MEGA蛋白序列比对-保守序列分析-进化树
- 格式:pdf
- 大小:354.21 KB
- 文档页数:3


保守结构域序列构建进化树是一个非常常见且重要的生物信息学分析步骤。
通过将同源蛋白中的保守序列区域聚合在一起,研究者可以对同一蛋白家族的多种蛋白质进行分析,并且使用这些保守结构域的序列信息进行进化树的构建,可以帮助我们理解蛋白质家族的进化关系和进化历程。
首先,我们需要收集一组同源蛋白的保守结构域序列。
这些序列通常来自于生物数据库中的已知蛋白质序列,通过比对和分析,我们可以找到这些序列中的保守区域。
这些保守区域通常代表了蛋白质的功能和结构的重要部分,因此,通过比较和分析这些序列,我们可以了解蛋白质家族的进化关系。
接下来,我们需要将这些序列导入到一个进化树构建软件中。
常用的软件包括MEGA、PHYLIP、Clustal等。
这些软件通常会使用一种叫做邻接法(Neighbor-joining)的算法来构建进化树。
邻接法是一种基于距离的算法,它通过比较序列之间的差异来构建树状图。
这种方法在处理大样本和复杂的进化关系时表现得尤为出色。
在构建进化树的过程中,我们需要对软件中的参数进行适当的设置。
例如,我们可能需要选择适当的距离度量方法、调整树的进化模型、考虑种间或种内的系统发生信息等。
这些参数的选择和调整可能会影响到进化树的精度和可靠性。
一旦进化树构建完成,我们可以利用一些可视化的工具进行观察和解读。
例如,我们可以使用专门的绘图软件(如TREE-PUZZLE或ITOL)将进化树绘制成漂亮的图形,或者使用一些专门的软件来分析树中的分支和节点,以了解蛋白质家族的进化关系和进化历程。
总之,保守结构域序列构建进化树是一个非常有用的生物信息学分析步骤。
通过比较和分析同源蛋白中的保守序列区域,我们可以了解蛋白质家族的进化关系和进化历程,这对于理解生物多样性和物种进化的机制具有重要意义。


植物基因家族进化树的构建一、数据收集在构建植物基因家族进化树之前,需要收集相关的基因序列数据。
这些数据可以通过各种数据库,如NCBI、Ensembl等获取。
在收集数据时,需要注意以下几点:1. 选择具有代表性的物种,覆盖尽可能多的系统发育分支;2. 确保所收集的基因序列数据质量可靠,无测序错误和拼接错误;3. 对于每个基因家族,应尽可能收集多个成员的序列,以便进行多序列比对和树的构建。
二、序列比对在获得基因序列数据后,需要进行多序列比对。
比对的目的是为了找到不同物种间基因序列的相似性和差异性,从而确定它们之间的系统发育关系。
常用的多序列比对软件有MUSCLE、CLUSTAL W等。
在进行多序列比对时,需要注意以下几点:1. 选择合适的比对参数,以保证比对结果的准确性和可靠性;2. 在比对过程中,需要注意保持基因序列的原始阅读框,避免引入不必要的拼接错误;3. 对于较长的基因序列,可以分段进行比对,以提高计算效率和准确性。
三、距离矩阵计算在多序列比对的基础上,需要计算不同物种间基因序列之间的距离。
距离矩阵的计算是树构建的重要步骤之一。
常用的距离矩阵计算方法有:1. 欧氏距离法:直接计算不同物种间基因序列的差异数目,得到距离矩阵;2. Kimura距离法:基于Kimura模型计算不同物种间基因序列的差异概率,得到距离矩阵;3. Jukes-Cantor距离法:考虑基因序列的突变率和进化速率,计算不同物种间基因序列的差异概率,得到距离矩阵。
在选择距离矩阵计算方法时,需要根据具体情况选择适合的方法。
如果数据量较大或序列较短时,可以考虑使用欧氏距离法;如果数据量较小或序列较长时,可以考虑使用Kimura或Jukes-Cantor距离法。
四、树构建方法选择在获得距离矩阵后,需要选择合适的树构建方法来构建进化树。
常用的树构建方法有:1. UPGMA(Unweighted Pair Group Method with Arithmetic Mean):将距离矩阵中的行或列进行聚类分析,根据聚类结果构建树;2. Neighbor Joining:基于距离矩阵中的最近邻关系构建树;3. Maximum Parsimony:基于树的构建准则函数(如最小改变数、最小代价等)构建树。

MEGA软件构建系统发育树摘要:以白色念珠菌属下面的十个种的18s RNA 为例,构建系统发育树来说明MEGA 软件的使用方法。
1背景简介1.1 MEGA(分子进化遗传分析)MEGA 的全称是Molecular Evolutionary Genetics Analysis。
MEGA is an integrated tool for automatic and manual sequence alignment, inferring phylogenetic trees, mining web-based databases, estimating rates of molecular evolution, and testing evolutionary hypotheses. MEGA 可用于序列比对、进化树的推断、估计分子进化速度、验证进化假说等。
MEGA 还可以通过网络(NCBI)进行序列的比对和数据的搜索。
最新版本:MEGA 5.1 Beta (软件开发者建议其结果不用于发表文章)建议下载版本:MEGA 5.05 for Windows and Mac OS。
MEGA 5 has been tested on the following Microsoft Windows® operating systems: Windows 95/98, NT, 2000, XP, Vista, version 7, Linux and Mac OS [1].MEGA 5.05 可免费下载,只需输入名字及有效邮箱,下载链接会发送至邮箱,点击可下载。
1.2 系统发育树定义系统发育树(英文:Phylogenetic tree)又称为演化树(evolutionary tree),是表明被认为具有共同祖先的各物种间演化关系的树。
是一种亲缘分支分类方法(cladogram)。
在树中,每个节点代表其各分支的最近共同祖先,而节点间的线段长度对应演化距离(如估计的演化时间)1.3 系统发育树的分类根据有根和无根来区分:树可分为有根树和无根树两类。

生物信息学中的序列比对与进化树构建算法研究序列比对是生物信息学中重要的分析方法之一,通过比对不同生物种类的DNA、RNA或蛋白质序列,可以揭示它们之间的相似性和差异性,并为分析进化关系、功能预测等提供基础。
序列比对的基本思想是将两个或多个序列进行比对,并找出它们之间的相似性。
在序列比对中,常用的方法有全局比对、局部比对和多序列比对。
全局比对方法是将整个序列进行比对,一般采用Needleman-Wunsch算法或Smith-Waterman算法。
这些算法根据序列间的单个碱基或氨基酸之间的匹配、错配和缺失情况,计算出序列的相似度得分。
全局比对方法适用于较短的序列,优点是能够找到完全匹配的区域,但是对长序列不适用,计算复杂度较高。
局部比对方法主要用于比对较长的序列或存在较大插入缺失的序列。
常用的算法有BLAST和FASTA算法。
这些算法采用快速搜索的策略,先找出序列间的高度相似的片段,然后再进行比对和分析。
局部比对方法能够找到较长序列内的相似片段,但可能无法找到全局的最优比对。
多序列比对方法用于比对三个或更多序列,揭示它们之间的共同特征和区别。
常用的方法有多重序列比对和进化树构建。
多重序列比对旨在将多个序列按照匹配和错配的原则进行比对,以找到共同的序列区域。
进化树构建方法基于序列的相似性和进化关系,将多个序列构建成进化树,以揭示它们之间的进化关系。
在序列比对的过程中,常用的比对算法还包括Pairwise比对、局部比对、多重比对等方法。
这些方法都有自己的特点和适用范围,根据具体的研究目的和数据特点选择合适的方法进行序列比对。
进化树构建是生物信息学中的重要研究方向之一,用于揭示不同生物种类之间的进化关系。
进化树是一种图形化的表示方式,能够清晰地展示物种间的分支关系、共同祖先以及进化时间。
进化树的构建主要基于序列的相似性和进化关系。
在进化树构建中,常见的方法包括距离法、最大简约法和最大似然法。
距离法基于序列间的距离矩阵,通过测量序列间的差异程度来构建进化树。
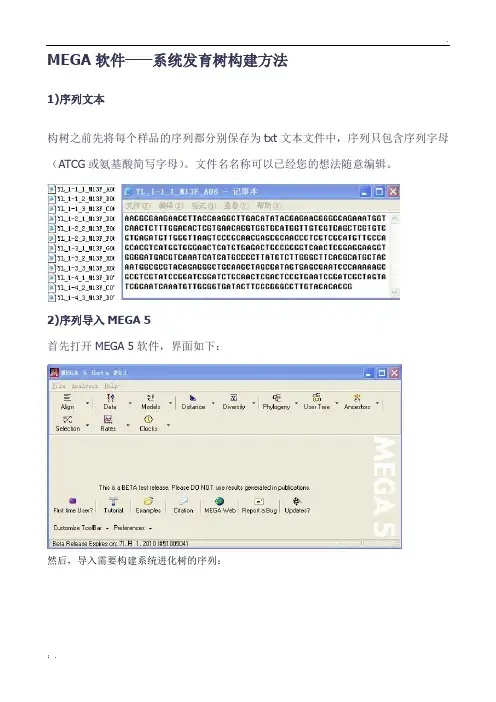
MEGA软件——系统发育树构建方法1)序列文本构树之前先将每个样品的序列都分别保存为txt文本文件中,序列只包含序列字母(ATCG或氨基酸简写字母)。
文件名名称可以已经您的想法随意编辑。
2)序列导入MEGA 5首先打开MEGA 5软件,界面如下:然后,导入需要构建系统进化树的序列:点击OK出现新的对话框,创建新的数据文件导入成功3)序列比对分析点击W,开始比对。
比对完成后删除序列两端不能完全对其的碱基。
系统分析然后,关闭该窗口,在弹出的对话框中选择保存文件,文件名随便去,比如保存为1。
4)系统发育树构建以NJ为例Bootstrap选择1000,点Computer,开始计算计算完毕后,生成系统发育树。
以下“系统发育树树的修饰”方法沿用斑竹brightfuture01的方法5)树的修饰建好树之后,往往需要对树做一些美化。
这个工作完全可以在word中完成,达到发表文章的要求。
点击image,copy to clipboard。
新建一个word文档,选择粘贴。
见下图:在图上点击右键-编辑图片,就可以对文字的字体大小,倾斜等做出修饰。
见下图:这个时候可以通过Adobe professional 对其进行图像导出:先将此word文档打印成PDF,见下图:将打印出来的PDF保存在桌面上,打开,如下图:此时,点击工具,高级编辑工具,裁剪工具,如下图所示:选择需要的区域以删除周围的空白区,双击发育树,会出现下图:点击确定,出现下图(把空边切掉了):点击文件,另存为,在保存类型一栏中选择TIFF格式,点击确定后会生成下面这个图片,所生成图片绝对可以满足文章的发表:OK,结束了,自己玩一把吧。

生物信息学中的序列比对与进化树构建生物信息学是一门涉及生命科学和计算科学的交叉学科,其应用在分子生物学、生物医学、生态学、进化论、生物技术等诸多领域中。
序列比对和进化树构建是生物信息学的重要组成部分,是理解生物学进化的重要途径之一。
一、序列比对序列比对是将两个或多个蛋白质或核酸序列究竟有多少相同、多少不同进行比较的过程。
序列比对在生物学中极其重要,因为它可以帮助科学家确定两个生物物种之间的相似性,进而推断它们之间的亲缘关系以及共同祖先的时间。
序列比对中最基础和常用的方法是全局比对和局部比对。
全局比对试图比较两个序列的完整长度,一般用于比较相似性较高的序列,它最先被应用于分析DNA和蛋白质,是序列比对过程中最古老、最经典的算法方法。
而局部比对则更注重比较两个序列中的相似区域,忽略其中任何间隔,通常用于比较两个较短的序列或者两个相对较不相关的序列。
例如,在核酸序列比对中,这种算法更适用于获取多个剪接变异或者重复序列之间的相似性。
另外,序列比对有一个关键问题,就是如何准确的衡量两条序列的相似性和相异性。
在这方面有很多方法,例如编辑距离、盒子型、PAM矩阵、BLOSUM 矩阵等等,其中都采用了不同的评分标准。
二、进化树构建进化树(Phylogenetic Tree)是用来表示生物物种间亲缘关系的结构,也称演化树或家谱树。
进化树是通过对基于DNA和RNA等生物分子序列进行分析,推导出各物种之间共同祖先的关系构建起来的,同时它也综合了形态、系统和分子信息等其他生物学数据。
进化树的构建过程中涉及许多算法,其中最基础的是贪心算法。
贪心法从序列的最初状态开始,一步步选择最佳的演化路径,最终得到最优的进化树;而Neighborhood-joining (NJ)算法则是以序列之间的 Jukes-Cantor 模型距离或 Kimura 二参数模型距离为基础,使用最小进化步骤(Minimum Evolution,ME)标准构建进化树,是目前应用比较广泛的算法。
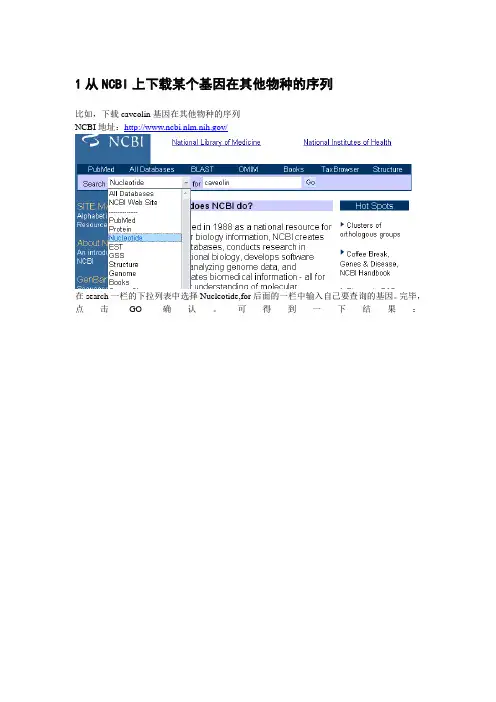
1从NCBI上下载某个基因在其他物种的序列比如,下载caveolin基因在其他物种的序列NCBI地址:/在search一栏的下拉列表中选择Nucleotide,for后面的一栏中输入自己要查询的基因。
完毕,点击GO确认。
可得到一下结果:每一条记录分别是某个物种的caveolin的序列,以第10条记录为例,称为GenBank 登录号。
为拉丁文的人类的字母,表示物种,表示基因名称(caveolin基因家族共有3个主要基因,分别称为1,2,3)表示此序列为cDNA,不含内含子。
下图中的NEXT表示翻页,查看剩余的记录。
打开第10条记录可看到下图:现在你需要保存下来得就是上面的这一串(碱基)核酸序列。
复制黏贴(包括上面表示顺序的数字)到TXT文本中备用。
打开DNAMAN软件,左上角点击file-new,出现下图:可以把先前从NCBI下载的序列(保存到TXT文本中得)复制到箭头指示处,得到:并按照上图左上角file-save as(注意此文件得保存名称为保存的此物中得名称),已上是DNAMAN软件中seq序列格式的保存方法。
2 序列编辑和比对(DNAMAN软件)你们实验PCR得到的序列只是某个基因上的一部分,所以为了进行不同物种间的比对,要把下载下来的其他物种的某个基因的序列进行删减,以使两段基因是大约相同长度的片段进行比对。
以人类caveolin1基因为例说明一下。
按照1,2,3得顺序依次打开,得到下图:点击上图中的1,你会得到下图,点击2是清楚所有刚才选进比对的序列(为了重新选择序列),3是有选择的删除某个序列。
当然,把你的所有准备的序列保存好以后,从查找范围这个下拉列表中寻找你要比对的序列。
可以按住ctrl点击你要比对的几个序列(同时选中)选完点击打开。
再点下图中得确定键。
得到下图:找好这两个物种重合的那个核苷酸的序号(前后两段都是),然后打开你保存的seq格式的序列,数出刚才比对重合部分的后端的碱基数,把这个碱基后面的序列删掉,再用此方法把比对重合部分前段得序列删掉,保存。

MEGA构建系统进化树的步骤(以MEGA7为例)本文是看中国慕课山东大学生物信息学课程总结出来的分子进化的研究对象是核酸和蛋白质序列。
研究某个基因的进化,是用它的DNA序列,还是翻译后的蛋白质序列呢?序列的选取要遵循以下原则:1)如果DNA序列的两两间的一致度≥70%,选用DNA 序列。
因为,如果DNA序列都如此相似,它的蛋白质会相似到看不出区别,这对构建系统发生树是不利的。
所以这种情况下应该选用DNA序列,而不选蛋白质序列。
2)如果DNA序列的两两间的一致度≤70%,DNA序列和蛋白质序列都可以选用。
1. 将要用于构建系统进化树的所有序列合并到同一个fasta格式文件,注意:所有序列的方向都要保持一致( 5’-3’)。
想要做系统发生树先要做多序列比对,然后把多序列比对的结果提交给建树软件进行建树,所以在用MEGA建树时可以输入一个已经比对好的多序列比对,也可以输入一条原始序列,让MEGA先来做多序列比对,再建树(一般我们都是原始序列)。
所以我们以后者为例。
2.打开MEGA软件,选择主窗口的”File”→“Open A File”→找到并打开fasta文件,这时会询问以何种方式打开,我们是原始序列,需要先进行多序列比对,所以选择“Align”。
如果是比对好的多序列比对可以直接选择“Analyze”。
3.在打开的Alignment Explorer窗口中选择”Alignment”-“Align by ClustalW”进行多序列比对(MEGA提供了ClustalW和Muscle两种多序列比对方法,这里选择熟悉的ClustalW),弹出窗口询问“Nothing selected for alignment,Select all?”选择“OK”。
4. 之后,弹出多序列比对参数设置窗口。
这个窗口和EMBL在线多序列比对一样,可以设置替换记分矩阵、不同的空位罚分(罚分填写的是正数,计算时按负数计算)等参数。
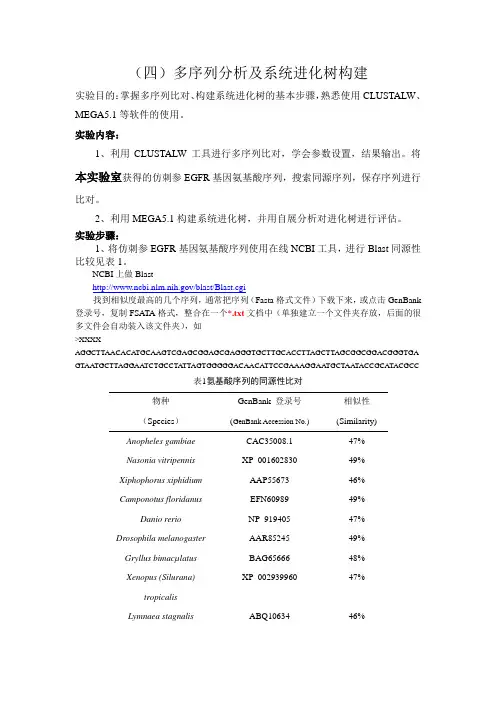
(四)多序列分析及系统进化树构建实验目的:掌握多序列比对、构建系统进化树的基本步骤,熟悉使用CLUSTALW、MEGA5.1等软件的使用。
实验内容:1、利用CLUSTALW工具进行多序列比对,学会参数设置,结果输出。
将本实验室获得的仿刺参EGFR基因氨基酸序列,搜索同源序列,保存序列进行比对。
2、利用MEGA5.1构建系统进化树,并用自展分析对进化树进行评估。
实验步骤:1、将仿刺参EGFR基因氨基酸序列使用在线NCBI工具,进行Blast同源性比较见表1。
NCBI上做Blast/blast/Blast.cgi找到相似度最高的几个序列,通常把序列(Fasta格式文件)下载下来,或点击GenBank 登录号,复制FSATA格式,整合在一个*.txt文档中(单独建立一个文件夹存放,后面的很多文件会自动装入该文件夹),如>XXXXAGGCTTAACACA TGCAAGTCGAGCGGAGCGAGGGTGCTTGCACCTTAGCTTAGCGGCGGACGGGTGA GTAATGCTTAGGAATCTGCCTA TTAGTGGGGGACAACATTCCGAAAGGAATGCTAATACCGCATACGCC表1氨基酸序列的同源性比对物种(Species)GenBank 登录号(GenBank Accession No.)相似性(Similarity)Anopheles gambiae CAC35008.1 47% Nasonia vitripennis XP_001602830 49% Xiphophorus xiphidium AAP55673 46% Camponotus floridanus EFN60989 49% Danio rerio NP_919405 47% Drosophila melanogaster AAR85245 49% Gryllus bimacµlatus BAG65666 48% Xenopus (Silurana)tropicalisXP_002939960 47% Lymnaea stagnalis ABQ10634 46%Gallus gallus NP_990828 47%Rattus norvegicu s EDL97896.1 47%2、仿刺参EGFR氨基酸序列通过GENBANK数据库比较,经CLUSTAL W多重序列比对分析(图1)(注:图为部分比对序列图)。
蛋白进化树构建一、什么是蛋白进化树?蛋白进化树(Protein Evolutionary Tree)是通过比较不同蛋白质序列之间的相似性和差异性来揭示蛋白质之间的进化关系的一种方法。
二、蛋白进化树的构建方法1. 序列比对序列比对是构建蛋白进化树的第一步,它通过将不同蛋白质序列进行比对,找出它们之间的相似性和差异性。
常用的比对算法包括Smith-Waterman和Needleman-Wunsch算法。
2. 构建进化模型构建进化模型是构建蛋白进化树的第二步,它通过统计序列比对结果中的变异情况,建立起蛋白质序列的进化模型。
常见的进化模型包括Dayhoff模型和JTT模型。
3. 构建进化树构建进化树是构建蛋白进化树的最后一步,它利用进化模型中的信息,将蛋白质序列分为不同的群组。
常用的构建进化树的方法包括最大似然法和贝叶斯法。
三、蛋白进化树的应用领域蛋白进化树在生物学研究中有着广泛的应用,以下列举了其中几个重要的应用领域:### 1. 物种演化研究蛋白进化树可以用于研究不同物种之间的进化关系。
通过比较不同物种的蛋白质序列,可以揭示它们之间的亲缘关系和进化历程。
2. 功能预测蛋白进化树可以用于预测蛋白质的功能。
通过比较已知功能的蛋白质和未知功能的蛋白质的进化关系,可以预测未知蛋白质的功能。
3. 疾病研究蛋白进化树可以用于研究疾病的起源和传播途径。
通过比较病原体的蛋白质序列,可以揭示不同病原体之间的进化关系和疾病的来源。
4. 药物研发蛋白进化树可以用于药物研发。
通过比较靶蛋白的进化关系,可以预测药物的作用和副作用,指导药物的设计和开发。
四、蛋白进化树构建的挑战与改进方法1. 组装错误在蛋白进化树构建的过程中,可能会出现组装错误的情况。
这种错误可能是由于序列比对的错误或者进化模型的假设不准确所致。
解决这个问题的方法之一是使用更高级的序列比对算法,如BLAST和HMMER,或者使用更准确的进化模型,如GTR模型。
MEGA蛋白序列比对-保守序列分析-进化树
蛋白质序列进化(proteinsequencephylogenetic},一种用于测定各种生物之间遗
传关系的技术。
#百度百科#一般通过蛋白质的氨基酸序列进行比对后建树,方法
过程如下:
首先由NCBI或其他查询基因途径获取要比对的目的蛋白氨基酸序列(网站上有
很多此类说明)我的由于序列较多,就先把氨基酸序列复制到文本文件中
之后将序列文本文件扩展名改为.fas
之后打开MEGA软件进行序列比对,选择Align---Edit/Build/Alignment---Retrieve
sequencefromafile---选择文件---确定,输出结果默认以最右端蛋氨酸对齐,如图
在建树之前序列应该以保守序列比对模式进行,选择Alignment---Alignby
ClustalW,以输出以保守序列比对结果,如图
保存序列比对文件,默认格式为.mas格式,并选择phylogeny---construct/T est
UPGMATree进行建树,步骤如图
选择蛋白序列
之后就会输出树,如下
之后可以根据不同要求更改树形,选择下图按钮进行输出设置并输出环形树
之后可以保存到指定文件,同时也可以将树以pdf格式导出,选择image---Save
aspdffile或者pngfile。
若何用MEGA构建进化树是一个关于序列剖析以及比较统计的对象包,个中包含有距离建树法和MP建树法;可主动或手动进行序列比对,揣摸进化树,估算分子进化率,进行进化假设磨练,还能联机的Web数据库检索.下载后可直接应用,重要包含几个方面的功效软件:i)DNA和蛋白质序列数据的剖析软件.ii)序列数据转变成距离数据后,对距离数据剖析的软件. iii)对基因频率和持续的元素剖析的软件.iv)把序列的每个碱基/氨基酸自力对待(碱基/氨基酸只有0和1的状况)时,对序列进行剖析的软件.v)绘制和修正良化树的软件,进行网上blast搜刮.用MEGA构建进化树有以下步调:1. 16S rDNA测序和参考序列拔取从情况平分别到单克隆,去反复后扩增16S rDNA序列并测序,然后与数据库比对,找到类似度最高的几个序列,肯定一下你分别的细菌大约属于哪个科哪个属,假如类似度达到百分之百那根本可以肯定你分别得到的就是Blast到的谁人,然后找一到两个同科的,再找一到两个同目标,再找一到两个同纲的细菌,把序列全手下下来,以FSATA情势整合在TXT文档中,如>TS1 GCAGTCGAACGATGAAGCCCAGCTTGCTGGGTGGATTAGTGGCGAACGGGTGAGTAA CACGTGGGTGATCTGCCCTGCACTTCGGGATAAGCCTGGGAAACTGGGTCTAATACC GGATAGGACCTCGGGATGCATGTTCCGGGGTGGAAAGGTTTTCCGGTGCAGGATGGGCC>gi|117572706|gb|EF028124.1| Rhodococcus sp. Atl25 16S ribosomal RNA gene, partial sequence CGATTAGAGTTTGATCCTGGCTCAGGACGAACGCTGGCGGCGTGCTTAACACATGCA AGTCGAACGATGAAGCCCAGCTTGCTGGGTGGATTAGTGGCGAACGGGTGAGTAACA CGTGGGTGATCTGCCCTGCACTTCGGGATAAGCCTGGGAAACTGGGTCTAATACCGG AT>TS2 TGCAAGTCGAGCGAATGGATTAAGAGCTTGCTCTTATGAAGTTAGCGGCGGACGGGT GAGTAACACGTGGGTAACCTGCCCATAAGACTGGGATAACTCCGGGAAACCGGGGCT AATACCGGATAACATTTTGAACTGCATGGTTCGAAATTGAAAGGCGGCTTCGGCTGT CACT GATGAACGCTGGCGGCGTGCCTAATACATGCAAGTCGAGCGAATGGATTAAGAGCTT GCTCTTATGAAGTTAGCGGCGGACGGGTGAGTAACACGTGGGTAACCTGCCCATAAG ACTGGGATAACTCCGGGAAACCGGGGCTAATACCGGATAACATTTTGAACYGCATGG TTC………………………….………………………….参考序列选择有几个原则:a,不选非造就(unclutured)微生物为参比;b,所选参考序列要准确,里面无错误碱基;c,在包管同属的前提下,优先选择16S rDNA全长测序或全基因组测序的种;d,每个种属选择一个参考序列,假如本身的序列中统一属的较多,可恰当选择两个参考序列.2. 序列比对将整顿好的序列导入,如图接着程序主动运行,得出成果,主动输出 .aln和.dnd 为后缀的两个文件.序列比对也可以直接用MEGA来做.MEGA,如下图所示:4.只能打开meg格局的文件,但是它可以把其他格局的多序列比对文件转换过来,用.aln格局(Clustal的输出文件)转换.meg文件.点File:Convert to MEGA Format,打开转换文件对话框,从目标文件夹中选中Clustal 比较剖析后所产生的.aln文件,点击打开.5. 转换好的meg文件,会弹出一个提醒信息,点击ok.检讨meg序列文件最后是否正常,若消失clustal. *行,即可删除.点存盘保管meg文件,meg文件会和aln文件保管在统一个目次.6. 封闭转换窗口,回到主窗口,如今点面板上的“Click me to activate a data file”打开适才的meg文件.假如为蛋白质序列,选择“protein sequence”,电击“OK”,得到以下图示,数据输入之后的样子,窗口下面有序列文件名和类型.而在别的一个窗口内,消失以下数据文件点击选择和编辑数据分类图标,可对所选择的序列进行编辑,完成后点击close即可.序列编辑完成后,可进行保管,点击保管后消失以下界面,点击ok 即可.7. 构建进化树的算法重要分为两类:自力元素法(discrete character methods)和距离依附法(distance methods).所谓自力元素法是指进化树的拓扑外形是由序列上的每个碱基/氨基酸的状况决议的(例如:一个序列上可能包含很多的酶切位点,而每个酶切位点的消失与否是由几个碱基的状况决议的,也就是说一个序列碱基的状况决议着它的酶切位点状况,当多个序列进行进化树剖析时,进化树的拓扑外形也就由这些碱基的状况决议了).而距离依附法是指进化树的拓扑外形由两两序列的进化距离决议的.进化树枝条的长度代表着进化距离.自力元素法包含最大简约性法(Maximum Parsimony methods)和最大可能性法(Maximum Likelihood methods);距离依附法包含除权配对法(UPGMAM)和邻位相连法(Neighbor-joining).(1)phylogeny→UPGMA(2)用Bootstrap构建进化树,MEGA的重要功效就是做Bootstrap验证的进化树剖析,Bootstrap验证是对进化树进行统计验证的一种办法,可以作为进化树靠得住性的一个器量.各类算法固然不合,但是操纵办法根本一致.进化树的构建是一个统计学问题.我们所构建出来的进化树只是对真实的进化关系的评估或者模仿.假如我们采取了一个恰当的办法,那么所构建的进化树就会接近真实的“进化树”.模仿的进化树须要一种数学办法来对其进行评估.不合的算法有不合的实用目标.一般来说,最大简约性法实用于相符以下前提的多序列:i 所要比较的序列的碱基不同小,ii 对于序列上的每一个碱基有近似相等的变异率,iii 没有过多的颠换/转换的偏向,iv 所磨练的序列的碱基数量较多(大于几千个碱基);用最大可能性法剖析序列则不需以上的诸多前提,但是此种办法盘算极其耗时.假如剖析的序列较多,有可能要花上几天的时光才干盘算完毕.进程如下①参数的设置:phylogeny→bootstrap test of phylogeny→NJ②体系进化树的测试办法,可以选择用Bootstrap,也可以选择不进行测试.反复次数(Replications)平日设定至少要大于100比较好,随机数种子可以本身随便设定,不会影响盘算成果.一般选择500或1000.有很多Model供选择,默以为Kimura 2-paramete r,不合的Model有不合的算法,具体请参考专业的生物信息学书本.设定完成,点compute,开端盘算.②成果输出:这个进程所耗时光和序列的数量和长短成正比,程序就会产生这么一个树,该窗口中有两个属性页,一个是原始树,一个是bootstrap验证过的一致树.树枝上的数字暗示bootstrap验证中该树枝可托度的百分比.成果如下:8. 进化树的优化:1)应用该软件可得到不合树型,如下图所示:除此之外,还可以有多种树型,依据须要来选择.2)显示建树的相干信息:点击图标i.3)点击优化图标,可进行各项优化:Tree栏中,可以进行树型选择:rectangular tree/circle tree/radiation tree.每种树都可以进行长度,宽度或角度等的设定Branch:可对树枝上的信息进行修正.Lable:可对树枝的名字进行修正.Scale:标尺设置Cutoff:cutoff for consensus tree.一般为50%. 9.进化树的分类优化Place root on branch:可以来反转展转换.Flip subtree:180度翻转分枝,名字翻转180度.Swab subtree:交流分枝,名字不翻转.Compress/expand subtree与Set divergent time:可以把统一分枝的基因紧缩或扩大.点击Compress/expand subtree后,在要紧缩的分枝处点击,消失以下界面,在name/caption 中输入文件名(例如wwww),其他还有很多的选项,设置好了,点击OK.所得到的成果,可以在紧缩和扩大之间转换.10. 调剂进化树依据所的进化树的后果,要进行调剂,包含过剩序列删除.缺少序列添加.种属名称标注等等,还要依据投稿杂志请求在PHOTOSHOP中修正等.完成后的进化树应包含充足的信息.本身所做进化树完成图如下:。
如何利用生物大数据技术解析蛋白质進化的模式如何利用生物大数据技术解析蛋白质进化的模式摘要:蛋白质是生物体中最重要的功能分子之一,其结构和功能的进化模式一直是生物学家关注的研究领域。
随着生物大数据技术的发展,我们能够利用大规模的蛋白质序列和结构数据来解析蛋白质的进化模式。
本文将介绍如何利用生物大数据技术来揭示蛋白质进化过程中的模式,包括序列比对、进化树构建和结构比较等方法。
1. 序列比对序列比对是解析蛋白质进化模式的第一步。
通过分析不同物种中的蛋白质序列,我们可以比较它们的差异和共同特征。
生物大数据技术提供了快速和高效的方法来进行序列比对,例如使用BLAST或者HMMER等工具。
这些工具可以比较不同蛋白质序列之间的相似性,从而推断它们的进化关系。
2. 进化树构建进化树是揭示蛋白质进化模式的重要工具。
它可以帮助我们理解蛋白质的起源和演化过程。
生物大数据技术提供了多种方法来构建进化树,例如最大似然法、最小演化距离法和贝叶斯推断法等。
这些方法可以将大量的蛋白质序列数据转化为树状结构,展示不同物种或蛋白质家族之间的进化关系。
3. 结构比较蛋白质的结构决定了其功能和进化模式。
通过比较蛋白质的结构,我们可以发现不同物种或蛋白质家族之间的结构差异和相似性。
生物大数据技术提供了多种结构比较工具,例如DaliLite和TM-align等。
这些工具可以比较蛋白质的三维结构,从而揭示蛋白质进化过程中的结构变化和功能演化。
4. 功能预测蛋白质的功能与其结构和序列密切相关。
通过生物大数据技术,我们可以利用大规模的蛋白质序列和结构数据来预测蛋白质的功能。
例如,通过比较目标蛋白质与已知功能蛋白质的相似性,我们可以预测目标蛋白质的功能。
另外,还可以利用机器学习和深度学习技术来预测蛋白质的功能和结构。
5. 网络分析蛋白质组成复杂的网络,相互之间存在着复杂的相互作用关系。
通过生物大数据技术,我们可以构建蛋白质交互网络,揭示蛋白质进化模式中的功能互补和相互作用。
干货师兄,我想用MEGA建个树,咋整?作者:解螺旋.冬至转载需授权并注明来源:解螺旋,医生科研助手师妹:师兄,我想建个树。
师兄:啥树啊!你家的family tree啊?师妹:师兄,你不要调戏我,我就建一个简单的进化树!这个怎么做啊?简单呀,你可以用MEGA,先去MEGA官网(/)下载这个软件,免费的啊。
MEGA(Molecular Evolutionary Genetics Analysis )是一个功能非常强大的分子进化遗传分析软件,可用于序列比对、进化树的推断、估计分子进化速度、验证进化假说等。
下面师兄给你详细介绍如何利用Mega软件构建进化树。
1.首先将需要进行建树的序列保存为fasta格式,并将文件扩展名改为.fasta。
.fasta序列格式以“>”开头。
“>”后面这一行写名称,回车,下一行写序列,氨基酸序列类似,所有序列保存在一个txt文件中。
例如:>gene1/speciesname NCBI accession numberATCGGCGTAGCTAGATGCTAGTATCGTA>gene1/speciesname NCBI accession numberAGTAGCTAGTGATGTA2. 点击Align--Edit/built Alignment,选择创建一个新的比对,点OK根据要求选择DNA或者蛋白质序列3.打开需要比对的.fasta文件4. 点击Alignment-Align by Clustal W,选择所有序列,出现下图,所有参数为默认,点击OK。
5. 我们看到在未对齐之前,由于序列长度不一样,有些序列长出来很多,而有的序列在这些位点全是gap,为了排除gap位点的干扰。
我们需要将序列两端对齐。
两端以比对上最短的序列为准,删除其他序列5’和3’多余的部分,可以看到在序列比对上的部分,最上面一行软件标记为“*”,我们需要将没有标记“*”的位点删除,可以用shift一起选择没有标记“*”开始和末端的位点,选好后点击鼠标右键,单击delete删除。
蛋白质进化树
蛋白质是细胞内部的基本分子,它们在生物体内担任着各种不同
的功能,包括催化、传递、支持和防御等等。
对蛋白质进化的研究可
以帮助科学家进一步理解生命进化的过程以及生物体之间的亲缘关系。
蛋白质进化树便是一种通过分子比较生物学技术来分析蛋白质进化的
方法。
第一步:序列比对
蛋白质进化树的第一步是进行序列比对。
科学家使用计算机程序
将一个给定的蛋白质的氨基酸序列与其他类似蛋白质的氨基酸序列进
行比较。
这些比较通常会比较差异性,因为蛋白质的结构、功能、生
理特性以及它们存在的环境可能会随时间而改变。
第二步:构建基本树
通过对序列进行比较,科学家便可以为每个蛋白质构建相对应的
进化树。
这些进化树可以通过计算机程序以及数学的方法来构建,并
且会要求选定一个轴,将各种进化树对齐,进一步将基本树构建在一起。
第三步:统计分析
在构建了基本树之后,科学家将进行多种统计分析以确定树的适
应性、可靠性和正确性。
例如,他们可以使用置信区间来使用概率分
布来检查蛋白质进化树的可信度。
第四步:修改树结构
如果统计分析表明树的结构不正确,那么科学家将会修改进化树
以解决这些问题。
这些修改可能包括添加或删除蛋白质分析,更改统
计方法,或者更改序列比对参数等。
综上所述,蛋白质进化树是一种非常重要的生物信息学技术,可
以帮助科学家更好地理解生命的进化以及各种生物之间的亲缘关系。
通过序列比对、构建基本树、统计分析以及修改树结构,科学家可以
快速、准确地为不同的蛋白质构建迭代进化树,并且不断完善这些树的适应性和可靠性。
蛋白质序列进化(protein sequence phylogenetic},一种用于测定各种生物之间遗传关系的技术。
#百度百科#一般通过蛋白质的氨基酸序列进行比对后建树,方法过程如下:
首先由NCBI或其他查询基因途径获取要比对的目的蛋白氨基酸序列(网站上有很多此类说明)我的由于序列较多,就先把氨基酸序列复制到文本文件中
之后将序列文本文件扩展名改为.fas
之后打开MEGA软件进行序列比对,选择Align---Edit/Build/Alignment---Retrieve sequence from a file---选择文件---确定,输出结果默认以最右端蛋氨酸对齐,如图
在建树之前序列应该以保守序列比对模式进行,选择Alignment---Align by ClustalW,以输出以保守序列比对结果,如图
保存序列比对文件,默认格式为*.mas格式,并选择phylogeny---construct/Test UPGMA Tree进行建树,步骤如图
选择蛋白序列
之后就会输出树,如下
之后可以根据不同要求更改树形,选择下图按钮进行输出设置并输出环形树
之后可以保存到指定文件,同时也可以将树以pdf格式导出,选择image---Save as pdf file或者png file。