AMOS做验证性因子分析报告材料
- 格式:doc
- 大小:331.50 KB
- 文档页数:4



AMOS输出解读惠顿研究惠顿数据文件在各种结构方程模型中被当作经典案例,包括AMOS和LISREL。
本文以惠顿的社会疏离感追踪研究为例详细解释AMOS的输出结果。
AMOS同样能处理与时间有关的自相关回归。
惠顿研究涉及三个潜变量,每个潜变量由两个观测变量确定。
67疏离感由67无力感(在1967年无力感量表上的得分)和67无价值感(在1967年无价值感量表上的得分)确定。
71疏离感的处理方式相同,使用1971年对应的两个量表的得分。
第三个潜变量,SES(社会经济地位)是由教育(上学年数)和SEI (邓肯的社会经济指数)确定。
解读步骤1.导入数据。
AMOS在文件ex06-a.amw中提供惠顿数据文件。
使用File/Open,选择这个文件。
在图形模式中,文件显示如下。
虽然这里是预定义模式,图形模式允许你给变量添加椭圆,方形,箭头等元素建立新模型2.模型识别。
潜变量的方差和与它关联的回归系数取决于变量的测量单位,但刚开始谁知道呢。
比如说要估计误差的回归系数同时也估计误差的方差,就好像说“我买了10块钱的黄瓜,然后你就推测有几根黄瓜,每根黄瓜多少钱”,这是不可能实现的,因为没有足够的信息。
如何告诉你“我买了10块钱的黄瓜,有5根”,你便可以推出每根黄瓜2块钱。
对潜变量,必须给它们指定一个数值,要么是与潜变量有关的回归系数,要么是它的方差。
对误差项的处理也是一样。
一旦做完这些处理,其它系数在模型中就可以被估计。
在这里我们把与误差项关联的路径设为1,再从潜变量指向观测变量的路径中选一条把它设为1。
这样就给每个潜变量设置了测量尺度,如果没有这个测量尺度,模型是不确定的。
有了这些约束,模型就可以识别了。
注释:设置的数值可以是1,也可以是其它数,这些数对回归系数没有影响,但对误差有影响,在标准化的情况下,误差项的路径系数平方等于它的测量方差。
3.解释模型。
模型设置完毕后,在图形模式中点击工具栏中计算估计按钮运行分析。
AMOS输出解读惠顿研究惠顿数据文件在各种结构方程模型中被当作经典案例,包括AMOS和LISREL。
本文以惠顿的社会疏离感追踪研究为例详细解释AMOS的输出结果。
AMOS同样能处理与时间有关的自相关回归。
惠顿研究涉及三个潜变量,每个潜变量由两个观测变量确定。
67疏离感由67无力感(在1967年无力感量表上的得分)和67无价值感(在1967年无价值感量表上的得分)确定。
71疏离感的处理方式相同,使用1971年对应的两个量表的得分。
第三个潜变量,SES(社会经济地位)是由教育(上学年数)和SEI (邓肯的社会经济指数)确定。
解读步骤1.导入数据。
AMOS在文件ex06-a.amw中提供惠顿数据文件。
使用File/Open,选择这个文件。
在图形模式中,文件显示如下。
虽然这里是预定义模式,图形模式允许你给变量添加椭圆,方形,箭头等元素建立新模型2.模型识别。
潜变量的方差和与它关联的回归系数取决于变量的测量单位,但刚开始谁知道呢。
比如说要估计误差的回归系数同时也估计误差的方差,就好像说“我买了10块钱的黄瓜,然后你就推测有几根黄瓜,每根黄瓜多少钱”,这是不可能实现的,因为没有足够的信息。
如何告诉你“我买了10块钱的黄瓜,有5根”,你便可以推出每根黄瓜2块钱。
对潜变量,必须给它们指定一个数值,要么是与潜变量有关的回归系数,要么是它的方差。
对误差项的处理也是一样。
一旦做完这些处理,其它系数在模型中就可以被估计。
在这里我们把与误差项关联的路径设为1,再从潜变量指向观测变量的路径中选一条把它设为1。
这样就给每个潜变量设置了测量尺度,如果没有这个测量尺度,模型是不确定的。
有了这些约束,模型就可以识别了。
注释:设置的数值可以是1,也可以是其它数,这些数对回归系数没有影响,但对误差有影响,在标准化的情况下,误差项的路径系数平方等于它的测量方差。
3.解释模型。
模型设置完毕后,在图形模式中点击工具栏中计算估计按钮运行分析。

验证性因素分析范文验证性因素分析是一种统计分析方法,主要用于评估和验证一个已经建立的理论模型是否与实际数据相吻合。
它基于因子分析的基本原理,并且通过拟合度指标和参数估计等统计量来评估模型拟合好坏,从而判断模型是否有效。
验证性因素分析常用于心理学、社会科学、市场研究等领域,用于测量和验证潜在的观测变量之间的关系。
其基本步骤包括:确定研究目的、建立理论模型、选择合适的变量、采集数据、运行验证性因素分析模型以及分析结果。
在进行验证性因素分析之前,需要明确研究目的和假设。
研究目的通常是通过数据分析验证或者修正一个已经建立的理论模型。
在建立模型时,需要定义潜在的观测变量以及它们之间的关系,形成一系列假设。
根据这些假设,选择适当的测量工具和样本进行数据采集。
数据采集完成后,可以运行验证性因素分析模型。
这里常用的模型包括结构方程模型(SEM)和对应分析模型(CFA)。
这些模型可以通过最大似然估计法来估计参数。
通过分析结果,可以得到各个观测变量的测量值以及它们对应的因子负荷量。
同时通过拟合度指标如卡方统计量、均方根误差逼近度(RMSEA)、标准化均方差残差(χ2/df)等对模型进行评估。
除了拟合度指标,还可以通过参数估计来评估模型拟合的好坏。
参数估计包括路径系数、因子间相关系数、因子负荷量以及测量误差。
通常认为,路径系数和因子间相关系数应该显著不为零,而因子负荷量应该大于0.4、此外,还可以通过测量误差的估计来检验观测变量的可靠性。
最后,根据验证性因素分析的结果,可以得到一系列结论。
如果拟合度较好,那么可以认为建立的理论模型与实际数据较好符合,模型是有效的。
如果拟合度较差,就需要对模型进行修改和改进,以更好地与实际数据相吻合。
总之,验证性因素分析是一种重要的数据分析方法,它可以用于评估和验证一个已经建立的理论模型是否与实际数据相吻合。
通过分析结果,可以得到各个观测变量的测量值以及它们对应的因子负荷量,以及拟合度指标和参数估计等统计量,从而判断模型是否有效。


因子分析实验报告范本一、实验目的本次因子分析实验旨在探究多个变量之间的潜在结构关系,通过降维的方法提取出主要的公共因子,以更简洁、有效地解释数据中的信息。
二、实验数据来源及描述实验数据来源于_____调查,共收集了_____个样本,涉及_____个变量。
这些变量包括但不限于:1、变量 1:_____,用于衡量_____。
2、变量 2:_____,反映了_____。
3、变量 3:_____,其代表的含义是_____。
三、实验方法1、数据预处理对缺失值进行处理,采用_____方法进行填充。
对数据进行标准化处理,以消除量纲的影响。
2、因子提取方法选用主成分分析法提取公共因子。
根据特征根大于 1 的原则确定因子个数。
3、因子旋转方法采用方差最大化正交旋转,以使因子更具有可解释性。
四、实验步骤1、导入数据使用统计软件(如 SPSS)将数据文件导入。
2、数据预处理按照上述预处理方法进行操作。
3、因子分析在软件中选择因子分析模块,设置相应的参数进行分析。
4、结果解读观察公因子方差表,了解每个变量被公共因子解释的程度。
查看总方差解释表,确定提取的公共因子个数及解释的总方差比例。
分析旋转后的成分矩阵,解读公共因子的含义。
五、实验结果1、公因子方差变量 1 的公因子方差为_____,表明公共因子能够解释其_____%的方差。
变量 2 的公因子方差为_____,意味着公共因子对其的解释程度为_____%。
2、总方差解释提取了_____个公共因子,其特征根分别为_____、_____、_____。
这_____个公共因子累计解释了总方差的_____%。
3、旋转后的成分矩阵公共因子 1 在变量 1、变量 2 上有较高的载荷,分别为_____、_____,可以将其解释为_____因素。
公共因子 2 在变量 3、变量 4 上的载荷较大,分别为_____、_____,代表了_____方面。
六、结果讨论1、因子的可解释性提取的公共因子在实际意义上具有一定的合理性和可解释性,能够较好地概括原始变量所包含的信息。
验证性因子分析1、作用验证性因子分析(confirmatory factor analysis, CFA)是用于测试一个因子与相对应的测度项之间的关系是否符合研究者所设计的理论关系的一种研究方法,可用于调查问卷的量表分析。
2、输入输出描述输入:至少两项或以上的定量变量或有序的定类变量。
输出:测量因子与变量之间的对应关系是否符合研究者所设计的理论关系。
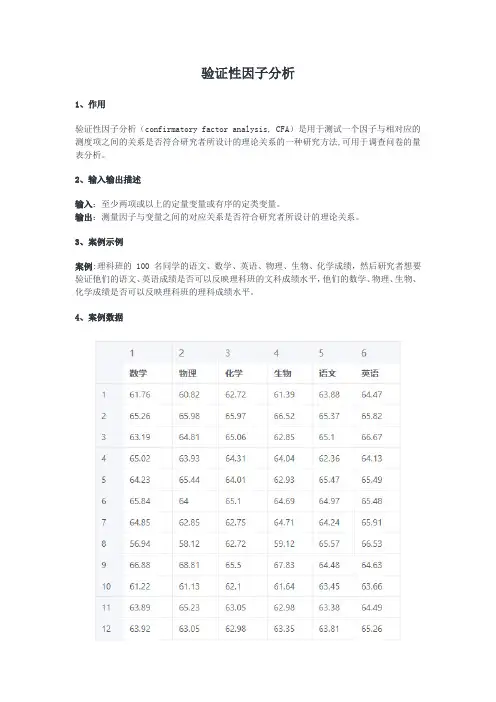
3、案例示例案例:理科班的 100 名同学的语文、数学、英语、物理、生物、化学成绩,然后研究者想要验证他们的语文、英语成绩是否可以反映理科班的文科成绩水平,他们的数学、物理、生物、化学成绩是否可以反映理科班的理科成绩水平。
4、案例数据验证性因子分析案例数据模型要求为至少两项或以上的定量变量或有序的定类变量,其中数学、物理、化学、生物为一个因子,语文和英语为一个因子。
5、案例操作Step1:新建分析;Step2:上传数据;Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;Step4:选择【验证性因子分析】;Step5:查看对应的数据数据格式,【验证性因子分析】要求特征序列至少两项或以上的定量变量或有序的定类变量。
在因子 1 拖入需验证的变量。
Step6:当涉及到多个因子时,点击【创建因子】.Step7:在因子 2 拖入需验证的变量。
Step8: 点击【开始分析】,完成全部操作6、输出结果分析输出结果 1:因子基本汇总表图表说明: 上表展示了样本频数的统计情况,包括样本中各个因子的字段频数、总计、总样本频数,CFA分析要求总样本数据最少要是因子内个别量表的5倍以上,且一般情况下至少需要200个样本。
结果分析:样本数据集共有因子数量 2 个,变量数 6 个,样本数 200 满足验证性因子分析基本数据要求。
输出结果 2:因子载荷系数表图表说明:上表为模型的因子载荷系数表格,包括潜变量、分析项、非标准载荷系数、z检验结果等。
测量关系时第一项会被作为参照项,因此不会呈现P值等统计量。

电子科技大学政治与公共管理学院本科教学实验报告(实验)课程名称:数据分析技术系列实验电子科技大学教务处制表电子科技大学实验报告学生:晨飞学号:27指导教师:高天鹏一、实验室名称:电子政务可视化实验室二、实验项目名称:因子分析三、实验原理使用SPSS软件的因子分析对数据样本进行分析相关分析的原理:步骤一:将原始数据标准化。
因子分析的第一步是主成分分析,将总量较多的因素通过线性组合的方式组合成几个因素,且这些因素之间相互独立。
步骤二:建立变量的相关系数矩阵RAnalyse->Dimention Ruduction-> Fctor ->Extraction->勾选Correlation matrix 可以输出相关系数矩阵,相关系数矩阵计算了变量之间两两的pearson相关系数。
步骤三:适用性检验使用Bartlett球形检验或者KMO球形检验来检验样本是否适合进行因子分析。
评价标准:KMO检验用于检验变量间的偏相关系数是否过小,一般情况下,当KMO大于0.9时效果最佳,小于0.5时不适宜做因子分析。
Bartlett球形检验用于检验相关系数矩阵是否是单位阵,如果结论是不拒绝该假设,则表示各个变量都是各自独立的。
步骤四:根据因子贡献率选取因子,特征值和特征向量构建因子载荷矩阵A。
处于简化和抽取核心的思想,一般会按照某种标准选取前几个对观测结果影响较大的因素构建因子载荷矩阵,一般的标准是选取特征根大于1的因子。
并要求累积贡献率达到90%以上。
步骤五:对A进行因子旋转因子旋转的目的是使因子载荷矩阵的结构发生变化,使每个变量仅在一个因子上有较大载荷。
是将因子矩阵在一个空间里投影,使单个向量的投影在仅在一个变量的方向有较大的值,这样做可以简化分析。
步骤六:计算因子得分:计算因子得分是计算在不同样本水平下观测指标的水平的方式。
计算因子得分需要用到因子得分计算函数,这个计算的结果是无量纲的,仅表示各因子在这个水平下观测指标的值,这也是因子分析的目标,将不可观测的目标观测量用一个函数与可以观测的变量联系起来。

协方差结构模型被广泛用于探讨问卷调查或实验性的数据。
(协方差:两个变量间的线性关系)一个完整的协方差结构模型包含两个次模型:测量模型+结构模型。
结构方程模型(Structural equation modeling,简称SEM),它综合了因素分析和路径分析两种统计方法,同时检验模型中包含的显性变量、潜在变量、干扰或误差变量之间的关系,进而获得自变量对依变量影响的直接效果、间接效果或总效果。
(是一种验证性统计方法)Amos(Analysis of Moment Structures,矩结构分析)是一种结构方程模型软件,又称为协方差结构分析、潜在变量分析、验证性因子分析Amos属于结构方程式模型的一种,其功能在于探讨多变量或单变量之间的因果关系。
还可以让我们检验数据是否符合所建立的模型,以及进行模型探索(逐步建立最适当的模型)。
基本理论认为潜在变量是无法直接测量的,必须借由观察变量来间接推测得知。
Spss进行的因子分析是一种探索性因子分析,Amos属于验证性因子分析,即先以因子(观察变量、或称预测变量)为建构基础,来验证是否能代表一个变量(潜在变量)Amos是对问卷的结构效度进行分析结构效度:一个测验能真正测到其所要测量的心理能力或技能的程度,即实验是否真正测量到假设的理论。
它将测验结果的实际组成部分与某些潜在的理论和行为类型建立起了联系,也可以理解为测验实际测量了所要测量的构想或特质的程度。
结构方程模型有两个基本模型:1.测量模型:探讨潜在变量与观察变量之间的关系2.结构模型:探讨潜在变量之间的关系,以及其他无法被解释的部分在结构方程模型中可以设置三种类型的变量:1.潜在变量:它是无法测量的变量,是观察变量间所形成的特质或抽象概念,在Amos中用椭圆形表示2.观察变量:又称测量变量、显性变量,是可以直接测量的变量,是量表或问卷等测量工具所得的数据,如果我们以spss 来建立基本数据,则在spss中的变量成为观察变量。
SPSS及AMOS进行中介效应分析资料报告中介效应分析是社会科学研究中常用的统计方法,可以用来探究变量之间的关系以及中介变量在这个关系中的作用。
SPSS和AMOS是进行中介效应分析的常用软件工具。
本文将以一个实际案例为例,介绍如何使用SPSS和AMOS进行中介效应分析,并对结果进行解读。
【引言】介绍研究背景和目的,说明为什么需要进行中介效应分析。
【方法】1.变量选择:选择独立变量、中介变量和因变量。
独立变量是影响中介变量的因素,中介变量在独立变量和因变量之间起到介导作用,因变量是希望了解的结果。
3.测量工具:介绍使用的测量工具,并评估其信度和效度。
4.数据收集:详细说明数据收集过程,如何保证数据质量。
5.数据分析:使用SPSS进行描述性统计分析,探索变量间的关系。
然后使用AMOS进行结构方程建模,进行中介效应分析,并进行模型拟合度检验。
【结果】1.描述性统计分析结果:列出各变量的均值、标准差等统计指标,描述样本的基本情况。
2.相关分析结果:展示各变量之间的相关关系,判断是否存在相关性。
3.结构方程模型结果:列出模型的参数估计值、标准误差、置信区间等统计指标,探究变量之间的关系。
4.中介效应分析结果:根据模型结果计算中介效应的大小和显著性。
【讨论】1.结果解读:解释结构方程模型结果和中介效应分析结果,说明变量之间的关系和中介变量的作用。
2.结果讨论:分析结果的意义和影响,探讨与现有研究的一致性和差异性。
3.研究局限性:指出研究的局限性和不足之处。
4.建议和展望:根据研究结果提出建议,并对未来研究方向进行展望。
【结论】总结研究的主要发现,强调中介效应分析对于理解变量关系的重要性,提出对相关领域的启示和建议。
共同方法偏差检验与验证性因子分析7.3 验证性因子分析(缩减版)•7.3.1 验证性因子分析是做什么的•7.3.2 验证性因子分析的一些概念•7.3.3 模型拟合指数有哪些?有什么标准?7.3.1 验证性因子分析是做什么的•SPSS里面的探索性因子分析(Exploratory Factor Analysis,EFA,又称探索性因素分析)的目的是寻找一些题目的共同的东西,这个共同的东西,我们称为潜变量(latent variable)。
•比如,我们进行探索性因子分析发现,语文、英文、历史等科目可以归为一个类别;数学、物理、化学可以归为另一个类别。
这两个类别我们分别命个名叫文科和理科。
六门课程探索性因子分析结果科目成分1成分2语文0.876英语0.768历史0.689数学0.899物理0.876化学0.786另外两个例子7.3.1 验证性因子分析是做什么的•探索的过程就是对质量不高的题目进行删除的过程,最终留下来的题目个数不会超过最初的题目个数;最终获得多少个component,就说明这些题目背后有多少个潜变量,也就是有多少个因子/因素。
•但是,探索出来的因子个数以及每个因子下面的题目是否恰当,还需要另外的数据来验证。
这个验证的过程就是验证性因子分析(confirmatory factor analysis, CFA)。
7.3.2 验证性因子分析的一些概念•(1)因子个数及模型叫法•若经SPSS探索性因子分析后发现,所有题目只能得到一个component,则称为单因子/因素。
这样,在验证性因子分析中,就称之为单因子/因素模型,也称为单维问卷/单维测验等。
•当然,若所有题目经探索性分析后可以得到多个component,则称为多因素/因子。
在验证性因子分析中,就称为多因素模型,一般都说的很具体,也就是说,双因子模型、三因子模型等。
•一阶模型和二阶模型7.3.2 验证性因子分析的一些概念•(2)模型图与因子载荷(factor loading)•用Amos做验证性因子分析需要预先画出模型图,用Mplus做则直接写代码,程序运行后可以自动出图。
结构方程AMOS什么是结构方程AMOS?结构方程AMOS(Analysis of Moment Structures)是一种统计分析方法,用于评估和验证在复杂系统中的潜在变量之间的关系。
它是一种基于线性代数和统计学原理的多变量建模技术,广泛应用于社会科学、教育研究、心理学等领域。
结构方程AMOS可以帮助研究人员探索和解释潜在变量之间的关系,以及这些关系对观察变量的影响。
它通过测量和分析多个指标来评估模型的拟合度,并提供了一种验证模型假设的方法。
结构方程AMOS的基本原理1. 潜在变量潜在变量是无法直接观测到的,但可以通过观察其指标进行间接测量的变量。
例如,幸福感无法直接观测到,但可以通过测量生活满意度、快乐指数等指标来间接测量。
2. 指标指标是对潜在变量进行直接观测或测量的具体表现形式。
每个潜在变量都有一个或多个指标与之相关联。
例如,幸福感可以通过测量生活满意度、快乐指数等指标来间接测量。
3. 结构方程模型结构方程模型是一种描述潜在变量之间关系的统计模型。
它由两部分组成:测量模型和结构模型。
•测量模型用于描述潜在变量与其指标之间的关系。
它通过测量指标与潜在变量之间的协方差来评估指标对潜在变量的测量效果。
•结构模型用于描述潜在变量之间的因果关系。
它通过分析协方差矩阵来评估潜在变量之间的关系强度和方向。
4. 模型拟合度模型拟合度用于评估结构方程模型与实际数据之间的吻合程度。
常用的拟合度指标包括:•卡方检验(Chi-Square test):用于检验观察数据与理论模型是否存在显著差异。
•比较拟合指数(Comparative Fit Index, CFI):衡量观察数据对理论模型的拟合程度,取值范围为0到1,值越接近1表示拟合越好。
•根均方误差逼近指数(Root Mean Square Error of Approximation, RMSEA):衡量观察数据与理论模型之间的误差,取值范围为0到1,值越接近0表示拟合越好。
AMOS输出解读惠顿研究惠顿数据文件在各种结构方程模型中被当作经典案例,包括AMOS 和LISREL。
本文以惠顿的社会疏离感追踪研究为例详细解释AMOS的输出结果。
AMOS同样能处理与时间有关的自相关回归。
惠顿研究涉及三个潜变量,每个潜变量由两个观测变量确定。
67疏离感由67无力感(在1967年无力感量表上的得分)和67无价值感(在1967年无价值感量表上的得分)确定。
71疏离感的处理方式相同,使用1971年对应的两个量表的得分。
第三个潜变量,SES(社会经济地位)是由教育(上学年数)和SEI (邓肯的社会经济指数)确定。
解读步骤1.导入数据。
AMOS在文件ex06-a.amw中提供惠顿数据文件。
使用File/Open,选择这个文件。
在图形模式中,文件显示如下。
虽然这里是预定义模式,图形模式允许你给变量添加椭圆,方形,箭头等元素建立新模型2.模型识别。
潜变量的方差和与它关联的回归系数取决于变量的测量单位,但刚开始谁知道呢。
比如说要估计误差的回归系数同时也估计误差的方差,就好像说“我买了10块钱的黄瓜,然后你就推测有几根黄瓜,每根黄瓜多少钱”,这是不可能实现的,因为没有足够的信息。
如何告诉你“我买了10块钱的黄瓜,有5根”,你便可以推出每根黄瓜2块钱。
对潜变量,必须给它们指定一个数值,要么是与潜变量有关的回归系数,要么是它的方差。
对误差项的处理也是一样。
一旦做完这些处理,其它系数在模型中就可以被估计。
在这里我们把与误差项关联的路径设为1,再从潜变量指向观测变量的路径中选一条把它设为1。
这样就给每个潜变量设置了测量尺度,如果没有这个测量尺度,模型是不确定的。
有了这些约束,模型就可以识别了。
注释:设置的数值可以是1,也可以是其它数,这些数对回归系数没有影响,但对误差有影响,在标准化的情况下,误差项的路径系数平方等于它的测量方差。
3.解释模型。
模型设置完毕后,在图形模式中点击工具栏中计算估计按钮运行分析。
实用标准文案
精彩文档
Amos模型设定操作
在使用AMOS进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,
并确定潜变量与可测变量的名称,以避免不必要的返工。
1. 绘制潜变量
使用建模区域绘制模型中的潜变量,在潜变量上点击右键选择Object Properties,为潜变量
命名。
2. 为潜变量设置可测变量及相应的残差变量
使用绘制。在可测变量上点击右键选择Object Properties为可测变量命名。其中Variable
Name对应的是数据的变量名,在残差变量上右键选择Object Properties为残差变量命名。
实用标准文案
精彩文档
3. 配置数据文件,读入数据
File——Data Files——File Name——OK。
4. 模型拟合
View——Analysis Properties——Estimation——Maximum Likelihood。
5. 标准化系数
实用标准文案
精彩文档
Analysis Properties——Output——Standardized Estimates——因子载荷标准化系数。
6. 参数估计结果
Analyze——Calculate Estimates。红色框架部分是模型运算基本结果信息,点击View the
Output Path Diagram查看参数估计结果图。
7. 模型评价
点击查看AMOS路径系数或载荷系数以及拟合指标评价。
路径系数/载荷系数的显著性
模型评价首先需要对路径系数或载荷系数进行统计显著性检验。
实用标准文案
精彩文档
模型拟合指数
模型拟合指数是考察理论结构模型对数据拟合程度的统计指标。拟合指数的作用是考察理论模型
与数据的适配程度,并不能作为判断模型是否成立的唯一依据。拟合优度高的模型只能作为参考,还
需要根据所研究问题的背景知识进行模型合理性讨论。
指数名称 评价标准1
绝对拟合指数
2
(卡方) 越小越好
GFI 大于0.9
RMR 、SRMR、 RMSEA 小于0.05,越小越好
相对拟合指数 NFI 、TLI、CFI 大于0.9,越接近1越好
信息指数 AIC、 CAIC 越小越好