R语言与核密度估计(非参数统计)-PPT文档资料
- 格式:ppt
- 大小:773.50 KB
- 文档页数:29

⾮参数估计——核密度估计(Parzen 窗) 核密度估计,或Parzen 窗,是⾮参数估计概率密度的⼀种。
⽐如机器学习中还有K 近邻法也是⾮参估计的⼀种,不过K 近邻通常是⽤来判别样本类别的,就是把样本空间每个点划分为与其最接近的K 个训练抽样中,占⽐最⾼的类别。
直⽅图 ⾸先从直⽅图切⼊。
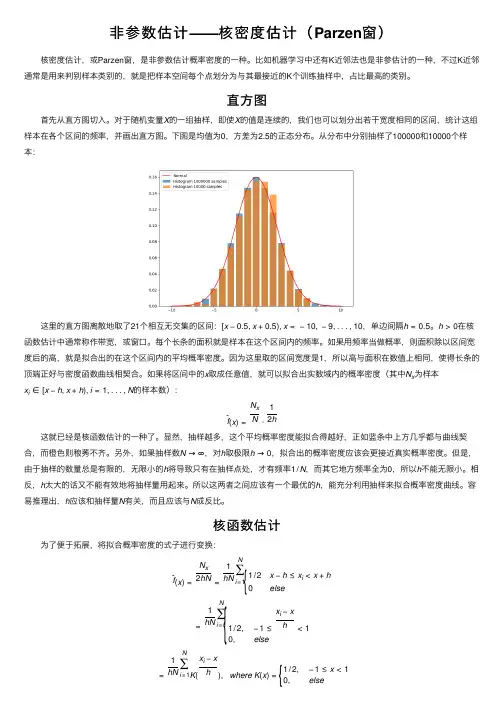
对于随机变量X 的⼀组抽样,即使X 的值是连续的,我们也可以划分出若⼲宽度相同的区间,统计这组样本在各个区间的频率,并画出直⽅图。
下图是均值为0,⽅差为2.5的正态分布。
从分布中分别抽样了100000和10000个样本: 这⾥的直⽅图离散地取了21个相互⽆交集的区间:[x −0.5,x +0.5),x =−10,−9,...,10,单边间隔h =0.5。
h >0在核函数估计中通常称作带宽,或窗⼝。
每个长条的⾯积就是样本在这个区间内的频率。
如果⽤频率当做概率,则⾯积除以区间宽度后的⾼,就是拟合出的在这个区间内的平均概率密度。
因为这⾥取的区间宽度是1,所以⾼与⾯积在数值上相同,使得长条的顶端正好与密度函数曲线相契合。
如果将区间中的x 取成任意值,就可以拟合出实数域内的概率密度(其中N x 为样本x i ∈[x −h ,x +h ),i =1,...,N 的样本数):ˆf (x )=N xN ⋅12h 这就已经是核函数估计的⼀种了。
显然,抽样越多,这个平均概率密度能拟合得越好,正如蓝条中上⽅⼏乎都与曲线契合,⽽橙⾊则稂莠不齐。
另外,如果抽样数N →∞,对h 取极限h →0,拟合出的概率密度应该会更接近真实概率密度。
但是,由于抽样的数量总是有限的,⽆限⼩的h 将导致只有在抽样点处,才有频率1/N ,⽽其它地⽅频率全为0,所以h 不能⽆限⼩。
相反,h 太⼤的话⼜不能有效地将抽样量⽤起来。
所以这两者之间应该有⼀个最优的h ,能充分利⽤抽样来拟合概率密度曲线。
容易推理出,h 应该和抽样量N 有关,⽽且应该与N 成反⽐。

r语言核密度估计应用-回复R语言核密度估计应用核密度估计(Kernel Density Estimate,简称KDE)是一种用于估计概率密度函数的非参数方法。
在R语言中,有许多包提供了核密度估计的实现,如density()函数和ksd()函数。
这篇文章将介绍如何使用R语言进行核密度估计,并探索其在数据分析中的应用。
首先,我们需要了解核密度估计的原理。
核密度估计的核心思想是使用核函数来估计概率密度函数。
核函数可以看作是单位面积为1的一个函数,通常是一个钟形曲线。
核密度估计的公式如下:是一个核函数,h是一个平滑参数,n是样本数,xi是样本点。
核密度估计的结果是在每个数据点处的概率密度值。
在R语言中,我们可以使用density()函数进行核密度估计。
density()函数是R中一个常用的用于连续型变量的密度估计函数。
它返回一个包含估计的密度值的向量。
我们可以通过plot()函数将结果可视化。
下面以一个实际的例子来说明如何进行核密度估计。
假设我们有一组表示某个城市人口年龄分布的数据,我们想要估计该城市人口年龄分布的概率密度函数。
首先,我们需要加载数据:R加载数据data <- read.csv("population_age.csv")接下来,我们使用density()函数进行核密度估计,并将结果可视化:R进行核密度估计density_est <- density(dataage)可视化结果plot(density_est, main = "Population Age Distribution",xlab = "Age", ylab = "Density")运行上述代码后,我们将得到类似于城市人口年龄分布的概率密度函数的图像。




R语言与非参数统计(核密度估计)背景核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parzen窗(Parzen window)。
原理假设我们有n个数X1-Xn,我们要计算某一个数X的概率密度有多大。
核密度估计的方法是这样的:其中K为核密度函数,h为设定的窗宽。
核密度估计的原理其实是很简单的。
在我们对某一事物的概率分布的情况下。
如果某一个数在观察中出现了,我们可以认为这个数的概率密度很大,和这个数比较近的数的概率密度也会比较大,而那些离这个数远的数的概率密度会比较小。
基于这种想法,针对观察中的第一个数,我们都可以f(x-xi)去拟合我们想象中的那个远小近大概率密度。
当然其实也可以用其他对称的函数。
针对每一个观察中出现的数拟合出多个概率密度分布函数之后,取平均。
如果某些数是比较重要,某些数反之,则可以取加权平均。
但是核密度的估计并不是,也不能够找到真正的分布函数。
代码作图示例我们可以举一个极端的例子:在R中输入:●[plain]view plaincopyprint?1.plot(density(rep(0, 1000)))可以看到它得到了正态分布的曲线,但实际上呢?从数据上判断,它更有可能是一个退化的单点分布。
但是这并不意味着核密度估计是不可取的,至少他可以解决许多模拟中存在的异方差问题。
比如说我们要估计一下下面的一组数据:●[plain]view plaincopyprint?1.set.seed(10)2.dat<-c(rgamma(300,shape=2,scale=2),rgamma(100,shape=10,scale=2))可以看出它是由300个服从gamma(2,2)与100个gamma(10,2)的随机数构成的,他用参数统计的办法是没有办法得到一个好的估计的。
那么我们尝试使用核密度估计:[plain]view plaincopyprint?1.plot(density(dat),ylim=c(0,0.2))将利用正态核密度与标准密度函数作对比[plain]view plaincopyprint?1.dfn<-function(x,a,alpha1,alpha2,theta){2.a*dgamma(x,shape=alpha1,scale=theta)+(1-a)*dgamma(x,shape=alpha2,scale=theta)}3.pfn<-function(x,a,alpha1,alpha2,theta){4.a*pgamma(x,shape=alpha1,scale=theta)+(1-a)*pgamma(x,shape=alpha2,scale=theta)}5.curve(dfn(x,0.75,2,10,2),add=T,col="red")得到下图:(红色的曲线为真实密度曲线)可以看出核密度与真实密度相比,得到大致的估计是不成问题的。

R语言与核密度估计R语言是一种基于S语言开发的开源统计计算和图形分析软件。
它提供了丰富的统计计算函数和图形绘制函数,使得数据分析和可视化非常便捷。
核密度估计是一种非参数统计方法,用于估计概率分布的密度函数。
在R语言中,核密度估计可以使用density(函数实现。
该函数的输入是一个向量,表示需要估计的数据集。
它会返回一个核密度估计结果,包括估计的密度函数值和对应的横轴坐标。
下面我们将通过一个简单的例子来演示如何使用R语言进行核密度估计。
首先,我们生成一个服从正态分布的随机数集合,并将其保存为一个向量。
```data <- rnorm(1000)```然后,我们可以使用density(函数对这个随机数进行核密度估计。
```dens <- density(data)```接下来,我们可以使用plot(函数将估计的密度函数图形化。
```plot(dens, main="Kernel Density Estimation")```运行这段代码后,会弹出一个窗口显示核密度估计的结果图。
在这个例子中,我们使用了默认的核函数和带宽参数。
核函数用于衡量每个数据点对于估计的贡献程度,而带宽参数决定了估计的平滑程度。
如果带宽较小,估计的密度函数会比较尖锐;如果带宽较大,估计的密度函数会比较平滑。
除了默认参数外,density(函数还提供了其他参数,如kernel和bw,可以用于指定核函数和带宽参数的选择。
通过调整这些参数,可以对估计的结果进行进一步的调优。
除了使用单变量数据进行核密度估计外,R语言还支持使用多变量数据进行核密度估计。
在多变量情况下,可以使用kde2d(函数进行估计。
该函数的输入是两个向量,表示需要估计的二维数据集。
它会返回一个二维密度矩阵,表示在不同横纵坐标上的密度估计值。
```x <- rnorm(1000)y <- rnorm(1000)dens2d <- kde2d(x, y)```类似地,我们可以使用persp(函数将二维密度函数图形化。


非参数统计中的核密度估计使用技巧引言非参数统计是一种不依赖于总体分布形式的统计方法,核密度估计就是其中的一种重要方法。
核密度估计是一种通过核函数对数据进行平滑处理来估计概率密度函数的方法,广泛应用于数据分析、模式识别和机器学习等领域。
在实际应用中,正确使用核密度估计的技巧对于得到准确的概率密度估计是至关重要的。
本文将从数据预处理、核函数选择、带宽选择和可视化等方面介绍非参数统计中核密度估计的使用技巧。
数据预处理在进行核密度估计之前,需要对数据进行一些预处理工作。
特别是在处理实际采集的数据时,数据可能存在缺失值、异常值或者需要进行标准化处理。
对于缺失值和异常值,可以选择删除、填充或者插值等方法进行处理;对于需要标准化的数据,可以进行Z-score标准化或者最小-最大标准化等方法。
数据预处理的目的是保证核密度估计的准确性和稳定性,避免因为数据质量问题而导致估计结果失真。
核函数选择核函数是核密度估计中的重要参数,它决定了对数据进行平滑处理的方式。
常用的核函数包括高斯核、矩核和Epanechnikov核等。
在选择核函数时,需要考虑数据的分布特性和估计的目的。
例如,对于对称分布的数据,可以选择高斯核函数;对于偏态分布的数据,可以选择矩核函数。
此外,还可以根据不同的核函数进行比较,选择最适合的核函数进行估计。
带宽选择带宽是核密度估计中的另一个重要参数,它决定了平滑的程度。
带宽过小会导致估计过拟合,带宽过大会导致估计欠拟合。
常用的带宽选择方法包括最小平均交叉验证法、最小均方误差法和银行估计等。
在选择带宽时,需要注意避免过拟合和欠拟合的问题,选择合适的带宽方法进行估计。
可视化核密度估计的结果可以通过可视化的方式呈现出来,帮助人们直观地理解数据分布的特点。
常用的可视化方法包括直方图、散点图和核密度图等。
通过可视化方法,可以直观地观察到数据的分布形态和密度分布情况,辅助我们对数据进行分析和解释。
结论核密度估计是非参数统计中的一种重要方法,正确使用核密度估计的技巧对于数据分析和模式识别具有重要意义。

非参数统计方法与核密度估计的基本原理与应用一、引言统计学是研究收集、分析和解释数据的科学,而非参数统计方法是其中的重要分支。
与参数统计方法不同,非参数统计方法不需要对总体的概率分布做出任何明确的假设,因而具有更广泛的适用性和灵活性。
核密度估计作为一种典型的非参数统计方法,被广泛应用于数据分析、模式识别等领域。
本文将介绍非参数统计方法的基本原理,并重点讨论核密度估计的原理与应用。
二、非参数统计方法的基本原理非参数统计方法是一种基于数据的分布函数进行推断的统计方法。
与参数统计方法相比,非参数统计方法不要求对总体的概率分布进行任何假设或者限制。
因此,在实际应用中,非参数统计方法更加适用于具有复杂、未知或不符合常见分布形式的数据集。
非参数统计方法的基本原理是基于经验分布函数的构建与推断。
经验分布函数是样本中每个观测值的累积分布函数的估计,它的定义为:F_n(x) = (1/n) * Σ(1[x_i ≤ x])其中,F_n(x)表示经验分布函数,n表示样本大小,x_i表示第i个观测值,1[x_i ≤ x]表示指示函数,当x_i ≤ x时,它的值为1,否则为0。
根据经验分布函数的定义,可以利用它来估计总体的分布函数,并进行相应的推断。
非参数统计方法的常用推断包括置信区间估计、假设检验等。
三、核密度估计的原理核密度估计是一种常用的非参数统计方法,它用于估计未知总体的概率密度函数。
核密度估计的基本思想是将每个观测值周围的小区域内的概率质量集中到该观测值上,通过对这些局部概率质量的加权平均来估计总体的概率密度函数。
核密度估计的核心是核函数的选择。
核函数是一个非负函数,并且满足积分等于1的性质。
常用的核函数有高斯核、矩形核、三角核等。
以高斯核为例,核密度估计可以表示为:f(x) = (1/(nh)) * ΣK((x-x_i)/h)其中,f(x)表示估计的概率密度函数,n表示样本大小,h表示带宽,x_i表示第i个观测值,K(·)表示核函数。
非参数统计中的核密度估计使用技巧在统计学中,核密度估计是一种非参数统计方法,用于估计随机变量的概率密度函数。
与参数统计方法相比,核密度估计不需要对数据的分布做出假设,因此更加灵活和通用。
在实际应用中,核密度估计经常用于数据的光滑和可视化,例如在探索性数据分析和密度估计中。
本文将介绍核密度估计的原理、使用技巧和注意事项。
1. 核密度估计的原理核密度估计的基本思想是将每个数据点周围的小区间内的数据点贡献到该点的概率密度估计中,然后将所有点的估计值加总起来,得到整个数据集的概率密度估计。
在核密度估计中,核函数起到了平滑数据的作用,常用的核函数包括高斯核函数、矩核函数和Epanechnikov核函数等。
核函数的选择对于核密度估计的性能有着重要影响,不同的核函数适用于不同的数据分布类型。
通常来说,高斯核函数是最常用的核函数,因为它在理论上具有最小的均方误差。
2. 核密度估计的使用技巧在实际应用中,核密度估计需要根据实际数据情况来选择合适的参数和核函数。
以下是一些使用核密度估计的技巧和注意事项:(1)带宽选择:带宽是核密度估计中一个重要的参数,它控制了核函数的宽度和平滑程度。
带宽过大会导致估计过度平滑,带宽过小则会导致估计过度波动。
常用的带宽选择方法包括最小交叉验证法和银子规则等。
在实际应用中,需要根据数据的分布情况和应用需求来选择合适的带宽。
(2)核函数选择:除了高斯核函数外,还有其他的核函数可供选择。
在实际应用中,需要根据数据的特点来选择合适的核函数。
例如,对于有界数据,Epanechnikov核函数更适合;对于长尾分布,矩核函数可能更合适。
(3)多变量核密度估计:对于多维数据,可以使用多变量核密度估计来估计数据的概率密度函数。
多变量核密度估计可以通过多维核函数来实现,例如多变量高斯核函数。
在实际应用中,需要注意选择合适的多变量核函数和带宽。
3. 核密度估计的应用注意事项在使用核密度估计时,需要注意以下一些事项:(1)数据量:核密度估计对数据量的要求比较高,特别是在多维数据的情况下。
R核心知识培训课件(一)R核心知识培训课件是一份全面系统的R语言学习资料,对于想要学习R语言的初学者及有一定基础但欠缺系统性学习的人来说,都是非常有价值的资源。
本课件主要分为以下几个部分:第一部分:R语言基础知识该部分主要介绍了R语言的基础知识,包括R语言的安装、R语言的界面、常用的R语言包以及R语言的数据类型等。
这些知识点是学习R语言的必要前置知识,掌握好这些知识点能够为后续学习提供很好的帮助。
第二部分:R语言的数据处理该部分介绍了R语言的数据处理相关知识,包括了R语言的数据导入、数据清洗、数据变换、数据重塑以及数据汇总等等。
这些知识点对于数据分析师及数据工程师来说都是非常重要的,能够提高数据处理的效率和可靠性。
第三部分:R语言的统计分析该部分介绍了R语言的统计分析相关知识,包括了R语言的统计描述、单变量分析、双变量分析、回归分析、时间序列分析以及聚类分析等等。
这些知识点是数据分析师必须掌握的,可以用于解决实际问题并提供可靠的数据决策。
第四部分:R语言的图形展示该部分介绍了R语言的图形展示相关知识,包括了R语言的进阶绘图、ggplot2绘图、Lattice绘图以及3D绘图等等。
这些知识点是数据可视化必须掌握的,可以让数据分析师更好的展示数据分析结果和报告。
第五部分:R语言的应用案例该部分列举了一些实际应用中R语言的案例,包括了传统统计分析、数据采集和处理、文本挖掘以及机器学习等等。
通过这些案例的学习,读者能够更好的了解R语言的应用场景,提高自己对R语言的理解和使用能力。
此外,本课件还附带了丰富的实战练习和R语言基础题目,通过不断的学习和实践,读者能够更加深入的了解R语言并熟练掌握其应用。
总之,R核心知识培训课件是一份非常有价值的学习资料,其系统性、条理性和实用性都非常高,读者只需要按照课件的步骤,逐步学习,相信一定能够轻松上手并运用R语言进行数据分析和可视化。
在统计学中,核密度估计是一种用来估计概率密度函数的非参数统计方法。
与参数统计方法不同,核密度估计不需要对概率密度函数假设特定的形式,而是根据数据样本的分布情况来估计概率密度函数。
在实际应用中,核密度估计可以用于分析数据的分布特征、异常值检测、模式识别等领域。
本文将讨论在非参数统计中的核密度估计使用技巧。
首先,核密度估计的核函数选择非常重要。
核函数是核密度估计的核心部分,它决定了估计的精度和偏差。
在选择核函数时,常用的有高斯核函数、矩形核函数、三角核函数等。
不同的核函数对于不同类型的数据适用,需要根据具体情况进行选择。
一般来说,高斯核函数在估计光滑连续的概率密度函数时效果较好,而矩形核函数在估计离散的概率密度函数时更为适用。
其次,带宽的选择对于核密度估计的效果同样至关重要。
带宽决定了核密度估计的尺度大小,过大或过小的带宽都会导致估计结果的偏差。
通常可以使用交叉验证或银子法则等方法来选择合适的带宽。
在实际应用中,可以尝试不同的带宽来进行比较,选择最优的带宽以获得更加准确的概率密度函数估计结果。
另外,对于多维数据的核密度估计,需要特别注意维度灾难的问题。
在高维空间中,样本点之间的距离变得非常稀疏,导致核密度估计的精度下降。
因此,在多维数据的核密度估计中,需要考虑降维或者使用特定的核函数来解决维度灾难的问题。
同时,对于高维数据的核密度估计,带宽的选择也变得更加重要,需要通过交叉验证等方法来选取合适的带宽。
此外,核密度估计还可以结合其他的非参数统计方法进行分析。
例如,可以利用核密度估计来进行异常值检测,通过比较样本的概率密度值来识别异常值。
同时,核密度估计还可以应用在模式识别中,用来对数据进行分类和聚类分析。
通过将核密度估计与其他方法结合,可以更加全面地分析数据的分布特征和模式。
总之,在非参数统计中的核密度估计使用技巧有很多,核函数的选择、带宽的选择、维度灾难的问题、与其他方法的结合等都需要进行合理的考虑。
第十章非参数密度估计密度估计的参数解是首先假设一个参数模型,X1,…,X n~i.i.d. f Xθ,其中θ为低维参数向量。
然后通过一些估计方法得到θ,如极大似然估计,矩估计等等。
然后到处密度函数。
此方法的危险性在于初始假设模型的不正确可能导致严重的推断错误。
一种常见的非参数密度估计是直方图,他是一种分段常数的密度估计。
另一种基本的密度估计可通过考虑密度函数如何将概率分配到各区间上受到启发,如果f 足够光滑,我们假设f将某概率不但赋予给x i点,而且赋予给x i周围的一个区域。
因此,要从X1,…,X n~i.i.d.f估计f,将X i周围区域的概率密度累加起来时合理的。
10.1 绩效度量绩效度量是为了评价密度估计量的性质。
令f为整个支撑区域上f的估计量,引入积分平方误差ISE h= f x−f x 2 dx∞−∞如果我们想讨论估计量的一般性质,那么在所有可能的样本上对ISE h进行平均是比较合理的。
积分平均误差为MISE h=E{ISE h}其中的期望是关于分布f。
因此MISE h可以看成是误差(ISE h)关于抽样密度的整体度量的平均值。
又由期望和积分的可交换性,MISE h=MSE f x dx其中MSE f x=E f x−f x 2=var f x+ bias f x2bias f x=E f x−f(x)MISE和ISE都可用来研究选择h值的准则。
两者的好坏已知都有争论,详见Birgit Grunda; Peter Hallb; J. S. Marronc.Loss and risk in smoothing parameter selectionPeter Hall and J. S. Marron.lower bounds for bandwidth selection in density estimation10.2 核密度估计一元核密度估计允许采取灵活的加权方案,即拟合f x=1nhK(x−X i)ni=1(10.6)其中K为核密度,h为固定值,通常称为窗宽。