称为总体参数的区间估计
- 格式:ppt
- 大小:733.50 KB
- 文档页数:31


第一章绪论1.描述统计(descriptive statistics)主要研究如何将实验或调查得到的大量数据进行图表整理或简缩成有代表性的数字(即统计量数),使其能客观、全面地反映这组数据的全貌,将其所提供的信息充分显现出来,为进一步统计分析和推论提供可能。
2.描述统计只限于对试验样本所得观测数据的统计分析,不考察其总体的特性。
3.推论统计(inferential statistics)是以描述统计为基础,从而解决由局部到全体的推论问题,即通过对一组统计量的计算分析,推论该组数据所代表的总体特性。
4.变量(variables):一个可以取不同数值的物体属性/事件。
5.事前无法预期结果的变量——随机变量6.观测值(原始取值):事后测定的某一结果。
7.概念理解:[涉及“实验”] 自变量(及其各水平)& 因变量(及相应的反应指标);[涉及“调查”,粗略对应于] 属性变量& 反应变量8.计数资料(count data):计算个数的数据,(如人口数,学校数,男女数等)9.计量资料(measurement data):借助于一定的测量工具或一定的测量标准而获得的数据(如分数,身高,体重,IQ)10.称名数据(nominal data):只区分属性或类别上的不同,只可计数,不能排序(性别,学科,职业)11.等级/顺序数据(ordinal data):可排序,但无相等单位,不能加减。
(等级评定,受教育程度,职称)12.等距数据(interval data):具有相等单位,无绝对零的数据,能加减不能乘除。
13.比率数据(ratio data):既表明量的大小,又具有相等单位,可以加减乘除,具有绝对零点。
14.称名数据和顺序数据合称为离散数据。
15.等距数据和比率数据合称为连续数据。
16.离散数据(discrete data)又称为不连续数据,这类数据在任何两个数据点之间所取的数据的个数是有限的。
17.连续数据(continuous data)指任意两个数据点之间都可以细分出无限多个大小不同的数值。

统计学参数估计参数估计是统计学中的一个重要概念,它是指在推断统计问题中,通过样本数据对总体参数进行估计的过程。
这一过程是通过样本数据来推断总体参数的未知值,从而进行总体的描述和推断。
在统计学中,参数是指总体的其中一种特征的度量,比如总体均值、总体方差等。
而样本则是从总体中获取的一部分观测值。
参数估计的目标就是基于样本数据来估计总体参数,并给出估计的精确程度,即估计的可信区间或置信区间。
常见的参数估计方法包括点估计和区间估计。
点估计是一种通过单个数值来估计总体参数的方法。
点估计的核心是选择合适的统计量作为估计量,并使用样本数据计算出该统计量的具体值。
常见的点估计方法包括最大似然估计和矩估计。
最大似然估计是一种寻找参数值,使得样本数据出现的概率最大的方法。
矩估计则是通过样本矩的函数来估计总体矩的方法。
然而,点估计只能提供一个参数的具体值,无法提供该估计值的精确程度。
为了解决这个问题,区间估计被引入。
区间估计是指通过一个区间来估计总体参数的方法。
该区间被称为置信区间或可信区间。
置信区间是在一定置信水平下,总体参数的真值落在该区间内的概率。
置信区间的计算通常涉及到抽样分布、标准误差和分位数等概念。
在实际应用中,参数估计经常用于统计推断、统计检验和决策等环节。
例如,在医学研究中,研究人员可以通过对患者进行抽样调查来估计其中一种药物的有效性和不良反应的发生率。
在市场调研中,市场研究人员可以通过抽取部分样本来估计一些产品的市场份额或宣传效果。
参数估计的准确性和可靠性是统计分析的关键问题。
估计量的方差和偏倚是影响估计准确性的主要因素,通常被称为估计量的精确度和偏倚性。
经典的参数估计要求估计量是无偏且有效的,即估计量的期望值等于真值,并且方差最小。
总之,参数估计是统计学中的一个重要概念,它通过样本数据对总体参数进行估计,并给出估计值的精确程度。
参数估计在统计推断、统计检验和决策等领域具有广泛的应用。
估计量的准确性和可靠性是参数估计的关键问题,通常通过方差和偏倚的分析来评价估计量的性质。


统计推断的基本解法统计推断是统计学的重要分支,用于从样本中推断总体特征。
在统计分析中,我们通常使用一些基础的解法来进行统计推断。
本文将介绍一些常用的基本解法。
点估计点估计是一种基本的统计推断方法,用于估计总体参数的值。
在点估计中,我们通过样本数据得到一个点估计量,作为总体参数的估计值。
例如,常见的点估计方法包括样本均值、样本方差和样本比例等。
区间估计区间估计是一种更精确的统计推断方法,用于估计总体参数的范围。
在区间估计中,我们通过样本数据得到一个区间估计量,包含了总体参数真值的可能范围。
例如,常见的区间估计方法包括置信区间和可信区间等。
假设检验假设检验是一种常用的统计推断方法,用于验证关于总体参数的假设。
在假设检验中,我们首先提出一个原假设和一个备择假设,然后使用样本数据来判断哪个假设更为合理。
例如,常见的假设检验方法包括单样本检验、双样本检验和方差分析等。
相关分析相关分析是一种用于研究变量之间关系的统计推断方法。
在相关分析中,我们通过计算相关系数来衡量变量之间的相关程度。
例如,常见的相关分析方法包括皮尔逊相关系数和斯皮尔曼相关系数等。
回归分析回归分析是一种用于预测和探索变量之间关系的统计推断方法。
在回归分析中,我们使用回归方程来建立变量之间的函数关系,并通过回归系数来解释这种关系。
例如,常见的回归分析方法包括线性回归和逻辑回归等。
综上所述,统计推断的基本解法包括点估计、区间估计、假设检验、相关分析和回归分析等。
这些方法在统计学领域中被广泛应用,帮助我们从样本中推断总体的特征和关系。

总体参数的区间估计公式在进行区间估计时,我们首先需要收集到一个样本,并根据样本对总体参数进行估计。
然后根据样本的统计量,结合分布的性质和抽样方法,建立置信区间。
设总体参数为θ,我们希望得到它的置信水平为1-α的置信区间。
置信水平表示我们对总体参数的估计的可信程度,一般常用的置信水平有90%、95%和99%等。
参数估计的方法有很多,具体的方法选择取决于总体参数的性质、样本的大小以及其他假设条件。
常见的参数估计方法有:1.总体均值的区间估计:假设总体呈正态分布,样本大小为n,则总体均值的区间估计公式为:[样本均值-Z值(α/2)*总体标准差/√(n),样本均值+Z值(α/2)*总体标准差/√(n)]其中Z值(α/2)为标准正态分布的分位数,可以从标准正态分布表中查得。
2.总体比例的区间估计:假设总体为二项分布,样本大小为n,成功的次数为x,则总体比例的区间估计公式为:[样本比例-Z值(α/2)*√(样本比例*(1-样本比例)/n),样本比例+Z值(α/2)*√(样本比例*(1-样本比例)/n)]其中Z值(α/2)为标准正态分布的分位数,可以从标准正态分布表中查得。
3.总体方差的区间估计:假设总体呈正态分布,样本大小为n,则总体方差的区间估计公式为:[(n-1)*样本方差/卡方分布(α/2),(n-1)*样本方差/卡方分布(1-α/2])]其中卡方分布是用于描述自由度为n-1的卡方随机变量的概率分布,可以从卡方分布表中查得。
以上是常见的总体参数区间估计公式,这些公式是根据统计学理论推导而来的,适用于不同情况下的参数估计。
在实际应用中,我们根据具体问题和假设条件选择适当的参数估计方法,计算置信水平的区间估计,从而对总体参数进行估计和推断。


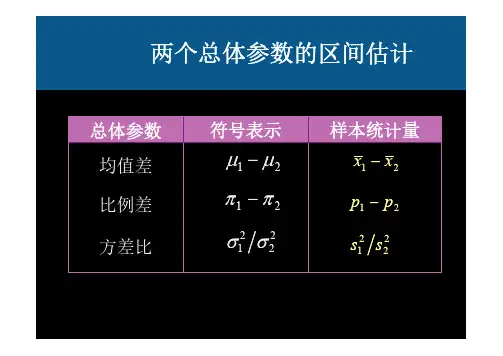
双正态总体参数的区间估计双正态总体参数的区间估计是统计学中的一种方法,用于估计由两个正态分布组成的总体的参数。
这种方法适用于当我们需要估计两个总体的平均值或比例时,且这两个总体可以被假定为来自两个不同的正态分布。
下面我们将详细介绍双正态总体参数的区间估计的原理和步骤。
双正态总体参数的区间估计可以分为两种情况:一种是当我们需要估计两个总体的平均值,另一种是当我们需要估计两个总体的比例。
首先,假设我们需要估计两个总体的平均值。
我们可以用样本平均值来估计总体平均值,并通过计算标准误差来构建置信区间。
如果我们假设两个总体的方差相等,则可以使用统计学中的配对t检验方法来进行推断。
具体步骤如下:1.收集样本数据。
从每个总体中随机抽取一定数量的样本,并记录下每个样本的观测值。
2.计算样本平均值。
对于每个总体,计算对应样本的平均值。
3.计算差值。
对于每个配对样本,计算它们的差值。
如果我们关注的是总体平均值的差异,则用两个总体对应样本的平均值之差来作为差值。
4.计算标准差。
计算差值样本的标准差,用来估计差值的标准误差。
5.确定置信水平。
选择一个置信水平,通常为95%。
这意味着我们希望有95%的置信度认为估计的区间包含真实的总体差异。
6.计算临界值。
确定配对t检验的自由度,并使用自由度和置信水平来查找相应的t临界值。
7.构建置信区间。
使用差值平均值±t临界值*标准误差来构建置信区间,这个区间将包含真实的总体差异。
另一种情况是当我们需要估计两个总体的比例。
在这种情况下,我们可以使用两个样本中的比例差异来估计总体的比例差异。
具体步骤如下:1.收集样本数据。
从每个总体中随机抽取一定数量的样本,并记录下每个样本中的成功次数和总次数。
2.计算样本比例。
对于每个总体,计算对应样本的比例,即成功次数除以总次数。
3.计算差异。
对于每个配对样本,计算它们的比例之差。
4.计算标准误差。
计算比例差异样本的标准误差,用来估计比例差异的标准误差。


统计学学习题及解答一、填空题:1、“统计”一词,一般有三种涵义,即统计资料、统计工作和统计学。
2、统计指标按其反映的总体内容不同,可分为数量指标与质量指标;按其作用和表现形式不同,可分为总量指标、相对指标和平均指标。
结构相对指标是部分(或各组)总量与总体总量之比。
3、总量指标时间数列是基本的时间数列,它有时期数列和时点数列两种。
4、当我们研究某个班学生的学习情况时,某个班的学生便构成总体,而这个班的每一名学生则是总体单位。
5、可变的数量标志称为变量,而数量标志的表现则称标志值。
6、标志是用来说明总体单位特征的名称,而指标是说明总体的综合数量特征的。
7、人口按性别、民族、职业分组,属于按品质标志分组,而人口按年龄、工资、身高分组,则属于按数量标志分组。
8、方差分析中,如果在实验中变化的因素只有一个,这时的方差分析称为单因素方差分析。
9、直线相关系数等于0,说明两变量之间无线性相关关系;直线相关系数等于1,说明两变量之间完全线性正相关。
直线相关系数越接近于1,说明两变量之间相关关系越密切;直线相关系数越接近于0,说明两变量之间相关关系越不密切。
10、相关系数的取值在-1 和 1 之间,即[-1,1]。
11、从内容上看,统计表由主词栏和宾词栏两部分组成。
12、假设检验分为两类:参数假设检验和非参数假设检验。
p13、是非标志的平均数等于,是非标志的标准差等于14、统计调查按调查对象所包括的范围不同,可分为全面调查和非全面调查。
15、按照说明现象的范围不同,统计指数可分为个体指数和总指数。
16、保证时间数列中各个指标数值的可比性是编制时间数列的基本原则。
17、组中值是各组上限和下限的简单平均。
18、投资额与消费额的比例为1:3(A)。
投资额占国内生产总值使用额的25%(B)。
在这一资料中,A为比例相对指标,B为结构相对指标。
19、统计数据的表现形式有绝对数、相对数和平均数三种。
20、相关关系按相关的方向可分为正相关和负相关。
应用统计单项选择题1.社会经济统计是(C)的有利工具。
A.处理问题B.进行交流C.认识社会D.引进外资2.(A)是用图形、表格和概括性的数字对数据进行描述的统计方法。
A.描述统计B.推断统计C.理论统计D.应用统计3.(A)是我们所要研究的所有基本单位(通常是人、物体、交易或事件)的总和。
A.总体B.变量C.样本D.统计4.经济数据是对(B)进行计算的结果。
A.主观现象B.客观现象C.数字特征D.社会现象5.美国盖洛普(Gallup)调查公司在美国总统大选前通常会从全美国的选民中随机抽取1500人左右,对大选结果进行调查和预测,并会给出2%左右的预测误差。
这是利用样本信息和概率论原理进行(B)的过程。
A.统计描述B.统计推断C.统计分析D.统计应用6.统计学的核心内容是(C)。
A.统计数据的收集B.统计数据的整理C.统计数据的分析D.统计数据的应用7.(A)在《政治算术》一书中用大量的数字对英国、法国、荷兰三国的经济实力进行比较,用数字、重量、尺度等定量的方法进行分析和比较,表达他的思想和观点。
A.威廉配第B.约翰格朗特C.帕斯卡D.费马8.统计整理主要是对(C)的整理。
9.著名统计学家(B)给出了F统计量、最大似然估计、方差分析等方法和思想。
A.戈赛特B.费希尔C.奈曼和皮尔逊D.沃尔德10.统计数据的搜集活动是(B)。
A.应用统计B.统计工作C.统计数据D.统计学第02章-统计数据的描述1.某企业男性职工占60%,月平均工资为550元,女性职工占40%,月平均工资为500元,该企业全部职工的平均工资为(B)。
A.525元B.530元C.535元D.540元2.如果数据是左偏分布,则有(C)。
A.平均数=中位数=众数B.平均数>中位数>众数C.平均数A.抽样调查B.典型调查C.重点调查D.普查4.今有四位工人的工资分别为:400元,600元,700元,900元,计算四人平均工资,应采用的计算方式是(A)。
复习资料(资料总结,仅供参考)判断题1.研究人员测量了100例患者外周血的红细胞数,所得资料为计数资料。
X 2.统计分析包括统计描述和统计推断。
3.计量资料、计数资料和等级资料可根据分析需要相互转化。
4.均数总是大于中位数。
X 5.均数总是比标准差大。
X 6.变异系数的量纲和原量纲相同。
X 7.样本均数大时,标准差也一定会大。
X 8.样本量增大时,极差会增大。
9.若两样本均数比较的假设检验结果P 值远远小于,则说明差异非常大。
X 10.对同一参数的估计,99%可信区间比90%可信区间好。
X 11.均数的标准误越小,则对总体均数的估计越精密。
12. 四个样本率做比较,2)3(05.02χχ> ,可认为各总体率均不相等。
X 13.统计资料符合参数检验应用条件,但数据量很大,可以采用非参数方法进行初步分析。
14.对同一资料和同一研究目的,应用参数检验方法,所得出的结论更为可靠。
X 15.等级资料差别的假设检验只能采用秩和检验,而不能采用列联表χ2检验等检验方法X 。
16.非参数统计方法是用于检验总体中位数、极差等总体参数的方法。
X 17.剩余平方和SS 剩1=SS 剩2,则r 1必然等于r 2。
X 18.直线回归反映两变量间的依存关系,而直线相关反映两变量间的相互直线关系。
19.两变量关系越密切r 值越大。
X 20.一个绘制合理的统计图可直观的反映事物间的正确数量关系。
21.在一个统计表中,如果某处数字为“0”,就填“0”,如果数字暂缺则填“…”,如果该处没 有数字,则不填。
X 22.备注不是统计表的必要组成部分,不必设专栏,必要时,可在表的下方加以说明。
23.散点图是描写原始观察值在各个对比组分布情况的图形,常用于例数不是很多的间断性分组资料的比较。
24.百分条图表示事物各组成部分在总体中所占比重,以长条的全长为100%,按资料的原始顺序依次进行绘制,其他置于最后。
X 25.用元参钩藤汤治疗80名高血压患者,服用半月后比服用前血压下降了,故认为该药有效( X )。