数学建模葡萄酒问题二的分析
- 格式:doc
- 大小:454.00 KB
- 文档页数:14

葡萄酒的评价摘要本文主要研究的是如何对葡萄酒进行评价的问题。
通过对评酒员的评分与酿酒葡萄的理化指标和葡萄酒的理化指标等原始数据进行统计、分析和处理,我们得出了一个较为合理地评价葡萄酒质量优劣的模型。
在问题一中,我们采用T检验法,首先进行正态分布拟合检验,判断出它们服从正态分布。
之后,我们通过T检验法判断出了两组评酒员的评价结果具有显著性差异。
而对于如何判断哪一组评酒员的评价结果更可信,由于评酒员评分的客观性,我们通过计算评酒员评分均值的置信区间,利用置信区间的长短来判断评分的可信程度。
置信区间越窄,说明其越可信。
利用Matlab软件求出了第二组评酒员的评分均值的置信区间更窄,所以第二组评酒员的评价结果更可信。
在问题二中,我们采用主成分分析法,把给定的一组相关变量通过线性变换转成另一组不相关的变量,这些新的变量再按照方差依次递减的顺序排列。
在数学变换中保持变量的总方差不变,使第一变量具有最大的方差。
第二变量的方差次大,并且和第一变量不相关。
由于变量较多,虽然每个变量都提供了一定的信息,但其重要性有所不同。
依次类推,最后我们将酿酒葡萄分为了四个等级:优质、次优、中等、下等。
在问题三中,我们通过多项式曲线拟合的方法,构造一个以葡萄酒的理化指标为自变量,酿酒葡萄的理化指标为因变量的函数,并利用Matlab软件进行曲线拟合,最后得出酿酒葡萄与葡萄酒的理化指标之间的关系为呈线性正相关。
在问题四中,我们用无交互作用的双因素试验的方差分析方法,通过对观测、比较、分析实验数据的结果,鉴别出了两个因素在水平发生变化时对实验结果产生显著性影响的大小程度。
最后,我们认为能用酿酒葡萄和葡萄酒的理化指标来评价葡萄酒的质量,且酿酒葡萄的理化指标对葡萄酒质量影响相对葡萄酒的理化指标更显著。
关键词:T检验法,Matlab,正态分布,主成分分析法,多项式曲线拟合,方差分析一.问题的重述确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。

葡萄酒的评价模型摘要近年来,我国掀起了一场葡萄酒热,对葡萄酒的需求与日俱增。
特别是随着食品科学技术的发展,人们不再满足传统感官评价葡萄酒的水平。
如何运用数据资料定量研究葡萄酒的品质,加快建立葡萄酒市场指标规则成为人们关注的焦点。
本文通过对感官评价分析,结合葡萄酒和酿酒葡萄的理化指标和芳香物质的大量数据,建立了客观可靠的葡萄酒质量综合评价模型。
针对问题一:本题需要检验两组品酒员的评价结果是否存在显著差异,并选出更可靠的一组。
我们将各种葡萄酒的10个二级指标得分,相加得到每种酒的总分。
在判断知每组品酒员的评价总分均服从正态分布后,用t检验分析两组品酒员对各葡萄酒评价的差异性,由此计算得到两组评价的显著性差异率为13.36%,即总体上两组品酒员的评价不存在显著差异。
但由于两组品酒员的评价仍存在部分差异,我们比较两组品酒员对55种葡萄酒评价的方差,发现第二组评分的方差普遍小于第一组,所以第二组的评价结果更可信。
针对问题二:为了对酿酒葡萄进行分级,我们将葡萄的理化指标作为媒介。
先根据国际指标制定适用于本题评分的分级标准,将葡萄酒进行分级,再根据理化指标经标准化之后的数值,利用欧氏距离对酿酒的55种酿酒葡萄进行Q型聚类分析。
聚类得到红白葡萄各六个分类后,再把各类酿酒葡萄对应至相应葡萄酒的等级,将酿酒红葡萄和酿酒白葡萄各分为五级。
针对问题三:由于各种酿酒葡萄的理化指标种类复杂,我们用主成分分析的方法,从酿酒红葡萄和酿酒白葡萄的27个有效指标中各提取出了8个和9个主要成分。
考虑到酿酒葡萄经化学反应酿造成葡萄酒的过程中各项理化指标一般存在线性关系,我们建立多元线性回归模型,得出酿酒葡萄和葡萄酒各项有效理化指标的正负相关关系。
关键词:显著性检验;聚类分析;主成分分析;多元回归。
一、问题的重述确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。
每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。

西安邮电大学(理学院)数学建模报告葡萄酒的评价专业名称:信息与计算科学班级: 1302班学生姓名:张梦倩学号(8位): 07131057指导教师:支晓斌一、问题重述确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。
每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。
酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
附件1给出了某一年份一些葡萄酒的评价结果,附件2和附件3分别给出了该年份这些葡萄酒的和酿酒葡萄的成分数据。
请尝试建立数学模型讨论下列问题:1. 分析附件1中两组评酒员的评价结果有无显著性差异,哪一组结果更可信?2. 根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级。
二、问题分析这是一个关于大型数据处理和分析的问题。
问题1要求我们分析两组评酒员评价结果有无显著差异。
利用多元统计分析的相关知识,先对原始评分数据进行了检验,进而通过差异性检验得出两组评论结果具有显著性差异。
利用SPSS 软件绘制出第一组红、白葡萄酒以及第二组红、白葡萄酒在评酒员评价结果下的评分分布直方图,得出数据基本服从正态分布,利用Q-Q 图对其进行正态性分布检验,得出有无显著性差异关于问题2,要求根据酿酒葡萄的理化指标和葡萄酒的质量对酿酒葡萄进行分级。
综合考虑葡萄酒质量和葡萄理化指标与葡萄质量的相关性,以品酒员的感官评价为主,葡萄理化指标为辅,采用逐步回归分析、聚类分析、判别分析的数学方法,建立了葡萄分级模型,利用此模型对酿酒红、白葡萄进行分类,得出可靠结果。
三、基本假设1、假设品酒员给出的葡萄酒评价能够准确反映葡萄酒的质量;2、假设附件三数据中芳香物质数据的单位不一定相同;3、假设现有的评价体系能够准确的反映葡萄酒的质量。
四、符号说明1、j i P ,表示第j 号品酒员对第i 号酒样的评分;2、y 表示葡萄酒各个理化指标(一级);3、x 表示酿酒葡萄各个理化指标(一级);4、S 表示品酒员对葡萄或葡萄酒的综合评分;5、d 表示度量酿酒葡萄与分级标准的“距离”;6、表示葡萄或葡萄酒的芳香物质。

数学建模经典案例分析以葡萄酒质量评价为例一、本文概述本文旨在通过深入剖析数学建模在葡萄酒质量评价中的应用,展示数学建模的经典案例。
我们将首先简要介绍数学建模的基本概念及其在各个领域的应用,然后聚焦葡萄酒质量评价这一具体问题,阐述如何通过数学建模对其进行科学、客观的分析。
文章将详细分析数据的收集与处理、模型的建立与求解、模型的验证与优化等关键环节,并探讨不同数学模型在葡萄酒质量评价中的优缺点。
我们将总结数学建模在葡萄酒质量评价中的实际应用效果,展望其在未来葡萄酒产业中的发展前景。
通过阅读本文,读者将能够了解数学建模在葡萄酒质量评价中的重要作用,掌握相关数学建模方法和技术,为类似问题的解决提供有益的参考和借鉴。
本文也将促进数学建模在葡萄酒产业中的应用与发展,推动葡萄酒产业的科技进步和产业升级。
二、数学建模基础数学建模是一种将实际问题抽象化、量化的过程,通过数学工具和方法来求解问题的近似解。
在葡萄酒质量评价这一案例中,数学建模提供了从复杂的实际生产环境中提取关键信息,并建立预测模型的可能。
这需要我们具备一定的数学基础,如统计学、线性代数、微积分等,同时也需要理解并掌握数据处理的基本技术,如数据清洗、特征提取和选择等。
在葡萄酒质量评价问题中,我们首先需要收集大量的葡萄酒样本数据,这些数据可能包括葡萄品种、产地、气候、土壤、酿造工艺、化学成分等多个方面的信息。
然后,我们需要对这些数据进行预处理,如去除缺失值、异常值,进行数据标准化等,以提高模型的稳定性和准确性。
接下来,我们可以选择适合的模型进行训练。
在这个案例中,我们可以选择线性回归、决策树、随机森林、神经网络等模型进行尝试。
我们需要根据数据的特性和问题的需求,选择最合适的模型。
同时,我们还需要进行模型的训练和验证,通过调整模型的参数,提高模型的预测能力。
我们需要对模型进行评估和优化。
这可以通过交叉验证、ROC曲线、AUC值等评估指标来进行。
如果模型的预测能力不足,我们需要对模型进行优化,如改进模型的结构、增加更多的特征等。

葡萄酒评价模型摘要本文讨论了葡萄酒的评价问题。
对问题一,分别求出两组评酒员对各葡萄酒样品的平均评分,通过SPSS软件对同一类酒的两组得分进行T检验,检验结果表明两组评酒员的评价结果有显著性差异。
再建立评酒员和样品葡萄酒得分的典型相关分析模型,运用MATLAB 求解,以样品葡萄的得分与评酒员的相关系数越大评分越不可信为依据,得出第二组的评分更可信的结论。
对问题二,以第二组的评分为准,对葡萄酒的质量进行排序,得出排序向量,对酿酒葡萄中各个理化指标进行排序,得出排序矩阵,排序向量与排序矩阵的各列进行点乘,得到葡萄酒质量与酿酒葡萄中各个理化指标的内积,以此内积作为葡萄酒的质量与酿酒葡萄中各个理化指标的相似度指标,选出相似度较高的五项指标作为酿酒葡萄分级的参考指标。
根据参考指标对酿酒葡萄进行分级,分别得出了依香气、口感、外观进行分级的酿酒葡萄分级结果(见表五,表六)。
对问题三,建立非线性回归模型,讨论酿酒葡萄与葡萄酒理化指标的联系。
将葡萄和葡萄酒的理化指标进行无量纲化处理,利用最短距离法,选出葡萄理化指标中对葡萄酒理化指标影响最大的五项作为回归自变量,以葡萄酒的理化指标为回归因变量,运用MATLAB求解得到酿酒葡萄与葡萄酒的理化指标之间的4次函数关系式(见表七,表八)。
对问题四,建立酿酒葡萄的理化指标、葡萄酒的理化指标与葡萄酒质量的多重T检验模型。
应用SPSS软件进行T检验,通过检验结果所体现出的向量整体差异程度表明,酿酒葡萄和葡萄酒的理化指标对葡萄酒质量影响较大,故可以用酿酒葡萄和葡萄酒的理化指标评价葡萄酒质量。
关键词理化指标;T检验;典型相关系数;回归模型;葡萄酒评价一、问题重述由于葡萄酒不仅饮用口感佳,而且还具有延缓衰老、滋补养颜、预防心脑血管病、预防癌症等功效,因而受到越来越多人的亲睐。
葡萄酒厂在对葡萄酒质量进行鉴定时,一般是通过聘请一批有专业知识和资质的评酒员对葡萄酒进行品评。
每名评酒员品评后会根据评判标准对所品葡萄酒进行打分,然后求其所有评酒员的打分之和,从而确定葡萄酒的质量。

葡萄酒评价模型摘要本文讨论了葡萄酒的评价问题。
对问题一,分别求出两组评酒员对各葡萄酒样品的平均评分,通过SPSS软件对同一类酒的两组得分进行T检验,检验结果表明两组评酒员的评价结果有显著性差异。
再建立评酒员和样品葡萄酒得分的典型相关分析模型,运用MATLAB 求解,以样品葡萄的得分与评酒员的相关系数越大评分越不可信为依据,得出第二组的评分更可信的结论。
对问题二,以第二组的评分为准,对葡萄酒的质量进行排序,得出排序向量,对酿酒葡萄中各个理化指标进行排序,得出排序矩阵,排序向量与排序矩阵的各列进行点乘,得到葡萄酒质量与酿酒葡萄中各个理化指标的内积,以此内积作为葡萄酒的质量与酿酒葡萄中各个理化指标的相似度指标,选出相似度较高的五项指标作为酿酒葡萄分级的参考指标。
根据参考指标对酿酒葡萄进行分级,分别得出了依香气、口感、外观进行分级的酿酒葡萄分级结果(见表五,表六)。
对问题三,建立非线性回归模型,讨论酿酒葡萄与葡萄酒理化指标的联系。
将葡萄和葡萄酒的理化指标进行无量纲化处理,利用最短距离法,选出葡萄理化指标中对葡萄酒理化指标影响最大的五项作为回归自变量,以葡萄酒的理化指标为回归因变量,运用MATLAB求解得到酿酒葡萄与葡萄酒的理化指标之间的4次函数关系式(见表七,表八)。
对问题四,建立酿酒葡萄的理化指标、葡萄酒的理化指标与葡萄酒质量的多重T检验模型。
应用SPSS软件进行T检验,通过检验结果所体现出的向量整体差异程度表明,酿酒葡萄和葡萄酒的理化指标对葡萄酒质量影响较大,故可以用酿酒葡萄和葡萄酒的理化指标评价葡萄酒质量。
关键词理化指标;T检验;典型相关系数;回归模型;葡萄酒评价一、问题重述由于葡萄酒不仅饮用口感佳,而且还具有延缓衰老、滋补养颜、预防心脑血管病、预防癌症等功效,因而受到越来越多人的亲睐。
葡萄酒厂在对葡萄酒质量进行鉴定时,一般是通过聘请一批有专业知识和资质的评酒员对葡萄酒进行品评。
每名评酒员品评后会根据评判标准对所品葡萄酒进行打分,然后求其所有评酒员的打分之和,从而确定葡萄酒的质量。

2012数学建模葡萄酒原题题目描述:葡萄酒是世界著名的酒类之一。
葡萄酒的种类繁多,其中又以红葡萄酒和白葡萄酒最为常见。
红葡萄酒和白葡萄酒的酸度和pH值具有不同的特点,对其品质和保存期限等方面具有重要影响。
1、问题背景葡萄酒酿造过程中,葡萄经过榨汁、发酵、陈酿等一系列过程,最终形成红葡萄酒和白葡萄酒。
目前,酸度和pH值是衡量葡萄酒质量的两个非常重要的指标,也是鉴别红葡萄酒和白葡萄酒的重要依据。
2、问题提出2.1、问题一通过分析红葡萄酒和白葡萄酒的酸度和pH值的数据,比较红葡萄酒和白葡萄酒的酸度和pH值的差异。
2.2、问题二通过分析红葡萄酒和白葡萄酒的酸度和pH值的数据,预测不同保存条件下红葡萄酒和白葡萄酒的酸度和pH值的变化趋势。
3、问题分析3.1、问题一为了比较红葡萄酒和白葡萄酒的酸度和pH值的差异,需要首先收集红葡萄酒和白葡萄酒的酸度和pH值的数据,并进行数据处理和分析,例如绘制散点图、直方图、箱线图等。
同时,还需要进行统计分析和假设检验,比较红葡萄酒和白葡萄酒的酸度和pH值的差异是否显著。
3.2、问题二为了预测不同保存条件下红葡萄酒和白葡萄酒的酸度和pH值的变化趋势,需要分析红葡萄酒和白葡萄酒的酸度和pH值与保存条件之间的关系,例如温度、湿度、光照等。
同时,还需要建立数学模型,预测不同保存条件下红葡萄酒和白葡萄酒的酸度和pH值的变化趋势。
最后,需要对模型进行验证和评估,确定其预测效果是否准确。
4、解决方案4.1、问题一(1)数据收集:通过调查、实地采样等方式,收集红葡萄酒和白葡萄酒的酸度和pH值数据。
(2)数据处理:对收集到的数据进行处理和分析,例如统计描述、散点图、直方图、箱线图等。
(3)统计分析:通过假设检验、方差分析等方法,比较红葡萄酒和白葡萄酒的酸度和pH值的差异是否显著。
4.2、问题二(1)数据收集:通过调查、实地采样等方式,收集不同保存条件下红葡萄酒和白葡萄酒的酸度和pH值数据。
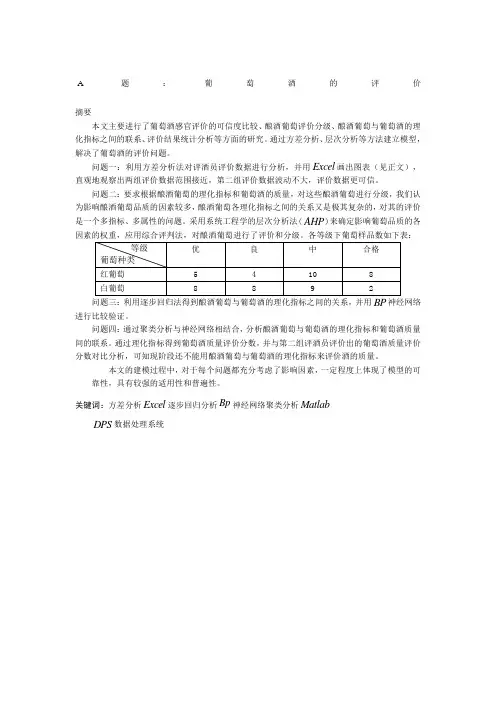
A题:葡萄酒的评价摘要本文主要进行了葡萄酒感官评价的可信度比较、酿酒葡萄评价分级、酿酒葡萄与葡萄酒的理化指标之间的联系、评价结果统计分析等方面的研究。
通过方差分析、层次分析等方法建立模型,解决了葡萄酒的评价问题。
问题一:利用方差分析法对评酒员评价数据进行分析,并用Excel画出图表(见正文),直观地观察出两组评价数据范围接近,第二组评价数据波动不大,评价数据更可信。
问题二:要求根据酿酒葡萄的理化指标和葡萄酒的质量,对这些酿酒葡萄进行分级,我们认为影响酿酒葡萄品质的因素较多,酿酒葡萄各理化指标之间的关系又是极其复杂的,对其的评价是一个多指标、多属性的问题。
采用系统工程学的层次分析法(AHP)来确定影响葡萄品质的各因素的权重,应用综合评判法,对酿酒葡萄进行了评价和分级。
各等级下葡萄样品数如下表:问题三:利用逐步回归法得到酿酒葡萄与葡萄酒的理化指标之间的关系,并用神经网络进行比较验证。
问题四:通过聚类分析与神经网络相结合,分析酿酒葡萄与葡萄酒的理化指标和葡萄酒质量间的联系。
通过理化指标得到葡萄酒质量评价分数,并与第二组评酒员评价出的葡萄酒质量评价分数对比分析,可知现阶段还不能用酿酒葡萄与葡萄酒的理化指标来评价酒的质量。
本文的建模过程中,对于每个问题都充分考虑了影响因素,一定程度上体现了模型的可靠性,具有较强的适用性和普遍性。
关键词:方差分析Excel逐步回归分析Bp神经网络聚类分析MatlabDPS数据处理系统一、问题重述通过聘请一些有资质的评酒员品尝葡萄酒,根据他们反馈意见来确定葡萄酒的质量。
酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
已知某一年份一些葡萄酒的评价结果,及该年份这些葡萄酒的和酿酒葡萄的成分数据。
根据上述条件建立数学模型解决以下问题:1.分析两组评酒员的评价结果有无显着性差异,哪一组结果更可信。
2.根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级。

2021葡萄酒质评的数学建模分析范文 摘要: 已知酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系, 葡萄酒和酿酒葡萄监测的理化指标会在一定程度上反映葡萄酒和酿酒葡萄的质量等条件, 建立模型解决问题。
文章主要通过正态分布、方差检验, 建立主成分分析、多元线性回归、聚类分析、相关系数和逐步回归模型来解决问题。
关键词: 葡萄酒;正态分布; 主成分分析; 多元线性回归; 聚类分析; Abstract: Itis known that the quality of wine grapes has a direct relationship with the quality of the wines being brewed. The physical and chemical indicators of wine and wine grape monitoring will ref lect the conditions of wine and wine grapes to some extent, and establish models to solve problems. This paper mainly solves the problem by using normal distribution and variance test, establishing principal component analysis, multiple linear regression, cluster analysis, correlation coefficient and stepwise regression model. Keyword: wine;normal distribution; principal component analysis; multiple linear regression; cluster analysis; 确定葡萄酒的质量好坏需要有资质的评酒员对其进行分类指标打分,最后综合确定葡萄酒的质量。


葡萄酒的评价摘要本文主要运用统计分析方法,解决与所酿葡萄酒有关的问题。
对于问题一,,分别对白酒和红酒的两组数据进行差异性检验。
构建一个能反应葡萄酒本身质量的量,对两组数据分别进行相关性分析,得到第二组评酒员的结果更可信。
对于问题二,先做聚类分析,再做线性回归分析,得到白、红葡萄分为4级和3级。
对于问题三,利用问题二中聚类得到的7个主成分,把每种葡萄酒的理化指标与酿酒葡萄之间的7个主成分进行相关性分析,得到7个回归方程,即为酿酒葡萄与葡萄酒的理化指标之间的联系。
对于问题四,首先建立模型:12W=a *Y +b *Y 。
其中a,b 分别为酿酒葡萄和葡萄酒对葡萄酒质量的贡献率,1Y ,2Y 分别为两种因素的贡献值。
然后,通过确定芳香物质是否对葡萄酒的评分有影响来论证能否用葡萄和葡萄酒的理化指标评价葡萄酒的质量。
问题一中,本文运用excel 做两组数据的显著性差异检验,得到两组评酒员在评论白酒和红酒都存在显著性差异,且通过了F 检验。
接着本文通过确定各指标的权重,构建一个能反应各葡萄酒实际平分的量,把两组数据与之做相关性分析,发现第二组与之相关性更大,故第二组评酒员的结果更可信。
问题二中,本文通过SPSS 做理化指标的聚类分析,得到7个主成分;再做指标与评分的线性回归分析,得到白葡萄的分级结果为4级:一级:白酿酒葡萄14,22;二级:白酿酒葡萄4,5,9,19,23,25,26,28;三级:白酿酒葡萄24,27;四级:白酿酒葡萄1,2,3,6,7,8,10,11,12,13,15,16,17,18,20。
红葡萄酒为3级:一级:红酿酒葡萄2,9;二级:红酿酒葡萄3,4,10,22,24;三级:红酿酒葡萄1,5,6,7,8,11,12,13,14,15,16,17,18,19,20,21,23,25,26,27。
问题三中,本文运用excel 将葡萄酒的一级指标分别与7个主成分进行相关性分析然后对每种主要成分利用SPSS 进行线性回归分析得到以下7个回归方程:()()()()()r1134r21367r3137r4136r6137r71Y =-39.542+1.727+21.850+3.9463Y =4.044+0.026-0.156-0.005-0.1954Y =2.807+0.021-0.030-0.1895Y =2.700+0.024-0.169-0.0056Y =0.069+0.001-0.006-0.0077Y =70.028-0.188+x x x x x x x x x x x x x x x x x ()()2347r8123560.841+0.280-0.187+1.7048Y =58.545-0.021-1.028+1.666+27.045-0.0049x x x x x x x x x 即为每种酿酒葡萄与葡萄酒理化指标之间的联系。
葡萄酒的评价摘要本文针对题目中的问题,运用系统建模及计算机仿真,解决葡萄酒的评价问题。
问题(1)中,首先运用正态概率纸发对葡萄酒得分进行分布检验,在葡萄酒得分分布具有正态性的条件下,建立双因素重复实验方差模型,结果显示二组品酒员打分具有显著性差异;然后采用双因素无重复实验方差分析对二组品酒员打分进行可信度评定,评定认为第一组品酒员对红葡萄酒的打分更可信,第二组品酒员对白葡萄酒的打分更可信。
问题(2)中,首先对酿酒葡萄理化指标建立主成分分析模型,提取白葡萄酒酿酒葡萄的11个主成分和红葡萄酒酿酒葡萄的9个主成分;然后将主成分结合对应葡萄酒的质量,建立基于最邻近规则的酿酒葡萄试探聚类模型,最佳聚类数目利用统计量2R来确定;最后根据酿酒葡萄的聚类情况,计算各类酿酒葡萄对应葡萄酒的质量,并依此建立酿酒葡萄的分级模型。
问题(3)中,首先对酿酒葡萄和葡萄酒理化指标数据进行直接正交处理,消除数据在采集过程中所产生噪声的影响;然后建立葡萄酒和酿酒葡萄理化指标之间的偏最小二乘回归模型,求解出葡萄酒理化指标与酿酒葡萄理化指标的多元线性关系;最后通过分析葡萄酒和酿酒葡萄理化指标标准数据的相关系数和葡萄酒理化指标的预测图定性讨论回归方程的效果。
问题(4)中,运用典型相关分析方法,通过比较酿酒葡萄和葡萄酒理化指标、感官指标与葡萄酒质量的相关系数,得到酿酒葡萄和葡萄酒的理化指标影响葡萄酒的质量这一结论。
关键词:显著性检验主成分分析试探聚类偏最小二乘回归一、问题重述与分析1.1问题重述确定葡萄酒质量时一般是通过聘请有资质的评酒员进行品评。
每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。
酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
附件1给出了某一年份一些葡萄酒的评价结果,附件2和附件3分别给出了该年份这些葡萄酒的和酿酒葡萄的成分数据。
葡萄酒的评价摘要本文就影响葡萄酒的质量的因素进行了探究。
在问题一中,评酒员间存在评价尺度、评价位置以及评价方向等方面的差异,导致不同评酒员对同一酒样的评价差异很大,于是我们需要探讨两组评酒员的可信度。
对此,我们建立了单元素方差模型对其进行了显著性差异的判断,最后我们得出结论:两组评酒员的评价结果有显著性差异,并且第二组评酒员评价的结果更加可信。
在问题二中,我们首先将大量的数据进行了样本住分析塞选,大大减少了计算量,就红、白葡萄酒前17组样本葡萄酒的分数进行训练,由后十组的理性指标进行检验,也可检验俩个的准确性。
最后我们认为可以给酿酒葡萄分为一、二、三、四四个等级。
在问题三中,因为要讨论酿酒葡萄与葡萄酒的理化指标之间的联系,我们就其两者的重要理化指标进行了探讨,应用了回归模型将其各项重要指标进行了多元拟合处理,最后得出了葡萄酒和酿酒葡萄中的重要指标的等式关系。
在问题四中,我们首先利用了回归原理求得葡萄酒质量与葡萄酒和酿酒葡萄的理化指标之间的等式关系,由等式和图像细致的分析了葡萄酒和酿酒葡萄理化指标对葡萄酒质量的影响。
在一定范围内,理化指标的与葡萄酒的质量呈正相关,达到一定的量后呈现负相关趋势。
关键词:显著性差异判别主成分分析 BP神经网络回归模型1.问题的重述现今社会,随着人们生活水平的提高,人们对葡萄酒的质量要求也越来越高。
在确定葡萄酒质量的时候,一般聘请一批资深的评酒员进行评比,根据不同的指标所得的分数从而求得总分,以此确定葡萄酒的质量。
其中酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
本题给出了3份材料,材料1是某一年份一些葡萄酒的评价结果,材料2和材料3分别给出了该年份这些葡萄酒和酿酒葡萄的成分数据。
我们必须解决以下问题:问题一:分析材料1中两组评酒员的评价结果是否有明显的差异,并且求出哪组评酒员的评价结果更可信。
问题二:根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄的品质进行分级。
数学实验计算机科学与技术成员:xxx学号:xxxxxxxxxx葡萄酒的评价摘要本文主要研究的是如何对葡萄酒进行评价的问题。
通过对评酒员的评分与酿酒葡萄的理化指标和葡萄酒的理化指标等原始数据进行统计、分析和处理,我们得出了一个较为合理地评价葡萄酒质量优劣的模型。
在问题一中,我们采用T检验法,首先进行正态分布拟合检验,判断出它们服从正态分布。
之后,我们通过T检验法判断出了两组评酒员的评价结果具有显著性差异。
而对于如何判断哪一组评酒员的评价结果更可信,由于评酒员评分的客观性,我们通过计算评酒员评分均值的置信区间,利用置信区间的长短来判断评分的可信程度。
置信区间越窄,说明其越可信。
利用Matlab软件求出了第二组评酒员的评分均值的置信区间更窄,所以第二组评酒员的评价结果更可信。
在问题二中,我们采用主成分分析法,把给定的一组相关变量通过线性变换转成另一组不相关的变量,这些新的变量再按照方差依次递减的顺序排列。
在数学变换中保持变量的总方差不变,使第一变量具有最大的方差。
第二变量的方差次大,并且和第一变量不相关。
由于变量较多,虽然每个变量都提供了一定的信息,但其重要性有所不同。
依次类推,最后我们将酿酒葡萄分为了四个等级:优质、次优、中等、下等。
在问题三中,我们通过多项式曲线拟合的方法,构造一个以葡萄酒的理化指标为自变量,酿酒葡萄的理化指标为因变量的函数,并利用Matlab软件进行曲线拟合,最后得出酿酒葡萄与葡萄酒的理化指标之间的关系为呈线性正相关。
在问题四中,我们用无交互作用的双因素试验的方差分析方法,通过对观测、比较、分析实验数据的结果,鉴别出了两个因素在水平发生变化时对实验结果产生显著性影响的大小程度。
最后,我们认为能用酿酒葡萄和葡萄酒的理化指标来评价葡萄酒的质量,且酿酒葡萄的理化指标对葡萄酒质量影响相对葡萄酒的理化指标更显著。
关键词:T检验法,Matlab,正态分布,主成分分析法,多项式曲线拟合,方差分析一.问题的重述确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。
葡萄酒评价的数学模型摘要自埃及有了制造葡萄酒的记录后,我们大多数都对他亲睐有加。
然而葡萄酒的鉴定却需要一批更加专业的以及有资历的评酒员进行评价,并通过这一环节得到葡萄酒的分类指标分值,进而得到总分,从而确定葡萄酒的质量。
酿葡萄酒的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
本文主要解决以下几个问题:对于问题1,采用单因素分析法,运用MATLAB软件及SPSS进行求解分析,最后再根据方差来判断。
对于问题2,在问题一中得到的数据评分较为可靠,因此根据评分来分级,通过MATLAB软件对该组的成分进行检验,并且根据Excel软件作图分析数据,找出影响葡萄酒分级的成分,并在酿造葡萄酒的理化指标中找出与之相同的成分,再结合问题一中葡萄酒的评分对其进行分级,得出葡萄样品成分的排列,结合成分的量和葡萄酒分级得出影响酿酒葡萄分级的范围。
对于问题3,在问题2的基础上利用题目所提供的附件2,对所有理化指标进行分析,并用MATLAB软件拟合数据,做出拟合线性图,并采用多元回归分析法进行回归分析,最后综合分析各理化指标之间的关系。
对于问题4,可以结合题目中的附件3中关于芳香物质的数据,利用MATLAB 进行分析,拟合感官指标和理化指标的依据,得出结论:可以用葡萄和葡萄酒的理化指标来评价葡萄酒的质量。
关键字:方差分析法分级理化指标线性相关回归分析一.问题的重述作为世界上最富于变化的葡萄酒,是有生命的酒,得到了世界各地人们的亲睐,在我国也不例外。
据IWSR预测三年后中国将超过日本成为世界第七大葡萄酒消费市场,同事,一些不法商贩开始造假酒,影响国人的健康,虽然我国的GB15037-2006《葡萄酒》国家标准对葡萄酒的质量作了规定,但是我国关于葡萄酒质量等级划分的标准还未完善,国家需要制定相关统一的等级制度。
确定葡萄酒质量是一般通过聘请一些有资质的评酒家对葡萄酒的各类指标进行分类打分,最后得到总分,从而确定其质量。
对葡萄酒的评价分析摘要本文主要应用数理统计中的t检验法,回归分析法等方法对葡萄酒的评价的相关问题进行了分析,建立相应的模型。
针对问题一,首先,对样本进行K-S检验得出数据取自的总体服从正态分布,进而运用成对数据t检验法进行检验,得出两组评酒员对每种葡萄酒的总评分有显著差异;在此基础上,采用两种方法分别判断哪组评酒员的可信度更高。
方法一是计算出每组评酒员对每种葡萄酒的总评分的置信区间,评分处于置信区间内的人次百分比较高的一组可信度较高;方法二是比较两组评酒员对每种葡萄酒的总评分的方差的大小,总体方差分布较小的一组,可信度较高。
两种方法均得出了同一结论,即第二组评酒员的结果更可信。
针对问题二,基于问题一得到的结论,建立了酿酒葡萄品质的综合评价模型。
首先,对数据指标进行归一化处理,并计算出酿酒葡萄与各指标因素间的相关系数。
然后,分别用层次分析法和因子分析法确定了各指标因素的权重。
最后,利用确定的权重,建立了酿酒葡萄品质的综合评价模型,对葡萄进行分级。
如,优质的红葡萄样品是8、23、3、1。
针对问题三,从两个层次建立相关性系数模型。
首先,运用Excel软件分析葡萄酒各理化指标与酿酒葡萄成分的相关性;然后,进一步分析酿酒葡萄的综合评价指标与葡萄酒的理化指标之间的联系。
得出结论:酿酒葡萄的花色苷成分与葡萄酒的花色苷呈显著正相关。
针对问题四,分别建立回归分析模型和综合评价模型,其中综合评价模型建立方法同问题二,回归分析模型则先将葡萄和葡萄酒的各理化指标进行因子分析法降维后得数量较少的因子变量,对简化后的新指标进行回归分析,此处尝试用SPSS软件的回归分析中5种回归拟合方法,继而选取拟合度最佳的模型,得回归系数,建立多元线性回归方程分析各理化指标对葡萄酒质量的影响;将新指标得分带入方程,可求得线性拟合后的葡萄酒质量评分。
进一步引入芳香物质作为评判指标,同样建立线性回归模型求得葡萄酒质量评分,将有无引入芳香物质作为指标的质量评价结果分别与可信度较高的评酒员对葡萄酒的评价结果进行回归模型检验比较和差值平方和比较,得到结论用葡萄和葡萄酒的理化指标来评价葡萄酒的质量是完全可行的,但加入芳香物质作为评价指标更能准确合理地评价葡萄酒的质量。
葡萄酒的评价分析摘要本文主要对葡萄酒的评价问题进行了分析,建立了多种模型,较好的解决了题目所提出的问题。
针对问题一,首先对附件1的数据预处理,采用7检验的方法,得出不论是红葡萄酒、还是白葡萄酒,两组评酒员的评价结果均存在显著性差异的结论;然后通过方差分析,可知第二组评酒员的评价结果误差更小,即第二组结果更可信。
针对问题二,首先分析并整理出酿酒葡萄的理化指标数据,结合问题一中葡萄酒的质量得分,根据它们对葡萄酒质量的影响,进行主成分分析,从而确定选出8个主成分, 然后对27种红葡萄进行综合分析,并计算岀具体的分数,按照分数高低划分6个等级, 同理对白葡萄分析并划分为6个等级,最后利用SPSS软件对结果进行了检验与分析,证明了本题所建立的主成分综合评价模型是合理的。
针对问题三,首先根据附件2中的数据,选取8个指标进行分析。
考虑到酿酒葡萄、葡萄酒之间的理化指标变化规律不明显,于是利用层次分析法,对8个指标赋以相应权重。
然后采用加权平均法得到酿酒葡萄、葡萄酒的综合指标,通过相关度分析,建立两者之间的一元线性回归模型,得到两综合指标之间的一元线性函数关系式,即反映了酿酒葡萄与葡萄酒的理化指标之间的联系。
针对问题四,首先分析酿酒葡萄和葡萄酒的理化指标对葡萄酒质量的影响,采用灰色关联度分析法,得到影响葡萄酒质量的权重值分别为0.6124, 0.3874,即酿酒葡萄的理化指标对葡萄酒质量的影响要大一些;然后对葡萄和葡萄酒的芳香物质进行分析,筛选出芳香物质的有效指标并采用主成分分析法得到两类理化指标的综合得分。
最后结合葡萄和葡萄酒的理化指标、葡萄的芳香物质三个指标对葡萄酒的质量进行相关性分析,发现葡萄的芳香物质与葡萄酒的质量的相关系数最大,充分论证了不能用葡萄和葡萄酒的理化指标来评价葡萄酒的质量,即在葡萄酒质量的评价条件中,需加入葡萄的芳香物质。
最后建立了多元回归模型,对原来模型进行改进。
本文在最后对结果进行分析,结果较好的符合题中所给数据,并对模型进行推广。
一、问题重述确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。
每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。
酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
附件1给出了某一年份一些葡萄酒的评价结果,附件2和附件3分别给出了该年份这些葡萄酒的和酿酒葡萄的成分数据。
请尝试建立数学模型讨论下列问题:1. 分析附件1中两组评酒员的评价结果有无显著性差异,哪一组结果更可信?2. 根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级。
3. 分析酿酒葡萄与葡萄酒的理化指标之间的联系。
4.分析酿酒葡萄和葡萄酒的理化指标对葡萄酒质量的影响,并论证能否用葡萄和葡萄酒的理化指标来评价葡萄酒的质量?附件1:葡萄酒品尝评分表(含4个表格)附件2:葡萄和葡萄酒的理化指标(含2个表格)附件3:葡萄和葡萄酒的芳香物质(含4个表格)二、问题分析问题二的分析问题二要根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级。
题目对葡萄酒样品给出了葡萄酒品尝评分表、理化指标分析表和芳香物质分析表。
由于葡萄酒理化指标分析表和芳香物质分析表没有一个可行的分析方法对葡萄酒的质量进行判断。
因此,把葡萄酒品尝评分表作为对葡萄酒质量的评定。
由问题一,得到第二组评酒员的评价结果更可信。
先对葡萄酒评分求平均值。
再用主成分分析法处理酿酒葡萄的理化指标,将30个指标缩减为几个主成分。
由于数据的计量单位不同,对葡萄酒的平均分和酿酒葡萄的理化指标量纲化处理。
通过spss求出葡萄样本各指标与主成分的相关系数矩阵。
从而求出各葡萄样本与主成分的关系矩阵Y=()yij最后用综合主成分分析法,将各葡萄酒的平均值(量纲化处理)与各葡萄样本跟主成分的关系矩阵建立一个线性关系。
通过这个线性关系对葡萄样品进行打分,再用分值对葡萄进行分级。
三、模型假设1、葡萄酒的质量仅由葡萄酒的评分决定。
2、葡萄酒的二级理化指标的信息全部反应在相对应得一级理化指标中。
四、符号说明μ 表示综合得分的数学期望,i α 表示第i 组评分与总平均值之差,ij β 表示第i 组第j 个评酒师的评分与第i 组评分均值的偏差;ijk x 表示第i 组的第j 号评酒师对第k 号酒的综合评分ijk ε 表示第i 组第j 个评酒师弟K 号样品酒分析结果与第j 号评酒师评分的偏离;A SS 称为因素A 的离差平方和, E SS 称为因素E 的离差平方和,B SS 称为因素B 的离差平方和 i X 酿酒葡萄的不同的理化指标Y 各葡萄样本与主成分的关系矩阵i a 酿酒葡萄理化指标提取的主成分对应理化指标中的贡献率 i b 各葡萄酒评分量纲化处理后的数值i Z 主成分Y 与其贡献率i a 的乘积加上葡萄酒评分数值构成线性组合五、模型建立及求解5.1.1问题一模型的建立及求解葡萄酒历史悠久,在葡萄酒诞生之初,人类就给予了它对于其它任何食物与饮品都没有的偏爱。
然而即使是极品葡萄酒不同的人对他的评价也不可能完全一样,本问就是要讨论两组评酒员的评价结果有无显著性差异,及哪一组结果更可信。
对于要分析无显著性差异,这里是通过用三因素(酒类,品酒员,组号)方差分析及T 检验法,T 检验当中的值小于0.05则说明而对于要判断哪一组结果更可信,则是通过计算出每组样品酒方差的平均来判断,平均值越小则说明越稳定,结果就更可靠。
首先建立三因素方差分析的数学模型 三因素方差分析的数学模型:ijk i ij ijk x μαβε=+++ (1,2;1,......10;1,......28)i j ==μ表示综合得分的数学期望,i α表示第i 组评分与总平均值之差,ij β表示第i 组第j 个评酒师的评分与第i 组评分均值的偏差;ijk x 表示第i 组的第j 号评酒师对第k 号酒的综合评分ijk ε表示第i 组第j 个评酒师弟K 号样品酒分析结果与第j 号评酒师评分的偏离;三因素方差分析的计算步骤根据数理统计原理,计算各离差平方和:2211111111()()a b ca b cA ijkijk bcabci j k i j k SS xx =======-∑∑∑∑∑∑221111111()abc abcE ijk ijkci j k i j k SS x x=======-∑∑∑∑∑∑2211111111()()a b c a b cB ijk ijk c bc i j k i j k SS x x =======-∑∑∑∑∑∑ A SS 称为因素A 的离差平方和,反映因素A 对试验指标的影响。
E SS 称为因素E 的离差平方和,反映因素E 对试验指标的影响。
B SS 称为因素B 的离差平方和,反映因素B 对试验指标的影响计算样本方差21A A ASS SS A A f a MS S -===2(1)B BBSS SS B B f a b MS S -=== 2(1)EE E SS SS E E f ab c MS S -=== Sig 单总体T 检验X t σ-∆=。
如果样本是属于大样本(n >30)也可写成:X t σ-∆=。
在这里,t 为样本平均数与总体平均数的离差统计量;X 为样本平均数;∆为总体平均数;X σ为样本标准差;n 为样本容量。
以0.05为显著性水平, t>0.05则说明无显著性差异。
反之说明有显著性差异。
可信度分析的数学模型ijn M 表示第i 组的第j 号评酒师对第n 个评分项目的分值(n =1……10,分别表示澄清度,色调,香气分析当中的纯正度,香气分析当中的浓度,香气分析当中的质量,纯正度,浓度,持久性,质量,整体评价 )1210......ijk ij ij ij x M M M =++1210()......ik i k i k i k E X x x x =++2221210var()(())(())......(())ik i k ik i k ik i k ik x x E x x E x x E x =-+-+-1227var()var()......var()i i i Q x x x =++()ik E X 表示第i 组中第j 号酒的综合得分期望。
var()ik x 表示第i 组j 号酒的综合得分方差。
Q 表示该组方差的平均值方差的平均越小说明越稳定,则可信度越高。
数据的处理及结果根据附表一中的数据通过excel 可以算出白酒第一组中毎位评酒师对各样品酒的综合得分,例如第26号酒的综合得分如表一所示:表一总分:100 品酒员1 …品酒员1026 项目满分酒样品26 …外观分析 5 澄清度 4 (4)15 10 色调 6 (8)香气分析 6 纯正度 5 (5)30 8 浓度7 (7)16 质量14 (14)口感分析 6 纯正度 4 (4)44 8 浓度7 (6)8 持久性7 (7)22 质量13 (19)平衡/整体评价11 8 (10)75 (84)如表一所示算出第一组及第二组每种样品酒的综合得分,将所有白酒的数据整理得到下表二:组别品酒员酒样品综合得分1 品酒1号26 751 品酒2号26 66…………2品酒员1号2680...………全表为附录表一将附录表一当中的数据导入到SPSS,分析综合得分与酒类,品酒员,组号的关系,得到数据如表三:T检验当中组别的t小于0.05可得知白酒的两组评价员的结果有显著性差异。
同样的方法用SPSS对红酒进行三因素分析得到表四:表四T检验当中组别的t小于0.05可得知白酒的两组评价员的结果有显著性差异。
不管是白酒还是红酒,两组评价员的结果都有显著性差异。
附录表一当中已经算出来所有样品酒的综合得分利用excel可以很容易的算出每组综合得分的方差平均值,结果如表五所示:表五从表五中可以看出不管是白酒还是红酒,第二组方差的平均值都小于第一组的方差平均值,可得出结论第二组的稳定性更好,结果更可靠。
5.3.1问题三模型的建立及求解为了研究酿酒葡萄与葡萄酒的理化指标之间的联系,将葡萄酒的理化指标定义为Y,把酿酒葡萄的理化指标定义为X,先利用相关性分析,可以分别算出每一个Y关于所有X的相关系数矩阵。
取出其中相关系数大于0.35的X,在利用多元线性回归,分别算出每一个Y关于相关系数大于0.35的X的R2,及各X的系数与置信区间。
根据R2的值把Y分成三类:A类为R2大于0.8。
B类为R2介于0.5到0.8之间C类为R2小于0.5.对于A类如果置信区间包含0,则把相应的变量踢除。
根据这些新的变量,从新做一次线性回归如果R2的值与剔除变量之前相差不大,就取剔除变量之后的变量。
若相差较大则取没有剔除变量的那些X来表示Y。
对于B类可直接得出Y关于X的线性方程,对于C类,模型的建立与求解:问题二的模型葡萄酒的理化指标分为一级指标和二级指标。
由于二级指标都在一级指标中进行反应,剔除二级指标。
对多次测试的项目取平均值,精简得到酿酒葡萄的理化指标分析表,共30个指标。
由于指标太多,并且多指标之间往往存在着一定程度的相关性。
为了把指标复杂的关系进行简化,对理化指标做主成分分析。
由于理化指标中的指标不同,其计量单位不同,所以数据量纲也不一致。
因此,在进行主成分分析前,先对数据进行量纲化处理。
统计学原理告诉我们,要对多组不同量纲数据进行比较,可以先将它们标准化转化成无量纲的标准化数据。
而综合评价就是要将多组不同的数据进行综合,因而可以借助于标准化方法来消除数据量纲的影响。
无量纲标准化法:sxx y i i -=上式中: ∑==n i i x n x 11 ∑=--=n i i x x n s 12)(11 无量纲化处理葡萄样品的评分、葡萄酒的理化指标结果(以下仅是表的一部分)如下:红葡萄 得分平均均值标准化 氨基酸总量标准蛋白质标准 VC 含标准葡萄样品1-0.607044289 -0.23 -0.05 -0.13葡萄样品20.876117601 -0.16 1.56 -0.22葡萄样品31.026947623 3.84 0.65 -0.09白葡萄 得分平均值标准化 氨基酸总量标准蛋白质标准 VC 含标准葡萄样品1 0.431372889 -0.73 -0.18 2.2 葡萄样品2 -0.230891494 -0.08 0.55 -0.75 葡萄样品3 -0.293964293 3.37 -0.69 -0.29主成分分析模型:酿酒葡萄的无量纲化理化指标有30个,设为12330,,X X X X 。
令X=(12330,,X X X X ),假定存在二阶矩阵,其均值和协方差分别记为(),()E X D X μ=∑=。