大数据分析工具 rapidminer 操作实践
- 格式:pptx
- 大小:2.64 MB
- 文档页数:19


实验目的:使用RapidMiner对数据进行分析实验工具:RapidMiner实验数据:实验数据说明:实验数据是通过研究对象的三种特征,一个是每年坐飞机飞行的里程数miles,二个是玩视频游戏所耗时间的百分比gamepercent,每周消费的冰淇淋公升数icecream,来判断一个人是否具有吸引力(didn't like、smallDoses,lagerDoses)实验过程:打开RapidMiner ,新建一个Process导入数据,如图所示点击下一步到出现如图所示界面,将Response设为label最后将数据存储在如下图的位置,命名为TrainingData,点击finish完成将数据TrainingData拖拽到process窗口中,用线连接至result接口,可以看到如下数据其中有些Response的值丢失了,共有31个这时需要使用Filter Examples 过滤掉没有值得Response行,操作如下图数据筛选完成之后,选择Decision Tree Model,拖入到process中,连接起来,参数选择默认设置训练好模型之后,我们可以用模型预测一下TrainingData中没有标记的样例,与上面的数据过滤方法相同,只是设置有所不同,如下图使用Apply Model来运用模型整个连接图如下所示实验的预测结果部分决策树截图如图,加入一个Validation其参数如下图,默认的10表示将样例分为十份,取一份作为测试数据双击Validation右下角的矩形表框进入,建议决策树模型,应用模型退出Validation 如图连接到result运行输出结果如下上图显示准确率为96%左右,正负误差为%,表明训练所得模型是比较稳定的实验总结1.我在这个过程中运用的测试集与训练集是相同的,这可能会使整个模型的预测能力比实际要偏大2.该实验的难点是数据源的收集与筛选,选择什么样的数据,需要怎样的处理才有意义是不容易的3.模型算子的选择对于我来说比较难,因为对这个是不熟悉的,所以基本上所有的参数都是默认的,这个感觉不太好4.对结果的分析不是很明白。
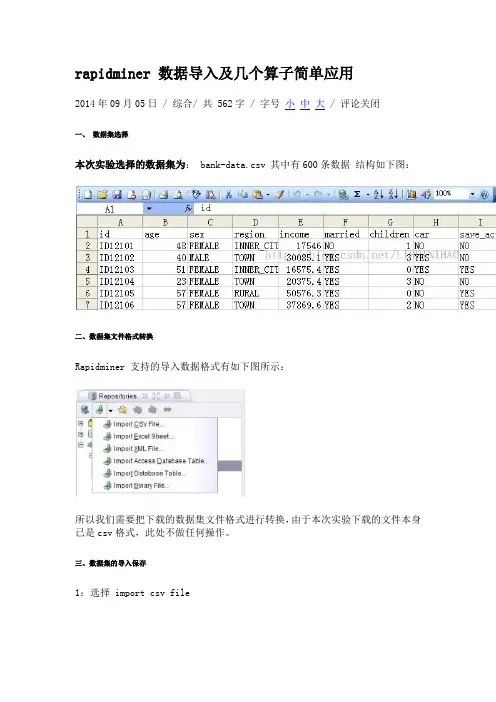
rapidminer 数据导入及几个算子简单应用
2014年09月05日⁄综合⁄共 562字⁄字号小中大⁄评论关闭
一、数据集选择
本次实验选择的数据集为: bank-data.csv 其中有600条数据结构如下图:
二、数据集文件格式转换
Rapidminer 支持的导入数据格式有如下图所示:
所以我们需要把下载的数据集文件格式进行转换,由于本次实验下载的文件本身已是csv格式,此处不做任何操作。
三、数据集的导入保存
1:选择 import csv file
2:选择 Next
3:选择 Next
4:选择 Next
5:选择 Next
6:选择 Finish, 完成导入数据
7:查看目录中生成的导入数据
四、流程创建及简单算子测试
1:选择 FileàNew Process 即可创建一个空白流程:2:将上述中导入的数据拖放到流程中并链接:
运行查看结果:
2:sample算子使用
在Data Transformation 中选择 sample 算子拖到流程中:此处设置选择100条数据
运行,查看结果:
3: 在Data Transformation 中选择 sort 算子拖到流程中:此处设置以income属性进行升序排序:
运行查看结果:
4: 在Data Transformation 中选择 selection 算子拖到流程中:此处选择4个属性:
运行查看结果:
5: 在Data Transformation 中选择 filterexample 算子拖到流程中:此处过滤掉年龄小于30岁的数据:
运行查看结果:。

rapidminer的使用方法和流程一、快速介绍RapidMiner是一款强大的数据挖掘和数据分析工具,它提供了丰富的功能和易用的界面,使得用户能够快速地进行数据预处理、特征提取、模型训练和评估等操作。
本文档将详细介绍RapidMiner的使用方法和流程,帮助用户更好地掌握这款工具。
二、安装和配置1. 下载并安装RapidMiner软件:访问RapidMiner官方网站,下载适合您操作系统的安装包,并按照安装向导进行安装。
2. 配置环境变量:确保RapidMiner的路径被正确添加到系统环境变量中,以便系统能够找到并使用它。
3. 启动RapidMiner:打开RapidMiner软件,您将看到一个简洁的界面,其中包括各种可用的操作节点。
三、使用流程1. 数据准备:使用数据源节点导入数据,并进行必要的预处理操作,如清洗、转换等。
2. 特征提取:使用各种特征提取节点,如数值编码、聚类、分箱等,对数据进行特征提取。
3. 模型训练:使用适合您的算法和模型类型,如决策树、支持向量机、神经网络等,进行模型训练。
4. 模型评估:使用各种评估指标,如准确率、精度、召回率等,对模型进行评估和调整。
5. 结果展示:使用可视化节点将结果进行展示和导出,以便进一步分析和应用。
四、常见问题及解决方案1. 数据格式不正确:检查您的数据文件是否符合RapidMiner的输入要求,并进行必要的格式转换。
2. 节点无法连接:检查网络连接和节点配置,确保节点之间能够正常通信。
3. 算法或模型选择错误:根据您的数据和任务需求,选择适合的算法和模型,并进行必要的参数调整。
4. 结果不准确:检查评估指标是否合理,并进行必要的调整和优化。
五、进阶技巧1. 使用脚本进行自动化操作:通过编写脚本,实现数据的批量处理和模型的批量训练,提高工作效率。
2. 使用模型选择方法:根据评估指标和交叉验证结果,选择最佳的模型进行预测和分析。
3. 利用并行处理加速运算:利用RapidMiner的并行处理功能,加速模型的训练和评估过程。

数据挖掘RapidMiner工具使用这里以学校的学生成绩进行聚类分析为案例1、背景随着我国经济的发展,网络已被应用到各个行业,人们对网络带来的高效率越来越重视,然而大量数据信息给人们带来方便的同时,也随之带来了许多新问题,大量数据资源的背后隐藏着许多重要的信息,人们希望能对其进行更深入的分析,以便更好地利用这些数据,从中找出潜在的规律。
那么,如何从大量的数据中提取并发现有用信息以提供决策的依据,已成为一个新的研究课题。
目前普遍使用的成绩分析方法一般只能得到均值、方差等一类信息,且仅仅是从一门课程独立数据进行的分析,但在实际教学中,比如学生在学习某一门课程时,是哪一门或者几门课程对其影响很大,包括教学以外的哪些因素对学生成绩造成了较大的影响等各种有价值的信息往往无法获知。
2、聚类分析在数据库中的知识发现和数据挖掘(KDDM)受到目前人工智能与数据库界的广泛重视。
KDDM的目的是从海量的数据中提取人们感兴趣的、有价值的知识和重要的信息,聚类则是KDDM领域中的一个重要分支。
所谓聚类是将物理或抽象的集合分组成为类似的对象组成的多个类的过程。
聚类分析就是将一组数据分组,使其具有最大的组内相似性和最小的组间相似性。
简单的说就是达到不同聚类中的数据尽可能不同,而同一聚类中的数据尽可能相似,它与分类不同,分类是对于目标数据库中存在哪些类这一信息是知道的,所要做的就是将每一条记录分别属于哪一类标记出来;而聚类是在预先不知道目标数据库到底有多少类的情况下,希望将所有的记录组成不同的簇或者说“聚类”,并且使得在这种分类情况下,以某种度量为标准的相似性,在同一聚类之间最小化,而在不同聚类之间最大化。
事实上,聚类算法中很多算法的相似性都基于距离而且由于现实数据库中数据类型的多样性,关于如何度量两个含有非数值型字段的记录之间的距离的讨论有很多,并提出了相应的算法。
聚类分析的算法可以分为以下几类:划分方法、层次方法、基于密度方法等。

第4章数据和结果可视化前面的部分中,我们已经看到了RapidMiner Studio图形用户界面是如何建立起来的,以及如何用它来定义和执行分析流程。
在流程的最后,流程结果会显示在结果视图中。
现在在工具栏上点击一下就能跳转到结果视图了。
这一章会详细阐述结果视图。
依据您是否已经生成了可被描述的结果,在默认设置前提下,您现在应该至少能大致看到这些显示内容,如图4.1所示。
图4.1:RapidMiner的结果透视图或者,您可以在“View(视图)”菜单中=“Restore Default Perspective(恢复默认透视图)”这一选项重新建立这个预设透视图。
在介绍过的设计透视图之后,结果透视图是RapidMiner Studio的第二个主要工作环境。
我们已经讨论了右侧的资源库视图,因此这一章节我们会关注视图的其他组成部分。
4.1结果可视化我们已经看到了在流程执行完成后,流程中右侧结果端口的结果会自动显示在结果视图中。
结果视图中左上角的大部分会被用到,那里显示了分析结果概述,在这一章节的结尾我们会讨论这些分析结果。
目前每一个打开的和显示的结果都会在这一区域以一个附加标签显示,如图4.2所示。
严格来说,每个结果都是一个视图,像以往一样,您可以随心所欲的移动这些视图。
这样的话就能同时看到几个结果视图了。
图4.2:每个打开的结果都在左侧的区域显示为附加的一个标签当然您也可以单机标签上的×号来关闭单个视图,也就是标签。
视图的其他功能例如最大化也是完全可以的。
RapidMiner Studio会关闭之前的结果后再显示新的结果。
4.1.1显示结果的方法您可以通过很多方法显示结果。
以下是所有显示方法:1.自动打开我们已经看到了流程的最终分析结果,即在流程中右侧结果端口自动显示的内容。
在断点状态下,连接到结果端口的内容荣也能自动显示。
您可以在一个分析流程结束以后,在结果端口只收集所有您想要的分析结果,这些结果会在结果透视图中以一个个标签的形式展示出来。

rapidminer使用流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!RapidMiner 使用流程。
1. 数据导入。
从文件、数据库或 Web 服务中导入数据。
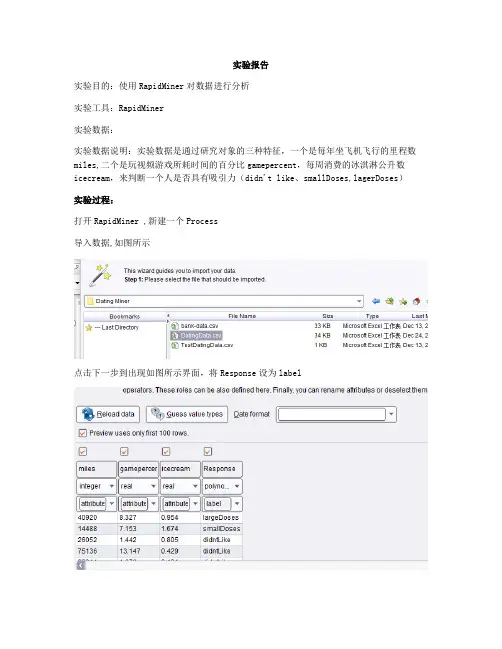
实验报告实验目的:使用RapidMiner对数据进行分析实验工具:RapidMiner实验数据:实验数据说明:实验数据是通过研究对象的三种特征,一个是每年坐飞机飞行的里程数miles,二个是玩视频游戏所耗时间的百分比gamepercent,每周消费的冰淇淋公升数icecream,来判断一个人是否具有吸引力(didn't like、smallDoses,lagerDoses)实验过程:打开RapidMiner ,新建一个Process导入数据,如图所示点击下一步到出现如图所示界面,将Response设为label最后将数据存储在如下图的位置,命名为TrainingData,点击finish完成将数据TrainingData拖拽到process窗口中,用线连接至result接口,可以看到如下数据其中有些Response的值丢失了,共有31个这时需要使用Filter Examples 过滤掉没有值得Response行,操作如下图数据筛选完成之后,选择Decision Tree Model,拖入到process中,连接起来,参数选择默认设置训练好模型之后,我们可以用模型预测一下TrainingData中没有标记的样例,与上面的数据过滤方法相同,只是设置有所不同,如下图使用Apply Model来运用模型整个连接图如下所示实验的预测结果部分决策树截图如图,加入一个Validation其参数如下图,默认的10表示将样例分为十份,取一份作为测试数据双击Validation右下角的矩形表框进入,建议决策树模型,应用模型退出Validation 如图连接到result运行输出结果如下上图显示准确率为96%左右,正负误差为%,表明训练所得模型是比较稳定的实验总结1.我在这个过程中运用的测试集与训练集是相同的,这可能会使整个模型的预测能力比实际要偏大2.该实验的难点是数据源的收集与筛选,选择什么样的数据,需要怎样的处理才有意义是不容易的3.模型算子的选择对于我来说比较难,因为对这个是不熟悉的,所以基本上所有的参数都是默认的,这个感觉不太好4.对结果的分析不是很明白。

RapidMiner5简易教程广东外语外贸大学杜剑峰RapidMiner教程1.RapidMiner简介2.预测建模3.交叉验证4.文本分类5.中文网页分类6.中文网页聚类7.关联分析课程的总体目标和要求:v熟悉RapidMiner的基本操作和各项功能v熟悉RapidMiner的框架,可以自学新部件v掌握文本分类和文本聚类实验的流程›准备数据›选择算法和参数运行›评估实验结果1、RapidMiner简介v RapidMiner,以前叫YALE (Yet Another Learning Environment) 。
v RapidMinder提供的实验由大量的算子组成,使用图形化的用户接口可以将这些算子以积木块的方式搭建成系统。
v RapidMiner是世界领先的数据挖掘解决方案,在一个非常大的程度上有着先进技术。
它数据挖掘任务涉及范围广泛,包括各种数据艺术,能简化数据挖掘过程的设计和评价。
——百度百科v下载地址:/content/view/26/201/v注意使用Update RapidMiner功能添加Text Preprocessing 和Weka构件,或者下载构件压缩包放置lib\plugins子目录中1、RapidMiner简介(续1)v欢迎界面1、RapidMiner简介(续2) v操作界面1、RapidMiner简介(续3) v结果界面2、预测建模v操作界面(建立分类模型并使用外部测试集评估模型)2、预测建模(续)v结果界面3、交叉验证v操作界面(主进程)3、交叉验证(续) v操作界面(Validation内进程)3、交叉验证(续)v结果界面v文本预处理:文档à向量空间模型英文›词项抽取: 简单›停用词移除›词干提取›频率统计和计算TF-IDF 词权值中文›词项抽取: 简单›分词›频率统计和计算TF-IDF 词权值4、文本分类预备知识停用词移除v英语中很多经常使用的词在信息检索和文本挖掘中是没有用的–这些词称作停用词.›the, of, and, to, ….›典型地有400到500个这样的词›对于特定应用, 可以构造一个附加的领域依赖的停用词表.v为什么需要移除停用词?›减少索引(或数据) 文件的大小v停用词占20-30%的总词量.›提高效率和有效性v停用词对于搜索或文本挖掘是没有用的.v它们还可能迷惑检索系统.词干提取v词干提取是简化单词的技术, 用于将单词变成它们的词根或词干. 比如,›user engineering›users engineered›used engineer›usingv词干: use engineer用处:v提高信息检索和文本挖掘的有效性›匹配相似的单词›主要提高查全率v减少索引的大小›合并相同词干的单词可以将索引大小减少到40-50%.基本的词干提取方法使用一组规则. 比如,v移除词尾›若单词以一个不是s的辅音字母再跟s结尾, 则删除s.›若单词以es结尾, 则去掉s.›若单词以ing结尾, 则除非余下部分仅有一个字母或者是th, 否则删除ing.›若单词以ed结尾, 并且ed前面是一个辅音字母, 则除非仅剩下一个字母, 否则删除ed.›…...v变换单词›若单词以ies而不是eies或aies结尾, 则将ies改成y.频率统计+ TF-IDFv统计文档中某个单词出现的总次数.›使用出现次数表示单词在文档中的相对重要性.›若单词在文档中经常出现, 则文档很可能阐述的是关联于该单词的主题.v统计在文档集中包含某个单词的文档数目.›若单词出现在数据集的很多文档中, 则它可能并不是很重要, 或者说没有区别度.v然后计算TF-IDF, 将文档转换成向量空间模型.向量空间模型v 一个文档同样看作是一组词. v 每个文档被表示成一个权值向量.v 但是, 权值不再是0或1. 每个词的权值基于词频率(TF )表或词逆向文档频率(TF-IDF )表或它们的变异版本计算得到.v词频率(TF)表:文档d j 中的t i 权值就是在d j 中t i 出现的次数, 记作f ij . 在此基础上还可以进行标准化.TF-IDF 词权值表v这是最著名的权值表›TF: 仍然是词频›IDF: 逆向文档频率N : 文档总数df i : 包含t i 的文档数目v最终的TF-IDF 词权值是:TF-IDF 词权的计算例子13212132df i020单词841104013文档341340320文档244003012文档1max f i,j单词7单词6单词5单词4单词3单词2单词1n i,j 根据,变成(2/4)*log 2(3/2)=0.292iji i j i j i df Nf f w 2,,,log max ⋅=21413文档301440320文档214003012文档1单词8单词7单词6单词5单词4单词3单词2单词14、文本分类v操作界面(建立文本分类模型并使用外部数据集评估)4、文本分类(续)v操作界面(类别目录配置)4、文本分类(续)v操作界面(Process Documents from Files内进程)4、文本分类(续)v外部测试集评估结果界面4、文本分类(续)v操作界面(建立文本分类模型交叉验证评估并保存模型)4、文本分类(续) v操作界面(Validation内进程)4、文本分类(续) v交叉验证结果界面4、文本分类(续) v操作界面(应用保存的模型进行新闻归类)4、文本分类(续) v结果界面(归类结果,看prediction属性)5、中文网页分类v操作界面(建立中文网页分类模型并用外部测试集评估)5、中文网页分类(续)v以某个目录下的网页测试中文网页分类模型›测试集使用Process Documents from Files部件读入,设置第一个参数为测试网页所在的路径,对应的class name可以任意填写。


RapidMiner数据分析工具介绍RapidMiner是一种开源的数据分析工具,它可以在没有编程背景的情况下进行数据分析、挖掘和预测。
该工具采用了易于使用的图形用户界面,使得数据分析不再需要复杂的编码和统计学知识。
在本文中,我们将介绍RapidMiner的主要功能、优点和使用方式,以帮助您更好地了解该工具的特点。
1. RapidMiner的主要功能RapidMiner为您提供了一套完整的数据挖掘和机器学习工具,允许您对多种不同数据类型进行分析。
RapidMiner支持大量的数据输入格式,例如Excel文件、CSV文件、XML文件、数据库表、web数据和API等。
此外,RapidMiner还具有以下主要功能:1.1 数据预处理RapidMiner允许您对数据进行属性选择、特征提取、缺失值处理、归一化、标准化和离散化等预处理步骤,以便更好地进行分析。
1.2 数据可视化通过RapidMiner,您可以创建各种可视化图表和图形,以帮助您更好地理解和解释数据集的内容和关系。
图表类型包括散点图、折线图、饼图、直方图、热图和树状图等等。
1.3 数据挖掘和机器学习RapidMiner提供了各种数据挖掘和机器学习算法,包括分类、聚类、回归、关联规则和时间序列等。
这些算法可用于从数据中提取模式、预测未来、识别异常等。
1.4 模型评估和优化RapidMiner还提供了用于评估和优化模型的工具,例如交叉验证、网格搜索、参数优化和模型选择等。
这些工具可以帮助您选择最佳的模型,并优化其性能。
2. RapidMiner的优点2.1 易于使用RapidMiner采用了图形用户界面,使得数据分析不再需要复杂的编码和统计学知识。
新手用户可以很容易地上手,而有经验的用户也可以通过高级功能进行定制化设置和扩展。
2.2 强大的功能RapidMiner提供了一套完整的数据挖掘和机器学习工具,可用于处理各种数据类型和数据规模。
此外,RapidMiner还提供了各种模型评估和优化工具,以帮助用户找到最佳的解决方案。
RapidMiner学习二(简单的分类器构建)RapidMiner学习二 (简单的分类器构建)2009-05-18 21:42在第一节中我们看到了RapidMiner从XML文件中读取配置信息,然后将样本信息打印出来的过程. 整个过程我们是依赖于XML配置文件的,当然通过配置XML来实现对实验流程的控制是一个非常好的方法.然而,当希望基于它进行二次开发时,我们该如何做,这才是问题的关键.做数据挖掘的人都会知道,在做实验室我们需要不断地调整算法及实验框架,这个时候二次开发是最基本的要求.因此我在这一节简要的介绍一下基于RapideMiner的开发.在RapidMiner中所有的操作都是基于Operator来做的,无论是读取文件,构建分类器,或者是其它的一些工作. 那么当我们希望脱离XML配置文件来工作时,一个自然地想法就是自己初始化一个Operator对象,让它为我们服务,一切的工作由我们来控制.那么在构建一个简单的分类器过程中会涉及到两类Operator,一类是读取数据信息的;一类是构建分类器.具体流程如下:1. 构建好读取样本数据信息的Operator;2. 读取样本数据信息3. 构建分类器Operator4. 用读取的样本数据训练分类器5. 获得分类器训练的模型代码如下:package com.test;import com.rapidminer.example.ExampleSet;import com.rapidminer.operator.IOObject;import com.rapidminer.operator.Model;import com.rapidminer.operator.OperatorDescription;import com.rapidminer.operator.io.ArffExampleSource;import com.rapidminer.operator.learner.tree.ID3Learner;import com.rapidminer.operator.learner.tree.TreeModel;/** Date: 2009.5.18* by: Wang Yi*Email:************************.cn* QQ: 270135367**/public class TestID3 {public static void main(String[] args){try{/** 获得当前本地的classLoader*/ClassLoader loader = Thread.currentThread().getContextClassLoader();/** 定义Operator的Descirption对象,这时构建一个operator对象的必要条件* 感觉在这里RapidMiner做的不是很好,它没有提供一个构建默认Operator的方法* 使二次开发变得繁琐*//** 读取数据信息的Operator 在这里是专门为了读取weka中的信息*/OperatorDescription arffDes = new OperatorDescription(loader,"arff","com.rapidminer.operator. io.ArffExampleSource",null,null,"IO.Examples","ArffExample Source",null);/** 获得一个分类器对象, 在这里专指ID3Learner的分类器对象*/OperatorDescription classifierDes = new OperatorDescription(loader,"classifier","com.rapidminer.ope rator.learner.tree.ID3Learner",null,null,"Learner.Supervised.Tr ees","ID3",null);/** 用Descirption对象构造对应的Operator对象*/ArffExampleSource arffSource = new ArffExampleSource(arffDes);ID3Learner ID3 = new ID3Learner(classifierDes);/** 为operator订制特定的参数,例如文件来源,类别属性,等等*/arffSource.setParameter("data_file", "D:\\我的文档\\rm_workspace\\sample\\data\\contact-lenses.arff");arffSource.setParameter("label_attribute", "contact-lenses");/** 读取样本文件信息,这里是通过operator的apply方法*/IOObject[] ioObject = arffSource.apply();ExampleSet set = (ExampleSet)ioObject[0];System.out.println("example:" + set);/** 通过ID3的学习会得到一个TreeModel,通过这个对象我们可以做很多工作,例如用它分类测试样本,获得树的根节点等等*/TreeModel model = (TreeModel)(ID3.learn(set));}catch(Exception e){e.printStackTrace();}}}在开发这段代码的过程中,我发现在RapidMiner上做二次开发要比在weka上要繁琐多了.也许开发它的目的更多的是为了终端不进行二次开发的客户吧. RapidMiner在界面的人性化方面做的挺不错. 但是要想在上面做二次开发应该是一个相当的挑战.希望在这方面做的同仁要费一番心思了.!。