
S P S S聚类分析和判别分析 论文 Prepared on 22 November 2020
基于聚类分析的我国城镇居民消费结构实证分析摘要:近年来,我国城镇居民的整体消费水平逐渐提高,但各地区间的消费结构仍存在较大差别。文章选用8个城镇居民消费结构统计指标,采用欧式距离平方和离差平方和法,对我国31个省、直辖市及自治区的2013年城镇居民消费结构进行聚类分析和比较研究。这不仅从总体上掌握了我国消费结构类型的地区分布,而且系统分析了我国各地区消费结构的特点及产生原因,为国家制定消费政策提供了决策依据。 关键词:消费结构;聚类分析;判别分析;政策建议; 一、引言 近年来,随着我国经济的快速发展,城镇居民的收入不断增加,并且在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,我国各地区城镇居民的消费支出也强劲增长,消费结构发生了巨大的变化,结构不合理现象也得到了一定程度的调整。但是,由于各地区的经济发展不平衡及原有经济基础的差异,使各地区的消费结构仍存在着明显差别。为了进一步改善消费结构,正确引导消费,提高我国城市居民的消费水平和生活质量,有必要考察我国各地区城镇居民的消费结构之间的异同并进行比较研究,以期发现特点和规律,从宏观上把握各地区城镇居民的消费现状和不同地区消费水平的差异,为提高我国各地区消费水平和谐增长提供决策依据。 二、消费结构的数据分析 消费结构指居民在生活消费过程中,不同类型消费的比例及其相互之间的配合、替代、制约的关系。就其数量关系来看,消费结构是指在消费过程中不同商品或劳务消费支出占居民总消费支出的比重,反映了一定社会经济条件下人们对各类商品及劳务的需求结构,体现一国或各地区的经济发展水平和居民生活状况。 (一)数据来源 为了更加深入地了解我国城镇居民消费结构,先利用2013年全国数据(如表1所示),对全国31个省、直辖市、自治区进行聚类分析。分析采用选用了城镇居民食品、衣着、居住、家庭用品及服务设备、医疗保健、交通和通信、教育文化娱乐服务、其它商品和服务八项指标,分别用来反映较高、中等、较低居民消费结构。
判别分析(Discriminant Analysis) 一、概述: 判别问题又称识别问题,或者归类问题。 判别分析是由Pearson于1921年提出,1936年由Fisher首先提出根据不同类别所提取的特征变量来定量的建立待判样品归属于哪一个已知类别的数学模型。 根据对训练样本的观测值建立判别函数,借助判别函数式判断未知类别的个体。 所谓训练样本由已知明确类别的个体组成,并且都完整准确地测量个体的有关的判别变量。 训练样本的要求:类别明确,测量指标完整准确。一般样本含量不宜过小,但不能为追求样本含量而牺牲类别的准确,如果类别不可靠、测量值不准确,即使样本含量再大,任何统计方法语法弥补这一缺陷。 判别分析的类别很多,常用的有:适用于定性指标或计数资料的有最大似然法、训练迭代法;适用于定量指标或计量资料的有:Fisher二类判别、Bayers多类判别以及逐步判别。半定量指标界于二者之间,可根据不同情况分别采用以上方法。 类别(有的称之为总体,但应与population的区别)的含义——具有相同属性或者特征指标的个体(有的人称之为样品)的集合。如何来表征相同属性、相同的特征指标呢? 同一类别的个体之间距离小,不同总体的样本之间距离大。 距离是一个原则性的定义,只要满足对称性、非负性和三角不等式的函数就可以称为距 绝对距离 马氏距离:(Manhattan distance) 设有两个个体(点)X与Y(假定为一维数据,即在数轴上)是来自均数为μ,协方差阵为∑的总体(类别)A的两个个体(点),则个体X与Y的马氏距离为 (,)X与总体(类别)A的距离D X Y= (,) 为D X A= 明考斯基距离(Minkowski distance):明科夫斯基距离 欧几里德距离(欧氏距离) 二、Fisher两类判别 一、训练样本的测量值 A类训练样本
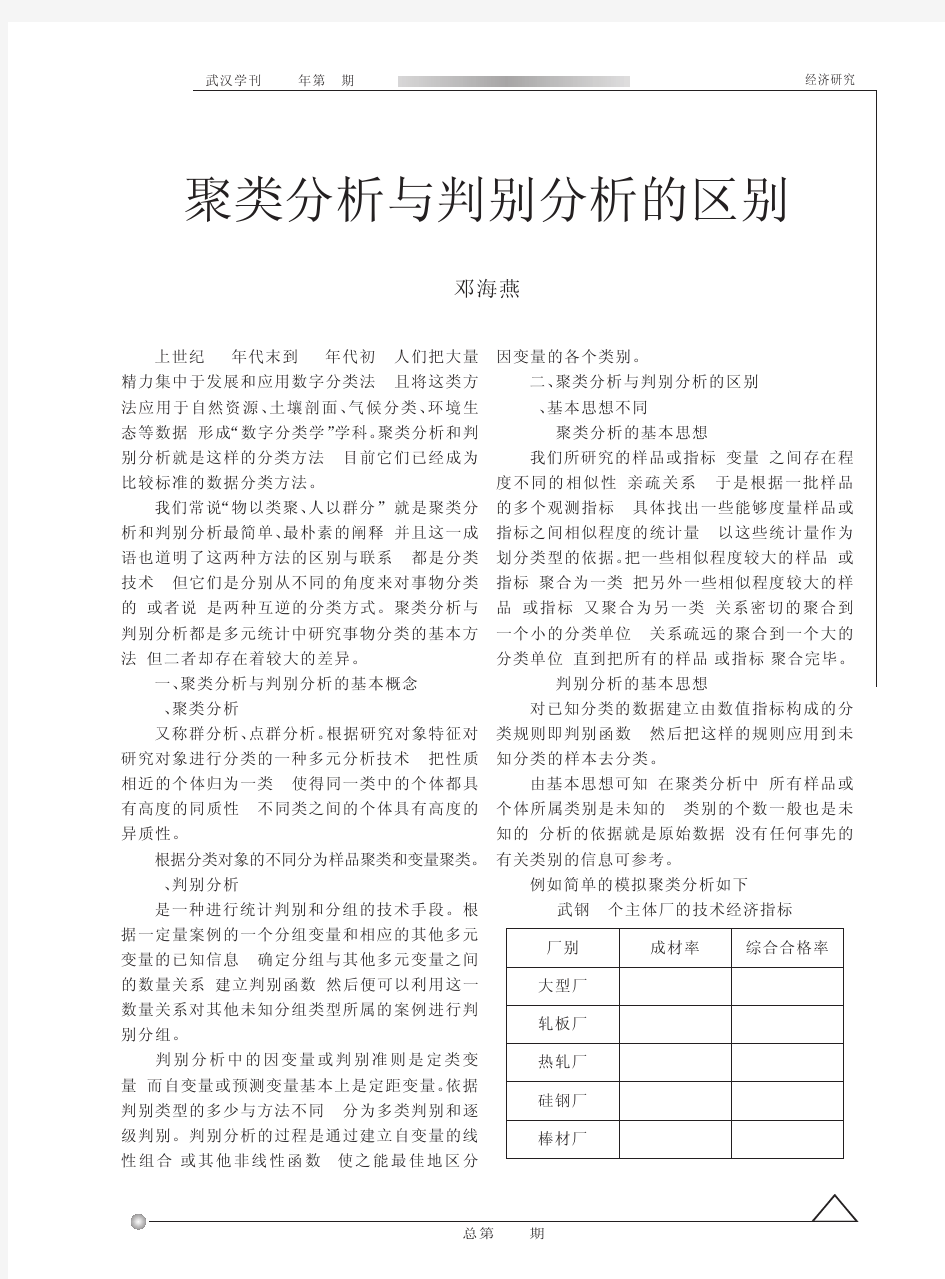
聚类分析与判别分析区别1 2 聚类分析和判 3 别分析就是这样的分类方法 4 , 5 目前它们已经成为 6 比较标准的数据分类方法。 7 我们常说 8 “物以类聚、 9 人以群分” 10 , 11 就是聚类分 12 析和判别分析最简单、 13 14 最朴素的阐释 15 , 16 并且这一成 17 语也道明了这两种方法的区别与联系 , 18 19 都是分类 20 技术 , 21 22 但它们是分别从不同的角度来对事物分类 的 23 24 , 25 或者说 , 26 27 是两种互逆的分类方式。聚类分析与 28 判别分析都是多元统计中研究事物分类的基本方 29 法 30 , 31 但二者却存在着较大的差异。 32 一、 33 聚类分析与判别分析的基本概念 34 1 35 、 36 聚类分析 37 又称群分析、 38 点群分析。 39 根据研究对象特征对 40 研究对象进行分类的一种多元分析技术 , 41 42 把性质
相近的个体归为一类 1 2 , 3 使得同一类中的个体都具 4 有高度的同质性 5 , 6 不同类之间的个体具有高度的 异质性。 7 8 根据分类对象的不同分为样品聚类和变量聚类。9 2 、 10 11 判别分析 12 是一种进行统计判别和分组的技术手段。根 13 据一定量案例的一个分组变量和相应的其他多元14 变量的已知信息 15 , 16 确定分组与其他多元变量之间 17 的数量关系 18 , 19 建立判别函数 , 20 21 然后便可以利用这一 22 数量关系对其他未知分组类型所属的案例进行判23 别分组。 24 判 25 别 26 分 27 析 28 中 29 的 30 因 变 31 32 量 33 或 34 判 35 别 36 准 则 37 38 是 39 定 类 40 41 变 42 量 , 43 44 而自变量或预测变量基本上是定距变量。
全国各省经济的聚类分析及判别分析 唐鹏钧(DY1001109) 摘要:利用SPSS软件对全国31个省、直辖市、自治区(浙江、湖南、甘肃除外)的主要经济指标进行聚类分析,将其经济分成4种类型,并对浙江、湖南、甘肃进行类型判别分析。通过这两个方法对全国各省进行经济分类。本文选取了7项经济指标作为决定经济类型的影响因素,各项数据均来自2010年国家统计年鉴。分析结果表明:北京市和上海市为第一类经济类型;江苏省和山东省为第三类型;广东省为第四类经济;其他25个省、直辖市、自治区均属于第二类型。 关键词:聚类分析、判别分析、经济类型 0引言 聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称。它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。系统聚类分析又称集群分析,是聚类分析中应用最广的一种方法,它根据样本的多指标(变量)、多个观察数据,定量地确定样品、指标之间存在的相似性或亲疏关系,并据此连结这些样品或指标,归成大小类群,构成分类树状图或冰柱图。 判别分析是根据多种因素(指标)对事物的影响来实现对事物的分类,从而对事物进行判别分类的统计方法。判别分析适用于已经掌握了历史上分类的每一个类别的若干样品,希望根据这些历史的经验(样品),总结出分类的规律性(判别函数)来指导未来的分类。 聚类分析与判别分析都是研究分类的,但是它们有所区别: (1)聚类分析一般寻求客观的分类方法,在进行聚类分析以前,对总体到底有几种类型并不知道。判别分析则是在总体类型划分已知,在各总体分布或来自总体训练样本的基础上,对当前的新样本判定它们属于哪个总体。 (2)两类方法的建立的模型不一样,因此在处理某些特定的问题时,就会得
基于聚类分析的我国城镇居民消费结构实证分析 摘要:近年来,我国城镇居民的整体消费水平逐渐提高,但各地区间的消费结构仍 存在较大差别。文章选用8个城镇居民消费结构统计指标,采用欧式距离平方和离差平 方和法,对我国31个省、直辖市及自治区的2013年城镇居民消费结构进行聚类分析和 比较研究。这不仅从总体上掌握了我国消费结构类型的地区分布,而且系统分析了我国 各地区消费结构的特点及产生原因,为国家制定消费政策提供了决策依据。 关键词:消费结构;聚类分析;判别分析;政策建议; 一、引言 近年来,随着我国经济的快速发展,城镇居民的收入不断增加,并且在国家连续出台 住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济 政策的影响下,我国各地区城镇居民的消费支出也强劲增长,消费结构发生了巨大的变 化,结构不合理现象也得到了一定程度的调整。但是,由于各地区的经济发展不平衡及 原有经济基础的差异,使各地区的消费结构仍存在着明显差别。为了进一步改善消费结 构,正确引导消费,提高我国城市居民的消费水平和生活质量,有必要考察我国各地区 城镇居民的消费结构之间的异同并进行比较研究,以期发现特点和规律,从宏观上把握 各地区城镇居民的消费现状和不同地区消费水平的差异,为提高我国各地区消费水平和 谐增长提供决策依据。 二、消费结构的数据分析 消费结构指居民在生活消费过程中,不同类型消费的比例及其相互之间的配合、替 代、制约的关系。就其数量关系来看,消费结构是指在消费过程中不同商品或劳务消费 支出占居民总消费支出的比重,反映了一定社会经济条件下人们对各类商品及劳务的需 求结构,体现一国或各地区的经济发展水平和居民生活状况。 (一)数据来源 为了更加深入地了解我国城镇居民消费结构,先利用2013年全国数据(如表1所示), 对全国31个省、直辖市、自治区进行聚类分析。分析采用选用了城镇居民食品、衣着、 居住、家庭用品及服务设备、医疗保健、交通和通信、教育文化娱乐服务、其它商品和 服务八项指标,分别用来反映较高、中等、较低居民消费结构。 表1 各地区城镇居民家庭平均每人全年消费支出 (2013年)
聚类分析、判别分析、主成分分析、因子分析 主成分分析与因子分析的区别 1. 目的不同:因子分析把诸多变量看成由对每一个变量都有作用的一些公共因子和仅对某一个变量有作用的特殊因子线性组合而成,因此就是要从数据中控查出对变量起解释作用的公共因子和特殊因子以及其组合系数;主成分分析只是从空间生成的角度寻找能解释诸多变量变异的绝大部分的几组彼此不相关的新变量(主成分)。 2. 线性表示方向不同:因子分析是把变量表示成各公因子的线性组合;而主成分分析中则是把主成分表示成各变量的线性组合。 3. 假设条件不同:主成分分析中不需要有假设;因子分析的假设包括:各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。 4. 提取主因子的方法不同:因子分析抽取主因子不仅有主成分法,还有极大似然法,主轴因子法,基于这些方法得到的结果也不同;主成分只能用主成分法抽取。 5. 主成分与因子的变化:当给定的协方差矩阵或者相关矩阵的特征值唯一时,主成分一般是固定的;而因子分析中因子不是固定的,可以旋转得到不同的因子。 6. 因子数量与主成分的数量:在因子分析中,因子个数需要分析者指定(SPSS 根据一定的条件自动设定,只要是特征值大于1的因子主可进入分析),指定的因子数量不同而结果也不同;在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等)。 7. 功能:和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势;而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。当然,这种情况也可以使用因子得分做到,所以这种区分不是绝对的。 1 、聚类分析 基本原理:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。 常用聚类方法:系统聚类法,K-均值法,模糊聚类法,有序样品的聚类,分解法,加入法。
第9章 判别分析和聚类分析 §9.1 判别分析问题的一般形式 在生产、科研和日常生活中,我们经常会遇到判别分类的问题。在这些问题中,已经知道研究对象可以分为几个类别,而且对这些类别已经作了一些观测,取得了一批样本数据。要求从已知的样本观测数据出发,建立一种判别方法,当我们取得一个新的样品时,可以根据这个样品的观测值,判定它属于哪一类,这种做法就称为判别分析(Discriminant Analysis )。 例1 岩石分类 从某矿床取得14块已知是铀矿石的样品和14块已知是围岩的样品,分别测定其中7种成分的含量,取得了一批观测数据: 要求建立一种判别方法,当我们从这个矿床取得一个新的岩石样品时,可以通过测定这个样品中7种成分的含量,判定它是铀矿石还是围岩。 例2 精神病的诊断(Rao 和Slater ,1949) 对114个处于焦虑状态的病人,33个患癔病的病人,32个有精神变态的病人,17个有强迫观念的病人,5个有变态人格的病人,以及55个正常人,分别进行3种精神病测试,得到测试分数1X ,2X 和3X 。 要求根据上述已知的测试数据,建立一种诊断方法,使得我们可以对一个新来的求诊者进行这3种精神病测试,根据测试得到的分数1X ,2X 和3X ,判断出求诊者是否正常,如果不正常,诊断出他患有哪一类精神病。 例3 (全国数学建模竞赛2000年A 题)DNA 序列分类 对于A,B 两种不同的DNA ,给出了20个类别已知的DNA 序列样品,其中1号~10号序列属于A 类,11号~20号序列属于B 类。另外还有20个类别未知的DNA 序列样品。 要求建立一种判别方法,判别出类别未知的DNA 序列样品属于哪一类。
利用聚类分析和判别分析对我国各省市经济发展状况的分析 统计081 许建霞 089114284 摘要:转变经济发展方式是我国未来经济发展过程中一项重要而十分艰巨的任务,《中共中央关于制定国民经济和社会发展第十二个五年规划的建议》更是提出“十二五”时期要以加快转变经济发展方式为主线。要实现这一转变,它与调整经济结构是高度相关、相辅相成的,其中,产业结构的转型升级更是经济发展方式转变的体现和依托。当前我国经济发展方式粗放与面临着的诸多结构性矛盾,在很大程度上根源于我国经济发展过程中的“三个过度和一个缺失”,即:经济增长过度依赖投资、全球分工中过度依赖加工制造环节和加工贸易、竞争战略过度依赖成本价格,而产业链和价值链中研发设计、营销、品牌和供应链管理等高端环节缺失。要加快转变经济发展方式,就必须改变上述“三个过度和一个缺失”,促进产业结构转型升级,这也关系到当前战略性新兴产业发展是否能够摆脱过去发展模式,走出一条可持续发展的道路。 关键词: 聚类分析 判别分析 经济发展 一.研究背景 我国产业结构基本上分享了经济的增长效应,但协调效应、分配效应和就业效应不理想,环境效应问题比较突出,并且在总体上具有名义高度化较快而实际高度化不足的特征,我们必须紧紧抓住机遇,承担起历史使命,把加快经济发展方式转变作为深入贯彻落实科学发展观的重要目标和战略举措,毫不动摇地加快经济发展方式转变,不断提高经济发展质量和效益,不断提高我国经济的国际竞争力和抗风险能力,使我国发展质量越来越高、发展空间越来越大、发展道路越走越宽。 二.方法介绍 1.聚类分析方法介绍 聚类分析是从事物数量上的特征出发对事物进行分类,是事物分类学和多元统计技术结合的结果,是一种较为粗糙的,理论并非完善的分析方法,但是其使用简便,分类效果较好,其内容也在不断丰富中,是常用的数据探索性分析工具。 聚类分析(Cluster Analysis )又称为集群分析,其分析的基本思想是依照事物的数值特征,来观察各样品之间的亲疏关系。而样品之间的亲疏关系则是由样品之间的距离来衡量的,一旦样品之间的距离定义之后,则把距离近的样品归为一类 。聚类分析既可以对样品聚类,又可以对变量聚类,样品聚类也称为Q 型聚类,变量聚类也称为R 型聚类。本文先采用样品聚类,然后再采用变量聚类。 2.判别分析方法介绍 费希尔判别的基本思想是投影。将k 组m 元数据投影到某一个方向,使得投影后组与组之间尽可能地分开。而衡量组与组之间是否分开的方法借助于一元方差分析的思想。利用方差分析的思想来导出判别函数,这个函数可以是线性的,也可以是很一般的函数。因线性判别函数在实际应用中最方便,本节仅讨论线性判别函数的导出。 设从总体),,1(k t G t 分别抽取m 元样本如下:
多元统计分析实验报告 ——研究房价与人民生活水平的关系 一、实验目的 本文旨在研究全国各省市住宅型商品房的平均价格水平,同时分析各省市住宅型商品房平均销售价格与其人民生活水平的关系。本文将用各省市人均GDP、城镇居民人均可支配收入、农村居民人均纯收入三个变量来衡量各省市的人民生活水平。住宅型商品房平均销售价格应该与人民生活水平成正相关关系。接下来,本文不仅要根据2012年全国各省市住宅型商品房平均销售价格如表1-1进行聚类分析和判别分析,还会根据2012年全国各省市人民生活水平数据如表1-2进行聚类分析与判别分析,观察房价较高的省市与人民生活水平较高的省市是否相符合,用以评价各省市房地产市场的定价是否符合该省市人民生活水平。 表1-1 2012年全国各省市住宅型商品房平均销售价格(元/平方米) 地区X 地区X 北京16553.48 湖南3669.63 天津8009.58 广东7667.89 河北4141.96 广西3909.83 山西3690.88 海南7811.26 内蒙古3656.41 重庆4804.80 辽宁4717.21 四川4959.19 吉林3875.10 贵州3695.36 黑龙江3725.51 云南3861.01 上海13869.88 西藏2982.19 浙江10679.69 甘肃3376.08 安徽4495.12 陕西4803.05 福建8365.92 青海3692.21 江西4381.18 宁夏3620.77 山东4556.63 新疆3593.82 河南3511.26 江苏6422.85 湖北4668.00 其中,X表示住宅型商品房平均销售价格。 数据来源:国家统计局、各省市统计部门官方网站。 表1-2 2012年全国各省市人民生活水平数据单位:元
第六章 判别分析 §6.1 什么是判别分析 判别分析是判别样品所属类型的一种统计方法,其应用之广可与回归分析媲美。 在生产、科研和日常生活中经常需要根据观测到的数据资料,对所研究的对象进行分类。例如在经济学中,根据人均国民收入、人均工农业产值、人均消费水平等多种指标来判定一个国家的经济发展程度所属类型;在市场预测中,根据以往调查所得的种种指标,判别下季度产品是畅销、平常或滞销;在地质勘探中,根据岩石标本的多种特性来判别地层的地质年代,由采样分析出的多种成份来判别此地是有矿或无矿,是铜矿或铁矿等;在油田开发中,根据钻井的电测或化验数据,判别是否遇到油层、水层、干层或油水混合层;在农林害虫预报中,根据以往的虫情、多种气象因子来判别一个月后的虫情是大发生、中发生或正常; 在体育运动中,判别某游泳运动员的“苗子”是适合练蛙泳、仰泳、还是自由泳等;在医疗诊断中,根据某人多种体验指标(如体温、血压、白血球等)来判别此人是有病还是无病。总之,在实际问题中需要判别的问题几乎到处可见。 判别分析与聚类分析不同。判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。对于聚类分析来说,一批给定样品要划分的类型事先并不知道,正需要通过聚类分析来给以确定类型的。 正因为如此,判别分析和聚类分析往往联合起来使用,例如判别分析是要求先知道各类总体情况才能判断新样品的归类,当总体分类不清楚时,可先用聚类分析对原来的一批样品进行分类,然后再用判别分析建立判别式以对新样品进行判别。 判别分析内容很丰富,方法很多。判别分析按判别的组数来区分,有两组判别分析和多组判别分析;按区分不同总体的所用的数学模型来分,有线性判别和非线性判别;按判别时所处理的变量方法不同,有逐步判别和序贯判别等。判别分析可以从不同角度提出的问题,因此有不同的判别准则,如马氏距离最小准则、Fisher 准则、平均损失最小准则、最小平方准则、最大似然准则、最大概率准则等等,按判别准则的不同又提出多种判别方法。本章仅介绍四种常用的判别方法即距离判别法、Fisher 判别法、Bayes 判别法和逐步判别法。 §6.2 距离判别法 基本思想:首先根据已知分类的数据,分别计算各类的重心即分组(类)的均值,判别准则是对任给的一次观测,若它与第i 类的重心距离最近,就认为它来自第i 类。 距离判别法,对各类(或总体)的分布,并无特定的要求。 1 两个总体的距离判别法 设有两个总体(或称两类)G 1、G 2,从第一个总体中抽取n 1个样品,从第二个总体中抽取n 2个样品,每个样品测量p 个指标如下页表。 今任取一个样品,实测指标值为),,(1'=p x x X ,问X 应判归为哪一类? 首先计算X 到G 1、G 2总体的距离,分别记为),(1G X D 和),(2G X D ,按距离最近准则
上海电力学院 《应用多元统计分析》——判别分析与聚类分析 学院: 姓名: 学号: 2016年4月
我国部分城市经济发展水平的聚类分析 和判别分析 摘要:本文基于《中国统计年鉴》(2012年版)统计数据,寻找评价城市经济发展水平的指标,包括第二三产业发展水平、固定投资额、社会消费零售总额和进出口贸易交流五个指标,利用统计软件SPSS综合考虑各指标,对所选城市进行K-Means 聚类分析,利用Fisher 线性判别待判城市类型,进一步验证所建模型的有效性。 关键字:聚类分析,判别分析,SPSS,城市经济发展水平 1,引言 经过改革开放后三十多年的长足进展,中国城市化已步入中期阶段,步伐加快,质量显著提高。同时,中国城市化又处于周期转折点上,上一周期行将结束,下一周期将要开始。2011年中国城市化率首次突破50%,意味着中国城镇人口首次超过农村人口,中国城市化进入关键发展阶段,这必将引起深刻的社会变革。 根据2011年4月公布的第六次人口普查数据,2010年中国居住城镇的人口接近6.6亿人,城镇化率达到49.68%,全国已有近一半的人口居住在城镇,这意味着中国将进入城镇时代。在过去30多年中,中国的城市化发展取得了很大成绩。然而,总体上中国的城市化道路是城市化滞后于工业化的非均衡道路;是土地城市化快于人口城市化的非规整道路;是以抑制农村、农业、农民的经济利益来支持城市发展,导致不能兼顾效率和公平的非协调道路;是片面追求城市发展的数量和规模,而以生态环境损失为代价的非持续道路;是以生产要素的高投入,而不是投入少、产值高、依靠科技拉动经济增长的非集约道路。传统的城市化存在着诸多弊端,中国未来的城市化必须走出一条具有自身特色的新型城市化道路。 具体而言,中国城市经济发展水平受限于地理、环境、资源以及国家政策等因素的影响,我国不同区域的城市化进程尚存在很大差异。2012年中国城市发展报告中指出,从区域角度看,目前沿海一带城市发展起步早,与国际贸易交流往来频率高,经济发展水平较高,西部地区受到国家政策的大力扶持,表现出了强劲的增长势头,西部主要城市经济发展水平仅次于沿海发达地区,而中部地区
一、案例背景 随着现代人力资源管理理论的迅速发展,绩效考评技术水平也在不断提高。绩效的多因性、多维性,要求对绩效实施多标准大样本科学有效的评价。对企业来说,对上千人进行多达50~60个标准的考核是很常见的现象。但是,目前多标准大样本大型企业绩效考评问题仍然困扰着许多人力资源管理从业人员。为此,有必要将当今国际上最流行的视窗统计软件SPSS应用于绩效考评之中。 在分析企业员工绩效水平时,由于员工绩效水平的指标很多,各指标之间还有一定的关联性,缺乏有效的方法进行比较。目前较理想的方法是非参数统计方法。本文将列举某企业的具体情况确定适当的考核标准,采用主成分分析以及聚类分析方法,比较出各员工绩效水平,从而为企业绩效管理提供一定的科学依据。 最后采用判别分析建立判别函数,同时与原分类进行比较。 聚类分析 二、绩效考评的模型建立 1、为了分析某企业绩效水平,按照综合性、可比性、实用性和易操作性的选取指标原则,本文选择了影响某企业绩效水平的成果、行为、态度等6个经济指标(见表1)。 2、对某企业,搜集整理了28名员工2009年第1季度的数据资料。构建1个28×6维的矩阵(见表2)。
3、应用SPSS数据统计分析系统首先对变量进行及主成分分析,找到样本的主成分及各变量在成分中的得分。去结果中的表3、表 4、表5备用。
表 5 成份得分系数矩阵a 成份 1 2 Zscore(X1) .227 -.295 Zscore(X2) .228 -.221 Zscore(X3) .224 -.297 Zscore(X4) .177 -.173 Zscore(X5) .186 .572 Zscore(X6) .185 .587 提取方法 :主成份。 构成得分。 a. 系数已被标准化。 4、从表3中可得到前两个成分的特征值大于1,分别为3.944和1.08,所以选取两个主成分。根据累计贡献率超过80%的一般选取原则,主成分1和主成分2的累计贡献率已达到
降维与分类是多元统计分析的两个主题,在这里,我浅谈一下的聚类分析和判别分析主要用于 分类。 聚类分析 按分析对象可分为两种:Q型聚类(对样本的聚类),R型聚类(对变量的聚类) 按具体方法可分为两种:一般小样本数据可以用谱系聚类法,大样本数据一般用快速聚类法(K 均值聚类法)。 用谱系聚类法聚类时,聚多少类合适需要根据统计量判断,一般用R2统计量、半偏相关统计量、伪t2统计量以及伪F统计量。 这里给出谱系聚类法算法: 1)n个样品开始时作为n个类,计算两两之间的距离,构成一个对称距离矩阵 2)选择D(0)中的非对角线上的最小元素,设这个最小元素是D(pq)。这时G(p)={x(p)},G(q)={x(q)}。将G(p),G(q)合并成一个新类G(r)={G(p),G(q)}。在D(0)中消去G(p),G(q)所对应的行与列,并加入由新类G(r)与剩下的其他未聚合的类间的距离所组成的一行和一列,得到一个新的距离矩阵 D(1),它是n-1阶方阵。 3)从D(1)出发重复步骤2的作法得D(2)。再由D(2)出发重复上述步骤,直到n个样品聚为1 个大类为止。 4)在合并过程中要记下合并样品的编号及两类合并时的水平(即距离)并绘制聚类谱系图。 判别分析 首先这里马氏距离的概念很重要,如下图。Σ是总体G的协方差矩阵,μ是总体G的均值向量 这构成了距离判别的核心。 其他主要几种判别法是Fisher判别,Bayes判别和逐步判别。一般用Fisher判别即可,要考虑概率及误判损失最小的用Bayes判别,但变量较多时,一般先进行逐步判别筛选出有统计意义的变量,再结合实际情况选择用哪种判别方法。 聚类分析与判别分析的区别与联系 都是研究分类的,在进行聚类分析前,对总体到底有几种类型不知道(研究分几类较为合适需从
聚类分析、判别分析、主成分分析、因子分析主成分分析与因子分析的区别 1. 目的不同:因子分析把诸多变量看成由对每一个变量都有作用的一些公共因子和仅对某一个变量有作用的特殊因子线性组合而成,因此就是要从数据中控查出对变量起解释作用的公共因子和特殊因子以及其组合系数;主成分分析只是从空间生成的角度寻找能解释诸多变量变异的绝大部分的几组彼此不相关的新变量(主成分)。 2. 线性表示方向不同:因子分析是把变量表示成各公因子的线性组合;而主成分分析中则是把主成分表示成各变量的线性组合。 3. 假设条件不同:主成分分析中不需要有假设;因子分析的假设包括:各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。 4. 提取主因子的方法不同:因子分析抽取主因子不仅有主成分法,还有极大似然法,主轴因子法,基于这些方法得到的结果也不同;主成分只能用主成分法抽取。 5. 主成分与因子的变化:当给定的协方差矩阵或者相关矩阵的特征值唯一时,主成分一般是固定的;而因子分析中因子不是固定的,可以旋转得到不同的因子。 6. 因子数量与主成分的数量:在因子分析中,因子个数需要分析者指定(SPSS根据一定的条件自动设定,只要是特征值大于1的因子主可进入分析),指定的因子数量不同而结果也不同;在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等)。 7. 功能:和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势;而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。当然,这种情况也可以使用因子得分做到,所以这种区分不是绝对的。