快排最坏时间复杂度
- 格式:docx
- 大小:32.80 KB
- 文档页数:1

排序算法比较
排序算法的效率主要取决于算法的时间复杂度。
以下是常见的几种排序算法的时间复杂度和优缺点的对比:
1. 冒泡排序
冒泡排序的时间复杂度为O(n^2)。
优点是它的实现简单易懂,缺点是排序速度很慢,对大规模数据排序不太适用。
2. 插入排序
插入排序的时间复杂度也为 O(n^2)。
它的优点是适用于小数
据量的排序,缺点是对于大规模数据排序仍然效率不高。
3. 选择排序
选择排序的时间复杂度也为 O(n^2)。
它的优点是对于小数据
量的排序速度较快,但是因为其算法结构固定,所以其效率在大规模数据排序中表现不佳。
4. 快速排序
快速排序的时间复杂度为 O(nlogn)。
它是一种非常常用的排序算法,适用于大规模数据排序。
快速排序的优点在于分治的思想,可以充分发挥多线程并行计算的优势,缺点是在极端情况下(如输入的数据已经有序或者逆序)排序速度会较慢。
5. 堆排序
堆排序的时间复杂度为 O(nlogn)。
它的优点在于实现简单、稳定,可以用于实时系统中的排序。
缺点是在排序过程中需要使用一个堆结构来维护排序序列,需要额外的内存开销。
同时,由于堆的性质,堆排序不能发挥多线程并行计算的优势。
6. 归并排序
归并排序的时间复杂度为 O(nlogn)。
它的优点在于稳定、可靠,效率在大规模数据排序中表现良好。
归并排序在实现过程中需要使用递归调用,需要额外的内存开销。
同时,归并排序不适用于链式存储结构。

算法分类,时间复杂度,空间复杂度,优化算法算法 今天给⼤家带来⼀篇关于算法排序的分类,算法的时间复杂度,空间复杂度,还有怎么去优化算法的⽂章,喜欢的话,可以关注,有什么问题,可以评论区提问,可以与我私信,有什么好的意见,欢迎提出.前⾔: 算法的复杂度分为时间复杂度与空间复杂度,时间复杂度指执⾏算法需要需要的计算⼯作量,空间复杂度值执⾏算法需要的内存量,可能在运⾏⼀些⼩数据的时候,⼤家体会不到算法的时间与空间带来的体验. 优化算法就是将算法的时间优化到最快,将空间优化到最⼩,假如你写的mod能够将百度游览器的搜索时间提升0.5秒,那都是特别厉害的成绩.本章内容: 1,算法有哪些 2,时间复杂度,空间复杂度 3,优化算法 4,算法实例⼀,算法有哪些 常见的算法有冒泡排序,快排,归并,希尔,插⼊,⼆分法,选择排序,⼴度优先搜索,贪婪算法,这些都是新⼿⼊门必须要了解的,你可以不会,但是你必须要知道他是怎么做到的,原理是什么,今天就给⼤家讲⼀讲我们常⽤的冒泡排序,选择排序,这两个排序算法,1,冒泡排序(Bubble Sort), 为什么叫他冒泡排序呢? 因为他就像是从海底往海⾯升起的⽓泡⼀样,从⼩到⼤,将要排序的数从⼩到⼤排序,冒泡的原理: 他会⼀次⽐较两个数字,如果他们的顺序错误,就将其调换位置,如果排序正确的话,就⽐较下⼀个,然后重复的进⾏,直到⽐较完毕,这个算法的名字也是这样由来的,越⼤的数字,就会慢慢的'浮'到最顶端. 好了该上代码了,下⾯就是冒泡排序的代码,冒泡相对于其他的排序算法来说,⽐较的简单,⽐较好理解,运算起来也是⽐较迅速的,⽐较稳定,在⼯作中也会经常⽤到,推荐使⽤# 冒泡排序def bubble_sort(alist):n = len(alist)# 循环遍历,找到当前列表中最⼤的数值for i in range(n-1):# 遍历⽆序序列for j in range(n-1-i):# 判断当前节点是否⼤于后续节点,如果⼤于后续节点则对调if alist[j] > alist[j+1]:alist[j], alist[j+1] = alist[j+1], alist[j]if__name__ == '__main__':alist = [12,34,21,56,78,90,87,65,43,21]bubble_sort(alist)print(alist)# 最坏时间复杂度: O(n^2)# 最优时间复杂度: O(n)# # 算法稳定性:稳定2,选择排序(selection sort) 选择排序(selection sort)是⼀种简单直观的排序⽅法, 他的原理是在要排序的数列中找到最⼤或者最⼩的元素,放在列表的起始位置,然后从其他⾥找到第⼆⼤,然后第三⼤,依次排序,依次类,直到排完, 选择排序的优点是数据移动, 在排序中,每个元素交换时,⾄少有⼀个元素移动,因此N个元素进⾏排序,就会移动 1--N 次,在所有依靠移动元素来排序的算法中,选择排序是⽐较优秀的⼀种选择排序时间复杂度与稳定性:最优时间复杂度: O(n2)最坏时间复杂度:O(n2)算法稳定性 :不稳定(考虑每次升序选择最⼤的时候)# if alist[j] < alist[min_index]:# min_index = j## # 判断min_index索引是否相同,不相同,做数值交换# if i != min_index:# alist[i],alist[min_index] = alist[min_index],alist[i]### if __name__ == '__main__':# alist = [12,34,56,78,90,87,65,43,21]# # alist = [1,2,3,4,5,6,7,8,9]# select_sort(alist)# print(alist)# O(n^2)# 不稳定def select_sort(alist):"""选择排序"""n = len(alist)for i in range(n - 1):min_index = i # 最⼩值位置索引、下标for j in range(i+1, n):if alist[j] < alist[min_index]:min_index = j# 判断min_index ,如果和初始值不相同,作数值交换if min_index != i:alist[i], alist[min_index] = alist[min_index],alist[i]if__name__ == '__main__':alist = [8,10,15,30,25,90,66,2,999]select_sort(alist)print(alist)这是⼀些算法的时间复杂度与稳定性时间复杂度,空间复杂度 接下来就要来说说时间复杂度与空间复杂度: 时间复杂度就是假如你泡茶,从开始泡,到你喝完茶,⼀共⽤了多长时间,你中间要执⾏很多步骤,取茶叶,烧⽔,上厕所,接电话,这些都是要花时间的,在算法中,时间复杂度分为 O(1)最快 , O(nn)最慢,O(1) < O(logn) <O(n)<O(n2)<O(n3)<O(2n) <O(nn) ⼀般游览器的速度都在O(n),做我们这⼀⾏,要注意客户体验,如果你程序的运⾏特别慢,估计别⼈来⼀次,以后再也不会来了下⾯给⼤家找了张如何计算时间复杂度的图⽚: 空间复杂度(space complexity) ,执⾏时所需要占的储存空间,记做 s(n)=O(f(n)),其中n是为算法的⼤⼩, 空间复杂度绝对是效率的杀⼿,曾经看过⼀遍⽤插⼊算法的代码,来解释空间复杂度的,觉得特别厉害,我就⽐较low了,只能给⼤家简单的总结⼀下我遇到的空间复杂度了, ⼀般来说,算法的空间复杂度值得是辅助空间,⽐如:⼀组数字,时间复杂度O(n),⼆维数组a[n][m] :那么他的空间复杂度就是O(n*m) ,因为变量的内存是⾃动分配的,第⼀个的定义是循环⾥⾯的,所以是n*O(1) ,如果第⼆个循环在外边,那么就是1*O(1) ,这⾥也只是⼀个了解性的东西,如果你的⼯作中很少⽤到,那么没有必要深究,因为⽤的真的很少优化算法这边带来了代码,你们在复制下来了python上运⾏⼀下,看⼀下⽤的时间与不同, ⾃然就懂了,这是未优化的算法''已知有a,b,c三个数,都是0-1000之内的数,且: a+b+c=1000 ⽽且 a**2+b**2=c**2 ,求a,b,c⼀共有多少种组合'''# 在这⾥加⼀个时间模块,待会好计算出结果import time# 记录开头时间start_time=time.time()# 把a,b,c循环出来for a in range(1001):for b in range(1001):for c in range(100):# 判断他主公式第⼀次,并未优化if a+b+c==1000 and a**2 + b**2 == c**2 :# 打印print("a=" ,a)print("b=" ,b)print("c=" ,c)else:passstop_time = time.time()print('⼀共耗时: %f'%(stop_time-start_time))# ⼀共耗时 156.875001秒这是第⼀次优化import time# 记录开头时间start_time=time.time()# 把a,b,c循环出来for a in range(1001):# 这⾥改成1001-a之后,他就不⽤再循环b了for b in range(1001-a):for c in range(100):# 判断他主公式第⼆次,优化了b,if a+b+c==1000 and a**2 + b**2 == c**2 :print("a=" ,a)print("b=" ,b)print("c=" ,c)else:passstop_time = time.time()print('⼀共耗时: %f'%(stop_time-start_time))# ⼀共耗时 50.557070秒最后⼀次优化import time# 记录开头时间start_time=time.time()# 把a,b,c循环出来for a in range(1001):for b in range(1001-a):c=1000 - a - b# 判断他主公式第三次,优化了b和cif a+b+c==1000 and a**2 + b**2 == c**2 :print("a=" ,a)print("b=" ,b)print("c=" ,c)else:passstop_time = time.time()print('⼀共耗时: %f'%(stop_time-start_time))# ⼀共耗时 2.551449秒从156秒优化到l2秒, 基本运算总数 * 基本运算耗时 = 运算时间这之间的耗时和你的机器有着很⼤的关系今天是12⽉30⽇,明天就要跨年了,祝⼤家2019年事业有成,⼯资直线上升,早⽇脱单,。

NOIP2009年普及组初赛题目及答案解析一、单项选择题(共20题,每题1.5分,共计30分。
每题有且仅有一个正确答案。
)1、关于图灵机下面的说法哪个是正确的:(D)A.图灵机是世界上最早的电子计算机。
B.由于大量使用磁带操作,图灵机运行速度很慢。
C.图灵机是英国人图灵发明的,在二战中为破译德军的密码发挥了重要作用。
D.图灵机只是一个理论上的计算模型。
【解析】所谓的图灵机就是指一个抽象的机器,它有一条无限长的纸带,纸带分成了一个一个的小方格,每个方格有不同的颜色。
有一个机器头在纸带上移来移去。
机器头有一组内部状态,还有一些固定的程序。
在每个时刻,机器头都要从当前纸带上读入一个方格信息,然后结合自己的内部状态查找程序表,根据程序输出信息到纸带方格上,并转换自己的内部状态,然后进行移动。
2、关于计算机内存下面的说法哪个是正确的:(B)A.随机存储器(RAM)的意思是当程序运行时,每次具体分配给程序的内存位置是随机而不确定的。
B.1MB内存通常是指1024*1024字节大小的内存。
C.计算机内存严格说来包括主存(memory)、高速缓存(cache)和寄存器(register)三个部分。
D.一般内存中的数据即使在断电的情况下也能保留2个小时以上。
【解析】A项:RAM不是位置随机,而是随时访问。
所谓“随机存储”,指的是“当存储器中的消息被读取或写入时,所需要的时间与这段信息所在的位置无关。
”B项:1MB=1024KB,1KB=1024BC项:计算机内存包括严格来说包括只读存储器(RAM)、随机存储器(ROM)和高速缓存(CACHE)。
如果不严格来说只包含只读存储器和随机存储器。
D项:内存中的数据断电立即丢失。
3、关于BIOS下面说法哪个是正确的:(A)A.BIOS是计算机基本输入输出系统软件的简称。
B.BIOS里包含了键盘、鼠标、声卡、显卡、打印机等常用输入输出设备的驱动程序。
C.BIOS一般由操作系统厂商来开发完成。

排序—时间复杂度为O(n2)的三种排序算法1 如何评价、分析⼀个排序算法?很多语⾔、数据库都已经封装了关于排序算法的实现代码。
所以我们学习排序算法⽬的更多的不是为了去实现这些代码,⽽是灵活的应⽤这些算法和解决更为复杂的问题,所以更重要的是学会如何评价、分析⼀个排序算法并在合适的场景下正确使⽤。
分析⼀个排序算法,主要从以下3个⽅⾯⼊⼿:1.1 排序算法的执⾏效率1)最好情况、最坏情况和平均情况时间复杂度待排序数据的有序度对排序算法的执⾏效率有很⼤影响,所以分析时要区分这三种时间复杂度。
除了时间复杂度分析,还要知道最好、最坏情况复杂度对应的要排序的原始数据是什么样的。
2)时间复杂度的系数、常数和低阶时间复杂度反映的是算法执⾏时间随数据规模变⼤的⼀个增长趋势,平时分析时往往忽略系数、常数和低阶。
但如果我们排序的数据规模很⼩,在对同⼀阶时间复杂度的排序算法⽐较时,就要把它们考虑进来。
3)⽐较次数和交换(移动)次数内排序算法中,主要进⾏⽐较和交换(移动)两项操作,所以⾼效的内排序算法应该具有尽可能少的⽐较次数和交换次数。
1.2 排序算法的内存消耗也就是分析算法的空间复杂度。
这⾥还有⼀个概念—原地排序,指的是空间复杂度为O(1)的排序算法。
1.3 稳定性如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变,那么这种排序算法叫做稳定的排序算法;如果前后顺序发⽣变化,那么对应的排序算法就是不稳定的排序算法。
在实际的排序应⽤中,往往不是对单⼀关键值进⾏排序,⽽是要求排序结果对所有的关键值都有序。
所以,稳定的排序算法往往适⽤场景更⼴。
2 三种时间复杂度为O(n2)的排序算法2.1 冒泡排序2.1.1 原理两两⽐较相邻元素是否有序,如果逆序则交换两个元素,直到没有逆序的数据元素为⽌。
每次冒泡都会⾄少让⼀个元素移动到它应该在的位置。
2.1.2 实现void BubbleSort(int *pData, int n) //冒泡排序{int temp = 0;bool orderlyFlag = false; //序列是否有序标志for (int i = 0; i < n && !orderlyFlag; ++i) //执⾏n次冒泡{orderlyFlag = true;for (int j = 0; j < n - 1 - i; ++j) //注意循环终⽌条件{if (pData[j] > pData[j + 1]) //逆序{orderlyFlag = false;temp = pData[j];pData[j] = pData[j + 1];pData[j + 1] = temp;}}}}测试结果2.1.3 算法分析1)时间复杂度最好情况时间复杂度:当待排序列已有序时,只需⼀次冒泡即可。
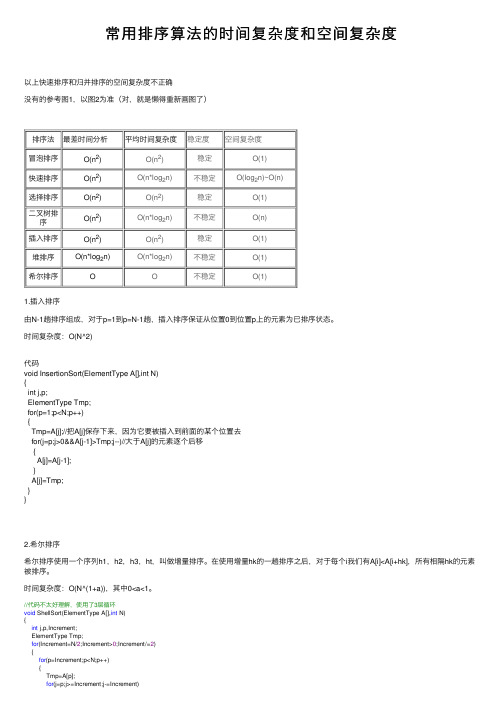
常⽤排序算法的时间复杂度和空间复杂度以上快速排序和归并排序的空间复杂度不正确没有的参考图1,以图2为准(对,就是懒得重新画图了)排序法最差时间分析平均时间复杂度稳定度空间复杂度冒泡排序O(n2)O(n2)稳定O(1)快速排序O(n2)O(n*log2n)不稳定O(log2n)~O(n)选择排序O(n2)O(n2)稳定O(1)⼆叉树排O(n2)O(n*log2n)不稳定O(n)序插⼊排序O(n2)O(n2)稳定O(1)堆排序O(n*log2n)O(n*log2n)不稳定O(1)希尔排序O O不稳定O(1)1.插⼊排序由N-1趟排序组成,对于p=1到p=N-1趟,插⼊排序保证从位置0到位置p上的元素为已排序状态。
时间复杂度:O(N^2)代码void InsertionSort(ElementType A[],int N){int j,p;ElementType Tmp;for(p=1;p<N;p++){Tmp=A[j];//把A[j]保存下来,因为它要被插⼊到前⾯的某个位置去for(j=p;j>0&&A[j-1]>Tmp;j--)//⼤于A[j]的元素逐个后移{A[j]=A[j-1];}A[j]=Tmp;}}2.希尔排序希尔排序使⽤⼀个序列h1,h2,h3,ht,叫做增量排序。
在使⽤增量hk的⼀趟排序之后,对于每个i我们有A[i]<A[i+hk],所有相隔hk的元素被排序。
时间复杂度:O(N^(1+a)),其中0<a<1。
//代码不太好理解,使⽤了3层循环void ShellSort(ElementType A[],int N){int j,p,Increment;ElementType Tmp;for(Increment=N/2;Increment>0;Increment/=2){for(p=Increment;p<N;p++){Tmp=A[p];for(j=p;j>=Increment;j-=Increment){if(A[j]<A[j-Increment])A[j]=A[j-Increment];elsebreak;}A[j]=Tmp;}}}3. 堆排序思想:建⽴⼩顶堆,然后执⾏N次deleteMin操作。

各种排序算法的时间复杂度和空间复杂度(阿⾥)⼆分查找法的时间复杂度:O(logn) redis,kafka,B+树的底层都采⽤了⼆分查找法参考:⼆分查找法 redis的索引底层的跳表原理实现参考:⼆分查找法参考:⼆分查找法:1.⼆分查找⼆分查找也称为折半查找,它是⼀种效率较⾼的查找⽅法。
⼆分查找的使⽤前提是线性表已经按照⼤⼩排好了序。
这种⽅法充分利⽤了元素间的次序关系,采⽤分治策略。
基本原理是:⾸先在有序的线性表中找到中值,将要查找的⽬标与中值进⾏⽐较,如果⽬标⼩于中值,则在前半部分找,如果⽬标⼩于中值,则在后半部分找;假设在前半部分找,则再与前半部分的中值相⽐较,如果⼩于中值,则在中值的前半部分找,如果⼤于中值,则在后半部分找。
以此类推,直到找到⽬标为⽌。
假设我们要在 2,6,11,13,16,17,22,30中查找22,上图所⽰,则查找步骤为:⾸先找到中值:中值为13(下标:int middle = (0+7)/2),将22与13进⾏⽐较,发现22⽐13⼤,则在13的后半部分找;在后半部分 16,17,22,30中查找22,⾸先找到中值,中值为17(下标:int middle=(0+3)/2),将22与17进⾏⽐较,发现22⽐17⼤,则继续在17的后半部分查找;在17的后半部分 22,30查找22,⾸先找到中值,中值为22(下标:int middle=(0+1)/2),将22与22进⾏⽐较,查找到结果。
⼆分查找⼤⼤降低了⽐较次数,⼆分查找的时间复杂度为:O(logn),即。
⽰例代码:public class BinarySearch {public static void main(String[] args) {int arr[] = {2, 6, 11, 13, 16, 17, 22, 30};System.out.println("⾮递归结果,22的位置为:" + binarySearch(arr, 22));System.out.println("递归结果,22的位置为:" + binarySearch(arr, 22, 0, 7));}//⾮递归static int binarySearch(int[] arr, int res) {int low = 0;int high = arr.length-1;while(low <= high) {int middle = (low + high)/2;if(res == arr[middle]) {return middle;}else if(res <arr[middle]) {high = middle - 1;}else {low = middle + 1;}}return -1;}//递归static int binarySearch(int[] arr,int res,int low,int high){if(res < arr[low] || res > arr[high] || low > high){return -1;}int middle = (low+high)/2;if(res < arr[middle]){return binarySearch(arr, res, low, middle-1);}else if(res > arr[middle]){return binarySearch(arr, res, middle+1, high);}else {return middle;}}}其中冒泡排序加个标志,所以最好情况下是o(n)直接选择排序:排序过程:1 、⾸先在所有数据中经过 n-1次⽐较选出最⼩的数,把它与第 1个数据交换,2、然后在其余的数据内选出排序码最⼩的数,与第 2个数据交换...... 依次类推,直到所有数据排完为⽌。

【转】三种快速排序算法以及快速排序的优化⼀. 快速排序的基本思想快速排序使⽤分治的思想,通过⼀趟排序将待排序列分割成两部分,其中⼀部分记录的关键字均⽐另⼀部分记录的关键字⼩。
之后分别对这两部分记录继续进⾏排序,以达到整个序列有序的⽬的。
⼆. 快速排序的三个步骤1) 选择基准:在待排序列中,按照某种⽅式挑出⼀个元素,作为 “基准”(pivot);2) 分割操作:以该基准在序列中的实际位置,把序列分成两个⼦序列。
此时,在基准左边的元素都⽐该基准⼩,在基准右边的元素都⽐基准⼤;3) 递归地对两个序列进⾏快速排序,直到序列为空或者只有⼀个元素;三. 选择基准元的⽅式对于分治算法,当每次划分时,算法若都能分成两个等长的⼦序列时,那么分治算法效率会达到最⼤。
也就是说,基准的选择是很重要的。
选择基准的⽅式决定了两个分割后两个⼦序列的长度,进⽽对整个算法的效率产⽣决定性影响。
最理想的⽅法是,选择的基准恰好能把待排序序列分成两个等长的⼦序列。
⽅法⼀:固定基准元(基本的快速排序)思想:取序列的第⼀个或最后⼀个元素作为基准元。
/// <summary>/// 1.0 固定基准元(基本的快速排序)/// </summary>public static void QsortCommon(int[] arr, int low, int high){if (low >= high) return; //递归出⼝int partition = Partition(arr, low, high); //将 >= x 的元素交换到右边区域,将 <= x 的元素交换到左边区域QsortCommon(arr, low, partition - 1);QsortCommon(arr, partition + 1, high);}/// <summary>/// 固定基准元,默认数组第⼀个数为基准元,左右分组,返回基准元的下标/// </summary>public static int Partition(int[] arr, int low, int high){int first = low;int last = high;int key = arr[low]; //取第⼀个元素作为基准元while (first < last){while (first < last && arr[last] >= key)last--;arr[first] = arr[last];while (first < last && arr[first] <= key)first++;arr[last] = arr[first];}arr[first] = key; //基准元居中return first;}注意:基本的快速排序选取第⼀个或最后⼀个元素作为基准。

快排复杂度及其证明快速排序(Quicksort)是一种经典的排序算法,其平均时间复杂度为O(nlogn)。
该算法的核心思想是通过递归地将数组分割成较小的子数组,然后分别对子数组进行排序。
快速排序的步骤如下:首先选择一个基准元素,然后将数组中比基准元素小的元素放在基准元素的左边,将比基准元素大的元素放在基准元素的右边。
接着递归地对左右两个子数组进行排序,直到整个数组有序。
快速排序的时间复杂度分析如下:在最好情况下,每次划分都能平分数组,时间复杂度为O(nlogn);在最坏情况下,每次划分只能将数组分成一个元素和其余元素两部分,时间复杂度为O(n^2)。
然而,通过随机选择基准元素或者使用三数取中法可以避免最坏情况的发生,从而保证快速排序的平均时间复杂度为O(nlogn)。
快速排序的时间复杂度证明可以通过数学归纳法进行推导。
假设对n个元素的数组进行快速排序的时间复杂度为T(n),则有:T(n) = 2T(n/2) + O(n)。
其中2T(n/2)表示对左右两个子数组进行排序的时间复杂度,O(n)表示划分数组的时间复杂度。
根据主定理(Master Theorem)可知,对于递推式T(n) = aT(n/b) + f(n),其中a>=1,b>1,f(n)是多项式,有以下三种情况:1. 若f(n) = O(n^d),其中d<logba,则T(n) = O(n^logba);2. 若f(n) = Θ(n^d * log^k n),其中d=logba,则T(n) = O(n^d * log^(k+1) n);3. 若f(n) = Ω(n^d),其中d>logba,则T(n) = O(f(n))。
根据快速排序的递推式T(n) = 2T(n/2) + O(n),可以得到a=2,b=2,f(n)=O(n)。
因此,根据主定理可知,快速排序的时间复杂度为O(nlogn)。
快速排序是一种时间复杂度为O(nlogn)的高效排序算法,通过合理选择基准元素和递归地划分子数组,可以在平均情况下实现较快的排序速度。

关于堆排序、归并排序、快速排序的⽐较时间复杂度:堆排序归并排序快速排序最坏时间 O(nlogn) O(nlogn) O(n^2)最好时间 O(nlogn) O(nlogn) O(nlogn)平均时间 O(nlogn) O(nlogn) O(nlogn)辅助空间 O(1) O(n) O(logn)~O(n)从时间复杂度看堆排序最好有⼈说代码实现后,数据量⾜够⼤的时候,快速排序的时间确实是⽐堆排序短解释是,对于数组,快速排序每下⼀次寻址都是紧挨当前地址的,⽽堆排序的下⼀次寻址和当前地址的距离⽐较长。
⽹友解答:1#4种⾮平⽅级的排序:希尔排序,堆排序,归并排序,快速排序我测试的平均排序时间:数据是随机整数,时间单位是秒数据规模快速排序归并排序希尔排序堆排序1000万 0.75 1.22 1.77 3.575000万 3.78 6.29 9.48 26.541亿 7.65 13.06 18.79 61.31堆排序是最差的。
这是算法硬伤,没办法的。
因为每次取⼀个最⼤值和堆底部的数据(记为X)交换,重新筛选堆,把堆顶的X调整到位,有很⼤可能是依旧调整到堆的底部(堆的底部X显然是⽐较⼩的数,才会在底部),然后再次和堆顶最⼤值交换,再调整下来。
从上⾯看出,堆排序做了许多⽆⽤功。
⾄于快速排序为啥⽐归并排序快,我说不清楚。
2#算法复杂度⼀样只是说明随着数据量的增加,算法时间代价增长的趋势相同,并不是执⾏的时间就⼀样,这⾥⾯有很多常量参数的差别,即使是同样的算法,不同的⼈写的代码,不同的应⽤场景下执⾏时间也可能差别很⼤。
快排的最坏时间虽然复杂度⾼,但是在统计意义上,这种数据出现的概率极⼩,⽽堆排序过程⾥的交换跟快排过程⾥的交换虽然都是常量时间,但是常量时间差很多。
3#请问你的快快速排序是怎么写的,我写的快速排序,当测试数组⼤于5000的时候就栈溢出了。
其他的⼏个排序都对着,不过他们呢没有⽤栈。
这是快速排序的代码,win7 32位,vs2010.1int FindPos(double *p,int low,int high)2 {3double val = p[low];4while (low<high)5 {6while(low<high&&p[high]>=val)7 high--;8 p[low]=p[high];9while(low<high&&p[low]<val)10 low++;11 p[high]=p[low];12 }13 p[low]=val;14return low;15 }16void QuickSort(double *a,int low,int high)17 {18if (!a||high<low)19return;2021if (low<high)22 {23int pos=FindPos(a,low,high);24 QuickSort(a,low,pos-1);25 QuickSort(a,pos+1,high);26 }27 }……7#谁说的快排好啊?我⼀般都⽤堆的,我认为堆好。

一、插入排序特点:stable sort、In-place sort最优复杂度:当输入数组就是排好序的时候,复杂度为O(n),而快速排序在这种情况下会产生O(n^2)的复杂度。
最差复杂度:当输入数组为倒序时,复杂度为O(n^2)插入排序比较适合用于“少量元素的数组”。
其实插入排序的复杂度和逆序对的个数一样,当数组倒序时,逆序对的个数为n(n-1)/2,因此插入排序复杂度为O(n^2)。
在算法导论2-4中有关于逆序对的介绍。
伪代码:证明算法正确性:循环不变式:在每次循环开始前,A[1...i-1]包含了原来的A[1...i-1]的元素,并且已排序。
初始:i=2,A[1...1]已排序,成立。
保持:在迭代开始前,A[1...i-1]已排序,而循环体的目的是将A[i]插入A[1...i-1]中,使得A[1...i]排序,因此在下一轮迭代开始前,i++,因此现在A[1...i-1]排好序了,因此保持循环不变式。
终止:最后i=n+1,并且A[1...n]已排序,而A[1...n]就是整个数组,因此证毕。
而在算法导论2.3-6中还问是否能将伪代码第6-8行用二分法实现?实际上是不能的。
因为第6-8行并不是单纯的线性查找,而是还要移出一个空位让A[i]插入,因此就算二分查找用O(lgn)查到了插入的位置,但是还是要用O(n)的时间移出一个空位。
问:快速排序(不使用随机化)是否一定比插入排序快?答:不一定,当输入数组已经排好序时,插入排序需要O(n)时间,而快速排序需要O(n^2)时间。
递归版插入排序二、冒泡排序特点:stable sort、In-place sort思想:通过两两交换,像水中的泡泡一样,小的先冒出来,大的后冒出来。
最坏运行时间:O(n^2)最佳运行时间:O(n^2)(当然,也可以进行改进使得最佳运行时间为O(n))算法导论思考题2-2中介绍了冒泡排序。
伪代码:证明算法正确性:运用两次循环不变式,先证明第4-6行的内循环,再证明外循环。

时间复杂度大小排序口诀在这个信息爆炸的时代,时间就像一条飞速奔流的河流,我们常常在思考如何让它流淌得更快些。
说到效率,时间复杂度就是我们不能忽视的话题。
你知道吗?它就像一道神秘的公式,帮我们分析算法的好坏。
咱们今天就来聊聊这个“复杂度”的故事,顺便给你一套排序口诀,保证让你轻松记住。
想象一下,假如你在一个热闹的集市上,摆摊卖东西。
你的摊位前排起了长龙,顾客们急得像热锅上的蚂蚁。
这个时候,时间复杂度就像一块天平,帮助你衡量每个顾客在你摊位前所花的时间。
最简单的情况是O(1),也就是常数时间,顾客们像闪电一样走过来,买完东西就走,爽快得很。
想想看,那样多好,买卖皆欢喜。
再往上走一步,O(log n)就来了。
这就像是你有一把神奇的钥匙,每次进店都能直接跳过一半的顾客。
越来愉快,这种效率简直就是上天的恩赐!可你知道,这样的情况可不常见,更多时候我们需要面对O(n)的线性时间复杂度。
想象一下,你在拥挤的地铁上,得一个个地挤过人群,虽然有点磨蹭,但总能到达目的地,哈哈,真是有点心累。
然后,O(n log n)就像是个狡猾的家伙,它把线性和对数结合在一起,做得特别好。
比如,你的快递要排序,这种情况下就像是你先把快递按区域分好,再慢慢给每个区域里的快递排序,效率就高了不少,心里那个踏实,简直太赞了。
然而,有些时候,我们就要面对O(n²)的二次时间复杂度。
想象一下,参加一个舞会,你得和每一个人跳舞,结果你会发现,你的时间全被消耗在了不停的跳舞中。
即便你舞技了得,这种时间消耗也让人心累,尤其是人越多,问题越大。
最麻烦的情况是O(2^n),这是个指数级的复杂度,感觉就像在参加一场马拉松,谁能熬到最后谁就是赢家。
这种情况下,选手们都快累趴下了,时间就像没完没了的折磨,令人痛苦不已。
想想看,没几个人能熬得过去,简直是“苦不堪言”。
复杂度还可以更高,但我们今天就聊到这里。
简单来说,时间复杂度就像一张地图,指引我们如何更聪明地解决问题。

数组各种排序算法和复杂度分析Java排序算法1)分类:插⼊排序(直接插⼊排序、希尔排序)交换排序(冒泡排序、快速排序)选择排序(直接选择排序、堆排序)归并排序分配排序(箱排序、基数排序)所需辅助空间最多:归并排序所需辅助空间最少:堆排序平均速度最快:快速排序不稳定:快速排序,希尔排序,堆排序。
2)选择排序算法的时候要考虑数据的规模、数据的类型、数据已有的顺序。
⼀般来说,当数据规模较⼩时,应选择直接插⼊排序或冒泡排序。
任何排序算法在数据量⼩时基本体现不出来差距。
考虑数据的类型,⽐如如果全部是正整数,那么考虑使⽤桶排序为最优。
考虑数据已有顺序,快排是⼀种不稳定的排序(当然可以改进),对于⼤部分排好的数据,快排会浪费⼤量不必要的步骤。
数据量极⼩,⽽起已经基本排好序,冒泡是最佳选择。
我们说快排好,是指⼤量随机数据下,快排效果最理想。
⽽不是所有情况。
3)总结:——按平均的时间性能来分:时间复杂度为O(nlogn)的⽅法有:快速排序、堆排序和归并排序,其中以快速排序为最好;时间复杂度为O(n2)的有:直接插⼊排序、起泡排序和简单选择排序,其中以直接插⼊为最好,特别是对那些对关键字近似有序的记录序列尤为如此;时间复杂度为O(n)的排序⽅法只有,基数排序。
当待排记录序列按关键字顺序有序时,直接插⼊排序和起泡排序能达到O(n)的时间复杂度;⽽对于快速排序⽽⾔,这是最不好的情况,此时的时间性能蜕化为O(n2),因此是应该尽量避免的情况。
简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布⽽改变。
——按平均的空间性能来分(指的是排序过程中所需的辅助空间⼤⼩):所有的简单排序⽅法(包括:直接插⼊、起泡和简单选择)和堆排序的空间复杂度为O(1);快速排序为O(logn ),为栈所需的辅助空间;归并排序所需辅助空间最多,其空间复杂度为O(n );链式基数排序需附设队列⾸尾指针,则空间复杂度为O(rd )。
——排序⽅法的稳定性能:稳定的排序⽅法指的是,对于两个关键字相等的记录,它们在序列中的相对位置,在排序之前和经过排序之后,没有改变。

快速排序(C语⾔)-解析快速排序快速排序是⼀种排序算法,对包含 n 个数的输⼊数组,最坏情况运⾏时间为O(n2)。
虽然这个最坏情况运⾏时间⽐较差,但快速排序通常是⽤于排序的最佳的实⽤选择,这是因为其平均性能相当好:期望的运⾏时间为O(nlgn),且O(nlgn)记号中隐含的常数因⼦很⼩。
另外,它还能够进⾏就地排序,在虚存环境中也能很好的⼯作。
快速排序(Quicksort)是对的⼀种改进。
快速排序由C. A. R. Hoare在1962年提出。
它的基本思想是:通过⼀趟排序将要排序的数据分割成独⽴的两部分,其中⼀部分的所有数据都⽐另外⼀部分的所有数据都要⼩,然后再按此⽅法对这两部分数据分别进⾏快速排序,整个排序过程可以进⾏,以此达到整个数据变成有序。
像合并排序⼀样,快速排序也是采⽤分治模式的。
下⾯是对⼀个典型数组A[p……r]排序的分治过程的三个步骤:分解:数组 A[p……r]被划分为两个(可能空)⼦数组 A[p……q-1] 和 A[q+1……r] ,使得 A[p……q-1] 中的每个元素都⼩于等于 A(q) , ⽽且,⼩于等于 A[q+1……r] 中的元素。
⼩标q也在这个划分过程中进⾏计算。
解决:通过递归调⽤快速排序,对于数组 A[p……q-1] 和 A[q+1……r] 排序。
合并:因为两个⼦数组是就地排序的,将它们的合并不需要操作:整个数组 A[p……r] 已排序。
下⾯的过程实现快速排序(伪代码):QUICK SORT(A,p,r)1if p<r2 then q<-PARTITION(A,p,r)3 QUICKSORT(A,p,q-1)4 QUICKSORT(A,q+1,r)为排序⼀个完整的数组A,最初的调⽤是QUICKSORT(A,1,length[A])。
数组划分: 快速排序算法的关键是PARTITION过程,它对⼦数组 A[p……r]进⾏就地重排(伪代码):PARTITION(A,p,r)1 x <- A[r]2 i <- p-13for j <- p to r-14do if A[j]<=x5 then i <- i+16 exchange A[i] <-> A[j]7 exchange A[i + 1] <-> A[j]8return i+1排序演⽰⽰例假设⽤户输⼊了如下数组:下标012345数据627389创建变量i=0(指向第⼀个数据), j=5(指向最后⼀个数据), k=6(为第⼀个数据的值)。

各种排序算法的稳定性和时间复杂度小结选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
冒泡法:这是最原始,也是众所周知的最慢的算法了。
他的名字的由来因为它的工作看来象是冒泡:复杂度为O(n*n)。
当数据为正序,将不会有交换。
复杂度为O(0)。
直接插入排序:O(n*n)选择排序:O(n*n)快速排序:平均时间复杂度log2(n)*n,所有内部排序方法中最高好的,大多数情况下总是最好的。
归并排序:log2(n)*n堆排序:log2(n)*n希尔排序:算法的复杂度为n的1.2次幂关于快速排序分析这里我没有给出行为的分析,因为这个很简单,我们直接来分析算法:首先我们考虑最理想的情况1.数组的大小是2的幂,这样分下去始终可以被2整除。
假设为2的k次方,即k=log2(n)。
2.每次我们选择的值刚好是中间值,这样,数组才可以被等分。
第一层递归,循环n次,第二层循环2*(n/2)......所以共有n+2(n/2)+4(n/4)+...+n*(n/n) = n+n+n+...+n=k*n=log2(n)*n所以算法复杂度为O(log2(n)*n)其他的情况只会比这种情况差,最差的情况是每次选择到的middle都是最小值或最大值,那么他将变成交换法(由于使用了递归,情况更糟)。
但是你认为这种情况发生的几率有多大??呵呵,你完全不必担心这个问题。
实践证明,大多数的情况,快速排序总是最好的。
如果你担心这个问题,你可以使用堆排序,这是一种稳定的O(log2(n)*n)算法,但是通常情况下速度要慢于快速排序(因为要重组堆)。
本文是针对老是记不住这个或者想真正明白到底为什么是稳定或者不稳定的人准备的。
首先,排序算法的稳定性大家应该都知道,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。
在简单形式化一下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。

常见排序算法及对应的时间复杂度和空间复杂度转载请注明出处:(浏览效果更好)排序算法经过了很长时间的演变,产⽣了很多种不同的⽅法。
对于初学者来说,对它们进⾏整理便于理解记忆显得很重要。
每种算法都有它特定的使⽤场合,很难通⽤。
因此,我们很有必要对所有常见的排序算法进⾏归纳。
排序⼤的分类可以分为两种:内排序和外排序。
在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使⽤外存,则称为外排序。
下⾯讲的排序都是属于内排序。
内排序有可以分为以下⼏类: (1)、插⼊排序:直接插⼊排序、⼆分法插⼊排序、希尔排序。
(2)、选择排序:直接选择排序、堆排序。
(3)、交换排序:冒泡排序、快速排序。
(4)、归并排序 (5)、基数排序表格版排序⽅法时间复杂度(平均)时间复杂度(最坏)时间复杂度(最好)空间复杂度稳定性复杂性直接插⼊排序O(n2)O(n2)O(n2)O(n2)O(n)O(n)O(1)O(1)稳定简单希尔排序O(nlog2n)O(nlog2n)O(n2)O(n2)O(n)O(n)O(1)O(1)不稳定较复杂直接选择排序O(n2)O(n2)O(n2)O(n2)O(n2)O(n2)O(1)O(1)不稳定简单堆排序O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(1)O(1)不稳定较复杂冒泡排序O(n2)O(n2)O(n2)O(n2)O(n)O(n)O(1)O(1)稳定简单快速排序O(nlog2n)O(nlog2n)O(n2)O(n2)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)不稳定较复杂归并排序O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(nlog2n)O(n)O(n)稳定较复杂基数排序O(d(n+r))O(d(n+r))O(d(n+r))O(d(n+r))O(d(n+r))O(d(n+r))O(n+r)O(n+r)稳定较复杂图⽚版①插⼊排序•思想:每步将⼀个待排序的记录,按其顺序码⼤⼩插⼊到前⾯已经排序的字序列的合适位置,直到全部插⼊排序完为⽌。

python数组排序的⽅法排序算法是《数据结构与算法》中最基本的算法之⼀。
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进⾏排序,⽽外部排序是因排序的数据很⼤,⼀次不能容纳全部的排序记录,在排序过程中需要访问外存。
常见的内部排序算法有:插⼊排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。
⽤⼀张图概括:关于时间复杂度:1. 平⽅阶 (O(n2)) 排序各类简单排序:直接插⼊、直接选择和冒泡排序。
2. 线性对数阶 (O(nlog2n)) 排序快速排序、堆排序和归并排序;3. O(n1+§)) 排序,§ 是介于 0 和 1 之间的常数。
希尔排序4. 线性阶 (O(n)) 排序基数排序,此外还有桶、箱排序。
关于稳定性:排序后 2 个相等键值的顺序和排序之前它们的顺序相同稳定的排序算法:冒泡排序、插⼊排序、归并排序和基数排序。
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
名词解释:n:数据规模k:“桶”的个数In-place:占⽤常数内存,不占⽤额外内存Out-place:占⽤额外内存1、冒泡排序冒泡排序(Bubble Sort)也是⼀种简单直观的排序算法。
它重复地⾛访过要排序的数列,⼀次⽐较两个元素,如果他们的顺序错误就把他们交换过来。
⾛访数列的⼯作是重复地进⾏直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越⼩的元素会经由交换慢慢“浮”到数列的顶端。
作为最简单的排序算法之⼀,冒泡排序给我的感觉就像 Abandon 在单词书⾥出现的感觉⼀样,每次都在第⼀页第⼀位,所以最熟悉。
冒泡排序还有⼀种优化算法,就是⽴⼀个flag,当在⼀趟序列遍历中元素没有发⽣交换,则证明该序列已经有序。
但这种改进对于提升性能来说并没有什么太⼤作⽤。
(1)算法步骤1. ⽐较相邻的元素。
如果第⼀个⽐第⼆个⼤,就交换他们两个。
2. 对每⼀对相邻元素作同样的⼯作,从开始第⼀对到结尾的最后⼀对。

快速排序算法的时间复杂度在不同情况下有所不同。
在最理想的情况下,即每次选
择的基准值都能将数组平均分成两半,其时间复杂度可以达到O(n log n),其中n
是待排序数组的长度。
这是因为每次递归调用都会处理大约一半的元素,所以递归
的深度是log n,而每一层递归都需要遍历整个数组,所以总的时间复杂度是O(n log n)。
然而,在最坏的情况下,即待排序数组已经是有序的(或者逆序),或者选择的基准值每次都是最小(或最大)的元素,那么每次划分操作只会得到一个空列表和一
个包含所有剩余元素的列表,这导致递归调用的次数达到n,每次递归又需要遍历整个数组,所以时间复杂度会达到O(n^2)。
为了避免最坏情况的发生,通常会采用一些策略来优化基准值的选择,比如随机选
择基准值,或者使用“三数取中”等方法。
此外,在实际应用中,当待排序的数组长
度较小时,通常会切换到其他更简单的排序算法(如插入排序)来完成排序,以减小递归调用的开销。
综上所述,快速排序算法的平均时间复杂度是O(n log n),但在最坏情况下会达到O(n^2)。
因此,在实现快速排序算法时,需要注意避免最坏情况的发生,以确保算法的高效性。
快速排序的平均时间复杂度和最坏时间复杂度分别是O(nlgn)、O(n^2)。
当排序已经成为基本有序状态时,快速排序退化为O(n^2),一般情况下,排序为指数复杂度。
快速排序最差情况递归调用栈高度O(n),平均情况递归调用栈高度O(logn),而不管哪种情况栈的每一层处理时间都是O(n),所以,平均情况(最佳情况也是平均情况)的时间复杂度O(nlogn),最差情况的时间复杂度为O(n^2)。
扩展资料
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序,它采用了一种分治的策略,通常称其为分治法。
快速排序算法通过多次比较和交换来实现排序,其排序流程如下:
(1)首先设定一个分界值,通过该分界值将数组分成左右两部分。
(2)将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。
此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
(3)然后,左边和右边的数据可以独立排序。
对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。
右侧的数组数据也可以做类似处理。
(4)重复上述过程,可以看出,这是一个递归定义。
通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。
当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。