
Ⅰ组Ⅱ组Ⅲ组
序号x1x2x3x4序号x1x2x3x4序号x1x2x3x4
1 5.1 3.5 1.4 0.
2 51 7.0 3.2 4.7 1.4 101 6.
3 3.3 6.0 2.5
2 4.9 3.0 1.4 0.2 52 6.4 3.2 4.5 1.5 102 5.8 2.7 5.1 1.9
3 4.7 3.2 1.3 0.2 53 6.9 3.1 4.9 1.5 103 7.1 3.0 5.9 2.1
4 4.6 3.1 1.
5 0.2 54 5.5 2.3 4.0 1.3 104 6.3 2.9 5.
6 1.8
5 5.0 3.
6 1.4 0.2 55 6.5 2.8 4.6 1.5 105 6.5 3.0 5.8 2.2
6 5.4 3.9 1.
7 0.4 56 5.7 2.
8 4.5 1.3 106 7.6 3.0 6.6 2.1
7 4.6 3.4 1.4 0.3 57 6.3 3.3 4.7 1.6 107 4.9 2.5 4.5 1.7
8 5.0 3.4 1.5 0.2 58 4.9 2.4 3.3 1.0 108 7.3 2.9 6.3 1.8
9 4.4 2.9 1.4 0.2 59 6.6 2.9 4.6 1.3 109 6.7 2.5 5.8 1.8
10 4.9 3.1 1.5 0.1 60 5.2 2.7 3.9 1.4 110 7.2 3.6 6.1 2.5
11 5.4 3.7 1.5 0.2 61 5.0 2.0 3.5 1.0 111 6.5 3.2 5.1 2.0
12 4.8 3.4 1.6 0.2 62 5.9 3.0 4.2 1.5 112 6.4 2.7 5.3 1.9
13 4.8 3.0 1.4 0.1 63 6.0 2.2 4.0 1.0 113 6.8 3.0 5.5 2.1
14 4.3 3.0 1.1 0.1 64 6.1 2.9 4.7 1.4 114 5.7 2.5 5.0 2.0
15 5.8 4.0 1.2 0.2 65 5.6 2.9 3.6 1.3 115 5.8 2.8 5.1 2.4
16 5.7 4.4 1.5 0.4 66 6.7 3.1 4.4 1.4 116 6.4 3.2 5.3 2.3
17 5.4 3.9 1.3 0.4 67 5.6 3.0 4.5 1.5 117 6.5 3.0 5.5 1.8
18 5.1 3.5 1.4 0.3 68 5.8 2.7 4.1 1.0 118 7.7 3.8 6.7 2.2
19 5.7 3.8 1.7 0.3 69 6.2 2.2 4.5 1.5 119 7.7 2.6 6.9 2.3
20 5.1 3.8 1.5 0.3 70 5.6 2.5 3.9 1.1 120 6.0 2.2 5.0 1.5
21 5.4 3.4 1.7 0.2 71 5.9 3.2 4.8 1.8 121 6.9 3.2 5.7 2.3
22 5.1 3.7 1.5 0.4 72 6.1 2.8 4.0 1.3 122 5.6 2.8 4.9 2.0
23 4.6 3.6 1.0 0.2 73 6.3 2.5 4.9 1.5 123 7.7 2.8 6.7 2.0
24 5.1 3.3 1.7 0.5 74 6.1 2.8 4.7 1.2 124 6.3 2.7 4.9 1.8
25 4.8 3.4 1.9 0.2 75 6.4 2.9 4.3 1.3 125 6.7 3.3 5.7 2.1
26 5.0 3.0 1.6 0.2 76 6.6 3.0 4.4 1.4 126 7.2 3.2 6.0 1.8
27 5.0 3.4 1.6 0.4 77 6.8 2.8 4.8 1.4 127 6.2 2.8 4.8 1.8
28 5.2 3.5 1.5 0.2 78 6.7 3.0 5.0 1.7 128 6.1 3.0 4.9 1.8
29 5.2 3.4 1.4 0.2 79 6.0 2.9 4.5 1.5 129 6.4 2.8 5.6 2.1
30 4.7 3.2 1.6 0.2 80 5.7 2.6 3.5 1.0 130 7.2 3.0 5.8 1.6
31 4.8 3.1 1.6 0.2 81 5.5 2.4 3.8 1.1 131 7.4 2.8 6.1 1.9
32 5.4 3.4 1.5 0.4 82 5.5 2.4 3.7 1.0 132 7.9 3.8 6.4 2.0
33 5.2 4.1 1.5 0.1 83 5.8 2.7 3.9 1.2 133 6.4 2.8 5.6 2.2
34 5.5 4.2 1.4 0.2 84 6.0 2.7 5.1 1.6 134 6.3 2.8 5.1 1.5
35 4.9 3.1 1.5 0.2 85 5.4 3.0 4.5 1.5 135 6.1 2.6 5.6 1.4
36 5.0 3.2 1.2 0.2 86 6.0 3.4 4.5 1.6 136 7.7 3.0 6.1 2.3
37 5.5 3.5 1.3 0.2 87 6.7 3.1 4.7 1.5 137 6.3 3.4 5.6 2.4
38 4.9 3.6 1.4 0.1 88 6.3 2.3 4.4 1.3 138 6.4 3.1 5.5 1.8
39 4.4 3.0 1.3 0.2 89 5.6 3 4.1 1.3 139 6.0 3.0 4.8 1.8
40 5.1 3.4 1.5 0.2 90 5.5 2.5 4.0 1.3 140 6.9 3.1 5.4 2.1
41 5.0 3.5 1.3 0.3 91 5.5 2.6 4.4 1.2 141 6.7 3.1 5.6 2.4
42 4.5 2.3 1.3 0.3 92 6.1 3.0 4.6 1.4 142 6.9 3.1 5.1 2.3
43 4.4 3.2 1.3 0.2 93 5.8 2.6 4.0 1.2 143 5.8 2.7 5.1 1.9
44 5.0 3.5 1.6 0.6 94 5.0 2.3 3.3 1.0 144 6.8 3.2 5.9 2.3
45 5.1 3.8 1.9 0.4 95 5.6 2.7 4.2 1.3 145 6.7 3.3 5.7 2.5
46 4.8 3.0 1.4 0.3 96 5.7 3.0 4.2 1.2 146 6.7 3 5.2 2.3
47 5.1 3.8 1.6 0.2 97 5.7 2.9 4.2 1.3 147 6.3 2.5 5 1.9
48 4.6 3.2 1.4 0.2 98 6.2 2.9 4.3 1.3 148 6.5 3 5.2 2
49 5.3 3.7 1.5 0.2 99 5.1 2.5 3.0 1.1 149 6.2 3.4 5.4 2.3
50 5.0 3.3 1.4 0.2 100 5.7 2.8 4.1 1.3 150 5.9 3 5.1 1.8
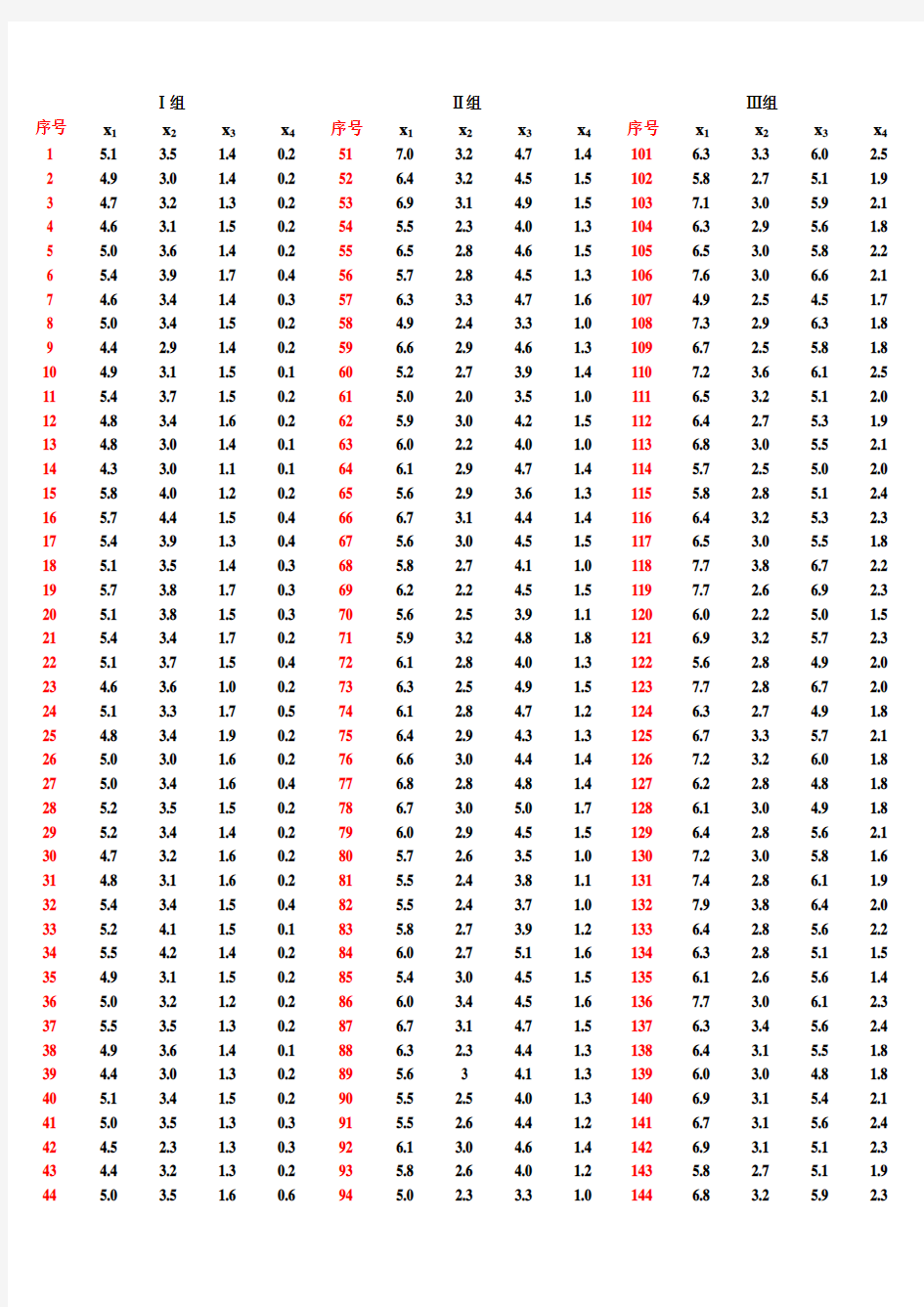
类别1234 样本x 1x 2x 1x 2x 1x 2x 1x 2 10.1 1.17.1 4.2-3.0-2.9-2.0-8.4 2 6.87.1-1.4-4.30.58.7-8.90.23-3.5-4.1 4.50.0 2.9 2.1-4.2-7.74 2.0 2.7 6. 3 1.6-0.1 5.2-8.5-3.25 4.1 2.8 4.2 1.9-4.0 2.2-6.7-4.06 3.1 5.0 1.4-3.2-1.3 3.7-0.5-9.27-0.8-1.3 2.4-4.0-3. 4 6.2-5.3-6.7 80.9 1.2 2.5-6.1-4.1 3.4-8.7-6.4 9 5.0 6.48.4 3.7-5.1 1.6-7.1-9.7 10 3.9 4.0 4.1-2.2 1.9 5.1-8.0-6.3 实验一 感知器准则算法实验 一、实验目的: 贝叶斯分类方法是基于后验概率的大小进行分类的方法,有时需要进行概率密度函数的估计,而概率密度函数的估计通常需要大量样本才能进行,随着特征空间维数的增加,这种估计所需要的样本数急剧增加,使计算量大增。 在实际问题中,人们可以不去估计概率密度,而直接通过与样本和类别标号有关的判别函数来直接将未知样本进行分类。这种思路就是判别函数法,最简单的判别函数是线性判别函数。采用判别函数法的关键在于利用样本找到判别函数的系数,模式识别课程中的感知器算法是一种求解判别函数系数的有效方法。本实验的目的是通过编制程序,实现感知器准则算法,并实现线性可分样本的分类。 二、实验内容: 实验所用样本数据如表2-1给出(其中每个样本空间(数据)为两维,x 1表示第一维的值、x 2表示第二维的值),编制程序实现1、 2类2、 3类的分类。分析分类器算法的性能。 2-1 感知器算法实验数据 具体要求 1、复习 感知器算法;2、写出实现批处理感 知器算法的程序1)从a=0开 始,将你的程序应用在和的训练数据上。记下收敛的步数。2)将你的程序应用在和类上,同样记下收敛的步数。3)试解释它们收敛步数的差别。 3、提高部分:和的前5个点不是线性可分的,请手工构造非线性映射,使这些点在映射后的特征空间中是线性可分的,并对它们训练一个感知
操作系统上机题目 一、题目 实验1:LINUX/UNIX Shell部分 (一)系统基本命令 1.登陆系统,输入whoami 和pwd ,确定自己的登录名和当前目录; 登录名yuanye ,当前目录/home/yuanye 2.显示自己的注册目录?命令在哪里? a.键入echo $HOME,确认自己的主目录;主目录为/home/yuanye b.键入echo $PA TH,记下自己看到的目录表;/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games c.键入which abcd,看看得到的错误信息; 再键入which ls 和which vi,对比刚刚得到的结果的目录是否在a.、b. 两题看到的目录表中; /bin/ls /usr/bin/vi 3.ls 和cd 的使用: a.键入ls,ls -l ,ls -a ,ls -al 四条命令,观察输出,说明四种不同使用方式的区别。 1. examples.desktop 公共的模板视频图片文档音乐桌面; 总计32 2.-rw-r--r-- 1 yuanye yuanye 357 2011-03-22 22:15 examples.desktop drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 公共的 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 模板 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 视频 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 图片 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 文档 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 音乐 drwxr-xr-x 2 yuanye yuanye 4096 2011-03-22 23:25 桌面 3. . .fontconfig .local .Xauthority .. .gconf .mozilla .xsession-errors .bash_logout .gconfd .nautilus 公共的 .bashrc .gksu.lock .profile 模板 .cache .gnome2 .pulse 视频 .chewing .gnome2_private .pulse-cookie 图片 .config .gnupg .recently-used.xbel 文档 .dbus .gstreamer-0.10 .scim 音乐 .dmrc .gtk-bookmarks .sudo_as_admin_successful 桌面 .esd_auth .gvfs .update-manager-core
实验一误差分析 实验1.1(病态问题) 实验目的:算法有“优”与“劣”之分,问题也有“好”与“坏”之别。对数值方法的研究而言,所谓坏问题就是问题本身对扰动敏感者,反之属于好问题。通过本实验可获得一个初步体会。 数值分析的大部分研究课题中,如线性代数方程组、矩阵特征值问题、非线性方程及方程组等都存在病态的问题。病态问题要通过研究和构造特殊的算法来解决,当然一般要付出一些代价(如耗用更多的机器时间、占用更多的存储空间等)。 问题提出:考虑一个高次的代数多项式 显然该多项式的全部根为1,2,…,20共计20个,且每个根都是单重的。现考虑该多项式的一个扰动 其中ε(1.1)和(1.221,,,a a 的输出b ”和“poly ε。 (1(2 (3)写成展 关于α solve 来提高解的精确度,这需要用到将多项式转换为符号多项式的函数poly2sym,函数的具体使用方法可参考Matlab 的帮助。 实验过程: 程序: a=poly(1:20); rr=roots(a); forn=2:21 n form=1:9 ess=10^(-6-m);
ve=zeros(1,21); ve(n)=ess; r=roots(a+ve); -6-m s=max(abs(r-rr)) end end 利用符号函数:(思考题一)a=poly(1:20); y=poly2sym(a); rr=solve(y) n
很容易的得出对一个多次的代数多项式的其中某一项进行很小的扰动,对其多项式的根会有一定的扰动的,所以对于这类病态问题可以借助于MATLAB来进行问题的分析。 学号:06450210 姓名:万轩 实验二插值法
模式识别实验报告
————————————————————————————————作者:————————————————————————————————日期:
实验报告 实验课程名称:模式识别 姓名:王宇班级: 20110813 学号: 2011081325 实验名称规范程度原理叙述实验过程实验结果实验成绩 图像的贝叶斯分类 K均值聚类算法 神经网络模式识别 平均成绩 折合成绩 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 2014年 6月
实验一、 图像的贝叶斯分类 一、实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念: 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。 最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示为
实验一、基于感知函数准则线性分类器设计 1.1 实验类型: 设计型:线性分类器设计(感知函数准则) 1.2 实验目的: 本实验旨在让同学理解感知准则函数的原理,通过软件编程模拟线性分类器,理解感知函数准则的确定过程,掌握梯度下降算法求增广权向量,进一步深刻认识线性分类器。 1.3 实验条件: matlab 软件 1.4 实验原理: 感知准则函数是五十年代由Rosenblatt 提出的一种自学习判别函数生成方法,由于Rosenblatt 企图将其用于脑模型感知器,因此被称为感知准则函数。其特点是随意确定的判别函数初始值,在对样本分类训练过程中逐步修正直至最终确定。 感知准则函数利用梯度下降算法求增广权向量的做法,可简单叙述为: 任意给定一向量初始值)1(a ,第k+1次迭代时的权向量)1(+k a 等于第k 次的权向量)(k a 加上被错分类的所有样本之和与k ρ的乘积。可以证明,对于线性可分的样本集,经过有限次修正,一定可以找到一个解向量a ,即算法能在有限步内收敛。其收敛速度的快慢取决于初始权向量)1(a 和系数k ρ。 1.5 实验内容 已知有两个样本空间w1和w2,这些点对应的横纵坐标的分布情况是: x1=[1,2,4,1,5];y1=[2,1,-1,-3,-3]; x2=[-2.5,-2.5,-1.5,-4,-5,-3];y2=[1,-1,5,1,-4,0]; 在二维空间样本分布图形如下所示:(plot(x1,y1,x2,y2))
-6-4-20246 -6-4 -2 2 4 6w1 w2 1.6 实验任务: 1、 用matlab 完成感知准则函数确定程序的设计。 2、 请确定sample=[(0,-3),(1,3),(-1,5),(-1,1),(0.5,6),(-3,-1),(2,-1),(0,1), (1,1),(-0.5,-0.5),( 0.5,-0.5)];属于哪个样本空间,根据数据画出分类的结果。 3、 请分析一下k ρ和)1(a 对于感知函数准则确定的影响,并确定当k ρ=1/2/3时,相应 的k 的值,以及)1(a 不同时,k 值得变化情况。 4、 根据实验结果请说明感知准则函数是否是唯一的,为什么?
实验(一) Windows 7基本操作 一、实验目的 1.掌握文件和文件夹基本操作。 2.掌握“资源管理器”和“计算机”基本操作。 二、实验要求 1.请将操作结果用Alt+Print Screen组合键截图粘贴在题目之后。 2.实验完成后,请将实验报告保存并提交。 三、实验内容 1.文件或文件夹的管理(提示:此题自行操作一遍即可,无需抓图)★期末机试必考题★ (1) 在D:盘根目录上创建一个名为“上机实验”的文件夹,在“上机实验”文件夹中创建1个名为“操作系统上机实验”的空白文件夹和2个分别名为“2.xlsx”和“3.pptx”的空白文件,在“操作系统上机实验”文件夹中创建一个名为“1.docx”的空白文件。 (2) 将“1.docx”改名为“介绍信.docx”;将“上机实验”改名为“作业”。 (3) 在“作业”文件夹中分别尝试选择一个文件、同时选择两个文件、一次同时选择所有文件和文件夹。 (4) 将“介绍信.docx”复制到C:盘根目录。 (5) 将D:盘根目录中的“作业”文件夹移动到C:盘根目录。 (6) 将“作业”文件夹中的“2.xlsx”文件删除放入“回收站”。 (7) 还原被删除的“2.xlsx”文件到原位置。 2.搜索文件或文件夹,要求如下: 查找C盘上所有以大写字母“A”开头,文件大小在10KB以上的文本文件。(提示:搜索时,可以使用“?”和“*”。“?”表示任意一个字符,“*”表示任意多个字符。)
3. 在桌面上为C:盘根目录下的“作业”文件夹创建一个桌面快捷方式。★期末机试必考题★ 3.“计算机”或“资源管理器”的使用 (1) 在“资源管理器”窗口,设置以详细信息方式显示C:\WINDOWS中所有文件和文件夹,使所有图标按类型排列显示,并不显示文件扩展名。(提示:三步操作全部做完后,将窗口中显示的最终设置结果抓一张图片即可) (2) 将C:盘根目录中“介绍信.docx”的文件属性设置为“只读”和“隐藏”,并设置在窗口中显示“隐藏属性”的文件或文件夹。(提示:请将“文件夹”对话框中选项设置效果与C:盘根目录中该文件图标呈现的半透明显示效果截取在一整张桌面图片中即可) 4.回收站的设置 设置删除文件后,不将其移入回收站中,而是直接彻底删除功能。
《文献检索》实验指导书 刘军安编写 适用专业:机械类各专业 总学时:24~32学时 实验学时:6~14 机械设计与制造教研室 2014. 3
一、课程总实验目的与任务 《文献检索》课程实验是机械学院机械类专业的选修课的实验。通过实验内容与过程,主要培养学生在信息数字化、网络化存储环境下信息组织与检索的原理、技术和方法,以及在数字图书馆系统和数字信息服务系统中检索专业知识的能力,辅助提高21世纪大学生人文素质。通过实验,使学生对信息检索的概念及发展、检索语言、检索策略、检索方法、检索算法、信息检索技术、网络信息检索原理、搜索引擎、信息检索系统的结构、信息检索系统的使用、信息检索系统评价以及所检索信息的分析等技术有一个全面熟悉和掌握。本实验主要培养和考核学生对信息检索基本原理、方法、技术的掌握和知识创新过程中对知识的检索与融合能力。实验主要侧重于培养学生对本专业技术原理和前言知识的信息检索能力,引导学生应理论联系实际,同时要了解本专业科技信息的最新进展和研究动态与走向。 二、实验内容 通过课程的学习,结合老师给出的检索主题,学生应该完成以下内容的实验: 实验一:图书馆专业图书检索(印刷版图书) 实验二:中文科技期刊信息检索 实验三:科技文献数据库信息检索 实验四:网络科技信息检索(含报纸和网络) 文献检索参考主题: 1.工业工程方向: 工业工程;工业工程师的素质、精神、修养、气质与能力;工业工程的本质;企业文化与工业工程;战略工程管理;工程哲学;创新管理;生产管理;品质管理;优化管理或管理的优化;零库存;敏捷制造;敏捷管理;(优秀的、现代的、或未来的)管理哲学;生产管理七大工具;质量管理;设备管理;基础管理;现场管理;六西格玛管理;生产线平衡;工程经济;系统哲学;系统管理;柔性制造;看板管理;工程心理学;管理心理学;激励管理;管理中的真、善、美(或假、恶、丑);工程哲学;工业工程中的责任;安全管理;优化调度;系统工程;系统管理与过程控制;设计哲学;智能管理;工业工程中的数学;智能工业工程,或工业工程的智能化;生态工程管理;绿色工业工程,或绿色管理;协同学与协同管理;工业工程中的协同;概念工程与概念管理;工业工程与蝴蝶效应;管理中的蝴蝶效应,等等…… 2.机械电子工程方向: CAD;CAM;CAE;CAPP;PDM;EPR;CIMS;VD;VM;FMS;PLC;协同设计;协同制造;概念设计;自底向上;自顶向下;智能设计;智能制造;智能材料;特种加工(线切割、电火花、激光加工、电化学加工、超声波加工、光刻技术、快速成型、反求工程);微机械;精密加工;精密制造;机电一体化;自动化;控制论;线性控制;非线性控制;混沌控制;模糊控制;人工智能;神经网络;纳米技术;纳米制造;机器人;智能机器人;传感器;智能传感器;自动化生产线;机械手;智能机械手;自动检测;数据采集;信号处理;信息识别、模式识别等等……
大连理工大学实验报告 学院(系):专业:班级: 姓名:学号:组:___ 实验时间:实验室:实验台: 指导教师签字:成绩: 实验名称:进程控制 一、实验目的和要求 (1)进一步加强对进程概念的理解,明确进程和程序的区别 (2)进一步认识并发执行的实质 二、实验环境 在windows平台上,cygwin模拟UNIX运行环境 三、实验内容 (1) getpid()---获取进程的pid 每个进程都执行自己独立的程序,打印自己的pid; (2) getpid()---获取进程的pid 每个进程都执行自己独立的程序,打印自己的pid; 父进程打印两个子进程的pid;
(3)写一个命令处理程序,能处理max(m,n), min(m,n),average(m,n,l)这几个命令(使用exec函数族)。 Max函数 Min函数 Average函数 Exec函数族调用 四、程序代码 五、运行结果 六、实验结果与分析 七、体会 通过这次上机,我了解了fork函数的运行方法,同时更深刻的了解了进程的并行执行的本质,印证了在课堂上学习的理论知识。同时通过编写实验内容(3)的命令处理程序,学会了exec函数族工作原理和使用方法。通过这次上机实验让我加深了对课堂上学习的理论知识的理解,收获很多。
大连理工大学实验报告 学院(系):专业:班级: 姓名:学号:组:___ 实验时间:实验室:实验台: 指导教师签字:成绩: 实验名称:进程通讯 一、实验目的和要求 了解和熟悉UNIX支持的共享存储区机制 二、实验环境 在windows平台上,cygwin模拟UNIX运行环境 三.实验内容 编写一段程序, 使其用共享存储区来实现两个进程之间的进程通讯。进程A创建一个长度为512字节的共享内存,并显示写入该共享内存的数据;进程B将共享内存附加到自己的地址空间,并向共享内存中写入数据。 四、程序代码 五、运行结果 六、实验结果与分析 七、体会
数值分析上机实验报告
《数值分析》上机实验报告 1.用Newton 法求方程 X 7-X 4+14=0 在(0.1,1.9)中的近似根(初始近似值取为区间端点,迭代6次或误差小于0.00001)。 1.1 理论依据: 设函数在有限区间[a ,b]上二阶导数存在,且满足条件 {}α?上的惟一解在区间平方收敛于方程所生的迭代序列 迭代过程由则对任意初始近似值达到的一个中使是其中上不变号 在区间],[0)(3,2,1,0,) (') ()(],,[x |))(),((|,|,)(||)(|.4;0)(.3],[)(.20 )()(.110......b a x f x k x f x f x x x Newton b a b f a f mir b a c x f a b c f x f b a x f b f x f k k k k k k ==- ==∈≤-≠>+ 令 )9.1()9.1(0)8(4233642)(0)16(71127)(0)9.1(,0)1.0(,1428)(3 2 2 5 333647>?''<-=-=''<-=-='<>+-=f f x x x x x f x x x x x f f f x x x f 故以1.9为起点 ?? ?? ? ='- =+9.1)()(01x x f x f x x k k k k 如此一次一次的迭代,逼近x 的真实根。当前后两个的差<=ε时,就认为求出了近似的根。本程序用Newton 法求代数方程(最高次数不大于10)在(a,b )区间的根。
1.2 C语言程序原代码: #include
概念形成 简介: 概念是人脑反映事物本质属性的思维形式。个体掌握一类事物本质属性的过程,就是概念形成的过程。实验室中为了研究概念形成的过程,常使用人工概念。 制造人工概念时先确定一个或几个属性作为分类标准,但并不告诉被试,只是将材料交给被试,请其分类。在此过程中,反馈给被试是对还是错。通过这种方法,被试可以发现主试的分类标准,从而学会正确分类,即掌握了这个人工概念。通过人工概念的研究,可以了解概念形成的过程。一般来讲,被试都是经过概括-假设-验证的循环来达到概念形成的。 叶克斯复杂选择器可用来制造人工概念。本实验模拟叶克斯复杂选择器来研究简单空间位置关系概念的形成。 方法与程序: 本实验共有4个人工概念,难度顺次增加,被试可以任选其中1个。 实验时,屏幕上会出现十二个圆键,有空心和实心两种。其中只有一个实心圆与声音相联系,此键出现的相对位置是有规律的,被试要去发现其中的规律(概念),找到这个键。被试用鼠标点击相应的实心圆,如果没有发生任何变化,表明选择错误;如果有声音呈现,同时该圆变为红色,则表明选择正确。只有选择正确,才能继续下一试次。当连续三次第一遍点击就找对了位置时,就认为被试已形成了该人工概念,实验即结束。如果被试在60个试次内不能形成正确概念,实验自动终止。 结果与讨论: 结果文件第一行是被试达到标准所用的遍数(不包括连续第一次就对的三遍)。其后的结果分三列印出:第一列是遍数;第二列为每遍中反应错的次数,如为0则表示这一遍第一次就做对了;第三列表示这一遍所用的时间,以毫秒为单位。 根据结果试说明被试概念形成的过程。 交叉参考:思维策略 参考文献: 杨博民主编心理实验纲要北京大学出版社 319-321页
操作系统上机实验报告 实验名称: 生产者与消费者问题模拟 实验目的: 通过模拟生产者消费者问题理解进程或线程之间的同步与互斥。 实验内容: 1、设计一个环形缓冲区,大小为10,生产者依次向其中写入1到20,每个缓冲区中存放一个数字,消费者从中依次读取数字。 2、相应的信号量; 3、生产者和消费者可按如下两种方式之一设计; (1)设计成两个进程; (2)设计成一个进程内的两个线程。 4、根据实验结果理解信号量的工作原理,进程或线程的同步\互斥关系。 实验步骤及分析: 一.管道 (一)管道定义 所谓管道,是指能够连接一个写进程和一个读进程的、并允许它们以生产者—消费者方式进行通信的一个共享文件,又称为pipe文件。由写进程从管道的写入端(句柄1)将数据写入管道,而读进程则从管道的读出端(句柄0)读出数据。(二)所涉及的系统调用 1、pipe( ) 建立一无名管道。 系统调用格式 pipe(filedes) 参数定义 int pipe(filedes); int filedes[2]; 其中,filedes[1]是写入端,filedes[0]是读出端。 该函数使用头文件如下: #include
int read(fd,buf,nbyte); int fd; char *buf; unsigned nbyte; 3、write( ) 系统调用格式 read(fd,buf,nbyte) 功能:把nbyte 个字节的数据,从buf所指向的缓冲区写到由fd所指向的文件中。如文件加锁,暂停写入,直至开锁。 参数定义同read( )。 (三)参考程序 #include
课题一:拉格朗日插值法 1.实验目的 1.学习和掌握拉格朗日插值多项式。 2.运用拉格朗日插值多项式进行计算。 2.实验过程 作出插值点(1.00,0.00),(-1.00,-3.00),(2.00,4.00)二、算法步骤 已知:某些点的坐标以及点数。 输入:条件点数以及这些点的坐标。 输出:根据给定的点求出其对应的拉格朗日插值多项式的值。 3.程序流程: (1)输入已知点的个数; (2)分别输入已知点的X坐标; (3)分别输入已知点的Y坐标; 程序如下: #include
插值算法*/ { int i,j; float *a,yy=0.0; /*a作为临时变量,记录拉格朗日插值多项*/ a=(float*)malloc(n*sizeof(float)); for(i=0;i<=n-1;i++) { a[i]=y[i]; for(j=0;j<=n-1;j++) if(j!=i) a[i]*=(xx-x[j])/(x[i]-x[j]); yy+=a[i]; } free(a); return yy; } int main() { int i; int n; float x[20],y[20],xx,yy; printf("Input n:");
scanf("%d",&n); if(n<=0) { printf("Error! The value of n must in (0,20)."); getch();return 1; } for(i=0;i<=n-1;i++) { printf("x[%d]:",i); scanf("%f",&x[i]); } printf("\n"); for(i=0;i<=n-1;i++) { printf("y[%d]:",i);scanf("%f",&y[i]); } printf("\n"); printf("Input xx:"); scanf("%f",&xx); yy=lagrange(x,y,xx,n); printf("x=%f,y=%f\n",xx,yy); getch(); } 举例如下:已知当x=1,-1,2时f(x)=0,-3,4,求f(1.5)的值。
华南理工大学《模式识别》大作业报告 题目:模式识别导论实验 学院计算机科学与工程 专业计算机科学与技术(全英创新班) 学生姓名黄炜杰 学生学号201230590051 指导教师吴斯 课程编号145143 课程学分2分 起始日期2015年5月18日
实验概述 【实验目的及要求】 Purpose: Develop classifiers,which take input features and predict the labels. Requirement: ?Include explanations about why you choose the specific approaches. ?If your classifier includes any parameter that can be adjusted,please report the effectiveness of the parameter on the final classification result. ?In evaluating the results of your classifiers,please compute the precision and recall values of your classifier. ?Partition the dataset into2folds and conduct a cross-validation procedure in measuring the performance. ?Make sure to use figures and tables to summarize your results and clarify your presentation. 【实验环境】 Operating system:window8(64bit) IDE:Matlab R2012b Programming language:Matlab
实验一 误差分析 实验(病态问题) 实验目的:算法有“优”与“劣”之分,问题也有“好”与“坏”之别。对数值方法的研究而言,所谓坏问题就是问题本身对扰动敏感者,反之属于好问题。通过本实验可获得一个初步体会。 数值分析的大部分研究课题中,如线性代数方程组、矩阵特征值问题、非线性方程及方程组等都存在病态的问题。病态问题要通过研究和构造特殊的算法来解决,当然一般要付出一些代价(如耗用更多的机器时间、占用更多的存储空间等)。 问题提出:考虑一个高次的代数多项式 )1.1() ()20()2)(1()(20 1∏=-=---=k k x x x x x p 显然该多项式的全部根为1,2,…,20共计20个,且每个根都是单重的。现考虑该多项式的一个扰动 )2.1(0 )(19=+x x p ε 其中ε是一个非常小的数。这相当于是对()中19x 的系数作一个小的扰动。我们希望比较()和()根的差别,从而分析方程()的解对扰动的敏感性。 实验内容:为了实现方便,我们先介绍两个Matlab 函数:“roots ”和“poly ”。 roots(a)u = 其中若变量a 存储n+1维的向量,则该函数的输出u 为一个n 维的向量。设a 的元素依次为121,,,+n a a a ,则输出u 的各分量是多项式方程 01121=+++++-n n n n a x a x a x a 的全部根;而函数 poly(v)b =
的输出b 是一个n+1维变量,它是以n 维变量v 的各分量为根的多项式的系数。可见“roots ”和“poly ”是两个互逆的运算函数。 ;000000001.0=ess );21,1(zeros ve = ;)2(ess ve = ))20:1((ve poly roots + 上述简单的Matlab 程序便得到()的全部根,程序中的“ess ”即是()中的ε。 实验要求: (1)选择充分小的ess ,反复进行上述实验,记录结果的变化并分析它们。 如果扰动项的系数ε很小,我们自然感觉()和()的解应当相差很小。计算中你有什么出乎意料的发现表明有些解关于如此的扰动敏感性如何 (2)将方程()中的扰动项改成18x ε或其它形式,实验中又有怎样的现象 出现 (3)(选作部分)请从理论上分析产生这一问题的根源。注意我们可以将 方程()写成展开的形式, ) 3.1(0 ),(1920=+-= x x x p αα 同时将方程的解x 看成是系数α的函数,考察方程的某个解关于α的扰动是否敏感,与研究它关于α的导数的大小有何关系为什么你发现了什么现象,哪些根关于α的变化更敏感 思考题一:(上述实验的改进) 在上述实验中我们会发现用roots 函数求解多项式方程的精度不高,为此你可以考虑用符号函数solve 来提高解的精确度,这需要用到将多项式转换为符号多项式的函数poly2sym,函数的具体使用方法可参考Matlab 的帮助。
《模式识别》实验报告 一、数据生成与绘图实验 1.高斯发生器。用均值为m,协方差矩阵为S 的高斯分布生成N个l 维向量。 设置均值 T m=-1,0 ?? ??,协方差为[1,1/2;1/2,1]; 代码: m=[-1;0]; S=[1,1/2;1/2,1]; mvnrnd(m,S,8) 结果显示: ans = -0.4623 3.3678 0.8339 3.3153 -3.2588 -2.2985 -0.1378 3.0594 -0.6812 0.7876 -2.3077 -0.7085 -1.4336 0.4022 -0.6574 -0.0062 2.高斯函数计算。编写一个计算已知向量x的高斯分布(m, s)值的Matlab函数。 均值与协方差与第一题相同,因此代码如下: x=[1;1]; z=1/((2*pi)^0.5*det(S)^0.5)*exp(-0.5*(x-m)'*inv(S)*(x-m)) 显示结果: z = 0.0623 3.由高斯分布类生成数据集。编写一个Matlab 函数,生成N 个l维向量数据集,它们是基于c个本体的高斯分布(mi , si ),对应先验概率Pi ,i= 1,……,c。 M文件如下: function [X,Y] = generate_gauss_classes(m,S,P,N) [r,c]=size(m); X=[]; Y=[]; for j=1:c t=mvnrnd(m(:,j),S(:,:,j),fix(P(j)*N)); X=[X t]; Y=[Y ones(1,fix(P(j)*N))*j]; end end
调用指令如下: m1=[1;1]; m2=[12;8]; m3=[16;1]; S1=[4,0;0,4]; S2=[4,0;0,4]; S3=[4,0;0,4]; m=[m1,m2,m3]; S(:,:,1)=S1; S(:,:,2)=S2; S(:,:,3)=S3; P=[1/3,1/3,1/3]; N=10; [X,Y] = generate_gauss_classes(m,S,P,N) 二、贝叶斯决策上机实验 1.(a)由均值向量m1=[1;1],m2=[7;7],m3=[15;1],方差矩阵S 的正态分布形成三个等(先验)概率的类,再基于这三个类,生成并绘制一个N=1000 的二维向量的数据集。 (b)当类的先验概率定义为向量P =[0.6,0.3,0.1],重复(a)。 (c)仔细分析每个类向量形成的聚类的形状、向量数量的特点及分布参数的影响。 M文件代码如下: function plotData(P) m1=[1;1]; S1=[12,0;0,1]; m2=[7;7]; S2=[8,3;3,2]; m3=[15;1]; S3=[2,0;0,2]; N=1000; r1=mvnrnd(m1,S1,fix(P(1)*N)); r2=mvnrnd(m2,S2,fix(P(2)*N)); r3=mvnrnd(m3,S3,fix(P(3)*N)); figure(1); plot(r1(:,1),r1(:,2),'r.'); hold on; plot(r2(:,1),r2(:,2),'g.'); hold on; plot(r3(:,1),r3(:,2),'b.'); end (a)调用指令: P=[1/3,1/3,1/3];
锅炉温度定值控制系统模式识别及仿真专业:电气工程及其自动化姓名:郭光普指导教师:马安仁 摘要本文首先简要介绍了锅炉内胆温度控制系统的控制原理和参数辨识的概念及切线近似法模式识别的基本原理,然后对该系统的温控曲线进行模式识别,而后着重介绍了用串级控制和Smith预估器设计一个新的温度控制系统,并在MATLAB的Simulink中搭建仿真模型进行仿真。 关键词温度控制,模式识别,串级控制,Smith预测控制 ABSTRACT This article first briefly introduced in the boiler the gallbladder temperature control system's control principle and the parameter identification concept and the tangent approximate method pattern recognition basic principle, then controls the curve to this system to carry on the pattern recognition warm, then emphatically introduced designs a new temperature control system with the cascade control and the Smith estimator, and carries on the simulation in the Simulink of MATLAB build simulation model. Key Words:Temperature control, Pattern recognition, Cascade control, Smith predictive control
数值分析实验报告模板 篇一:数值分析实验报告(一)(完整) 数值分析实验报告 1 2 3 4 5 篇二:数值分析实验报告 实验报告一 题目:非线性方程求解 摘要:非线性方程的解析解通常很难给出,因此线性方程的数值解法就尤为重要。本实验采用两种常见的求解方法二分法和Newton法及改进的Newton法。利用二分法求解给定非线性方程的根,在给定的范围内,假设f(x,y)在[a,b]上连续,f(a)xf(b) 直接影响迭代的次数甚至迭代的收敛与发散。即若x0 偏离所求根较远,Newton法可能发散的结论。并且本实验中还利用利用改进的Newton法求解同样的方程,且将结果与Newton法的结果比较分析。 前言:(目的和意义) 掌握二分法与Newton法的基本原理和应用。掌握二分法的原理,验证二分法,在选对有根区间的前提下,必是收
敛,但精度不够。熟悉Matlab语言编程,学习编程要点。体会Newton使用时的优点,和局部收敛性,而在初值选取不当时,会发散。 数学原理: 对于一个非线性方程的数值解法很多。在此介绍两种最常见的方法:二分法和Newton法。 对于二分法,其数学实质就是说对于给定的待求解的方程f(x),其在[a,b]上连续,f(a)f(b) Newton法通常预先要给出一个猜测初值x0,然后根据其迭代公式xk?1?xk?f(xk) f'(xk) 产生逼近解x*的迭代数列{xk},这就是Newton法的思想。当x0接近x*时收敛很快,但是当x0选择不好时,可能会发散,因此初值的选取很重要。另外,若将该迭代公式改进为 xk?1?xk?rf(xk) 'f(xk) 其中r为要求的方程的根的重数,这就是改进的Newton 法,当求解已知重数的方程的根时,在同种条件下其收敛速度要比Newton法快的多。 程序设计: 本实验采用Matlab的M文件编写。其中待求解的方程写成function的方式,如下 function y=f(x);
实验1 图像的贝叶斯分类 1.1 实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 1.2 实验仪器设备及软件 HP D538、MATLAB 1.3 实验原理 1.3.1 基本原理 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。此过程中,确定阈值是分割的关键。 对一般的图像进行分割处理通常对图像的灰度分布有一定的假设,或者说是基于一定的图像模型。最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背
景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示 1122()()()p x P p x P p x =+ 式中1p 和2p 分别为 212 1()21()x p x μσ--= 222()22()x p x μσ-- = 121P P += 1σ、2σ是针对背景和目标两类区域灰度均值1μ与2μ的标准差。若假定目标的灰 度较亮,其灰度均值为2μ,背景的灰度较暗,其灰度均值为1μ,因此有 12μμ< 现若规定一门限值T 对图像进行分割,势必会产生将目标划分为背景和将背景划分为目标这两类错误。通过适当选择阈值T ,可令这两类错误概率为最小,则该阈值T 即为最佳阈值。 把目标错分为背景的概率可表示为 12()()T E T p x dx -∞ =? 把背景错分为目标的概率可表示为