
基于朴素贝叶斯的短文本分类研究 自然语言处理是目前智能科学领域中的一个非常热门的方向,文本的分类同样也是自然语言处理中的一项关键的技术。随着深度学习发展,朴素贝叶斯算法也已经在文本的分类中取得到了良好的分类效果。本文针对短文本的分类问题,首先对短文本数据进行了预处理操作,其中包括中文分词、去除停用词以及特征的提取,随后阐明了朴素贝叶斯算法构建分类器的过程,最后将朴素贝叶斯算法与逻辑回归和支持向量机分类算法的分类效果进行了对比分析,得出朴素贝叶斯算法在训练所需的效率上及准确率上有较为优异的表现。 标签:自然语言处理文本分类机器学习朴素贝叶斯 引言 文本分类问题是自然语言处理中的一个非常经典的问题。文本分类是计算机通过按照一定的分类标准进行自动分类标记的有监督学习过程。在文本特征工程中,和两种方法应用最为广泛[1] 。在分類器中,使用普遍的有朴素贝叶斯,逻辑回归,支持向量机等算法。其中朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分类方法,有着坚实的数学基础,以及稳定的分类效率。基于此,本文采用基于的特征提取的朴素贝叶斯算法进行文本分类,探求朴素贝叶斯算法在短文本分类中的适用性。 1数据预处理 1.1中文分词 中文分词是指将一个汉字序列切分成一个个单独的词。中文分词是中文文本处理的一个基础步骤,也是对中文处理较为重要的部分,更是人机自然语言交流交互的基础模块。在进行中文自然语言处理时,通常需要先进行中文分词处理[2] 。 1.2停用词处理 去除停用词能够节省存储空间和计算时间,降低对系统精度的影响。对于停用词的处理,要先对语料库进行分词、词形以及词性的类化,为区分需求表述和信息内容词语提供基础。去停用词后可以更好地分析文本的情感极性,本文采用广泛使用的哈工大停用词表进行去停用词处理。 1.3特征提取 文本数据属于非结构化数据,一般要转换成结构化的数据,一般是将文本转换成“文档-词频矩阵”,矩阵中的元素使用词频或者。它的计算为,
朴素贝叶斯算法 1.算法简介 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。 2.算法定义 朴素贝叶斯分类的正式定义如下: 1)设为一个待分类项,而每个a为x的一个特征属性; 2)有类别集合; 3)计算。 4)如果,则。 其中关键是如何计算步骤3)中的各个条件概率。计算过程如下: (1)找到一个已知分类的待分类项集合,该集合称为训练样本集。 (2)统计得到在各类别下各个特征属性的条件概率估计。即 (3)如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导: 因为分母对于所有类别为常数,因此只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有: 可以看到,整个朴素贝叶斯分类分为三个阶段: 第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。 第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条
件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。 第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。 3.估计类别下特征属性划分的条件概率及Laplace校准 ?估计类别下特征属性划分的条件概率 计算各个划分的条件概率P(a|y)是朴素贝叶斯分类的关键性步骤,当特征属性为离散值时,只要很方便的统计训练样本中各个划分在每个类别中出现的频率即可用来估计P(a|y),下面重点讨论特征属性是连续值的情况。 当特征属性为连续值时,通常假定其值服从高斯分布(也称正态分布)。即: 而 因此只要计算出训练样本中各个类别中此特征项划分的各均值和标准差,代入上述公式即可得到需要的估计值。 ?Laplace校准 当某个类别下某个特征项划分没有出现时,会产生P(a|y)=0的现象,这会令分类器质量大大降低。为了解决这个问题,引入Laplace校准,就是对每个类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。 ●Laplace校准详解 假设离散型随机变量z有{1,2,…,k}共k个值,用 j (),{1,2,,} p z j j k Φ=== 来表示每个值的概率。假设在m个训练样本中,z的观察值是其中每一个观察值对应k个值中的一个。那么z=j出现的概率为: Laplace校准将每个特征值出现次数事先都加1,通俗讲就是假设它们都出现过一次。那么修改后的表达式为:
基于朴素贝叶斯模型的两类问题分类 一、实验目的 通过实验,加深对统计判决与概率密度估计基本思想、方法的认识,了解影响Bayes分类器性能的因素,掌握基于Bayes决策理论的随机模式分类的原理和方法,并理解ROC曲线的意义 二、实验内容 通过Bayes决策理论的分类器,从给定样本集选择训练集以及测试集进行训练并分类,用matlab实现,绘制ROC曲线,得到最优的分类阈值 三、实验原理 Bayes分类器的基本思想是依据类的概率、概密,按照某种准则使分类结果从统计上讲是最佳的。换言之,根据类的概率、概密将模式空间划分成若干个子空间,在此基础上形成模式分类的判决规则。准则函数不同,所导出的判决规则就不同,分类结果也不同。使用哪种准则或方法应根据具体问题来确定 朴素贝叶斯的一个基本假设是所有特征在类别已知的条件下是相互独立的,即 p(x│w_i )=p(x_1,x_2,...,x_d│w_i )=∏_(j=1)^d?〖p(x_j│w_i ) 〗 在构建分类器时,只需要逐个估计出每个类别的训练样本在每一维上的分布形式,就可以得到每个类别的条件概率密度,大大减少了需要估计的参数的数量。朴素贝叶斯分类器可以根据具体问题确定样本在每一维特征上的分布形式,最常用的一种假设是每一个类别的样本都服从各维特征之间相互独立的高斯分布,即 p(x│w_i )=∏_(j=1)^d?〖p(x_j│w_i )=∏_(j=1)^d?{1/(√2πσ_ij ) exp[-(x_j-μ_ij )^2/(2σ_ij )] } 〗 式中u_ij--第i类样本在第j维特征上的均值 σ_ij--相应的方差 可以得到对数判别函数: 〖g〗_i (x)=ln?〖p(x│w_i )〗+ln?P(w_i ) =∑_(j=1)^d?[-1/2 ln?2π-ln?〖σ_ij 〗-(x_j-μ_ij )^2/(2σ_ij )] +ln?P(w_i )=-d/2 ln?2π-∑_(j=1)^d?ln?〖σ_ij-∑_(j=1)^d?〖(x_j-μ_ij )^2/(2σ_ij )+〗〗ln?P(w_i ) 其中的第1项与类别无关,可以忽略,由此得到判别函数: 〖g〗_i (x)=ln?P(w_i )-∑_(j=1)^d?ln?〖σ_ij-∑_(j=1)^d?(x_j-μ_ij )^2/(2σ_ij )〗 四、实验步骤 1、用给定的两类样本集,各选取前400个作为训练样本,通过调用MATLAB工具箱的NaiveBayes类的fit函数训练分类器 2、通过1得到的训练器,选取样本集后100个样本作为测试样本,得到分类结果。 3、对测试集的分类结果进行统计,计算正确率。 4、绘制相应的ROC曲线 五、实验代码 function [Train,TrainLabel] = getTrain(c1,c2) %UNTITLED 得到训练样本 % 根据给定两类样本集各选取前400行样本作为训练样本 c1 = c1(1:400,:);
朴素贝叶斯算法详细总结 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法,是经典的机器学习算法之一,处理很多问题时直接又高效,因此在很多领域有着广泛的应用,如垃圾邮件过滤、文本分类等。也是学习研究自然语言处理问题的一个很好的切入口。朴素贝叶斯原理简单,却有着坚实的数学理论基础,对于刚开始学习算法或者数学基础差的同学们来说,还是会遇到一些困难,花费一定的时间。比如小编刚准备学习的时候,看到贝叶斯公式还是有点小害怕的,也不知道自己能不能搞定。至此,人工智能头条特别为大家寻找并推荐一些文章,希望大家在看过学习后,不仅能消除心里的小恐惧,还能高效、容易理解的get到这个方法,从中获得启发没准还能追到一个女朋友,脱单我们是有技术的。贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。这篇文章我尽可能用直白的话语总结一下我们学习会上讲到的朴素贝叶斯分类算法,希望有利于他人理解。 ▌分类问题综述 对于分类问题,其实谁都不会陌生,日常生活中我们每天都进行着分类过程。例如,当你看到一个人,你的脑子下意识判断他是学生还是社会上的人;你可能经常会走在路上对身旁的朋友说“这个人一看就很有钱、”之类的话,其实这就是一种分类操作。 既然是贝叶斯分类算法,那么分类的数学描述又是什么呢? 从数学角度来说,分类问题可做如下定义: 已知集合C=y1,y2,……,yn 和I=x1,x2,……,xn确定映射规则y=f(),使得任意xi∈I有且仅有一个yi∈C,使得yi∈f(xi)成立。 其中C叫做类别集合,其中每一个元素是一个类别,而I叫做项集合(特征集合),其中每一个元素是一个待分类项,f叫做分类器。分类算法的任务就是构造分类器f。 分类算法的内容是要求给定特征,让我们得出类别,这也是所有分类问题的关键。那么如何由指定特征,得到我们最终的类别,也是我们下面要讲的,每一个不同的分类算法,对
最近发现很多公司招聘数据挖掘的职位都提到贝叶斯分类,其实我不太清楚他们是要求理解贝叶斯分类算法,还是要求只需要通过工具(SPSS,SAS,Mahout)使用贝叶斯分类算法进行分类。 反正不管是需求什么都最好是了解其原理,才能知其然,还知其所以然。我尽量简单的描述贝叶斯定义和分类算法,复杂而有全面的描述参考“数据挖掘:概念与技术”。贝叶斯是一个人,叫(Thomas Bayes),下面这哥们就是。 本文介绍了贝叶斯定理,朴素贝叶斯分类算法及其使用MapReduce实现。 贝叶斯定理 首先了解下贝叶斯定理 P X H P(H) P H X= 是不是有感觉都是符号看起来真复杂,我们根据下图理解贝叶斯定理。 这里D是所有顾客(全集),H是购买H商品的顾客,X是购买X商品的顾客。自然X∩H是即购买X又购买H的顾客。 P(X) 指先验概率,指所有顾客中购买X的概率。同理P(H)指的是所有顾客中购买H 的概率,见下式。
X P X= H P H= P(H|X) 指后验概率,在购买X商品的顾客,购买H的概率。同理P(X|H)指的是购买H商品的顾客购买X的概率,见下式。 X∩H P H|X= X∩H P X|H= 将这些公式带入上面贝叶斯定理自然就成立了。 朴素贝叶斯分类 分类算法有很多,基本上决策树,贝叶斯分类和神经网络是齐名的。朴素贝叶斯分类假定一个属性值对给定分类的影响独立于其他属性值。 描述: 这里有个例子假定我们有一个顾客X(age = middle,income=high,sex =man):?年龄(age)取值可以是:小(young),中(middle),大(old) ?收入(income)取值可以是:低(low),中(average),高(high) ?性别(sex)取值可以是:男(man),女(woman) 其选择电脑颜色的分类标号H:白色(white),蓝色(blue),粉色(pink) 问题: 用朴素贝叶斯分类法预测顾客X,选择哪个颜色的分类标号,也就是预测X属于具有最高后验概率的分类。 解答: Step 1 也就是说我们要分别计算X选择分类标号为白色(white),蓝色(blue),粉色(pink)的后验概率,然后进行比较取其中最大值。 根据贝叶斯定理
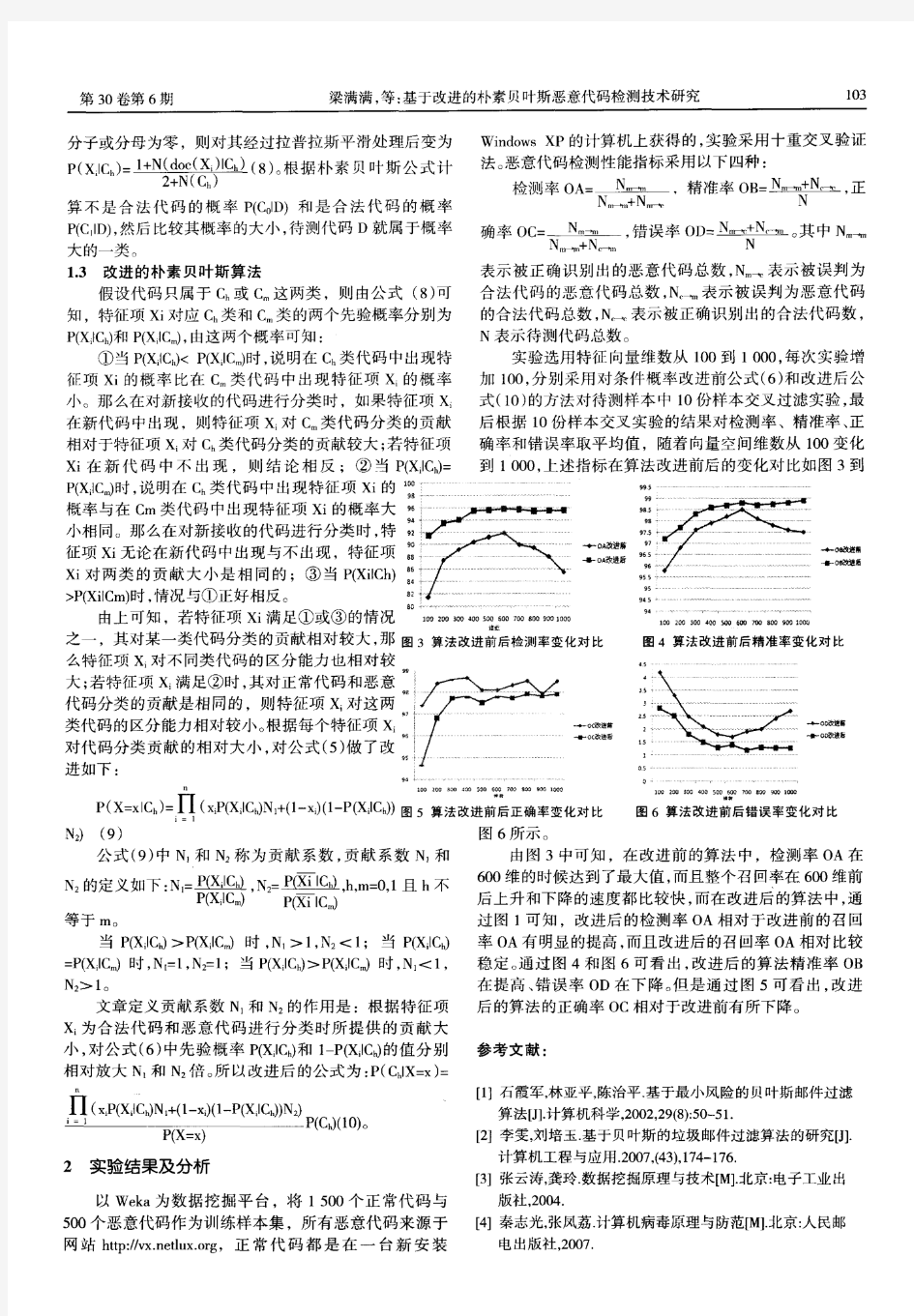
2019年1月 取此事件作为第一事件,其时空坐标为P1(0,0,0,0),P1′(0,0,0,0),在Σ′系经过时间t′=n/ν′后,Σ′系中会看到第n个波峰通过Σ′系的原点,由于波峰和波谷是绝对的,因此Σ系中也会看到第n个波峰通过Σ′系的原点,我们把此事件记为第二事件,P2(x,0,0,t),P2′(0,0,0,t′).则根据洛伦兹变换,我们有x=γut′,t=γt′。在Σ系中看到t时刻第n个波峰通过(x, 0,0)点,则此时该电磁波通过Σ系原点的周期数为n+νxcosθ/c,也就是: n+νxcosθc=νt→ν=ν′ γ(1-u c cosθ)(5)这就是光的多普勒效应[2],如果ν′是该电磁波的固有频率的话,从式(5)可以看出,两参考系相向运动时,Σ系中看到的光的频率会变大,也就是发生了蓝移;反之,Σ系中看到的光的频率会变小,也就是发生了红移;θ=90°时,只要两惯性系有相对运动,也可看到光的红移现象,这就是光的横向多普勒效应,这是声学多普勒效应中没有的现象,其本质为狭义相对论中的时间变缓。3结语 在本文中,通过对狭义相对论的研究,最终得到了光的多普勒效应的表达式,并通过与声学多普勒效应的对比研究,理解了声学多普勒效应和光学多普勒效应的异同。当限定条件为低速运动时,我们可以在经典物理学的框架下研究问题,比如声学多普勒效应,但如果要研究高速运动的光波,我们就需要在狭义相对论的框架下研究问题,比如光的多普勒效应。相对论乃是当代物理学研究的基石,通过本次研究,使我深刻的意识到了科学家为此做出的巨大贡献,为他们献上最诚挚的敬意。 参考文献 [1]肖志俊.对麦克斯韦方程组的探讨[J].通信技术,2008,41(9):81~83. [2]金永君.光多普勒效应及应用[J].现代物理知识,2003(4):14~15.收稿日期:2018-12-17 朴素贝叶斯在文本分类上的应用 孟天乐(天津市海河中学,天津市300202) 【摘要】文本分类任务是自然语言处理领域中的一个重要分支任务,在现实中有着重要的应用,例如网络舆情分析、商品评论情感分析、新闻领域类别分析等等。朴素贝叶斯方法是一种常见的分类模型,它是一种基于贝叶斯定理和特征条件独立性假设的分类方法。本文主要探究文本分类的流程方法和朴素贝叶斯这一方法的原理并将这种方法应用到文本分类的一个任务—— —垃圾邮件过滤。 【关键词】文本分类;监督学习;朴素贝叶斯;数学模型;垃圾邮件过滤 【中图分类号】TP391.1【文献标识码】A【文章编号】1006-4222(2019)01-0244-02 1前言 随着互联网时代的发展,文本数据的产生变得越来越容易和普遍,处理这些文本数据也变得越来越必要。文本分类任务是自然语言处理领域中的一个重要分支任务,也是机器学习技术中一个重要的应用,应用场景涉及生活的方方面面,如网络舆情分析,商品评论情感分析,新闻领域类别分析等等。 朴素贝叶斯方法是机器学习中一个重要的方法,这是一种基于贝叶斯定理和特征条件独立性假设的分类方法。相关研究和实验显示,这种方法在文本分类任务上的效果较好。2文本分类的流程 文本分类任务不同于其他的分类任务,文本是一种非结构化的数据,需要在使用机器学习模型之前进行一些适当的预处理和文本表示的工作,然后再将处理后的数据输入到模型中得出分类的结论。 2.1分词 中文语言词与词之间没有天然的间隔,这一点不同于很多西方语言(如英语等)。所以中文自然语言处理首要步骤就是要对文本进行分词预处理,即判断出词与词之间的间隔。常用的中文分词工具有jieba,复旦大学的fudannlp,斯坦福大学的stanford分词器等等。 2.2停用词的过滤 中文语言中存在一些没有意义的词,准确的说是对分类没有意义的词,例如语气词、助词、量词等等,去除这些词有利于去掉一些分类时的噪音信息,同时对降低文本向量的维度,提高文本分类的速度也有一定的帮助。 2.3文本向量的表示 文本向量的表示是将非结构化数据转换成结构化数据的一个重要步骤,在这一步骤中,我们使用一个个向量来表示文本的内容,常见的文本表示方法主要有以下几种方法: 2.3.1TF模型 文本特征向量的每一个维度对应词典中的一个词,其取值为该词在文档中的出现频次。 给定词典W={w1,w2,…,w V},文档d可以表示为特征向量d={d1,d2,…,d V},其中V为词典大小,w i表示词典中的第i个 词,t i表示词w i在文档d中出现的次数。即tf(t,d)表示词t在文档d中出现的频次,其代表了词t在文档d中的重要程度。TF模型的特点是模型假设文档中出现频次越高的词对刻画文档信息所起的作用越大,但是TF有一个缺点,就是不考虑不同词对区分不同文档的不同贡献。有一些词尽管在文档中出现的次数较少,但是有可能是分类过程中十分重要的特征,有一些词尽管会经常出现在众多的文档中,但是可能对分类任务没有太大的帮助。于是基于TF模型,存在一个改进的TF-IDF模型。 2.3.2TF-IDF模型 在计算每一个词的权重时,不仅考虑词频,还考虑包含词 论述244
朴素贝叶斯分类器的应用 作者:阮一峰 日期:2013年12月16日 生活中很多场合需要用到分类,比如新闻分类、病人分类等等。 本文介绍朴素贝叶斯分类器(Naive Bayes classifier),它是一种简单有效的常用分类算法。 一、病人分类的例子 让我从一个例子开始讲起,你会看到贝叶斯分类器很好懂,一点都不难。 某个医院早上收了六个门诊病人,如下表。 症状职业疾病 打喷嚏护士感冒 打喷嚏农夫过敏 头痛建筑工人脑震荡 头痛建筑工人感冒 打喷嚏教师感冒 头痛教师脑震荡 现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大? 根据贝叶斯定理: P(A|B) = P(B|A) P(A) / P(B)
可得 P(感冒|打喷嚏x建筑工人) = P(打喷嚏x建筑工人|感冒) x P(感冒) / P(打喷嚏x建筑工人) 假定"打喷嚏"和"建筑工人"这两个特征是独立的,因此,上面的等式就变成了 P(感冒|打喷嚏x建筑工人) = P(打喷嚏|感冒) x P(建筑工人|感冒) x P(感冒) / P(打喷嚏) x P(建筑工人) 这是可以计算的。 P(感冒|打喷嚏x建筑工人) = 0.66 x 0.33 x 0.5 / 0.5 x 0.33 = 0.66 因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。 这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。 二、朴素贝叶斯分类器的公式 假设某个体有n项特征(Feature),分别为F1、F2、...、F n。现有m个类别(Category),分别为C1、C2、...、C m。贝叶斯分类器就是计算出概率最大的那个分类,也就是求下面这个算式的最大值: P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C) / P(F1F2...Fn) 由于 P(F1F2...Fn) 对于所有的类别都是相同的,可以省略,问题就变成了求 P(F1F2...Fn|C)P(C) 的最大值。
基于朴素贝叶斯的文本分类算法 摘要:常用的文本分类方法有支持向量机、K-近邻算法和朴素贝叶斯。其中朴素贝叶斯具有容易实现,运行速度快的特点,被广泛使用。本文详细介绍了朴素贝叶斯的基本原理,讨论了两种常见模型:多项式模型(MM)和伯努利模型(BM),实现了可运行的代码,并进行了一些数据测试。 关键字:朴素贝叶斯;文本分类 Text Classification Algorithm Based on Naive Bayes Author: soulmachine Email:soulmachine@https://www.doczj.com/doc/f011084929.html, Blog:https://www.doczj.com/doc/f011084929.html, Abstract:Usually there are three methods for text classification: SVM、KNN and Na?ve Bayes. Na?ve Bayes is easy to implement and fast, so it is widely used. This article introduced the theory of Na?ve Bayes and discussed two popular models: multinomial model(MM) and Bernoulli model(BM) in details, implemented runnable code and performed some data tests. Keywords: na?ve bayes; text classification 第1章贝叶斯原理 1.1 贝叶斯公式 设A、B是两个事件,且P(A)>0,称 为在事件A发生的条件下事件B发生的条件概率。 乘法公式P(XYZ)=P(Z|XY)P(Y|X)P(X) 全概率公式P(X)=P(X|Y 1)+ P(X|Y 2 )+…+ P(X|Y n ) 贝叶斯公式 在此处,贝叶斯公式,我们要用到的是
朴素贝叶斯分类--多项式模型 1.多项式模型简介 朴素贝叶斯分类器是一种有监督学习,针对文本分类常见有两种模型,多项式模型(词频型)和伯努利模型(文档型)。多项式模型以单词为粒度,伯努利模型以文件为粒度。对于一个文档A,多项式模型中,只有在A中出现过的单词,才会参与后验概率计算。 2.多项式模型基本原理及实例 2.1基本原理 已知类别C={C1,C2,C3,?,C k}与文档集合 D={D1,D2,?,D n} 设某一文档D j的词向量为D j={d j1,d j2,?d j l j }(可重复)设训练文档中出现的单词(单词出现多次,只算一次)即语料库为V 对于待分类文档A={A1,A2,?A m},则有: 1)计算文档类别的先验概率 P C i= D j D j∈C i D j n j=1 P(C i)则可以认为是类别C i在整体上占多大比例(有多大可能性)。
2)某单词d j l j 在类别C i下的条件概率 P d j l j C i= d j l j +1 D j+V D j∈C i P d j l j C i可以看作是单词d j l j 在证明D j属于类C i上提供了 多大的证据。 3)对于待分类文档A被判为类C i的概率 假设文档A中的词即A1,A2,?A m相互独立,则有 P C i A=P C i∩A = P C i P A C i =P C i P A1,A2,?A m C i P A =P C i P A1C i P A2C i?P A m C i P A 对于同一文档P A一定,因此只需计算分子的值。 多项式模型基于以上三步,最终以第三步中计算出的后验概率最大者为文档A所属类别。 2.2 实例 给定一组分好类的文本训练数据,如下:
机器学习实验报告 朴素贝叶斯学习和分类文本 (2015年度秋季学期) 一、实验内容 问题:通过朴素贝叶斯学习和分类文本 目标:可以通过训练好的贝叶斯分类器对文本正确分类二、实验设计
实验原理与设计: 在分类(classification)问题中,常常需要把一个事物分到某个类别。一个事物具有很多属性,把它的众多属性看做一个向量,即x=(x1,x2,x3,…,xn),用x这个向量来代表这个事物。类别也是有很多种,用集合Y=y1,y2,…ym表示。如果x属于y1类别,就可以给x打上y1标签,意思是说x属于y1类别。 这就是所谓的分类(Classification)。x的集合记为X,称为属性集。一般X和Y 的关系是不确定的,你只能在某种程度上说x有多大可能性属于类y1,比如说x有80%的可能性属于类y1,这时可以把X和Y看做是随机变量,P(Y|X)称为Y的后验概率(posterior probability),与之相对的,P(Y)称为Y的先验概率(prior probability)1。在训练阶段,我们要根据从训练数据中收集的信息,对X和Y的每一种组合学习后验概率P(Y|X)。分类时,来了一个实例x,在刚才训练得到的一堆后验概率中找出所有的P(Y|x),其中最大的那个y,即为x所属分类。根据贝叶斯公式,后验概率为 在比较不同Y值的后验概率时,分母P(X)总是常数,因此可以忽略。先验概率P(Y)可以通过计算训练集中属于每一个类的训练样本所占的比例容易地估计。 在文本分类中,假设我们有一个文档d∈X,X是文档向量空间(document space),和一个固定的类集合C={c1,c2,…,cj},类别又称为标签。显然,文档向量空间是一个高维度空间。我们把一堆打了标签的文档集合
两种最广泛的分类模型——决策树模型和朴素贝叶斯模型。该模型是由贝叶斯公式延伸而来。讲到贝叶斯公式先要看条件概率公式 该公式说明了如何计算已知B发生的前提下A还要发生的概率。A和B是随机事件,是否独立事件都适合这个公式。举个例子比喻就是你宿舍哥们在北师找了个女朋友,之后分手了,那么在他已经在北师成功一次的条件下再次去北师找女朋友成功的概率。如果是独立事件呢,那就是问在他分手之后,你去北师找女朋友成功的概率(在他不参与指导的前提下)跟他找女朋友是两码子事。 回正题,之后出场了贝叶斯公式 公式很简单,但是该公式真的超级有用,它揭示了在某种未发生条件下和已发生条件下概率的计算关系,即根据B发生条件下A发生的概率可以推理出A发生下B发生的概率。在真实生活中我们很难获得P(B|A)的概率,但是根据我们已知的P(A|B)就可以获得它,所以该定理的用途十分广大,可以用作数据的预测分类等。 贝叶斯分类算法有很多如朴素贝叶斯算法,TAN算法等 朴素贝叶斯是一种很简单的分类思想,对于给出的带分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大就认为该待分类项属于哪个类别。简单点说,就是你在学院路上发现一个学生摸样的美女,让你猜这美女是哪的。大家十有八九会猜是北师的,因为北师有美女的概率更高,在没有其他更多信息的条件下,我们就将这个美女分类到了北师里。这就是朴素贝叶斯的思想。 朴素贝叶斯分类的正式定义如下: 1、设为一个待分类项,而每个a为x的一个特征属性。 2、有类别集合。 3、计算。 4、如果,则。 对于贝叶斯的分类步骤说明如下,那病毒检测分类,对于一个病毒的定义可能会是包含多个向量的一个病毒的特征就是一个X,它包含N个特征向量,而对于学习集即N++个各种病
数据挖掘(8):朴素贝叶斯分类算法原理与实践 隔了很久没有写数据挖掘系列的文章了,今天介绍一下朴素贝叶斯分类算法,讲一下基本原理,再以文本分类实践。 一个简单的例子 朴素贝叶斯算法是一个典型的统计学习方法,主要理论基础就是一个贝叶斯公式,贝叶斯公式的基本定义如下: 这个公式虽然看上去简单,但它却能总结历史,预知未来。公式的右边是总结历史,公式的左边是预知未来,如果把Y看出类别,X看出特征,P(Yk|X)就是在已知特征X的情况下求Yk类别的概率,而对P(Yk|X)的计算又全部转化到类别Yk的特征分布上来。举个例子,大学的时候,某男生经常去图书室晚自习,发现他喜欢的那个女生也常去那个自习室,心中窃喜,于是每天买点好吃点在那个自习室蹲点等她来,可是人家女生不一定每天都来,眼看天气渐渐炎热,图书馆又不开空调,如果那个女生没有去自修室,该男生也就不去,每次男生鼓足勇气说:“嘿,你明天还来不?”,“啊,不知道,看情况”。然后该男生每天就把她去自习室与否以及一些其他情况做一下记录,用Y表示该女生是否去自习室,即Y={去,不去},X是跟去自修室有关联的一系列条件,比如当天上了哪门主课,蹲点统计了一段时间后,该男生打算今天不再蹲点,而是先预测一下她会不会去,现在已经知道了今天上了常微分方法这么主课,于是计算P(Y=去|常微分方
程)与P(Y=不去|常微分方程),看哪个概率大,如果P(Y=去|常微分方程) >P(Y=不去|常微分方程),那这个男生不管多热都屁颠屁颠去自习室了,否则不就去自习室受罪了。P(Y=去|常微分方程)的计算可以转为计算以前她去的情况下,那天主课是常微分的概率P(常微分方程|Y=去),注意公式右边的分母对每个类别(去/不去)都是一样的,所以计算的时候忽略掉分母,这样虽然得到的概率值已经不再是0~1之间,但是其大小还是能选择类别。 后来他发现还有一些其他条件可以挖,比如当天星期几、当天的天气,以及上一次与她在自修室的气氛,统计了一段时间后,该男子一计算,发现不好算了,因为总结历史的公式: 这里n=3,x(1)表示主课,x(2)表示天气,x(3)表示星期几,x(4)表示气氛,Y仍然是{去,不去},现在主课有8门,天气有晴、雨、阴三种、气氛有A+,A,B+,B,C五种,那么总共需要估计的参数有8*3*7*5*2=1680个,每天只能收集到一条数据,那么等凑齐1 680条数据大学都毕业了,男生打呼不妙,于是做了一个独立性假设,假设这些影响她去自习室的原因是独立互不相关的,于是 有了这个独立假设后,需要估计的参数就变为,(8+3+7+5)*2 = 46个了,而且每天收集的一条数据,可以提供4个参数,这样该男生就预测越来越准了。
朴素贝叶斯分类算法 一.贝叶斯分类的原理 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化。 贝叶斯分类器是用于分类的贝叶斯网络。该网络中应包含类结点C,其中C 的取值来自于类集合( c1 , c2 , ... , cm),还包含一组结点X = ( X1 , X2 , ... , Xn),表示用于分类的特征。对于贝叶斯网络分类器,若某一待分类的样本D,其分类特征值为x = ( x1 , x2 , ... , x n) ,则样本D 属于类别ci 的概率P( C = ci | X1 = x1 , X2 = x 2 , ... , Xn = x n) ,( i = 1 ,2 , ... , m) 应满足下式: P( C = ci | X = x) = Max{ P( C = c1 | X = x) , P( C = c2 | X = x ) , ... , P( C = cm | X = x ) } 贝叶斯公式: P( C = ci | X = x) = P( X = x | C = ci) * P( C = ci) / P( X = x) 其中,P( C = ci) 可由领域专家的经验得到,而P( X = x | C = ci) 和P( X = x) 的计算则较困难。 二.贝叶斯伪代码 整个算法可以分为两个部分,“建立模型”与“进行预测”,其建立模型的伪代码如下: numAttrValues 等简单的数据从本地数据结构中直接读取 构建几个关键的计数表 for(为每一个实例) { for( 每个属性 ){ 为 numClassAndAttr 中当前类,当前属性,当前取值的单元加 1 为 attFrequencies 中当前取值单元加 1 } } 预测的伪代码如下: for(每一个类别){ for(对每个属性 xj){ for(对每个属性 xi){
判别模型、生成模型与朴素贝叶斯方法 JerryLead csxulijie@https://www.doczj.com/doc/f011084929.html, 2011年3月5日星期六1判别模型与生成模型 上篇报告中提到的回归模型是判别模型,也就是根据特征值来求结果的概率。形式化表示为p(y|x;θ),在参数θ确定的情况下,求解条件概率p(y|x)。通俗的解释为在给定特征后预测结果出现的概率。 比如说要确定一只羊是山羊还是绵羊,用判别模型的方法是先从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。换一种思路,我们可以根据山羊的特征首先学习出一个山羊模型,然后根据绵羊的特征学习出一个绵羊模型。然后从这只羊中提取特征,放到山羊模型中看概率是多少,再放到绵羊模型中看概率是多少,哪个大就是哪个。形式化表示为求p(x|y)(也包括p(y)),y是模型结果,x是特征。 利用贝叶斯公式发现两个模型的统一性: 由于我们关注的是y的离散值结果中哪个概率大(比如山羊概率和绵羊概率哪个大),而并不是关心具体的概率,因此上式改写为: 其中p(x|y)称为后验概率,p(y)称为先验概率。 由p(x|y)? p(y)=p(x,y),因此有时称判别模型求的是条件概率,生成模型求的是联合概率。 常见的判别模型有线性回归、对数回归、线性判别分析、支持向量机、boosting、条件随机场、神经网络等。 常见的生产模型有隐马尔科夫模型、朴素贝叶斯模型、高斯混合模型、LDA、Restricted Boltzmann Machine等。 这篇博客较为详细地介绍了两个模型: https://www.doczj.com/doc/f011084929.html,/home.php?mod=space&uid=248173&do=blog&id=227964
朴素贝叶斯分类器的改进 摘要:朴素贝叶斯分类器是一种简单而高效的分类器,但是它的属性独立性假设使其无法表示现实世界属性之间的依赖关系,以及它的被动学习策略,影响了它的分类性能。本文从不同的角度出发,讨论并分析了三种改进朴素贝叶斯分类性能的方法。为进一步的研究打下坚实的基础。 关键词:朴素贝叶斯;主动学习;贝叶斯网络分类器;训练样本;树增广朴素贝叶斯 1 问题描述 随着计算机与信息技术的发展,人类获取的知识和能够及时处理的数据之间的差距在加大,从而导致了一个尴尬的境地,即“丰富的数据”和“贫乏的知识”并存。在数据挖掘技术中,分类技术能对大量的数据进行分析、学习,并建立相应问题领域中的分类模型。分类技术解决问题的关键是构造分类器。分类器是一个能自动将未知文档标定为某类的函数。通过训练集训练以后,能将待分类的文档分到预先定义的目录中。常用的分类器的构造方法有决策树、朴素贝叶斯、支持向量机、k近邻、神经网络等多种分类法,在各种分类法中基于概率的贝叶斯分类法比较简单,在分类技术中得到了广泛的应用。在众多的分类器的构造方法与理论中,朴素贝叶斯分类器(Naive Bayesian Classifiers)[1]由于计算高效、精确度高。并具有坚实的理论基础而得到了广泛的应用。文献朴素贝叶斯的原理、研究成果进行了具体的阐述。文章首先介绍了朴素贝叶斯分类器,在此基础上分析所存在的问题。并从三个不同的角度对朴素贝叶斯加以改进。 2 研究现状 朴素贝叶斯分类器(Na?ve Bayesian Classifier)是一种基于Bayes理论的简单分类方法,它在很多领域都表现出优秀的性能[1][2]。朴素贝叶斯分类器的“朴素”指的是它的条件独立性假设,虽然在某些不满足独立性假设的情况下其仍然可能获得较好的结果[3],但是大量研究表明此时可以通过各种方法来提高朴素贝叶斯分类器的性能。改进朴素贝叶斯分类器的方式主要有两种:一种是放弃条件独立性假设,在NBC的基础上增加属性间可能存在的依赖关系;另一种是重新构建样本属性集,以新的属性组(不包括类别属性)代替原来的属性组,期望在新的属性间存在较好的条件独立关系。 目前对于第一种改进方法研究得较多[2][4][5]。这些算法一般都是在分类精度和算法复杂度之间进行折衷考虑,限制在一定的范围内而不是在所有属性构成的完全网中搜索条件依赖关系。虽然如
朴素贝叶斯 优点:在数据较少的情况下仍然有效,可以处理多类别问题 缺点:对于输入数据的准备方式较为敏感 适用数据类型:标称型数据 贝叶斯准则: 使用朴素贝叶斯进行文档分类 朴素贝叶斯的一般过程 (1)收集数据:可以使用任何方法。本文使用RSS源 (2)准备数据:需要数值型或者布尔型数据 (3)分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好 (4)训练算法:计算不同的独立特征的条件概率 (5)测试算法:计算错误率 (6)使用算法:一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本。 准备数据:从文本中构建词向量 摘自机器学习实战。 [['my','dog','has','flea','problems','help','please'], 0 ['maybe','not','take','him','to','dog','park','stupid'], 1 ['my','dalmation','is','so','cute','I','love','him'], 0
['stop','posting','stupid','worthless','garbage'], 1 ['mr','licks','ate','my','steak','how','to','stop','him'], 0 ['quit','buying','worthless','dog','food','stupid']] 1 以上是六句话,标记是0句子的表示正常句,标记是1句子的表示为粗口。我们通过分析每个句子中的每个词,在粗口句或是正常句出现的概率,可以找出那些词是粗口。 在bayes.py文件中添加如下代码: [python]view plaincopy 1.# coding=utf-8 2. 3.def loadDataSet(): 4. postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please' ], 5. ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], 6. ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], 7. ['stop', 'posting', 'stupid', 'worthless', 'garbage'], 8. ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], 9. ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] 10. classVec = [0, 1, 0, 1, 0, 1] # 1代表侮辱性文字,0代表正常言论 11.return postingList, classVec 12. 13.def createVocabList(dataSet): 14. vocabSet = set([]) 15.for document in dataSet: 16. vocabSet = vocabSet | set(document) 17.return list(vocabSet) 18. 19.def setOfWords2Vec(vocabList, inputSet): 20. returnVec = [0] * len(vocabList) 21.for word in inputSet: 22.if word in vocabList: 23. returnVec[vocabList.index(word)] = 1 24.else: 25.print"the word: %s is not in my Vocabulary!" % word 26.return returnVec
基于朴素贝叶斯分类器的文本分类算法(上) 2010-02-21 10:23:43| 分类:Lucene | 标签:|字号大中小订阅 转载请保留作者信息: 作者:phinecos(洞庭散人) Blog:https://www.doczj.com/doc/f011084929.html,/ Email:phinecos@https://www.doczj.com/doc/f011084929.html, Preface 本文缘起于最近在读的一本书-- Tom M.Mitchell的《机器学习》,书中第6章详细讲解了贝叶斯学习的理论知识,为了将其应用到实际中来,参考了网上许多资料,从而得此文。文章将分为两个部分,第一部分将介绍贝叶斯学习的相关理论(如果你对理论不感兴趣,请直接跳至第二部分<<基于朴素贝叶斯分类器的文本分类算法(下)>>)。第二部分讲如何将贝叶斯分类器应用到中文文本分类,随文附上示例代码。 Introduction 我们在《概率论和数理统计》这门课的第一章都学过贝叶斯公式和全概率公式,先来简单复习下: 条件概率 定义设A, B是两个事件,且P(A)>0 称P(B∣A)=P(AB)/P(A)为在条件A下发生的条件事件B发生的条件概率。 乘法公式设P(A)>0 则有P(AB)=P(B∣A)P(A) 全概率公式和贝叶斯公式 定义设S为试验E的样本空间,B1, B2, …Bn为E的一组事件,若BiBj=Ф, i≠j, i, j=1, 2, …,n; B1∪B2∪…∪Bn=S则称B1, B2, …, Bn为样本空间的一个划分。 定理设试验E的样本空间为,A为E的事件,B1, B2, …,Bn为的一个划分,且P(Bi)>0 (i=1, 2, …n),则P(A)=P(A∣B1)P(B1)+P(A∣B2)+ …+P(A∣Bn)P(Bn)称为全概率公式。 定理设试验俄E的样本空间为S,A为E的事件,B1, B2, …,Bn为的一个划分,则 P(Bi∣A)=P(A∣Bi)P(Bi)/∑P(A|Bj)P(Bj)=P(B|Ai)P(Ai)/P(A) 称为贝叶斯公式。说明:i,j均为下标,求和均是1到n 下面我再举个简单的例子来说明下。 示例1 考虑一个医疗诊断问题,有两种可能的假设:(1)病人有癌症。(2)病人无癌症。样本数据来自某化验测试,它也有两种可能的结果:阳性和阴性。假设我们已经有先验知识:在所有人口中只有0.008的人患病。此外,化验测试对有病的患者有98%的可能返回阳性结果,对无病患者有97%的可能返回阴性结果。 上面的数据可以用以下概率式子表示: