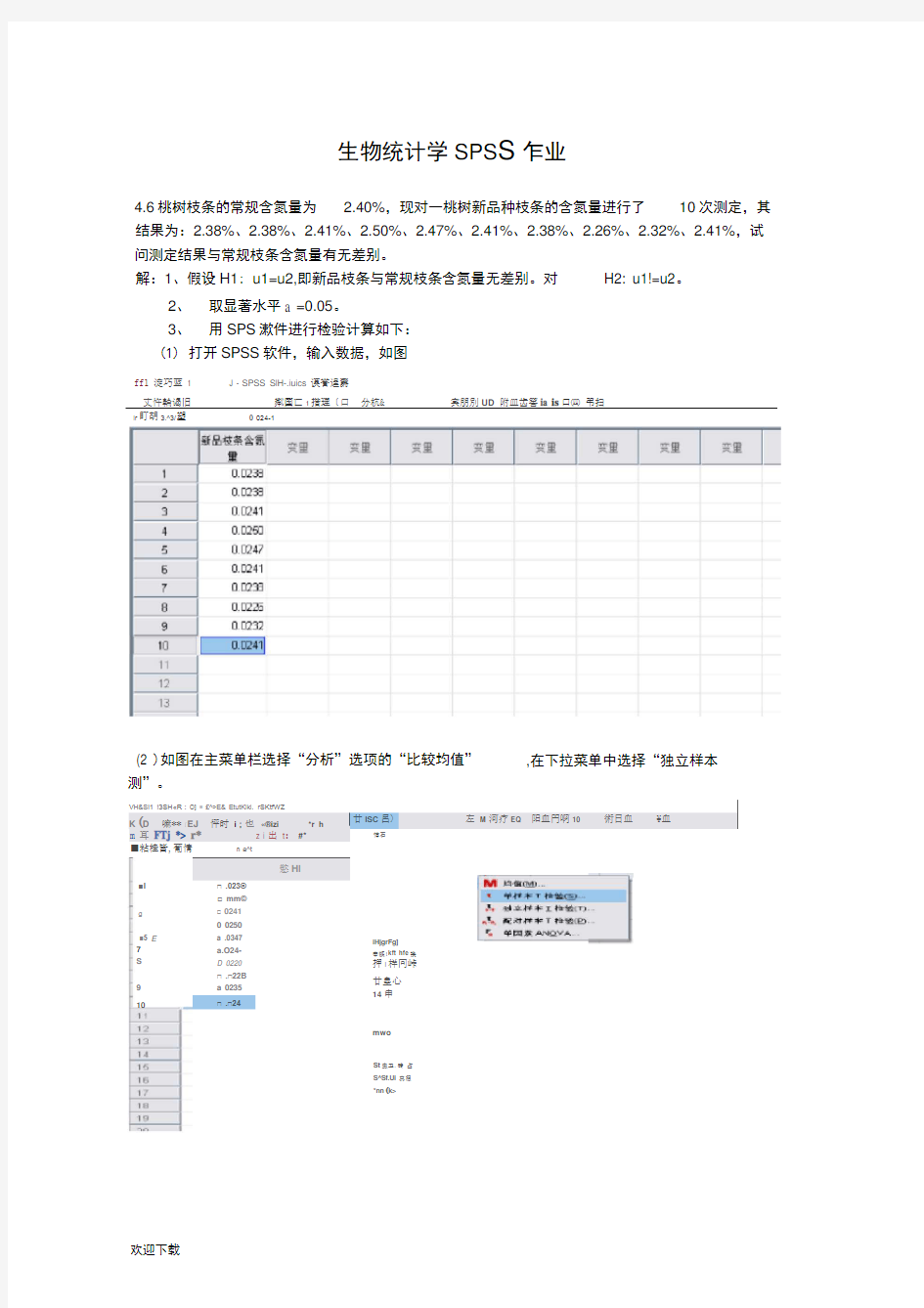

VH&SI1 !3SH?R:
O] ■ £^>E& EtutKlki. rSKtfWZ
K (D 嘛**〔EJ 怦时 i ;也 ??izi
*r h 左 M 河疗EQ 阳血円啊10 術日血 ¥血 m 耳 FTj *> r* z i 出 t : #* ■粘桂皆,葡情 n a^t 慾Hl ■i □ .023? 口 mm? g □ 0241 0 0250 ■5 E 7 S a .0347 a.O24- D 0220 □ .□22B 9 a 0235 10 □ .□24 iHjgrFg] 申旣!kft hfe 换 押i 样冋峠 廿皇心 14申 mwo St 虫卫.砖 占 S^Sf.Ui 真租*nn (k> 生物统计学SPS S 乍业 4.6桃树枝条的常规含氮量为 2.40%,现对一桃树新品种枝条的含氮量进行了 10次测定,其 结果为:2.38%、2.38%、2.41%、2.50%、2.47%、2.41%、2.38%、2.26%、2.32%、2.41%,试 问测定结果与常规枝条含氮量有无差别。 解:1、假设H1: u1=u2,即新品枝条与常规枝条含氮量无差别。对 H2: u1!=u2。 2、 取显著水平a =0.05。 3、 用SPS 漱件进行检验计算如下: (1) 打开SPSS 软件,输入数据,如图 ffl 淀巧蓝 1 J - SPSS SlH-.iuics 谟誉逞欝 丈忤輪谒旧 粼国匸1揩理〔口 分杭& 宾朋別UD 附皿齿窖ia is 口㈣ 弔扫 (2 )如图在主菜单栏选择“分析”选项的“比较均值” ,在下拉菜单中选择“独立样本 测”。 ir 盯胡3.^3/塑 0 024-1 悴石 (3 )在下图中将左边方框中的“新品枝条含氮量”放到右边的“检验变量”方框中,并选 择“确定”。即可得出“单样本 T 检验”的检验结果。 '二輪駆? 血弋咔? 井西〔町圏師? 口冃肪I!』聊时執§ 阿 iA R 林4祐垂8? A <4 13 16 [sf 品檢斎空址 Q.0233 0.023E QO2i1 0.0250 0.024? 00241 0.0233 0.0226 0.0332 00241 17 i 0 10 11 12 3.: : 14 15 拙 1 反容 1] - EPSS Stadstia 臺吕 口 笛颂口 牡用3 即嵐Q? 尸枷口 齣入① 端畫 廿珂山 阳菲回 斗砌?删』 FT 口血 駅岂 I 鸟 Bl H E 切 2 S ^)& S? ?T rzsr /TESTTAL^O. 0240 /HIJS :UQ-AMALYSJS A'^. I ABLE 3-新吕枝¥含歳星 /JhU'EKLA^lGSS). L 數据舆■一 4、结果分析 由SPSS “单样本T 检验” 检验结果可知 t=-0.371 Sig. (2-Tailed)是双尾t 检验显著概率 0719大于0.05,所以可以接受假设 H1,即新品枝条与常规枝条含氮量无差别 {簡出 -(£日志 —回ns 验 nW (n _?晦注 -L □咅欣福隼 遍罩牛1帝綾计黑 —(S 羊亍祥 枣豔 ie 日志 I 冋晞邂 颌 E 吻唯注 P 活堆㈱援焦 T4I 羊十祥盘耶谨 单$丼本收验 4.8假说:“北方动物比南方动物具有较短的附肢。 ”未验证这一假说,调查了如下鸟翅长 (mm )资料:北方的:120 113 125 118 116 119 ;南方的:116 117 121 114 116 118 123 120。 试 检验这一假说。 解:1、假设H1: u1=u2,即北方动物和南方动物的附肢没有差别。对 H2: u1!=u2。 2、 取显著水平a =0.05。 3、 用SPS 漱件进行检验计算如下: (1)打开SPSS 软件,输入数据,如图 (2 )如图在主菜单栏选择“分析”选项的“比较均值” ,在下拉菜单中选择“独立样本 T 检 测”。 (3)在下图中将左边方框中的“翅长”放到右边的“样本变量 (s)”方框中,将“状态”放 到“分组变量”中,并选择“定义组” 虽忖存 In 坯牛 梅古 15址苍 a-n ■Stf 审 f i 110 00 1 SflM It 罷曰也1御i £ 116 00 1 裤右虛里? 神汹Fl 咸 & 111 H J X 1 7 I ~____ )1^00 1 9 11161 3] 2 9 )17 00 10 121.00 11 11J.H 5 12 HIE DC T 乳岚EJ 13 1110.00 2 Hit 14 123 CD 2 撇曙(⑥ 15 120.00 2 1S WWD 17 10 19 20 f qjiiHijj 21 s^ia^riU 12 jr 懦就? FH HOC- 址沁 沁归M 牝 IMX I % * r 网蚩 生物统计学 名词解释: 1.生物统计学:是数理统计在生物学研究中的应用,它是应用数理统计的原理,运用 统计方法来认识、分析、推断和解释生命过程中的各种现象和试验调查资料的科学。 2.总体:具有相同性质或属性的个体所组成的集合称为总体,它是指研究对象的全 体; 3.个体:组成总体的基本单元称为个体; 4.样本:从总体中抽出若干个体所构成的集合称为样本; 5.样本容量:样本中所包含的个体数目称为样本容量。 6.集中性:资料中的观测值从某一数值为中心而分布的性质。 7.离散性:是变量有差离中心分散变异的性质。 8.变量(变数):指相同性质的事物间表现差异性或差异特征的数据。 9.常数:表示能代表事物特征和性质的数值,通常由变量计算而来,在一定过程中是 不变的。 10.参数:描述总体特征的数量称为参数,也称参量。常用希腊字母表示参数,例如用 μ表示总体平均数,用σ表示总体标准差; 11.统计数:描述样本特征的数量称为统计数,也称统计量。常用拉丁字母表示统计数, 例如用x表示样本平均数,用S表示样本标准差。 12.效应:通过施加试验处理,引起试验差异的作用称为效应。效应是一个相对量,而 非绝对量,表现为施加处理前后的差异。效应有正效应与负效应之分。 13.互作(连应):是指两个或两个以上处理因素间相互作用产生的效应。互作也有正效 应(协同作用)与负效应(拮抗作用)之分。 14.准确性:也叫准确度,指在调查或试验中某一试验指标或性状的观测值与其真值接 近的程度。 15.精确性:也叫精确度,指调查或试验中同一试验指标或性状的重复观测值彼此接近 的程度。 16.随机误差(抽样误差):这是由于试验中无法控制的内在和外在的偶然因素所造成。 随机误差越小,试验精确性越高。 17.系统误差(片面误差):这是由于试验条件控制不一致、测量仪器不准、试剂配制 不当、试验人员粗心大意使称量、观测、记载、抄录、计算中出现错误等人为因素而引起的。系统误差影响试验的准确性。只要以认真负责的态度和细心的工作作风是完全可以避免的。 18.试验误差:在试验过程中,由于试验条件及人为的一些因素而造成的试验结果与真 实值之间的偏差,来源于试验材料固有的差异和外界因素(管理措施、试验条件等)。 19.数量性状:是指能够以计数和测量或度量的方式表示其特征的性状。 20.质量性状:是指能观察到而不能直接测量的性状 21.次数资料:由质量性状量化得来的资料叫做次数资料。 22.试验:是对已有的或没有的事物加以处理的方法。 23.大数定律:是概率论中用来阐述大量随机现象平均结果稳定性的一系列定律的总称。 主要内容:样本容量越大,样本统计数与总体参数之差越小。 24.泊松分布:是一种可以用来描述和分析随机地发生在单位空间或时间里的稀有事件 的概率分布,也是一种离散型随机变量的分布。 25.假设检验:又称显著性检验,就是根据总体的理论分布和小概率原理,对未知或不完 全知道的总体提出两种彼此对立的假设,然后由样本的实际原理,经过一定的计算, 重庆西南大学 2012 至 2013 学年度第 2 期 生物统计学 试题(A ) 试题使用对象: 2011 级 专业(本科) 命题人: 考试用时 120 分钟 答题方式采用: 闭卷 说明:1、答题请使用黑色或蓝色的钢笔、圆珠笔在答题纸上书写工整. 2、考生应在答题纸上答题,在此卷上答题作废. 一:判断题;(每小题1分,共10分 ) 1、正确无效假设的错误为统计假设测验的第一类错误。( ) 2、标准差为5,B 群体的标准差为12,B 群体的变异一定大于A 群体。( ) 3、一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( ) 4、30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1 (已知84.321,05.0=χ)。 ( ) 5、固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于推断处理的总体。( ) 6、率百分数资料进行方差分析前,应该对资料数据作反正弦转换。( ) 7、比较前,应该先作F 测验。 ( ) 8、验中,测验统计假设H 00:μμ≥ ,对H A :μμ<0 时,显著水平为5%,则测验的αu 值为1.96( ) 9、行回归系数假设测验后,若接受H o :β=0,则表明X 、Y 两变数无相关关系。 ( ) 10、株高的平均数和标准差为30150±=±s y (厘米),果穗长的平均数和标准差为s y ±1030±=(厘米),可认为该玉米的株高性状比果穗性状变异大。 ( ) 二:选择题;(每小题2分,共10分 ) 1分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( )。 A 、[-9.32,11.32] B 、[-4.16,6.16] 生物统计学考试 一.判断题(每题2分,共10分) √1. 分组时,组距和组数成反比。 ×2. 粮食总产量属于离散型数据。 ×3. 样本标准差的数学期望是总体标准差。 ×4. F分布的概率密度曲线是对称曲线。 √5. 在配对数据资料用t检验比较时,若对数n=13,则查t表的自由度为12。 二. 选择题(每题3分,共15分) 6.x~N(1,9),x1,x2,…,x9是X的样本,则有() x N(0,1)B.11 - x ~N(0,1)C.91 - x ~N(0,1)D.以上答案均不正确 7. 假定我国和美国的居民年龄的方差相同。现在各自用重复抽样方法抽取本国人口的1%计 算平均年龄,则平均年龄的标准误() A.两者相等 B.前者比后者大 D.不能确定大小 8. 设容量为16人的简单随机样本,平均完成工作需时13分钟。已知总体标准差为3分钟。 若想对完成工作所需时间总体构造一个90%置信区间,则() u值 B.应用t分布表查出t值 C.应用卡方分布表查出卡方值 D.应用F分布表查出F值 9. 1-α是() A.置信限 B.置信区间 C.置信距 10. 如检验k (k=3)个样本方差s i2 (i=1,2,3)是否来源于方差相等的总体,这种检验在统计上称为 ( )。 B. t检验 C. F检验 D. u检验 三. 填空题(每题3分,共15分) 11. 12. 13. 已知F分布的上侧临界值F0.05(1,60)=4.00,则左尾概率为0.05,自由度为(60,1) 的F 14. 15.已知随机变量x服从N (8,4),P(x < 4.71)(填数字) 四.综合分析题(共60分) 生物统计学教案 第五章统计推断 教学时间:5学时 教学方法:课堂板书讲授 教学目的:重点掌握两个样本的差异显著性检验,掌握一个样本的差异显著性检验,了解二项分布的显著性检验。 讲授难点:一个、两个样本的差异显著性检验 统计假设检验:首先对总体参数提出一个假设,通过样本数据推断这个假设是否可以接受,如果可以接受,样本很可能抽自这个总体,否则拒绝该假设,样本抽自另外总体。 参数估计:通过样本统计量估计总体参数。 5.1 单个样本的统计假设检验 5.1.1 一般原理及两种类型的错误 例:已知动物体重服从正态分布N(μ,σ2),实验要求动物体重μ=10.00g。已知总体标准差σ=0.40g,总体平均数μ未知,为了得出对总体平均数μ的推断,以便决定是否接受这批动物,随机抽取含量为n的样本,通过样本平均数,推断μ。 1、假设: H 0: μ=μ 或H0: μ-μ0=0 H A : μ>μ μ<μ μ≠μ 三种情况中的一种。 本例的μ =10.00g,因此 H : μ=10.00 H A : μ>10.00或μ<10.00或μ≠10.00 2、小概率原理小概率的事件,在一次试验中几乎是不会发生的,若根据一定的假设条件计算出来该事件发生的概率很小,而在一次试验中,它竟然发生了,则可以认为假设的条件不正确,从而拒绝假设。 从动物群体中抽出含量为n的样本,计算样本平均数,假设该样本是从N(10.00,0.402)中抽取的,标准化的样本平均数 服从N (0,1)分布,可以从正态分布表中查出样本抽自平均数为μ的总体的概率,即 P (U >u ), P (U <-u ), 以及P (|U |>u )的概率。如果得到的值很小,则 x 抽自平均数 为μ0的总体的事件是一个小概率事件,它在一次试验中几乎是不会发生的,但实际上它发生了,说明假设的条件不正确,从而拒绝零假设,接受备择假设。 显著性检验:根据小概率原理建立起来的检验方法。 显著性水平:拒绝零假设时的概率值,记为α。通常采用α=0.05和α=0.01两个水平,当P < 0.05时称为差异显著,P < 0.01时称为差异极显著。 3、临界值 例 从上述动物群体中抽出含量n =10的样本,计算出 x =10.23g ,并已知 该批动物的总体平均数μ绝不会小于10.00g ,规定的显著水平α=0.05。根据以上条件进行统计推断。 H 0: μ=10.00 H A : μ>10.00 根据备择假设,为了得到x 落在上侧尾区的概率P (U > u ),将x 标准化,求 出u 值。 P (U >1.82)=0.03438,P < 0.05,拒绝H 0,接受 H A 。 在实际应用中,并不直接求出概率值,而是建立在α水平上H 0的拒绝域。从 正态分布上侧临界值表中查出P (U > u α)= α时的u α值,U > u α的区域称为在α水平上的H 0拒绝域,而U < u α的区域称为接受域。接受域的端点一般称为临界值。本例的u =1.82,从附表3可以查出u 0.05=1.645, u > u α,落在拒绝域内,拒绝H 0而接受H A 。 4、单侧检验和双侧检验 上尾单侧检验:上例中的H A :μ>μ0,相应的拒绝域为U > u α。对应于H A :μ>μ0时的检验称为上尾单侧检验。 下尾单侧检验:对应于H A :μ<μ0时的检验称为下尾单侧检验。 n x n x u 40 .000.100 -= -= σ μ82 .110 40 .000 .1023.100 =-= -= n x u σ μ 生物统计学SPSS作业 4.6 桃树枝条的常规含氮量为2.40%,现对一桃树新品种枝条的含氮量进行了10次测定,其结果为:2.38%、2.38%、2.41%、2.50%、2.47%、2.41%、2.38%、2.26%、2.32%、2.41%,试问测定结果与常规枝条含氮量有无差别。 解:1、假设H1:u1=u2,即新品枝条与常规枝条含氮量无差别。对H2: u1!=u2。 2、取显著水平α=0.05。 3、用SPSS软件进行检验计算如下: (1)打开SPSS软件,输入数据,如图 (2)如图在主菜单栏选择“分析”选项的“比较均值”,在下拉菜单中选择“独立样本T检测”。 (3)在下图中将左边方框中的“新品枝条含氮量”放到右边的“检验变量”方框中,并选择“确定”。即可得出“单样本T检验”的检验结果。 4、结果分析 由SPSS “单样本T检验”检验结果可知t=-0.371 Sig. (2-Tailed)是双尾t检验显著概率0719大于0.05,所以可以接受假设H1,即新品枝条与常规枝条含氮量无差别 4.8 假说:“北方动物比南方动物具有较短的附肢。”未验证这一假说,调查了如下鸟翅长(mm)资料:北方的:120 113 125 118 116 119 ;南方的:116 117 121 114 116 118 123 120 。试检验这一假说。 解:1、假设H1:u1=u2,即北方动物和南方动物的附肢没有差别。对H2: u1!=u2。 2、取显著水平α=0.05。 3、用SPSS软件进行检验计算如下: (1)打开SPSS软件,输入数据,如图 (2)如图在主菜单栏选择“分析”选项的“比较均值”,在下拉菜单中选择“独立样本T检测”。 (3)在下图中将左边方框中的“翅长”放到右边的“样本变量(s)”方框中,将“状态”放到“分组变量”中,并选择“定义组”。 1. 什么是生物统计学生物统计学的主要内容和作用是什么 生物统计学是用数理统计的原理和方法来分析和解释生物界各种现象和试验调查资料,是研究生命过程中以样本来推断总体的一门学科。 生物统计学主要包括试验设计和统计分析两大部分的内容。其基本作用表现在以下4个方面:1.提供整理和描述数据资料的科学方法,确定某些性状和特性的数量特征。2.判断试验结果的可靠性。3.提供由样本推断总体的方法。4.提供试验设计的一些重要原则。 2. 随即误差与系统误差有何区别随机误差也称为抽样误差或偶然误差,它是由于试验中许多无法控制的偶然因素所造成的试验结果与真实结果之间的误差,是不可避免的,随机误差可以通过试验设计和精心管理设法减小,而不能完全消除。 系统误差也称为片面误差,是由于试验处理以外的其他条件明显不一致所产生的带有倾向性或定向性的偏差。系统误差主要由一些相对固定的因素引起,在某种程度上是可控制的。 3. 准确性与精确性有何区别 准确性指在调查和实验中某一实验指标或性状的观测值和真实值接近程度。精确性指调查和实验中同一实验指标或性状的重复观察值彼此接近的程度。准确性是说明测定值和真实值之间符合程度的大小;精确性是反映多次测定值的变异程度。 4. 平均数与标准差在统计分析中有何用处他们各有哪些特性平均数的用处: ①平均数指出了一组数据的中心位置,标志着资料所代表性状的数量水平和质量水平;②作为样本或资料的代表数据与其他资料进行比较。平均数的特征:①离均差之和为零;②离均差平方和为最小。 标准差的用处:①标准差的大小,受实验后调查资料中的多个观测值的影响,如果观测值之间的差异大,离均差就越大;②在计算标准差是如果对观察值加上一个或减去一个a,标准差不变;如果给各观测值乘以或除以一个常数a,所得的标准差就扩大或缩小a倍;③在正态分布中,X+-S内的观测值个数占总个数的%,X-+2s内的观测值个数占总个数的%,x-+3s 内的观测值个数占总个数的%。标准差的特征:①表示变量分布的离散程度;②标准差的大小可以估计出变量的次数分布及各类观测值在总体中所占的比例;③估计平均数的标准差;④进行平均数区间估计和变异数的计算。 5. 什么是正态分布什么是标准正太分布正态分布曲线有什么特点μ和σ对正态分布曲线有何影响 正态分布是一种连续型随机变量的概率分布,它的分布特征是大多数变量围绕在平均数左右,由平均数到分布的两侧,变量数减小,即中间多,两头少,两侧对称。 U=0,σ2=1的正态分布为标准正态分布。 正态分布具有以下特点:标准正态分布具有以下特点:①、正态分布曲线是以平均数μ为峰值的曲线,当x=μ时,f(x)取最大值;②、正态分布是以μ 第一章 统计数据的收集与整理 1.1 算术平均数是怎样计算的?为什么要计算平均数? 答:算数平均数由下式计算:,含义为将全部观测值相加再被观测值的个数 除,所得之商称为算术平均数。计算算数平均数的目的,是用平均数表示样本数据的集中点, 或是说是样本数据的代表。 1.2 既然方差和标准差都是衡量数据变异程度的,有了方差为什么还要计算标准差? 答:标准差的单位与数据的原始单位一致,能更直观地反映数据地离散程度。 1.3 标准差是描述数据变异程度的量,变异系数也是描述数据变异程度的量,两者之间有什么不同? 答:变异系数可以说是用平均数标准化了的标准差。在比较两个平均数不同的样本时所得结果更可靠。 1.4 完整地描述一组数据需要哪几个特征数? 答:平均数、标准差、偏斜度和峭度。 1.5 下表是我国青年男子体重(kg )。由于测量精度的要求,从表面上看像是离散型数据,不要忘记,体重是通过度量得到的,属于连续型数据。根据表中所给出的数据编制频数分布表。 66 69 64 65 64 66 68 65 62 64 69 61 61 68 66 57 66 69 66 65 70 64 58 67 66 66 67 66 66 62 66 66 64 62 62 65 64 65 66 72 60 66 65 61 61 66 67 62 65 65 61 64 62 64 65 62 65 68 68 65 67 68 62 63 70 65 64 65 62 66 62 63 68 65 68 57 67 66 68 63 64 66 68 64 63 60 64 69 65 66 67 67 67 65 67 67 66 68 64 67 59 66 65 63 56 66 63 63 66 67 63 70 67 70 62 64 72 69 67 67 66 68 64 65 71 61 63 61 64 64 67 69 70 66 64 65 64 63 70 64 62 69 70 68 65 63 65 66 64 68 69 65 63 67 63 70 65 68 67 69 66 65 67 66 74 64 69 65 64 65 65 68 67 65 65 66 67 72 65 67 62 67 71 69 65 65 75 62 69 68 68 65 63 66 66 65 62 61 68 65 64 67 66 64 60 61 68 67 63 59 65 60 64 63 69 62 71 69 60 63 59 67 61 68 69 66 64 69 65 68 67 64 64 66 69 73 68 60 60 63 38 62 67 65 65 69 65 67 65 72 66 67 64 61 64 66 63 63 66 66 66 63 65 63 67 68 66 62 63 61 66 61 63 68 65 66 69 64 66 70 69 70 63 64 65 64 67 67 65 66 62 61 65 65 60 63 65 62 66 64 答:首先建立一个外部数据文件,名称和路径为:E:\data\exer1-5e.dat 。所用的SAS 程序和计算结果如下: proc format; value hfmt 56-57='56-57' 58-59='58-59' 60-61='60-61' 62-63='62-63' 64-65='64-65' 66-67='66-67' 68-69='68-69' 70-71='70-71' 72-73='72-73' 74-75='74-75'; run; n y y n i i ∑== 1 014福师《生物统计学》在线作业一 黄镇 一、单选题(共25 道试题,共50 分。) 1. 对含有两个随机变量的同一批资料,既作直线回归分析,又作直线相关分析。令对相关系数检验的t值为tr,对回归系数检验的t值为tb,二者之间具有什么关系?C A. tr>tb B. tr 漳州师范学院 生物系_____________专业_____级本科_______班 《生物统计学》课程期末考试卷(A) (2011—2012学年度第一学期) 学号___________姓名________考试时间:2011-12-29 一、名词解释(6×2) 1统计数: 2小概率原理: 3无偏估计: 4准确性: 5纳伪错误: 6方差: 二、判断题:请在下列正确的题目后面打“√”,错误的打“×”。(12×1) 1 t分布曲线的平均数与中位数相等(√) 2众数是总体中出现最多个体的次数。(×) 3 正态分布曲线形状与样本容量n无关(√) 4 假设检验显著水平越高,检验效果越好(×) 5 样本频率假设检验如果需要连续性矫正时,矫正系数=0. 5(×) 6 样本标准差是总体标准差的无偏估计(×) 7计算相关系数的两个变量都是随机变量(√) 8 试验因素的任一水平就是一个处理(×) 9 在同一显著水平下,双尾检验的临界正态离差大于单位检验(√) 10 LSD检验方法实质上就是t检验(×) 11对多个样本平均数仍可采用t测验进行两两独立比较。(×) 12假设测验结果或犯α错误或犯β错误。( × ) 三、选择题(18×2) 1、某学生某门课成绩为75分,则其中的变量为[ ] A. 某学生 B. 某门课成绩 C. 75分 D. 某学生的成绩 2、算术平均数的重要特性之一是离均差之和[ ] A 、最小 B 、最大 C 、等于零 D 、接近零 3、在回归直线y=a+bx 中,若b <0,则x 与y 之间的相关系数[ ] A. r=0 B. r=1 C. 0<r <1 D. -1<r <0 4、假定我国和美国的居民年龄的方差相同。现在各自用重复抽方 法抽取本国人口的1%计算平均年龄,则平均年龄的标准误 [ ] A.两者相等 B.前者比后者大 C 前者比后者小 D.不能确定大小 5、1-α是[ ] A.置信限 B.置信区间 C.置信距 D 置信水平 6、在一组数据中,如果一个变数10的离均差是2,那么该组数据的平均数是[ ] A 、12 B 、10 C 、8 D 、2 7、两个二项成数的差异显著性一般用[ ]测验。 A 、t B 、F C 、u D 、卡方测验 8、测验回归截距的显著性时,()/a t a s α=-遵循自由度为[ ] 的学生氏分布。 A 、n -1 B 、n -2 C 、n -m -1 D 、n 9、对一批大麦种子做发芽试验,抽样1000粒,得发芽种子870粒,若规定发芽率达90%为合格,测验这批种子是否合格的差异显著性为[ ]。 A 、不显著 B 、显著 C 、极显著 D 、不好确定 10设容量为16人的简单随机样本,平均完成工作需时13分钟。 已知总体标准差为3分钟。若想对完成工作所需时间总体构 造一个90%置信区间,则[ ] A 应用标准正态概率表查出u 值 B.应用t 分布表查出t 值 C.应用卡方分布表查出卡方值 D.应用F 分布表查出F 值 第一章 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量。 2.样本统计数是总体(参数)的估计值。 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科。 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分。 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现代推断统计学)3个阶段。 6.生物学研究中,一般将样本容量(n ≥30)称为大样本。 7.试验误差可以分为(随机误差)和(系统误差)两类。 判断 1.对于有限总体不必用统计推断方法。(×) 2.资料的精确性高,其准确性也一定高。(×) 3.在试验设计中,随机误差只能减小,而不能完全消除。(∨) 4.统计学上的试验误差,通常指随机误差。(∨) 第二章 填空 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变量。 2. 直方图适合于表示(连续变量)资料的次数分布。 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性)。 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数)。 5.样本标准差的计算公式s=( )。 判断题 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布。(×) 3. 离均差平方和为最小。(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数。(∨) 5. 变异系数是样本变量的绝对变异量。(×) 单项选择 1. 下列变量中属于非连续性变量的是( C ). A. 身高 B.体重 C.血型 D.血压 2. 对某鱼塘不同年龄鱼的尾数进行统计分析,可做成( A )图来表示. A. 条形 B.直方 C.多边形 D.折线 3. 关于平均数,下列说法正确的是( B ). A. 正态分布的算术平均数和几何平均数相等. B. 正态分布的算术平均数和中位数相等. C. 正态分布的中位数和几何平均数相等. D. 正态分布的算术平均数、中位数、几何平均数均相等。 4. 如果对各观测值加上一个常数a ,其标准差( D )。 A. 扩大√a 倍 B.扩大a 倍 C.扩大a 2倍 D.不变 5. 比较大学生和幼儿园孩子身高的变异度,应采用的指标是( C )。 A. 标准差 B.方差 C.变异系数 D.平均数 第三章 12 2--∑∑n n x x )( 《生物统计学》第三版课后作业答案(李春喜、姜丽娜、邵云、王文林编着) 第一章概论(P7) 习题1.1 什么是生物统计学?生物统计学的主要内容和作用是什么? 答:(1)生物统计学(biostatistics)是用数理统计的原理和方法来分析和解释生物界各种现象和实验调查资料,是研究生命过程中以样本来推断总体的一门学科。 (2)生物统计学主要包括实验设计和统计推断两大部分的内容。其基本作用表现在以下四个方面:①提 供整理和描述数据资料的科学方法;②确定某些性状和特性的数量特征;③判断实验结果的可靠性; ④提供由样本推断总体的方法;⑤提供实验设计的一些重要原则。 习题1.2 解释以下概念:总体、个体、样本、样本容量、变量、参数、统计数、效应、互作、随机误差、系统误差、准确性、精确性。 答:(1)总体(populatian)是具有相同性质的个体所组成的集合,是研究对象的全体。 (2)个体(individual)是组成总体的基本单元。 (3)样本(sample)是从总体中抽出的若干个个体所构成的集合。 (4)样本容量(sample size)是指样本个体的数目。 (5)变量(variable)是相同性质的事物间表现差异性的某种特征。 (6)参数(parameter)是描述总体特征的数量。 (7)统计数(statistic)是由样本计算所得的数值,是描述样本特征的数量。 (8)效应(effection)试验因素相对独立的作用称为该因素的主效应,简称效应。 (9)互作(interaction)是指两个或两个以上处理因素间的相互作用产生的效应。 (10)实验误差(experimental error)是指实验中不可控因素所引起的观测值偏离真值的差异,可以分为随 机误差和系统误差。 (11)随机误差(random)也称抽样误差或偶然误差,它是有实验中许多无法控制的偶然因素所造成的实验 结果与真实结果之间产生的差异,是不可避免的。随机误差可以通过增加抽样或试验次数降低随机误差,但不能完全消。 (12) 系统误差(systematic)也称为片面误差,是由于实验处理以外的其他条件明显不一致所产生的倾 向性的或定向性的偏差。系统误差主要由一些相对固定的因素引起,在某种程度上是可控制的,只要试验工作做得精细,在试验过程中是可以避免的。 (13) 准确性(accuracy)也称为准确度,指在调查或实验中某一实验指标或性状的观测值与其真值接 近的程度。 (14) 精确性(precision)也称精确度,指调查或实验中同一实验指标或性状的重复观测值彼此接近程 度的大小。 (15)准确性是说明测定值堆真值符合程度的大小,用统计数接近参数真值的程度来衡量。精确性是反映 多次测定值的变异程度,用样本间的各个变量间变异程度的大小来衡量。 习题1.3 误差与错误有何区别? 答:误差是指实验中不可控制因素所引起的观测值偏离真值的差异,其中随机误差只可以设法降低,但不能避免,系统误差在某种程度上可控制、可克服的;而错误是指在实验过程中,人为的作用所引起的差错,是完全可以避免的。 第二章实验资料的整理与特征数的计算(P22、P23) 一、单选题(共 32 道试题,共 64 分。) V 1. 最小二乘法是指各实测点到回归直线的 A. 垂直距离的平方和最小 B. 垂直距离最小 C. 纵向距离的平方和最小 D. 纵向距离最小 2. 被观察到对象中的()对象称为() A. 部分,总体 B. 所有,样本 C. 所有,总体 D. 部分,样本 3. 必须排除______因素导致“结果出现”的可能,才能确定“结果出现”是处理因素导致的。只有确定了______,才能确定吃药后出现的病愈是药导致的。 A. 非处理因素,不吃药就不可能出现病愈 B. 处理因素,不吃药就不可能出现病愈 C. 非处理因素,吃药后确实出现了病愈 D. 处理因素,吃药后确实出现了病愈 4. 张三观察到李四服药后病好了。由于张三的观察是“个案”,因此不能确定______。 A. 确实进行了观察 B. 李四病好了 C. 病好的原因 D. 观察结果是可靠的 5. 四个样本率作比较,χ2>χ20.05,ν可认为 A. 各总体率不同或不全相同 B. 各总体率均不相同 C. 各样本率均不相同 D. 各样本率不同或不全相同 6. 下列哪种说法是错误的 A. 计算相对数尤其是率时应有足够的观察单位或观察次数 B. 分析大样本数据时可以构成比代替率 C. 应分别将分子和分母合计求合计率或平均率 D. 样本率或构成比的比较应作假设检验 7. 总体指的是()的()对象 A. 要研究,部分 B. 观察到,所有 C. 观察到,部分 D. 要研究,所有 8. 以下叙述中,除了______外,其余都是正确的。 A. 在比较未知参数是否不等于已知参数时,若p(X>x)<α/2,则x为小概率事件。 B. 在比较未知参数是否等于已知参数时,若p(X=x)<α,则x为小概率事件。 C. 在比较未知参数是否大于已知参数时,若p(X>x)<α,则x为小概率事件。 D. 在比较未知参数是否小于已知参数时,若p(X 考试轮次:2017-2018学年第一学期期末考试试卷编号 考试课程:[120770] 生物统计与实验设计命题负责人曾汉元 适用对象:生物与食品工程学院生物科学专业2015级审查人签字 考核方式:上机考试试卷类型:A卷时量:150分钟总分:100分 注意:答案中要求保留必要的计算和推理过程,全部答案保存为一个Word文档,文件名 为学号最后两位数+姓名。考试结束后不要关机。提交答卷后,请到主机看一下是否提交成功。第1题12分,第3题5分,第10题13分,其余的题各10分。 1、下表为某大学96位男生的体重测定结果(单位:kg),请根据资料分别计算以下指标:(1)算术平均数;(2)几何平均数;(3)中位数;(4)众数;(5)极差;(6)方差;(7)标准差;(8)变异系数;(9)标准误。(10) 绘制各体重分布柱形图。 66 69 64 65 64 66 70 64 59 67 66 66 60 66 65 61 61 66 67 68 62 63 70 65 64 66 68 64 63 60 60 66 65 61 61 66 59 66 65 63 58 66 66 68 64 65 71 61 62 69 70 68 65 63 66 65 67 66 74 64 70 64 59 67 66 66 60 66 65 61 61 66 67 68 62 63 70 65 64 66 68 64 63 60 60 66 65 61 61 66 59 66 65 63 58 66 2、已知1000株水稻的株高服从正态分布N(97,3 2),求: (1)株高在94cm以上的概率? (2)株高在90~99cm之间的概率? (3)株高在多少cm之间的中间概率占全体的99%? 3.已知某批30个小麦样品的平均蛋白质含量为14.5%,σ=2.50%,试进行95%置信度下的蛋白质含量的区间估计和点估计。 4、有一大麦杂交组合,F2代的芒性状表型有钩芒、长芒和短芒三种,观察计得其株数依次分别为348、11 5、157,试检验其比率是否符合9:3:4的理论比率。 5、某医院用某种中药治疗7例再生障碍性贫血患者,现将血红蛋白含量(g/L)变化的数据列在下面,假定资料满足各种假设测验所要求的前提条件,问:治疗前后之间的差别有无显著性意义? 患者编号 1 2 3 4 5 6 7 治疗前血红蛋白含量65 75 50 76 65 72 68 治疗后血红蛋白含量82 112 125 85 80 105 128 生物统计学复习资料(70%) 填空:10题×1’=10’选择:5题×1’=5’ 名词解释:5题×2’=10’ 判断:5题×1’=5’ 简答:3题×5’=15’ 统计推断:4题10’+10’+10’+20’=50’ 第1章绪论 生物统计学:是研究收集、整理、分析和解释生物科学试验数据的科学,是统计学原理在生物学研究领域的应用。 生物统计学的主要内容 生物统计学包括试验数据的获取、整理和分析等相关内容,具体来说,包括试验或调查设计、数据的整理(描述统计学)、概率论基础(统计理论基础)、统计推断方法(推断统计学)等内容。 调查设计:是指整个调查计划的制订,包括调查研究的目的、对象与范围,调查项目及调查表内容,抽样方法的选取,抽样单位和抽样数量的确定,数据处理方法,调查组织工作,调查报告撰写等内容。 试验设计:是指试验单位的选取、生物学重复数的确定及试验单位的分组等。 生物统计学发展简史 (1)古典记录统计学 (2)近代描述统计学 (3)近代推断统计学 总体:是研究对象的全体。 个体:是总体中的一个研究单位。 样本:是从总体中抽取的用于代表总体的一部分个体。 样本容量记为n,通常把n≤30的样本称为小样本,n>30的样本称为大样本。(判断区别)随机抽样:是指总体中的每一个个体都有同等的被抽取的机会组成样本。 参数:由总体计算的特征数。 统计数:由样本计算的特征数。 准确性:也叫准确度,是指在试验中某一试验指标的观测值与其真值接近的程度。 精确性:也叫精确度,是指同一试验指标的重复观测值彼此接近的程度。 随机误差:是由于无法控制的内在和外在的偶然因素所造成的,是客观存在的,在实验中,即使十分小心也难以消除。 系统误差:也叫片面误差,是由试验材料的初始条件不同或测量仪器不准等引起的倾向性或定向性偏差。 (小题)误差怎么控制? (小题)随机误差可完全避免(×) (小题)减小统计误差的方法是(B) A、提高准确度 B、提高精确度 C、减少样本容量 D、增加样本容量 《生物统计学》复习题 1.变量之间的相关关系主要有两大类:(因果关系),(平行关系) 2.在统计学中,常见平均数主要有(算术平均数)、(几何平均数) 3.样本标准差的计算公式( 1 ) (2 --= ∑n X X S ) 4.小概率事件原理是指(某事件发生的概率很小,人为的认为不会发生) 5.在分析变量之间的关系时,一个变量X 确定,Y 是随着X 变化而变化,两变量呈因果关系,则X 称为(自变量),Y 称为(因变量) ADCAA BABCB DADBB ADBCB 1、下列数值属于参数的是: A 、总体平均数 B 、自变量 C 、依变量 D 、样本平均数 2、 下面一组数据中属于计量资料的是 A 、产品合格数 B 、抽样的样品数 C 、病人的治愈数 D 、产品的合格率 3、在一组数据中,如果一个变数10的离均差是2,那么该组数据的平均数是 A 、12 B 、10 C 、8 D 、2 4、变异系数是衡量样本资料 程度的一个统计量。 A 、变异 B 、同一 C 、集中 D 、分布 5、方差分析适合于, 数据资料的均数假设检验。 A 、两组以上 B 、两组 C 、一组 D 、任何 6、在t 检验时,如果t = t 0、01 ,此差异是: A 、显著水平 B 、极显著水平 C 、无显著差异 D 、没法判断 7、 生物统计中t 检验常用来检验 A 、两均数差异比较 B 、两个数差异比较 C 、两总体差异比较 D 、多组数据差异比较 8、平均数是反映数据资料 性的代表值。 A 、变异性 B 、集中性 C 、差异性 D 、独立性 9、在假设检验中,是以 为前提。 A 、 肯定假设 B 、备择假设 C 、 无效假设 D 、有效假设 10、抽取样本的基本首要原则是 A 、统一性原则 B 、随机性原则 C 、完全性原则 D 、重复性原则 11、统计学研究的事件属于 事件。 A 、不可能事件 B 、必然事件 C 、小概率事件 D 、随机事件 12、下列属于大样本的是 A 、40 B 、30 C 、20 D 、10 13、一组数据有9个样本,其样本标准差是0.96,该组数据的标本标准误(差)是 A 、0.11 B 、8.64 C 、2.88 D 、0.32 14、在假设检验中,计算的统计量与事件发生的概率之间存在的关系是 。 A 、正比关系 B 、反比关系 C 、加减关系 D 、没有关系 15、在方差分析中,已知总自由度是15,组间自由度是3,组内自由度是 A 、18 B 、12 C 、10 D 、5 16、已知数据资料有10对数据,并呈线性回归关系,它的总自由度、回归自由度和残差自由度分别是 A 、9、1和8 B 、1、8和9 C 、8、1和9 D 、 9、8和1 18、下列那种措施是减少统计误差的主要方法。 A 、提高准确度 B 、提高精确度 C 、减少样本容量 D 、增加样本容量 19、相关系数显著性检验常用的方法是 第一次作业 习题2.5 某地100例30~40岁健康男子血清总胆固醇(mol/L)测定结果如下: 4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.71 5.69 4.12 4.56 4.37 5.39 6.30 5.21 7.22 5.54 3.93 5.21 6.51 5.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.69 4.38 4.89 6.25 5.32 4.50 4.63 3.61 4.44 4.43 4.25 4.03 5.85 4.09 3.35 4.08 4.79 5.30 4.97 3.18 3.97 5.16 5.10 5.85 4.79 5.34 4.24 4.32 4.77 6.36 6.38 4.88 5.55 3.04 4.55 3.35 4.87 4.17 5.85 5.16 5.09 4.52 4.38 4.31 4.58 5.72 6.55 4.76 4.61 4.17 4.03 4.47 3.40 3.91 2.70 4.60 4.09 5.96 5.48 4.40 4.55 5.38 3.89 4.60 4.47 3.64 4.34 5.18 6.14 3.24 4.90 试根据所给资料编制次数分布表. 解:1.求全距7.22-2.70=4.52(mol/L) 2.确定组数和组距组数10 组距=4.52/10=0.452(mol/L)取组距为0.5(mol/L) 3.确定组限和组中值 2.5~ 3.0~ 3.5~ 4.0~ 4.5~ 5.0~ 5.5~ 6.0~ 6.5~ 7.0~ 习题2.7 根据习题2.5的资料,计算平均数、标准差和变异系数。 习题2.8 根据习题2.5的资料,计算中位数,并与平均数进行比较。 习题2.9 某海水养殖场进行贻贝单养和贻贝与海带混养的对比试验,收获时各随机抽取50绳测其毛重(kg),结果分别如下: 单养50绳重量数据: 45,45,33,53,36,45,42,43,29,25,47,50,43,49,36,30,39,44,35,38,46,51,42,38,51,45,41,51,50,47, 44,43,46,55,42,27,42,35,46,53,32,41,48,50,51,46,41,34,44,46; 1. 什么是生物统计学?生物统计学的主要容和作用是什么? 生物统计学是用数理统计的原理和方法来分析和解释生物界各种现象和试验调查资料,是研究生命过程中以样本来推断总体的一门学科。 生物统计学主要包括试验设计和统计分析两大部分的容。其基本作用表现在以下4个方面:1.提供整理和描述数据资料的科学方法,确定某些性状和特性的数量特征。2.判断试验结果的可靠性。3.提供由样本推断总体的方法。4.提供试验设计的一些重要原则。 2. 随即误差与系统误差有何区别?随机误差也称为抽样误差或偶然误差,它是由于试验中许多无法控制的偶然因素所造成的试验结果与真实结果之间的误差,是不可避免的,随机误差可以通过试验设计和精心管理设法减小,而不能完全消除。 系统误差也称为片面误差,是由于试验处理以外的其他条件明显不一致所产生的带有倾向性或定向性的偏差。系统误差主要由一些相对固定的因素引起,在某种程度上是可控制的。 3. 准确性与精确性有何区别? 准确性指在调查和实验中某一实验指标或性状的观测值和真实值接近程度。精确性指调查和实验中同一实验指标或性状的重复观察值彼此接近的程度。准确性是说明测定值和真实值之间符合程度的大小;精确性是反映多次测定值的变异程度。 4. 平均数与标准差在统计分析中有何用处?他们各有哪些特性?平均数的用处:①平均数指出了一组数据的中心位置,标志着资料所代表性状的数量水平和质量水平;②作为样本或资料的代表数据与其他资料进行比较。平均数的特征:①离均差之和为零;②离均差平方和为最小。 标准差的用处:①标准差的大小,受实验后调查资料中的多个观测值的影响,如果观测值之间的差异大,离均差就越大;②在计算标准差是如果对观察值加上一个或减去一个a,标准差不变;如果给各观测值乘以或除以一个常数a,所得的标准差就扩大或缩小a倍;③在正态分布中,X+-S的观测值个数占总个数的68.26%,X-+2s的观测值个数占总个数的95.49%,x-+3s 的观测值个数占总个数的99.73%。标准差的特征:①表示变量分布的离散程度;②标准差的大小可以估计出变量的次数分布及各类观测值在总体中所占的比例;③估计平均数的标准差;④进行平均数区间估计和变异数的计算。 5. 什么是正态分布?什么是标准正太分布?正态分布曲线有什么特点?μ和σ对正态分布曲线有何影响?生物统计学 (2)
生物统计学考试题及答案
生物统计学试题及答案
生物统计学教案(5)
生物统计学作业
生物统计学简答题
生物统计学答案 第一章 统计数据的收集与整理
014福师《生物统计学》在线作业一、二
生物统计学期末考试试题A
生物统计学期末复习题库及答案
李春喜生物统计学第三版课后作业答案
2017福师《生物统计学》答案
生物统计学考试试卷及答案
生物统计学(自理重点)
《生物统计学-2019》复习题
生物统计学作业操作步骤及分析3
生物统计学简答题
相关主题
文本预览