Matlab与统计分析
- 格式:doc
- 大小:331.50 KB
- 文档页数:8


在MATLAB中进行浮点运算统计,可以使用MATLAB内置的函数和工具。
以下是一些常用的函数和工具:
1. `flops`函数:用于计算一个操作所需的浮点运算次数。
例如,`flops(A*B)`将计算矩阵A和B相乘所需的浮点运算次数。
2. `profile`函数:用于分析MATLAB代码的执行时间,包括浮点运算次数。
使用`profile on`开启分析,然后运行代码,最后使用`profile off`关闭分析。
在分析结果中,可以查看每个函数的执行时间和浮点运算次数。
3. `timeit`函数:用于测量MATLAB代码的执行时间。
使用`timeit(func)`测量函数func的执行时间,包括浮点运算次数。
4. `tic`和`toc`函数:用于测量代码段的执行时间。
使用`tic`开始计时,然后在代码段结束后使用`toc`结束计时。
计时结果包括浮点运算次数。
这些函数和工具可以帮助您分析和优化MATLAB代码中的浮点运算性能。

matlab统计种类Matlab是一种用于数值计算和数据可视化的高级编程语言和环境。
它在科学研究、数据分析和工程设计方面都有广泛的应用。
在数据统计方面,Matlab提供了多种用于统计分析、数据处理和模型建立的函数和工具箱。
下面将介绍一些常用的Matlab统计函数和工具箱。
1. 基本统计功能:Matlab提供了一系列基本的统计计算函数,如平均数、标准差、方差、中位数等。
这些函数可以直接应用于数据向量或矩阵。
2. 概率分布函数:Matlab提供了多种概率分布函数,如正态分布、二项分布、泊松分布等。
这些函数可用于生成服从指定分布的随机数,或计算概率密度函数和累积分布函数。
3. 统计图表:Matlab内置的绘图函数可以用于创建各种统计图表,如直方图、散点图、箱线图等。
这些图表可用于数据的可视化和分析。
4. 回归分析:Matlab提供了回归分析函数和工具箱,可用于拟合线性或非线性回归模型。
这些函数可用于评估变量之间的关系,并预测未来的观测值。
5. 方差分析:Matlab提供了方差分析函数和工具箱,可用于比较多个组别之间的均值差异。
方差分析可用于检验因素对观测值之间差异的显著性。
6. 非参数统计:Matlab提供了多种非参数统计函数和工具箱,如Mann-Whitney U检验、Wilcoxon符号秩检验等。
非参数统计方法可应用于不满足正态分布假设的数据。
7. 时间序列分析:Matlab提供了时间序列分析函数和工具箱,可用于模型拟合、趋势分析、季节性调整等。
时间序列分析可用于预测未来的观测值或分析时间序列数据的波动性。
8. 多元分析:Matlab提供了多元分析函数和工具箱,如主成分分析、因子分析、聚类分析等。
多元分析可用于降维、数据压缩和数据分类。
9. 假设检验:Matlab提供了多种假设检验函数和工具箱,可用于验证统计推断的显著性。
常见的假设检验方法包括t检验、卡方检验、F检验等。
10. 贝叶斯统计:Matlab提供了贝叶斯统计函数和工具箱,可用于贝叶斯推断和模型选择。

MATLAB数据分析方法
MATLAB是一种强大的数据分析工具,它提供了丰富的函数和工具箱,可以帮助用户进行各种数据处理和分析。
在本文中,我们将介绍一些常用的MATLAB 数据分析方法,包括数据可视化、统计分析、机器学习等内容。
首先,数据可视化是数据分析的重要环节之一。
MATLAB提供了丰富的绘图函数,可以用来绘制各种类型的图表,如折线图、散点图、柱状图等。
通过可视化数据,我们可以更直观地了解数据的分布规律、趋势变化和异常情况,从而为后续的分析工作提供重要参考。
其次,统计分析是数据分析的核心内容之一。
MATLAB中有许多统计分析的函数和工具箱,可以用来进行描述性统计、假设检验、方差分析等分析。
通过统计分析,我们可以对数据的分布特征、相关性、差异性等进行深入分析,从而揭示数据背后的规律和规律。
此外,机器学习在数据分析中也扮演着重要的角色。
MATLAB提供了丰富的机器学习工具箱,包括分类、回归、聚类、降维等算法,可以帮助用户构建和训练机器学习模型,从而实现对数据的自动化分析和预测。
机器学习的应用领域非常广泛,包括金融、医疗、电商等领域,可以帮助用户挖掘数据中的潜在价值,为决策提供支持。
总之,MATLAB是一种非常强大的数据分析工具,它提供了丰富的函数和工具箱,可以帮助用户进行各种数据处理和分析。
通过数据可视化、统计分析、机器学习等方法,我们可以更好地理解数据,揭示数据背后的规律和规律,为决策提供支持。
希望本文介绍的MATLAB数据分析方法对您有所帮助,谢谢阅读!。

使用MATLAB进行数据分析的基本步骤数据分析是现代科学研究和工程实践中不可或缺的一环。
随着大数据时代的到来,对于海量数据的分析和处理变得尤为重要。
MATLAB作为一种强大的数据分析工具,能够帮助研究人员和工程师高效地进行数据分析。
本文将介绍使用MATLAB进行数据分析的基本步骤。
一、数据准备在进行数据分析之前,首先需要准备好待分析的数据。
数据可以来自于各种渠道,如实验采集、传感器监测、数据库等。
在导入数据之前,需要对数据进行预处理,包括数据清洗、缺失值处理、异常值检测等。
MATLAB提供了丰富的数据处理函数和工具箱,可以方便地完成这些任务。
二、数据导入在MATLAB中,可以使用多种方式导入数据,如直接读取文本文件、Excel文件、数据库查询等。
对于文本文件,可以使用readtable函数进行导入,对于Excel文件,可以使用xlsread函数进行导入。
对于大型数据库,可以使用Database Toolbox进行连接和查询操作。
导入数据后,可以使用MATLAB的数据结构进行存储和处理。
三、数据可视化数据可视化是数据分析的重要环节,能够直观地展示数据的分布和趋势。
MATLAB提供了丰富的绘图函数和工具箱,可以绘制各种类型的图形,如折线图、散点图、柱状图等。
通过调整绘图参数和添加标签,可以使图形更加美观和易于理解。
数据可视化可以帮助研究人员和工程师更好地理解数据,发现潜在的规律和关联。
四、数据分析在数据可视化的基础上,可以进行更深入的数据分析。
MATLAB提供了丰富的统计分析函数和工具箱,包括描述统计分析、假设检验、方差分析、回归分析等。
可以根据具体的问题选择合适的分析方法,并使用MATLAB进行计算和结果展示。
数据分析的目的是从数据中提取有用的信息和知识,为进一步的决策和优化提供依据。
五、模型建立与预测在某些情况下,可以通过建立数学模型对数据进行预测和优化。
MATLAB提供了强大的建模和仿真工具,如曲线拟合、回归分析、神经网络等。


常用统计分析软件常用的统计分析软件有很多,下面我将介绍一些常见的统计分析软件及其特点。
1. SPSS(Statistical Package for the Social Sciences):是一款统计分析软件,具有强大的数据处理、数据分析和报告生成功能。
它可进行描述性统计、假设检验、方差分析、回归分析、聚类分析、因子分析等常用统计分析。
2. SAS(Statistical Analysis System):是一种完整的统计分析解决方案,包含数据管理、数据分析、统计建模和数据可视化等功能。
它适用于大规模数据的处理和分析,具有高效、稳定和灵活的特点。
3.R:是一种免费的开源统计分析软件,拥有丰富的统计分析函数和高级绘图功能。
R语言具有强大的数据处理能力和灵活的编程特点,适用于各种统计分析及数据可视化的需求。
4. Python:是一种通用的编程语言,也可以进行统计分析。
配合一些科学计算库(如NumPy、SciPy、Pandas等),Python可以进行各种统计分析任务,包括数据处理、数据分析、机器学习等。
5. Excel:是一种常用的电子表格软件,也可以进行一些简单的统计分析。
Excel提供了一些常用的统计函数和图表功能,对于小规模数据的分析和可视化比较便捷。
6.MATLAB:是一种功能强大的数学计算软件,也可以用于统计分析。
MATLAB提供了丰富的数学和统计函数,可以进行各种统计分析任务,包括回归分析、方差分析、时间序列分析等。
7. Stata:是一种统计分析软件,广泛应用于社会科学研究。
Stata 具有易用的用户界面和灵活的命令语言,提供了丰富的统计分析函数和专门的模块,满足各种统计分析需求。
8. Minitab:是一种易学易用的统计分析软件,广泛应用于工业和质量管理等领域。
Minitab提供了丰富的统计分析和质量管理工具,方便用户进行数据处理和分析,能够生成报告和图表。
9. Gretl:是一种专门用于计量经济学研究的统计分析软件。

利用Matlab实现数据分析的基本方法引言:数据分析是指通过对收集到的数据进行整理、加工和分析,以获取其中的信息和规律。
随着计算机技术的发展,数据分析已经成为现代科学研究和商业运营中不可或缺的一部分。
Matlab作为一种功能强大的科学计算工具,可以提供丰富的函数库和工具箱来支持各种数据分析任务。
本文将介绍利用Matlab实现数据分析的基本方法,包括数据读取、数据清洗、数据可视化和数据建模等方面。
一、数据读取在进行数据分析之前,首先需要将数据从外部文件中读取进来。
Matlab提供了多种读取数据的函数,常见的有`xlsread`、`csvread`、`load`等。
具体的使用方法可以参考Matlab官方文档或相关教程。
在读取数据时,需要注意数据的格式和结构,以便后续的数据处理和分析。
二、数据清洗在真实的数据中,常常会存在一些问题,比如缺失值、异常值和重复值等。
这些问题会干扰我们对数据的准确理解和分析。
因此,在进行数据分析之前,需要对数据进行清洗。
Matlab提供了一些函数和方法来进行数据清洗,比如`isnan`、`isinf`、`unique`等。
通过这些函数,我们可以找出并删除缺失值、异常值和重复值,从而使得数据更加准确可靠。
三、数据可视化数据可视化是数据分析中重要的一环,可以帮助我们更直观地理解和分析数据。
Matlab提供了强大的数据可视化工具,比如`plot`、`scatter`、`histogram`等。
可以根据实际需求选择合适的图表类型,展示数据的分布、趋势和相关性等信息。
同时,Matlab还支持图表的美化和定制,可以通过设置线条颜色、图例位置等来增加图表的可读性和美观度。
四、数据统计与分析数据统计和分析是数据分析的重要环节,通过对数据的统计和分析,我们可以揭示数据中的规律和趋势。
Matlab提供了丰富的统计分析函数和工具箱,可以进行描述统计分析、假设检验和回归分析等。
例如,可以使用`mean`计算数据的均值,使用`ttest`进行两样本均值差异的显著性检验,使用`regress`进行线性回归分析等。

Matlab在统计建模中的实践技巧统计建模是现代数据分析中的重要环节,它利用统计方法对数据进行建模和分析,以揭示数据背后的规律和特征。
作为一种功能强大的数学软件,Matlab在统计建模中发挥了重要作用。
本文将介绍一些在统计建模中使用Matlab的实践技巧,具体包括数据处理、探索性分析、建模和评估等方面。
一、数据处理在进行统计建模前,数据处理是必不可少的一步。
Matlab提供了多种数据处理函数和工具,可以帮助我们对数据集进行清洗、缺失值处理和异常值检测等操作。
首先,我们可以使用Matlab中的数据导入工具将数据加载到工作空间中。
例如,可以使用readtable函数读取Excel或CSV文件中的数据,并将其转换为Matlab表格格式,方便后续的处理和分析。
其次,我们可以利用Matlab中的数据清洗函数进行数据清洗。
例如,使用fillmissing函数可以根据指定的方法填充缺失值,使用rmmissing函数可以删除含有缺失值的样本。
另外,我们还可以使用Matlab中的统计函数对数据进行异常值检测和处理。
例如,使用zscore函数可以计算每个观测值相对于其所在样本的均值和标准差的偏差值,从而判断是否存在异常值。
二、探索性分析在进行统计建模前,我们需要对数据进行探索性分析,以了解数据的基本特征和潜在规律。
Matlab提供了丰富的可视化函数和工具,可以帮助我们对数据进行可视化分析和探索。
首先,我们可以使用Matlab中的plot函数绘制各种类型的图表,如散点图、箱线图和直方图等。
这些图表可以帮助我们观察变量之间的关系、分布情况和异常情况等。
其次,Matlab还提供了统计工具箱,其中包括各种统计模型和方法的函数。
我们可以利用这些函数来计算相关系数、频数分布和概率分布等统计指标,以深入了解数据的特征和分布情况。
另外,Matlab还提供了交互式工具,如数据编辑器和变量编辑器等。
我们可以通过这些工具直观地查看和编辑数据,对数据进行某些操作,如添加、删除、修改和筛选等。

Distributions.Parameter estimation.betafit - Beta parameter estimation.binofit - Binomial parameter estimation.dfittool - Distribution fitting tool.evfit - Extreme value parameter estimation.expfit - Exponential parameter estimation.fitdist - Distribution fitting.gamfit - Gamma parameter estimation.gevfit - Generalized extreme value parameter estimation.gmdistribution - Gaussian mixture model estimation.gpfit - Generalized Pareto parameter estimation.lognfit - Lognormal parameter estimation.mle - Maximum likelihood estimation (MLE).mlecov - Asymptotic covariance matrix of MLE.nbinfit - Negative binomial parameter estimation.normfit - Normal parameter estimation.paretotails - Empirical cdf with generalized Pareto tails.poissfit - Poisson parameter estimation.raylfit - Rayleigh parameter estimation.unifit - Uniform parameter estimation.wblfit - Weibull parameter estimation.Probability density functions (pdf).betapdf - Beta density.binopdf - Binomial density.chi2pdf - Chi square density.evpdf - Extreme value density.exppdf - Exponential density.fpdf - F density.gampdf - Gamma density.geopdf - Geometric density.gevpdf - Generalized extreme value density.gppdf - Generalized Pareto density.hygepdf - Hypergeometric density.lognpdf - Lognormal density.mnpdf - Multinomial probability density function.mvnpdf - Multivariate normal density.mvtpdf - Multivariate t density.nbinpdf - Negative binomial density.ncfpdf - Noncentral F density.nctpdf - Noncentral t density.ncx2pdf - Noncentral Chi-square density.normpdf - Normal (Gaussian) density.pdf - Density function for a specified distribution.poisspdf - Poisson density.raylpdf - Rayleigh density.tpdf - T density.unidpdf - Discrete uniform density.unifpdf - Uniform density.wblpdf - Weibull density.Cumulative Distribution functions (cdf).betacdf - Beta cumulative distribution function.binocdf - Binomial cumulative distribution function.cdf - Specified cumulative distribution function.chi2cdf - Chi square cumulative distribution function.ecdf - Empirical cumulative distribution function (Kaplan-Meier estimate). evcdf - Extreme value cumulative distribution function.expcdf - Exponential cumulative distribution function.fcdf - F cumulative distribution function.gamcdf - Gamma cumulative distribution function.geocdf - Geometric cumulative distribution function.gevcdf - Generalized extreme value cumulative distribution function.gpcdf - Generalized Pareto cumulative distribution function.hygecdf - Hypergeometric cumulative distribution function.logncdf - Lognormal cumulative distribution function.mvncdf - Multivariate normal cumulative distribution function.mvtcdf - Multivariate t cumulative distribution function.nbincdf - Negative binomial cumulative distribution function.ncfcdf - Noncentral F cumulative distribution function.nctcdf - Noncentral t cumulative distribution function.ncx2cdf - Noncentral Chi-square cumulative distribution function.normcdf - Normal (Gaussian) cumulative distribution function.poisscdf - Poisson cumulative distribution function.raylcdf - Rayleigh cumulative distribution function.tcdf - T cumulative distribution function.unidcdf - Discrete uniform cumulative distribution function.unifcdf - Uniform cumulative distribution function.wblcdf - Weibull cumulative distribution function.Critical Values of Distribution functions.betainv - Beta inverse cumulative distribution function.binoinv - Binomial inverse cumulative distribution function.chi2inv - Chi square inverse cumulative distribution function.evinv - Extreme value inverse cumulative distribution function.expinv - Exponential inverse cumulative distribution function.finv - F inverse cumulative distribution function.gaminv - Gamma inverse cumulative distribution function.geoinv - Geometric inverse cumulative distribution function.gevinv - Generalized extreme value inverse cumulative distribution function. gpinv - Generalized Pareto inverse cumulative distribution function. hygeinv - Hypergeometric inverse cumulative distribution function.icdf - Specified inverse cumulative distribution function.logninv - Lognormal inverse cumulative distribution function.nbininv - Negative binomial inverse distribution function.ncfinv - Noncentral F inverse cumulative distribution function.nctinv - Noncentral t inverse cumulative distribution function.ncx2inv - Noncentral Chi-square inverse distribution function.norminv - Normal (Gaussian) inverse cumulative distribution function. poissinv - Poisson inverse cumulative distribution function.raylinv - Rayleigh inverse cumulative distribution function.tinv - T inverse cumulative distribution function.unidinv - Discrete uniform inverse cumulative distribution function.unifinv - Uniform inverse cumulative distribution function.wblinv - Weibull inverse cumulative distribution function.Random Number Generators.betarnd - Beta random numbers.binornd - Binomial random numbers.chi2rnd - Chi square random numbers.evrnd - Extreme value random numbers.exprnd - Exponential random numbers.frnd - F random numbers.gamrnd - Gamma random numbers.geornd - Geometric random numbers.gevrnd - Generalized extreme value random numbers.gprnd - Generalized Pareto inverse random numbers.hygernd - Hypergeometric random numbers.iwishrnd - Inverse Wishart random matrix.johnsrnd - Random numbers from the Johnson system of distributions. lognrnd - Lognormal random numbers.mhsample - Metropolis-Hastings algorithm.mnrnd - Multinomial random vectors.mvnrnd - Multivariate normal random vectors.mvtrnd - Multivariate t random vectors.nbinrnd - Negative binomial random numbers.ncfrnd - Noncentral F random numbers.nctrnd - Noncentral t random numbers.ncx2rnd - Noncentral Chi-square random numbers.normrnd - Normal (Gaussian) random numbers.pearsrnd - Random numbers from the Pearson system of distributions.poissrnd - Poisson random numbers.randg - Gamma random numbers (unit scale). random - Random numbers from specified distribution. randsample - Random sample from finite population. raylrnd - Rayleigh random numbers.slicesample - Slice sampling method.trnd - T random numbers.unidrnd - Discrete uniform random numbers.unifrnd - Uniform random numbers.wblrnd - Weibull random numbers.wishrnd - Wishart random matrix.Quasi-Random Number Generators.haltonset - Halton sequence point set.qrandstream - Quasi-random stream.sobolset - Sobol sequence point set.Statistics.betastat - Beta mean and variance.binostat - Binomial mean and variance.chi2stat - Chi square mean and variance.evstat - Extreme value mean and variance.expstat - Exponential mean and variance.fstat - F mean and variance.gamstat - Gamma mean and variance.geostat - Geometric mean and variance.gevstat - Generalized extreme value mean and variance. gpstat - Generalized Pareto inverse mean and variance. hygestat - Hypergeometric mean and variance.lognstat - Lognormal mean and variance.nbinstat - Negative binomial mean and variance.ncfstat - Noncentral F mean and variance.nctstat - Noncentral t mean and variance.ncx2stat - Noncentral Chi-square mean and variance. normstat - Normal (Gaussian) mean and variance. poisstat - Poisson mean and variance.raylstat - Rayleigh mean and variance.tstat - T mean and variance.unidstat - Discrete uniform mean and variance.unifstat - Uniform mean and variance.wblstat - Weibull mean and variance.Likelihood functions.betalike - Negative beta log-likelihood.evlike - Negative extreme value log-likelihood.explike - Negative exponential log-likelihood.gamlike - Negative gamma log-likelihood.gevlike - Generalized extreme value log-likelihood.gplike - Generalized Pareto inverse log-likelihood.lognlike - Negative lognormal log-likelihood.nbinlike - Negative binomial log-likelihood.normlike - Negative normal likelihood.wbllike - Negative Weibull log-likelihood.Probability distribution objects.ProbDistUnivKernel - Univariate kernel smoothing distributions. ProbDistUnivParam - Univariate parametric distributions.Descriptive Statistics.bootci - Bootstrap confidence intervals.bootstrp - Bootstrap statistics.corr - Linear or rank correlation coefficient.corrcoef - Linear correlation coefficient (in MATLAB toolbox).cov - Covariance (in MA TLAB toolbox).crosstab - Cross tabulation.geomean - Geometric mean.grpstats - Summary statistics by group.harmmean - Harmonic mean.iqr - Interquartile range.jackknife - Jackknife statistics.kurtosis - Kurtosis.mad - Median Absolute Deviation.mean - Sample average (in MA TLAB toolbox).median - 50th percentile of a sample (in MATLAB toolbox).mode - Mode, or most frequent value in a sample (in MATLAB toolbox). moment - Moments of a sample.nancov - Covariance matrix ignoring NaNs.nanmax - Maximum ignoring NaNs.nanmean - Mean ignoring NaNs.nanmedian - Median ignoring NaNs.nanmin - Minimum ignoring NaNs.nanstd - Standard deviation ignoring NaNs.nansum - Sum ignoring NaNs.nanvar - Variance ignoring NaNs.partialcorr - Linear or rank partial correlation coefficient.prctile - Percentiles.quantile - Quantiles.range - Range.skewness - Skewness.std - Standard deviation (in MATLAB toolbox).tabulate - Frequency table.trimmean - Trimmed mean.var - Variance (in MATLAB toolbox).Linear Models.addedvarplot - Created added-variable plot for stepwise regression.anova1 - One-way analysis of variance.anova2 - Two-way analysis of variance.anovan - n-way analysis of variance.aoctool - Interactive tool for analysis of covariance.dummyvar - Dummy-variable coding.friedman - Friedman's test (nonparametric two-way anova).glmfit - Generalized linear model fitting.glmval - Evaluate fitted values for generalized linear model.invpred - Inverse prediction for simple linear regression.kruskalwallis - Kruskal-Wallis test (nonparametric one-way anova).leverage - Regression diagnostic.lscov - Ordinary, weighted, or generalized least-squares (in MATLAB toolbox). lsqnonneg - Non-negative least-squares (in MATLAB toolbox).manova1 - One-way multivariate analysis of variance.manovacluster - Draw clusters of group means for manova1.mnrfit - Nominal or ordinal multinomial regression model fitting.mnrval - Predict values for nominal or ordinal multinomial regression. multcompare - Multiple comparisons of means and other estimates.mvregress - Multivariate regression with missing data.mvregresslike - Negative log-likelihood for multivariate regression.polyconf - Polynomial evaluation and confidence interval estimation.polyfit - Least-squares polynomial fitting (in MATLAB toolbox).polyval - Predicted values for polynomial functions (in MATLAB toolbox). rcoplot - Residuals case order plot.regress - Multiple linear regression using least squares.regstats - Regression diagnostics.ridge - Ridge regression.robustfit - Robust regression model fitting.rstool - Multidimensional response surface visualization (RSM).stepwise - Interactive tool for stepwise regression.stepwisefit - Non-interactive stepwise regression.x2fx - Factor settings matrix (x) to design matrix (fx).Nonlinear Models.coxphfit - Cox proportional hazards regression.nlinfit - Nonlinear least-squares data fitting.nlintool - Interactive graphical tool for prediction in nonlinear models. nlmefit - Nonlinear mixed-effects data fitting.nlpredci - Confidence intervals for prediction.nlparci - Confidence intervals for parameters.Design of Experiments (DOE).bbdesign - Box-Behnken design.candexch - D-optimal design (row exchange algorithm for candidate set). candgen - Candidates set for D-optimal design generation.ccdesign - Central composite design.cordexch - D-optimal design (coordinate exchange algorithm). daugment - Augment D-optimal design.dcovary - D-optimal design with fixed covariates.fracfactgen - Fractional factorial design generators.ff2n - Two-level full-factorial design.fracfact - Two-level fractional factorial design.fullfact - Mixed-level full-factorial design.hadamard - Hadamard matrices (orthogonal arrays) (in MATLAB toolbox). lhsdesign - Latin hypercube sampling design.lhsnorm - Latin hypercube multivariate normal sample.rowexch - D-optimal design (row exchange algorithm).Statistical Process Control (SPC).capability - Capability indices.capaplot - Capability plot.controlchart - Shewhart control chart.controlrules - Control rules (Western Electric or Nelson) for SPC data.gagerr - Gage repeatability and reproducibility (R&R) study.histfit - Histogram with superimposed normal density.normspec - Plot normal density between specification limits.runstest - Runs test for randomness.Multivariate Statistics.Cluster Analysis.cophenet - Cophenetic coefficient.cluster - Construct clusters from LINKAGE output.clusterdata - Construct clusters from data.dendrogram - Generate dendrogram plot.gmdistribution - Gaussian mixture model estimation.inconsistent - Inconsistent values of a cluster tree.kmeans - k-means clustering.linkage - Hierarchical cluster information.pdist - Pairwise distance between observations.silhouette - Silhouette plot of clustered data.squareform - Square matrix formatted distance.Classification.classify - Linear discriminant analysis.NaiveBayes - Naive Bayes classification.Dimension Reduction Techniques.factoran - Factor analysis.nnmf - Non-negative matrix factorization.pcacov - Principal components from covariance matrix. pcares - Residuals from principal components.princomp - Principal components analysis from raw data. rotatefactors - Rotation of FA or PCA loadings.Copulascopulacdf - Cumulative probability function for a copula. copulafit - Fit a parametric copula to data.copulaparam - Copula parameters as a function of rank correlation. copulapdf - Probability density function for a copula. copularnd - Random vectors from a copula.copulastat - Rank correlation for a copula.Plotting.andrewsplot - Andrews plot for multivariate data.biplot - Biplot of variable/factor coefficients and scores. interactionplot - Interaction plot for factor effects. maineffectsplot - Main effects plot for factor effects.glyphplot - Plot stars or Chernoff faces for multivariate data. gplotmatrix - Matrix of scatter plots grouped by a common variable. multivarichart - Multi-vari chart of factor effects.parallelcoords - Parallel coordinates plot for multivariate data.Other Multivariate Methods.barttest - Bartlett's test for dimensionality.canoncorr - Canonical correlation analysis.cmdscale - Classical multidimensional scaling.mahal - Mahalanobis distance.manova1 - One-way multivariate analysis of variance. mdscale - Metric and non-metric multidimensional scaling. mvregress - Multivariate regression with missing data. plsregress - Partial least squares regression.procrustes - Procrustes analysis.Decision Tree Techniques.classregtree - Classification and regression tree.TreeBagger - Ensemble of bagged decision trees. CompactTreeBagger - Lightweight ensemble of bagged decision trees.Hypothesis Tests.ansaribradley - Ansari-Bradley two-sample test for equal dispersions.dwtest - Durbin-Watson test for autocorrelation in linear regression. linhyptest - Linear hypothesis test on parameter estimates.ranksum - Wilcoxon rank sum test (independent samples).runstest - Runs test for randomness.sampsizepwr - Sample size and power calculation for hypothesis test. signrank - Wilcoxon sign rank test (paired samples).signtest - Sign test (paired samples).ttest - One sample t test.ttest2 - Two sample t test.vartest - One-sample test of variance.vartest2 - Two-sample F test for equal variances.vartestn - Test for equal variances across multiple groups.ztest - Z test.Distribution Testing.chi2gof - Chi-square goodness-of-fit test.jbtest - Jarque-Bera test of normality.kstest - Kolmogorov-Smirnov test for one sample.kstest2 - Kolmogorov-Smirnov test for two samples.lillietest - Lilliefors test of normality.Nonparametric Functions.friedman - Friedman's test (nonparametric two-way anova). kruskalwallis - Kruskal-Wallis test (nonparametric one-way anova). ksdensity - Kernel smoothing density estimation.ranksum - Wilcoxon rank sum test (independent samples).signrank - Wilcoxon sign rank test (paired samples).signtest - Sign test (paired samples).Hidden Markov Models.hmmdecode - Calculate HMM posterior state probabilities. hmmestimate - Estimate HMM parameters given state information. hmmgenerate - Generate random sequence for HMM.hmmtrain - Calculate maximum likelihood estimates for HMM parameters. hmmviterbi - Calculate most probable state path for HMM sequence.Model Assessment.confusionmat - Confusion matrix for classification algorithms.crossval - Loss estimate using cross-validation.cvpartition - Cross-validation partition.perfcurve - ROC and other performance measures for classification algorithms.Model Selection.sequentialfs - Sequential feature selection.stepwise - Interactive tool for stepwise regression.stepwisefit - Non-interactive stepwise regression.Statistical Plotting.andrewsplot - Andrews plot for multivariate data.biplot - Biplot of variable/factor coefficients and scores.boxplot - Boxplots of a data matrix (one per column).cdfplot - Plot of empirical cumulative distribution function.ecdf - Empirical cdf (Kaplan-Meier estimate).ecdfhist - Histogram calculated from empirical cdf.fsurfht - Interactive contour plot of a function.gline - Point, drag and click line drawing on figures.glyphplot - Plot stars or Chernoff faces for multivariate data.gname - Interactive point labeling in x-y plots.gplotmatrix - Matrix of scatter plots grouped by a common variable.gscatter - Scatter plot of two variables grouped by a third.hist - Histogram (in MATLAB toolbox).hist3 - Three-dimensional histogram of bivariate data.ksdensity - Kernel smoothing density estimation.lsline - Add least-square fit line to scatter plot.normplot - Normal probability plot.parallelcoords - Parallel coordinates plot for multivariate data.probplot - Probability plot.qqplot - Quantile-Quantile plot.refcurve - Reference polynomial curve.refline - Reference line.scatterhist - 2D scatter plot with marginal histograms.surfht - Interactive contour plot of a data grid.wblplot - Weibull probability plot.Data Objectsdataset - Create datasets from workspace variables or files.nominal - Create arrays of nominal data.ordinal - Create arrays of ordinal data.Statistics Demos.aoctool - Interactive tool for analysis of covariance.disttool - GUI tool for exploring probability distribution functions.polytool - Interactive graph for prediction of fitted polynomials. randtool - GUI tool for generating random numbers.rsmdemo - Reaction simulation (DOE, RSM, nonlinear curve fitting). robustdemo - Interactive tool to compare robust and least squares fits.File Based I/O.tblread - Read in data in tabular format.tblwrite - Write out data in tabular format to file.tdfread - Read in text and numeric data from tab-delimited file. caseread - Read in case names.casewrite - Write out case names to file.Utility Functions.cholcov - Cholesky-like decomposition for covariance matrix. combnk - Enumeration of all combinations of n objects k at a time. corrcov - Convert covariance matrix to correlation matrix.grp2idx - Convert grouping variable to indices and array of names. hougen - Prediction function for Hougen model (nonlinear example). statget - Get STA TS options parameter value.statset - Set STATS options parameter value.tiedrank - Compute ranks of sample, adjusting for ties.zscore - Normalize matrix columns to mean 0, variance 1.Overloaded methods:xregusermod/statsxregunispline/statsxregnnet/statsxregmultilin/statsxregmodel/statsxreglinear/statsxreginterprbf/statsxregarx/stats。
MATLAB数据分析方法MATLAB是一种强大的数据分析工具,它可以帮助我们对各种类型的数据进行有效的分析和处理。
在本文中,我们将介绍一些常用的MATLAB数据分析方法,希望能够帮助大家更好地利用这一工具进行数据分析。
首先,我们将介绍如何在MATLAB中进行数据可视化分析。
数据可视化是数据分析的重要环节,通过图表和图形的展示,我们可以更直观地理解数据之间的关系和规律。
在MATLAB中,我们可以利用plot函数绘制二维图表,利用surf函数绘制三维图形,还可以使用histogram函数绘制直方图等。
这些图表和图形可以帮助我们更好地理解数据的分布和趋势,从而为后续的分析提供重要参考。
其次,我们将介绍如何在MATLAB中进行数据预处理。
数据预处理是数据分析的关键步骤之一,它可以帮助我们清洗数据、填补缺失值、处理异常值等。
在MATLAB中,我们可以利用isnan函数和isinf函数来识别缺失值和异常值,利用interp1函数和fillmissing函数来填补缺失值,利用deleteoutliers函数来处理异常值等。
这些方法可以帮助我们在数据分析之前,对数据进行有效的清洗和处理,提高数据分析的准确性和可靠性。
接下来,我们将介绍如何在MATLAB中进行统计分析。
统计分析是数据分析的重要内容之一,它可以帮助我们了解数据的分布、均值、方差、相关性等。
在MATLAB中,我们可以利用mean函数和std函数计算数据的均值和标准差,利用corr函数计算数据的相关系数,利用histfit函数绘制数据的直方图和拟合曲线等。
这些方法可以帮助我们更全面地了解数据的统计特征,为后续的分析和决策提供重要依据。
最后,我们将介绍如何在MATLAB中进行数据建模分析。
数据建模分析是数据分析的高级阶段,它可以帮助我们建立数据的数学模型,预测未来的趋势和结果。
在MATLAB中,我们可以利用regress 函数进行线性回归分析,利用fit函数进行曲线拟合分析,利用forecast函数进行时间序列预测分析等。
matlab中的mean函数
mean函数是matlab中最常用的统计分析函数之一,它可以统计某组数据的算术平均数。
该函数可以接受两种不同参数,即数据集和维数参数。
mean函数可以对任意类型的数据集进行处理,只要数据大小在其参数范围之内即可。
该函数的语法如下:M = mean(A,dim)
其中M为输出的算术平均数,A是输入数据集,dim代表数据集中的维度。
该函数的应用非常广泛,用户可以用它来求解向量、数组或多维矩阵的中心值,以便对其进行更深入的统计分析。
此外,用户可以通过在给定维度上求出平均值来进行更高级的分析,如求出一维或多维数组中特定元素或特定列/行的平均值。
总结而言,mean函数是一个功能强大、易于使用的工具,它能够帮助用户取出数据中的统计值,进行更深入的数据分析,为实现更优的结果提供重要指导。
Matlab在《概率论与数理统计》教学中的应用概率论与数理统计是一门重要的数学学科,它主要研究随机事件发生的概率和随机变量的规律性。
Matlab是一种强大的科学计算软件,具有丰富的数学计算工具和图形绘制功能,因此在《概率论与数理统计》教学中,Matlab被广泛应用于概率论和数理统计的理论研究、统计分析和数据可视化等方面。
一、概率论的应用1. 概率计算:Matlab可以进行各种概率计算,包括事件的概率计算、条件概率计算、概率分布计算等。
通过编写相应的概率计算程序,可以方便地进行概率问题的求解和验证。
2. 模拟实验:概率论中常常需要进行大量的随机实验,通过模拟实验来验证概率理论的结论。
Matlab提供了丰富的随机数生成函数,可以生成各种分布的随机样本并进行相关的分析和验证。
3. 统计分布拟合:在概率论中,常常需要对实际观测数据进行统计分布的拟合。
Matlab提供了多种分布的函数和工具箱,可以帮助进行数据的拟合和参数估计。
二、数理统计的应用1. 描述统计分析:Matlab可以对数据进行基本的描述统计分析,包括数据的中心趋势、离散程度和分布状况的度量等。
通过编写相应的统计分析程序,可以方便地获取数据的平均值、方差、标准差等统计指标。
2. 参数估计与假设检验:在数理统计中,常常需要对总体参数进行估计和假设检验。
Matlab提供了多种参数估计和假设检验的函数和工具箱,可以进行参数的点估计、区间估计和假设检验等分析。
3. 数据可视化与分析:Matlab具有强大的数据可视化功能,可以绘制各种图表和图形,包括直方图、散点图、箱线图等。
通过对数据进行可视化分析,可以更直观地了解数据的分布特征和相关关系。
除了以上应用,Matlab还可以在概率论与数理统计的教学中进行实际案例分析和建模。
通过编写相应的程序和脚本,可以更具体地研究和解决实际问题,提高学生的应用能力和创新思维。
Matlab在《概率论与数理统计》教学中的应用范围广泛,包括概率计算、模拟实验、统计分布拟合、描述统计分析、参数估计与假设检验、数据可视化与分析等方面。
如何使用MATLAB进行数据分析一、引言MATLAB是一种强大的数据分析工具,广泛应用于各个领域。
在本文中,我们将介绍如何使用MATLAB进行数据分析。
我们将从数据预处理开始,包括数据清洗和数据变换;接着讨论数据可视化的方法,如绘制折线图、柱状图和散点图;最后,我们将探讨一些常用的数据分析技术,如回归分析和聚类分析。
二、数据预处理数据预处理是数据分析的重要一步。
首先,我们需要进行数据清洗,即处理数据中的缺失值、异常值和重复值。
MATLAB提供了许多函数来处理这些问题,如isnan()函数判断缺失值,isoutlier()函数判断异常值,unique()函数去除重复值。
此外,我们还可以对数据进行变换,以便更好地进行分析。
常用的数据变换方法包括对数转换、标准化和归一化等。
在MATLAB中,log()函数用于进行对数转换,zscore()函数可进行标准化,而minmax()函数则可实现归一化。
三、数据可视化数据可视化是数据分析中必不可少的一环。
通过可视化,我们可以更直观地理解数据的分布和关系。
在MATLAB中,我们可以使用plot()函数绘制折线图,bar()函数绘制柱状图,scatter()函数绘制散点图。
此外,MATLAB还提供了许多其他的绘图函数,如histogram()函数绘制直方图、pie()函数绘制饼图等,可以根据需要选择合适的函数进行数据可视化。
四、数据分析技术除了数据预处理和数据可视化,MATLAB还提供了丰富的数据分析技术。
其中,回归分析是用于分析两个或多个变量之间关系的方法。
MATLAB提供了regress()函数来进行回归分析,可以计算出拟合直线或曲线的系数和误差。
另外,聚类分析是将相似的对象组合在一起的方法。
MATLAB 中的kmeans()函数可以根据数据的特征将其分为多个簇。
除了回归分析和聚类分析,MATLAB还支持其他各种统计分析方法,如方差分析、主成分分析等。
根据具体需求,选择合适的方法进行数据分析。
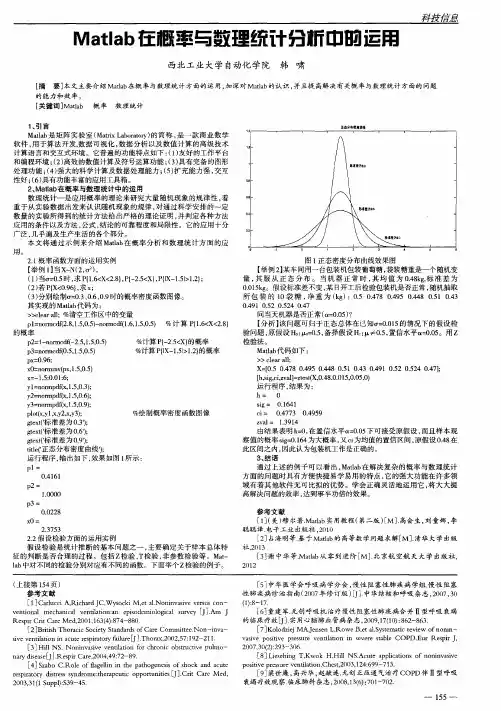
佛山科学技术学院上机报告课程名称数学应用软件上机项目 MATLAB统计工具箱中的回归分析命令专业班级一. 上机目的本节课我们认识了用MA TALB统计工具箱中的回归命令,主要有以下内容:regress命令即可用于多元回归分析也可用于一元线性回归,其格式如下:1.确定回归系数的命令是regress,用命令:b=regress(Y,X).2.求回归系数的点的估计和区间估计,并检验回归模型,用命令:[b,bint,r,rint,stats]=regress(Y,X,alpha)3.画出残差及其置性区间,用命令:rcoplot(r,rint)二元多项式回归:[p,S]=polyfit(x,y,2)二. 上机内容1.第十六章课后习题1;2.第十六章课后习题2;3.第十六章课后习题3。
三. 上机方法与步骤给出相应的问题分析及求解方法,并写出Matlab程序,并有上机程序显示截图。
第1题:要求一元线性回归方程及检验其显著性,用命令[b,bint,r,rint,stats]=regress(Y,X);求置信区间和预测值用命令rstool(x,y,'purequadratic')回归方程及检验其显著性:x=[20 25 30 35 40 45 50 55 60 65]';X=[ones(10,1) x];Y=[13.2 15.1 16.4 17.1 17.9 18.7 19.6 21.2 22.5 24.3]';[b,bint,r,rint,stats]=regress(Y,X);b,bint,stats残差分析,作残差图:rcoplot(r,rint)预测及作图:z=b(1)+b(2)*xplot(x,Y,'k+',x,z,'r')预测值及置信区间:x=[20 25 30 35 40 45 50 55 60 65]';y=[13.2 15.1 16.4 17.1 17.9 18.7 19.6 21.2 22.5 24.3]'; rstool(x,y,'purequadratic')第2题:要求二元多项式回归方程用命令[p,S]=polyfit(x,y,2)二元回归方程:用polyfit命令编程:x=0:2:20;y=[0.6 2.0 4.4 7.5 11.8 17.1 23.3 31.2 39.6 49.7 61.7]; [p,S]=polyfit(x,y,2)用regress命令编程:x=[0 2 4 6 8 10 12 14 16 18 20];Y=[0.6 2.0 4.4 7.5 11.8 17.1 23.3 31.2 39.6 49.7 61.7]'; X=[ones(11,1) x' (x.^2)'];[b,bint,r,rint,stats]=regress(Y,X);b,stats预测及作图:Y=polyconf(p,x,y)plot(x,y,'k+',x,Y,'r')第3题:要求lny a b x=+型回归方程,用命令[beta,r,J]=nlinfit(x',y','volum3',beta0);function y=volum3(beta,x)y=beta(1)+beta(2)*log(x);x=[2 3 4 5 7 9 12 14 17 21 28 56];y=[35 42 47 53 59 65 68 73 76 82 86 99];beta0=[1 1]';[beta,r,J]=nlinfit(x',y','volum3',beta0);beta四.上机结果学会了编写程序,运用上机语言求出问题结果,验证结果。
Matlab与统计分析 一、 回归分析 1、多元线性回归 1.1 命令 regress( ), 实现多元线性回归,调用格式为 [b,bint,r,rint,stats]=regress(y,x,alpha) 其中因变量数据向量Y和自变量数据矩阵x按以下排列方式输人
nnknnkkyyyyxxxxxxxxxx21212222111211,1
1
1
对一元线性回归,取k=1即可。alpha为显著性水平(缺省时设定为0.05),输出向量b,bint为回归系数估计值和它们的置信区间,r,rint为残差及其置信区间,stats是用于检验回归
模型的统计量,有三个数值,第一个是2R, 其中R是相关系数,第二个是F统计量值,第三个是与统计量F对应的概率P,当P 时拒绝0H,回归模型成立. 注:1、两组数据的相关系数在概率论的标准定义是: R= E{(x - E{x}) * (y - E{y})} / (sqrt({(x - E{x})^2) * sqrt({(y - E{y})^2)) E{}求取期望值。也就是两组数据协方差与两者标准差乘积的商。如果|R|=1说明两者相关,R=0说明两者不相关.
1、F是方差分析中的一个指标,一般方差分析是比较组间差异的。F值越大,P值越小,表示结果越可靠.
1.2 命令 rcoplot(r,rint),画出残差及其置信区间. 1.3 实例 1 已知某胡八年来湖水中COD浓度实测值(v)与影响因素湖区工业产值(x1)、总人口数(x2 )、捕鱼量(x3 )、降水量( x4)资料,建立污染物Y的水质分析模型.
Step 1 输入数据 x1=[1.376, 1.375, 1.387, 1.401, 1.412, 1.428, 1.445, 1.477]; x2=[0.450,0.475,0.485,0.500,0.535,0.545,0.550,0.575]; x3=[2.170,2.554,2.676,2.713,2.823,3.088,3.122,3.262]; x4=[0.8922, 1.1610,0.5346,0.9589, 1.0239, 1.0499,1.1065, 1.1387]; Y=[5.19, 5.30,5.60,5.82,6.00,6.06,6.45,6.95];
Step 2 保存数据(以数据文件.mat 形式保存,便于以后调用) save data x1 x2 x3 x4 y load data %取出数据
Step 3 执行回归命令 x=[ones(8,1),x1,x2,x3,x4]; [b,bint,r,rint,stats]=regress(y,x)
得到结果: b=(-16.5283, 15.7206, 2.0327.-0.2106,-0.1991)' stats=(0.9908,80.9530,0.0022)' 即 Y= -16.5283+15.7206x1+2.0327x2-0.2106xl+0.1991x4
2R
=0.9908, F=80.9530,P=0.0022
2、非线性回归 2.1 命令 nlinfit( ) 实现非线性回归,调用格式为 [beta,r,J]=nlinfit(x,y,‘model’,beta0) 其中,输入数据x,y分别为n×m矩阵和n维列向量,对一元非线性回归,x为n维列向量;model是事先用m-文件定义的非线性函数,beta0是回归系数的初值.beta是估计出的回归系数,r是残差,J是Jacobian矩阵,它们是估计预测误差需要的数据.
2.2 命令 nlpredci( ) 预测和预测误差的估计,调用格式为 [y,delta]=npredci('model',x,beta,r,j) 2.3 实例 2 对实例1中COD浓度实测值(Y),建立时序预测模型,这里选用logistic模型,即 ktbeay1 Step 1 建立非线性函数 对所要拟合的非线性模型建立m-文件model.m如下 function yhat=model(beta,t) yhat=beta(1)./(1+beta(2)*exp(-beta(3)*t))
Step 2 输入数据 t= 1:8 load data y(在data.mat中取出数据y) beta0=[50,10,1]’
Step 3 求回归系数 [beta,r,J]=nlinfit(t,Y,‘model’, beta0) 得结果: beta=(56.1157,10.4006,0.0445)’ 即
0445.04006.1011157.56e
y
Step 4 预测及作图 [YY,delta]=nlpredci(‘model’,x',beta,r ,J); plot(x,y,'k+',x,YY,'r')
3、逐步回归 逐步回归的命令是stepwise, 它提供了一个交互式画面.通过此工具可自由地选择变量,进行统计分析.调用格式为:
stepwise(x,y,inmodel,alpha) 其中x是自变量数据,是mn阶矩阵,y是因变量数据,1n阶矩阵,inmodel是矩阵的列数指标(给出初始模型中包括的子集(缺省时设定为全部自变量),alpha是显著性水平(缺省时为0.5). 运行stepwise命令时产生三个图形窗口:Stepwise Plot,Stepwise Table,Stepwise History.在Stepwise Plot窗口,显示出各项的回归系数及其置信区间.Stepwise Table 窗口中列出了一个统计表,包括回归系数及其置信区间,以及模型的统计量剩余标准差(RMSE)、相关系数(R-square)、F值、与F对应的概率P.
二、 主成分分析 这里给出江苏省生态城市主成份分析实例。 我们对江苏省十个城市的生态环境状况进行了调查,得到生态环境指标的指数值,见表 1。现对生态环境水平进行分析和评价。
我们利用Matlab6.5中的princomp命令实现。具体程序如下 x= [0.7883 0.7391 0.8111 0.6587 0.6543 0.8259 0.8486 0.6834 0.8495 0.7846 0.7633 0.7287 0.7629 0.8552 0.7564 0.7455 0.7800 0.9490 0.8918 0.8954 0.4745 0.5126 0.8810 0.8903 0.8288 0.7850 0.8032 0.8862 0.3987 0.3970 0.8246 0.7603 0.6888 0.8977 0.7926 0.7856 0.6509 0.8902 0.6799 0.9877 0.8791 0.8736 0.8183 0.9446 0.9202 0.9263 0.9185 0.9505 0.8620 0.8873 0.9538 0.9257 0.9285 0.9434 0.9154 0.8871 0.9357 0.8760 0.9579 0.9741 0.8785 0.8542 0.8537 0.9027 0.8729 0.8485 0.8473 0.9044 0.8866 0.9035 0.6305 0.6187 0.6313 0.7415 0.6398 0.6142 0.5734 0.8980 0.6186 0.7382 0.8928 0.7831 0.5608 0.8419 0.8464 0.7616 0.8234 0.6384 0.9604 0.8514]
x=x'; stdr=std(x); %求各变量标准差 [n,m]=size(x); sddata= x./stdr(ones(n,1),:); %标准化变换 [p,princ,egenvalue]=princomp(sddata) %调用主成分分析程序 p3=p(:,1:3) %输出前三个主成分系数 sc=princ(:,1:3) %输出前三个主成分得分 egenvalue %输出特征根 per=100*egenvalue/sum(egenvalue) % 输出各个主成分贡献率
执行后得到所要结果,这里是前三个主成分、主成分得分、特征根。即
egenvalue=[3.8811,2.6407,1.0597]' , per=[43.12,29.34,11.971]' . 这样,前三个主成分为 Zl = -0.3677xl+ 0.3702x2+ 0.1364x3+ 0.4048x4+ 0.3355x5-0.1318x6+0.4236x7+ 0.4815x8-0.0643x9
Z2 = 0.1442xl+ 0.2313x2-0.5299x3+ 0.1812x4-0.1601x5+ 0.5273x6+0.3116x7-0.0267x8+ 0.4589x9
Z3 = -0.3282xl-0.3535x2+ 0.0498x3+ 0.0582x4+ 0.5664x5-0.0270x6-0.0958x7-0.2804x8+ 0.5933x9
第一主成分贡献率为43.12%,第二主成分贡献率为29.34%,第三主成分贡献率为11.97%,前三个主成分累计贡献率达84.24%。
如果按80% 以上的信息量选取新因子,则可以选取前三个新因子。第一新因子Z1包含的 信息量最大为43.12%%,它的主要代表变量为x8(城市文明)、x7(生产效率)、 x4(城市绿 化),其权重系数分别为0.4815、0.4236、0.4048,反映了这三个变量与生态环境水平密切相关,第二新因子Z2包含的信息量次之为29.34%,它的主要代表变量为x3(地理结构)、x6(资源配置)、 x9(可持续性),其权重系数分别为0.5299、0.5273、0.4589,第三新因子 Z3包含的信息量为11.97%,代表总量为 x9(可持续性)、 x5(物质还原),权重系数分别为0.5933、0.5664。
这些代表变量反映了各自对该新因子作用的大小,它们是生态环境系统中最重要的影响因