15)1.6 恢复销毁的zpool (16)1.7 zpool的I/O统计 (18)1.8 迁移ZFS 存储池 (19)1.9 zpool的版本升级 (20)第二章ZFS文件系统的建立和设置 (22) 2.1 ZFS文件系统的创建和删除 (22) 2.1.1 ZFS文件系统的创建 (22)2.1.2 ZFS文件系统重命名 (23)2.1.3 删除ZFS文件系统 (23)2.2 ZFS属性介绍 (24)2.3 查询ZFS文件系统信息 (25)2.4 管理ZFS属性 (25)2.4.1 设置set (26)2.4.2 继承inherit (27)2.4.3 查询get (27)2.4.4 ZFS文件系统的mount和umount (34) 2.4.5 ZFS文件系统的share和unshare (36) 2.4.6 ZFS文件系统的配额和预留空间 (37)第三章使用ZFS进行快照或者克隆 (40)3.1 快照snapshot (40)3.1.1 创建和销毁快照 (40)3.1.2 快照的显示和重命名 (41)3.1.3 使用快照回滚 (41)3.2 克隆 (43)3.2.1 创建clone (43)3.2.2 删除clone (44)3.2.3 使用clone来代替文件系统 (44)3.3 快照的保存和恢复 (45)3.3.1 快照的保存 (45)3.3.2 使用快照文件恢复文件系统 (46)附录:ZFS卷 (48)ZFS主要使用两条命令及其子命令:zfszpool第一章zpool的管理zpool 命令菜单:# zpoolmissing commandusage: zpool command args ...where 'command' is one of the following: create [-fn] [-R root] [-m mountpoint] ... destroy [-f]add [-fn] ...removelist [-H] [-o field[,field]*] [pool] ...iostat [-v] [pool] ... [interval [count]]status [-vx] [pool] ...online ...offline [-t] ...clear [device]attach [-f]detachreplace [-f] [new_device]scrub [-s] ...import [-d dir] [-D]import [-d dir] [-D] [-f] [-o opts] [-R root] -aimport [-d dir] [-D] [-f] [-o opts] [-R root ] [newpool]export [-f] ...upgradeupgrade -vupgrade <-a | pool>history []1.1 创建zpoolZFS文件系统是建立在存储池pool的基础上,所以要建立文件系统必须先建立底层的pool。

红宝书笔记总结《JavaScript高级程序设计》(红宝书)是一本经典的JavaScript编程指南,由Nicholas C. Zakas撰写。
本书涵盖了JavaScript语言的基础知识、高级概念和最佳实践,对于想要深入学习和理解JavaScript的开发人员来说是一本不可或缺的参考书。
本文将对红宝书中的主要内容进行总结和归纳。
第一部分:JavaScript语言基础第一部分介绍了JavaScript的基本语法、数据类型和操作符等基础知识。
重点包括以下几个方面:1.JavaScript的基本语法:介绍了JavaScript的变量声明、函数定义和控制流语句等基本概念,使读者能够熟悉JavaScript的语法规则。
2.数据类型和变量:详细介绍了JavaScript的基本数据类型(数字、字符串、布尔值等)以及如何声明和操作变量。
3.操作符:介绍了JavaScript的各种操作符,包括算术操作符、比较操作符和逻辑操作符等,以及它们的优先级和使用方法。
4.语句:介绍了JavaScript的各种语句,包括条件语句、循环语句和跳转语句等,使读者能够使用这些语句实现复杂的程序逻辑。
第二部分:引用类型第二部分讲解了JavaScript中的引用类型,包括对象、数组、函数和正则表达式等。
以下是主要内容:1.对象:介绍了JavaScript中对象的基本概念和创建方法,以及如何使用点操作符和方括号操作符来访问对象的属性和方法。
2.数组:详细介绍了JavaScript中数组的特性和操作方法,如如何添加和删除数组元素、排序和迭代数组等。
3.函数:介绍了JavaScript中函数的定义和调用方法,以及函数的参数、作用域和闭包等概念。
4.正则表达式:解释了JavaScript中正则表达式的基本语法和常用方法,以及如何使用正则表达式进行模式匹配和替换等操作。
第三部分:面向对象的JavaScript第三部分讲解了JavaScript中的面向对象编程,包括面向对象的基本概念、继承和封装等。

1、javaScript严格区分大小写,但javaScript中的关键字都是小写;内置对象通常是以大写字母开头,如:String、Data;javascript中的变量名可以是以字母或下划线开始,其变量有三种类型,数字型、字符串型和布尔型和空值(null)和未定义值(undefined)2、JavaScript程序中,每条功能执行语句的最后要用分号结束;3、javascript的注释有单行和多行,单行用//多行用HTML注释方法(/**/)4、javascript中,变量有全局变量和局部变量之分。
全局变量定义在所有函数体之外,作用范围是整个函数,而局部变量定义在函数体内,只对该函数有效5、字符串型在首位添加成对的双引号或单引号。
6、x%y返回x与y的模(x除以y的余数)7、javascript语言为弱类型语言,不同类型之间的变量进行运算时,有限考虑字符串型,如8+“8”结果为888、try catch finaly是用于处理异常的语句,在执行语句块的时候,如果没有执行成功,就会跳到catch语句块,如果没有错误,就会跳过catch语句,finally在tyr语句和catch语句执行完之后执行。
finally的作用简单概括就是:无论try里面的代码正常执行或者发生异常,都会继续执行finally里面的代码,所以,一般会在finally里面执行一些清理操作。
9、javascript函数定义通常放在<head></head>标记之间,function 函数名(形参1,形参2,...){函数体;}javascript中的函数区分大小写,要执行一个函数,必须在程序中调用,调用函数需要创建一个调用语句,函数的调用一般放在<body></body>10、eval()函数是系统函数,用于计算并返回字符串表达式的值;parseInt()函数用于将字符串开头的整数部分分解出来;而parseInt(“dra21”)返回值为NaN,表示非数字。

壹 FreeNas8.3学习笔记1安装忙了许久,终于开始空下来了。
想学点东西。
刚好前段时间学校的共享区也出了点问题。
特别是有些人会误操作删除别人的东西或把别人的数据移到其他目录下了。
本来想用AD进行管理的,怕老师们一下子不习惯。
后来想到用FTP,但大家都有抵触心理,毕竟FTP的易用性不强。
后来就想到使用FreeNas。
于是就萌生了学习这个的想法。
今天就是学习一下如何安装。
起先想在虚拟机里做实验的,后来因为家里的旧电脑有5个80G IDE接口的硬盘,还有一个RAID卡加上学校里的500GSATA硬盘,就把家里的旧电脑(大机箱,电源是用航嘉磐石500,声音太响,东西是个好东西的。
所以再多几个硬盘也没有问题)整套拿到单位里来做这个实验了。
安装之后想不到我的这个RAID卡还是被FreeNas支持的;开心一下。
说了这么多,也开始讲讲如何安装了。
其实这东西的安装比以前的容易许多。
我到官网上下载了一个FreeNAS-8.3.0-RELEASE-x86.iso(/project/freenas/FreeNAS-8.3.0/RELEASE/x8 6/FreeNAS-8.3.0-RELEASE-x86.iso)据说7的版本现在叫NAS4Free;这个我也不是很清楚。
不知道现在这个版本是不是还免费呢?看到这里如果你根本不知道FreeNas是做什么用的,那么就请你先看看/view/1777672.htm(关于freenas的百度百科)看过百科之后,大家应该会明白是谁,会需要FreeNAS!* 玩家:这么有趣的系统没玩过太可惜了!* 信息化的家庭:利用旧计算机,方便管理大量的多媒体数据。
* 学研单位:快速备份大量的研究数据,并且透过网络存取利用。
* 中小企业:免费、功能齐全、容易架设与维护、更新迅速的NAS系统。
* 大型企业:当年度结余不足以添购一台RAID NAS服务器的时候。
介绍一下FreeNAS主要的功能有1. CIFS:Samba,也就是Windows的网络芳邻2. FTP:最快速的档案传输协议3. NFS:所有UNIX-Like系统最常用的网络档案存取方式4. RSYNCD:备份与同步化的最佳解决方案5. SSHD:支持SFTP安全档案传输协议6. Unison:支持安全加密的档案同步协议7. AFP:Mac下的网络档案分享协议8. UPnP:网络传送影音多媒体常用的协议对于硬盘的管理功能,FreeNAS有1. UFS/EXT2/EXT3磁盘读写2. NTFS磁盘读写功能3. 软件RAID 0/1/5/JBOD4. iSCSI支援5. 全磁盘加密保护6. S.M.A.R.T 监控支援7. 噪音控制8. 休眠控制使用者权限的管理支持1. 本机端使用者管理2. 远程AD3. LDAP还有一些不错的功能1. 网络传输速度实时绘图!2. CPU负载实时绘图!3. 在线磁盘/CPU/主机板温度监控!4. 在线Vcore/+-5V/+-12V电压监控!5. 在线风扇转速监控!6. 远程Syslog支持7. 系统电源管理8. 上传/下载档案9. 完整的CPU/内存负载10. 支援Swap11. ntpdate时间同步协议12. 软件更新功能还是费话少说,讲讲安装过程吧。

黑马程序员:三大框架Spring-day09笔记Bean的属性注入在spring中bean的属性注入有两种1.1构造器注入1.2Setter方法注入关于ref属性作用使用ref来引入另一个bean对象,完成bean之间注入1.3集合属性的注入在spring中对于集合属性,可以使用专门的标签来完成注入例如:list set map properties等集合元素来完成集合属性注入.1.3.1List属性注入如果属性是数组类型也可以使用list完成注入1.3.2Set属性注入1.3.3Map属性注入1.3.4Properties属性注入Java.util.Properties是java.utilsMap的实现类,它的key与value都是String类型.1.4名称空间p和c的使用Spring2.0以后提供了xml命名空间。
P名称空间C名称空间首先它们不是真正的名称空间,是虚拟的。
它是嵌入到spring内核中的。
使用p名称空间可以解决我们setter注入时<property>简化使用c名称空间可以解决我们构造器注入时<constructor-arg>简化使用setter注入在applicationContext.xml文件中添加p名称空间简化setter注入使用c名称空间来解决构造器注入在applicationContext.xml文件中添加c名称空间注:如果c或p名称空间操作的属性后缀是”-ref”代表要引入另一个已经存在的bean,例如1.5SpElspring expression language 是在spring3.0以后的版本提供它类似于ognl或el表达式,它可以提供在程序运行时构造复杂表达式来完成对象属性存储及方法调用等。
Spel表达式的格式#{表达式}示例1:完成bean之间的注入示例2 支持属性调用及方法调用第2章Spring注解开发在spring中使用注解,我们必须在applicationContext.xml文件中添加一个标签<context:annotation-config/>作用是让spring中常用的一些注解生效。
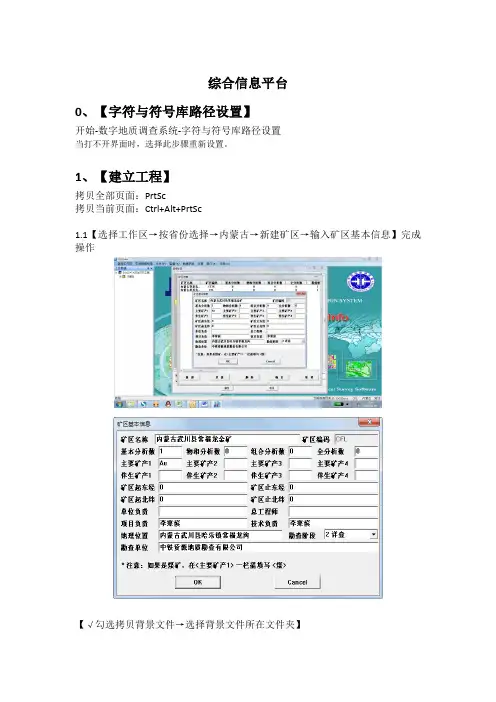
综合信息平台0、【字符与符号库路径设置】开始-数字地质调查系统-字符与符号库路径设置当打不开界面时,选择此步骤重新设置。
1、【建立工程】拷贝全部页面:PrtSc拷贝当前页面:Ctrl+Alt+PrtSc1.1【选择工作区→按省份选择→内蒙古→新建矿区→输入矿区基本信息】完成操作【√勾选拷贝背景文件→选择背景文件所在文件夹】若拷贝不成功,可在后面手工添加文件【背景图层】:背景即为基本的图层信息包括地形、地质、图框(生成标准图框)、基点基线、重要工程点不包括勘探线、工程信息、品位信息,之后系统从外部导入数据自己建立工程库,管理所有数据,并成图。
2、【建立探矿工程属性结构】建立ZK、TC、KD、QJ工程的属性结构将外部数据结构导入系统本身数据结构中【准备工作】将ZK、TC、KD、QJ整理为标准格式的数据表字段顺序不固定,但是关键字段必须有,其中字段含义见【字典】【点投影】将ZK、TC、KD、QJ投影为wt格式文件2.1【添加项目→选择ZK、TC、KD、QJ】2.2【工具→合并图层→选择合并文件】点文件的必要所有关键字段,与钻孔数据库格式保持一致。
否则工程点系统自动投影出错。
注意关键字段:TC、KD、QJ:均为XX3,YY3,HH3ZK:COORD_X1,COORD_Y1 ,COORD_H1TC、KD的左右壁均为2,否则素描图将窄。
2.3【探矿工程数据→工程点批量重投影→探槽、钻孔、坑道】以显示合并后工程点,对照比较2.4【设置→查看坐标信息】查看当前坐标信息,以防出错。
3、【导入探矿工程数据】3.1【探矿工程数据→批量建立工程数据目录→分别选择探槽、钻孔、坑道】3.2【探矿工程数据→工程区基本数据库→打开数据库文件】【把剖面基本信息数据库、剖面测量数据库拷贝到【03Mine_Pro_BaseInfo】粘贴剖面线(勘探线)基本信息(起点、终点)作为剖面起止标示用【04Exp_Pro_Survey】粘贴剖面线(勘探线)测量信息(起点、桩点、终点)作为剖面地形用【点击剖面基本信息、剖面线测量信息】显示相关信息3.3【探矿工程数据-工程数据导入导出(分别导入探槽、钻孔的各个数据表)】【选择excel文件→选择原始文件→选择相应表头→导入】TC:导线文件、分层文件、分样文件,其他产状文件ZK:回次文件、弯曲度文件、分层文件、分样文件、岩性文件、岩性花纹文件,其他产状文件KD:导线文件、分层文件、分样文件,其他产状文件QJ:分样文件注意文件结构与系统结构一致,否则出错注意列号、行号对应系统没有文件,可以自动添加表名注意:分层—岩性描述,否则钻孔柱状图中栏目为0分样—采取率,否则钻孔柱状图中栏目为0注意TC、KD采样位置为2,否则采样条位于底部。

JavaScript笔记(狂神说)本⽂章根据b站狂神说javascript视频教程整理视频链接:0、前端知识体系想要成为真正的“互联⽹Java全栈⼯程师”还有很长的⼀段路要⾛,其中前端是绕不开的⼀门必修课。
本阶段课程的主要⽬的就是带领Java后台程序员认识前端、了解前端、掌握前端,为实现成为“互联⽹Java全栈⼯程师”再向前迈进⼀步。
0.1、前端三要素HTML(结构):超⽂本标记语⾔(Hyper Text Markup Language),决定⽹页的结构和内容CSS(表现):层叠样式表(Cascading Style Sheets),设定⽹页的表现样式。
JavaScript(⾏为):是⼀种弱类型脚本语⾔,其源码不需经过编译,⽽是由浏览器解释运⾏,⽤于控制⽹页的⾏为0.2、结构层(HTML)太简单,略0.3、表现层(CSS)CSS层叠样式表是⼀门标记语⾔,并不是编程语⾔,因此不可以⾃定义变量,不可以引⽤等,换句话说就是不具备任何语法⽀持,它主要缺陷如下:语法不够强⼤,⽐如⽆法嵌套书写,导致模块化开发中需要书写很多重复的选择器;没有变量和合理的样式复⽤机制,使得逻辑上相关的属性值必须以字⾯量的形式重复输出,导致难以维护;这就导致了我们在⼯作中⽆端增加了许多⼯作量。
为了解决这个问题,前端开发⼈员会使⽤⼀种称之为【CSS预处理器】的⼯具,提供CSS缺失的样式层复⽤机制、减少冗余代码,提⾼样式代码的可维护性。
⼤⼤的提⾼了前端在样式上的开发效率。
什么是CSS预处理器CSS预处理器定义了⼀种新的语⾔,其基本思想是,⽤⼀种专门的编程语⾔,为CSS增加了⼀些编程的特性,将CSS作为⽬标⽣成⽂件,然后开发者就只需要使⽤这种语⾔进⾏CSS的编码⼯作。
转化成通俗易懂的话来说就是“⽤⼀种专门的编程语⾔,进⾏Web页⾯样式设计,再通过编译器转化为正常的CSS⽂件,以供项⽬使⽤”。
常⽤的CSS预处理器有哪些SASS:基于Ruby ,通过服务端处理,功能强⼤。

SAP BW 学习笔记版本:V1.3本文是笔者在SAP学习SAP BW期间对所学知识旳整顿但愿对大家学习BW有协助IndexNew Questions ..................................................................................................错误!未定义书签。
Tcode..................................................................................................................错误!未定义书签。
Tcode Collection .....................................................................................错误!未定义书签。
SE16 数据浏览器 ....................................................................................错误!未定义书签。
RSA5与RSA6旳区别? ..........................................................................错误!未定义书签。
InfoObject..........................................................................................................错误!未定义书签。
创立IO旳三种方式 ................................................................................错误!未定义书签。

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==中兴笔记使用篇一:中兴IMS系统学习笔记中兴IMS系统学习笔记控制层:CSCF 呼叫会话控制功能P-CSCF:代理CSCF;I-CSCF:查询CSCF;S-CSCF:服务CSCF。
P-CSCF是承载层至控制层的第一个网元,基于SIP接入。
(AGCF与之类似,但它是基于其他协议接入)。
I-CSCF:用于查找服务的S-CSCF,不存什么信息,通常会去查询HSS。
S-CSCF:提供服务鉴权。
HSS:归属用户服务器,存储用户的签约、位置信息。
SLF:签约定位功能。
与HSS一起工作,用于网络中有多个HSS的情况。
查询HSS1SIP-AS:基于SIP协议的应用服务器。
SSS:补充业务服务器,是一类特殊的SIP-AS。
MGCF:媒体网关控制功能,用于控制IM-MGW。
用于与其它网络互通IM-MGW:IMS媒体网关。
IM-SGW:IMS信令网关。
MRFC:媒体资源功能控制器。
与SSS合一实现。
MRFP:媒体资源功能提供者,提供语音、多方通话、会议桥,与MGW合一实现。
BGCF:边界网关控制功能,目前中兴设备上功能弱化,与S-CSCF合一。
IM-SSF:IMS交换功能,与传统智能网的SCP对接。
*I-CSCF查询时查HSS或SLF简易流程: 1、注册: HSS SSS终端SBC(注册完成后,PCSCF和SCSCF互相知道对方信息)2、会话:1)IMS--->IMS信令流:终端1 ONU PCSCF PCSCF 终端2媒体流:终端1--->ONU--->SBC----->SBC----->ONU----->终端22)IMS---->CS SSS 信令流:终端1--->ONU--->SBC----->PCSCF----->SCSCF--->MGCF----->PSTN--->终端2SSS反向:终端一、ICSCF接口1:接受SBC送来的注册及会话请求,及相反。

ZFS文件系统Snapshot技术的分析摘要:快照是一种重要的存储数据的技术,可以在不停止应用程序的情况下对数据进行备份。
本文对Solaris平台下的ZFS文件系统中的快照技术进行了分析,介绍了快照的工作原理、实现技术及数据结构,并在ZFS中进行快照创建、数据恢复的实例分析,结果表明ZFS文件系统中的快照技术能避免数据的丢失,可以有效地保护该系统下的数据,并且在操作系统的实验教学中对文件系统的分析具有较大的实践意义。
关键词:快照;Copy-on-Write;ZFS;Solaris1引言随着计算机技术在各个领域的广泛应用,信息量迅速增长,越来越多的单位、公司以及个人对计算机数据的依赖性逐步增强,数据的损坏或者丢失将对用户造成不可弥补的损失。
为保护重要数据,用户不得不频繁地备份数据。
传统的数据备份是冷备份,需要停止系统运行才能进行,在备份期间,无法进行正常的数据访问。
但对于许多关键性的应用环境,如电子商务系统或者银行系统等,系统需要连续不断地运转,停机就意味着业务的停顿和商业机会的丢失,停止系统来进行数据备份就会造成难以估量的损失。
因此,如何在系统运行期间对系统数据进行备份,并保证数据版本的一致性就变得尤为重要。
Snapshot技术正是为了解决该问题提出的。
Snapshot能在不停止应用程序的情况下生成某一瞬间的数据映像,用户可以对该数据映像进行保存备份,当系统出现问题或者数据丢失时,用户可以安全方便地获得快照创建时刻的数据映像。
2Snapshot技术介绍Snapshot也称为快照,是本地保留的按时间点保存的数据映像。
产生一个文件系的Snapshot,并不是对所有数据块进行拷贝,只是对文件系统当前点的信息记录。
快照不能被直接访问,但是可以对它们执行克隆、备份、回滚等操作,通过这些操作,系统可以有效地保护数据。
Snapshot技术的实现方式目前有两种:即写即拷(Copy-on-Write)方式和分割镜像(Split-Mirror)方式。

什么是ZFS⽂件系统?ZFS概念及特点简介什么是 ZFS?ZFS(Zettabyte File System)是由SUN公司的Jeff Bonwick领导设计的⼀种基于Solaris的⽂件系统,最初发布于20014年9⽉14⽇。
SUN被Oracle收购后,现在称为Oracle Solaris ZFS。
ZFS全称是 Zettabyte File System,单个ZFS⽂件系统最多⽀持 256 quadrillion zettabytes (ZB), 1ZB等于2的70次⽅字节。
相对于传统的EXT、XFS、JFS、ReiserFS或NTFS,ZFS的⼀个重要侧重点就是突出了对数据完整性的保护。
ZFS ⽂件系统是⼀种⾰新性的新⽂件系统,可从根本上改变⽂件系统的管理⽅式,并具有⽬前⾯市的其他任何⽂件系统所没有的功能和优点。
ZFS 强健可靠、可伸缩、易于管理。
因为其先进性,ZFS被称为最后的操作系统,21世纪最好的操作系统,也曾经被苹果⽤于Mac OSX 10.5操作系统中,但是当Mac OSX10.6雪豹发布时,⼤家发现苹果完全弃⽤了ZFS。
原因可能是,当Oracle收购SUN时,Oracle⾃⼰已经有了开源⽂件系统BTRFS,外界认为它⽆⼒分⾝继续ZFS的开发;另⼀⽅⾯,Netapp称ZFS⽂件系统侵犯其WAFL专利技术,综合这些,苹果最终停⽌⽀持ZFS⽂件系统。
ZFS 池存储ZFS 使⽤存储池的概念来管理物理存储。
以前,⽂件系统是在单个物理设备的基础上构造的。
为了利⽤多个设备和提供数据冗余性,引⼊了卷管理器的概念来提供单个设备的表⽰,以便⽆需修改⽂件系统即可利⽤多个设备。
此设计增加了更多复杂性,并最终阻碍了特定⽂件系统的继续发展,因为这类⽂件系统⽆法控制数据在虚拟卷上的物理放置。
ZFS 可完全避免使⽤卷管理。
ZFS 将设备聚集到存储池中,⽽不是强制要求创建虚拟卷。
存储池说明了存储的物理特征(设备布局、数据冗余等),并充当可以从其创建⽂件系统的任意数据存储库。
js笔记总结好的,以下是一份JavaScript的笔记总结:1. 基础语法:变量:使用`var`、`let`或`const`声明变量。
数据类型:JavaScript有7种数据类型,包括`Number`、`String`、`Boolean`、`Object`、`Null`、`Undefined`和Symbol。
函数:使用`function`关键字定义函数。
控制结构:如`if`、`for`、`while`等。
2. 面向对象编程:构造函数:使用构造函数创建对象。
原型链:JavaScript使用原型链实现继承。
原型和实例:每个JavaScript对象都有一个指向其原型的内部链接。
3. 数组和对象:数组:JavaScript中的数组是一种特殊的对象,用于表示和操作有序的数据。
对象:对象是一种复杂的数据类型,用于存储多个值作为键值对。
4. 事件处理:事件监听器:用于监听和响应用户与网页的交互。
5. 函数式编程:高阶函数:接受函数作为参数或返回函数的函数。
闭包:当一个函数在其词法作用域外部被引用时,就会形成一个闭包。
6. 异步编程:Promise:用于处理可能不立即完成的操作。
async/await:使异步代码看起来像同步代码。
7. 错误处理:try/catch/finally:用于捕获和处理运行时错误。
8. DOM操作:获取元素:使用`()`、`()`等。
修改元素:改变元素的内容、样式等。
9. 浏览器兼容性:使用工具如Babel将ES6+代码转换为ES5代码,以确保在所有浏览器中都能运行。
10. 性能优化:使用工具如Chrome DevTools进行性能分析,优化代码。
11. 模块化:使用模块化编程来组织和管理代码,例如使用ES6模块或CommonJS模块。
12. 工具和库:使用工具如webpack、Gulp等构建工具和库如React、Vue等前端框架,简化开发过程。
13. 测试和调试:使用工具如Jest、Mocha等进行单元测试和集成测试,使用console和debugger进行调试。
软考重点知识笔记(1)2019-03-07 一、计算机组成与体系结构主要知识点1.数据的表示2.运算器与控制器3.Flynn分类器4.CISC与RISC5.流水线技术6.存储系统7.总线系统8.可靠性9.校验码这九个知识点中,1、2、5、6属于每年必考考点,9属于常考点,3、4、7属于不常考点,但是也是重点知识点。
1.数据的表示(1)数据进制转换十进制->二进制或者 R进制短除法R进制或者二进制—> 十进制特别注意小数点后面取的指数为负(2)各种码制原码反码补码移码(3)数值是有表示范围的(4)浮点运算浮点数表示 N=尾数*基数指数运算对阶>尾数计算>结果格式化特点:一般尾数用补码,阶码用移码;阶码的位数决定数的表示范围,位数越多范围越大;尾数的位数决定数的有效精读,位数越多精读越高;对阶时,小数向大数看齐;对阶是通过较小数的尾数右移实现。
2.运算器与控制器(1)计算机结构运算器包括:a.算术逻辑单元ALU,作用是做数据的算术运算和逻辑运算;b.累加寄存器AC,通用寄存器,为ALU提供一个工作区,用以暂存数据;c.数据缓冲寄存器DR,写内存时,暂存指令或数据 d.状态条件寄存器PSW,储存状态标志与控制标志,当然PSW也有人将其归为控制器。
控制器a.程序计数器PC,存储下一条需要执行指令的地址;b.指令寄存器IR,存储即将执行的指令;c.指令译码器ID,对指令中的操作码字段进行解析;d.时序部件,提供时序控制信号指令的基本概念一条指令就是机器语言的一个语句,他是一组有意义的二进制码,指令基本格式包括操作码字段和地址码字段。
FreeNas8.3学习笔记4 windows(CIFS)服务配置及权限设置单位中大家一定遇到过数据共享的需求,而这种需求往往需要一定的权限管理。
可能有些朋友会说用AD进行管理呀。
现在学校里使用AD来管理的还真的不是很多。
所以用CIFS来管理数据的共享会更好些。
毕竟用FTP之类的做数据共享会很不方便。
还有用HTTP File Server 做也不是很好,都需要上传和下载。
而CIFS就是一种共享功能,带权限的共享,可以防止同事不小心而删除别人数据的问题。
那么接下来就与我一起学习CIFS的设置吧。
首先我们模拟一个实验环境吧。
在这里开始使用实体电脑。
所以IP会与前面的有所不一样。
希望不要影响大家。
另外:我这台电脑用了6个硬盘分别是5个80G (其中一个用于安装freenas系统)、1个500G硬盘。
用户:qxadmin (领导用户,可以读写所有共享数据)qx01 (普通用户,只可以读写自己的目录,可以读所有共享数据)qx02(普通用户,只可以读写自己的目录,可以读所有共享数据)组:qxschool (学校组,所有成员,及qxadmin组成员)qxadmin (学校领导组)目录:share (主共享目录20G)share/qxadmin (qxadmin的目录2G)share/qx01 (qx01的目录 2G)share/qx02(qx02的目录 2G)share/qxshare (所有人可以写入的目录,用于数据收集时使用 2G)【添加组】添加2个组,分别是qxadmin和qxschool【添加用户】将用户qxadmin添加到qxadmin组中其他用户添加到qxschool组中。
另外说明一下:Owner是个人,Group是组,Other是其他Read是读权限,Write是写权限,Execute是执行权限这里对于权限就默认就行了,不用去改。
拉到下面输入密码【给qxschool组添加其他组】因为qxadmin管理员是添加到qxadmin组中,而管理员也是属于qxschool组的,所以要将其添加到qxschool组。
ZFS是什么?使⽤ZFS的理由及特性介绍ZFS 的历史Z ⽂件系统(Z File System)(ZFS)是由 Matthew Ahrens 和 Jeff Bonwick 在 2001 年开发的。
ZFS 是作为太阳微系统(Sun MicroSystem) 公司的 OpenSolaris 的下⼀代⽂件系统⽽设计的。
在 2008 年,ZFS 被移植到了 FreeBSD 。
同⼀年,⼀个移植ZFS 到 Linux 的项⽬也启动了。
然⽽,由于 ZFS 是通⽤开发和发布许可证 (Common Development and Distribution License)(CDDL)许可的,它和 GNU 通⽤公共许可证不兼容,因此不能将它迁移到 Linux 内核中。
为了解决这个问题,绝⼤多数Linux 发⾏版提供了⼀些⽅法来安装 ZFS。
在甲⾻⽂公司收购太阳微系统公司之后不久,OpenSolaris 就闭源了,这使得 ZFS 的之后的开发也变成闭源的了。
许多 ZFS 开发者对这件事情⾮常不满。
三分之⼆的 ZFS 核⼼开发者,包括 Ahrens 和 Bonwick,因为这个决定⽽离开了甲⾻⽂公司。
他们加⼊了其它公司,并于 2013 年 9 ⽉创⽴了 OpenZFS 这⼀项⽬。
该项⽬引领着 ZFS 的开源开发。
让我们回到上⾯提到的许可证问题上。
既然 OpenZFS 项⽬已经和 Oracle 公司分离开了,有⼈可能好奇他们为什么不使⽤和GPL 兼容的许可证,这样就可以把它加⼊到 Linux 内核中了。
根据 OpenZFS 官⽹的介绍,更改许可证需要联系所有为当前OpenZFS 实现贡献过代码的⼈(包括初始的公共 ZFS 代码以及 OpenSolaris 代码),并得到他们的许可才⾏。
这⼏乎是不可能的(因为⼀些贡献者可能已经去世了或者很难找到),因此他们决定保留原来的许可证。
ZFS 是什么,它有什么特性?正如前⾯所说过的,ZFS 是⼀个先进的⽂件系统。
SAP学习手册IV发表人:sunxufeng | 发表时间: 2006年三月27日, 17:32请教各位,我已经在测试系统里,归档了销售订单以及其发票,会计凭证和交货单,但是我想看看归档的效果,请问R3系统有可以查看到归档数据的功能吗?另外,交货单还对应一张物料凭证,我就是直接归档交货单了,不知道是不是应该先归档物料凭证再归档交货单?因为归档发票的时候,需要先归档发票对应的会计凭证,再归档发票。
否则系统不让通过。
怎样做归档的资料在本论坛前几天我发的帖子里有人提供了,基本上是STEP BY STEP的教,很详细。
你去那下载吧。
只是归档不同的数据要选择不同的归档对象就可以了。
如归档销售订单用的归档对象是SD_VBAK, 归档交货单用RV_LIKP, 归档销售发票用:SD_VBRK, 归档会计凭证用:FI_DOCUMNT我提的问题是如何查看已经被归档的数据?在每个归档对象中,都有一个管理功能,你选择一下,就可以查看该归档对象所归档的全部内容,系统按日期排列但是我归档的销售订单,数量字段都显示为空。
其实这些订单都有数量。
不知道是没有把数量字段拷贝到归档文件,还是读取程序有误没有显示数量字段。
请帮我再看看好吗?选择某一次归档会话,点击“√”:然后系统显示这次会话归档的销售订单清单,但是奇怪的是,所有的销售订单数量字段为空,如下图:为何计量单位显示为****** 导致无法使用,如何解决?计量单位是在后台设置的。
系统中有一个基本计量单位,你现在所看到的计量单位是自己定义的。
可以任意设置,只要填对两者的换算关系就行了。
物料主数据的单位,不是在你当前语言环境下创建的吧, 看看你的物料主数据是否在英文环境下被建立,没有建立中文单位.请教!怎么删掉SM37中Active状态的进程?有几个进程的状态是ACTIVE 而且执行的时间已经很长了。
现在想把进程DELETE,可是用什么方法都无法办到。
SM50吧,但是在sm37里不是有stop这个功能么?在SM50中看不到这个进程。
ZFS 学习笔记第一章zpool的管理 (2)1.1 创建zpool (3)1.1.1 创建单边zpool (3)1.1.2 创建mirror pool (4)1.1.3 创建raidz zpool (6)1.2 删除zpool (7)1.3 对zpool进行管理 (8)1.3.1 镜像和拆镜像 (8)1.3.2 添加zpool空间 (9)1.3.3 spare盘的添加和删除 (10)1.4 zpool的维护/故障盘的更换 (12)1.5 zpool的迁移 (15)1.6 恢复销毁的zpool (16)1.7 zpool的I/O统计 (18)1.8 迁移ZFS 存储池 (19)1.9 zpool的版本升级 (20)第二章ZFS文件系统的建立和设置 (22)2.1 ZFS文件系统的创建和删除 (22)2.1.1 ZFS文件系统的创建 (22)2.1.2 ZFS文件系统重命名 (23)2.1.3 删除ZFS文件系统 (23)2.2 ZFS属性介绍 (24)2.3 查询ZFS文件系统信息 (25)2.4 管理ZFS属性 (25)2.4.1 设置set (26)2.4.2 继承inherit (27)2.4.3 查询get (27)2.4.4 ZFS文件系统的mount和umount (34)2.4.5 ZFS文件系统的share和unshare (36)2.4.6 ZFS文件系统的配额和预留空间 (37)第三章使用ZFS进行快照或者克隆 (40)3.1 快照snapshot (40)3.1.1 创建和销毁快照 (40)3.1.2 快照的显示和重命名 (41)3.1.3 使用快照回滚 (41)3.2 克隆 (43)3.2.1 创建clone (43)3.2.2 删除clone (44)3.2.3 使用clone来代替文件系统 (44)3.3 快照的保存和恢复 (45)3.3.1 快照的保存 (45)3.3.2 使用快照文件恢复文件系统 (46)附录:ZFS卷 (48)ZFS主要使用两条命令及其子命令:zfszpool第一章zpool的管理zpool 命令菜单:# zpoolmissing commandusage: zpool command args ...where 'command' is one of the following:create [-fn] [-R root] [-m mountpoint] <pool> <vdev> ...destroy [-f] <pool>add [-fn] <pool> <vdev> ...remove <pool> <device>list [-H] [-o field[,field]*] [pool] ...iostat [-v] [pool] ... [interval [count]]status [-vx] [pool] ...online <pool> <device> ...offline [-t] <pool> <device> ...clear <pool> [device]attach [-f] <pool> <device> <new_device>detach <pool> <device>replace [-f] <pool> <device> [new_device]scrub [-s] <pool> ...import [-d dir] [-D]import [-d dir] [-D] [-f] [-o opts] [-R root] -aimport [-d dir] [-D] [-f] [-o opts] [-R root ] <pool | id> [newpool]export [-f] <pool> ...upgradeupgrade -vupgrade <-a | pool>history [<pool>]1.1 创建zpoolZFS文件系统是建立在存储池pool的基础上,所以要建立文件系统必须先建立底层的pool。
1.1.1 创建单边zpoolzpool create yz c3t0d0 c3t0d1# zpool create First c3t2d0 c3t4d0invalid vdev specificationuse '-f' to override the following errors:/dev/dsk/c3t2d0s2 contains a ufs filesystem./dev/dsk/c3t2d0s7 contains a ufs filesystem.加入pool的硬盘可以是整块盘,也可以是某个分区,条件允许的时候建议使用整块盘,这样便于pool对硬盘的管理。
由于加入pool的磁盘之前曾经使用过ufs,所以在创建过程中需要使用-f选项来忽视ufs文件格式将硬盘强制加入pool中。
Note:加入pool的硬盘的原来数据会被破坏。
# zpool create –f first c3t2d0 c3t3d0 创建两块盘组成的pool# zpool listNAME SIZE USED A V AIL CAP HEALTH ALTROOTfirst 136G 90K 136G 0% ONLINE -# zpool statuspool: firststate: ONLINEscrub: none requestedconfig:NAME STA TE READ WRITE CKSUMfirst ONLINE 0 0 0c3t2d0ONLINE 0 0 0c3t3d0ONLINE 0 0 0errors: No known data errors1.1.2 创建mirror pool# zpool create –f yz mirror c3t0d0 c3t1d0# zpool listNAME SIZE USED A V AIL CAP HEALTH ALTROOTfirst 136G 90K 136G 0% ONLINE -yz 68G 6.08G 61.9G 8% ONLINE -# zpool statuspool: yzstate: ONLINEscrub: none requestedconfig:NAME STA TE READ WRITE CKSUMyz ONLINE 0 0 0mirror ONLINE 0 0 0c3t0d0ONLINE 0 0 0c3t1d0ONLINE 0 0 0errors: No known data errors创建镜像盘组成的pool,如果加入的硬盘为多个的话,则默认的raid类型为raid1+0,下例中,镜像为3份,单盘为68G,而pool总量为136G。
RCGSM-root-/yztest/2>zpool create xxx mirror c3t0d0 c3t1d0 c3t2d0 mirror c3t3d0 c3t4d0 c3t5d0RCGSM-root-/yztest/2> zpool listNAME SIZE USED A V AIL CAP HEALTH ALTROOTxxx 136G90K 136G 0% ONLINE -RCGSM-root-/yztest/2> zpool statuspool: xxxstate: ONLINEscrub: none requestedconfig:NAME STA TE READ WRITE CKSUMxxx ONLINE 0 0 0mirror ONLINE 0 0 0c3t0d0 ONLINE 0 0 0c3t1d0 ONLINE 0 0 0c3t2d0 ONLINE 0 0 0mirror ONLINE 0 0 0c3t3d0 ONLINE 0 0 0c3t4d0 ONLINE 0 0 0c3t5d0 ONLINE 0 0 0errors: No known data errors# zpool status -xall pools are healthy# df -hFilesystem size used avail capacity Mounted on first 134G 24K 134G 1% /first1.1.3 创建raidz zpoolzpool支持的raidz有raidz1和raidz2两种,类似于传统的raid5,raidz至少需要3个devices 来实现对数据的校验。
raidz也就是raidz1会消耗一块盘的空间,raidz2消耗凉快盘的空间。
# zpool create yz raidz1 c3t0d0 c3t1d0 c3t2d0 c3t3d0# zpool statuspool: yzstate: ONLINEscrub: none requestedconfig:NAME STA TE READ WRITE CKSUMyz ONLINE 0 0 0raidz1 ONLINE 0 0 0c3t0d0 ONLINE 0 0 0c3t1d0 ONLINE 0 0 0c3t2d0 ONLINE 0 0 0c3t3d0 ONLINE 0 0 0errors: No known data errors# zpool listNAME SIZE USED A V AIL CAP HEALTH ALTROOTyz 272G 147K 272G 0% ONLINE -# df -hFilesystem size used avail capacity Mounted onyz 200G 36K 200G 1% /yz# zpool create yz raidz2 c3t0d0 c3t1d0 c3t2d0 c3t3d0# zpool listNAME SIZE USED A V AIL CAP HEALTH ALTROOTyz 272G 226K 272G 0% ONLINE -# df -hFilesystem size used avail capacity Mounted onyz 133G 36K 133G 1% /yz# zpool listNAME SIZE USED A V AIL CAP HEALTH ALTROOTyz 272G 226K 272G 0% ONLINE -# zpool statuspool: yzstate: ONLINEscrub: none requestedconfig:NAME STA TE READ WRITE CKSUMyz ONLINE 0 0 0raidz2 ONLINE 0 0 0c3t0d0 ONLINE 0 0 0c3t1d0 ONLINE 0 0 0c3t2d0 ONLINE 0 0 0c3t3d0 ONLINE 0 0 0errors: No known data errorsNote:同样是四块盘的raidz,raidz2消耗掉两块盘的空间,raidz1消耗一块盘的空间。