K3主要表结构与关联
- 格式:ppt
- 大小:1009.00 KB
- 文档页数:53


1. 用树型结构表示实体类型及实体间联系的数据模型称为(层次模型)。
2. 模式/内模式映象为数据库提供了(物理)数据独立性。
3. 在层次、网状模型中,数据之间联系用(指针)实现。
4. 数据库管理技术的发展经过三个阶段(人工管理阶段),(文件系统阶段),(数据库阶段)。
5. 三种主要的数据模型包括(层次模型),(网状模型),(关系模型)。
6. 数据模型的三要素包括(数据结构),(数据操作),(数据完整性约束)。
7. 由于数据冗余,当进行更新时,稍不谨慎,易引起(数据不一致性)。
8. 层次模型的特点是记录之间的联系通过(指针)来实现;关系模型是用结构表示实体集,用(公共属性)表示实体间的联系。
9. 数据库管理系统的主要功能包括(定义),(操纵),(保护),(存储),(维护)和(数据字典)。
10. 关系数据库的数据操纵语言(DML)的语句分成(检索)和(更新)。
11. DBMS是由(查询处理器)和(存储处理器)两大部分组成。
12. 数据库管理系统的效率包括计算机系统的内部资源的使用效率、(数据库管理系统DBMS)运行效率和(用户的生成率)。
13. 利用数据库管理数据时,把现实世界的事物及其之间的联系转换成机器世界的数据模型的一个中间环节是信息世界的(概念模型)。
14. 数据库管理系统(DBMS)提供数据定义语言(DDL)及它的翻译程序,DDL定义数据库的模式、外模式和内模式,并通过翻译程序分别翻译成相应的目标模式,存放在(数据字典)。
15. 在数据库的体系结构中,数据库存储的改变会引起内模式的改变。
为使数据库的模式保持不变,从而不必修改应用程序,这是通过改变模式与内模式之间的映像来实现。
这样,使数据库具有(物理独立性)。
16. 在数据库技术中使用数据模型的概念来描述数据库的结构和语义。
数据模型有概念数据模型和结构数据模型两类,实体联系模型(ER模型)是(概念)数据模型。
17. 在数据库系统的三级模式体系结构中,描述数据在数据库中的物理结构或存储方式的是(内模式)。

K/3系统功能树总账系统报表系统现金流量系统固定资产管理系统工资管理系统财务分析系统现金管理系统应收款管理系统应付款管理系统K/3系统功能树合并报表系统结算中心管理系统采购管理系统销售管理系统仓存管理系统存货核算系统成本管理系统采购管理(商业)系统采购申请单IC-1-1-1采购订单IC-1-1-2 业务处理IC-1-1 收料通知单IC-1-1-3采购发票IC-1-1-4退料通知单IC-1-1-5外购入库IC-1-1-6待检仓调拔单IC-1-1-7采购申请单IC-1-2-1采购订单IC-1-2-2IC-1-2 料通知单位IC-1-2-3采购发票IC-1-2-3退料通知单IC-1-2-4外购入库IC-1-2-5待检仓调拔单IC-1-2-6 IC-1采购业务报表IC-1-3-1 账薄报表IC-1-3 采购业务分析IC-1-3-2万能报表IC-1-3-3查询分析工具IC-1-3-4核算参数IC-1-4-1用户管理IC-1-4-2IC-1-4 上机日志IC-1-4-3系统设置IC-1-4-4基础资料IC-1-5-1备注资料IC-1-5-2IC-1-5 BOM IC-1-5-3供应商供货信息IC-1-5-4价格资料IC-1-5-5折扣资料IC-1-5-6公司机构管理IC-1-5-7业务处理验收入库IC-3-1-1IC-3-1 领料/发货IC-3-1-2仓库调拔IC-3-1-3库存调整IC-3-1-4备份账套数据IC-3-2-1 仓存管理打印盘点表IC-3-2-2 IC-3 IC-3-2 录入盘点数据IC-3-2-3编制盘点报告表IC-3-2-4验收入库IC-3-3-1领料/发货IC-3-3-2IC-3-3 仓库调拔IC-3-3-3库存调整IC-3-3-4仓库业务报表IC-3-4-1仓库分析报表IC-3-4-2IC-3-4 万能报表IC-3-4-3查询分析工具IC-3-4-4核算参数IC-3-5-1IC-3-5 用户管理IC-3-5-2上机日志IC-3-5-3系统设置IC-3-5-4基础资料IC-4-6-1备注资料IC-4-6-2IC-4-6 B O M IC-4-6-3供应商供货信息IC-4-6-4价格资料IC-4-6-5折扣资料IC-4-6-6公司机构管理IC-4-6-7销售报价单IC-2-1-1销售订单IC-2-1-2发货通知单IC-2-1-3IC-2-1 销售发票IC-2-1-4退货通知单IC-2-1-5销售出库单IC-2-1-6销售报价单IC-2-2-1销售订单IC-2-2-2发货通知单IC-2-2-3IC-2-2 销售发票IC-2-2-4退货通知单IC-2-2-5销售出库单IC-2-2-6销售业务报表IC-2-3-1销售分析报表IC-2-3-2 销售管理账薄报表IC-2-3 万能报表IC-2-3-3 IC-2 查询分析工具IC-2-3-4查询分析工具IC-2-3-5核算参数IC-2-4-1IC-2-4 用户管理IC-2-4-2上机日志IC-2-4-3系统设置IC-2-4-4基础资料IC-2-5-1备注资料IC-2-5-2IC-2-5 B O M IC-2-5-3供应商供货信息IC-2-5-4价格资料IC-2-5-5折扣资料IC-2-5-6公司机构管理IC-2-5-7存货核算IC-4-1 外购入库核算IC-4-1-1存货估价入库IC-4-1-2自制入库核算IC-4-1-3其他入库核算IC-4-1-4委外加工入核算IC-4-1-5材料出库核算IC-4-2-1产成品出库核算IC-4-2-2出库核算IC-4-2 不确定单价单据IC-4-2-3红字出库核算IC-4-2-4核算单据查询IC-4-2-5记账凭证查询IC-4-3-1IC-4-3 生成凭证IC-4-3-2凭证模板IC-4-3-3录入调价单据IC-4-4-1计划成本管理IC-4-4 调价单据查询IC-4-4-2历史价格维护IC-4-4-3存货核算IC-4 期末结账IC-4-5-1期末处理IC-4-5 期末余额调整IC-4-5-2金额调整IC-4-5-3核算账薄IC-4-6-1账薄报表IC-4-6 核算报表IC-4-6-2万能报表IC-4-6-3核算参数IC-4-7-1系统维护IC-4-7 用户管理IC-4-7-2上机日志IC-4-7-3系统设置IC-4-7-4基础资料IC-4-8-1资料维护IC-4-8 备注资料IC-4-8-2B O M IC-4-8-3供应商供货信息IC-4-8-4价格资料IC-4-8-5折扣资料IC-4-8-6公司机构管理IC-4-8-7共耗材料分配标准CB-5-1-1在产品成本分配标准CB-5-1-2其他费用分配标准CB-5-1-3 分配标准CB-5-1 共耗材料分配标准数据录入CB-5-1-4分配标准数据录入CB-5-1-5材料费用分配CB-5-2-1辅助生产费用分配CB-5-2-2 成本计算CB-5-2 制造费用分配CB-5-2-3其他费用分配CB-5-2-4产品成本计算CB-5-2-5产品成本自动计算CB-5-2-6材料费用汇总表CB-5-3-1其他要素费用汇总表CB-5-3-2 报表CB-5-3 部门费用汇总表CB-5-3-3材料费用分配表CB-5-3-4材料耗用明细表CB-5-3-5其他要素费用分配表CB-5-3-6成本计算单CB-5-3-7批次成本汇总表CB-5-4-1 成本管理CB-5-4 库存产品明细账CB-5-4-2部门成本汇总表CB-5-4-3万能报表CB-5-4-4成本类型数据CB-5-5-1 成本分析CB-5-5 成本结构分析CB-5-5-2成本比较分析CB-5-5-3期间成本分析CB-5-5-4凭证模板CB-5-6-1 期末处理CB-5-6 凭证生成CB-5-6-2凭证查询CB-5-6-3期末结转CB-5-6-4系统维护CB-5-7 基础资料CB-5-7-1系统参数CB-5-7-2数据来源CB-5-7-3。

数据库原理及应用第二、三章知识点第二章知识点1. 关系数据结构的相关概念域,基数,笛卡尔积,元组,分量,关系,度/目,属性域:一组具有相同数据类型的值的集合基数:基数是数据列所包含的不同值的数量笛卡尔积:是所有域的所有取值的一个组合,其中的元组没有重复元祖:表中的一行即为一个元组分量:元组中的一个属性值关系:一个关系对应通常说的一张表度/目:属性的个数属性:关系的每一列对应一个域,给每列起一个名字,称为属性 2. 关系的数据结构的逻辑表达,即关系逻辑上可以看做是什么?3.关系的6个性质是什么?你能解释为什么要有这6条性质吗?其中最重要的是哪一条? 1.关系中每列的数据属于同一个域,每一列称为一个属性,列名被称为属性名,每一列的值被称为属性值,同一关系中的所有属性名必须是可区分的,即互不相同,同一属性所有值可以相同也可以不同.2.不同列允许对应同一个域,此时列名不能同时直接采用域名,当一个列唯一对应一个域时,其列名即可以直接采用域名,也可以重新命名.3.一个关系中属性的次序在理论上可以任意,这表明一个关系只与属性,属性个数及元组内容在前,而与属性次序无关,但在一般实际数据库系统中,认为属性是先后有序的.4.一个关系中的任意两个元组不允许完全相同,即不允许出现重复元组,这与集合的概念是一致的,此可知关系就是集合,当然这两个元组中,只要有一个分量值不同则这两个元组就不同.5.一个关系中元组的次序可以任意,这表明具有相同元组而具有不同排列的每个关系为同一关系.6.一个元组中的每个属性值都必须是单值,即不可再分,这就要求这个关系的结构不允许出现嵌套4.关系模式的五元组定义是什么?这五元分别是用字母/缩写表示?分别是什么意思?关系模式与关系的区别与联系。
关系模式是一个五元组R,U,D,dom,F R 关系的名称 U 属性的集合 D 属性的域dom 属性向域的映像集合。
F属性间的互相依赖集关系模式:对关系的描述,一般表示为:关系名,而且属性之间有一定的逻辑关系,比如3NF,2NF等. 关系:就是一5.定性的表达出码、超码、候选码、主码、外码、参照关系、被参照关系这几个概念码:码就是能唯一标识实体的属性超码: 超码是一个或多个属性的集合,这些属性可以让我们在一个实体集中唯一地标识一个实体候选码: 候选码是最小超码主码: 如果一个关系有多个候选码,则选定其中一个为主码外码: 设F是基本关系R的一个或者一组属性,但不是关系R的码。


k3固定资产数据结构与表关系一、引言本文档旨在详细描述K3固定资产数据结构与表关系,以便为相关人员提供参考和指导。
本文档将介绍固定资产数据的组织结构、表关系以及数据字段的定义等方面的内容。
二、数据结构1:资产基本信息表资产基本信息表用于记录各种固定资产的基本信息,包括资产编号、资产名称、资产分类、使用部门、责任人等。
字段:- 资产编号:固定资产的唯一标识符。
- 资产名称:固定资产的名称。
- 资产分类:固定资产所属的分类,如机械设备、办公设备等。
- 使用部门:固定资产所属的部门。
- 责任人:固定资产的责任人。
2:资产维修记录表资产维修记录表用于记录固定资产的维修情况,包括维修日期、维修内容、维修费用等。
字段:- 维修日期:固定资产维修的时间。
- 维修内容:固定资产维修的具体内容。
- 维修费用:固定资产维修所需的费用。
3:资产报废记录表资产报废记录表用于记录固定资产的报废情况,包括报废日期、报废原因等。
字段:- 报废日期:固定资产报废的时间。
- 报废原因:固定资产报废的原因。
三、表关系1:资产基本信息表与资产维修记录表的关系:- 资产基本信息表与资产维修记录表采用一对多的关系,即一个固定资产可以有多条维修记录。
2:资产基本信息表与资产报废记录表的关系:- 资产基本信息表与资产报废记录表采用一对多的关系,即一个固定资产可以有多条报废记录。
四、数据字典1:资产编号(AssetID):固定资产的唯一标识符,由系统自动。
2:资产名称(AssetName):固定资产的名称。
3:资产分类(AssetCategory):固定资产所属的分类,如机械设备、办公设备等。
4:使用部门(Department):固定资产所属的部门。
5:责任人(ResponsiblePerson):固定资产的责任人。
6:维修日期(ReprDate):固定资产维修的时间。
7:维修内容(ReprContent):固定资产维修的具体内容。
8:维修费用(ReprCost):固定资产维修所需的费用。

受体相互作用蛋白激酶1(RIPK1)调控人结肠癌HT-29细胞程序性坏死的分子机制王海玉;张波【摘要】目的研究受体相互作用蛋白激酶1 (receptor interacting protein kinase 1,RIPK1)在人结肠HT-29细胞程序性坏死过程中的作用,并探讨E3泛素连接酶三重结构域包含蛋白16 (tripartite domain containingprotein 16,Trim16)对其作用的潜在调控机制.方法用肿瘤坏死因子α(tumor necrosis factor α,TNFα)建立HT-29细胞的程序性坏死模型,采用Annexin V-FITC/PI双染色法检测其对凋亡、坏死细胞数目的影响.分别用Western blot和qRT-PCR检测RIPK1在细胞程序性坏死中的表达.构建稳定表达Flag标记的RIPK1的HT-29细胞株,采用Flag 标记的pulldown试验结合质谱检测发现与RIPK1有相互作用的新蛋白.应用Ni-NTA pulldown试验检测筛选出的E3泛素连接酶对RIPK1泛素化的调控.结果TNFα能够成功诱导HT-29细胞程序性坏死.HT-29细胞在TNFα和半胱天蛋白酶抑制剂z-VAD处理后,表现出RIPK1、RIPK3、混合系列蛋白激酶样结构域(mixed lineage kinase domain-like protein,MLKL)表达水平显著增加,并伴随着炎性因子白介素1α(IL1α)和白介素6(IL6)水平明显升高.Flag标记的pulldown试验结合质谱检测发现一个与RIPK1有相互作用的E3泛素连接酶Trim16,体外实验表明Trim16可以增强RIPK1的泛素化程度,其可能调节RIPK1在程序性坏死过程中的作用.结论 RIPK1在TNFα和z-VAD诱导人结肠癌HT-29细胞的程序性坏死过程中起重要作用,E3泛素连接酶Trim16对此过程可能有重要调控作用.【期刊名称】《复旦学报(医学版)》【年(卷),期】2014(041)006【总页数】8页(P720-726,741)【关键词】受体相互作用蛋白激酶1 (RIPK1);人结肠癌细胞;程序性坏死;E3泛素连接酶;三重结构域包含蛋白16 (Trim16)【作者】王海玉;张波【作者单位】复旦大学附属中山医院普外科上海200032;复旦大学附属中山医院普外科上海200032【正文语种】中文【中图分类】R735.2programmed necrosis;E3 ubiquitin ligase;tripartite domain containing protein 16(Trim16)结肠癌在全球女性和男性恶性肿瘤发病率中分别居第2位和第3位[1],进展期的结肠癌患者辅助治疗后中位生存期仅为20个月左右[2]。


第一章习题参考答案一、选择题1. C2. B3. D4. C5. D6. A7. A8. B9. D 10. B11. C 12. D 13. A 14. D 15. B16. C 17. D 18. A 19. D 20. A二、填空题1. 数据库系统阶段2. 关系3. 物理独立性4. 操作系统5. 数据库管理系统(DBMS)6. 一对多7. 独立性8. 完整性控制9. 逻辑独立性10. 关系模型11. 概念结构(逻辑)12. 树有向图二维表嵌套和递归13. 宿主语言(或主语言)14. 数据字典15. 单用户结构主从式结构分布式结构客户/服务器结构浏览器/服务器结构第2章习题参考答案一、选择题1. A2. C3. C4. B5. B6. C7. B8. D9. C 10. A11. B 12. A 13. A 14. D 15. D二、填空题1. 选择(选取)2. 交3. 相容(或是同类关系)4. 并差笛卡尔积选择投影5. 并差交笛卡尔积6. 选择投影连接7. σf(R)8. 关系代数关系演算9. 属性10. 同质11. 参照完整性12. 系编号,系名称,电话办公地点13. 元组关系域关系14. 主键外部关系键15. R和S没有公共的属性第3章习题参考答案一、选择题1. B2. A3. C4. B5. C6. C7. B8. D9. A 10. D二、填空题结构化查询语言(Structured Query Language)数据查询、数据定义、数据操纵、数据控制外模式、模式、内模式数据库、事务日志NULL/NOT NULL、UNIQUE约束、PRIMARY KEY约束、FOREIGN KEY约束、CHECK 约束聚集索引、非聚集索引连接字段行数定义系统权限、对象权限基本表、视图12.(1)INSERT INTO S VALUES('990010','李国栋','男',19)(2)INSERT INTO S(No,Name) VALUES('990011', '王大友')(3)UPDATE S SET Name='陈平' WHERE No='990009'(4)DELETE FROM S WHERE No='990008'(5)DELETE FROM S WHERE Name LIKE '陈%'13.CHAR(8) NOT NULL14.o=o15.ALTER TABLE StudentADDSGrade CHAR(10)第4章习题参考答案一、选择题1. B2. B3. D4. B5. C6. D7. B8. D9. C 10. A二、填空题1. 超键(或超码)2. 正确完备3. 属性集X的闭包X + 函数依赖集F的闭包F +4. 平凡的函数依赖自反性5. {AD→C} φ6. 2NF 3NF BCNF7. 无损连接保持函数依赖8. AB BC BD9. B→φ B→B B→C B→BC10. B→C A→D D→C11. AB 1NF12. AD 3NF第5章习题参考答案一、选择题1. B2. B3. C4. A5. C6. D7. A8. C9. D 10. D11. B 12. B 13. A 14. D 15. A二、填空题安全性控制、完整性控制、并发性控制、数据库恢复数据对象、操作类型授权粒度、授权表中允许的登记项的范围原始数据(或明文)、不可直接识别的格式(或密文)、密文事务、原子性、一致性、隔离性、持久性丢失更新、污读、不可重读封锁、排它型封锁、共享封锁利用数据的冗余登记日志文件、数据转储事务故障、系统故障、介质故障完整性登录账号、用户账号public服务器、数据库第6章习题参考答案一、选择题1. B2. C3. C4. A5. C6. B7. C8. B9. D 10. C11. D 12. B 13. B 14. D二、填空题数据库的结构设计、数据库的行为设计新奥尔良法分析和设计阶段、实现和运行阶段需求分析概念结构设计自顶向下、自底向上属性冲突、命名冲突、结构冲突逻辑结构设计确定物理结构、评价物理结构数据库加载运行和维护物理数据字典需求分析载入第7章习题参考答案一、选择题1. B2.C3.B4.D5.A二、填空题局部变量、全局变量- -、/*……*/DECLARESQL、流程控制AFTER 触发器、INSTEAD OF 触发器插入表、删除表数据库备份、事务日志备份、差异备份、文件和文件组备份简单还原、完全还原、批日志还原硬盘、磁带、管道下面是古文鉴赏,不需要的朋友可以下载后编辑删除!!谢谢!!九歌·湘君屈原朗诵:路英君不行兮夷犹,蹇谁留兮中洲。
目录第一篇k3系统原理及数据结构分析1、总账系统1.1 根底资料1.1.1 科目涉及的表为t_account〔科目表〕,常用到的字段为fitemid(科目内码),ffullname(科目全名),fquantity(是否数量金额辅助核算), FmeasureUnitID〔计量单位内码〕,fdetailid(核算工程内码)等等。
fitemid〔科目内码〕:一个新增加的科目,在初始数据中录入数据,后来把此科目的数据删除了,或录入了一张此科目的凭证,又把此凭证删除了,然后想把此新增科目删除;或者是结转新账套之后,想把一些没有余额的科目删除。
这时系统提示科目已有业务发生,不能删除。
其实这涉及到很多数据库表引用了t_account〔科目表〕的Fitemid字段,这些表总账系统中有t_balance〔余额表〕,t_quantitybalance〔数量余额表〕,t_voucherentry 〔凭证体表〕,t_profitandloss〔损益科目实际发生额表〕;固定资产系统中有t_faexpense 〔费用分配表〕,t_fabalexpense〔用于折旧计算的费用分配表〕,t_facard〔固定资产卡片表〕,t_fabalcard〔卡片变动表〕;工业物流中有t_icitem〔物料明细资料表〕;商业物流中有com_item〔商品明细资料表〕。
只要在这些表中存在记录,那么相对应的科目就不能在界面中删除。
Ffullname(科目全名):这个字段主要是在录入凭证,查看账薄时用到。
如果在录入凭证,查看账薄时,系统只显示科目的最明细一级的名称,那就是因为科目全名字段中的值不正确。
这个问题有个相关的补丁可以解决,补丁名叫。
fquantity(是否数量金额辅助核算):此字段主要是标识此科目是否需要数量金额辅助核算,一般此字段与FmeasureUnitID〔计量单位内码〕一起使用,当fquantity字段的值为1时,FmeasureUnitID字段中一定也要有相应的值,且此值与t_measureunit表中的FmeasureUnitID字段值相对应。
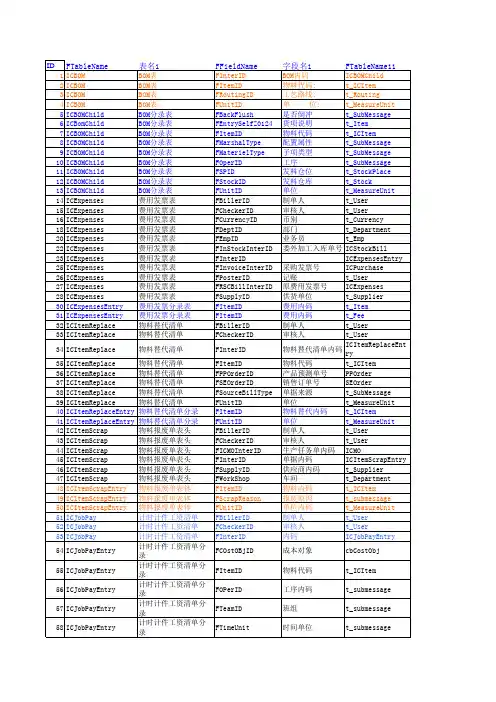
k3固定资产数据结构与表关系K3 固定资产数据结构与表关系在企业的财务管理中,固定资产的管理是一个重要的组成部分。
而金蝶 K3 作为一款广泛应用的企业管理软件,其固定资产模块的数据结构和表关系对于准确、高效地管理固定资产起着关键作用。
首先,我们来了解一下 K3 固定资产模块中的主要数据表。
其中,“t_FixedAsset”表是核心表之一,它存储了固定资产的基本信息,如资产编号、资产名称、资产类别、原值、预计使用年限等。
每一条记录都代表着一项固定资产的主要属性。
“t_FixedAssetDepr”表则用于记录固定资产的折旧信息。
包括折旧方法、已折旧月份、累计折旧额等。
通过这个表,可以清晰地了解到每一项固定资产的折旧情况,为财务核算提供重要的数据支持。
“t_FixedAssetLocation”表用于存储固定资产的存放地点信息。
这对于企业准确掌握资产的位置,方便资产的盘点和管理非常重要。
“t_FixedAssetUseDept”表记录了固定资产的使用部门。
明确资产的使用部门有助于将资产的折旧费用合理分摊到相应的部门成本中。
接下来,我们探讨一下这些表之间的关系。
“t_FixedAsset”表与“t_FixedAssetDepr”表通过资产编号进行关联。
在进行数据查询和处理时,系统可以根据资产编号从“t_FixedAsset”表中获取资产的基本信息,同时从“t_FixedAssetDepr”表中获取折旧相关的信息,从而全面了解一项固定资产的情况。
“t_FixedAsset”表与“t_FixedAssetLocation”表也是通过资产编号建立联系。
这样,当需要了解某一固定资产的存放位置时,能够迅速找到对应的信息。
“t_FixedAsset”表和“t_FixedAssetUseDept”表同样基于资产编号相关联。
这使得在分析资产的使用部门和相关成本时,可以快速获取准确的数据。
这些表关系的建立,确保了在 K3 固定资产模块中,无论是进行资产的新增、修改、删除,还是查询、统计和分析,都能够实现数据的一致性和准确性。
0、发酵生长因子从广义上讲,凡是微生物生长不可缺少的微量的有机物质,如氨基酸、嘌呤、嘧啶、维生素等均称生长因子1.氨基等电点(isoelctric point):氨基酸溶液在某一定pH值时,使某特定氨基酸分子上所带正负电荷相等,成为两性离子,在电场中既不向阳极也不向阴极移动,此时溶液的pH值即为该氨基酸的等电点(isoelctric point)。
2.肽平面:由于羰基碳-氧双键的靠拢,允许存在共振结构(resonance structure),碳与氮之间的肽键有部分双键性质,由CO-NH构成的肽单元呈现相对的刚性和平面化,肽键中的4个原子和它相邻的两个α-碳原子多处于同一个平面上。
3.超二级结构:蛋白质分子中,特别是球状蛋白质中,由若干相邻的二级结构单元(即α—螺旋、β—折叠片和β—转角等)彼此相互作用组合在一起,形成有规则、在空间上能辨认的二级结构组合体,充当三级结构的构件单元,称超二级结构,已知的超二级结构有3种基本组合形式:αα、βαβ、ββ。
4.结构域:二级结构及超二级结构的基础上,多肽链进一步卷曲折叠,组装成几个相对独立、近似球形的三维实体。
结构域是球状蛋白的折叠单位,多肽链折叠的最后一步是结构域间的缔合。
结构域的概念有三种涵义:即独立的结构单位、独立的功能单位和独立的折叠单位。
类型:α -螺旋域;β -折叠域;α+β域;α /β域;无规则卷曲+β-回折域;无规则卷曲+ α -螺旋结构域,对于较小的蛋白质分子或亚基来说,结构域和三级结构往往是一个意思,就是说这些蛋白质是单结构域的。
5.变性作用:白质各自所特有的高级结构,是表现其物理性质和化学特性以及生物学功能的基础。
当天然蛋白质受到某些物理因素和化学因素的影响,使其分子内部原有的高级构象发生变化时,蛋白质的理化性质和生物学功能都随之改变或丧失,但并未导致其一级结构的变化,这种现象称为变性作用(denaturation)变性的实质:次级键(有时包括二硫键)被破坏,天然构象解体。
综论与综述H A I X I A K E X U E TLR s信号转导通路及负调控分子研究进展*福建医科大学基础医学院聂惠蓉泉州师范学院生物学系李裕红福建医科大学基础医学院刘迎春[摘要]生物机体存在着多种T LR s的负调控机制,以维持免疫反应的平衡。
该文综述了Tol l样受体(Tol l-l i ke r ecept or s, T LR s)的结构、分布及主要的内源性和外源性配体,重点阐述T LR s信号通路的类型和转导机制,并分析论述TLR s信号通路中的负性调控分子。
[关键词]TLR s信号转导通路负调控分子Toll蛋白最早发现于果蝇胚胎发育过程中,在背腹侧体轴细胞的形成过程中起重要调控作用[1,2]。
Toll样受体是一类病原相关模式识别受体(PRR),该家族与果蝇的Toll蛋白家族在结构上有高度同源性。
TLRs广泛表达于哺乳动物等细胞表面,是一种跨膜信号转导蛋白。
通过识别微生物的PAMPs或自身的内源性配体激活胞内信号通路,从而诱导产生促炎性细胞因子、趋化因子、干扰素和共刺激因子,在机体识别和清除病原微生物、介导下游细胞因子产生、天然免疫防御、连接先天性和获得性免疫中发挥重要作用。
1TL R s的结构、分布及配体研究1.1TL R s的结构与在细胞内的定位TLRs属于I型跨膜受体,由胞外区、跨膜区和胞内TIL(Toll/IL-R1)区组成。
胞外区富含亮氨酸重复序列,约550~980个氨基酸,可识别病原微生物的PAMPs;跨膜区是富含半胱氨酸的区域;胞内TIL(Toll/IL-R1)约有200个氨基酸,为所有TI R及IL-l R分子胞内段所共有。
该结构域可以与胞内其他带有相同TI R结构域的分子发生相互作用,启动信号传递,是信号传导的主要区域[3]。
目前,在人体中相继发现了11个TLRs,即TLR1~11,小鼠中不表达TLR10但发现了人没有的TLR11~13[4]。
根据TLRs细胞内定位的不同,可将其分为两类,即位于细胞膜表面的TLR1、TLR2、TLR4、TLR5、TLR6、TTLR11和位于细胞内细胞器膜(如细胞内体、溶酶体或内质网膜)的TLR3、TLR7/8和TLR9。
第一概论1.1 引言两项基本任务:数据表示,数据处理软件系统生存期:软件计划,需求分析,软件设计,软件编码,软件测试,软件维护由一种逻辑结构和一组基本运算构成的整体是实际问题的一种数学模型,这种数学模型的建立,选择和实现是数据结构的核心问题。
机外表示------逻辑结构------存储结构处理要求-----基本运算和运算-------算法1.2.1 数据,逻辑结构和运算数据:凡是能够被计算机存储,加工的对象通称为数据数据元素:是数据的基本单位,在程序中作为一个整体加以考虑和处理。
又称元素、顶点、结点、记录。
数据项:数据项组成数据元素,但通常不具有完整确定的实际意义,或不被当作一个整体对待。
又称字段或域,是数据不可分割的最小标示单位。
1.2.2 数据的逻辑结构逻辑关系:是指数据元素之间的关联方式,又称“邻接关系”逻辑结构:数据元素之间逻辑关系的整体称为逻辑结构。
即数据的组织形式。
四种基本逻辑结构:1 集合:任何两个结点间没有逻辑关系,组织形式松散2 线性结构:结点按逻辑关系依次排列成一条“锁链”3 树形结构:具有分支,层次特性,形态像自然界中的树4. 图状结构:各个结点按逻辑关系互相缠绕,任何两个结点都可以邻接。
注意点:1.逻辑结构与数据元素本身的形式,容无关。
2.逻辑结构与数据元素的相对位置无关3.逻辑结构与所含结点个数无关。
运算:运算是指在任何逻辑结构上施加的操作,即对逻辑结构的加工。
加工型运算:改变了原逻辑结构的“值”,如结点个数,结点容等。
引用型运算:不改变原逻辑结构个数和值,只从中提取某些信息作为运算的结果。
引用:查找,读取加工:插入,删除,更新同一逻辑结构S上的两个运算A和B, A的实现需要或可以利用B,而B的实现不需要利用A,则称A可以归约为B。
假如X是S上的一些运算的集合,Y是X的一个子集,使得X中每一运算都可以规约为Y中的一个或多个运算,而Y中任何运算不可规约为别的运算,则称Y中运算(相对于X)为基本运算。
【Science子刊】王晓东院士...王晓东院士课题组最新发现,外泌体释放和溶酶体降解两种途径为通过抑制MLKL功能来治疗阿尔茨海默病提供了进一步的依据。
坏死性凋亡“刽子手”的退出在坏死性凋亡的细胞中,假激酶MLKL被磷酸化从而能够破坏质膜。
然而,磷酸化MLKL的出现并不总是导致坏死性凋亡,这促使王晓东课题组研究这种坏死性凋亡“刽子手”的活性是如何被抑制的。
他们发现磷酸化的MLKL可能被flotillin-1和flotillin-2导入脂筏,随后进入溶酶体。
此外,磷酸化的MLKL可通过依赖于ESCRT蛋白ALIX 和syntenin-1的外泌体从细胞中释放出去。
这些机制可能是确保只有足够强度的信号才能诱导坏死性凋亡的保障措施。
摘要坏死性凋亡是一种受调节的坏死,与包括阿尔茨海默病在内的各种人类疾病有关。
坏死性凋亡需要假激酶MLKL在被激酶RIPK3磷酸化后从胞质溶胶转移到质膜。
使用蛋白质交联,然后进行亲和纯化,研究人员在膜定位的MLKL免疫沉淀物中检测到脂筏相关蛋白flotillin-1和flotillin-2以及ESCRT相关蛋白ALIX和syntenin-1。
通过flotillin 介导的内吞作用随后溶酶体降解或ALIX-syntenin-1介导的胞吐作用从膜中除去磷酸化的MLKL。
因此,在发生质膜破坏之前,经历坏死性凋亡的细胞需要克服这些独立的抑制机制。
响应于肿瘤坏死因子受体(TNFR)的激活,哺乳动物细胞可以激活多种信号传导途径,包括通过细胞凋亡或坏死导致细胞死亡的途径。
如果凋亡拮抗剂Smac(也称为Diablo)的细胞抑制剂丰度高并且引起细胞凋亡的胱天蛋白酶-8的活性相对较低,则发生一种这样的坏死性细胞死亡——坏死性凋亡(necroptosis)。
因此,通过组合TNFα、一种模拟Smac蛋白功能的小分子和泛半胱天冬酶抑制剂可以强有力地诱导坏死性凋亡。
这种处理激活受体相互作用蛋白激酶RIPK1,然后RIPK1通过它们各自的RIP同型相互作用基序区域的相互作用募集相关激酶RIPK3,导致RIPK3活化。