编译器的语法分析详解
- 格式:doc
- 大小:106.50 KB
- 文档页数:34

编译原理中的词法分析与语法分析原理解析编译原理中的词法分析和语法分析是编译器中两个基本阶段的解析过程。
词法分析(Lexical Analysis)是将源代码按照语法规则拆解成一个个的词法单元(Token)的过程。
词法单元是代码中的最小语义单位,如标识符、关键字、运算符、常数等。
词法分析器会从源代码中读取字符流,将字符流转换为具有词法单元类型和属性值的Token序列输出。
词法分析过程中可能会遇到不合法的字符序列,此时会产生词法错误。
语法分析(Syntax Analysis)是对词法单元序列进行语法分析的过程。
语法分析器会根据语法规则,将词法单元序列转换为对应的抽象语法树(Abstract Syntax Tree,AST)。
语法规则用于描述代码的结构和组织方式,如变量声明、函数定义、控制流结构等。
语法分析的过程中,语法分析器会检查代码中的语法错误,例如语法不匹配、缺失分号等。
词法分析和语法分析是编译器的前端部分,也是编译器的基础。
词法分析和语法分析的正确性对于后续的优化和代码生成阶段至关重要。
拓展部分:除了词法分析和语法分析,编译原理中还有其他重要的解析过程,例如语义分析、语法制导翻译、中间代码生成等。
语义分析(Semantic Analysis)是对代码进行语义检查的过程。
语义分析器会根据语言的语义规则检查代码中的语义错误,例如类型不匹配、变量声明未使用等。
语义分析还会进行符号表的构建,维护变量和函数的属性信息。
语法制导翻译(Syntax-Directed Translation)是在语法分析的过程中进行语义处理的一种技术。
通过在语法规则中嵌入语义动作(Semantic Action),语法制导翻译可在语法分析的同时进行语义处理,例如求解表达式的值、生成目标代码等。
中间代码生成(Intermediate Code Generation)是将高级语言源代码转换为中间表示形式的过程。
中间代码是一种抽象的表示形式,可以是三地址码、四元式等形式。

gcc 语法树文件解析GCC(GNU Compiler Collection)是一种流行的编译器,它使用一种称为抽象语法树(Abstract Syntax Tree, AST)的数据结构来表示源代码的结构。
AST是源代码的抽象表示,它反映了代码的语法结构,并且可以用于多种目的,例如静态分析、代码生成、重构等。
要解析GCC的语法树文件,你需要使用GCC的内部表示和访问AST的API。
GCC提供了一个称为"libgccjit"的库,它允许你与AST进行交互。
libgccjit是一个用于创建GCC插件的API,它可以让你读取、修改和生成AST。
以下是使用libgccjit解析AST的基本步骤:1. 创建一个GCC插件:首先,你需要创建一个GCC插件,这是使用libgccjit的起点。
插件是一个动态链接库,它与GCC一起加载并执行。
2. 初始化libgccjit:在插件中,你需要初始化libgccjit库,以便能够使用其功能。
这通常涉及到设置一些参数和配置选项。
3. 读取AST文件:你需要加载包含AST的文件。
AST文件是由GCC在编译过程中生成的,通常保存在目标目录下的".tu"文件中。
你可以使用libgccjit提供的函数来打开和读取AST文件。
4. 遍历AST:一旦你加载了AST文件,你可以使用libgccjit提供的API来遍历AST并访问其节点。
AST的结构反映了源代码的语法结构,你可以通过遍历AST来分析和操作代码。
5. 修改AST:如果你需要对AST进行修改,你可以使用libgccjit提供的API来修改节点。
你可以添加、删除或修改节点,以实现你想要的代码变换。
6. 生成新的AST:最后,你可以使用libgccjit生成新的AST。
你可以根据需要创建新的节点和结构,然后将其保存为AST文件或直接编译为目标代码。
需要注意的是,解析和操作AST需要深入理解编译器原理和编程语言语法。

条件编译语法摘要:一、条件编译简介二、条件编译的语法规则1.语法结构2.条件表达式3.循环语句4.分支语句三、条件编译的应用场景四、实战案例解析五、总结与展望正文:一、条件编译简介条件编译(Conditional Compilation)是一种编程技巧,用于在程序运行过程中根据特定条件选择性地执行代码片段。
这种技术在编程语言中广泛应用,可以帮助开发者灵活地处理不同情况,提高代码的可维护性和可读性。
二、条件编译的语法规则1.语法结构条件编译的语法结构主要包括以下几个部分:- 关键字:if、else if、else- 条件表达式:用于判断条件- 代码片段:满足条件时执行的代码2.条件表达式条件表达式用于判断某个条件是否满足,常见的条件表达式有以下几种:- 比较运算符:==、!=、>、<、>=、<=- 逻辑运算符:&&、||、!- 布尔运算符:true、false3.循环语句条件编译中,可以使用循环语句(for、while、do-while)来实现代码片段的重复执行。
4.分支语句条件编译中,可以使用分支语句(if、else if、else)来实现代码片段的选择性执行。
三、条件编译的应用场景条件编译的应用场景主要包括以下几种:1.根据不同平台或版本实现不同功能2.根据用户输入或配置文件动态调整程序行为3.代码调试与测试4.模块化编程,便于后期维护和扩展四、实战案例解析以下是一个简单的条件编译实战案例:```cpp#include <iostream>int main() {int a = 10;int b = 20;if (a > b) {std::cout << "a > b" << std::endl;} else if (a < b) {std::cout << "a < b" << std::endl;} else {std::cout << "a == b" << std::endl;}return 0;}```这个案例中,我们根据变量a和b的大小关系,选择性地输出不同的结果。

C语言编译原理词法分析和语法分析编程语言的编写和使用离不开编译器的支持,而编译器的核心功能之一就是对代码进行词法分析和语法分析。
C语言作为一种常用的高级编程语言,也有着自己的词法分析和语法分析规则。
一、词法分析词法分析是编译器的第一阶段,也是将源代码拆分为一个个独立单词(token)的过程。
在C语言中,常见的单词包括关键字(如if、while等)、标识符(如变量名)、常量(如数字、字符常量)等。
词法分析器会根据预定义的规则对源代码进行扫描,并将扫描到的单词转化为对应的符号表示。
词法分析的过程可以通过有限自动机来实现,其中包括各种状态和状态转换规则。
词法分析器通常会使用正则表达式和有限自动机的方法来进行实现。
通过词法分析,源代码可以被分解为一个个符号,为后续的语法分析提供基础。
二、语法分析语法分析是编译器的第二阶段,也是将词法分析得到的单词序列转换为一棵具有语法结构的抽象语法树(AST)的过程。
在C语言中,语法分析器会根据C语言的文法规则,逐句解析源代码,并生成相应的语法树。
C语言的语法规则相对复杂,其中包括了各种语句、表达式、声明等。
语法分析的过程主要通过递归下降分析法、LR分析法等来实现。
语法分析器会根据文法规则建立语法树的分析过程,对每个语法结构进行逐步推导和分析,最终生成一棵完整的语法树。
三、编译器中的词法分析和语法分析在编译器中实现词法分析和语法分析是一项重要的技术任务。
编译器通常会将词法分析和语法分析整合在一起,形成一个完整的前端。
在C语言编译器中,词法分析和语法分析器会根据C语言的词法规则和文法规则,对源代码进行解析,并生成相应的中间表示形式,如语法树或者中间代码。
词法分析和语法分析的结果会成为后续编译器中各个阶段的输入,如语义分析、中间代码生成、目标代码生成等。
编译器的优化和错误处理也与词法分析和语法分析有密切关系。
因此,对词法分析和语法分析的理解和实现对于编译器开发者而言是非常重要的。

计算机编程语言中的语法与语义分析计算机编程语言是人与计算机进行交流的工具,它具有自身的语法和语义规则。
语法和语义分析是计算机编程中非常重要的概念,它们帮助程序员确保代码的正确性和一致性。
本文将探讨计算机编程语言中的语法和语义分析的概念、作用和实际应用。
一、语法分析语法分析是计算机编译器或解释器的一个重要组成部分。
它负责将输入的代码按照语法规则进行解析,并构建相应的语法树或抽象语法树。
语法分析的目的是确定代码的结构和规则是否符合语法要求。
在计算机编程中,语法规则由编程语言的定义决定。
不同的编程语言具有不同的语法规则。
例如,C语言要求每条语句以分号结尾,而Python语言使用缩进来表示代码块的层次结构。
语法分析器通常使用上下文无关文法(Context-Free Grammar)来描述语言的语法规则。
上下文无关文法使用产生式(Production)描述非终结符和终结符之间的关系。
例如,在C语言中,一个赋值语句的产生式可以表示为:`expression = expression`。
语法分析的过程通常使用自顶向下或自底向上的方法进行。
在自顶向下的方法中,分析从整个代码出发,根据语法规则逐步向下分解,直到最小的语法单元。
而在自底向上的方法中,分析是从最小的语法单元开始,根据语法规则逐步向上合并,直到整个代码。
通过语法分析,编译器或解释器可以检测代码中的语法错误,并及时提示程序员。
这有助于提高代码的可读性和可维护性。
二、语义分析语义分析是在语法分析的基础上,对代码的意义和行为进行分析。
它关注代码中的语义错误、冲突和逻辑问题。
语义分析的目的是确保代码在语法上正确,并具有正确的语义。
语义分析器通常检查以下方面的问题:1. 类型检查:计算机编程语言通常具有静态类型或动态类型的特性。
语义分析器检查代码中的类型声明和操作,以确保类型的一致性。
例如,在Java中,如果一个方法声明为接收整数参数,那么调用该方法时必须传入整数类型的参数。

armcc语法
ARM C编译器的语法规则包括以下方面:
1.符号:程序中用到的各种变量和函数都要用符号(包括变量名、函数名等)来表示。
2.注释:在程序中,注释是一种非常重要的语法元素,它用来对程序进行说明和解释。
3.变量:在程序中,变量是一种非常重要的数据存储单元,它用来存储程序中需要处理的数据。
4.运算符:在程序中,运算符是一种非常重要的语法元素,它用来对变量进行各种运算操作。
5.语句:在程序中,语句是一种非常重要的语法元素,它用来表示程序中的各种操作。
6.函数:在程序中,函数是一种非常重要的语法元素,它用来将程序中的一段代码封装成一个独立的模块,以便于重复使用。
以上是ARM C编译器的一些基本语法规则,当然还有很多其他的规则和细节需要掌握。

⾼级语⾔程序的两种处理⽅式——编译和解释编译⽅式编译程序的功能就是把⾼级语⾔书写的源程序翻译成与之等价的⽬标程序(汇编语⾔或机器语⾔)。
编译程序的⼯作过程词法分析在词法分析阶段,源程序可以简单的看做是⼀个多⾏的字符串。
词法分析阶段是编译过程的第⼀阶段,主要任务是对源程序从前到后(从左到右)逐个字符进⾏扫描,从中识别出⼀个个“单词”符号。
词法分析程序输出的”单词“常采⽤⼆元组的⽅式,即单词类别和单词⾃⾝的值。
词法分析过程依据的语⾔的此法规则,即描述“单词”结构的规则。
词法分析器⼀般来说有两种⽅法构造:⼿⼯构造和⾃动⽣成。
⼿⼯构造可使⽤状态图进⾏⼯作,⾃动⽣成使⽤确定的有限⾃动机来实现。
词法分析器的功能输⼊源程序,按照构词规则分解成⼀系列单词符号。
单词是语⾔中具有独⽴意义的最⼩单位,包括:(1)关键字是由程序语⾔定义的具有固定意义的标识符。
(2)标识符⽤来表⽰各种名字,如变量名,数组名,过程名等等。
(3)常数常数的类型⼀般有整型、实型、布尔型、⽂字型等。
(4)运算符如+、-、*、/等等。
(5)界符如逗号、分号、括号、等等。
语法分析编译程序的语法分析器以单词符号作为输⼊,分析单词符号串是否形成符合语法规则的语法单位,如表达式、赋值、循环等,最后看是否构成⼀个符合各类语法的构成规则,按该语⾔使⽤的语法规则分析检查每条语句是否有正确的逻辑结构,程序是最终的⼀个语法单位。
语法分析的⽅法分为两种:⾃上⽽下分析法和⾃下⽽上分析法。
⾃上⽽下就是从⽂法的开始符号出发,向下推导,推出句⼦。
⽽⾃下⽽上分析法采⽤的是移进归约法,基本思想是:⽤⼀个寄存符号的先进后出栈,把输⼊符号⼀个⼀个地移进栈⾥,当栈顶形成某个产⽣式的⼀个候选式时,即把栈顶的这⼀部分归约成该产⽣式的左邻符号。
语法分析只考虑构成该句⼦的语法单位是否符合语法规则。
例如在分析除法表达式时在语法分析阶段只分析运算符左右两边是否为变量、常量、表达式等,⽽不去管除数是否为0。

clang 语法摘要:1.引言2.clang 语法简介3.clang 语法特点4.clang 语法工具与资源5.总结正文:【引言】本文将介绍clang 语法,它是一种广泛使用的C/C++ 语言的语法分析器。
我们将讨论它的基本概念、特点以及相关工具和资源,帮助读者更好地理解和使用clang 语法。
【clang 语法简介】clang 是一种基于LLVM 架构的编译器,它可以解析C/C++ 语言源代码并生成抽象语法树(Abstract Syntax Tree,AST)。
AST 是源代码的树形结构表示,它包含了源代码的语法信息,可以用于代码分析、优化和生成目标代码等。
【clang 语法特点】clang 语法具有以下特点:1.高度可定制:clang 提供了丰富的选项和扩展,可以根据需要进行定制和调整。
2.多语言支持:除了C 和C++,clang 还可以解析其他语言,如Objective-C、C++11、Java、Fortran 等。
3.强大的错误和警告提示:clang 可以生成详细的错误和警告提示,帮助开发者快速发现和修复代码中的问题。
4.支持多种AST 格式:clang 支持多种AST 格式,如XML、JSON、DOT 等,方便开发者进行代码分析和可视化。
【clang 语法工具与资源】clang 提供了丰富的工具和资源,如下所示:1.clang 编译器:clang 编译器是clang 语法的基础,可以用于解析源代码并生成AST。
2.clang 语法检查器:clang 语法检查器可以用于检查源代码中的语法错误和警告。
3.clang 代码生成器:clang 代码生成器可以将AST 转换为目标代码,如x86、ARM 等。
4.clang 开发者文档:clang 提供了详细的开发者文档,包括使用手册、API 文档、示例代码等。
5.clang 社区:clang 社区是一个非常活跃的社区,提供了丰富的技术支持和资源,如论坛、邮件列表、博客等。

编译原理词法分析
编译原理的词法分析是编译器中的一个重要过程,它负责将源代码分
割成一个个的词法单元(Token)。
词法单元是程序中的最小语法单位,
如标识符、关键字、运算符、常数等。
词法分析的主要任务是从左到右扫描源代码字符流,逐个字符进行解析,并根据预先定义的词法规则识别出各种词法单元。
为了实现词法分析,通常会采用有限自动机(DFA)或正则表达式来描述词法规则。
具体的词法分析过程包括以下几个步骤:
1.建立输入缓冲区:将源代码存储在缓冲区中,方便逐个字符进行读
取和处理。
2.扫描字符流:从缓冲区中逐个字符读取并处理,跳过空白字符(空格、制表符、换行符等)。
3.根据词法规则识别词法单元:根据预先定义的词法规则,将字符序
列转换为词法单元,并记录其类型和属性信息。
4.错误处理:如果遇到无法识别的字符序列或不符合词法规则的情况,进行相应的错误处理并报告错误。
5.输出词法单元流:将识别出的词法单元按照顺序输出,作为下一步
的输入。
词法分析是编译器的前端处理阶段,它为语法分析提供了基础数据,
将源代码转化为一个个的词法单元,为后续的语法分析、语义分析和代码
生成等阶段提供支持。

编译原理语法分析器编译原理语法分析器是编译器中的重要组成部分,它负责将源代码解析成抽象语法树,为后续的语义分析和代码生成做准备。
本文将介绍语法分析器的原理、分类和常用算法。
一、语法分析器的原理语法分析器的主要任务是根据给定的文法定义,将源代码解析成一个个语法单元,并构建出一棵抽象语法树。
它通过递归下降、预测分析和LR分析等算法来实现。
1. 递归下降法递归下降法是一种基于产生式的自顶向下分析方法。
它从文法的开始符号出发,通过不断地推导和回溯,逐步地构建抽象语法树。
递归下降法易于理解和实现,但对左递归和回溯有一定的局限性。
2. 预测分析法预测分析法也是自顶向下的分析方法,它通过预测下一个输入符号来选择适当的产生式进行推导。
为了提高效率,预测分析法使用预测分析表来存储各个非终结符和终结符的关系。
3. LR分析法LR分析法是一种自底向上的分析方法,它使用LR自动机和LR分析表来进行分析。
LR自动机是一个有限状态控制器,通过状态转移和规约动作来解析源代码。
LR分析表存储了状态转移和规约的规则。
二、语法分析器的分类根据语法分析器的特性和实现方式,可以将其分为LL分析器和LR 分析器。
1. LL分析器LL分析器是基于递归下降法和预测分析法的一类分析器。
它从左到右、从左到右地扫描源代码,并根据预测分析表进行推导。
常见的LL分析器有LL(1)分析器和LL(k)分析器。
2. LR分析器LR分析器是基于LR分析法的一类分析器。
它先通过移进-归约的方式建立一棵语法树,然后再进行规约操作。
LR分析器具有强大的语法处理能力,常见的LR分析器有LR(0)、SLR(1)、LR(1)和LALR(1)分析器。
三、常用的语法分析算法除了递归下降法、预测分析法和LR分析法,还有一些其他的语法分析算法。
1. LL算法LL算法是一种递归下降法的改进算法,它通过构造LL表和预测分析表实现分析过程。
LL算法具有很好的可读性和易于理解的特点。
2. LR算法LR算法是一种自底向上的分析方法,它通过建立LR自动机和构造LR分析表来进行分析。
编译原理的词法分析与语法分析编译原理是计算机科学中的一门重要课程,它研究如何将源代码转换为可执行的机器代码。
在编译过程中,词法分析和语法分析是其中两个基本的阶段。
本文将分别介绍词法分析和语法分析的基本概念、原理以及实现方法。
1. 词法分析词法分析是编译过程中的第一个阶段,主要任务是将输入的源代码分解成一个个的词法单元。
词法单元是指具有独立意义的最小语法单位,比如变量名、关键字、操作符等。
词法分析器通常使用有限自动机(finite automaton)来实现。
在词法分析的过程中,需要定义词法规则,即描述每个词法单元的模式。
常见的词法规则有正则表达式和有限自动机。
词法分析器会根据这些规则匹配输入的字符序列,并生成相应的词法单元。
2. 语法分析语法分析是编译过程中的第二个阶段,它的任务是将词法分析器生成的词法单元序列转换为语法树(syntax tree)或抽象语法树(abstract syntax tree)。
语法树是源代码的一种抽象表示方式,它反映了源代码中语法结构和运算优先级的关系。
语法分析器通常使用上下文无关文法(context-free grammar)来描述源代码的语法结构。
常见的语法分析算法有递归下降分析法、LR分析法和LL分析法等。
递归下降分析法是一种自顶向下的分析方法,它从源代码的起始符号开始,递归地展开产生式,直到匹配到输入的词法单元。
递归下降分析法的实现比较直观,但对于左递归的文法处理不方便。
LR分析法是一种自底向上的分析方法,它使用一个自动机来分析输入的词法单元,并根据文法规则进行规约操作,最终生成语法树。
常见的LR分析法有LR(0)、SLR、LR(1)和LALR等。
LL分析法是一种自顶向下的分析方法,它从源代码的起始符号开始,预测下一个要匹配的词法单元,并进行相应的推导规则。
LL分析法常用于编程语言中,如Java和Python。
3. 词法分析和语法分析的关系词法分析是语法分析的一个子阶段,它为语法分析器提供了一个符号序列,并根据语法规则进行分析和匹配。
PL0编译原理词法语法分析介绍PL/0语言是Pascal语言的一个子集,我们这里分析的PL/0的编译程序包括了对PL/0语言源程序进行分析处理、编译生成类PCODE 代码,并在虚拟机上解释运行生成的类PCODE代码的功能。
PL/0语言编译程序采用以语法分析为核心、一遍扫描的编译方法。
词法分析和代码生成作为独立的子程序供语法分析程序调用。
语法分析的同时,提供了出错报告和出错恢复的功能。
在源程序没有错误编译通过的情况下,调用类PCODE解释程序解释执行生成的类PCODE 代码。
词法分析子程序分析:词法分析子程序名为getsym,功能是从源程序中读出一个单词符号(token),把它的信息放入全局变量sym、id和num中,语法分析器需要单词时,直接从这三个变量中获得。
(注意!语法分析器每次用完这三个变量的值就立即调用getsym子程序获取新的单词供下一次使用。
而不是在需要新单词时才调用getsym过程。
)getsym过程通过反复调用getch子过程从源程序过获取字符,并把它们拼成单词。
getch过程中使用了行缓冲区技术以提高程序运行效率。
词法分析器的分析过程:调用getsym时,它通过getch过程从源程序中获得一个字符。
如果这个字符是字母,则继续获取字符或数字,最终可以拼成一个单词,查保留字表,如果查到为保留字,则把sym变量赋成相应的保留字类型值;如果没有查到,则这个单词应是一个用户自定义的标识符(可能是变量名、常量名或是过程的名字),把sym置为ident,把这个单词存入id变量。
查保留字表时使用了二分法查找以提高效率。
如果getch获得的字符是数字,则继续用getch 获取数字,并把它们拼成一个整数,然后把sym置为number,并把拼成的数值放入num变量。
如果识别出其它合法的符号(比如:赋值号、大于号、小于等于号等),则把sym则成相应的类型。
如果遇到不合法的字符,把sym置成nul。
语法分析子程序分析:语法分析子程序采用了自顶向下的递归子程序法,语法分析同时也根据程序的语意生成相应的代码,并提供了出错处理的机制。
编译器构造与语法分析在计算机科学中,编译器是一个重要的概念。
它是将高级编程语言翻译成计算机能够理解的低级语言的工具。
编译器的构造和语法分析是编译器设计中的两个关键步骤。
本文将介绍编译器的构造原理和语法分析算法。
一、编译器构造在编译器构造中,主要包括以下几个步骤:词法分析、语法分析、语义分析、中间代码生成和代码优化。
1. 词法分析词法分析是将源代码分割成一个个词法单元的过程。
词法单元包括关键字、标识符、运算符、常量和分隔符等。
词法分析器会从源代码中逐个读取字符,并根据预定的规则将其组合成具有特定含义的词法单元。
2. 语法分析语法分析是将词法分析的结果进行语法分析的过程。
语法分析器根据预定的文法规则,检查源代码是否符合语法规范。
常用的语法分析算法有自顶向下的递归下降分析和自底向上的LR分析等。
3. 语义分析语义分析是对源代码进行语义检查和语义处理的过程。
在语义分析阶段,编译器会根据预定的语义规则检查源代码中是否存在语义错误,并生成相应的语法树或符号表。
4. 中间代码生成中间代码生成是将源代码转换成中间代码的过程。
中间代码是介于源代码和目标代码之间的一种抽象表示形式,通常是一种类似于三地址码或虚拟机指令的形式。
5. 代码优化代码优化是对中间代码进行优化的过程。
通过对中间代码进行逻辑优化和算法优化,可以提高生成目标代码的效率和质量。
二、语法分析语法分析是编译器设计中的一个重要环节,它负责分析源代码的语法结构,并根据语法规则构建语法树。
常用的语法分析算法有自顶向下的递归下降分析和自底向上的LR分析。
1. 自顶向下的递归下降分析自顶向下的递归下降分析是一种简单直观的语法分析方法。
它从文法的起始符号开始,通过递归地调用子程序来逐步分析源代码,直到达到终结符号或非终结符号的底部。
2. 自底向上的LR分析自底向上的LR分析是一种自底向上的语法分析方法。
它从输入的末尾开始,逐步向前移动,以确定语法规则。
通过构建LR分析表和状态机,可以在线性时间内进行语法分析。
编译原理词法分析与语法分析在计算机科学领域,编译器是一个非常重要的工具,它将高级程序语言转换为能够被计算机处理的低级机器语言。
编译器的设计与开发离不开以下两个主要部分:词法分析和语法分析。
本文将着重介绍编译原理中的词法分析和语法分析的定义、原理、方法以及它们之间的关系。
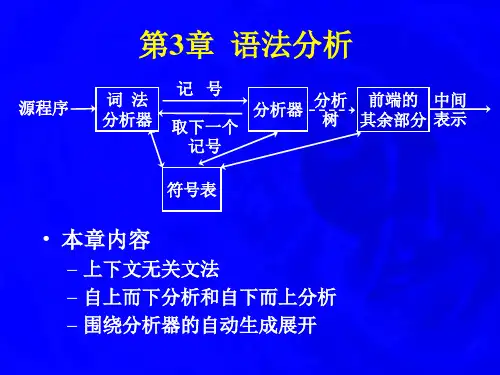
一、词法分析词法分析是编译器的第一个阶段,负责将源代码转化为一个个“词法单元”,也称为“记号”。
词法单元是计算机程序中的最小语义单位,例如变量名、关键字、操作符等。
词法分析器会从源代码中连续读取字符,并将其组成具有独立意义的词法单元。
词法分析的主要任务是识别代码中的词法单元,并将其分类。
它采用正则表达式来定义词法单元的模式,并通过有限状态自动机(FSM)进行匹配。
以下是词法分析的一般步骤:1. 输入源代码,逐字符读取。
2. 将字符组合成词法单元。
3. 跳过空格、换行符等不相关的字符。
4. 使用正则表达式判断词法单元的类型。
5. 将识别出的词法单元传递给语法分析阶段。
二、语法分析语法分析是编译器的第二个阶段,它将从词法分析器获得的词法单元串转换为语法树。
语法树是一种树状结构,用于表示程序的语法结构。
它通过分析词法单元之间的关系来检查程序是否符合语法规则。
在语法分析过程中,会根据源代码中的语法规则使用上下文无关文法(Context-Free Grammar)进行分析。
常用的语法分析算法有自顶向下分析(Top-Down Parsing)和自底向上分析(Bottom-Up Parsing)。
自顶向下分析是从语法的起始符号开始,逐步展开已识别的符号,直到生成源代码。
这种分析方法常用的算法有LL(k)和递归下降(Recursive Descent)。
自顶向下分析器按照语法规则从上到下预测并展开符号。
自底向上分析是从词法单元串的底部开始,逐步归约已识别的符号,直到生成源代码。
这种分析方法常用的算法有LR(k)和LALR(k)。
自底向上分析器按照语法规则从下往上扫描,并进行归约操作。
// EOF set.cpl0.c:// pl0 compiler source code#include <stdio.h>#include <stdlib.h>#include <string.h>#include <ctype.h>#include "set.h"#include "pl0.h"////////////////////////////////////////////////////////////////////// // print error message.void error(int n){int i;printf(" ");for (i = 1; i <= cc - 1; i++)printf(" ");fprintf(outfile, " ");fprintf(outfile, "^\n");printf("^\n");fprintf(outfile, "Error %3d: %s\n", n, err_msg[n]);printf("Error %3d: %s\n", n, err_msg[n]);err++;} // error////////////////////////////////////////////////////////////////////// void getch(void){if (cc == ll){if (feof(infile)){printf("\nPROGRAM INCOMPLETE\n");exit(1);}ll = cc = 0;fprintf(outfile, "%5d ", cx);printf("%5d ", cx);while ( (!feof(infile)) // added & modified by alex 01-02-09 && ((ch = getc(infile)) != '\n')){fprintf(outfile, "%c", ch);printf("%c", ch);line[++ll] = ch;} // whilefprintf(outfile, "\n");printf("\n");line[++ll] = ' ';}ch = line[++cc];} // getch////////////////////////////////////////////////////////////////////// // gets a symbol from input stream.void getsym(void){int i, k;char a[MAXIDLEN + 1];while (ch == ' '|| ch == '\t')// modified by yzhang 02-03-12,add some white spacegetch();if (isalpha(ch)){ // symbol is a reserved word or an identifier.k = 0;do{if (k < MAXIDLEN)a[k++] = ch;getch();}while (isalpha(ch) || isdigit(ch));a[k] = 0;strcpy(id, a);word[0] = id;i = NRW;while (strcmp(id, word[i--]));if (++i)sym = wsym[i]; // symbol is a reserved wordelsesym = SYM_IDENTIFIER; // symbol is an identifier }else if (isdigit(ch)){ // symbol is a number.k = num = 0;sym = SYM_NUMBER;do{num = num * 10 + ch - '0';k++;getch();}while (isdigit(ch));if (k > MAXNUMLEN)error(25); // The number is too great. }else if (ch == ':'){getch();if (ch == '='){sym = SYM_BECOMES; // :=getch();}else{sym = SYM_NULL; // illegal?}}else if (ch == '>'){getch();if (ch == '='){sym = SYM_GEQ; // >=getch();}else{sym = SYM_GTR; // >}}else if (ch == '<'){getch();if (ch == '='){sym = SYM_LEQ; // <=getch();}else if (ch == '>'){sym = SYM_NEQ; // <>getch();}else{sym = SYM_LES; // <}}else{ // other tokensi = NSYM;csym[0] = ch;while (csym[i--] != ch);if (++i){sym = ssym[i];getch();}else{printf("Fatal Error: Unknown character.\n");fprintf(outfile, "Fatal Error: Unknown character.\n");exit(1);}}} // getsym//////////////////////////////////////////////////////////////////////// generates (assembles) an instruction.void gen(int x, int y, int z){if (cx > CXMAX){fprintf(outfile, "Fatal Error: Program too long.\n");printf("Fatal Error: Program too long.\n");exit(1);}code[cx].f = x;code[cx].l = y;code[cx++].a = z;} // gen//////////////////////////////////////////////////////////////////////// tests if error occurs and skips all symbols that do not belongs to s1 or s2. void test(symset s1, symset s2, int n){symset s;if (! inset(sym, s1)){showset(s1);showset(s2);printf("sym=%d, id=%s\n", sym, id);error(n);s = uniteset(s1, s2);while(! inset(sym, s))getsym();destroyset(s);}} // test////////////////////////////////////////////////////////////////////// int dx; // data allocation index// enter object(constant, variable or procedre) into table.void enter(int kind){mask* mk;// added by yzhang 02-02-28if ( position(id)> 0 ){error(26); //Redeclared identifier.}// endtx++;strcpy(table[tx].name, id);table[tx].kind = kind;switch (kind){case ID_CONSTANT:if (num > MAXADDRESS){error(25); // The number is too great.num = 0;}table[tx].value = num;break;case ID_VARIABLE:mk = (mask*) &table[tx];mk->level = level;mk->address = dx++;break;case ID_PROCEDURE:mk = (mask*) &table[tx];mk->level = level;break;} // switch} // enter//////////////////////////////////////////////////////////////////////// locates identifier in symbol table.int position(char* id){int i;strcpy(table[0].name, id);i = tx + 1;while (strcmp(table[--i].name, id) != 0);return i;} // position//////////////////////////////////////////////////////////////////////void constdeclaration(){if (sym == SYM_IDENTIFIER){getsym();if (sym == SYM_EQU || sym == SYM_BECOMES){if (sym == SYM_BECOMES)error(1); // Found ':=' when expecting '='.getsym();if (sym == SYM_NUMBER){enter(ID_CONSTANT);getsym();}else{error(2); // There must be a number to follow '='.}}else{error(3); // There must be an '=' to follow the identifier.}}else //added by yzhang 02-02-28error(4); // There must be an identifier to follow 'const', 'var', or 'procedure'. } // constdeclaration//////////////////////////////////////////////////////////////////////void vardeclaration(void){if (sym == SYM_IDENTIFIER){enter(ID_VARIABLE);getsym();}else{error(4); // There must be an identifier to follow 'const', 'var', or 'procedure'.}} // vardeclaration//////////////////////////////////////////////////////////////////////void listcode(int from, int to){int i;printf("\n");fprintf(outfile, "\n");for (i = from; i < to; i++){printf("%5d %s\t%d\t%d\n", i, mnemonic[code[i].f], code[i].l, code[i].a);fprintf(outfile, "%5d %s\t%d\t%d\n", i, mnemonic[code[i].f], code[i].l, code[i].a);}printf("\n");fprintf(outfile, "\n");} // listcode//////////////////////////////////////////////////////////////////////void factor(symset fsys){void expression();int i;symset set;test(facbegsys, fsys, 24); // The symbol can not be as the beginning of an expression.while (inset(sym, facbegsys)){if (sym == SYM_IDENTIFIER){if ((i = position(id)) == 0){error(11); // Undeclared identifier.}else{switch (table[i].kind){mask* mk;case ID_CONSTANT:gen(LIT, 0, table[i].value);break;case ID_VARIABLE:mk = (mask*) &table[i];gen(LOD, level - mk->level, mk->address);break;case ID_PROCEDURE:error(21); // Procedure identifier can not be in an expression.break;} // switch}getsym();}else if (sym == SYM_NUMBER){if (num > MAXADDRESS){error(25); // The number is too great.num = 0;}gen(LIT, 0, num);getsym();}else if (sym == SYM_LPAREN){getsym();set = uniteset(createset(SYM_RPAREN, SYM_NULL), fsys);expression(set);destroyset(set);if (sym == SYM_RPAREN){getsym();}else{error(22); // Missing ')'.}}else // added by yzhang 02-02-28test(fsys, createset(SYM_LPAREN, SYM_NULL), 23);} // while} // factor//////////////////////////////////////////////////////////////////////void term(symset fsys){int mulop;symset set;set = uniteset(fsys, createset(SYM_TIMES, SYM_SLASH, SYM_NULL));factor(set);while (sym == SYM_TIMES || sym == SYM_SLASH){mulop = sym;getsym();factor(set);if (mulop == SYM_TIMES){gen(OPR, 0, OPR_MUL);}else{gen(OPR, 0, OPR_DIV);}} // whiledestroyset(set);} // term////////////////////////////////////////////////////////////////////// void expression(symset fsys){int addop;symset set;set = uniteset(fsys, createset(SYM_PLUS, SYM_MINUS, SYM_NULL));if (sym == SYM_PLUS || sym == SYM_MINUS){addop = sym;getsym();term(set);if (addop == SYM_MINUS){gen(OPR, 0, OPR_NEG);}}else{term(set);}while (sym == SYM_PLUS || sym == SYM_MINUS){addop = sym;getsym();term(set);if (addop == SYM_PLUS){gen(OPR, 0, OPR_ADD);}else{gen(OPR, 0, OPR_MIN);}} // whiledestroyset(set);} // expression////////////////////////////////////////////////////////////////////// void condition(symset fsys){int relop;symset set;if (sym == SYM_ODD){getsym();expression(fsys);gen(OPR, 0, 6);}else{set = uniteset(relset, fsys);expression(set);destroyset(set);if (! inset(sym, relset)){error(20);}else{relop = sym;getsym();expression(fsys);switch (relop){case SYM_EQU:gen(OPR, 0, OPR_EQU);break;case SYM_NEQ:gen(OPR, 0, OPR_NEQ);break;case SYM_LES:gen(OPR, 0, OPR_LES);break;case SYM_GEQ:gen(OPR, 0, OPR_GEQ);break;case SYM_GTR:gen(OPR, 0, OPR_GTR);break;case SYM_LEQ:gen(OPR, 0, OPR_LEQ);break;} // switch} // else} // else} // condition////////////////////////////////////////////////////////////////////// void statement(symset fsys){int i, cx1, cx2;symset set1, set;if (sym == SYM_IDENTIFIER){ // variable assignmentmask* mk;if (! (i = position(id))){error(11); // Undeclared identifier.}else if (table[i].kind != ID_VARIABLE){error(12); // Illegal assignment.i = 0;}getsym();if (sym == SYM_BECOMES){getsym();}else{error(13); // ':=' expected.}expression(fsys);mk = (mask*) &table[i];if (i){gen(STO, level - mk->level, mk->address);}}else if (sym == SYM_CALL){ // procedure callgetsym();if (sym != SYM_IDENTIFIER){error(14); // There must be an identifier to follow the 'call'.}else{if (! (i = position(id))){error(11); // Undeclared identifier.}else if (table[i].kind == ID_PROCEDURE){mask* mk;mk = (mask*) &table[i];gen(CAL, level - mk->level, mk->address);}else{error(15); // A constant or variable can not be called.}getsym();} // else}else if (sym == SYM_IF){ // if statementgetsym();set1 = createset(SYM_THEN, SYM_DO, SYM_NULL);set = uniteset(set1, fsys);condition(set);destroyset(set1);destroyset(set);if (sym == SYM_THEN){getsym();}else{error(16); // 'then' expected.cx1 = cx;gen(JPC, 0, 0);statement(fsys);code[cx1].a = cx;}else if (sym == SYM_BEGIN){ // blockgetsym();set1 = createset(SYM_SEMICOLON, SYM_END, SYM_NULL);set = uniteset(set1, fsys);statement(set);while (sym == SYM_SEMICOLON || inset(sym, statbegsys)) {if (sym == SYM_SEMICOLON){getsym();}else{error(10);}statement(set);} // whiledestroyset(set1);destroyset(set);if (sym == SYM_END){getsym();}else{error(17); // ';' or 'end' expected.}}else if (sym == SYM_WHILE){ // while statementcx1 = cx;getsym();set1 = createset(SYM_DO, SYM_NULL);set = uniteset(set1, fsys);condition(set);destroyset(set1);destroyset(set);cx2 = cx;gen(JPC, 0, 0);if (sym == SYM_DO)getsym();}else{error(18); // 'do' expected.}statement(fsys);gen(JMP, 0, cx1);code[cx2].a = cx;}else //added by yzhang 02-02-28test(fsys, phi, 19);} // statement////////////////////////////////////////////////////////////////////// void block(symset fsys){int cx0; // initial code indexmask* mk;int block_dx;int savedTx;symset set1, set;dx = 3;block_dx = dx;mk = (mask*) &table[tx];mk->address = cx;gen(JMP, 0, 0);if (level > MAXLEVEL){error(32); // There are too many levels.}do{if (sym == SYM_CONST){ // constant declarationsgetsym();do{constdeclaration();while (sym == SYM_COMMA){getsym();constdeclaration();}if (sym == SYM_SEMICOLON){getsym();}else{error(5); // Missing ',' or ';'.}}while (sym == SYM_IDENTIFIER);} // ifif (sym == SYM_VAR){ // variable declarationsgetsym();do{vardeclaration();while (sym == SYM_COMMA){getsym();vardeclaration();}if (sym == SYM_SEMICOLON){getsym();}else{error(5); // Missing ',' or ';'.}}while (sym == SYM_IDENTIFIER);block_dx = dx; // modified by yzhang 02-03-15} // ifwhile (sym == SYM_PROCEDURE){ // procedure declarationsgetsym();if (sym == SYM_IDENTIFIER){enter(ID_PROCEDURE);getsym();}else{error(4); // There must be an identifier to follow 'const', 'var', or 'procedure'.}if (sym == SYM_SEMICOLON){getsym();}else{error(5); // Missing ',' or ';'.}level++;savedTx = tx;set1 = createset(SYM_SEMICOLON, SYM_NULL);set = uniteset(set1, fsys);block(set);destroyset(set1);destroyset(set);tx = savedTx;level--;if (sym == SYM_SEMICOLON){getsym();set1 = createset(SYM_IDENTIFIER, SYM_PROCEDURE, SYM_NULL);set = uniteset(statbegsys, set1);test(set, fsys, 6);destroyset(set1);destroyset(set);}else{error(5); // Missing ',' or ';'.}} // whileset1 = createset(SYM_IDENTIFIER, SYM_NULL);set = uniteset(statbegsys, set1);test(set, declbegsys, 7);destroyset(set1);destroyset(set);}while (inset(sym, declbegsys));code[mk->address].a = cx;mk->address = cx;cx0 = cx;gen(INT, 0, block_dx);set1 = createset(SYM_SEMICOLON, SYM_END, SYM_NULL);set = uniteset(set1, fsys);statement(set);destroyset(set1);destroyset(set);gen(OPR, 0, OPR_RET); // returntest(fsys, phi, 8); // test for error: Follow the statement is an incorrect symbol.listcode(cx0, cx);} // block//////////////////////////////////////////////////////////////////////int base(int stack[], int currentLevel, int levelDiff){int b = currentLevel;while (levelDiff--)b = stack[b];return b;} // base//////////////////////////////////////////////////////////////////////// interprets and executes codes.void interpret(){int pc; // program counterint stack[STACKSIZE];int top; // top of stackint b; // program, base, and top-stack registerinstruction i; // instruction registerprintf("Begin executing PL/0 program.\n");fprintf(outfile, "Begin executing PL/0 program.\n");pc = 0;b = 1;top = 3;stack[1] = stack[2] = stack[3] = 0;do{i = code[pc++];switch (i.f){case LIT:stack[++top] = i.a;break;case OPR:switch (i.a) // operator{case OPR_RET:top = b - 1;pc = stack[top + 3];b = stack[top + 2];break;case OPR_NEG:stack[top] = -stack[top];break;case OPR_ADD:top--;stack[top] += stack[top + 1];break;case OPR_MIN:top--;stack[top] -= stack[top + 1];break;case OPR_MUL:top--;stack[top] *= stack[top + 1];break;case OPR_DIV:top--;if (stack[top + 1] == 0){fprintf(stderr, "Runtime Error: Divided by zero.\n");fprintf(stderr, "Program terminated.\n");continue;}stack[top] /= stack[top + 1];break;case OPR_ODD:stack[top] %= 2;break;case OPR_EQU:top--;stack[top] = stack[top] == stack[top + 1];break;case OPR_NEQ:top--;stack[top] = stack[top] != stack[top + 1];case OPR_LES:top--;stack[top] = stack[top] < stack[top + 1];break;case OPR_GEQ:top--;stack[top] = stack[top] >= stack[top + 1];case OPR_GTR:top--;stack[top] = stack[top] > stack[top + 1];break;case OPR_LEQ:top--;stack[top] = stack[top] <= stack[top + 1];} // switchbreak;case LOD:stack[++top] = stack[base(stack, b, i.l) + i.a];break;case STO:stack[base(stack, b, i.l) + i.a] = stack[top];//printf("%d\n", stack[top]);fprintf(outfile, "%d\n", stack[top]);top--;break;case CAL:stack[top + 1] = base(stack, b, i.l);// generate new block markstack[top + 2] = b;stack[top + 3] = pc;b = top + 1;pc = i.a;break;case INT:top += i.a;break;case JMP:pc = i.a;break;case JPC:if (stack[top] == 0)pc = i.a;top--;break;} // switch}while (pc);//printf("End executing PL/0 program.\n");fprintf(outfile, "End executing PL/0 program.\n");} // interpret////////////////////////////////////////////////////////////////////// void main (){FILE* hbin;char s[80],*finddot;int i;symset set, set1, set2;printf("Please input source file name: "); // get file name to be compiledscanf("%s", s);if ((infile = fopen(s, "r")) == NULL){printf("File %s can't be opened.\n", s);exit(1);}#if 1 // added by yzhang 02-02-28// open the output filefinddot = strchr(s,'.');if (finddot!=NULL){strcpy(finddot, ".out");}else{strcat(s, ".out");printf("%s\n", s);}printf("Output File is %s\n", s);if ((outfile = fopen(s, "w")) == NULL){printf("File %s can't be opened.\n", s);exit(1);}#endifphi = createset(SYM_NULL);relset = createset(SYM_EQU, SYM_NEQ, SYM_LES, SYM_LEQ, SYM_GTR, SYM_GEQ, SYM_NULL);// create begin symbol setsdeclbegsys = createset(SYM_CONST, SYM_VAR, SYM_PROCEDURE, SYM_NULL);statbegsys = createset(SYM_BEGIN, SYM_CALL, SYM_IF, SYM_WHILE, SYM_NULL);facbegsys = createset(SYM_IDENTIFIER, SYM_NUMBER, SYM_LPAREN, SYM_NULL);err = cc = cx = ll = 0; // initialize global variablesch = ' ';kk = MAXIDLEN;getsym();set1 = createset(SYM_PERIOD, SYM_NULL);set2 = uniteset(declbegsys, statbegsys);set = uniteset(set1, set2);block(set);destroyset(set1);destroyset(set2);destroyset(set);destroyset(phi);destroyset(relset);destroyset(declbegsys);destroyset(statbegsys);destroyset(facbegsys);if (sym != SYM_PERIOD)error(9); // '.' expected.if (err == 0){hbin = fopen("hbin.txt", "w");for (i = 0; i < cx; i++)fwrite(&code[i], sizeof(instruction), 1, hbin);fclose(hbin);}if (err == 0)interpret();elseprintf("There are %d error(s) in PL/0 program.\n", err);listcode(0, cx);// close all files, added by yzhang, 02-02-28fclose(infile);fclose(outfile);getchar();getchar();} // main////////////////////////////////////////////////////////////////////// // eof pl0.c五、程序截图;六、实验体会通过该课程设计,全面系统的理解了编译原理程序构造的一般原理和基本实现方法。