用 Apache Derby 进行数据库开发,第 4 部分
- 格式:doc
- 大小:126.00 KB
- 文档页数:9

Hive⼊门第⼀章 Hive 基本概念1.1 什么是 HiveApache Hive是⼀款建⽴在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop⽂件中的结构化、半结构化数据⽂件映射为⼀张数据库表,基于表提供了⼀种类似SQL的查询模型,称为Hive查询语⾔(HQL),⽤于访问和分析存储在Hadoop⽂件中的⼤型数据集。
Hive核⼼是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执⾏。
Hive由Facebook实现并开源。
1.2 为什么使⽤Hive使⽤Hadoop MapReduce直接处理数据所⾯临的问题⼈员学习成本太⾼需要掌握java语⾔MapReduce实现复杂查询逻辑开发难度太⼤使⽤Hive处理数据的好处操作接⼝采⽤类SQL语法,提供快速开发的能⼒(简单、容易上⼿)避免直接写MapReduce,减少开发⼈员的学习成本⽀持⾃定义函数,功能扩展很⽅便背靠Hadoop,擅长存储分析海量数据集1.3 Hive与Hadoop的关系从功能来说,数据仓库软件,⾄少需要具备下述两种能⼒:存储数据的能⼒分析数据的能⼒Apache Hive作为⼀款⼤数据时代的数据仓库软件,当然也具备上述两种能⼒。
只不过Hive并不是⾃⼰实现了上述两种能⼒,⽽是借助Hadoop。
Hive利⽤HDFS存储数据,利⽤MapReduce查询分析数据。
这样突然发现Hive没啥⽤,不过是套壳Hadoop罢了。
其实不然,Hive的最⼤的魅⼒在于⽤户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
1.4 Hive与MysqlHive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都⼗分相似,但应⽤场景却完全不同。
Hive只适合⽤来做海量数据的离线分析。
Hive的定位是数据仓库,⾯向分析的OLAP系统。
因此时刻告诉⾃⼰,Hive不是⼤型数据库,也不是要取代Mysql承担业务数据处理。
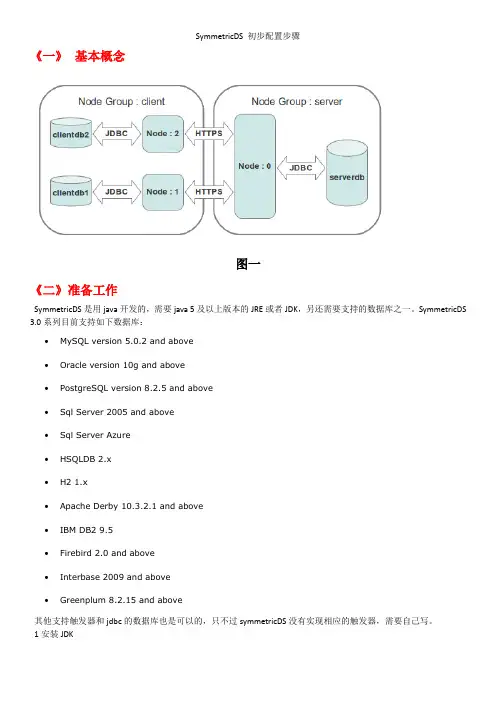
SymmetricDS 初步配置步骤《一》基本概念图一《二》准备工作SymmetricDS是用java开发的,需要java 5及以上版本的JRE或者JDK,另还需要支持的数据库之一。
SymmetricDS 3.0系列目前支持如下数据库:∙MySQL version 5.0.2 and above∙Oracle version 10g and above∙PostgreSQL version 8.2.5 and above∙Sql Server 2005 and above∙Sql Server Azure∙HSQLDB 2.x∙H2 1.x∙Apache Derby 10.3.2.1 and above∙IBM DB2 9.5∙Firebird 2.0 and above∙Interbase 2009 and above∙Greenplum 8.2.15 and above其他支持触发器和jdbc的数据库也是可以的,只不过symmetricDS没有实现相应的触发器,需要自己写。
1安装JDK2 添加java可执行文件的路径到环境变量path2安装数据库,这个步骤本文省略,我们假定所有同步的数据库都是sql server 2005 或者2008《三》安装SymmetricDS安装很简单,直接解压symmetric-ds-3.x.x-server.zip到某个目录《四》创建数据库:本文省略该步骤《五》配置server节点:node_01复制samples/server.properties文件到engines目录2设置server.properties文件里各项参数如下:(1)=server1 :这里指明该代理的名字(2)db.driver=net.sourceforge.jtds.jdbc.Driver :连接SQL server数据库的JDBC驱动,驱动程序已经在安装文件里;(3)db.url=jdbc:jtds:sqlserver://localhost:1433/sample :连接数据库的URL,symmetric所监听的数据库为:sample (4)er=sa db.password=sa :登陆数据库的用户名和密码(5)registration.url= :在所有节点中有一个是symmetricDS的初始数据和参数存放的地方,这个节点称为注册节点,其他节点在第一次启动时需要向该节点申请注册,然后从注册节点获取相应初始数据和参数。

大数据华为认证考试(习题卷3)第1部分:单项选择题,共51题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]ElasticSearch 存放所有关键词的地方是()A)字典B)关键词C)词典D)索引答案:C解析:2.[单选题]DWS DN的高可用架构是:( )。
A)主备从架构B)一主多备架构C)两者兼有D)其他答案:A解析:3.[单选题]关于Hive与传统数据仓库的对比,下列描述错误的是:( )。
A)Hive元数据存储独立于数据存储之外,从而解耦合元数据和数据,灵活性高,二传统数据仓库数据应用单一,灵活性低B)Hive基于HDFS存储,理论上存储可以无限扩容,而传统数据仓库存储量有上限C)由于Hive的数据存储在HDFS上,所以可以保证数据的高容错,高可靠D)由于Hive基于大数据平台,所以查询效率比传统数据仓库快答案:D解析:4.[单选题]以下哪种机制使 Flink 能够实现窗口中无序数据的有序处理?()A)检查点B)窗口C)事件时间D)有状态处理答案:C解析:5.[单选题]下面( )不是属性选择度量。
A)ID3 使用的信息增益B)C4.5 使用的增益率C)CART 使用的基尼指数D)NNM 使用的梯度下降答案:D解析:C)HDFSD)DB答案:C解析:7.[单选题]关于FusionInsight HD Streaming的Supervisor描述正确的是:( )。
A)Supervisor负责资源的分配和任务的调度B)Supervisor负责接受Nimbus分配的任务,启动停止属于自己管理的Worker进程C)Supervisor是运行具体处理逻辑的进程D)Supervisor是在Topology中接收数据然后执行处理的组件答案:B解析:8.[单选题]在有N个节点FusionInsight HD集群中部署HBase时、推荐部署( )个H Master进程,( )个Region Server进程。

特征列表与其他数据库引擎的对比H2案例连接模式J D B C数据库连接U R L说明连接本地内嵌数据库内存数据库数据库文件加密数据库文件锁定仅打开存在的数据库关闭数据库忽略未知参数设置打开连接时设置参数更新记入索引指定文件读写模式多连接数据库文件说明日志记录与恢复兼容性自动重连自动切换到混合模式使用跟踪选项使用第三方日志包只读数据库Z i p或J a r文件只读数据库智能磁盘监控包含计算列方法列的索引复合索引使用密码用户自定义方法和存储过程触发器压缩数据库缓存设置特征列表主要特征∙超快的数据库引擎∙开源∙纯JA V A编写∙支持标准SQL和JDBC∙支持内嵌模式、服务器模式和集群∙高强度的安全保障∙支持PostgreSQL的ODBC驱动∙多种并发机制其他特征∙支持磁盘和内存数据库,支持只读数据库,支持临时表∙支持事务(读提交和序列化事务隔离),支持2阶段提交∙支持多连接,支持表级锁∙使用基于成本的优化机制,对于复杂查询使用零遗传算法进行管理∙支持可滑动可更新的结果集,支持大型结果集、支持结果集排序,支持方法返回结果集∙支持数据库加密(使用AES或XTEA进行加密),支持SHA-256密码加密,提供加密函数,支持SSLSQL支持∙支持多个schemas和信息schema∙支持数据完整性约束,外键约束,主键约束∙支持内连接和外连接,子查询,只读视图和内联视图∙支持触发器,JA V A方法,存储过程∙大量内置方法,包括XML和无损数据压法方法∙广泛的数据类型,包括大数据类型(BLOB/CLOB)和数组∙序列和自增字段,计算字段(可用于索引)∙ORDER BY, GROUP BY, HA VING, UNION, LIMIT, TOP∙排序规则的支持,以及用户和角色的支持∙兼容IBM DB2, Apache Derby, HSQLDB, MS SQL Server, MySQL, Oracle, 和PostgreSQL等多种数据库.安全属性∙已经包含了一个SQL注入问题的解决方案∙用户密码使用SHA-256进行加密∙服务器连接模式,用户的密码在网络上传输时已经不是明文(即使使用非安全连接,但不包括将密码写在连接URL中时,即当把密码写在URL中时,传输过程中密码是明文)∙所有的数据库文件(包括备份数据导出的脚本文件)都可以使用AES-256和XTEA 进行加密∙远程的JDBC驱动支持基于SSL/TLS的TCP/IP连接∙内置的WEB服务支持基于SSL/TLS的连接∙密码能被发送到数据库通过字符数组而不是字符串其他特征和工具∙小尺寸(不到1MB),低内存需求∙多种索引类型(b-tree, tree, hash)∙支持复合索引∙支持CSV (逗号分隔)文件∙支持连接表,内置了虚拟范围表∙支持执行计划EXPLAIN PLAN,多种跟踪选项∙能延迟关闭数据库或禁用数据库,以提高性能∙基于WEB的控制台应用程序∙数据库可以导出为SQL脚本文件∙包含一个恢复工具,可以转储数据库∙支持变量(如计算汇总数)∙自动完成语法分析和优化∙只使用很少的数据库文件∙使用校验和保障每条记录和日志的完整性∙已经经过周密的测试(高代码覆盖,随机压力测试)与其他数据库引擎的对比特征H2Derby HSQLDB MySQL PostgreSQL 纯JA VA Yes Yes Yes No No内嵌入Java应用Yes Yes Yes No No性能(内嵌模式)Fast Slow Fast N/A N/A内存数据库模式Yes Yes Yes No No事务隔离Yes Yes No Yes Yes成本优化器Yes Yes No Yes Yes解释计划(Explain Plan)Yes No Yes Yes Yes集群Yes No No Yes Yes数据库加密Yes Yes No No No连接表Yes No Partially *1Partially *2NoODBC驱动Yes No No Yes Yes全文检索Yes No No Yes Yes用户自定义数据类型Yes No No Yes Yes每数据库文件数Few Many Few Many Many表级锁Yes Yes No Yes Yes行级锁Yes *9Yes No Yes Yes多种并发机制Yes No No No Yes基于角色的安全机制Yes Yes *3Yes Yes Yes可更新结果集Yes Yes *7No Yes Yes序列(Sequences)Yes No Yes No Yes限制和偏移(Limit and Offset)Yes No Yes Yes Yes临时表Yes Yes *4Yes Yes Yes信息Schema Yes No *8No *8Yes Yes计算列Yes No No No Yes *6不区分大小写列Yes No Yes Yes Yes *6自定义聚合方法Yes No No Yes Yes尺寸(jar/dll 大小)~1 MB *5~2 MB~700 KB~4 MB~6 MB*1 HSQLDB 支持文本表*2 MySQL 支持标记为'federated tables'的链接表*3 Derby 有一个选项可以支持基于角色的安全和密码认证*4 Derby 仅支持全局的临时表*5 H2的jar文件包含了调试信息,其他数据的jar文件中不不包括*6 PostgreSQL 支持方法索引*7 Derby 仅支持在查询结果集未被排序的情况下的可更新*8 Derby 和HSQLDB 都不支持标准的信息schema表*9 H2 在多并发的情况下支持行级锁Derby 和HSQLDB在进程非正常退出(如断电)情况下,H2在不需要任何用户干预的情况能安全的恢复。

在Derby中使用内建用户名和密码5一月,2011(06:24)|Derby|By:CrazyLee帮助1 2 3 4 5 6 7 8 9--首先指定为内建用户名和密码CALLSYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY('derby.authentication.prov ider','BUILTIN');CALLSYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY('derby.connection.requireA uthentication','true');--创建一个用户名为root密码为1234567的访问用户CALLSYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY('er.root','1234567 ');--设置全局访问用户为rootCALLSYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY('derby.database.fullAccess Users','root');--全局默认连接方式为未连接CALLSYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY('derby.database.defaultCon nectionMode','noAccess');在ij下执行以上语句,执行完毕后,重新使用ij登录时,就需要输入用户名和密码了(切记Derby的数据库服务器需要重启!!!):与其他开放源代码数据库相比,Derby是独一无二的。
它的确是功能丰富的关系型数据库。
而且,它完全是免费提供的,没有商业许可限制。
MyEclipse Derby服务器:自动进行JDBC连接;可配置的启动选项。

Java数据库连接池介绍(7)--HikariCP介绍HikariCP 是⼀个快速、简单、可靠的 JDBC 连接池,在性能上做了很多优化,是⽬前最快的数据库连接池;本⽂主要介绍 HikariCP 的基本使⽤,⽂中使⽤到的软件版本:Java 1.8.0_191、HikariCP 4.0.3、Spring Boot 2.3.12.RELEASE。
1、配置参数HikariCP 所有时间相关的参数单位都为 ms。
1.1、基本配置参数默认值描述dataSourceClassName none驱动⾥⾯数据源的类名称;不⽀持 XA数据源,各数据源对应的数据源类名可参见 ”2、数据源类名“jdbcUrl none连接 url;该参数与 dataSourceClassName 设置⼀个即可username none⽤户名password none密码1.2、常⽤配置参数默认值描述autoCommit true连接返回连接池时,是否⾃动提交事务connectionTimeout30000从连接池获取连接的最⼤超时时间idleTimeout60000空闲连接存活的最⼤时间,当空闲连接数>minimumIdle 且连接的空闲状态时间>idleTimeout 时,将把该连接从连接池中删除;只有当 minimumIdle < maximumPoolSize 时,该设置才⽣效;0 表⽰永不超时keepaliveTime 0保持空闲连接可⽤的检测频率;0 表⽰不检测maxLifetime1800000连接存活的最⼤时间;0 表⽰没有限制connectionTestQuery none连接检测的查询语句;如果驱动⽀持 JDBC 4,强烈建议不要设置此参数minimumIdle same asmaximumPoolSize最⼩空闲连接数;为了提⾼性能,建议不要设置此参数,使连接池为固定⼤⼩maximumPoolSize10最⼤连接数metricRegistry none该参数仅通过编程配置或 IoC 容器可⽤;该参数⽤于指定池使⽤的 Codahale/DropwizardMetricRegistry实例来记录各种指标。

Java程序员应该知道的20个有⽤的lib开源库⼀般⼀个经验丰富的开发者,⼀般都喜欢使⽤开源的第三⽅api库来进⾏开发,毕竟这样能够提⾼开发效率,并且能够简单快速的集成到项⽬中去,⽽不⽤花更多的时间去在重复造⼀些⽆⽤的轮⼦,多了解⼀些第三⽅库可以提⾼我们的开发效率,下⾯就来看⼀下在开发过程中经常会⽤到的⼀些开发第三⽅库,也可能不是太全,就列举⼀些常见或者常⽤的吧。
1,⽇志库
⽇志库是最常⽤的,毕竟在开发项⽬的过程中都需要使⽤⽇志来记录项⽬的运⾏信息,从⽽很快的定位项⽬的发⽣的问题。尽管JDK附带了⾃⼰的⽇志库,但是还有更好的选择,例如Log4j、SLF4j和LogBack。⼀般建议使⽤SLF4j。⽐如Alibaba开发⼿册上也是这样说的,毕竟SLF4J使您的代码独⽴于任何特定的⽇志API,就是在项⽬的其它框架中使⽤了其它的⽇志框架库也能够很好的集成。
2,JSON转换库
在当今的web服务、⼿机api接⼝开发和物联⽹世界中,JSON已经成为将信息从客户端传送到服务器的⾸选协议。它们已经取代了XML,成为以独⽴于平台的⽅式传输信息的⾸选⽅式。不幸的是,JDK没有JSON库。但是,有许多优秀的第三⽅库允许您解析和创建JSON消息,⽐如Jackson和Gson,FastJson。
3,单元测试库库
单元测试是区分普通开发⼈员和优秀开发⼈员的最重要的东西。程序员经常被给予不写单元测试的借⼝,但是最常见的避免单元测试的借⼝是缺乏流⾏的单元测试库的经验和知识,包括JUnit、Mockito和PowerMock。
4,通⽤类库
Java开发⼈员可以使⽤⼀些优秀的通⽤第三⽅库,⽐如Apache Commons和⾕歌Guava。我总是在我的项⽬中包含这些库,因为它们简化了许多任务。正如约书亚•布洛赫(Joshua Bloch)在《Effective Java》⼀书中正确指出的那样,重新发明轮⼦是没有意义的。我们应该使⽤经过测试的库,⽽不是时不时地编写我们⾃⼰的程序。对于开发⼈员来说,熟悉Apache Commons和⾕歌Guava是很有⽤的。

JetspeedJetExpress Tutorial Portal笔记1定制portal安装1.0约定目录分隔符使用’/'等同于’\',文中仅使用’/’1.1资源∙Jetspeed Tutorial地址:/tutorials/jetspeed-2/index.html∙Jetspeed Tutorial Resources文件:/tutorials/resources/jetspeed-2-resources.zip∙Jetspeed Tutorial Repository:/maven2/repository.zip∙Java : 1.4+(本文使用1.5)∙Maven : 2.0.x (本文使用2.0.7)∙Tomcat 5.5(要求5.0或5.5):/download-55.cgi1.2工作环境配置(初始化)∙环境:windows XP SP2∙目录:Jetspeed Tutorial根目录定义为c:/JetspeedTraining,以下仅书写为/JetspeedTrainingo创建/JetspeedTraining目录o创建/JetspeedTraining/tomcat-express目录,拷贝tomcat5.5到这个目录o修改/JetspeedTraining/tomcat-express/conf/tomcat-users.xml文件如下(全部内容):<?xml version=”1.0″ encoding=”UTF-8″?><tomcat-users><user name=”tomcat” password=”tomcat” roles=”tomcat” /><user username=”j2deployer” password=”j2deployer”roles=”admin,manager,tomcat”/></tomcat-users>o创建/JetspeedTraining/maven/repository目录,解压/maven2/repository.zip在这个目录o创建/JetspeedTraining/resources目录,解压/tutorials/resources/jetspeed-2-resources.zip后的文件夹改名为resources后放在这里o创建/JetspeedTraining/database目录,用于存放Derby数据库文件(简化配置,暂不使用mysql,相关配置在jetspeed的getting started文档有,很简单)o创建/JetspeedTraining/workspace目录,作为工作目录o配置:拷贝/JetspeedTraining/resources/maven/settings.xml.jetexpress “%USERPROFILE%/.m2/settings.xml”!!!未做任何修改,主要是上面的配置是按它给的配置文件配的注 1 : /JetspeedTraining/database/jetexpress目录不能预先创建,只能创建/JetspeedTraining/database目录,否则3.2步时会出现数据库无法创建的错误。


SymmetricDS数据同步工具安装使用说明书随着大数据产品功能的丰富,以及用户对于大数据的时效性的需求,需要」款能够实现跨数据库,以及同一种数据库跨版本的数据同步工具,同时要能够支撑数据库到Kafka的数据推送。
目前大数据技术组研发了一款yhbi的同步工具,支持从oracle到oracle的同步,以及oracle 到Kafka的同步,但是受限于不能支持oracle12c版本数据的同步。
OGG也可以实现oracle至ijoracle,以及oracle到其他目标端数据库或者消息队列的同步,但OGG的费用、维护成本较高。
故采用了一款名为SymmetricDS的开源数据库同步工具。
2.简介SymmetricDS就像其名称一样,是为了实现数据源的对称性"也就是数据同步。
SymmetricDS是用于数据库和文件同步的开源软件,支持多主复制、过滤同步和转换。
它使用web(HTTP传输)和数据库技术(触发器)将更改数据复制为预定的或接近实时的操作,并且它还包含了完整数据负载的初始负载特性。
该软件的设计目的是针对大量节点,跨低带宽连接工作,并经得起网络中断。
2.1.概述SymmetricDS的同步原理如下图所示。
节点负责使用HTTP 将来自数据库或文件系统的数据与网络中的其他节点进行同步。
节点被分配给作为一个单元配置在一起的节点组之一。
节点组与组链接链接在一起,以定义推或拉通信。
pull 使一个节点与其他节点连接并请求正在等待的更改,而push 使一个节点在需要发送更改时与其他节点连接。
每个节点都通过使用连接URL 用户名和密码的Java 数据库连接(JDB 砥区动程序连接到数据库。
虽然节点可以跨广泛的区域网络进行分隔,但是为了获得最佳性能,节点所连接的数据库应该位于局域网络附近。
节点使用其数据库连接创建表作为配置设置和运行时操作的数据模型。
用户填充配置表以定义同步,运行时表捕获更改并跟踪活动。
要同步的表可以位于连接可访问的任何目录和模式中,而要同步的文件可以位于本地服务器可访问的任何目录中。
1、MySQL WorkbenchMySQL Workbench是一款专为MySQL设计的ER/数据库建模工具。
它是著名的数据库设计工具DBDesigner4的继任者。
你可以用MySQL Workbench 设计和创建新的数据库图示,建立数据库文档,以及进行复杂的MySQL 迁移MySQL Workbench是下一代的可视化数据库设计、管理的工具,它同时有开源和商业化的两个版本。
该软件支持Windows和Linux系统,下面是一些该软件运行的界面截图:2、数据库管理工具Navicat LiteNavicat TM是一套快速、可靠并价格相宜的资料库管理工具,大可使用来简化资料库的管理及降低系统管理成本。
它的设计符合资料库管理员、开发人员及中小企业的需求。
Navicat是以直觉化的使用者图形介面所而建的,让你可以以安全且简单的方式建立、组织、存取并共用资讯。
界面如下图所示:Navicat 提供商业版Navicat Premium 和免费的版本Navicat Lite 。
免费版本的功能已经足够强大了。
Navicat 支持的数据库包括MySQL、Oracle、SQLite、PostgreSQL和SQL Server 等。
3、开源ETL工具KettleKettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定(数据迁移工具)。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
•授权协议:LGPL•开发语言:Java•操作系统:跨平台4、Eclipse SQL ExplorerSQLExplorer是Eclipse集成开发环境的一种插件,它可以被用来从Eclipse连接到一个数据库。
SQLExplorer插件提供了一个使用SQL语句访问数据库的图形用户接口(GUI)。
通过使用SQLExplorer,你能够显示表格、表格结构和表格中的数据,以及提取、添加、更新或删除表格数据。
birt报表初级教程之数据源配置数据源配置在布局编辑器中开始设计报表之前,构建BIRT数据源以将报表连接至数据库或其他类型的数据源。
构建数据源时,要指定驱动程序类、数据源名称和其他连接信息(例如,用户名和密码)。
Birt自带一个已经配置为与BIRT报表设计器配合使用的样本数据库Classic Models,对于本教程使用的是Derby数据库。
1.选择数据资源管理器(Data Explorer)。
如果使用缺省报表设计透视图,则数据资源管理器位于布局编辑器的左边,在选用板(Palette)的旁边,如图所示。
如果它尚未打开,则选择窗口->显示视图->数据资源管理器。
2.右键单击Data Sources然后从上下文菜单中选择新建数据源。
新建数据源显示可以创建的数据源的类型,如图所示。
●Classic Models Inc.Sample DataBase———上面说过是BIRT样本数据库。
●Flat File Data Source———从CSV、SSV、TSV、PSV四种格式的文件获取数据源。
●JDBC Data Source———通过配置jdbc连接数据库。
●Script Data Source———通过编写脚本获取数据源。
●Web Services Data Source———通过web service方式获取数据源。
●XML Data Source———从xml文件获取数据源。
3.这里我们介绍通过JDBC Data Source配置数据源。
选择JDBC Data Source,输入数据源名称,点击Next,配置Jdbc信息。
如下图:●首先,单击Manage Drivers添加驱动包。
如下图:单击add,选择derby数据库的derbyclient.jar驱动包。
点击ok,驱动完成添加。
●配置信息:Driver Class:org.apache.derby.jdbc.ClientDriver(v10.1)(通过下拉菜单可以找到)Database URL:jdbc:derby://【host】:1527/【database】User Name:用户名Password:密码4.测试连接,测试前查看derby数据库是否启动;点击Test Connection。
使用迁移工具将应用及其配置从Tomcat 迁移到WAS v8.5.5 Liberty ProfileCheryl King, IBM China顾问软件工程师本文提供了将应用程序及其配置信息从Apache Tomcat 迁移到IBM® WebSphere® Application Server V8.5.5 Liberty Profile 的说明,使用两个实用程序(其中一个是新的,适用于V8.5.5)可让迁移变得简单可靠。
简介Apache Tomcat 是一个HTTP 服务器和servlet 容器,常用于简单的Web 应用程序,以及使用不需要完整的Java™ EE 服务器的框架的应用程序。
然而,用户经常会发现,当对Apache Tomcat 有更多需求时,其最初的简单性就会变得复杂且不实用。
例如,也许Apache Tomcat 安装的占用空间会变得太大,因为您需要添加第三方库来提供所需的功能。
或者,服务器的启动时间也可能是一个问题,因为对server.xml 文件的任何配置更改都需要重新启动Apache Tomcat 服务器。
又或者,集成和维护第三方库已经变得过于费时。
以上任何一种情况都足以让您考虑将Apache Tomcat 应用程序及其配置信息迁移到IBM WebSphere Application Server V8.5.5 Liberty Profile。
Liberty Profile 提供一个轻量级且简单易用的应用程序服务器,其占用空间小,并且服务器的启动也很快。
它还包括许多Apache Tomcat 所没有的Java EE 特性,因而减少了集成和维护第三方库的需求。
利用Liberty Profile:∙用户配置其应用程序所需要的组件,使服务器占用空间较小且服务器启动时间更快。
∙配置变更不需要重新启动服务器。
它们是自动生效的。
∙WebSphere Application Server Developer T ools for Eclipse 使在Liberty profile 上开发、测试和发布Web 应用程序变得更容易。
SSH框架Struts2.1+Spring3.1.1+Hibernate4.2.0编号:SSH-S2-S3-H4版本:V1.1环境说明本文章是根据个人的搭建经验完成的轻量级SSH框架,也是实际应用中比较全面的基础框架。
其中SSH指:Struts,Spring, Hibernate,是一个将MVC思想发挥的很好的web框架。
开发平台: Windows 7 + MyEclipse 2014 + Tomcat 8.0.3+ JDK 1.8 + Mysql不同的版本大同小异。
其中SSH所需的包均直接使用MyEclipse2014内集成的jar包,这样无需手动添加,比较方便。
建立工程目录新建工程打开MyEclipse,新建一个web project:file -> new -> Web Project 如下图所示:然后next两步,到下面时,修改一点:之后直接next到finish即可,建立后目录如下:建立src目录为了使得目录结构清晰,将不同层次的源程序放到不同包内,分别建立如下4个目录:- com.ssh.action :存放Action代码- com.ssh.service :存放Service代码- com.ssh.dao :存放Dao代码- com.ssh.entity :存放数据库实体类直接右击src, 然后new -> package 如下图:然后直接finishi即可。
同样的步骤建立剩下三个目录。
这一步完成后的目录如下:导入Struts,Spring,Hibernate环境就是导入SSH环境了,这里使用的是MyEclipse集成的jar包导入Struts过程:右击项目名SSH 然后 MyEclipse ->Project Facets[capabilities]->Install Apache Struts 2.x Facet初始图如下:next到这步修改为第三项(重要):之后一直到finish即可。
Hive 是什么在接触一个新的事物首先要回到的问题是:这是什么?这里引用Hive wiki 上的介绍:Hive is a data warehouse infrastructure built on top of Hadoop. It provides tools to enable easy data ETL, a mechanism to put structures on the data, and the capability to querying and analysis of large data sets stored in Hadoop files. Hive defines a simple SQL-like query language, called QL, that enables users familiar with SQL to query the data. At the same time, this language also allows programmers who are familiar with the MapReduce fromwork to be able to plug in their custom mappers and reducers to perform moresophisticated analysis that may not be supported by the built-in capabilities of the language.Hive 是建立在Hadoop 上的数据仓库基础构架。
它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop 中的大规模数据的机制。
Hive 定义了简单的类SQL 查询语言,称为QL,它允许熟悉SQL 的用户查询数据。
同时,这个语言也允许熟悉MapReduce 开发者的开发自定义的mapper 和reducer 来处理内建的mapper 和reducer 无法完成的复杂的分析工作。
用 Apache Derby 进行数据库开发,第 4 部分 Apache Derby 软件提供了功能强大的开发源码数据库,可用作范围广泛的数据库应用程序的持久存储库。它受欢迎的主要原因之一是 Apache Derby 的查询支持,该支持允许您有选择地从一个或多个表的特定行中提取满足某个布尔条件的列。了解 Apache Derby 的查询能力以及如何使用 SELECT 语句执行复杂查询。 数据库查询
本系列的前一篇文章 用 Apache Derby 进行开发 —— 取得节节胜利:用 Apache Derby 进行数据库开发,第 3 部分:运行脚本和插入数据,在结束时运行了一个脚本,该脚本插入了 10 行,然后显示这些行进行验证。那篇文章没有讨论如何选择显示的行,因为它侧重于介绍如何将数据插入 Apache Derby 数据库中。本 文的主题是从 Apache Derby 数据库中选择和提取数据。在可以执行数据库查询之前,必需创建一个数据库,其中包含用相关数据填充的多个表。 本文并没有假设您具有这样的一个数据库或者要求您完成本系列前几篇文章中列出的步骤,而是提供了一个叫做 derby5.build.sql 的 SQL 脚本文件,它捆绑在叫做 derby5.zip 的 .zip 文件(参阅本文后面的 下载 一节)中。该 SQL 脚本文件首先创建一个数据库,然后以各自的模式创建两个表,在每个表中插入 10 行,然后显示两个表的内容进行验证。要运行该脚本文件中的命令,可以使用本系列前一篇文章中讨论的三种方法之一,或者使用 清单 1 所示的命令。
清单 1. 初始化 Derby 工作区 rb$ mkdir derbyWork rb$ cd derbyWork/ rb$ unzip ../derby5.zip Archive: ../derby5.zip inflating: derby.build.sql rb$ ls derby.build.sql rb$ java org.apache.derby.tools.ij < ../derby.build.sql ij version 10.1 ij>ij> ERROR 42Y07: Schema 'BIGDOG' does not exist ij> ERROR 42Y07: Schema 'BIGDOG' does not exist ij> 0 rows inserted/updated/deleted ij> 0 rows inserted/updated/deleted ij> 10 rows inserted/updated/deleted ij> 10 rows inserted/updated/deleted ij> ITEMNUMBER |PRICE |STOCKDATE |DESCRIPTION ------------------------------------------------------------------------ 1 |19.95 |2006-03-31|Hooded sweatshirt 2 |99.99 |2006-03-29|Beach umbrella 3 |0.99 |2006-02-28| 4 |29.95 |2006-02-10|Male bathing suit, blue 5 |49.95 |2006-02-20|Female bathing suit, one piece, aqua 6 |9.95 |2006-01-15|Child sand toy set 7 |24.95 |2005-12-20|White beach towel 8 |32.95 |2005-12-22|Blue-striped beach towel 9 |12.95 |2006-03-12|Flip-flop 10 |34.95 |2006-01-24|Open-toed sandal
10 rows selected ij> ITEMNUMBER |VENDORNUMB&|VENDORNAME ------------------------------------------------------ 1 |1 |Luna Vista Limited 2 |1 |Luna Vista Limited 3 |1 |Luna Vista Limited 4 |2 |Mikal Arroyo Incorporated 5 |2 |Mikal Arroyo Incorporated 6 |1 |Luna Vista Limited 7 |1 |Luna Vista Limited 8 |1 |Luna Vista Limited 9 |3 |Quiet Beach Industries 10 |3 |Quiet Beach Industries
10 rows selected ij> rb$
清单 1 所示的命令创建并更改工作目录(在本例中为 derbyWork),展开包含本文其余部分所需的 SQL 构建命令的 .zip 文件,并使用 ij Apache Derby 交互式 SQL 工具运行脚本文件中的 SQL 命令。虽然您不必执行其中所有命令,但却需要处理 derby.build.sql 脚本文件,因为它创建两个表并用数据填充这些表。 在本例中,您可能会获得几个错误之一。例如,您可能获得 database exists 错误,或者是 清单 1 所示的 schema does not exist 错误。这两个错误都可以安全地忽略。如果获得其他错误,或者没有得到包含 10 rows selected 消息的行列表,则发生了一些必须解决的错误。有关可能出现的问题的更多信息,请参阅本系列的第一篇文章 用 Apache Derby 进行开发 —— 取得节节胜利:Apache Derby 简介,或 Apache Derby 网站(参阅本文末尾处的 参考资料 一节中的链接)。
选择数据 在 SQL 编程语言中,执行查询的任务属于 SELECT 语句。为了提供数据库应用程序所需的所有查询功能,SELECT 语句的能力十分广泛。下文将介绍 SELECT 语句的基础知识,它允许您为启用数据库的应用程序构建功能强大的查询。首先,在下一节中将介绍 SELECT 的形式语法。 SELECT 语句语法
回页首 在形式上,SELECT 语句的语法十分简单,如 清单 2 所示。基本格式是 SELECT ... FROM ... WHERE;您可以从一个或多个表的行中选择您感兴趣的满足特定条件的列。当然,事情可以变得更加复杂。本文将介绍 SELECT 的基本功能,而将比较高级的问题留给后续文章。
清单 2. SELECT 语句的形式语法 SELECT [ DISTINCT | ALL ] SelectItem [ , SelectItem ]* FROM clause [ WHERE clause ] [ GROUP BY clause ] [ HAVING clause ]
从 清单 2 的语法中,可以看到基本的 SELECT 语句只需要 SELECT 和 FROM 语句;必须指定要选择的数据并指明您感兴趣的数据的位置。其他内容都是可选的(用方括号表示)。DISTINCT 和 ALL 关键字是可选的限定符,分别用于指明应选择包含惟一值的行还是选择所有行。默认情况下,ALL 是隐式指定的,并且每个 SELECT 语句只可以使用一个 DISTINCT 限定符。 在 SELECT 关键字之后,SELECT 语句可以列出多个列。Apache Derby 目前的限制为 SELECT 关键字之后最多可以有 1,012 个元素 —— 这意味着您可能永远无需担心这个限制!多个元素(或者更通俗地说,是多个列名称)用逗号分隔开。例如,SELECT a, b, c 选择三个列 a、b 和 c。要选择表中的所有列,可以使用星号 (*) 作为所有列的简写。值得注意的重要一点是,任何 SELECT 语句的结果都是 Apache Derby 表,您可以用几乎与使用更持久的表相同的方式来使用该表。 SELECT 语句的 FROM 组件指明将从哪个表(或多个表)中提取数据。这一节将重点介绍如何从单表中选择数据;本文中的 最后一节 将介绍表连接和如何从多个表中进行选择。在这种情况下,要查询的表的完全限定名称必须位于 FROM 关键字之后。 SELECT 语句的其他部分都是可选的。但是,在构建第一个查询之前,您应该知道 Apache Derby 对 SELECT 语句组件的求值顺序。当 Apache Derby 处理查询时,求值顺序是:
1. FROM 子句 2. WHERE 子句 3. GROUP BY 子句 4. HAVING 子句 5. SELECT 子句
当您对 Apache Derby 处理查询时执行的过程进行分解时,该顺序十分直观。首先必须定位要分析的数据,然后过滤出感兴趣的行。下一步是对相关行进行分组,最后是选择感兴趣的实际列。 从表中选择行
为了演示 SELECT 语句,可以提取位于 bigdog 模式中的 products 表中的所有列,如 清单 3 所示。
清单 3. 使用 SELECT 语句提取 Apache Derby 表中的行 rb$ java org.apache.derby.tools.ij ij version 10.1 ij> connect 'jdbc:derby:test' ; ij> SELECT * FROM bigdog.products ; ITEMNUMBER |PRICE |STOCKDATE |DESCRIPTION ------------------------------------------------------------------------ 1 |19.95 |2006-03-31|Hooded sweatshirt