运筹学课件——第4讲 马尔可夫决策培训资料
- 格式:ppt
- 大小:350.50 KB
- 文档页数:52

马尔可夫决策过程简介马尔可夫决策过程(Markov Decision Process,MDP)是一种在人工智能和运筹学领域广泛应用的数学模型。
它可以描述一类随机决策问题,并提供了一种优化决策的框架。
在现实世界中,许多问题都可以被建模为马尔可夫决策过程,比如自动驾驶车辆的路径规划、机器人的行为控制和资源分配等。
1. 马尔可夫决策过程的基本概念在马尔可夫决策过程中,问题被建模为一个五元组(S, A, P, R, γ):- S 表示状态空间,包括所有可能的状态;- A 表示动作空间,包括所有可能的动作;- P 表示状态转移概率,描述了在某个状态下采取某个动作后转移到下一个状态的概率分布;- R 表示奖励函数,描述了在某个状态下采取某个动作后获得的即时奖励;- γ(gamma)表示折扣因子,用于平衡当前奖励和未来奖励的重要性。
2. 马尔可夫决策过程的模型马尔可夫决策过程的模型可以用有向图表示,其中节点表示状态,边表示从一个状态到另一个状态的动作,边上的权重表示状态转移概率和即时奖励。
通过对模型进行分析和计算,可以找到最优的决策策略,使得在长期累积奖励最大化的情况下,系统能够做出最优的决策。
3. 马尔可夫决策过程的求解方法对于小规模的马尔可夫决策过程,可以直接使用动态规划方法进行求解,比如值迭代和策略迭代。
值迭代是一种迭代算法,通过不断更新状态值函数来找到最优策略;策略迭代则是一种迭代算法,通过不断更新策略函数来找到最优策略。
这些方法可以保证最终收敛到最优解,但是计算复杂度较高。
对于大规模的马尔可夫决策过程,通常采用近似求解的方法,比如蒙特卡洛方法、时序差分学习方法和深度强化学习方法。
蒙特卡洛方法通过对大量样本进行采样和统计来估计状态值函数和策略函数;时序差分学习方法则是一种在线学习算法,通过不断更新估计值函数来逼近真实值函数;深度强化学习方法则是一种基于神经网络的方法,通过端到端的学习来直接从环境中学习最优策略。

马尔可夫决策基础理论内容提要本章介绍与研究背景相关的几类决策模型及算法。
模型部分,首先是最基本的马尔可夫决策模型,然后是在此基础上加入观察不确定性的部分可观察马尔可夫决策模型,以及进一步加入多智能体的分布式部分可观察马尔可夫决策模型和部分可观察的随机博弈模型。
算法部分,针对上述几类模型,我们均按照后向迭代和前向搜索两大类进行对比分析。
最后,我们介绍了半马尔可夫决策模型及Option理论,这一理论为我们后面设计分等级的大规模多智能体系统的决策模型及规划框架提供了重要基础。
2.1 MDP基本模型及概念马尔可夫决策过程适用的系统有三大特点:一是状态转移的无后效性;二是状态转移可以有不确定性;三是智能体所处的每步状态完全可以观察。
下面我们将介绍MDP基本数学模型,并对模型本身的一些概念,及在MDP模型下进行问题求解所引入的相关概念做进一步解释。
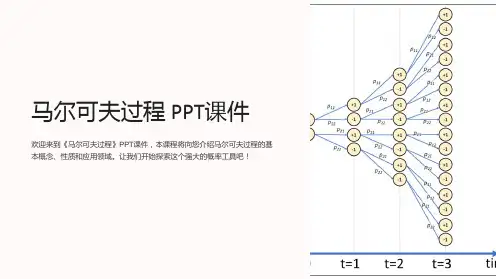
2.1.1 基本模型马尔科夫决策过程最基本的模型是一个四元组S,A,T,R(Puterman M, 1994):♦状态集合S:问题所有可能世界状态的集合;♦行动集合A:问题所有可能行动的集合;♦状态转移函数T: S×A×S’→[0,1]: 用T(s, a, s’)来表示在状态s,执行动作P s s a;a,而转移到状态s’的概率('|,)♦报酬函数R: S×A→R:我们一般用R(s,a)来表示在状态s执行动作a所能得到的立即报酬。
虽然有针对连续参数情况的MDP模型及算法,然而本文在没有特殊说明的情况都只讨论离散参数的情况,如时间,状态及行动的参数。
图2.1描述的是在MDP模型下,智能体(Agent)与问题对应的环境交互的过程。
智能体执行行动,获知环境所处的新的当前状态,同时获得此次行动的立即收益。
图 0.1 MDP 的基本模型2.1.2 状态状态是对于在某一时间点对该世界(系统)的描述。
最一般化的便是平铺式表示[],即对世界所有可能状态予以标号,以s 1,s 2,s 3,…这样的方式表示。







