
(
实验报告
学院(系)名称:计算机与通信工程学院
姓名学号专业计算机科学与技术?
二班实验项目数据库设计与查询优化
班级
课程名称数据库系统概论课程代码0660096
)
2016/12/8实验地点7-216实验时间
批改意见成绩
}
教师签字:
一、实验目的
了解教材中介绍的ER图等数据库设计方法
]
了解基本的数据库优化方法
二、实验的软硬件环境
软件环境:Windows 2000 MS SQL Server
硬件环境:P4 256内存
三、实验内容
考虑单表查询、连接查询、嵌套查询3种SQL操作,从以下方面进行优化,并分析优化结果。
(1):
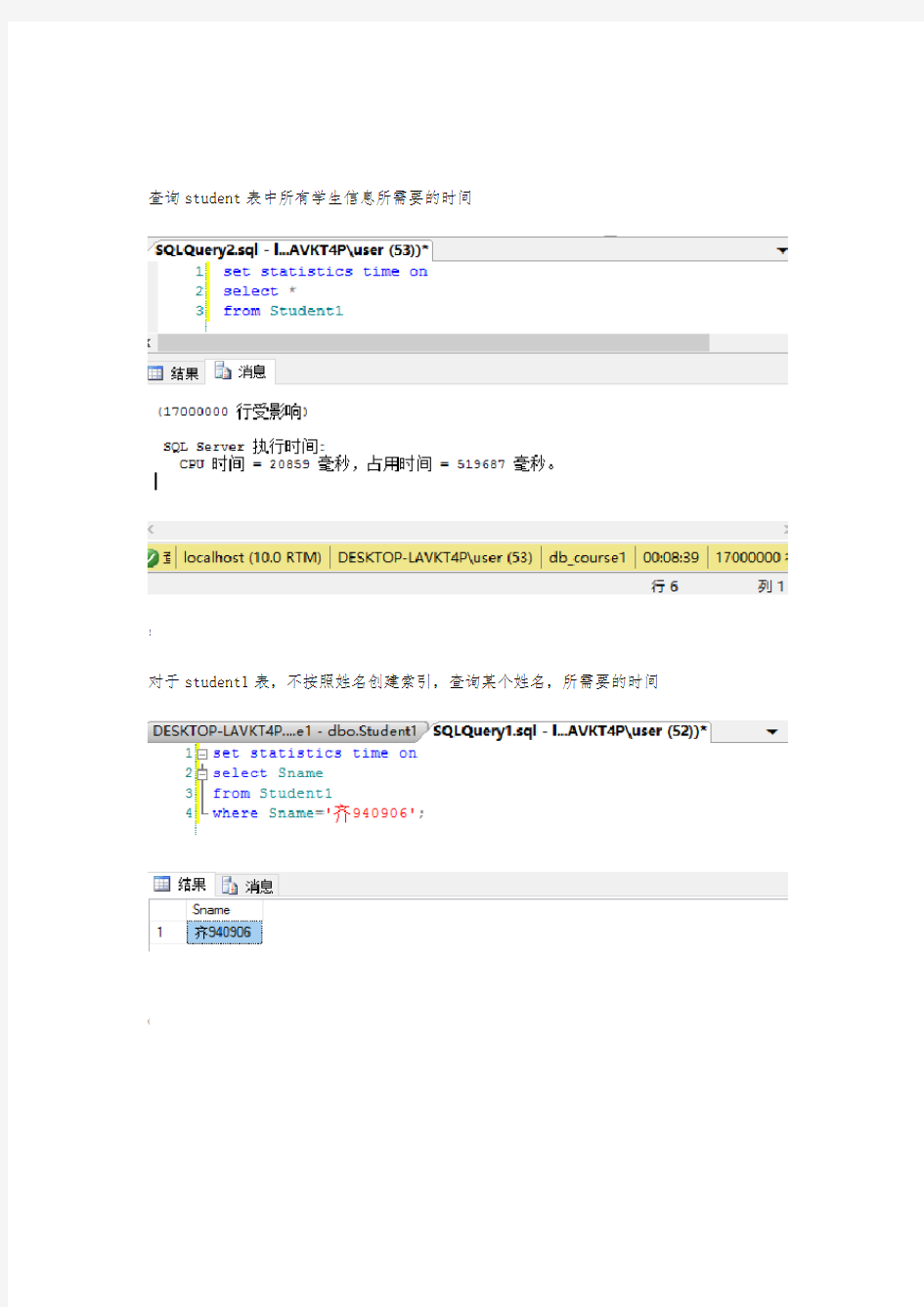
(2)单表查询。比较建立索引以后的查询效率
查询student表中所有学生信息所需要的时间
对于student1表,不按照姓名创建索引,查询某个姓名,所需要的时间。
对于student1表,按照姓名创建索引,查询某个姓名,所需要的时间。
对于student1表,不按照系别创建索引,查询某个系所有学生,所需要的
时间。
对于student1表,按照系别创建索引,查询某个系所有学生,所需要的时>
查询student表中所有学生信息所需要的时间
!
对于student1表,不按照姓名创建索引,查询某个姓名,所需要的时间
(
对于student1表,按照姓名创建索引,查询某个姓名,所需要的时间
%
对于student1表,按照系别创建索引,查询某个系所有学生,所需要的时间
对于student1表,不按照系别创建索引,查询某个系所有学生,所需要的时间
%
(3)连接查询
查询选修某门课程的学生姓名。比较在student、course、SC三个表建立
索引和不建立索引的情况
不建立索引的情况
!
建立索引的情况
(4)》
(5)针对不同属性查询
比较两个查询“查询某门课程选修的学生”和“某个学生选修的课程”
的查询时间效率,并分析原因(两个查询均用连接查询、嵌套查询分别实
现).
查询某门课程选修的学生(连接查询)
@
查询某门课程选修的学生(嵌套查询)
某个学生选修的课程(连接查询)
^
某个学生选修的课程(嵌套查询)
(4)—
(5)数据库概念模式设计(选作)
自己选定一种场景或一个应用问题,为之设计数据库的概念模式(ER图),
要求不少于6个实体,实体之间有一对多、多对多关系。并将其转化为关
系模式,并标示出每个关系模式的主键。(提示:学生管理系统、图书馆
管理系统、仓库管理系统、网上商城等)
四、实验过程及结果
1.实验所基于的表
Course1
—
!
SC1 )
Student1
五、问题及体会
本次试验清楚的展示给了我们做每种查询所用的时间,可以直观的比较每种查询的优缺点。还有,对于大数据,尽可能的建立索引,这样会大大节约时间和空间,有了索引后,查询效率会成倍的提升,在今后的使用过程中,一定要养成良好的习惯。
华北科技学院计算机系综合性实验 实验报告 课程名称数据库原理与应用 实验学期 2009 至 2010 学年第一学期学生所在系部管理系 年级三年级专业班级商务B071班 学生姓名李荣妹学号 4121 任课教师郭红 实验成绩 计算机系制
《数据库原理与应用》课程综合性实验报告
(3)建表如下图: 图书表的结构 读者表的结构罚款表的结构 借阅表的结构密码表的结构 输入数据:图书 读者 S只学生,t指老师,1指没有超期,0表示超期 借阅 罚款
密码: (4)、创建视图。以sa的身份登录数据库,创建视图V1,V2,V3 create VIEW V1 create VIEW V2 create VIEW V3 AS AS AS select * from 图书 select * from 借阅 select * from 罚款 建立视图V5,查看在库的图书:create view V5 as select *from 图书 where 借阅状态=‘在库’ 建立已被借出去的图书视图 create view V6 as
select * from 图书 where 借阅状态='出库' 建立逾期未还的图书的学生视图: create view V7 as select * from 借阅 where datediff(day,convert(smalldatetime,借出日期),getdate())>’30’ and 借书证号 in(select 借书证号 from 读者,借阅 Where 借阅.借书证号=读者.借书证号 and 读者类别=‘s’ 四、物理设计和自定义完整性 建立索引:为了提高在表中搜索元组的速度,在实际实现的时候应该基于键码建立索引是表中建立索引的表项: 图书表(图书编号,条形码号)读者(借书证号)借阅(借书证号,条形码号)罚款表(借书证号,条形码号)密码(借书证号) (2)建立触发器 a.对已有借书证的读者进行查询借书是否超期(这里归定30天): create trigger T1 on 读者 for insert as select 借阅.借书证号,读者.读者姓名,图书.图书编号,图书.书名,借阅.借出日期 from 读者,借阅,图书 where 读者.借书证号=借阅.借书证号 and 图书.条形码号=借阅.条形码号 and 读者类别='s' and Datediff(day,convert(smalldatetime,借出日期),getdate())>=30 b.建立触发器T2(还书时): create trigger T2 on 借阅 for insert as begin update 图书 set 借阅状态='在库' where 条形码号=(select 条形码号 from inserted) update 借阅 set 归还日期=getdate(); update 读者 set 书数=书数-1 where 借书证号=(select 借书证号 from inserted) end c.建立触发器T3(借书书时): create trigger T3 on 借阅 for insert as begin update 图书 set 借阅状态='入库' where 条形码号=(select 条形码号 from inserted) update 借阅 set 借出日期=getdate(); update 读者 set 书数=书数+1 where 借书证号=(select 借书证号 from inserted) end d.建立触发器T4,实现超出借书数目时禁借(针对老师的): create trigger T4 on 读者 for insert
大型ORACLE数据库优化设计方案 本文主要从大型数据库ORACLE环境四个不同级别的调整分析入手,分析ORACLE的系统结构和工作机理,从九个不同方面较全面地总结了ORACLE数据库的优化调整方案。 对于ORACLE数据库的数据存取,主要有四个不同的调整级别,第一级调整是操作系统级 包括硬件平台,第二级调整是ORACLE RDBMS级的调整,第三级是数据库设计级的调整,最后一个调整级是SQL级。通常依此四级调整级别对数据库进行调整、优化,数据库的整体性能会得到很大的改善。下面从九个不 同方面介绍ORACLE数据库优化设计方案。 一.数据库优化自由结构OFA(Optimal flexible Architecture) 数据库的逻辑配置对数据库性能有很大的影响,为此,ORACLE公司对表空间设计提出了一种优化结构OFA。使用这种结构进行设计会大大简化物理设计中的数据管理。优化自由结构OFA,简单地讲就是在数据库中可以高效自由地分布逻辑数据对象,因此首先要对数据库中的逻辑对象根据他们的使用方式和物理结构对数据库的影响来进行分类,这种分类包括将系统数据和用户数据分开、一般数据和索引数据分开、低活动表和高活动表分开等等。数据库逻辑设计的结果应当符合下面的准则:(1)把以同样方式使用的段类型存储在一起; (2)按照标准使用来设计系统;(3)存在用于例外的分离区域;(4)最小化表空间冲突;(5)将数 据字典分离。 二、充分利用系统全局区域SGA(SYSTEM GLOBAL AREA) SGA是oracle数据库的心脏。用户的进程对这个内存区发送事务,并且以这里作为高速缓存读取命中的数据,以实现加速的目的。正确的SGA大小对数据库的性能至关重要。SGA 包括以下几个部分: 1、数据块缓冲区(data block buffer cache)是SGA中的一块高速缓存,占整个数据库大小 的1%-2%,用来存储从数据库重读取的数据块(表、索引、簇等),因此采用least recently used (LRU,最近最少使用)的方法进行空间管理。 2、字典缓冲区。该缓冲区内的信息包括用户账号数据、数据文件名、段名、盘区位置、表 说明和权限,它也采用LRU方式管理。 3、重做日志缓冲区。该缓冲区保存为数据库恢复过程中用于前滚操作。 4、SQL共享池。保存执行计划和运行数据库的SQL语句的语法分析树。也采用LRU算法 管理。如果设置过小,语句将被连续不断地再装入到库缓存,影响系统性能。 另外,SGA还包括大池、JAVA池、多缓冲池。但是主要是由上面4种缓冲区构成。对这
创新思维实践 实验设计报告 实验名称萃取实验 实验报告人学号 13 班级 090233 同组人 实验日期年月日 室温大气压 指导老师 评分
实验名称:萃取实验 一、实验目的 1.了解转盘萃取塔的结构和特点; 2.掌握液—液萃取塔的操作; 3.掌握传质单元高度的测定方法,并分析外加能量对液液萃取塔传质单元 高度和通量的影响。 二、基本原理 萃取是利用原料液中各组分在两个液相中的溶解度不同而使原料液混合物得以分离。将一定量萃取剂加入原料液中,然后加以搅拌使原料液与萃取剂充分混合,溶质通过相界面由原料液向萃取剂中扩散,所以萃取操作与精馏、吸收等过程一样,也属于两相间的传质过程。 与精馏,吸收过程类似,由于过程的复杂性,萃取过程也被分解为理论级和级效率;或传质单元数和传质单元高度,对于转盘塔,振动塔这类微分接触的萃取塔,一般采用传质单元数和传质单元高度来处理。传质单元数表示过程分离难易的程度。 对于稀溶液,传质单元数可近似用下式表示: ?-=1 2 x x *OR x x dx N (1) 式中: N OR ——萃余相为基准的总传质单元数; X ——萃余相中的溶质的浓度,以摩尔分率表示; x*——与相应萃取浓度成平衡的萃余相中溶质的浓度,以摩尔分率表示。 x 1、x 2——分别表示两相进塔和出塔的萃余相浓度 传质单元高度表示设备传质性能的好坏,可由下式表示: OR OR N H H = (2) Ω =OR x H L a K (3) 式中: H OR ——以萃余相为基准的传质单元高度,m; H —— 萃取塔的有效接触高度,m; K x a ——萃余相为基准的总传质系数,kg/(m 3?h ?△x); L ——萃余相的质量流量,kg/h; Ω——塔的截面积,m 2 ; 已知塔高度H 和传质单元数N OR 可由上式取得H OR 的数值。H OR 反映萃取设备传质性 能的好坏,H OR 越大,设备效率越低。影响萃取设备传质性能H OR 的因素很多,主
MK超市数据库设计实验报告 课程名称数据库系统原理成绩评定 实验项目名称数据库设计指导教师朱蔚恒 实验项目编号实验四实验项目类型设计性 学生姓名,学号郭美岑2012050754 梁蕴嘉2012050725 学院公共管理应急管理学院系应急管理专业应急管理
一背景 最初的时候,超市管理由人力完成,但是超市的规模越来越大的时候,再以人力管理可能会造成数据缺失冗余等各种各样的问题,而且人力工作效率低。因此用数据库进行管理可以把数据集中、统一、规划,实现科技管理。本数据库主要作用是在一个小超市中,进行对员工档案。库存商品的管理以及销售管理。这个数据库提供的是信息咨询信息检索,信息储存的多项功能。可以实现多项功能。 二实验目的 1学习数据库的我们不仅是要了解数据库的基本知识和简单操作,而且要能掌握数据库设计的方法和步骤,而且能自己动手设计出一个能够付诸于实际的数据库,能够为企业或者是小团体带来方便。同时数据库设计也能考察我们对数据库的实际应用能力。 三实验步骤 1. 需求分析 2. 概念模型设计(E-R图) 3. 逻辑结构设计 4. 物理结构分析 5. 将SQL语言输入数据库 6. 数据库的实施,包括加载数据库和调试运行程序 步骤一: 需求分析: 主要包括员工档案管理、库存商品管理、销售设计程序,厂商信息员工档案管理:包括员工的基本个人信息(编号姓名性别年龄电话) 库存商品信息:包括进货和剩余货物的详细信息,易于查找库存量 销售设计程序:包括每次售出商品的详细信息 厂商信息:能够查找到每个货物的厂家。查询商品的基本信息(编号名称地址电话号联系人) 商品信息:包括商品编号,金额,数量等等 具体的功能有:1.输入信息的功能 (1)输入商品的信息:包括编号,名称,数量,进货价,和卖出价格 (2)需要输入员工的信息:包括姓名,性别,年龄,电话号码等 (3)需要输入入库记录信息:包括商品编号,商品名称,商品类别等 2.具有信息储存的功能 3.具有信息浏览的功能 4.具有信息查询的功能 6.具有系统维护功能 步骤二:
数据库综合实验 题目:图书借阅管理系统 专业:计算机类班级: 姓名:学号: 指导教师:杨柯成绩: 完成日期:2016 年6月18 日
1.系统需求分析 图书借阅管理系统的具体要求如下所述: (1)图书信息的录入:要求能够将图书信息录入到数据库中。 (2)图书信息的修改:根据需要修改、删除图书信息。 (3)用户登录:根据用户权限登录此系统。 (4)系统用户管理:要求可以管理系统的用户,包括添加、修改和删除用户。 (5)借阅证件信息录入:可以输入不同类型的借阅者信息,并根据需要修改、删除借阅证信息。 (6)借阅证管理:包括借阅证丢失、过期等管理。 (7)借阅管理:包括借书、还书、过期还书与书籍丢失处罚等管理。 2.系统功能设计 图书借阅管理系统的功能基本结构图如图1所示: 图1 图书借阅管理系统功能结构图 (1)用户管理模块:主要用于录入用户的信息,显示用户名及类型,包括添加用户、删除用户、修改用户等功能。用户类型的设置使得只有超级用户才有权限访问此界面。 (2)重新登录模块:用于其他用户重新登录。 (3)图书分类管理模块:将图书分为二级分类进行管理,包括添加、删除、修改图书分
类等功能。 (4)图书基本信息管理模块:根据图书分类录入图书信息,对图书信息进行管理,其基本功能包括添加、删除、修改图书信息。 (5)借阅证件类型管理模块:用于管理借阅证件类型,根据借阅证件类型确定借阅图书的时间、续借时间、借阅图书的数目等,包括添加、删除、修改借阅证件类型信息等基本功能。 (6)借阅证件管理模块:根据借阅证件状态(有效、过期、挂失等)与证件类型对借阅证件信息进行管理,确定借阅者的单位、身份、借书天数、借书数目等信息,包括添加、删除、修改借阅证件信息等基本功能。 (7)图书借阅管理:为系统核心部分,他根据图书借阅状态(借阅、续借、过期)来管理图书的借阅操作,包括借阅、续借、归还、丢失图书等操作功能。 3.数据库概念结构设计 根据系统需求分析和功能设计,可以将数据规划为以下实体:图书实体、读者实体、借阅实体。它们之间的关系如图2所示: 图2 图书借阅管理系统E-R图 4.数据库逻辑结构设计 根据功能设计和E-R图,设计6个数据表如下: 表1 BookType 图书分类信息表
SQL SERVER性能优化综述 近期因工作需要,希望比较全面的总结下SQL SERVER数据库性能优化相关的注意事项,在 网上搜索了一下,发现很多文章,有的都列出了上百条,但是仔细看发现,有很多似是而非或 者过时(可能对SQL SERVER6.5以前的版本或者ORACLE是适用的)的信息,只好自己根据以 前的经验和测试结果进行总结了。 我始终认为,一个系统的性能的提高,不单单是试运行或者维护阶段的性能调优的任务,也不单单是开发阶段的事情,而是在整个软件生命周期都需要注意,进行有效工作才能达到的。所以我希望按照软件生命周期的不同阶段来总结数据库性能优化相关的注意事项。 一、分析阶段 一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性、可用性、可靠性、安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能 性需求,必须根据系统的特点确定其实时性需求、响应时间的需求、硬件的配置等。最好能 有各种需求的量化的指标。 另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统)。 二、设计阶段 设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎所有性能 调优的过程—数据库设计。 在数据库设计完成后,可以进行初步的索引设计,好的索引设计可以指导编码阶段写出高效 率的代码,为整个系统的性能打下良好的基础。 以下是性能要求设计阶段需要注意的: 1、数据库逻辑设计的规范化 数据库逻辑设计的规范化就是我们一般所说的范式,我们可以这样来简单理解范式: 第1规范:没有重复的组或多值的列,这是数据库设计的最低要求。 第2规范: 每个非关键字段必须依赖于主关键字,不能依赖于一个组合式主关键字的某些组 成部分。消除部分依赖,大部分情况下,数据库设计都应该达到第二范式。 第3规范: 一个非关键字段不能依赖于另一个非关键字段。消除传递依赖,达到第三范式应该是系统中大部分表的要求,除非一些特殊作用的表。 更高的范式要求这里就不再作介绍了,个人认为,如果全部达到第二范式,大部分达到第三
《面向对象程序设计》数学与计算机学院 VC++课程设计 设计题目:学生信息管理系统 学生学号:1007020304 学生姓名:刘正 学生专业:信息与计算科学 学生班级:10级信计三班 指导老师:李建湘 制作时间:2011年12月14日
目录 一、前言 (2) 二、系统需求分析 (3) 三、程序设计思路 (3) 四、模块分析 (5) 五、主要功能图示及代码 (9) 六、创新内容 (17) 七、存在的问题与不足 (17) 八、收获与感想 (18) 九、程序其它重要源代码 (19) 十、后记 (27) 十一、参考文献 (28)
前言 作为大二的一名学生,我们已经学习汇编语言快一年了,但是自己从来没有做过一个有实用价值的程序。总是怀疑我们学的c语言,c++以后会有用吗?几乎都是编写一些数学计算题。直到老是教我们MFC编程后,才知道应用程序的设计过程。说实话,在课程设计之前,我没有听过什么MFC编程,所以在设计的过程中也是困难重重,每走一步都是相当艰难的。从开始设计到完成设计,我花了两个多星期,中间重做了无数次。真的难以想象爱迪生发明电灯时是怎么熬过来的。这个程序虽然不完美,但是花了我不少的心血。这将是我程序生涯的开始! 学习MFC编程,最重要的就是自学。刚开始,什么都不懂,为什么要这么做?好多函数都不不知道是干什么用的,更不用说使用它们。因此,不得不借助图书馆和网络了解它们。MFC函数库很庞大,我这次用到的微乎其微,以后还得不断的学习和熟悉。一个那么庞大的函数库,我们该如何掌握它呢?通过这半个多月的学习,我个人觉得最重要的就是多练习,只有不断的练习,才能掌握它们的规律,帮助我们学好MFC函数库。 接下来,我将把这些天的成果在这里展现出来,与大家一起分享这份来之不易的喜悦!
北邮数据库实验四数据 库模式的设计 Revised by Chen Zhen in 2021
北京邮电大学 实验报告 课程名称数据库 实验名称数据库模式的设计班级 姓名 学号 指导老师 成绩_________ 实验
.1.实验目的 1.了解E-R图的基本概念和根据数据需求描述抽象出E-R图并将其转换为数据库逻辑模式进而实现数据库中的表和视图。 2.通过进行数据库表的建立操作,熟悉并掌握Power designer数据库表的建立方法,理解关系数据库表的结构,巩固SQL标准中关于数据库表的建立语句。 3.通过对Power designer中建立、维护视图的实验,熟悉Power designe中对视图的操作方法和途径,理解和掌握视图的概念。 .2.实验内容 1 针对以下需求信息,尽可能全面地给出各个实体的属性和实体之间的系。 在线考试系统需求信息如下: 在线考试系统是关于一门课程的授课教师安排自己的学生在线参加各种考试的应 用,如果阶段性考试,期中考试和期末考试等。在线考试系统要求有用户的登录和登出。在线考试系统主要包括用户管理、试题管理、试卷管理和考试管理功能。需要实现教师输入试题,从试题生成试卷;学生参加考试获取试卷,提交答案和给出考试成绩等主要逻辑功能。 系统的用户包括教师、学生角色,一个用户有且只有一种角色。 鉴于在线考试的客观条件限制,试题完全采用单项选择形式。试题有所属知识点、内容、分值、备选答案和唯一正确答案等属性组成。课程的知识点是确定的,可以扩展,一道试题只能考察一个知识点。
教师录入各种试题构成题库,并根据考察的知识点不同生成试卷,相同知识点的试题只能在一张试卷中出现一次,试卷由试卷标题和一定数量(即知识点的数量)的试题组成。试卷生成后,教师指定某次考试使用的试卷,学生参加考试使用统一的试卷,考试信息还包含考试标题、任教老师、考试时间。 学生登录后,可以参加考试并在提交答案后立刻得到自己的考试成绩,也可以查看自己的考试历史记录。教师登录后可以查看学生的成绩。 ?2将E-R图输入Power Designer形成概念模型 ? 3 使用Power Designe将输入的E-R图转换成数据库物理模型 ? 4 使用Power Designe将输入的数据库物理模型转化为生成数据库中的表和视图的脚 本 ? 5 执行SQl脚本,生成表和视图 ? 6 成功后,查看生成的表和视图的情况 .3.实验环境 普通PC、Windows系列操作系统、IBM DB2 数据库管理系统 .4.实验步骤、结果与分析 1)五个实体: 用户: 用户ID( UserID )、用户名(UserName)、角色(Role)、密码(Password). 试题库(ItemBank): 题目代码(ItemID)、题目内容(Icontent)、分数(Iscore)、选项(Ioption)、正确答案(Ianswer)、知识点代码(PointID)(froeign). 知识点(KonwledgePoint): 知识点代码(PointID)、知识点内容(Pcontent)、知识点学科(Psubject). 试卷(Paper):
数据库优化方案设计 XX信息管理平台从大型数据库环境四个不同级别的调整分析入手,分析数据库平台的系统结构和工作机理,从九个不同方面设计数据库的优化方案。 对于数据库的数据优化,主要有四个不同的调整级别,第一级调整是操作系统级包括硬件平台,第二级调整是RDBMS级的调整,第三级是数据库设计级的调整,最后一个调整级是SQL级。通常依此四级调整级别对数据库进行调整、优化,数据库的整体性能会得到很大的改善。下面从九个不同方面介绍数据库优化设计方案。 一、数据库优化自由结构 数据库的逻辑配置对数据库性能有很大的影响。为此,数据库平台一般对表空间设计提出有相应的优化结构,如ORACLE公司的OFA(Optimal flexible Architecture),使用这种结构进行设计会大大简化物理设计中的数据管理。优化自由结构,简单地讲就是在数据库中可以高效自由地分布逻辑数据对象,因此首先要对数据库中的逻辑对象根据他们的使用方式和物理结构对数据库的影响来进行分类,这种分类包括将系统数据和用户数据分开、一般数据和索引数据分开、低活动表和高活动表分开等等。 数据库逻辑设计的结果应当符合下面的准则: (1)把以同样方式使用的段类型存储在一起; (2)按照标准使用来设计系统; (3)存在用于例外的分离区域; (4)最小化表空间冲突; (5)将数据字典分离。 二、充分利用系统全局区域 系统全局区域是数据库平台的心脏,如Oracle数据库的SGA(SYSTEM GLOBAL AREA) 。用户的进程对这个内存区发送事务,并且以这里作为高速缓存读取命中的数据,以实现加速的目的。正确的SGA大小对数据库的性能至关重要。SGA包括以下几个部分: 1、数据块缓冲区(data block buffer cache)是SGA中的一块高速缓存,占整个数据库大小的1%-2%,用来存储从数据库重读取的数据块(表、索引、簇等),因此采用least recently used (LRU,最近最少使用)的方法进行空间管理。 2、字典缓冲区。该缓冲区内的信息包括用户账号数据、数据文件名、段名、盘区位置、表说明和权限,它也采用LRU方式管理。 3、重做日志缓冲区。该缓冲区保存为数据库恢复过程中用于前滚操作。 4、SQL共享池。保存执行计划和运行数据库的SQL语句的语法分析树。也采用LRU 算法管理。如果设置过小,语句将被连续不断地再装入到库缓存,影响系统性能。 另外,SGA还包括大池、JAVA池、多缓冲池。但是主要是由上面4种缓冲区构成。对这些内存缓冲区的合理设置,可以大大加快数据查询速度,一个足够大的内存区可以把绝大多数数据存储在内存中,只有那些不怎么频繁使用的数据,才从磁盘读取,这样就可以大大提高内存区的命中率。 三、规范与反规范设计数据库
一、数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器端程序的编程和维护的难度,而且将会影响系统实际运行的性能。所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的。 在一个系统分析、设计阶段,因为数据量较小,负荷较低。我们往往只注意到功能的实现,而很难注意到性能的薄弱之处,等到系统投入实际运行一段时间后,才发现系统的性能在降低,这时再来考虑提高系统性能则要花费更多的人力物力,而整个系统也不可避免的形成了一个打补丁工程。 所以在考虑整个系统的流程的时候,我们必须要考虑,在高并发大数据量的访问情况下,我们的系统会不会出现极端的情况。(例如:对外统计系统在7月16日出现的数据异常的情况,并发大数据量的访问造成,数据库的响应时间不能跟上数据刷新的速度。具体情况是:在日期临界时(00:00:00),判断数据库中是否有当前日期的记录,没有则插入一条当前日期的记录。在低并发访问的情况下,不会发生问题,但是在当日期临界时的访问量相当大,且在做这一判断的时候,会出现多次条件成立,则数据库里会被插入多条当前日期的记录,从而造成数据错误。),数据库的模型确定下来之后,我们有必要做一个系统内数据流向图,分析可能出现的瓶颈。 为了保证数据库的一致性和完整性,在逻辑设计的时候往往会设计过多的表间关联,尽可能的降低数据的冗余。(例如用户表的地区,我们可以把地区另外存放到一个地区表中)如果数据冗余低,数据的完整性容易得到保证,提高了数据吞吐速度,保证了数据的完整性,清楚地表达数据元素之间的关系。而对于多表之间的关联查询(尤其是大数据表)时,其性能将会降低,同时也提高了客户端程序的编程难度,因此,物理设计需折衷考虑,根据业务规则,确定对关联表的数据量大小、数据项的访问频度,对此类数据表频繁的关联查询应适当提高数据冗余设计但增加了表间连接查询的操作,也使得程序的变得复杂,为了提高系统的响应时间,合理的数据冗余也是必要的。设计人员在设计阶段应根据系统操作的类型、频度加以均衡考虑。 另外,最好不要用自增属性字段作为主键与子表关联,不便于系统的迁移和数据恢复。 原来的表格必须可以通过由它分离出去的表格重新构建。使用这个规定的好处是,你可以确保不会在分离的表格中引入多余的列,所有你创建的表格结构都与它们的实际需要一样大。应用这条规定是一个好习惯,不过除非你要处理一个非常大型的数据,否则你将不需要用到它。(例如一个通行证系统,我可以将USERID,USERNAME,USERPASSWORD,单独出来做个表,再把USERID作为其他表的外键) 表的设计具体注意的问题: 1、数据行的长度不要超过8020字节,如果超过这个长度的话在物理页中这条数据会占用两行从而造成存储碎片,降低查询效率。 2、能够用数字类型的字段尽量选择数字类型而不用字符串类型的(电话号码),这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接回逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。 3、对于不可变字符类型char和可变字符类型varchar 都是8000字节,char 查询快,但是耗存储空间,varchar查询相对慢一些但是节省存储空间。在设计
辉光盘实验报告设计 一、实验目的 观察平板晶体中的高压辉光放电现象。 二、实验仪器 辉光盘演示仪 三、实验原理 闪电盘是在两层玻璃盘中密封了涂有荧光材料的玻璃珠,玻璃珠间充有稀薄的惰性气体(如氩气等)。控制器中有一块振荡电路板,通过电源变换器,将12V低压直流电转变为高压高频电压加在电极上。 通电后,振荡电路产生高频电压电场,由于稀薄气体受到高频电场的电离作用二产生紫外辐射,玻璃珠上的荧光材料受到紫外辐射激发而发出可见光,其颜色由玻璃珠上涂敷的荧光材料决定。由于电极上电压很高,故所发生的光是一些辐射状的辉光,绚丽多彩,光芒四射,在黑暗中非常好看。 四、实验步骤 1.将闪电盘后控制器上的电位器调节到最小; 2.插上220V电源,打开开关; 3.调高电位器,观察闪电盘上图像变化,当电压超过一定域值后,盘上出现闪光; 4.用手触摸玻璃表面,观察闪光随手指移动变化; 5.缓慢调低电位器到闪光恰好消失,对闪电盘拍手或说话,观察辉光岁声音的变化。 五、注意事项 1.闪电盘为玻璃质地,注意轻拿轻放; 2.移动闪电盘时请勿在控制器上用力,避免控制器与盘面连接断裂; 3.闪电盘不可悬空吊挂。
实验报告要求: 学生在完成实验报告时,需要写出所观察到的实验现象及实验感悟。 个人对演示实验的认识: 演示实验形象直观,能够引起学生的学习兴趣,同时演示实验能激发学生对实验的思考。学生学习的特点就是好奇心强,所以作为老师应根据学生这一认知特点,在物理教学中恰当进行演示实验,激发学生学习的好奇心和兴趣。演示实验留下的印象远比单纯的讲解要深得多。比如这个辉光盘实验能使学生了解平板晶体中的高压辉光放电的原理,通电后,由于稀薄气体受到高频电场的电离作用二产生紫外辐射,玻璃珠上的荧光材料受到紫外辐射激发而发出可见光,其颜色由玻璃珠上涂敷的荧光材料决定,由于电极上电压很高,故所发生的光是一些辐射状的辉光,绚丽多彩,光芒四射,在黑暗中非常好看。
实验三数据库设计 一、实验目的: (1)巩固和加深对数据库原理基本知识的理解,提高综合运用课程知识的能力。 (2)掌握数据库应用系统设计的基本方法和步骤,培养进行数据库设计的能力。 二、实验步骤 数据库设计: (1)需求分析 (2)概念结构设计: 通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型E-R模型: 定义实体,属性,确定联系类型:如: (3)逻辑结构设计: 将概念结构转换为某个DBMS所支持的数据模型,是数据库基本模型,主要用来 定义数据库结构的一些数据结构如表,约束。 1.关系模型: 将E-R图转换为关系模型:将实体、实体的属性和实体之间的联系转换为关系模式。 一个实体型转换为一个关系模式。 ?关系的属性:实体型的属性 ?关系的码:实体型的码 实体型间的联系有以下不同情况: 1.一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模 式合并。 ?转换为一个独立的关系模式 ?关系的属性:与该联系相连的各实体的码以及联系本身的属性 ?关系的候选码:每个实体的码均是该关系的候选码 ?与某一端实体对应的关系模式合并 ?合并后关系的属性:加入对应关系的码和联系本身的属性 ?合并后关系的码:不变
2.一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合 并。 ?转换为一个独立的关系模式 ?关系的属性:与该联系相连的各实体的码以及联系本身的属性 ?关系的码:n端实体的码 ?与n端对应的关系模式合并 ?合并后关系的属性:在n端关系中加入1端关系的码和联系本身的 属性 ?合并后关系的码:不变 3. 一个m:n联系转换为一个关系模式。 ?关系的属性:与该联系相连的各实体的码以及联系本身的属性 ?关系的码:两端实体的码 2.设计用户子模式: 定义用户外模式时应该注重考虑用户的习惯与方便 包括三个方面: (1) 使用更符合用户习惯的别名 (2) 针对不同级别的用户定义不同的View ,以满足系统对安全性的要求。 (3) 简化用户对系统的使用 (4)物理结构设计: 为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构和存取方法),如索引、聚簇的定义 (5)数据库实施: 运用DBMS提供的数据库语言(如SQL)及宿主语言,根据逻辑设计和物理设计的 结果,建立数据库 (6)数据库运行与维护 三、实验内容:图书借阅管理数据库的设计 1.本数据库简化的需求情况如下: (1)所有借阅人都可以随时查询可借阅图书的情况,如图书编号,图书名称,出版日期,图书出版社,图书存放位置,图书数量等,以便于借阅。 (2)借阅人查询图书情况后可以借阅所需图书,一次可以借阅多本图书,每本图书一次只借阅一本,若有图书超期,需缴纳罚金才能进行借阅。 (3)图书室需要办理借阅证方可借阅图书,需要记录如下信息:借阅人姓名,所在单位,借阅图书的上限数(不同级别的借阅人,借阅图书上限数不同),图书室为每一位借阅人提供唯一的图书借阅证编号。 (4)每位借阅人一次可以借阅多本图书,但不能超过其借阅上限数,借阅图书期限为两个月。超过期限需要缴纳罚金后(每天二分×超期天数)方可借阅。 (5)借阅图书时需登记相应借书日期及还书日期。 (6)图书室同时提供出版社(出版社名称,邮编,地址,电话,E-mail)及作者(作者姓名,性别,出生日期,籍贯,备注)相关信息便于借阅人查询。一本书籍只能在一个出版社出版,由于图书可以再次出版,所以每次出版的图书都有不同的出版日期。 (7)借阅人可以查看所有信息,却不能更新所有信息。 (8)图书借阅管理员可以查看及更新借阅信息,不能进行其他访问操作。
大型ORACLE数据库优化设计方案 摘要主要从大型数据库ORACLE环境四个不同级别的调整分析入手,分析ORACLE的系统结构和工作机理,从九个不同方面较全面地总结了ORACLE数据库的优化调整方案。 关键词ORACLE数据库环境调整优化设计方案 对于ORACLE数据库的数据存取,主要有四个不同的调整级别,第一级调整是操作系统级包括硬件平台,第二级调整是ORACLERDBMS级的调整,第三级是数据库设计级的调整,最后一个调整级是SQL级。通常依此四级调整级别对数据库进行调整、优化,数据库的整体性能会得到很大的改善。下面从九个不同
方面介绍ORACLE数据库优化设计方案。 一.数据库优化自由结构OFA(OptimalflexibleArchitecture) 数据库的逻辑配置对数据库性能有很大的影响,为此,ORACLE公司对表空间设计提出了一种优化结构OFA。使用这种结构进行设计会大大简化物理设计中的数据管理。优化自由结构OFA,简单地讲就是在数据库中可以高效自由地分布逻辑数据对象,因此首先要对数据库中的逻辑对象根据他们的使用方式和物理结构对数据库的影响来进行分类,这种分类包括将系统数据和用户数据分开、一般数据和索引数据分开、低活动表和高活动表分开等等。 二、充分利用系统全局区域SGA (SYSTEMGLOBALAREA) SGA是oracle数据库的心脏。用户的进程对这个内存区发送事务,并且以这里作为高速缓存读取命中的数据,以实现加速的目的。正确的SGA大小对数据库
的性能至关重要。SGA包括以下几个部分: 2、字典缓冲区。该缓冲区内的信息包括用户账号数据、数据文件名、段名、盘区位置、表说明和权限,它也采用LRU 方式管理。 3、重做日志缓冲区。该缓冲区保存为数据库恢复过程中用于前滚操作。 4、SQL共享池。保存执行计划和运行数据库的SQL语句的语法分析树。也采用LRU算法管理。如果设置过小,语句将被连续不断地再装入到库缓存,影响系统性能。 另外,SGA还包括大池、JA V A池、多缓冲池。但是主要是由上面4种缓冲区构成。对这些内存缓冲区的合理设置,可以大大加快数据查询速度,一个足够大的内存区可以把绝大多数数据存储在内存中,只有那些不怎么频繁使用的数据,才从磁盘读取,这样就可以大大提高内存区的命中率。三、规范与反规范设计数据库
实验一:流水灯 程序: #include
unsigned int y; for(;x>0;x--) for(y=500;y>0;y--); }
实验二:单个数码管显示0~9循环 #include
关于数据库优化方面的文章很多,但是有的写的似是而非,有的不切实际,对一个数据库来说,只能做到更优,不可能最优,并且由于实际需求不同,优化方案还是有所差异,根据实际需要关心的方面(速度、存储空间、可维护性、可拓展性)来优化数据库,而这些方面往往又是相互矛盾的,下面结合网上的一些看法和自己的一些观点做个总结。 一个系统的性能的提高,不单单是试运行或者维护阶段的性能调优,也不单单是开发阶段的事情,而是在整个软件生命周期都需要注意。所以我希望按照软件生命周期的不同阶段来总结数据库性能优化相关的注意事项。 一、分析阶段 一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性、可用性、可靠性、安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能性需求,必须根据系统的特点确定其实时性需求、响应时间的需求、硬件的配置等。最好能有各种需求的量化的指标。 另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统)。 二、设计阶段 设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎所有性能调优的过程—数据库设计。 在数据库设计完成后,可以进行初步的索引设计,好的索引设计可以指导编码阶段写出高效率的代码,为整个系统的性能打下良好的基础。 以下是性能要求设计阶段需要注意的: 1、数据库逻辑设计的规范化 数据库逻辑设计的规范化就是我们一般所说的范式,我们可以这样来简单理解范式:第1规范:没有重复的组或多值的列,这是数据库设计的最低要求。 第2规范: 每个非关键字段必须依赖于主关键字,不能依赖于一个组合式主关键字的某些组成部分。消除部分依赖,大部分情况下,数据库设计都应该达到第二范式。 第3规范: 一个非关键字段不能依赖于另一个非关键字段。消除传递依赖,达到第三范式应该是系统中大部分表的要求,除非一些特殊作用的表。 更高的范式要求这里就不再作介绍了,个人认为,如果全部达到第二范式,大部分达到第三范式,系统会产生较少的列和较多的表,因而减少了数据冗余,也利于性能的提高。 2、合理的冗余 完全按照规范化设计的系统几乎是不可能的,除非系统特别的小,在规范化设计后,有计划地加入冗余是必要的。 冗余可以是冗余数据库、冗余表或者冗余字段,不同粒度的冗余可以起到不同的作用。 冗余可以是为了编程方便而增加,也可以是为了性能的提高而增加。从性能角度来说,冗余数据库可以分散数据库压力,冗余表可以分散数据量大的表的并发压力,也可以加快特殊查询的速度,冗余字段可以有效减少数据库表的连接,提高效率。 3、主键的设计 主键是必要的,SQL SERVER的主键同时是一个唯一索引,而且在实际应用中,我们往往选择最小的键组合作为主键,所以主键往往适合作为表的聚集索引。聚集索引对查询的影响是比较大的,这个在下面索引的叙述。 在有多个键的表,主键的选择也比较重要,一般选择总的长度小的键,小的键的比较速度快,同时小的键可以使主键的B树结构的层次更少。 主键的选择还要注意组合主键的字段次序,对于组合主键来说,不同的字段次序的主键的性能差别可能会很大,一般应该选择重复率低、单独或者组合查询可能性大的字段放在前
数据库综合实验报告 班级:计科*** 班 学号: **** 姓名: *** 2011年12月
数据库应用系统的初步开发 一、实验类别:综合型实验 二、实验目的 1.掌握数据库设计的基本技术,熟悉数据库设计的每个步骤中的任务和实施方案,并加深对数据库系统系统概念和特点的理解。 2.初步掌握基于C/S 的数据库应用系统分析、设计和实现方法。 3.进一步提高学生的知识综合运用能力。 三、实验内容 在SQL Server2000数据库管理系统上,利用 Microsoft Visual C++ 6.0开发工具开发一个学生成绩管理系统的数据库应用系统。 四、实验过程 (一.)系统需求说明 1 系统功能要求设计:此系统实现如下系统功能: (1)使得学生的成绩管理工作更加清晰、条理化、自动化。 (2)通过用户名和密码登录系统,查询课程基本资料,学生所选课程成绩,修改用户密码等功能。 容易地完成学生信息的查询操作。 (3) 设计人机友好界面,功能安排合理,操作使用方便,并且进一步考虑系统在安全性,完整性,并发控制,备份和恢复等方面的功能要求。 2 系统模块设计 成绩管理系统大体可以分成二大模块如, 一是学生的基本信息模块,里面应该包含学生的各方面的基本信息;再者便是课程管理模块, 在该模块中应该包含有对学生成绩信息的查询和处理,如平均成绩、最好成绩、最差成绩以及不及格学生的统计等功能模块;再其次还有教师、课程等相关信息的模块;可以得到系统流程图: 登陆失败 退出系统 用户 验证 登陆成功
3 数据字典 数据项是数据库的关系中不可再分的数据单位,下表分别列出了数据的名称、数据类型、长度、取值能否为空。利用SQL Server 2000建立“学生选课”数据库,其基本表清单及表结构描述如下: 数据库中用到的表: 数据库表名关系模式名称备注 Student 学生学生学籍信息表 Course 课程课程基本信息表 Score 成绩选课成绩信息表 Student基本情况数据表,结构如下: 字段名字段类型Not Null 说明 Student _sno Char Primary key 学号 Student _sn char Not Null 学生姓名 Student _sex char ‘男’或‘女’性别 Student _dept char 系别 Student_age char 年龄 Student_address char 地址 course数据表,结构如下: 字段名字段类型约束控制说明 course_cno char 主键(primary key)课程号 char not null 课程名称course_cnam e course_hour int not null 课时 course_score numeric(2,1) not null 学分 score情况数据表,结构如下: 字段名字段类型约束控制说明 score_id int not null 成绩记录号 course_cno char 外部键课程号 student_sno char 外部键学号 score int 成绩 (二)数据库结构设计 1.概念结构设计 由需求分析的结果可知,本系统设计的实体包括: (1)学生基本信息:学号,姓名,性别,地址,年龄,专业。 (2)课程基本信息:课程名,课程号,分数,学时,学分。
试验设计与数据处理试验报告 正交试验设计 1.为了通过正交试验寻找从某矿物中提取稀土元素的最优工艺条件,使稀土元素提取率最高,选取的水平如下:
需要考虑交互作用有A×B,A×C,B×C,如果将A,B,C分别安排在正交表L8(2)的 1,2,4列上,试验结果(提取量/ml)依次是1.01,,1,33,1,13,1.06,,1.03,0.08,,0.76,0.56. 试用方差分析法(α=0.05)分析实验结果,确定较优工艺条件 解:(1)列出正交表L8(27)和实验结果,进行方差分析。 试验号 A B A×B C A×C B×C 空号提取量(ml) 1 1 1 1 1 1 1 1 1.01 2 1 1 1 2 2 2 2 1.33 3 1 2 2 1 1 2 2 1.13 4 1 2 2 2 2 1 1 1.06 5 2 1 2 1 2 1 2 1.03 6 2 1 2 2 1 2 1 0.8 7 2 2 1 1 2 2 1 0.76 8 2 2 1 2 1 1 2 0.56 K1 4.53 4.17 3.66 3.93 3.5 3.66 3.63 K2 3.15 3.51 4.02 3.75 4.18 4.02 4.05 k1 2.265 2.085 1.83 1.965 1.75 1.83 1.815 k2 1.575 1.755 2.01 1.875 2.09 2.01 2.025 极差R 1.38 0.66 0.36 0.18 0.68 0.36 0.42 因素主次 A A×C B A×B B×C 优选方案 A1B1C1 SS J 0.23805 0.05445 0.0162 0.00405 0.0578 0.0162 0.02205 Q 7.7816 总和T 7.68 P=T^2/n 7.3728 SS T 0.4088 差异源SS df MS F 显著性 A 0.23805 1 0.23805 19.5925 9259 * B 0.05445 1 0.05445 4.48148 1481 A*B 0.0162 1 0.0162 1.33333 3333 C 0.00405 1 0.00405 0.33333 3333 A*C 0.0578 1 0.0578 4.75720 1646