CABAC编码协议详细分析(初稿)
- 格式:doc
- 大小:696.00 KB
- 文档页数:21

cabac编码过程的解读cabac编码过程的解读CABAC是H.264/AVC标准中两种熵编码方法中的一种,是将自适应的二进制算术编码与一个设计精良的上下文模型结合起来得到的方法。
它很好地利用了语法元素数值之间的高阶信息,使得熵编码的效率得到了进一步提高。
它的主要特点有:利用每个语法元素的上下文关系,根据已编码元素为待编码元素选择概率模型,即上下文建模;根据当前的统计特性自适应地进行概率估计;使用算术编码。
[5] 在CABAC中编码一个单独的句法元素的通用方框图。
这个编码过程主要由三个基本步骤组成:1、二值化;2、上下文建模;3、基于表格的二进制算术编码。
在第一步,一个给出的非二进制值的句法元素唯一地对应到一个二进制序列,叫二进制串。
当给出一个二进制值的句法元素时,这一初始步骤将被跳过,如图1所示。
对于每个元素的二进制串或每个二进制值的句法元素,后面会根据编码模式有一两个子步骤。
接下来就是对二元数据进行编码,标准中有两种编码模式可供选择。
在常规编码模式(regular coding mode)中,一个句法元素的每一个二进值(bin)按其判决产生的顺序进入上下文模型器,在这里,模型器根据已经编码过的句法元素或二进值为每一个输入的二进值分配一个概率模型,这就是上下文模型化。
然后该二进值和分配给它的概率模型一起被送进常规算术编码器进行编码,此外编码器还要根据该二元位的值反馈一个信息给上下文模型器,用以更新上下文模型,这就是编码中的自适应;另一种模式是旁路编码模式(bypass coding mode),在该模式中,没有模型器为每个二进值分配一个特定的概率模型,输入的二元数据是直接用一个简单的旁路编码器进行编码的,这样做是为了加快整个编码(以及另一端解码)的速度,当然,该模式只用于某些特殊的二进值。
后面将更加详细地讨论二值化,上下文建模与基于表格的二进制算术编码这三个主要步骤以及它们之间的相互联系。
2.2二值化CABAC的二值化方案有四种基本类型:一元码,截断一元码,k 阶指数哥伦布编码,与定长编码。
Context-Based Adaptive Binary Arithmetic Coding in the H.264/A VC简称Cabac,H264中的一种熵编码方式:基于上下文的自适应二进制算术编码内容安排:1,介绍算术编码2,介绍二进制算术编码3介绍Cabac及其一些实用的实现方式(参考JSVM代码,也可以参考JM)---张新发一,算术编码算术编码是一种常用的变字长编码,它是利用信源概率分布特性、能够趋近熵极限的编码方法。
它与Huffman 一样,也是对出现概率大的符号赋予短码,对概率小的符号赋予长码。
但它的编码过程与Huffman 编码却不相同,而且在信源概率分布比较均匀的情况下其编码效率高于Huffman 编码。
它和Huffman 编码最大的区别在于它不是使用整数码。
Huffman 码是用整数长度的码字来编码的最佳方法,而算法编码是一种并不局限于整数长度码字的最佳编码方法。
算术编码是把各符号出现的概率表示在单位概率[0,1] 区间之中,区间的宽度代表概率值的大小。
符号出现的概率越大对应于区间愈宽,可用较短码字表示;符号出现概率越小对应于区间愈窄,需要较长码字表示。
举例如下:S S S S为例以符号3324在算术编码中通常采用二进制分数表示概率,每个符号所对应的概率区间都是半开区间,即该区间包括左端点,而不包括右端点,如S1对应[0, 0.001),S2 对应[0.001, 0.01) 等。
算术编码产生的码字实际上是一个二进制数值的指针,指向所编的符号对应的概率区间。
S S S S…… 的第一个符号S3 用指向第3 个子区间的指针 符号序列3324来代表,可以用这个区间内的任意一个小数来表示这个指针,这里约定这个区间的左端点代表这个指针,因此得到第一个码字.011。
⏹后续的编码将在前面编码指向的子区间内进行,将[.011, .111] 区间再按概率大小划分为 4 份,第二个符号S3 指向.1001 (S3 区间的左端),输出码字变为.1001。

High Throughput CABAC EntropyCoding in HEVCVivienne Sze,Member,IEEE,and Madhukar Budagavi,Senior Member,IEEEAbstract—Context-adaptive binary arithmetic coding(CAB-AC)is a method of entropy codingfirst introduced in H.264/A VC and now used in the newest standard High Efficiency Video Coding(HEVC).While it provides high coding efficiency,the data dependencies in H.264/A VC CABAC make it challenging to parallelize and thus,limit its throughput.Accordingly,during the standardization of entropy coding for HEVC,both coding efficiency and throughput were considered.This paper highlights the key techniques that were used to enable HEVC to potentially achieve higher throughput while delivering coding gains relative to H.264/A VC.These techniques include reducing context coded bins,grouping bypass bins,grouping bins with the same context, reducing context selection dependencies,reducing total bins, and reducing parsing dependencies.It also describes reductions to memory requirements that benefit both throughput and implementation costs.Proposed and adopted techniques up to draft international standard(test model HM-8.0)are discussed. In addition,analysis and simulation results are provided to quantify the throughput improvements and memory reduction compared with H.264/A VC.In HEVC,the maximum number of context-coded bins is reduced by8×,and the context memory and line buffer are reduced by3×and20×,respectively.This paper illustrates that accounting for implementation cost when designing video coding algorithms can result in a design that enables higher processing speed and lowers hardware costs,while still delivering high coding efficiency.Index Terms—Context-adaptive binary arithmetic coding (CABAC),entropy coding,high-efficiency video coding(HEVC), video coding.I.IntroductionH IGH EFFICIENCY Video Coding(HEVC)is currentlybeing developed by the Joint Collaborative Team for Video Coding(JCT-VC).It is expected to deliver up to a 50%higher coding efficiency compared to its predecessor H.264/A VC.HEVC uses several new tools for improving coding efficiency,including larger block and transform sizes, additional loopfilters,and highly adaptive entropy coding. While high coding efficiency is important for reducing the transmission and storage cost of video,processing speed and area cost also need to be considered in the development of next-generation video coding to handle the demand for higher resolution and frame rates.Manuscript received April16,2012;revised July7,2012;accepted August 21,2012.Date of publication October2,2012;date of current version January 8,2013.This paper was recommended by Associate Editor F.Wu.The authors are with Texas Instruments,Dallas,TX75243USA(e-mail: sze@;madhukar@).Color versions of one or more of thefigures in this paper are available online at .Digital Object Identifier10.1109/TCSVT.2012.2221526Context-adaptive binary arithmetic coding(CABAC)[1]is a form of entropy coding used in H.264/A VC[2]and also in HEVC[3].While CABAC provides high coding efficiency, its data dependencies cause it to be a throughput bottleneck for H.264/A VC video codecs[4].This makes it difficult to support the growing throughput requirements for next-generation video codecs.Furthermore,since high throughput can be traded off for power savings using voltage scaling [5],the serial nature of CABAC limits the battery life for video codecs that reside on mobile devices.This limitation is a critical concern,as a significant portion of the video codecs today are battery operated.Accordingly,both coding efficiency and throughput improvement tools,and the tradeoff between these requirements,were investigated in the standard-ization of entropy coding for HEVC.The tradeoff between coding efficiency and throughput exists,since dependencies are a result of removing redundancy,which improves coding efficiency;however,dependencies make parallel processing difficult,which degrades throughput.This paper describes how CABAC entropy coding has evolved from H.264/A VC to HEVC(Draft International Stan-dard,HM-8.0)[3],[6].While both coding efficiency and throughput improvement tools are discussed,the focus of this paper will be on tools that increase throughput while maintaining coding efficiency.Section II provides an overview of CABAC entropy coding.Section III explains the cause of the throughput bottleneck.Section IV describes several key techniques used to improve the throughput of the CABAC engine.Sections V and VI describe how these techniques are applied to prediction unit(PU)coding and transform unit(TU) coding,respectively.Section VII compares the overall CABAC throughput and memory requirements of H.264/A VC and HEVC for both common conditions and worst-case conditions.II.CABAC Entropy CodingEntropy coding is a form of lossless compression used at the last stage of video encoding(and thefirst stage of video decoding),after the video has been reduced to a series of syntax elements.Syntax elements describe how the video sequence can be reconstructed at the decoder.This includes the method of prediction(e.g.,spatial or temporal prediction,intra prediction mode,and motion vectors)and prediction error,also referred to as residual.Table I shows the syntax elements used in HEVC and H.264/A VC.These syntax elements describe properties of the coding unit(CU),1051-8215/$31.00c 2012IEEETABLE ICABAC Coded Syntex Elements in HEVC and H.264/AVCHEVC H.264/A VCsplit−cu−flag,pred−mode−flag,part−mode,pcm−flag,mb−type,sub−mb−type,Coding unit Block structure and cu−transquant−bypass−flag,skip−flag,cu−qp−delta−abs,mb−skip−flag,mb−qp−delta, (CU)quantization cu−qp−delta−sign,end−of−slice−flag end−of−slice−flag,mb−field−decoding−flagprev−intra4x4−pred−mode−flag,prev−intra−luma−pred−flag,mpm−idx,prev−intra8×8−pred−mode−flag, Intra mode coding rem−intra−luma−pred−mode,rem−intra4x4−pred−mode,intra−chroma−pred−mode rem−intra8x8−pred−mode,intra−chroma−pred−mode Prediction unit merge−flag,merge−idx,inter−pred−idc,(PU)ref−idx−l0,ref−idx−l1,Motion data abs−mvd−greater0−flag,abs−mvd−greater1−flag,ref−idx−l0,ref−idx−l1,mvd−l0,mvd−l1abs−mvd−minus2,mvd−sign−flag,mvp−l0−flag,mvp−l1−flagno−residual−syntax−flag,split−transform−flag,cbf−luma,coded−block−flag,cbf−cb,cbf−cr,transform−skip−flag,last−significant−coded−block−pattern,coeff−x−prefix,last−significant−coeff−y−prefix,last−significant−transform−size−8x8−flag,Transform Unit (TU)Transform coefficient coeff−x−suffix,last−significant−coeff−y−suffix,coded−sub−significant−coeff−flag, coding block−flag,significant−coeff−flag,coeff−abs−level−last−significant−coeff−flag, greater1−flag,coeff−abs−level−greater2−flag,coeff−abs−level−coeff−abs−level−minus1,remaining,coeff−sign−flag coeff−sign−flag Sample adaptive sao−merge−left−flag,sao−merge−up−flag,sao−type−idx−luma,Loopfilter(LF)offset(SAO)sao−type−idx−chroma,sao−offset−abs,sao−offset−sign,n/a parameters sao−band−position,sao−eo−class−luma,sao−eo−class−chromaprediction unit(PU),transform unit(TU),and loopfilter(LF) of a coded block of pixels.For a CU,the syntax elements describe the block structure and whether the CU is inter or intra predicted.For a PU,the syntax elements describe the intra prediction mode or a set of motion data.For a TU,the syntax elements describe the residual in terms of frequency position,sign,and magnitude of the quantized transform coefficients.The LF syntax elements are sent once per largest coding unit(LCU),and describe the type(edge or band)and offset for sample adaptive offset in-loopfiltering. Arithmetic coding is a type of entropy coding that can achieve compression close to the entropy of a sequence by effectively mapping the symbols(i.e.,syntax elements)to codewords with a noninteger number of bits.In H.264/A VC, CABAC provides a9%to14%improvement over the Huffman-based CA VLC[1].In an early test model for HEVC (HM-3.0),CABAC provides a5%–9%improvement over CA VLC[7].CABAC involves three main functions:binarization,con-text modeling,and arithmetic coding.Binarization maps the syntax elements to binary symbols(bins).Context modeling estimates the probability of the bins.Finally,arithmetic coding compresses the bins to bits based on the estimated probability.A.BinarizationSeveral different binarization processes are used in HEVC, including unary(U),truncated unary(TU),k th-order Exp-Golomb(EGk),andfixed length(FL).These forms of binarization were also used in H.264/A VC.These various methods of binarization can be explained in terms of how they would signal an unsigned value N.An example is also provided in Table II.1)Unary coding involves signaling a bin string of lengthN+1,where thefirst N bins are1and the last bin isTABLE IIExample of Different Binarizations Used in HEVC Unary(U)Truncated Exp-Golomb Fixed N unary(TU)(EGk)length(FL)cMax=7k=0cMax=7 000100011010010001211011001101031110111000100011411110111100010110051111101111100011010161111110111111000111110711111110111111100010001110.The decoder searches for a0to determine when thesyntax element is complete.2)Truncated unary coding has one less bin than unarycoding by setting a maximum on the largest possible value of the syntax element(cMax).When N+1<cMax, the signaling is the same as unary coding.However, when N+1=cMax,all bins are1.The decoder searches for a0up to cMax bins to determine when the syntax element is complete.3)k th order Exp-Golomb is a type of universal code.Thedistribution can be changed based on the k parameter.More details can be found in[1].4)Fixed length uses afixed number of bins,ceil(log2(cMax+1)),with most significant bits signaled before least significant bits.The binarization process is selected based on the type of syntax element.In some cases,binarization also de-pends on the value of a previously processed syntax ele-ments(e.g.,the binarization of coeff−abs−level−remaining depends on the previous coefficient levels)or slice pa-rameters that indicate if certain modes are enabled(e.g., the binarization of partition mode,part−mode,depends on whether asymmetric motion partition is enabled).The ma-jority of the syntax elements use the binarization pro-cesses listed in Table II,or some combination of them(e.g.,coeff−abs−level−remaining uses U(prefix)+FL(suffix)[8];cu−qp−delta−abs uses TU(prefix)+EG0(suffix)[9]). However,certain syntax elements(e.g.,part−mode and intra−chroma−pred−mode)use custom binarization processes.B.Context ModelingContext modeling provides an accurate probability estimate required to achieve high coding efficiency.Accordingly,it is highly adaptive and different context models can be used for different bins and the probability of that context model is updated based on the values of the previously coded bins. Bins with similar distributions often share the same context model.The context model for each bin can be selected based on the type of syntax element,bin position in syntax element(binIdx),luma/chroma,neighboring information,etc.A context switch can occur after each bin.The probability models are stored as7-b entries[6-b for the probability state and1-b for the most probable symbol(MPS)]in a context memory and addressed using the context index computed by the context selection logic.HEVC uses the same probability update method as H.264/A VC;however,the context selection logic has been modified to improve throughput.C.Arithmetic CodingArithmetic coding is based on recursive interval division.A range,with an initial value of0to1,is divided into two subintervals based on the probability of the bin.The encoded bits provide an offset that,when converted to a binary fraction, selects one of the two subintervals,which indicates the value of the decoded bin.After every decoded bin,the range is updated to equal the selected subinterval,and the interval division process repeats itself.The range and offset have limited bit precision,so renormalization is required whenever the range falls below a certain value to prevent underflow. Renormalization can occur after each bin is decoded. Arithmetic coding can be done using an estimated proba-bility(context coded),or assuming equal probability of0.5 (bypass coded).For bypass coded bins,the division of the range into subintervals can be done by a shift,whereas a look up table is required for the context coded bins.HEVC uses the same arithmetic coding as H.264/A VC.III.Throughput BottleneckCABAC is a well-known throughput bottleneck in the video codec implementations(particularly,at the decoder). The throughput of CABAC is determined based on the number of binary symbols(bins)that it can process per second.The throughput can be improved by increasing the number of bins that can be processed in a cycle.However,the data dependencies in CABAC make processing multiple bins in parallel difficult and costly toachieve.Fig.1.Three key operations in CABAC:binarization,context selection,and arithmetic coding.Feedback loops in the decoder are highlighted with dashed lines.Fig.1highlights the feedback loops in the CABAC decoder. Below is a list and description of these feedback loops.1)The updated range is fed back for recursive intervaldivision.2)The updated context is fed back for an accurate proba-bility estimate.3)The context selection depends on the type of syntaxelement.At the decoder,the decoded bin is fed back to determine whether to continue processing the same syntax element,or to switch to another syntax element.If a switch occurs,the bin may be used to determine which syntax element to decode next.4)The context selection also depends on the bin position inthe syntax element(binIdx).At the decoder,the decoded bin is fed back to determine whether to increment binIdx and continue to decode the current syntax element,or set binIdx equal to0and switch to another syntax element. Note that the context update and range update feedback loops are simpler than the context selection loops and thus do not affect throughput as severely.If the context of a bin depends on the value of another bin being decoded in parallel, then speculative computations are required,which increases area cost and critical path delay[10].The amount of specula-tion can grow exponentially with the number of parallel bins which limits the throughput that can be achieved[11].Fig.2 shows an example of the speculation tree for significance map in H.264/A VC.Thus,the throughput bottleneck is primarily due to the context selection dependencies.IV.Techniques to Improve Throughput Several techniques were used to improve the throughput of CABAC in HEVC.There was a lot of effort spent in determining how to use these techniques with minimal coding loss.They were applied to various parts of entropy coding in HEVC and will be referred to throughout the rest of this paper.1)Reduce Context Coded Bins:Throughput is limited for context coded bins due to the data dependencies described in Section III.However,it is easier to process bypass coded bins in parallel since they do not have the data dependencies related to context selection(i.e.,feedback loops2,3,and4in Fig.1). In addition,arithmetic coding for bypass bins is simpler as it only requires a right shift versus a table look up for context coded bins.Thus,the throughput can be improved by reducing the number of context coded bins and using bypass coded bins instead[12]–[14].Fig.2.Context speculation required to achieve 5×parallelism when processing the significance map in H.264/A VC.i =coefficient position,i 1=MaxNumCoeff(BlockType)−1,EOB =end of block,SIG =significant −coeff −flag,LAST =last −significant −coeff −flag.2)Group Bypass Coded Bins:Multiple bypass bins can be processed in the same cycle if they occur consecutively within the bitstream.Thus,bins should be reordered such that bypass coded bins are grouped together in order to increase the likelihood that multiple bins are processed per cycle [15]–[17].3)Group Bins With the Same Context:Processing multiple context coded bins in the same cycle often requires speculative calculations for context selection.The amount of speculative computations increases if bins using different contexts and context selection logic are interleaved,since various combina-tions and permutations must be accounted for.Thus,to reduce speculative computations,bins should be reordered such that bins with the same contexts and context selection logic are grouped together so that they are likely to be processed in the same cycle [18]–[20].This also reduces context switching resulting in fewer memory accesses,which also increases throughput and reduces power consumption.This technique was first introduced in [18]and referred to as parallel context processing (PCP)throughout the standardization process.4)Reduce Context Selection Dependencies:Speculative computations are required for multiple bins per cycle decoding due to the dependencies in the context selection.Reducing these dependencies simplifies the context selection logic and reduces the amount of speculative calculations required to process multiple bins in parallel [11],[21],[22].5)Reduce Total Number of Bins:In addition to increasing the throughput,it is desirable to reduce the workload itself by reducing the total number of bins that need to be processed.This can be achieved by changing binarization,inferring the value of some bins,and sending higher level flags to avoid signaling redundant bins [23],[24].6)Reduce Parsing Dependencies:As parsing with CABAC is already a tight bottleneck,it is important to minimize any dependency on other video coding modules,which could cause the CABAC to stall [25].Ideally,the parsing process should be decoupled from all other processing.7)Reduce Memory Requirements:Memory accesses often contribute to the critical path delay.Thus,reducing memory storage requirements is desirable as fewer memory accesses increases throughput as well as reduces implementation cost and power consumption [26],[27].V .Prediction Unit CodingThe PU syntax elements describe how the prediction is performed in order to reconstruct the pixels.For inter prediction,the motion data are described by merge flag(merge −flag),merge index (merge −idx),prediction direction (inter −pred −idc),reference index (ref −idx −l0,ref −idx −l1),motion vector predictor flag (mvp −l0−flag,mvp −l1−flag)and motion vector difference (abs −mvd −greater0−flag,abs −mvd −greater1−flag,abs −mvd −minus2,mvd −sign −flag).For intra prediction,the intra prediction mode is described by prediction flag (prev −intra −luma −pred −flag),most probable mode index (mpm −idx),remainder mode (rem −intra −luma −pred −mode)and intra prediction mode for chroma (intra −chroma −pred −mode).Coding efficiency improvements have been made in HEVC for both motion data coding and intra mode coding.While H.264/A VC uses a single motion vector predictor (unless direct mode is used)or most probable mode,HEVC uses multiple candidate predictors and an index or flag is signaled to select the predictor.This section will discuss how to avoid parsing dependencies for the various methods of prediction and other throughput improvements.A.Motion Data CodingIn HEVC,merge mode enables motion data (e.g.,predic-tion direction,reference index,and motion vectors)to be inherited from a spatial or temporal (co-located)neighbor.A list of merge candidates are generated from these neighbors.merge −flag is signaled to indicate whether merge is used in a given PU.If merge is used,then merge −idx is signaled to indi-cate from which candidate the motion data should be inherited.merge −idx is coded with truncated unary,which means that the bins are parsed until a nonzero is reached or when the number of bins is equal to the cMax,the max allowed number of bins.1)Removing Parsing Dependencies for Merge:Determin-ing how to set cMax involved evaluating the throughput and coding efficiency tradeoffs in a core experiment [28].For optimal coding efficiency,cMax should be set to equal the merge candidate list size of the PU.Furthermore,merge −flag should not be signaled if the list is empty.However,this makes parsing depend on list construction,which is needed to determine the list size.Constructing the list requires a large amount of computation since it involves reading from multiple locations (i.e.,fetching the co-located neighbor and spatial neighbors)and performing several comparisons to prune the list;thus,dependency on list construction would significantly degrade parsing throughput [25],[29].To decouple the list generation process from the parsing process such that they can operate in parallel in HEVC,cMax is signaled in the slice header and does not depend on list size.To compensate for the coding loss due to the fixed cMax,combined and zero merging candidates are added when the list size is less than cMax as described in[30].This ensures that the list is never empty and that merge−flag is always signaled [31].2)Removing Parsing Dependencies for Motion Vector Prediction:If merge mode is not used,then the motion vector is predicted from its neighboring blocks and the difference between motion vector prediction(mvp)and motion vector (mv),referred to as motion vector difference(mvd),is signaled asmvd=mv-mvp.In H.264/A VC,a single predictor is calculated for mvp from the median of the left,top,and top-right spatial4×4neighbors. In HEVC,advanced motion vector prediction(AMVP)is used,where several candidates for mvp are determined from spatial and temporal neighbors[32].A list of mvp candidates is generated from these neighbors,and the list is pruned to remove redundant candidates such that there is a maximum of2candidates.A syntax element called mvp−l0−flag(or mvp−l1−flag depending on the reference list)is used to indicate which candidate is used from the list as the mvp. To ensure that parsing is independent of list construction, mvp−l0−flag is signaled even if there is only one candidate in the list.The list is never empty as the zero vector is used as the default candidate.3)Reducing Context Coded Bins:In HEVC,improve-ments were also made on the coding process of mvd it-self.In H.264/A VC,thefirst9bins of mvd are context coded truncated unary bins,followed by bypass coded third-order Exp-Golomb bins.In HEVC,the number of context coded bins for mvd is significantly reduced[13].Only the first two bins are context coded(abs−mvd−greater0−flag, abs−mvd−greater1−flag),followed by bypass codedfirst-order Exp-Golomb bins(abs−mvd−minus2).4)Reducing Memory Requirements:In H.264/A VC,con-text selection for thefirst bin in mvd depends on whether the sum of the motion vectors of the top and left4×4 neighbors are greater than32(or less than3).This requires 5-b storage per neighboring motion vector,which accounts 24576of the30720-b CABAC line buffer needed to support a4k×2k sequence.[27]highlighted the need to reduce the line buffer size in HEVC by modifying the context selection logic.It proposed that the motion vector for each neighbor befirst compared to a threshold of16,and then use the sum of the comparison for context selection,which would reduce the storage to1-b per neighboring motion vector.This was further extended in[33]and[34],where all dependencies on the neighbors were removed and the context is selected based on the binIdx(i.e.,whether it is thefirst or second bin).5)Grouping Bypass Bins:To maximize the impact of fast bypass coding,the bypass coded bins for both the x and y components of mvd are grouped together in HEVC[16]. B.Intra Mode CodingSimilar to motion coding,a predictor mode(most probable mode)is calculated for intra mode coding.In H.264/A VC,the minimum mode of the top and left neighbors is used as theTABLE IIIDifferences Between PU Coding in HEVC and H.264/AVCProperties HEVC H.264/A VCIntra mode AMVP Merge Intra mode MVP Max number of32511 candidates in listSpatial neighbor Used Used Used Used Used Temporal co-located Not Used Used Not Not neighbor used used used Number of contexts2102620 Max context coded2122798 bins per PUmost probable mode.prev−intra4x4−pred−mode−flag (or prev−intra8x8−pred−mode−flag)is signaled to indicate whether the most probable mode is used.If the most probable mode is not used,the remainder mode rem−intra4x4−pred−mode−flag(or rem−intra8x8−pred−mode−flag)is signaled.In HEVC,additional most probable modes are used to improve coding efficiency.A candidate list of most probable modes with afixed length of three is constructed based on the left and top neighbors.The additional candidate modes (DC,planar,vertical,+1or−1angular mode)can be added if the left and top neighbors are the same or unavailable. prev−intra−pred−mode−flag is signaled to indicate whether one of the most probable modes is used.If a most probable mode is used,a most probable mode index(mpm−idx)is signaled to indicate which candidate to use.It should be noted that in HEVC,the order in which the coefficients of the residual are parsed(e.g.,diagonal,vertical,or horizontal) depends on the reconstructed intra mode(i.e.,the parsing of the TU data that follows depends on list construction and intra mode reconstruction).Thus,the candidate list size was limited to three for reduced computation to ensure that it would not affect entropy decoding throughput[35],[36].1)Reducing Context Coded Bins:The number of context coded bins was reduced for intra mode coding in HEVC.In H.264/A VC,the remainder mode is a7-bin value where the first bin is context coded,while in HEVC,the remainder mode is a5-bin value that is entirely bypass coded.The most proba-ble mode index(mpm−idx)is also entirely bypass coded.The number of contexts used to code intra−chroma−pred−mode is reduced from4to1.2)Grouping Bypass Bins:To maximize the impact of fast bypass coding,the bypass coded bins for intra mode within a CU are grouped together in HEVC[17].C.Summary of Differences Between HEVC and H.264/AVC The differences between H.264/A VC and HEVC are sum-marized in Table III.HEVC uses both spatial and temporal neighbors as predictors,while H.264/A VC only uses spatial neighbors(unless direct mode is enabled).In terms of the impact of the throughput improvement techniques,HEVC has8×fewer maximum context coded bins per PU than H.264/A VC.HEVC also requires1.8×fewer contexts for PU syntax elements than H.264/A VC.VI.Transform Unit CodingIn video coding,both intra and inter prediction are used to reduce the amount of data that needs to be transmitted. Rather than sending the pixels,the prediction error is trans-mitted.This prediction error is transformed from spatial to frequency domain to leverage energy compaction properties, and after quantization,it can be represented in terms of a few coefficients.The method of signaling the value and the frequency position of these coefficients is referred to as transform coefficient coding.For regions with many edges (e.g.,screen content coding),coding gains can be achieved by skipping the transform from spatial to frequency domain [37],[38];when transform is skipped,the prediction error is coded in the same manner as transform coefficient coding(i.e., the spatial error is coded as transform coefficients).Syntax elements of the transform unit account for a signif-icant portion of the bin workload as shown in Table IV.At the same time,the transform coefficients also account for a significant portion of the total bits of a compressed video,and as a result the compression of transform coefficients signifi-cantly impacts the overall coding efficiency.Thus,transform coefficient coding with CABAC must be carefully designed in order to balance coding efficiency and throughput demands. Accordingly,as part of the HEVC standardization process, a core experiment on coefficient scanning and coding was established to investigate tools related to transform coefficient coding[39].It is also important to note that HEVC supports more transform sizes than H.264/A VC;H.264/A VC uses4×4and 8×8transforms,where as HEVC uses4×4,8×8,16×16, and32×32transforms.While these larger transforms provide significant coding gains,they also have implications in terms of memory storage as this represents an increase of4×to 16×in the number of coefficients that need to be stored per transform unit(TU).In CABAC,the position of the coefficients is transmitted in the form of a significance map.Specifically,the significance map indicates the location of the nonzero coefficients.The coefficient level information is then only transmitted for the coefficients with values greater than one,while the coefficient sign is transmitted for all nonzero coefficients.This section describes how transform coefficient coding evolved from H.264/A VC to thefirst test model of HEVC (HM-1.0)to the Draft International Standard of HEVC(HM-8.0),and discusses the reasons behind design choices that were made.Many of the throughput improvement techniques were applied,and new tools for improved coding efficiency were simplified.As a reference for the beginning and end points of the development,Figs.3and4show examples of transform coefficient coding in H.264/A VC and HEVC(HM-8.0),respectively.A.Significance MapIn H.264/A VC,the significance map is signaled by transmit-ting a significant−coeff−flag(SCF)for each position to indi-cate whether the coefficient is nonzero.The positions are pro-cessed in an order based on a zig–zag scan.After eachnonzero Fig.3.Example of transform coefficient coding for a4×4TU in H.264/AVC.Fig.4.Example of transform coefficient coding for a4×4TU in HEVC (HM-8.0).SCF,an additionalflag called last−significant−coeff−flag (LSCF)is immediately sent to indicate whether it is the last nonzero SCF;this prevents unnecessary SCF from being signaled.Different contexts are used depending on the position within the4×4and8×8transform unit(TU),and whether the bin represents an SCF or LSCF.Since SCF and LSCF are interleaved,the context selection of the current bin depends on the immediate preceding bin.The dependency of LSCF on SCF results in a strong bin to bin dependency for context selection for significance map in the H.264/A VC as illustrated in Fig.2.1)significant−coeff−flag(SCF):In HM-1.0,additional dependencies were introduced in the context selection of SCF for16×16and32×32TU to improve coding efficiency.The context selection for SCF in these larger TU depended on the number of nonzero neighbors to give coding gains between 1.4%to2.8%[42].Specifically,the context of SCF depended on up to ten neighbors as shown in Fig.5(a)[42],[43].To reduce context selection dependencies,and storage costs,[21]proposed using fewer neighbors and showed that it could be done with minimal cost to coding efficiency.For。



拖尾系数指值为+1/-1的系数,最大数目为3。
如果超过3个,那么只有最后三个被视为拖尾系数。
拖尾系数的数目被赋值到变量TrailingOnes。
非零系数包括所有的拖尾系数,其数目被赋值到变量TotalCoeffs)。
2. 计算nC(numberCurrent,当前块值)。
nC值由左边块的非零系数nA和上面块非零系数nB来确定,计算公式为:nC=round((nA+nB)/2);若nA存在nB不存在,则nC=nA;若nA不存在而nB存在,则nC=nB;若nA和nB都不存在,则nC=0。
nC值用于选择VLC编码表,如下图所示。
这里体现了上下文相关(contextadaptive)的特性,例如当nC值较小即周围块的非零系数较少时,就会选择比较短的码,从而实现了数据压缩。
3. 查表获得coff_token的编码。
根据之前编码和计算过程所得的变量TotalCoeffs、TrailingOnes和nC值可以查H.264标准附录CAVLC码表,即可得出coeff_token编码序列。
4. 编码每个拖尾系数的符号,按zig-zag的逆序进行编码。
每个符号用1个bit位来表示,0表示―+‖,1表示―—‖。
当拖尾系数超过三个时只有最后三个被认定为拖尾系数,引词编码顺序为从后向前编码。
5. 编码除拖尾系数之外非零系数的level(Levels)。
每个非零系数的level包括sign和magnitude,扫描顺序是逆zig-zag序。
level的编码由前缀(level_prefix)和后缀(level_suffix)组成。
前缀的长度在0到6之间,后缀的长度则可通过下面的步骤来确定:将后缀初始化为0。
(若非零系数的总数超过10且拖尾系数不到3,则初始化为1)。
编码频率最高(即按扫描序最后)的除拖尾系数之外的非零系数。
若这个系数的magnitude超过某个门槛值(threshold),则增加后缀的长度。
下表是门槛值的列表:6. 编码最后一个非零系数之前0的个数(totalZeos)。

上下文建模为基本的CABAC 编码过程,一种regular coding mode 另一种为 bypass coding mode.只有regular coding mode 应用了上下文模型,而直通模式用于加速编码流程,当概率近似为50%的时候。
这部分主要说明regular coding mode的进程。
这里,先说理论,再讲流程。
理论:1,CABAC 算术编码基础算术编码的复杂度主要体现在概率的估计和更新,CABAC建立了一个基于查表的概率模型,将0~0.5 划分为64个概率量化值,这些概率对应于LPS字符,而MPS的概率为(1-Plps),概率的估计值被限制在查表内,概率的刷新也是依据于查表。
如果当前出现的字符是MPS,则Plps 变小。
划分子区间的乘法运算 R=R x Px对于这里的乘法运算,CABAC首先建立了一个二维表格,存储预先计算好的乘法结果,表格的入口参数一个来自Px( 对应于theta,概率量化值),另一个来自R(R的量化为:p=(R>>6)&3 ),流程图:图中,灰色部分是概率的刷新部分,表TABRangeLPS存储预先计算好的乘法结果,表TransIDxLPS是与对应的概率表。
有三个值是比较特殊的,:theata=0 时,LPS的概率已达到了最大值0.5,如果下一个出现的是LPS,则此时LPS和MPS的字符交换位置.Theta=63对应着LPS的最小概率值,但它并没有纳入CABAC的概率估计和更新的范围,这个值被用做特殊场合,传递特殊信息,比如,当解码器检测到当前区间的划分依据是这个值时,认为表示当前流的结束.Theta=62 ,这是表中的最小值,它对应的刷新值是它自身,当MPS连续出现,LPS 的概率持续减小,到62保持不变。
2 CABAC 上下文模型CABAC将片作为算术编码的生命周期,h.264将一个片内可能出现的数据划分为399个上下文模型,每个模型均有自己的CtxIdx(上下文序号),每个不同的字符依据对应的上下文模型,来索引自身的概率查找表。
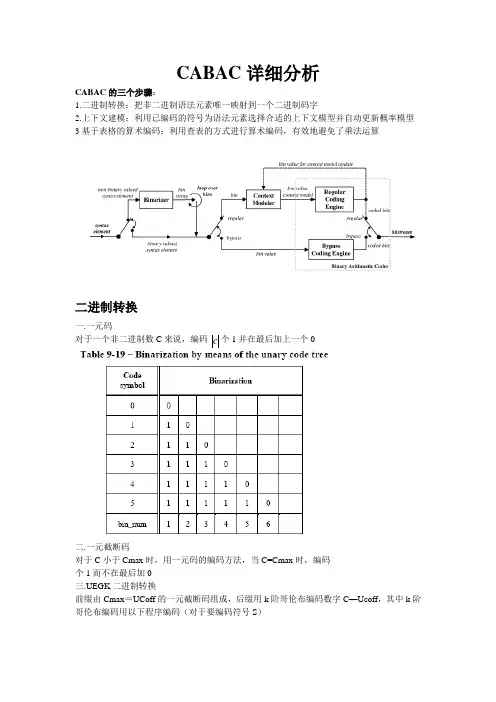
CABAC详细分析CABAC的三个步骤:1.二进制转换:把非二进制语法元素唯一映射到一个二进制码字2.上下文建模:利用已编码的符号为语法元素选择合适的上下文模型并自动更新概率模型3基于表格的算术编码:利用查表的方式进行算术编码,有效地避免了乘法运算二进制转换一.一元码对于一个非二进制数C来说,编码个1并在最后加上一个c二.一元截断码对于C小于Cmax时,用一元码的编码方法,当C=Cmax时,编码个1而不在最后加0三.UEGK二进制转换前缀由Cmax=UCoff的一元截断码组成,后缀用k阶哥伦布编码数字C—Ucoff,其中k阶哥伦布编码用以下程序编码(对于要编码符号S)四.固定长度二进制转换对于字母表【0,1,2,…,Cmax】,编码的二进制长度其中,二进制1对应其中重要性最低的符号,随着重要性的增加,二进制也会跟着增加五.对于宏块与子宏块类型的具体二进制化对应当adaptive_block_size_transform_flag==0时(非ABT变换,以下都针对非ABT变换),参看表格9-20,9-21,9-22:关于表格的说明:对应在SI帧内的宏块类型二进制转换按以下方法:前缀构成:当类型为mb_type_Sintra_4*4没有后缀,否则由表9-20给出对于在P和SP图像的帧内预测宏块,mb_type=7~30的前缀由表9-21给出,后缀用表9-20 对于在B图像中的帧内预测宏块,mb_type=23~47的前缀由表9-21给出,后缀用表9-20以上都是对非ABT变换来说的,对于ABT变换,要参考其他二进制方案表格,此处略去。
各种不同的语法元素,都是用到前面的4种二进制方案或者某两种二进制方案的串接,下面举例对变换系数的二进制方案进行说明:首先该过程分为3个步骤:1.如果coded_block_flag=0,说明没有重要系数(非0系数),不需要对宏块的信息进行编码,否则进行第二步2.在扫描的过程中,对于每个扫描位置i,如果i位置的系数是0,那么significant_coeff_flag[i]=0,否则significant_coeff_flag[i]=1,当significant_coeff_flag[i]=1时,继续编码last_ significant_coeff_flag[i],如果该系数不是最后一个非0系数,last_ significant_coeff_flag[i]=0,否则=1,当等于1时不需要再对宏块剩余的0系数进行编码3.对应那些significant_coeff_flag[i]=1的系数,要编码coeff_absolute_value_minus_1和coeff_sign,对于前者,采用UEG0编码(UCoff=14),对于后者直接采用旁路编码器(将在后文说到)上下文定义与分配首先,每个语法元素对应一个或者多个上下文指示器context_id,经过二进制转换后的语法元素可能有不止一位的二进制值,以mb_type_I(I帧图像内的宏块类型)为例,对应的context_id为ctx_mb_type_I,该语法元素二进制化后有6位二进制值,分别对应ctx_mb_type_I[k],1<=k<=6即max_idx_ctx_id=6,而每个context_id 对应一定范围内的上下文变量context label,可参看下表:具体每个CTX_ID[K]对应哪几个LABEL可进一步参考下表:上下文模板具体某一位context_id[k]可能对应几个不同的context label,那么究竟具体对应哪个就由上下文模板来决定,上下文模板将在下面进行说明;一.利用两个相邻符号的上下文模板如图所示,正要编码的符号S是在当前宏块块C中,A,B是C的相邻宏块通过关系式:ctx_var_spat=cond_term(A,B) (9-1)计算出符号S的上下文增量X,通过用OFFSET+X得出对应的context label的值。


*******************实践教学*******************兰州理工大学计算机与通信学院2012年春季学期计算机通信与网络课程设计题目:差错控制编码的编译码设计与仿真专业班级:09级通信一班姓名:李杰学号:09250106指导教师:彭铎成绩:摘要通信系统必须具备发现及检测差错的能力,并采取措施纠正,使差错控制在所能允许的尽可能小的范围内,这就是差错控制过程,也是数据链路层的主要功能之一。
本课程设计编辑了巴克码的编码和译码的程序,并实现了它的编译码过程;该程序可以对输入的5位的信息码进行巴克码编码,对于接收到的5位码字可以进行译码,从而判定是否是巴克码,整个过程是用MATLAB语言实现的。
关键词:编码;译码;MATLAB;巴克码目录前言 (1)第1章基本原理 (2)1.1 设计目的及意义 (2)1.2 巴克码与帧同步 (2)1.3 巴克码的产生和识别 (5)第2章 MATLAB软件与介绍 (8)2.1 MATLAB软件的特点 (8)2.2 现有工业控制系统 (10)2.3 MATLAB应用的工业控制系统中去的应用前景 (10)第3章仿真过程及结果分析 (11)3.1 程序流程图 (11)3.2 仿真程序 (13)3.3 程序仿真图 (15)参考文献 (20)总结 (21)致谢.................................................................................................................... 错误!未定义书签。
前言在通信系统中,同步技术起着相当重要的作用。
通信系统能否有效地、可靠地工作,很大程度上依赖于有无良好的同步系统。
通信系统中的同步可分为载波同步、位同步、帧同步等几大类。
当采用同步解调或相干检测时,接收端需要提供一个与发射端调制载波同频同相的相干载波,获得此相干载波的过程称为载波提取,或称为载波同步。

基于上下文的二进制算术编码基于上下文的自适应二进制算术编码(CABAC)是一种体现了新思想、具备新特点的新型二进制算术编码方法。
它的主要面对视频流的相关统计特性,其特点在于采用了高效的算术编码思想,充分考虑视频流的数据特点,大大提高了编码效率,针对视频数据流处理的H.264/AVC即采用了这种新的二进制算术编码。
CABAC的基本编码步骤可分为三步:1、二进制化;2、上下文建模;3、二进制算术编码。
第一步主要是将非二进制的各语法元素值转换成二进制的比特序列,如果语法元素本身是二进制的,则该步骤可省略;第二步主要是为已二进制化的语法元素的比特序列的每一位提供概率模型,进行概率预测;第三步则进行二进制算术编码,在CABAC中,有两种编码模式,一种叫做“regular coding mode”,另一种叫做“by pass coding mode”,其中“regular coding mode”采用了上下文建模,而“by pass coding mode”为了加快编码速度不采用上下文建模,整个编码过程如下图所示。
图3.4CABAC编码流程图CABAC基本步骤简述:首先是二进制化:为了降低算术编码的复杂度,提高编码速度,CABAC采用了二进制的算术编码,而非其它多进制的算术编码,为此需要事先将每一语法元素转换成独一无二的二进制序列,在H.264中称BIT STRING,同时为了便于后面的算术编码,尽可能降低编码复杂度,应该尽可能减小二进制序列的大小,CABAC采用了4 种基本二进制转换方式:Unary Binarization,Truncated unary Binarization,kth order Exp-Golomb Binarization和Fixed-length Binarization,相应的有4种二进制码Unary code,Truncated unary code,kth order Exp-Golomb code和Fixed-length code。
基于熵编码CABAC的信源信道联合解码器
王粤;解蓉
【期刊名称】《上海交通大学学报》
【年(卷),期】2013(47)7
【摘要】H.264的熵编码都采用基于上下文自适应二进制算术编码(CABAC),能达到较高的压缩性能,但对信道误码非常敏感.文中提出了一种基于CABAC的算数码变长码联合解码算法,联合信源信道算数码解码之后的信息作为变长码的输入信息,再通过变长码格状图搜索获得最佳的符号序列.同时,在算数码解码部分可以利用变长码的码字结构信息来删除无效搜索路径,提高解码性能.仿真实验表明,该联合迭代解码算法明显优于传统的分离解码器.
【总页数】6页(P1143-1148)
【关键词】联合信源信道解码;上下文自适应二进制算术编码;变长码;高斯白噪声信道
【作者】王粤;解蓉
【作者单位】浙江工商大学信息与电子工程学院;上海交通大学电子信息与电气工程学院
【正文语种】中文
【中图分类】TN911
【相关文献】
1.基于H.264的CABAC熵编码器实现研究 [J], 侯超
2.利用残留冗余量的联合信源信道解码在EVRC语音解码器中的应用 [J], 阿哈麦德;尤肖虎;高西奇
3.基于Markov信源和LDPC编码的信源信道联合译码算法 [J], 梅中辉;李晓飞
4.基于HMM信源估计和LDPC的联合信源信道译码 [J], 王兰勋;王贵贵;尹超;田晓燕
5.二元对称信道上均匀无记忆信源的信源-信道联合编码的研究 [J], 谭学治;高伟华;沙学军
因版权原因,仅展示原文概要,查看原文内容请购买。
CABAC 详细分析CABAC 的三个步骤:1.二进制转换:把非二进制语法元素唯一映射到一个二进制码字2.上下文建模:利用已编码的符号为语法元素选择合适的上下文模型并自动更新概率模型 3基于表格的算术编码:利用查表的方式进行算术编码,有效地避免了乘法运算二进制转换一.一元码对于一个非二进制数C 来说,编码 个1并在最后加上一个0二.一元截断码对于C 小于Cmax 时,用一元码的编码方法,当C=Cmax 时,编码 个1而不在最后加0 三.UEGK 二进制转换前缀由Cmax =UCoff 的一元截断码组成,后缀用k 阶哥伦布编码数字C —Ucoff ,其中k 阶哥伦布编码用以下程序编码(对于要编码符号S )c四.固定长度二进制转换对于字母表【0,1,2,…,Cmax】,编码的二进制长度其中,二进制1对应其中重要性最低的符号,随着重要性的增加,二进制也会跟着增加五.对于宏块与子宏块类型的具体二进制化对应当adaptive_block_size_transform_flag==0时(非ABT变换,以下都针对非ABT变换),参看表格9-20,9-21,9-22:关于表格的说明:对应在SI帧内的宏块类型二进制转换按以下方法:前缀构成:当类型为mb_type_Sintra_4*4没有后缀,否则由表9-20给出对于在P和SP图像的帧内预测宏块,mb_type=7~30的前缀由表9-21给出,后缀用表9-20 对于在B图像中的帧内预测宏块,mb_type=23~47的前缀由表9-21给出,后缀用表9-20以上都是对非ABT变换来说的,对于ABT变换,要参考其他二进制方案表格,此处略去。
各种不同的语法元素,都是用到前面的4种二进制方案或者某两种二进制方案的串接,下面举例对变换系数的二进制方案进行说明:首先该过程分为3个步骤:1.如果coded_block_flag=0,说明没有重要系数(非0系数),不需要对宏块的信息进行编码,否则进行第二步2.在扫描的过程中,对于每个扫描位置i,如果i位置的系数是0,那么significant_coeff_flag[i]=0,否则significant_coeff_flag[i]=1,当significant_coeff_flag[i]=1时,继续编码last_ significant_coeff_flag[i],如果该系数不是最后一个非0系数,last_ significant_coeff_flag[i]=0,否则=1,当等于1时不需要再对宏块剩余的0系数进行编码3.对应那些significant_coeff_flag[i]=1的系数,要编码coeff_absolute_value_minus_1和coeff_sign,对于前者,采用UEG0编码(UCoff=14),对于后者直接采用旁路编码器(将在后文说到)上下文定义与分配首先,每个语法元素对应一个或者多个上下文指示器context_id,经过二进制转换后的语法元素可能有不止一位的二进制值,以mb_type_I(I帧图像内的宏块类型)为例,对应的context_id为ctx_mb_type_I,该语法元素二进制化后有6位二进制值,分别对应ctx_mb_type_I[k],1<=k<=6即max_idx_ctx_id=6,而每个context_id 对应一定范围内的上下文变量context label,可参看下表:具体每个CTX_ID[K]对应哪几个LABEL可进一步参考下表:上下文模板具体某一位context_id[k]可能对应几个不同的context label,那么究竟具体对应哪个就由上下文模板来决定,上下文模板将在下面进行说明;一.利用两个相邻符号的上下文模板如图所示,正要编码的符号S是在当前宏块块C中,A,B是C的相邻宏块通过关系式:ctx_var_spat=cond_term(A,B) (9-1)计算出符号S的上下文增量X,通过用OFFSET+X得出对应的context label的值。
其中cond_term()表示的是一种函数关系,对于9-1式,有以下3种具体情况:此外,ctx_coded_block依赖的是表9-28中的6种块类型,对于上下文变量ctx_abs_mvd_h[1]和ctx_abs_mvd_v[1],按以下式子编码:二、利用先前bin值的上下文模板关系式:对应的表格:三.关于变换系数信息的上下文定义有关变换系数的上下文信息都由context_category决定,参看context_category的定义表:ctx_sig_coeff和ctx_last_coeff对应的是significant_coeff_flag和last_significant_coeff_flag,有以下关系式:其中scanning_pos指示的位置与zig-zag扫描相关,对于ctx_abs_level包含2个变量ctx_abs_level[1]和ctx_abs_level[2],有以下关系式:其中num_decod_abs_lev_eql指的是已编码的绝对值等于1的系数,Num_decod_abs_lev_gtl指的是已编码的绝对值大于1的系数(两者都在当前宏块中计算)上下文模型的初始化前文解决了如何给语法元素的每一位分配context label的问题,现在来解决一下究竟每一个context label对应什么样的状态。
首先是状态的初始化问题,状态包含一个代表状态的数字和MPS(最大概率符号),实质上上下文模型状态的初始化是由该帧图像的量化参数QP决定的,对于每一个context label都分配一对数组{m,n},状态的初始化按以下的三步进行:1.计算pre_state=((m*(QP-12))>>4)+n;2.对于P和B帧图像限制pre_state在[0,101]内,对于I帧图像,限制pre_state在[27,74]内,即pre_state= min(101,max(0, pre_state)) (对P和B帧),pre_state=min (74,max(27, pre_state)) (对I帧)3.将pre_state按以下规则映射到数组{state,MPS},规则:如果pre_state<=50, {state=50- pre_state,MPS=0},否则{state= pre_state-51,MPS=1}对于不同context label的{m,n}分配,参看以下表格:基于表格的算术编码算术编码是基于区间细分的,CABAC的算术编码有以下3个明显性质:1.概率的估计是对小概率符号LPS的概率而言的,是通过基于表格中64个不同状态之间的转换而实现的。
2.区间长度R通过一组预先量化的值{Q1,Q2,Q3,Q4}进行量化以计算新的间隔区间。
通过储存一个64*4的表格(Qi*Pk)来避免R*Pk的乘法运算。
3.一个独立的编码路径(旁路编码)用于对近似均匀分布(Plps=0.5)的语法元素一. 概率估计概率估计在H.264/A VC 中的免除乘法的二进制编码基本思想依赖于一个假设:每一个上下文模型估计的概率可以用一个有效的有限的特征值集合来表征。
对于CABAC ,对LPS 有64个特征概率值[0.01875,0.5]p σ∈。
11/6301 (63)0.01875()0.50.5p p for all and p σσασα-====伸缩因子0.95α≈,N =64一方面想要获得快速的自适应0;α→N 要小;另一方面,如果想获得更加稳定更加精确的估计,则1;α→需要更大的N 。
注意在MQ 编码中,在CABAC 方法中,不需要对LPS 的概率值{|063}p σσ≤≤进行表格化。
在算术编码中,每一个概率p σ仅仅用其相关的索引σ作为地址。
这样设计的结果导致,CABAC 中的每一个上下文模型可以有两个参数完全决定:LPS 概率当前估计值(063σ≤≤)和MPS 的值ϖ(0或者1)。
这样,在CABAC 的概率估计中有128个不同的状态,每一个状态用一个7位整型数来表达。
实际上,有一个状态的索引(63σ=)与一个自治的非自适应的状态相关,它带有一个固定值的MPS ,它仅仅在算术码字终止前用于编码二进制决定位(binary decisions ).因此只有126个有效概率状态。
1)概率状态的更新对于一个给定概率状态,概率的更新取决于状态索引和已经编码的符号值(MPS or LPS )。
更新过程导致一个新的概率状态,潜在的LPS 概率修正,如果有必要需要修改MPS 的值。
62max(,),,M PS (1),M PS LPS old new old p p if a M PS occurs p p if a LPS occurs ααα⋅⎧=⎨⋅+-⎩保持不变,与切换表格9-35显示的是编码MPS 或LPS 后的状态转移规则。
对于I 帧图像来说把状态控制在前24个内是有利的,因此,表9-35包含了独立的一列用作I 帧图像。
在编码一个MPS 或者LPS 后,概率估计自动从一个状态转移到另外一个状态进行自动更新,对于I 帧图像来说,有:If (decision==MPS)State<-Next_State_MPS_INTRA(State)ElseState<-Next_State_LPS (State)对于其他帧的图像来说,有:If (decision==MPS)State<-Next_State_MPS (State)ElseState<-Next_State_LPS (State)此外,当状态在0的时候(就是Plps=0.5), 如果编码得到的是一个LPS,那么LPS的概率就超过了原来MPS的概率,因此,LPS与MPS的值要进行交换。
二.算术编码器的总体描述算术编码器的情形是由一个指向编码子区间的V值和一个表示该区间长度的R值描述的。
图9-3显示了编码的流程:对于编码器的初始化(InitDecoder),将在后文中谈到,其中V和R将被初始化。
对于每一个编码决定的S(具体说编1或者0),有两个步骤。
一是读取上下文模型,上文已经解决了该问题;二是根据上下文决定S的值,这将在后面给出。
A.算术编码器的初始化初始化如图9-4所示,V是通过GetByte函数获得2个压缩数据的字节,R的初始化设置为0x8000。
关于GetByte函数:图9-7显示了压缩数据是如何输入的;首先,一个新的压缩数据的字节从比特串C中读取,然后指向当前比特串位置的CL增加1,比特计算器BG被设置成7B.编码决定图9-5显示的是一个编码决定,即决定具体编码的符号是MPS还是LPS。