抽象语法树_图文-课件PPT(演示稿)-课件
- 格式:ppt
- 大小:1.14 MB
- 文档页数:28

注释语法分析树概念语法制导翻译的基本思想在语法分析基础上边分析边翻译•翻译的依据:语义规则或语义子程序•翻译的结果:相应的中间代码•翻译的做法:为每个产生式配置相应的语义子程序,每当使用某个产生式进行规约或推导时,就调用语义子程序,完成一部分翻译工作•语法分析完成时,翻译工作也告结束sdd && sdt•语法制导定义 syntax-directed definitions(sdd)o将文法符号和某些属性相关联规则与产生式相关联o并通过语义规则来描述如何计算属性的值 e → e 1+ t e . v a l = e 1. v a l + t . v a l e→e1+t e.val=e1.val + t.vale→e1+te.val=e1.val+t.val•语法制导的翻译方案 syntax-directed translationscheme(sdt)o在产生式体中加入语义动作,并在适当的时候执行这些语义动作o e → e 1 + t { e . v a l = e 1. v a l + t . va l ; } e → e1+t \{e.val=e1.val + t.val;\}e→e1+t{e.val=e1.val+t.val;}语义规则•描述一个产生式所对应的翻译工作,如:o改变某些变量的值;o填/查各种符号表;o发现并报告源程序错误;o产生中间代码•决定于翻译的目的,例如:产生什么样的中间代码文法属性(s,l)•综合属性:分析树节点n上的非终结符的综合属性只能通过该节点或子节点的属性来定义。
终结符可以具有综合属性,值由词法分析器提供。
•继承属性分析树节点n上的非终结符的继承属性只能通过该节点或父节点或兄弟节点的属性来定义。
终结符没有继承属性sdd•只包含综合属性的sdd称为s属性的sdd•含有继承属性的sdd在对sdd的求值过程中,如果结点n的属性a依赖于结点m1的属性a1, m2的属性a2,…。

抽象语法树(AST)抽象语法树(AST)最近在做一个类JAVA语言的编译器,整个开发过程,用抽象语法树(Abstract SyntaxTree,AST)作为程序的一种中间表示,所以首先就要学会建立相对应源代码的AST和访问AST。
Eclipse AST是Eclipse JDT的一个重要组成部分,定义在包org.eclipse.jdt.core.dom中,用来表示JAVA语言中的所有语法结构。
Eclipse AST的总体结构1、org.eclipse.jdt.core.dom.AST(AST节点类)Eclipse AST的工厂类,用于创建表示各种语法结构的节点。
2、org.eclipse.jdt.core.dom.ASTNode及其派生类(AST类)用于表示JAVA语言中的所有语法结构,在实际使用中常作为AST 上的节点出现。
3、org.eclipse.jdt.core.dom.ASTVisitor(ASTVisitor类)Eclipse AST的访问者类,定义了统一的访问AST中各个节点的方法。
详细介绍:一、AST节点类整体结构包括CompilationUnit类(编译单元)、TypeDeclaration类(类型声明)、MethodDeclaration类(方法声明);语句包括Block类(语句块)、ExpressionStatement类(表达式)、IfStatement(if语句)、WhileStatement类(while语句)、EmptyStatement类(空语句)、BreakStatement类和ContinueStatement类;表达式包括MethodInvocation类(方法调用)、Assignment 类(赋值表达式)(“=”、“+=”、“-=”、“*=”、“/=”)、InfixExpression类(中缀表达式)(“+”、“-”、“*”、“/”、“%”、“==”、“!=”、“<"、“<=”、“>=”、“&&”、“||”。
抽象语法树(AST)AST描述 在计算机科学中,抽象语法树(AST)或语法树是⽤编程语⾔编写的源代码的抽象语法结构的树表⽰。
树的每个节点表⽰在源代码中出现的构造。
语法是“抽象的”,因为它不代表真实语法中出现的每个细节,⽽只是结构,内容相关的细节。
例如,分组括号在树结构中是隐式的,并且可以通过具有三个分⽀的单个节点来表⽰类似于if-condition-then表达式的句法结构。
这将抽象语法树与传统上指定的解析树区分开来,这些语法树通常由解析器在源代码转换和编译过程中构建。
⼀旦构建,通过后续处理(例如,上下⽂分析)将附加信息添加到AST 。
抽象语法树也⽤于程序分析和程序转换系统。
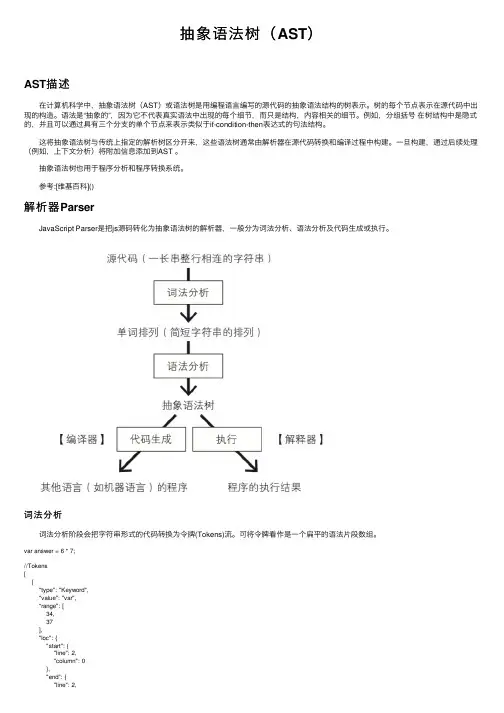
参考:[维基百科]()解析器Parser JavaScript Parser是把js源码转化为抽象语法树的解析器,⼀般分为词法分析、语法分析及代码⽣成或执⾏。
词法分析 词法分析阶段会把字符串形式的代码转换为令牌(Tokens)流。
可将令牌看作是⼀个扁平的语法⽚段数组。
var answer = 6 * 7;//Tokens[{"type": "Keyword","value": "var","range": [34,37],"loc": {"start": {"line": 2,"column": 0},"end": {"line": 2,"column": 3}}},{"type": "Identifier", "value": "answer", "range": [38,44],"loc": {"start": {"line": 2,"column": 4},"end": {"line": 2,"column": 10 }}},{"type": "Punctuator", "value": "=","range": [45,46],"loc": {"start": {"line": 2,"column": 11 },"end": {"line": 2,"column": 12 }}},{"type": "Numeric", "value": "6","range": [47,48],"loc": {"start": {"line": 2,"column": 13 },"end": {"line": 2,"column": 14 }}},{"type": "Punctuator", "value": "*","range": [49,50],"loc": {"start": {"line": 2,"column": 15 },"end": {"line": 2,"column": 16 }}},{"type": "Numeric", "value": "7","range": [51,52],"loc": {"start": {"line": 2,"column": 17},"end": {"line": 2,"column": 18}}},{"type": "Punctuator","value": ";","range": [52,53],"loc": {"start": {"line": 2,"column": 18},"end": {"line": 2,"column": 19}}}]语法分析 语法分析阶段会把⼀个令牌流转换成抽象语法树(AST)的形式,这个阶段会使⽤令牌中的信息把它们转换成⼀个AST的树结构。




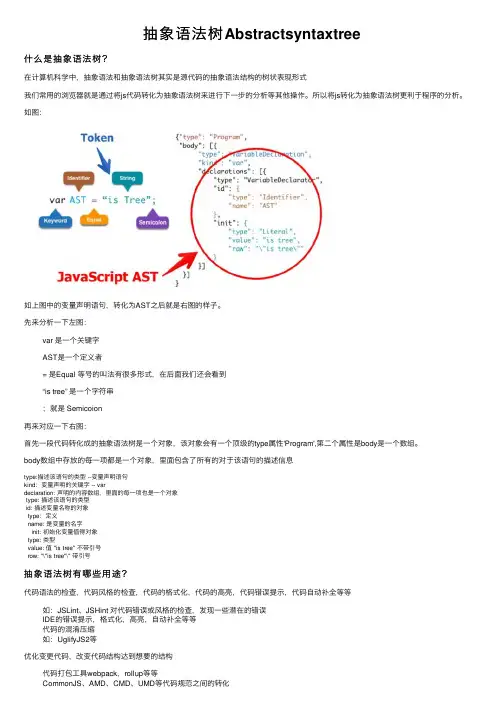
抽象语法树Abstractsyntaxtree什么是抽象语法树?在计算机科学中,抽象语法和抽象语法树其实是源代码的抽象语法结构的树状表现形式我们常⽤的浏览器就是通过将js代码转化为抽象语法树来进⾏下⼀步的分析等其他操作。
所以将js转化为抽象语法树更利于程序的分析。
如图:如上图中的变量声明语句,转化为AST之后就是右图的样⼦。
先来分析⼀下左图:var 是⼀个关键字AST是⼀个定义者= 是Equal 等号的叫法有很多形式,在后⾯我们还会看到“is tree” 是⼀个字符串;就是 Semicoion再来对应⼀下右图:⾸先⼀段代码转化成的抽象语法树是⼀个对象,该对象会有⼀个顶级的type属性'Program',第⼆个属性是body是⼀个数组。
body数组中存放的每⼀项都是⼀个对象,⾥⾯包含了所有的对于该语句的描述信息type:描述该语句的类型 --变量声明语句kind:变量声明的关键字 -- vardeclaration: 声明的内容数组,⾥⾯的每⼀项也是⼀个对象type: 描述该语句的类型id: 描述变量名称的对象type:定义name: 是变量的名字init: 初始化变量值得对象type: 类型value: 值 "is tree" 不带引号row: "\"is tree"\" 带引号抽象语法树有哪些⽤途?代码语法的检查,代码风格的检查,代码的格式化,代码的⾼亮,代码错误提⽰,代码⾃动补全等等如:JSLint、JSHint 对代码错误或风格的检查,发现⼀些潜在的错误IDE的错误提⽰,格式化,⾼亮,⾃动补全等等代码的混淆压缩如:UglifyJS2等优化变更代码,改变代码结构达到想要的结构代码打包⼯具webpack,rollup等等CommonJS、AMD、CMD、UMD等代码规范之间的转化CoffeeScript、TypeScript、JSX等转化为原⽣Javascript通过什么⼯具或库来实现源码转化为抽象语法树?那就是javascript Parser 解析器,他会把js源码转化为抽象的语法树。


SUIF抽象语法树1.概述本次实验中实验三的目标是通过解析语法分析的输出文件来生成中间代码。
至于中间代码的形式,我们要求采用抽象语法树。
抽象语法树的结构则是借鉴SUIF的中间表示。
2.SUIF编译系统中间表示总体上来说,SUIF中间表示由三部分组成:抽象语法树(AST)、符号表、和指令表达式。
2.1.SUIF的层级结构SUIF中间表示组织成4级层次结构,包括:文件级,过程级,高级结构控制级和指令表达式树级。
SUIF中间表示的主要部分是一个混合式的抽象语法树(AST)。
从层次结构上来看,包括高级结构控制级和指令表达式树级,即除了传统的指令级别的操作,它还包含三个高级的结构:循环,条件声明和数组访问。
循环和条件表示类似于抽象语法树,但却是语言无关的。
图2-1展示了SUIF中间表示的层级结构:图2-1:SUIF中间表示的层次结构2.2.SUIF的符号表示SUIF的符号表分为global symbal table,file symbal table,proc symbal table和block symbal table这4种。
它们也是高到低,逐级的贯穿在了SUIF中间表示前3个层级中。
图2-2则表明了这个层次结构:图2-2:SUIF的符号表示2.3.SUIF的面向对象实现SUIF系统的内核提供了一个面向对象的SUIF中间表示的实现。
SUIF库对每个程序表示元素定义了一个C++类,允许我们对隐藏了细节的数据结构提供接口。
在这个系统中,各个类之间存在若干相互联系和共享的属性,这由类的继承和动态邦定功能实现。
例如:变量、标号和过程都是符号,他们共享相同的符号接口,但过程除了符号还有函数体。
除了基本的SUIF数据结构,SUIF的内核中还定义了很多基本的数据结构,包括哈希表,可扩展数组等。
对每个类来说,经常需要用到的函数都被定义为成员函数。
图2-3给出了主要的SUIF数据结构的类层次,所有的类都从suif_object基类继承。
第三章抽象语法树在现代编译器的构造过程中,前端主要实现从源程序到中间形式(Intermediate Representation)的转换,而编译器的后端用来完成从中间形式到具体目标机代码的转换,这是一种广泛采用的编译器构造模型。
虽然源程序到目标程序的直接转换是可行的,但是使用独立于具体目标平台的中间形式有以下优点:(1)使用中间形式可以比较容易地构造面向不同目标平台和不同语言的编译器。
在不改动已有编译器前端的情况下,为新的目标平台构造一个生成该平台目标程序的后端,就可以构造出新平台的编译器。
同样对于一个新的语言,在不改动已有编译器后端的情况下,为新语言构造一个识别该语言的前端,就可以构造出新语言的编译器。
(2)针对中间形式,可以进行独立于目标平台的代码优化。
这样可以生成较高质量的目标代码,在此基础上可以对目标代码进行平台相关的优化,进而生成更高质量的目标代码。
使用中间形式的主要缺点是,产生中间代码的编译过程与不产生中间代码的编译过程相比在效率上会显得有些低。
这是因为中间代码还要进行再一次的翻译才能生成目标代码。
但是,增加一层中间形式可以使编译器更好地模块化,并且可以在中间形式上做很多优化,这些足以抵消两次翻译所带来的低效率。
所以,很多现代的编译器都使用了中间形式,比较常见的中间形式有逆波兰表示,N元表示和树形表示三种。
由于,在本系统中,我们使用抽象语法树作为中间形式,所以不再对前两种中间形式做以介绍,感兴趣的读者可以参考《编译原理》(Alfred V.Aho编著)。
3.1 树形表示树形表示是一种非常流行的中间形式,它与三元式表示有着密切的关系,三元式表示可以看成是树形表示的直接形式。
例如,表达式W*X+(Y+Z)的树形表示如图3.1所示:图3.1 表达式W*X+(Y+Z)的树形表示在现代编译器的构造过程中,经常使用抽象语法树(Abstract Syntax Tree)作为一种中间形式,这样做可以把翻译过程从语法分析过程中分离出来,使得层次非常清晰。