MSC_MARC单机多核并行计算示例教学文案
- 格式:doc
- 大小:1.74 MB
- 文档页数:16

并行计算课程设计一、课程目标知识目标:1. 让学生理解并行计算的基本概念,掌握并行计算的发展历程及分类;2. 培养学生掌握并行编程的基本方法,了解并行算法的设计原则;3. 使学生了解并行计算在现实生活中的应用,并能结合实际问题进行分析。
技能目标:1. 培养学生运用并行计算技术解决实际问题的能力,提高计算思维;2. 培养学生掌握并行编程工具和软件的使用,能进行简单的并行程序设计;3. 培养学生通过团队合作,进行问题分析、方案设计和程序实现的能力。
情感态度价值观目标:1. 培养学生对并行计算的兴趣,激发其探索未知领域的热情;2. 培养学生具备良好的团队合作精神,学会尊重他人、沟通协作;3. 培养学生认识到科技发展对社会进步的重要性,树立正确的科技观。
课程性质:本课程为选修课,旨在拓展学生的计算思维和编程技能,提高解决实际问题的能力。
学生特点:学生具备一定的计算机基础,对编程有一定了解,对并行计算感兴趣,但可能对并行编程方法和技巧掌握不足。
教学要求:结合学生特点和课程性质,注重理论与实践相结合,充分调动学生的积极性,培养其创新能力和实践能力。
通过本课程的学习,使学生能够将并行计算技术应用于实际问题,达到学以致用的目的。
在教学过程中,将目标分解为具体的学习成果,便于教学设计和评估。
二、教学内容1. 并行计算基本概念:包括并行计算的定义、发展历程、分类及特点。
教材章节:第一章 并行计算概述2. 并行编程模型:介绍 Flynn 分类法,讲解共享内存和分布式内存编程模型。
教材章节:第二章 并行编程模型3. 并行编程语言与工具:学习 MPI、OpenMP、CUDA 等并行编程语言和工具。
教材章节:第三章 并行编程语言与工具4. 并行算法设计:讲解并行算法设计原则,分析常见并行算法。
教材章节:第四章 并行算法设计5. 并行计算应用:介绍并行计算在科学计算、大数据处理等领域的应用。
教材章节:第五章 并行计算应用6. 实践环节:安排学生进行并行程序设计和实现,针对实际问题进行团队协作。

并行计算的课程设计一、课程目标知识目标:1. 让学生理解并行计算的基本概念,掌握并行计算的核心原理。
2. 学会分析问题,识别适合并行计算的算法和场景。
3. 掌握并行编程的基本技巧,能运用所学知识对简单程序进行并行化改造。
技能目标:1. 培养学生运用并行计算技术解决问题的能力,提高计算效率。
2. 培养学生具备团队协作和沟通能力,能参与并行计算项目的开发和优化。
3. 培养学生具备自主学习能力,能够紧跟并行计算领域的发展趋势。
情感态度价值观目标:1. 激发学生对并行计算的兴趣,培养其探索精神和创新意识。
2. 培养学生具备良好的科学素养,认识到并行计算在科技发展中的重要作用。
3. 引导学生树立正确的价值观,明确并行计算为社会进步带来的积极影响。
分析课程性质、学生特点和教学要求,本课程将目标分解为以下具体学习成果:1. 学生能够解释并行计算的基本概念,阐述并行计算的核心原理。
2. 学生能够分析实际问题,提出并行计算解决方案,并评估其性能。
3. 学生能够掌握并行编程技巧,完成至少一个简单的并行程序设计。
4. 学生能够积极参与团队合作,共同完成并行计算项目。
5. 学生能够关注并行计算领域的发展动态,了解其应用前景。
本课程教学内容依据课程目标,结合教材章节,科学系统地组织如下:1. 并行计算基本概念:介绍并行计算的定义、分类及其发展历程,使学生了解并行计算的基本框架。
2. 并行计算原理:讲解并行计算的基本原理,如并发性、并行性、数据并行、任务并行等,并通过实例分析,使学生掌握并行计算的核心思想。
3. 并行计算模型:介绍 Flynn 分类法、SIMD、MIMD 等并行计算模型,让学生了解不同并行计算模型的特点及应用场景。
4. 并行编程技术:讲解并行编程的基本方法,如 OpenMP、MPI、CUDA 等,使学生掌握并行编程的技巧和注意事项。
5. 并行算法设计:分析常见并行算法设计方法,如分治法、迭代法、管道线法等,并通过实例让学生学会设计并行算法。


MARC并行计算安装说明最近很多朋友问到如何安装并行,我抽空写了个说明,与大家分享安装环境:1、三台电脑,电脑名分别为computer1computer2computer3,他们处于同一个工作组workgroup.computer1有1个CPU,Computer2有2个CPU,Computer3有3个CPU。
2、三台电脑安装的操作系统都为Windows XPSP23、computer1computer2computer3上MARC的安装路径都为D:\MSC.Software4、Computer1的工作路径为D:\work1,用户名为user1密码为passuser1Computer2的工作路径为E:\work2,用户名为user2密码为passuser2Computer3的工作路径为F:\work3,用户名为user3密码为passuser3安装步骤1、确保三台电脑能够连通,该连通主要指的是能够相互读写文件。
有的时候局域网可能出现:网络拒绝访问,请联系系统管理员,确保您有权限访问该台计算机之类的提示,这时可以按以下步骤操作方法1:在各台计算机上都建立相同的帐户名,如user007,采用相同的密码。
这时,只要网络是通的,一般都没有问题,能够相互访问方法2:各台计算机上的帐户名和密码都不同:1)确保各台计算机的用户名和密码非空2)启用Guest帐户3)开始—运行—gpedit.msc---计算机配置---Windows设置---安全设置---本地策略---用户权利指派---拒绝从网络访问这台计算机。
将Guest帐户删掉4)去掉―使用简单文件共享‖项2、设定一台Host机,两台remote机:在这里设置Computer1为Host机,其他两台为remote机3、将Host机,即Compter1,的安装目录,即D:\MSC.Software完全共享将Remote机,即Computer2computer3的安装目录和工作目录完全共享,即:两台电脑的D:\msc.software完全共享;Computer2的E:\work2;Computer3的F:\work3完全共享4、重置MP-MPICH密码在每台电脑上都执行相应的操作,这里以Computer1为例在DOS窗口下:cdD:\MSC.Software\MSC.Marc\2005r3\marc2005r3\nt_mpich\bin\mpiexec –store–save..\..\tools\setdomain.bat可以看到一些提示符,要求你输入一些参数,即输入每台计算机的计算机所述域、用户名密码。
现在的PC即使是单机单CPU也会有多核多线程,如果计算时不启用并行运算,计算效率会很低,会花更长时间,而且也浪费很多硬件资源,所以目前主流的CAE软件都会支持单机并行运算或者多机并行运算。
SimuFact.Forming 13.3已经发布半年多了,这个版本的细节部分有很多的更新,在并行计算领域,这个版本有比较大变化,设置更加方便了,下面做一下详细的说明。
SimuFact.Forming软件有FE和FV两种求解器,目前大部分计算都是用FE求解器,FE求解器实际就是MARC,这两种求解器都支持并行运算。
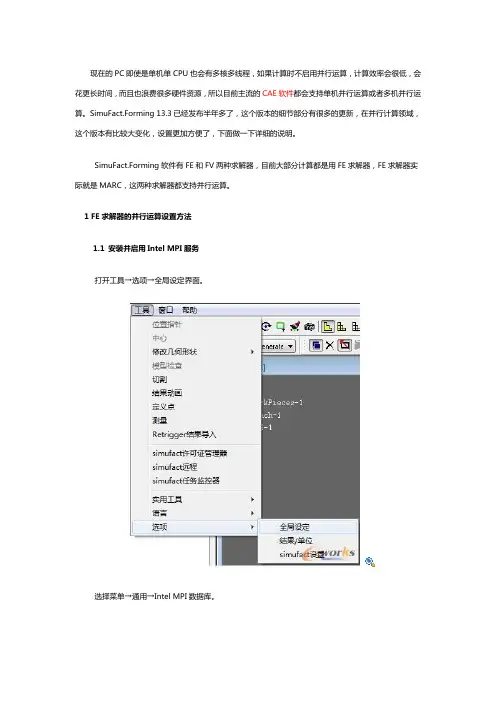
1 FE求解器的并行运算设置方法1.1 安装并启用Intel MPI服务打开工具→选项→全局设定界面。
选择菜单→通用→Intel MPI数据库。
点击注册MPI账户,这里输入具有管理员权限的用户名和密码(可以为域用户)。
输入完成后点Register按钮;点OK退出。
然后点击启用MIP服务!1.2 设置FE并行运算整体模拟设置完毕后点击成形→菜单→并行,并行前打勾。
这里有两个地方需要设置:域的数量和共享内存并行。
假如分析用的工作站为双CPU、8核心、16线程(license许可最大数量16),可以做如下设置:域数量8;共享内存并行1;CPU核心激活8;利用率:50%。
域数量2;共享内存并行4;CPU核心激活8;利用率:50%。
域数量1;共享内存并行8;CPU核心激活8;利用率:50%。
CPU核心激活=域数量*共享内存并行核数。
一般情况下,推荐域数量1,共享内存并行为CPU总核数。
域数量为FE(MARC)求解器独有的一项技术,可以将分析工件划分成几个区域进行分析,以前单CPU 的年代主要用于多计算机并行分析;共享内存并行,Intel提供的计算软件直接调用多核或者多CPU资源的一项技术;总而言之,在license许可的数量(本地主机上可以用的核数许可限制里面的数值)域和共享内存并行的乘积小于等于本地主机的最大cpu核数;上面两个步骤完成后,就可以提交计算,并利用本地主机的多核进行并行计算了,而软件能够调用的CPU核数取决你设置的多少!(域数量直接体现是:假如设置为2,就会有2个marc求解器线程出现,如果设置为1,就只有一个marc求解器线程,然后出现的MARC线程调用的CPU核数为设置的内存并行数量)1.3 不同设置的计算效率对比同样的激活核数,不同是设置方式计算时间会有略微的差异。

并行计算方案第1篇并行计算方案一、背景随着大数据时代的到来,计算任务呈现出数据量大、计算复杂度高等特点,对计算性能和效率提出了更高的要求。
为满足日益增长的计算需求,本方案提出一种基于并行计算的解决方案,旨在提高计算速度和资源利用率,降低计算成本。
二、目标1. 提高计算速度,缩短计算任务完成时间。
2. 提高资源利用率,降低计算成本。
3. 保障计算任务的可靠性和安全性。
4. 易于扩展,满足不断增长的计算需求。
三、方案设计1. 总体架构本方案采用分布式并行计算架构,将计算任务划分为多个子任务,分配给不同的计算节点进行处理。
各节点之间通过高速网络连接,实现数据传输和同步。
2. 计算节点(1)节点配置:计算节点采用高性能服务器,配置多核CPU、大容量内存和高速硬盘,以满足不同类型计算任务的需求。
(2)节点部署:根据计算任务的特点,合理配置节点数量,实现计算资源的合理分配和优化。
3. 并行算法(1)任务划分:根据计算任务的特点,采用合适的任务划分策略,将任务划分为多个相互独立的子任务。
(2)负载均衡:通过动态负载均衡算法,确保各节点计算负载均衡,提高资源利用率。
(3)同步机制:采用分布式锁、消息队列等技术,实现各节点之间的数据同步和通信。
4. 数据存储与管理(1)数据存储:采用分布式文件系统,实现数据的高效存储和读取。
(2)数据管理:建立数据索引,提高数据检索速度;采用数据压缩和去重技术,降低存储成本。
5. 安全与可靠性(1)数据安全:采用加密技术,保证数据传输和存储的安全性。
(2)计算安全:通过安全策略和监控机制,防止恶意攻击和计算任务篡改。
(3)容错机制:采用冗余计算和故障转移策略,确保计算任务的可靠性和稳定性。
四、实施步骤1. 需求分析:深入了解计算任务的特点,明确并行计算的需求。
2. 系统设计:根据需求分析,设计并行计算系统架构,确定计算节点配置和并行算法。
3. 系统开发:采用成熟的技术和框架,开发并行计算系统。


随着科技的不断发展,计算机的性能需求也在不断提高。
在过去,单核处理器是主流,但是由于单核处理器的性能限制,难以满足复杂计算任务的需求。
因此,多核学习中的并行计算与加速技术成为了研究的热点。
多核学习是指在计算机处理器中集成多个核心,以实现更高的性能和更高的计算效率。
在多核学习中,如何充分利用多核处理器的性能,是一个重要的问题。
并行计算与加速技术正是解决这一问题的关键。
一、并行计算技术并行计算技术是指将一个计算任务分解成多个子任务,并且同时在多个处理器上进行计算。
这样可以充分利用多核处理器的性能,加快计算速度。
并行计算技术主要包括任务并行和数据并行两种方式。
任务并行是指将一个大的计算任务拆分成多个小任务,然后分配给多个处理器同时进行计算。
通过任务并行,可以充分利用多核处理器的计算能力,提高计算效率。
数据并行是指将大规模数据分成多个子集,然后分配给多个处理器同时进行处理。
通过数据并行,可以减少数据传输和通信开销,提高计算效率。
二、加速技术除了并行计算技术,还有一些其他的加速技术也可以提高多核学习中的计算效率。
例如,GPU加速技术可以利用图形处理器进行并行计算,加快计算速度。
GPU拥有大量的处理单元,能够同时处理多个计算任务,因此在深度学习、神经网络等计算密集型任务中有很大的应用前景。
另外,FPGA加速技术也可以提高多核学习中的计算效率。
FPGA是一种灵活可编程的硬件,可以根据计算任务的需求进行重新配置,具有较高的并行计算能力和低延迟。
因此,在加速深度学习、模式识别等任务中有很大的潜力。
三、挑战与展望尽管并行计算与加速技术可以提高多核学习中的计算效率,但是也面临着一些挑战。
例如,多核处理器之间的通信和数据同步是一个复杂的问题,如何合理地分配计算任务和数据,以充分利用多核处理器的性能,是一个需要深入研究的问题。
此外,如何将并行计算与加速技术应用于实际的多核学习中,也需要进一步探索。
例如,在深度学习、自然语言处理、计算机视觉等领域,如何充分利用多核处理器的性能,加快计算速度,提高计算效率,是一个需要深入研究的问题。
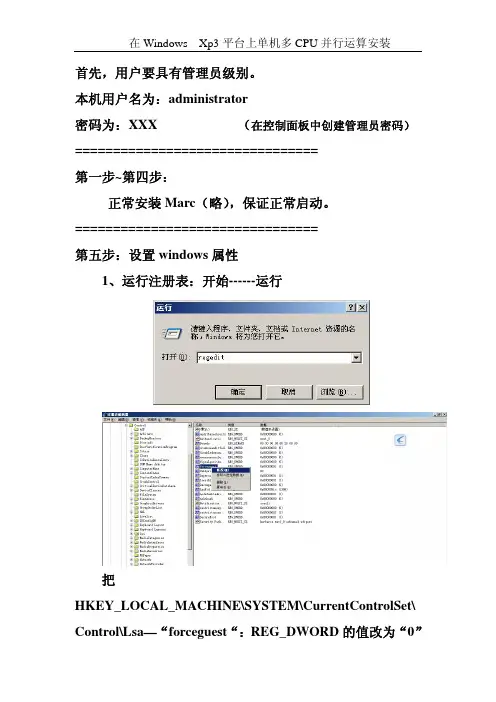
首先,用户要具有管理员级别。
本机用户名为:administrator密码为:XXX (在控制面板中创建管理员密码)================================第一步~第四步:正常安装Marc(略),保证正常启动。
================================第五步:设置windows属性1、运行注册表:开始------运行把HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\ Control\Lsa—“forceguest“:REG_DWORD的值改为“0”2、开始------运行-----gpedit.msc组策略-----计算机配置-------管理模板---------系统---------远程过程调用----------RPC终点映射程序客户端验证--------鼠标右键---------属性--------已启用3、桌面图标“我的电脑”-----鼠标右键------系统属性------高级-------性能,设置-----------数据执行保护-------仅为基本windows程序和服务启用DEP。
确定。
第六步 Marc设置1、开始-----运行------cmd进入dos界面进入Marc安装目录下的tools目录输入:net share > 回车,退出dos2、打开Mrac安装目录中C:\MSC.Software\MSC.Marc\2005r3\marc2005r3\nt_mpich\ bin文件夹:单击rcluma-update.bat进入dos界面:这是如果有杀毒软件进行木马阻拦,请暂时关闭杀毒保护(注意上图右下角提示)。
再重新启动rcluma-update.bat 进入dos界面:总是允许(有文件监控软件时显示)输入:Login:administratorDomain:localPassword:XXX在password:后面输入密码时,光标无提示,输入完后回车,正常退出dos界面。


关于单核和多核微处理器调度策略和调度算法进程调度负责动态地将CPU分配给各个进程。
主要功能是:(1)记住进程的状态。
当前运行的进程在调用进程调度程序时,进程调度程序将该进程的现场信息,如程序计数器及通用寄存器的内容等保留在该进程的进程控制块PCB的现场信息区内;(2)决定哪个进程,什么时候获得CPU以及占用多长时间;(3)把CPU分配给进程。
即将选中进程的PCB内有关现场的信息,如程序状态寄存器、通用寄存器等内容送入CPU的相应的寄存器中,从而让该进程占用CPU去运行;(4)收回CPU。
将CPU有关寄存器内容送入该进程的进程控制块PCB内的相应单元中,然后将此进程链入相应的管理队列(等待或就绪),从而使该进程让出它所占用的CPU。
那么在什么时候进入进程调度为最好?一般认为,只要现行进程不再能继续运行,或者有理由认为可以更好地将CPU使用在别的方面,那么就启动进程调度程序。
下面列举启动进程调度程序的各种时机。
(1)在一次外部中断之后,该中断改变了某个进程的状态。
因而使某个进程有可能抢占CPU。
(2)在一次系统调用之后,而该调用使现行进程暂时不能继续运行。
这样就需要再次挑选出一进程,将CPU分配给它。
(3)在一次出错处理之后,使现行进程在出错处理时被封锁。
进程调度程序在被执行时,首先检查现行进程是否仍然是最适宜于在CPU 上运行的进程。
如果是,则恢复由中断硬件保护起来的程序计数器值,并将控制返回到断点;否则将现行进程的现场保护进它本身的进程控制块PCB中,然后将最适宜于运行的进程去占用CPU,并将该进程的有关信息送入相应的寄存器中,再将控制转向该进程,使之占用CPU运行。
在计算机系统中,进程只有占用了CPU才能真正活动起来。
但是系统中处于就绪状态并可以立即使用CPU的进程数往往超过CPU的数目。
于是,系统需要按照自己的性能要求选择调度算法,分配CPU。
1.分时系统调度策略在分时系统中,为了提高对交互作用的响应速度,使各进程在较短时间间隔内都有机会占用CPU,则需要比较频繁地对CPU进行调度。
marc并行计算配置步骤详细说明若要使用副程式(user subroutine),請先安Fortran (Compaq Fortran6.6b 或Intel Fortran 8.0 or Later)DDM•Marc 可安裝在所有的電腦上(Share Installation) ,也可只安裝在一台電腦上(Distribute Installation)•所有的電腦必須有相同使用者帳號及密碼(本例為帳號為aaa密碼為ppp•所有電腦至少有一個目錄供分享,當主機分配運算工作時會將相關檔案自動放至該目錄(本例為d:\test\ddm)•詳細資訊可參考marc_install_instruct.pdf1700@abc License sever 所在電腦名稱•鍵入net share > cd\MARC2005\marc2005\tools•Login:aaa•Domain:Local(如果電腦不在Domain內就鍵入Local)•Password:pppPS: aaa/ppp為登入本機時的帳號/密碼•開始 執行 輸入regedt32 確定•在HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Lsa 找出“forceguest”將DWORD值改為1 GENERATE Enter Number of Domains:鍵入2 (2台電腦或2個CPU) USE DDM ID DomainPS:本例假設為兩台電腦平行處理•將該檔案存為hostfilePS:本例假設為兩台電腦進行平行運算,名稱各為computer1 及computer2•DDM設定完成,可以正常執行Marc安裝完成,可以快樂地使用Marc 的平行運算了。
多核处理器的并行计算模型与任务调度算法优化随着计算机技术的快速发展,多核处理器的应用越来越广泛。
多核处理器可以同时执行多个任务,提高计算机系统的性能。
然而,如何有效地管理和调度多核处理器中的任务,以实现高效的并行计算,是一个重要且复杂的问题。
本文将介绍多核处理器的并行计算模型和一些常用的任务调度算法,并探讨如何优化任务调度算法以提高并行计算性能。
首先,我们来介绍多核处理器的并行计算模型。
多核处理器可以分为两种并行计算模型:单指令流多数据流(SIMD)和多指令流多数据流(MIMD)。
SIMD模型中,处理器的每个核心都执行相同的指令,但操作的数据可以不同,适合于数据量大、结构相同的并行计算任务;MIMD模型中,处理器的每个核心可以执行不同的指令,适合于任务之间存在依赖关系或具有不同的计算需求的场景。
在实际应用中,多核处理器通常采用混合的SIMD和MIMD模型,以兼顾不同类型的并行计算任务。
为了实现高效的并行计算,任务调度算法在多核处理器中起着关键作用。
任务调度算法的目标是对任务进行合理分配和调度,以最大程度地利用多核处理器的计算资源,提高系统的性能。
常用的任务调度算法包括静态调度算法和动态调度算法。
静态调度算法在任务执行之前就确定好任务的调度顺序。
最简单的静态调度算法是轮询调度算法,即按照任务的顺序一个接一个地执行。
轮询调度算法简单高效,但不能适应任务之间的不均衡情况。
为了解决不均衡问题,还可以使用负载均衡算法,在任务之间动态地分配计算资源,使得多核处理器的负载均衡。
常见的负载均衡算法有最短作业优先调度算法、最小处理器优先调度算法和自适应负载均衡算法等。
动态调度算法根据任务的运行时情况来动态地调整任务的执行顺序。
最常见的动态调度算法是基于任务优先级的调度算法。
每个任务都有一个优先级,优先级高的任务会被优先执行。
常用的任务优先级调度算法有静态优先级调度算法和动态优先级调度算法。
静态优先级调度算法在任务开始执行之前就确定任务的优先级,而动态优先级调度算法是根据任务的运行时信息不断调整任务的优先级。
并行计算导论第二版课程设计一、设计背景当前,计算机技术不断发展,计算机系统的运算速度不断提高,但是随着计算量和数据规模的增加,单机计算已经无法满足需求。
并行计算作为一种新的计算模式,逐渐成为人们关注的焦点。
为了培养学生对并行计算的了解和应用能力,本课程设计了并行计算导论第二版。
二、课程目标本课程旨在让学生了解并行计算的基本概念和应用技术,了解并发编程的原理,了解多核计算和集群计算的场景和应用,了解分布式存储和计算的技术,掌握并行计算的编程方法和调试技巧,培养学生问题解决的能力和团队合作能力。
三、课程内容3.1 并行计算基础本章主要介绍并行计算的基本概念和基本理论,包括并行计算的分类、并行计算的架构、并行计算的性能指标、并行计算的通信原理、并行计算的并发管理和任务调度算法等内容。
3.2 并发编程原理本章主要介绍并发编程的原理和技术,包括进程和线程的概念、进程和线程的创建和管理、线程同步和互斥的机制、消息队列的使用、信号量、条件变量等内容。
学生将通过编写简单的并发程序来理解并发编程的实现原理和技巧。
3.3 多核计算和集群计算本章主要介绍多核计算和集群计算的场景和应用,包括多核计算的硬件架构、多核计算的编程模型、集群计算的原理和构成、集群计算的管理和调度等内容。
学生将通过编写多核计算和集群计算的程序来掌握相关的技术和方法。
3.4 分布式存储和计算本章主要介绍分布式存储和计算的技术和应用,包括分布式文件系统的原理和构成、分布式数据库的原理和构成、分布式计算的任务分配和协同以及分布式计算的容错和可靠性等问题。
学生将通过编写简单的分布式存储和计算程序来理解相关技术和方法。
3.5 并行计算编程方法本章主要介绍并行计算的编程方法和调试技巧,包括多线程并发编程、MPI并行编程、OpenMP并行编程、CUDA并行编程等内容。
学生将通过编写简单的并行程序来掌握相关的编程方法和调试技巧。
3.6 并行计算应用本章主要介绍并行计算的应用实例,包括图像处理、生物信息学计算、大数据分析、模拟计算等方面的应用。
燕山大学课程讲义并行计算导论授课人:郭栋梁学时:32学时其中实验课:8学时三级项目:16学时第1章引言1.1概述单处理器计算机即将成为过时的概念.我们需要考虑如下因素来着手改进提高计算机的性能:(1)单纯依靠单处理器很难提升现有计算机的性能.即使有一个性能十分强大的单处理器,其功耗也让人无法接受.想要提升计算机的性能,更加可行的方法是同时使用多个简单处理器,它所能达到的性能可能是现有单处理器计算机性能的几千倍。
(2)观察结果显示,除非使用并行处理技术,一个程序在一台型号更新的单处理器计算机上的运行速度,可能比在旧的计算机上的运行速度更慢。
能依照给定算法检测出程序中的并行结构的编程工具还有待开发。
此算法需要能够检测出变ja之间的依赖关系是否规则;而且不管这些依赖是否规则,此算法都能在保证程序正确性的前提下,通过将程序中的一些子任务并行化来加速程序的执行。
(3)提升未来的计算机性能的关键就在于并行程序的开发,这涉及各个层面的工作:算法、程序开发、操作系统、编译器及硬件设备。
(4)并行计算除了要考虑到参与并行计算的处理器的数量,还应该考虑处理器与处理器、处理器与内存之间的通信。
最终计算性能的提升既依赖于算法能够提升的空间,更依赖于处理器执行算法的效率。
而通信性能的提升则依赖于处理器对数据的供应和提取的速度。
(5)内存系统的速度始终比处理器慢,而且由于一次只能进行单个字的读写操作,内存系统的带宽也有限制。
(6)内存系统的速度始终比处理器慢,而且由于一次只能进行单个字的读写操作,内存系统的带宽也有限制。
本书内容主要涉及并行算法与为了实现这些算法而设计的硬件结构。
硬件和软件是相互影响的,任何软件的最终运行环境是由处理器组成的底层硬件设备和相应的操作系统组成.我们在本章开始的部分会介绍一些概念,之后再来讨论为了实现这些概念有哪些方法和限制.1.2自动并行编程对于算法在软件中的实现过程我们都很熟悉。
在编程并不需要了解目标计算机系统的具体细节,因为编译器会处理这些细节.但是在编程和调试时依旧沿用着在单一央处理器(CPU)上顺序处理的模式.从另一方面讲,为了实现并行算法,硬件和软件之间的相互联系需要比我们想象的更加密切。
M S C_M A R C单机多核并行计算示例
MSC MARC2011单机多核并行计算示例
并行计算可以有效利用本地或者网络计算机计算资源,提高计算效率,特别是针对一些计算规模相对较大的问题。
本文作为MARC单机多核并行计算的一个示例。
测试平台:WIN7 64Bit MARC2011
0、提前设置
将电脑名字最好改为administrator,或者通过修改电脑名称,会使user和display后面的名子保持一致。
改电脑名字:
计算机右键—属性—更改设置—更改—计算机名
1、启动多核运算
打开dos界面输入
(1)D:按enter回车键(d为marc所在盘)
(2)cd+空格+
D:\MSC.Software\Marc\2010\marc2010\intelmpi\win64\bin按
enter回车键
(3)ismpd+空格+ –install 按enter回车键
(4)出现上图中的
关闭窗口。
2、基本配置
(1)在MARC安装目录下的intelmpi\win64\bin目录(32Bit计算机选择
win32文件夹),运行wmpiregister.exe.
(2)输入用户名(登陆windows的账户名,通常为administrator)及密码(若密码为空,需要重新设置一个密码),点击register按钮,下面的对话框中会出现“Password encrypted into the Registry”信息。
(3)运行ismpd.exe,或者到dos提示符下,进入该目录,运行ismpd -install。
假如提示都正常的话,到此即完成进行并行计算的前提条件了。
3、测试
(1)在MARC安装目录下的intelmpi\win64\bin目录(32Bit计算机选择win32文件夹),运行wmpiconfig.exe
(2)依次点击下面1和2.
(3)红框中出现
如果出现
administr
Unable to connect to 'administr:8678',
sock error: generic socket failure, error stack:
MPIDU_Sock_post_connect(1200): unable to connect to administr on port 8678, exhausted all endpoints (errno -1)
MPIDU_Sock_post_connect(1216): gethostbyname failed, 请求的名称有效,但是找不到请求的类型的数据。
(errno 11004)
表示第2步注册的电脑名字或密码不对。
如果出现
Administrator
The credentials for Administrator rejected connect。
表示电脑的名字不对。
通过修改电脑名重新就行上述几步直至不出现
上述两种情况。
4、分配单元
单机多核计算提高效率的途径在于几个核心同时进行计算,因此对一个模型完成所有的建模后需要为参与计算的多核分配计算任务(软件自动分配或者用户手动分配),也就是单元,最后在提交任务前提示软件进行并行计算。
(1)打开一个已经调试无误的待计算文件
(2)为多核分配单元
测试电脑为双核4线程,这里设置2核计算。
①Jobs—>User Domains调出面板,②Generate!按钮设置参与计算的CPU内核数,③输入分配的内核数2,回车确定,④软件自动为两个内核分配单元,并输出单元数信息,⑤勾选Identify,显示单元分配情况,最终如图所示。
也可以用户手动分配单元,①选择Manul Decomposition,出现手动分配单元的一些命令按钮,②Delete All删除之前自动分配情况,③Add Elements分别为内核分配不同的单元,④手动分配情况如图所示。
5、提交计算
完成上述步骤后,勾选Parallelization选项即可进行并行计算。
①Job—>Show Menu进入Job面板,②Run命令进入Run Job面板,③点击Parallelization进入相应面板,④勾选 Use DDM选项,假如使用用户分配的单元,选择 Decomposition In Mentat,⑤点击OK回到Run Job面板,⑥点击Submit即可提交任务进行并行计算。
运行情况如图所示。