语音信号处理综合实验
- 格式:pdf
- 大小:203.77 KB
- 文档页数:5

语音信号处理实验报告实验二一、实验目的本次语音信号处理实验的目的是深入了解语音信号的特性,掌握语音信号处理的基本方法和技术,并通过实际操作和数据分析来验证和巩固所学的理论知识。
具体而言,本次实验旨在:1、熟悉语音信号的采集和预处理过程,包括录音设备的使用、音频格式的转换以及噪声去除等操作。
2、掌握语音信号的时域和频域分析方法,能够使用相关工具和算法计算语音信号的短时能量、短时过零率、频谱等特征参数。
3、研究语音信号的编码和解码技术,了解不同编码算法对语音质量和数据压缩率的影响。
4、通过实验,培养我们的动手能力、问题解决能力和团队协作精神,提高我们对语音信号处理领域的兴趣和探索欲望。
二、实验原理(一)语音信号的采集和预处理语音信号的采集通常使用麦克风等设备将声音转换为电信号,然后通过模数转换器(ADC)将模拟信号转换为数字信号。
在采集过程中,可能会引入噪声和干扰,因此需要进行预处理,如滤波、降噪等操作,以提高信号的质量。
(二)语音信号的时域分析时域分析是对语音信号在时间轴上的特征进行分析。
常用的时域参数包括短时能量、短时过零率等。
短时能量反映了语音信号在短时间内的能量分布情况,短时过零率则表示信号在单位时间内穿过零电平的次数,可用于区分清音和浊音。
(三)语音信号的频域分析频域分析是将语音信号从时域转换到频域进行分析。
通过快速傅里叶变换(FFT)可以得到语音信号的频谱,从而了解信号的频率成分和分布情况。
(四)语音信号的编码和解码语音编码的目的是在保证一定语音质量的前提下,尽可能降低编码比特率,以减少存储空间和传输带宽的需求。
常见的编码算法有脉冲编码调制(PCM)、自适应差分脉冲编码调制(ADPCM)等。
三、实验设备和软件1、计算机一台2、音频采集设备(如麦克风)3、音频处理软件(如 Audacity、Matlab 等)四、实验步骤(一)语音信号的采集使用麦克风和音频采集软件录制一段语音,保存为常见的音频格式(如 WAV)。
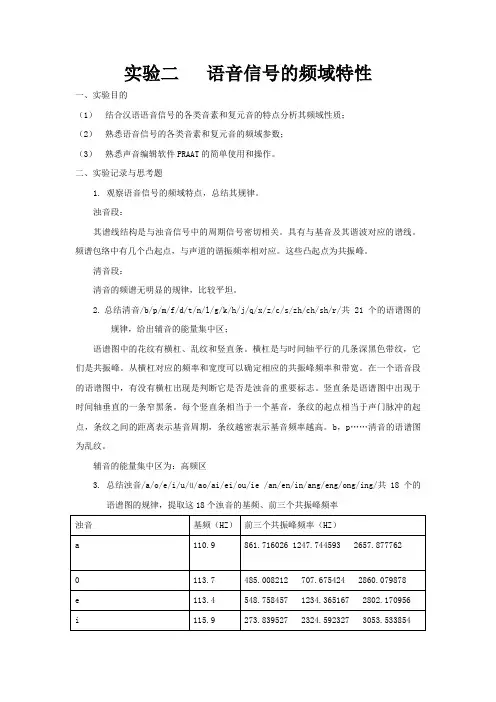
实验二语音信号的频域特性一、实验目的(1)结合汉语语音信号的各类音素和复元音的特点分析其频域性质;(2)熟悉语音信号的各类音素和复元音的频域参数;(3)熟悉声音编辑软件PRAAT的简单使用和操作。
二、实验记录与思考题1. 观察语音信号的频域特点,总结其规律。
浊音段:其谱线结构是与浊音信号中的周期信号密切相关。
具有与基音及其谐波对应的谱线。
频谱包络中有几个凸起点,与声道的谐振频率相对应。
这些凸起点为共振峰。
清音段:清音的频谱无明显的规律,比较平坦。
2.总结清音/b/p/m/f/d/t/n/l/g/k/h/j/q/x/z/c/s/zh/ch/sh/r/共21个的语谱图的规律,给出辅音的能量集中区;语谱图中的花纹有横杠、乱纹和竖直条。
横杠是与时间轴平行的几条深黑色带纹,它们是共振峰。
从横杠对应的频率和宽度可以确定相应的共振峰频率和带宽。
在一个语音段的语谱图中,有没有横杠出现是判断它是否是浊音的重要标志。
竖直条是语谱图中出现于时间轴垂直的一条窄黑条。
每个竖直条相当于一个基音,条纹的起点相当于声门脉冲的起点,条纹之间的距离表示基音周期,条纹越密表示基音频率越高。
b,p……清音的语谱图为乱纹。
辅音的能量集中区为:高频区3. 总结浊音/a/o/e/i/u/ü/ao/ai/ei/ou/ie /an/en/in/ang/eng/ong/ing/共18个的语谱图的规律,提取这18个浊音的基频、前三个共振峰频率4./r/、/m/、/n/、/l/ 从这几个音素的的基频、共振峰频率5.分析宽带语谱图和窄带语谱图的不同之处,请解释原因;语谱图中的花纹有横杠、乱纹和竖直条等。
横杠是与时间轴平行的几条深黑色带纹,它们是共振峰。
从横杠对应的频率和宽度可以确定相应的共振峰频率和带宽。
在一个语音段的语谱图中,有没有横杠出现是判断它是否是浊音的重要标志。
竖直条(又叫冲直条)是语谱图中出现与时间轴垂直的一条窄黑条。
每个竖直条相当于一个基音,条纹的起点相当于声门脉冲的起点,条纹之间的距离表示基音周期。

通信工程学院12级1班罗恒2012101032实验一语音信号的低通滤波和短时分析综合实验一、实验要求1、根据已有语音信号,设计一个低通滤波器,带宽为采样频率的四分之一,求输出信号;2、辨别原始语音信号与滤波器输出信号有何区别,说明原因;3、改变滤波器带宽,重复滤波实验,辨别语音信号的变化,说明原因;4、利用矩形窗和汉明窗对语音信号进行短时傅立叶分析,绘制语谱图并估计基音周期,分析两种窗函数对基音估计的影响;5、改变窗口长度,重复上一步,说明窗口长度对基音估计的影响。
二、实验目的1.在理论学习的基础上,进一步地理解和掌握语音信号低通滤波的意义,低通滤波分析的基本方法。
2.进一步理解和掌握语音信号不同的窗函数傅里叶变化对基音估计的影响。
三、实验设备1.PC机;2。
MATLAB软件环境;四、实验内容1。
上机前用Matlab语言完成程序编写工作.2。
程序应具有加窗(分帧)、绘制曲线等功能。
3.上机实验时先调试程序,通过后进行信号处理。
4.对录入的语音数据进行处理,并显示运行结果。
5。
改变滤波带宽,辨别与原始信号的区别。
6。
依据曲线对该语音段进行所需要的分析,并且作出结论。
7.改变窗的宽度(帧长),重复上面的分析内容。
五、实验原理及方法利用双线性变换设计IIR滤波器(巴特沃斯数字低通滤波器的设计),首先要设计出满足指标要求的模拟滤波器的传递函数Ha(s),然后由Ha(s)通过双线性变换可得所要设计的IIR滤波器的系统函数H(z)。
如果给定的指标为数字滤波器的指标,则首先要转换成模拟滤波器的技术指标,这里主要是边界频率Wp和Ws的转换,对ap和as指标不作变化。
边界频率的转换关系为∩=2/T tan(w/2).接着,按照模拟低通滤波器的技术指标根据相应设计公式求出滤波器的阶数N和3dB截止频率∩c ;根据阶数N查巴特沃斯归一化低通滤波器参数表,得到归一化传输函数Ha(p);最后,将p=s/ ∩c 代入Ha(p)去归一,得到实际的模拟滤波器传输函数Ha(s)。
语音信号处理实验报告——语音信号分析实验一.实验目的及原理语音信号分析是语音信号处理的前提和基础,只有分析出可表示语音信号本质特征的参数,才有可能利用这些参数进行高效的语音通信、语音合成和语音识别等处理,并且语音合成的音质好坏和语音识别率的高低,都取决于对语音信号分析的准确性和精确性。
贯穿语音分析全过程的是“短时分析技术”。
因为从整体来看,语音信号的特性及表征其本质特征的参数均是随时间变化的,所以它是一个非平稳态过程,但是在一个短时间范围内(一般认为在10~30ms的时间内),其特性基本保持不变,即相对稳定,可将其看做一个准稳态过程,即语音信号具有短时平稳性。
所以要将语音信号分帧来分析其特征参数,帧长一般取为10ms~30ms。
二.实验过程1.2. 仿真结果(1) 时域分析男声及女声(蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率)x 104-0.6-0.4-0.200.20.40.60.81x 105-0.4-0.200.20.40.60.811.2某一帧的自相关函数-1-0.8-0.6-0.4-0.200.20.40.60.813. 频域分析①一帧信号的倒谱分析和FFT 及LPC 分析对应的倒谱系数:119.2,-7.6895,……对应的LPC 预测系数:1,-0.1,-0.02,-0.4,-0.27,……②男声和女声的倒谱分析③浊音和清音的倒谱分析原语音波形一帧语音波形一帧语音的倒谱④浊音和清音的FFT分析和LPC分析(红色为FFT图像,绿色为LPC图像)三.实验结果分析1.时域分析实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变化起着决定性影响。
这里窗长合适,En能够反应语音信号幅度变化。
同时,从图像可以看出,En可以作为区分浊音和清音的特征参数。
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。
从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大。

华南理工大学《语音信号处理》实验报告实验名称:基音周期估计姓名:学号:班级:10级电信5班日期:2013年5 月15日1.实验目的本次试验的目的是通过matlab编程,验证课本中基音周期估计的方法,本实验采用的方法是自相关法。
2. 实验原理1、基音周期基音是发浊音时声带震动所引起的周期性,而基音周期是指声带震动频率的倒数。
基音周期是语音信号的重要的参数之一,它描述语音激励源的一个重要特征,基音周期信息在多个领域有着广泛的应用,如语音识别、说话人识别、语音分析与综合以及低码率语音编码,发音系统疾病诊断、听觉残障者的语音指导等。
因为汉语是一种有调语言,基音的变化模式称为声调,它携带着非常重要的具有辨意作用的信息,有区别意义的功能,所以,基音的提取和估计对汉语更是一个十分重要的问题。
由于人的声道的易变性及其声道持征的因人而异,而基音周期的范围又很宽,而同—个人在不同情态下发音的基音周期也不同,加之基音周期还受到单词发音音调的影响,因而基音周期的精确检测实际上是一件比较困难的事情。
基音提取的主要困难反映在:①声门激励信号并不是一个完全周期的序列,在语音的头、尾部并不具有声带振动那样的周期性,有些清音和浊音的过渡帧是很难准确地判断是周期性还是非周期性的。
②声道共振峰有时会严重影响激励信号的谐波结构,所以,从语音信号中直接取出仅和声带振动有关的激励信号的信息并不容易。
③语音信号本身是准周期性的(即音调是有变化的),而且其波形的峰值点或过零点受共振峰的结构、噪声等的影响。
④基音周期变化范围大,从老年男性的50Hz到儿童和女性的450Hz,接近三个倍频程,给基音检测带来了一定的困难。
由于这些困难,所以迄今为止尚未找到一个完善的方法可以对于各类人群(包括男、女、儿童及不向语种)、各类应用领域和各种环境条件情况下都能获得满意的检测结果。
尽管基音检测有许多困难,但因为它的重要性,基音的检测提取一直是一个研究的课题,为此提出了各种各样的基音检测算法,如自相关函数(ACF)法、峰值提取算法(PPA)、平均幅度差函数(AMDF)法、并行处理技术、倒谱法、SIFT、谱图法、小波法等等。
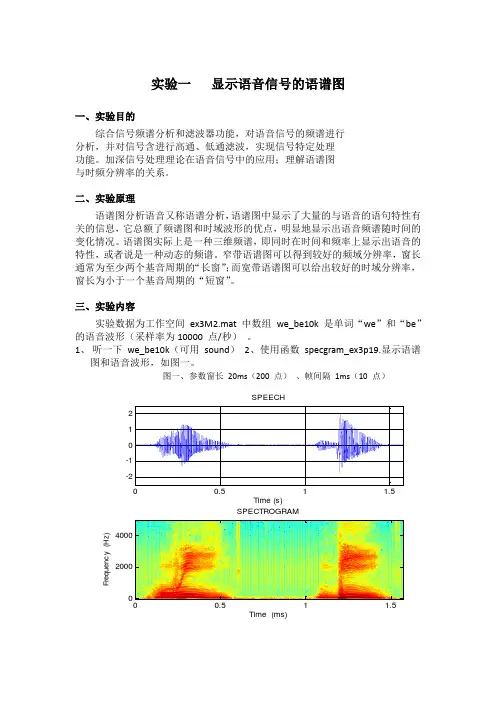
实验一 显示语音信号的语谱图一、实验目的综合信号频谱分析和滤波器功能,对语音信号的频谱进行 分析,并对信号含进行高通、低通滤波,实现信号特定处理 功能。
加深信号处理理论在语音信号中的应用;理解语谱图 与时频分辨率的关系。
二、实验原理语谱图分析语音又称语谱分析,语谱图中显示了大量的与语音的语句特性有关的信息,它总额了频谱图和时域波形的优点,明显地显示出语音频谱随时间的变化情况。
语谱图实际上是一种三维频谱,即同时在时间和频率上显示出语音的特性,或者说是一种动态的频谱。
窄带语谱图可以得到较好的频域分辨率,窗长通常为至少两个基音周期的“长窗”;而宽带语谱图可以给出较好的时域分辨率,窗长为小于一个基音周期的“短窗”。
三、实验内容实验数据为工作空间 ex3M2.mat 中数组 we_be10k 是单词“we ”和“be ”的语音波形(采样率为10000 点/秒) 。
1、 听一下 we_be10k (可用 sound )2、使用函数 specgram_ex3p19.显示语谱图和语音波形,如图一。
图一、参数窗长 20ms (200 点) 、帧间隔 1ms (10 点)0.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.5200040002、 对比调用参数窗长 20ms (200 点) 、帧间隔 1ms (10 点),(如图一)和参数窗长5ms (50点) 、帧间隔 1ms (10点)(如图二) ;图二、参数窗长5ms (50点) 、帧间隔 1ms (10点)图三、参数窗长30ms (300点) 、帧间隔 1ms (10点)0.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.5200040000.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.520004000图四、参数窗长20ms (200点) 、帧间隔 5ms (50点)3、 再对比窗长>20ms 或小于5ms ,以及帧间隔>1ms 时的语谱图说明宽带语谱图、窄带语谱图与时频分辨率的关系及如何得到时频折中。

华南理工大学《语音信号处理》实验报告实验名称:DTW算法实现及语音模板匹配姓名:学号:班级:10级电信5班日期:2013年6 月17日一、实验目的运用课堂上所学知识以及matlab工具,利用DTW(Dynamic Time Warping,动态时间规整)算法,进行说话者的语音识别。
二、实验原理1、语音识别系统概述一个完整特定人语音识别系统的方案框图如图1所示。
输入的模拟语音信号首先要进行预处理,包括预滤波、采样和量化、加窗、端点检测、预加重等,然后是参数特征量的提取。
提取的特征参数满足如下要求:(1)特征参数能有效地代表语音特征,具有很好的区分性;(2)参数间有良好的独立性;(3)特征参数要计算方便,要考虑到语音识别的实时实现。
图1 语音识别系统方案框图语音识别的过程可以被看作模式匹配的过程,模式匹配是指根据一定的准则,使未知模式与模型库中的某一个模型获得最佳匹配的过程。
模式匹配中需要用到的参考模板通过模板训练获得。
在训练阶段,将特征参数进行一定的处理后,为每个词条建立一个模型,保存为模板库。
在识别阶段,语音信号经过相同的通道得到语音特征参数,生成测试模板,与参考模板进行匹配,将匹配分数最高的参考模板作为识别结果。
2、语音信号的处理1、语音识别的DTW算法本设计中,采用DTW算法,该算法基于动态规划(DP)的思想解决了发音长短不一的模板匹配问题,在训练和建立模板以及识别阶段,都先采用端点检测算法确定语音的起点和终点。
在本设计当中,我们建立的参考模板,m为训练语音帧的时序标号,M为该模板所包含的语音帧总数,R(m)为第m帧的语音特征矢量。
所要识别的输入词条语音称为测试模板,n为测试语音帧的时序标号,N为该模板所包含的语音帧总数,T(n)为第n帧的语音特征矢量。
参考模板和测试模板一般都采用相同类型的特征矢量(如LPCC系数)、相同的帧长、相同的窗函数和相同的帧移。
考虑到语音中各段在不同的情况下持续时间会产生或长或短的变化,因而更多地是采用动态规划DP的方法。
语音信号处理试验实验一:语音信号时域分析实验目的:(1)录制两段语音信号,内容是“语音信号处理”,分男女声。
(2)对语音信号进行采样,观察采样后语音信号的时域波形。
实验步骤:1、使用window自带录音工具录制声音片段使用windows自带录音机录制语音文件,进行数字信号的采集。
启动录音机。
录制一段录音,录音停止后,文件存储器的后缀默认为.Wav。
将录制好文件保存,记录保存路径。
男生女生各录一段保存为test1.wav和test2.wav。
图1基于PC机语音信号采集过程。
2、读取语音信号在MATLAB软件平台下,利用wavread函数对语音信号进行采样,记住采样频率和采样点数。
通过使用wavread函数,理解采样、采样频率、采样位数等概念!Wavread函数调用格式:y=wavread(file),读取file所规定的wav文件,返回采样值放在向量y中。
[y,fs,nbits]=wavread(file),采样值放在向量y中,fs表示采样频率(hz),nbits表示采样位数。
y=wavread(file,N),读取前N点的采样值放在向量y中。
y=wavread(file,[N1,N2]),读取从N1到N2点的采样值放在向量y中。
3、编程获取语音信号的抽样频率和采样位数。
语音信号为test1.wav和test2.wav,内容为“语音信号处理”,两端语音保存到工作空间work文件夹下。
在M文件中分别输入以下程序,可以分两次输入便于观察。
[y1,fs1,nbits1]=wavread('test1.wav')[y2,fs2,nbits2]=wavread('test2.wav')结果如下图所示根据结果可知:两端语音信号的采样频率为44100HZ,采样位数为16。
4、语音信号的时域分析语音信号的时域分析就是分析和提取语音信号的时域参数。
进行语音分析时,最先接触到并且夜市最直观的是它的时域波形。

最新语音信号处理实验报告实验二实验目的:本实验旨在通过实际操作加深对语音信号处理理论的理解,并掌握语音信号的基本处理技术。
通过实验,学习语音信号的采集、分析、滤波、特征提取等关键技术,并探索语音信号处理在实际应用中的潜力。
实验内容:1. 语音信号采集:使用语音采集设备录制一段时长约为10秒的语音样本,确保录音环境安静,语音清晰。
2. 语音信号预处理:对采集到的语音信号进行预处理,包括去噪、归一化等操作,以提高后续处理的准确性。
3. 语音信号分析:利用傅里叶变换等方法分析语音信号的频谱特性,观察并记录基频、谐波等特征。
4. 语音信号滤波:设计并实现一个带通滤波器,用于提取语音信号中的特定频率成分,去除噪声和非目标频率成分。
5. 特征提取:从处理后的语音信号中提取关键特征,如梅尔频率倒谱系数(MFCC)等,为后续的语音识别或分类任务做准备。
6. 实验总结:根据实验结果,撰写实验报告,总结语音信号处理的关键技术和实验中遇到的问题及其解决方案。
实验设备与工具:- 计算机一台,安装有语音信号处理相关软件(如Audacity、MATLAB 等)。
- 麦克风:用于采集语音信号。
- 耳机:用于监听和校正采集到的语音信号。
实验步骤:1. 打开语音采集软件,调整麦克风输入设置,确保录音质量。
2. 录制语音样本,注意控制语速和音量,避免过大或过小。
3. 使用语音分析软件打开录制的语音文件,进行频谱分析,记录观察结果。
4. 设计带通滤波器,设置合适的截止频率,对语音信号进行滤波处理。
5. 应用特征提取算法,获取语音信号的特征向量。
6. 分析滤波和特征提取后的结果,评估处理效果。
实验结果与讨论:- 描述语音信号在预处理、滤波和特征提取后的变化情况。
- 分析实验中遇到的问题,如噪声去除不彻底、频率成分丢失等,并提出可能的改进措施。
- 探讨实验结果对语音识别、语音合成等领域的潜在应用价值。
结论:通过本次实验,我们成功实现了语音信号的基本处理流程,包括采集、预处理、分析、滤波和特征提取。

语⾳信号处理实验报告语⾳信号处理实验报告【实验⼀】⼀、实验题⽬Short time analysis⼆、实验要求Write a MA TLAB program to analyze a speech and simultaneously, on a single page, plot the following measurements:1. the entire speech waveform2. the short-time energy, En3. the short-time magnitude, Mn4. the short-time zero-crossing, Zn5. the narrowband spectrogram6. the wideband spectrogramUse both the speech waveforms in the wznjdx_normal.wav. Choose appropriate window sizes, window shifts, and window for the analysis. Explain your choice of these parameters.三、实验程序clear[x,fs]=wavread('wznjdx_normal.wav');n=length(x);N=320;subplot(4,1,1);plot(x);h=linspace(1,1,N);En=conv(h,x.*x);subplot(4,1,2);plot(En);Mn=conv(h,abs(x));subplot(4,1,3);plot(Mn);for i=1:n-1if x(i)>=0 y(i)=1;else y(i)=-1;endif x(i+1)>=0 y(i+1)=1;else y(i+1)=-1;endw(i)=abs(y(i+1)-y(i));endk=1;j=0;while (k+N-1)Zm(k)=0;for i=0:N-1Zm(k)=Zm(k)+w(k+i);endj=j+1;k=k+N/2;endfor w=1:jQ(w)=Zm(160*(w-1)+1)/(2*N);endsubplot(4,1,4);plot(Q);grid;figure(2);subplot(2,1,1);spectrogram(x,h,256,200,0.0424*fs); subplot(2,1,2);spectrogram(x,h,256,200,0.0064*fs);四、实验结果语谱图:(Matlab 7.0 ⽤不了spectrogram)【实验⼆】⼀、实验题⽬Homomorphic analysis⼆、实验要求Write a MATLAB program to compute the real cepstrums of a section of voiced speech and unvoiced speech. Plot the signal, the log magnitude spectrum, the real cepstrum, and the lowpass liftered log magnitude spectrum.三、实验程序nfft=256;[x,fs] = wavread('wznjdx_normal.wav');fx=x;Xvm=log(abs(fft(fx,nfft)));xhv=real(ifft(Xvm,nfft));lifter=zeros(1,nfft);lifter(1:30)=1;lifter(nfft-28:nfft)=1;fnlen=0.02*fs; % 20mswin=hamming(fnlen);%加窗n=fnlen;%窗宽度赋给循环⾃变量nnoverlap=0.5*fnlen;while(n<=length(x)-1)fx=x(n-fnlen+1:n).*win;n=n+noverlap;endxhvp=xhv.*lifter';figure;subplot(4,1,1)plot(lifter);title('倒谱滤波器');subplot(4,1,2)plot(x);title('语⾳信号波形');subplot(4,1,3)plot(Xvm);title('Xvm');subplot(4,1,4)plot(xhv);title('xhv');四、实验结果【实验三】⼀、实验题⽬LP analysis⼆、实验要求Write a MATLAB program to convert from a frame of speech to a set of linear prediction coefficients. Plot the LPC spectrum superimposed on the corresponding STFT.三、实验程序clear;[x,fs]=wavread('wznjdx_normal.wav');fx=x(4000:4160-1);p=10;[a,e,k]=aryule(fx,p);G=sqrt(e*length(fx));f=log(abs(fft(fx)));h0=zeros(1,160);h=log(G)-log(abs(fft(a,160)));figure(1);subplot(211);plot(fx);subplot(212);plot(f);hold on;plot((0:160-1),h,'r');四、实验结果【实验四】⼀、实验题⽬Pitch estimation⼆、实验内容Write a program to implement the pitch estimation and the voiced/unvoiced decision using the LPC-based method.三、实验程序clear[x,fs]=wavread('wznjdx_normal.wav');n=length(x);Q = x';NFFT=512;N = 256;Hamm = hamming(N);frame = 30;M = Q(((frame -1) * (N / 2) + 1):((frame - 1) * (N / 2) + N)); Frame = M .* Hamm';% lowpass filter[b2,a2]=butter(2,900/4000);speech2=filter(b2,a2,Frame); % filter% residual[a,e] = lpc(speech2,20);errorlp=filter(a,1,speech2); % residual% Short-term autocorrelation.re = xcorr(errorlp);% Find max autocorrelation for lags in the interval minlag to maxlag. minlag = 17; % F0: 450Hzmaxlag =160; % F0: 50Hz[remax,idx] = max(re(fnlen+minlag:fnlen+maxlag));figuresubplot(3,1,1);plot(Frame);subplot(3,1,2);plot(speech2);subplot(3,1,3);plot(re);text(500,0,'idx');idx=idx-1+minlagremax四、实验结果【实验五】⼀、实验题⽬Speech synthesis⼆、实验内容Write a program to analyze a speech and synthesize it using the LPC-based method.三、实验程序主程序clear;[x,sr] = wavread('wznjdx_normal.wav');p=[1 -0.9];x=filter(p,1,x);N=256;inc=128;y=lpcsyn(x,N,inc);wavplay(y,sr);⼦程序lpcsynfunction y=lpcsyn(x,N,inc)%[x,sr] = wavread('wznjdx_normal.wav');%pre = [1 -0.97];%x = filter(pre,1,x);%N=256;%inc=128;fn=floor(length(x)/inc);y=zeros(1,50000);for (i=1:fn)x(1:N,i)=x((i-1)*inc+1:(i+1)*inc);[A(i,:),G(i),P(i),fnlen,fnshift] = lpcana(x(1:N,i),order); if (P(i)) % V oiced frame.e = zeros(N,1);e(1:P(i):N) = 1; % Impulse-train excitation.else % Unvoiced frame.e = randn(N,1); % White noise excitation.endyt=filter(G(i),A(i,:),e);j=(i-1)*inc+[1:N];y(j) = y(j)+yt';end;end⼦程序lpcanafunction [A,G,P,fnlen,fnshift] = lpcana(x,order) fnlen=256;fnshift=fnlen/2;n=length(x);[b2,a2]=butter(2,900/4000);speech2=filter(b2,a2,x);[A,e]=lpc(speech2,order);errorlp=filter(A,1,speech2);re=xcorr(errorlp);G=sqrt(e*length(speech2));minlag=17;maxlag=160;[remax,idx]=max(re(n+minlag:n+maxlag));P=idx-1+minlag;end四、实验结果【实验六】⼀、实验题⽬Speech enhancement⼆、实验内容Write a program to implement the basic spectral magnitude subtraction.三、实验程序clear[speech,fs,nbits]=wavread('wznjdx_normal.wav');%读⼊数据alpha=0.04;%噪声⽔平winsize=256;%窗长size=length(speech);%语⾳长度numofwin=floor(size/winsize);%帧数hamwin=zeros(1,size);%定义汉明窗长度enhanced=zeros(1,size);%定义增强语⾳的长度ham=hamming(winsize)';%%产⽣汉明窗x=speech'+alpha*randn(1,size);%信号加噪声noisy=alpha*randn(1,winsize);%噪声估计N=fft(noisy);nmag=abs(N);%噪声功率谱%分帧for q=1:2*numofwin-1frame=x(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2);%对带噪语⾳帧间重叠⼀半取值hamwin(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)=...hamwin(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)+ham;%加窗y=fft(frame.*ham);mag=abs(y);%带噪语⾳功率谱phase=angle(y);%带噪语⾳相位%幅度谱减for i=1:winsizeif mag(i)-nmag(i)>0clean(i)=mag(i)-nmag(i);else clean(i)=0;endend%频域中重新合成语⾳spectral=clean.*exp(j*phase);%反傅⾥叶变换并重叠相加enhanced(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)=...enhanced(1+(q-1)*winsize/2:winsize+(q-1)*winsize/2)+real(ifft(spectral));endfigure(1);subplot(3,1,1);plot(speech);xlabel('样点数');ylabel('幅度');title('原始语⾳波形'); subplot(3,1,2);plot(x);xlabel('样点数');ylabel('幅度');title('语⾳加噪波形'); subplot(3,1,3);plot(enhanced);xlabel('样点数');ylabel('幅度');title('增强语⾳波形');四、实验结果。

实验一、语音信号采集与分析一、实验目的:1)了解语音信号处理基本知识:语音信号的生成的数学模型。
2)在理论学习的基础上,进一步地理解和掌握语音信号的读入、回放、波形显示。
语音信号时域和频域分析方法。
二、实验原理一定时宽的语音信号,其能量的大小随时间有明显的变化。
其中清音段(以清音为主要成份的语音段),其能量比浊音段小得多。
短时过零数也可用于语音信号分析中,发浊音时,其语音能量约集中于3kHz以下,而发清音时,多数能量出现在较高频率上,可认为浊音时具有较低的平均过零数,而清音时具有较高的平均过零数,因而,对一短时语音段计算其短时平均能量及短时平均过零数,就可以较好地区分其中的清音段和浊音段,从而可判别句中清、浊音转变时刻,声母韵母的分界以及无声与有声的分界。
这在语音识别中有重要意义。
FFT在数字通信、语音信号处理、图像处理、匹配滤波以及功率谱估计、仿真、系统分析等各个领域都得到了广泛的应用。
本实验通过分析加噪的语音信号频谱,可以作为分离信号和噪声的理论基础。
三、实验内容:Matlab编程实验步骤:1.新建M文件,扩展名为“.m”,编写程序;2.选择File/Save命令,将文件保存在F盘中;3.在Command Window窗中输入文件名,运行程序;程序一、用MATLAB对原始语音信号进行时域分析,分析短时平均能量及短时平均过零数。
程序二、用MATLAB对原始语音信号进行频域分析,画出它的时域波形和频谱给原始的语音信号加上一个高频余弦噪声,频率为5kHz。
画出加噪后的语音信号时域和频谱图。
程序1.a=wavread(' D:\II.wav'); %读取语音信号的数据,赋给变量x1,这里的文件的全路径和文件名由个人设计n=length(a);N=320;subplot(3,1,1),plot(a);h=linspace(1,1,N);%形成一个矩形窗,长度为NEn=conv(h,a.*a);%求卷积得其短时能量函数Ensubplot(3,1,2),plot(En);for i=1:n-1if a(i)>=0b(i)= 1;elseb(i) = -1;endif a(i+1)>=0b(i+1)=1;elseb(i+1)=-1;endw(i)=abs(b(i+1)-b(i));end%求出每相邻两点符号的差值的绝对值k=1;j=0;while (k+N-1)<nZm(k)=0;for i=0:N-1;Zm(k)=Zm(k)+w(k+i);endj=j+1;k=k+160; %每次移动半个窗endfor w=1:jQ(w)=Zm(160*(w-1)+1)/640;%短时平均过零率endsubplot(3,1,3),plot(Q);实验结果打印粘贴到右侧:程序2:fs=22050; %语音信号采样频率为22050x1=wavread('D:\II.wav'); %读取语音信号的数据,赋给变量x1sound(x1,22050); %播放语音信号f=fs*(0:511)/1024;t=0:1/22050:(size(x1)-1)/22050; %将所加噪声信号的点数调整到与原始信号相同Au=0.03;d=[Au*cos(2*pi*5000*t)]'; %噪声为5kHz的余弦信号x2=x1+d;sound(x2,22050); %播放加噪声后的语音信号y2=fft(x2,1024); %对信号做1024点FFT变换figure(1)subplot(2,1,1);plot(x1) %做原始语音信号的时域图形title('原始语音信号');xlabel('time n');ylabel('幅值 n');subplot(2,1,2);plot(t,x2)title('加噪后的信号');xlabel('time n');ylabel('幅值 n');figure(2)subplot(2,1,1);plot(f,abs(x1(1:512)));title('原始语音信号频谱');xlabel('Hz');ylabel('幅值');subplot(2,1,2);plot(f,abs(y2(1:512)));title('加噪后的信号频谱');xlabel('Hz'); ylabel('幅值');实验结果打印粘贴到右侧:050010001500200025003000350040004500原始语音信号time n幅值 n加噪后的信号time n幅值 n020004000600080001000012000原始语音信号频谱Hz幅值加噪后的信号频谱Hz幅值四、实验分析加入噪声后音频文件可辨性下降,波形的平缓,频谱图上看,能量大部分集中在2000HZz到4000Hz之间。
一、实验目的1. 理解语音信号处理的基本原理和流程。
2. 掌握语音信号的采集、预处理、特征提取和识别等关键技术。
3. 提高实际操作能力,运用所学知识解决实际问题。
二、实验原理语音信号处理是指对语音信号进行采集、预处理、特征提取、识别和合成等操作,使其能够应用于语音识别、语音合成、语音增强、语音编码等领域。
实验主要包括以下步骤:1. 语音信号的采集:使用麦克风等设备采集语音信号,并将其转换为数字信号。
2. 语音信号的预处理:对采集到的语音信号进行降噪、去噪、归一化等操作,提高信号质量。
3. 语音信号的特征提取:提取语音信号中的关键特征,如频率、幅度、倒谱等,为后续处理提供依据。
4. 语音信号的识别:根据提取的特征,使用语音识别算法对语音信号进行识别。
5. 语音信号的合成:根据识别结果,合成相应的语音信号。
三、实验步骤1. 语音信号的采集使用麦克风采集一段语音信号,并将其保存为.wav文件。
2. 语音信号的预处理使用MATLAB软件对采集到的语音信号进行预处理,包括:(1)降噪:使用谱减法、噪声抑制等算法对语音信号进行降噪。
(2)去噪:去除语音信号中的杂音、干扰等。
(3)归一化:将语音信号的幅度归一化到相同的水平。
3. 语音信号的特征提取使用MATLAB软件对预处理后的语音信号进行特征提取,包括:(1)频率分析:计算语音信号的频谱,提取频率特征。
(2)幅度分析:计算语音信号的幅度,提取幅度特征。
(3)倒谱分析:计算语音信号的倒谱,提取倒谱特征。
4. 语音信号的识别使用MATLAB软件中的语音识别工具箱,对提取的特征进行识别,识别结果如下:(1)将语音信号分为浊音和清音。
(2)识别语音信号的音素和音节。
5. 语音信号的合成根据识别结果,使用MATLAB软件中的语音合成工具箱,合成相应的语音信号。
四、实验结果与分析1. 语音信号的采集采集到的语音信号如图1所示。
图1 语音信号的波形图2. 语音信号的预处理预处理后的语音信号如图2所示。
语音信号处理实验指导书实验一:语音信号的采集与播放实验目的:了解语音信号的采集与播放过程,掌握采集设备的使用方法。
实验器材:1. 电脑2. 麦克风3. 扬声器或者耳机实验步骤:1. 将麦克风插入电脑的麦克风插孔。
2. 打开电脑的录音软件(如Windows自带的录音机)。
3. 在录音软件中选择麦克风作为录音设备。
4. 点击录音按钮开始录音,讲话或者唱歌几秒钟。
5. 点击住手按钮住手录音。
6. 播放刚刚录制的语音,检查录音效果。
7. 将扬声器或者耳机插入电脑的音频输出插孔。
8. 打开电脑的音频播放软件(如Windows自带的媒体播放器)。
9. 选择要播放的语音文件,点击播放按钮。
10. 检查语音播放效果。
实验二:语音信号的分帧与加窗实验目的:了解语音信号的分帧和加窗过程,掌握分帧和加窗算法的实现方法。
实验器材:1. 电脑2. 麦克风3. 扬声器或者耳机实验步骤:1. 使用实验一中的步骤1-5录制一段语音。
2. 将录制的语音信号进行分帧处理。
选择合适的帧长和帧移参数。
3. 对每一帧的语音信号应用汉明窗。
4. 将处理后的语音帧进行播放,检查分帧和加窗效果。
实验三:语音信号的频谱分析实验目的:了解语音信号的频谱分析过程,掌握频谱分析算法的实现方法。
实验器材:1. 电脑2. 麦克风3. 扬声器或者耳机实验步骤:1. 使用实验一中的步骤1-5录制一段语音。
2. 将录制的语音信号进行分帧处理。
选择合适的帧长和帧移参数。
3. 对每一帧的语音信号应用汉明窗。
4. 对每一帧的语音信号进行快速傅里叶变换(FFT)得到频谱。
5. 将频谱绘制成图象,观察频谱的特征。
6. 对频谱进行谱减法处理,去除噪声。
7. 将处理后的语音帧进行播放,检查频谱分析效果。
实验四:语音信号的降噪处理实验目的:了解语音信号的降噪处理过程,掌握降噪算法的实现方法。
实验器材:1. 电脑2. 麦克风3. 扬声器或者耳机实验步骤:1. 使用实验一中的步骤1-5录制一段带噪声的语音。
华南理工大学《语音信号处理》实验报告实验名称:端点检测姓名:学号:班级:10级电信5班日期:2013年5 月9日1.实验目的1.语音信号端点检测技术其目的就是从包含语音的一段信号中准确地确定语音的起始点和终止点,区分语音和非语音信号,它是语音处理技术中的一个重要方面。
本实验的目的就是要掌握基于MATLAB编程实现带噪语音信号端点检测,利用MATLAB对信号进行分析和处理,学会利用短时过零率和短时能量,对语音信号的端点进行检测。
2. 实验原理1、短时能量语音和噪声的区别可以体现在它们的能量上,语音段的能量比噪声段能量大,语音段的能量是噪声段能量叠加语音声波能量的和。
在信噪比很高时,那么只要计算输入信号的短时能量或短时平均幅度就能够把语音段和噪声背景区分开。
这是仅基于短时能量的端点检测方法。
信号{x(n)}的短时能量定义为:语音信号的短时平均幅度定义为:其中w(n)为窗函数。
2、短时平均过零率短时过零表示一帧语音信号波形穿过横轴(零电平)的次数。
过零分析是语音时域分析中最简单的一种。
对于连续语音信号,过零意味着时域波形通过时间轴;而对于离散信号,如果相邻的取样值的改变符号称为过零。
过零率就是样本改变符号次数。
信号{x(n)}的短时平均过零率定义为:式中,sgn为符号函数,即:过零率有两类重要的应用:第一,用于粗略地描述信号的频谱特性;第二,用于判别清音和浊音、有话和无话。
从上面提到的定义出发计算过零率容易受低频干扰,特别是50Hz交流干扰的影响。
解决这个问题的办法,一个是做高通滤波器或带通滤波,减小随机噪声的影响;另一个有效方法是对上述定义做一点修改,设一个门限T,将过零率的含义修改为跨过正负门限。
于是,有定义:3、检测方法利用过零率检测清音,用短时能量检测浊音,两者配合。
首先为短时能量和过零率分别确定两个门限,一个是较低的门限数值较小,对信号的变化比较敏感,很容易超过;另一个是比较高的门限,数值较大。
通信与信息工程学院信息处理综合实验报告班级:电子信息工程1502班指导教师:设计时间:2018/10/22-2018/11/23评语:通信与信息工程学院二〇一八年实验题目:语音信号分析与处理一、实验内容1. 设计内容利用MATLAB对采集的原始语音信号及加入人为干扰后的信号进行频谱分析,使用窗函数法设计滤波器滤除噪声、并恢复信号。
2.设计任务与要求1. 基本部分(1)录制语音信号并对其进行采样;画出采样后语音信号的时域波形和频谱图。
(2)对所录制的语音信号加入干扰噪声,并对加入噪声的信号进行频谱分析;画出加噪后信号的时域波形和频谱图。
(3)分别利用矩形窗、三角形窗、Hanning窗、Hamming窗及Blackman 窗几种函数设计数字滤波器滤除噪声,并画出各种函数所设计的滤波器的频率响应。
(4)画出使用几种滤波器滤波后信号时域波形和频谱,对滤波前后的信号、几种滤波器滤波后的信号进行对比,分析信号处理前后及使用不同滤波器的变化;回放语音信号。
2. 提高部分(5)录制一段音乐信号并对其进行采样;画出采样后语音信号的时域波形和频谱图。
(6)利用MATLAB产生一个不同于以上频段的信号;画出信号频谱图。
(7)将上述两段信号叠加,并加入干扰噪声,尝试多次逐渐加大噪声功率,对加入噪声的信号进行频谱分析;画出加噪后信号的时域波形和频谱图。
(8)选用一种合适的窗函数设计数字滤波器,画出滤波后音乐信号时域波形和频谱,对滤波前后的信号进行对比,回放音乐信号。
二、实验原理1.设计原理分析本设计主要是对语音信号的时频进行分析,并对语音信号加噪后设计滤波器对其进行滤波处理,对语音信号加噪声前后的频谱进行比较分析,对合成语音信号滤波前后进行频谱的分析比较。
首先用PC机WINDOWS下的录音机录制一段语音信号,并保存入MATLAB软件的根目录下,再运行MATLAB仿真软件把录制好的语音信号用audioread函数加载入MATLAB仿真软件的工作环境中,输入命令对语音信号进行时域,频谱变换。
语音信号处理实验报告语音信号处理实验报告一、引言语音信号处理是一门研究如何对语音信号进行分析、合成和改善的学科。
在现代通信领域中,语音信号处理起着重要的作用。
本实验旨在探究语音信号处理的基本原理和方法,并通过实验验证其有效性。
二、实验目的1. 了解语音信号处理的基本概念和原理。
2. 学习使用MATLAB软件进行语音信号处理实验。
3. 掌握语音信号的分析、合成和改善方法。
三、实验设备和方法1. 设备:计算机、MATLAB软件。
2. 方法:通过MATLAB软件进行语音信号处理实验。
四、实验过程1. 语音信号的采集在实验开始前,我们首先需要采集一段语音信号作为实验的输入。
通过麦克风将语音信号输入计算机,并保存为.wav格式的文件。
2. 语音信号的预处理在进行语音信号处理之前,我们需要对采集到的语音信号进行预处理。
预处理包括去除噪声、归一化、去除静音等步骤,以提高后续处理的效果。
3. 语音信号的分析语音信号的分析是指对语音信号进行频谱分析、共振峰提取等操作。
通过分析语音信号的频谱特征,可以了解语音信号的频率分布情况,进而对语音信号进行进一步处理。
4. 语音信号的合成语音信号的合成是指根据分析得到的语音信号特征,通过合成算法生成新的语音信号。
合成算法可以基于传统的线性预测编码算法,也可以采用更先进的基于深度学习的合成方法。
5. 语音信号的改善语音信号的改善是指对语音信号进行降噪、增强等处理,以提高语音信号的质量和清晰度。
常用的语音信号改善方法包括时域滤波、频域滤波等。
六、实验结果与分析通过实验,我们得到了经过语音信号处理后的结果。
对于语音信号的分析,我们可以通过频谱图观察到不同频率成分的分布情况,从而了解语音信号的特点。
对于语音信号的合成,我们可以听到合成后的语音信号,并与原始语音信号进行对比。
对于语音信号的改善,我们可以通过降噪效果的评估来判断处理的效果。
七、实验总结通过本次实验,我们深入了解了语音信号处理的基本原理和方法,并通过实验验证了其有效性。