第三章词法分析及词法分析程序
正规表达式相关作业
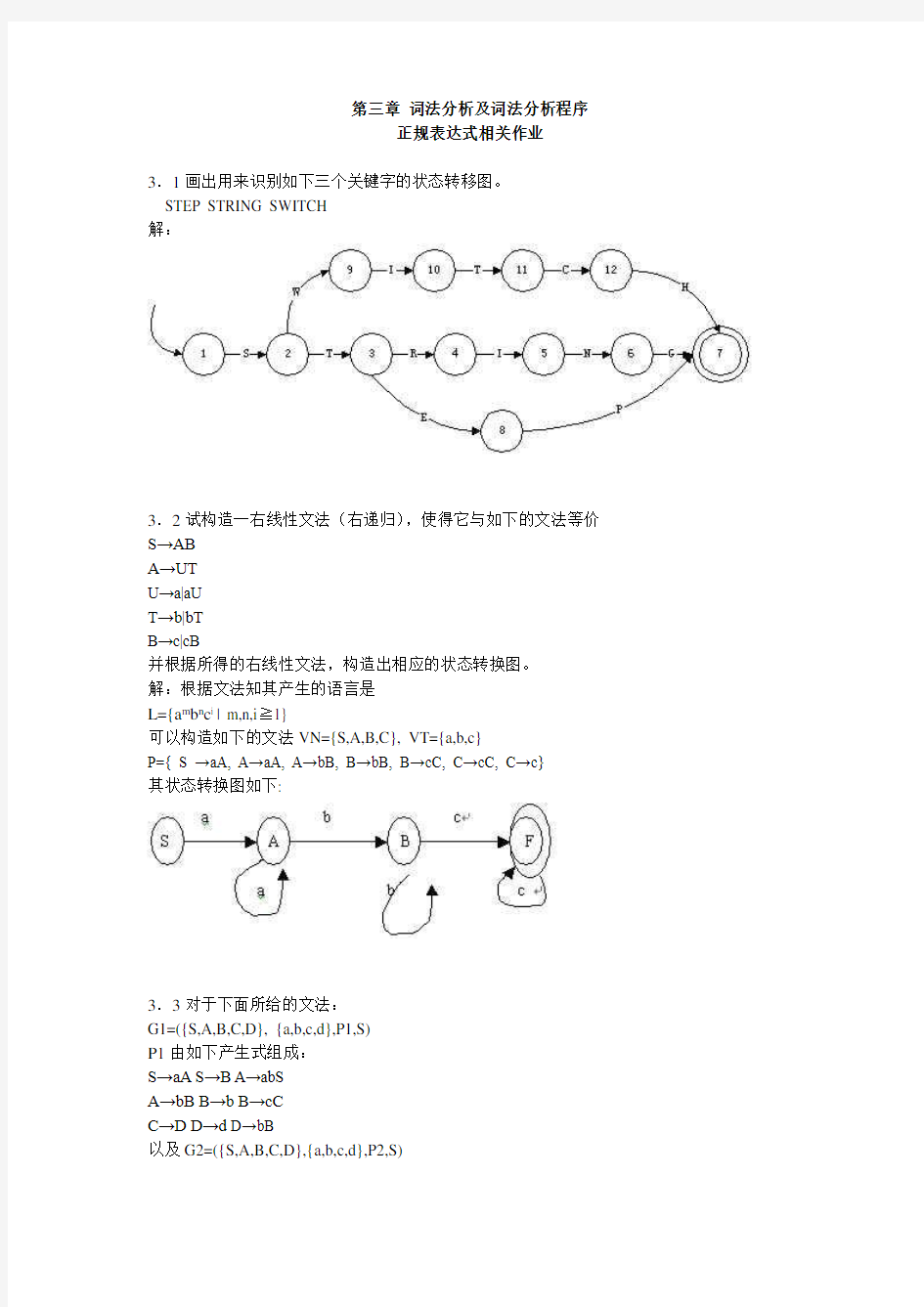
3.1画出用来识别如下三个关键字的状态转移图。
STEP STRING SWITCH
解:
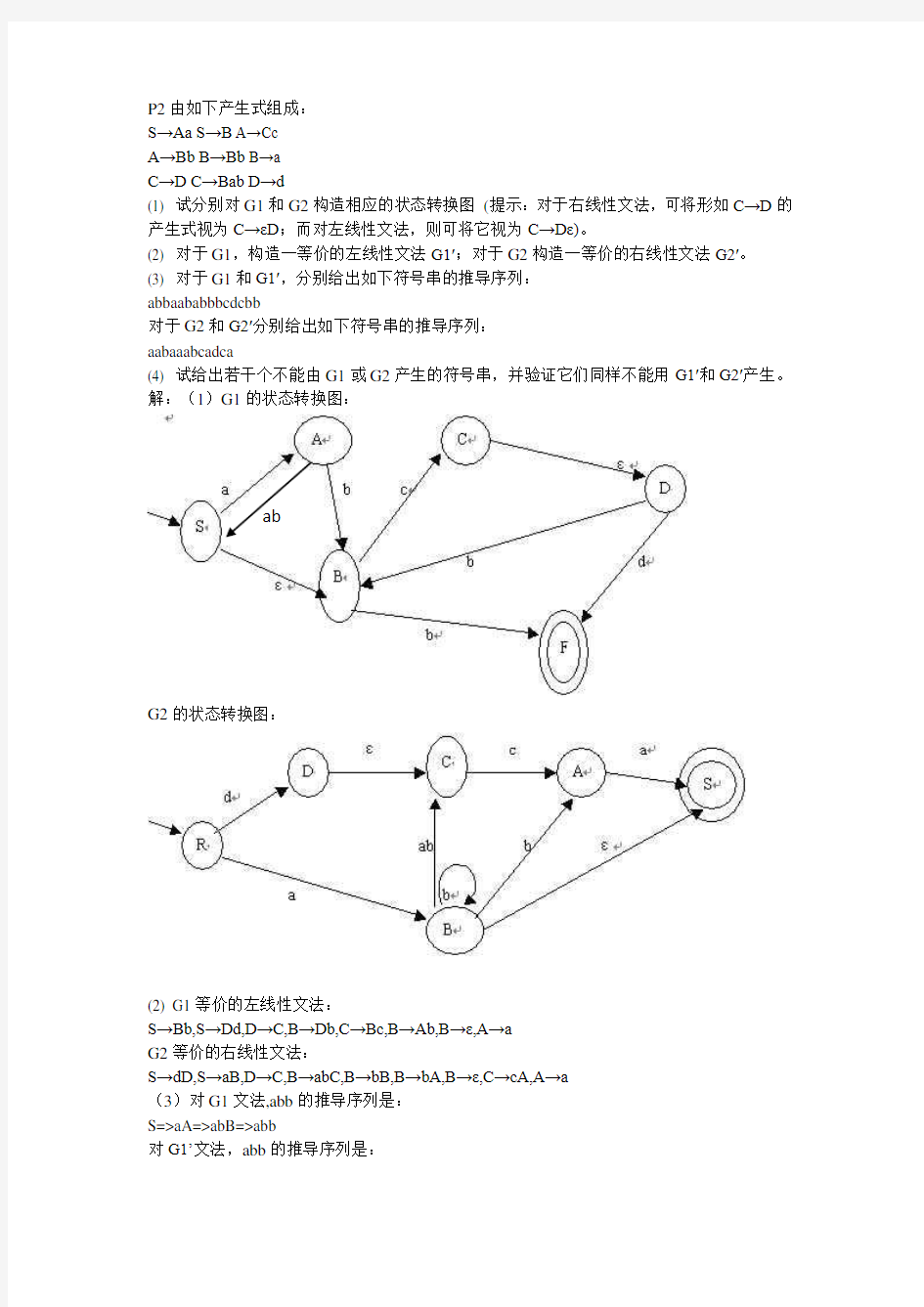
3.2试构造一右线性文法(右递归),使得它与如下的文法等价S→AB
A→UT
U→a|aU
T→b|bT
B→c|cB
并根据所得的右线性文法,构造出相应的状态转换图。
解:根据文法知其产生的语言是
L={a m b n c i | m,n,i≧1}
可以构造如下的文法VN={S,A,B,C}, VT={a,b,c}
P={ S →aA, A→aA, A→bB, B→bB, B→cC, C→cC, C→c}
其状态转换图如下:
3.3对于下面所给的文法:
G1=({S,A,B,C,D}, {a,b,c,d},P1,S)
P1由如下产生式组成:
S→aA S→B A→abS
A→bB B→b B→cC
C→D D→d D→bB
以及G2=({S,A,B,C,D},{a,b,c,d},P2,S)
P2由如下产生式组成:
S→Aa S→B A→Cc
A→Bb B→Bb B→a
C→D C→Bab D→d
(1) 试分别对G1和G2构造相应的状态转换图(提示:对于右线性文法,可将形如C→D的产生式视为C→εD;而对左线性文法,则可将它视为C→Dε)。
(2) 对于G1,构造一等价的左线性文法G1′;对于G2构造一等价的右线性文法G2′。
(3) 对于G1和G1′,分别给出如下符号串的推导序列:
abbaababbbcdcbb
对于G2和G2′分别给出如下符号串的推导序列:
aabaaabcadca
(4) 试给出若干个不能由G1或G2产生的符号串,并验证它们同样不能用G1′和G2′产生。解:(1)G1的状态转换图:
ab
G2的状态转换图:
(2) G1等价的左线性文法:
S→Bb,S→Dd,D→C,B→Db,C→Bc,B→Ab,B→ε,A→a
G2等价的右线性文法:
S→dD,S→aB,D→C,B→abC,B→bB,B→bA,B→ε,C→cA,A→a
(3)对G1文法,abb的推导序列是:
S=>aA=>abB=>abb
对G1’文法,abb的推导序列是:
S=>Bb=>Abb=>abb
对G2文法,aabca的推导序列是:
S=>Aa=>Cca=>Babca=>aabca
对G2’文法,aabca的推导序列是:
S=>aB=>aabC=>aabcA=>aabca
(4)对串acbd来说,G1,G1’文法都不能产生。
3.4设r,s等为任意的正规式,试证明下列的关系式成立:
(1) r*=(ε|r)*=ε|rr*=(r*)*
(2) (rs)*r=r(sr)*
(3) (r|s)*=(r*s*)*=(r*|s*)*
解:(1) r*表示的正规式集是{ε,r,rr,rrr,…}
(ε|r)*表示的正规式集是{ε, εε,…}∪{r,rr,rrr,…}={ε,r,rr,rrr,…}
ε|rr*表示的正规式集是{ε,r,rr,rrr,…}
(r*)*=r*={ε,r,rr,rrr,…}
所以四者是等价的。
(2)(rs)*r表示的正规式集是{ε,rs,rsrs,rsrsrs,…}r ={r,rsr,rsrsr,rsrsrsr,…} r(sr)* 表示的正规式集是r{ε,sr,srsr,srsrsr,…} ={ r,rsr,rsrsr,rsrsrsr,…}
所以两者等价。
(3)类同上
3.5设有如下的文法G[〈标号说明〉]:
〈标号说明〉→′LABEL′〈标号表〉
〈标号表〉→d〈标号段〉
〈标号段〉→d〈标号段〉|,〈标号〉|;
〈标号〉→d〈标号段〉
其中′LABEL′,′d′,′,′,′;′等为终结符号。
试求出描述此文法所产生语言的正规式;
解:识别此语言的正规式是S=’LABEL’d(d|,d)*;
编译原理 第三章词法分析和词法分析程序
设计扫描器时应考虑的问题 ?词法分析程序亦称为扫描器 ?任务:扫描程序,识别单词 ?扫描器的输出是语法分析程序的输入
词法分析的必要性 ?描述单词的结构比其它语法结构简单,仅用3型文法就够了; ?将单词识别从语法分析识别分离出来,可采用更有效的工具实现; ?有些语言的单词识别与前后文相关,不宜将其与语法分析合并; ?使编译程序各部分独立出来,有利于设计、调试和维护
单词符号的内部表示 ?常用的内部表示方法: (class,value) ?为便于阅读,常用助记符(或常量标识符、宏定义等)表示class。 ?在识别出变量名、函数(过程)名时,还应进行查填符号表的工作。
识别标识符的若干约定和策略 ?在允许长度下,应按最长匹配原则进行识别 ?有时需要超前扫描来进行单词识别。
由正规文法构造状态转换图 例:正规文法如下: 3.2 正规文法和状态转换图 <无符号数> → d.<余留无符号数> <无符号数> → .<十进小数> <无符号数> → E<指数部分> <余留无符号数> → d<余留无符号数> <余留无符号数> → .<十进小数> <余留无符号数> → E<指数部分> <余留无符号数> → ε <十进小数> → d<余留十进小数><余留十进小数> → d<余留十进小数> <余留十进小数> → E<指数部分> <余留十进小数> → ε <指数部分> → d<余留整指数> <指数部分> → +<整指数> <指数部分> → -<整指数> <整指数> → d<余留整指数> <余留整指数> → d<余留整指数> <余留整指数> → ε
第三章 词法分析 知识结构: 功能 词法分析器的要求 单词符号分类 词法分析 单词内部形式 器的设计 设计方发 词法分析器的设计 状态图 词法分析器组成 正规表达式 单词描述工具 正规集 词法分析器 正规文法 确定有限自动机(DFA ) 单词识别工具 非确定有限自动机(NFA ) DFA 的最小化 正规式与FA 的等价转换 等价转换 正规文法与FA 的等价转换 第一节 对词法分析器的要求 一、词法分析器的功能 输入源程序,输出单词符号(二元式表示)。
关键字:是由程序语言定义的具有固定意义的标识符。 标识符:用来表示各种名字,如变量等。 常数:常数的类型有整型,实型等。 运算符:算术运算符,关系运算符,逻辑运算符。 界限符:逗号,分号等。 三、单词符号内部的表示形式 内部的单词符号TOKEN字(二元式),TOKEN字占用机器字的长度,依据信息量的多少而定。 1、TOKEN字结构 CLASS:用整数表示。 VALUE:表示单词符号的属性(符号表指针)。 2、TOKEN的作用 CLASS:用于语法分析器对源程序结构的分析。 VALUE:用于语义分析器对源程序具体操作的分析。 3、单词种别码划分原则 CLASS:关键字,运算符,界限符(编译程序定义的符号) 使用一字一种编码。VALUE值省略。 VALUE:标识符,常数(用户定义的符号),存放符号表 常数表的指针。标识符,常数每一类为一种编码。 例:BEGIN A:= B END; 词法分析结果:符号表
(BEGIN,---- )Array(A ,K1 ) K1 (:= ,--- ) (B ,K3 ) K3 (END ,--- ) (;,--- ) 四、词法分析器的结构 1、一遍扫描(交互式结构)。 2、多遍扫描(独立式结构)。 第二节词法分析器的设计 一、设计步骤 1、确定词法分析器的接口关系; 2、确定单词分类和TOKEN字的结构; 3、对每一类单词构造状态转换图; 4、根据状态转换图设计算法。 二、功能描述 1、组织源程序输入; 2、按词法规则拼读单词符号,并转换成二元式; 3、删除注解行,空格和无用符号; 4、检查词法错误。 三、设计方法 1、输入(读取原文件) 原文件存储方式: 一种方式将原文件一次读入内存,另一种方式利用缓冲区技
第3章词法分析
3.5 有穷自动机 ?有穷自动机是一个更一般化的状态转换图,是一个语言的识别器(recognizer),对输入的串说 “yes”or “no” ?确定的和不确定 ?识别的语言恰好是正规表达式所能描述的语言 ?介绍三类有穷自动机 ?NFA ? -NFA ?DFA
3.5.1 不确定的有穷自动机 ?不确定的有穷自动机(Non-Deterministic Finite Automata,简称NFA)是一个五元组 M=(∑,S,δ,s0,F),其中: ?输入符号集合∑; ?状态集合S; ?转移函数δ:S?(∑?{ε})→P(S); ?可以用转换图或转移表表示 ?状态s 0是开始状态,s ∈S; ?F?S,接受状态(终止状态)集合。
S = { 0, 1, 2, 3 } s 0= 0F = { 3 } = { a, b } 例3.14 识别语言(a|b)*abb 的NFA 转换图(Transition Diagrams ) 1 start a 0a b b 3 b 2
输入符号a b 0{0, 1}{0}1 ? {2} 2?{3}状态 识别语言(a|b)*abb 的NFA 转换表(Transition Tables ) 1start a 0a b b 3 b 2
例,Input: ababb 接受输入字符串ababb 的状态转移序列 1 start a 0a b b 3 b 2 ? 210000*********?→??→??→??→??→??→??→??→??→??→??→??→??→?a b a b b a b a b b a b a ACCEPT !
第三章词法分析(作业) 1、求正则式(a|b)(a|b|0|1)*对应的正则文法(右线性文法),画状态转换图。 解:(a|b):S—>a|b (a|b|0|1)*:A—>aA|bA|0A|1A 合并: S—>a|b A—>aA|bA|0A|1A| ε 2、已知正则文法 G[Z]:Z0Z|1Z|0A A0B B0 (1)求对应的正则式? (2)G[Z]所描述的语言? 解: 1)(0|1)*000 2)G[Z]所描述的语言是L(G[Z])={x|x∈(0|1|000)} 3、已知有限自动机如图 (1)以上状态转换图表示的语言有什么特征? (2)写出其正规式与正规文法. (3)构造识别该语言的有限自动机 DFA. 解: (1)L={W |W {0,1},并且W至少有两个连续的1} (2)正则式为(0|1)*11(0|1)* 正则文法G(Z)为: Z—>0Z|1Z|1A A—>1B|1 B—>0B|1B|0|1
(3)将图中有限自动机确定化: 首先从处态A出发: I I0 I1 (1){A} (1){A} (2){A,B} (2){A,B} (1){A} (3){A,B,C} (3){A,B,C} (4){A,C} (3){A,B,C} (4){A,C} (4){A,C} (3){A,B,C} 其相应的DFA如下图: 将这个DFA最小化: 首先分终态和非终态两个集K1={1,2} 和 K2={3,4}。 由于状态1输入1到达状态K1集,而状态2输入1到达K2集故将k1分为K11={1}, K12={2}。 由于状态3,和 4 输入1,或0 都到达k2集,所以状态3,4等价。则可以分割成三个子集:{1},{2},{3,4} 所以将DFA最小化的状态图如下: 4、请构造与正则式 R=(a*b)*ba(a|b)* 等价的状态最少的 DFA(确定有限自动机) 解: (1)首先构造转换系统图:
第三章词法分析及词法分析程序 正规表达式相关作业 3.1画出用来识别如下三个关键字的状态转移图。 STEP STRING SWITCH 解: 3.2试构造一右线性文法(右递归),使得它与如下的文法等价S→AB A→UT U→a|aU T→b|bT B→c|cB 并根据所得的右线性文法,构造出相应的状态转换图。 解:根据文法知其产生的语言是 L={a m b n c i | m,n,i≧1} 可以构造如下的文法VN={S,A,B,C}, VT={a,b,c} P={ S →aA, A→aA, A→bB, B→bB, B→cC, C→cC, C→c} 其状态转换图如下: 3.3对于下面所给的文法: G1=({S,A,B,C,D}, {a,b,c,d},P1,S) P1由如下产生式组成: S→aA S→B A→abS A→bB B→b B→cC C→D D→d D→bB 以及G2=({S,A,B,C,D},{a,b,c,d},P2,S)
P2由如下产生式组成: S→Aa S→B A→Cc A→Bb B→Bb B→a C→D C→Bab D→d (1) 试分别对G1和G2构造相应的状态转换图(提示:对于右线性文法,可将形如C→D的产生式视为C→εD;而对左线性文法,则可将它视为C→Dε)。 (2) 对于G1,构造一等价的左线性文法G1′;对于G2构造一等价的右线性文法G2′。 (3) 对于G1和G1′,分别给出如下符号串的推导序列: abbaababbbcdcbb 对于G2和G2′分别给出如下符号串的推导序列: aabaaabcadca (4) 试给出若干个不能由G1或G2产生的符号串,并验证它们同样不能用G1′和G2′产生。解:(1)G1的状态转换图: ab G2的状态转换图: (2) G1等价的左线性文法: S→Bb,S→Dd,D→C,B→Db,C→Bc,B→Ab,B→ε,A→a G2等价的右线性文法: S→dD,S→aB,D→C,B→abC,B→bB,B→bA,B→ε,C→cA,A→a (3)对G1文法,abb的推导序列是: S=>aA=>abB=>abb 对G1’文法,abb的推导序列是: