攻城掠地最新神兵数据汇总
攻城掠地最新神兵数据汇总
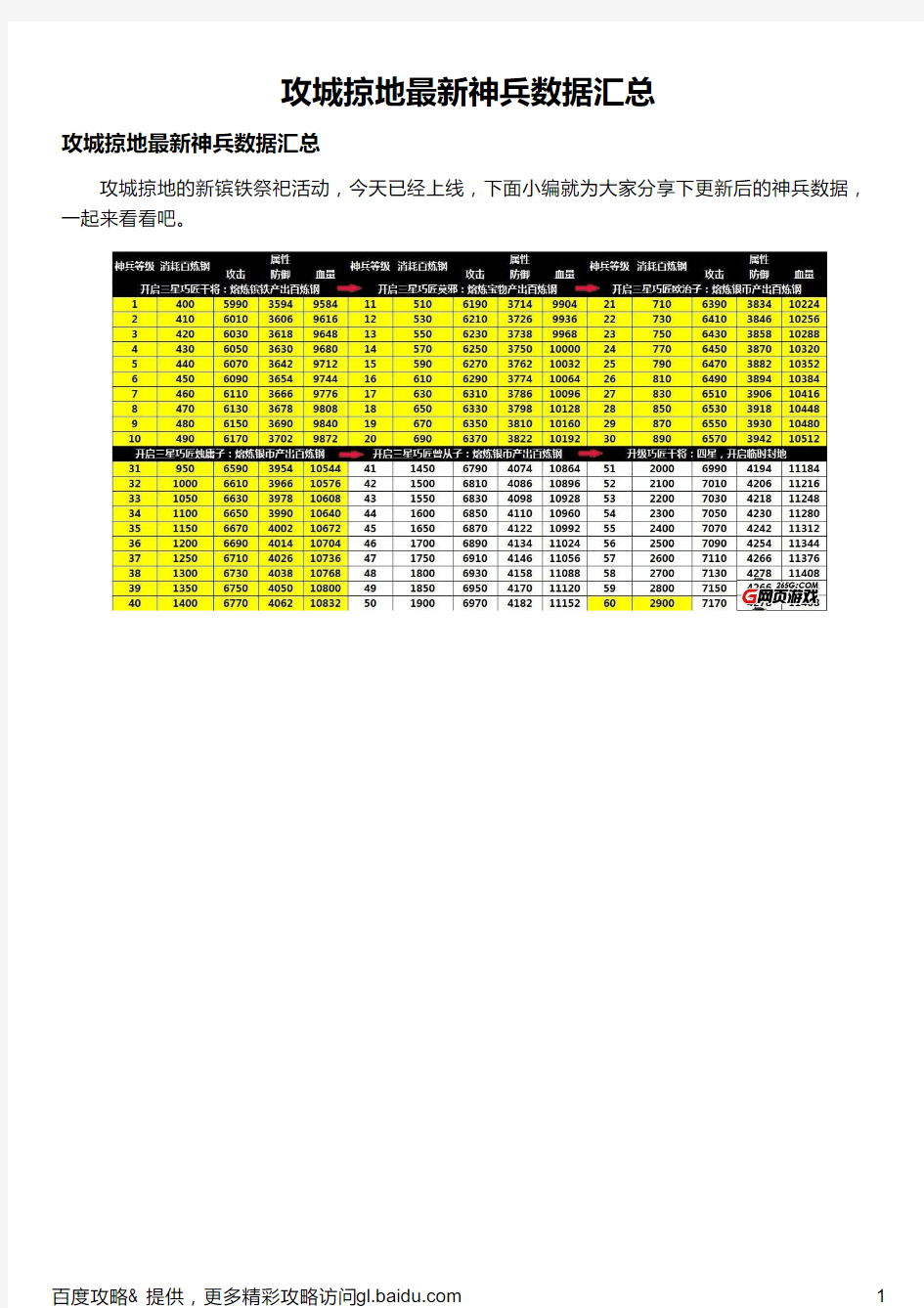
攻城掠地的新镔铁祭祀活动,今天已经上线,下面小编就为大家分享下更新后的神兵数据,一起来看看吧。
百度攻略& 提供,更多精彩攻略访问https://www.doczj.com/doc/fa5727272.html,
1
学习收藏数据库增删改查 --查询信息系和计算机系的学生,并按学生所在系和学号排序。select sno,sname,Sdept from Student where Sdept='CS'OR Sdept='IS' order by Sdept,sno ASC --查询学生表中最小的年龄。 select MIN(sage from student --查询课程名中包含“数据”的课程名。 select cno,cname from course where Cname like'%数据%' --查询先行课程为空值的课程号、课程名及学分 select cno,cname,ccredit from Course where Cpno is null --查询李勇选修的数据库课程的成绩 select grade from SC where Sno=(select Sno from Student where Sname='李勇'and Cno=(select Cno from Course where cname='数据库' --查询平均成绩分以上的学生的学号 select distinct sno from SC scx where (select AVG(Grade from SC scy
where scy.sno=scx.Sno>85 --求计算机系没有选修数据库课程的学生姓名 select sname from Student where Sno not in(select Sno from SC where Cno in(select Cno from Course where Sname='数据库'and Sdept='IS' --求至少选修了学号为S1所选修的全部课程的学生学号 select distinct sno from SC scx where not exists(select*from SC scy where scy.Sno='20021522'and not exists(select* from sc scz where scz.sno=scx.sno and https://www.doczj.com/doc/fa5727272.html,o=https://www.doczj.com/doc/fa5727272.html,o --求各系的系的学生人数的,并将结果按学生人数的降序排序 select Sdept,COUNT(sno from Student group by Sdept order by Sdept ASC --查询选修了数学课程并且成绩高于该门课程平均分的学生学号和成绩 select sno,grade from SC scx where Grade>=(select AVG(Grade from SC scy where Cno=(select Cno from Course where Cname='数学'and Cno=(select Cno from Course
信息系统的主要作用就是对企业信息的整合处理,而信息的载体和表达都要通过数据完成。对项目实施来讲,基础数据的准备工作难度最大。 首先,基础数据涉及面广,涵盖了企业中所有可见信息和不可见信息。物料基本信息,产品结构数据,会计科目,供应商客户信息,部门、工厂、仓库、车间信息等等属于可见信息,这些信息在手工作业中也会用到。不可见信息如单据类型、仓库性质、计划参数等,这些信息在手工管理信息时是不会涉及到的,它们会影响到系统计算。 另外,基础数据准备的工作量大,以上各类信息的记录数从几个到几十万都有,而每条记录包含的字段又可多达上百个,两者的乘积简直是天文数字,通常造成项目延期的原因有90%来自于基础数据整理。 数据的正确性是最重要的,基础数据是许多程序正确运行的基础,如物料计划和生产计划就是根据物料文件设定的提前期、库存量、BOM结构等计算得到的,如果其中任何一个数据与实际不符,计划结果就将没有任何指导意义。 正是因为基础数据具有这些特征,从而造成了收集准备工作量大、难组织,一般需要多个部门协调,投入的人力和时间都比较多,见效周期长,因此阻力也是很大的。 为了帮助企业更有效地实施ERP,下面谈一下如何快速、低成本、低错误率地完成基础数据准备。 第一步:确定工作范围 首先根据ERP项目范围确定哪些数据需要准备,然后确定参与部门和人员配备,进而确定工作计划,切记不可将所有工作只交给一个部门甚至一个人做,必须对此项工作的艰难程度有充分的认识。工作计划中还要注意安排定期的会议,以方便工作人员之间沟通。 第二步:建立必要的编码原则 ERP软件对数据的管理是通过编码实现的,编码可以对数据进行唯一的标识,并且贯穿以后的查询和应用,建立编码原则是为了使后面的工作有一个可以遵循的原则,也为庞杂的数据确定了数据库可以识别的唯一标识方法,所谓磨刀不误砍柴工,大家切不可急于求成,忽略了这些重要的工作。 另外,编码原则的制定属于企业级标准的建立,应该按照ISO9000的标准制定和管理,尤其对于量大的基础数据(如物料主文件的编码)必须由多个部门共同确定方案。 第三步:建立公用信息 建立的公用信息包括公司、子公司、工厂、仓库、部门、员工信息、货币代码等基本信息。这些数据会在其他基础数据中被引用,并且数据量不大,可以利用较少的时间和人力完成。如果整理其他数据的时候发现缺少公用信息再补的话,整体效率和进度会大打折扣。 第四步:BOM结构的确定(根据企业情况可选) 如果企业应用生产系统、计划或产品研发模块,BOM就是必须的基础数据。这里首先应该明确原料到半成品、半成品到产品的级次关系,这步工作的难点是半成品设定的问题。如果
数据库增删改查基本语句 adoquery1.Fielddefs[1].Name; 字段名 dbgrid1.columns[0].width:=10; dbgrid的字段宽度 adoquery1.Fields[i].DataType=ftString 字段类型 update jb_spzl set kp_item_name=upper(kp_item_name) 修改数据库表中某一列为大写select * from master.dbo.sysobjects ,jm_https://www.doczj.com/doc/fa5727272.html,ers 多库查询 adotable1.sort:='字段名称ASC' adotable排序 SQL常用语句一览 sp_password null,'新密码','sa' 修改数据库密码 (1)数据记录筛选: sql="select * from 数据表where 字段名=字段值orderby 字段名[desc] " sql="select * from 数据表where 字段名like '%字段值%' orderby 字段名[desc]" sql="select top10 * from 数据表where 字段名orderby 字段名[desc]" sql="select * from 数据表where 字段名in('值1','值2','值3')" sql="select * from 数据表where 字段名between 值1 and 值2" (2)更新数据记录: sql="update 数据表set 字段名=字段值where 条件表达式" sql="update 数据表set 字段1=值1,字段2=值2……字段n=值n where 条件表达式" (3)删除数据记录: sql="delete from 数据表where 条件表达式" sql="delete from 数据表"(将数据表所有记录删除) (4)添加数据记录: sql="insert into 数据表(字段1,字段2,字段3…) values(值1,值2,值3…)" sql="insert into 目标数据表select * from 源数据表"(把源数据表的记录添加到目标数据表)
实验二 SPSS数据录入与编辑 一、实验目的 通过本次实验,要求掌握SPSS的基本运行程序,熟悉基本的编码方法、了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.录入数据 2.保存数据文件 3.编辑数据文件 五、实验学时 2学时(可根据实际情况调整学时) 六、实验方法与步骤 1.开机 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS 3.认识SPSS数据编辑窗 4.按要求录入数据 5.联系基本的数据修改编辑方法 6.保存数据文件 7.关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。 3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员 同意,禁止使用移动存储器。
4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换, 应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业 一、定义变量 1.试录入以下数据文件,并按要求进行变量定义。 数据:
要求: 1)对性别(Sex)设值标签“男=0;女=1”。 2)正确设定变量类型。其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。 3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
2.试录入以下数据文件,保存为“数据”。
实验三统计图的制作与编辑 一、实验目的 通过本次实验,了解如何制作与编辑各种图形。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.条形图的绘制与编辑 2.直方图的绘制与编辑 3.饼图的绘制与编辑 五、实验学时 2学时 六、实验方法与步骤 1.开机; 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS; 3.按要求完成上机作业; 4. 关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。 3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换,应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业
02.连接命令:mysql -h[主机地址] -u[用户名] -p[用户密码] 03.创建数据库:create database [库名] 04.显示所有数据库: show databases; 05.打开数据库:use [库名] 06.当前选择的库状态:SELECT DATABASE(); 07.创建数据表:CREATE TABLE [表名]([字段名] [字段类型]([字段要求]) [字段参数], ......); 08.显示数据表字段:describe 表名; 09.当前库数据表结构:show tables; 10.更改表格 11. ALTER TABLE [表名] ADD COLUMN [字段名] DATATYPE 12. 说明:增加一个栏位(没有删除某个栏位的语法。 13. ALTER TABLE [表名] ADD PRIMARY KEY ([字段名]) 14. 说明:更改表得的定义把某个栏位设为主键。 15. ALTER TABLE [表名] DROP PRIMARY KEY ([字段名]) 16. 说明:把主键的定义删除。 17.显示当前表字段:show columns from tablename; 18.删库:drop database [库名]; 19.删表:drop table [表名]; 20.数据操作 21.添加:INSERT INTO [表名] VALUES('','',......顺序排列的数据); 22.查询: SELECT * FROM [表名] WHERE ([条件]); 23.建立索引:CREATE INDEX [索引文件名] ON [表名] ([字段名]); 24.删除:DELETE FROM [表名] WHERE ([条件]); 25.修改:UPDATE [表名] SET [修改内容如name = 'Mary'] WHERE [条件]; 26. 27.导入外部数据文本: 28.1.执行外部的sql脚本 29.当前数据库上执行:mysql < input.sql 30.指定数据库上执行:mysql [表名] < input.sql 31.2.数据传入命令load data local infile "[文件名]" into table [表名]; 32.备份数据库:(dos下) 33.mysqldump --opt school>school.bbb 34. 35. 36. 37.提示:常用MySQL命令以";"结束,有少量特殊命令不能加";"结束,如备份数据库 38.一. 增删改查操作 39. 40.============================================================================ ===== 41.1. 增: 42.insert into 表名values(0,'测试'); 43.注:如上语句,表结构中有自动增长的列,也必须为其指定一个值,通常为0 44.insert into 表名(id,name) values(0,'尹当')--同上
资源数据采集技术方案 公司名称 2011年7月 二O一一年七月 目录 第1 部分概述 (3 1.1 项目概况 (3 1.2 系统建设目标 (3 1.3 建设的原则 (4 1.3.1 建设原则 (4 1.4 参考资料和标准 (5 第2 部分系统总体框架与技术路线 (5 2.1 系统应用架构 (6 2.2 系统层次架构 (6 2.3 关键技术与路线 (7 第3 部分系统设计规范 (9 第4 部分系统详细设计 (9 第1 部分概述 1.1 项目概况
Internet已经发展成为当今世界上最大的信息库和全球范围内传播知识的主要渠道,站点遍布全球的巨大信息服务网,为用户提供了一个极具价值的信息源。无论是个人的发展还是企业竞争力的提升都越来越多地依赖对网上信息资源的利用。 现在是信息时代,信息是一种重要的资源,它在人们的生活和工作中起着重要的作用。计算机和现代信息技术的迅速发展,使Internet成为人们传递信息的一个重要的桥梁。网络的不断发展,伴随着大量信息的产生,如何在海量的信息源中查找搜集所需的信息资源成为了我们今后建设在线预订类旅游网重要的组成部分。 因此,在当今高度信息化的社会里,信息的获取和信息的及时性。而Web数据采集可以通过一系列方法,依据用户兴趣,自动搜取网上特定种类的信息,去除无关数据和垃圾数据,筛选虚假数据和迟滞数据,过滤重复数据。直接将信息按照用户的要求呈现给用户。可以大大减轻用户的信息过载和信息迷失。 1.2 系统建设目标 在线预订类旅游网是在线提供机票、酒店、旅游线路等旅游商品为主,涉及食、住、行、游、购、娱等多方面的综合资讯信息、全方位的旅行信息和预订服务的网站。 如果用户要搜集这一类网站的相关数据,通常的做法是人工浏览网站,查看最近更新的信息。然后再将之复制粘贴到Excel文档或已有资源系统中。这种做法不仅费时费力,而且在查找的过程中可能还会遗漏,数据转移的过程中会出错。针对这种情况,在线预订类旅游网信息自动采集的系统可以实现数据采集的高效化和自动化。 1.3 建设的原则 1.3.1 建设原则 由于在线预订类旅游网的数据采集涉及的方面多、数据量大、采集源数据结构多样化的特点。因此,在进行项目建设的过程中,应该遵循以下原则:
征信系统管理平台 整体解决方案 项目背景
随着经济市场化程度的加深,加快企业和个人征信体系建设已成为社会共识。党的十六大报告明确提出要“健全现代市场经济的社会信用体系”,十六届三中全会明确提出“按照完善法规、特许经营、商业运作、专业服务的方向,加快建设企业和个人信用服务体系。”温家宝总理明确指示,社会信用体系建设从信贷信用征信起步,多次强调要加快全国统一的企业和个人信用信息基础数据库建设,形成覆盖全国的信用信息网络,加快征信立法,促进征信行业的发展,积极发展专业化的信用机构,有步骤、有重点开放征信市场,逐步建立失信惩戒制度,规范社会征信机构,加强征信市场监督管理。 应用价值 征信系统管理平台的建设和推广应用,特别是通过企业和个人重要经济活动的影响和规范,逐步形成诚实守信、遵纪守法、重合同讲信用的社会风气,推动社会信用体系建设,提高社会诚信水平,促进文明社会的建设; 征信系统管理平台帮助商业银行等金融机构控制信用风险,维护金融稳定,扩大信贷范围,促进消费增长,改善经济增长结构,促进经济的可持续发展; 提高审贷效率,方便广大群众借贷,防止不良贷款,防止个人过度负债; 帮助商业银行核实客户身份,从信贷活动的源头杜绝信贷欺诈、保证信贷交易的合法性; 该平台全面反映企业和个人的信用状况,帮助商业银行确定是否提供贷款及贷款金额大小、利率高低等因素,以及奖励守信者,惩戒失信者; 该征信系统管理平台利用企业和个人征信系统遍布全国各地的网络及其对企业和个人信贷交易等重大经济活动的影响,提高法院、税务、工商、海关等政府部门的行政执法力度;通过企业和个人征信系统的约束性和影响力,培养和提高企业和个人遵守法律、尊重规则、尊重合同、恪守信用的意识,提高社会诚信水平,建设和谐美好的社会。
第四章数据录入与上报 图4-1 点击“录入与上报”,显示8个子菜单,其主要作用分述如下: ⑴单位确定:选择企业和装置,确定系统的操作范围。 ⑵数据录入:进行数据录入工作。 ⑶数据修改:完成数据的修改与维护工作。 ⑷上报数据:上报基础数据。 ⑸上报状态查询:查询上报状态、上报时间。 ⑹数据接收:接收上报数据。 ⑺接收状态检查:检查接收状态、接收时间。 ⑻退出:退出子系统。 一、单位确定 系统启动后,首先要进行单位的确定。单位确定是“数据检索”功能所必需的。
图4-2 一进入子系统,将自动弹出该窗口,见图32-2。在该窗口中用户可选择直属企业或二级企业及所属装置或罐区,按“确定”键即可。子系统在“数据检索”的各项功能中将以所选择的企业和装置(罐区)为对象,进行数据查询处理等工作。 二、数据录入 点击“数据录入”,进入数据录入窗口,见图32-3,本系统的所有基础数据都是在“数据录入”窗口中输入。 图4-3 本子系统涉及基础表37个,采用集中控制管理录入的方式,将37个基础表按层次关系以树状形式分级显示,列在屏幕左方,点击相应表名,屏幕右方会出现该表的录入窗口。下面介绍“数据录入”窗口:
图4-4 1、企业选择框 点击 “”,显示企业列表框,选择需要录入数据的企业。 图4-5 2、直属企业与二级企业切换按钮: 在“二级”状态下点击,企业选择框中只列出所选企业下的二级企业,“二级”切换成“直属”状态;在“直属”状态下点击,企业选择框中只列出直属企业,“直属”状态切换成“二级”状态。 图4-6 3、基表列表 基表列表中涉及基础表37个,按层次关系以树状形式分级显示,列在屏幕左方,点击相应表名,屏幕右方会出现该表的录入窗口。用户点击带“+”标志的基表,可展开与当前基表相关联的二级基表。30 个基础表的层次关系见下图 ①企业选择框 正在输入数 据的基表名 ③基表列表 ⑤数据录入窗口 ④控制按钮 点击“直属”按 扭 点击“二级”按
oracle数据库表空间大小的查看、修改 1、通过oracle客户端连接到oracle数据库 a)安装好oracle客户端后,通过net manager工具配置本地net服务名, 依次点击开始,程序,Oracle - OraClient10g_home1,配置和移植工具,Net Manager。 b)进入Net Manager配置窗口。
c)依次点击本地,服务命名。 d)可以看到左侧的号变成绿色,此时可以点击该,弹出net服务名的 配置窗口
e)这里的网络服务名是指的oracle客户端所在机器的本地服务名,随便设 置个名字,例如sbzw,点击下一步。 f)默认设置,点击下一步。 g)在主机名后的输入框中输入oracle数据库所在的服务器的ip地址,例 如:192.168.1.236.,点击下一步。
h)在服务名后的输入框中输入oracle数据库的全局服务名,例如tjsb, 点击下一步。 i)此处不要点击完成,先点击测试查看连接是否正常。
j)在连接测试窗口中显示的应该是测试没有成功,此时请点击更改登录。 k)修改了用户名和密码后,点击确定,然后再次点击“测试”,提示连接成功后,关闭连接测试窗口,点击完成,至此本地net服务名配置完成。 2、通过oracle客户端的企业管理器修改数据库的表空间大小
a)依次点击开始,程序,Oracle - OraClient10g_home1,Enterprise Manager Console(企业管理器)。 b)进入了oracle的企业管理器 c)依次点击数据库,sbzw,弹出登录窗口,
智能手机终端的数据采集及分析系统 主要功能如下: 采集使用数据采集程序手机的手机号码:数据采集程序必须开通GPRS,实时传输采集数据及监听服务端指令;所以会有一定的数据量。为解决用户因GPRS传输采集数据产生的费用,所以记录用户的手机号码。 采集GPS信息:经纬度,时间,速度; 采集无线网络状况信息:GSM,GPRS网络情况; 获取的无线网络信息并附加GPS信息,帮助数据分析专家系统分析处理; 数据采集终端的主要功能如下: 实时诊断网络信息; 诊断分为空闲时诊断与使用时诊断; 空闲时诊断:根据运营商的相关规定设定网络异常指标;当手机处于空闲状态时,指定频率(秒)获取无线网络的基本参数,如CID,LAC,BSIC,BCCH,RxQuality,RxLevel,C/I,C/A,TxPower,TA,TS等;根据设定的异常指标来判断是否出现异常;如果出现异常则保存本次信息,并获取此时此地的GPS信息、本手机的手机号码一并发送至指定服务器,由“数据分析专家系统”分析处理。 发送数据内容:本手机的手机号码+无线网络基本参数+GPS信息; 数据格式:XML文件格式; 传输方式:使用GPRS进行数据传输; 使用时诊断:用户使用手机时,检测用户使用过程中无线网络的状况;如手机数据下载过程中,检测总的下载量,下载时间,是否下载成功,如果不正常则记录本次使用过程; 诊断项: 2通话:未接通、掉话、呼叫时延; 2短信(SMS),彩信(MMS):是否发送或接受成功、发送或接受时间; 2 GPRS Attach:Attach是否成功、Attach成功的时长PDP激活,PDP激活是否成功、激活成功的时长; 2 WAP数据传输:WAP登陆测试;WAP登陆是否成功;WAP登陆成功时长; 2 WAP刷新测试:WAP刷新是否成功;WAP刷新成功时长;
Excel中数据的排序、筛选与分类汇总 课程导入:通过前几次课公式和函数的系统学习,我们已经知道Excel电子表格具有强大的数据运算能力。但只有数据,而无法快速有效的查阅有效信息,这无疑是在做无用功,是一种资源的浪费。今天这次课我们将要学习Excel中的数据处理,真正对数据进行统计和分析。 引入实例:Excel在学生成绩统计中有独特的优势,能方便快速的进行学生成绩的各类统计,如能方便快捷的进行成绩的排序、分类汇总、数据的高效筛选、快速的进行学科及总分的分段统计等等。 要点:数据的处理重点从数据的排序、数据的筛选、数据的分类汇总入手。 教学内容一:数据排序和筛选 一、数据的排序:排序就是按某种规则排列数据以便分析。 排序的三种方式:a. “升序”排列,选中要排序列中的一个单元格,按按钮 b. “降序”排列,选中要排序列中的一个单元格,按按钮 c. 自定义排列,选择【数据】->【排序】,利用多个关键字进行复杂 排序。首先考虑的是“主要关键字”,当主要关键字排序出现相 同数据时,将按次要关键字再次排序,如果次要关键字还出现相 同数据时,可以按照第三关键字最后排序。 注意:如果Excel没能够正确地进行排序,可能是因为它没有正确地获取排序区域。特别应该注意的是,排序区域中不能够包含已合并的单元格。 教学实例一:《高一期末成绩分析》(排序) (1)打开D:\excel实例\操作一.xls,选择“高一期末成绩(排序)”。 (2)按总分进行数据排序。选定H列中的任意一个单元格(注意,不要选定H列,否则将只对H列排序),单击常用工具栏中的按钮,即从大到小排序。 (3)要求总分相同的学生按语数外总分降序排序,语数外总分相同的学生按照理综降序排序。选定表中任意单元格,单击【数据】->【排序】,指定主要关键字为总分,排序方式为降序;次要关键字为语数外,排序方式也为降序;第三关键字为理综,排序方式为降序。注意:若不想对标题行进行排序,那要选择“有标题行”。 (4)保存该文件。 操作后效果图如下:
实验二--SPSS数据录入与编辑
实验二 SPSS数据录入与编辑 一、实验目的 通过本次实验,要求掌握SPSS的基本运行程序,熟悉基本的编码方法、了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.录入数据 2.保存数据文件 3.编辑数据文件 五、实验学时 2学时(可根据实际情况调整学时) 六、实验方法与步骤 1.开机 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS 3.认识SPSS数据编辑窗 4.按要求录入数据 5.联系基本的数据修改编辑方法 6.保存数据文件 7.关闭SPSS,关机。 七、实验注意事项 1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员 同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换, 应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业 一、定义变量 1.试录入以下数据文件,并按要求进行变量定义。 学号姓名性 别生日身高 (cm) 体重 (kg) 英语(总 分100 分) 数学(总 分100 分) 生活费 ($代表 人民币) 200201 刘一迪男1982.01.12 156.42 47.54 75 79 345.00 200202 许兆辉男1982.06.05 155.73 37.83 78 76 435.00 200203 王鸿屿男1982.05.17 144.6 38.66 65 88 643.50 200204 江飞男1982.08.31 161.5 41.68 79 82 235.50 200205 袁翼鹏男1982.09.17 161.3 43.36 82 77 867.00 200206 段燕女1982.12.21 158 47.35 81 74 200207 安剑萍女1982.10.18 161.5 47.44 77 69 1233.00 200208 赵冬莉女1982.07.06 162.76 47.87 67 73 767.80 200209 叶敏女1982.06.01 164.3 33.85 64 77 553.90 200210 毛云华女1982.09.12 144 33.84 70 80 343.00 200211 孙世伟男1981.10.13 157.9 49.23 84 85 453.80 200212 杨维清男1981.12.6 176.1 54.54 85 80 843.00 200213 欧阳已 祥 男1981.11.21 168.55 50.67 79 79 657.40 200214 贺以礼男1981.09.28 164.5 44.56 75 80 1863.90 200215 张放男1981.12.08 153 58.87 76 69 462.20 200216 陆晓蓝女1981.10.07 164.7 44.14 80 83 476.80 200217 吴挽君女1981.09.09 160.5 53.34 79 82 200218 李利女1981.09.14 147 36.46 75 97 452.80 200219 韩琴女1981.10.15 153.2 30.17 90 75 244.70 200220 黄捷蕾女1981.12.02 157.9 40.45 71 80 253.00 1)对性别(Sex)设值标签“男=0;女=1”。 2)正确设定变量类型。其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。 3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
修改及查看mysql数据库的字符集 来源: ChinaUnix博客日期: 2008.03.23 22:20 (共有条评论) 我要评论https://www.doczj.com/doc/fa5727272.html,/techdoc/database/2008/03/23/986386.shtml Liunx下修改MySQL字符集: 1.查找MySQL的cnf文件的位置 find / -iname '*.cnf' -print /usr/share/mysql/https://www.doczj.com/doc/fa5727272.html,f /usr/share/mysql/https://www.doczj.com/doc/fa5727272.html,f /usr/share/mysql/https://www.doczj.com/doc/fa5727272.html,f /usr/share/mysql/https://www.doczj.com/doc/fa5727272.html,f /usr/share/mysql/https://www.doczj.com/doc/fa5727272.html,f /usr/share/texmf/web2c/https://www.doczj.com/doc/fa5727272.html,f /usr/share/texmf/web2c/https://www.doczj.com/doc/fa5727272.html,f /usr/share/texmf/web2c/https://www.doczj.com/doc/fa5727272.html,f /usr/share/texmf/tex/xmltex/https://www.doczj.com/doc/fa5727272.html,f /usr/share/texmf/tex/jadetex/https://www.doczj.com/doc/fa5727272.html,f /usr/share/doc/MySQL-server-community-5.1.22/https://www.doczj.com/doc/fa5727272.html,f /usr/share/doc/MySQL-server-community-5.1.22/https://www.doczj.com/doc/fa5727272.html,f /usr/share/doc/MySQL-server-community-5.1.22/https://www.doczj.com/doc/fa5727272.html,f /usr/share/doc/MySQL-server-community-5.1.22/https://www.doczj.com/doc/fa5727272.html,f /usr/share/doc/MySQL-server-community-5.1.22/https://www.doczj.com/doc/fa5727272.html,f 2. 拷贝 https://www.doczj.com/doc/fa5727272.html,f、https://www.doczj.com/doc/fa5727272.html,f、https://www.doczj.com/doc/fa5727272.html,f、https://www.doczj.com/doc/fa5727272.html,f 其中的一个到/etc下,命名为https://www.doczj.com/doc/fa5727272.html,f cp /usr/share/mysql/https://www.doczj.com/doc/fa5727272.html,f /etc/https://www.doczj.com/doc/fa5727272.html,f 3. 修改https://www.doczj.com/doc/fa5727272.html,f vi /etc/https://www.doczj.com/doc/fa5727272.html,f 在[client]下添加 default-character-set=utf8 在[mysqld]下添加 default-character-set=utf8 4.重新启动MySQL [root@bogon ~]# /etc/rc.d/init.d/mysql restart Shutting down MySQL [ 确定 ] Starting MySQL. [ 确定 ] [root@bogon ~]# mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.1.22-rc-community-log MySQL Community Edition (GPL)
在对Excel 2010中,对数据表进行排序时,在"排序"对话框中能够指定的排序关键字个数限制为______。 选择一项:b a. 2个 b. 任意 c. 3个 d. 1个 在Excel 2010的高级筛选中,条件区域中写在同一行的条件是________。 选择一项:d a. 或关系 b. 非关系 c. 异或关系 d. 与关系 在Excel 2010中,关于排序说法不正确的是______。 选择一项:a a. 排序可进行有标题行与无标题行排序 b. 排序的关键字可以多个 c. 多次排序的只保留最后一次排序的结果 d. 排序只有升序和降序两种排序次序 在Excel 2010中,进行分类汇总前,首先必须对数据表中的某个列标题(即属性名,又称字段名)进行______。 选择一项:a a. 排序 b. 高级筛选 c. 查找 d. 自动筛选 在Excel 2010的自动筛选中,每个列标题(又称属性名或字段名)上的下三角按钮都对应一个______。 选择一项:c a. 窗口 b. 条件 c. 对话框 d. 工具栏 对于筛选方法,下列说法正确______。
选择一项:d a. 创建自定义筛选条件 b. 使用搜索框输入筛选条件 c. 从列表框中选择筛选条件 d. 以上三种都正确 在Excel 2010的高级筛选中,条件区域中不同行的条件是________。 选择一项:a a. 或关系 b. 非关系 c. 异或关系 d. 与关系 在Excel 2010中,假定存在着一个职工简表,要对职工工资按职称属性进行分类汇总,则在分类汇总前必须进行数据排序,所选择的关键字为______。 选择一项:b a. 职工号 b. 职称 c. 性别 d. 工资 在Excel 2010中,若需要将工作表中某列上大于某个值的记录挑选出来,应执行数据菜单中的______。 选择一项:c a. 合并计算命令 b. 分类汇总命令 c. 筛选命令 d. 排序命令
Eviews操作入门:输入数据,对数据进行描述统计和画图 首先是打开Eviews软件,可以双击桌面上的图标,或者从windows开始菜单中寻找Eviews,打开Eviews后,可以看到下面的窗口如图F1-1。 图F1-1 Eviews窗口 关于Eviews的操作可以点击F1-1的Help,进行自学。 打开Eviews后,第一项任务就是建立一个新Workfile或者打开一个已有的Workfile,单击File,然后光标放在New上,最后单击Workfile。如图F1-2 图F1-2 图F1-2左上角点击向下的三角可以选则数据类型,如同F1-3。数据类型分三类截面数据,时间序列数据和面板数据。
图F1-3 图F1-2右上角可以选中时间序列数据的频率,见图F1-4。 图F1-4 对话框中选择数据的频率:年、半年、季度、月度、周、天(5天一周或7天1周)或日内数据(用integer data)来表示。 对时间序列数据选择一个频率,填写开始日期和结束日期, 日期格式: 年:1997 季度:1997:1 月度:1997:01 周和日:8:10:1997表示1997年8月10号,美式表达日期法。 8:10:1997表示1997年10月8号,欧式表达日期法。 如何选择欧式和美式日期格式呢?从Eviews窗口点击Options再点击dates and Frequency conversion,得到窗口F1-5。F1-5的右上角可以选择日期格式。
图F1-5 假设建立一个月度数据的workfile,填写完后点OK,一个新Workfile就建好了。见图F1-6。保存该workfile,单击Eviews窗口的save命令,选择保存位置即可。 图F1-6 新建立的workfile之后,第二件事就是输入数据。数据输入有多种方法。 1)直接输入数据,见F1-7 在Eviews窗口下,单击Quick,再单击Empty group(edit series),直接输数值即可。注意在该窗口中命令行有一个Edit+/-,可以点一下Edit+/-就可以变成如图所示的空白格,输完数据后,为了避免不小心改变数据,可以再点一下Edit+/-,这时数据就不能被修改了。
网络数据抽取系统的调查 摘要-互联网大量的有用信息通常为其用户格式化,这使得用户很难从不同来源的信息中提取相关数据。因此,一个功能强大、有效率的数据抽出(IE)系统,能够有效的把网页转变成一种数据结构,如一个表示关系的数据库,是必要的。虽然多数网页的数据抽出的方法已经被发展,已经有很多这方面的的工具。但是,能够具体抽的取出用户需要的一小部分的数据,已知的工具抽取的结果还是不尽人意的。这篇文章主研研究网络数据抽出方法而且从三个维度比较他们:任务领域,自动化程度,和技术的运用。第一个维度的标准是解释为什么一个IE系统未能处理一些网站特别的结构。第二方面的标准,即基于分类系统技术的应用。三维空间的标准衡量,即系统的自动化程度。我们相信这些标准能够很好的分析不同的抽取系统 编入索引中数据的抽出,网络采矿、包裹器,包裹器归纳法。 1介绍 全球互联网信息的爆炸式增长和普及导致了大量的信息资源在互联网上呈现。然而,由于缺乏结构的非均质性和网络信息的来源,访问这个巨大的信息集合体限制了浏览和搜索。复杂的Web挖掘系统,就像挑选物品的机器人一样,需要准确的判断能力,来应对不同的数据格式。自动翻译成结构化数据的输入页面,很多的研究一直致力于面积信息提取(IE)。与信息检索(IR),它涉及如何识别有关信息,IE产生结构化数据的等待处理,这是至关重要的,许多应用对其网络挖掘和搜索工具。 形式上,一个IE的任务是定义输入和提取目标。非结构化文件的输入可以像自由文本写自然语言(例如,图1),或者在网页内的数据,如列表(例如,图2。提取一个IE的目标任务可能是是一个关系的k-tuple(在k是属性的数量达到),也可能是一个复杂的对象与层级组织的资料。对于一些IE的任务,一个要求是没有一个错误并且拥有一个多重化的记录。一个IE的任务可能变得更加复杂当输入文件的排版错误和各种属性错误。 IE系统去执行任务的程序被称为抽取器或者 是包装器。一个包装器最初是被定义为在一个信息融合系统一个统一的查询接口访问多个信息来源。在一个信息集成系统中包装程序通常是“包裹”着信息来源(例如,一个数据库服务器或网络服务器)。这样的信息融合系统可以访问这些信息来源并且不改变其核心查询应答机制。在这样的情形,网络信息来源服务器,一个包装器必须查询的网络服务器收集结果页必须通过HTTP协议来进行信息提取,提取的HTML文档的内容,最后结合其他资料来源。在这三个程序,提出extrac收到信息最受重视和一些使用包装来表示解压程序。因此,我们使用术语萃取和包装互换。 包裹器归纳法(WI)和信息抽取系统(IE)是设计包裹器的系统程序工具。一个包裹器通常运行一个模式匹配程序,例如一种有限状态机制,并且依赖一套提取规则。配合一组抽出规则的程序的样式 图片1
速达30000基础数据录入设计 一、功能简介 企业的货品达几百上千,该如何管理?能否控制销售的价格不低于采购的价格?货品库存数量能否进行控制,以免产生超储积压?如何知道什么时候需要采购货品,采购批量定多少呢?货品资料主要用来记录货品的名称、规格、种类、价格等有关资料,还可以设置库存上下限,使用户能够将库存数量控制在一个合理的范围之内,从而大大降低经营风险。 二、操作路径 「进销存初始化」(或「资料」→「货品资料」)以及“采购管理”、“销售管理”、“仓库管理”等导航图。 货品资料 货品资料是本系统基础资料中最重要的部分,提供了与货品相关的详细数据录入项,为了用户能够很好的管理货品,请多加重视。 货品的详细信息共分为基本信息、价格信息、存货信息、组装信息等,其中货品名称和货品编码为必须的。 操作指南 (一) 基本信息 1. 加权价:如果成本核算方法选择“移动加权法”则输入该货品的移动平均单价;如果选择“个别指定法”则输入货品总金额与其各批次库存数量之和相除后的单位价格;如果选择“全月一次法”则输入货品的全月平均单价。加权价会随着货品的数量、金额的变动而自动更新(成本核算方法的变更请查看>>>); 2. 主供应商:指企业采购某个货品的主要供应商; 3. 有效期:请用户根据货品上标明的期限输入; 4. 提前期:指采购货品需要提前的天数; 5. 最小订货批量:指采购的最小数量,它可以根据包装、运输、仓储等费用最小的原则来制定,用户可以通过经济批量的管理方法,设置与供应商订货时的最小订货数量; 6. 订货批量增量:指在满足最小订货批量前提下,订货数减去最小订货批量后的余数,且为整数,它常常是由包装数量来决定的。 (二) 价格信息 价格信息包括了单位的设置,并且可以根据不同的核算单位设置不同的价格。 1. 单位名称:请首先录入新增货品的基本单位,这时基本单位栏会自动打勾,即说明该单位是货品的基本计量单位,如果您想重新选择其他单位作为基本单位,可以用鼠标点击该栏使其打勾,而对应的比率一栏会相应的变为1,您需要重新设置其他计量单位的比率值; 2. 比率:基本单位默认设置为1,不可以修改。其他单位按照与基本单位的数值比例来输入; 3. 货品条码:即货品的电子条码,该条码在系统内应是唯一的; 4. 称重码:是商品称重条码的组成部分,该编码最多只能录入五位数,不足五位数的,系统自动在前面加“0”补足五位。(如称重编码录入为1234,保存该记录后,则称重编码显示为01234)。称重编码可以为空,但非空时不能重复。 5. 参考购货价:该货品在进货时的参考进价,请在该栏手工输入; 6. 参考售货价:销售时的参考售价,请输入相应的单价即可; 7. 最低售价:设置销售货品的最低价格,防止低于此价格进行销售; 8. 最高进价:设置采购货品的最高价格,防止高于此价格进行采购; 9. 会员价:如果企业发行会员卡时,部分商品应设置相应的会员价,这样在POS前台使用会员卡时就可以调用商品的会员价; 10. 批发价:系统可提供五级批发价供用户参考使用,如果企业对客户的销售措施采用分级方式,则分级批发价必须预先设置; 11. 输入上述的信息后,点击[完成]即可。如果该货品还有其他核算单位,则继续重复上述操作步骤。
点击文章中飘蓝词可直接进入官网查看 日志收集与分析系统 安全日志就是计算机系统、设备、软件等在某种情况下记录的信息。日志收集与分析 是其中比较重要的环节,事前及时预警发现故障,事后提供详实的数据用于追查定位问题,下面给大家介绍一下日志收集与分析系统中关于日志审计数据收集,日志分析,审计管理 平台等相关内容。并谈一谈日志收集与分析系统哪家好? 南京风城云码软件技术有限公司是获得国家工信部认定的“双软”企业,具有专业的 软件开发与生产资质。多年来专业从事IT运维监控产品及大数据平台下网络安全审计产品研发。开发团队主要由留学归国软件开发人员及管理专家领衔组成,聚集了一批软件专家、技术专家和行业专家,依托海外技术优势,使开发的软件产品在技术创新及应用领域始终 保持在领域上向前发展。 目前公司软件研发部门绝大部分为大学本科及以上学历;团队中拥有系统架构师、软 件工程师、中级软件工程师、专业测试人员;服务项目覆盖用户需求分析、系统设计、代码开发、测试、系统实施、人员培训、运维整个信息化过程,并具有多个项目并行开发的 能力。 日志收集与分析系统通过高性能的日志收集引擎,实时自动化收集日志,解决手工处 理的低效率问题。收集到的所有日志均统一加密存储管理,可根据存储空间情况灵活扩展 存储位置。支持常见操作系统、应用系统、数据库、网络设备、安全设备等类型的日志收集,对于客户网络中特定的日志类型,支持定制扩展收集分析脚本,不再忧心类型复杂问题。可将不同系统和设备日志授权给指定人员进行管理,管理人员各司其职,负责自身所 管辖的系统或设备日志的审计管理,互不干涉、互不影响,使日志审计工作更加清晰、易 操作。 实时收集应用程序的日志信息,进行实时的统计和数据过滤。 实时显示应用程序中业务功能的动态性能视图,提供阀值报警。