dubbo源码解析2.0
- 格式:pdf
- 大小:2.56 MB
- 文档页数:97

(万字好⽂)Dubbo服务熔断与降级的深⼊讲解代码实战原⽂链接:⼀、Dubbo服务降级实战1 mock 机制谈到服务降级,Dubbo 本⾝就提供了服务降级的机制;⽽ Dubbo 的服务降级机制主要是利⽤服务消费者的 mock 属性。
服务消费者的 mock 属性有以下三种使⽤⽅式,下⾯将带着例⼦简单介绍⼀下。
1.1 服务消费者注册url的mock属性例⼦:mock=return+null,即当服务提供者出现异常(宕机或者业务异常),则返回null给服务消费者。
2021-01-26 09:39:54.631 [main] [INFO ] [o.a.d.r.z.ZookeeperRegistry] [] [] - [DUBBO] Notify urls for subscribe url consumer://127.0.0.1/com.winfun.service.DubboServiceOne?application=dubbo-service&category=providers,configurators,routers& 1.2 @DubboReference注解或者标签的mock属性例⼦:mock="return null",即当服务提供者出现异常(宕机或者业务异常),则返回null给服务消费者。
public class HelloController{@DubboReference(check = false,lazy = true,retries = 1,mock = "return null")private DubboServiceOne dubboServiceOne;//.....}1.3 服务消费者mock属性设置为true+Mock实现类例⼦:Mock实现类为 Dubbo接⼝的实现类,并且 Mock实现类与 Dubbo接⼝放同⼀个路径下(可不同项⽬,但是保证包路径是⼀致的)。


Dubbo原理解析-注册中心之Zookeeper协议注册中心下面我们来看下开源dubbo推荐的业界成熟的zookeeper做为注册中心,zookeeper是hadoop的一个子项目是分布式系统的可靠协调者,他提供了配置维护,名字服务,分布式同步等服务。
对于zookeeper的原理本文档不分析,后面有时间在做专题。
zookeeper注册中心Zookeeper对数据存储类似linux的目录结构,下面给出官方文档对dubbo注册数据的存储示例假设读者对zookeeper有所了解,能够搭建zookeeper服务,其实不了解也没关系,谷歌百度下分分钟搞起。
作为测试调试dubbo,我是在本地起的zookeeper指定zookeeper配置文件地址配置文件中两个关键参数:dataDir zookeeper存储文件的地址clientPort 客户端链接的端口号Dubbo服务提供者配置<dubbo:registry protocol=”zookeeper” address="127.0.0. 1:2181" /><beanid="demoService" class="com.alibaba.dubbo.demo.provider.DemoServiceImpl"/><dubbo:serviceinterface="com .alibaba.dubbo.demo.DemoServi ce"ref="demoService"/>除了配置注册中心的,其他都一样Dubbo服务消费者配置<dubbo:registryprotocol=”zookeeper” address="127.0.0. 1:2181"/><dubbo:referenceid="demoService"interface="com.a libaba.dubbo.demo.DemoService"/>除了配置注册中心的,其他都一样客户端获取注册器服务的提供者和消费者在RegistryProtocol利用注册中心暴露(export)和引用(refer)服务的时候会根据配置利用Dubbo的SPI机制获取具体注册中心注册器Registry registry =registryFactory.getRegistry(url);这里的RegistryFactory是ZookeeperRegistryFactory看如下工厂代码public class ZookeeperRegistryFactory extends AbstractRegistryFactory { public Registry createRegistry(URL url) { return new ZookeeperRegistry(url, zookeeperTransporter); }}这里创建zookeepr注册器ZookeeperRegistryZookeeperTransporter是操作zookeepr 的客户端的工厂类,用来创建zookeeper客户端,这里客户端并不是zookeeper源代码的自带的,而是采用第三方工具包,主要来简化对zookeeper的操作,例如用zookeeper做注册中心需要对zookeeper节点添加watcher 做反向推送,但是每次回调后节点的watcher都会被删除,这些客户会自动维护了这些watcher,在自动添加到节点上去。

Dubbo源码解析经过上一篇dubbo源码解析-简单原理、与spring融合的铺垫,我们已经能简单的实现了dubbo的服务引用.其实上一篇中的代码,很多都是从dubbo源码中复制出来,甚至有些类名,变量名都没改.那请问,我为什么要这么做?我认为学习一个框架,无非就三个步骤.•掌握基本使用•看过源码,知道其中原理•临摹源码,自己仿写一个简易的框架其实大家都清楚,编程这东西,最关键是多动手.也就是,第三步才是最关键的.但是现实也是非常残酷的,绝大多数人都停留在第一步.光是第二步,都有些让人产生的心里恐惧.所以在写服务引用的时候,我就想到了小时候看纪晓岚的一个片段.当时红楼梦是禁书,纪晓岚为了让太后看红楼梦,就把红楼梦这个名字换成了石头记.这样太后自然就没有心里负担.我觉得用一个图来描述可能更贴切当然临摹源码的这个过程,依肥朝拙见,也需要分为三个过程,分别是入门版(用最简单的代码表达出框架原理)、进阶版(加入设计模式等思想,在入门版的基础上优化代码)、高级版(和框架代码基本一致).当然上一篇的入门版只是抛砖引玉,等整个dubbo源码解析系列完结之后,和大家一起临摹dubbo源码也在计划当中.当然更多后续进展关注肥朝即可.•描述一下dubbo服务引用的过程,原理•既然你提到了dubbo的服务引用中封装通信细节是用到了动态代理,那请问创建动态代理常用的方式有哪些,他们又有什么区别?dubbo中用的是哪一种?(高频题)•除了JDK动态代理和CGLIB动态代理外,还知不知道其他实现代理的方式?(区分度高)看源码对于大多数人来说,最难的一点莫过于"从源码的哪个地方开始看".虽然我之前数十篇dubbo源码解析都在回答这个问题,但是每发出一篇,都还是有小伙伴私信问我同样的问题.对此,我当然是选择"原谅他".因此,本篇我又再次粗暴式的点题,"怎么看源码".就把本篇来说,这个服务引用的原理,我们要从哪里开始看呢?我们一起看一下官方文档如果你在上一篇中把我贴出来的demo都实现过一遍,再看到这个图,就不难总结出服务引用无非就是做了两件事•将spring的schemas标签信息转换bean,然后通过这个bean 的信息,连接、订阅zookeeper节点信息创建一个invoker •将invoker的信息创建一个动态代理对象温馨提示:除了看官方文档入手,在dubbo源码解析-服务暴露原理中我还提到了从输出日志入手.当然,我这里列举了两种方式只是给你提供参考,并不是说一共就只有这两种方式,也不是说,这两种就是最优的.直入主题有部分朋友反馈说代码贴图手机阅读不友好,但是如果不贴图的话,很多朋友看完文章自己debug的时候找相应的类和方法又要花费大量时间,所以折中一下,贴图和贴代码结合public Invoker refer(Class type, URL url) throws RpcException {url = url.setProtocol(url.getParameter(Constants.REGISTRY_KEY, Constants.DEFAULT_REGISTRY)).removeParameter(Constants.RE GISTRY_KEY);//序号2,这里的逻辑和之前分享的'zookeeper连接'基本一致,不熟悉的可以回去看看Registry registry = registryFactory.getRegistry(url);if (RegistryService.class.equals(type)) {return proxyFactory.getInvoker((T) registry, type, url);}// group="a,b" or group="*"Map qs = StringUtils.parseQueryString(url.getParameterAndDecoded(Con stants.REFER_KEY));String group = qs.get(Constants.GROUP_KEY);if (group != null && group.length() > 0 ) {if( ( MA_SPLIT_PATTERN.split( group ) ).length > 1 || "*".equals( group ) ) {return doRefer( getMergeableCluster(), registry, type, url );}}return doRefer(cluster, registry, type, url);}private Invoker doRefer(Cluster cluster, Registry registry, Class type, URL url) {RegistryDirectory directory = new RegistryDirectory(type, url);directory.setRegistry(registry);directory.setProtocol(protocol);URL subscribeUrl = new URL(Constants.CONSUMER_PROTOCOL, NetUtils.getLocalHost(), 0, type.getName(), directory.getUrl().getParameters());if (! Constants.ANY_VALUE.equals(url.getServiceInterface()) && url.getParameter(Constants.REGISTER_KEY, true)) {registry.register(subscribeUrl.addParameters(Constants.CAT EGORY_KEY, Constants.CONSUMERS_CATEGORY,Constants.CHECK_KEY, String.valueOf(false)));}//序号3,这里的逻辑和之前分享的'zookeeper订阅'基本一致,不熟悉的可以回去看看directory.subscribe(subscribeUrl.addParameter(Constants.C ATEGORY_KEY,Constants.PROVIDERS_CATEGORY+ "," + Constants.CONFIGURATORS_CATEGORY+ "," + Constants.ROUTERS_CATEGORY));//序号4,cluster关键字在集群容错系列也提到过,不熟悉的可以回去看看return cluster.join(directory);}上面的这4步,就完成了schemas标签信息到invoker的转换,那么下面就是创建代理对象了(序号5)private T createProxy(Map map){//......(省略部分代码)// 创建服务代理return (T) proxyFactory.getProxy(invoker);}我们知道,要封装这个通信细节,让用户像以本地调用方式调用远程服务,就必须使用代理,然后说到动态代理,一般我们就想到两种,一种是JDK的动态代理,一种是CGLIB的动态代理,那我们看看两者有什么特点.JDK的动态代理代理的对象必须要实现一个接口,而针对于没有接口的类,则可用CGLIB.要明白两者区别必须要了解原理,之前反复强调,明白了原理自然一通百通.CGLIB其原理也很简单,对指定的目标类生成一个子类,并覆盖其中方法实现增强,但由于采用的是继承,所以不能对final修饰的类进行代理.除了以上两种大家都很熟悉的方式外,其实还有一种方式,就是javassist生成字节码来实现代理(后面会详细讲,dubbo多处用到了javassist).那dubbo究竟用到了哪种方式实现代理呢?我们往下看序号5的结束本篇也接近了尾声.本篇综合性较强,其中涉及到之前的内容本篇将不再重复提及,可根据注释中的标记自行查看.2017即将结束,这一年来,给我的一些感悟就是,任何事情无关大小,只要加上"坚持"二字,都会变得格外的不易.大家都知道,健身房主要赚的就是那些坚持不下去人的钱,我就有一个爱好健身的朋友,他能坚持每天健身,我也问过他"秘诀".他是这样说的别人都是为了做别的事轻易就放弃健身,而我最常和别人说的话是,我要去健身了,不能聚会了这个真实的例子,总结起来也就一句话时间在哪,成就就在哪.其实所谓门槛,能力够了就是门,能力不足就是坎.期待下周的dubbo源码解析继续与你相遇.鉴于本人才疏学浅,不对的地方还望斧正,也欢迎关注我的简书,名称为肥朝。
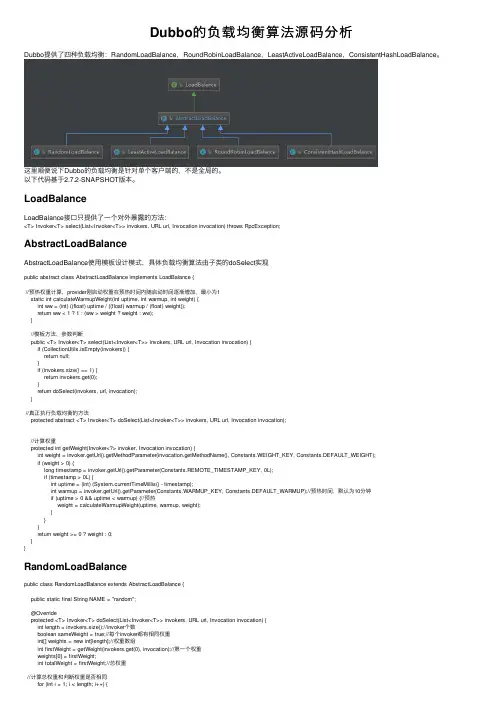
Dubbo的负载均衡算法源码分析Dubbo提供了四种负载均衡:RandomLoadBalance,RoundRobinLoadBalance,LeastActiveLoadBalance,ConsistentHashLoadBalance。
这⾥顺便说下Dubbo的负载均衡是针对单个客户端的,不是全局的。
以下代码基于2.7.2-SNAPSHOT版本。
LoadBalanceLoadBalance接⼝只提供了⼀个对外暴露的⽅法:<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;AbstractLoadBalanceAbstractLoadBalance使⽤模板设计模式,具体负载均衡算法由⼦类的doSelect实现public abstract class AbstractLoadBalance implements LoadBalance {//预热权重计算,provider刚启动权重在预热时间内随启动时间逐渐增加,最⼩为1static int calculateWarmupWeight(int uptime, int warmup, int weight) {int ww = (int) ((float) uptime / ((float) warmup / (float) weight));return ww < 1 ? 1 : (ww > weight ? weight : ww);}//模板⽅法,参数判断public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {if (CollectionUtils.isEmpty(invokers)) {return null;}if (invokers.size() == 1) {return invokers.get(0);}return doSelect(invokers, url, invocation);}//真正执⾏负载均衡的⽅法protected abstract <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation);//计算权重protected int getWeight(Invoker<?> invoker, Invocation invocation) {int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.WEIGHT_KEY, Constants.DEFAULT_WEIGHT);if (weight > 0) {long timestamp = invoker.getUrl().getParameter(Constants.REMOTE_TIMESTAMP_KEY, 0L);if (timestamp > 0L) {int uptime = (int) (System.currentTimeMillis() - timestamp);int warmup = invoker.getUrl().getParameter(Constants.WARMUP_KEY, Constants.DEFAULT_WARMUP);//预热时间,默认为10分钟if (uptime > 0 && uptime < warmup) {//预热weight = calculateWarmupWeight(uptime, warmup, weight);}}}return weight >= 0 ? weight : 0;}}RandomLoadBalancepublic class RandomLoadBalance extends AbstractLoadBalance {public static final String NAME = "random";@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {int length = invokers.size();//invoker个数boolean sameWeight = true;//每个invoker都有相同权重int[] weights = new int[length];//权重数组int firstWeight = getWeight(invokers.get(0), invocation);//第⼀个权重weights[0] = firstWeight;int totalWeight = firstWeight;//总权重//计算总权重和判断权重是否相同for (int i = 1; i < length; i++) {int weight = getWeight(invokers.get(i), invocation);weights[i] = weight;totalWeight += weight;if (sameWeight && weight != firstWeight) {sameWeight = false;}}//权重不相同if (totalWeight > 0 && !sameWeight) {//得到⼀个在[0,totalWeight)的偏移量,然后这个偏移量所在的invokerint offset = ThreadLocalRandom.current().nextInt(totalWeight);for (int i = 0; i < length; i++) {offset -= weights[i];if (offset < 0) {return invokers.get(i);}}}//权重相同,直接随机[0,length)return invokers.get(ThreadLocalRandom.current().nextInt(length));}}RoundRobinLoadBalancepublic class RoundRobinLoadBalance extends AbstractLoadBalance {public static final String NAME = "roundrobin";//循环周期,如果在这个周期内invoker没有被客户端获取,那么该invoker对应的轮询记录将被删除。

Dubbo解析XML的过程1. 概述Dubbo是阿里巴巴开源的一款高性能的Java RPC框架,提供了服务治理、服务容错、负载均衡等功能。
在Dubbo中,XML配置文件是非常重要的一部分,通过XML配置来定义服务接口和各种配置参数。
对于Dubbo框架来说,解析XML配置文件是一个非常关键的过程,本文将深入探讨Dubbo框架是如何解析XML配置的。
2. 加载配置文件Dubbo在启动的时候会加载XML配置文件,这些配置文件通常包含了服务的接口定义、协议配置、注册中心位置区域、服务提供者的配置等信息。
Dubbo会在启动时读取这些配置文件,并将其解析成对应的配置对象。
3. 解析XMLDubbo使用了基于XSD的XML Schema来定义配置文件的结构,可以通过XSD文件来验证XML配置文件的合法性。
Dubbo框架内部使用了一些类来进行XML解析的工作,其中包括了XML文档解析器、元素解析器等。
4. 创建对象模型在XML解析的过程中,Dubbo会将解析得到的配置信息转化成对应的Java对象模型。
对于服务接口的定义,Dubbo会创建对应的接口描述对象;对于协议配置,Dubbo会创建对应的协议配置对象。
5. 配置参数赋值一旦XML配置文件被成功解析成对象模型,Dubbo会将这些对象模型中的配置参数赋值给对应的组件。
将服务接口描述对象中的接口名称赋值给服务接口代理对象。
6. 注册配置解析XML配置文件的最后一步是将解析得到的配置信息注册到Dubbo框架中。
这个过程包括了将服务接口注册到服务接口管理器、将协议配置注册到协议管理器、将注册中心位置区域注册到注册中心管理器等。
7. 总结在Dubbo框架中,XML配置文件的解析是一个非常重要的过程,它直接影响着整个Dubbo框架的运行。
通过本文的介绍,希望读者能够更加深入地了解Dubbo是如何解析XML配置文件的。
同时也能够更好地理解Dubbo框架的内部工作原理,为使用和定制Dubbo框架提供参考和帮助。

Dubbo服务发现源码解析模块源码模块⼀、⼀、源码1.1 源码模块组织Dubbo⼯程是⼀个Maven多Module的项⽬,以包结构来组织各个模块。
核⼼模块及其关系,如图所⽰:1.2 模块说明dubbo-common 公共逻辑模块,包括Util类和通⽤模型。
dubbo-remoting 远程通讯模块,相当于Dubbo协议的实现,如果RPC⽤RMI协议则不需要使⽤此包。
dubbo-rpc 远程调⽤模块,抽象各种协议,以及动态代理,只包含⼀对⼀的调⽤,不关⼼集群的管理。
dubbo-cluster 集群模块,将多个服务提供⽅伪装为⼀个提供⽅,包括:负载均衡、容错、路由等,集群的地址列表可以是静态配置的,也可以是由注册中⼼下发。
dubbo-registry 注册中⼼模块,基于注册中⼼下发地址的集群⽅式,以及对各种注册中⼼的抽象。
dubbo-monitor 监控模块,统计服务调⽤次数,调⽤时间的,调⽤链跟踪的服务。
dubbo-config 配置模块,是Dubbo对外的API,⽤户通过Config使⽤Dubbo,隐藏Dubbo所有细节。
dubbo-container 容器模块,是⼀个Standalone的容器,以简单的Main类加载Spring启动,因为服务通常不需要Tomcat/JBoss等Web容器的特性,没必要⽤Web容器去加载服务。
因为服务通常不需要 Tomcat/JBoss 等 Web 容器的特性,没必要⽤ Web 容器去加载服务。
⼆、服务发现Dubbo的应⽤会在启动时完成服务注册或订阅(不论是⽣产者,还是消费者)如下图所⽰。
图中⼩⽅块Protocol, Cluster, Proxy, Service, Container, Registry, Monitor代表层或模块,蓝⾊的表⽰与业务有交互,绿⾊的表⽰只对Dubbo内部交互。
图中背景⽅块Consumer, Provider, Registry, Monitor代表部署逻辑拓普节点。
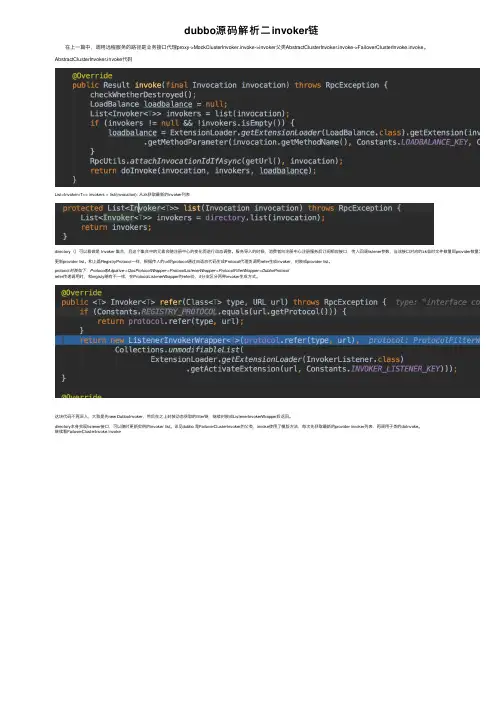
dubbo源码解析⼆invoker链 在上⼀篇中,调⽤远程服务的路径是业务接⼝代理proxy->MockClusterInvoker.invoke->invoker⽗类AbstractClusterInvoker.invoke->FailoverClusterInvoke.invoke。
AbstractClusterInvoker.invoke代码List<Invoker<T>> invokers = list(invocation); 从zk获取最新的invoker列表directory()可以看做是 Invoker 集合,且这个集合中的元素会随注册中⼼的变化⽽进⾏动态调整。
服务导⼊的时候,消费者向注册中⼼注册服务后订阅相应接⼝,传⼊回调listener参数,当该接⼝对应的zk临时⽂件数量即provider数量发⽣变化时,z 更新provider list。
和上篇RegistryProtocol⼀样,根据传⼊的url的protocol通过⾃适应代码⽣成Protocol代理类调⽤refer⽣成invoker,封装成provider list。
protocol封装如下:Protocol$Adpative->QosProtocolWrapper->ProtocolListenerWrapper->ProtocolFilterWrapper->DubboProtocolrefer传递调⽤时,和registy略有不⼀样,在ProtocolListenerWrapper的refer处,if分⽀区分两种invoker⽣成⽅式。
这块代码不再深⼊,⼤致是先new DubboInvoker,然后在之上封装动态获取的filter链,继续封装成ListenerInvokerWrapper后返回。
directory本⾝实现listener接⼝,可以随时更新实例的invoker list。

Dubbo源码解析(⼀)DubboSPIDubbo 扩展机制 SPI在 Dubbo 中,SPI 贯穿在整个 Dubbo 的核⼼。
所以有必要先对 Dubbo 中 SPI 做⼀个详细的介绍。
JDK SPI之前写过⼀篇介绍,可以点击查看。
Dubbo SPIDubbo 实现了⾃⼰的 SPI 机制除了可以配置在 META-INF/services ⽬录下,还可以配置在 META-INF/dubbo 和 META-INF/dubbo/internal配置⽂件内容采⽤ key=value 的形式。
这样可以按需实例化加载类,⽽不⽤像 JDK ⼀样在启动时⼀次性加载实例化扩展点的所有实现,浪费性能。
出现异常时可以更准确定位增加了对 Duboo ⾃⼰实现的 IOC 和 AOP 的⽀持源码解析这⾥使⽤的版本是 dubbo-2.6.4这⾥的分析流程是根据例⼦来分析内部源码的实现注意,在阅读下⾯的源码解析时,有些跟当前流程⽆关的代码我会标注忽略点 - X,表⽰这段代码先跳过,不影响当前流程,且在后⾯⽤到的地⽅我会再重新解释该忽略点的意思。
1、Dubbo SPI 的基本⽰例接⼝,注意加 @SPI 注解@SPIpublic interface Robot {void sayHello();}实现类public class MIRobot implements Robot {@Overridepublic void sayHello() {System.out.println("⼤家好,我是⼩⽶机器⼈...");}}在⽂件夹 resources/META-INF/services 下添加配置⽂件,⽂件名 com.lin.spi.Robot(接⼝的路径)⽂件内容miRobot = com.lin.spi.MIRobot在测试类中调⽤public class DubboSPITest {@Testpublic void test() {ExtensionLoader<Robot> extensionLoader =ExtensionLoader.getExtensionLoader(Robot.class);Robot miRobot = extensionLoader.getExtension("miRobot");miRobot.sayHello();}}输出⼤家好,我是⼩⽶机器⼈...Process finished with exit code 0上⾯就是 Dubbo SPI 的基本使⽤,接下来开始源码分析。

Dubbo源码分析(六)Dubbo通信的编码解码机制TCP的粘包拆包问题我们知道Dubbo的⽹络通信框架Netty是基于TCP协议的,TCP协议的⽹络通信会存在粘包和拆包的问题,先看下为什么会出现粘包和拆包当要发送的数据⼤于TCP发送缓冲区剩余空间⼤⼩,将会发⽣拆包待发送数据⼤于MSS(最⼤报⽂长度),TCP在传输前将进⾏拆包要发送的数据⼩于TCP发送缓冲区的⼤⼩,TCP将多次写⼊缓冲区的数据⼀次发送出去,将会发⽣粘包接收数据端的应⽤层没有及时读取接收缓冲区中的数据,将发⽣粘包以上四点基本上是出现粘包和拆包的原因,业界的解决⽅法⼀般有以下⼏种:将每个数据包分为消息头和消息体,消息头中应该⾄少包含数据包的长度,这样接收端在接收到数据后,就知道每⼀个数据包的实际长度了(Dubbo就是这种⽅案)消息定长,每个数据包的封装为固定长度,不够补0在数据包的尾部设置特殊字符,⽐如FTP协议Dubbo消息协议头规范在dubbo.io官⽹上找到⼀张图,协议头约定dubbo的消息头是⼀个定长的 16个字节的数据包:magic High & Magic Low:2byte:0-7位 8-15位:类似java字节码⽂件⾥的魔数,⽤来判断是不是dubbo协议的数据包,就是⼀个固定的数字Serialization id:1byte:16-20位:序列id,21 event,22 two way ⼀个标志位,是单向的还是双向的,23 请求或响应标识,status:1byte: 24-31位:状态位,设置请求响应状态,request为空,response才有值Id(long):8byte:32-95位:每⼀个请求的唯⼀识别id(由于采⽤异步通讯的⽅式,⽤来把请求request和返回的response对应上)data length:4byte:96-127位:消息体长度,int 类型看完这张图,⼤致可以理解Dubbo通信协议解决的问题,Dubbo采⽤消息头和消息体的⽅式来解决粘包拆包,并在消息头中放⼊了⼀个唯⼀Id来解决异步通信关联request和response的问题,下⾯以⼀次调⽤为⼊⼝分为四个部分来看下源码具体实现Comsumer端请求编码private class InternalEncoder extends OneToOneEncoder {@Overrideprotected Object encode(ChannelHandlerContext ctx, Channel ch, Object msg) throws Exception {com.alibaba.dubbo.remoting.buffer.ChannelBuffer buffer =com.alibaba.dubbo.remoting.buffer.ChannelBuffers.dynamicBuffer(1024);NettyChannel channel = NettyChannel.getOrAddChannel(ch, url, handler);try {codec.encode(channel, buffer, msg);} finally {NettyChannel.removeChannelIfDisconnected(ch);}return ChannelBuffers.wrappedBuffer(buffer.toByteBuffer());}}这个InternalEncoder是⼀个NettyCodecAdapter的内部类,我们看到codec.encode(channel, buffer, msg)这⾥,这个时候codec=DubboCountCodec,这个是在构造⽅法中传⼊的,DubboCountCodec.encode-->ExchangeCodec.encode-->ExchangeCodec.encodeRequestprotected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {//获取序列化⽅式,默认是Hessian序列化Serialization serialization = getSerialization(channel);// new了⼀个16位的byte数组,就是request的消息头byte[] header = new byte[HEADER_LENGTH];// 往消息头中set magic数字,这个时候header中前2个byte已经填充Bytes.short2bytes(MAGIC, header);// set request and serialization flag.第三个byte已经填充header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());if (req.isTwoWay()) header[2] |= FLAG_TWOWAY;if (req.isEvent()) header[2] |= FLAG_EVENT;// set request id.这个时候是0Bytes.long2bytes(req.getId(), header, 4);// 编码 request data.int savedWriteIndex = buffer.writerIndex();buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);//序列化ObjectOutput out = serialization.serialize(channel.getUrl(), bos);if (req.isEvent()) {encodeEventData(channel, out, req.getData());} else {//编码消息体数据encodeRequestData(channel, out, req.getData());}out.flushBuffer();bos.flush();bos.close();int len = bos.writtenBytes();checkPayload(channel, len);//在消息头中设置消息体长度Bytes.int2bytes(len, header, 12);// writebuffer.writerIndex(savedWriteIndex);buffer.writeBytes(header); // write header.buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);}就是这⽅法,对request请求进⾏了编码操作,具体操作我写在代码的注释中,就是刚刚我们分析的消息头的代码实现Provider端请求解码看到NettyCodecAdapter中的InternalDecoder这个类的messageReceived⽅法,这⾥就是Provider端对于Consumer端的request请求的解码public void messageReceived(ChannelHandlerContext ctx, MessageEvent event) throws Exception {···try {// decode object.do {saveReaderIndex = message.readerIndex();try {msg = codec.decode(channel, message);} catch (IOException e) {buffer = com.alibaba.dubbo.remoting.buffer.ChannelBuffers.EMPTY_BUFFER;throw e;}···进⼊DubboCountCodec.decode--ExchangeCodec.decode// 检查 magic number.if (readable > 0 && header[0] != MAGIC_HIGH···}// check 长度如果⼩于16位继续等待if (readable < HEADER_LENGTH) {return DecodeResult.NEED_MORE_INPUT;}// get 消息体长度int len = Bytes.bytes2int(header, 12);checkPayload(channel, len);//消息体长度+消息头的长度int tt = len + HEADER_LENGTH;//如果总长度⼩于tt,那么返回继续等待if (readable < tt) {return DecodeResult.NEED_MORE_INPUT;}// limit input stream.ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);try {//解析消息体内容return decodeBody(channel, is, header);} finally {···}这⾥对于刚刚的request进⾏解码操作,具体操作步骤写在注释中了Provider端响应编码当服务端执⾏完接⼝调⽤,看下服务端的响应编码,和消费端不⼀样的地⽅是,服务端进⼊的是ExchangeCodec.encodeResponse⽅法try {//获取序列化⽅式默认Hession协议Serialization serialization = getSerialization(channel);// 初始化⼀个16位的headerbyte[] header = new byte[HEADER_LENGTH];// set magic 数字Bytes.short2bytes(MAGIC, header);// set request and serialization flag.header[2] = serialization.getContentTypeId();if (res.isHeartbeat()) header[2] |= FLAG_EVENT;// set response status.这⾥返回的是OKbyte status = res.getStatus();header[3] = status;// set request id.Bytes.long2bytes(res.getId(), header, 4);int savedWriteIndex = buffer.writerIndex();buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);ObjectOutput out = serialization.serialize(channel.getUrl(), bos);// 编码返回消息体数据或者错误数据if (status == Response.OK) {if (res.isHeartbeat()) {encodeHeartbeatData(channel, out, res.getResult());} else {encodeResponseData(channel, out, res.getResult());}} else out.writeUTF(res.getErrorMessage());out.flushBuffer();bos.flush();bos.close();int len = bos.writtenBytes();checkPayload(channel, len);Bytes.int2bytes(len, header, 12);// writebuffer.writerIndex(savedWriteIndex);buffer.writeBytes(header); // write header.buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);} catch (Throwable t) {// 发送失败信息给Consumer,否则Consumer只能等超时了if (!res.isEvent() && res.getStatus() != Response.BAD_RESPONSE) {try {// FIXME 在Codec中打印出错⽇志?在IoHanndler的caught中统⼀处理?logger.warn("Fail to encode response: " + res + ", send bad_response info instead, cause: " + t.getMessage(), t);Response r = new Response(res.getId(), res.getVersion());r.setStatus(Response.BAD_RESPONSE);r.setErrorMessage("Failed to send response: " + res + ", cause: " + StringUtils.toString(t));channel.send(r);return;} catch (RemotingException e) {logger.warn("Failed to send bad_response info back: " + res + ", cause: " + e.getMessage(), e);}}// 重新抛出收到的异常···}基本上和消费⽅请求编码⼀样,多了⼀个步骤,⼀个是在消息头中加⼊了⼀个状态位,第⼆个是如果发送有异常,则继续发送失败信息给Consumer,否则Consumer只能等超时了Conmsuer端响应解码和上⾯的解码⼀样,具体操作是在ExchangeCodec.decode--DubboCodec.decodeBody中。

【Dubbo源码解析】05_Dubbo服务发现引⽤Dubbo 服务发现&引⽤Dubbo 引⽤的服务消费者最终会构造成⼀个 Spring 的 Bean,具体是通过ReferenceBean来实现的。
它是⼀个 FactoryBean,所有的服务消费者 Bean 都通过它来⽣产。
ReferenceBean#getObject() --> ReferenceConfig#get()ReferenceConfig 最终会创建⼀个动态代理类返回:private T createProxy(Map<String, String> map) {......// assemble URL from register center's configuration// 从注册中⼼的配置组装 URL(服务发现)List<URL> us = loadRegistries(false);if (us != null && !us.isEmpty()) {for (URL u : us) {URL monitorUrl = loadMonitor(u);if (monitorUrl != null) {map.put(Constants.MONITOR_KEY, URL.encode(monitorUrl.toFullString()));}urls.add(u.addParameterAndEncoded(Constants.REFER_KEY, StringUtils.toQueryString(map)));}}......if (urls.size() == 1) {// 创建 Invokerinvoker = refprotocol.refer(interfaceClass, urls.get(0));} else {List<Invoker<?>> invokers = new ArrayList<Invoker<?>>();URL registryURL = null;for (URL url : urls) {invokers.add(refprotocol.refer(interfaceClass, url));if (Constants.REGISTRY_PROTOCOL.equals(url.getProtocol())) {registryURL = url; // use last registry url}}if (registryURL != null) { // registry url is available// use AvailableCluster only when register's cluster is availableURL u = registryURL.addParameter(Constants.CLUSTER_KEY, );// 当服务提供者有多个时,就创建⼀个 ClusterInvokerinvoker = cluster.join(new StaticDirectory(u, invokers));} else { // not a registry urlinvoker = cluster.join(new StaticDirectory(invokers));}}......// create service proxyreturn (T) proxyFactory.getProxy(invoker);}服务发现dubbo 的服务发现,是通过从注册中⼼订阅服务提供者组装成 URL,然后通过 URL 创建出 Invoker 来实现的。
Dubbo入门——Dubbo原理详解Dubbo背景和简介官网:/zh-cn/Dubbo开始于电商系统,因此在这里先从电商系统的演变讲起。
1.单一应用框架(ORM)2.当网站流量很小时,只需一个应用,将所有功能如下单支付等都部署在一起,以减少部署节点和成本。
3.缺点:单一的系统架构,使得在开发过程中,占用的资源越来越多,而且随着流量的增加越来越难以维护单一应用框架1.垂直应用框架(MVC)2.垂直应用架构解决了单一应用架构所面临的扩容问题,流量能够分散到各个子系统当中,且系统的体积可控,一定程度上降低了开发人员之间协同以及维护的成本,提升了开发效率。
3.缺点:但是在垂直架构中相同逻辑代码需要不断的复制,不能复用。
垂直应用框架1.分布式应用架构(RPC)2.当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心1.流动计算架构(SOA)2.随着服务化的进一步发展,服务越来越多,服务之间的调用和依赖关系也越来越复杂,诞生了面向服务的架构体系(SOA),也因此衍生出了一系列相应的技术,如对服务提供、服务调用、连接处理、通信协议、序列化方式、服务发现、服务路由、日志输出等行为进行封装的服务框架从以上是电商系统的演变可以看出架构演变的过程:流动计算架构(SOA)•单一应用架构•当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。
•此时,用于简化增删改查工作量的数据访问框架(ORM) 是关键。
•垂直应用架构•当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。
•此时,用于加速前端页面开发的 Web框架(MVC) 是关键。
•分布式服务架构•当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
•此时,用于提高业务复用及整合的分布式服务框架(RPC) 是关键。
dubbo源码分析5(dubbo服务暴露⼊⼝) 经过了前⾯这么多的铺垫,没错,前⾯说了这么⼀⼤堆的都是铺垫,我们说了spi,以及基于spring的扩展,这⼀篇就开始说说dubbo 吧!1.dubbo的配置⽂件解析 在的时候,我们运⾏了dubbo2.7.5(注意版本)的源码中的demo,我们可以看看服务提供者的配置⽂件,下⾯红⾊框框中应该不陌⽣了吧,嘿嘿( ̄▽ ̄)ノ 然后我们,去找到对应的命名空间处理器,下图所⽰; 所以我们就能知道命名空间处理器是DubboNamespaceHandler,⽽且我们还能看到⼀些有意思的东西,由于dubbo已经被阿⾥给贡献到开源社区apache了,所以这⾥还保留了之前ali的命名空间,我们也能继续使⽤,嘿嘿 ⾃⼰有兴趣的话,可以⾃⼰看看下图中的spring.schemas⽂件以及对应的xsd⽂件了,看看这个xsd⽂件就能知道dubbo的每个标签都有些什么属性了(我表⽰没有这么⼤的兴趣乛◡乛,你们⾃⼰看,哈哈哈) 继续看看这个DubboNamespaceHandler中,下图所⽰,我们随便看⼀秒钟就能知道dubbo的配置⽂件中,跟dubbo相关的标签就是这么14个,⽽且解析每个标签的解析起都是DubboBeanDefinitionParser去解析成BeanDefinition对象,只不过每个BeanDefinition⾥⾯封装的对象不⼀样罢了 这么多标签我们说哪⼀个呢?先说说我最感兴趣的⼀个标签<dubbo:service />, ⼤家知道这个标签是⼲啥的么,咱们后⾯慢慢看2.分布式服务基础 在说明<dubbo:service />标签的作⽤之前,我们先说说为什么要有远程调⽤?或者说dubbo在分布式架构中使⽤的位置,下⾯就⽤于给萌新科普⼀下,嘿嘿~ 下图所⽰是我们看到的⼀个很经典的后端MVC三层结构, 这个应该都很熟悉了,⽽且这⾥后端的那三层都是在同⼀个机器上; 那么问题来了,如果我要将service层放在另外⼀台机器上,你觉得Controller调⽤Service怎么做会⽐较好?下⾯有两种⽅式 ⽅式⼀:我们在另外⼀台机器B上搭建⼀套MVC结构,注意,此时的机器B上的Controller中没有任何逻辑代码,就只是单纯的暴露⼀个机器B的⼊⼝,所以下⾯的步骤2可以直接使⽤Http请求去调⽤,⽐如使⽤Feign,HttpClient等http⼯具,聪明的⼈已经知道了,这特喵的就是springcloud的远程调⽤的⽅式嘛(╯-╰)/ ⽅式⼆,我们在机器B中,完全不需要Controller层,不就是两台机器通信么?⼤家知道java的⽹络编程吧,直接使⽤Socket建⽴⽹络通信就ok了; 我们现在使⽤dubbo就是⽤于实现下⾯的步骤2,更通俗的理解就是封装了java的⽹络编程(其实就是封装了netty框架),使得两台服务器之间可以进⾏远程调⽤,⽽不需要使⽤http请求的⽅式了; ⽅式2优化:但是由于我们的机器B可能有很多台,我们总不能在机器A中每次调⽤B机器的接⼝的时候,都要知道B的ip和端⼝吧?那多坑爹呀! 所以我们在机器B1和机器B2启动的时候,需要将机器B1和机器B2的接⼝信息(ip+端⼝+接⼝+⽅法+版本等信息)都放到注册中⼼(如下图的步骤1和步骤2),然后机器A从注册中⼼中将所有接⼝信息都给下载下(步骤3),然后决定去调⽤哪个机器上的服务(这⾥会涉及到负载均衡策略); 所以前端调⽤机器A,机器A根据调⽤的接⼝就可以找到对应接⼝所在的机器是B2(步骤5),然后通过⽹络编程去连接机器B2就好了 在这⾥机器A就是服务消费者,机器B1和机器B2就是服务提供者;3.dubbo服务提供者暴露服务⼊⼝ 在上⾯我们知道了,dubbo其实就是解决⼀台机器去远程调⽤另外⼀台机器的接⼝,⽽且还将服务暴露到注册中⼼⾥,并提供负载均衡策略的远程调⽤框架; 那么在dubbo中什么叫做服务呀?我们看看服务提供者的配置⽂件,下图所⽰⼀个<dubbo:service>标签就对应着⼀个服务接⼝,这个接⼝的信息需要暴露到注册中⼼的; 业余⼩知识:可以思考⼀下,下图中这个接⼝只会暴露到注册中⼼中去么?(肯定是暴露到注册中⼼中⼀份,也会暴露⼀份到当前所在机器的jvm中呀!为什么呢?因为也有可能当前机器中其他的服务会使⽤到这个demoService服务呀,同⼀台机器上就不必⾛注册中⼼,肯定直接⾛jvm会更快呀) 所以我们⼜可以知道暴露服务,可以分为本地暴露和远程暴露嘛!当然,我们主要看的是远程暴露吧,哈哈哈哈乛◡乛 下⾯我们就看看是怎么解析这个<dubbo:service>标签的过程 3.1.DubboNamespaceHandler 这⾥就是缓存了dubbo每⼀个标签所对应的⼀个解析器,当实际去解析<dubbo:service>标签的时候,就会从缓存中获取解析起,new DubboBeanDefinitionParser(ServiceBean.class, true),然后调⽤这个解析起的parse⽅法 这⾥,继续科普⼀下,在spring中的BeanDefinition的作⽤:对xml⽂件中每⼀个bean的⼀个统⼀的抽象,简单来说就是⾸先会将所有解析的bean都变成BeanDefinition<T>对象,然后后⾯统⼀对所有的BeanDefinition进⾏实例化真正对象T,可以看看这个,很清晰,嘿嘿(╯-╰)/ 3.2 DubboBeanDefinitionParser的parse⽅法 这个⽅法很长,我们只看解析ServiceBean的地⽅ 在看这个⽅法之前,继续强调⼀点,这⾥只是封装了BeanDefinition<ServiceBean>这种对象,在spring的机制中,后续才会真正的根据BeanDefinition去实例化出ServiceBean对象的(你要问spring中到底是哪⾥会实例化的,这个要⾃⼰去学习了,这⾥只是粗略的带过⼀下,这⾥重点还是dubbo) 看到这⾥,暂时不往后看了,后⾯⼀堆逻辑容易头晕,趁着头脑还很冷静,我们看点清神醒脑的 3.3.实例化ServiceBean对象 在spring的后续初始化流程中,会对所有BeanDefinition中封装的实际的对象进⾏实例化,其中⼀个就是ServcieBean,我们看看ServiceBean是个什么东东( ̄o ̄) . z Z 这⾥请注意dubbo2.7.5之前和2.7.5之后的版本,变化很⼤很⼤,⽹上很多的ServcieBean的解析的博客都是2.7.5之前的,远古版本的了,我也在试着查了⼀些资料,尝试总结⼀下吧o(︶︿︶)o 3.3.1 先看看2.7.5之前 我把代码图和类的继承图都给出来,这⾥简单说⼀下spring中的原理,就不仔细看源码了 实现了InitializingBean和ApplicationListener接⼝的bean实例化的时候会做的事情,就是⼀个Bean⾸先在xml中进⾏配置,然后spring 的容器在初始化的时候,会⾸先经过加载编程BeanDefinition对象,然后进⾏实例化BeanDefinition中实际的类型,这⾥实际的类型就是ServiceBean,在创建了⼀个ServiceBean对象之后,设置属性值,然后就是对ServiceBean进⾏初始化操作:会判断是否实现了InitializingBean接⼝,实现了的话,就会执⾏afterPropertiesSet⽅法先初始化⼀下,然后会判断ServcieBean有没有初始化⽅法,就是配置⽂件中<bean>标签指定的init-method⽅法, 执⾏init-method⽅法之后,后续还有可能执⾏其他的各种对bean和容器的初始化操作,在经过了九九⼋⼗⼀难之后,ioc容器和bean都会初始化完毕,此时ioc容器会判断所有实例化之后的bean有没有实现ApplicationListener接⼝,进⽽去执⾏每个bean的onApplicationEvent⽅法,此时ServiceBean就会去执⾏onApplicationEvent()⽅法,实际的去开始暴露⾃⼰服务 3.3.2 dubbo2.7.5的版本 我们看看代码和类图,很明显已经看不到那个EventListener接⼝了,那么我们就要看看这⾥是怎么暴露服务的 dubbo2.7.5提供了⼀个类DubboBootstrap类,这只是⼀个普通的监听器,但是⾥⾯有⼀个start⽅法,这⾥会调⽤exportServices()⽅法,然后就会去调⽤ServiceConfig的export()⽅法(注意,serviceBean是ServiceConfig的⼀个⼦类),其实就可以看做会调⽤我们ServiceBean的export()⽅法,进⾏服务的暴露 那么我们再看看从哪⾥调⽤的这个DubboBootstrap的start()⽅法,那么我们就知道所有流程了,下⾯再贴⼏段代码 我们理⼀下思路,其实spring的初始化流程跟2.7.5之前是⼀样的,只不过在最后ioc和bean初始化完成之后,spring容器开始发布事件,在ioc容器中所有的实现了ApplicationListener接⼝的bean,⾸先会执⾏OneTimeExecutionApplicationContextEventListener的onApplicationEvent()⽅法,在这个⽅法⾥⾯再执⾏DubboBootstrapApplicationListener的onApplicationContextEvent()⽅法,在这⽅法⾥⾯会执⾏当前类的onContextRefreshedEvent()⽅法,最后就是执⾏dubboBootstrap.start();开始开始暴露服务4.总结 这篇博客其实就是说了我们从哪个⾓度去切⼊到dubbo框架中,说的东西很少,但是⾮常⾮常重要,只有找到了切⼊点之后,我们才可以痛快的继续往后⾛,不然学了⼀下就忘了,特喵的,以后每次都要看⼀遍,多⿇烦呀! 只要跟着我这⾥往后⾛,以后想看哪⾥点哪⾥,就不⽤百度了,哈哈哈哈 其实本篇要说的最重要的就是dubbo的2.7.5版本,与之前相⽐暴露服务的⽅式做了很⼤的改变,使⽤到了⼀个DubboBootstarp启动器,在spring容器初始化完成之后,会发布对应的事件然后会带着dubbo的启动器也会跑起来,从中我们也可以看出来spring的扩展性是真的厉害,dubbo也设计的⾮常巧妙,哈哈哈哈 下⼀篇真正的看看暴露服务的逻辑吧( ̄▽ ̄)ノ。
Dubbo源码安装与编译源码地址:需要提前准备好 Maven 环境,相关准备⽅法请看:我这⾥通过 github 的客户端⼯具下载到了下⾯⽬录。
/Users/ghj1976/project/github/alibaba/dubbo在dubbo的根⽬录下,执⾏ mvn install注意,这⾥执⾏的是,跳过测试。
mvn install -Dmaven.test.skip=truemvn install 在本地Repository中安装jar参考:当第⼀次运⾏ maven 命令的时候,你需要 Internet 连接,因为它要从⽹上下载⼀些⽂件。
那么它从哪⾥下载呢?它是从 maven 默认的远程库(/maven2) 下载的。
这个远程库有 maven 的核⼼插件和可供下载的 jar ⽂件。
但是不是所有的 jar ⽂件都是可以从默认的远程库下载的,⽐如说我们⾃⼰开发的项⽬。
这个时候,有两个选择:要么在公司内部设置定制库,要么⼿动下载和安装所需的jar⽂件到本地库。
本地库是指 maven 下载了插件或者 jar ⽂件后存放在本地机器上的拷贝。
在 Linux 上,它的位置在 ~/.m2/repository,在 Windows XP 上,在 C:\Documents and Settings\username\.m2\repository ,在 Windows 7 上,在 C:\Users\username\.m2\repository。
当 maven 查找需要的jar ⽂件时,它会先在本地库中寻找,只有在找不到的情况下,才会去远程库中找。
运⾏下⾯的命令能把我们的 helloworld 项⽬安装到本地库:$mvn install⼀旦⼀个项⽬被安装到了本地库后,你别的项⽬就可以通过 maven 坐标和这个项⽬建⽴依赖关系。
⽐如如果我现在有⼀个新项⽬需要⽤到helloworld,那么在运⾏了上⾯的 mvn install 命令后,我就可以如下所⽰来建⽴依赖关系:<dependency> <groupId>com.mycompany.helloworld</groupId> <artifactId>helloworld</artifactId> <version>1.0-SNAPSHOT</version> </dependency> 参考:我们 ~/.m2/repository ⽂件的⽬录如下:dubbo 项⽬的也在这⾥:创建idea项⽬:mvn idea:ideamvn idea:idea我们也会看到类似的成功标⽰。
DolphinScheduler2.0.0源码分析过程(01)今天这篇⽂章分析⼀下DolphinScheduler2.0.0 版本的源码关于如何搭建DolphinScheduler2.0.0源码分析环境,可以参考官⽅⽹站和我之前的⽂章。
下⾯开始分析:第⼀步:先在idea启动ApiApplicationServer和MasterServer进程和WorkerServer进程。
第⼆步:启动前端程序,切换到dolphinscheduler-ui⼦⽂件夹下,⽤cmd运⾏npm run start第三步:⽤浏览器打开localhost:8888,输⼊⽤户名密码登录。
初始的⽤户名密码是: dolphinscheduler / dolphinscheduler123进去后,新建⼀个项⽬如下第四步:创建⼀个新⼯作流第五步:切换到后台mysql数据库,看⼀下此时数据库的情况:打开t_ds_task_definition表,查看⼀下,信息保存如下:第六步:上线刚才的任务进⾏运⾏看⼀下提交之后,后台MasterServer进程的⽇志输出情况:[INFO] 2021-11-23 11:43:00.387 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[1162] - remove task from stand by list, id: 1 name:test_shell[INFO] 2021-11-23 11:43:00.392 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[291] - process event: State Event :key: null type: TASK_STATE_CHANGE executeStatus: FAILURE task instance id: 1 process [INFO] 2021-11-23 11:43:00.397 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[369] - work flow 1 task 1 state:FAILURE[INFO] 2021-11-23 11:43:00.397 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[1146] - add task to stand by list: test_shell[INFO] 2021-11-23 11:43:00.397 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[376] - failure task will be submitted: process id: 1, task instance id: 1 state:FAILURE retry times:0 / 1, interval:30[INFO] 2021-11-23 11:44:00.038 org.apache.dolphinscheduler.service.quartz.ProcessScheduleJob:[74] - scheduled fire time :Tue Nov 23 11:44:00 CST 2021, fire time :Tue Nov 23 11:44:00 CST 2021, process id :1[INFO] 2021-11-23 11:44:00.917 org.apache.dolphinscheduler.server.master.runner.MasterSchedulerService:[243] - find command 2, slot:0 :[INFO] 2021-11-23 11:44:00.918 org.apache.dolphinscheduler.server.master.runner.MasterSchedulerService:[186] - find one command: id: 2, type: SCHEDULER[INFO] 2021-11-23 11:44:00.936 org.apache.dolphinscheduler.server.master.runner.MasterSchedulerService:[209] - handle command end, command 2 process 2 start...[INFO] 2021-11-23 11:44:00.951 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[1146] - add task to stand by list: test_shell[INFO] 2021-11-23 11:44:00.954 org.apache.dolphinscheduler.service.process.ProcessService:[1093] - start submit task : test_shell, instance id:2, state: RUNNING_EXECUTION[INFO] 2021-11-23 11:44:00.966 org.apache.dolphinscheduler.service.process.ProcessService:[1106] - end submit task to db successfully:2 test_shell state:SUBMITTED_SUCCESS complete, instance id:2 state: RUNNING_EXECUTION [INFO] 2021-11-23 11:44:00.967 monTaskProcessor:[120] - task ready to submit: TaskInstance{id=2, name='test_shell', taskType='SHELL', processInstanceId=2, processInstanceNam [ERROR] 2021-11-23 11:44:00.981 monTaskProcessor:[334] - tenant not exists,process instance id : 2,task instance id : 2[INFO] 2021-11-23 11:44:00.993 monTaskProcessor:[130] - master submit success, task : test_shell[ERROR] 2021-11-23 11:44:00.993 org.apache.dolphinscheduler.server.master.consumer.TaskPriorityQueueConsumer:[116] - dispatcher task errorng.NullPointerException: nullat org.apache.dolphinscheduler.server.master.consumer.TaskPriorityQueueConsumer.dispatch(TaskPriorityQueueConsumer.java:131)at org.apache.dolphinscheduler.server.master.consumer.TaskPriorityQueueConsumer.run(TaskPriorityQueueConsumer.java:100)[INFO] 2021-11-23 11:44:00.997 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[1162] - remove task from stand by list, id: 2 name:test_shell[INFO] 2021-11-23 11:44:01.000 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[291] - process event: State Event :key: null type: TASK_STATE_CHANGE executeStatus: FAILURE task instance id: 2 process [INFO] 2021-11-23 11:44:01.002 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[369] - work flow 2 task 2 state:FAILURE[INFO] 2021-11-23 11:44:01.003 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[1146] - add task to stand by list: test_shell[INFO] 2021-11-23 11:44:01.003 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[376] - failure task will be submitted: process id: 2, task instance id: 2 state:FAILURE retry times:0 / 1, interval:30再过⼀分钟,再次调⽤的时候,再次输出新⽇志如下:[INFO] 2021-11-23 11:45:00.079 org.apache.dolphinscheduler.service.quartz.ProcessScheduleJob:[74] - scheduled fire time :Tue Nov 23 11:45:00 CST 2021, fire time :Tue Nov 23 11:45:00 CST 2021, process id :1[INFO] 2021-11-23 11:45:00.657 org.apache.dolphinscheduler.server.master.runner.MasterSchedulerService:[243] - find command 3, slot:0 :[INFO] 2021-11-23 11:45:00.657 org.apache.dolphinscheduler.server.master.runner.MasterSchedulerService:[186] - find one command: id: 3, type: SCHEDULER[INFO] 2021-11-23 11:45:00.748 org.apache.dolphinscheduler.server.master.runner.MasterSchedulerService:[209] - handle command end, command 3 process 3 start...[INFO] 2021-11-23 11:45:00.767 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[1146] - add task to stand by list: test_shell[INFO] 2021-11-23 11:45:00.769 org.apache.dolphinscheduler.service.process.ProcessService:[1093] - start submit task : test_shell, instance id:3, state: RUNNING_EXECUTION[INFO] 2021-11-23 11:45:00.799 org.apache.dolphinscheduler.service.process.ProcessService:[1106] - end submit task to db successfully:3 test_shell state:SUBMITTED_SUCCESS complete, instance id:3 state: RUNNING_EXECUTION [INFO] 2021-11-23 11:45:00.800 monTaskProcessor:[120] - task ready to submit: TaskInstance{id=3, name='test_shell', taskType='SHELL', processInstanceId=3, processInstanceNam [ERROR] 2021-11-23 11:45:00.810 monTaskProcessor:[334] - tenant not exists,process instance id : 3,task instance id : 3[INFO] 2021-11-23 11:45:00.821 monTaskProcessor:[130] - master submit success, task : test_shell[ERROR] 2021-11-23 11:45:00.821 org.apache.dolphinscheduler.server.master.consumer.TaskPriorityQueueConsumer:[116] - dispatcher task errorng.NullPointerException: nullat org.apache.dolphinscheduler.server.master.consumer.TaskPriorityQueueConsumer.dispatch(TaskPriorityQueueConsumer.java:131)at org.apache.dolphinscheduler.server.master.consumer.TaskPriorityQueueConsumer.run(TaskPriorityQueueConsumer.java:100)[INFO] 2021-11-23 11:45:00.825 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[1162] - remove task from stand by list, id: 3 name:test_shell[INFO] 2021-11-23 11:45:00.827 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[291] - process event: State Event :key: null type: TASK_STATE_CHANGE executeStatus: FAILURE task instance id: 3 process [INFO] 2021-11-23 11:45:00.829 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[369] - work flow 3 task 3 state:FAILURE[INFO] 2021-11-23 11:45:00.829 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[1146] - add task to stand by list: test_shell[INFO] 2021-11-23 11:45:00.829 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteThread:[376] - failure task will be submitted: process id: 3, task instance id: 3 state:FAILURE retry times:0 / 1, interval:30第七步:根据上⾯⼀步的输出,去源代码中找到输出⽇志的⽂件位置:我们先来找第⼀句:[INFO] 2021-11-23 11:45:00.079 org.apache.dolphinscheduler.service.quartz.ProcessScheduleJob:[74] - scheduled fire time :Tue Nov 23 11:45:00 CST 2021, fire time :Tue Nov 23 11:45:00 CST 2021, process id :1我们以红⾊的为关键词,⽤idea的find in path整个⼯程去找到这个输出是在哪个java⽂件的哪个类哪个⽅法。
dubbo@service@dubboService解析⽼规矩,从框架的使⽤⽅式⼊⼿分析,类似mybatis,dubbo也有个扫描服务的注解:org.apache.dubbo.config.spring.context.annotation.DubboComponentScan同样地,配套⼀个@Import:org.apache.dubbo.config.spring.context.annotation.DubboComponentScanRegistrar,作⽤就是把BeanDefinitionRegistry交给你全权处理,对应这⾥就是构建⼀个org.apache.dubbo.config.spring.beans.factory.annotation.ServiceAnnotationBeanPostProcessor的BeanDefinition,然后加⼊BeanDefinitionRegistry。
这是个BeanDefinitionRegistry后处理bean,主要逻辑在⽗类org.apache.dubbo.config.spring.beans.factory.annotation.ServiceClassPostProcessor,最新版本直接就⽤了⽗类。
在如下dubbo springboot⾃动配置包中有个⾃动配置类,也是通过该后置bean解析@dubboService类的,不同的是,该⾃动配置的⽅式是从yaml获取服务类所在的包路径:⾃动配置类org.apache.dubbo.spring.boot.autoconfigure.DubboAutoConfiguration:对应yaml⽂件内容如下,这种⽅式配置的好处是可以把该配置项放到配置中⼼统⼀管理:下⾯我们具体看下这个类:实现了接⼝BeanDefinitionRegistryPostProcessor,对BeanDefinitionRegistry进⾏后处理,主要逻辑在org.apache.dubbo.config.spring.beans.factory.annotation.ServiceClassPostProcessor#registerServiceBeans⽅法:private void registerServiceBeans(Set<String> packagesToScan, BeanDefinitionRegistry registry) {DubboClassPathBeanDefinitionScanner scanner =new DubboClassPathBeanDefinitionScanner(registry, environment, resourceLoader);BeanNameGenerator beanNameGenerator = resolveBeanNameGenerator(registry);scanner.setBeanNameGenerator(beanNameGenerator);// refactor @since 2.7.7serviceAnnotationTypes.forEach(annotationType -> {// 设置扫描的包下被指定注解标注的类是需要处理的serviceAnnotationTypes包含如下⼏个注解// org.apache.dubbo.config.annotation.DubboService,2.7.7版本后直接⽤这个注解暴露服务// org.apache.dubbo.config.annotation.Service,@Deprecated// com.alibaba.dubbo.config.annotation.Service,@Deprecatedscanner.addIncludeFilter(new AnnotationTypeFilter(annotationType));});for (String packageToScan : packagesToScan) {// 注册注解标注的类BeanDefinition// Registers @Service Bean firstscanner.scan(packageToScan);// Finds all BeanDefinitionHolders of @Service whether @ComponentScan scans or not.Set<BeanDefinitionHolder> beanDefinitionHolders =findServiceBeanDefinitionHolders(scanner, packageToScan, registry, beanNameGenerator);if (!CollectionUtils.isEmpty(beanDefinitionHolders)) {for (BeanDefinitionHolder beanDefinitionHolder : beanDefinitionHolders) {// 构建org.apache.dubbo.config.spring.ServiceBean对应的BeanDefinition并注册到BeandefinitionRegistryregisterServiceBean(beanDefinitionHolder, registry, scanner);}if (logger.isInfoEnabled()) {(beanDefinitionHolders.size() + " annotated Dubbo's @Service Components { " +beanDefinitionHolders +" } were scanned under package[" + packageToScan + "]");}} else {if (logger.isWarnEnabled()) {logger.warn("No Spring Bean annotating Dubbo's @Service was found under package["+ packageToScan + "]");}}}}重点看下注册ServiceBean代码:private void registerServiceBean(BeanDefinitionHolder beanDefinitionHolder, BeanDefinitionRegistry registry,DubboClassPathBeanDefinitionScanner scanner) {Class<?> beanClass = resolveClass(beanDefinitionHolder);Annotation service = findServiceAnnotation(beanClass);/*** The {@link AnnotationAttributes} of @Service annotation*/AnnotationAttributes serviceAnnotationAttributes = getAnnotationAttributes(service, false, false); // 服务接⼝类,可通过@DubboService的interfaceClass或者interfaceName指定,默认为注解标注类对应的接⼝classClass<?> interfaceClass = resolveServiceInterfaceClass(serviceAnnotationAttributes, beanClass);String annotatedServiceBeanName = beanDefinitionHolder.getBeanName();// 构建ServiceBean的BeanDefinition⽤于注册AbstractBeanDefinition serviceBeanDefinition =buildServiceBeanDefinition(service, serviceAnnotationAttributes, interfaceClass, annotatedServiceBeanName);// ServiceBean Bean nameString beanName = generateServiceBeanName(serviceAnnotationAttributes, interfaceClass);if (scanner.checkCandidate(beanName, serviceBeanDefinition)) { // check duplicated candidate bean// 注册ServiceBean的BeanDefinitionregistry.registerBeanDefinition(beanName, serviceBeanDefinition);if (logger.isInfoEnabled()) {("The BeanDefinition[" + serviceBeanDefinition +"] of ServiceBean has been registered with name : " + beanName);}} else {if (logger.isWarnEnabled()) {logger.warn("The Duplicated BeanDefinition[" + serviceBeanDefinition +"] of ServiceBean[ bean name : " + beanName +"] was be found , Did @DubboComponentScan scan to same package in many times?");}}}private AbstractBeanDefinition buildServiceBeanDefinition(Annotation serviceAnnotation,AnnotationAttributes serviceAnnotationAttributes,Class<?> interfaceClass,String annotatedServiceBeanName) {BeanDefinitionBuilder builder = rootBeanDefinition(ServiceBean.class);AbstractBeanDefinition beanDefinition = builder.getBeanDefinition();MutablePropertyValues propertyValues = beanDefinition.getPropertyValues();String[] ignoreAttributeNames = of("provider", "monitor", "application", "module", "registry", "protocol","interface", "interfaceName", "parameters");propertyValues.addPropertyValues(new AnnotationPropertyValuesAdapter(serviceAnnotation, environment, ignoreAttributeNames));// References "ref" property to annotated-@Service Bean// 指向标注@DubboService注解的原始Bean(在服务暴露的时候会⽤到)addPropertyReference(builder, "ref", annotatedServiceBeanName);// Set interface// 指向@DubboService配置的服务接⼝类名,默认为标注类的接⼝类(在服务暴露的时候会⽤到)builder.addPropertyValue("interface", interfaceClass.getName());// Convert parameters into mapbuilder.addPropertyValue("parameters", convertParameters(serviceAnnotationAttributes.getStringArray("parameters")));// Add methods parametersList<MethodConfig> methodConfigs = convertMethodConfigs(serviceAnnotationAttributes.get("methods"));if (!methodConfigs.isEmpty()) {builder.addPropertyValue("methods", methodConfigs);}/*** Add {@link org.apache.dubbo.config.ProviderConfig} Bean reference*/String providerConfigBeanName = serviceAnnotationAttributes.getString("provider");if (StringUtils.hasText(providerConfigBeanName)) {addPropertyReference(builder, "provider", providerConfigBeanName);}/*** Add {@link org.apache.dubbo.config.MonitorConfig} Bean reference*/String monitorConfigBeanName = serviceAnnotationAttributes.getString("monitor");if (StringUtils.hasText(monitorConfigBeanName)) {addPropertyReference(builder, "monitor", monitorConfigBeanName);}/*** Add {@link org.apache.dubbo.config.ApplicationConfig} Bean reference*/String applicationConfigBeanName = serviceAnnotationAttributes.getString("application");if (StringUtils.hasText(applicationConfigBeanName)) {addPropertyReference(builder, "application", applicationConfigBeanName);}/*** Add {@link org.apache.dubbo.config.ModuleConfig} Bean reference*/String moduleConfigBeanName = serviceAnnotationAttributes.getString("module");if (StringUtils.hasText(moduleConfigBeanName)) {addPropertyReference(builder, "module", moduleConfigBeanName);}/*** Add {@link org.apache.dubbo.config.RegistryConfig} Bean reference*/String[] registryConfigBeanNames = serviceAnnotationAttributes.getStringArray("registry");List<RuntimeBeanReference> registryRuntimeBeanReferences = toRuntimeBeanReferences(registryConfigBeanNames);if (!registryRuntimeBeanReferences.isEmpty()) {builder.addPropertyValue("registries", registryRuntimeBeanReferences);}/*** Add {@link org.apache.dubbo.config.ProtocolConfig} Bean reference*/String[] protocolConfigBeanNames = serviceAnnotationAttributes.getStringArray("protocol");List<RuntimeBeanReference> protocolRuntimeBeanReferences = toRuntimeBeanReferences(protocolConfigBeanNames);if (!protocolRuntimeBeanReferences.isEmpty()) {builder.addPropertyValue("protocols", protocolRuntimeBeanReferences);}return builder.getBeanDefinition();}。
Dubbo原理和源码解析之服务暴露github新增仓库 "dubbo-read"(),集合所有《Dubbo原理和源码解析》系列⽂章,后续将继续补充该系列,同时将针对Dubbo所做的功能扩展也进⾏分享。
不定期更新,欢迎Follow。
⼀、框架设计在官⽅《》架构部分,给出了服务调⽤的整体架构和流程:另外,在官⽅《》框架设计部分,给出了整体设计:以及暴露服务时序图:本⽂将根据以上⼏张图,分析服务暴露的实现原理,并进⾏详细的代码跟踪与解析。
⼆、原理和源码解析2.1 标签解析从⽂章《》中我们知道,<dubbo:service> 标签会被解析成 ServiceBean。
ServiceBean 实现了 InitializingBean,在类加载完成之后会调⽤ afterPropertiesSet() ⽅法。
在 afterPropertiesSet() ⽅法中,依次解析以下标签信息:<dubbo:provider>Thread.sleep(delay);} catch (Throwable e) {}doExport();}});thread.setDaemon(true);thread.setName("DelayExportServiceThread");thread.start();} else {doExport();}}由上⾯代码可知,如果设置了 delay 参数,Dubbo 的处理⽅式是启动⼀个守护线程在 sleep 指定时间后再 doExport。
2.3 参数检查在 ServiceConfig 的 doExport() ⽅法中会进⾏参数检查和设置,包括:泛化调⽤本地实现本地存根本地伪装配置(application、registry、protocol等)ServiceConfig.javaprotected synchronized void doExport() {if (unexported) {throw new IllegalStateException("Already unexported!");}if (exported) {return;}exported = true;if (interfaceName == null || interfaceName.length() == 0) {throw new IllegalStateException("<dubbo:service interface=\"\" /> interface not allow null!");}checkDefault();//省略if (ref instanceof GenericService) {interfaceClass = GenericService.class;generic = true;} else {try {interfaceClass = Class.forName(interfaceName, true, Thread.currentThread().getContextClassLoader());} catch (ClassNotFoundException e) {throw new IllegalStateException(e.getMessage(), e);}checkInterfaceAndMethods(interfaceClass, methods);checkRef();generic = false;}if(local !=null){if(local=="true"){local=interfaceName+"Local";}Class<?> localClass;try {localClass = ClassHelper.forNameWithThreadContextClassLoader(local);} catch (ClassNotFoundException e) {throw new IllegalStateException(e.getMessage(), e);}if(!interfaceClass.isAssignableFrom(localClass)){throw new IllegalStateException("The local implemention class " + localClass.getName() + " not implement interface " + interfaceName); }}if(stub !=null){if(stub=="true"){stub=interfaceName+"Stub";}Class<?> stubClass;try {stubClass = ClassHelper.forNameWithThreadContextClassLoader(stub);} catch (ClassNotFoundException e) {throw new IllegalStateException(e.getMessage(), e);}if(!interfaceClass.isAssignableFrom(stubClass)){throw new IllegalStateException("The stub implemention class " + stubClass.getName() + " not implement interface " + interfaceName); }}//此处省略:检查并设置相关参数doExportUrls();}2.4 多协议、多注册中⼼在检查完参数之后,开始暴露服务。