第三章 灰色预测模型(谷风教育)
- 格式:ppt
- 大小:857.50 KB
- 文档页数:14

灰色预测模型灰色预测是就灰色系统所做的预测. 所谓灰色系统是介于白色系统和黑箱系统之间的过渡系统,其具体的含义是:如果某一系统的全部信息已知为白色系统,全部信息未知为黑箱系统,部分信息已知,部分信息未知,那么这一系统就是灰箱系统. 一般地说,社会系统、经济系统、生态系统都是灰色系统.灰色系统理论认为对既含有已知信息又含有未知或非确定信息的系统进行预测,就是对在一定方位内变化的、与时间有关的灰色过程的预测. 尽管过程中所显示的现象是随机的、杂乱无章的,但毕竟是有序的、有界的,因此这一数据集合具备潜在的规律,灰色预测就是利用这种规律建立灰色模型对灰色系统进行预测.灰色预测模型只需要较少的观测数据即可,这和时间序列分析,多元回归分析等需要较多数据的统计模型不一样. 因此,对于只有少量观测数据的项目来说,灰色预测是一种有用的工具.一、GM(1,1)模型灰色系统理论是邓聚龙教授在1981年提出来的,是一种对含有不确定因素系统进行预测的方法. 通过鉴别系统因素之间发展趋势的相异程度,进行关联分析,并通过对原始数据进行生成处理来寻找系统的变化规律,生成较强规律性数据序列,然后建立相应微分方程模型,从而预测事物未来的发展趋势和未来状态. 目前使用最广泛的灰色预测模型是关于数列预测的一个变量、一阶微分的GM(1,1)模型.GM(1,1)模型是基于灰色系统的理论思想,将离散变量连续化,用微分方程代替差分方程,按时间累加后所形成的新的时间序列呈现的规律可用一阶线性微分方程的解来逼近,用生成数序列代替原始时间序列,弱化原始时间序列的随机性,这样可以对变化过程作较长时间的描述,进而建立微分方程形式的模型. 其建模的实质是建立微分方程的系数,将时间序列转化为微分方程,通过灰色微分方程可以建立抽象系统的发展模型. 经证明,经一阶线性微分方程的解逼近所揭示的原始时间数列呈指数变化规律时,灰色预测GM(1,1)模型的预测将是非常成功的.1.1 GM(1,1)模型的建立灰色理论认为一切随机量都是在一定范围内、一定时间段上变化的灰色量及灰色过程. 数据处理不去寻找其统计规律和概率分布, 而是对原始数据作一定处理后, 使其成为有规律的时间序列数据, 在此基础上建立数学模型.GM(1,1)模型是指一阶,一个变量的微分方案预测模型,是一阶单序列的线性动态模型,用于时间序列预测的离散形式的微分方程模型.设时间序列()0X 有n 个观察值,()()()()()()(){}00001,2,,X x x x n =,为了使其成为有规律的时间序列数据,对其作一次累加生成运算,即令()()()()101tn xt x n ==∑从而得到新的生成数列()1X ,()()()()()()(){}11111,2,,X x x x n =,新的生成数列()1X 一般近似地服从指数规律. 则生成的离散形式的微分方程具体的形式为dxax u dt+= 即表示变量对于时间的一阶微分方程是连续的. 求解上述微分方程,解为当t =1时,()(1)x t x =,即(1)c x a=-,则可根据上述公式得到离散形式微分方程的具体形式为()()()11a t u u x t x e a a --⎛⎫=-+ ⎪⎝⎭其中,ax 项中的x 为dxdt的背景值,也称初始值;a ,u 是待识别的灰色参数,a 为发展系数,反映x 的发展趋势;u 为灰色作用量,反映数据间的变化关系.按白化导数定义有0()()limt dx x t t x t dt t→+-= 显然,当时间密化值定义为1时,当1t →时,则上式可记为1lim(()())t dxx t t x t dt→=+- 这表明dxdt是一次累减生成的,因此该式可以改写为 (1)(1)(1)()dxx t x t dt=+- 当t 足够小时,变量x 从()x t 到()x t t +是不会出现突变的,所以取()x t 与()x t t +的平均值作为当t 足够小时的背景值,即(1)(1)(1)1()(1)2x x t x t ⎡⎤=++⎣⎦将其值带入式子,整理得(0)(1)(1)1(1)()(1)2x t a x t x t u ⎡⎤+=-+++⎣⎦ 由其离散形式可得到如下矩阵:(1)(1)(0)(1)(1)(0)(0)(1)(1)1(1)(2)2(2)1(2)(3)(3)2()1(1)()2x x x x x x a u x n x n x n ⎛⎫⎡⎤-+ ⎪⎣⎦⎛⎫ ⎪ ⎪ ⎪⎡⎤-+ ⎪⎣⎦ ⎪=+ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭ ⎪⎡⎤--+ ⎪⎣⎦⎝⎭令 (0)(0)(0)(2),(3),,()TY x x x n ⎡⎤=⎣⎦(1)(1)(1)(1)(1)(1)11(1)(2)211(2)(3)21(1)()12x x x x B x n x n ⎛⎫⎡⎤-+ ⎪⎣⎦ ⎪ ⎪⎡⎤-+⎣⎦ ⎪= ⎪ ⎪ ⎪⎡⎤--+ ⎪⎣⎦⎝⎭()Ta u α=称Y 为数据向量,B 为数据矩阵,α为参数向量. 则上式可简化为线性模型:Y B α=由最小二乘估计方法得()1T T a B B B Y uα-⎛⎫== ⎪⎝⎭上式即为GM(1,1)参数,a u 的矩阵辨识算式,式中()1T T B B B Y -事实上是数据矩阵B 的广义逆矩阵.将求得的a ,u 值代入微分方程的解式,则()1(1)()((1))a t u u x t x e a a--=-+其中,上式是GM(1,1)模型的时间响应函数形式,将它离散化得(1)(0)(1)ˆ()(1)a t u u xt x e a a --⎛⎫=-+ ⎪⎝⎭ 对序列()()1ˆxt 再作累减生成可进行预测. 即 ()(0)(1)(1)(0)(1)ˆˆˆ()()(1)(1)1a a t xt x t x t u x e e a --=--⎛⎫=-- ⎪⎝⎭ 上式便是GM(1,1)模型的预测的具体计算式.或对()at ux t ce a-=+求导还原得(0)(0)(1)ˆ()((1))a t uxt a x e a--=-- 1.2 GM(1,1)模型的检验GM(1,1)模型的检验包括残差检验、关联度检验、后验差检验三种形式. 每种检验对应不同功能:残差检验属于算术检验,对模型值和实际值的误差进行逐点检验;关联度检验属于几何检验范围,通过考察模型曲线与建模序列曲线的几何相似程度进行检验,关联度越大模型越好;后验差检验属于统计检验,对残差分布的统计特性进行检验,衡量灰色模型的精度. ➢ 残差检验残差大小检验,即对模型值和实际值的残差进行逐点检验.设模拟值的残差序列为(0)()e t ,则(0)(0)(0)ˆ()()()e t x t xt =- 令()t ε为残差相对值,即残差百分比为(0)(0)(0)ˆ()()()%()x t xt t x t ε⎡⎤-=⎢⎥⎣⎦令∆为平均残差,11()nt t n ε=∆=∑.设残差的方差为22S ,则[]22211()n t S e t e n ==-∑. 故后验差比例C 为21/C S S =,误差频率P 为{}1()0.6745P P e t e S =-<.对于,C P 检验指标如下表: 检验指标好 合格 勉强 不合格 P >0.95 >0.80 >0.70 <0.70 表 1 灰色预测精确度检验等级标准一般要求()20%t ε<,最好是()10%t ε<,符合要求.➢ 关联度检验关联度是用来定量描述各变化过程之间的差别. 关联系数越大,说明预测值和实际值越接近.设 {}(0)(0)(0)(0)ˆˆˆˆ()(1),(2),,()Xt x x x n =⋯ {}(0)(0)(0)(0)()(1),(2),,()X t x x x n =⋯序列关联系数定义为(){}{}{}(0)(0)(0)(0)(0)(0)(0)(0)ˆˆmin ()()max ()(),0ˆˆ()()max ()()1,0x t x t x t x t t t x t x t x t x t t σξσ⎧-+-⎪≠⎪=⎨-+-⎪=⎪⎩ 式中,(0)(0)ˆ()()x t x t -为第t 个点(0)x 和(0)ˆx 的绝对误差,()t ξ为第t 个数据的关联系数,ρ称为分辨率,即取定的最大差百分比,0ρ<<1,一般取0.5ρ=.(0)()x t 和(0)ˆ()xt 的关联度为 ()11nt r t n ξ==∑精度等级 关联度 均方差比值 小误差概率 好(1级) 0.90≥ 0.35≤ 0.95≥ 合格(2级) 0.80≥ 0.50≤ 0.80≥ 勉强(3级) 0.70≥ 0.65≤ 0.70≥ 不合格(4级) 0.70< 0.65> 0.70<表 2 精度检验等级关联度大于60%便满意了,原始数据与预测数据关联度越大,模型越好.➢ 后验差检验后验差检验,即对残差分布的统计特性进行检验. 检验步骤如下:1、计算原始时间数列(){}0(0)(0)(0)(1),(2),,()X x x x n =的均值和方差()2(0)(0)2(0)11111(),()n n t t xx t S x t x n n ====-∑∑ 2、计算残差数列{}(0)(0)(0)(0)(1),(2),,()e e e e n =的均值e 和方差22s ()2(0)2(0)21111(),()n n t t e e t S e t e n n ====-∑∑其中(0)(0)(0)ˆ()()(),1,2,,e t x t x t t n =-=为残差数列.3、计算后验差比值21C S S =4、计算小误差频率{}(0)1()0.6745P P e t e S =-<令0S =0.67451S ,(0)()|()|t e t e ∆=-,即{}0()P P t S =∆<.若对给定的00C >,当0C C <时,称模型为方差比合格模型;若对给定的00P >,当0P P >时,称模型为小残差概率合格模型.P C 模型精度 >0.95 <0.35 优 >0.80 <0.5 合格 >0.70 <0.65 勉强合格 <0.70 >0.65 不合格表 3 后验差检验判别参照表1.3 残差GM(1,1)模型当原始数据序列(0)X 建立的GM(1,1)模型检验不合格时,可以用GM(1,1)残差模型来修正. 如果原始序列建立的GM(1,1)模型不够精确,也可以用GM(1,1)残差模型来提高精度.若用原始序列(0)X 建立的GM(1,1)模型(1)(0)ˆ(1)[(1)]at u uxt x e a a-+=-+ 可获得生成序列(1)X 的预测值,定义残差序列(0)(1)(1)ˆ()()()e k x k xk =-. 若取k=t , t+1, …, n ,则对应的残差序列为{}(0)(0)(0)(0)()(1),(2),,()e k e e e n =计算其生成序列(1)()e k ,并据此建立相应的GM(1,1)模型(1)(0)ˆ(1)[(1)]e a k e ee eu u et e e a a -+=-+ 得修正模型(1)(0)(0)(1)(1)()()(1)e a k ak e e e u u u x t x e k t a e e a a a δ--⎡⎤⎡⎤+=-++---⎢⎥⎢⎥⎣⎦⎣⎦其中1()0k tk t k tδ≥⎧-=⎨≤⎩为修正参数.应用此模型时要考虑:1、一般不是使用全部残差数据来建立模型,而只是利用了部分残差.2、修正模型所代表的是差分微分方程,其修正作用与()k t δ-中的t 的取值有关.1.4 GM(1,1)模型的适用范围定理:当GM(1,1)发展系数||2a ≥时,GM(1,1)模型没有意义.我们通过原始序列()0i X 与模拟序列()0ˆiX 进行误差分析,随着发展系数的增大,模拟误差迅速增加. 当发展系数0.3a -≤时,模拟精度可以达到98%以上;发展系数0.5a -≤时,模拟精度可以达到95%以上;发展系数1a ->时,模拟精度低于70%;发展系数 1.5a ->时,模拟精度低于50%.进一步对预测误差进行考虑,当发展系数0.3a -<时,1步预测精度在98%以上,2步和5步预测精度都在90%以上,10步预测精度亦高于80%;当发展系数0.8a ->时,1步预测精度已低于70%.通过以上分析,可得下述结论:1、当0.3a -<时,GM(1,1)可用于中长期预测;2、当0.30.5a <-≤时,GM(1,1)可用于短期预测,中长期预测慎用;3、当0.50.8a <-≤时,GM(1,1)作短期预测应十分谨慎;4、当0.81a <-≤时,应采用残差修正GM(1,1)模型;5、当1a ->时,不宜采用GM(1,1)模型.1.5 GM(1,1)模型实例分析()()(0)(0)(0)(0)(0)(1),(2),(3),(4)79,74.825,74.29,76.98X x x x x ==对(0)X 作一次累加后的数列为()()(1)(1)(1)(1)(1)(1),(2),(3),(4)79,153.825,228.115,305.095X x x x x == 对(1)X 做紧邻均值生成. 令(1)(1)(1)()0.5()0.5(1)Z k x k x k =+-,得()()(1)(1)(1)(1)(2),(3),(4)116.4125,151.47,150.1925Z z z z ==则数据矩阵B 及数据向量Y 为(1)(1)(1)(2)1116.41251(3)1151.471(4)1150.19251z B z z ⎡⎤--⎡⎤⎢⎥⎢⎥=-=-⎢⎥⎢⎥⎢⎥⎢⎥--⎣⎦⎣⎦,(0)(0)(0)(2)74.825(3)74.29(4)76.98x Y x x ⎡⎤⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦ 对参数列ˆ[,]T aa b =进行最小二乘估计,得 176.61ˆ()[,]0.0144T T T T a B B B Y B Y a u -⎡⎤====⎢⎥-⎣⎦即 0.0144a =-,76.61u = 则GM(1,1)模型为()()110.014476.61dx x dt-= 时间响应式为(1)0.0144ˆ(1)5399.13895320.1389xk e -+=- 当1k =时,我们取(1)(0)(0)ˆˆ(1)(1)(0)79xx x === 还原求出(0)X 的模拟值. 由(0)(1)(1)ˆˆˆ()()(1)Xk x k x k =--,取2,3,4k =,得 ()()(0)(0)(0)(0)(0)ˆˆˆˆˆ(1),(2),(3),(4)79,74.281,74.3584,76.4513xx x x x == 通过预测,得到实际值与预测值如下表:实际值 预测值相对误差()k ε 第一学期79 79 0 第二学期 74.825 74.2810 0.73% 第三学期 74.29 74.3584 0.0921% 第四学期76.9876.45130.7051%表 4 四学期的实际值与预测值的误差表因为()10%k ε<,那就可得学生的预测值,与现实值进行比较得出该模型精度较高,可进行预测和预报.我们对学生未来两个学期(也就是第五、六个学期)的成绩进行预测,分别为77.5602分和78.6851分.例:某大型企业1999年至2004年的产品销售额如下表,试建立GM(1,1)预测模型,并预测2005年的产品销售额。


灰色预测模型的研究及应用
灰色预测模型是一种用于预测问题的数学模型,广泛应用于各个领域。
它在1982年由中国科学家GM灰所提出,因此得名为“灰色预测模型”。
灰色预测模型基于灰色系统理论,它假设事物的发展具有一定的规律性和趋势性,但也存在不确定性的因素。
它通过对已知数据的分析和处理,来预测未来的发展趋势。
灰色预测模型的核心思想是将已知数据序列分解为两个部分:灰色部分和白色部分。
灰色部分是由数据的数量级和函数形式决定的,因此可以用来预测未来的趋势。
白色部分则是由不确定的随机因素引起的,往往被视为噪声,不具备预测能力。
灰色预测模型有多种形式,其中最常用的是GM(1,1)模型。
该模型通过建立一阶线性微分方程来描述数据的变化趋势,然后利用指数累减生成灰色模型。
基于灰色模型,可以进一步进行累加、累减、累乘等操作,来实现更复杂的预测。
灰色预测模型在各个领域都有广泛的应用。
其中最典型的应用是经济预测领域,包括国民经济、金融市场等。
此外,它还可以应用于工业生产、环境保护、农业发展、医疗卫生等方面的预测。
灰色预测模型的优点是简单易懂、计算量小、适用范围广。
它可以对数据的趋势进行较为准确的预测,尤其适用于数据量较小或者不完整的情况下。
缺点是对数据的要求较高,数据的采
样点要均匀分布,并且在建立模型时需要进行一些参数的选择,可能存在主观性和不确定性。
总之,灰色预测模型是一种有效的预测方法,具有广泛的应用前景。
在实际应用中,需要对具体问题进行合理的建模和参数选择,以提高预测的准确性。




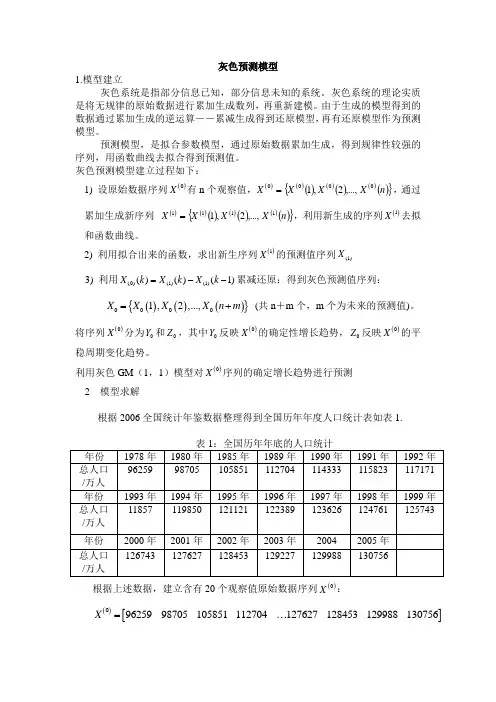
灰色预测模型1.模型建立灰色系统是指部分信息已知,部分信息未知的系统。
灰色系统的理论实质是将无规律的原始数据进行累加生成数列,再重新建模。
由于生成的模型得到的数据通过累加生成的逆运算――累减生成得到还原模型,再有还原模型作为预测模型。
预测模型,是拟合参数模型,通过原始数据累加生成,得到规律性较强的序列,用函数曲线去拟合得到预测值。
灰色预测模型建立过程如下:1) 设原始数据序列()0X 有n 个观察值,()()()()()()(){}n X X X X 0000,...,2,1=,通过累加生成新序列 ()()()()()()(){}n X X X X 1111,...,2,1=,利用新生成的序列()1X 去拟和函数曲线。
2) 利用拟合出来的函数,求出新生序列()1X 的预测值序列(1)X 3) 利用(0)(1)(1)()()(1)X k X k X k =--累减还原:得到灰色预测值序列: ()()(){}00001,2,...,X X X X n m =+ (共n +m 个,m 个为未来的预测值)。
将序列()0X 分为0Y 和0Z ,其中0Y 反映()0X 的确定性增长趋势,0Z 反映()0X 的平稳周期变化趋势。
利用灰色GM (1,1)模型对()0X 序列的确定增长趋势进行预测 2 模型求解根据2006全国统计年鉴数据整理得到全国历年年度人口统计表如表1.根据上述数据,建立含有20个观察值原始数据序列()0X :()[]09625998705105851112704127627128453129988130756X =利用Matlab 软件对原是数列()0X 进行一次累加,得到新数列为()1X ,如表2:表2:新数列()1X 误差和误差率1、利用表2,拟合函数,如下:0.011624(1)92800439183784t x t e +=-2、精度检验值c =0.3067 (很好) P =0.9474 (好)3、得到未来20年的预测值:。



预测⽅法——灰⾊预测模型灰⾊预测模型主要特点是模型使⽤的不是原始数据序列,⽽是⽣成的数据序列,核⼼体系为灰⾊模型(GM),即对原始数据作做累加⽣成(累减⽣成,加权邻值⽣成)得到近似指数规律再进⾏建模。
优点:不需要很多数据;将⽆规律原始数据进⾏⽣成得到规律性较强的⽣成序列。
缺点:只适⽤于中短期预测,只适合指数增长的预测。
GM(1,1)预测模型GM(1,1)模型是⼀阶微分⽅程,且只含⼀个变量。
1. 模型预测⽅法2. 模型预测步骤1. 数据检验与处理为保证建模⽅法可⾏,需要对已知数据做必要的检验处理。
设原始数据列为x(0)=(x0(1),x0(2),….x0(n)),计算数列的级⽐λ(k)=x(0)(k−1)x(0)(k),k=2,3,...,n如果所有的级⽐都落在可容覆盖区间X=(e−2n+1,e2n+1)内,则数列可以建⽴GM(1,1)模型且可以进⾏灰⾊预测。
否则,对数据做适当的变换处理,如平移变换:y(0)(k)=x(0)(k)+c,k=1,2,...,n取c使得数据列的级⽐都落在可容覆盖内。
2. 建⽴模型根据1中⽅程的解,进⼀步推断出预测值ˆx(1)(k+1)=(x(0)(1)−ba)e−ak+ba,k=1,2,...,n−13. 检验预测值1. 残差检验ε(k)=x(0)(k)−ˆx(0)(k)x(0)(k),k=1,2,...,n如果对所有的|ε(k)|<0.1|ε(k)|<0.1,则认为到达较⾼的要求;否则,若对所有的|ε(k)|<0.2|ε(k)|<0.2,则认为达到⼀般要求。
2. 级⽐偏差值检验ρ(k)=1−1−0.5a1+0.5aλ(k)如果对所有的|ρ(k)|<0.1,则认为达到较⾼的要求;否则,若对于所有的|ρ(k)|<0.2,则认为达到⼀般要求。
4. 预测预报根据问题需要给出预测预报。
3. py实现import numpy as npimport pandas as pddata=[71.1,72.4,72.4,72.1,71.4,72.0,71.6] # 数据来源len=len(data) # 数据量# 数据检验lambdas=[]for i in range(1,len):lambdas.append(data[i-1]/data[i])X_Min=np.e**(-2/(len+1))X_Max=np.e**(2/(len+1))l_min,l_max=min(lambdas),max(lambdas)if l_min<X_Min or l_max> X_Max:print("该组数据为通过数据检验,不能建⽴GM模型!")else:print("改组数据通过检验")# 建⽴GM(1,1)模型data_1=[] # 累加数列z_1=[]data_1.append(data[0])for i in range(1,len):data_1.append(data[i]+data_1[i-1])z_1.append(-0.5*(data_1[i]+data_1[i-1]))B=np.array(z_1).reshape(len-1,1)one=np.ones(len-1)B=np.c_[B,one]Y=np.array(data[1:]).reshape(len-1,1)a,b=np.dot(np.dot(np.linalg.inv(np.dot(B.T,B)),B.T),Y)print('a='+str(a))print('b='+str(b))## 数据预测data_1_prd=[]data_1_prd.append(data[0])data_prd=[] # 预测datadata_prd.append(data[0])for i in range(1,len):data_1_prd.append((data[0]-b/a)*np.e**(-a*i)+b/a)data_prd.append(data_1_prd[i]-data_1_prd[i-1])# 模型检验## 残差检验e=[]for i in range(len):e.append((data[i]-data_prd[i])/data[i])e_max=max(e)if e_max<0.1:print("数据预测达到较⾼要求!")elif e_max<0.2:print("数据预测达到⼀般要求!")# 输出预测数据for i in range(len):print(data_prd[i])灰⾊Verhulst预测模型主要⽤于描述具有饱和状体的过程,即S型过程,常⽤于⼈⼝预测,⽣物⽣长,繁殖预测及产品经济寿命预测等。
灰色預測模型理論灰色系統理論是一較新且具發展潛力之研究方法,此理論於1982年由大陸學者鄧聚龍教授提出,歷經幾年來的發展,已初步形成以灰關連空間為基礎的分析體系,灰色模型GM 為主體的模型體系,以及其它相關研究領域。
灰色系統理論最主要的功能即是找出影響系統之參數,並建立其數學關係式,依據模型之用途與描述方法不同,則有不同的關係式。
此灰色系統理論是將一切隨機過程看作是在一定範圍內變化的灰色量,將隨機過程看作是在一定範圍內變化的、與時間有關的灰色量過程,只要原始數據有4筆以上,就可通過生成變換來建立灰色模型(註三),也就是說灰色系統理論透過對資料的累加運算、累減運算、均值運算後形成生成空間,直接對生成空間進行建模預測,而後再還原成原始數列,達到預測目的。
此外,在灰色系統理論中對數據量的要求並不嚴苛,因此只需少量的數據便可進行建模,對於訊息不完整或資料數過少的系統環境,此理論也就發揮了它的實用性與強健性。
比較預測值與實際值之殘差比較預測值與實際值之殘差⑷回归分析法(P107);⑸速度比例法(P110)。
(讲解)结构比例法。
是一种用结构比例来测定相关指标值的方法。
检验比例是一个相对数,比如在货运企业的经营活动中,销售成本、税金、费用以及利润与销售收入有一定比例关系。
运用历史数据,求出加权平均结构比例,可预测求得与销售收入相关项目的比值。
(例)某公司1991年至1995年销售收入动态表,预测1996年的销售量。
表一是一组反映某公司1991年至1995年销售收入发展速度的动态数列,是一组预测未来值的重要数据。
现用“环比发展速度”方法进行计算。
计算环比发展速度 1、计算公式ii i A A X 11++ (1) 式中:X i+1为第i +1年销售收入环比发展速度 A i+1为第i +1年销售收H (当年) A i 第i 年销售收入(上一年) 2、以表一数据计算销售收入逐年环比速度1992年 1.22910991351X 2==1993年1.73413512342X 3==1994年 1.67023423910X 4==1995年1.92539107527X 5==将以上计算结果列表如下: 表二某公司销售收入环比速度动态表计量单位:万元1、计算公式1-n n324j X ......X X X X ⋅⋅⋅= (2)式中X j 为几何平均发展速度。