概率论中三个重要分布共19页
- 格式:ppt
- 大小:1.50 MB
- 文档页数:42




概率论中几种常用的重要的分布摘要:本文主要探讨了概率论中的几种常用分布,的来源和他们中间的关系。
其在实际中的应用。
关键词1 一维随机变量分布随机变量的分布是概率论的主要内容之一,一维随机变量部分要介绍六中常用分布,即( 0 -1) 分布、二项分布、泊松分布、均匀分布、指数分布和正态分布. 下面我们将对这六种分布逐一地进行讨论.随机事件是按试验结果而定出现与否的事件。
它是一种“定性”类型的概念。
为了进一步研究有关随机试验的问题,还需引进一种“定量”类型的概念,即,根据试验结果而定取什么值(实值或向量值)的变数。
称这种变数为随机变数。
本章内将讨论取实值的这种变数—— 一维随机变数。
定义1.1 设X 为一个随机变数,令 ()([(,)])([]),()F x P X x P Xx x=∈-∞=-∞+∞.这样规定的函数()F x 的定义域是整个实轴、函数值在区间[0,1]上。
它是一个普通的函数。
成这个函数为随机函数X 的分布函数。
有的随机函数X 可能取的值只有有限多个或可数多个。
更确切地说:存在着有限多个值或可数多个值12,,...,a a 使得 12([{,,...}])1P X a a ∈=称这样的随机变数为离散型随机变数。
称它的分布为离散型分布。
【例1】下列诸随机变数都是离散型随机变数。
(1)X 可能取的值只有一个,确切地说,存在着一个常数a ,使([])1P X a ==。
称这种随机变数的分布为退化分布。
一个退化分布可以用一个常数a 来确定。
(2)X 可能取的值只有两个。
确切地说,存在着两个常数a ,b ,使([{,}])1P X a b ∈=.称这种随机变数的分布为两点分布。
如果([])P X b p ==,那么,([])1P X a p ===-。
因此,一个两点分布可以用两个不同的常数,a b 及一个在区间(0,1)内的值p 来确定。
特殊地,当,a b 依次为0,1时,称这两点分布为零-壹分布。

概率论与数理统计中的三种重要分布摘要:在概率论与数理统计课程中,我们研究了随机变量的分布,具体地研究了离散型随机变量的分布和连续型随机变量的分布,并简单的介绍了常见的离散型分布和连续型分布,其中二项分布、Poisson 分布、正态分布是概率论中三大重要的分布。
因此,在这篇文章中重点介绍二项分布、Poisson 分布和正态分布以及它们的性质、数学期望与方差,以此来进行一次比较完整的概率论分布的学习。
关键词:二项分布;Poisson 分布;正态分布;定义;性质一、二项分布二项分布是重要的离散型分布之一,它在理论上和应用上都占有很重要的地位,产生这种分布的重要现实源泉是所谓的伯努利试验。
(一)泊努利分布[Bernoulli distribution ] (两点分布、0-1分布)1.泊努利试验在许多实际问题中,我们感兴趣的是某事件A 是否发生。
例如在产品抽样检验中,关心的是抽到正品还是废品;掷硬币时,关心的是出现正面还是反面,等。
在这一类随机试验中,只有两个基本事件A 与A ,这种只有两种可能结果的随机试验称为伯努利试验。
为方便起见,在一次试验中,把出现A 称为“成功”,出现A 称为“失败” 通常记(),p A P = ()q p A P =-=1。
2.泊努利分布定义:在一次试验中,设p A P =)(,p q A P -==1)(,若以ξ记事件A 发生的次数,则⎪⎪⎭⎫⎝⎛ξp q 10~,称ξ服从参数为)10(<<p p 的Bernoulli 分布或两点分布,记为:),1(~p B ξ。
(二)二项分布[Binomial distribution]把一重Bernoulli 试验E 独立地重复地进行n 次得到n 重Bernoulli 试验。
定义:在n 重Bernoulli 试验中,设(),()1P A p P A q p ===-若以ξ记事件A 发生的次数,则ξ为一随机变量,且其可能取值为n ,,2,1,0 ,其对应的概率由二项分布给出:{}k n kk n p p C k P --==)1(ξ,n k ,,3,2,1,0 =,则称ξ服从参数为)10(,<<p p n 的二项分布,记为),(~p n B ξ。

概率分布的重要性质概率分布是概率论中的重要概念,用于描述随机变量的取值与其对应的概率之间的关系。
概率分布具有许多重要的性质,这些性质对于理解和应用概率论具有重要意义。
本文将介绍概率分布的几个重要性质,并探讨其在实际问题中的应用。
一、概率分布的归一性概率分布的归一性是指所有可能事件的概率之和等于1。
对于离散型随机变量,概率分布可以用概率质量函数(Probability Mass Function,简称PMF)来描述,其满足以下性质:∑P(X=x)=1其中,P(X=x)表示随机变量X取值为x的概率。
对于连续型随机变量,概率分布可以用概率密度函数(Probability Density Function,简称PDF)来描述,其满足以下性质:∫f(x)dx=1其中,f(x)表示随机变量X的概率密度函数。
概率分布的归一性是概率论的基本原理之一,它保证了所有可能事件的概率之和为1,使得概率分布具有可解释性和可比较性。
在实际应用中,概率分布的归一性可以用来验证概率模型的合理性,以及计算事件的概率和期望值等。
二、概率分布的期望值概率分布的期望值是描述随机变量平均取值的指标,它是随机变量所有可能取值的加权平均。
对于离散型随机变量,期望值可以用以下公式计算:E(X)=∑xP(X=x)其中,E(X)表示随机变量X的期望值。
对于连续型随机变量,期望值可以用以下公式计算:E(X)=∫xf(x)dx其中,f(x)表示随机变量X的概率密度函数。
概率分布的期望值是概率论中的重要概念,它可以用来描述随机变量的平均取值,反映了随机变量的集中趋势。
在实际应用中,期望值可以用来计算风险、收益、成本等指标,对于决策和评估具有重要意义。
三、概率分布的方差和标准差概率分布的方差和标准差是描述随机变量取值的离散程度的指标。
方差是随机变量与其期望值之差的平方的期望值,标准差是方差的平方根。
对于离散型随机变量,方差可以用以下公式计算:Var(X)=∑(x-E(X))^2P(X=x)其中,Var(X)表示随机变量X的方差。

概率论三大分布1. 介绍概率论是一门非常基础和重要的数学分支,它对于社会科学、自然科学、工程学等领域都有着重要的应用。
而概率论的三大分布,则是这门学科中最为基础和经典的概率分布。
本文将会介绍概率论的三大分布,并解释它们在不同领域的应用及实例。
2. 正态分布正态分布又称为高斯分布,是最为常见和典型的概率分布。
在自然界中,千变万化的现象几乎都有很强的正态分布倾向。
例如人的身高、智力分数、温度变化等等,都能够用正态分布来描述。
正态分布的密度函数图呈钟形曲线,其两侧的概率密度逐渐递减,呈现出对称性。
在统计学中,正态分布对于数据的描述和归一化处理非常有效。
许多统计学模型都是基于正态分布推导出来的,如t检验、回归分析等都是基于正态分布的同时,正态分布还有着重要的应用:它是中心极限定理的一个重要实例,即当随机变量很多时,其总和会呈现正态分布。
3. 泊松分布泊松分布是描述在一定时间内随机事件发生的频次的概率分布。
例如在一定时间内交通事故的发生次数、某网站被访问的次数等等,这些都可以用泊松分布来描述。
泊松分布的概率密度函数表现出事件发生的非常不稳定性。
在实际中,泊松分布可以用于一些常见的领域应用,如:生物学中的光学场效应、传媒中的新闻报道发生次数、地震学中的地震发生次数、医学中的所研究病人数、管理学中的随机事件数量等等,都可以用泊松分布来刻画。
4. 二项分布二项分布是对于某一二项试验中成功次数的概率分布,其中每次试验独立且成功率相同。
例如在n次抛硬币中,正面朝上的次数服从二项分布。
二项分布概率密度函数图呈现出一条拐角分界的直线,而且随着次数变多,这条拐角分界的密集区域会逐渐向成功概率p的方向移动。
二项分布在现实中的应用体现得比较直观,如:生物学中对于不同品系的性状比较、医学中对于新药的试验、市场研究中对于不同产品的销量预测等等。
在商业领域中,二项分布的应用十分广泛,它可以帮助商家对于市场走向和产品竞争力预测提供重要依据。


概率论中的常见分布和期望与方差——概率论知识要点概率论是数学中的一个重要分支,研究随机现象的规律性。
在概率论中,常见的分布函数和概率密度函数描述了随机变量的分布规律,而期望和方差则是描述随机变量的中心位置和离散程度的重要指标。
本文将介绍概率论中的常见分布以及期望和方差的概念和计算方法。
一、离散型分布在概率论中,离散型分布描述了随机变量取有限个或可列个数值的概率分布。
以下是几个常见的离散型分布:1. 伯努利分布伯努利分布是最简单的离散型分布,描述了只有两个可能结果的随机试验,比如抛硬币的结果。
设随机变量X表示试验的结果,取值为1或0,表示成功或失败的情况。
伯努利分布的概率质量函数为:P(X=k) = p^k * (1-p)^(1-k),其中k=0或1,p为成功的概率。
2. 二项分布二项分布描述了一系列独立的伯努利试验中成功的次数。
设随机变量X表示成功的次数,取值范围为0到n,n为试验的次数,p为每次试验成功的概率。
二项分布的概率质量函数为:P(X=k) = C(n,k) * p^k * (1-p)^(n-k),其中C(n,k)为组合数。
3. 泊松分布泊松分布描述了在一定时间或空间内随机事件发生的次数。
设随机变量X表示事件发生的次数,取值范围为0到无穷大。
泊松分布的概率质量函数为:P(X=k) = (λ^k * e^(-λ)) / k!,其中λ为事件发生的平均次数。
二、连续型分布在概率论中,连续型分布描述了随机变量在某个区间内取值的概率分布。
以下是几个常见的连续型分布:1. 均匀分布均匀分布描述了随机变量在某个区间内取值的概率相等的情况。
设随机变量X 在[a, b]区间内取值,均匀分布的概率密度函数为:f(x) = 1 / (b-a),其中a≤x≤b。
2. 正态分布正态分布是概率论中最重要的分布之一,也被称为高斯分布。
正态分布的概率密度函数为:f(x) = (1 / √(2πσ^2)) * e^(-(x-μ)^2 / (2σ^2)),其中μ为均值,σ为标准差。

四大分布简述一、正态分布1. 概述正态分布又名常态分布。
高斯在研究误差理论时曾用它来刻画误差,故很多文献中亦称之为高斯分布。
正态分布是概率论中最重要的分布,并有极其广泛的实际背景,很多随机变量的概率分布都可以近似地用正态分布来描述。
统计学中的三大分布(2χ分布、t分布和F分布)均是由它导出的。
2. 定义如果随机变量X的概率密度为()222(),xμσφx x--=-∞<<+∞则称X服从正态分布,记作2~(,)X Nμσ,其中,μ为随机变量X的数学期望,σ为随机变量X的标准差。
特别地,当0μ=,1σ=时,有22(),xφx x-=-∞<<+∞相应的正态分布(0,1)N称为标准正态分布。
标准正态分布的重要性在于,任何一个普通的正态分布都可以通过线性变换转化为标准正态分布。
标准化过程为若2~(,)X Nμσ,则(0,1)XμZ~Nσ-=。
3. 性质和特点1)正态分布的概率密度函数的图像为钟形,关于xμ=对称。
2)标准差σ决定正态曲线的陡峭或扁平程度。
σ越小,曲线越高狭;σ越大,曲线越低阔。
3)普遍性:一个变量如果收到大量的独立因素的影响(无主导因素),则它一般服从正态分布。
4. 应用1) 估计频数分布。
2) 制定参考值范围。
3) 质量控制:3σ准则。
4) 二项分布、t 分布等的正态近似计算。
5) 正态分布是许多统计方法的理论基础。
检验、方差分析、相关和回归分析等多种统计方法均要求分析的指标服从正态分布。
二、2χ分布1. 概述2χ分布是由海尔默特(Hermert )和皮尔逊(Pearson )分别于1875年和1900年推导出来的。
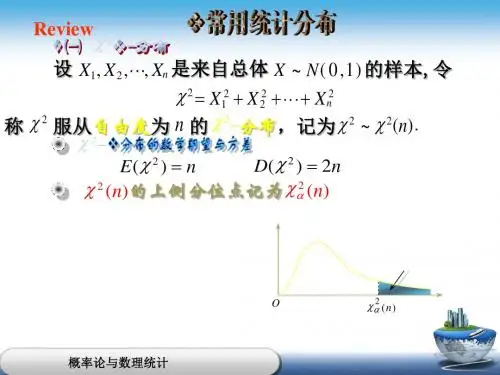
2. 定义设随机变量12,,,n X X X 相互独立,且()1,2,,=i X i n 服从标准正态分布(0,1)N ,则它们的平方和21=∑n i i X 服从自由度为n 的2χ分布,记作2()χn 。
3. 性质和特点1) 2χ分布的密度函数在第一象限内呈正偏态(右偏态)。
《概率论与数理统计》(19)电子科技大学应用数学学院,徐全智吕恕主编。
2004版第6章数理统计的基本概念概率论与数理统计是两个紧密联系的姊妹学科,概率论是数理统计学的理论基础,而数理统计学则是概率论的重要应用.数理统计学是使用概率论和数学的方法,研究如何用有效的方式收集带有随机误差的数据,并在设定的模型下,对收集的数据进行分析,提取数据中的有用信息,形成统计结论,为决策提供依据. 这就不难理解,数理统计应用的广泛性,几乎渗透到人类活动的一切领域! 如:农业、生物和医学领域的“生物统计”,教育心理学领域的“教育统计”,管理领域的“计量经济”,金融领域的“保险统计”等等,这些统计方法的共同基础都是数理统计.数理统计学的内容十分丰富,概括起来可以分为两大类:其一是研究如何用有效的方式去收集随机数据,即抽样理论和试验设计;其二是研究如何有效地使用随机数据对所关心的问题做出合理的、尽可能精确和可靠的结论,即统计推断.本书主要介绍统计推断的基本内容和基本方法. 在这一章中先给出数理统计中一些必要的基本概念,然后给出正态总体抽样分布的一些重要结论.6.1总体、样本与统计量一、总体在数理统计中,我们将研究对象的全体称为总体或母体,而把组成总体的每个基本元素称为个体.二、样本样本是按一定的规定从总体中抽出的一部分个体" 这里的“按一定的规定”,是指为保证总体中的每一个个体有同等的被抽出的机会而采取的一些措施" 取得样本的过程,称为抽样.三、统计量6.2抽样分布统计量是我们对总体的分布规律或数字特征进行推断的基础. 由于统计量是随机变量,所以在使用统计量进行统计推断时必须要知道它的分布. 统计量的分布称为抽样分布.一、三个重要分布二、抽样分布定理6.3应用一、顺序统计量及其应用二、极值的分布及其应用。