大数据架构图
- 格式:pptx
- 大小:9.58 MB
- 文档页数:49

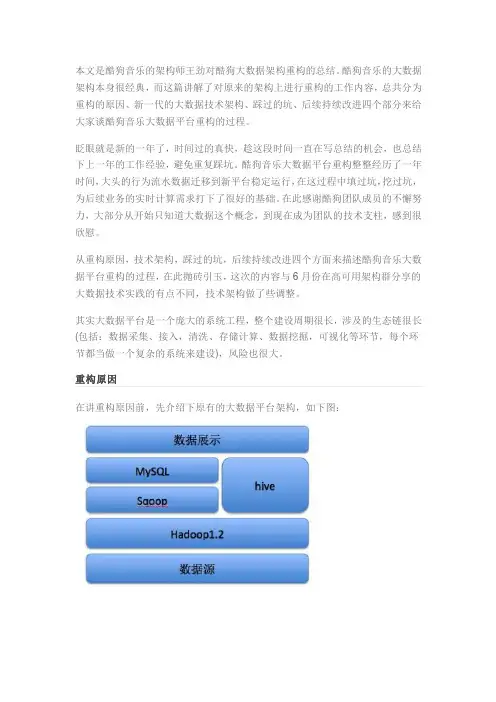



数据架构规划一.当前架构结合研发二部数据量最大的校讯通产品来描述,其他的产品在性能上出现瓶颈,可以向校讯通靠拢。
数据库整体架构:目前校讯通产品根据用户量的多少以及数据库服务资源的繁忙程度,横向采用了历史库+当前库的分库架构或者单一的当前库架构,其中历史库只作为web平台读数据库,纵向结合了applications的memcache+Sybase ASE12.5传统永久磁盘化数据库架构。
数据模型架构:原则上采用了一事一地的数据模型(3NF范式),为了性能考虑,一些大数据量表适当的引用了数据冗余,根据业务再结合采用了当前表+历史表的数据模型。
以下就用图表来进行当前数据架构的说明:横向分库数据库架构图:纵向app layer+memcache layler+disk db layer图:其中web层指的是客户端浏览器层,逻辑上:app层指的是应用服务层,mc 层指的是memcache的客户端层,ms层指的是memcache的服务层,db层指的是目前永久磁盘化的数据库层,当然在物理机器上可能app层跟mc层,ms层是重叠的部署在相同服务器上。
数据模型架构图:其中以上数据模型中除了少数几张表外其他的都有历史表存在,当然有很多表是没在这个模型图中的,这部分是核心数据模型。
这部分模型对象中也包括了一些冗余性的设计,比如用户中有真实姓名,特别是不在这个模型内,由模型核心表产生的一些统计报表,为了查询的性能冗余了合理一些学校名称,地区名称等方面的设计。
二.劣势现象1.流水表性能瓶颈当前架构的性能瓶颈集中在流水表的访问上,最大流水表的记录量达到了超5亿级别,这是由于目前外网在用的sybase数据库系统版本,没有采取很好的关于分区的技术。
曾经有过把流水表进行物理水平分割,把不同月份的数据分割放在不同的物理表上的模型改造设想,碍于产生的应用程序修改工作量大,老旧数据迁移的麻烦,再加上进行了从单库架构改造到分库架构后,数据库性能瓶颈就不是特别突出。

工业大数据技术架构概述目录第一章工业大数据系统综述 (1)1.1建设意义及目标 (1)1.2重点建设问题 (2)第二章工业大数据技术架构概述 (3)2.1数据采集与交换 (5)2.2数据集成与处理 (6)2.3数据建模与分析 (8)2.4决策与控制应用 (9)2.5技术发展现状 (10)— 1 —第一章工业大数据系统综述1.1建设意义及目标工业大数据是工业生产过程中全生命周期的数据总和,包括产品研发过程中的设计资料;产品生产过程中的监控与管理数据;产品销售与服务过程的经营和维护数据等。
从业务领域来看,可以分为企业信息化数据、工业物联网数据和外部跨界数据。
现阶段工业企业大数据存在的问题包括数据来源分散、数据结构多样、数据质量参差不齐、数据价值未有效利用等情况。
工业大数据技术的应用,核心目标是全方位采集各个环节的数据,并将这些数据汇聚起来进行深度分析,利用数据分析结果反过来指导各个环节的控制与管理决策,并通过效果监测的反馈闭环,实现决策控制持续优化。
如果将工业互联网的网络比做神经系统,那工业大数据的汇聚与分析就是工业互联网的大脑,是工业互联网的智能中枢。
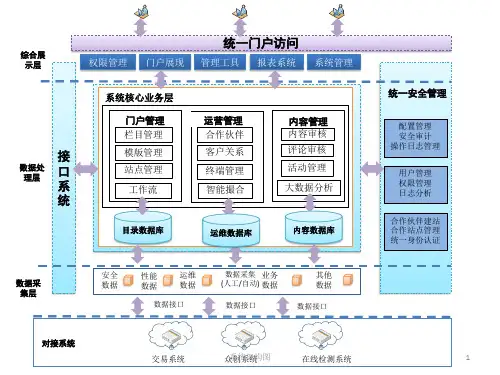
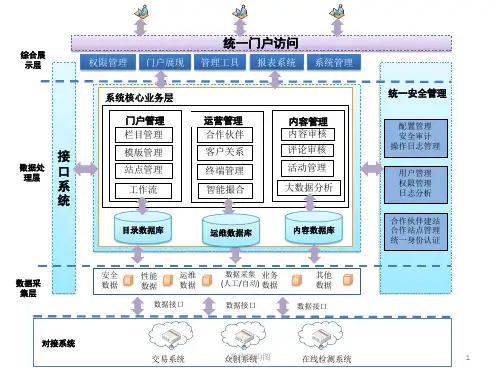
工业大数据系统的建设首要解决的是如何将多来源的海量异构数据进行统一采集和存储。
工业数据来源广泛,生产流程中的每个关键环节都会不断的产生大量数据,例如设计环节中非结构化的设计资料、生产过程中结构化的传感器及监控数据、管理流程中的客户和交易数据、以及外部行业的相关数据等,不仅数据结构不同,采集周期、存储周期及应用场景也不尽相同。
这就需要一个能够适应多种场景的采集系统对各环节的数据进行统一的收集和整理,并设计合理的存储方案来满足各种数据的留存要求。
同时需要依据合适的数据治理要求对汇入系统的数据进行标准和质量上的把控,根据数据的类型与特征进行有效管理。
之后就需要提供计算引擎服务来支撑各类场景的分析建模需求,包括基础的数据脱敏过滤、关联数据的轻度汇总、更深入的分析挖掘等。

大数据治理解决方案(含数据架构图)目录页面五个方面,现状分析、治理理念、治理策略、发展计划、运行机制。
现状分析•数据源头不统••系统分散建设基础数据不同现状分析治理理念治理概念、治理目标、治理规范、分析应用治理理念IIfaUai4bM8.l«BMhIdBI —LldlilriLIdl治理概念啡治理的目航是提离S鞘更S证R S裁时安全住.实观!S现状 分析轴罗头芒理.喩少专I…对煎翁管理讲X 监告和控制E9组g 仁息系埼的建谊和営井胆褪分戢左言部门,致使数据驾阳的职责分戢.稅夷不聯.系统分散建设基M 数据不统 越乏对政务单拉主咖的葺理,就无:药柬睡主煎溜占整亍■业爭国円W 陆一悅完整和可控,导甄业务議据正确性无试得删障哆慕厩分戢建设」没佃规范说的旨刼数据诉准和裁捱模型”0敕g 不规抵不母、[总.d 丄黑尹S3觊I 观治理目标跖挪原在各泪奴机构葫门扫娃車;推卑信孚翻的8&芦*对拥時.从両腳索那■司或JfcKEt承自恳征\敬跆折昱买郦愕直理的方曲刮毎現代信溜瓷式工^对计豐机应用忑貌生磁嫩摇囲询L充廿裁期晦中赵醐逅磁艇師融融瓏治理策略分桁利用數堀咏准.數馆采集.或厨南扳數砌沪、切盼乐戢融用,杭垢岌布、ErtS 传tfi,IH齢届[■&£、恢劉、确竇全管理、控、趟妇童爭闕.数据的生命周期数据生成--数据存储--数据处理--数据应用--数据销毁数毋应该能密按祖數据屋星京程和蛙展需要产性,应礙辄緒施翌证数摺的准确性社完整性.业务垂址上统甬i应邃迸行惑要旳安全测试」且朋证上述措施的fism 对于丈部分数娼应釆观辆与储區方过”不仅存储在本地鐵盘±r还应该在磁芾上,建至运理更制到磴盘阵列中.我者采用光孟疾进行魂需餐从数璋库中握丑煎据后洱对sm进行必要的分肝处点.在遗个过程口就濫參捷注数掲捉瞰幽柞寵否可能对数据库造輙坏径点此处输入立宇内容应明踊邂销轆誌程,采用心贾的工具,數障时谓毁应俊肖尧邸牺己舄尤貝泉对于盂硬送出叶部熔淫的存捕踽,送榕之前应跑敎捱进行可辆期5。
1.1.1水务大数据模型设计水务大数据总体技术架构水务大数据基于本次工程采购的数据集成平台、大数据平台实现水务业务大数据管理。
数据集成平台完成数据的汇聚与采集,数据治理工具对采集后的数据进行治理,形成标准规范的水务大数据主题库存储在大数据平台上,然后以API 的形式开发给应用层进行数据的使用与分析。
具体水务大数据架构图如下:水务大数据技术架构图水务数据采集数据源包括各市政单位数据、区水务局数据、水务局内部数据及给排水企业数据等相关数据,数据的类别包括结构化数据、非结构化数据和半结构化数据,数据格式包括关系数据格式、XML、JSON等Web服务格式,文件、视频、图片等格式。
集成层使用大数据采集组件、文件接口、消息中间件、API等进行数据采集,并提供文件导入、流式数据采集、Kafka接入、各类Socket接口、Http API等多种接口适配方式;采集后数据经过数据治理工具进行治理和融合,并通过统一的平台对采集日志、采集协议及接口进行综合管控。
数据存储与治理层使用分布式并行数据库MPPDB组件、分布式存储HBase 组件、分布式SQL引擎Hive组件、分布式文件系统HDFS组件相关的结构化数据存储和非结构化的数据存储组件,利用Redis建立数据缓存,以供高效服务;使用YARN对资源进行统一管理,使用Flink/Storm进行实时处理,使用Spark 进行内存计算,使用MapReduce进行离线计算。
通过以上各大数据高性能组件为水务各种监测场景、各种数据分析场景及各种应急调度场景等提供高性能的数据采集、数据计算和数据存储。
服务层基于市政大数据平台提供的多维分析Kylin组件、机器学习AI组件、即席分析SparkSQL组件及第三方工具为大数据应用服务提供技术支撑。
满足水务大数据各种数据共享交换服务、数据目录和资源目录的管理和检索查询,为各种水务业务大数据场景分析提供技术支撑。
数据使能层通过API Gateway进行数据服务API的管理,调度,发布以及路由,上层应用通过API进行数据的访问。