最新利用SPSS软件对量表
- 格式:ppt
- 大小:1.53 MB
- 文档页数:39
第一节 SPSS 概述 张岩波 sxmuzyb@目的要求:掌握SPSS 基本功能一、软件简介1、 统计软件简介:SPSS 、SAS 、STATA 、BMDP2、 SPSS 简介:版本,优点,兼容性(数据,软件),数据管理功能3、SPSS 窗口:主窗口(数据窗口),结果输出窗口,程序窗口File: 文件操作Edit: 编辑Data: 数据操作 Transform: 变量转换 Analyze: 统计分析 Graphs: 统计图形4、 主要文件类型:数据文件:.SAV 可读入或输出各种数据格式,常见DBASE,EXCEL 结果文件:.SPO 可输出Word ,Htm ,TXT ,也可直接粘贴到外部文档 程序文件:.SPS 用于批处理编程,或菜单不可完成的统计方法 其它非SPSS 文件:XLS DBF TXT二、数据的建立,调用与存储1、创建或打开数据文件:2、数据文件格式:同Dbase,变量名的命名规则;二维格式行(记录):通常每个个体或观察单位为一个记录列(变量):各种统计方法中注意各类变量的区分:观察效应,处理因素3、数据类型:变量设置变量名类型宽度小数位数变量标签赋值4、数据文件的存储调用:兼容EXCEL,SAS,dBASE,ACCESS等各种格式,可调用/导出三、善于利用帮助系统四、数据库的管理Data(数据操作)Transform(变量转换)五、统计方法:Graphs第二节统计描述一、计量资料、计数资料的统计描述(一)目标与教学要求1.掌握常用统计方法的选择、频数分布分析、描述统计量、探索分析及平均数分析。
2.熟悉资料统计工作的步骤、资料的分类、变量变换。
(二)课程内容:1. 常用统计方法的选择:●定量资料与定性资料●统计描述与统计推断●比较分析与关联性分析2. 频数分布分析:●正态分布:连续性资料,分布对称●二项分布:二分类资料,数据独立(非传染/遗传性疾病)●POISSION分布:稀有事件的发生率3. 描述统计量定量资料统计描述常用的统计指标及其适用场合描述内容指标意义适用场合平均水平均数个体的平均值对称分布。

利用SPSS进行数据分析的技巧与方法数据分析是信息时代的重要技能之一,尤其在商业、金融、科学和社会科学等领域。
而SPSS软件是一种广泛使用的统计分析软件,能够帮助用户简化数据分析过程。
本文将介绍利用SPSS进行数据分析的技巧和方法,包括数据输入、数据清洗、数据可视化、假设检验和回归分析等方面。
一、数据输入SPSS支持多种数据来源的导入,包括CSV、TXT、Microsoft Excel、Access、SAS和Stata等文件格式,还可以从关系型数据库中读取数据。
在SPSS中打开数据集后,应该检查数据集的编码、缺失值和重复值。
首先,确保数据集的编码与文件格式一致,例如,如果数据集使用UTF-8编码,那么也要确保文件格式为UTF-8。
其次,检查数据集是否存在缺失值和重复值,并决定如何处理它们。
二、数据清洗数据清洗是数据分析的关键步骤之一,可以有效提高数据质量。
数据清洗的主要任务是检查数据集中存在的错误、缺失值和异常值。
SPSS软件提供了各种功能来识别和处理这些问题,例如,数据转换、数据筛选和变量相关性矩阵等。
在数据清洗中,要学会对缺失值、异常值和无效值进行处理。
对于缺失值,可以通过删除、插值或替换为特定值等方法进行处理;对于异常值,可以通过对数据进行修正、平滑或转换等方法进行处理。
三、数据可视化数据可视化是数据分析不可或缺的一个环节,它可以帮助用户更好地了解数据的分布情况和变化趋势。
SPSS软件提供了多种数据可视化功能,如散点图、直方图、箱线图等。
在数据可视化时,要注意选择合适的图表类型来呈现数据。
例如,散点图非常适合呈现多变量之间的关系,而直方图则适合呈现单变量的分布情况。
此外,还要注意选择好图表的颜色、字体和标签等设置。
四、假设检验假设检验是通过一定的样本数据来推断总体参数的一种方法。
SPSS软件提供了多种假设检验方法,包括单样本t检验、独立样本t检验、方差分析、卡方检验等。
假设检验的关键是选择适当的检验方法和确定显著性水平。


使用SPSS统计软件进行数据分析入门指南第一章:SPSS统计软件简介SPSS(Statistical Package for the Social Sciences,社会科学统计软件包)是一款专门用于数据分析和统计建模的软件工具。
它提供了一系列的数据处理、描绘和统计分析方法,可用于解决各种统计学问题。
本章将介绍SPSS软件的基本概念和功能,并指导读者进行安装和设置。
1.1 SPSS软件的背景和发展历程1.2 SPSS软件的版本和特点1.3 安装SPSS软件1.4 设置SPSS软件的语言和界面1.5 SPSS数据文件的格式和类型1.6 打开、保存和关闭SPSS数据文件第二章:SPSS数据管理与数据清洗数据分析的第一步是数据的收集和管理。
本章将介绍如何在SPSS软件中进行数据的导入、清洗和变换,以确保数据的质量和准确性。
2.1 导入数据文件2.2 数据类型和变量属性设置2.3 缺失值处理2.4 数据的筛选与排序2.5 数据的变换与合并2.6 数据文件的导出和备份第三章:SPSS数据描述统计分析在进行深入的数据分析之前,首先需要对数据进行描述和总结,以获得对数据分布和特征的初步了解。
本章将介绍SPSS如何进行数据的描述性统计分析和数据可视化。
3.1 数据的描述性统计量3.2 数据的频数和交叉分析3.3 数据的描述性图表3.4 数据的相关分析3.5 数据的因子分析3.6 数据的聚类分析第四章:SPSS统计推断分析统计推断分析是利用样本数据对总体进行推断的一种方法。
本章将介绍如何利用SPSS软件进行统计推断分析,并解释如何进行假设检验、方差分析和回归分析等常用的统计方法。
4.1 参数统计分析与假设检验4.2 方差分析与多元方差分析4.3 相关与回归分析4.4 判别分析与逻辑回归分析4.5 非参数统计分析方法4.6 多元统计分析方法第五章:SPSS高级数据分析与报告生成在完成基本的数据分析后,可以进行一些更高级的操作和分析,以进一步深入了解数据的内在关系和结构。

SPSS分析调查问卷数据的方法当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以p为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.Sp处理:第一步:定义变量我们知道在p中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:1.请问你的年龄属于下面哪一个年龄段()以上为问卷中常见的单项选择题型的变量设置,下面将对一些特殊情况的变量设置也作一下说明.1.开放式题型的设置:诸如你所在的省份是_____这样的填空题即为开放题,设置这些变量的时候只需要将Value、Miing两项不设置即可.2.多选题的变量设置:这类题型的设置有两种方法即多重二分法和多重分类法,在这里我们只对多重二分法进行介绍.这种方法的基本思想是把该题每一个选项设置成一个变量,然后将每一个选项拆分为两个选项项,即选中该项和不选中该项.现在举例来说明在p中的具体操作.比如如下一例:请问您通常获取新闻的方式有哪些()1报纸2杂志3电视4收音机5网络在p中设置变量时可为此题设置五个变量,假如此题为问卷第三题,那么变量名分别为3_1、3_2、3_3、3_4、3_5,然后每一个选项有两个选项选中和不选中,只需在Value一项中为每一个变量设置成1=选中此项、0=不选中此项即可.使用该窗口,我们可以把一个问卷中的所有问题作为变量在这个窗口中一次定义。
第二步:数据录入Sp数据录入有很多方式,大致有一下几种:1.读取SPSS格式的数据2.读取E某cel等格式的数据3.读取文本数据(Fi某ed和Delimiter)4.读取数据库格式数据(分如下两步)(1)配置ODBC(2)在SPSS中通过ODBC和数据库进行但是对于问卷的数据录入其实很简单,只要在p的数据录入窗口中直接输入就可以了,只是在这里有几点注意的事项需要说明一下.1.在数据录入窗口,我们可以看到有一个表格,这个表格中的每一行代表一份问卷,我们也称为一个个案.在数据录入完成后,我们要做的就是我们的关键部分,即问卷的统计分析了,因为这时我们已经把问卷中的数据录入我们的软件中了.第三步:统计分析有了数据,可以利用SPSS的各种分析方法进行分析,但选择何种统计分析方法,即调用哪个统计分析过程,是得到正确分析结果的关键。

《SPSS统计软件应用》实验报告册20 15 - 20 16 学年第 1 学期班级: T1353-3 学号: 20130530305 姓名:徐云授课教师:薛昌春实验教师:薛昌春实验学时:一周实验组号:目录1.实验一 SPSS的数据管理2.实验二描述性统计分析3.实验三均值检验4.实验四相关分析5.实验五因子分析6.实验六聚类分析7.实验七回归分析8.实验八判别分析实验一 SPSS的数据管理一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置;2.掌握SPSS的数据管理功能。
二、实验内容:1、定义spss数据结构。
下表是某大学的一个问卷调查,要求将问卷调查结果表示成spss可识别的数据文件,利用spss软件进行分析和处理。
练习:创建数据文件的结构,即数据文件的变量和定义变量的属性。
实验步骤:(1)打开SPSS 软件,新建一张date数据表;(2)打开 variable view 界面,对相应的变量数据进行属性设置;(3)打开 date view界面,输入数据,点击保存;实验结果及分析:略2 、高校提前录取名单的确定某高校今年对部分考生采取单独出题、提前录取的招生模式。
现有20名来自国内不同省市的考生报考该校,7个录取名额。
见数据文件compute.sav. 该校制定了如下录取原则:(1)文化课成绩由数学、语文、英语和综合四门成绩组成。
文化课成绩制定最低录取分数线:400分。
(2)个人档案中若有“不良记录”,不予录取。
(3)对西部考生和少数民族考生,给予加分优惠。
少数民族考生加20分,西部考生加10分。
(4)对参加过省以上竞赛并取得三等奖以上名次的考生,每项加10分。
(5)文化课成绩和加分总和构成综合分,录取综合排名为前7名的学生。
练习:利用spss软件,综合利用所学,给出成绩排名的操作步骤。
实验步骤:(1)打开给的原数据文件;(2)执行 date/select case 命令,打开select case对话框,选择 if condiction is satisfatied ,输入“(数学 + 语文 + 英语 + 综合) >= 400 and 不良记录 = 0”,点击continue。

SPSS 分析调查问卷数据的方法SPSS 分析调查问卷数据的方法当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此 ,我们以 spss 为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存 .下面将从这四个方面来对问卷的处理做详细的介绍 . Spss 处理 :第一步 :定义变量大多数情况下我们需要从头定义变量,在打开SPSS 后,我们可以看到和excel 相似的界面,在界面的左下方可以看到Data View, Variable View 两个标签 ,只需单击左下方的Variable View 标签就可以切换到变量定义界面开始定义新变量。
在表格上方可以看到一个变量要设置如下几项:name( 变量名 )、 type( 变量类型 )、 width( 变量值的宽度 )、decimals( 小数位) 、label( 变量标签) 、Values( 定义具体变量值的标签)、Missing( 定义变量缺失值 )、Colomns( 定义显示列宽 )、Align( 定义显示对齐方式 )、Measure( 定义变量类型是连续、有序分类还是无序分类 ).我们知道在spss 中,我们可以把一份问卷上面的每一个问题设为一个变量 ,这样一份问卷有多少个问题就要有多少个变量与之对应 ,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明 ,可假设此题为 :1. 请问你的年龄属于下面哪一个年龄段( )?A:20 —29 B:30 — 39 C:40 — 49 D:50--59 那么我们的变量设置可如下: name 即变量名为1,type 即类型可根据答案的类型设置,答案我们可以用1、2、 3、4 来代替A、B、C 、D,所以我们选择数字型的,即选择 Numeric, width宽度为 4, decimals 即小数位数位为0(因为答案没有小数点), label 即变量标签为“年龄段查询”。

分类号:密级:学校代码: ***** 学号:硕士学科论文利用统计软件Spss进行试卷质量分析姓名敬晓萍指导教师冯长焕教授培养单位数学与信息学院学科专业教育统计与测评研究方向数学教育学位类别教育硕士年级 2010级西华师范大学学位评定委员会四川·南充利用统计软件Spss进行试卷质量分析摘要试卷分析是教学工作中的重要组成部分,同时也是每个教师必须完成的工作。
通过对试卷进行分析,可以反馈学生学习结果和教师教学效果,帮助教师发现教学活动中的薄弱环节,提高教学质量。
课程期末考试的试题应该如何命题,怎样组卷?如何把握一份试卷的整体难度和分量,使考试成绩及其成绩的分布符合正态,防止平均成绩的大起大落,避免不及格率的过高过低,以适应大众教育的需要等,这对稳定学校正常的教学秩序,保证学生正常的学习心态和情绪,直至就业应聘是否顺利等都会产生直接的影响。
本文利用统计软件Spss对试卷分析的各项指标进行了定量分析,介绍了操作方法,以便为广大教师进行试卷分析提供一种模式参考,从而科学地进行试卷质量分析,提高教学质量和效率。
关键字:成绩统计;试卷分析;难度;区分度;信度考试是教育评价的有效办法,随着高职高专技能教学改革的深入开展,对教学评价的要求越来越客观,对教学结果的分析越来越依赖于统计理论和方法。
本文的目的是借助统计学软件Spss,介绍对试卷质量定量分析的方法。
一、考试试卷的统计分析[1](一)试卷难度的分析所谓难度是指考试中试题或者试卷的难易程度,是考试题目对学生知识和能力水平适合程度的指标。
1.难度的计算以往教师在考试中对试题难度的测定大部分是凭感觉。
这种方法本身比较模糊,对有经验的教师也并不是非常有效。
根据难度的概念,得到如下公式:若第i题全部答对,则di =0;若第i题全部答错,则di=1;当di=0.5,说明此题难度适中。
试卷难度:试卷难度的测定建立在试题难度的基础上,以试题难度为变量,以试题满分值为权数的加权算数平均数:一般而言,试卷都是以100分为满分,于是:对于学校的常规考试,目的在于测量个体差异。
![用spss对学生成绩进行分析[精选.]](https://uimg.taocdn.com/3b856c5202020740be1e9bff.webp)
<<SPSS统计分析软件>> 课程设计报告班级姓名学号指导教师用统计软件spss分析学生成绩摘要:应用统计软件spss,对某校一、二班学生语文,数学,英语成绩进行分析。
学生成绩分析是考试后老师应做的一项比较麻烦的工作,主要包括:计算平均值和标准差,绘制学生成绩分布直方图等,用统计分析软件spss来进行这类数据的处理,速度快,直观,全面。
spss是世界顶尖的统计软件,其功能-几乎涵盖了数理统计的各个方面,适用于自然科学于社会科学各个领域进行分析统计,给人们进行数据分析爱来很大方便。
关键字:频数分析,描述性分析,均值比较,独立样本均值检验一、数据调查(1)数据调查方法:由于学校的班级比较多,涉及到学生有上千人,如果对于每一个学生的学习成绩进行普查,会加大工作难度,并且不利于从繁杂的数据中获取信息。
因此采用抽样的方法进行数据调查。
(2)数据来源:抽取一班、二班的各十名,共二十名同学,采集语文成绩,数学成绩,英语成绩作为本次统计分析的表1 学生成绩表(原始数据)二、spss软件应用分析1、频数分析(1)语文成绩的频数分析由分析可得,语文成绩为86分的最多,占总人数15% (2)数学成绩频数分析由此得知,数学成绩为60分的人数最多,占总人数的15%。
(3)英语成绩频数分析有分析得知,英语成绩为78分的人最多。
占总人数的15%。
2、描述性统计有分析得知:语文成绩的最低分是66分,最大值是88分,标准差是7.725。
数学成绩的最低分是40分,最大值是90分,标准差是13.214 。
英语的最低分是44分,最大值是89分,标准差是10.723可见,英语的标准差最大,水平相差较大。
3、均值比较独立样本均值检验一班和二班的英语成绩分组统计量表独立样本均值检验表由图得知:分组统计量表显示两组数据的样本容量,均值,标准差,和抽样平均误差。
一班的英语平均成绩低于二班。
独立样本均值检验表包含了两组样本的独立检验统计量。

SPSS分析调查问卷数据的方法当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存。
下面将从这四个方面来对问卷的处理做详细的介绍.Spss处理:第一步:定义变量大多数情况下我们需要从头定义变量,在打开SPSS后,我们可以看到和excel相似的界面,在界面的左下方可以看到Data View,Variable View两个标签,只需单击左下方的Varia ble View标签就可以切换到变量定义界面开始定义新变量。
在表格上方可以看到一个变量要设置如下几项:name(变量名)、type(变量类型)、width(变量值的宽度)、decimals(小数位) 、label(变量标签)、Values(定义具体变量值的标签)、Missing(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measure(定义变量类型是连续、有序分类还是无序分类)。
我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置。
为了便于说明,可假设此题为:1。
请问你的年龄属于下面哪一个年龄段( )?A:20-29 B:30—39 C:40—49 D:50—-59那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeric, width宽度为4,decimals即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询".Values用于定义具体变量值的标签,单击Value框右半部的省略号,会弹出变量值标签对话框,在第一个文本框里输入1,第二个输入20—29,然后单击添加即可.同样道理我们可做如下设置,即1=20—29、2=30—39、3=40-49、4=50--59;Missing,用于定义变量缺失值,单击missing框右侧的省略号,会弹出缺失值对话框,界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值”,最多可以定义3个值;最后一项为“缺失值范围加可选的一个缺失值”,在此我们不设置缺省值,所以选中第一项如图;Col omns,定义显示列宽,可自己根据实际情况设置;Align,定义显示对齐方式,有居左、居右、居中三种方式;Measure,定义变量类型是连续、有序分类还是无序分类。
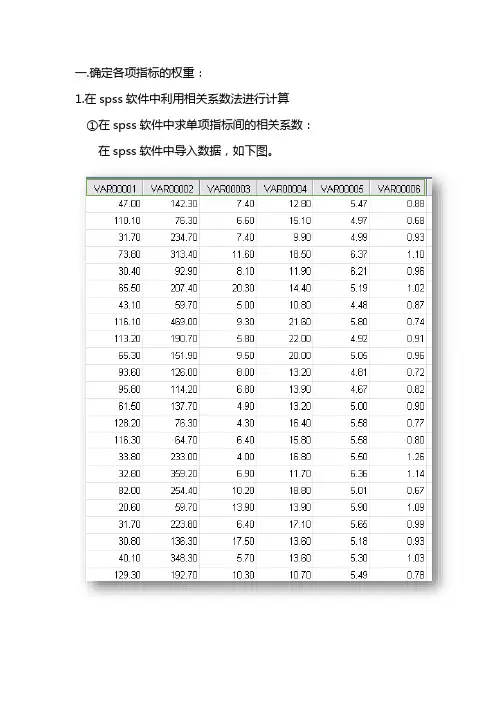
一.确定各项指标的权重:1.在spss软件中利用相关系数法进行计算①在spss软件中求单项指标间的相关系数:在spss软件中导入数据,如下图。
②在spss软件中的变量视图界面中把之前表格中的表头“VAR00001、VAR00002、VAR00003、VAR00004、VAR00005、VAR00006”依次修改为“om、ak、ap、cec、pH、bd”,如下图所示:③在spss软件的界面中,依次点击分析、相关和双变量,打开下图所示的对话框:④在上图所示的界面中中,分别点击表头“om、ak、ap、cec、pH 和bd”,点击按钮,移至变量框并且保证其他参数不变,最后点确定按钮,出现下图所示的界面:⑤上图的界面的输出框中,把相关性的表格进行剪切,粘贴在新的Excel表中,如下图所示:⑥把上图的表头进行复制,建立新的Excel表,双击输入=ABS()的公式,敲击回车进行计算,利用填充柄将表格填充完毕,如下图所示:2.之后求取各单项指标以及其他指标间的相关系数的平均值,然后计算平均值占所有指标的相关系数平均值总和的比率。
①计算单项指标与其他指标间相关系数的和:双击单元格,输入=SUM()- 1的公式,求取各指标与其他指标相关系数的和,利用填充柄计算所有的数值。
②计算单项指标与其他指标间相关系数的平均值;总和为各相关系数平均值的总和;计算比率与权重的比值;计算各对应相关系数的平均值与对应的总和值做比值,如下图所示:3.利用主成分分析法进行计算:①在SPSS软件中依次电击分析、降维和因子分析,点击因子分析打开对话框,把om、ak、ap、cec、pH、和bd移动到变量框中,最后点击确定按钮,生成下图:②在输出对话框中,把公因子方差表格剪切,粘贴到新的Excel表中,双击,单元格中输入=sum()求和公式进行求和计算:③计算各项数值的权重:双击单元格,输入=各提取值/ 4.422的公式进行计算,并利用填充柄计算所有数值,如下图所示:二.进行评价指标的标准化的计算:1.利用下图的函数来建立隶属度函数①在双击单元格输入公式=0.9*(X-X1)/(X2-X1)+0.1,敲击回车进行计算,利用填充柄计算所有的数值。
SPSS软件的基本使用方法
SPSS(Statistical Package for the Social Sciences)是一款常用的统计分析软件,用于数据管理、数据分析、图画绘制等多个方面的应用。
以下是SPSS软件的基本使用方法:
1. 打开SPSS软件:启动后,出现欢迎界面。
2. 新建数据集:在欢迎界面选择“新建数据集”或菜单栏“文件→新建→数据”,设置数据集名称和变量名。
3. 输入数据:输入每个变量的数据,包括定量变量和定性变量。
4. 数据预处理:对数据进行清理和预处理,可以删除无用数据、缺失数据和异常数据,调整数据格式和变量类型等。
5. 描述性统计分析:从菜单栏选择“统计→描述性统计→描述性统计”,选择需要统计的变量,生成基本统计量和频数表等内容。
6. 探索性数据分析:从菜单栏选择“图形→探索性数据分析”,选择需要绘制的图形类型,如直方图、散点图、箱线图等。
7. 统计分析:从菜单栏选择“统计→一般线性模型”,选择需要分析的变量和分析方法,如t检验、方差分析、回归分析等。
8. 输出结果:将分析结果输出到文件或打印出来。
以上是SPSS软件的基本使用方法,需要不断练习和深入学习。
量表题交叉分析
spss中交叉分析主要用来检验两个变量之间是否存在关系,或者说是否独立,其零假设为两个变量之间没有关系。
在实际工作中,经常用交叉表来分析比例是否相等。
例如分析不同的性别对不同的报纸的选择有什么不同。
spss交叉表分析方法与步骤:
1、在spss中打开数据,然后依次打开:analyze–descriptive–crosstabs,打开交叉表对话框
2、将性别放到行列表,将对读物的选择变量放到列,这样就构成了一个交叉表
3、设置输出的结果,点击statistics,打开一个新的对话框
4、勾选chi-square(卡方检验),勾选phi and cramer’s V(衡量交互分析中两个变量关系强度的指标),点击continue,回到交叉表对话框
5、点击cells,设置cell中要展示的数据
6、在这里勾选observed(各单元格的观测次数),勾选row(行单元格的百分比),点击continue,回到交叉表对话框
7、点击ok按钮,输出检验结果
8、先看到的第一个表格就是交叉表,性别为行、选择的读物为列
9、卡方检验结果:主要看pearson卡方检验,sig值小于0.05,因此认为不同的性别的人对周末读物的选择有显著的差别
10、最后一个表格,输出的是phi值和V值,两个都代表两个变量之间的关系的紧密度,数值小于0.1说明关系不紧密,即性别与周末读物的选择没有明显的关系,这个结论和上面的卡方检验有出入,所以需要进一步进行两两比较。
SPSS基本操作步骤详解本文采用SPSS21.0版本,其它版本操作步骤大体相同一、基本步骤(一)检查数据在进行项目分析或统计分析之前,要检核输入的数据文件有无错误,即检核missing。
例,“XX量表”采用Likert scale五点量表式填答,每个题项的数据只有五个水平:1,2,3,4,5。
1.执行次数分布表的程序Analyze(分析)→Descriptive statistics(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Frequencies(频率)→Statistics(统计量)→Minimum (最小值)、Maximum(最大值)→Continue(继续)→OK(确定)2.执行描述统计量的程序Analyze(分析)→(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Descriptives(描述)→Options(选项)→Minimum(最小值)、Maximum(最大值)【此处一般为默认状态即可】→Continue(继续)→OK(确定)(二)反项计分若是分析的预试量表中没有反向题,则此操作步骤可以省略;量表或问卷题中如果有反向题,则在进行题项加总之前将反向题反向计分,否则测量分数所表示的意义刚好相反。
例,“XX量表”采用Likert scale五点量表式填答,反向题重向编码计分:1→5,2→4,3→3【可不写】,4→2,5→1。
Transform(转换)→Recode into same Variables(重新编码为相同变量)→将要反向的题目键入至Variables(变量)框中【例,a1,a3,a5】→Old and new values(旧值和新值)→在左边Old value—value中键入1,在右边New value—value中键入5,Add (添加)→……依次进行此步骤……在左边Old value—value中键入5,在右边New value —value中键入1,Add(添加)→Continue(继续)→OK(确定)【注意不同量表计分方式不同,因而反向编码计分也不同,常见的有四点量表、五点量表和六点量表等】(三)题项加总量表题项加总的目的在于便于进行观察值得高低分组。