
怎样对数据做相关性检验?
最简单直观的方法就是做相关系数矩阵了,另外就是 Pearson 相关系数或者 Spearman 相关系数
用SPSS软件或者SAS软件都可以分析。用SPSS更简单。如果你用SPSS软件,分析的步骤如下:
1.点击“分析(Analyze)”
2. 选中“相关(Correlate)”
3. 选中“双变量(Bivariate)”
4 选择你想要分析的变量
5 选择 Pearson 相关系数(或者 Spearman 相关系数)
6 选择恰当的统计检验(单边或双边)
7 点击“OK”即可
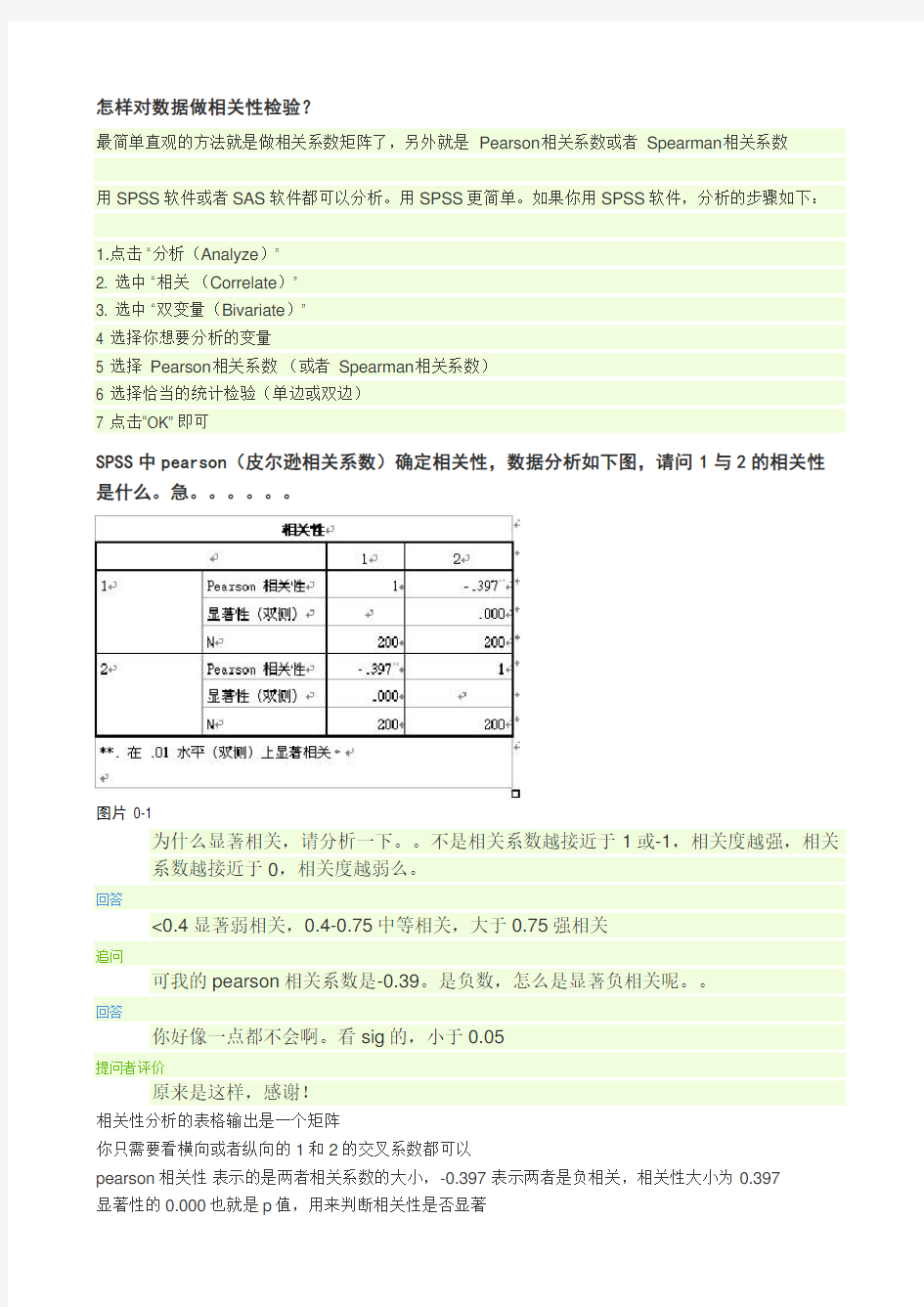
SPSS中pearson(皮尔逊相关系数)确定相关性,数据分析如下图,请问1与2的相关性是什么。急。。。。。。
图片 0-1
为什么显著相关,请分析一下。。不是相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱么。
回答
<0.4显著弱相关,0.4-0.75中等相关,大于0.75强相关
追问
可我的pearson相关系数是-0.39。是负数,怎么是显著负相关呢。。
回答
你好像一点都不会啊。看sig的,小于0.05
提问者评价
原来是这样,感谢!
相关性分析的表格输出是一个矩阵
你只需要看横向或者纵向的1和2的交叉系数都可以
pearson相关性表示的是两者相关系数的大小,-0.397 表示两者是负相关,相关性大小为0.397
如何使用SPSS进行皮尔森相关系数分析??Pearson’s correlation coefficients
1.单击“Analyze”,展开下拉菜单
2.下拉菜单中寻找“Correlate”弹出小菜单,从小菜单上寻找“Bivariate...”,单击之,则弹出相关分析“Bivariate Correlations”对话框
3.把左边的源变量中要分析相关的变量调入右边的“Va riables:”下的矩形框内
4.勾选“Correlation Coelficients”中的“Pearson”选项
5.点击“OK”即可
求问了:因子分析明明是基于相关系数矩阵的,但为什么大家都直接把数据导进去就分析呢?= =!
因子分析是有一定条件需求的,变量之间要存在一定的相关性,而因子分析时也会有一个检验,从过程上将必须先做了这些之后才做因子分析的,所以说很多人都是在想当然的用,很多发表的论文上都存在用法不当的问题
利用SPSS,相关系数矩阵怎么算
analyze-correlate-bivariate-选择变量
OK
输出的是相关系数矩阵
相关系数下面的Sig.是显著性检验结果的P值,越接近0越显著。
另外,表格下会显示显著性检验的判断结果,你看看表格下的解释就知道,比如“**. Correlation is significant at the 0.01 level (2-tailed).”
就是说,如果相关系数后有"**"符号,代表在0.01显著性水平下显著相关
粗略判断的方法是,相关系数0.6以上,可以认为显著相关了
、
eviews 相关系数矩阵是什么。怎么做截面数据的相关系数矩阵!急急急!
相关系数啊,就是自变量和变量之间的相关程度
相关系数多大才算相关性比较好啊
大于0.8
相关系数多少算具有相关性?
我做教育统计,发放过问卷后统计相关性,我想问下相关性系数怎么界定具体相关程度的大小呢?
1.相关性的强、弱、不相关系数分别是多少?
2.界定的标准从何而来,论文中想引用一下
3.相关性系数我自己做的统计方法算出来的数据,也能用上面的强弱系数的标准么?
谢谢各位了~~万分感激!
相关系数的强弱仅仅看系数的大小是不够的。一般来说,取绝对值后,0-0.09为没有相关性,0.3-弱,0.1-0.3为弱相关,0.3-0.5为中等相关,0.5-1.0为强相关。但是,往往你还需要做显著性差异检验,即t-test,来检验两组数据是否显著相关,这在SPSS里面会自动为你计算的。
样本书越是大,需要达到显著性相关的相关系数就会越小。所以这关系到你的样本大小,如果你的样本
很大,比如说超过300,往往分析出来的相关系数比较低,比如0.2,因为你样本量的增大造成了差异的增大,但显著性检验却认为这是极其显著的相关。
一般来说,我们判断强弱主要看显著性,而非相关系数本身。但你在撰写论文时需要同时报告这两个统
计数据。
提问者评价
谢谢!
相关性是什么意思
就是有关系的,比如一件事因另一件事而发生的,这件事与另一件事具有,比如一笔费用因某个业务而
发生的,两者具有相关性。
这是数学方向的问题.相关是非确定性问题,用于统计分析.与函数相对自变量和函数不是一一对应的关系SPSS关于两组数据的相关性分析的操作方法,越简单越好,急!
可使用Statistics菜单->Correlate子菜单->Bivariate过程
观察Correlation Coefficients值和Test of Significance值即可,
惟必须注意,变量须为等距尺度 (interval level of measurement)。
若变项只属顺序尺度 (ordinary level of measurement),
则可选择计算Kendall's等级相关系数和Spearman相关系数。
spss相关性分析相关性
相关性
X1 X2 X3 X4 X5 X6 X7 X8
X1 Pearson 相关性 1 -.022 -.447 .999** .999** .982** .994** .975 **
显著性(双侧).972 .451 .000 .000 .003 .001 .005
N 5 5 5 5 5 5 5 5
X2 Pearson 相关性-.022 1 .261 -.059 -.025 -.179 -.117 -.206 显著性(双侧).972 .671 .925 .969 .773 .852 .740
N 5 5 5 5 5 5 5 5
X3 Pearson 相关性-.447 .261 1 -.481 -.415 -.405 -.448 -.469 显著性(双侧).451 .671 .413 .488 .499 .450 .426
N 5 5 5 5 5 5 5 5
X4 Pearson 相关性.999** -.059 -.481 1 .997** .982** .994** .977 **
显著性(双侧).000 .925 .413 .000 .003 .001 .004 N 5 5 5 5 5 5 5 5
X5 Pearson 相关性.999** -.025 -.415 .997** 1 .985** .994** .975 **
显著性(双侧).000 .969 .488 .000 .002 .001 .005 N 5 5 5 5 5 5 5 5
X6 Pearson 相关性.982** -.179 -.405 .982** .985** 1 .996** .995 **
显著性(双侧).003 .773 .499 .003 .002 .000 .000 N 5 5 5 5 5 5 5 5
X7 Pearson 相关性.994** -.117 -.448 .994** .994** .996** 1 .994 **
显著性(双侧).001 .852 .450 .001 .001 .000 .001 N 5 5 5 5 5 5 5 5
X8 Pearson 相关性.975** -.206 -.469 .977** .975** .995** .994** 1 显著性(双侧).005 .740 .426 .004 .005 .000 .001
N 5 5 5 5 5 5 5 5
**. 在 .01 水平(双侧)上显著相关。
一般直接看相关系数和显著性双侧。你这个一列一列的看要方便些,比如第一列,表示为x1和其他各变量之间的相关性,x1和x2的相关系数为-.022,显著性双侧为0.972,说明这两个变量间无相关性,依次类推。只要是显著性<0.05即可说明两变量具有相关性,而相关性的大小取决于相关系数,相关系数越接近1,相关性越好。看了一下你的x1和x4-x8的相关系数都在0.9以上了。是非常好的。
利用SPSS,相关系数矩阵怎么算
analyze-correlate-bivariate-选择变量
OK
输出的是相关系数矩阵
相关系数下面的Sig.是显著性检验结果的P值,越接近0越显著。
另外,表格下会显示显著性检验的判断结果,你看看表格下的解释就知道,比如“**. Correlation is significant at the 0.01 level (2-tailed).”
就是说,如果相关系数后有"**"符号,代表在0.01显著性水平下显著相关
粗略判断的方法是,相关系数0.6以上,可以认为显著相关了
person系数是什么意思
皮尔森系数
皮尔森相关系数
皮尔森相关系数(Pearson correlation coefficient)
也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数。皮
尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强。
person是人的意思
SPSS中pearson(皮尔逊相关系数)看r值还是P值,确定相关性
两个值都要看,r值表示在样本中变量间的相关系数,表示相关性的大小;p值是检验值,是检验两变量在样本来自的总体中是否存在和样本一样的相关性。
相关系数为 0.61,能否证明两个变量相关性较高?
实验结果表明两个变量的相关系数是 0.61,能否表明这2个变量有较高的相关性?目前研究这2个变量表示的内容的关系的人还比较少,所以我没法和别人的对比。所以想问问数学系的同学,这个结果够不
够“充分”?谢谢!
可根据相关系数的临界值去判断。
追问
能否说的具体一些?谢谢!
回答
1. 可根据相关系数r的临界值去判断。可查资料,资料很多。
2. “当0<|r|<1时,表示两变量存在一定程度的线性相关。且|r|越接近1,两变量间线性关系越密
切;|r|越接近于0,表示两变量的线性相关越弱。一般可按三级划分:|r|<0.4为低度线性相关;0.
4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关。”这是一种简单的判断方法:因此
r=0.61为显著相关。
追问
(1)我这个不是“线性相关系数”
(2)“显著相关”是什么概念?若2个变量“显著相关”,能不能作为一个较好的结果?其他2条回答
2013-04-04 16:16热心网友
皮尔森相关(简单相关)检验的应该就是线性相关楼上说的是对的
相关性大小是指相关系数的绝对值
是否显著、极显著是指显著性水平,即看P值的大小
相关系数多大才算相关性比较好啊
大于0.8
为什么会出现相关系数小但是相关性显著的情况呢
当显著性水平小于0.05时说明两个变量之间存在显著相关,反之则不存在。相关系数是表示两个变量之间的相关性强弱的。
假设检验只是判断相关系数是否为0,r<0.4为低度相关。
相关系数为0.59表示相关性大还是不大?
你可以把它理解为两个量以某种方式相关的概率,则0.59表示它们有59%的可能性相关。若为1,则表示100%相关。
所以此处相关系数为0.59,我们认为其相关性不大。
SPSS中pearson(皮尔逊相关系数)看r值还是P值,确定相关性
两个值都要看,r值表示在样本中变量间的相关系数,表示相关性的大小;p值是检验值,是检验两变量在样本来自的总体中是否存在和样本一样的相关性。
相关系数是0.9985,是否能说明相关性很好?
已经很好了
楼上说的不对
相关系数不表示概率
用SPSS软件进行相关性分析时,得出的相关系数为负值。进行逐步回归分析时,得出的
系数确为正值。为什么?
这种情况是可以出现的。在相关性分析时,你看到的是两个变量之间的关系,其他变量的影响是不被考
虑的;但是,进行逐步回归分析时,如果入选的变量不止一个,那么入选变量之间可以产生影响,这种
影响甚至可以改变一些原来不算强的相关性的方向。这表明你的数据存在偏相关、部分相关或伪相关等情况。
相关系数说明两个现象之间相关关系密切程度的统计分析指标。相关系数用希腊字母γ表示,γ值的范围在-1和+1之间。γ>0为正相关,γ<0为负相关。γ=0表示不相关;γ的绝
对值越大,相关程度越高。两组数据的相关系数如果是负数则表示一组数据增大,另一组数据也反而减小;一组数据减小,另一组数据反而增大。
相关系数如果是负数表明两种资产的收益率呈反方向变动,负数代表负相关.正数代表正相关.0代表不相关. 你好,请教一下,主成分分析中,综合得分都是负值怎么比较?
你是用什么软件操作?
SPSS中,主成分分析实现是利用因子分析,只要累计方差贡献率达到80%以上即可,你说的综合得分指的是因子分析的得分?
追问
谢谢!是的,是各因子的得分,以下是计算结果
第一次用,是不是哪里出错了,数据不知道怎么解释?我的qq:2628230137
回答
首先,你要先确定你的变量不存在问题:不存在共线、异方差等,在做因子分析前,你是否进行了KMO检验?是否有必要做因子旋转?累计方差贡献率是否达到80%以上
以上问题都排除之后,说明你的变量应该是不存在问题。
那么一般因子分析得分出现负数,只能说明因子得分是在平均分以下,我头一次见到所有因子和主因子得分都是负数……建议你先看下变量是否存在问题,我晚上不上Q Q,如果你白天有时间,可以加个QQ聊下。
用SPSS进行主成分分析,最后得出的一个综合指标关系式,但是带入相应的数据后为负值。请问原因及解决方法
有负值是正常的
因为所有评价对象的综合指标的和为0
不同评价对象的综合指标必须有正有负的
主成分分析要求数据必须正态分布吗?
聚类分析对数据有什么要求?
主成分分析要求数据接近正态分布,不一定要严格的正态分布条件,一般来说样本量在100以上就基本符合条件。
聚类分析对数据的要求是聚类的各组的组内方差较小,而组间方差较大,正常来说只要方法选择得当,这个要求会比较容易做到的。
eviews异方差、自相关检验与解决办法 一、异方差检验: 1.相关图检验法 LS Y C X 对模型进行参数估计 GENR E=RESID 求出残差序列 GENR E2=E^2 求出残差的平方序列 SORT X 对解释变量X排序 SCAT X E2 画出残差平方与解释变量X的相关图 2.戈德菲尔德——匡特检验 已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。 SORT X 将样本数据关于X排序 SMPL 1 10 确定子样本1 LS Y C X 求出子样本1的回归平方和RSS1 SMPL 17 26 确定子样本2 LS Y C X 求出子样本2的回归平方和RSS2 计算F统计量并做出判断。 解决办法 3.加权最小二乘法 LS Y C X 最小二乘法估计,得到残差序列 GRNR E1=ABS(RESID) 生成残差绝对值序列 LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计 二、自相关 1.图示法检验 LS Y C X 最小二乘法估计,得到残差序列 GENR E=RESID 生成残差序列 SCAT E(-1) E et—et-1的散点图 PLOT E 还可绘制et的趋势图 2.广义差分法 LS Y C X AR(1) AR(2)
首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。接着,使用spss16来解决自相关。第一步,输入变量,做线性回归,注意在Liner Regression 中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。第三步,再做滞后一期的X1和Y1,即自变量和因变量的滞后一期的值,也是直接COPY。第四步,最后定义两个新变量,即X2=X-B*X1,Y2=Y-B*X2,最后做X2和Y2的回归,这样广义差分就完成了。但是这仅仅只是一次广义差分,观察X2和Y2的回归分析表,如果DW值仍然显示有自相关,则还要做一次差分,即重复上述步骤即可。 一般来说,广义差分最多做2次就行了。。。 本文来自: 人大经济论坛SPSS专版版,详细出处参考:https://www.doczj.com/doc/ec711722.html,/forum.php?mod=viewthread&tid=289529&page=1
实验五自相关性 【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】 利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。 【实验步骤】 一、回归模型的筛选 ⒈相关图分析 SCAT X Y 相关图表明,GDP指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。 ⒉估计模型,利用LS命令分别建立以下模型 ⑴线性模型:LS Y C X t (-6.706) (13.862) = 2 R=0.9100 F=192.145 S.E=5030.809 ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX t (-31.604) (64.189) = 2 R=0.9954 F=4120.223 S.E=0.1221 ⑶对数模型:LS Y C LNX
=t (-6.501) (7.200) 2R =0.7318 F =51.8455 S.E =8685.043 ⑷指数模型:LS LNY C X =t (23.716) (14.939) 2R =0.9215 F =223.166 S.E =0.5049 ⑸二次多项式模型:GENR X2=X^2 LS Y C X X2 =t (3.747) (-8.235) (25.886) 2R =0.9976 F =3814.274 S.E =835.979 ⒊选择模型 比较以上模型,可见各模型回归系数的符号及数值较为合理。各解释变量及常数项都通过了t 检验,模型都较为显著。除了对数模型的拟合优度较低外,其余模型都具有高拟合优度,因此可以首先剔除对数模型。 比较各模型的残差分布表。线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,指数模型则大体相反,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这两种函数形式设置是不当的。而且,这两个模型的拟合优度也较双对数模型和二次多项式模型低,所以又可舍弃线性模型和指数模型。双对数模型和二次多项式模型都具有很高的拟合优度,因而初步选定回归模型为这两个模型。 二、自相关性检验 ⒈DW 检验; ⑴双对数模型 因为n =21,k =1,取显著性水平α=0.05时,查表得L d =1.22, U d =1.42,而0<0.7062=DW 实验二序列相关性 【实验目的】 掌握序列相关性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。 【实验内容】 经济理论指出,商品进口主要由进口国的经济发展水平,以及商品进口价格指数与国内价格指数对比因素决定的。由于无法取得价格指数数据,我们主要研究中国商品进口与国内生产总值的关系。 以1978-2001年中国商品进口额与国内生产总值数据为例,练习检查和克服模型的序列相关性的操作方法。 【实验步骤】 一、建立线性回归模型 利用表中数据建立M 关于GDP 的散点图(SCAT GDP M )。 可以看到M 与GDP 呈现接近线性的正相关关系。 建立一个线性回归模型(LS M C GDP )。 即得到的回归式为: GDP M 0204.09058.152+= (3.32) (20.1) 9461.02=R D.W.=0.63 F=405 二、 进行序列相关性检验 1、 观察残差图 做出残差项与时间以及与滞后一期的残差项的折线图,可以看出随机项存在正序列相关性。 2、 用D.W.检验判断 由回归结果输出D.W.=0.628。若给定05.0=α,已知n=24,k=2,查D.W.检验上下界表可得,45.1,27.1==U L d d 。由于D.W.=0.628<1.27=L d ,故存在正自相关。 3、 用LM 检验判断 在估计窗口中选择Serial Correlation LM Test,设定滞后期Lag=1,得到LM 检验结果。 由于P值为0.0027,可以拒绝原假设,表明存在自相关。 4、用回归检验法判断 对初始估计结果得到的残差序列定义为E1,首先做一阶自回归(LS E1 E1(-1))。 实验五 自相关性【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。表5-1 我国城乡居民储蓄存款与GDP 统计资料(1978年=100)年份 存款余额Y GDP 指数X 年份存款余额Y GDP 指数X 1978 210.60100.019895146.90271.31979 281.00107.619907034.20281.71980 399.50116.019919107.00307.61981 523.70122.1199211545.40351.41982 675.40133.1199314762.39398.81983 892.50147.6199421518.80449.31984 1214.70170.0199529662.25496.51985 1622.60192.9199638520.84544.11986 2237.60210.0199746279.80592.01987 3073.30234.0199853407.47638.219883801.50260.7【实验步骤】一、回归模型的筛选 ⒈相关图分析SCAT X Y 相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而 加以比较分析。⒉估计模型,利用LS 命令分别建立以下模型⑴线性模型: LS Y C X x y 5075.9284.14984?+-= (-6.706) (13.862)=t =0.9100 F =192.145 S.E =5030.8092R ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX 、管路敷设技术护层防腐跨接地线弯曲半径标高等,要求技术交底。管线敷设技术中包含线槽、管架等多项方式,为解决高中语文电气课件中管壁薄、接口不严等问题,合理利用管线敷设技术。线缆敷设原则:在分线盒处,当不同电压回路交叉时,应采用金属隔板进行隔开处理;同一线槽内,强电回路须同时切断习题电源,线缆敷设完毕,要进行检查和检测处理。、电气课件中调试写复杂设备与装置高中资料试卷调试方案,编写重要设备高中资料试卷试验方案以及系统启动方案;对整套启动过程中高中资料试卷电气设备进行调试工作并且进行过关运行高中资料试卷技术指导。对于调试过程中高中资料试卷技术问题,作为调试人员,需要在事前掌握图纸资料、设备制造厂家出具高中资料试卷试验报告与相关技术资料,并且了解现场设备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规、电气设备调试高中资料试卷技术工况进行自动处理,尤其要避免错误高中资料试卷保护装置动作,并且拒绝动作,来避免不必要高中资料试卷突然停机。因此,电力高中资料试卷保护装置调试技术,要求电力保护装置做到准确灵活。对于差动保护装置高中资料试卷调试技术是指发电机一变压器组在发生内部故障时,需要进行外部电源高中资料试卷切除从而采用高中资料试卷主要保护装置。 Eviews运用于计量经济学的三个举证 、异方差检验:首先做出相应的Is模型, White检验:在 Heteroskedastici tyTest : White 中检验p值,如果p.f值小于0.05则表示有异方差,反之没有异方差 G — Q检验 20对数据中在上方输入 排序 选出1~7 *做回归 得出Sum squared resid 同样再输入smpl 14 20/ls y c x 得出第二个rss 用rss(1)/rss(2) 做f 检验 其他检验方式中用genr 定义变量进行回归分析 确定最大的r2 等值来确定其异方差形式 ? 修正方法 加权最小2 定义e1 为相应的resid (e) 在ls 规划时将opion 中的weight 设为abs(e1) 进行来说规划即可这时会去掉其异方差性 二、多重共线性对数据建模ls 分析数据看哪个每个解释变量的f 值,检验其是否有多重共线性 求其相关系数矩阵“ Correlations ”得出后和0.8 比较,如果大于0.8 说明两者之间有激情。修正方法:逐步回 归先对每一个进行ls 分析建模然后取出对y 影响最大的做为基础然后更具其相关系数大小排序,用做出先关的检验,选择加入的元素如上图就是加入了x3 三、序列相关性同样的ls 对其d.w 做出分析,如果接近2 则没有一次相关,若出了范围则有相应的相关性 其他次的相关性可以由Im检验得到(小于0.05即有序列相关性)。 自相关的检验还有view/residual/con -- Q -- 做出如图所示的表 修正方法杜宾两步法:进行如下的Is 估计 可得:将p 的值带入查分模型 如下输入: 结果如下: d.w 含糊可以用lm 检验其是否任然具有相关性。 用b(贝塔)0/ (1-p) p=之前的0.6278或者是第一次的1-d.w/2 最小二乘法 输入如下 结果如下 我用的是Eviews3.1注册版(因为其他的版本没注册都不稳定容易自己关闭程序),但大抵操作应该是相同的。 首先建立新的workfile,在命令窗口输入series,弹出新建的数列窗口,把要检验的数据存进去。然后再数列窗口下点击view,找到unit root test就是单位根检验,弹出来的窗口的左上角是选择检验方式,一般保持默认的DF那一项就好了,Eviews里面的这个DF选项是把DF与ADF检验都包括在一起了。右边的intercept啦intercept and trend啦是针对ADF 检验的不同模型,如果搞不清楚干脆就按默认吧。左下角的level,1st differential,2st什么的是问你是针对原始数据、还是一阶差分、二阶差分来做检验,默认是level,就是原始数据。都选好之后点击OK就好了。输出的结果主要是看上面的表,第一个表左边给出一个值,右边给了三个值,分别是置信度99%,95%,90%的ADF检验临界值。左边的值如果小于右边的某个值,说明该数据落在右边那个对应值的置信区间里。比如左边给出-3,右边对应95%置信度的值是-1,-3<-1所以数据不存在单位根,是平稳的,这一检验的置信度是95%。 大概是这样吧,具体的ADF模型选择等等最好看一看相关书籍。Eviews不难学的~~嘿嘿我也就是三天恶补大概看完的。 ADF检验的原假设是存在单位根,一般EVIEWS输出的是ADF检验的统计值,只要这个统计值是小于1%水平下的数字就可以极显著的拒绝原假设,认为数据平稳。注意,ADF值一般是负的,也有正的,但是它只有小于1%水平下的才能认为是及其显著的拒绝原假设 这样的话,如果你的变量是水平变量。那么,你需要取对数,一般来说,取对数后的变量一般是平稳的,这样,你无需作协整;如果对数变量非平稳,再取一阶差分(绝大多数的水平变量取对数后再一阶差分是平稳的),你就可以作协整了了。 如果你的变量已是相对数,xt 与yt 并非I(1),那么,不能作协整,仅作一般的时间序列分析即可。 可靠性数据分析的计算方法 PROCEEDINGS,Annual RELIABILITY and MAINTAINABILITY Symposium(1996) 可靠性数据分析的计算方法 Gordon Johnston, SAS Institute Inc., Cary 关键词:寿命数据分析加速试验修复数据分析软件工具 摘要&结论 许多从事组件和系统可靠度研究的专业人员并没有意识到,通过廉价的台式电脑的普及使用,很多用于可靠度分析的功能强大的统计工具已经用于实践中。软件的计算功能还可以将复杂的计算统计和图形技术应用于可靠度分析问题。这大大的便利了工业统计学家和可靠性工程师,他们可以将这些灵活精确的方法应用于在可靠度分析时所遇到的许多不同类型的数据。 在本文中,我们在SAS@系统中将一些最有用的统计数据和图形技术应用到例子的当中,这些例子主要包涵了寿命数据,加速试验数据,以及可修复系统中的数据。随着越来越多的人意识到创新性软件在可靠性数据分析中解决问题的需要,毫无疑问,计算密集型技术在可靠性数据分析中的应用的趋势将会继续扩大。 1.介绍 本文探讨了人们在可靠性数据分析普遍遇到的三个方面: 寿命数据分析 试验加速数据分析 可修复系统数据的分析 在上述各领域,图形和分析的统计方法已被开发用于探索性数据分析,可靠性预测,并用于比较不同的设计系统,供应商等的可靠性性能。 为了体现将现代统计方法用于结合使用高分辨率图形的使用价值,在下面的章节中图形和统计方法将被应用于含有上述三个方面的可靠性数据的例子中。2.寿命数据分析 概率统计图的寿命数据分析中使用的最常见的图形工具之一。Weibull 图是最常见的使用可靠性的概率图的类型,但是当Weibull概率分布并不符合实际数据的时候,类似于对数正态分布和指数分布这一类的概率图在寿命数据分析中也能够起到帮助。 在许多情况下,可用的数据不仅包含故障时间,但也包含在分析时没有发生故障的单位的运行时间。在某些情况下,只能够知道两次故障发生之间的时间间隔。例如,在测试大量的电子元件时,如果记录每一个发生故障的元件的故障时间,那么这可能不经济。相反,在固定的时间间隔内 E v i e w s运用于计量经济学的三个举证 一、异方差 检验:首先做出相应的ls模型, White检验:在 HeteroskedasticityTest :White 中检验p值,如果值小于则表示有异方差,反之没有异方差。 G—Q检验 20对数据中在上方输入 *排序 *选出1~7 *做回归 得出Sum squared resid 同样再输入smpl 14 20/ls y c x 得出第二个rss 用rss(1)/rss(2)做f检验 其他检验方式中用genr 定义变量进行回归分析 确定最大的r2等值来确定其异方差形式 ? 修正方法 加权最小2 定义e1为相应的resid (e) 在ls规划时将opion中的weight设为abs(e1) 进行来说规划即可这时会去掉其异方差性 二、多重共线性 对数据建模ls分析数据看哪个每个解释变量的f值,检验其是否有多重共线性 求其相关系数矩阵“Quick\Group Statistics\Correlations”得出后和比较,如果大于说明两者之间有激情。 修正方法: 逐步回归 先对每一个进行ls分析建模 然后取出对y影响最大的做为基础 然后更具其相关系数大小排序,用 做出先关的检验,选择加入的元素 如上图就是加入了x3 三、序列相关性 同样的ls对其做出分析,如果接近2 则没有一次相关,若出了范围则有相应的相关性 其他次的相关性可以由lm检验得到(小于即有序列相关性)。 自相关的检验还有view/residual/con-----Q---- 做出如图所示的表 修正方法 杜宾两步法:进行如下的ls估计 可得: 将p 的值带入查分模型 如下输入: 结果如下: 含糊可以用lm检验其是否任然具有相关性。 用b(贝塔)0/(1-p)p=之前的或者是第一次的2 最小二乘法 输入如下 结果如下 Lm检验: 可用。 差分法 直接输入: 同样也可知取出了其序列相关性 ----made by . e v i e w s统计分析报告 IMB standardization office【IMB 5AB- IMBK 08- IMB 2C】 统计分析报告 基于eviews软件的湖北省人均GDP时间序 列模型构建与预测 姓名:刘金玉 学院:经济管理学院 学号: 指导教师:李奇明 日期:2014年12月14日 基于eviews软件的湖北省人均GDP时间序列 模型构建与预测 1、选题背景 改革开放以来,中国的经济得到飞速发展。1978年至今,中国GDP年均增长超过9%。中国的经济实力明显增强。2001年GDP超过万亿美元,排名升到世界第六位。外汇储备已达2500亿美元。市场在资源配置中已经明显地发挥基础性作用。公有、私有、外资等多种所有制经济共同发展的格局基本形成。宏观调控体系初步建立。我国社会生产力、综合国力、地区发展、产业升级、所有制结构、商品供求等指标均反映出我国经济运行质量良好,为实现第三步战略。在全国的经济飞速发展的大环境下,各省GDP的增长也是最能反映其经济发展状况的指标。而人均GDP是最能体现一个省的经济实力、发展水平和生活水准的综合性指标,它不仅考虑了经济总量的大小,而且结合了人口多少的因素,在国际上被广泛用于评价和比较一个地区经济发展水平。尤其是我们这样的人口大国,用这一指标反映经济增长和发展情况更加准确、深刻和富有现实意义。深入分析这一指标对于反映我国经济发展历程、探讨增长规律、研究波动状况,制定相应的宏观调控政策有着十分重要的意义。 本文是以湖北省人均GDP作为研究对象。湖北省人均GDP的增长速度在上世纪90年代增长率有下滑的趋势(见表1)。进入21世纪,继东部沿海地区先发展起来,并涌现出环渤海、长三角、珠三角等城市群,以及中共中央提出“西部大开发”的战略后,中部地区成了“被遗忘的区域”,中部地区经济发展严重滞后于东部沿海地区,为此,中共中央提出了“中部崛起”的重大战略决策。自2004年提出“中部崛起”的重要战略构思后,山西、河南、安徽、湖北、湖南、江西六个省都依托自己的资源和地理优势来扩大地区竞争力,湖北省尤为突出。那么,研究湖北省人均GDP的统计 实验一ARMA 模型建模 一、实验目的 学会检验序列平稳性、随机性。学会分析时序图与自相关图。学会利用最小二乘法等方法对ARMA 模型进行估计,以及掌握利用ARMA 模型进行预测的方法。学会运用Eviews 软件进行ARMA 模型的识别、诊断、估计和预测和相关具体操作。 二、基本概念 1 平稳时间序列: 定义:时间序列{zt}是平稳的。如果{zt}有有穷的二阶中心矩,而且满足: (a )ut= Ezt =c; (b )r(t,s) = E[(zt-c)(zs-c)] = r(t-s,0) 则称{zt}是平稳的。 2 AR 模型: AR 模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测。具有如下结构的模型称为P 阶自回归模型,简记为AR(P)。 ? ???? ?? 11222 0()0(),()0,t t t t q t q q t t t s x E Var E s t εμεθεθεθεθεεσεε---?=+----? ≠??===≠?L , 4 ARMA 模型: ARMA 模型:自回归模型和滑动平均模型的组合, 便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA 。具有如下结构的模型称为自回归移动平均回归模型,简记为ARMA(p,q)。 ? ???? ?? 实验五 自相关性 【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】 利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。 【实验步骤】 一、回归模型的筛选 ⒈相关图分析 SCAT X Y 相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。 ⒉估计模型,利用LS 命令分别建立以下模型 ⑴线性模型: LS Y C X x y 5075.9284.14984?+-= =t (-6.706) (13.862) 2 R =0.9100 F =192.145 S.E =5030.809 ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX x y ln 9588.20753.8?ln +-= =t (-31.604) (64.189) 2 R =0.9954 F =4120.223 S.E =0.1221 ⑶对数模型:LS Y C LNX x y ln 82.236058.118140?+-= =t (-6.501) (7.200) 2 R =0.7318 F =51.8455 S.E =8685.043 ⑷指数模型:LS LNY C X x y 010005.03185.5?ln += =t (23.716) (14.939) 2 R =0.9215 F =223.166 S.E =0.5049 ⑸二次多项式模型:GENR X2=X^2 LS Y C X X2 21966.05485.4456.2944?x x y +-= =t (3.747) (-8.235) (25.886) 2 R =0.9976 F =3814.274 S.E =835.979 ⒊选择模型 比较以上模型,可见各模型回归系数的符号及数值较为合理。各解释变量及常数项都通过了t 检验,模型都较为显著。除了对数模型的拟合优度较低外,其余模型都具有高拟合优度,因此可以首先剔除对数模型。 比较各模型的残差分布表。线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,指数模型则大体相反,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这两种函数形式设置是不当的。而且,这两个模型的拟合优度也较双对数模型和二次多项式模型低,所以又可舍弃线性模型和指数模型。双对数模型和二次多项式模型都具有很高的拟合优度,因而初步选定回归模型为这两个模型。 二、自相关性检验 ⒈DW 检验; ⑴双对数模型 因为n =21,k =1,取显著性水平α=0.05时,查表得L d =1.22,U d =1.42,而0<0.7062=DW 使用eviews做线性回归分析 关键字: linear regression Glossary: ls(least squares)最小二乘法 R-sequared样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整 Adjust R-seqaured() S.E of regression回归标准误差 Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间 Mean dependent var因变量的均值 S.D. dependent var因变量的标准差 Akaike info criterion赤池信息量(AIC)(越小说明模型越精确) Schwarz ctiterion:施瓦兹信息量(SC)(越小说明模型越精确) Prob(F-statistic)相伴概率 fitted(拟合值) 线性回归的基本假设: 1.自变量之间不相关 2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布 3.样本个数多于参数个数 建模方法: ls y c x1 x2 x3 ... x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。模型的实际业务含义也有指导意义,比如 m1同gdp肯定是相关的。 模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。 模型检验: 1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度 F大于临界值则说明拒绝0假设。 Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。 2)回归系数显著性检验(t检验):检验每一个自变量的合理性 |t|大于临界值表示可拒绝系数为0的假设,即系数合理。t分布的自由度为 n-p-1,n为样本数,p为系数位置 统计分析报告 基于eviews软件的湖北省人均GDP时间序列模型构建与预测 姓名:刘金玉 学院:经济管理学院 学号:20121002942 指导教师:李奇明 日期:2014年12月14日 基于eviews软件的湖北省人均GDP时间序列 模型构建与预测 1、选题背景 改革开放以来,中国的经济得到飞速发展。1978年至今,中国GDP年均增长超过9%。中国的经济实力明显增强。2001年GDP超过1.1万亿美元,排名升到世界第六位。外汇储备已达2500亿美元。市场在资源配置中已经明显地发挥基础性作用。公有、私有、外资等多种所有制经济共同发展的格局基本形成。宏观调控体系初步建立。我国社会生产力、综合国力、地区发展、产业升级、所有制结构、商品供求等指标均反映出我国经济运行质量良好,为实现第三步战略。在全国的经济飞速发展的大环境下,各省GDP的增长也是最能反映其经济发展状况的指标。而人均GDP 是最能体现一个省的经济实力、发展水平和生活水准的综合性指标,它不仅考虑了经济总量的大小,而且结合了人口多少的因素,在国际上被广泛用于评价和比较一个地区经济发展水平。尤其是我们这样的人口大国,用这一指标反映经济增长和发展情况更加准确、深刻和富有现实意义。深入分析这一指标对于反映我国经济发展历程、探讨增长规律、研究波动状况,制定相应的宏观调控政策有着十分重要的意义。 本文是以湖北省人均GDP作为研究对象。湖北省人均GDP的增长速度在上世纪90年代增长率有下滑的趋势(见表1)。进入21世纪,继东部沿海地区先发展起来,并涌现出环渤海、长三角、珠三角等城市群,以及中共中央提出“西部大开发”的战略后,中部地区成了“被遗忘的区域”,中部地区经济发展严重滞后于东部沿海地区,为此,中共中央提出了“中部崛起”的重大战略决策。自2004年提出“中部崛起”的重要战略构思后,山西、河南、安徽、湖北、湖南、江西六个省都依托自己的资源和地理优势来扩大地区竞争力,湖北省尤为突出。那么,研究湖北省人均GDP的统计规律性和变动趋势,对于了解湖北省的经济增长规律以及地方政策的制定有特别重要的意义。因此本文试图以湖北省1978-2013年人均GDP历史数据为样本,通过ARMA 模型对样本进行统计分析,以揭示湖北省人均GDP 变化的内在规律性,建立计量经济模型,并在此基础上进行短期外推预测,作为湖北未来几年经济发展的重要参考依据。 表一湖北省·1978年-2013年的人均GDP Year PRE GDP/ 元 增长率Year PRE GDP/元 增长率Year PRE GDP/ 元 增长率 1978 332.03 1990 1541.17 12.23% 2002 7436.58 8.29% 1979 409.35 23.29% 1991 1668.03 8.23% 2003 8378.01 12.66% 1980 427.98 4.55% 1992 1962.45 17.65% 2004 9897.64 18.14% 1981 466.32 8.96% 1993 2360.53 20.28% 2005 11554 16.73% 1982 506.33 8.58% 1994 2991.33 26.72% 2006 13360 15.63% e v i e w s异方差自相关检 验与解决办法 This model paper was revised by the Standardization Office on December 10, 2020 eviews异方差、自相关检验与解决办法 一、异方差检验:1.相关图检验法 LS Y C X 对模型进行参数估计 GENR E=RESID 求出残差序列 GENR E2=E^2 求出残差的平方序列 SORT X 对解释变量X排序 SCAT X E2 画出残差平方与解释变量X的相关图 2.戈德菲尔德——匡特检验 已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。 SORT X 将样本数据关于X排序 SMPL 1 10 确定子样本1 LS Y C X 求出子样本1的回归平方和RSS1 SMPL 17 26 确定子样本2 LS Y C X 求出子样本2的回归平方和RSS2 计算F统计量并做出判断。 解决办法 3.加权最小二乘法 LS Y C X 最小二乘法估计,得到残差序列 GRNR E1=ABS(RESID) 生成残差绝对值序列 LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计 二、自相关 1.图示法检验 LS Y C X 最小二乘法估计,得到残差序列 GENR E=RESID 生成残差序列 SCAT E(-1) E et—et-1的散点图 PLOT E 还可绘制et的趋势图 2.广义差分法 LS Y C X AR(1) AR(2) 首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。接着,使用spss16来解决自相关。第一步,输入变量,做线性回归,注意在Liner Regression中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。第三 E v i e w s序列相关性实 验报告 WTD standardization office【WTD 5AB- WTDK 08- WTD 2C】 实验二序列相关性【实验目的】 掌握序列相关性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews 操作方法。 【实验内容】 经济理论指出,商品进口主要由进口国的经济发展水平,以及商品进口价格指数与国内价格指数对比因素决定的。由于无法取得价格指数数据,我们主要研究中国商品进口与国内生产总值的关系。 以1978-2001年中国商品进口额与国内生产总值数据为例,练习检查和克服模型的序列相关性的操作方法。 【实验步骤】 一、 建立线性回归模型 利用表中数据建立M 关于GDP 的散点图(SCAT GDP M )。 可以看到M 与GDP 呈现接近线性的正相关关系。 建立一个线性回归模型(LS M C GDP )。 即得到的回归式为: 9461.02=R .=0.63 F=405 二、 进行序列相关性检验 1、 观察残差图 做出残差项与时间以及与滞后一期的残差项的折线图,可以看出随机项存在正序列相关性。 2、 用.检验判断 由回归结果输出.=。若给定05.0=α,已知n=24,k=2,查.检验上下界表可得,45.1,27.1==U L d d 。由于.=<=L d ,故存在正自相关。 3、 用LM 检验判断 在估计窗口中选择Serial Correlation LM Test ,设定滞后期Lag=1,得到LM 检验结果。 由于P 值为,可以拒绝原假设,表明存在自相关。 4、 用回归检验法判断 对初始估计结果得到的残差序列定义为E1,首先做一阶自回归(LS E1 E1(- 1))。 可靠性数据收集与分析方法 【摘要】可靠性数据是开展可靠性工作的基础,是提高产品质量、改进使用和维修方法的重要资料,其对推进可靠性技术的发展起着重要作用。本文重点介绍了数据的来源、数据类型的分类、数据收集的要求及流程。 【关键词】可靠性数据收集;数据类型;完全数据;删失数据 Abstract:Reliability data is the basis of the work of reliability,which is the important information of improving the quality of product,ameliorating use and maintenance methods. It plays an important effect for the development of reliability technology. This essay introduces the source of the data,the sorts of the data type,the requirements and the flow of data collection. Key words:Reliability Data Collection;Data types;Complete Data ;Censored Data 前言 可靠性数据是系统可靠性设计、研究、分析、评定和改进的依据,数据收集、处理与分析则是一切可靠性工作的基础。对收集的可靠性数据进行严格的筛选,正确地分析处理,建立可靠性相关模型,真实地反映部件的失效规律,用于指导产品的可靠性设计、分析及评估。 可靠性数据处理及分析为可靠性设计和可靠性试验提供了基础,为可靠性管理提供了决策依据。可靠性数据分析可以定量评估车辆的可靠性,发现可靠性设计的薄弱环节,改进设计。有效的可靠性数据是开展可靠性、维修性、保障性分析的基础,是决策的依据。 可靠性工作贯穿于产品的设计、制造、使用、维修等全寿命周期历程,因而可靠性数据及其分析也伴随着产品寿命周期的各个阶段的可靠性工作而进行。可靠性数据分析是从数据的产生、收集到分析可靠性参数、寿命指标的综合过程。工程研制阶段的可靠性数据分析结果,可为产品的改进和定型提供科学的依据;生产阶段的可靠性数据分析结果,可为产品的设计和制造提供较权威的评价;使用阶段的可靠性数据分析结果,可以反映产品趋向成熟期或到达成熟期的可靠性水平,可为今后新产品的可靠性设计和改进原产品设计提供最有益的参考。 1.可靠性数据的来源 数据是可靠性分析和评估的基础,为进行产品的可靠性分析,首先进行可靠性数据收集,然后进行分析评价,为进一步提高产品的可靠性提供科学依据。 按可靠性数据的来源,可分为试验数据和现场数据。试验数据是在实验室中 E v i e w s序列相关性实验报 告 Prepared on 22 November 2020 实验二序列相关性 【实验目的】 掌握序列相关性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。 【实验内容】 经济理论指出,商品进口主要由进口国的经济发展水平,以及商品进口价格指数与国内价格指数对比因素决定的。由于无法取得价格指数数据,我们主要研究中国商品进口与国内生产总值的关系。 以1978-2001年中国商品进口额与国内生产总值数据为例,练习检查和克服模型的序列相关性的操作方法。 1999 2000 2001 【实验步骤】 一、建立线性回归模型 利用表中数据建立M关于GDP的散点图(SCAT GDP M)。 可以看到M与GDP呈现接近线性的正相关关系。 建立一个线性回归模型(LS M C GDP)。 即得到的回归式为: GDP M 0204.09058.152+= 9461.02=R .=0.63 F=405 二、 进行序列相关性检验 1、 观察残差图 做出残差项与时间以及与滞后一期的残差项的折线图,可以看出随机项存在正序列相关性。 2、 用.检验判断 由回归结果输出.=。若给定05.0=α,已知n=24,k=2,查.检验上下界表可得,45.1,27.1==U L d d 。由于.=<=L d ,故存在正自相关。 3、 用LM 检验判断 在估计窗口中选择Serial Correlation LM Test,设定滞后期Lag=1,得到LM检验结果。 由于P值为,可以拒绝原假设,表明存在自相关。 4、用回归检验法判断 对初始估计结果得到的残差序列定义为E1,首先做一阶自回归(LS E1 E1(-1))。 计量经济学实验报告 实验目的:掌握自相关问题的检验以及相关的Eviews的操作方法。实验内容:消费总量的多少主要有GDP决定。为了考察GDP对消费 总额的影响,可使用如下模型:Y i = 1 β β+ i X;其中,X表示GDP, Y表示消费总量。下表列出了中国1990-2000的GDP的X与消费总额Y的统计数据。 一、估计回归方程 OLS法的估计结果如下: Y=2329.401+0.546950X (1.954322)(36.71110) R2=0.990446,R2=0.989711,SE=2091.475,D.W.=0.478071。 二、进行序列相关性检验 (1)图示检验法 (2)回归检验法 一阶回归检验 二阶回归检验 e=1.144406e1-t-0.343796e2-t+εt t 3)拉格朗日乘数(LM)检验法 Breusch-Godfrey Serial Correlation LM Test: F-statistic 29.41781 Probability 0.000038 Obs*R-squared 12.63731 Probability 0.001802 Test Equation: Dependent Variable: RESID Method: Least Squares Date: 12/17/12 Time: 21:51 C 37.31393 644.3315 0.057911 0.9549 X -0.002008 0.009377 -0.214144 0.8344 RESID(-1) 1.744086 0.234326 7.442998 0.0000 RESID(-2) -1.088243 0.315853 -3.445408 0.0055 R-squared 0.842487 Mean dependent var 4.37E-12 Adjusted R-squared 0.799529 S.D. dependent var 2015.396 S.E. of regression 902.3726 Akaike info criterion 16.67111 Sum squared resid 8957040. Schwarz criterion 16.85992 Log likelihood -121.0333 F-statistic 19.61188 C=37.31393 x=-0.002008 RESID(-1)=1.744086 RESID(-2)= -1.088243 三、序列相关的补救 Dependent Variable: DY Method: Least Squares Date: 12/17/12 Time: 22:07 Sample(adjusted): 1991 2004 Included observations: 14 after adjusting endpoints Variable Coefficient Std. Error t-Statistic Prob. C 2369.885 789.9844 2.999914 0.0111 R-squared 0.954604 Mean dependent var 13875.68 Adjusted R-squared 0.950821 S.D. dependent var 5320.847 S.E. of regression 1179.971 Akaike info criterion 17.11593 Sum squared resid 16707973 Schwarz criterion 17.20722 Log likelihood -117.8115 F-statistic 252.3397 Durbin-Watson stat 0.521473 Prob(F-statistic) 0.000000Eviews序列相关性实验报告
【免费下载】eviews自相关性检验
eviews的相关计量经济学操作
eviews检验相关方法(2)
可靠性数据分析的计算方法
eviews的相关计量经济学操作
eviews统计分析报告
eviews时间序列分析实验
eviews自相关性检验
使用eviews做线性回归分析
eviews统计分析报告
eviews异方差自相关检验与解决办法
Eviews序列相关性实验报告
可靠性数据收集与分析方法
Eviews序列相关性实验报告
自相关问检验的Eviews的操作方法
相关主题
文本预览