SPSSMolder常用函数简介
- 格式:doc
- 大小:242.00 KB
- 文档页数:18


SPSS Molder常用函数简介SPSS Molder软件包含多种功能丰富的函数,几乎涵盖了我们日常工作的各种需要,主要有信息函数、转换函数、比较函数、逻辑函数、数值函数、三角函数、概率函数、位元整数运算、随机函数、字符串函数、日期和时间函数、序列函数、全局函数、空值和Null值处理函数、特殊函数等15大类,本附录将逐一介绍并说明其注意事项。
在本附录中涉及到的函数,具体的字段格式按照如下约定表示。
此外,本附录中的函数以函数、结果类型(整数、字符串等)和说明(如果有)各占一列的形式一一列举说明。
例如,对函数rem的说明如下。
1. 信息函数信息函数用于深入了解特定字段的值。
它们通常用于派生标志字段。
例如,可以使用@BLANK函数来创建一个标志字段,以指示选定字段的值为空值的记录。
同样,可以使用存储类型函数(如is_string)来检查某个字段的存储类型。
2. 转换函数转换函数可用来构建新字段和转换现有文件的存储类型。
例如,可通过将字符串连接在一起或分拆字符串来形成新字符串。
若要连接两个字符串,请使用运算符“><”。
例如,字段Site的值为"BRAMLEY",则"xx"><Site将返回"xxBRAMLEY"。
即使参数不是字符串,“><”的结果也始终是字符串,因此,如果字段V1为3,字段V2为5,则V1><V2将返回"35"(字符串而非数值)。
请注意,转换函数及其他要求特定类型输入(如日期或时间值)的函数取决于“流选项”对话框中指定的当前格式。
例如,要将值为Jan2003、Feb2003等的字符串字段转换为日期存储格式,请选择MONYYYY作为流的默认日期格式。
3. 比较函数比较函数用于字段值的相互比较或与指定字符串进行比较。
例如,可以使用“=”来检查字符串是否相等。
字符串相等的验证示例:Class="class1"。

随机函数:RV.BERNOULLI(prob)。
数值。
返回具有指定概率参数prob 的Bernoulli 分布中的随机值。
RV.BETA(shape1, shape2)。
数值。
返回具有指定形状参数的Beta 分布中的随机值。
RV.BINOM(n, prob)。
数值。
返回具有指定试验次数和概率参数的二项式分布中的随机值。
RV.CAUCHY(loc, scale)。
数值。
返回具有指定位置和刻度参数的Cauchy 分布中的随机值。
RV.CHISQ(df)。
数值。
返回具有指定自由度df 的卡方分布中的随机值。
RV.EXP(scale)。
数值。
返回具有指定刻度参数的指数分布中的随机值。
RV.F(df1, df2)。
数值。
返回具有指定自由度df1 和df2 的F 分布中的随机值。
RV.GAMMA(shape, scale)。
数值。
返回具有指定形状和刻度参数的Gamma 分布中的随机值。
RV.GEOM(prob)。
数值。
以指定的概率参数从几何分布中返回一个随机值。
RV.HALFNRM(mean, stddev)。
数值。
以指定的均值和标准差从半正态分布中返回一个随机值。
RV.HYPER(total, sample, hits)。
数值。
以指定的参数从超几何分布中返回一个随机值。
RV.IGAUSS(loc, scale)。
数值。
以指定的位置和刻度参数从逆高斯分布中返回一个随机值。
PLACE(mean, scale)。
数值。
返回具有指定均值和刻度参数的Laplace 分布中的随机值。
RV.LNORMAL(a, b)。
数值。
返回具有指定参数的对数正态分布中的随机值。
RV.LOGISTIC(mean, scale)。
数值。
返回具有指定均值和刻度参数的logistic 分布中的随机值。
RV.NEGBIN(threshold, prob)。
数值。
返回具有指定阈值和概率参数的负二项式分布中的随机值。
RV.NORMAL(mean, stddev)。


SPSSModeler数据的基本分析SPSSModeler数据的基本分析1.读取数据以某校学生在校表现与就业情况汇总表(文件名为“原始数据.xlsx”)为例,将文件导入到数据流中,读取文件。
2.计算基本描述统计量通常对于数值型变量,应计算基本描述统计量以准确把握变量的集中程度和离散程度。
基本描述统计量的计算通过输出选项卡中的“统计量”节点来实现。
2.计算基本描述统计量从结果上,我们可以得到“绩点”“是否做过干事”“是否是党员”“在校得分”对“是否就业”都存在相关性。
“绩点”“是否做过干事”“在校得分”的(1-概率-p值)大于0.95,所以他们与“是否就业”相关性强,而“是否是党员”的(1-概论-p值)为0.836,小于0.95,则表示其与“是否就业”相关性弱。
3.绘制散点图4.变量分布的探索变量分布的探索通过输出选项卡的“变换”节点来实现。
5.两变量相关性的图形分析两变量相关性的图形分析通过图形选项卡的“分布”节点来实现。
6.两变量相关性的数值分析两变量相关性的数值分析通过输出选项卡的“矩阵”节点来实现。
6.两变量相关性的数值分析在100个学生中,当过干事的学生人数是42人,其中就业的学生是37人,没有就业的是5人,当过干事的学生占就业比重的88.095%;在没有当过干事的58人中,就业的有32人,没有就业的有26人,没有当过干事就业的学生比重是55.172%。
由此可以见,当过干事的学生就业率要高于没有当过干事学生的就业率。
7.变量重要性的分析变量的重要性分析通过建模选项卡的“特征选择”节点来实现。
7.变量重要性的分析Thanks!。

算术函数ABS(numexpr) 数值。
返回numexpr(必须为数值)的绝对值。
ARSIN(numexpr) 数值。
返回numexpr 的反正弦(以弧度为单位),求出的值必须为-1 和+1 之间的数字值。
ARTAN(numexpr) 数值。
返回numexpr 的反正切(以弧度为单位),numexpr 必须为数字值。
COS(radians) 数值。
返回radians 的余弦(以弧度为单位),radians 必须为数字值。
EXP(numexpr) 数值。
返回e 的numexpr 次幂,其中e 是自然对数的底数,而numexpr 是数值。
较大的numexpr 值可能会产生超过机器性能的结果。
LN(numexpr) 数值。
返回以e 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
LNGAMMA(numexpr) 数值。
返回numexpr 的完全Gamma 函数的对数,numexpr 必须为大于0 的数值。
LG10(numexpr) 数值。
返回以10 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
MOD(numexpr,modulus) 数值。
返回numexpr 除以modulus 所得到的余数。
两个参数都必须为数值,且modulus 不得为0。
RND(numexpr) 数值。
返回对numexpr 舍入后产生的整数,numexpr 必须为数值。
刚好以 .5 结尾的数值将舍去0 以后的数值。
SIN(radians) 数值。
返回radians 的正弦(以弧度为单位),radians 必须为数字值。
SQRT(numexpr) 数值。
返回numexpr 的正平方根,numexpr 必须为非负数。
TRUNC(numexpr) 数值。
返回numexpr 被截断为整数(向0 的方向)的值。
统计函数后缀.n 可在所有统计函数中使用以指定有效参数的数目。
例如,仅当至少两个变量含有效值时,MEAN.2(A,B,C,D) 对变量A、B、C 和D 返回其有效值的均值。
Modeler 建立线性回归模型示例线性回归模型是一种常用的统计学模型。
IBM SPSS Modeler 是一个强大的数据挖掘分析工具,本文将介绍如何用它进行线性回归预测模型的建立和使用。
在本文中,将通过建立一个理赔欺诈检测模型的实例来展示如何利用IBM SPSS Modeler 建立线性回归预测模型以及如何解释及应用该模型。
回归分析(Regression Analysis)是一种统计学上对数据进行分析的方法,主要是希望探讨数据之间是否有一种特定关系。
线性回归分析是最常见的一种回归分析,它用线性函数来对因变量及自变量进行建模(自变量和因变量都必须是连续型变量),这种方式产生的模型称为线性模型。
线性回归模型由于其运算速度快、直观性强以及参数易于确定等特点,在实践中应用最为广泛,也是建立预测模型的重要手段之一。
IBM SPSS Modeler 是一组数据挖掘工具,通过这些工具可以采用商业技术快速建立预测性模型,并将其应用于商业活动,从而改进决策过程。
在后面的文章中,将通过一个理赔欺诈检测的实际商业应用来介绍如何用IBM SPSS Modeler 建立、分析及应用线性回归分析模型。
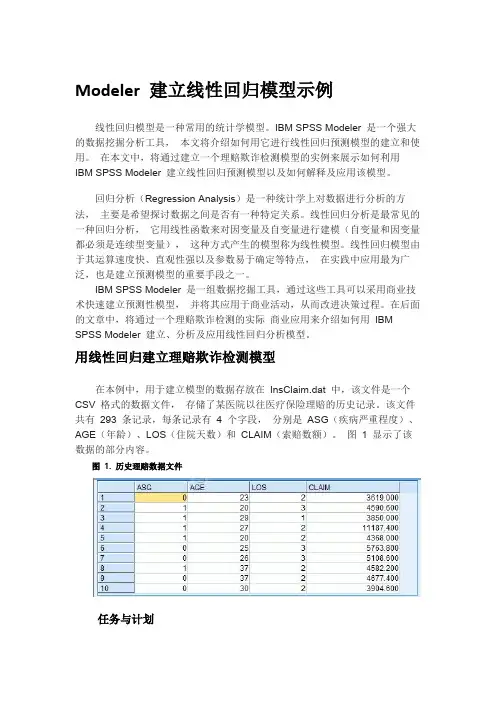
用线性回归建立理赔欺诈检测模型在本例中,用于建立模型的数据存放在InsClaim.dat 中,该文件是一个CSV 格式的数据文件,存储了某医院以往医疗保险理赔的历史记录。
该文件共有293 条记录,每条记录有 4 个字段,分别是ASG(疾病严重程度)、AGE(年龄)、LOS(住院天数)和CLAIM(索赔数额)。
图1 显示了该数据的部分内容。
图 1. 历史理赔数据文件任务与计划基于已有的数据,我们的任务主要有如下内容:∙建立理赔金额预测模型,该模型将基于病人的疾病严重程度、住院天数及年龄预测其索赔金额。
∙假设模型匹配良好,分析那些与预测误差较大的病人资料。
∙通过模型来进行索赔欺诈预测。
根据经验及对数据进行的初步分析(这个数据初步分析可以通过IBM SPSS Modeler 的功能实现,此处不是重点,故不做深入介绍),可以猜测理赔金额与疾病严重程度、住院天数以及年龄存在线性相关关系,因此我们将首先选用线性回归模型进行建模,因此可以得到下面这样一个初步计划:∙应用线性回归分析来建立模型。

IBM® SPSS® Modeler 中最常见的鼠标用法如下所示:•单击。
使用鼠标左键或右键选择菜单选项,打开上下文相关菜单以及访问其他各种标准控件和选项。
单击并按住按键可移动和拖动节点。
•双击。
双击鼠标左键可将节点置于流工作区并编辑现有节点。
•中键单击。
单击鼠标中键并拖动光标可在流工作区中连接节点。
双击鼠标中键可断开某个节点的连接。
如果没有三键鼠标,可在单击并拖动鼠标时通过按Alt 键来模拟此功能。
每个选项板选项卡均包含一组不同的流操作阶段中使用的相关节点,如:•源。
此类节点可将数据引入SPSS Modeler。
•记录选项。
此类节点可对数据记录执行操作,如选择、合并和追加等。
•字段选项。
此类节点可对数据字段执行操作,如过滤、导出新字段和确定给定字段的测量级别等。
•图形。
此类节点可在建模前后以图表形式显示数据。
图形包括散点图、直方图、网络节点和评估图表。
•建模。
此类节点可使用SPSS Modeler 中提供的建模算法,如神经网络、决策树、聚类算法和数据排序等。
•数据库建模。
节点使用Microsoft SQL Server、IBM DB2 和Oracle 数据库中可用的建模算法。
•输出。
节点生成可在SPSS Modeler 中查看的数据、图表和模型等多种输出结果。
•导出。
节点生成可在外部应用程序(如IBM® SPSS® Data Collection 或Excel)中查看的多种输出。
•SPSS Statistics。
节点将数据导入IBM® SPSS® Statistics 或从中导出数据,以及运行SPSS Statistics 过程。
随着对SPSS Modeler 的熟悉,您也可以自定义供自己使用的选项板内容。
词汇表Box 的M 检验. 组协方差矩阵的等同性检验。
对于足够大的样本,不显著的p 值表示断定矩阵不同的证据不足。
该检验对于偏离多变量正态性很敏感。

用IBM SPSS Modeler 建立线性回归预测模型Modeler 线性回归模型示例线性回归模型是一种常用的统计学模型。
IBM SPSS Modeler 是一个强大的数据挖掘分析工具,本文将介绍如何用它进行线性回归预测模型的建立和使用。
在本文中,将通过建立一个理赔欺诈检测模型的实例来展示如何利用IBM SPSS Modeler 建立线性回归预测模型以及如何解释及应用该模型。
1评论:廖志刚, 软件工程师, IBM陈刚, 软件工程师, IBM杨家飞, 软件工程师, IBM2011 年10 月27 日•内容简介回归分析(Regression Analysis)是一种统计学上对数据进行分析的方法,主要是希望探讨数据之间是否有一种特定关系。
线性回归分析是最常见的一种回归分析,它用线性函数来对因变量及自变量进行建模(自变量和因变量都必须是连续型变量),这种方式产生的模型称为线性模型。
线性回归模型由于其运算速度快、直观性强以及参数易于确定等特点,在实践中应用最为广泛,也是建立预测模型的重要手段之一。
IBM SPSS Modeler 是一组数据挖掘工具,通过这些工具可以采用商业技术快速建立预测性模型,并将其应用于商业活动,从而改进决策过程。
在后面的文章中,将通过一个理赔欺诈检测的实际商业应用来介绍如何用IBM SPSS Modeler 建立、分析及应用线性回归分析模型。
用线性回归建立理赔欺诈检测模型在本例中,用于建立模型的数据存放在InsClaim.dat 中,该文件是一个CSV 格式的数据文件,存储了某医院以往医疗保险理赔的历史记录。
该文件共有293 条记录,每条记录有4 个字段,分别是ASG(疾病严重程度)、AGE(年龄)、LOS (住院天数)和CLAIM(索赔数额)。
图1 显示了该数据的部分内容。
图1. 历史理赔数据文件任务与计划基于已有的数据,我们的任务主要有如下内容:•建立理赔金额预测模型,该模型将基于病人的疾病严重程度、住院天数及年龄预测其索赔金额。

算术函数ABS(numexpr) 数值。
返回numexpr(必须为数值)的绝对值。
ARSIN(numexpr) 数值。
返回numexpr 的反正弦(以弧度为单位),求出的值必须为-1 和+1 之间的数字值。
ARTAN(numexpr) 数值。
返回numexpr 的反正切(以弧度为单位),numexpr 必须为数字值。
COS(radians) 数值。
返回radians 的余弦(以弧度为单位),radians 必须为数字值。
EXP(numexpr) 数值。
返回e 的numexpr 次幂,其中e 是自然对数的底数,而numexpr 是数值。
较大的numexpr 值可能会产生超过机器性能的结果。
LN(numexpr) 数值。
返回以e 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
LNGAMMA(numexpr) 数值。
返回numexpr 的完全Gamma 函数的对数,numexpr 必须为大于0 的数值。
LG10(numexpr) 数值。
返回以10 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
MOD(numexpr,modulus) 数值。
返回numexpr 除以modulus 所得到的余数。
两个参数都必须为数值,且modulus 不得为0。
RND(numexpr) 数值。
返回对numexpr 舍入后产生的整数,numexpr 必须为数值。
刚好以 .5 结尾的数值将舍去0 以后的数值。
SIN(radians) 数值。
返回radians 的正弦(以弧度为单位),radians 必须为数字值。
SQRT(numexpr) 数值。
返回numexpr 的正平方根,numexpr 必须为非负数。
TRUNC(numexpr) 数值。
返回numexpr 被截断为整数(向0 的方向)的值。
统计函数后缀.n 可在所有统计函数中使用以指定有效参数的数目。
例如,仅当至少两个变量含有效值时,MEAN.2(A,B,C,D) 对变量A、B、C 和D 返回其有效值的均值。
(一)算术函数
二)统计函数
注:X1为使用者界定缺失值,X2为系统缺失值,X3为非缺失值四)字符串型函数
五)时间日期函数
注:1 要正确显示以上函数值,必须先赋予其SPSS得日期型变量(DATA)格式,假设以上日期用mm/dd/yy格式显示,时间则用hh:mm:ss格式表示
2 1<=d<=31、1<=m<=12、1<=w<=52、1<=q<=4
六)其他函数
SPSS除了上述函数外,尚有日期和时间转换函数
(YOMODA\CTMIESDAYS\CTIMEHOURS\MDAYS等)、连续几率密度函数
(CDF\BINOM\CHISQ\CDF\EXP\LOGISTIC等),此外还有NORMAL(stddev)可产生平均数为0,标准差为stddev的正态分布随机数字。
UNIFORM(max)可产生平均数为0与max间呈均等分布的随机数字。
PS:还可以像EXCEL一样利用脚本编写自定义函数,目前SPSS支持python,Sax Basic(一种与VB兼容的编程语言)等语言,利用new--script可编写出自己需要的函数。
script界
面如下:。
IBM SPSS Modeler 说明数据挖掘和建模数据挖掘是一个深入您的业务数据,以发现隐藏的模式和关系的过程。
数据挖掘解决了一个常见的问题:您拥有的数据越多,就越难有效地分析并得出数据的意义,并且耗时也越长。
金矿无法开采,通常是由于缺乏人力、时间或专业技术。
数据挖掘使用清晰的业务流程和强大的分析技术,快速、彻底地探索大量的数据,抽取并为您提供有用且有价值的信息,这正是您所需要的“商务智能”。
尽管您数据中的这些以前未知的模式和关系本身很有趣,但一切并不止于此。
如果您可以使用这些过去行为的模式来预测未来可能发生的事情,那又会怎样?这就是建模的目标 - 模型,它包含一组从源数据中抽取的规则、公式或方程式,并允许您通过它们生成预测结果。
这正是预测分析的核心。
关于预测分析预测分析是一个业务流程,其中包含一组相关技术,通过从您的数据中总结出有关当前状况与未来事件的可靠结论,帮助制定有效的行动措施。
它是以下方面的组合:•高级分析•决策优化高级分析使用多种工具和技术,分析过去与现在的事件,并预测未来的结果。
决策优化确定您的哪些措施可以产生最好的可能结果,并确保这些建议措施能够最有效地融入到您的业务流程中。
有关预测分析如何工作的深入信息,请访问公司网站/predictive_analytics/work.htm。
建模技术建模技术基于对算法的使用,算法是解决特定问题的指令序列。
您可以使用特定算法创建相应类型的模型。
有三种主要的建模技术类别,IBM® SPSS® Modeler 为每种类别提供了一些示例:•Classification•关联•细分(有时称为“聚类”)分类模型使用一个或多个输入字段的值来预测一个或多个输出(或目标)字段的值。
这些技术的部分示例为:决策树(C&R 树、QUEST、CHAID 和 C5.0 算法)、回归(线性、logistic、广义线性和Cox 回归算法)、神经网络、Support Vector Machine (SVM) 和贝叶斯网络。
IBM SPSS MODELER 的日常应用详解Modeler 中 EXCEL 数据处理白杨, 软件工程师, IBM简介:本文主要介绍 IBM SPSS Modeler 的日常应用。
Modeler 不只是一款可以用于复杂数据挖掘的贵族型软件,更是一款可以在简单办公室工作中帮助大家节约时间智慧工作的平民型软件。
本文通过 Modeler 帮一个高级 HR 工作人员从重复性手动操作处理 EXCEL 文件到组建串流自动处理着手,让读者更容易地了解 Modeler 在数据处理方面的广泛应用。
本文的标签:best_practices, 关于产品, 应用开发, 管理标记本文!发布日期: 2011 年 7 月 14 日级别:初级访问情况 377 次浏览建议: 0 (添加评论)平均分(共 0 个评分)Alice 是公司的一个人力资源专员。
像每个在跨国企业人力资源部工作的普通人员一样,她每天都需要和这个公司上万人员的资料数据打交道。
对于一个非编程技术人员,使用 EXCEL 只可以完成一些简单的排序工作。
不会写程序,只能通过手动一条条的把自己需要的数据资料从成千上万行 excel 数据中挑选出来,分成不同的,适合不同用途的 Excel 文档是一个既浪费时间又浪费人力的体力活。
这些繁琐的重复性劳动每天都占用了 Alice 大量的时间。
更不要说人力劳动可能出现的小小纰漏,常常使 Alice 无可奈何的接受领导的批评。
本文将会通过对 IBM SPSS MODELER 产品基础功能的简单描述,让也许和 ALICE 有着一样困惑的您在最短的时间内之内将这些数据分割成任何你可能会需要的文件。
也希望这篇对 Modeler 应用小技巧的文章,增加大家对 Modeler 产品的了解和发展 Modeler 产品的应用。
本文的数据文件是以人力资源部的员工文件为脚本,在更改了员工姓名,经理NoteID 和部门信息等资料后选取了有代表性的 49 行资料来分析处理。
SPSS Modeler常用函数简介SPSS Modeler软件包含多种功能丰富的函数,几乎涵盖了我们日常工作的各种需要,主要有信息函数、转换函数、比较函数、逻辑函数、数值函数、三角函数、概率函数、位元整数运算、随机函数、字符串函数、日期和时间函数、序列函数、全局函数、空值和Null 值处理函数、特殊函数等15大类,本讲义将逐一介绍并说明其注意事项。
在本讲义中涉及到的函数,具体的字段格式按照如下约定表示:此外,本讲义中的函数以函数、结果类型(整数、字符串等)和说明(如果有)各占一列的形式一一列举说明。
例如,对函数rem的说明如下。
1. 信息函数信息函数用于深入了解特定字段的值。
它们通常用于派生标志字段。
例如,可以使用@BLANK函数来创建一个标志字段,以指示选定字段的值为空值的记录。
同样,可以使用存储类型函数(如is_string)来检查某个字段的存储类型。
2. 转换函数转换函数可用来构建新字段和转换现有文件的存储类型。
例如,可通过将字符串连接在一起或分拆字符串来形成新字符串。
若要连接两个字符串,请使用运算符“><”。
例如,字段Site的值为"BRAMLEY",则"xx"><Site将返回"xxBRAMLEY"。
即使参数不是字符串,“><”的结果也始终是字符串,因此,如果字段V1为3,字段V2为5,则V1><V2将返回"35"(字符串而非数值)。
请注意,转换函数及其他要求特定类型输入(如日期或时间值)的函数取决于“流选项”对话框中指定的当前格式。
例如,要将值为Jan2003、Feb2003等的字符串字段转换为日期存储格式,请选择MONYYYY作为流的默认日期格式。
3. 比较函数比较函数用于字段值的相互比较或与指定字符串进行比较。
例如,可以使用“=”来检查字符串是否相等。
SPSS Molder常用函数简介
SPSS Molder软件包含多种功能丰富的函数,几乎涵盖了我们日常工作的各种需要,主要有信息函数、转换函数、比较函数、逻辑函数、数值函数、三角函数、概率函数、位元整数运算、随机函数、字符串函数、日期和时间函数、序列函数、全局函数、空值和Null 值处理函数、特殊函数等15大类,本附录将逐一介绍并说明其注意事项。
在本附录中涉及到的函数,具体的字段格式按照如下约定表示。
此外,本附录中的函数以函数、结果类型(整数、字符串等)和说明(如果有)各占一列的形式一一列举说明。
例如,对函数rem的说明如下。
1. 信息函数
信息函数用于深入了解特定字段的值。
它们通常用于派生标志字段。
例如,可以使用@BLANK函数来创建一个标志字段,以指示选定字段的值为空值的记录。
同样,可以使用存储类型函数(如is_string)来检查某个字段的存储类型。
2. 转换函数
转换函数可用来构建新字段和转换现有文件的存储类型。
例如,可通过将字符串连接在一起或分拆字符串来形成新字符串。
若要连接两个字符串,请使用运算符“><”。
例如,字段Site的值为"BRAMLEY",则"xx"><Site将返回"xxBRAMLEY"。
即使参数不是字符串,“><”的结果也始终是字符串,因此,如果字段V1为3,字段V2为5,则V1><V2将返回"35"(字符串而非数值)。
请注意,转换函数及其他要求特定类型输入(如日期或时间值)的函数取决于“流选项”对话框中指定的当前格式。
例如,要将值为Jan2003、Feb2003等的字符串字段转换为日期存储格式,请选择MONYYYY作为流的默认日期格式。
3. 比较函数
比较函数用于字段值的相互比较或与指定字符串进行比较。
例如,可以使用“=”来检查字符串是否相等。
字符串相等的验证示例:Class="class1"。
对数值比较来说,大于表示离正无穷更近,小于表示离负无穷更近,即所有负数均小于任意正数。
4. 逻辑函数
MOLDER表达式可用来执行逻辑运算,主要功能如下。
5. 数值函数
MOLDER包含许多常用的数值函数,主要功能如下。
6. 三角函数
三角函数以角度为参数或返回结果为角度,无论哪种情况,角度单位(弧度或度数)均由相关流选项的设置控制。
7. 概率函数
概率函数返回基于各种分布的概率,主要功能如下。
8. 位元整数运算
借助上述函数,可以按表示二进制补码值的位模式(其中位的位置N的权重为2**N)来操控整数。
位从0开始往上数,这些运算就好像是把整数的符号位向左无限延伸,因此,最高有效位前的所有位,正整数均为0,负整数均为1,注意:不能从脚本中调用位元函数。
9. 随机函数
以下函数用于随机选择项目或随机生成数值,主要功能如下。
10. 字符串函数
在
MOLDER 中可以对字符串执行以下操作:比较字符串、创建字符串、访问字符串。
在MOLDER 中,字符串是一对英文双引号("string quotes")之间的一组字符序列。
这里所用的字符(CHAR )可以是任何一个字母、数字字符。
这些字符已在MOLDER 表达式中使用反单引号并以'<character>'的形式声明过,例如'z'、'A'或'2'。
如果字符超出边界或为字符中的负指数,则结果将返回Null 值。
11. 日期和时间函数
MOLDER包含一系列处理含有字符串日期时间存储变量的字段函数,这些字符串变量代表日期和时间。
可在“流属性”对话框中指定具体到每个流的日期和时间格式。
日期和时间函数根据当前选定的格式来解析日期和时间字符串。
如果用两位数指定日期中的年(即未指定世纪),则Molder将采用“流属性”对话框中所指定的默认世纪,注意:不能从脚本中调用日期和时间函数。
日期和时间函数的主要功能如下。
12. 序列函数
对于某些操作而言,事件序列很重要。
Molder应用程序可使您处理以下记录序列:序列和时间序列、序列函数、记录索引、求值的平均数、总和以及对值进行比较等。
对于许多应用程序,每个通过流传递的记录可以看成是独立于所有其他记录的单个案例。
此种情况下,记录的顺序通常并不重要。
然而对于某些类别的问题,记录序列非常重要。
这些一般是发生在时间序列中的情况,其中记录序列代表事件的有序排列。
每条记录代表着时间中的某个特定时刻的快照,大部分最重要的信息可能并未包含在瞬时值中,而是包含在随时间的流逝、不断变更发展的方式中。
通过以下特征可以立即识别出序列和特殊函数:这些函数的前缀均为“@”;函数名称采用大写。
序列函数可以引用节点当前处理的记录、已通过节点的记录,甚至是尚未通过节点的记录。
序列函数可与其他MOLDER表达式组件自由组合,虽然某些函数对参数有所限制。
例如:您会发现了解自某一特定事件发生或条件为真以来的时间长度非常有用。
使用函数@SINCE可实现上述目的,例如:@SINCE(Income>Outgoings)函数返回最后一条满足此条件记录的偏移量,即在此记录之前满足条件的记录数。
如果条件从不为真,则@SINCE 返回@INDEX+1。
有时您可能需要在@SINCE所用的表达式中引用当前记录的值,此时可以使用函数
@THIS指定一个始终应用于当前记录的字段名。
若要找出最后一条满足Concentration字段值是当前记录两倍的记录的偏移量,可使用表达式:@SINCE(Concentration>2*@THIS(Concentration)),有时,当前记录的@SINCE函数的定义条件为真,例如:@SINCE(ID==@THIS(ID)),基于这种原因,@SINCE函数将不对当前记录的条件求值。
如果要对当前记录以及前面记录的条件求值,请使用类似函数@SINCE0;如果当前记录的条件为真,则@SINCE0返回值为0。
注意:不得从脚本调用@函数。
序列函数的主要功能如下。
13. 全局函数
函数@MEAN、@SUM、@MIN、@MAX和@SDEV用于处理所有已读取的记录(包括当前记录)。
但在某些时候,它可用于检测如何将当前记录中的值与整个数据集中的值进行比较。
如果使用设置全局量节点来生成整个数据集中的值,则您可在使用全局函数的MOLDER表达式中访问这些值。
例如:@GLOBAL_MAX(Age)返回数据集中的最大Age 值,同时表达式(Value-@GLOBAL_MEAN(Value))/@GLOBAL_SDEV(Value)将给出该记录Value和作为标准偏差的全局平均数之间的差,仅当设置全局量节点并计算出全局值后,方
可使用它们。
通过单击“流属性”对话框中“全局量”选项中的ClearGlobalValues按钮,您可以撤消当前所有全局值。
注意:不得从脚本调用@函数。
全局函数的主要功能如下。
14. 空值和Null值处理函数
借助于MOLDER,您可以指定在某个字段中用作“空白”或缺失值的特定值。
下列函数可用于处理空值。
注意:不得从脚本调用@函数。
在过滤节点中可以“填写”空值字段。
在过滤和导出节点(仅多种模式)中,特殊的
MOLDER函数@FIELD将指向正在检查的当前字段。
15. 特殊函数
特殊函数用于指示所检查的具体字段,或用于生成输入字段列表。
例如,当一次导出多个字段时,应使用@FIELD函数来指示“对选定字段执行导出操作”。
使用表达式log(@FIELD)来为每个选定字段导出一个新的日志字段。
注意:不得从脚本调用@函数。