SPSS基本操作与数据预处理
- 格式:ppt
- 大小:1.49 MB
- 文档页数:47

SPSS数据的预处理SPSS是研究社会科学数据和其他统计分析领域中常用的软件之一。
在进行分析之前,我们需要进行预处理来准备我们的数据集。
数据的清理在进行数据分析之前,我们需要了解数据集中的每个变量并确保它们是正确的,并且符合我们的需要。
在数据清理过程中,我们需要进行以下操作:处理缺失值在数据集中,某些变量可能会缺乏部分值,我们需要进行缺失值处理,以便于数据的分析和处理。
填补缺失值的方法主要有以下几种:1.删除缺失值:删除含有缺失值的行或者列,但是需要注意删除的行和列如果数据量较大,可能会对后续的分析产生影响。
2.插补法:使用其他观测下的变量的平均值、中位数,众数等来填补缺失值。
在SPSS中,我们可以通过Transform->Replace Missing Values来进行缺失值的填补。
其中的缺失值可以设置被替换的数值类型,如我们可以用平均数代替缺失值,也可以用最近邻样本的替换策略等。
处理异常值当数据集中存在异常值时,需要使用删除或替换方法对其进行去除或更正。
异常值是指由于测量、数据输入或其他原因导致的不合理的数据值。
对于极端的异常数据值,删除数据可能是最好的解决方案。
在SPSS中,我们可以使用Analyze->Descriptive Statistics->Explore来寻找异常值,它会检查所有数据和变量,并给我们提供总体统计、中心趋势度量和分布度量等描述。
数据的转换在进行分析之前,我们还需要对数据进行转换来满足分析的要求。
最常见的转换包括下列几种:变量归一化某些变量或变量的值可能存在不同的测量单位,为了能够在同等条件下进行比较,需要对数据进行标准化处理。
在SPSS中,我们可以使用Transform->Recode Into Same Variables来进行数据的归一化操作。
例如,我们可以将数值变量转换为区间变量或类别变量。
变量离散化连续型数据为了进行分析常需要将其转换为类别变量。

如何正确使用SPSS统计分析软件SPSS(Statistical Product and Service Solutions)是现今最为流行的统计分析软件之一,它拥有强大的分析能力和灵活的数据处理手段,可以帮助研究人员更加高效地处理和分析大量数据。
然而,许多使用者在使用SPSS软件时,可能会遇到各种问题,包括数据预处理、数据清洗、数据分析等方面的问题。
本文将从SPSS软件的使用角度出发,为大家讲解如何正确使用SPSS统计分析软件。
一. 数据预处理和清洗数据预处理和数据清洗是SPSS数据分析的关键步骤。
在数据预处理和数据清洗过程中,需要对数据进行检查和清理,以保证统计分析的结果尽可能准确。
下面是几个常见的数据清洗步骤:1. 数据去重如果数据集中存在重复数据,会影响统计结果的准确性。
在使用SPSS前,需要对数据集进行去重操作,以确保数据集中每个样本只出现一次。
2. 数据过滤在对数据进行分析时,需要排除一些无用信息或异常数据。
在SPSS中可以使用过滤技术去掉无用数据。
3. 数据缺失值处理在数据采集时,难免会出现一些数据缺失的情况。
在进行统计分析时,需要对缺失值进行处理,以确保后续的分析准确无误。
二. 数据分析数据分析是SPSS软件的主要功能之一。
通过SPSS软件中的数据分析功能,研究人员可以采取各种不同的分析方法,进行数据的定量分析和定性分析。
下面是几种常见的数据分析方法:1. 描述性统计分析描述性统计分析是指研究人员通过图形和描述性统计量,对数据的基本特征进行分析和描述。
SPSS中可以使用的描述性统计方法包括频数、百分比、平均值、中位数、标准差、四分位数等。
2. 方差分析方差分析是一种常见的数据分析方法,可以用来检验变量之间是否存在显著差异。
在SPSS中,可以使用ANOVA(Analysis Of Variance,方差分析)方法进行方差分析。
3. 回归分析回归分析是一种用来分析和描述两个或多个变量之间关系的统计分析方法,可以预测连续型变量的值。

论文写作中如何利用SPSS进行数据预处理与清洗在进行论文研究时,数据预处理与清洗是非常重要的一步。
数据的质量直接影响着研究结论的可信度和准确性。
SPSS(Statistical Package for the Social Sciences)是一款常用的统计分析软件,它提供了丰富的功能和工具,可以帮助研究人员进行数据的预处理和清洗。
本文将介绍如何利用SPSS进行数据预处理与清洗的方法和步骤。
一、数据导入与查看在使用SPSS进行数据预处理与清洗之前,首先需要将数据导入到SPSS软件中。
SPSS支持多种数据格式的导入,包括Excel、CSV等常见格式。
导入数据后,可以使用SPSS的数据查看功能,对数据进行初步的了解和分析。
可以查看数据的结构、变量类型、缺失情况等信息,以便后续的数据处理工作。
二、数据清洗1. 处理缺失值缺失值是指数据中的某些变量或观测值缺失的情况。
在进行数据分析之前,需要对缺失值进行处理。
SPSS提供了多种处理缺失值的方法,包括删除缺失值、插补缺失值等。
可以根据具体情况选择合适的方法进行处理。
2. 处理异常值异常值是指数据中的一些极端值或离群值,可能会对分析结果产生影响。
在数据清洗过程中,需要对异常值进行处理。
SPSS可以通过计算变量的均值和标准差,识别出异常值,并进行相应的处理,如删除或替换。
3. 数据转换与标准化在进行数据分析之前,有时需要对数据进行转换和标准化,以便更好地满足统计分析的要求。
SPSS提供了多种数据转换和标准化的方法,如对数转换、归一化等。
可以根据具体研究需求选择合适的方法进行数据处理。
三、数据预处理1. 变量选择在进行数据分析之前,需要根据研究目的和问题,选择合适的变量进行分析。
SPSS可以通过变量筛选功能,根据变量的相关性、方差分析等指标,选取与研究问题相关的变量。
2. 数据分组在某些情况下,需要对数据进行分组分析。
SPSS提供了数据分组的功能,可以根据变量的不同取值,将数据分为不同的组进行分析。


spss数据的预处理基本统计分析心得感悟
在进行SPSS数据的预处理基本统计分析时,我有以下心得感悟:
1. 对数据进行清洗和筛选
在进行数据分析之前,需要对数据进行清洗和筛选,去除无用的数据和异常值,提高数据的准确性和可靠性。
2. 理解数据的分布情况
在进行基本统计分析时,需要理解数据的分布情况,包括数据的平均值、方差、标准差、偏度和峰度等统计指标。
这有助于了解数据是否符合正态分布,数据的离散程度,以及数据的分布形态。
3. 分析变量之间的关系
分析变量之间的关系可以使用相关分析、回归分析、t检验等方法。
通过分析变量之间的关系,可以了解不同变量之间的相关性,并找出影响变量的因素。
4. 对数据进行可视化处理
可视化处理是一种直观的分析方法,可以使用直方图、散点图等图表来表示数据的分布情况、变量之间的关系和趋势。
通过可视化处理可以更加直观地了解数据的特征和规律。
综上所述,进行SPSS数据的预处理基本统计分析需要仔细分析数据的特征,了解变量之间的关系,并运用统计分析和可视化处理等方法,以提高分析结果的精度和有效性。

市场调研分析工具:SPSS操作基础课件及试题答案市场调研分析工具:SPSS操作基础一、SPSS基本操作1.SPSS的基本认识SPSS是市场调查的有效工具之一,对这一工具应当具备以下基本认识:SPSS的输出结果基本和office兼容SPSS提供了一个类似于Excel的操作界面,同时SPSS可以打开Excel文件。
由于很多公司的各类信息是录入到Excel文件中的,这样就能够顺利地将相关信息导入SPSS。
SPSS具备很好的画图功能SPSS可以将各类信息整理成各类实用而清晰的图表,这是很多公司都非常关心的一项功能。
图1 SPSS的操作界面如图1所示,SPSS的操作界面与Excel非常相似,这款软件是20世纪50年代斯坦福大学的三个研究生研发成功的,此后不断发展成为世界上最著名和客户占有量最大的统计软件。
2009年,这一软件被IBM公司收购,随后在商务上得到快速推进,因为IBM计划将SPSS打造成一款商务智能软件,而不是只局限在高校范围内。
比如,该软件有一个“直销”(Direct sells)模块,这是在数据分析中经常用到的模块,里面放入了一些非常著名的商务分析模型,如客户价值判断模型(RFM),这一模型可以根据客户的购买频次、购买金额、最后一次购买时间等信息,对客户做出价值判断并进行分组,这些都是SPSS 被IBM收购后发生的变化。
目前,中国移动、各大银行、淘宝网等知名公司都在应用这些数据分析模块。
由于国内的软件版权保护制度比较落后,IBM目前并不以软件销售作为主赢利渠道,而是主要通过商务咨询和相关服务获取利润。
2.SPSS的操作流程SPSS的主要操作流程大致可以分为五部分:第一,数据读入——是将相关数据读入SPSS 中;第二,数据预处理——数据读入后,要稍微做一下预处理才能继续操作;第三,模型处理——选择一个模型进行分析,然后SPSS就会输出相应的结果;第四,结果解读——对输出的结果要进行必要的解读;第六,结果二次处理——最后对结果进行一些再处理。
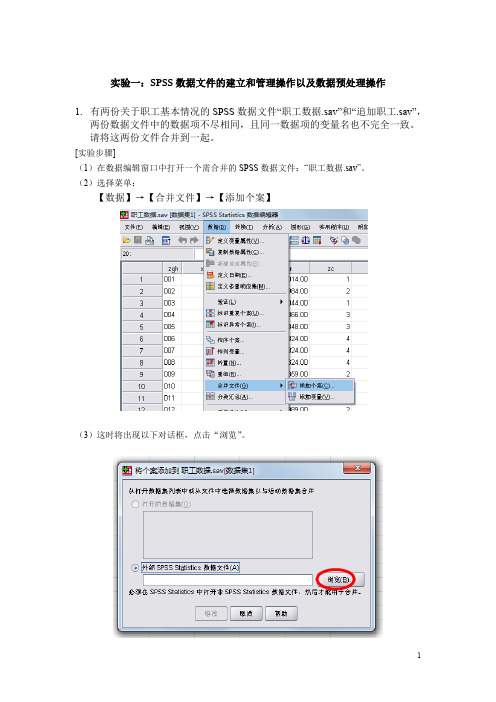
实验一:SPSS数据文件的建立和管理操作以及数据预处理操作1.有两份关于职工基本情况的SPSS数据文件“职工数据.sav”和“追加职工.sav”,两份数据文件中的数据项不尽相同,且同一数据项的变量名也不完全一致。
请将这两份文件合并到一起。
[实验步骤](1)在数据编辑窗口中打开一个需合并的SPSS数据文件:“职工数据.sav”。
(2)选择菜单:【数据】→【合并文件】→【添加个案】(3)这时将出现以下对话框,点击“浏览”。
(4)打开需进行纵向合并处理的SPSS数据文件“追加职工.sav”。
按“继续”后,显示纵向合并数据文件窗口。
(如下图)(5)对话框右边【新的活动数据集中的变量】框中显示的变量名是两个数据文件中的同名变量,对话框左边【非成对变量】框中显示的变量名是两个文件中的不同名变量。
其中,变量名后面的【*】表示该变量是当前数据编辑窗口中(“职工数据.sav”)的变量,【+】表示该变量是(2)“追加职工.sav”中指定的磁盘文件中的变量。
SPSS默认这些变量的含义不同,且不放入合并后的新文件中。
如果不接受这种默认,可选择其中的两个变量名并按【对】按钮指定配对,表示虽然它们的名称不同但数据含义是相同的,可进入合并后的数据文件中。
本题中,显然职称zc(*)和职称zc1(+)两个变量名需要按【对】按钮指定配对。
方法是:按住“Ctrl键”,同时鼠标点zc(*)和zc1(+),然后按【对】按钮,这时【新的活动数据集中的变量】框中出现“zc&zc1”变量名。
(6)把【非成对变量】框中显示的其他变量名全部标记,按右向箭头。
(7)按【确定】,完成操作。
2.根据“住房状况调查.sav”数据,通过数据排序功能分析本市户口和外地户口家庭的住房面积情况。
(按升序排列)[实验步骤](1)在数据编辑窗口中打开SPSS数据文件:“住房状况调查.sav”。
(2)选择菜单:【数据】→【排序个案】(3)指定主排序变量“户口状况”到【排序依据】框中,并选择【排序顺序】框中的选项指出该变量按升序还是降序排序。


第三章spss数据的预处理1.利用第2章第7题数据,采用spss数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地在“沿海或中心繁华城市”且本次存款金额在1000~5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份数据文件:第二份数据文件:2.利用第2章第7题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
3.利用第2章第9题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
定义:得优分数段90-100得良分数段80-90计算得优课程数:从输出结果可知:60名学生中有四门成绩得优的学生有2个,属于品学兼优的少数人;两门成绩得优的学生有9个;一门成绩得优的学生有23个,没有成绩得优的学生有26个,累计占到百分之八十,说明该60名学生成绩普遍不是很理想。
计算得良课程数:从输出结果可知:60名学生中有四门成绩得良的学生有6个;三门成绩得良的学生有12个;两门成绩得良的学生有15个;一门成绩得良的学生有15个;没有成绩得良的学生有12个。
其中有70%的学生得良课程在两门及两门以下,成绩仍旧不乐观。
按得优课程数降序排序:4.利用第2章第9题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
每个学生课程平均分ave:每个学生课程标准差s:平均分ave与标准差s:男生与女生各科成绩平均分:第一步:按性别拆分文件第二步:分析→统计描述→描述第三步:结果输出5. 利用第2章第7题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
数据分组过程: K=1+2n 1n2821=9 组距=91-100001=11111 近似取12000数据分组结果:6.在第2章第7题的数据中,如果认为调查中“今年的收入比去年增加”且“预计未来一两年收入仍会增加”的人是对自己收入比较满意和乐观的人,请利用spss的计数和数据筛选功能找到这些人。


实验报告姓名学号专业班级课程名称统计分析SPSS软件实验室成绩指导教师实验名称SPSS数据的预处理一、实验目的:学会SPSS数据的基本预处理:排序、分组、分类汇总、变量计算、筛选数据二、实验题目:根据数据文件“住房状况调查.sav",完成以下要求:(1)按现住面积(降序)、家庭收入(降序)、年龄(升序)进行多重排序。
(2)根据家庭收入的数据分布状况,选择恰当的组数和组距进行分组。
(3)根据从业状况进行分类汇总,计算各行业的现住面积的平均值和标准差(4)计算人均收入、人均住房面积、计划面积和现住面积的差。
(5)将数据文件分成两份文件,第一份数据文件要求是“常住人口不少于3人”且“现住面积在50平方米以下"的调查数据;第二份数据文件要求是按照简单随机抽样所选取的70%的样本数据.三、实验步骤(最好有截图):(1)打开“住房状况调查.sav”文件。
选择菜单:【Data】→【Sort Cases】,再指定现住面积变量到【Sort by】框中,并选择【Sort Order】框中的选项指出该变量按降序排序,并依次指定第二家庭收入变量按降序排列,最后再指定第三年龄变量按升序排列。
按“OK”键确定。
最后保存文件。
至此,数据编辑窗口中的数据便自动按用户指定的顺序重新排列并显示出来,如下图(2)打开“住房状况调查。
sav”文件。
选择菜单:【Transform】→【Recode into Different Variables】,选择分组变量到【Numeric Variable-〉Output】框中。
这里选择“家庭收入”。
在【Output Variable】框中的【Name】后输入存放分组结果的变量名,并按“Change”按钮确认,这里的变量名为收入分布。
按“Old and New Values”按钮进行分组区间定义,按组距10000,组数4进行分组。
最后保存文件。
如下图(3) 打开“住房状况调查.sav”文件。




Spss的数据预处理一、数据预处理的目的:在数据文件建立好后,通常还要对待分析的数据进行必要的预加工处理,这是数据分析过程中不可缺少的一个关键环节。
数据的预加工处理是服务与数据分析和建模的,需要解决的问题如下:1、缺失值和异常数据的处理.2、数据的转换处理.数据的转换处理是在原有数据的基础上,计算产生一些含有更丰富信息的新数据或对数据原有分布进行转换等.3、数据抽样。
从实际问题、算法或效率等方面考虑,并非收集到的所有数据(个案)在某项分析中都有用途,有必要按照一定的规则从大量数据中选取部分样本参与分析.4、选取变量。
并非所有数据项(变量)在某项分析中均有意以,选取部分变量参与分析是必要的。
Spss提供了一些专门的功能辅助用户实现数据的预加工处理工作,通过预处理还可以使用户对数据的总体分布有所了解。
二、数据预处理步骤:1、数据的排序:(1)数据排序的目的:a、通常数据编辑窗口中个案的前后次序是由数据数录入的先后顺序决定的,数据排序便于数据的浏览,有助于了解数据取值状况、缺失值数量的多少。
b\、通过数据排序能够快速找到最大值和最小值,进而可以计算出数据的全距,快速把握和比较数据的离散程度。
c、通过数据排序能够快速发现数据的异常值。
(2)、数据排序的步骤:a、选择菜单:【Date】→【Sort Cases】b、指定主排序量到【Sort by】框中,并选择【Sort Order】框中的选项指出该变量按升序还是降序排序排序。
【Ascending】表示升序,【Descending】表示降序。
c、如果是多重排序,还要依次指定第二、第三排序变量及相应的排序规则。
否则本部可略。
排序窗口如下图:图12、变量计算:(1)变量计算的目的:a、通过数据的转换处理,在原有数据的基础上,计算产生一些含量更丰富的新数据。
b\、对数据的原有分布状态进行转换,由于数据分析和建模中某些模型对数据分布有一定的要求,因此可以利用变量计算对原有数据的分布进行转换.c、spss变量计算是在原有数据的基础上,根据用户给出的spss的算术表达式以及函数,对所有个案或满足条件的部分个案,计算产生一系列新变量。


广东金融学院实验报告课程名称:市场调查与预测
四、实验结果(包括程序或图表(截图)、结论陈述、数据记录及分析等,可附页)
1.①变量视图截图(zc和zcl合并为zc)
②数据视图的截图(“职工数据.sav”的变量中多了income)
2. 数据视图的截图(户口状况和现住面积都是按升序排的,且先排户口状况再排现住
面积)
3.数据视图的截图(户口状况=2,即属于外地户口的都被划掉了,从而筛选出本市户口,
此外后面的filter_$为1是被选中的数据)
4. 数据视图的截图(由图看出本市户口人均面积的均值为48.93,外地户口人均面积的
均值为34.03,两者在人均面积上有较大的差异,但本市户口和外地户口计划面积的均值都为90.00,所以两者在计划面积上没有较大的差异)
五、实验总结(包括心得体会、问题回答及实验改进意见,可附页)
1.通过实验,我熟练掌握了SPSS数据文件的合并,排序筛选个案和分类汇总的具体操
作。
2.实验的过程必须要自己亲自练习才有效果,所以即使有步骤,也不要怕麻烦,多练几
次。
3.SPSS是一个数据统计的强大工具,我们必须好好学习。
六、教师评语
1.□优秀(90~100分):完成所有规定实验内容,实验步骤正确,结果正确;
2.□良好(80~89分):完成绝大部分规定实验内容,实验步骤正确,结果正确;
3.□中等(70~79分):完成绝大部分规定实验内容,实验步骤基本正确,结果基本正确;
4.□及格(60~69分):基本完成规定实验内容,实验步骤基本正确,完成结果基本正确;
5.□不及格(< 60分):未能完成规定实验内容或实验步骤不正确或结果不正确。
教师签名:
2013年12 月8 日。

SPSS软件的基本使用方法
SPSS(Statistical Package for the Social Sciences)是一款常用的统计分析软件,用于数据管理、数据分析、图画绘制等多个方面的应用。
以下是SPSS软件的基本使用方法:
1. 打开SPSS软件:启动后,出现欢迎界面。
2. 新建数据集:在欢迎界面选择“新建数据集”或菜单栏“文件→新建→数据”,设置数据集名称和变量名。
3. 输入数据:输入每个变量的数据,包括定量变量和定性变量。
4. 数据预处理:对数据进行清理和预处理,可以删除无用数据、缺失数据和异常数据,调整数据格式和变量类型等。
5. 描述性统计分析:从菜单栏选择“统计→描述性统计→描述性统计”,选择需要统计的变量,生成基本统计量和频数表等内容。
6. 探索性数据分析:从菜单栏选择“图形→探索性数据分析”,选择需要绘制的图形类型,如直方图、散点图、箱线图等。
7. 统计分析:从菜单栏选择“统计→一般线性模型”,选择需要分析的变量和分析方法,如t检验、方差分析、回归分析等。
8. 输出结果:将分析结果输出到文件或打印出来。
以上是SPSS软件的基本使用方法,需要不断练习和深入学习。