SAS简介,Univariate,Means,Freq过程
- 格式:ppt
- 大小:171.50 KB
- 文档页数:29

几种描述性统计分分析的SAS过程描述性统计是统计学中的一种方法,用于总结和描述数据集的主要特征。
它有助于了解数据的整体分布、偏差和离散性等。
SAS(统计分析系统)是一种流行的统计软件,具有丰富的分析功能。
以下是几种常用的SAS过程,用于执行描述性统计分析。
1.PROCMEANS:PROCMEANS是一种计算统计指标的SAS过程,包括均值、总和、最小值、最大值、标准差等。
可以使用该过程对数值变量进行描述性统计,并在输出中显示这些统计指标。
可以通过指定多个变量和分组变量来计算针对不同子组的统计指标。
该过程还可以生成频数和百分比。
2.PROCFREQ:PROCFREQ是一种用于计算分类变量频数和百分比的SAS过程。
它可以计算每个类别的频数,并使用该信息生成频数表。
该过程还可以计算两个或更多分类变量之间的交叉频数表,并计算出每个类别的百分比。
3.PROCUNIVARIATE:PROCUNIVARIATE是一种用于执行单变量分析的SAS过程。
它可以计算变量的均值、标准差、峰度、偏度等统计指标。
该过程可以绘制直方图、箱线图、正态检验图和PP图等,以帮助理解数据的分布特征。
还可以执行分位数分析、离散度分析和异常值识别等。
4.PROCCORR:PROCCORR是一种用于计算变量之间相关性的SAS过程。
它可以计算变量间的皮尔逊相关系数,并使用协方差矩阵和相关系数矩阵来描述变量之间的线性关系。
该过程还可以绘制散点图矩阵和相关系数图,以直观地显示变量之间的关系。
5.PROCGLM:PROCGLM是一种用于执行多因素方差分析的SAS过程。
它可以根据自变量的水平和交互作用来分解因变量的方差,并进行显著性检验。
该过程可以计算组间差异的F值和p值,并生成方差分析表。
PROCGLM还支持使用协变量进行调整的方差分析,以控制对方差的影响。
以上是几种常用的SAS过程,用于执行描述性统计分析。
每个过程都有各自的功能和输出,可以根据数据和分析需求选择合适的过程。

SAS中的描述性统计过程(2012-08-01 18:07:01)▼分类:数据分析挖掘标签:杂谈SAS中的描述性统计过程描述性统计指标的计算可以用四个不同的过程来实现,它们分别是means过程、summary过程、univariate过程以及tabulate过程。
它们在功能范围和具体的操作方法上存在一定的差别,下面我们大概了解一下它们的异同点。
相同点:他们均可计算出均数、标准差、方差、标准误、总和、加权值的总和、最大值、最小值、全距、校正的和未校正的离差平方和、变异系数、样本分布位置的t检验统计量、遗漏数据和有效数据个数等,均可应用by语句将样本分割为若干个更小的样本,以便分别进行分析。
不同点:(1)means过程、summary过程、univariate过程可以计算样本的偏度(skewness)和峰度(kurtosis),而tabulate过程不计算这些统计量;(2)univariate过程可以计算出样本的众数(mode),其它三个过程不计算众数;(3)summary过程执行后不会自动给出分析的结果,须引用output语句和print过程来显示分析结果,而其它三个过程则会自动显示分析的结果;(4)univariate过程具有统计制图的功能,其它三个过程则没有;(5)tabulate过程不产生输出资料文件(存储各种输出数据的文件),其它三个均产生输出资料文件。
统计制图的过程均可以实现对样本分布特征的图形表示,一般情况下可以使用的有chart过程、plot过程、gchart过程和gplot过程。
大家有没有发现前两个和后两个只有一个字母‘g’(代表graph)的差别,其实它们之间(只差一个字母g的过程之间)的统计描述功能是相同的,区别仅在于绘制出的图形的复杂和美观程度。
chart过程和plot过程绘制的图形类似于我们用文本字符堆积起来的图形,只能概括地反映出资料分布的大体形状,实际上这两个过程绘制的图形并不能称之为图形,因为他根本就没有涉及一般意义上图形的任何一种元素(如颜色、分辨率等)。

20个SAS过程步
1、PROC
MEANS--数据描述:计算均数、标准差、最大值、最小值、变量有效数据个数、变量缺失个数
2、PROC UNIV ARIATE--正态性检验
3、PROC TTEST--两独立样本检验
4、PROC NPAR1WAR--秩和检验
5、PROC ANOV A--方差分析
6、PROC CORR--相关性分析
7、PROC REG--回归分析
8、PROC FREQ--计数资料描述;卡方检验;诊断试验
9、PROC LOGISTIC--结局是二分类的Logisitc回归分析
10、PROC PHREG--生存分析
11、PROC POWER--样本量及把握度计算
12、PROC PRINT--显示数据集
13、PROC GLM--回归分析或协方差分析
14、PROC RANK--给某变量排次或按序分组
15、PROC SORT--按某变量排序
16、PROC SURVEYSELECT--概率抽样
17、PORC IMPORT--导入数据集
18、PROC EXPORT--导出数据集
19、PROC CONTENTS--产生一个数据集的头文件,包含了多种该数据集的信息
20、PROC TABULATE--输出报表。

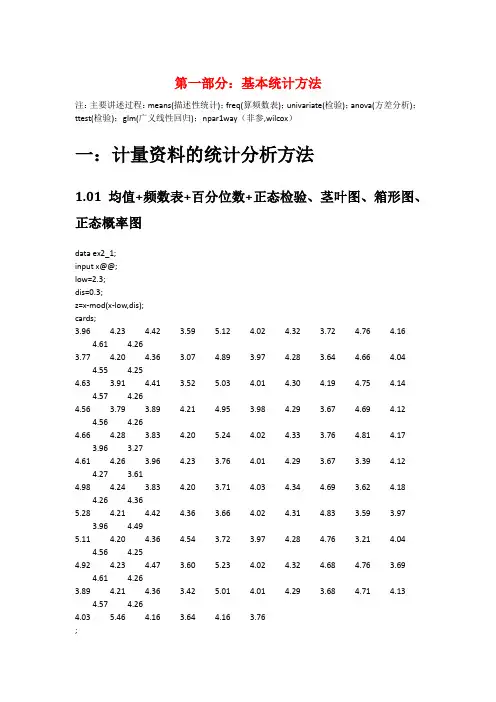
第一部分:基本统计方法注:主要讲述过程:means(描述性统计);freq(算频数表);univariate(检验);anova(方差分析);ttest(检验);glm(广义线性回归);npar1way(非参,wilcox)一:计量资料的统计分析方法1.01均值+频数表+百分位数+正态检验、茎叶图、箱形图、正态概率图data ex2_1;input x@@;low=2.3;dis=0.3;z=x-mod(x-low,dis);cards;3.964.23 4.42 3.595.12 4.02 4.32 3.72 4.76 4.164.61 4.263.774.20 4.36 3.07 4.89 3.97 4.28 3.64 4.66 4.044.55 4.254.63 3.91 4.41 3.525.03 4.01 4.30 4.19 4.75 4.144.57 4.264.56 3.79 3.89 4.21 4.95 3.98 4.29 3.67 4.69 4.124.56 4.264.66 4.28 3.83 4.205.24 4.02 4.33 3.76 4.81 4.173.96 3.274.61 4.26 3.96 4.23 3.76 4.01 4.29 3.67 3.39 4.124.27 3.614.98 4.24 3.83 4.20 3.71 4.03 4.34 4.69 3.62 4.184.26 4.365.28 4.21 4.42 4.36 3.66 4.02 4.31 4.83 3.59 3.973.964.495.11 4.20 4.36 4.54 3.72 3.97 4.28 4.76 3.21 4.044.56 4.254.92 4.23 4.47 3.605.23 4.02 4.32 4.68 4.76 3.694.61 4.263.894.21 4.36 3.425.01 4.01 4.29 3.68 4.71 4.134.57 4.264.035.46 4.16 3.64 4.16 3.76;/*freq语句,算频数表*/proc freq;tables z;run;proc means data=ex2_1n mean std stderr clm;var x;run;data ex2_1;input x f@@;cards;3.07 23.27 33.47 93.67 143.87 224.07 304.27 214.47 154.67 104.87 65.07 45.27 2;run;proc means;freq f;var x;run;/*把freq f改成weight f就是把f当权重或频数来算,f则在0,1之间*//*计算x的95%的置信区间*/proc univariate data=ex2_1;var x;output out=pctpctlpre=ppctlpts=2.5 97.5;run;proc print data=pct;run;/*正态检验、茎叶图、箱形图、正态概率图*/proc univariate data=ex2_1normalplot;var x;run;/*Extreme Observation显示的值是最小的5个极值和最大的5个极值*/1.02几何均值data ex2_5;input x f@@;y=log10(x);cards;10 420 340 1080 10160 11320 15640 141280 2;proc means noprint;/*调用means过程,不显示结果*/var y;freq f;output out=b/*结果输出到数据集b中*/mean=logmean;/*把数据集b中均数的变量名mean改为logmean*/run;data c;/*新建数据集c*/set b;/*调用数据集b*/g=10**logmean;/*计算变量logmean的反对数,该值就是x的几何均数,将该值赋值给变量g*/ proc print data=c;var g;run;/*这个是计算平通平均数的值*/proc means data=ex2_5;var x;freq f;run;1.03已知均值和方差求置信区间-单样本+单样本与总体/*单样本*/data ex3_2;n=10;mean=166.95;std=3.64;t=tinv(0.975,n-1);pts=t*std/sqrt(n);lclm=mean-pts;uclm=mean+pts;proc print;var lclm uclm;run;/*单样本与总体均值*/data ex3_5;n=36;/*样本量*/s_m=130.83;/*样本均值*/std=25.74;/*样本标准差*/p_m=140;/*总体均值*/df=n-1;/*自由度*/t=(s_m-p_m)/(std/sqrt(n));p=(1-probt(abs(t),df))*2;/*根据t值计算p值*/run;proc print;var t p;run;1.06双样本均值相等检验+两组分开+两组一起算+两组样本量不同/*双样本分开算*/data ex3_4;n1=29;n2=32;m1=20.10;m2=16.89;s1=7.02;s2=8.46;ss1=s1**2*(n1-1);ss2=s2**2*(n2-1);sc2=(ss1+ss2)/(n1+n2-2);se=sqrt(sc2*(1/n1+1/n2));t=tinv(0.975,n1+n2-2);lclm=(m1-m2)-t*se;uclm=(m1-m2)+t*se;proc print;var t se lclm uclm;run;/*双样本相减后再算*//*用MEANS作配对资料两个样本均数比较的t检验*/data ex3_6;input x1 x2 @@;d=x1-x2;cards;0.840 0.5800.591 0.5090.674 0.5000.632 0.3160.687 0.3370.978 0.5170.750 0.4540.730 0.5121.200 0.9970.870 0.506;proc means t prt;var d;run;/*用UNIVARIATE过程作配对资料两样本均数比较的t检验*/ proc univariate data=ex3_6;var d;run;/*双样本两组样本量不同*/data ex3_7;input x@@;if _n_<21 then c=1;/*当观测数小于21时,变量c的值为1,表示试验组*/else c=2;/*其余变量c的值为2,表示对照组*/cards;-0.70 -5.60 2.00 2.80 0.70 3.50 4.00 5.80 7.10 -0.502.50 -1.60 1.703.00 0.404.50 4.60 2.50 6.00 -1.403.70 6.50 5.00 5.20 0.80 0.20 0.60 3.40 6.60 -1.106.00 3.80 2.00 1.60 2.00 2.20 1.20 3.10 1.70 -2.00;proc ttest;/*调用ttest过程*/var x;/*定义分析变量为x*/class c;/*定义分组变量为c*/run;1.08-1.13anova方差分析过程+一维分组+二维分组+三维分组/*只有一组分组因素*/data ex4_2;input x c @@;cards;3.53 1 2.42 2 2.86 3 0.89 44.59 1 3.36 2 2.28 3 1.06 44.34 1 4.32 2 2.39 3 1.08 42.66 1 2.34 2 2.28 3 1.27 43.59 1 2.68 2 2.48 3 1.63 43.13 1 2.95 2 2.28 3 1.89 43.30 1 2.36 2 3.48 3 1.31 44.04 1 2.56 2 2.42 3 2.51 43.53 1 2.52 2 2.41 3 1.88 43.56 1 2.27 2 2.66 3 1.41 43.85 1 2.98 2 3.29 3 3.19 44.07 1 3.72 2 2.70 3 1.92 41.37 12.65 2 2.66 3 0.94 43.93 1 2.22 2 3.68 3 2.11 42.33 1 2.90 2 2.65 3 2.81 42.98 1 1.98 2 2.66 3 1.98 44.00 1 2.63 2 2.32 3 1.74 43.55 1 2.86 2 2.61 3 2.16 42.64 1 2.93 23.64 3 3.37 42.56 1 2.17 2 2.58 3 2.97 43.50 1 2.72 2 3.65 3 1.69 43.25 1 1.56 2 3.21 3 1.19 42.96 13.11 2 2.23 3 2.17 44.30 1 1.81 2 2.32 3 2.28 43.52 1 1.77 2 2.68 3 1.72 43.93 1 2.80 2 3.04 3 2.47 44.19 1 3.57 2 2.81 3 1.02 42.96 1 2.97 23.02 3 2.52 44.16 1 4.02 2 1.97 3 2.10 42.59 1 2.31 2 1.68 33.71 4;proc anova;/*调用anova过程*/class c;/*定义分组变量为c*/model x=c;/*定义模型,分析g对x的影响*/means c/dunnett;/*用LSD法对多组均数过行两两比较*/means c/hovtest;/*作方差齐性检验,默认levene法,p值大于0.05,则认为是g组方差相等*/run;quit;/*有两组分组因素*/data ex4_4;input x a b@@;cards;0.82 1 10.65 2 10.51 3 10.73 1 20.54 2 20.23 3 20.43 1 30.34 2 30.28 3 30.41 1 40.21 2 40.31 3 40.68 1 50.43 2 50.24 3 5;proc anova;class a b;/*定义分组变量a和b*/model x=a b;/*定义模型,分析a和b对x影响*/means a/snk;/*用SNK法对变量a的多组均数进行两两比较*/run;quit;1.15嵌套设计资料的方差分析glm过程一级因素+二组因素(glm过程要先class再model)/*嵌套设计资料的方差分析*/data ex11_6;input x a b @@;cards;82 1 184 1 191 1 288 1 285 1 383 1 365 2 461 2 462 2 559 2 556 2 660 2 671 3 767 3 775 3 878 3 885 3 989 3 9;proc glm;/*调用glm过程*/class a b;/*定义分组变量为a和b*/model x=a a(b);/*定义模型,以a为一组因素,b为二级因素*/run;quit;1.17重复测量资料的方差分析data ex12_2;input t1 t2 g@@;/*确定变量名称,t1和t2分别为两个时间点的分析变量,g为处理因素变量,b为区组变量*/cards;130 114 1124 110 1136 126 1128 116 1122 102 1118 100 1116 98 1138 122 1126 108 1124 106 1118 124 2132 122 2134 132 2114 96 2118 124 2128 118 2118 116 2132 122 2120 124 2134 128 2;proc glm;/*调用glm过程*/class g;/*定义分组变量g*/model t1 t2=g;/*定义模型,分析g对变量t1和t2的影响*/repeated time 2/*命名重复因子为time,有2个水平*/contrast(1)/*表示以第一时间点为对照点*//summary;/*考察不同时间点与对照时间点比较的结果*/run;quit;data ex12_3;input t0-t4 g@@;cards;120 108 112 120 117 1118 109 115 126 123 1119 112 119 124 118 1121 112 119 126 120 1127 121 127 133 126 1121 120 118 131 137 2122 121 119 129 133 2128 129 126 135 142 2117 115 111 123 131 2118 114 116 123 133 2131 119 118 135 129 3129 128 121 148 132 3123 123 120 143 136 3123 121 116 145 126 3125 124 118 142 130 3;proc glm;class g;model t0-t4=g;repeated time 5/*命名重复因子为time,有2个水平*/contrast(1);run;quit;二:计数资料的统计分析方法2.1四格表资料的卡方检验data ex7_1;input r c f@@;/*确定变量名称,r为行变量,c为列变量,f为频数变量*/ cards;1 1 991 2 52 1 752 2 21;proc freq;/*调用freq过程*/weight f;/*定义f为频数变量*/tables r*c/*作r*c的列联表*//chisq/*对列联表作卡方检验*/expected;/*输出每个格的理论频数*/run;2.5阳性事件发生的概率(二项分布)data ex6_1;do x=6 to 8;/*建立循环,变量x从6到8*/p1=probbnml(0.7,10,x);/*计算二项分布随机变量不大于x的概率*/p2=probbnml(0.7,10,x-1);/*计算二项分布随机变量不大于x-1的概率*/p=p1-p2;*/计算出现x的概率*/output;/*结果输出*/end;proc print;var x p;run;2.6正态分布法计算总体率的可信区间data ex6_3;n=100;x=55;p=x/n;sp=sqrt(p*(1-p)/n);u=probit(0.975);usp=u*sp;lclm=p-usp;uclm=p+usp;proc print;var n p sp lclm uclm;run;2.7样本率与总体率的比较(直接法——单侧检验)data ex6_4;d=probbnml(0.55,10,8);p=1-d;proc print;var p;run;2.8样本率与总体率的比较(直接法——双侧检验)data ex6_5;p01=probbnml(0.6,10,9);p02=probbnml(0.6,10,8);p0=p01-p02;/*计算出现9的概率*/do i=0to10;/*建立循环,变量i从0到10*/p11=probbnml(0.6,10,i);p12=probbnml(0.6,10,i-1);p1=p11-p12;/*计算出现i的概率*/if i=0then p1=p11; /*定义出现0的概率*/if p1<=p0 then output; /*如果出现i的概率小于出现9的概率,则保留在数据集中*/ end;proc means sum;var p1;run;2.9两个样本率比较的z检验data ex6_7;n1=120;n2=110;x1=36;x2=22;p1=x1/n1;p2=x2/n2;pc=(x1+x2)/(n1+n2);/*计算合并发生率*/sp=sqrt(pc*(1-pc)*(1/n1+1/n2));/*计算两个率相差的标准误差*/u=(p1-p2)/sp;/*计算u值*/p=(1-probnorm(abs(u)))*2;/*计算p值*/format u p 5.4;/*输出格式为小数点后保留4位*/proc print;var pc sp u p;run;2.10.Poisson分布的样本均数与总体均数比较(直接法)data ex6_12;n=120;/*确定样本例数*/pai=0.008; /*确定总体率*/lam=n*pai; /*计算总体均数lamda*/x=4; /*确定实际发生数*/p=1-poisson(lam,x-1);/*计算实际发生数所对应的概率*/proc print;var lam p;run;2.11 Poisson分布的样本均数与总体均数比较(正态近似法)data ex6_12;n=25000;/*样本量*/x=123; /*样本均数*/pi=0.003; /*确定总体率*/lam=n*pi; /*计算总体均数*/u=(x-lam)/sqrt(lam*(1-pi)); /*计算u值*/p=1-probnorm(abs(u)); /*计算u值所对应的p值*/proc print;var lam u p;run;2.14负二项分布的参数估计data ex6_16;input x f@@;cards;0 301 142 83 44 25 06 2;proc univariate;var x;freq f;output out=mv2var=v;run;data k;set mv2;k=mu**2/(v-mu);proc print;var mu k;run;三、非参数统计方法3.2单个样本中位数和总体中位数比较data ex8_2;input x1@@;median=45.30;/*假设中位数为45.30*/d=x1-median; /*计算x1和假设中位数的差值*/cards;44.21 45.30 46.39 49.47 51.05 53.1653.26 54.37 57.16 67.37 71.05 87.37;proc univariate; /*调用univariate过程度*/var d;run;proc means median; /*调用means过程计算x1实际的中位数*/var x1;run;3.3两个独立样本比较的Wilcoxon秩和检验(R对应函数wilcox.test())data ex8_3;input x c @@;/*确定变量名称,x、c分别为分析变量和分组变量(类别多于两类一样的写法)*/2.78 13.23 14.20 14.87 15.12 16.21 17.18 18.05 18.56 19.60 13.23 23.50 24.04 24.15 24.28 24.34 24.47 24.64 24.75 24.82 24.95 25.10 2;proc npar1way wilcoxon;/*调用npar1way过程,进行wilcoxon分析*/var x;/*定义分析变量为x*/class c;/*定义分组变量为c*/run;3.4等级资料的两样本比较data ex8_4;input c g f@@;/*确定变量名称,f为频数,c为分类,g为要分析的变量(分类多种类似)*/ cards;1 1 11 2 81 3 161 4 101 5 42 1 22 2 232 3 112 5 0;proc npar1way wilcoxon;/*调用npar1way过程,进行wilcoxon分析*/freq f;/*确定频数变量为f*/var g;/*定义分析变量g*/class c;/*定义分组变量c*/run;第二部分:多元统计分析方法注:主要讲述过程:reg(回归),corr(相关分析),nlin(对数曲线回归),logistic(逻辑回归),phreg(条件logistic回归分析+cox回归),life test(生存分析),discrim(判别分析),stepdisc(逐步回归),cluster(聚类),varclus(指标聚类),princomp(主成分分析),factor(因子分析),cancorr(典型相关分析)一:回归和相关分析1.1两个变量的直线回归分析data ex9_1;input x y;/*确定变量名称*/cards;13 3.5411 3.019 3.096 2.488 2.5610 3.3612 3.187 2.65;proc reg;/*调用reg过程*/model y=x;/*定义模型,以y为应变量,以x为自变量*//*在model语句后面加上选项,得到一些有用的统计量,常用的有:stb(输出标准化偏回归系数)、p(输出每个观测的实际值、预测值和残差)、cli(输出每个观测预测值均数的双侧95%置信区间)、clm(输出每个观测预测值的双侧95%置信范围)*//*例如:model y=x /stb p cli */plot y*x;/*画出散点图*/run;1.2两个变量的直线相关分析data ex9_5;input x y;cards;43 217.2274 316.1851 231.1158 220.9650 254.7065 293.8454 263.2857 271.7367 263.4669 276.5380 341.1548 261.0038 213.2085 315.1254 252.08;proc corr;/*若要求作spearman相关分析,则可以写成proc corr spearman */ var x y;run;/*得到一个相关系数矩阵*/1.4加权直线加回data ex9_9;input x y;w=1/(x*x); /*设置权重变量w*/cards;0.11 4.000.12 5.100.21 9.500.30 9.000.34 17.200.44 14.000.56 18.900.60 29.400.69 22.100.80 41.50;proc reg;weight w;/*定义权重变量w*/model y=x;/*定义模型,以y为因变量,以x为自变量*/run;1.5两个直线回归系数的比较data ex9_12;input x y c@@;cards;13 3.54 111 3.01 19 3.09 16 2.48 18 2.56 110 3.36 112 3.18 17 2.65 110 3.01 29 2.83 211 2.92 212 3.09 215 3.98 216 3.89 28 2.21 27 2.39 210 2.74 215 3.36 2;proc glm;class c;model y=x c x*c;/*定义模型,分析x、c以及x和c的交互作用对y的影响,即判断两总体直线回归系数是否相同*/run;proc glm;class c;model y=x c;/*上一步已排除协变量的影响,然后再分析两分析变量是否来自同一总体*/run;1.6两个变量的对数曲线回归data ex9_13;input x y;cards;0.005 34.110.050 57.990.500 94.495.000 128.5025.000 169.98;proc nlin;/*调用nlin过程*/parms a=0 b=0; /*定义初始值*/model y=a+b*log10(x); /*定义对数模型,以y为因变以量,x为自变量*/ run;1.7两个变量的指数曲线回归分析data ex9_14;input x y;cards;2 545 507 4510 3714 3519 2526 2031 1634 1838 1345 852 1153 860 465 6;proc nlin;parms a=4 b=0.03;/*定义初始值*/model y=exp(a+b*x);/*定义指数模型,以y为因变量,x为自变量*/run;1.8多元回归data ex15_1;input x1-x4 y@@;/*确定变量名称,x1,x2,x3,x4分别为自变量,y为应变量*/ cards;5.68 1.90 4.53 8.20 11.203.79 1.64 7.32 6.90 8.806.02 3.56 6.95 10.80 12.304.85 1.075.88 8.30 11.604.60 2.32 4.05 7.50 13.406.05 0.64 1.42 13.60 18.304.90 8.50 12.60 8.50 11.107.08 3.00 6.75 11.50 12.103.85 2.11 16.28 7.90 9.604.65 0.63 6.59 7.10 8.404.59 1.97 3.61 8.70 9.304.29 1.97 6.61 7.80 10.607.97 1.93 7.57 9.90 8.406.19 1.18 1.42 6.90 9.606.13 2.06 10.35 10.50 10.905.71 1.78 8.53 8.00 10.106.40 2.40 4.53 10.30 14.806.06 3.67 12.797.10 9.105.09 1.03 2.53 8.90 10.806.13 1.71 5.28 9.90 10.205.78 3.36 2.96 8.00 13.605.43 1.13 4.31 11.30 14.906.50 6.21 3.47 12.30 16.007.98 7.92 3.37 9.80 13.2011.54 10.89 1.20 10.50 20.005.84 0.92 8.616.40 13.303.84 1.20 6.45 9.60 10.40;proc reg;model y=x1-x4;/*也可以写成model y=x1 x2 x3 x4;*/run;1.9逐步回归data ex12_2;input x1-x4 y@@;cards;5.68 1.90 4.53 8.20 11.203.79 1.64 7.32 6.90 8.806.02 3.56 6.95 10.80 12.304.85 1.075.88 8.30 11.604.60 2.32 4.05 7.50 13.406.05 0.64 1.42 13.60 18.304.90 8.50 12.60 8.50 11.107.08 3.00 6.75 11.50 12.103.85 2.11 16.28 7.90 9.604.65 0.63 6.59 7.10 8.404.59 1.97 3.61 8.70 9.304.29 1.97 6.61 7.80 10.607.97 1.93 7.57 9.90 8.406.19 1.18 1.42 6.90 9.606.13 2.06 10.35 10.50 10.905.71 1.78 8.53 8.00 10.106.40 2.40 4.53 10.30 14.806.06 3.67 12.797.10 9.105.09 1.03 2.53 8.90 10.806.13 1.71 5.28 9.90 10.205.78 3.36 2.96 8.00 13.605.43 1.13 4.31 11.30 14.906.50 6.21 3.47 12.30 16.007.98 7.92 3.37 9.80 13.2011.54 10.89 1.20 10.50 20.005.84 0.92 8.616.40 13.303.84 1.20 6.45 9.60 10.40;proc reg;model y=x1-x4/selection=stepwise/*定义模型,以y因变量,x1-x4为变量进行多元回归分析*/ sle=0.10/*定义入先变量的界值*/sls=0.10;/*定义剔除变量的界值*/run;三:logistic回归3.1 两个变量logistic回归分析data ex16_1;input y x1 x2 f@@;/*确定变量名称,y为发病情况,x1为吸烟情况,x2为饮酒情况,f为发生频数*/cards;1 0 0 631 0 1 631 1 0 441 1 1 2650 0 0 1360 0 1 1070 1 0 570 1 1 151;proc logistic;/*调用logistic过程*/freq f;/*定义频数变量f*/model y=x1 x2;/*定义模型,以y为因变量,x1和x2为自变量*/run;3.2 1:M配对资料的条件logistic回归分析data ex16_3;input i y x1-x6 @@;/*确定变量名称,i为区组变量,y为病人情况,1为病例,0为对照,x1-x6为危险因素*/t=2-y;/*定义时间变量*/cards;1 1 3 5 1 1 1 01 0 1 1 1 3 3 01 0 1 1 1 3 3 02 1 13 1 1 3 02 0 1 1 13 2 02 0 1 2 13 2 03 1 14 1 3 2 03 0 1 5 1 3 2 03 0 14 1 3 2 04 1 1 4 1 2 1 14 0 2 1 1 3 2 05 1 2 4 2 3 2 0 5 0 1 2 1 3 3 05 0 2 3 1 3 2 06 1 1 3 1 3 2 1 6 0 1 2 1 3 2 06 0 1 3 2 3 3 07 1 2 1 1 3 2 1 7 0 1 1 1 3 3 07 0 1 1 1 3 3 08 1 1 2 3 2 2 0 8 0 1 5 1 3 2 08 0 1 2 1 3 1 09 1 3 4 3 3 2 0 9 0 1 1 1 3 3 09 0 1 4 1 3 1 010 1 1 4 1 3 3 1 10 0 1 4 1 3 3 010 0 1 2 1 3 1 011 1 3 4 1 3 2 0 11 0 3 4 1 3 1 011 0 1 5 1 3 1 012 1 1 4 3 3 3 0 12 0 1 5 1 3 2 012 0 1 5 1 3 3 013 1 1 4 1 3 2 0 13 0 1 1 1 3 1 013 0 1 1 1 3 2 014 1 1 3 1 3 2 1 14 0 1 1 1 3 1 014 0 1 2 1 3 3 015 1 1 4 1 3 2 0 15 0 1 5 1 3 3 015 0 1 5 1 3 3 016 1 1 4 2 3 1 0 16 0 2 1 1 3 3 016 0 1 1 3 3 2 017 1 2 3 1 3 2 0 17 0 1 1 2 3 2 017 0 1 2 1 3 2 018 1 1 4 1 3 2 0 18 0 1 1 1 2 1 0 18 0 1 2 1 3 2 019 0 1 1 1 2 1 019 0 2 2 2 3 1 020 1 1 4 2 3 2 120 0 1 5 1 3 3 020 0 1 4 1 3 2 021 1 1 5 1 2 1 021 0 1 4 1 3 2 021 0 1 2 1 3 2 122 1 1 2 2 3 1 022 0 1 2 1 3 2 022 0 1 1 1 3 3 023 1 1 3 1 2 2 023 0 1 1 1 3 1 123 0 1 1 2 3 2 124 1 1 2 2 3 2 124 0 1 1 1 3 2 024 0 1 1 2 3 2 025 1 1 4 1 1 1 125 0 1 1 1 3 2 025 0 1 1 1 3 3 0;proc phreg;/*调用phreg过程*/model t*y(0)=x1-x6/*定义模型,以t为时间变量,y为截尾变量,x1-x6为自变量*//selection=stepwise/*选择逐步回归方法筛选变量*/sle=0.1sls=0.1/*入选和剔除的界值均为0.1*/ties=discrete;/*用离散logistic模型替代比例危险模型*/strata i;/*定义区组变量*/run;2.3 应变量为多分类资料的logistic回归data ex16_5;input x1 x2 y f;/*x1是两个社区,x2是性别,Y是获取健康知识途径(传统大众媒介=1,网络=2,社区宣传=3,f为频数)*/cards;0 0 1 200 0 2 350 0 3 260 1 1 100 1 2 270 1 3 571 0 1 421 02 171 1 1 161 12 121 1 3 26;proc logistic;freq f;/*定义频数变量为f*/model y(ref='3')/*定义模型,以y为因变量,ref语句指时参照的类别为“社区宣传”,最后得到结果均为与“社区宣传”相对应*/=x1 x2/*定义x1和x2为自变量*//link=glogit;/*指定多分类应变量回归模型*/run;四:生存分析4.1乘积极限法估计生存率,例17-2甲、乙两种手术方法的生存率估计data ex17_2;input t d@@;/*确定变量名称,t为时间变量,d为截尾变量*/cards;1 13 15 15 15 16 16 16 17 18 110 110 114 017 119 020 022 026 034 134 044 159 1;proc lifetest;/*调用lifetest过程*/time t*d(0);/*定义模型,以t为时间变量,d为截尾变量,变量值为0表示截尾数据*/ run;4.2寿命表法估计生存率data ex17_3;input t d f@@;cards;0 0 00 1 4561 0 391 1 2262 0 222 1 1523 0 233 1 1714 0 244 1 1355 0 1075 1 1256 0 1336 1 837 0 1027 1 748 0 688 1 519 0 649 1 4210 0 4510 1 4311 0 5311 1 3412 0 3312 1 1813 0 2714 0 3314 1 615 0 2015 1 0;proc lifetest method=life/*调用lifetest过程,指定用寿命表法估计生存率*/ width=1;/*表示每间隔1估计生存率*/freq f;/*表示以f为频数变量*/time t*d(0);/*定义模型,以t为时间变量,d为截尾变量,变量值为0表示截尾数据*/ run;4.3生存曲线比较的log-rank检验及制作生存曲线data ex17_4;input t d g @@;cards;1 1 13 1 15 1 15 1 15 1 16 1 16 1 16 1 17 1 18 1 110 1 110 1 114 0 117 1 119 0 120 0 122 0 126 0 131 0 134 1 134 0 144 1 159 1 11 1 21 1 22 1 23 1 23 1 24 1 24 1 24 1 26 1 26 1 28 1 29 1 29 1 210 1 211 1 212 1 213 1 215 1 217 1 218 1 2;proc lifetest plot=(s);/*调用lifetest过程并做生存曲线图*/ time t*d(0);strata g;/*定义变量g为分组变量*/run;4.4.cox回归分析data ex17_5;input x1-x6 t y @@;cards;54 0 0 1 1 0 52 057 0 1 0 0 0 51 058 0 0 0 1 1 35 143 1 1 1 1 0 103 048 0 1 0 0 0 7 140 0 1 0 0 0 60 044 0 1 0 0 0 58 036 0 0 0 1 1 29 139 1 1 1 0 1 70 042 0 1 0 0 1 67 042 0 1 0 0 0 66 042 1 0 1 1 0 87 051 1 1 1 0 0 85 055 0 1 0 0 1 82 052 1 1 1 0 1 74 0 48 1 1 1 0 0 63 0 54 1 0 1 1 1 101 0 38 0 1 0 0 0 100 0 40 1 1 1 0 1 66 1 38 0 0 0 1 0 93 0 19 0 0 0 1 0 24 1 67 1 0 1 1 0 93 0 37 0 0 1 1 0 90 0 43 1 0 0 1 0 15 149 0 0 0 1 0 3 150 1 1 1 1 1 87 0 53 1 1 1 0 0 120 0 32 1 1 1 0 0 120 0 46 0 1 0 0 1 120 043 1 0 1 1 0 120 044 1 0 1 1 0 120 0 62 0 0 0 1 0 120 0 40 1 1 1 0 1 40 1 50 1 0 0 1 0 26 1 33 1 1 0 0 0 120 0 57 1 1 1 0 0 120 0 48 1 0 0 1 0 120 0 28 0 0 0 1 0 3 1 54 1 0 1 1 0 120 1 35 0 1 0 1 1 7 1 47 0 0 0 1 0 18 1 49 1 0 1 1 0 120 0 43 0 1 0 0 0 120 0 48 1 1 0 0 0 15 1 44 0 0 0 1 0 4 1 60 1 1 1 0 0 120 0 40 0 0 0 1 0 16 1 32 0 1 0 0 1 24 1 44 0 0 0 1 1 19 1 48 1 0 0 1 0 120 0 72 0 1 0 1 0 24 1 42 0 0 0 1 0 2 1 63 1 0 1 1 0 120 0 55 0 1 1 0 0 12 1 39 0 0 0 1 0 5 1 44 0 0 0 1 0 120 0 42 1 1 1 0 0 120 061 0 1 0 1 0 40 145 1 0 1 1 0 108 038 0 1 0 0 0 24 162 0 0 0 1 0 16 1;proc phreg;model t*y(1)=x1-x6/*定义模型,以t为时间变量,y为截尾变量,变量值1表示截尾数据,x1-x6为危险因素*//selection=stepwisesle=0.05sls=0.05;run;五:判别和聚类分析5.1判别分析data ex18_4;input x1-x4 g; /*确定变量名称,x1-x4为用于进行判别分析的指标,g为分组变量*/ cards;6.0 -11.5 19 90 1-11.0 -18.5 25 -36 390.2 -17.0 17 3 2-4.0 -15.0 13 54 10.0 -14.0 20 35 20.5 -11.5 19 37 3-10.0 -19.0 21 -42 30.0 -23.0 5 -35 120.0 -22.0 8 -20 3-100.0 -21.4 7 -15 1-100.0 -21.5 15 -40 213.0 -17.2 18 2 2-5.0 -18.5 15 18 110.0 -18.0 14 50 1-8.0 -14.0 16 56 10.6 -13.0 26 21 3-40.0 -20.0 22 -50 3;proc discrim;class g;/*定义分组变量为g*/var x1-x4;/*定义用于分析的指标变量为x1-x4*/run;(结果横向是真实值,竖向的预测值)5.2逐步判别分析data ex18_5;input x1-x4 g;cards;6.0 -11.5 19 90 1-11.0 -18.5 25 -36 390.2 -17.0 17 3 2-4.0 -15.0 13 54 10.0 -14.0 20 35 20.5 -11.5 19 37 3-10.0 -19.0 21 -42 30.0 -23.0 5 -35 120.0 -22.0 8 -20 3-100.0 -21.4 7 -15 1-100.0 -21.5 15 -40 213.0 -17.2 18 2 2-5.0 -18.5 15 18 110.0 -18.0 14 50 1-8.0 -14.0 16 56 10.6 -13.0 26 21 3-40.0 -20.0 22 -50 3;proc stepdisc /*调用stepdisc过程*/slentry=0.2/*确定入选标准为0.2*/slstay=0.3;/*确定剔除标准为0.3*/class g;/*定义分组变量为g*/var x1-x4;/*定义用于分析的指标变量为x1-x4*/run;(筛选出变量后,调用discrim过程对筛选出的变量作判别分析,即先做5.2再做5.1)5.3作样品聚类和指标聚类data ex19_3;input x1-x9;cards;46 25 5 2138 1.68 0.35 8.11 4 4 35 12 20 3510 2.76 1.43 6.84 3 3 52 25 20 2784 2.19 0.54 4.11 3 3 32 7 20 2451 1.93 0.47 11.45 9 6 38 22 0 3247 2.56 0.80 11.68 5 5 51 31 30 3710 2.92 0.37 11.60 2 2 40 9 10 3194 2.51 0.40 11.40 5 5 34 17 20 4658 3.67 0.46 11.35 3 3 50 29 0 5019 3.95 0.47 13.45 10 8 42 20 20 7482 5.89 0.12 13.11 0 0 57 30 15 3800 2.99 0.19 10.76 2 236 15 20 2478 1.95 0.25 10.00 0 037 12 0 3827 3.01 0.82 10.50 4 4 52 32 0 2984 2.35 0.16 11.15 3 3 52 32 10 3749 2.95 0.72 11.45 11 10 42 27 30 4941 3.89 0.73 13.80 7 6 44 27 20 3948 3.11 0.33 13.65 16 14 40 21 5 3360 2.64 0.37 11.40 0 0 38 21 5 2936 2.31 0.69 11.40 1 1 44 27 20 6851 5.39 0.99 12.28 7 6 43 27 0 3926 3.09 0.47 11.95 0 0 26 10 3 4381 3.45 0.52 11.80 7 5 37 18 20 7142 5.62 0.85 11.81 5 5 28 9 20 2612 2.06 0.37 11.65 1 1 25 9 30 2638 2.08 0.78 12.25 1 1 34 14 20 4322 3.40 0.41 15.00 5 5 50 32 20 2862 2.25 0.69 8.80 2 2;proc cluster/*调用cluster过程*/method=average;/*采用类平均法进行聚类*/var x1-x9;/*定义用于分析的指标变量x1-x9*/run;proc treegraphics haxis=axis1 horizontal;/*调用tree过程输出聚类图,并将图横向输出*/ run;/*对各个指标聚类,即对9个变量聚类*/proc varclus;/*调用varclus过程*/var x1-x9;/*定义用于分析的指标变量x1-x9*/run;六、主成分分析和因子分析6.1主成分分析data ex20_1;input x1-x6;cards;92 77 80 95 99 12697 75 77 80 95 12595 80 70 78 89 12075 75 73 88 98 11092 68 72 79 88 11390 85 80 70 78 10372 93 75 77 80 10088 70 76 72 81 10264 70 69 85 93 10570 73 70 87 84 10078 69 75 73 89 9778 72 71 68 75 9675 64 63 76 73 9284 66 77 55 65 7670 64 51 60 67 8858 72 75 62 52 7582 73 40 50 48 6145 65 42 47 43 60;proc princomp;/*调用princomp过程,对6个变量做主成分分析,结果包括主成分累积贡献率,特征向量矩阵*/run;6.2因子分析data ex20_2;input x1-x9;cards;4.34 389 99.06 1.23 25.46 93.15 3.56 97.51 61.663.45 271 88.28 0.85 23.55 94.31 2.44 97.94 73.334.38 385 103.97 1.21 26.54 92.53 4.02 98.484.18 377 99.48 1.19 26.89 93.86 2.92 99.41 63.164.32 378 102.01 1.19 27.63 93.18 1.99 99.71 80.004.13 349 97.55 1.10 27.34 90.63 4.38 99.03 63.164.57 361 91.66 1.14 24.89 90.60 2.73 99.69 73.534.31 209 62.18 0.52 31.74 91.67 3.65 99.48 61.114.06 425 83.27 0.93 26.56 93.81 3.09 99.48 70.734.43 458 92.39 0.95 24.26 91.12 4.21 99.76 79.074.13 496 95.43 1.03 28.75 93.43 3.50 99.10 80.494.10 514 92.99 1.07 26.31 93.24 4.22 100.00 78.954.11 490 80.90 0.97 26.90 93.68 4.97 99.77 80.533.53 344 79.66 0.68 31.87 94.77 3.59 100.00 81.974.16 508 90.98 1.01 29.43 95.75 2.77 98.72 62.864.17 545 92.98 1.08 26.92 94.89 3.14 99.41 82.354.16 507 95.10 1.01 25.82 94.41 2.80 99.35 60.614.86 540 93.17 1.07 27.59 93.47 2.77 99.80 70.215.06 552 84.38 1.10 27.56 95.15 3.10 98.63 69.234.03 453 72.69 0.90 26.03 91.94 4.50 99.05 60.424.15 529 86.53 1.05 22.40 91.52 3.84 98.58 68.423.94 515 91.01 1.02 25.44 94.88 2.56 99.36 73.914.12 552 89.14 1.10 25.70 92.65 3.87 95.52 66.674.42 597 90.18 1.18 26.94 93.03 3.76 99.28 73.813.05 437 78.81 0.87 23.05 94.46 4.03 96.223.94 477 87.34 0.95 26.78 91.784.57 94.28 87.344.14 638 88.57 1.27 26.53 95.16 1.67 94.50 91.673.87 583 89.82 1.16 22.66 93.43 3.55 94.49 89.074.08 552 90.19 1.10 22.53 90.36 3.47 97.88 87.144.14 551 90.81 1.09 23.06 91.65 2.47 97.72 87.134.04 574 81.36 1.14 26.65 93.74 1.61 98.20 93.023.93 515 76.87 1.02 23.88 93.82 3.09 95.46 88.373.90 555 80.58 1.10 23.08 94.38 2.06 96.82 91.793.62 554 87.21 1.10 22.50 92.43 3.22 97.16 87.773.75 586 90.31 1.12 23.73 92.47 2.07 97.74 93.893.77 627 86.47 1.24 23.22 91.17 3.40 98.98 89.80;proc factor/*调用factor过程*/n=4;/*确定因子数为4,如果不写就默认为3*/run;proc factorn=4rotate=quartimax;/*因子旋转的方法为四次方最大正交旋转*/run;七、典型相关分析(具体解释看ppt“SAS-典型相关分析(可以先上本章_再上对应分析)”)data ex21_1;input x1-x4 y1-y4;cards;1210 120.7 23.4 59.8 11.3 67.6 1.92 2.71 1040 121.2 22.9 59.0 10.1 66.5 1.92 2.60 1620 121.5 24.6 59.5 9.5 67.8 1.95 2.64 1690 122.5 24.4 60.7 11.0 69.2 2.08 2.64 1150 122.7 27.2 64.5 10.5 69.1 2.19 2.84 1150 123.2 20.0 56.1 10.4 59.3 1.83 2.61 1460 123.3 24.9 58.4 10.5 69.0 2.01 2.72 1190 123.4 21.8 59.0 10.6 67.4 1.90 2.71 1840 123.9 23.5 60.2 9.6 67.1 2.00 2.84 1250 124.5 25.2 63.0 11.2 67.8 2.05 2.78 1480 124.8 22.3 58.1 10.7 67.9 2.05 2.73 1310 124.9 22.0 58.0 10.5 67.8 1.98 2.68 1660 125.3 24.7 60.0 10.8 69.3 1.95 2.80 1580 125.6 22.8 59.0 9.4 69.1 2.00 2.65 1460 125.8 25.7 61.0 10.2 69.6 1.95 2.70 1240 126.0 30.2 68.0 9.2 67.1 2.14 2.88 1100 126.2 25.2 60.5 9.8 68.4 1.98 2.72 1250 126.8 23.6 58.5 10.2 67.5 1.94 2.74 1270 127.1 23.0 57.7 10.8 69.8 1.90 2.78 1300 127.6 24.3 59.0 10.3 67.9 1.93 2.84 1350 127.7 24.1 60.0 11.0 69.7 2.03 2.77 1250 128.3 21.6 55.5 10.4 68.5 1.83 2.70 1720 128.5 27.1 62.0 11.4 71.2 2.03 2.75 1480 128.5 22.6 57.4 10.0 67.3 2.04 2.83 1380 129.4 24.9 60.5 11.5 69.8 2.04 2.76 1170 129.0 26.7 63.7 9.6 67.4 2.13 2.98 1640 129.8 26.1 62.0 9.8 71.0 2.00 2.84 1640 131.6 28.7 62.8 9.7 70.7 1.89 2.89 1150 130.2 25.0 58.6 10.5 71.8 1.96 2.78 1430 130.5 26.1 60.7 10.8 68.6 2.05 2.77 1150 130.6 23.4 54.4 11.8 69.2 1.96 2.78 1150 131.4 25.5 63.2 10.2 70.4 2.05 2.84 1320 131.6 25.6 58.9 10.9 70.2 2.06 2.86 1360 131.7 27.4 62.0 10.9 73.5 1.99 2.70 1460 132.0 26.3 61.5 11.1 71.2 2.17 2.13 1380 132.2 25.7 61.4 10.1 70.1 1.96 2.83 1300 132.5 24.5 57.0 10.8 71.8 2.02 2.84 1220 132.7 27.0 61.3 10.1 72.2 2.08 2.80 1320 132.9 25.2 60.5 11.2 73.1 2.01 2.73 1910 133.1 30.1 67.0 9.0 87.1 2.15 2.97 1800 133.5 26.5 62.5 9.8 71.7 2.07 2.82 1560 133.6 24.8 58.5 10.3 72.2 1.93 2.79 1840 134.0 26.0 60.5 10.4 73.0 1.98 2.741590 134.4 25.5 60.7 9.6 69.9 1.99 2.81 1430 134.1 26.6 63.0 11.2 72.2 2.06 2.90 1760 134.6 32.5 66.0 9.9 87.4 2.61 2.98 1470 135.3 27.9 61.8 10.1 73.3 2.20 2.78 1580 135.6 28.1 65.8 9.8 73.1 2.05 2.89 1580 136.5 28.2 62.0 11.8 72.9 2.17 2.92 1840 137.1 27.6 62.8 9.5 72.4 2.11 2.91 1810 137.4 28.3 62.5 9.4 74.2 2.06 3.00 1850 138.1 29.5 62.4 9.7 72.3 2.12 4.02 2120 140.0 34.9 68.8 9.5 87.9 2.74 4.15 1760 140.7 32.0 64.4 10.2 74.0 2.17 4.05 1800 141.0 32.5 63.8 9.5 88.2 2.65 4.08 1260 141.7 29.1 65.0 9.7 88.2 2.68 2.90 1860 142.4 19.3 70.0 10.1 89.6 2.71 4.06 1800 144.7 27.0 58.3 10.8 74.8 2.10 2.82 1470 136.8 26.3 61.4 10.0 72.2 2.07 2.93 1260 121.1 22.9 59.0 10.6 66.3 2.05 2.76 1570 132.7 25.3 58.6 11.5 73.6 2.16 2.78 1290 125.0 25.7 60.5 10.1 68.8 2.00 2.69 1580 133.2 27.3 60.7 9.6 71.7 2.11 2.85 1690 132.8 28.6 64.7 9.6 72.9 2.19 4.08 1670 131.6 25.4 59.7 10.6 69.8 2.14 2.76 1300 133.1 25.9 58.0 10.1 69.7 2.12 2.83 1610 134.0 25.8 59.6 9.4 70.8 2.10 2.88 1580 134.3 26.3 61.2 10.2 72.2 2.14 2.84 1570 129.1 27.7 62.2 11.1 72.9 2.09 2.93 1660 140.1 32.1 67.0 9.3 87.1 2.15 4.03 1040 132.6 27.9 62.0 10.3 72.5 2.08 2.81 1290 128.3 23.6 58.5 9.3 69.0 1.97 2.76 1980 145.8 34.5 68.0 9.8 89.7 2.68 4.25 1210 133.3 25.6 61.5 9.9 71.0 2.11 2.82 1300 134.3 25.6 61.0 10.5 73.2 2.02 2.83 1310 138.1 27.8 61.2 9.9 73.5 2.09 2.78 1590 135.6 25.9 59.6 9.6 72.8 2.10 2.91 1270 128.3 24.1 58.5 10.3 69.2 1.92 2.77 1310 129.7 24.7 61.7 10.1 69.4 2.03 2.80 2280 143.6 37.6 70.0 9.7 88.8 2.17 4.18 1580 136.6 32.3 67.2 10.3 87.1 2.66 4.04 2370 147.4 38.8 73.0 10.8 90.7 2.82 4.38 ;proc cancorr;/*调用cancorr过程*/var x1-x4;/*定义一组变组变量*/with y1-y3;/*定义另一组变量*/。




SAS中的描述性统计过程(2012-08-01 18:07:01)转载▼标签:分类:数据分析挖掘杂谈SAS中的描述性统计过程描述性统计指标的计算可以用四个不同的过程来实现,它们分别是means过程、summary过程、univariate过程以及tabulate过程。
它们在功能范围和具体的操作方法上存在一定的差别,下面我们大概了解一下它们的异同点。
相同点:他们均可计算出均数、标准差、方差、标准误、总和、加权值的总和、最大值、最小值、全距、校正的和未校正的离差平方和、变异系数、样本分布位置的t检验统计量、遗漏数据和有效数据个数等,均可应用by语句将样本分割为若干个更小的样本,以便分别进行分析。
不同点:(1)means过程、summary过程、univariate过程可以计算样本的偏度(skewness)和峰度(kurtosis),而tabulate过程不计算这些统计量;(2)univariate过程可以计算出样本的众数(mode),其它三个过程不计算众数;(3)summary过程执行后不会自动给出分析的结果,须引用output语句和print过程来显示分析结果,而其它三个过程则会自动显示分析的结果;(4)univariate过程具有统计制图的功能,其它三个过程则没有;(5)tabulate过程不产生输出资料文件(存储各种输出数据的文件),其它三个均产生输出资料文件。
统计制图的过程均可以实现对样本分布特征的图形表示,一般情况下可以使用的有chart过程、plot过程、gchart过程和gplot过程。
大家有没有发现前两个和后两个只有一个字母‘g’(代表graph)的差别,其实它们之间(只差一个字母g的过程之间)的统计描述功能是相同的,区别仅在于绘制出的图形的复杂和美观程度。
chart过程和plot过程绘制的图形类似于我们用文本字符堆积起来的图形,只能概括地反映出资料分布的大体形状,实际上这两个过程绘制的图形并不能称之为图形,因为他根本就没有涉及一般意义上图形的任何一种元素(如颜色、分辨率等)。

基本描述性统计分析Sas学习第六天1.means 过程SAS系统的BASE模块提供了一些计算基础统计量的过程,如:means过程、univariate过程、corr过程、freq 过程等。
这些过程可完成单变量或多变量的描述统计量计算。
SAS系统Means过程可以用来计算数据集中指定的各变量的一些基本描述性统计量的值(如观测值个数、均值、标准差、方差、偏度、峰度等)。
Means过程的一般格式为:proc means 输入数据集名选项列表;var 变量列表;class 变量列表;by 变量列表;freq 变量;weight 变量;id 变量列表;output out=输出数据集名统计量关键字=变量名列表>;run ;语句说明:V AR语句——指定要分析的变量名列;BY语句——按变量名列分组统计(数据集需事先按该变量名列排序);CLASS语句——按变量名列分组统计(数据集不需事先排序);FREQ语句——表明该变量为分析变量的频数;WEIGHT语句——表明分析变量在统计时要按该变量加权;ID语句——输出时加上该变量作为索引;OUTPUT语句——指定统计量输出的数据集及输出的内容(OUT指定统计量的输出数据集名,统计量关键字指定统计量在输出数据集中对应的新变量名).选项说明:PROC MEANS语句,选项列表中常用“选项options”有:①DATA=SAS数据集名:指明要分析的SAS数据集,缺省为最近建立的SAS数据集。
②MAXDEC=k:规定输出结果小数部分的最大位数,③ALPHA=value:设置置信区间的置信水平α。
④统计量关键词常用的有:例:针对讲义4中生成的成绩数据集updatescore(程序4.2、4.4所生成),按班级和性别分组统计语文chinese、英语english、数学math、平均分avg的均值、方差、均值标准误差、99%置信区间上下界。
并将这四个变量的均值统计量值输入到数据集stat里面去。

sas系统proc univariate过程1. 介绍SAS(Statistical Analysis System)是统计分析系统,是业界广泛使用的数据分析工具之一。
SAS提供了多个过程(PROC)来处理和分析数据,其中之一是Proc Univariate过程。
本文将详细介绍SAS系统中的Proc Univariate过程的相关内容。
2. Proc Univariate过程的作用Proc Univariate过程用于对数据进行单变量分析,主要目的是研究单个变量的统计特征和分布情况。
该过程可用于描述变量的中心位置、离散程度、分布形状等统计指标,同时还能生成各种图形以帮助进一步分析数据。
3. 使用方法使用Proc Univariate过程需要先导入相关的数据,以下是使用Proc Univariate 的基本示例代码:PROC UNIVARIATE DATA=data;VAR variable;HISTOGRAM;QQPLOT;RUN;在此示例中,data代表数据集的名称,variable代表需要分析的变量名。
使用VAR 语句指定需要分析的变量。
HISTOGRAM和QQPLOT是两个示例输出图形,代表直方图和正态概率图(Q-Q plot)。
4. 常见输出使用Proc Univariate过程后,会生成多个输出,包括描述性统计指标、分位数、图形等。
4.1 描述性统计指标描述性统计指标可以用于描述变量的中心位置、离散程度等,常见的统计指标包括:•平均值(Mean)•中位数(Median)•众数(Mode)•标准差(Standard Deviation)•方差(Variance)•偏度(Skewness)•峰度(Kurtosis)4.2 分位数分位数是将数据分成若干部分的统计量,常见的分位数包括:•中位数(50%分位数)•四分位数(25%和75%分位数)•百分位数(例如10%、90%分位数)4.3 图形Proc Univariate过程还可以生成多种图形,用于帮助分析数据的分布情况,常见的图形包括:•直方图(Histogram)•密度曲线图(Density Plot)•箱线图(Box Plot)•正态概率图(Q-Q Plot)•生存曲线(Survival Plot)5. 实际应用案例以下是一个使用Proc Univariate过程的实际案例,以探究某公司员工的薪资分布情况:PROC UNIVARIATE DATA=employees;VAR salary;HISTOGRAM;QQPLOT;MEANS;RUN;在该案例中,employees是包含员工数据的数据集,salary是需要分析的薪资变量。
sas freq过程(原创版)目录1.SAS freq 过程概述2.SAS freq 过程的主要用途3.SAS freq 过程的基本语法4.SAS freq 过程的例子及解析5.SAS freq 过程的注意事项正文【1.SAS freq 过程概述】SAS freq 过程是 SAS(Statistical Analysis System,统计分析系统)中的一个过程,主要用于对数据进行频数分析。
频数分析是一种常用的统计方法,用于计算各变量在数据集中出现的次数,以了解数据的分布特征。
通过使用 SAS freq 过程,我们可以更方便地对数据进行频数分析,从而为后续的统计分析提供依据。
【2.SAS freq 过程的主要用途】SAS freq 过程的主要用途有以下几点:- 计算各变量的频数:对于分类变量,可以计算各类别的频数;对于数值变量,可以计算数据的频数分布。
- 计算累积频数:通过对频数进行累加,可以得到各变量的累积频数,从而了解数据的累积分布情况。
- 计算相对频数:通过将各变量的频数除以样本容量,可以得到相对频数,以便于比较不同变量之间的频数分布。
- 计算概率:根据相对频数,可以计算各变量取某个值的概率。
【3.SAS freq 过程的基本语法】SAS freq 过程的基本语法如下:```FREQ process;```在 FREQ 过程中,可以使用以下选项进行设置:- CLASS:指定要分析的分类变量;- VAR:指定要分析的数值变量;- OUTPUT:指定输出的频数表;- ACCUMULATE:计算累积频数;- RELATIVE:计算相对频数;- PROB:计算概率;等。
【4.SAS freq 过程的例子及解析】假设有一个数据集,包含性别(男、女)、年龄(18-24、25-34、35-44、45-54、55-64、65-74、75 岁以上)两个变量,我们希望了解各年龄段在男女性别中的频数分布情况。
可以使用以下 SAS freq 过程代码:```data example;input gender $ age;run;proc freq data=example;class gender;var age;output out=freq_output;run;```代码解释:- 首先,创建一个名为“example”的数据集,包含性别和年龄两个变量;- 然后,使用 FREQ 过程对数据进行频数分析,指定性别变量为分类变量,年龄变量为数值变量;- 最后,将分析结果输出到名为“freq_output”的频数表中。
SAS中means过程及结果
偏度:研究分布形状是否对称,计算偏度g1.
若g1约等于0,则可认为分布是对称的。
若g1>0,右偏态(正偏),此时在均值右边的数据更为分散。
若g1<0,左偏态(负偏),此时在均值左边的数据更为分散。
峰度
是以正态分布为标准(假设正态分布的⽅差与所研究分布的⽅差相等)⽐较两侧极端数据分布情况的指标。
对于正态分布,g2=0
若g2>0,表⽰数据中含有较多远离均值的极端数据,此时分布有⼀沉重的尾巴(粗尾);
若g2<0,表⽰均值两侧的极端数据较少。
SAS程序:
data w1;
input w @@;
cards;
75 64 47.4 66.9 62.2 58.7 63.5 66.6 64 57 69 56.9 50 72
;
proc means data=w1 mean var std stderr median cv max min sum range skewness kurtosis;
var w;
run;
可以利⽤univariate过程求众数。
sas freq过程摘要:一、SAS 简介1.SAS 软件的作用2.SAS 软件在数据分析领域的应用二、SAS FREQ 过程1.SAS FREQ 过程的定义2.SAS FREQ 过程的功能3.SAS FREQ 过程的使用场景三、SAS FREQ 过程详解1.过程语法2.过程参数3.过程输出四、SAS FREQ 过程的实际应用1.频数分析2.频率分析3.累计频数与累计频率分析4.样本比例与总体比例分析五、SAS FREQ 过程与其他过程的关联1.SAS FREQ 过程与SAS MEANS 过程的关联2.SAS FREQ 过程与SAS VARIABLES 过程的关联六、SAS FREQ 过程在实际工作中的优势与局限1.优势a.快速处理大量数据b.灵活的统计方法c.高度的可定制性2.局限a.对数据质量要求较高b.需要一定的SAS 编程基础正文:SAS(Statistical Analysis System)是一款广泛应用于数据分析和决策支持的大型统计分析软件。
作为一款功能强大的数据处理工具,SAS 可以帮助用户进行数据清洗、统计分析、建模预测等多种操作,从而为用户提供准确的数据支持。
在众多的数据分析方法中,SAS FREQ 过程是一种十分常用的频数统计方法,它可以快速、准确地完成频数、频率、累计频数、累计频率等统计分析任务。
SAS FREQ 过程是SAS 软件中用于进行频数统计的一个过程。
它通过对输入的数据进行分组,计算各组的频数、频率、累计频数、累计频率等统计量,从而帮助用户了解数据的分布特征。
SAS FREQ 过程可以应用于各种领域,如市场调查、医学研究、社会科学等,为用户提供丰富的统计分析功能。
要使用SAS FREQ 过程,用户首先需要对过程语法有一定的了解。
SAS FREQ 过程的语法如下:```FREQ var1 [BY var2] [IF conditions] [IN range];```其中,`var1`表示需要进行频数统计的变量,`var2`表示进行分组依据的变量(可选),`conditions`表示输入数据需要满足的条件(可选),`range`表示数据范围(可选)。