【8A版】编译原理实验报告FIRST集和FOLLOW集
- 格式:doc
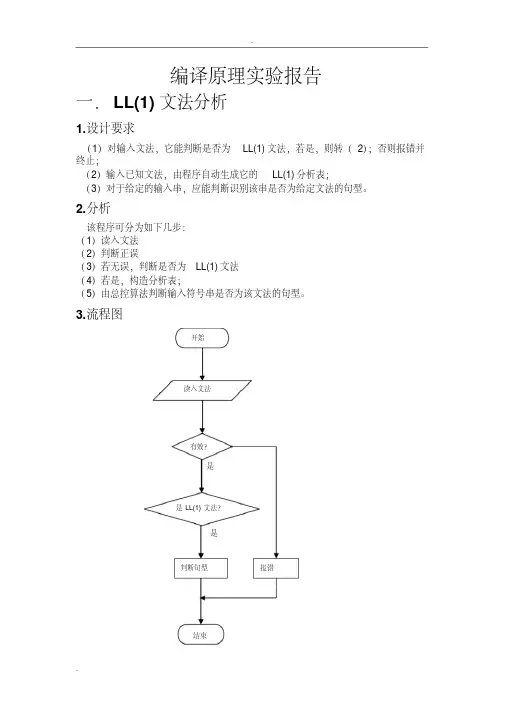
- 大小:64.50 KB
- 文档页数:8

编译原理中的first集合是指在文法中,一个非终结符号的所有可能的开始终结符号的集合。
在编译过程中,求解文法的first集合有着重要的意义。
下面将从定义、性质、求解方法和应用四个方面来详细介绍first集合。
一、定义在上下文无关文法中,对于一个非终结符号X,它的first集合定义为:1. 如果X可以直接推导出终结符号a,则将a加入X的first集合中;2. 如果X可以通过若干步推导出ε(空串),则将ε加入X的first集合中;3. 如果X可以通过若干步推导出Y1Y2...Yk,其中Y1,Y2,...,Yk是终结符号或者非终结符号,并且Y1不可为空,则将Y1的first集合中的所有元素(除去ε)加入X的first集合中。
二、性质1. first集合是关于文法的。
即不同的文法可能得到不同的first集合。
2. first集合可以为空。
即某些非终结符号的first集合可能为空集。
3. first集合的求解不一定唯一。
即针对同一个文法,可能有多种不同的求解方式。
三、求解方法在对文法的first集合进行求解时,常用的方法有两种:直接法和间接法。
1. 直接法:直接根据first集合的定义,对每个非终结符号进行推导,找出所有可能的开始终结符号。
2. 间接法:先求解终结符号的first集合,然后根据非终结符号的产生式和已经求解出的非终结符号和终结符号的first集合,来逐步求解非终结符号的first集合。
四、应用1. 在LL(1)文法的构造中,first集合的求解是至关重要的步骤。
通过求解文法符号的first集合,可以帮助我们构造出LL(1)文法,从而用于自顶向下的语法分析。
2. 在语法制导翻译中,通过利用first集合,可以帮助我们优化翻译过程,提高翻译的效率和准确性。
3. 在编译器的错误处理中,通过利用文法符号的first集合,可以帮助我们更好地定位并处理语法错误,提高编译器的鲁棒性和容错性。
first集合在编译原理中具有重要的地位和作用,它的求解对于文法分析、语法制导翻译和编译器的错误处理都具有重要意义。


【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集 近来复习编译原理,语法分析中的⾃上⽽下LL(1)分析法,需要构造求出⼀个⽂法的FIRST和FOLLOW集,然后构造分析表,利⽤分析表+⼀个栈来做⾃上⽽下的语法分析(递归下降/预测分析),可是这个FIRST集合FOLLOW集看得我头⼤。
教课书上的规则如下,⽤我理解的语⾔描述的:任意符号α的FIRST集求法:1. α为终结符,则把它⾃⾝加⼊FIRSRT(α)2. α为⾮终结符,则:(1)若存在产⽣式α->a...,则把a加⼊FIRST(α),其中a可以为ε(2)若存在⼀串⾮终结符Y1,Y2, ..., Yk-1,且它们的FIRST集都含空串,且有产⽣式α->Y1Y2...Yk...,那么把FIRST(Yk)-{ε}加⼊FIRST(α)。
如果k-1抵达产⽣式末尾,那么把ε加⼊FIRST(α) 注意(2)要连续进⾏,通俗地描述就是:沿途的Yi都能推出空串,则把这⼀路遇到的Yi的FIRST集都加进来,直到遇到第⼀个不能推出空串的Yk为⽌。
重复1,2步骤直⾄每个FIRST集都不再增⼤为⽌。
任意⾮终结符A的FOLLOW集求法:1. A为开始符号,则把#加⼊FOLLOW(A)2. 对于产⽣式A-->αBβ: (1)把FIRST(β)-{ε}加到FOLLOW(B) (2)若β为ε或者ε属于FIRST(β),则把FOLLOW(A)加到FOLLOW(B)重复1,2步骤直⾄每个FOLLOW集都不再增⼤为⽌。
⽼师和同学能很敏锐地求出来,⽽我只能按照规则,像程序⼀样⼀条条执⾏。
于是我把这个过程写成了程序,如下:数据元素的定义:1const int MAX_N = 20;//产⽣式体的最⼤长度2const char nullStr = '$';//空串的字⾯值3 typedef int Type;//符号类型45const Type NON = -1;//⾮法类型6const Type T = 0;//终结符7const Type N = 1;//⾮终结符8const Type NUL = 2;//空串910struct Production//产⽣式11 {12char head;13char* body;14 Production(){}15 Production(char h, char b[]){16 head = h;17 body = (char*)malloc(strlen(b)*sizeof(char));18 strcpy(body, b);19 }20bool operator<(const Production& p)const{//内部const则外部也为const21if(head == p.head) return body[0] < p.body[0];//注意此处只适⽤于LL(1)⽂法,即同⼀VN各候选的⾸符不能有相同的,否则这⾥的⼩于符号还要向前多看⼏个字符,就不是LL(1)⽂法了22return head < p.head;23 }24void print() const{//要加const25 printf("%c -- > %s\n", head, body);26 }27 };2829//以下⼏个集合可以再封装为⼀个⼤结构体--⽂法30set<Production> P;//产⽣式集31set<char> VN, VT;//⾮终结符号集,终结符号集32char S;//开始符号33 map<char, set<char> > FIRST;//FIRST集34 map<char, set<char> > FOLLOW;//FOLLOW集3536set<char>::iterator first;//全局共享的迭代器,其实觉得应该⽤局部变量37set<char>::iterator follow;38set<char>::iterator vn;39set<char>::iterator vt;40set<Production>::iterator p;4142 Type get_type(char alpha){//判读符号类型43if(alpha == '$') return NUL;//空串44else if(VT.find(alpha) != VT.end()) return T;//终结符45else if(VN.find(alpha) != VN.end()) return N;//⾮终结符46else return NON;//⾮法字符47 }主函数的流程很简单,从⽂件读⼊指定格式的⽂法,然后依次求⽂法的FIRST集、FOLLOW集1int main()2 {3 FREAD("grammar2.txt");//从⽂件读取⽂法4int numN = 0;5int numT = 0;6char c = '';7 S = getchar();//开始符号8 printf("%c", S);9 VN.insert(S);10 numN++;11while((c=getchar()) != '\n'){//读⼊⾮终结符12 printf("%c", c);13 VN.insert(c);14 numN++;15 }16 pn();17while((c=getchar()) != '\n'){//读⼊终结符18 printf("%c", c);19 VT.insert(c);20 numT++;21 }22 pn();23 REP(numN){//读⼊产⽣式24 c = getchar();25int n; RINT(n);26while(n--){27char body[MAX_N];28 scanf("%s", body);29 printf("%c --> %s\n", c, body);30 P.insert(Production(c, body));31 }32 getchar();33 }3435 get_first();//⽣成FIRST集36for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FIRST集37 printf("FIRST(%c) = { ", *vn);38for(first = FIRST[*vn].begin(); first != FIRST[*vn].end(); first++){39 printf("%c, ", *first);40 }41 printf("}\n");42 }4344 get_follow();//⽣成⾮终结符的FOLLOW集45for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FOLLOW集46 printf("FOLLOW(%c) = { ", *vn);47for(follow = FOLLOW[*vn].begin(); follow != FOLLOW[*vn].end(); follow++){48 printf("%c, ", *follow);49 }50 printf("}\n");51 }52return0;53 }主函数其中⽂法⽂件的数据格式为(按照平时做题的输⼊格式设计的):第⼀⾏:所有⾮终结符,⽆空格,第⼀个为开始符号;第⼆⾏:所有终结符,⽆空格;剩余⾏:每⾏描述了⼀个⾮终结符的所有产⽣式,第⼀个字符为产⽣式头(⾮终结符),后跟⼀个整数位候选式的个数n,之后是n个以空格分隔的字符串为产⽣式体。

华东交通大学课程设计(论文)任务书软件学院专业项目管理班级2005-4一、课程设计(论文)题目正规文法的First集合Follow集求解过程动态模拟二、课程设计(论文)工作:自2008年6月23 日起至2008年 6 月27 日止。
三、课程设计(论文)的内容要求:1、基本要求:进一步培养学生编译器设计的思想,加深对编译原理和应用程序的理解,针对编译过程的重点和难点内容进行编程,独立完成有一定工作量的程序设计任务,同时强调好的程序设计风格,并综合使用程序设计语言、数据结构和编译原理的知识,熟悉使用开发工具VC 6.0 或其它软件编程工具。
为了使学生从课程设计中尽可能取得比较大的收获,对课程设计题目可根据自己的兴趣选题(须经老师审核),或从老师给定题目中选择完成(具体见编译原理课程设计题目要求)。
通过程序实现、总结报告和学习态度综合考评,并结合学生的动手能力,独立分析解决问题的能力和创新精神。
成绩分优、良、中、及格和不及格五等。
2、具体要求设计一个由正规文法生成Fisrt集Follow集的动态过程模拟动态模拟算法的基本功能是:●输入一个正规文法;●输出由文法构造的First集的算法;●输出First集;●输出由文法构造的Follow集的算法;●输出Follow集;学生签名:2008 年 6 月 27 日课程设计(论文)评阅意见评阅人职称副教授2008 年 6 月 27 日目录一、需求分析 (3)二、总体设计 (4)三、详细设计 (9)四、课设小结 (12)五、谢辞 (13)六、参考文献 (14)一、 需求分析问题描述设计一个由正规文法生成First 集和Follow 集并进行简化的算法动态模拟。
(算法参见教材) 【基本要求】动态模拟算法的基本功能是: (1) 输入一个文法G ;(2) 输出由文法G 构造FIRST 集的算法; (3) 输出First 集;(4) 输出由文法G 构造FOLLOW 集的算法; (5) 输出FOLLOW 集。

计算f i r s t集合和f o l l o w集合--编译原理计算first 集合和follow 集合姓名:彦清 学号:E10914127一、实验目的输入:任意的上下文无关文法。
输出:所输入的上下文无关文法一切非终结符的first 集合和follow 集合。
二、实验原理设文法G[S]=(V N ,V T ,P ,S ),则首字符集为:FIRST (α)={a | α⇒*a β,a ∈V T ,α,β∈V *}。
若α⇒*ε,ε∈FIRST (α)。
由定义可以看出,FIRST (α)是指符号串α能够推导出的所有符号串中处于串首的终结符号组成的集合。
所以FIRST 集也称为首符号集。
设α=x 1x 2…x n ,FIRST (α)可按下列方法求得:令FIRST (α)=Φ,i =1;(1)若x i ∈V T ,则x i ∈FIRST (α); (2) 若x i ∈V N ;① 若ε∉FIRST (x i ),则FIRST (x i )∈FIRST (α);② 若ε∈FIRST (x i ),则FIRST (x i )-{ε}∈FIRST (α);(3) i =i+1,重复(1)、(2),直到x i ∈V T ,(i =2,3,…,n )或x i ∈V N 且若ε∉FIRST (x i )或i>n 为止。
当一个文法中存在ε产生式时,例如,存在A →ε,只有知道哪些符号可以合法地出现在非终结符A 之后,才能知道是否选择A →ε产生式。
这些合法地出现在非终结符A 之后的符号组成的集合被称为FOLLOW 集合。
下面我们给出文法的FOLLOW 集的定义。
设文法G[S]=(V N ,V T ,P ,S ),则FOLLOW (A )={a | S ⇒… Aa …,a ∈V T }。
若S ⇒*…A ,#∈FOLLOW (A )。
由定义可以看出,FOLLOW (A )是指在文法G[S]的所有句型中,紧跟在非终结符A 后的终结符号的集合。

first集合和follow集合的求法
FIRST集合和FOLLOW集合的求法如下:
1、FIRST集合的求法:
直接收取:如果X是终结符或为空,则First(X) = {X}。
反复传送:如果X是非终结符,则First集合一直传送下去,直到遇到终结符。
第一个状态减去ε(即空字符串)后加入到First集合中。
注意传送时非终结符是否可以为空,如果可以为空,则看下一个字符。
对于形如“…UP…”(P是非终结符)的组合,把First(P)直接收入到First集合中。
遇到形如E →TE’这样的产生式时,先把First(T)放入First(E),然后查看T是否能推导出ε(即空字符串)。
如果能,则把First(E’)放入First(E),以此类推。
若T不能推出ε,则First(E)求完。
2、FOLLOW集合的求法:
对于文法的开始符号S,将识别符号“#”置于FOLLOW(S)中。
若存在产生式A →αBβ,则将First(β) - {ε}加至FOLLOW(B)中。
这里,First(β)表示β能推导出的第一个终结符或非终结符的集合,但要去掉ε。
如果β可以推导出ε,则将FOLLOW(A)加至FOLLOW(B)中。
这意味着,如果B有可能是最后一个符号,那么A的FOLLOW集合应该加入到B的FOLLOW集合中。
反复使用上述规则,直到所求FOLLOW集合不再增大为止。
以上是对FIRST集合和FOLLOW集合求法的简要概述。
在实际应用中,需要根据具体的文法和产生式进行具体的分析和计算。

编译原理实验+求first集和follow集+代码/*说明:输入格式:每行输入一个产生式,左部右部中间的→用空格代替。
非终结符等价于大写字母^ 表示空输入到文件结束,或用 0 0 结尾。
Sample Input:(习题5·3):S MHS aH LSoH ^K dMLK ^L eHfM KM bLM0 0*/#include#include#include#include#includeusing namespace std;char l;string r;multimap sentence; //存储产生式multimap senRever; //产生式逆转set ter; //非终结符集合map toEmpty; //非终结符能否推出空bool flag;set fir; // 保存单个元素的first集set follow; //保存单个元素的follow集vector rightSide; //右部char Begin;bool capL(char c) //字母是否大写{if(c<='Z' && c>='A')return true;return false;}/*bool lowerL(char c) //小写字母{if(c<='z' && c>='a')return true;return false;}*/bool CapLString(string s) // 大写字符串{for(int i=0; iif(!capL(s[i])) {return false;}}return true;}bool isToEmpty(char ch) // 判断终结符能否推出空{bool flag;// for(set::iterator sIter = ter.begin(); sIter!=ter.end(); ++sIter) {flag = false;multimap::iterator mIter = sentence.find(ch);int cnt = sentence.count(ch);for(int i=0; iif(mIter->second=="^") {return true;// toEmpty[ch] = true;}else if(CapLString(mIter->second)){string s(mIter->second);bool flag2 = true;for(int j=0; jif(!isToEmpty(s[j]) || s[j]==ch) {flag2 = false;break;}}if(flag2) { // 右部全为终结符,全能推出空return true;}}}// }return false;}void getFirst(char ch, set &First) //求单个元素的 FIRST集{// if(flag)// return;multimap::iterator imul = sentence.find(ch);if(imul==sentence.end())return;int sum = sentence.count(imul->first);// cout<first<<endl;for(int i=0; i// cout<second<<endl;string s(imul->second);for(int j=0; jif(!capL(s[j])) {// cout<<" "<<s[j]<<endl;First.insert(s[j]);// flag = true;break;}else if(capL(s[j])) {if(s[j]==ch) { //有左递归,跳出循环break;;}getFirst(s[j], First);if(toEmpty[s[j] ]==false) {break;}}}}flag = true;}bool isLast(string s, char ch) //ch 是否是 s 的直接或间接的最后一个非终结符{if(!capL(ch))return false;for(int i=s.size()-1; i>=0; i--) {if(ch==s[i])return true;if(!capL(s[i]) || toEmpty[s[i] ]==false) {return false;}}return false;}void getFollow(char ch, set<cha</cha</s[j]<<endl;</endl;</endl;r> &follow) //求单个元素的 FOLLOW集{if(!capL(ch))return;for(vector::iterator iter=rightSide.begin(); iter!=rightSide.end(); ++iter) {for(int i=0; i<(*iter).size(); i++) {if(ch==(*iter)[i] && i!=(*iter).size()-1) {if(!capL((*iter)[i+1])) {follow.insert((*iter)[i+1]);}else {getFirst((*iter)[i+1], follow);}}if(ch==(*iter)[i] && i==(*iter).size()-1) { //判断是否是右部的最后一个非终结符 follow +#follow.insert('#');}else if(ch==(*iter)[i] && i<(*iter).size()-1){ //不是最后一个但之后全是非终结符且都能推出空 follow +#bool flag1=true;for(int j=i+1;j<(*iter).size(); j++) {if(!capL((*iter)[j]) || toEmpty[(*iter)[j]]==false) {flag1 = false;if(!capL((*iter)[j])) {follow.insert((*iter)[j]);}break;}}if(flag1 == true) {follow.insert('#');}}}if(isLast(*iter, ch)) { //ch是*iter的最后一个符号(直接或间接)int n = senRever.count(*iter);multimap::iterator mIter = senRever.find(*iter);for(int i=0 ;iif(mIter->second!=ch )getFollow(mIter->second, follow);}}}}int main(){int cnt=0;while(cin>>l>>r) {if(cnt==0) {Begin = l;cnt++;}if(l=='0')break;sentence.insert(make_pair(l, r)); //产生式senRever.insert(make_pair(r,l));ter.insert(l); //非终结符集合(左部)rightSide.push_back(r); //右部的集合/* if(r=="^") { // 判断是否有非终结符->^toEmpty[l] = true;}else {if(toEmpty.find(l)==toEmpty.end()) {toEmpty[l] = false;}} */}for(set::iterator sIter = ter.begin(); sIter!=ter.end(); ++sIter) { // 判断是否有非终结符->^if(isToEmpty(*sIter) ) {toEmpty[*sIter] = true;}else {toEmpty[*sIter] = false;}}for(set::iterator iter=ter.begin(); iter!=ter.end(); iter++) {flag = false;cout<<*iter<<" FIRST集 :";fir.clear();getFirst(*iter, fir);for(set::iterator iterF=fir.begin(); iterF!=fir.end(); iterF++) {cout<<" "<<*iterF;}cout<<endl;follow.clear();getFollow(*iter, follow);cout<<" FOLLOW集:";if(*iter==Begin) {cout<<" #";}for(set::iterator iterF=follow.begin(); iterF!=follow.end(); ++iterF) {if(*iterF!='^')cout<<" "<<*iterF;}cout<<endl<<endl;}system("pause");return 0;}</endl<<endl; </endl;。

《LL(1)分析器的构造》实验报告一、实验名称LL(1)分析器的构造二、实验目的设计、编制、调试一个LL(1)语法分析器,利用语法分析器对符号串的识别,加深对语法分析原理的理解。
三、实验内容和要求设计并实现一个LL(1)语法分析器,实现对算术文法:G[E]:E->E+T|TT->T*F|FF->(E)|i所定义的符号串进行识别,例如符号串i+i*i为文法所定义的句子,符号串ii+++*i+不是文法所定义的句子。
实验要求:1、检测左递归,如果有则进行消除;2、求解FIRST集和FOLLOW集;3、构建LL(1)分析表;4、构建LL分析程序,对于用户输入的句子,能够利用所构造的分析程序进行分析,并显示出分析过程。
四、主要仪器设备硬件:微型计算机。
软件: Code blocks(也可以是其它集成开发环境)。
五、实验过程描述1、程序主要框架程序中编写了以下函数,各个函数实现的作用如下:void input_grammer(string *G);//输入文法Gvoid preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k);//将文法G预处理得到产生式集合P,非终结符、终结符集合U、u,int eliminate_1(string *G,string *P,string U,string *GG);//消除文法G中所有直接左递归得到文法GGint* ifempty(string* P,string U,int k,int n);//判断各非终结符是否能推导为空string* FIRST_X(string* P,string U,string u,int* empty,int k,int n);求所有非终结符的FIRST集string FIRST(string U,string u,string* first,string s);//求符号串s=X1X2...Xn的FIRST集string** create_table(string *P,string U,string u,int n,int t,int k,string* first);//构造分析表void analyse(string **table,string U,string u,int t,string s);//分析符号串s2、编写的源程序#include<cstdio>#include<cstring>#include<iostream>using namespace std;void input_grammer(string *G)//输入文法G,n个非终结符{int i=0;//计数char ch='y';while(ch=='y'){cin>>G[i++];cout<<"继续输入?(y/n)\n";cin>>ch;}}void preprocess(string *G,string *P,string &U,string &u,int &n,int &t,int &k)//将文法G预处理产生式集合P,非终结符、终结符集合U、u,{int i,j,r,temp;//计数char C;//记录规则中()后的符号int flag;//检测到()n=t=k=0;for( i=0;i<50;i++) P[i]=" ";//字符串如果不初始化,在使用P[i][j]=a时将不能改变,可以用P[i].append(1,a)U=u=" ";//字符串如果不初始化,无法使用U[i]=a赋值,可以用U.append(1,a) for(n=0;!G[n].empty();n++){ U[n]=G[n][0];}//非终结符集合,n为非终结符个数for(i=0;i<n;i++){for(j=4;j<G[i].length();j++){if(U.find(G[i][j])==string::npos&&u.find(G[i][j])==string::npos)if(G[i][j]!='|'&&G[i][j]!='^')//if(G[i][j]!='('&&G[i][j]!=')'&&G[i][j]!='|'&&G[i][j]!='^')u[t++]=G[i][j];}}//终结符集合,t为终结符个数for(i=0;i<n;i++){flag=0;r=4;for(j=4;j<G[i].length();j++){P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';/* if(G[i][j]=='('){ j++;flag=1;for(temp=j;G[i][temp]!=')';temp++);C=G[i][temp+1];//C记录()后跟的字符,将C添加到()中所有字符串后面}if(G[i][j]==')') {j++;flag=0;}*/if(G[i][j]=='|'){//if(flag==1) P[k][r++]=C;k++;j++;P[k][0]=U[i];P[k][1]=':';P[k][2]=':';P[k][3]='=';r=4;P[k][r++]=G[i][j];}else{P[k][r++]=G[i][j];}}k++;}//获得产生式集合P,k为产生式个数}int eliminate_1(string *G,string *P,string U,string *GG)//消除文法G1中所有直接左递归得到文法G2,要能够消除含有多个左递归的情况){string arfa,beta;//所有形如A::=Aα|β中的α、β连接起来形成的字符串arfa、betaint i,j,temp,m=0;//计数int flag=0;//flag=1表示文法有左递归int flagg=0;//flagg=1表示某条规则有左递归char C='A';//由于消除左递归新增的非终结符,从A开始增加,只要不在原来问法的非终结符中即可加入for(i=0;i<20&&U[i]!=' ';i++){ flagg=0;arfa=beta="";for(j=0;j<100&&P[j][0]!=' ';j++){if(P[j][0]==U[i]){if(P[j][4]==U[i])//产生式j有左递归{flagg=1;for(temp=5;P[j][temp]!=' ';temp++) arfa.append(1,P[j][temp]);if(P[j+1][4]==U[i]) arfa.append("|");//不止一个产生式含有左递归}else{for(temp=4;P[j][temp]!=' ';temp++) beta.append(1,P[j][temp]);if(P[j+1][0]==U[i]&&P[j+1][4]!=U[i]) beta.append("|");}}}if(flagg==0)//对于不含左递归的文法规则不重写{GG[m]=G[i]; m++;}else{flag=1;//文法存在左递归GG[m].append(1,U[i]);GG[m].append("::=");if(beta.find('|')!=string::npos) GG[m].append("("+beta+")");else GG[m].append(beta);while(U.find(C)!=string::npos){C++;}GG[m].append(1,C);m++;GG[m].append(1,C);GG[m].append("::=");if(arfa.find('|')!=string::npos) GG[m].append("("+arfa+")");else GG[m].append(arfa);GG[m].append(1,C);GG[m].append("|^");m++;C++;}//A::=Aα|β改写成A::=βA‘,A’=αA'|β,}return flag;}int* ifempty(string* P,string U,int k,int n){int* empty=new int [n];//指示非终结符能否推导到空串int i,j,r;for(r=0;r<n;r++) empty[r]=0;//默认所有非终结符都不能推导到空int flag=1;//1表示empty数组有修改int step=100;//假设一条规则最大推导步数为100步while(step--){for(i=0;i<k;i++){r=U.find(P[i][0]);if(P[i][4]=='^') empty[r]=1;//直接推导到空else{for(j=4;P[i][j]!=' ';j++){if(U.find(P[i][j])!=string::npos){if(empty[U.find(P[i][j])]==0) break;}else break;}if(P[i][j]==' ') empty[r]=1;//多步推导到空else flag=0;}}}return empty;}string* FIRST_X(string* P,string U,string u,int* empty,int k,int n){int i,j,r,s,tmp;string* first=new string[n];char a;int step=100;//最大推导步数while(step--){// cout<<"step"<<100-step<<endl;for(i=0;i<k;i++){//cout<<P[i]<<endl;r=U.find(P[i][0]);if(P[i][4]=='^'&&first[r].find('^')==string::npos) first[r].append(1,'^');//规则右部首符号为空else{for(j=4;P[i][j]!=' ';j++){a=P[i][j];if(u.find(a)!=string::npos&&first[r].find(a)==string::npos)//规则右部首符号是终结符{first[r].append(1,a);break;//添加并结束}if(U.find(P[i][j])!=string::npos)//规则右部首符号是非终结符,形如X::=Y1Y2...Yk{s=U.find(P[i][j]);//cout<<P[i][j]<<":\n";for(tmp=0;first[s][tmp]!='\0';tmp++){a=first[s][tmp];if(a!='^'&&first[r].find(a)==string::npos)//将FIRST[Y1]中的非空符加入first[r].append(1,a);}}if(!empty[s]) break;//若Y1不能推导到空,结束}if(P[i][j]==' ')if(first[r].find('^')==string::npos)first[r].append(1,'^');//若Y1、Y2...Yk都能推导到空,则加入空符号}}}return first;}string FIRST(string U,string u,string* first,string s)//求符号串s=X1X2...Xn的FIRST集{int i,j,r;char a;string fir;for(i=0;i<s.length();i++){if(s[i]=='^') fir.append(1,'^');if(u.find(s[i])!=string::npos&&fir.find(s[i])==string::npos){ fir.append(1,s[i]);break;}//X1是终结符,添加并结束循环if(U.find(s[i])!=string::npos)//X1是非终结符{r=U.find(s[i]);for(j=0;first[r][j]!='\0';j++){a=first[r][j];if(a!='^'&&fir.find(a)==string::npos)//将FIRST(X1)中的非空符号加入fir.append(1,a);}if(first[r].find('^')==string::npos) break;//若X1不可推导到空,循环停止}if(i==s.length())//若X1-Xk都可推导到空if(fir.find(s[i])==string::npos) //fir中还未加入空符号fir.append(1,'^');}return fir;}string** create_table(string *P,string U,string u,int n,int t,int k,string* first)//构造分析表,P为文法G的产生式构成的集合{int i,j,p,q;string arfa;//记录规则右部string fir,follow;string FOLLOW[5]={")#",")#","+)#","+)#","+*)#"};string **table=new string*[n];for(i=0;i<n;i++) table[i]=new string[t+1];for(i=0;i<n;i++)for(j=0;j<t+1;j++)table[i][j]=" ";//table存储分析表的元素,“ ”表示error for(i=0;i<k;i++){arfa=P[i];arfa.erase(0,4);//删除前4个字符,如:E::=E+T,则arfa="E+T"fir=FIRST(U,u,first,arfa);for(j=0;j<t;j++){p=U.find(P[i][0]);if(fir.find(u[j])!=string::npos){q=j;table[p][q]=P[i];}//对first()中的每一终结符置相应的规则}if(fir.find('^')!=string::npos){follow=FOLLOW[p];//对规则左部求follow()for(j=0;j<t;j++){if((q=follow.find(u[j]))!=string::npos){q=j;table[p][q]=P[i];}//对follow()中的每一终结符置相应的规则}table[p][t]=P[i];//对#所在元素置相应规则}}return table;}void analyse(string **table,string U,string u,int t,string s)//分析符号串s{string stack;//分析栈string ss=s;//记录原符号串char x;//栈顶符号char a;//下一个要输入的字符int flag=0;//匹配成功标志int i=0,j=0,step=1;//符号栈计数、输入串计数、步骤数int p,q,r;string temp;for(i=0;!s[i];i++){if(u.find(s[i])==string::npos)//出现非法的符号cout<<s<<"不是该文法的句子\n";return;}s.append(1,'#');stack.append(1,'#');//’#’进入分析栈stack.append(1,U[0]);i++;//文法开始符进入分析栈a=s[0];//cout<<stack<<endl;cout<<"步骤分析栈余留输入串所用产生式\n";while(!flag){// cout<<"步骤分析栈余留输入串所用产生式\n"cout<<step<<" "<<stack<<" "<<s<<" ";x=stack[i];stack.erase(i,1);i--;//取栈顶符号x,并从栈顶退出//cout<<x<<endl;if(u.find(x)!=string::npos)//x是终结符的情况{if(x==a){s.erase(0,1);a=s[0];//栈顶符号与当前输入符号匹配,则输入下一个符号cout<<" \n";//未使用产生式,输出空}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(x=='#'){if(a=='#') {flag=1;cout<<"成功\n";}//栈顶和余留输入串都为#,匹配成功else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}if(U.find(x)!=string::npos)//x是非终结符的情况{p=U.find(x);q=u.find(a);if(a=='#') q=t;temp=table[p][q];cout<<temp<<endl;//输出使用的产生式if(temp[0]!=' ')//分析表中对应项不为error{r=9;while(temp[r]==' ') r--;while(r>3){if(temp[r]!='^'){stack.append(1,temp[r]);//将X::=x1x2...的规则右部各符号压栈i++;}r--;}}else{cout<<"error\n";cout<<ss<<"不是该文法的句子\n";break;}}step++;}if(flag) cout<<endl<<ss<<"是该文法的句子\n";}int main(){int i,j;string *G=new string[50];//文法Gstring *P=new string[50];//产生式集合Pstring U,u;//文法G非终结符集合U,终结符集合uint n,t,k;//非终结符、终结符个数,产生式数string *GG=new string[50];//消除左递归后的文法GGstring *PP=new string[50];//文法GG的产生式集合PPstring UU,uu;//文法GG非终结符集合U,终结符集合uint nn,tt,kk;//消除左递归后的非终结符、终结符个数,产生式数string** table;//分析表cout<<" 欢迎使用LL(1)语法分析器!\n\n\n";cout<<"请输入文法(同一左部的规则在同一行输入,例如:E::=E+T|T;用^表示空串)\n";input_grammer(G);preprocess(G,P,U,u,n,t,k);cout<<"\n该文法有"<<n<<"个非终结符:\n";for(i=0;i<n;i++) cout<<U[i];cout<<endl;cout<<"该文法有"<<t<<"个终结符:\n";for(i=0;i<t;i++) cout<<u[i];cout<<"\n\n 左递归检测与消除\n\n";if(eliminate_1(G,P,U,GG)){preprocess(GG,PP,UU,uu,nn,tt,kk);cout<<"该文法存在左递归!\n\n消除左递归后的文法:\n\n"; for(i=0;i<nn;i++) cout<<GG[i]<<endl;cout<<endl;cout<<"新文法有"<<nn<<"个非终结符:\n";for(i=0;i<nn;i++) cout<<UU[i];cout<<endl;cout<<"新文法有"<<tt<<"个终结符:\n";for(i=0;i<tt;i++) cout<<uu[i];cout<<endl;//cout<<"新文法有"<<kk<<"个产生式:\n";//for(i=0;i<kk;i++) cout<<PP[i]<<endl;}else{cout<<"该文法不存在左递归\n";GG=G;PP=P;UU=U;uu=u;nn=n;tt=t;kk=k;}cout<<" 求解FIRST集\n\n";int *empty=ifempty(PP,UU,kk,nn);string* first=FIRST_X(PP,UU,uu,empty,kk,nn);for(i=0;i<nn;i++)cout<<"FIRST("<<UU[i]<<"): "<<first[i]<<endl;cout<<" 求解FOLLOW集\n\n";for(i=0;i<nn;i++)cout<<"FOLLOW("<<UU[i]<<"): "<<FOLLOW[i]<<endl; cout<<"\n\n 构造文法分析表\n\n"; table=create_table(PP,UU,uu,nn,tt,kk,first);cout<<" ";for(i=0;i<tt;i++) cout<<" "<<uu[i]<<" ";cout<<"# "<<endl;for( i=0;i<nn;i++){cout<<UU[i]<<" ";for(j=0;j<t+1;j++)cout<<table[i][j];cout<<endl;}cout<<"\n\n 分析符号串\n\n";cout<<"请输入要分析的符号串\n";cin>>s;analyse(table,UU,uu,tt,s);return 0;}3、程序演示结果(1)输入文法(2)消除左递归(3)求解FIRST和FOLLOW集(4)构造分析表(5)分析符号串匹配成功的情况:匹配失败的情况五、思考和体会1、编写的LL(1)语法分析器应该具有智能性,可以由用户输入任意文法,不需要指定终结符个数和非终结符个数。

First集合的求法:First集合最终是对产生式右部的字符串而言的,但其关键是求出非终结符的First集合,由于终结符的First集合就是它自己,所以求出非终结符的First集合后,就可很直观地得到每个字符串的First集合。
1. 直接收取:对形如U-a…的产生式(其中a是终结符),把a收入到First(U)中2. 反复传送:对形入U-P…的产生式(其中P是非终结符),应把First(P)中的全部内容传送到First(U)中。
Follow集合的求法:Follow集合是针对非终结符而言的,Follow(U)所表达的是句型中非终结符U所有可能的后随终结符号的集合,特别地,“#”是识别符号的后随符。
1. 直接收取:注意产生式右部的每一个形如“…Ua…”的组合,把a直接收入到Follow(U)中。
2.直接收取:对形如“…UP…”(P是非终结符)的组合,把First(P)除ε直接收入到Follow(U)中。
3.反复传送:对形如P-…U的产生式(其中U是非终结符),应把Follow(P)中的全部内容传送到Follow(U)中。
(或 P-…UB且First(B)包含ε,则把First(B)除ε直接收入到Follow(U)中,并把Follow(P)中的全部内容传送到Follow(U)中)例1:判断该文法是不是LL(1)文法,说明理由 S→ABc A→a|ε B→b|ε?First集合求法就是:能由非终结符号推出的所有的开头符号或可能的ε,但要求这个开头符号是终结符号。
如此题A可以推导出a和ε,所以FIRST(A)={a,ε};同理FIRST (B)={b,ε};S可以推导出aBc,还可以推导出bc,还可以推导出c,所以FIRST(S)={a,b,c}。
Follow集合的求法是:紧跟随其后面的终结符号或#。
但文法的识别符号包含#,在求的时候还要考虑到ε。
具体做法是把所有包含你要求的符号的产生式都找出来,再看哪个有用。

摘要:编译原理是计算机科学与技术专业最重要的一门专业基础课程,内容庞大,涉及面广,知识点多。
由于该课程教、学难度都非常大,往往费了大量时间而达不到预期教学效果俗语说:学习的最好方法是实践。
本次课程设计的目的正是基于此,力求为学生提供一个理论联系实际的机会,通过布置一定难度的课题,要求学生独立完成。
我们这次课程设计的主要任务是编程实现对给定文法的FIRST 集和FOLLOW集的求解。
通过实践,建立系统设计的整体思想,锻炼编写程序、调试程序的能力,学习文档编写规范,培养独立学习、吸取他人经验、探索前言知识的习惯,树立团队协作精神。
同时,课程设计可以充分弥补课堂教学及普通实验中知识深度与广度有限的缺陷,更好地帮助学生从全局角度把握课程体系。
关键词:编译原理;FIRST集;FOLLOW集目录1 课题综述 (1)1.1 课题来源 (1)1.2 课题意义 (1)1.3 预期目标 (1)1.4 面对的问题 (1)1.5 需解决的关键技术 (1)2 系统分析 (2)2.1 基础知识 (2)2.1.1 FIRST集定义 (2)2.1.2FIRST集求解算法.................................................................... 错误!未定义书签。
2.1.3FOLLOW集的定义 (4)2.1.4 FOLLOW集算法 (4)2.2 解决问题的基本思路 (4)2.3 总体方案 (4)3 系统设计 (5)3.1 算法实现 (5)3.2 流程图 (6)4 代码编写 (10)5 程序调试 (15)6 运行与测试 (15)1 课题综述1.1 课题来源文法:包含若干终结符,非终结符,由终结符与非终结符组成的产生式。
本次课程设计就是对产生式进行左递归分析,待无左递归现象后进行FIRST集与FOLLOW集的求解。
1.2 课题意义由文法产生的若干个句子有可能是合法的或者不合法的,也有可能产生歧义,所以要消除歧义先消除文法左递归,然后根据求得的FIRST集与FOLLOW 集构造分析表,分析给定句子的合法性。
《编译原理》实验报告
专业班级:计101班
学号:109074002
姓名:卞恩会
指导老师:王森玉
实验内容:
1.求出每个非终结符的FIRST集合
2.求出每个产生式右部的FIRST集合
3.求出每个非终结符的Follow集合实验环境:
Visual Studio2010
实验目的:
掌握FIRST集合和FOLLOW集合的求法
测试数据1:
S->aH
H->aMd|d
M->Ab|@
A->aM|e
输出结果:
测试数据2:S->AB
S->bC
A->@
A->b
B->@
B->aD
C->AD
C->b
D->aS
D->c
测试数据3:E->TX
X->+TX|@ T->FY
Y->*FY|@ F->i|(E)
输出结果:
感受:通过上机调试代码让我对书上的单纯的理论的知识有了一个更深的理解同时让我明白了对待一个问题我们应该全面的去理解它,这样才能学到的更多。
程序清单:。
FIRST集合、FOLLOW集合及LL(1)⽂法求法FIRST集合定义可从α推导得到的串的⾸符号的集合,其中α是任意的⽂法符号串。
规则计算⽂法符号 X 的 FIRST(X),不断运⽤以下规则直到没有新终结符号或ε可以被加⼊为⽌:(1)如果 X 是⼀个终结符号,那么 FIRST(X) = X。
(2)如果 X 是⼀个⾮终结符号,且 X ->Y1 Y2 … Y k是⼀个产⽣式,其中 k≥1,那么如果对于某个i,a在 FIRST(Y1)、FIRST(Y2)… FIRST(Y i-1)中,就把a加⼊到 FIRST(X) 中。
(3)如果 X ->ε是⼀个产⽣式,那么将ε加⼊到 FIRST(X)中。
以上是书上的官⽅规则,不仅读起来很拗⼝,理解也很累。
下⾯看⼀下精简版的规则(从别⼈ @ 那⾥看来的,感觉很棒,这⾥引⽤⼀下):(1)如果X是终结符,则FIRST(X) = { X } 。
(2)如果X是⾮终结符,且有产⽣式形如X → a…,则FIRST( X ) = { a }。
(3)如果X是⾮终结符,且有产⽣式形如X → ABCdEF…(A、B、C均属于⾮终结符且包含ε,d为终结符),需要把FIRST( A )、FIRST( B )、FIRST( C )、FIRST( d )加⼊到 FIRST( X )中。
(4)如果X经过⼀步或多步推导出空字符ε,将ε加⼊FIRST( X )。
实践记得,曾经有⼈说过:只读,就会⽩给下⾯以这个⽂法为例讲解⼀波,会⽤精简版规则,更容易理解⼀些:E -> T E'E' -> + T E' | εT -> F T'T' -> * F T' | εF -> ( E ) | id12345FIRST(E) = FIRST(T)根据规则3,很容易理解,这⾥要注意的由于T不含ε,所以遍历到T就停⽌了,E’不会加⼊进来FIRST(E’) = FIRST(+) ∪ FIRST(ε)= { +, ε }根据规则2和4,,很好理解FIRST(T) = FIRST(F)根据规则3,和第⼀条推导过程⼀样FIRST(T’) = FIRST() ∪ FIRST(ε)= { , ε }根据规则2和4,和第⼆条推导⼀样FIRST(F) = FIRST( ( ) ∪ FIRST(id)= { ( , id }根据规则2结果:FIRST(E) = FIRST(T) = FIRST(F) = { ( , id }FIRST(E') = FIRST(+) ∪ FIRST(ε)= { + , ε }FIRST(E') = FIRST(*) ∪ FIRST(ε)= { * , ε }123FOLLOW集合定义对于⾮终结符号A,FOLLOW(A)被定义为可能在某些句型中紧跟在A右边的终结符号集合。
编译原理课程实验报告实验2:语法分析
三、系统设计得分
要求:分为系统概要设计和系统详细设计。
(1)系统概要设计:给出必要的系统宏观层面设计图,如系统框架图、数据流图、功能模块结构图等以及相应的文字说明。
1)系统的数据流图:
说明
说明:本语法分析器是基于上一个实验词法分析器的基础上,通过在界面写或者是导入源程序,词法分析器将源程序识别的词法单元传递给语法分析器,语法分析器验证这个词法单元组成的串是否可以由源语言的文法生成,能够输出语法分析的结果,文法的first集、follow 集和预测分析表,当然也可以以易于理解的方式报告语法错误。
2)系统框架图
本系统框架主要是三部分,一部分是词法分析,负责识别源程序的词法单元识别,并将其存
因为预测分析表实在是过于庞大,因此本处分段截取预测分析表,下面的表是接在上面表的右侧。
(3)针对一测试程序输出其句法分析结果;
测试程序:
语法分析结果:
语法分析树:
(4)输出针对此测试程序对应的语法错误报告;
带错误的测试程序:
语法错误报告:
(5)对实验结果进行分析。
总结:
本语法分析器具有强大的语法分析功能
●允许变量的连续声明,比如int a,b,c;
●允许声明的同时赋值,比如string c = “你好”;
●允许对数组的声明和引用,同时进行赋值,比如char[4] a = {‘a’,’b’,’c’,’d’};a[0] = ‘m’;
●支持多种类型的声明和赋值,比如int,short,long,flaot,double,char,string,boolean
的声明和赋值;
●允许声明和使用一个过程函数,比如:。
【编译原理】FIRST集、FOLLOW集算法原理和实现书中⼀些话,不知是翻译的原因。
还是我个⼈理解的原因感觉不是⾮常好理解。
个⼈重新整理了⼀下。
不过相对于消除左递归和提取左公因,FIRST集和FOLLOW集的算法相对来说⽐较简单。
书中的重点给出:FIRST:⼀个⽂法符号的FIRST集就是这个符号能推导出的第⼀个终结符号的集合, 包括空串。
例: A -> abc | def | ε那么FIRST(A) 等于 { a, d, ε }。
FOLLOW:蓝线画的部分很重要。
特别是这句话:请注意,在这个推导的某个阶段,A和a之间可能存在⼀些⽂法符号。
单如果这样,这些符号会推导得到ε并消失。
这句话的意思就是好⽐说: S->ABa B->c | ε 这个⽂法 FOLLOW(A)的值应该是FIRST(B)所有的终结符的集合(不包含ε),但是FIRST(B)是包含ε的,说明B是可空的,既然B是可空的S->ABa 也可以看成 S->Aa。
那么a就可以跟在A的后⾯.所以在这种情况下,FOLLOW(A)的值是包含a的。
换句话说就是。
⼀个⽂法符号A的FOLLOW集合就是它的下⼀个⽂法符号B的FIRST集合。
如果下⼀个⽂法符号B的FIRST集合包含ε,那么我们就要获取下⼀个⽂法符号B的FOLLOW集添加到FOLLOW(A)中代码中的注释已经很详细// 提取First集合func First(cfg []*Production, sym *Symbolic) map[string] *Symbolic {result := make(map[string] *Symbolic)// 规则⼀如果符号是⼀个终结符号,那么他的FIRST集合就是它⾃⾝if sym.SymType() == SYM_TYPE_TERMINAL || sym.SymType() == SYM_TYPE_NIL {result[sym.Sym()] = symreturn result}// 规则⼆如果⼀个符号是⼀个⾮终结符号// (1) A -> XYZ 如果 X 可以推导出nil 那么就去查看Y是否可以推导出nil// 如果 Y 推导不出nil,那么把Y的First集合加⼊到A的First集合// 如果 Y 不能推导出nil,那么继续推导 Z 是否可以推导出nil,依次类推// (2) A -> XYZ 如果XYZ 都可以推导出 nil, 那么说明A这个产⽣式有可能就是nil,这个时候我们就把nil加⼊到FIRST(A)中for _, production := range cfg {if production.header == sym.Sym() {nilCount := 0for _, rightSymbolic := range production.body { // 对于⼀个产⽣式ret := First(cfg, rightSymbolic) // 获取这个产⽣式体的First集合hasNil := falsefor k, v := range ret {if v.SymType() == SYM_TYPE_NIL { // 如果推导出nil, 标识当前产⽣式体的符号可以推导出nilhasNil = true} else {result[k] = v}}if false == hasNil { // 当前符号不能推导出nil, 那么这个产⽣式的FIRST就计算结束了,开始计算下⼀个产⽣式break}// 当前符号可以推导出nil,那么开始推导下⼀个符号nilCount++if nilCount == len(production.body) { // 如果产⽣式体都可以推导出nil,那么这个产⽣式就可以推导出nilresult["@"] = &Symbolic{sym: "@", sym_type: SYM_TYPE_NIL}}}}}return result}// 提取FOLLOW集合func Follow(cfg []*Production, sym string) [] *Symbolic {fmt.Printf("Follow ------> %s\n", sym)result := make([] *Symbolic, 0)// ⼀个⽂法符号的FOLLOW集就是可能出现在这个⽂法符号后⾯的终结符// ⽐如 S->ABaD, 那么FOLLOW(B)的值就是a。
first集合和follow集合的求法编译原理是计算机专业中的重要学科,其中语法分析是编译原理的基础。
而语法分析器(Parser)的核心就是构建语法分析表格。
而在构建语法分析表格的过程中,first集合和follow集合的求法是一个非常重要的问题,本文就将详细介绍first集合和follow集合的求法。
一、first集合first集合指的是文法中每个非终结符号的经过一次推导得到的所有终结符号的集合,也就是最小前缀(First)的集合。
例如对于一个简单的文法表达式E→E+T|T,其中E和T是非终结符号,+是终极符号。
那么开始寻找E的first集合时,我们应该先判断E能够推导出哪些符号,根据文法表达式,E可以推导出E+T和T。
接着我们可以判断E+T和T 所能推导出的所有终结符号,并将这些终结符号加入到E的first集合中。
具体步骤可以参考下面的推导过程:E → E + TE → TT → a那么最终E的first集合就是{a,+}。
二、follow集合follow集合指的是文法中每个非终结符号在所有推导过程中后跟的符号的集合。
例如对于一个简单的文法表达式E→E+T|T,其中E和T是非终结符号,+是终极符号。
求解E的follow集合时,首先要考虑的是E出现在了哪些地方。
通过分析E在文法表达式中的位置,我们可以发现E出现在了三种不同的情况下:1. E是文法的起始符号,此时E的follow集合中必须包含结束符$。
2. E出现在某些规则的右侧,此时E的follow集合中必须包含右侧的符号的first集合,但是需要注意的是,如果推导出空串,则应该将右侧的非终结符号所在位置的follow集合添加进来。
3. E的右侧是其所在规则的最末尾,此时需要将E所在规则的左侧符号所在位置的follow集合添加到E的follow集合中。
根据以上三种情况,我们可以结合上面的文法表达式来推导出E的follow集合。
具体步骤可以参考下面的推导过程:S → EE → E + TE → TT → a1. $ ∈ follow(E)2. follow(T) = {+, $}follow(E) = first(T) ∪ {+, $}follow(E) = {+, a, $}3. follow(E) = {+, $}那么最终E的follow集合就是{+, a, $}。
package cn.spy.action;import java.util.ArrayList;import java.util.Scanner;import java.util.StringTokenizer;*某一输入实例:* E->TE'* E'->+E|ε* T->FT'* T'->T|ε* F->PF'* F'->*F'|ε* P->(E)|a|b|^* end*/public class FirstFollow3 {public ArrayList<String[]> in=new ArrayList<String[]>();//这数据结构真是逼人绝路才去想到绝处逢生,哈哈,关键实现了可变长度文法接收,在这存放的是拆分后最简单的文法,也是由用户输入public ArrayList<String[]> first = new ArrayList<String[]>();//包括左推导符和其First集public ArrayList<String[]> follow = new ArrayList<String[]>(); public ArrayList<String[]> track = newArrayList<String[]>();//track有一条一条的非终结符串组成的路径数组public FirstFollow3(){Scanner sc = new Scanner(System.in);System.out.println("请分行输入一个完整文法:(end结束)");String sline="";sline=sc.nextLine();while(!sline.startsWith("end")){StringBuffer buffer=new StringBuffer(sline);int l=buffer.indexOf(" ");while(l>=0){//去空格buffer.delete(l,l+1);l=buffer.indexOf(" ");}sline=buffer.toString();String s[]=sline.split("->");//左推导符if(s.length==1)s=sline.split("→");//考虑到输入习惯和形式问题if(s.length==1)s=sline.split("=>");if(s.length==1){System.out.println("文法有误");System.exit(0);}StringTokenizer fx = new StringTokenizer(s[1],"|︱");//按英文隔符拆开产生式或按中文隔符拆开while(fx.hasMoreTokens()){String[] one = new String[2];//对于一个语句只需保存两个数据就可以了,语句左部和语句右部的一个简单导出式,假如有或符,就按多条存放one[0]=s[0];//头不变,0位置放非终结符one[1]=fx.nextToken();//1位置放导出的产生式,就是产生式右部的一个最简单导出式in.add(one);}sline=sc.nextLine();//求First集过程this.process("First");/** 打印First集算法和First集*/System.out.println("\nFirst集算法:");this.print(track);//打印First集算法System.out.println("\nFirst集:");for(int i=0;i<first.size();i++){String[] r=first.get(i);System.out.print("First("+r[0]+")={");for(int j=1;j<r.length;j++){System.out.print(r[j]);if(j<r.length-1)System.out.print(",");}System.out.println("}");}track.clear();//因为下面还要用,这里就先清空了//求Follow集过程this.process("Follow");System.out.println("\nFollow集算法:");for(int i=0;i<track.size();i++){String[] one = track.get(i);System.out.print("Follow("+follow.get(i)[0]+"):\t"); for(int j=0;j<one.length;j++)System.out.print(one[j]+"\t");System.out.println();}System.out.println("\nFollow集:");for(int i=0;i<follow.size();i++){String[] r=follow.get(i);System.out.print("Follow("+r[0]+")={");for(int j=1;j<r.length;j++){System.out.print(r[j]);if(j<r.length-1)System.out.print(",");}System.out.println("}");}}public void process(String firstORfollow){for(int i=0;i<in.size();i++){boolean bool=true;for(int j=0;j<i;j++)if(in.get(j)[0].equals(in.get(i)[0]))bool=false;if(bool){ArrayList<String> a=null;if(firstORfollow.equals("First"))a=this.getFirst(in.get(i)[0],"First("+in.get(i)[0]+")/"); else if(firstORfollow.equals("Follow"))a=this.getFollow(in.get(i)[0],in.get(i)[0],"");String[] sf=new String[a.size()/2+1];String[] st=new String[a.size()/2];sf[0]=in.get(i)[0];for(int j=0;j<a.size();j++){if(j%2==0)sf[j/2+1]=a.get(j);elsest[j/2]=a.get(j);}if(firstORfollow.equals("First"))first.add(sf);//first集else if(firstORfollow.equals("Follow"))follow.add(sf);track.add(st);//对应上面求得集的路径,在开始保存该非终结符了,因为已保存了该字符的First或Follow表示法}}}public ArrayList<String> getFirst(String s,String track1){//s表示左推导,track表示寻找路径,避免循环查找ArrayList<String> result = new ArrayList<String>();ArrayList<String> result1 = new ArrayList<String>();if(Character.isUpperCase(s.charAt(0))){//如果是非终结符,大写for(int i=0;i<in.size();i++){String[] one = in.get(i);if(s.equals(one[0])){if(track1.substring(0,track1.length()-9).indexOf("First("+s+")")>= 0)//假如在查找过程嵌套了这步,证明进入了无限循环,不需再找,此路径无结果;//有点要注意一下,本来一开始就把第一个开始推导符的First路径放进去了的,所以要避开这一次,不然已开始就结束了elseif(one[1].length()==1||one[1].charAt(1)!='\''&&one[1].charAt(1)!='’') result1=getFirst(one[1].charAt(0)+"",track1+"First("+one[1].char At(0)+")/");elseif(one[1].length()>1&&one[1].charAt(1)=='\''||one[1].charAt(1)=='’' )//假如接下来一个要求First的非终结符带了一撇,那一撇包括英文表示和中文表示result1=this.getFirst(one[1].substring(0,2),track1+"First("+one[1] .substring(0,2)+")/");result=addArrayString(result,result1);result1.clear();}}}else{//如果产生式首字符是终结字符if(s.equals("ε"))//注意:表示空的字符只能是这种了,其他形式在这个编译器中不能通过,还请原谅result1.add("#");elseresult1.add(s);result1.add(track1);//为了方便,把路径也加入了结果集,不然可能路径不匹配,没办法,因为中间有删去重复项result=result1;}return result;}public ArrayList<String> getFollow(String s,Stringelement,String track1){//从右至左反推,不是求Follow的等价Follow,因为推到后面的反而范围大ArrayList<String> result = new ArrayList<String>();ArrayList<String> result1 = new ArrayList<String>();if(Character.isUpperCase(s.charAt(0))){for(int i=0;i<in.size();i++){String[] one = in.get(i);int slen=s.length();int olen=one[1].length();if(element.equals(in.get(0)[0])){//如果是开始符号,或是可以反推到开始符号,证明也可以顺推导开始符号result1.add("#");result1.add(in.get(0)[0]+"→"+in.get(0)[0]+"\t");result = addArrayString(result,result1);result1.clear();}if(one[1].indexOf(s)>=0&&track1.indexOf((char)('a'+i)+"")>=0)//假如之前走过某一步,就不必再走了,那是死循环,之前在这语句前面加了个else,结果又部分内容显示不出来,总算发现了,就算反推到开始符号,也不一定就到结果了的,开始符号也可以反推,所以要继续;elseif(one[1].indexOf(s)>=0&&(olen-slen==one[1].indexOf(s)||slen==2 ||one[1].charAt(one[1].indexOf(s)+1)!='’'&&one[1].charAt(one[1].i ndexOf(s)+1)!='\'')){//如果在右产生式中真正存在需要求反推的字符,后面的条件控制它是真正存在,因为里面包含这个字符也不一定是真,就像E’中包含E,但这不是真正的包含int index=-1;index = one[1].indexOf(s,0);while(index>=0){//之前这没有用到循环,结果可能少点东西,仔细一想,必须要,就算是一个推导语句,也可能推出多个相同非终结符的组合,其实这也是一种特殊情况了,不考虑也可能正确了,也可能之前在其他地方把这样的结果求出来了,不求也没事,但就像假如要求T的Follow集,假如可以产生出T+a*T*b,这时还是有用的,万一吧if(olen-slen==index){//如果该非终结符在末尾,那么求导出该产生式的非终结符的倒推result1=getFollow(one[0], element,track1+(char)('a'+i));result=addArrayString(result,result1);result1.clear();}else{//如果后继非终结符在产生式中不是最后int t=index+slen;//指向在产生式非终结符s的后一个字符位置result1=returnFirstofFollow(s, element, track1, one[0], one[1], index, t);result=addArrayString(result,result1);//之前也没写这句话,结果把之前的内容覆盖了,就是之前的数据丢失result1.clear();}index = one[1].indexOf(s,index+1);}//endwhile}if(one[1].endsWith(element)){//如果最开始要求的Follow集非终结符在末尾result1.add("#");result1.add(in.get(0)[0]+"→"+one[1]+"\t");result=addArrayString(result,result1);//之前也没写这句话,结果把之前的内容覆盖了,就是之前的数据丢失result1.clear();}}//endfor}return result;}public ArrayList<String> returnFirstofFollow(String s,Stringelement,String track1,String one0,String one1,int index,int t){//返回求Follow集中要求的First集部分ArrayList<String> result = new ArrayList<String>();ArrayList<String> result1 = new ArrayList<String>();ArrayList<String > beckFirst;String lsh;//记录下一个字符if(t+1<one1.length()&&(one1.charAt(t+1)=='’'||one1.charAt(t+1)== '\''))//如果随后的非终结符还带了一撇符lsh=one1.substring(t,t+2);else//如果没带一撇,就只要截取一个字母就可以了lsh=one1.substring(t,t+1);String[] ls = null;int beflen=2;if(track1.length()>0){//这些都是为了算法输出容易理解点用的,其实要不输出这算法,要省下好多东西ls=in.get((int)(track1.charAt(track1.length()-1)-'a'));//得到上一步调用的语句if(Character.isUpperCase(ls[1].charAt(ls[1].length()-1)))beflen=1;}beckFirst=this.getFirst(lsh,"First("+lsh+")/");//相当于得到后继字符的First集for(int j=0;j<beckFirst.size()/2;j++){//调用求First集,返回的不一定只一个结果String lh="";if(beckFirst.get(j*2).equals("#")){result1.add(beckFirst.get(j*2));//这个加了是数据,下面一步就是把地址加上,就是一个结果,要两份数据if(ls==null)lh=in.get(0)[0]+"→"+one1+"→"+one1.substring(0,index)+elemen t+"ε"+one1.substring(t+lsh.length(),one1.length());elselh=in.get(0)[0]+"→"+one1+"→"+one1.s ubstring(0,index)+ls[1]+o ne1.substring(index+s.length(),one1.length())+"→."+element+"ε" +one1.substring(t+lsh.length(),one1.length());result1.add(lh);result=addArrayString(result,result1);result1.clear();if(1+index+lsh.length()<one1.length())//证明后面还有字符,为什么要这一步,打个比方把,假如要求F的Follow集,而存在产生式FPQ,而P的有个First集为空,那么得还接着求Q的First,类推,假如最后一个字符Q还是返回空,那么求要求产生式左边的推导非终结符的Follow集了,必须把这些结果都算到F的Follow集中去result1=returnFirstofFollow(s, element, track1, one0,one1, index, t+lsh.length());else//到最后,那么求要求产生式左边的推导非终结符的Follow集了,其实这和上面一种情况都很特殊了,一般用不上了result1=getFollow(one0, element, track1);}else{//其实下面这一大坨都是为了易懂一点,Follow集算法清晰一点,好苦啊if(Character.isUpperCase(one1.charAt(t))){//如果是有随后的一个非终结符的First集求出的结果if(ls==null)lh=in.get(0)[0]+"→"+one1+"→"+one1.substring(0,index)+element+beckFirst.get(j*2)+one1.substring(t+lsh.length(),one1.length()); elselh=in.get(0)[0]+"→"+one1+"→"+one1.substring(0,index)+ls[1]+o ne1.substring(index+s.length(),one1.length())+"→."+element+be ckFirst.get(j*2)+one1.substring(t+lsh.length(),one1.length());}else{//如果不是大写,就是终结符了,那么用First集求出来的结果连接起来还是一样的,所以不要重复打印两次了if(ls==null){if(element==in.get(0)[0]||s.equals(element))lh=in.get(0)[0]+"→"+one1.substring(0,index)+element+one1.sub string(t,one1.length())+"\t";elselh=in.get(0)[0]+"→"+one1+"→"+one1.substring(0,in dex)+elemen t+one1.substring(t,one1.length())+"\t";}else{if(ls[1].length()==1||ls[1].length()==2&&!ls[1].endsWith("’")&&!ls[ 1].endsWith("\'"))lh=in.get(0)[0]+"→"+one1+"→"+one1.substring(0,index)+elemen t+one1.substring(t,one1.length());elselh=in.get(0)[0]+"→"+one1+"→"+one1.substring(0,index)+ls[1]+o ne1.substring(index+s.length(),one1.length())+"→."+element+on e1.substring(t,one1.length())+"!";}}result1.add(beckFirst.get(j*2));//这个加了是数据,下面一步就是把地址加上,就是一个结果,要两份数据result1.add(lh);}}result=addArrayString(result,result1);//之前也没写这句话,结果把之前的内容覆盖了,就是之前的数据丢失result1.clear();return result;}public ArrayList<String> addArrayString(ArrayList<String>a,ArrayList<String> b){//两个字符串数组相加ArrayList<String> result = new ArrayList<String>();for(int i=0;i<a.size();i+=2){//因为这每一个结果,都保存了两个数据,第一个是结果,第二个位置保存的是得到这结果的路径String s = a.get(i);if(result.contains(s)||s.equals("")){//如果结果集包含了这个字符串,就不加入结果集了,就是为了去掉重复项int index=result.indexOf(s);if(result.get(index+1).length()>a.get(i+1).length()){//如果新来的路径比现有的短result.set(index, s);result.set(index+1,a.get(i+1));}continue;}result.add(s);result.add(a.get(i+1));//还是要把路径继续保存在新的结果集中}for(int i=0;i<b.size();i+=2){String s = b.get(i);if(result.contains(s)||s.equals("")){int index=result.indexOf(s);if(result.get(index+1).length()>b.get(i+1).length()){//如果新来的路径比现有的短result.set(index, s);result.set(index+1,b.get(i+1));}continue;}result.add(s);//偶数地址存放的是数据result.add(b.get(i+1));//奇数地址存放的是该数据获得的路径}return result;}public void print(ArrayList<String[]> list){for(int i=0;i<list.size();i++){//循环非终结符个数次数String[] one = list.get(i);//得到某一个非终结符运行的所有路径String[][] strings= new String[one.length][];String[] finals = new String[one.length];//路径最终站点int number=0;//记录某一步最终有效站点个数,本来有几条路径,就因该有几个有效站点,但可能有些站点有重复的,即从同一站点发出int max=0;for(int j=0;j<one.length;j++){strings[j]=one[j].split("/");if(strings[j].length>max)max=strings[j].length;//求得某一非终结符路径最长一条}for(int j=0;j<max;j++){//循环最长站点次数number=0;for(int k=0;k<strings.length;k++){//有多少条路径就循环多少次String lsh="";if(j>=strings[k].length){lsh=strings[k][strings[k].length-1];}else {lsh=strings[k][j];}int m=0;for(m=0;m<number;m++){//记录有效站点if(lsh.equals(finals[m]))break;}if(m==number){finals[number]=lsh;number++;}}for(int k=0;k<number;k++){//打印每一条路径的某个站点System.out.print(finals[k]);if(k!=number-1)System.out.print(" + ");}if(j<max-1)System.out.print(" = ");}System.out.println();}}public static void main(String[] args){new FirstFollow3();}}。