实验四-排序-实验报告
- 格式:docx
- 大小:72.54 KB
- 文档页数:9
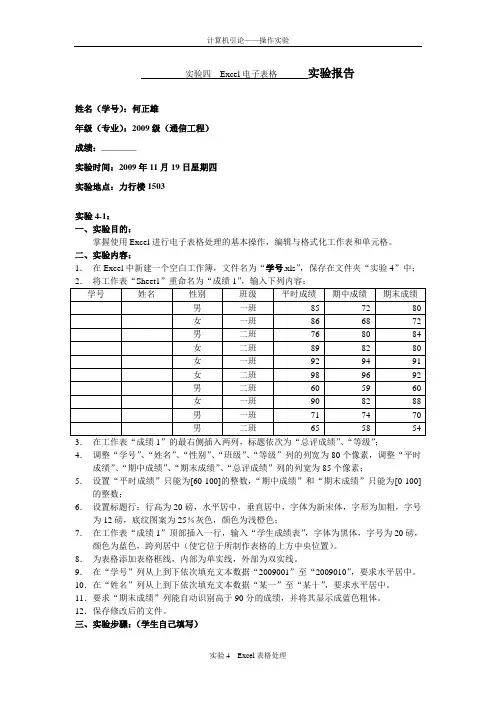
实验四Excel电子表格实验报告姓名(学号):何正雄年级(专业):2009级(通信工程)成绩:________实验时间:2009年11月19日星期四实验地点:力行楼1503实验4-1:一、实验目的:掌握使用Excel进行电子表格处理的基本操作,编辑与格式化工作表和单元格。
二、实验内容:1.在Excel中新建一个空白工作簿,文件名为“学号.xls”,保存在文件夹“实验4”中;4.调整“学号”、“姓名”、“性别”、“班级”、“等级”列的列宽为80个像素,调整“平时成绩”、“期中成绩”、“期末成绩”、“总评成绩”列的列宽为85个像素;5.设置“平时成绩”只能为[60-100]的整数,“期中成绩”和“期末成绩”只能为[0-100]的整数;6.设置标题行:行高为20磅,水平居中,垂直居中,字体为新宋体,字形为加粗,字号为12磅,底纹图案为25%灰色,颜色为浅橙色;7.在工作表“成绩1”顶部插入一行,输入“学生成绩表”,字体为黑体,字号为20磅,颜色为蓝色,跨列居中(使它位于所制作表格的上方中央位置)。
8.为表格添加表格框线,内部为单实线,外部为双实线。
9.在“学号”列从上到下依次填充文本数据“2009001”至“2009010”,要求水平居中。
10.在“姓名”列从上到下依次填充文本数据“某一”至“某十”,要求水平居中。
11.要求“期末成绩”列能自动识别高于90分的成绩,并将其显示成蓝色粗体。
12.保存修改后的文件。
三、实验步骤:(学生自己填写)1.在实验4中新建一个Excel工作表→命名为“20091060168.xls”.2.在工作表的左下方点击sheet1→单击右键→重命名为“成绩1”→在工作表“成绩1”中输入上面所需要输入的内容3.在工作表“成绩1”的最右侧另取两列→依次输入标题“总评成绩”、“等级”4.选中“学号”、“姓名”、“性别”、“班级”、“等级”→格式→列→列宽→80;选中“平时成绩”、“期中成绩”、“期末成绩”、“总评成绩”→格式→列→列宽→855.选中“平时成绩”这一列→数据→有效性→设为整数、介于最小值60,最大值100;再选中“期中成绩”“期末成绩”这两列→数据→有效性→设为整数、介于最小值0,最大值1006.选中标题行→单击右键→行高→20→单击右键→设置单元格格式→对齐→水平对齐:居中,垂直对齐:居中→字体:新宋体,加粗,12磅→图案→图案:浅橙色,底纹图案:25%灰色→确定7.选中标题行→单击右键→插入→选中前九列→单击工具栏里面的“合并及居中”→在里面输入“学生成绩表”→选中这一行→设置单元格格式→字体:黑体,20磅,颜色:蓝色8.选中整个表格→单击右键→设置单元格格式→边框→线条样式:单实线,内部;双实线,外边框→确定9.在“学号”列上的第一行,第二行依次输入2009001,2009002→选中这一列的前两行→将鼠标移到所选区域的右下角,出现一个实心十字→单击左键往下拉,直到2009106010为止→选中整列→工具栏→居中10.工具→选项→自定义序列→新序列→输入序列→输入“某一,某二,某三,某四,某五,某六,某七,某八,某九,某十”→添加→确定→在“姓名”列的第一二行依次输入“某一”“某二”→然后类同第9步依次填充文本数据“某一”至“某十”→选中这一列→工具栏→居中11.选中“期末成绩”列→格式→条件格式→设置:单元格数值大于90→格式→字形:加粗,颜色:蓝色→确定12.略实验4-2:一、实验目的:掌握Excel中公式和函数的使用。

第1篇一、实验目的1. 理解指针在排序算法中的应用。
2. 掌握几种常见的排序算法(如冒泡排序、选择排序、插入排序等)的指针实现方式。
3. 比较不同排序算法的效率,分析其优缺点。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发环境:Visual Studio 2019三、实验内容本次实验主要实现了以下排序算法:1. 冒泡排序2. 选择排序3. 插入排序以下是对每种排序算法的具体实现和性能分析。
1. 冒泡排序(1)算法原理冒泡排序是一种简单的排序算法。
它重复地遍历待排序的序列,比较每对相邻的元素,如果它们的顺序错误就把它们交换过来。
遍历序列的工作是重复地进行,直到没有再需要交换的元素为止。
(2)指针实现```cppvoid bubbleSort(int arr, int len) {for (int i = 0; i < len - 1; i++) {for (int j = 0; j < len - 1 - i; j++) {if ((arr + j) > (arr + j + 1)) {int temp = (arr + j);(arr + j) = (arr + j + 1);(arr + j + 1) = temp;}}}}```(3)性能分析冒泡排序的时间复杂度为O(n^2),空间复杂度为O(1)。
当待排序序列基本有序时,冒泡排序的性能较好。
2. 选择排序(1)算法原理选择排序是一种简单直观的排序算法。
它的工作原理是:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
(2)指针实现```cppvoid selectionSort(int arr, int len) {for (int i = 0; i < len - 1; i++) {int minIndex = i;for (int j = i + 1; j < len; j++) {if ((arr + j) < (arr + minIndex)) {minIndex = j;}}int temp = (arr + i);(arr + i) = (arr + minIndex);(arr + minIndex) = temp;}}```(3)性能分析选择排序的时间复杂度为O(n^2),空间复杂度为O(1)。

数据结构排序实验报告数据结构排序实验报告引言:数据结构是计算机科学中的重要概念之一,它涉及到数据的组织、存储和操作方式。
排序是数据结构中的基本操作之一,它可以将一组无序的数据按照特定的规则进行排列,从而方便后续的查找和处理。
本实验旨在通过对不同排序算法的实验比较,探讨它们的性能差异和适用场景。
一、实验目的本实验的主要目的是通过实际操作,深入理解不同排序算法的原理和实现方式,并通过对比它们的性能差异,选取合适的排序算法用于不同场景中。
二、实验环境和工具实验环境:Windows 10 操作系统开发工具:Visual Studio 2019编程语言:C++三、实验过程1. 实验准备在开始实验之前,我们需要先准备一组待排序的数据。
为了保证实验的公正性,我们选择了一组包含10000个随机整数的数据集。
这些数据将被用于对比各种排序算法的性能。
2. 实验步骤我们选择了常见的五种排序算法进行实验比较,分别是冒泡排序、选择排序、插入排序、快速排序和归并排序。
- 冒泡排序:该算法通过不断比较相邻元素的大小,将较大的元素逐渐“冒泡”到数组的末尾。
实现时,我们使用了双重循环来遍历整个数组,并通过交换元素的方式进行排序。
- 选择排序:该算法通过不断选择数组中的最小元素,并将其放置在已排序部分的末尾。
实现时,我们使用了双重循环来遍历整个数组,并通过交换元素的方式进行排序。
- 插入排序:该算法将数组分为已排序和未排序两部分,然后逐个将未排序部分的元素插入到已排序部分的合适位置。
实现时,我们使用了循环和条件判断来找到插入位置,并通过移动元素的方式进行排序。
- 快速排序:该算法通过选取一个基准元素,将数组分为两个子数组,并对子数组进行递归排序。
实现时,我们使用了递归和分治的思想,将数组不断划分为更小的子数组进行排序。
- 归并排序:该算法通过将数组递归地划分为更小的子数组,并将子数组进行合并排序。
实现时,我们使用了递归和分治的思想,将数组不断划分为更小的子数组进行排序,然后再将子数组合并起来。

一、实验目的1. 了解排序算法的基本原理和常用算法。
2. 掌握几种常用排序算法的代码实现。
3. 比较不同排序算法的性能,分析其优缺点。
4. 培养实验操作能力和分析问题能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 开发工具:PyCharm三、实验内容1. 实验一:冒泡排序2. 实验二:选择排序3. 实验三:插入排序4. 实验四:快速排序5. 实验五:归并排序四、实验步骤1. 实验一:冒泡排序(1)编写冒泡排序的Python代码。
(2)对一组随机生成的数据进行排序。
(3)观察排序过程,分析冒泡排序的优缺点。
2. 实验二:选择排序(1)编写选择排序的Python代码。
(2)对一组随机生成的数据进行排序。
(3)观察排序过程,分析选择排序的优缺点。
3. 实验三:插入排序(1)编写插入排序的Python代码。
(2)对一组随机生成的数据进行排序。
(3)观察排序过程,分析插入排序的优缺点。
4. 实验四:快速排序(1)编写快速排序的Python代码。
(2)对一组随机生成的数据进行排序。
(3)观察排序过程,分析快速排序的优缺点。
5. 实验五:归并排序(1)编写归并排序的Python代码。
(2)对一组随机生成的数据进行排序。
(3)观察排序过程,分析归并排序的优缺点。
五、实验结果与分析1. 实验一:冒泡排序(1)代码实现:```pythondef bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]```(2)排序过程:冒泡排序通过比较相邻两个元素的大小,将较大的元素向后移动,从而实现排序。
(3)优缺点分析:优点:易于理解,实现简单。
缺点:时间复杂度较高,对于大数据量排序效率较低。

第1篇一、实验背景与目的随着计算机技术的飞速发展,算法在计算机科学中扮演着至关重要的角色。
为了加深对算法设计与分析的理解,提高实际应用能力,本实验课程设计旨在通过实际操作,让学生掌握算法设计与分析的基本方法,学会运用所学知识解决实际问题。
二、实验内容与步骤本次实验共分为三个部分,分别为排序算法、贪心算法和动态规划算法的设计与实现。
1. 排序算法(1)实验目的:熟悉常见的排序算法,理解其原理,比较其优缺点,并实现至少三种排序算法。
(2)实验内容:- 实现冒泡排序、快速排序和归并排序三种算法。
- 对每种算法进行时间复杂度和空间复杂度的分析。
- 编写测试程序,对算法进行性能测试,比较不同算法的优劣。
(3)实验步骤:- 分析冒泡排序、快速排序和归并排序的原理。
- 编写三种排序算法的代码。
- 分析代码的时间复杂度和空间复杂度。
- 编写测试程序,生成随机测试数据,测试三种算法的性能。
- 比较三种算法的运行时间和内存占用。
2. 贪心算法(1)实验目的:理解贪心算法的基本思想,掌握贪心算法的解题步骤,并实现一个贪心算法问题。
(2)实验内容:- 实现一个贪心算法问题,如活动选择问题。
- 分析贪心算法的正确性,并证明其最优性。
(3)实验步骤:- 分析活动选择问题的贪心策略。
- 编写贪心算法的代码。
- 分析贪心算法的正确性,并证明其最优性。
- 编写测试程序,验证贪心算法的正确性。
3. 动态规划算法(1)实验目的:理解动态规划算法的基本思想,掌握动态规划算法的解题步骤,并实现一个动态规划算法问题。
(2)实验内容:- 实现一个动态规划算法问题,如背包问题。
- 分析动态规划算法的正确性,并证明其最优性。
(3)实验步骤:- 分析背包问题的动态规划策略。
- 编写动态规划算法的代码。
- 分析动态规划算法的正确性,并证明其最优性。
- 编写测试程序,验证动态规划算法的正确性。
三、实验结果与分析1. 排序算法实验结果:- 冒泡排序:时间复杂度O(n^2),空间复杂度O(1)。

数据结构实验报告-排序一、实验目的本实验旨在探究不同的排序算法在处理大数据量时的效率和性能表现,并对比它们的优缺点。
二、实验内容本次实验共选择了三种常见的排序算法:冒泡排序、快速排序和归并排序。
三个算法将在同一组随机生成的数据集上进行排序,并记录其性能指标,包括排序时间和所占用的内存空间。
三、实验步骤1. 数据的生成在实验开始前,首先生成一组随机数据作为排序的输入。
定义一个具有大数据量的数组,并随机生成一组在指定范围内的整数,用于后续排序算法的比较。
2. 冒泡排序冒泡排序是一种简单直观的排序算法。
其基本思想是从待排序的数据序列中逐个比较相邻元素的大小,并依次交换,从而将最大(或最小)的元素冒泡到序列的末尾。
重复该过程直到所有数据排序完成。
3. 快速排序快速排序是一种分治策略的排序算法,效率较高。
它将待排序的序列划分成两个子序列,其中一个子序列的所有元素都小于等于另一个子序列的所有元素。
然后对两个子序列分别递归地进行快速排序。
4. 归并排序归并排序是一种稳定的排序算法,使用分治策略将序列拆分成较小的子序列,然后递归地对子序列进行排序,最后再将子序列合并成有序的输出序列。
归并排序相对于其他算法的优势在于其稳定性和对大数据量的高效处理。
四、实验结果经过多次实验,我们得到了以下结果:1. 冒泡排序在数据量较小时,冒泡排序表现良好,但随着数据规模的增大,其性能明显下降。
排序时间随数据量的增长呈平方级别增加。
2. 快速排序相比冒泡排序,快速排序在大数据量下的表现更佳。
它的排序时间线性增长,且具有较低的内存占用。
3. 归并排序归并排序在各种数据规模下都有较好的表现。
它的排序时间与数据量呈对数级别增长,且对内存的使用相对较高。
五、实验分析根据实验结果,我们可以得出以下结论:1. 冒泡排序适用于数据较小的排序任务,但面对大数据量时表现较差,不推荐用于处理大规模数据。
2. 快速排序是一种高效的排序算法,适用于各种数据规模。

快速排序算法实验报告快速排序一、问题描述在操作系统中,我们总是希望以最短的时间处理完所有的任务。
但事情总是要一件件地做,任务也要操作系统一件件地处理。
当操作系统处理一件任务时,其他待处理的任务就需要等待。
虽然所有任务的处理时间不能降低,但我们可以安排它们的处理顺序,将耗时少的任务先处理,耗时多的任务后处理,这样就可以使所有任务等待的时间和最小。
只需要将n 件任务按用时去从小到大排序,就可以得到任务依次的处理顺序。
当有 n 件任务同时来临时,每件任务需要用时ni,求让所有任务等待的时间和最小的任务处理顺序。
二、需求分析1. 输入事件件数n,分别随机产生做完n件事所需要的时间;2. 对n件事所需的时间使用快速排序法,进行排序输出。
排序时,要求轴值随机产生。
3. 输入输出格式:输入:第一行是一个整数n,代表任务的件数。
接下来一行,有n个正整数,代表每件任务所用的时间。
输出:输出有n行,每行一个正整数,从第一行到最后一行依次代表着操作系统要处理的任务所用的时间。
按此顺序进行,则使得所有任务等待时间最小。
4. 测试数据:输入 95 3 4 26 1 57 3 输出1 2 3 3 4 5 5 6 7三、概要设计抽象数据类型因为此题不需要存储复杂的信息,故只需一个整型数组就可以了。
算法的基本思想对一个给定的进行快速排序,首先需要选择一个轴值,假设输入的数组中有k个小于轴值的数,于是这些数被放在数组最左边的k个位置上,而大于周知的结点被放在数组右边的n-k个位置上。
k也是轴值的下标。
这样k把数组分成了两个子数组。
分别对两个子数组,进行类似的操作,便能得到正确的排序结果。
程序的流程输入事件件数n-->随机产生做完没个事件所需时间-->对n个时间进行排序-->输出结果快速排序方法:初始状态 72 6 57 88 85 42 l r第一趟循环 72 6 57 88 85 42 l r 第一次交换 6 72 57 88 85 42 l r 第二趟循环 6 72 57 88 85 42 r l 第二次交换 72 6 57 88 85 42 r l反转交换 6 72 57 88 85 42 r l这就是依靠轴值,将数组分成两部分的实例。

实验课程:数据库原理及应用学号:学生姓名:班级:年月日实验1 创建和维护数据库一、实验目的(1)掌握在Windows 平台下安装与配置MySQL 5.5 的方法。
(2)掌握启动服务并登录MySQL 5.5 数据库的方法和步骤。
(3)了解手工配置MySQL 5.5 的方法。
(4)掌握MySQL 数据库的相关概念。
(5)掌握使用Navicat 工具和SQL 语句创建数据库的方法。
(6)掌握使用Navicat 工具和SQL 语句删除数据库的方法。
二、实验要求(1)学生提前准备好实验报告,预习并熟悉实验步骤;(2)遵守实验室纪律,在规定的时间内完成要求的内容;(3)1~2人为1小组,实验过程中独立操作、相互学习。
三、实验内容及步骤(1)在Windows 平台下安装与配置MySQL 5.5.36 版。
(2)在服务对话框中,手动启动或者关闭MySQL 服务。
(3)使用Net 命令启动或关闭MySQL 服务。
开始--运行--cmd--输入“net start mysql”回车,启动成功;输入“net--stop--mysql”回车,停止。
(4)分别用Navicat 工具和命令行方式登录MySQL。
①打开Navicat for MySQL,文件--新建连接--确定。
②开始--运行--cmd,输入mysql -h hostname(如果服务器在本机,可以输入localhost或127.0.0.1)user -p 回车后,系统会提示“Enter password”,输入配置的密码就可以登录上了。
(5)创建数据库。
①使用Navicat 创建学生信息管理数据库gradem。
②使用SQL 语句创建数据库MyDB。
①打开Navicat for MySQL,文件--新建连接--常规(设置连接名MySQL,主机名localhost)。
②使用Windows命令行方式登录MySQL,然后输入CREATE DATABASE mydb;回车,显示Query OK, 1 row affected (0.00 sec)创建成功。
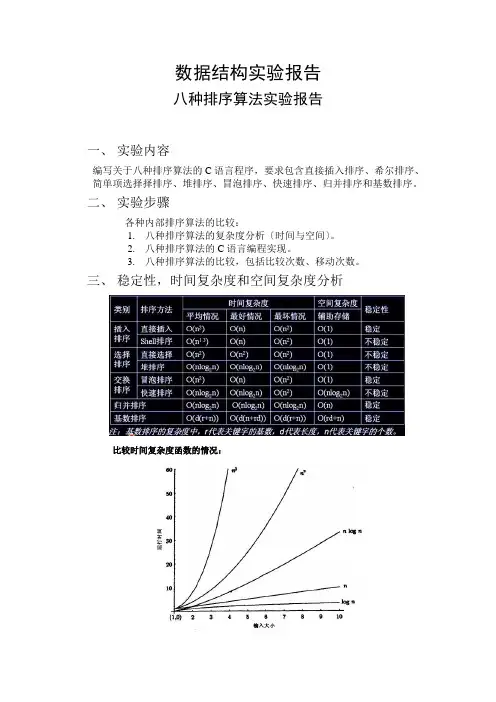
数据结构实验报告八种排序算法实验报告一、实验内容编写关于八种排序算法的C语言程序,要求包含直接插入排序、希尔排序、简单项选择择排序、堆排序、冒泡排序、快速排序、归并排序和基数排序。
二、实验步骤各种内部排序算法的比较:1.八种排序算法的复杂度分析〔时间与空间〕。
2.八种排序算法的C语言编程实现。
3.八种排序算法的比较,包括比较次数、移动次数。
三、稳定性,时间复杂度和空间复杂度分析比较时间复杂度函数的情况:时间复杂度函数O(n)的增长情况所以对n较大的排序记录。
一般的选择都是时间复杂度为O(nlog2n)的排序方法。
时间复杂度来说:(1)平方阶(O(n2))排序各类简单排序:直接插入、直接选择和冒泡排序;(2)线性对数阶(O(nlog2n))排序快速排序、堆排序和归并排序;(3)O(n1+§))排序,§是介于0和1之间的常数。
希尔排序(4)线性阶(O(n))排序基数排序,此外还有桶、箱排序。
说明:当原表有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O〔n〕;而快速排序则相反,当原表基本有序时,将蜕化为冒泡排序,时间复杂度提高为O〔n2〕;原表是否有序,对简单项选择择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
稳定性:排序算法的稳定性:假设待排序的序列中,存在多个具有相同关键字的记录,经过排序,这些记录的相对次序保持不变,则称该算法是稳定的;假设经排序后,记录的相对次序发生了改变,则称该算法是不稳定的。
稳定性的好处:排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。
基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。
另外,如果排序算法稳定,可以防止多余的比较;稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序四、设计细节排序有内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。

一、实验目的1. 理解快速排序算法的基本原理和实现方法。
2. 测试不同数据规模和不同数据分布情况下快速排序算法的性能。
3. 分析快速排序算法在不同数据类型和不同排序策略下的优缺点。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 测试数据:随机生成、有序、逆序、部分有序的整数数组三、实验内容1. 快速排序算法原理快速排序是一种分治策略的排序算法,其基本思想是选取一个基准值,将待排序的数组划分为两个子数组,一个子数组的所有元素均小于基准值,另一个子数组的所有元素均大于基准值。
然后递归地对这两个子数组进行快速排序,直至整个数组有序。
2. 快速排序算法实现```pythondef quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)```3. 性能测试为测试快速排序算法的性能,我们将对不同数据规模和不同数据分布的数组进行排序,并记录排序所需时间。
(1)随机数据测试数据规模:100、1000、10000、100000(2)有序数据测试数据规模:100、1000、10000、100000(3)逆序数据测试数据规模:100、1000、10000、100000(4)部分有序数据测试数据规模:100、1000、10000、1000004. 性能分析通过对不同数据规模和不同数据分布的数组进行排序,我们可以分析快速排序算法在不同情况下的性能。
四、实验结果与分析1. 随机数据从实验结果可以看出,快速排序算法在随机数据上的性能相对稳定,时间复杂度接近O(nlogn)。

一、实验目的1. 理解选择排序法的原理和步骤。
2. 通过编程实现选择排序法。
3. 分析选择排序法的时间复杂度和空间复杂度。
4. 比较选择排序法与其他排序算法的性能。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发工具:PyCharm三、实验原理选择排序法是一种简单直观的排序算法。
它的工作原理如下:1. 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
2. 然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
3. 重复步骤1和2,直到所有元素均排序完毕。
选择排序法的时间复杂度为O(n^2),空间复杂度为O(1)。
四、实验步骤1. 定义一个待排序的数组。
2. 使用两层循环遍历数组,外层循环控制排序的趟数,内层循环用于查找每一趟的最小(大)元素。
3. 将找到的最小(大)元素与未排序序列的第一个元素交换。
4. 重复步骤2和3,直到数组排序完成。
五、实验代码```pythondef selection_sort(arr):n = len(arr)for i in range(n):min_index = ifor j in range(i+1, n):if arr[j] < arr[min_index]:min_index = jarr[i], arr[min_index] = arr[min_index], arr[i]return arr# 测试数据test_arr = [64, 25, 12, 22, 11]sorted_arr = selection_sort(test_arr)print("Sorted array:", sorted_arr)```六、实验结果与分析1. 运行实验代码,得到排序后的数组:[11, 12, 22, 25, 64]。
2. 分析时间复杂度:选择排序法的时间复杂度为O(n^2),在处理大量数据时,效率较低。
本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==快速排序算法实验报告篇一:快速排序( 实验报告附C++源码)快速排序一、问题描述在操作系统中,我们总是希望以最短的时间处理完所有的任务。
但事情总是要一件件地做,任务也要操作系统一件件地处理。
当操作系统处理一件任务时,其他待处理的任务就需要等待。
虽然所有任务的处理时间不能降低,但我们可以安排它们的处理顺序,将耗时少的任务先处理,耗时多的任务后处理,这样就可以使所有任务等待的时间和最小。
只需要将n 件任务按用时去从小到大排序,就可以得到任务依次的处理顺序。
当有 n 件任务同时来临时,每件任务需要用时ni,求让所有任务等待的时间和最小的任务处理顺序。
二、需求分析1. 输入事件件数n,分别随机产生做完n件事所需要的时间;2. 对n件事所需的时间使用快速排序法,进行排序输出。
排序时,要求轴值随机产生。
3. 输入输出格式:输入:第一行是一个整数n,代表任务的件数。
接下来一行,有n个正整数,代表每件任务所用的时间。
输出:输出有n行,每行一个正整数,从第一行到最后一行依次代表着操作系统要处理的任务所用的时间。
按此顺序进行,则使得所有任务等待时间最小。
4. 测试数据:输入95 3 4 26 1 57 3 输出1 2 3 3 4 5 5 6 7三、概要设计抽象数据类型因为此题不需要存储复杂的信息,故只需一个整型数组就可以了。
算法的基本思想对一个给定的进行快速排序,首先需要选择一个轴值,假设输入的数组中有k 个小于轴值的数,于是这些数被放在数组最左边的k个位置上,而大于周知的结点被放在数组右边的n-k个位置上。
k也是轴值的下标。
这样k把数组分成了两个子数组。
分别对两个子数组,进行类似的操作,便能得到正确的排序结果。
程序的流程输入事件件数n-->随机产生做完没个事件所需时间-->对n个时间进行排序-->输出结果快速排序方法(因图难画,举一个实例):初始状态 72 6 57 88 85 42 l r 第一趟循环 72 6 57 88 85 42 l r 第一次交换 6 72 57 88 85 42 l r 第二趟循环 6 72 57 88 85 42 r l 第二次交换 72 6 57 88 85 42 r l反转交换 6 72 57 88 85 42 r l这就是依靠轴值,将数组分成两部分的实例(特殊情况下,可能为一部分,其中42是轴值)。
数组的排序实验报告实验目的本实验旨在探究不同排序算法在数组排序中的性能表现,通过对比不同算法的运行时间和空间复杂度,为实际应用提供排序算法选择的依据。
实验方法本次实验使用Python语言编写了四种常见的排序算法,包括冒泡排序、选择排序、插入排序和快速排序。
在排序算法的实现中,我们通过随机生成一定数量的整数构成的数组,并使用不同的算法对数组进行排序。
比较排序算法完成同样规模的排序时所需的时间,以及所占用的内存空间。
实验使用了Matplotlib库对数据进行可视化展示。
实验结果及分析冒泡排序冒泡排序是最简单的排序算法之一,其思想是通过相邻元素之间的比较和交换来实现数组的排序。
我们首先实现了冒泡排序算法,并使用相同的测试数据对四种排序算法进行排序。
实验结果显示,当数组规模增加时,冒泡排序的时间复杂度呈指数级增长,且性能远低于其他排序算法。
这是因为冒泡排序每一轮只能将一个元素移动到正确的位置,需要进行多次遍历和交换操作。
选择排序选择排序也是一种简单的排序算法,其思想是通过不断选择最小的元素,并将其放置到数组的起始位置。
我们实现了选择排序算法,并进行了实验。
实验结果显示,选择排序算法的性能相对较好。
虽然选择排序在时间复杂度上与冒泡排序相同,但其交换操作的次数明显减少。
选择排序的时间复杂度是固定的,即使是对大规模数组也不会增加。
插入排序插入排序是一种稳定的排序算法,其思想是通过将待排序元素逐个插入已排好的子序列中,将整个数组逐渐排序。
我们实现了插入排序算法,并进行了对比实验。
结果显示,插入排序的时间复杂度较好,且当数组接近有序时,其性能能达到最佳。
插入排序的交换操作和比较操作的次数都相对较少,使其在一定规模的数组排序中具有较好的性能。
快速排序快速排序是一种常用的排序算法,其使用了分治的思想。
我们实现了快速排序算法,并进行了实验。
结果显示,快速排序的性能非常好。
快速排序在平均情况下的时间复杂度是最低的,并且它的空间复杂度也较低。
一、实验目的1. 理解SQL中排序和分组查询的基本概念和用法。
2. 掌握使用SQL语句对数据进行排序和分组的方法。
3. 提高在实际数据库操作中对数据进行处理和分析的能力。
二、实验环境1. 数据库:MySQL 5.72. 数据库表:假设有一个名为“员工信息”的表,包含以下字段:员工编号(emp_id)、姓名(name)、性别(gender)、年龄(age)、部门编号(dept_id)、薪资(salary)。
三、实验内容1. 排序查询(1)按年龄升序排序```sqlSELECT FROM 员工信息 ORDER BY age ASC;```(2)按薪资降序排序```sqlSELECT FROM 员工信息 ORDER BY salary DESC;```2. 分组查询(1)按部门编号分组,统计每个部门的人数```sqlSELECT dept_id, COUNT() AS department_count FROM 员工信息 GROUP BY dept_id;```(2)按性别分组,统计男女员工的人数```sqlSELECT gender, COUNT() AS gender_count FROM 员工信息 GROUP BY gender;```(3)按年龄分组,统计每个年龄段的人数```sqlSELECT age, COUNT() AS age_count FROM 员工信息 GROUP BY age;```3. 排序分组查询(1)按部门编号分组,统计每个部门的人数,并按人数降序排序```sqlSELECT dept_id, COUNT() AS department_count FROM 员工信息 GROUP BYdept_id ORDER BY department_count DESC;```(2)按性别分组,统计男女员工的人数,并按人数降序排序```sqlSELECT gender, COUNT() AS gender_count FROM 员工信息 GROUP BY gender ORDER BY gender_count DESC;```四、实验结果与分析1. 排序查询执行上述SQL语句后,可以按照指定的排序方式查看结果。
操作系统实验4-4实验报告一、实验目的本次操作系统实验 4-4 的目的是深入了解和掌握操作系统中进程管理的相关知识和技术,通过实际操作和观察,加深对进程调度算法、进程同步与互斥等概念的理解,并提高解决实际问题的能力。
二、实验环境本次实验使用的操作系统为 Windows 10,编程环境为 Visual Studio 2019。
三、实验内容1、进程调度算法的实现先来先服务(FCFS)算法短作业优先(SJF)算法时间片轮转(RR)算法优先级调度算法2、进程同步与互斥的实现使用信号量实现生产者消费者问题使用互斥锁实现哲学家进餐问题四、实验步骤1、进程调度算法的实现先来先服务(FCFS)算法设计数据结构来表示进程,包括进程ID、到达时间、服务时间等。
按照进程到达的先后顺序将它们放入就绪队列。
从就绪队列中选择第一个进程进行处理,计算其完成时间、周转时间和带权周转时间。
短作业优先(SJF)算法在设计的数据结构中增加作业长度的字段。
每次从就绪队列中选择服务时间最短的进程进行处理。
计算相关的时间指标。
时间片轮转(RR)算法设定时间片的大小。
将就绪进程按照到达时间的先后顺序放入队列。
每个进程每次获得一个时间片的执行时间,若未完成则重新放入队列末尾。
优先级调度算法为每个进程设置优先级。
按照优先级的高低从就绪队列中选择进程执行。
2、进程同步与互斥的实现生产者消费者问题创建一个共享缓冲区。
生产者进程负责向缓冲区中生产数据,消费者进程从缓冲区中消费数据。
使用信号量来控制缓冲区的满和空状态,实现进程的同步。
哲学家进餐问题模拟多个哲学家围绕一张圆桌进餐的场景。
每个哲学家需要同时获取左右两边的筷子才能进餐。
使用互斥锁来保证筷子的互斥访问,避免死锁的发生。
五、实验结果与分析1、进程调度算法的结果与分析先来先服务(FCFS)算法优点:实现简单,公平对待每个进程。
缺点:对短作业不利,平均周转时间可能较长。
短作业优先(SJF)算法优点:能有效降低平均周转时间,提高系统的吞吐量。
入队:Status EnQueue (LinkQueue &Q, QElemType e){ // 插入元素e为Q的新队尾元素p = (QueuePtr) malloc (sizeof (QNode)); //生成新结点if (!p) exit (OVERFLOW); //存储分配失败p->data = e; p->next = NULL; //插入队尾Q.rear->next = p;Q.rear = p; //修改队尾指针指向队尾return OK;}出队:Status DeQueue (LinkQueue &Q, QElemType &e){ // 若队列不空,则删除Q的队头元素,用e 返回其值if (Q.front == Q.rear) return ERROR; //判空p = Q.front->next; e = p->data; //用e返回队头元素值Q.front->next = p->next; //修改头指针始终指向队首元素if (Q.rear == p) Q.rear = Q.front; //特殊情况处理空队free (p); //释放队首结点return OK;}代码一:#include <stdio.h>#include <malloc.h>typedef char ElemType;typedef struct qnode{ElemType data;struct qnode *next;} QNode;typedef struct{QNode *front;QNode *rear;} LiQueue;void InitQueue(LiQueue *&q);void DestroyQueue(LiQueue *&q);bool QueueEmpty(LiQueue *q);void enQueue(LiQueue *&q, ElemType e);bool deQueue(LiQueue *&q, ElemType &e);void InitQueue(LiQueue *&q)//初始化队列{q = (LiQueue *)malloc(sizeof(LiQueue));q->front = q->rear = NULL;}void DestroyQueue(LiQueue *&q)//销毁队列{QNode *p = q->front, *r;//p指向队头数据节点if (p != NULL)//释放数据节点占用空间{r = p->next;while (r != NULL){free(p);p = r; r = p->next;}}free(p);free(q);//释放链队节点占用空间}bool QueueEmpty(LiQueue *q)//判断队列是否为空{return(q->rear == NULL);}void enQueue(LiQueue *&q, ElemType e)//进队{QNode *p;p = (QNode *)malloc(sizeof(QNode));p->data = e;p->next = NULL;if (q->rear == NULL)//若链队为空,则新节点是队首节点又是队尾节点q->front = q->rear = p;else{q->rear->next = p;//将*p节点链到队尾,并将rear指向它q->rear = p;}}bool deQueue(LiQueue *&q, ElemType &e)//出队{QNode *t;if (q->rear == NULL)//队列为空return false;t = q->front;//t指向第一个数据节点if (q->front == q->rear) //队列中只有一个节点时q->front = q->rear = NULL;else//队列中有多个节点时q->front = q->front->next;e = t->data;free(t);return true;}void main(){ElemType e;LiQueue *q;printf("链队的基本运算如下:\n");printf(" (1)初始化链队q\n");InitQueue(q);printf(" (2)依次进链队元素a,b,c\n");enQueue(q, 'a');enQueue(q, 'b');enQueue(q, 'c');printf(" (3)链队为%s\n", (QueueEmpty(q) ? "空" : "非空"));if (deQueue(q, e) == 0)printf("\t提示:队空,不能出队\n");elseprintf(" (4)出队一个元素%c\n", e);printf(" (5)依次进链队元素d,e,f\n");enQueue(q, 'd');enQueue(q, 'e');enQueue(q, 'f');printf(" (6)出链队序列:");while (!QueueEmpty(q)){deQueue(q, e);printf("%c ", e);}printf("\n");printf(" (7)释放链队\n");DestroyQueue(q);}代码二:#include <stdio.h>#include <malloc.h>typedef struct qnode{int data;struct qnode *next;} QNode;//链队节点类型typedef struct{QNode *front, *rear;} QuType;//链队类型void Destroyqueue(QuType *&qu)//释放链队{QNode *p, *q;p = qu->front;if (p != NULL)//若链队不空{q = p->next;while (q != NULL)//释放队中所有的节点{free(p);p = q;q = q->next;}free(p);}free(qu);//释放链队节点}void SeeDoctor(){int sel, flag = 1, find, no;QuType *qu;QNode *p;qu = (QuType *)malloc(sizeof(QuType));//创建空队qu->front = qu->rear = NULL;while (flag == 1) //循环执行{printf("1:排队2:就诊3:查看排队4.不再排队,余下依次就诊5:下班请选择:");scanf("%d", &sel);switch (sel){case 1:printf(" >>输入病历号:");do{scanf("%d", &no);find = 0;p = qu->front;while (p != NULL && !find){if (p->data == no)find = 1;elsep = p->next;}if (find)printf(" >>输入的病历号重复,重新输入:");} while (find == 1);p = (QNode *)malloc(sizeof(QNode));//创建节点p->data = no; p->next = NULL;if (qu->rear == NULL)//第一个病人排队qu->front = qu->rear = p;else{qu->rear->next = p; qu->rear = p;//将*p节点入队}break;case 2:if (qu->front == NULL)//队空printf(" >>没有排队的病人!\n");else//队不空{p = qu->front;printf(" >>病人%d就诊\n", p->data);if (qu->rear == p)//只有一个病人排队的情况qu->front = qu->rear = NULL;elsequ->front = p->next;free(p);}break;case 3:if (qu->front == NULL) //队空printf(" >>没有排列的病人!\n");else //队不空{p = qu->front;printf(" >>排队病人:");while (p != NULL){printf("%d ", p->data);p = p->next;}printf("\n");}一:二:总结体会:通过本次实验掌握了链式存储队列的进队和出队等基本操作,通过这些基本操作,我对队列问题有了更深的理解,能够正确理解队列问题及其使用。
数据库实验4-实验报告数据库实验 4 实验报告一、实验目的本次数据库实验 4 的主要目的是深入理解和掌握数据库中的某些关键概念和操作,通过实际的操作和实践,提高对数据库管理系统的应用能力,增强解决实际问题的技能。
二、实验环境本次实验使用的数据库管理系统为_____,运行环境为_____操作系统,使用的开发工具为_____。
三、实验内容与步骤(一)创建数据库首先,打开数据库管理系统,使用相应的命令或操作界面创建了一个名为“_____”的数据库。
在创建过程中,指定了数据库的一些基本属性,如字符集、排序规则等,以满足后续数据存储和处理的需求。
(二)创建数据表在创建好的数据库中,根据实验要求创建了若干个数据表。
例如,创建了一个名为“students”的表,用于存储学生的信息,包括学号(student_id)、姓名(student_name)、年龄(age)等字段。
创建表时,仔细定义了每个字段的数据类型、长度、是否允许为空等属性,以确保数据的准确性和完整性。
(三)数据插入接下来,向创建的数据表中插入了一些测试数据。
通过执行相应的插入语句,将学生的具体信息逐个插入到“students”表中。
在插入数据的过程中,特别注意了数据的格式和合法性,避免了因数据错误导致的插入失败。
(四)数据查询完成数据插入后,进行了各种查询操作。
使用了简单的查询语句,如“SELECT FROM students”来获取所有学生的信息。
还使用了条件查询,如“SELECT FROM students WHERE age >18”来获取年龄大于 18 岁的学生信息。
通过这些查询操作,熟悉了如何从数据库中获取所需的数据。
(五)数据更新对已有的数据进行了更新操作。
例如,通过执行“UPDATE students SET age = 20 WHERE student_id =1”的语句,将学号为 1 的学生的年龄更新为20 岁。
在更新数据时,谨慎操作,确保只更新了预期的记录。
数据结构实验报告
实验名称:实验四排序
学生姓名:
班级:
班内序号:
学号:
日期:2012年12月21日
1、实验要求
题目2
使用链表实现下面各种排序算法,并进行比较。
排序算法:
1、插入排序
2、冒泡排序
3、快速排序
4、简单选择排序
5、其他
要求:
1、测试数据分成三类:正序、逆序、随机数据。
2、对于这三类数据,比较上述排序算法中关键字的比较次数和移动次数(其中关键字交换计为3次移动)。
3、对于这三类数据,比较上述排序算法中不同算法的执行时间,精确到微秒(选作)。
4、对2和3的结果进行分析,验证上述各种算法的时间复杂度。
编写测试main()函数测试线性表的正确性。
2、程序分析
存储结构
说明:本程序排序序列的存储由链表来完成。
其存储结构如下图所示。
(1)单链表存储结构:
(2)结点结构
struct Node
{
int data;
Node * next;
};
示意图:
关键算法分析
一:关键算法
(一)直接插入排序 void LinkSort::InsertSort()
直接插入排序是插入排序中最简单的排序方法,其基本思想是:依次将待排序序列中的每一个记录插入到一个已排好的序列中,直到全部记录都排好序。
(1)算法自然语言
1.将整个待排序的记录序列划分成有序区和无序区,初始时有序区为待排序记录序列中的第一个记录,无序区包括所有剩余待排序的记录;
2.将无须去的第一个记录插入到有序区的合适位置中,从而使无序区减少一个记录,有序区增加一个记录;
3.重复执行2,直到无序区中没有记录为止。
(2)源代码
void
2.
3.
4.重复执行2和3
直接插入排序过程
(2)源代码
void LinkSort::BubbleSort()
{
Node * P = front->next;
while
较的基准)
2.
3.
(2)源代码
void LinkSort::Qsort()
{
Node * End = front;
while(End->next)
{
End = End->next;
}
Partion(front, End);
}
void LinkSort::Partion(Node * Start, Node * End)
{ Array
if
2.使得有序区扩展
了一个记录,而无序区减少了一个记录。
3.不断重复2,直到无序区之剩下一个记录为止。
(2)源代码
void LinkSort::SelectSort() { Node * S = front; while (S->next->next) { Node * P = S;
Node * Min = P;
while (P->next) 入。
比较次数:" << setw(3)
<< CompareCount << "; 移动次数:" << setw(3) << MoveCount << "; 时间: " << TimeCount <<"us"<< endl;
CompareCount = 0; MoveCount = 0; TimeCount = 0;
QueryPerformanceCounter(&time_start); 泡。
比较次数:" <<
setw(3) << CompareCount << "; 移动次数:" << setw(3) << MoveCount <<
"; 时间: " << TimeCount << "us"<<endl;
CompareCount = 0; MoveCount = 0; TimeCount = 0;
QueryPerformanceCounter(&time_start); 速。
比较次数:" << setw(3) << CompareCount << "; 移动次数:" << setw(3) << MoveCount << "; 时间: " << TimeCount << "us"<<endl;
初始键值序列 [49 27 65 97 76 13 38]
第一趟排序结果 13 [27 65 97 76 49 38]
第二趟排序结果 13 27 [65 97 76 49 38]
第三趟排序结果 13 27 38 [97 76 49 65]
第四趟排序结果 13 27 38 49 [76 97 65] 第五趟排序结果 13 27 38 49 65 [97 76]
CompareCount = 0; MoveCount = 0; TimeCount = 0;
QueryPerformanceCounter(&time_start); 择。
比较次数:" << setw(3) << CompareCount << "; 移动次数:" << setw(3) << MoveCount << "; 时间: " << TimeCount << "us"<<endl;
}
(3)时间和空间复杂度
时间复杂度O(1)(因为不包含循环体)。
其他
3、程序运行结果
(1)程序流程图
(2)测试条件
规模为10个数字,在正序、逆序和乱序的条件下进行测试,未出现问题。
(3)运行结果:
(4)说明:各函数运行正常,没有出现bug。
四、总结
1、调试时出现的问题及解决方法
由于经过一种排序后,原始数据改变,导致后面的排序所用的数据全为排好后的数据。
将数据在排序前重新初始化后,该问题被排除。
还有就是因为编程时没有注意格式,所以在调试错误时花费了不少时间。
2、心得体会
这是最后一次编程实验。
这次试验,我觉得主要目的还是在掌握好课本知识的基础上,对代码进行相应的优化,以达到时间复杂度和空间复杂度的最佳。
其次,本次实验是经过借鉴课本上的程序进行编写,是基于课本完成的。
考虑到若完全由自己编写,则又可能限于自己能力问题,将较简单的算法编写的过于麻烦,造成关键码的比较次数和移动次数比一些复杂算法还多,从而影响结果。
基于课本编写,最大好处是可以借鉴、仔细研读书上的优秀例子,开拓以后编写程序的思路。
基于课本编写,最大坏处是自己独立思考、独立编写、修改程序的能力未得到锻炼。
对于正序序列,直接插入、起泡排序法有较高的效率。
对于逆序序列,简单选择排序效率较高。
对于在随机序列,快速排序法的效率比较高。
程序的优化是一个艰辛的过程,如果只是实现一般的功能,将变得容易很多,当加上优化,不论是效率还是结构优化,都需要精心设计。
这次做优化的过程中,遇到不少阻力。
由于优化中用到很多类的封装和访问控制方面的知识,而这部分知识恰好是大一一年学习的薄弱点。
因而以后要多花力气学习C++编程语言,必须要加强这方面的训练,这样才能在将编程思想和数据结构转换为代码的时候能得心应手。