VM虚拟机下配Eclipse+JDK+Tomcat+Hadoop环境搭建
- 格式:docx
- 大小:938.59 KB
- 文档页数:15

hadoop搭建与eclipse开发环境设置――邵岩飞1.Ubuntu 安装安装ubuntu11.04 desktop系统。
如果是虚拟机的话,这个无所谓了,一般只需要配置两个分区就可以。
一个是\另一个是\HOME 文件格式就用ext4就行了。
如果是实机的话建议在分配出一个\SWAP分区。
如果嫌麻烦建议用wubi安装方式安装。
这个比较傻瓜一点。
2.Hadoop 安装hadoop下载到阿帕奇的官方网站下载就行,版本随意,不需要安装,只要解压到适当位置就行,我这里建议解压到$HOME\yourname里。
3.1 下载安装jdk1.6如果是Ubuntu10.10或以上版本是不需要装jdk的,因为这个系统内置openjdk63.2 下载解压hadoop不管是kubuntu还是ubuntu或者其他linux版本都可以通过图形化界面进行解压。
建议放到$HOME/youraccountname下并命名为hadoop.如果是刚从windows系统或者其它系统拷贝过来可能会遇到权限问题(不能写入)那么这就需要用以下命令来赋予权限。
sudo chown –R yourname:yourname [hadoop]例如我的就是:sudo chown –R dreamy:dreamy hadoop之后就要给它赋予修改权限,这就需要用到:sudo chmod +X hadoop3.3 修改系统环境配置文件切换为根用户。
●修改环境配置文件/etc/profile,加入:你的JAVA路径的说明:这里需要你找到JAVA的安装路径,如果是Ubuntu10.10或10.10以上版本,则应该在/usr/bin/java这个路径里,这个路径可能需要sudo加权限。
3.4 修改hadoop的配置文件●修改hadoop目录下的conf/hadoop-env.sh文件加入java的安装根路径:●把hadoop目录下的conf/core-site.xml文件修改成如下:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>hadoop.tmp.dir</name><value>/hadoop</value></property><property><name></name><value>hdfs://ubuntu:9000</value></property><property><name>dfs.hosts.exclude</name><value>excludes</value></property><property>●把hadoop目录下的conf/ hdfs-site.xml文件修改成如下:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.data.dir</name><value>/hadoop/data</value></property><property><name>dfs.replication</name><value>3</value></property></configuration>●把hadoop目录下的conf/ mapred-site.xml文件修改成如下:注意:别忘了hadoop.tmp.dir,.dir,dfs.data.dir参数,hadoop存放数据文件,名字空间等的目录,格式化分布式文件系统时会格式化这个目录。

eclipse hadoop开发环境配置win7下安装hadoop完成后,接下来就是eclipse hadoop开发环境配置了。
具体的操作如下:一、在eclipse下安装开发hadoop程序的插件安装这个插件很简单,haoop-0.20.2自带一个eclipse的插件,在hadoop目录下的contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar,把这个文件copy到eclipse的eclipse\plugins目录下,然后启动eclipse就算完成安装了。
这里说明一下,haoop-0.20.2自带的eclipse的插件只能安装在eclipse 3.3上才有反应,而在eclipse 3.7上运行hadoop程序是没有反应的,所以要针对eclipse 3.7重新编译插件。
另外简单的解决办法是下载第三方编译的eclipse插件,下载地址为:/p/hadoop-eclipse-plugin/downloads/list由于我用的是Hadoop-0.20.2,所以下载hadoop-0.20.3-dev-eclipse-plugin.jar.然后将hadoop-0.20.3-dev-eclipse-plugin.jar重命名为hadoop-0.20.2-eclipse-plugin.jar,把它copy到eclipse的eclipse\plugins目录下,然后启动eclipse完成安装。
安装成功之后的标志如图:1、在左边的project explorer 上头会有一个DFS locations的标志2、在windows -> preferences里面会多一个hadoop map/reduce的选项,选中这个选项,然后右边,把下载的hadoop根目录选中如果能看到以上两点说明安装成功了。
二、插件安装后,配置连接参数插件装完了,启动hadoop,然后就可以建一个hadoop连接了,就相当于eclipse里配置一个weblogic的连接。
eclipse配置hadoop-eclipse-plugin(版本hadoop2.7.3)
.
版权声明:本文为博主原创文章,未经博主允许不得转载。
1:首先下载hadoop2.7.3
2:下载Hadoop-eclipse-plugin-2.7.3.jar(注:自己百度,可以下载csdn上有下载)
3:下载eclipse-mars-2
4:eclipse中安装hadoop-eclipse-plugin-2.7.3.jar插件。
(注:自己百度,把包导入到eclipse 的安装目录的plugins下重启eclipse就可以了)
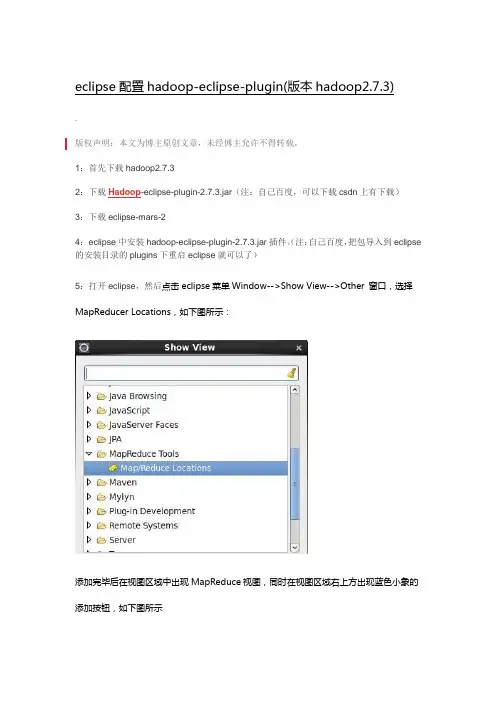
5:打开eclipse,然后点击eclipse菜单Window-->Show View-->Other 窗口,选择MapReducer Locations,如下图所示:
添加完毕后在视图区域中出现MapReduce视图,同时在视图区域右上方出现蓝色小象的添加按钮,如下图所示
6:新建Hadoop Location
点击蓝色小象新增按钮,提示输入MapReduce和HDFS Master相关信息,其中:Lacation Name:为该位置命名,能够识别该,可以随意些;
MapReduce Master:与$HADOOP_DIRCONF/mapred-site.xml配置保持一致;
HDFS Master:与$HADOOP_DIRCONF/core-site.xml配置保持一致
User Name:登录hadoop用户名,可以随意填写
7:配置完毕后,在eclipse的左侧DFS Locations出现CentOS HDFS的目录树,该目录为HDFS文件系统中的目录信息:。
Had oop安装及基于Eclipse的开发环境部署1、Had oop-1.2.1安装1.1 Hadoop安装工具1、操作系统:Win7系统2、虚拟机软件:VMware Workstation 103、Linux系统安装包:ubuntukylin-14.04-desktop-i386.iso(32位)4、JDK包:jdk-8u45-linux-i586.gz5、Hadoop-1.2.1程序安装包(非源码):/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz 1.2Hadoop安装步骤(部分详细内容可参见《Hadoop安装指南》)1、Ubuntu虚拟机安装(建议安装32位Ubuntu操作系统)2、Windows与linux之间的共享文件夹设置,实现windows与linux之间的文件共享;具体设置如下图:设置完成后,可以看到一个共享文件夹,通过该文件夹可以实现windows与linux之间的文件共享;该共享文件夹默认在linux系统的/mnt/hgfs目录下。
3、ssh安装(ubuntu默认没有安装ssh,需要通过apt-get install 进行安装,这里建议暂时不要生成公钥)4、网络连接配置;网络连接配置的主要目的是保证能够使用Xshell等工具链接虚拟机进行操作。
由于采用NAT模式没有连接成功,本文建议使用自定义的虚拟网络进行连接,具体步骤及设置如下:1)本地虚拟网络IP设置;具体设置如图(可以根据自己的情况设置IP(如192.168.160.1),该IP将作为虚拟机的网关):2)虚拟机网络适配器设置;建议采用自定义虚拟网络连接,设置如下:3)虚拟机网络IP设置;主要目的是设置自定义的IP、网关等;具体设置流程如下:4)当网络连接设置完成后,使用Ubuntu:service networking restart(centOS:service network restart)命令重启虚拟机网络服务;注意,重启网络服务后,建议在本机的DOS环境下ping一下刚刚在虚拟机中设置的IP地址,如果ping不通,可能是网卡启动失败,可以使用ifconfig eth0 up命令启动网卡(eh0是网卡名称,可以在网路连接设置中查看网卡名称)。

eclipse中需要配置jdk、需要配置jre吗?以及安装eclipse后需要做的⼀些配置1. 在eclipse中配置jdk直接配置eclipse中jdk环境即可,不需要配置jre的。
第⼀步:点击菜单栏的”windows“,之后选择”preference“。
第⼆dao步:找到”java“菜单下的”installed“,之后在此页⾯下点击”add“。
第三步:找到”jdk“的安装路径,之后点击”finsh“即可完成项⽬jdk的引⼊,以后创建项⽬后会默认的引⼊”jdk“包。
这样就完成了eclipse的引⼊为eclipse做的其他的配置,看完希望对你有帮助导航标题:1. 设置字符集编码为utf-8,防⽌乱码2. 设置eclipse的代码⾃动提⽰3. 在eclipse配置Maven1、在eclipse中配置jdkWindow–>Preferences–>java–>installed JREs–>add–>Standard VM–>选择jdk安装路径就好了2、设置字符集编码为utf-8,防⽌乱码设置字符集编码为UTF-8:Window–>Preferences–>General–>Workspace–>选择Other为UTF-8,General–>Content Types⾥⾯的Text内容全部设为UTF-8设置新建jsp页⾯默认为UTF-8编码:Window–>Preferences–>Web–>JSP Files–>Encoding设置为UTF-8(往上翻第⼀个)3、设置eclipse的代码⾃动提⽰Window–>Preferences–>java–>editor–>content assist–>右侧框⾥auto activation triggers for java值设置为 “abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXVZ.”,不要少了最后的⼀个点4、在eclipse配置MavenWindow–>Preferences–>Maven–>Installations–>add–>选择maven的解压⽬录就好了,然后勾选新增的maven,在配置User Settings–>选择maven的settings.xml⽂件。
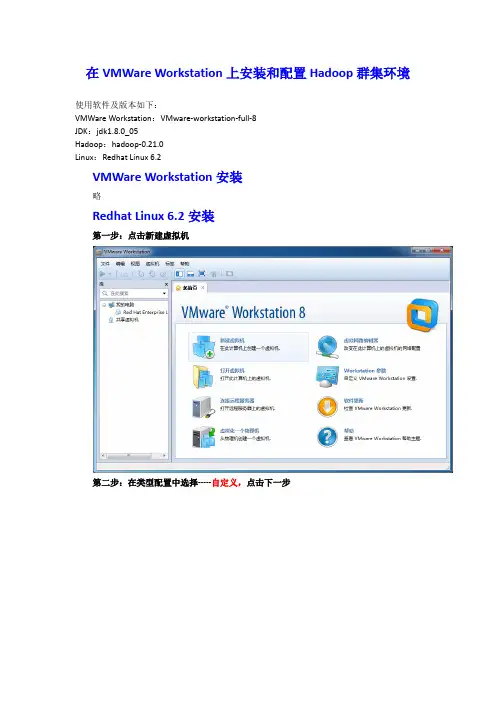
在VMWare Workstation上安装和配置Hadoop群集环境使用软件及版本如下:VMWare Workstation:VMware-workstation-full-8JDK:jdk1.8.0_05Hadoop:hadoop-0.21.0Linux:Redhat Linux 6.2VMWare Workstation安装略Redhat Linux 6.2安装第一步:点击新建虚拟机第二步:在类型配置中选择-----自定义,点击下一步第三步:选择虚拟机硬件兼容性,默认即可,下一步第四步,安装客户机操作系统,选择第三个,以后再安装,下一步第五步,选择一个操作系统,选择Linux,版本选择RedHat 6,下一步第六步,设置虚拟机名称和安装路径,建议名称可按节点的名称来取,安装路径最好不要放在C盘,下一步第七步,处理器配置,选择一个核心即可,如果你的机子配置比较牛逼,你也可以多选一个。
第八步,选择虚拟机内存,个人建议1G足够了第9步,设置网络连接方式,选用桥接第10步-第14步,默认即可。
第15步,指定磁盘大小,20GB即可,选择单个文件存储虚拟磁盘第16步,指定磁盘文件名称,默认即可第17步,准备创建虚拟机,点击定制硬件,第18步,在弹出的的界面左侧选择新的CD/DVD,右侧选择使用ISO镜像,并点击浏览选择已经下载好的镜像。
设置完成后点击关闭-----确定,完成后界面如下所示,点击打开虚拟机电源,开始Linux 系统的安装。
按照同样的步骤继续安装其他两个虚拟机第19步,安装RedHat Linux系统,具体安装步骤,参照:/link?url=SkVewxXQV6Ao5uenwDpOxdoSN2qd8C-dZBCBFbvxqHX-0t4Yru67odaK54dl m1SUAHr-kCzfLF8ZNuxOLHWxXdoy-ng4dSVpBKKc3R1kD4i20步,安装VMware tool,具体安装步骤参照:/link?url=hcgjMdlfnL36I5l0GyoeoHPz1t--AdW_EiOCAd8h4Y_EMu3Tk_G1 P3jVftr2yorVddPRoT2y_P69jgn0lUJp-fyC20DqkUf9e4ANdHhBjBu21、设置主机与虚拟机的共享文件夹,右击虚拟机---设置---选项---共享文件夹---启用,添加你需要共享的文件夹。

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。

eclipse怎么集成配置JDK和Tomcat
在eclipse中集成JDK和tomcat服务器方法很简单,我们可以在服务器上运行想要的东西。
比如我们学习javaweb时就要用到。
下面就让小编给大家说说eclipse怎么集成配置JDK和Tomcat吧。
eclipse集成配置JDK和Tomcat的方法
打开eclipse
点击window--preferences,如图
选择java---installed JRES,在右侧就会出现我们以前配置好的JDK(这里没有演示JDK的安装,大家到网上搜索一下就行),点击OK.
接下来我们要集成Tomcat,在刚才的对话框中选择Server--最后一项-(运行环境),在最上角点击Add添加
选择服务器,下一步
然后选择下方的JRES,完成
最后在自己的.jsp页面上右击选择在服务器上运行,出现结果猜你感兴趣的:
1.eclipse的使用方法
2.eclipse方法调用查找
3.eclipse svn使用方法
4.Eclipse怎么设置护眼背景色和字体颜色
5.java工程师求职简历怎么写
6.it项目成本管理论文。
hadoop搭建与eclipse开发环境设置――刘刚1.Windows下eclipse开发环境配置1.1 安装开发hadoop插件将hadoop安装包hadoop\contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar拷贝到eclipse的插件目录plugins下。
需要注意的是插件版本(及后面开发导入的所有jar包)与运行的hadoop一致,否则可能会出现EOFException异常。
重启eclipse,打开windows->open perspective->other->map/reduce 可以看到map/reduce开发视图。
1.2 设置连接参数打开windows->show view->other-> map/reduce Locations视图,在点击大象后弹出的对话框(General tab)进行参数的添加:参数说明如下:Location name:任意map/reduce master:与mapred-site.xml里面mapred.job.tracker设置一致。
DFS master:与core-site.xml里设置一致。
User name: 服务器上运行hadoop服务的用户名。
然后是打开“Advanced parameters”设置面板,修改相应参数。
上面的参数填写以后,也会反映到这里相应的参数:主要关注下面几个参数::与core-site.xml里设置一致。
mapred.job.tracker:与mapred-site.xml里面mapred.job.tracker设置一致。
dfs.replication:与hdfs-site.xml里面的dfs.replication一致。
hadoop.tmp.dir:与core-site.xml里hadoop.tmp.dir设置一致。
hadoop.job.ugi:并不是设置用户名与密码。

HadoopEclipse开发环境搭建This document is from my evernote, when I was still at baidu, I have a complete hadoop development/Debug environment. But at that time, I was tired of writing blogs. It costsme two day’s spare time to recovery from where I was stoped. Hope the blogs will keep on. Still cherish the time speed there, cause when doing the same thing at both differenttime and different place(company), the things are still there, but mens are no more than the same one. Talk too much, Let’s go on.在,已经搭建好了⼀个⽤于开发/测试的haoop集群,在这篇⽂章中,将介绍如何使⽤eclipse作为开发环境来进⾏程序的开发和测试。
2.) 在Eclipse的Windows->Preferences中,选择Hadoop Map/Reduce,设置好Hadoop的安装⽬录,这⾥,我直接从linux的/home/hadoop/hadoop-1.0.3拷贝过来的,点击OK按钮:3.) 新建⼀个Map/Reduce Project4.) 新建Map/Reduce Project后,会⽣成如下的两个⽬录, DFS Locations和suse的Java⼯程,在java⼯程中,⾃动加⼊对hadoop包的依赖:5.)是⽤该插件建⽴的⼯程,有专门的视图想对应:6.)在Map/Reduce Locations中,选择Edit Hadoop Location…选项,Map/Recuce Master和 DFS Master的设置:7.)在Advanced parameters中,设置Hadoop的配置选项,将dfs.data.dir设置成和linx环境中的⼀样,在Advanced parameters中,将所有与路径相关的都设置成对应的Linux路径即可:8.)将Hadoop集群相关的配置设置好后,可以在DFS location中看到Hadoop集群上的⽂件,可以进⾏添加和删除操作:9.)在⽣成的Java⼯程中,添加Map/Reduce程序,这⾥我添加了⼀个WordCount程序作为测试:10.)在Java⼯程的Run Configurations中设置WordCount的Arguments,第⼀个参数为输⼊⽂件在hdfs的路径,第⼆个参数为hdfs的输出路径:11.)设置好Word Count的RunConfiguration后,选择Run As-> Run on Hadoop:12.) 在Console中可以看到Word Count运⾏的输出⽇志信息:13.)在DFS Location中可以看到,Word Count在result⽬录下⽣成的结果:14.)进⾏Word Count程序的调试,在WordCount.java中设置好断点,点击debug按钮,就可以进⾏程序的调试了:⾄此, Hadoop+Eclipse的开发环境搭建完成。
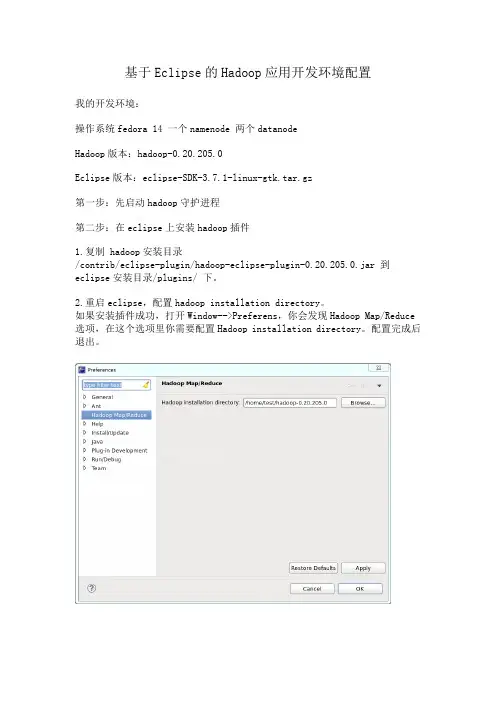
基于Eclipse的Hadoop应用开发环境配置我的开发环境:操作系统fedora 14 一个namenode 两个datanodeHadoop版本:hadoop-0.20.205.0Eclipse版本:eclipse-SDK-3.7.1-linux-gtk.tar.gz第一步:先启动hadoop守护进程第二步:在eclipse上安装hadoop插件1.复制 hadoop安装目录/contrib/eclipse-plugin/hadoop-eclipse-plugin-0.20.205.0.jar 到eclipse安装目录/plugins/ 下。
2.重启eclipse,配置hadoop installation directory。
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce 选项,在这个选项里你需要配置Hadoop installation directory。
配置完成后退出。
3.配置Map/Reduce Locations。
在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中新建一个Hadoop Location。
在这个View中,右键-->New Hadoop Location。
在弹出的对话框中你需要配置Location name,如Hadoop,还有Map/Reduce Master和DFS Master。
这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。
如:Map/Reduce Master192.168.1.1019001DFS Master192.168.1.1019000配置完后退出。
点击DFS Locations-->Hadoop如果能显示文件夹(2)说明配置正确,如果显示"拒绝连接",请检查你的配置。
hadoop搭建与eclipse开发环境设置――罗利辉1.前言1.1 目标目的很简单,为进行研究与学习,部署一个hadoop运行环境,并搭建一个hadoop开发与测试环境。
具体目标是:✓在ubuntu系统上部署hadoop✓在windows 上能够使用eclipse连接ubuntu系统上部署的hadoop进行开发与测试1.2 软硬件要求注意:Hadoop版本和Eclipse版本请严格按照要求。
现在的hadoop最新版本是hadoop-0.20.203,我在windows上使用eclipse(包括3.6版本和3.3.2版本)连接ubuntu上的hadoop-0.20.203环境一直没有成功。
但是开发测试程序是没有问题的,不过需要注意权限问题。
如果要减少权限问题的发生,可以这样做:ubuntu上运行hadoop的用户与windows 上的用户一样。
1.3 环境拓扑图ubuntu 192.168.69.231ubuntu2192.168.69.233 ubuntu1192.168.69.2322.Ubuntu 安装安装ubuntu11.04 server系统,具体略。
我是先在虚拟机上安装一个操作系统,然后把hadoop也安装配置好了,再克隆二份,然后把主机名与IP修改,再进行主机之间的SSH配置。
如果仅作为hadoop的运行与开发环境,不需要安装太多的系统与网络服务,或者在需要的时候通过apt-get install进行安装。
不过SSH服务是必须的。
3.Hadoop 安装以下的hadoop安装以主机ubuntu下进行安装为例。
3.1 下载安装jdk1.6安装版本是:jdk-6u26-linux-i586.bin,我把它安装拷贝到:/opt/jdk1.6.0_263.2 下载解压hadoop安装包是:hadoop-0.20.2.tar.gz。
3.3 修改系统环境配置文件切换为根用户。
●修改地址解析文件/etc/hosts,加入3.4 修改hadoop的配置文件切换为hadoop用户。
Eclipse+Tomcat+Lomboz的配置总结最近这几天在研究Eclipse插件的配置,也参考了网上的一些帖子,终于把Eclipse+Tomcat+Lomboz配置成功了,下面写出我的配置过程,有什么不妥之处请大家指教。
一,下载所需的各种工具和插件(以本机下载的版本举例)j2sdk-1_4_2_01eclipse-SDK-3.0-win32jakarta-tomcat-5.0.16(也可以是其他版本,最好是4。
0以上的)Lomboz301emf-sdo-runtime-2.0.1二,解压缩和安装各个组件1,安装JDK到C:\j2sdk1.4.2_012,安装或解压缩Tomcat到C:\Tomcat 5.03,配置环境变量ⅰ,新建系统变量java_home,值为C:\j2sdk1.4.2_01ⅱ,新建系统变量classpath,值.;C:\j2sdk1.4.2_01\lib\dt.jar;C:\j2sdk1.4.2_01\lib\tools.jar;C:\j2sdk1.4.2_01\jre\lib\rt.jar;C:\Tom cat 5.0\common\lib\servlet-api.jar(注意:.号不能少,它代表当前路径)ⅲ,新建系统变量CA TALINA_HOME,值为C:\Tomcat 5.0(可选)ⅳ,编辑系统变量Path,添加值C:\j2sdk1.4.2_01\bin在地址栏输入http://localhost:8080,按回车看到可爱的小猫就说明你的Tomcat配置成功了。
4,解压缩eclipse-SDK-3.0-win32到D:\Eclipse5,将emf-sdo-runtime-2.0.1和Lomboz301中的各个文件解压到Eclipse对应的plugins或features目录中去。
注意一定不用搞错了目录.6,启动Eclipse,选中windows->preferences,在弹出的窗口看不到Lomboz的情况时,先退出Eclipse,然后把Eclipse目录configuration中下面的org.eclipse.update文件夹删掉,再重新启动Eclipse就可以了。
基于Eclipse的Hadoop开发环境配置方法(1)启动hadoop守护进程在Terminal中输入如下命令:$ bin/hadoop namenode -format$ bin/start-all.sh(2)在Eclipse上安装Hadoop插件找到hadoop的安装路径,我的是hadoop-0.20.2,将/home/wenqisun/hadoop-0.20.2/contrib/eclipse-plugin/下的hadoop-0.20.2-eclipse-plugin.jar拷贝到eclipse安装目录下的plugins里,我的是在/home/wenqisun/eclipse /plugins/下。
然后重启eclipse,点击主菜单上的window-->preferences,在左边栏中找到Hadoop Map/Reduce,点击后在右边对话框里设置hadoop的安装路径即主目录,我的是/home/wenqisun/hadoop-0.20.2。
(3)配置Map/Reduce Locations在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中New一个Hadoop Location。
在打开的对话框中配置Location name(为任意的名字)。
配置Map/Reduce Master和DFS Master,这里的Host和Port要和已经配置的mapred-site.xml 和core-site.xml相一致。
一般情况下为Map/Reduce MasterHost:localhostPort:9001DFS MasterHost:localhostPort:9000配置完成后,点击Finish。
如配置成功,在DFS Locations中将显示出新配置的文件夹。
(4)新建项目创建一个MapReduce Project,点击eclipse主菜单上的File-->New-->Project,在弹出的对话框中选择Map/Reduce Project,之后输入Project的名,例如Q1,确定即可。
Eclipse配置Tomcat的方法图解1.访问Tomcat的官方网站。
第二步:安装并启动Eclipse接下来,你需要安装并启动Eclipse。
4.启动Eclipse。
第三步:配置Tomcat服务器现在,你需要配置Eclipse以使用已安装的Tomcat服务器。
1.打开Eclipse。
2.点击“Window”菜单,然后选择“Preferences”选项。
4.点击“Add”按钮来添加新的服务器运行时环境。
5.在弹出的对话框中,选择“Apache”文件夹,然后选择合适的Tomcat版本(例如,Tomcat 8.5)。
6.点击“Next”按钮。
7.在下一个界面上,点击“Browse”按钮,并导航到之前安装Tomcat的目录。
选择Tomcat的安装目录,然后点击“Finish”按钮。
8.完成以上步骤后,Eclipse将显示一个新的Tomcat版本。
点击“OK”按钮以保存配置。
第四步:创建一个新的动态Web项目现在,你可以创建一个新的动态Web项目,并将其部署到已配置的Tomcat服务器上。
1.点击“File”菜单,然后选择“New” > “Dynamic Web Project”选项。
2.在弹出的对话框中,输入项目的名称和目标运行时环境(即之前配置的Tomcat版本)。
3.点击“Next”按钮。
4.在下一个界面上,选择“Generate web.xml deployment descriptor”选项。
5.点击“Finish”按钮。
第五步:部署和运行项目最后,你可以将项目部署到已配置的Tomcat服务器上并运行它。
1.在Eclipse的“Package Explorer”视图中找到你的项目,右键点击它。
2.选择“Run As” > “Run on Server”选项。
3.在弹出的对话框中,选择之前配置的Tomcat版本,并点击“Finish”按钮。
4.等待项目部署和服务器启动,然后在默认的Web浏览器中打开项目。
VM虚拟机下配Eclipse+JDK+Tomcat+Hadoop环境搭建⼀、安装虚拟机VM⼀直next注:卸载VM的时候最好⽤强⼒点的软件卸载,因为如果卸载(尤其是注册表)的不彻底的话很可能会导致下次没法安装。
遇到这种情况⼿动删除注册表中关于VMware的信息。
参考:/doc/0e83d81f650e52ea551898c1.html /question/156744859.html?fr=qrl&cid=89&index=1⼆、安装好VM后打开⼀个CentOS步骤如下三、⼀般安装好之后会提⽰更新安装包,⽤来安装VMware Tools(⽤来⽅便和Window进⾏切换,如果没安装⿏标从VM中切换出来⽤Ctrl+Alt),如果没有则进⾏如下操作:点击中间的Virtual Machine,然后选择最下⾯的Install VMware Tools(如果安装好了则显⽰cancel VMware Tools Installation)该⽂件将会下载到/media/VMware Tools⽂件夹下⾯,找到该⽂件,然后进⾏如下操作:1.将它复制到root⽂件夹下,即位置——主⽂件夹下⾯(这⼀些操作都是root⽤户),然后解压,命令:tar zxvf VMwareTools-8.4.5-324285.tar.gz(注:ls⽤来查看当前⽂件夹下⾯的⽂件;⽂件名不⽤全部⼿敲,打出开头字母,然后按Tab键会⾃动补全的)2.解压后做如下图操作:a)开⼀个终端,输⼊如下命令:cd vmware-tools-distribb)然后输⼊./vmware-install.pl(前⾯有个.,输⼊这条命令前也可以先ls查看⼀下当前⽬录是否有这个⽂件)c)然后出现下图界⾯按回车就可以了d)后⾯会出现选择yes,就输⼊yes就可以了e)最后会有22个选项,是像素的,默认的是22,我们选择12f)安装好后注销⼀下,重新登录就可以了四、新建⼀个新的⽤户hadoop/doc/0e83d81f650e52ea551898c1.html eraddhadoop2.passwdhadoop(⽤户hadoop的密码)3.会让确认,将上⾯密码重新输⼊就可以了4.再注销⼀下,这次⽤⽤户hadoop登录如果想让⽤户有root权限则进⾏如果操作5.gedit /etc/passwd6.7.将⽤户hadoop x: 后⾯都改成0,参照root的格式改,保存退出就可以了五、安装JDK,Tomcat以及Eclipse(⼀)安装JDK1.下载j2sdk ,如jdk-6u23-linux-x64.bin2.在终端中转到jdk-6u23-linux-x64.bin所在的⽬录,输⼊命令chmod +755jdk-6u23-linux-x64.bin,添加执⾏的权限(有权限之后变成绿⾊)。
eclipse软件安装详解与JDK环境配置Eclipse是一款开放源代码的集成开发环境(IDE),主要用于Java
开发,但也可以用于其他编程语言的开发。
在使用Eclipse之前,需要先
进行软件的安装并配置JDK环境。
双击安装包,选择你想要安装的Eclipse版本并点击“Install”按钮。
接着,你需要选择一个安装目录,并点击“Launch”按钮来启动Eclipse安装程序。
在安装期间,你可以选择用于开发Java应用程序的Eclipse软件包。
通常来说,选择“Eclipse IDE for Java Developers”选项即可满足大
部分Java开发需求。
最后,点击“Finish”按钮来完成安装。
安装完成后,你可以通过双击Eclipse的安装文件来启动Eclipse。
接下来,让我们来配置JDK环境。
安装完JDK后,我们需要配置Eclipse以使用安装的JDK。
启动Eclipse,并在欢迎界面选择一个工作区。
点击“Windows”菜单,选择“Preferences”选项打开Eclipse的配
置面板。
在弹出的对话框中,展开“Java”节点,选择“Installed JREs”选项。
点击“Add”按钮,选择“Standard VM”并点击“Next”按钮。
在“JRE home”字段中,点击“Directory…”按钮并浏览到安装的JDK目录。
点击“Finish”按钮。
现在,你已经成功配置了JDK环境。
你可以在Eclipse中创建和进行Java项目开发了。
一、安装虚拟机VM一直next注:卸载VM的时候最好用强力点的软件卸载,因为如果卸载(尤其是注册表)的不彻底的话很可能会导致下次没法安装。
遇到这种情况手动删除注册表中关于VMware的信息。
参考:/question/156744859.html?fr=qrl&cid=89&index=1二、安装好VM后打开一个CentOS步骤如下三、一般安装好之后会提示更新安装包,用来安装VMware Tools(用来方便和Window进行切换,如果没安装鼠标从VM中切换出来用Ctrl+Alt),如果没有则进行如下操作:点击中间的Virtual Machine,然后选择最下面的Install VMware Tools(如果安装好了则显示cancel VMware Tools Installation)该文件将会下载到/media/VMware Tools文件夹下面,找到该文件,然后进行如下操作:1.将它复制到root文件夹下,即位置——主文件夹下面(这一些操作都是root用户),然后解压,命令:tar zxvf VMwareTools-8.4.5-324285.tar.gz(注:ls用来查看当前文件夹下面的文件;文件名不用全部手敲,打出开头字母,然后按Tab键会自动补全的)2.解压后做如下图操作:a)开一个终端,输入如下命令:cd vmware-tools-distribb)然后输入./vmware-install.pl(前面有个.,输入这条命令前也可以先ls查看一下当前目录是否有这个文件)c)然后出现下图界面按回车就可以了d)后面会出现选择yes,就输入yes就可以了e)最后会有22个选项,是像素的,默认的是22,我们选择12f)安装好后注销一下,重新登录就可以了四、新建一个新的用户hadooperaddhadoop2.passwdhadoop(用户hadoop的密码)3.会让确认,将上面密码重新输入就可以了4.再注销一下,这次用用户hadoop登录如果想让用户有root权限则进行如果操作5.gedit /etc/passwd6.7.将用户hadoop x: 后面都改成0,参照root的格式改,保存退出就可以了五、安装JDK,Tomcat以及Eclipse(一)安装JDK1.下载j2sdk ,如jdk-6u23-linux-x64.bin2.在终端中转到jdk-6u23-linux-x64.bin所在的目录,输入命令chmod +755jdk-6u23-linux-x64.bin,添加执行的权限(有权限之后变成绿色)。
3.输入安装命令./ jdk-6u23-linux-x64.bin然后开始安装,结束时候会提示让输入回车,等待一会出现Done 然后结束安装,出现下图界面。
4.设置环境变量,输入命令gedit/etc/profile ,在打开的文件中加入如下内容:JAVA_HOME=/usr/java/jdk1.6.0_23PATH=$JAVA_HOME/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport JAVA_HOMEexport PATHexport CLASSPATH如果出现权限不够则先切换到root用户给该文件分配权限,操作如下:1)su root2)输入密码3)sudochmod 777 /etc/profile(文件名) –R(加R表示文件夹下面的所有文件都有权限)通过java –version 查看JDK版本,如果是jdk1.6.0_23,则表示成功(二)安装Tomcat1)下载apache-tomcat-6.0.29.tar.gz2)终端到apache所在目录下,输入如下命令:tar zxvf apache-tomcat-6.0.29.tar.gz //解压3)cp -R apache-tomcat-6.0.29 /usr/local/tomcat //拷贝apache-tomcat-6.0.1到/usr/local/下并重命名为tomcat4) /usr/local/tomcat/bin/startup.sh //启动tomcat显示到此tomcat 已经安装完成,现在使用浏览器访问http://localhost:8080,出现tomcat 默认页面,说明已经安装成功。
(三)安装Eclipse1.终端到Eclipse文件所在目录下,输入如下命令:tar zxvfeclipse-jee-galileo-linux-gtk-x86_64.tar.gz //解压2.打开文件eclipse ,双击3.我们装好了哦~六、单机版Hadoop1.下载hadoop的jar包,下载地址:/dyn/closer.cgi/hadoop/core/2.终端到Hadoop的jar包所在的目录,解压文件,输入如下的命令:tarzxvf hadoop-0.20.2.tar.gz3.将其剪切到/usr/src目录下,当然不动也可以4.在/hadoop-0.20.2/conf/hadoop-env.sh文件中添加export JAVA_HOME=/usr/java/jdk1.6.0_23测试hadoop是否安装成功:在终端输入bin/hadoop(此时终端应该在文件hadoop-0.20.2下,可以输入ls看一下)输入bin/hadoop之后显示如下:5.配置环境变量:(gedit /etc/profile)HADOOP=/usr/src/hadoop-0.20.2PATH=$HADOOP/bin:$PATH配置好环境变量记得要重新登录哦~~~注销就可以啦~开一个新的终端,输入hadoop,出现上图表示配置成功6.在Eclipse中配置好hadoopa.将hadoop-0.20.2/contrib/eclipse-plugin/hadoop-0.20.2-eclipse-plugin.jar复制到Eclipse目录下的plugins(该目录是放插件的)b.开一个Eclipse,然后选择Window——preferences(最后一个)——HadoopMap/Reduce 然后选择Hadoop的安装目录c.然后新建一个Map/Reduce项目File—New—Project—other—Map/Reduce,然后next,输入Project Name为testMRd.然后新建一个Mapper(写map方法),Reduce(写reduce方法),MapReduce Driver(job的配置)方法:项目右键—New—other—Map/Reduce添加Mapper之后,自动生成的代码:添加Reduce后:添加了主函数MapReduce Driver后:注意,要将缺省的“setMapperClass”和“setReducerClass”改为刚才自己产生的类,比如“NewMapper”和“NewReduce”。
e.下面开始写程序了,我们写个简单的来测试一下7.写测试代码:a.将JUnit4的Jar文件导入到项目中,然后在要测试的类上面右键——>New——>Java——>JUnit——>JUnit Test Case,如下图:注:选择New JUnit4 test,建议将测试代码放在一个单独名为test的文件夹下面。
Ctrl+Shift+f调整项目格式。
将MRUnit的jar包导入到项目中就可以开始写MapReduce的测试代码了。
b.运行:右键——>Run As——>JUnit Testc.结果:在src里面程序代码package com.test;publicclass MyFirstTestClass {publicint multiply(int x,int y){return x/y;}}测试的代码:在test文件夹里面package com.test;importstatic org.junit.Assert.assertEquals;import org.junit.Test;publicclass MyFirstTestClassTest {@Testpublicvoid testMultiply() {MyFirstTestClass test = new MyFirstTestClass();assertEquals("Result", 50,test.multiply(10, 5)); //结果应该是2,由于写的50,所以错了}}改后结果:进一步了解JUnit4.1. setUp()与tearDown()对于每一个测试用例,你都可以实现setUp()和tearDown(). setUp在每一个测试用例初始化的时候被调用。
tearDown()在每一个测试用例结束的时候被调用。
4.2. 在Eclipse中使用Static importsJunit中大量使用了static方法。
Eclipse无法自动导入static imports。
你需要做的是将'org.junit.Assert'导入到Java > Editor > Content Assist > Favorites 中。
当你这么做了以后,你可以使用Content Assist (Ctrl+Space) 来添加方法。
4.3. AnnotationsJUnit 4.x中Annotations的使用如下:表1. Annotations 4.4. Assert语句JUnit 4.x中Assert语句的使用如下:表2. Assert语句。