处理器大小开端问题
- 格式:docx
- 大小:14.28 KB
- 文档页数:2

大端与小端存储模式详解端模式(Endian)的这个词出自Jonathan Swift书写的《格列佛游记》。
这本书根据将鸡蛋敲开的方法不同将所有的人分为两类,从圆头开始将鸡蛋敲开的人被归为Big Endian,从尖头开始将鸡蛋敲开的人被归为Littile Endian(这句话最为形象)。
小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。
在计算机业Big Endian和Little Endian也几乎引起一场战争。
在计算机业界,Endian表示数据在存储器中的存放顺序。
下文举例说明在计算机中大小端模式的区别。
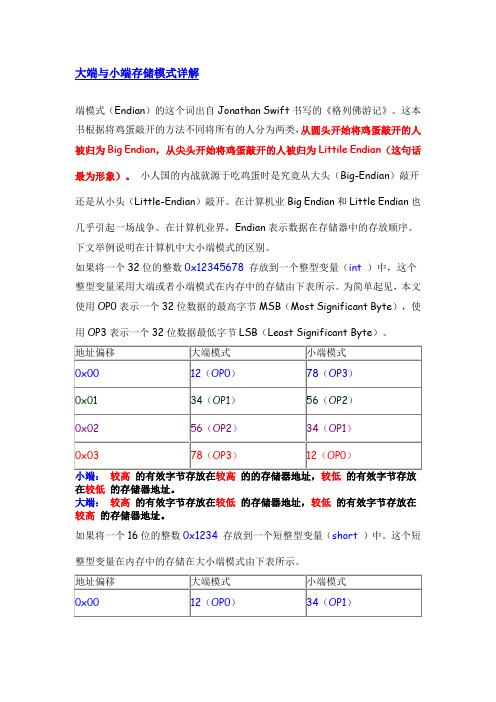
如果将一个32位的整数0x12345678存放到一个整型变量(int)中,这个整型变量采用大端或者小端模式在内存中的存储由下表所示。
为简单起见,本文使用OP0表示一个32位数据的最高字节MSB(Most Significant Byte),使用OP3表示一个32位数据最低字节LSB(Least Significant Byte)。
在较低的存储器地址。
大端:较高的有效字节存放在较低的存储器地址,较低的有效字节存放在较高的存储器地址。
如果将一个16位的整数0x1234存放到一个短整型变量(short)中。
这个短整型变量在内存中的存储在大小端模式由下表所示。
大端方式将高位存放在低地址,小端方式将高位存放在高地址。
采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
到目前为止,采用大端或者小端进行数据存放,其孰优孰劣也没有定论。
有的处理器系统采用了小端方式进行数据存放,如Intel的奔腾。
有的处理器系统采用了大端方式进行数据存放,如IBM半导体和Freescale的PowerPC处理器。
不仅对于处理器,一些外设的设计中也存在着使用大端或者小端进行数据存放的选择。
因此在一个处理器系统中,有可能存在大端和小端模式同时存在的现象。

如何判断一台计算机的CPU是大端还是小字端对齐呢?
那么首先得了解何为大端,何为小端,明确一下概念。
所谓大端模式,是指字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
小端格式:与大端存储格式相反,在小端存储格式中,低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。
那么如何使用C语言程序判断CPU是大端还是小端对齐呢?
有几个方法:
方法一:直接使用看变量的内存值,这里需要使用一些调试技巧。
方法二:使用C中的共用体:
请写一个C函数,若处理器是Big_endian的,则返回false;若是Little_endian的,则返回true。
bool IsLitte_Endian()
{
union w{
int a;
char b;
}c;
c.a=1;
return (c.b==1);
}
方法三:强制类型转换,和共用体的做法差不多。
bool IsLitte_Endian()
{
int wTest = 0x12345678;
short *pTest=(short*)&wTest;
return !(0x1234 == pTest[0]);
}。

很多的博文以及论坛曾经探讨过关于大小端定义,内存地址对齐的问题。
最近刚刚完成了一个关于COS(chip operating system )平台移植的项目,多处遇到此类问题,对此也有了全新的了解,阅读了一些前辈的文章,受益匪浅。
自己水平有限,不敢写文论述,这里整理两位前辈的文章,希望对大家有所帮助。
文一大小端和存储器对齐作者:dycxin我们常常看到“alignment", "endian"之类的字眼,但很少有C语言教材提到这些概念。
实际上它们是与处理器与内存接口,编译器类型密切相关的。
考虑这样一个例子: 两个异构的CPU 进行通信,定义了这样一个结果来传递消息:struct Message{short opcode;char subfield;long message_length;char version;short destination_processor;}message;用这样一个结构来传递消息貌似非常方便,但也引发了这样一个问题: 若这两种不同的CPU 对该结构的定义不一样,两者就会对消息有不同的理解。
有可能导致二义性。
会引发二义性的有这两个方面:1.内存地址对齐2.大小端定义本文先介绍内存地址对齐和大小端的概念,再回头来看这个例子就豁然开朗了。
内存地址对齐洋名叫做" Byte Alignment"。
大部分16位和32位的CPU不允许将字或者长字存储到内存中的任意地址。
比如Motorola 68000不允许将16位的字存储到奇数地址中,将一个16位的字写到奇数地址将引发异常。
实际上,对于c中的字节组织,有这样的对齐规则:1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;2) 结构体每个成员相对于结构首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。

(转)⼤⼩端模式详解int i=1;char *p=(char *)&i;if(*p==1)printf("1");elseprintf("2");⼤⼩端存储问题,如果⼩端⽅式中(i占⾄少两个字节的长度)则i所分配的内存最⼩地址那个字节中就存着1,其他字节是0.⼤端的话则1在i的最⾼地址字节处存放,char是⼀个字节,所以强制将char型量p指向i则p指向的⼀定是i的最低地址,那么就可以判断p中的值是不是1来确定是不是⼩端。
请写⼀个C函数,若处理器是Big_endian的,则返回0;若是Little_endian的,则返回1解答:int checkCPU( ){{union w{int a;char b;} c;c.a = 1;return(c.b ==1);}}剖析:嵌⼊式系统开发者应该对Little-endian和Big-endian模式⾮常了解。
采⽤Little-endian模式的CPU对操作数的存放⽅式是从低字节到⾼字节,⽽Big-endian模式对操作数的存放⽅式是从⾼字节到低字节。
例如,16bit宽的数0x1234在Little-endian模式CPU内存中的存放⽅式(假设从地址0x4000开始存放)为:内存地址0x40000x4001存放内容0x340x12⽽在Big-endian模式CPU内存中的存放⽅式则为:内存地址0x40000x4001存放内容0x120x3432bit宽的数0x12345678在Little-endian模式CPU内存中的存放⽅式(假设从地址0x4000开始存放)为:内存地址0x40000x40010x40020x4003存放内容0x780x560x340x12⽽在Big-endian模式CPU内存中的存放⽅式则为:内存地址0x40000x40010x40020x4003存放内容0x120x340x560x78联合体union的存放顺序是所有成员都从低地址开始存放,⾯试者的解答利⽤该特性,轻松地获得了CPU对内存采⽤Little-endian还是Big-endian模式读写。

在计算机系统中,数据存储与处理的字节序(Byte Order)问题涉及到多字节数据在内存中的存储顺序。
主要有两种字节序,即大端序(Big-Endian)和小端序(Little-Endian)。
大端序(Big-Endian):在大端序中,最高有效字节(Most Significant Byte,MSB)位于最低的内存地址,而最低有效字节(Least Significant Byte,LSB)位于最高的内存地址。
这类似于将多字节数据视为大数字的表示,其中最高位位于最左侧。
小端序(Little-Endian):在小端序中,最低有效字节(LSB)位于最低的内存地址,而最高有效字节(MSB)位于最高的内存地址。
这类似于将多字节数据视为小数字的表示,其中最低位位于最左侧。
具体的存储顺序将影响如何解释多字节数据。
例如,一个4字节整数0x12345678,在大端序中按照地址顺序存储为:0x12 0x34 0x56 0x78,而在小端序中按照地址顺序存储为:0x78 0x56 0x34 0x12。
在实际应用中,字节序问题主要体现在跨平台数据交换、网络通信和文件传输等方面。
为了确保不同平台之间的数据交互正确,需要进行字节序的转换。
在编程语言中,通常提供了相应的函数或方法来进行字节序的转换,如htons/ntohs(host to network short/ network to host short)和htonl/ntohl(host to network long/ network to host long)等。
这些函数可以在不同字节序之间进行转换,以保证数据在不同平台上的正确解释和传输。
了解一下CPU的缓存大小对性能的影响的方法CPU是计算机中最重要的组件之一,它的性能直接影响着计算机的运行速度和应用程序的执行效率。
而CPU的缓存大小是一个关键的指标,它对CPU性能有着重要影响。
本文将介绍了解CPU缓存大小对性能影响的方法。
一、了解CPU缓存的概念在介绍CPU缓存大小对性能影响的方法之前,我们首先需要了解CPU缓存的概念。
CPU缓存是一种高速存储器,它用于暂时存储CPU频繁使用的数据和指令,以减少CPU访问主内存的次数,提高数据读取和指令执行的速度。
CPU缓存主要分为三级:一级缓存(L1 Cache)、二级缓存(L2 Cache)和三级缓存(L3 Cache)。
这些缓存层级之间的容量逐级递增,速度逐级递减。
一级缓存距离CPU最近,速度最快,容量相对较小;二级缓存次之,容量较大,速度较快;三级缓存容量最大,速度相对较慢。
二、使用操作系统工具查看CPU缓存大小了解CPU缓存大小对性能影响的第一种方法是使用操作系统提供的工具来查看CPU缓存大小。
下面以Windows操作系统为例,介绍如何查看CPU缓存大小。
1. 打开任务管理器:可以通过按下“Ctrl+Shift+Esc”快捷键打开任务管理器。
2. 切换到“性能”选项卡:在任务管理器中,选择“性能”选项卡。
3. 查看CPU缓存大小:在“性能”选项卡中,可以看到左侧列出的各种性能指标。
找到“CPU”一栏,展开后可以看到各级缓存的大小信息。
三、使用CPU-Z等第三方工具查看CPU缓存大小除了使用操作系统提供的工具外,还可以使用第三方工具来查看CPU缓存大小。
其中,CPU-Z是一款常用的CPU信息查看工具。
下面以CPU-Z为例,介绍如何查看CPU缓存大小。
1. 下载并安装CPU-Z:可以在CPU-Z官方网站上下载到最新版本的CPU-Z,并按照提示进行安装。
2. 打开CPU-Z:安装完成后,打开CPU-Z程序。
3. 查看CPU缓存大小:在CPU-Z的主界面上,选择“Cache”选项卡,就可以看到各级缓存的大小信息。
1 大端模式&小端模式??? 在C语言中除了8位的char型之外,还有16位的short型,32位的long 型(要看具体的编译器),对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着如何将多个字节安排的问题。
因此就导致了大端存储模式和小端存储模式。
大端模式:字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
小端模式:与大端存储模式相反,在小端存储模式中,低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。
例如,16位宽的数0x1234在小端模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:内存地址0x40000x4001存放内容0x340x12而在大端模式CPU内存中的存放方式则为:内存地址0x40000x4001存放内容0x120x3432位宽的数0x12345678在小端模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:内存地址0x40000x40010x40020x4003存放内容0x780x560x340x12而在大端模式CPU内存中的存放方式则为:内存地址0x40000x40010x40020x4003存放内容0x120x340x560x78?????? 我们常用的X86结构是小端模式,而KEIL C51则为大端模式。
很多的ARM,DSP都为小端模式。
有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
Note:采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
(我的理解:小端模式在低字节就放一个低位)下面这段代码可以用来测试一下你的编译器是大端模式还是小端模式:int main(){short int x;char x0,x1;x=0x1122;x0=*((char*)&x); //低地址单元 ,或者((char*)&x)[0];x1=*((char*)&x + 1); //高地址单元,或者((char*)&x)[1];printf("x0=%x\nx1=%x\n",x0,x1);}若x0=0x11,则是大端; 若x0=0x22,则是小端......2 大端(Big Endian)与小端(Little Endian)详解【大端(Big Endian)与小端(Little Endian)简介】Byte Endian是指字节在内存中的组织,所以也称它为Byte Ordering,或Byte Order。
一、大端模式和小端模式的起源关于大端小端名词的由来,有一个有趣的故事,来自于Jonathan Swift的《格利佛游记》:Lilliput和Blefuscu这两个强国在过去的36个月中一直在苦战。
战争的原因:大家都知道,吃鸡蛋的时候,原始的方法是打破鸡蛋较大的一端,可以那时的皇帝的祖父由于小时侯吃鸡蛋,按这种方法把手指弄破了,因此他的父亲,就下令,命令所有的子民吃鸡蛋的时候,必须先打破鸡蛋较小的一端,违令者重罚。
然后老百姓对此法令极为反感,期间发生了多次叛乱,其中一个皇帝因此送命,另一个丢了王位,产生叛乱的原因就是另一个国家Blefuscu的国王大臣煽动起来的,叛乱平息后,就逃到这个帝国避难。
据估计,先后几次有11000余人情愿死也不肯去打破鸡蛋较小的端吃鸡蛋。
这个其实讽刺当时英国和法国之间持续的冲突。
Danny Cohen一位网络协议的开创者,第一次使用这两个术语指代字节顺序,后来就被大家广泛接受。
二、什么是大端和小端Big-Endian和Little-Endian的定义如下:1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如数字0x12 34 56 78在内存中的表示形式为:1)大端模式:低地址-----------------> 高地址0x12 | 0x34 | 0x56 | 0x782)小端模式:低地址------------------> 高地址0x78 | 0x56 | 0x34 | 0x12可见,大端模式和字符串的存储模式类似。
3)下面是两个具体例子:16bit宽的数0x1234在Little-endian模式(以及Big-endian 模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:32bit宽的数0x12345678在Little-endian模式以及Big-endian 模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:4)大端小端没有谁优谁劣,各自优势便是对方劣势:小端模式:强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
所谓的大端模式,是指数据的低位(就是权值较小的后面那几位)保存在
内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模
式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据
从高位往低位放;
所谓的小端模式,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中,这种存储模式将地址的高低和数据位权有效
地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法
一致。
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以
字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。
但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long 型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。
因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。
对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。
小端模式,刚好
相反。
我们常用的X86结构是小端模式,而KEIL C51则为大端模式。
很多的ARM,DSP都为小端模式。
有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
下面这段代码可以用来测试一下你的编译器是大端模式还是小端模式:short int x;
char x0,x1;
x=0x1122;
x0=((char*)&x)[0]; //低地址单元
x1=((char*)&x)[1]; //高地址单元
若x0=0x11,则是大端; 若x0=0x22,则是小端......
上面的程序还可以看出,数据寻址时,用的是低位字节的地址。
编辑本段linux操作系统中对大小端的判断:
static union { char c[4]; unsigned long l; } endian_test = { { 'l', '?', '?', 'b' } };
#define ENDIANNESS ((char)endian_test.l)
(如果ENDIANNESS=’l’表示系统为little endian,为’b’表示big endian )。
编辑本段使用C语言判断处理器的大小端
[1]int checkCPU()
{
{
union w
{
int a;
char b;
} c;
c.a = 1;
return (c.b == 1); }
}。