ELM-Chinese-Brief(极限学习机)
- 格式:pdf
- 大小:699.55 KB
- 文档页数:20

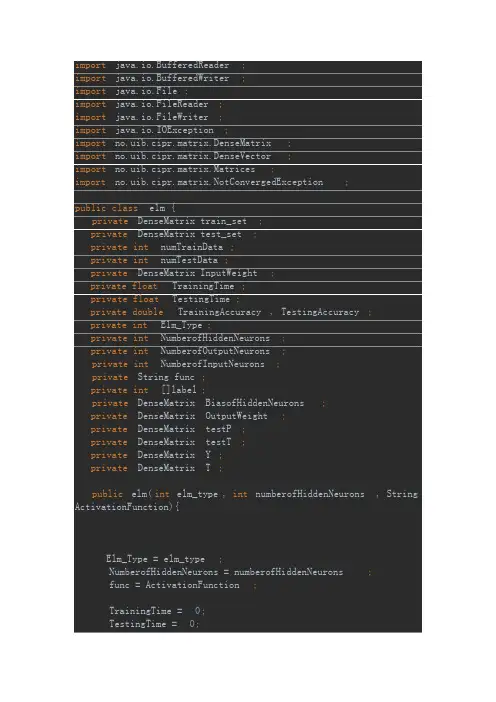
import java.io.BufferedReader;import java.io.BufferedWriter;import java.io.File;import java.io.FileReader;import java.io.FileWriter;import java.io.IOException;import no.uib.cipr.matrix.DenseMatrix;import no.uib.cipr.matrix.DenseVector;import no.uib.cipr.matrix.Matrices;import no.uib.cipr.matrix.NotConvergedException;public class elm {private DenseMatrix train_set;private DenseMatrix test_set;private int numTrainData;private int numTestData;private DenseMatrix InputWeight;private float TrainingTime;private float TestingTime;private double TrainingAccuracy, TestingAccuracy;private int Elm_Type;private int NumberofHiddenNeurons;private int NumberofOutputNeurons;private int NumberofInputNeurons;private String func;private int []label;private DenseMatrix BiasofHiddenNeurons;private DenseMatrix OutputWeight;private DenseMatrix testP;private DenseMatrix testT;private DenseMatrix Y;private DenseMatrix T;public elm(int elm_type, int numberofHiddenNeurons, String ActivationFunction){Elm_Type = elm_type;NumberofHiddenNeurons = numberofHiddenNeurons;func = ActivationFunction;TrainingTime = 0;TestingTime = 0;TrainingAccuracy= 0;TestingAccuracy = 0;NumberofOutputNeurons = 1;}public elm(){}public DenseMatrix loadmatrix(String filename) throws IOException{BufferedReader reader = new BufferedReader(new FileReader(new File(filename)));String firstlineString = reader.readLine();String []strings = firstlineString.split(" ");int m = Integer.parseInt(strings[0]);int n = Integer.parseInt(strings[1]);if(strings.length > 2)NumberofOutputNeurons = Integer.parseInt(strings[2]);DenseMatrix matrix = new DenseMatrix(m, n);firstlineString = reader.readLine();int i = 0;while (i<m) {String []datatrings = firstlineString.split(" ");for (int j = 0; j < n; j++) {matrix.set(i, j,Double.parseDouble(datatrings[j]));}i++;firstlineString = reader.readLine();}return matrix;}public void train(String TrainingData_File) throws NotConvergedException{try {train_set = loadmatrix(TrainingData_File);} catch (IOException e) {e.printStackTrace();}train();}public void train(double [][]traindata) throws NotConvergedException{//classification require a the number of classtrain_set = new DenseMatrix(traindata);int m = train_set.numRows();if(Elm_Type == 1){double maxtag = traindata[0][0];for (int i = 0; i < m; i++) {if(traindata[i][0] > maxtag)maxtag = traindata[i][0];}NumberofOutputNeurons = (int)maxtag+1;}train();}private void train() throws NotConvergedException{numTrainData = train_set.numRows();NumberofInputNeurons = train_set.numColumns() - 1;InputWeight = (DenseMatrix)Matrices.random(NumberofHiddenNeurons, NumberofInputNeurons);DenseMatrix transT = new DenseMatrix(numTrainData, 1);DenseMatrix transP = new DenseMatrix(numTrainData, NumberofInputNeurons);for (int i = 0; i < numTrainData; i++) {transT.set(i, 0, train_set.get(i, 0));for (int j = 1; j <= NumberofInputNeurons; j++)transP.set(i, j-1, train_set.get(i, j));}T = new DenseMatrix(1,numTrainData);DenseMatrix P = newDenseMatrix(NumberofInputNeurons,numTrainData);transT.transpose(T);transP.transpose(P);if(Elm_Type != 0) //CLASSIFIER{label = new int[NumberofOutputNeurons];for (int i = 0; i < NumberofOutputNeurons; i++) {label[i] = i; }DenseMatrix tempT = newDenseMatrix(NumberofOutputNeurons,numTrainData);tempT.zero();for (int i = 0; i < numTrainData; i++){int j = 0;for (j = 0; j < NumberofOutputNeurons; j++){if (label[j] == T.get(0, i))break;}tempT.set(j, i, 1);}T = newDenseMatrix(NumberofOutputNeurons,numTrainData); //T=temp_T*2-1;for (int i = 0; i < NumberofOutputNeurons; i++){for (int j = 0; j < numTrainData; j++)T.set(i, j, tempT.get(i, j)*2-1);}transT = newDenseMatrix(numTrainData,NumberofOutputNeurons);T.transpose(transT);}long start_time_train = System.currentTimeMillis();BiasofHiddenNeurons = (DenseMatrix)Matrices.random(NumberofHiddenNeurons, 1);DenseMatrix tempH = newDenseMatrix(NumberofHiddenNeurons, numTrainData);InputWeight.mult(P, tempH);//DenseMatrix ind = new DenseMatrix(1, numTrainData);DenseMatrix BiasMatrix = newDenseMatrix(NumberofHiddenNeurons, numTrainData);for (int j = 0; j < numTrainData; j++) {for (int i = 0; i < NumberofHiddenNeurons; i++) {BiasMatrix.set(i, j, BiasofHiddenNeurons.get(i, 0));}}tempH.add(BiasMatrix);DenseMatrix H = new DenseMatrix(NumberofHiddenNeurons, numTrainData);if(func.startsWith("sig")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTrainData; i++) {double temp = tempH.get(j, i);temp = 1.0f/ (1 + Math.exp(-temp));H.set(j, i, temp);}}}else if(func.startsWith("sin")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTrainData; i++) {double temp = tempH.get(j, i);temp = Math.sin(temp);H.set(j, i, temp);}}}else if(func.startsWith("hardlim")){}else if(func.startsWith("tribas")){}else if(func.startsWith("radbas")){}DenseMatrix Ht = newDenseMatrix(numTrainData,NumberofHiddenNeurons);H.transpose(Ht);Inverse invers = new Inverse(Ht);DenseMatrix pinvHt = invers.getMPInverse();OutputWeight = new DenseMatrix(NumberofHiddenNeurons, NumberofOutputNeurons);pinvHt.mult(transT, OutputWeight);long end_time_train = System.currentTimeMillis();TrainingTime = (end_time_train -start_time_train)* 1.0f/1000;DenseMatrix Yt = newDenseMatrix(numTrainData,NumberofOutputNeurons);Ht.mult(OutputWeight,Yt);Y = new DenseMatrix(NumberofOutputNeurons,numTrainData);Yt.transpose(Y);if(Elm_Type == 0){double MSE = 0;for (int i = 0; i < numTrainData; i++) {MSE += (Yt.get(i, 0) - transT.get(i, 0))*(Yt.get(i, 0) - transT.get(i, 0));}TrainingAccuracy = Math.sqrt(MSE/numTrainData);}else if(Elm_Type == 1){float MissClassificationRate_Training=0;for (int i = 0; i < numTrainData; i++) {double maxtag1 = Y.get(0, i);int tag1 = 0;double maxtag2 = T.get(0, i);int tag2 = 0;for (int j = 1; j < NumberofOutputNeurons; j++) {if(Y.get(j, i) > maxtag1){maxtag1 = Y.get(j, i);tag1 = j;}if(T.get(j, i) > maxtag2){maxtag2 = T.get(j, i);tag2 = j;}}if(tag1 != tag2)MissClassificationRate_Training ++;}TrainingAccuracy = 1 -MissClassificationRate_Training* 1.0f/numTrainData;}}public void test(String TestingData_File){try {test_set = loadmatrix(TestingData_File);} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}numTestData = test_set.numRows();DenseMatrix ttestT = new DenseMatrix(numTestData, 1);DenseMatrix ttestP = new DenseMatrix(numTestData, NumberofInputNeurons);for (int i = 0; i < numTestData; i++) {ttestT.set(i, 0, test_set.get(i, 0));for (int j = 1; j <= NumberofInputNeurons; j++)ttestP.set(i, j-1, test_set.get(i, j));}testT = new DenseMatrix(1,numTestData);testP = newDenseMatrix(NumberofInputNeurons,numTestData);ttestT.transpose(testT);ttestP.transpose(testP);long start_time_test = System.currentTimeMillis();DenseMatrix tempH_test = newDenseMatrix(NumberofHiddenNeurons, numTestData);InputWeight.mult(testP, tempH_test);DenseMatrix BiasMatrix2 = newDenseMatrix(NumberofHiddenNeurons, numTestData);for (int j = 0; j < numTestData; j++) {for (int i = 0; i < NumberofHiddenNeurons; i++) {BiasMatrix2.set(i, j, BiasofHiddenNeurons.get(i, 0));}tempH_test.add(BiasMatrix2);DenseMatrix H_test = newDenseMatrix(NumberofHiddenNeurons, numTestData);if(func.startsWith("sig")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTestData; i++) {double temp = tempH_test.get(j, i);temp = 1.0f/ (1 + Math.exp(-temp));H_test.set(j, i, temp);}}}else if(func.startsWith("sin")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTestData; i++) {double temp = tempH_test.get(j, i);temp = Math.sin(temp);H_test.set(j, i, temp);}}}else if(func.startsWith("hardlim")){}else if(func.startsWith("tribas")){}else if(func.startsWith("radbas")){}DenseMatrix transH_test = newDenseMatrix(numTestData,NumberofHiddenNeurons);H_test.transpose(transH_test);DenseMatrix Yout = newDenseMatrix(numTestData,NumberofOutputNeurons);transH_test.mult(OutputWeight,Yout);DenseMatrix testY = newDenseMatrix(NumberofOutputNeurons,numTestData);Yout.transpose(testY);long end_time_test = System.currentTimeMillis();TestingTime = (end_time_test -start_time_test)* 1.0f/1000;//REGRESSIONif(Elm_Type == 0){double MSE = 0;for (int i = 0; i < numTestData; i++) {MSE += (Yout.get(i, 0) -testT.get(0,i))*(Yout.get(i, 0) - testT.get(0,i));}TestingAccuracy = Math.sqrt(MSE/numTestData);}//CLASSIFIERelse if(Elm_Type == 1){DenseMatrix temptestT = newDenseMatrix(NumberofOutputNeurons,numTestData);for (int i = 0; i < numTestData; i++){int j = 0;for (j = 0; j < NumberofOutputNeurons; j++){if (label[j] == testT.get(0, i))break;}temptestT.set(j, i, 1);}testT = newDenseMatrix(NumberofOutputNeurons,numTestData);for (int i = 0; i < NumberofOutputNeurons; i++){for (int j = 0; j < numTestData; j++)testT.set(i, j, temptestT.get(i, j)*2-1);}float MissClassificationRate_Testing=0;for (int i = 0; i < numTestData; i++) {double maxtag1 = testY.get(0, i);int tag1 = 0;double maxtag2 = testT.get(0, i);int tag2 = 0;for (int j = 1; j < NumberofOutputNeurons; j++) { if(testY.get(j, i) > maxtag1){maxtag1 = testY.get(j, i);tag1 = j;}if(testT.get(j, i) > maxtag2){maxtag2 = testT.get(j, i);tag2 = j;}}if(tag1 != tag2)MissClassificationRate_Testing ++;}TestingAccuracy = 1 -MissClassificationRate_Testing* 1.0f/numTestData;}}public double[] testOut(double[][] inpt){test_set = new DenseMatrix(inpt);return testOut();}public double[] testOut(double[] inpt){test_set = new DenseMatrix(new DenseVector(inpt));return testOut();}//Output numTestData*NumberofOutputNeuronsprivate double[] testOut(){numTestData = test_set.numRows();NumberofInputNeurons = test_set.numColumns()-1;DenseMatrix ttestT = new DenseMatrix(numTestData, 1);DenseMatrix ttestP = new DenseMatrix(numTestData, NumberofInputNeurons);for (int i = 0; i < numTestData; i++) {ttestT.set(i, 0, test_set.get(i, 0));for (int j = 1; j <= NumberofInputNeurons; j++)ttestP.set(i, j-1, test_set.get(i, j));}testT = new DenseMatrix(1,numTestData);testP = newDenseMatrix(NumberofInputNeurons,numTestData);ttestT.transpose(testT);ttestP.transpose(testP);DenseMatrix tempH_test = newDenseMatrix(NumberofHiddenNeurons, numTestData);InputWeight.mult(testP, tempH_test);DenseMatrix BiasMatrix2 = newDenseMatrix(NumberofHiddenNeurons, numTestData);for (int j = 0; j < numTestData; j++) {for (int i = 0; i < NumberofHiddenNeurons; i++) {BiasMatrix2.set(i, j, BiasofHiddenNeurons.get(i, 0));}}tempH_test.add(BiasMatrix2);DenseMatrix H_test = newDenseMatrix(NumberofHiddenNeurons, numTestData);if(func.startsWith("sig")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTestData; i++) {double temp = tempH_test.get(j, i);temp = 1.0f/ (1 + Math.exp(-temp));H_test.set(j, i, temp);}}}else if(func.startsWith("sin")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTestData; i++) {double temp = tempH_test.get(j, i);temp = Math.sin(temp);H_test.set(j, i, temp);}}}else if(func.startsWith("hardlim")){}else if(func.startsWith("tribas")){}else if(func.startsWith("radbas")){}DenseMatrix transH_test = newDenseMatrix(numTestData,NumberofHiddenNeurons);H_test.transpose(transH_test);DenseMatrix Yout = newDenseMatrix(numTestData,NumberofOutputNeurons);transH_test.mult(OutputWeight,Yout);double[] result = new double[numTestData];if(Elm_Type == 0){for (int i = 0; i < numTestData; i++)result[i] = Yout.get(i, 0);}else if(Elm_Type == 1){for (int i = 0; i < numTestData; i++) {int tagmax = 0;double tagvalue = Yout.get(i, 0);for (int j = 1; j < NumberofOutputNeurons; j++) {if(Yout.get(i, j) > tagvalue){tagvalue = Yout.get(i, j);tagmax = j;}}result[i] = tagmax;}}return result;}public float getTrainingTime() {return TrainingTime;}public double getTrainingAccuracy() {return TrainingAccuracy;public float getTestingTime() {return TestingTime;}public double getTestingAccuracy() {return TestingAccuracy;}public int getNumberofInputNeurons() {return NumberofInputNeurons;}public int getNumberofHiddenNeurons() {return NumberofHiddenNeurons;}public int getNumberofOutputNeurons() {return NumberofOutputNeurons;}public DenseMatrix getInputWeight() {return InputWeight;}public DenseMatrix getBiasofHiddenNeurons() {return BiasofHiddenNeurons;}public DenseMatrix getOutputWeight() {return OutputWeight;}//for predicting a data file based on a trained model.public void testgetoutput(String filename) throws IOException {try {test_set = loadmatrix(filename);} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}numTestData = test_set.numRows();NumberofInputNeurons = test_set.numColumns() - 1;double rsum = 0;double []actual = new double[numTestData];double [][]data = newdouble[numTestData][NumberofInputNeurons];for (int i = 0; i < numTestData; i++) {actual[i] = test_set.get(i, 0);for (int j = 0; j < NumberofInputNeurons; j++) data[i][j] = test_set.get(i, j+1);}double[] output = testOut(data);BufferedWriter writer = new BufferedWriter(new FileWriter(new File("Output")));for (int i = 0; i < numTestData; i++) {writer.write(String.valueOf(output[i]));writer.newLine();if(Elm_Type == 0){rsum += (output[i] - actual[i])*(output[i] - actual[i]);}if(Elm_Type == 1){if(output[i] == actual[i])rsum ++;}}writer.flush();writer.close();if(Elm_Type == 0)System.out.println("Regression GetOutPut RMSE: "+Math.sqrt(rsum* 1.0f/numTestData));else if(Elm_Type == 1)System.out.println("Classfy GetOutPut Right:"+rsum*1.0f/numTestData);}}。

Extremelearningmachine(ELM)到底怎么样,有没有做的前途?【WeicongLiu的回答(20票)】:利益相关:我本科时候做过这个,发过两篇ELM的会议,其中一篇被推荐到某不知名SCI期刊。
不过读了phd之后就不做了。
我觉得做ELM这些人最大的问题在于:1. 喜欢把以前SVM上曾经有过的一些idea直接套用。
比如加入一些正则项,或者考虑imbalanced dataset,或者ensemble几个ELM,就可以将原算法改头换面发个新paper。
因为以前SVM上这类paper太多了,照搬的话就可以写出很多很多类似的paper。
大家可以浏览一下ELM历届会议的list,相信会有体会。
这样的paper,贡献会比较局限;2. 很多做ELM的paper直接把ELM用在某回归/分类的应用上,跟SVM比,因为速度快,所以也算是有贡献,所以也就发出来了。
不过实际上,这样的贡献还是很有限的,在那些问题上,1秒和0.01秒其实都没啥差别;3 做实验太喜欢用比较基础的数据集了,比如UCI,Yale B这种。
包括之前黄老师他们做的ELM Auto Encoder,用的也只是MNIST数据集;4 主要贡献大部分都是黄老师他们自己做出来的,其他人的贡献有限。
所以我的感觉是,做ELM可以发paper,但是很难在理论和应用上有突破进展。
当然我也只是个普通学生,从我自己的角度回答下,算是抛砖引玉。
我本人对黄老师非常尊敬,本科时候数次发邮件向他请教问题,他都非常耐心地给出了详细的解答。
【张明仁的回答(10票)】:ELM神经网络与传统方法确实区别比较明显。
在优化论中,随机性的引入通常有助于增强算法的泛化能力;而ELM神经网络随机化隐含层的做法,虽然大幅提高了运算速度,但却不可避免地造成了过拟合的隐患。
同时,所谓在理论上证明的ELM神经网络的表达能力,也不过是线性方程组的简单结论,从训练上讲与SVM、核回归等方法无本质差异,因此至少在理论上我不认为ELM有什么大的贡献和创新所在。


极限学习机简介
在 Deep Learning 大行其道热度不减时,有机会接触到了极限学习机(Extreme Learning Machine,ELM)。
这个算法是新加坡南洋理工大学的黄广斌教授提出来的,idea 始于 2003 年,2004 年正式发表文章。
这种算法是针对SLFNs (即含单个隐藏层的前馈型神经网络)的监督型学习算法,其主要思想是:输入层与隐藏层之间的权值参数,以及隐藏层上的偏置向量参数是 once for all 的(不需要像其他基于梯度的学习算法一样通过迭代反复调整刷新),求解很直接,只需求解一个最小范数最小二乘问题(最终化归成求解一个矩阵的Moore-Penrose 广义逆问题)。
因此,该算法具有训练参数少、速度非常快等优点(总觉得 ELM 中的 Extreme 指的是 extreme fast,哈哈)。
接下来的若干年,黄教授带领的团队在此基础上又做了更多的发展,例如,将 ELM 推广到复数域,提出基于 ELM 的在线时序算法等等。
本文主要对最基本的 ELM 算法做一个简要介绍。
作者: peghoty
出处: /peghoty/article/details/9277721 欢迎转载/分享, 但请务必声明文章出处.。

极限学习机(ELM)网络结构调整方法综述
翟敏;张瑞;王宇
【期刊名称】《西安文理学院学报(自然科学版)》
【年(卷),期】2014(017)001
【摘要】从原始ELM算法和增长结构ELM算法(I-ELM)的基本思想与基本理论出发,分析其优点与不足,概括基于不同角度所改进的网络结构调整方法,包括结构增长型算法、结构递减型算法和自适应型算法三大方面.最终对极限学习机(ELM)中网络结构的各种调整方法进行综述,为相关研究者提供该研究方向的发展历史和最新结果.
【总页数】6页(P1-6)
【作者】翟敏;张瑞;王宇
【作者单位】西北大学数学系,西安710127;西北大学数学系,西安710127;西北大学数学系,西安710127
【正文语种】中文
【中图分类】O29
【相关文献】
1.基于深度极限学习机的危险源识别算法HIELM [J], 李诗瑶;周良;刘虎
2.极限学习机 ELM 在图像分割中的应用研究 [J], 田钧;赵雪章
3.基于极限学习机(ELM)的视线落点估计方法 [J], 朱博;张天侠
4.改进序列前向选择法(ISFS)和极限学习机(ELM)相结合的SPC控制图模式识别方
法 [J], 张宇波;蔺小楠
5.核极限学习机的在线状态预测方法综述 [J], 戴金玲;吴明辉;刘星;李睿峰
因版权原因,仅展示原文概要,查看原文内容请购买。



基于极限学习机的机器人类人运动轨迹控制方法研究机器人类人运动轨迹控制是机器人控制领域中的一个重要研究方向,极限学习机(Extreme Learning Machine,简称ELM)是一种新型的机器学习算法,具有训练速度快、泛化能力强等优点。
本文将基于极限学习机,研究机器人类人运动轨迹控制方法。
首先,我们需要了解机器人类人运动轨迹控制的背景。
机器人类人运动轨迹控制是指通过控制机器人的关节或身体部件运动,使机器人的动作尽可能逼近人类运动的特点。
这一技术应用于机器人仿真和实物机器人的控制中,可以使机器人的运动更加具有人类的特点,提高机器人的社交、协作和服务能力。
接下来,我们将介绍极限学习机的基本原理和特点。
极限学习机是一种单隐层前向神经网络模型,在训练过程中只有输出权重需要被调整,隐层神经元的权重不需要调整。
这一特点使得ELM具有训练速度快的优势,可以有效地处理大规模训练数据。
此外,ELM还具有良好的泛化能力,可以在面对未知数据时取得较好的性能。
在机器人类人运动轨迹控制中,我们可以将控制问题视为一个回归问题,即通过给定的输入数据,预测机器人的运动轨迹。
ELM可以用来训练这一回归模型,将机器人的输入特征与运动轨迹之间的映射关系进行学习。
接着,我们可以使用ELM进行机器人运动轨迹控制模型的训练。
在ELM的训练过程中,随机初始化输入层与隐层之间的权重和偏置,然后利用训练数据集进行训练。
具体来说,首先计算隐层神经元的输出,然后利用最小二乘法求解输出权重。
训练完成后,我们就可以得到一个机器人运动轨迹控制模型。
最后,我们可以使用训练好的ELM模型进行机器人运动轨迹控制。
给定机器人的输入特征,通过ELM模型预测机器人的运动轨迹。
可以通过控制机器人的关节或身体部件运动实现预测的轨迹。
总之,基于极限学习机的机器人类人运动轨迹控制方法可以通过训练一个回归模型,实现对机器人运动的控制。
这一方法具有训练速度快、泛化能力强的优点,可以应用于机器人仿真和实物机器人的控制中,提高机器人的运动表现和交互能力。

1 介绍我们在这提出一个基于在线极限学习机和案例推理的混合预测系统。
人工神经网络(ANN)被认为是最强大和普遍的预测器,广泛的应用于诸如模式识别、拟合、分类、决策和预测等领域。
它已经被证明在解决复杂的问题上是非常有效的。
然而,神经网络不像其他学习策略,如决策树技术,不太常用于实际数据挖掘的问题,特别是在工业生产中,如软测量技术。
这是部分由于神经网络的“黑盒”的缺点,神经网络没能力来解释自己的推理过程和推理依据,不能向用户提出必要的询问,而且当数据不充分的时候,神经网络就无法进行工作。
所以需要神经网络和其他智能算法结合,弥补这个缺点。
案例推理的基本思想是:相似的问题有相似的解(类似的问题也有类似的解决方案)。
经验存储在案例中,存储的案例通常包括了问题的描述部分和解决方案部分;在解决一个新问题时,把新问题的描述呈现给CBR系统,系统按照类似案件与类似的问题描述来检索。
系统提交最类似的经验(解决方案部分),然后重用来解决新的问题。
CBR经过二十多年的发展,已经成为人工智能与专家系统的一种强有力的推理技术。
作为一种在缺乏系统模型而具有丰富经验场合下的问题求解方法,CBR系统在故障诊断、医疗卫生、设计规划集工业过程等大量依赖经验知识的领域取得了很大的成功。
但是由于案例属性权值的设定和更新问题,CBR 在复杂工业过程的建模与控制工作仍处于探索阶段,尤其对于预测回归问题,研究的更少。
不同于传统学习理论,2006年南洋理工大学Huang GB教授提出了一种新的前馈神经网络训练方法-极限学习机(ELM),能够快速的训练样本(比BP神经网络训练速度提高了数千倍),为在线学习和权值跟新奠定了基础。
我们提出的基于在线极限学习机的案例推理混合系统,能够使用案例来解释神经网络,用在线学习的方法为案例检索提供案例权值和更新案例权值,为在线预测某些工业生产提供了较好的模型。
2使用在线极限学习机训练特征权值的算法2.1 训练和更新样本特征权值(不是训练样本权值的,要记好,从新选择小题目)在这一节中我们提出如何使用在线极限学习机确定和更新案例库属性权值。

极限学习机分类器设计中的正则化策略研究极限学习机(Extreme Learning Machine,ELM)作为一种新兴的机器学习算法,已经在各个领域取得了许多成功应用。
然而,在实际应用中,由于数据量大、噪声干扰和模型复杂等问题的存在,ELM的泛化能力和鲁棒性仍然存在一定的挑战。
因此,在ELM分类器设计中引入正则化策略,对提升模型性能具有重要意义。
一、ELM简介作为一种非常简单高效的机器学习算法,ELM的主要思想是通过随机生成输入层和隐藏层之间的权重矩阵,将数据从低维空间映射到高维特征空间,并将其进一步分离为不同类别。
ELM通过快速计算输出层权重矩阵的逆矩阵来实现模型的训练过程。
二、ELM存在的问题尽管ELM具有快速学习速度和良好的泛化能力,但在实际应用中,由于以下问题的存在,ELM仍然面临一定的挑战。
1. 过拟合问题在某些高维特征空间中,数据样本的数量相对较少,容易导致过拟合现象,即模型在训练集上表现良好,但在测试集上泛化能力较差。
2. 鲁棒性不足ELM对于异常样本和噪声的敏感性较高,当输入数据中存在异常或者噪声时,模型的性能可能会受到严重影响。
三、正则化策略的引入为了克服上述问题,研究者们在ELM分类器设计中引入了正则化策略。
正则化可以通过约束模型的复杂度,有效减少过拟合的风险,提升模型的泛化能力和鲁棒性。
下面介绍几种常见的正则化策略。
1. L1正则化(Lasso正则化)L1正则化通过在目标函数中添加L1范数惩罚项,将权重矩阵中的一部分权重置为零,从而实现特征选择的效果。
这种正则化策略能够有效降低模型的复杂度,并提高特征的鲁棒性。
2. L2正则化(岭回归)L2正则化通过在目标函数中添加L2范数惩罚项,降低权重矩阵中每个权重的绝对值,从而减少特征之间的相关性,提高模型的稳定性和鲁棒性。
3. Dropout正则化Dropout正则化是一种数据增强技术,通过在训练过程中随机删除一部分神经元,减少神经元之间的依赖性,从而提高模型的泛化能力和鲁棒性。
编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(极限学习机简介)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为极限学习机简介的全部内容。
传统前馈神经网络采用梯度下降的迭代算法去调整权重参数,具有明显的缺陷:1) 学习速度缓慢,从而计算时间代价增大; 2) 学习率难以确定且易陷入局部最小值;3)易出现过度训练,引起泛化性能下降。
这些缺陷成为制约使用迭代算法的前馈神经网络的广泛应用的瓶颈。
针对这些问题,huang 等依据摩尔-彭罗斯(MP)广义逆矩阵理论提出了极限学习(ELM)算法,该算法仅通过一步计算即可解析求出学习网络的输出权值,同迭代算法相比,极限学习机极大地提高了网络的泛化能力和学习速度。
极限学习机的网络训练模型采用前向单隐层结构。
设,,m M n 分别为网络输入层、隐含层和输出层的节点数,()g x 是隐层神经元的激活函数,i b 为阈值。
设有N 个不同样本(),i i x t ,1i N ≤≤ ,其中[][]1212,,...,,,,...,TTm n i i i im i i i in x x x x R t t t t R =∈=∈ ,则极限学习机的网络训练模型如图1所示。
图1 极限学习机的网络训练模型极限学习机的网络模型可用数学表达式表示如下:()1,1,2,...,Mi ii i j i g x b o j N βω=+==∑式中,[]12,,...,i i i mi ωωωω= 表示连接网络输入层节点与第i 个隐层节点的输入权值向量;[]12,,...,Ti i i in ββββ= 表示连接第i 个隐层节点与网络输出层节点的输出权值向量;[]12,,...,T i i i in o o o o = 表示网络输出值.极限学习机的代价函数E 可表示为()1,Nj j j E S o t β==-∑式中,(),,1,2,...,i i s b i M ω== ,包含了网络输入权值及隐层节点阈值。
极端学习机模型在时序数据分析中的应用一、引言随着技术的发展,我们积累了大量有时间信息的数据,如语音、文本、气象、交通等等。
这类数据往往包含时间信息,与之前相比更具有复杂性和挑战性。
由于这种数据表示与模式具有时序和时间相关特征,所以需要新的算法来处理这种数据,以利用这种信息来改进预测准确度。
极限学习机(ELM)是一种新兴的机器学习方法,它的快速训练和优良通用性使得它在时序数据分析上得到广泛应用。
本文将深入探讨如何使用ELM模型进行时序数据分析。
二、什么是极端学习机(ELM)极限学习机(ELM)是一种新型单隐层前向神经网络(SLFN)结构,由黄广宝于2006年提出,其用于解决传统神经网络的两个缺点:训练过程慢和易陷入局部极小值。
ELM模型通常由输入层、隐层和输出层组成。
相比于传统的神经网络模型,它具有以下特点:1、隐层节点加权可直接随机选取,而不需要迭代计算;2、误差最小化精度要求较低,训练速度非常快;3、其输出权重以一次训练完成,从而在实践中具有非常快的训练速度。
三、使用极端学习机进行时序数据分析时间序列数据表示序列中相应特性随时间变化的变动情况。
使用机器学习算法进行时间序列分析是一种非常有效的方法。
ELM 模型在时序数据分析中的应用具有以下几个方面的优势:1、特征筛选功能:在时间序列分析中,我们需要选择相关的变量。
ELM模型能够对不同的特征进行筛选,帮助我们从复杂的时间序列数据中提取有用的信息。
2、高度通用性:ELM可以轻松处理不同类型的时间序列分析问题。
因此,它被证明是一种高度通用的算法。
3、高维度特征库:过高的维度会使模型建立过于复杂,缺乏泛化能力。
但ELM模型的高维度特征库具备对高维数据建模的能力,能够在高纬度数据中进行特征提取和表示。
4、快速训练和预测:由于一次完成ELM模型的权重训练,ELM具有非常快速的训练和预测能力,能够快速处理大规模的时间序列数据,从而进行高效的预测。
四、应用案例四、应用案例1.ELM 模型在医疗领域的应用ELM 模型可以通过对医疗的时序数据进行建模,从而预测不同病人的疾病。
基于极限学习机的人脸识别算法优化与实现随着“人脸识别”技术的不断发展和普及,“人脸识别”已经成为了人们了解实现生活中重要应用技术之一。
作为一种智能化技术,人脸识别技术同时也伴随着安全隐患和数据泄露问题。
因此,如何提高人脸识别的准确率和安全性是我们需要思考和解决的难题。
近年来,基于极限学习机的人脸识别算法成为了研究人员关注的热点之一。
极限学习机(Extreme Learning Machine,简称ELM)是一种全连接的单隐含层前馈人工神经网络模型,拥有较快的执行速度和存储、计算资源的开销。
人脸识别的思路与ELM的核心理念十分相似,均采用了特征提取、分类鉴别等技术,因此将ELM与人脸识别技术结合可以发挥出互补优势。
在实现基于ELM的人脸识别算法之前,我们需要进行一系列的优化。
首先,对输入数据进行预处理,包括去除噪声和标准化图像大小。
其次,特征提取是人脸识别算法中的主要环节,采用合适的特征提取算法可以增加识别准确性。
常见的特征提取算法有PCA、LDA、DWT等,我们可以采用这些算法的组合来增强特征提取效果。
最后,需要选择合适的分类器,以达到更高的识别准确度和更低的错误率。
通常使用支持向量机(SVM)作为最终的分类器。
在进行完优化后,我们接下来需要将优化后的算法实现。
首先需要搭建实验平台,设置实验参数和采集人脸照片。
然后,将采集到的人脸照片进行预处理、特征提取和分类识别,最终可以输出分类结果。
通过实验结果发现,基于ELM的人脸识别算法相比于传统的人脸识别技术表现更优,可以取得更高的识别率和更低的错误率。
并且,基于ELM的人脸识别算法还可以通过增加输入数据的数量和种类来提高识别准确度。
总之,基于极限学习机的人脸识别算法优化与实现是一项需要技术人员精心探索和研究的课题。
在今后的研究中,还可以采用深度学习算法,进一步提高人脸识别的准确率,使人脸识别技术更加安全、准确和便捷。
简单易学的机器学习算法——极限学习机(ELM)一、极限学习机的概念极限学习机(Extreme Learning Machine) ELM,是由黄广斌提出来的求解单隐层神经网络的算法。
ELM最大的特点是对于传统的神经网络,尤其是单隐层前馈神经网络(SLFNs),在保证学习精度的前提下比传统的学习算法速度更快。
二、极限学习机的原理ELM是一种新型的快速学习算法,对于单隐层神经网络,ELM 可以随机初始化输入权重和偏置并得到相应的输出权重。
(选自黄广斌老师的PPT)对于一个单隐层神经网络(见Figure 1),假设有个任意的样本,其中,。
对于一个有个隐层节点的单隐层神经网络可以表示为其中,为激活函数,为输入权重,为输出权重,是第个隐层单元的偏置。
表示和的内积。
单隐层神经网络学习的目标是使得输出的误差最小,可以表示为即存在,和,使得可以矩阵表示为其中,是隐层节点的输出,为输出权重,为期望输出。
,为了能够训练单隐层神经网络,我们希望得到,和,使得其中,,这等价于最小化损失函数传统的一些基于梯度下降法的算法,可以用来求解这样的问题,但是基本的基于梯度的学习算法需要在迭代的过程中调整所有参数。
而在ELM 算法中, 一旦输入权重和隐层的偏置被随机确定,隐层的输出矩阵就被唯一确定。
训练单隐层神经网络可以转化为求解一个线性系统。
并且输出权重可以被确定其中,是矩阵的Moore-Penrose广义逆。
且可证明求得的解的范数是最小的并且唯一。
三、实验我们使用《简单易学的机器学习算法——Logistic回归》中的实验数据。
原始数据集我们采用统计错误率的方式来评价实验的效果,其中错误率公式为:对于这样一个简单的问题,。
MATLAB代码主程序[plain]view plain copy1.%% 主函数,二分类问题2.3.%导入数据集4. A = load('testSet.txt');5.6.data = A(:,1:2);%特征bel = A(:,3);%标签8.9.[N,n] = size(data);10.11.L = 100;%隐层节点个数12.m = 2;%要分的类别数13.14.%--初始化权重和偏置矩阵15.W = rand(n,L)*2-1;16.b_1 = rand(1,L);17.ind = ones(N,1);18.b = b_1(ind,:);%扩充成N*L的矩阵19.20.tempH = data*W+b;21.H = g(tempH);%得到H22.23.%对输出做处理24.temp_T=zeros(N,m);25.for i = 1:N26. if label(i,:) == 027. temp_T(i,1) = 1;28. else29. temp_T(i,2) = 1;30. end31.end32.T = temp_T*2-1;33.34.outputWeight = pinv(H)*T;35.36.%--画出图形37.x_1 = data(:,1);38.x_2 = data(:,2);39.hold on40.for i = 1 : N41. if label(i,:) == 042. plot(x_1(i,:),x_2(i,:),'.g');43. else44. plot(x_1(i,:),x_2(i,:),'.r');45. end46.end47.48.output = H * outputWeight;49.%---计算错误率50.tempCorrect=0;51.for i = 1:N52. [maxNum,index] = max(output(i,:));53. index = index-1;54. if index == label(i,:);55. tempCorrect = tempCorrect+1;56. end57.end58.59.errorRate = 1-tempCorrect./N;激活函数[plain]view plain copy1.function [ H ] = g( X )2. H = 1 ./ (1 + exp(-X));3.endELM(Extreme Learning Machine)是一种新型神经网络算法,最早由Huang于2004年提出【Extreme learningmachine: a new learning scheme of feedforward neural networks】。
多样性正则化极限学习机的集成方法陈洋;王士同【期刊名称】《计算机科学与探索》【年(卷),期】2022(16)8【摘要】极限学习机(ELM)是一种单隐层前向网络的训练算法,随机确定输入层权值和隐含层偏置,通过分析的方法确定输出层的权值,ELM克服了基于梯度的学习算法的很多不足,如局部极小、不合适的学习速率、学习速度慢等,却不可避免地造成了过拟合的隐患且稳定性较差,特别是对于规模较大的数据集。
针对上述问题,提出多样性正则化极限学习机(DRELM)的集成方法。
首先,从改变隐层节点参数的分布来为每个ELM随机选取输入权重,采用LOO交叉验证方法和MSE^(PRESS)方法来寻找每个基学习器的最优隐节点数,计算并输出最优隐含层输出权重,训练出较好且具有差异性的基学习器。
然后,将有关多样性的新惩罚项显式添加到整个目标函数中,迭代更新每个基学习器的隐含层输出权重并输出结果。
最后,集成所有基学习器的输出结果对其求平均值,得到整个网络模型最后的输出结果。
该方法能够有效地实现多样性正则化极限学习机(RELM)的融合,兼顾准确率和多样性。
在10个不同规模的UCI数据集上的实验结果表明所提出的方法是行之有效的。
【总页数】10页(P1819-1828)【作者】陈洋;王士同【作者单位】江南大学人工智能与计算机学院;江南大学江苏省媒体设计与软件技术重点实验室【正文语种】中文【中图分类】TP181【相关文献】1.考虑变形因子模式下基于正则化极限学习机的大坝变形预报方法2.流形正则化框架下的极限学习机预测锂电池SOC方法3.融合多特征与互信息选择集成多核极限学习机的影像分类方法4.云模型和集成极限学习机相结合的滚动轴承故障诊断方法5.基于核极限学习机的多标签数据流集成分类方法因版权原因,仅展示原文概要,查看原文内容请购买。