
6.1 节的练习
为下面的表达式构造 DAG
((x+y)-((x+y)*(x-y)))+((x+y)*(x-y))
解答
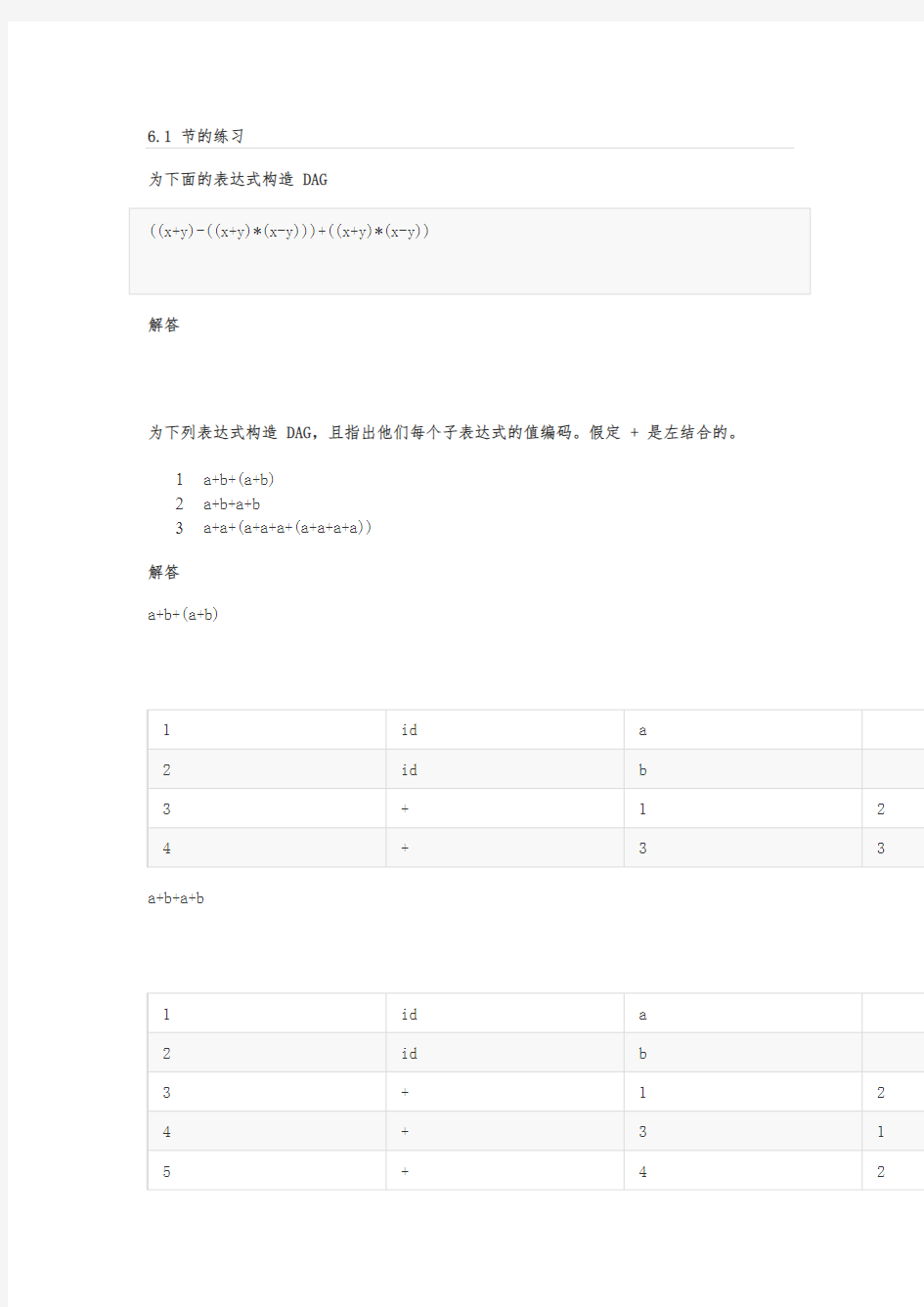
为下列表达式构造 DAG,且指出他们每个子表达式的值编码。假定 + 是左结合的。
1a+b+(a+b)
2a+b+a+b
3a+a+(a+a+a+(a+a+a+a))
解答
a+b+(a+b)
1 id a
2 id b
3 + 1 2
4 + 3 3 a+b+a+b
1 id a
2 id b
3 + 1 2
4 + 3 1
5 + 4 2
a+a+(a+a+a+(a+a+a+a))
1 id a
2 + 1 1
3 + 2 1
4 + 3 1
5 + 3 4
6 + 2 5
6.2 节的练习
6.2.1
将算数表达式 a+-(b+c) 翻译成
4抽象语法树
5四元式序列
6三元式序列
7间接三元式序列
解答
抽象语法树
四元式序列
op arg1 arg2
0 + b c t1
1 minus t1 t2
2 + a t2 t3三元式序列
op arg1
0 + b c
1 minus (0)
2 + a (1) 间接三元式序列
op arg1
0 + b c
1 minus (0)
2 + a (1)
instruction
0 (0)
1 (1)
2 (2)
参考
?间接三元式更详细的讲解
6.2.2
对下列赋值语句重复练习 6.2.1
8 a = b[i] + c[j]
9a[i] = b*c - b*d
10x = f(y+1) + 2
11x = *p + &y
解答
a = b[i] + c[j]
四元式
0) =[] b i t1
1) =[] c j t2
2) + t1 t2 t3
3) = t3 a
三元式
0) =[] b i
1) =[] c j
2) + (0) (1)
3) = a (2)
间接三元式
0) =[] b i
1) =[] c j
2) + (0) (1)
3) = a (2)
0)
1)
2)
3)
a[i] = b*c - b*d
四元式
0) * b c t1
1) * b d t2
2) - t1 t2 t3
4) = t3 t4
三元式
0) * b c
1) * b d
2) - (0) (1)
3) []= a i
4) = (3) (2)
间接三元式
0) * b c 1) * b d 2) - (0) (1) 3) []= a i 4) = (3) (2) 0) 1) 2) 3) 4)
x = f(y+1) + 2
四元式
0) + y 1 t1
1) param t1
2) call f 1 t2
3) + t2 2 t3
4) = t3 x
三元式
0) + y 1
1) param (0)
3) + (2) 2
4) = x (3)
间接三元式
0) + y 1
1) param (0)
2) call f 1
3) + (2) 2
4) = x (3)
0)
1)
2)
3)
4)
参考
数组元素的取值和赋值
6.2.3 !
说明如何对一个三地址代码序列进行转换,使得每个被定值的变量都有唯一的变量名。
6.3 节的练习
6.3.1
确定下列声明序列中各个标识符的类型和相对地址。
float x;
record {float x; float y;} p;
record {int tag; float x; float y;} q;
解答
SDT
S -> {top = new Evn(); offset = 0;}
D
D -> T id; {top.put(id.lexeme, T.type, offset);
offset += T.width}
D1
D -> ε
T -> int {T.type = interget; T.width = 4;}
T -> float {T.type = float; T.width = 8;}
T -> record '{'
{Evn.push(top), top = new Evn();
Stack.push(offset), offset = 0;}
D '}' {T.type = record(top); T.width = offset; top = Evn.top(); offset = Stack.pop();}
标识符类型和相对地址
line id type offset Evn
1) x float 0 1
2) x float 0 2
2) y float 8 2
2) p record() 8 1
3) tag int 0 3
3) x float 4 3
3) y float 12 3
3) q record() 24 1
6.3.2 !
将图 6-18 对字段名的处理方法扩展到类和单继承的层次结构。
12给出类 Evn 的一个实现。该实现支持符号表链,使得子类可以重定义一个字段名,也可以直接引用某个超类中的字段名。
13给出一个翻译方案,该方案能够为类中的字段分配连续的数据区域,这些字段中包含继承而来的域。继承而来的字段必须保持在对超类进行存储分配时获得的相对地址。
6.4 节的练习
6.4.1
向图 6-19 的翻译方案中加入对应于下列产生式的规则:
14 E -> E1 * E2
15 E -> +E1
解答
产生式语义规则
E -> E1 * E2 { E.addr = new Temp();
E.code = E1.code || E2.code ||
gen(E.addr '=' E1.addr '*' E2.addr); }
| +E1 { E.addr = E1.addr;
E.code = E1.code; }
6.4.2
使用图 6-20 的增量式翻译方案重复练习 6.4.1
解答
产生式语义规则
E -> E1 * E2 { E.addr = new Temp();
gen(E.addr '=' E1.addr '*' E2.addr; } | +E1 { E.addr = E1.addr; }
6.4.3
使用图 6-22 的翻译方案来翻译下列赋值语句:
16x = a[i] + b[j]
17x = a[i][j] + b[i][j]
18! x = a[b[i][j]][c[k]]
解答
x = a[i] + b[j]
语法分析树:
三地址代码
t_1 = i * awidth
t_2 = a[t_1]
t_3 = j * bwidth
t_4 = b[t_3]
t_5 = t_2 + t_4
x = t_5
x = a[i][j] + b[i][j]
语法分析树:
三地址代码:
t_1 = i * ai_width
t_2 = j * aj_width
t_3 = t_1 + t_2
t_4 = a[t_3]
t_5 = i * bi_width
t_6 = j * bj_width
t_7 = t_5 + t_6
t_8 = b[t_7]
t_9 = t_4 + t_8
x = t_9
! x = a[b[i][j]][c[k]]
6.4.4 !
修改图 6-22 的翻译方案,使之适合 Fortran 风格的数据引用,也就是说 n 维数组的引用为 id[E1, E2, …, En]
解答
仅需修改 L 产生式(同图 6-22 一样,未考虑消除左递归)
L -> id[A] { L.addr = A.addr;
global.array = top.get(id.lexeme); }
A -> E { A.array = global.array;
A.type = A.array.type.elem;
A.addr = new Temp();
gen(A.addr '=' E.addr '*' A.type.width; }
A -> A1,E { A.array = A1.array;
A.type = A1.type.elem;
t = new Temp();
A.addr = new Temp();
gen(t '=' E.addr '*' A.type.length);
gen(A.addr '=' A1.addr '+' t); }
注意
令 a 表示一个 i*j 的数组,单个元素宽度为 w
a.type = array(i, array(j, w))
a.type.length = i
a.type.elem = array(j, w)
6.4.5
将公式 6.7 推广到多维数据上,并指出哪些值可以被存放到符号表中并用来计算偏移量。
考虑下列情况:
19一个二维数组 A,按行存放。第一维的下标从 l_1 到 h_1,第二维的下标从 l_2 到h_2。单个数组元素的宽度为 w。
20其他条件和 1 相同,但是采用按列存放方式。
21!一个 k 维数组 A,按行存放,元素宽度为 w,第 j 维的下标从 l_j 到 h_j。
22!其他条件和 3 相同,但是采用按列存放方式。
解答
令 n_i 为第 i 维数组的元素个数,计算公式:n_i = h_i - l_i + 1
3. A[i_1]]…[i_k] = base +
(
(i_1 - l_1) * n_2 * … * n_k +
… +
(i_k-1 - l_k-1) * n_k +
(i_k - l_k)
) * w
4. A[i_1]]…[i_k] = base +
(
(i_1 - l_1) +
(i_2 - l_2) * n_1 +
… +
(i_k - l_k) * n_k-1 * n_k-2 * … * n_1
) * w
6.4.6
一个按行存放的整数数组 A[i, j] 的下标 i 的范围为 1~10,下标 j 的范围为 1~20。每个整数占 4 个字节。假设数组 A 从 0 字节开始存放,请给出下列元素的位置:
23A[4, 5]
24A[10, 8]
25A[3, 17]
解答
计算公式:((i-1) * 20 + (j-1)) * 4
26(3 * 20 + 4) * 4 = 256
27(9 * 20 + 7) * 4 = 748
28(2 * 20 + 16) * 4 = 224
6.4.7
假定 A 是按列存放的,重复练习 6.4.6
解答
计算公式:((j-1) * 10 + (j-1)) * 4
29(4 * 10 + 3) * 4 = 172
30(7 * 10 + 9) * 4 = 316
31(16 * 10 + 2) * 4 = 648
6.4.8
一个按行存放的实数型数组 A[i, j, k] 的下标 i 的范围为 1~4,下标 j 的范围为 0~4,且下标 k 的范围为 5~10。每个实数占 8 个字节。假设数组 A 从 0 字节开始存放,计算下列元素的位置:
32A[3, 4, 5]
33A[1, 2, 7]
34A[4, 3, 9]
解答
计算公式:((i-1) * 5 * 6 + j * 6 + (k-5)) * 8
35((3-1) * 5 * 6 + 4 * 6 + (5-5)) * 8 = 672
36((1-1) * 5 * 6 + 2 * 6 + (7-5)) * 8 = 112
37((4-1) * 5 * 6 + 3 * 6 + (9-5)) * 8 = 896
6.4.9
假定 A 是按列存放的,重复练习 6.4.8
解答
计算公式:((i-1) + j * 4 + (k-5) * 5 * 4) * 8
38((3-1) + 4 * 4 + (5-5) * 5 * 4) * 8 = 144
39((1-1) + 2 * 4 + (7-5) * 5 * 4) * 8 = 384
40((4-1) + 3 * 4 + (9-5) * 5 * 4) * 8 = 760
6.5 节的练习
6.5.1
假定图 6-26 中的函数 widen 可以处理图 6-25a 的层次结构中的所有类型,翻译下列表达式。假定 c 和 d 是字符类型,s 和 t 是短整型, i 和 j 为整型, x 是浮点型。
41x = s + c
42i = s + c
43x = (s + c) * (t + d)
解答
x = s + c
t1 = (int) s
t2 = (int) c
t3 = t1 + t2
x = (float) t3
i = s + c
t1 = (int) s
t2 = (int) c
i = t1 + t2
x = (s + c) * (t + d)
t1 = (int) s
t2 = (int) c
t3 = t1 + t2
t4 = (int) t
t5 = (int) d
t6 = t4 + t5
t7 = t3 + t6
x = (float) t7
6.5.2
像 Ada 中那样,我们假设每个表达式必须具有唯一的类型,但是我们根据一个子表达式本身只能推导出一个可能类型的集合。也就是说,将函数 E1 应用于参数 E2(文法产生式为 E -> E1(E2))有如下规则:
E.type = {t | 对 E2.type 中的某个 s, s -> t 在 E1.type 中}
描述一个可以确定每个字表达式的唯一类型的 SDD。它首先使用属性 type,按照自底向上的方式综合得到一个可能类型的集合。在确定了整个表达式的唯一类型之后,自顶向下地确定属性 unique 的值,整个属性表示各子表达式的类型。
6.6 节的练习
6.6.1
在图 6-36 的语法制导定义中添加处理下列控制流构造的规则:
44一个 repeat 语句:repeat S while B
45!一个 for 循环语句:for (S1; B; S2) S3
解答
Production Syntax Rule
S -> repeat S1 while B S1.next = newlabel()
B.true = newlabel()
B.false = S.next
S.code = label(B.true) || S1.code
|| label(S1.next) || B.code
S -> for (S1; B; S2) S3 S1.next = newlabel()
B.true = newlabel()
B.false = S.next
S2.next = S1.next
S3.next = newlabel()
S.code = S1.code
|| lable(S1.next) || B.code
|| lable(B.true) || S3.code
|| label(S3.next) || S2.code
|| gen('goto', S1.next)
6.6.2
现代计算机试图在同一个时刻执行多条指令,其中包括各种分支指令。因此,当计算机投机性地预先执行某个分支,但实际控制流却进入另一个分支时,付出的代价是很大的。因此我们希望尽可能地减少分支数量。请注意,在图 6-35c 中 while 循环语句的实现中,每个迭代有两个分支:一个是从条件 B 进入到循环体中,另一个分支跳转回 B 的代码。基于尽量减少分支的考虑,我们通常更倾向于将 while(B) S 当作 if(B) {repeat S until !(B)} 来实现。给出这种翻译方法的代码布局,并修改图 6-36 中 while 循环语句的规则。
解答
Production Syntax Rule
S -> if(B) { B.true = newlabel()
repeat S1 B.false = S.next
until !(B) S1.next = newlabel()
} S.code = B.code
|| label(B.true) || S1.code
|| label(S1.next) || B.code
6.6.3!
假设 C 中存在一个异或运算。按照图 6-37 的风格写出这个运算符的代码生成规则。解答
B1 ^ B2 等价于 !B1 && B2 || B1 && !B2 (运算符优先级 ! > && > ||) Production Syntax Rule
B -> B1 ^ B2 B1.true = newlabel()
B1.false = newlabel()
B2.true = B.true
B2.false = B1.true
b3 = newboolean()
b3.code = B1.code
b3.true = newlabel()
b3.false = B.false
b4 = newboolean()
b4.code = B2.code
b4.true = B.false
b4.false = B.true
S.code = B1.code
|| label(B1.false) || B2.code
|| label(B1.true) || b3.code
|| label(b3.true) || b4.code
6.6.4
使用 6.6.5 节中介绍的避免 goto 语句的翻译方案,翻译下列表达式:
46if (a==b && c==d || e==f) x == 1
47if (a==b || c==d || e==f) x == 1
48if (a==b || c==d && e==f) x == 1
解答
if (a==b && c==d || e==f) x == 1
ifFalse a==b goto L3
if c==d goto L2
L3: ifFalse e==f goto L1
L2: x == 1
L1:
if (a==b || c==d || e==f) x == 1
if a==b goto L2
if c==d goto L2
ifFalse e==f goto L1
L2: x==1
L1:
if (a==b || c==d && e==f) x == 1
if a==b goto L2
ifFalse c==d goto L1
ifFalse e==f goto L1
L2: x==1
L1:
6.6.5
基于图 6-36 和图 6-37 中给出的语法制导定义,给出一个翻译方案。
6.6.6
使用类似于图 6-39 和图 6-40 中的规则,修改图 6-36 和图 6-37 的语义规则,使之允许控制流穿越。
解答
仅补充完毕书中未解答部分
Production Syntax Rule
S -> if(B) S1 else S2 B.true = fall
B.false = newlabel()
S1.next = S.next
S2.next = S.next
S.code = B.code
|| S1.code
|| gen('goto' S1.next)
|| label(B.false) || S2.code
S -> while(B) S1 begin = newlabel()
B.true = fall
B.false = S.next
S1.next = begin
S.code = label(begin) || B.code
|| S1.code
|| gen('goto' begin)
S -> S1 S2 S1.next = fall
S2.next = S.next
S.code = S1.code || S2.code
B -> B1 && B2 B1.true = fall
B1.false = if B.false == fall
then newlabel()
else B.false
B2.true = B.true
B2.false = B.false
B.code = if B.false == fall
then B1.code || B2.code || label(B1.false) else B1.code || B2.code
6.6.7!
第六章 线性空间 1.设,N M ?证明:,M N M M N N ==I U 。 证 任取,M ∈α由,N M ?得,N ∈α所以,N M I ∈α即证M N M ∈I 。又因 ,M N M ?I 故M N M =I 。再证第二式,任取M ∈α或,N ∈α但,N M ?因此无论 哪 一种情形,都有,N ∈α此即。但,N M N Y ?所以M N N =U 。 2.证明)()()(L M N M L N M I Y I Y I =,)()()(L M N M L N M Y I Y I Y =。 证 ),(L N M x Y I ∈?则.L N x M x Y ∈∈且在后一情形,于是.L M x N M x I I ∈∈或所以)()(L M N M x I Y I ∈,由此得)()()(L M N M L N M I Y I Y I =。反之,若 )()(L M N M x I Y I ∈,则.L M x N M x I I ∈∈或 在前一情形,,,N x M x ∈∈因此 .L N x Y ∈故得),(L N M x Y I ∈在后一情形,因而,,L x M x ∈∈x N L ∈U ,得 ),(L N M x Y I ∈故),()()(L N M L M N M Y I I Y I ? 于是)()()(L M N M L N M I Y I Y I =。 若x M N L M N L ∈∈∈U I I (),则x ,x 。 在前一情形X x M N ∈U , X M L ∈U 且,x M N ∈U 因而()I U (M L ) 。 ,,N L x M N X M L M N M M N M N ∈∈∈∈∈?U U U I U U I U U U U I U I U 在后一情形,x ,x 因而且,即X (M N )(M L )所以 ()(M L )(N L )故 (L )=()(M L )即证。 3、检验以下集合对于所指的线性运算是否构成实数域上的线性空间: 1) 次数等于n (n ≥1)的实系数多项式的全体,对于多项式的加法和数量乘法; 2) 设A 是一个n ×n 实数矩阵,A 的实系数多项式f (A )的全体,对于矩阵的加法和数量 乘法; 3) 全体实对称(反对称,上三角)矩阵,对于矩阵的加法和数量乘法; 4) 平面上不平行于某一向量所成的集合,对于向量的加法和数量乘法; 5) 全体实数的二元数列,对于下面定义的运算: 2121211211 12 b a b a a b b a a k k b a ⊕+=+++-1111(a ,)((,) ()k 。(a ,)=(ka ,kb +
P532.8 构建一个语法制导翻译模式,将算术表达式从后缀表示翻译成中缀表示。给出输入95-2*和952*-的注释分析树。(仅供参考一定要保证转换后的中缀表达式与原后缀表达式的优先级相同) 1 后缀算术表达式的文法如下: expr →expr expr + | expr expr – | expr expr * | expr expr / |digit digit →0 | 1 | 2 | 3 | … | 9 2 将后缀表达式翻译成中缀表达式的语法制导定义(文法+语义规则)
4 95-2*和952*-的翻译成后缀形式的语义动作与注释分析树。 expr expr expr * print(‘(‘) print(‘)‘) expr expr - 5 9 digit 2 print(‘-’) ‘9’) print(‘5’) print(‘2’) print(‘*’) 95-2*的深度优先遍历语义动作 expr expr expr - print(‘(‘) print(‘)‘) expr expr digit 2 digit 5 digit 9 print(‘*’) ‘5’) print(‘2’) print(‘9’) print(‘-’) 952*-的深度优先遍历语义动作
expr.t=(9-5)*2 expr=(9-5) expr.t=2 * expr.t=9 expr.t=5 - digit.t=5 5 digit.t=9 9 digit.t=2 2 输入为95-2*的注释分析树 expr.t=(9-5*2) expr.t=5*2 expr.t=9 - expr.t=5 expr.t=2 * digit.t=2 2 digit.t=5 5 digit.t=9 9 输入为952*-的注释分析树
某个厂商的一项经济活动对其他厂商产生的有利影响,我们把这种行为称作()选择一项: A. 生产的外部不经济 B. 生产的外部经济 C. 消费的外部不经济 D. 消费的外部经济 反馈 你的回答正确 正确答案是:生产的外部经济 题目2 正确 获得1.00分中的1.00分 标记题目 题干 某人的吸烟行为属() 选择一项: A. 生产的外部经济 B. 生产的外部不经济 C. 消费的外部不经济 D. 消费的外部经济 反馈
你的回答正确 正确答案是:消费的外部不经济 题目3 正确 获得1.00分中的1.00分 标记题目 题干 如果上游工厂污染了下游居民的饮水,按科斯定理,()问题就可妥善解决选择一项: A. 只要产权明确,且交易成本为零 B. 只要产权明确,不管交易成本有多大 C. 不论产权是否明确,交易成本是否为零 D. 不管产权是否明确,只要交易成本为零 反馈 你的回答正确 正确答案是:只要产权明确,不管交易成本有多大 题目4 正确 获得1.00分中的1.00分 标记题目
题干 公共产品的产权是属于社会,而不属于任何个人是指它的()选择一项: A. 竞争性 B. 排他性 C. 非竞争性 D. 非排他性 反馈 你的回答正确 正确答案是:非排他性 题目5 正确 获得1.00分中的1.00分 标记题目 题干 当人们无偿地享有了额外收益时,称作() 选择一项: A. 外部经济 B. 外部不经济效果 C. 交易成本
D. 公共产品 反馈 你的回答正确 正确答案是:外部经济 题目6 正确 获得1.00分中的1.00分 标记题目 题干 只要交易成本为零,财产的法定所有权的分配就不影响经济运行的效率,这种观点称为()选择一项: A. 科斯定理 B. 看不见的手 C. 逆向选择 D. 有效市场理论 反馈 你的回答正确 正确答案是:科斯定理 题目7 正确 获得1.00分中的1.00分
第六章作业 一、选择题 1.若不考虑结点的数据信息的组合情况,具有3个结点的树共有种()形态,而二叉树共有( )种形态。 A.2 B.3 C.4 D.5 2.对任何一棵二叉树,若n0,n1,n2分别是度为0,1,2的结点的个数,则n0= ( ) A.n1+1 B.n1+n2 C.n2+1 D.2n1+1 3.已知某非空二叉树采用顺序存储结构,树中结点的数据信息依次存放在一个一维数组中,即 ABC□DFE□□G□□H□□,该二叉树的中序遍历序列为( ) A.G,D,B,A,F,H,C,E B.G,B,D,A,F,H,C,E C.B,D,G,A,F,H,C,E D.B,G,D,A,F,H,C,E 4、具有65个结点的完全二叉树的高度为()。(根的层次号为1) A.8 B.7 C.6 D.5 5、在有N个叶子结点的哈夫曼树中,其结点总数为()。 A 不确定 B 2N C 2N+1 D 2N-1 6、以二叉链表作为二叉树存储结构,在有N个结点的二叉链表中,值为非空的链域的个数为()。 A N-1 B 2N-1 C N+1 D 2N+1 7、树的后根遍历序列等同于该树对应的二叉树的( ). A. 先序序列 B. 中序序列 C. 后序序列 8、已知一棵完全二叉树的第6层(设根为第1层)有8个叶结点,则完全二叉树的结点个数最多是() A.39 B.52 C.111 D.119 9、在一棵度为4的树T中,若有20个度为4的结点,10个度为3的结点,1个度为2的结点,10个度为1的结点,则树T的叶节点个数是() A.41 B.82 C.113 D.122 二、填空题。 1、对于一个具有N个结点的二叉树,当它为一颗_____ 二叉树时,具有最小高度。 2、对于一颗具有N个结点的二叉树,当进行链接存储时,其二叉链表中的指针域的总数为_____ 个,其中_____个用于链接孩子结点,_____ 个空闲着。 3、一颗深度为K的满二叉树的结点总数为_____ ,一颗深度为K的完全二叉树的结点总数的最小值为_____ ,最大值为_____ 。 4、已知一棵二叉树的前序序列为ABDFCE,中序序列为DFBACE,后序序列为 三、应用题。 1、已知一棵树二叉如下,请分别写出按前序、中序、后序遍历时得到的结点序列,并将该二叉树还原成森林。 A B C D E F G H
第六章存货决策 一、单项选择题 1.下列各项中,与经济订货量无关的是(D )。 A.每日消耗量B.每日供应量 C.储存变动成本D.订货提前期 2.某公司使用材料A,一次订货成本为2000元,每单位采购成本为50元,经济订货批量为2000个,单位资本成本为单位采购成本的10%,全年用量为8000个。该材料单位储存成本中的付现成本是(B )元。 A.8 B.3 C.4 D.2 3.某商品的再订购点为680件,安全存量为200件,采购间隔日数为12天,假设每年有300个工作日,则年度耗用量为( C )件。 A.11000 B.10000 C.12000 D.13000 4.(D )不是存货的形式。 A.原材料B.在产品 C.产成品D.应收账款 5.在存货决策中,( B )可以不考虑。 A.订货成本 B.固定订货成本 C.变动订货成本 D.变动储存成本 6.下列各项中,不属于订货成本的是( C )。 A.采购部门的折旧费 B.检验费 C.按存货价值计算的保险费 D.差旅费 7.由于存货数量不能及时满足生产和销售的需要而给企业带来的损失称为 ( B )。 A.订货成本 B.缺货成本 C.采购成本 D.储存成本 8.在储存成本中,凡总额大小取决于存货数量的多少及储存时间长短的成 本,称为( C )。
A.固定储存成本 B.无关成本 C.变动储存成本 D.资本成本 二、多项选择题 1.当采购批量增加时,( AD )。 A.变动储存成本增加 B.变动储存成本减少 C.变动订货成本增加 D.变动订货成本减少 2.按存货经济订购批量模型,当订货批量为经济批量时,( ABCD )。 A.变动储存成本等于变动订货成本 B.变动储存成本等于最低相关总成本的一半 C.变动订货成本等于最低相关总成本的一半 D.存货相关总成本达到最低 3.计算经济订购批量时,不需用的项目是( BD )。 A.全年需要量 B.固定储存成本 C.每次订货成本 D.安全存量 4.在存货经济订购批量基本模型假设前提下确定经济订购批量,下列表述中正确的有( ABCD )。 A.随每次订购批量的变动,相关订货成本和相关储存成本两者的变动方向相反 B.相关储存成本的高低与每次订购批量成正比 C.相关订货成本的高低与每次订购批量成反比 D.年相关储存成本与年相关订货成本相等时的订购批量,即为经济订购批量 5.存货过多,会导致( ABCD )。 A.占用大量的流动资金 B.增加仓储设施 C.增加储存成本 D.自然损耗额增加 6.在有数量折扣、不允许缺货的情况下,属于订购批量决策相关成本的是( ACD )。 A.订货成本 B.缺货成本 C.采购成本 D.储存成本
1) What is the difference between a compiler and an interpreter? A compiler is a program that can read a program in one language - the source language - and translate it into an equivalent program in another language – the target language and report any errors in the source program that it detects during the translation process. Interpreter directly executes the operations specified in the source program on inputs supplied by the user. 2) What are the advantages of: (a) a compiler over an interpreter a. The machine-language target program produced by a compiler is usually much faster than an interpreter at mapping inputs to outputs. (b) an interpreter over a compiler? b. An interpreter can usually give better error diagnostics than a compiler, because it executes the source program statement by statement. 3) What advantages are there to a language-processing system in which the compiler produces assembly language rather than machine language? The compiler may produce an assembly-language program as its output, because assembly language is easier to produce as output and is easier to debug. 4.2.3 Design grammars for the following languages: a) The set of all strings of 0s and 1s such that every 0 is immediately followed by at least 1. S -> SS | 1 | 01 | 4.3.1 The following is a grammar for the regular expressions over symbols a and b only, using + in place of | for unions, to avoid conflict with the use of vertical bar as meta-symbol in grammars: rexpr -> rexpr + rterm | rterm rterm -> rterm rfactor | rfactor rfactor -> rfactor * | rprimary rprimary -> a | b a) Left factor this grammar. rexpr -> rexpr + rterm | rterm rterm -> rterm rfactor | rfactor rfactor -> rfactor * | rprimary rprimary -> a | b
图 1. 填空题 ⑴ 设无向图G中顶点数为n,则图G至少有()条边,至多有()条边;若G为有向图,则至少有()条边,至多有()条边。 【解答】0,n(n-1)/2,0,n(n-1) 【分析】图的顶点集合是有穷非空的,而边集可以是空集;边数达到最多的图称为完全图,在完全图中,任意两个顶点之间都存在边。 ⑵ 任何连通图的连通分量只有一个,即是()。 【解答】其自身 ⑶ 图的存储结构主要有两种,分别是()和()。 【解答】邻接矩阵,邻接表 【分析】这是最常用的两种存储结构,此外,还有十字链表、邻接多重表、边集数组等。 ⑷ 已知无向图G的顶点数为n,边数为e,其邻接表表示的空间复杂度为()。 【解答】O(n+e) 【分析】在无向图的邻接表中,顶点表有n个结点,边表有2e个结点,共有n+2e个结点,其空间复杂度为O(n+2e)=O(n+e)。 ⑸ 已知一个有向图的邻接矩阵表示,计算第j个顶点的入度的方法是()。 【解答】求第j列的所有元素之和 ⑹ 有向图G用邻接矩阵A[n][n]存储,其第i行的所有元素之和等于顶点i的()。 【解答】出度
⑺ 图的深度优先遍历类似于树的()遍历,它所用到的数据结构是();图的广度优先遍历类似于树的()遍历,它所用到的数据结构是()。 【解答】前序,栈,层序,队列 ⑻ 对于含有n个顶点e条边的连通图,利用Prim算法求最小生成树的时间复杂度为(),利用Kruskal 算法求最小生成树的时间复杂度为()。 【解答】O(n2),O(elog2e) 【分析】Prim算法采用邻接矩阵做存储结构,适合于求稠密图的最小生成树;Kruskal算法采用边集数组做存储结构,适合于求稀疏图的最小生成树。 ⑼ 如果一个有向图不存在(),则该图的全部顶点可以排列成一个拓扑序列。 【解答】回路 ⑽ 在一个有向图中,若存在弧、、,则在其拓扑序列中,顶点vi, vj, vk的相对次序为()。 【解答】vi, vj, vk 【分析】对由顶点vi, vj, vk组成的图进行拓扑排序。 2. 选择题 ⑴ 在一个无向图中,所有顶点的度数之和等于所有边数的()倍。 A 1/2 B 1 C 2 D 4 【解答】C 【分析】设无向图中含有n个顶点e条边,则。
第四章 习题4.2.1:考虑上下文无关文法: S->S S +|S S *|a 以及串aa + a* (1)给出这个串的一个最左推导 S -> S S * -> S S + S * -> a S + S * -> a a + S * -> aa + a* (3)给出这个串的一棵语法分析树 习题4.3.1:下面是一个只包含符号a和b的正则表达式的文法。它使用+替代表示并运算的符号|,以避免和文法中作为元符号使用的竖线相混淆: rexpr→ rexpr + rterm | rterm rterm→rterm rfactor | rfactor rfactor→ rfactor * | rprimary rprimary→a | b 1)对这个文法提取公因子 2)提取公因子的变换使这个文法适用于自顶向下的语法分析技术吗? 3)提取公因子之后,原文法中消除左递归 4)得到的文法适用于自顶向下的语法分析吗? 解 1)提取左公因子之后的文法变为 rexpr→ rexpr + rterm | rterm rterm→rterm rfactor | rfactor rfactor→ rfactor * | rprimary rprimary→a | b 2)不可以,文法中存在左递归,而自顶向下技术不适合左递归文法 3)消除左递归后的文法
rexpr -> rterm rexpr’ rexpr’-> + rterm rexpr’|ε rterm-> rfactor rterm’ rterm’-> rfactor rterm’|ε rfactor-> rprimay rfactor’ rfactor’-> *rfactor’|ε rprimary-> a | b 4)该文法无左递归,适合于自顶向下的语法分析 习题4.4.1:为下面的每一个文法设计一个预测分析器,并给出预测分析表。可能要先对文法进行提取左公因子或消除左递归 (3)S->S(S)S|ε (5)S->(L)|a L->L,S|S 解 (3) ①消除该文法的左递归后得到文法 S->S’ S’->(S)SS’|ε ②计算FIRST和FOLLOW集合 FIRST(S)={(,ε} FOLLOW(S)={),$} FIRST(S’)={(,ε} FOLLOW(S’)={),$} ③ (5) ①消除该文法的左递归得到文法 S->(L)|a
一、选择题 1.如果要求分析结果的相对误差在 0.1%以下,使用万分之一分析天平称取试 样时,至少应称取( )A. 0.1g B. 0.2g C. 0.05g D. 0.5g 解:选B 。根据下列公式可求得最少称样量: 相对误差×100% 试样质量 绝对误差 万分之一分析天平称量的绝对误差最大范围为±0.0002g ,为了使测量时的相对 误差在±0.1%以下,其称样量应大于0.2g 。 2.从精密度好就可断定分析结果准确度高的前提是( )A. 随机误差小 B. 系统误差小 C. 平均偏差小 D. 相对偏差小解:选B 。精密度是保证准确度的先决条件,精密度差说明测定结果的重现性 差,所得结果不可靠;但是精密度高不一定准确度也高,只有在消除了系统 误差之后,精密度越高,准确度才越高。 3.下列有关随机误差的论述不正确的是( )A.随机误差具有可测性 B.随机误差在分析中是不可避免的 C.随机误差具有单向性 D.随机误差是由一些不确定偶然因素造成的 解:选C 。分析测定过程中不可避免地造成随机误差。这种误差可大可小,可 正可负,无法测量, 不具有单向性。但从多次重复测定值来看,在消除系统 误差后,随机误差符合高斯正态分布规律,特点为:单峰性、有限性、对称 性、抵偿性。 4.下列各数中,有效数字位数为四位的是( )A. 0.0030 B. pH=3.24 C. 96.19% D. 4000 解:选C 。各个选项的有效数字位数为:A 两位 B 两位 C 四位 D 不确定 5.将置于普通干燥器中保存的Na 2B 4O 7.10H 2O 作为基准物质用于标定盐酸的浓 度,则盐酸的浓度将( ) A.偏高 B.偏低 C.无影响 D.不能确定解:选B 。普通干燥器中保存的Na 2B 4O 7·10H 2O 会失去结晶水,以失水的 Na 2B 4O 7·10H 2O 标定HCl 时,实际消耗V (HCl )偏高,故c (HCl )偏低。
第六章作业参考答案 1.在DSS数字签名标准中,取p=83=2×41+1,q=41,h=2,于是g≡22≡4 mod 83,若取x =57,则y≡g x≡457=77 mod 83。在对消息M=56签名时选择k=23,计算签名并进行验证。解:这里忽略对消息M求杂凑值的处理 计算r=(g k mod p) mod q=(423 mod 83) mod 41=51 mod 41=10 k-1mod q=23-1 mod 41=25 s=k-1(M+xr) mod q=25(56+57*10) mod 41=29 所以签名为(r,s)=(10,29) 接收者对签名(r',s')=(10,29)做如下验证: 计算w=(s')-1 mod q=29-1 mod 41=17 u1=[M'w] mod q=56*17 mod 41=9 u2=r'w mod q=10×17 mod 41=6 v=(g u1y u2 mod p) mod q=(49×776 mod 83) mod 41=10 所以有v=r',即验证通过。 2.在DSA签字算法中,参数k泄漏会产生什么后果? 解:如果攻击者获得了一个有效的签名(r,s),并且知道了签名中采用的参数k,那么由于在签名方程s=k-1(M+xr) mod q中只有一个未知数,即签名者的秘密钥x,因而攻击者可以求得秘密钥x=r-1(sk-M) mod q,即参数k的泄漏导致签名秘密钥的泄漏。 4.2. 试述DSA数字签名算法,包括密钥产生、签名算法和验证算法,并给出验证过程正确性证明 参考ppt 4.4. 已知schnorr签名的密钥产生和签名算法,试给出验证方程,并证明其正确性。 参考ppt 5.1.试证DSA签名中两次使用相同的会话密钥k,是不安全的 分别给出对m1和对m2的签名表达式,然后将两个关于s的方程联立,这时如果会话密钥k 相同则可直接解出k和秘密钥x,证明过程可根据此思路进行
第四章部分习题解答 Aho:《编译原理技术与工具》书中习题 (Aho)4.1 考虑文法 S →( L ) | a L →L, S | S a)列出终结符、非终结符和开始符号 解: 终结符:(、)、a、, 非终结符:S、L 开始符号:S b)给出下列句子的语法树 i)(a, a) ii)(a, (a, a)) iii)(a, ((a, a), (a, a))) c)构造b)中句子的最左推导 i)S?(L)?(L, S) ?(S, S) ?(a, S) ?(a, a) ii)S?(L)?(L, S) ?(S, S) ?(a, S) ?(a, (L)) ?(a, (L, S)) ?(a, (S, S)) ?(a, (a, S) ?(a, (a, a)) iii)S?(L)?(L, S) ?(S, S) ?(a, S) ?(a, (L)) ?(a, (L, S)) ?(a, (S, S)) ?(a, ((L), S)) ?(a, ((L, S), S)) ?(a, ((S, S), S)) ?(a, ((a, S), S)) ?(a, ((a, a), S)) ?(a, ((a, a), (L))) ?(a, ((a, a), (L, S))) ?(a, ((a, a), (S, S))) ?(a, ((a, a), (a, S))) ?(a, ((a, a), (a, a))) d)构造b)中句子的最右推导
i)S?(L)?(L, S) ?(L, a) ?(S, a) ?(a, a) ii)S?(L)?(L, S) ? (L, (L)) ?(L, (L, S)) ?(L, (L, a)) ?(L, (S, a)) ?(L, (a, a)) ?(S, (a, a)) ?(a, (a, a)) iii)S?(L)?(L, S) ?(L, (L)) ?(L, (L, S)) ?(L, (L, (L))) ?(L, (L, (L, S))) ?(L, (L, (L, a))) ?(L, (L, (S, a))) ?(L, (L, (a, a))) ?(L, (S, (a, a))) ?(L, ((L), (a, a))) ?(L, ((L, S), (a, a))) ?(L, ((L, a), (a, a))) ?(L, ((S, a), (a, a))) ?(L, ((a, a), (S, S))) ?(S, ((a, a), (a, a))) ?(a, ((a, a), (a, a))) e)该文法产生的语言是什么 解:设该文法产生语言(符号串集合)L,则 L = { (A1, A2, …, A n) | n是任意正整数,A i=a,或A i∈L,i是1~n之间的整数} (Aho)4.2考虑文法 S→aSbS | bSaS | ε a)为句子构造两个不同的最左推导,以证明它是二义性的 S?aSbS?abS?abaSbS?ababS?abab S?aSbS?abSaSbS?abaSbS?ababS?abab b)构造abab对应的最右推导 S?aSbS?aSbaSbS?aSbaSb?aSbab?abab S?aSbS?aSb?abSaSb?abSab?abab c)构造abab对应语法树 d)该文法产生什么样的语言? 解:生成的语言:a、b个数相等的a、b串的集合 (Aho)4.3 考虑文法 bexpr→bexpr or bterm | bterm bterm→bterm and bfactor | bfactor bfactor→not bfactor | ( bexpr ) | true | false a)试为句子not ( true or false)构造分析树 解:
参考答案[A型题] [X型题] 38.B C D 39.A B D 40.C E 41.A B C E 42.A C D 43.A D E 44.B C 45.C D 46.A D E 47.C E 48.C D 49.A B D E 50.B E 51.A B D E [B型题] 52.A 53.D 54.C 55.E 56.E 57.C 58.A 59.D 60.B 61.B 62.C 63.B 64.B 65.A 66.E 67.B 68.C 69.E 70.B 71.C 72.A 73.C 74.A 75.B 76.C 77.A [名词解释] 78.是指在致热源作用下使体温调节中枢的调定点上移而引起的调节性体温 升高。 79.人体在某些生理性情况下,如月经前期,妊娠期或剧烈运动时,体温也可上升高于0.5℃,属于生理性反应,称为生理性体温升高。 80.少数病理性体温升高,其升高的水平超过体温调定点水平,是体温调节机构
失控或调节障碍的结果,其本质不同于发热,称为过热。 81.凡能刺激体内产内生致热原细胞产生和释放内生致热原的物质,统称发热激 活物,包括外致热原和机体本身的某些产物。 82.指具有致热性或含致热成分的能引起人体或动物发热的物质。 83.在发热激活物的作用下,产内生致热原细胞被激活,进而产生和释放的 致热原。 84.属内生致热原的一种,是指在发热激活物的作用下,由单核-巨噬细胞系 统产生并释放的致热原。现已证明白细胞致热原就是白细胞介素-1。 85.指由下丘脑发出冲动,经运动神经传递到运动终板使骨骼肌产生不随意 的周期性收缩所致。 86.在发热的体温上升期,由于皮肤血管收缩,浅层血流减少,皮温下降并 刺激冷感受器,信息传入中枢而自感发冷,出现恶寒。 87.出生后6月-6岁的儿童,高热中可出现局部或全身的肌肉抽搐。 88.在人体,发热时最高体温很少有超过41℃-42℃者;在动物实验中,在 一定范围内,发热效应随致热原剂量增加而加强,量-效曲线上出现斜坡;但到达一定水平后,发热效应不再增强,曲线出现平坡。这种体温上升 被限制在一定高度以内,称为热限。热限是机体对调节性体温升高的自 我限制,是重要的稳态调节机制。 [问答题] 89.①(简述LP的概念) ②是一种小分子蛋白质:〈1〉不耐热。70℃,20可失去致热活性 〈2〉蛋白酶可破坏其致热活性 ③具有高度抗原特异性 ④有交叉致热性 5、有很强的致热性:0.1-0.2ug较纯的LP可使家兔体温升高1℃ 90.共四个环节(讲义图7-3) 发热激活物→产EP细胞→EP IL-1(LP) TNF 干扰素→POAH→cAMP↑→PGE↑ 炎症蛋白-1 →Na+/Ca +↑→调定点上移产热↑→体温升高 散热↓ 91. 体温上升期高峰期退热期 调定点>中心温度=中心温度<中心温度 热代谢产热>散热产热=散热产热<散热
第6章习题参考答案 1.CPU与外部设备通信为什么要使用接口? 答: CPU要与外部设备直接通信会存在以下两个方面的问题:首先是速度问题,CPU的运行速度要比外设的处理速度高得多,通常仅使用简单的一条输入/输出指令是无法完成CPU与外设之间的信息交换的;其次,外设的数据和控制线也不可能与CPU直接相连,如一台打印机不能将其数据线与CPU的管脚相连,键盘或者其他外设也是如此,同时外设的数据格式千差万别,也不可能直接与CPU 连接。所以,要完成CPU与外部各通信设备的信息交换,就需要接口电路以解决以上问题。 2. I/O接口有什么用途? 答: 主要由以下几个方面的用途: a完成地址译码或设备选择,使CPU能与某一指定的外部设备通信。 b状态信息的应答,以协调数据传输之前的准备工作。 c进行中断管理,提供中断信号。 d进行数据格式转换,如正负逻辑转换、串行与并行数据转换。 e进行电平转换,如TTL电平与MOS电平间的转换。 f协调速度,如采用锁存、缓冲、驱动等。 h时序控制,提供实时时钟信号。 3.I/O端口有哪两种寻址方式?各有何优缺点? 答: I/O端口的寻址方式有存储器映像I/O和I/O映像I/O两种寻址方式。存储器映像I/O 方式是将系统中存储单元和I/O端口的地址统一编址,这样一个I/O端口
地址就是一个存储单元地址,在硬件上没有区别,对I/O端口的访问与存储器的访问相同。其缺点是占用了储存器的地址空间,同时由于存储器地址和I/O 端口在指令形式上没有区别,增加了程序设计的难度。其优点是不需要专门为I/O端口设计电路,可与存储器地址访问硬件混合设计。另一个优点是,由于I/O端口和存储器地址是相同的形式,就可以直接使用与存储器相同的指令,这将会丰富对I/O端口的操作指令。 与存储器映像I/O相反,I/O映像I/O就必须为I/O端口设计专门的硬件电路,其端口地址也是独立于存储器,也有专门的输入/输出指令等其优缺点与存储器映像I/O正好相反。 4.在8086微机系统中有个外设,使用存储器映像的I/O寻址方式该外设地址为01000H。试画出其译码器的连接电路,使其译码器输出满足上述地址要求,译码器使用74LS138芯片。 答: 见图6-1
第六章 一、单项选择题 1.下面的函数关系是( ) A现代化水平与劳动生产率 B圆周的长度决定于它的半径 C家庭的收入和消费的关系 D亩产量与施肥量 2.相关系数r的取值范围( ) A -∞< r <+∞ B -1≤r≤+1 C -1< r < +1 D 0≤r≤+1 3.年劳动生产率x(干元)和工人工资y=10+70x,这意味着年劳动生产率每提高1千元时,工人工资平均( ) A增加70元 B减少70元 C增加80元 D减少80元 4.若要证明两变量之间线性相关程度高,则计算出的相关系数应接近于( ) A +1 B -1 C 0.5 D 1 5.回归系数和相关系数的符号是一致的,其符号均可用来判断现象( ) A线性相关还是非线性相关 B正相关还是负相关 C完全相关还是不完全相关 D单相关还是复相关 6.某校经济管理类的学生学习统计学的时间(x)与考试成绩(y)之间建立线性回归方程?=a+bx。经计算,方程为?=200—0.8x,该方程参数的计算( ) A a值是明显不对的 B b值是明显不对的 C a值和b值都是不对的 D a值和b值都是正确的 7.在线性相关的条件下,自变量的均方差为2,因变量均方差为5,而相关系数为0.8时,则其回归系数为:( ) A 8 B 0.32 C 2 D 12.5 8.进行相关分析,要求相关的两个变量( ) A都是随机的 B都不是随机的 C一个是随机的,一个不是随机的 D随机或不随机都可以 9.下列关系中,属于正相关关系的有( ) A合理限度内,施肥量和平均单产量之间的关系 B产品产量与单位产品成本之间的关系 C商品的流通费用与销售利润之间的关系
P1774.14 为练习4.3的文法构造一个预测语法分析器 bexpr→bexpr or bterm|bterm bterm→bterm and bfactor | bfactor bfactor→not bfactor|(bexpr)|true |false 解1 非递归方法 1)消除左递归 ①bexpr→bterm A ②A→or bterm A ③A→ε ④bterm→bfactor B ⑤B→and bfactor B ⑥B→ε ⑦bfactor→not bfactor ⑧bfactor→(bexpr) ⑨bfactor→true ⑩bfactor→false 2)求first集与follow集 针对以同一非总结符开头的产生式右部求first集如果该非终结符能产生ε则需要求其follow集 ①bexpr→bterm A first(bterm A)= {not,(,true,false} ②A→or bterm A first(or bterm A)={or} ③A→εfollow(A)=follow(bexpr)= {$, )} ④bterm→bfactor B first(bfactor B)={not,(,true,false} ⑤B→and bfactor B first(and bfactor B)={and} ⑥B→εfollow(B)=follow(bterm)=first(A) 因为first(A)= {or , ε} 包含ε 所以follow(B)=follow(bterm) =first(A)∪follow(A)-{ε}={or, $, )} ⑦bfactor→not bfactor first(not bfactor)={not} ⑧bfactor→(bexpr)first((bexpr))={(} ⑨bfactor→true first(true)={true} ⑩bfactor→false first(false)={false} 表中空白处填error,表示调用错误处理程序 4)根据步骤3)编写预测分析程序 下面给出通用的预测分析算法,具体程序留给同学们根据算法自己完善。 repeat
第六章 习题参考答案 1 解:C 6H 5NH 3+ —C 6H 5NH 2 Fe(H 2O)63+—Fe(H 2O)5(OH)2+ R-NH 2+CH 2COOH —R-NH 2+CH 2COO -(R-NH-CH 2COOH) 2解:Cu(H 2O)2(OH)2—Cu(H 2O)3(OH)+ R-NHCH 2COO -—R-NHCH 2COOH 4 解:(1) MBE: [K +]=C [HP -]+[H 2P]+[P 2-]=C CBE: [K +]+[H +]=[HP -]+2[P 2-]+[OH -] PBE: [H +]+[H 2P]=[OH -]+[P 2-] (2) MBE: [Na +]=C [NH 3]+[NH 4+]=C [HPO 42-]+[H 2PO 4-]+[H 3PO 4]+[PO 43-]=C CBE: [Na +]+[NH 4+]+[H +]=[OH -]+[H 2PO 4-]+2[HPO 42-]+3[PO 43-] PBE: [H +]+[H 2PO 4-]+2[H 3PO 4]=[OH -]+[NH 3]+[PO 43-] (3) MBE: [NH 3]+[NH 4+]=C [HPO 42-]+[H 2PO 4-]+[H 3PO 4]+[PO 43-]=C CBE: [NH 4+]+[H +]=[OH -]+[H 2PO 4-]+2[HPO 42-]+3[PO 43-] PBE: [H +]+[H 3PO 4]=[OH -]+[NH 3]+[HPO 42-]+2[PO 43-] (4) MBE: [NH 3]+[NH 4+]=C [CN -]+[HCN]=C CBE: [NH 4+]+[H +]=[OH -]+[CN -] PBE: [H +]+[HCN]=[OH -]+[NH 3] (5) MBE: [NH 3]+[NH 4+]=2C [HPO 42-]+[H 2PO 4-]+[H 3PO 4]+[PO 43-]=C CBE: [NH 4+]+[H +]=[OH -]+[H 2PO 4-]+2[HPO 42-]+3[PO 43-] PBE: [H +]+[H 2PO 4-]+2[H 3PO 4]=[OH -]+[NH 3]+[PO 43-] 5 解:(1) HA(浓度为C A )+HB(浓度为C B ) 混合酸溶液的PBE:[H +]=[A -]+[B -]+[OH -] 因混合酸溶液呈酸性,故[OH -]可忽略。 [H +]=[A -]+[B -]= ] [][] [][+++ H HB K H HA K HB HA ∴ [H +]=][][HB K HA K HB HA + (1) 若两种酸都较弱(C A /K HA ?400, C B /K HB ?400),则可忽略其解离的影响,此时:[HA]≈C A ,[HB]≈C B (1)式简化为:[H +]=HB B HA A K C K C + (2) (2)NH 4Cl 10 5 141 106.5108.1101---?=??==b w a K K K , H 3BO 3 Ka 2=×10 -10
习题六 6-1 (1) A; (2) C; (3) B; (4) C; (5) A 6-2 ,黑表笔插入COM,红表笔插入V/Ω(红笔的极性为“+”),将表笔连接在二极管,其读数为二极管正向压降的近似值。 用模拟万用表测量二极管时,万用表内的电池正极与黑色表笔相连;负极与红表笔相连。测试二极管时,将万用表拨至R×1k档,将两表笔连接在二极管两端,然后再调换方向,若一个是高阻,一个是低阻,则证明二极管是好的。当确定了二极管是好的以后就非常容易确定极性,在低阻时,与黑表笔连接的就是二极管正极。 6-3 什么是PN结的击穿现象,击穿有哪两种。击穿是否意味着PN结坏了?为什么? 答:当PN结加反向电压(P极接电源负极,N极接电源正极)超过一定的时候,反向电流突然急剧增加,这种现象叫做PN结的反向击穿。击穿分为齐纳击穿和雪崩击穿两种,齐纳击穿是由于PN结中的掺杂浓度过高引起的,而雪崩击穿则是由于强电场引起的。PN 结的击穿并不意味着PN结坏了,只要能够控制流过PN结的电流在PN结的允许范围内,不会使PN结过热而烧坏,则PN结的性能是可以恢复正常的,稳压二极管正式利用了二极管的反向特性,才能保证输出电压的稳定。 。 对于图(a)假定D1、D2、D3截止,输出端的电位为-18V,而D1、D2、D3的阳极电位分别是-6V、0V、-6V,因此,理论上D1、D2、D3都能导通,假定D1导通,则输出点的电位为-6V,由于该点电位也是D2的阴极电位,因此D2会导通,一旦D2导通,u O点的电位就为0V,因此,D1、D3的阴极电位为0V,而阳极端为-6V,这样D1、D3必定截止,所以输出电压u o=0V(这就是脉冲数字电路中的或门,0V为高电平,-6V为低电平,只要输入端有一个高电平,输出就为高电平)。 对于图(b)依同样的道理可知:D1、D2、D3的阳极电位都低于+18V,所以三个二极管均 截止,流过R的电流为0,故输出电位u o=18V 试分析图(b)中的三个二极管极性都反过来,输出电压u o=? 6-5 现有两只稳压二极管,它们的稳定电压分别为5V和9V,正向导通电压为0.7V。试问,若将它们串联相接,则可以得到几种稳压值,各为多少? 答:有四种不同的稳压值,分别是:14V、5.7V、9.7V、1.4V 6-6 二极管电路如题图6-2所示,判断图中的二极管是导通还是截止,并求出AO两端的电压U AO。
6.1 假如有下面的Pascal说明 TYPE atype=ARRAY [0..9,-10..10] OF integer; cell=RECORD a,b:integer END; pcell=↑cell; foo=ARRAY [1..100] OF cell; FUNCTION bar(r:integer;y:cell):pcell; BEGIN……END; 写出atype,cell,pcell,foo和bar的类型表达式。 解答: atype: ARRAY(0..9, ARRAY(-10..10, integer)); cell: RECORD((a× integer)× (b×integer)); pcell: POINTER(cell); 或 : POINTER(RECORD((a ×integer)× (b× integer))); foo: ARRAY(1..100, cell); 或 : ARRAY(1..100, RECORD((a ×integer)× (b× integer))); bar: integer× cell→pcell; 或 : integer× cell→POINTER(RECORD((a×integer) ×(b×integer))); 6.4 假定类型定义如下: TYPE link=↑cell; cell=RECORD info:integer; next: link END; 下面哪些表达式结构等价?哪些名字等价? (1)Link (2)pointer(cell) (3)pointer(Link) (4)pointer(record(info?integer)?(next ? pointer(cell))) 解答:(1)(2)(4)结构等价,无名字等价。