《数学建模与数学实验》实验报告
实验2 统计回归模型
数学建模实验报告
一、实验目的 1、通过具体的题目实例,使学生理解数学建模的基本思想和方法,掌握 数学建模分析和解决的基本过程。 2、培养学生主动探索、努力进取的的学风,增强学生的应用意识和创新 能力,为今后从事科研工作打下初步的基础。 二、实验题目 (一)题目一 1、题目:电梯问题有r个人在一楼进入电梯,楼上有n层。设每个 乘客在任何一层楼出电梯的概率相同,试建立一个概率模型,求直 到电梯中的乘客下完时,电梯需停次数的数学期望。 2、问题分析 (1)由于每位乘客在任何一层楼出电梯的概率相同,且各种可能的情况众多且复杂,难于推导。所以选择采用计算机模拟的 方法,求得近似结果。 (2)通过增加试验次数,使近似解越来越接近真实情况。 3、模型建立 建立一个n*r的二维随机矩阵,该矩阵每列元素中只有一个为1,其余都为0,这代表每个乘客在对应的楼层下电梯(因为每 个乘客只会在某一层下,故没列只有一个1)。而每行中1的个数 代表在该楼层下的乘客的人数。 再建立一个有n个元素的一位数组,数组中只有0和1,其中1代表该层有人下,0代表该层没人下。 例如: 给定n=8;r=6(楼8层,乘了6个人),则建立的二维随机矩阵及与之相关的应建立的一维数组为: m = 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 0 c = 1 1 0 1 0 1 1 1 4、解决方法(MATLAB程序代码):
n=10;r=10;d=1000; a=0; for l=1:d m=full(sparse(randint(1,r,[1,n]),1:r,1,n,r)); c=zeros(n,1); for i=1:n for j=1:r if m(i,j)==1 c(j)=1; break; end continue; end end s=0; for x=1:n if c(x)==1 s=s+1; end continue; end a=a+s; end a/d 5、实验结果 ans = 6.5150 那么,当楼高11层,乘坐10人时,电梯需停次数的数学期望为6.5150。 (二)题目二 1、问题:某厂生产甲乙两种口味的饮料,每百箱甲饮料需用原料6 千克,工人10名,可获利10万元;每百箱乙饮料需用原料5千 克,工人20名,可获利9万元.今工厂共有原料60千克,工人 150名,又由于其他条件所限甲饮料产量不超过8百箱.问如何 安排生产计划,即两种饮料各生产多少使获利最大.进一步讨 论: 1)若投资0.8万元可增加原料1千克,问应否作这项投资. 2)若每百箱甲饮料获利可增加1万元,问应否改变生产计划. 2、问题分析 (1)题目中共有3个约束条件,分别来自原料量、工人数与甲饮料产量的限制。 (2)目标函数是求获利最大时的生产分配,应用MATLAB时要转换
美国各航空公司业绩的统计数据公布在《华尔街日报1998年鉴》(The Wall Street Journal Almanac 1998)上,有关航班正点到达的比率和每10万名乘客投诉的次数的数据如下: 航空公司名称航班正点率(%)投诉率(次/10万名乘客)西南(Southwest)航空公司81.8 0.21 大陆(Continental) 航空公司76.6 0.58 西北(Northwest)航空公司76.6 0.85 美国(US Airways)航空公司75.7 0.68 联合(United)航空公司73.8 0.74 美洲(American)航空公司72.2 0.93 德尔塔(Delta)航空公司71.2 0.72 70.8 1.22 美国西部(America West)航空公 司 环球(TWA)航空公司68.5 1.25 a. 画出这些数据的散点图 b. 根据再(a)中作出的散点图,表明二变量之间存在什么关系? c. 求出描述投诉率是如何依赖航班按时到达正点率的估计的回归方程 d. 对估计的回归方程的斜率作出解释 e. 如何航班按时到达的正点率是80%,估计每10万名乘客投诉的次数是多少?
1)作散点图: 2)根据散点图可知,航班正点率和投诉率成负直线相关关系。 3)作简单直线回归分析: SUMMARY OUTPUT 回归统计 Multiple R0.882607 R Square0.778996 Adjusted R Square0.747424 标准误差0.160818 观测值9 方差分析 df SS MS F Significance F 回归分析10.6381190.63811924.673610.001624残差70.1810370.025862 总计80.819156 Coefficient s标准误差t Stat P-value Lower 95%Upper 95%下限95.0%上限95.0% Intercept 6.017832 1.05226 5.7189610.000721 3.5296358.506029 3.5296358.506029 X Variable 1-0.070410.014176-4.967250.001624-0.10393-0.03689-0.10393-0.03689 4)y = -0.0704x + 6.0178
数学建模方法模型 一、统计学方法 1 多元回归 1、方法概述: 在研究变量之间的相互影响关系模型时候用到。具体地说:其可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值带入回归方程可以求出因变量的估计值,从而可以进行预测等相关研究。 2、分类 分为两类:多元线性回归和非线性线性回归;其中非线性回归可以通过一定的变化转化为线性回归,比如:y=lnx 可以转化为 y=u u=lnx 来解决;所以这里主要说明多元线性回归应该注意的问题。 3、注意事项 在做回归的时候,一定要注意两件事: (1) 回归方程的显著性检验(可以通过 sas 和 spss 来解决) (2) 回归系数的显著性检验(可以通过 sas 和 spss 来解决) 检验是很多学生在建模中不注意的地方,好的检验结果可以体现出你模型的优劣,是完整论文的体现,所以这点大家一定要注意。 4、使用步骤: (1)根据已知条件的数据,通过预处理得出图像的大致趋势或者数据之间的大致关系; (2)选取适当的回归方程; (3)拟合回归参数; (4)回归方程显著性检验及回归系数显著性检验 (5)进行后继研究(如:预测等)
2 聚类分析 1、方法概述 该方法说的通俗一点就是,将 n个样本,通过适当的方法(选取方法很多,大家可以自行查找,可以在数据挖掘类的书籍中查找到,这里不再阐述)选取 m 聚类中心,通过研究各样本和各个聚类中心的距离 Xij,选择适当的聚类标准,通常利用最小距离法(一个样本归于一个类也就意味着,该样本距离该类对应的中心距离最近)来聚类,从而可以得到聚类结果,如果利用sas 软件或者 spss 软件来做聚类分析,就可以得到相应的动态聚类图。这种模型的的特点是直观,容易理解。 2、分类 聚类有两种类型: (1) Q型聚类:即对样本聚类; (2) R型聚类:即对变量聚类; 通常聚类中衡量标准的选取有两种: (1) 相似系数法 (2) 距离法 聚类方法: (1) 最短距离法 (2) 最长距离法 (3) 中间距离法 (4) 重心法 (5) 类平均法 (6) 可变类平均法 (7) 可变法
数学建模实验报告 实验一计算课本251页A矩阵的最大特征根和最大特征向量 1 实验目的 通过Wolfram Mathematica软件计算下列A矩阵的最大特征根和最大特征向量。 2 实验过程 本实验运用了Wolfram Mathematica软件计算,计算的代码如下:
3 实验结果分析 从代码的运行结果,可以得到最大特征根为5.07293,最大特征向量为 {{0.262281},{0.474395},{0.0544921},{0.0985336},{0.110298}},实验结果 与标准答案符合。
实验二求解食饵-捕食者模型方程的数值解 1实验目的 通过Wolfram Mathematica或MATLAB软件求解下列习题。 一个生物系统中有食饵和捕食者两种种群,设食饵的数量为x(t),捕食者为y(t),它们满足的方程组为x’(t)=(r-ay)x,y’(t)=-(d-bx)y,称该系统为食饵-捕食者模型。当r=1,d=0.5,a=0.1,b=0.02时,求满足初始条件x(0)=25,y(0)=2的方程的数值解。 2 实验过程 实验的代码如下 Wolfram Mathematica源代码: Clear[x,y] sol=NDSolve[{x'[t] (1-0.1y[t])x[t],y'[t] 0.02x[t]y[t]-0.5y[t],x[0 ] 25,y[0] 2},{x[t],y[t]},{t,0,100}] x[t_]=x[t]/.sol y[t_]=y[t]/.sol g1=Plot[x[t],{t,0,20},PlotStyle->RGBColor[1,0,0],PlotRange->{0,11 0}] g2=Plot[y[t],{t,0,20},PlotStyle->RGBColor[0,1,0],PlotRange->{0,40 }] g3=Plot[{x[t],y[t]},{t,0,20},PlotStyle→{RGBColor[1,0,0],RGBColor[ 0,1,0]},PlotRange->{0,110}] matlab源代码 function [ t,x ]=f ts=0:0.1:15; x0=[25,2]; [t,x]=ode45('shier',ts,x0); End function xdot=shier(t,x)
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件: 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open;
2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.
进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.
数学建模
论文题目: 一个医药公司的新药研究部门为了掌握一种新止痛剂的疗效,设计了一个药物试验,给患有同种疾病的病人使用这种新止痛剂的以下4个剂量中的某一个:2 g,5 g,7 g和10 g,并记录每个病人病痛明显减轻的时间(以分钟计). 为了解新药的疗效与病人性别和血压有什么关系,试验过程中研究人员把病人按性别及血压的低、中、高三档平均分配来进行测试. 通过比较每个病人血压的历史数据,从低到高分成3组,分别记作,和. 实验结束后,公司的记录结果见下表(性别以0表示女,1表示男). 请你为该公司建立一个数学模型,根据病人用药的剂量、性别和血压组别,预测出服药后病痛明显减轻的时间.
一、摘要 在农某医药公司为了掌握一种新止痛药的疗效,设计了一个药物实验,通过观测病人性别、血压和用药剂量与病痛时间的关系,预测服药后病痛明显减轻的时间。我们运用数学统计工具m i n i t a b软件,对用药剂量,性别和血压组别与病痛减轻
时间之间的数据进行深层次地处理并加以讨论概率值P (是否<)和拟合度R-S q的值是否更大(越大,说明模型越好)。 首先,假设用药剂量、性别和血压组别与病痛减轻时间之间具有线性关系,我们建立了模型Ⅰ。对模型Ⅰ用m i n i t a b 软件进行回归分析,结果偏差较大,说明不是单纯的线性关系,然后对不同性别分开讨论,增加血压和用药剂量的交叉项,我们在模型Ⅰ的基础上建立了模型Ⅱ,用m i n i t a b软件进行回归分析后,用药剂量对病痛减轻时间不显着,于是我们有引进了用药剂量的平方项,改进模型Ⅱ建立了模型Ⅲ,用m i n i t a b 软件进行回归分析后,结果合理。最终确定了女性病人服药后病痛减轻时间与用药剂量、性别和血压组别的关系模型: Y=1x 3x 1x 3x 2 1 x 对模型Ⅱ和模型Ⅲ关于男性病人用m i n i t a b软件进行回归分析,结果偏差依然较大,于是改进模型Ⅲ建立了模型Ⅳ,用m i n i t a b软件进行回归分析后,结果合理。最终确定了男性病人服药后病痛减轻时间与用药剂量、性别和血压组别的关系模 型:Y=1x1x 3x 2 1 x关键词止痛剂药剂量性别病痛减轻时 间
数学建模与数学实验报告 指导教师__郑克龙___ 成绩____________ 组员1:班级______________ 姓名______________ 学号_____________ 组员2:班级______________ 姓名______________ 学号______________ 实验1.(1)绘制函数cos(tan())y x π=的图像,将其程序及图形粘贴在此。 >> x=-pi:0.01:pi; >> y=cos(tan(pi*x)); >> plot(x,y) -4 -3 -2 -1 1 2 3 4 -1-0.8-0.6-0.4-0.200.20.40.60.8 1 (2)用surf,mesh 命令绘制曲面2 2 2z x y =+,将其程序及图形粘贴在此。(注:图形注意拖放,不要太大)(20分) >> [x,y]=meshgrid([-2:0.1:2]); >> z=2*x.^2+y.^2; >> surf(x,y,z)
-2 2 >> mesh(x,y,z) -2 2 实验2. 1、某校60名学生的一次考试成绩如下:
93 75 83 93 91 85 84 82 77 76 77 95 94 89 91 88 86 83 96 81 79 97 78 75 67 69 68 84 83 81 75 66 85 70 94 84 83 82 80 78 74 73 76 70 86 76 90 89 71 66 86 73 80 94 79 78 77 63 53 55 1)计算均值、标准差、极差、偏度、峰度,画出直方图;2)检验分布的正态性;3)若检验符合正态分布,估计正态分布的参数并检验参数. (20分) 1) >> a=[93 75 83 93 91 85 84 82 77 76 77 95 94 89 91 88 86 83 96 81 79 97 78 75 67 69 68 84 83 81 75 66 85 70 94 84 83 82 80 78 74 73 76 70 86 76 90 89 71 66 86 73 80 94 79 78 77 63 53 55]; >> pjz=mean(a) pjz = 80.1000 >> bzhc=std(a) bzhc = 9.7106 >> jc=max(a)-min(a) jc = 44 >> bar(a)
数学建模与数学实验 课程设计 学院数理学院专业数学与应用数学班级学号 学生姓名指导教师 2015年6月
数据的统计分析 摘要 问题:某校60名学生的一次考试成绩如下: 93 75 83 93 91 85 84 82 77 76 77 95 94 89 91 88 86 83 96 81 79 97 78 75 67 69 68 84 83 81 75 66 85 70 94 84 83 82 80 78 74 73 76 70 86 76 90 89 71 66 86 73 80 94 79 78 77 63 53 55 (1)计算均值、标准差、极差、偏度、峰度,画出直方图;(2)检验分布的正态性; (3)若检验符合正态分布,估计正态分布的参数并检验参数; 模型:正态分布。 方法:运用数据统计知识结合MATLAB软件 结果:符合正态分布
一. 问题重述 某校60名学生的一次考试成绩如下: 93 75 83 93 91 85 84 82 77 76 77 95 94 89 91 88 86 83 96 81 79 97 78 75 67 69 68 84 83 81 75 66 85 70 94 84 83 82 80 78 74 73 76 70 86 76 90 89 71 66 86 73 80 94 79 78 77 63 53 55 (1)计算均值、标准差、偏差、峰度,画出直方图; (2)检验分布的正态性; (3)若检验符合正态分布,估计正态分布的参数并检验参数。 二.模型假设 假设一:此组成绩没受外来因素影响。 假设二:每个学生都是独自完成考试的。 假设三:每个学生的先天条件相同。 三.分析与建立模型 像类似数据的信息量比较大,可以用MATLAB 软件决绝相关问题,将n 名学生分为x 组,每组各n\x 个学生,分别将其命为1x ,2X ……j x 由MATLAB 对随机统计量x 进行命令。此时对于直方图的命令应为 Hist(x,j) 源程序为: x1=[93 75 83 93 91 85 84 82 77 76 ] x2=[77 95 94 89 91 88 86 83 96 81 ] x3=[79 97 78 75 67 69 68 84 83 81 ]
matlab 试验报告 姓名 学号 班级 问题:.(插值) 在某海域测得一些点(x,y)处的水深z 由下表给出,船的吃水深度为5英尺,在矩形区域(75,200)*(-50,150)里的哪些地方船要避免进入。 问题的分析和假设: 分析:本题利用插值法求出水深小于5英尺的区域,利用题中所给的数据,可以求出通过空间各点的三维曲面。随后,求出水深小于5英尺的范围。 基本假设:1表中的统计数据均真实可靠。 2矩形区域外的海域不对矩形海域造成影响。 符号规定:x ―――表示海域的横向位置 y ―――表示海域的纵向位置 z ―――表示海域的深度 建模: 1.输入插值基点数据。 2.在矩形区域(75,200)×(-50,150)作二维插值,运用三次插值法。 3.作海底曲面图。 4.作出水深小于5的海域范围,即z=5的等高线。 x y z 129 140 103.5 88 185.5 195 105 7.5 141.5 23 147 22.5 137.5 85.5 4 8 6 8 6 8 8 x y z 157.5 107.5 77 81 162 162 117.5 -6.5 -81 3 56.5 -66.5 84 -33.5 9 9 8 8 9 4 9
求解的Matlab程序代码: x=[129 140 103.5 88 185.5 195 105.5 157.5 107.5 77 81 162 162 117.5]; y=[7.5 141.5 23 147 22.5 137.5 85.5 -6.5 -81 3 56.5 -66.5 84 -33.5]; z=[-4 -8 -6 -8 -6 -8 -8 -9 -9 -8 -8 -9 -4 -9]; cx=75:0.5:200; cy=-50:0.5:150; cz=griddata(x,y,z,cx,cy','cubic'); meshz(cx,cy,cz),rotate3d xlabel('X'),ylabel('Y'),zlabel('Z') %pause figure(2),contour(cx,cy,cz,[-5 -5]);grid hold on plot(x,y,'+') xlabel('X'),ylabel('Y') 计算结果与问题分析讨论: 运行结果: Figure1:海底曲面图:
某农场负责人认为早稻收获量(y:单位为kg/公顷)与春季降雨(x i:单位为mm)和春季温度(X2:单位为C )有一定的联系,通过7组试验获得了相关的数据。利用Excel得到下面的回归结果(a =0.1): 方差分析表 (1)将方差分析表中的所缺数值补齐。 (2 )写出早稻收获量与春季降雨量、春季温度的多元线性回归方程,并解释各回归系数的意义。 (3 )检验回归方程的线性关系是否显著? (4)检验各回归系数是否显著? 2 (5)计算判定系数R,并解释它的实际意义。 (6)计算估计标准误差Se,并解释它的实际意义。 (每个空格为0.5分) 2、设总体回归模型为Y= 口+ P 1X^^ 2X2+ & ?x^ ?x2,由EXCEL输出结果可知,?= -0.39 14.92x1估计回归方程为? = ? 218.45x2,回归系数 ?的意义指在温度不变的条件下,当降雨量每增加1mm早稻收获量平均增加 14.92 kg/公顷;回归系数:?的意义指在降雨量不变的条件下, 2 当温度增加1C,早稻收获量平均增加218.45 kg/公顷。---5 分 3、由于p值=0.000075 < a =0.05,则拒绝原假设,即表明回归方程的线性关系是显著的。
4、由于各回归系数的P值均小于a ( 0.05 ),所以各回归系数是显著的。 ---2 分5、2二§臾二1387849567二0.99,表示早稻收获量的总变异中有99%的部分可以由降 R SST 14000000 雨量、温度的联合变动来解释。---4 分 6、S =」SS E =V MST = J30376.08 =174.29(k为自变量个数),是总体回归模型 e n - k -1 中随机扰动项&的标准差的无偏估计量,用来衡量回归方程拟合程度的分析指标,S e越大,拟合程度越低;S e越小,拟合程度越高? —4 分
1. 一个班有7名男性工人,他们的身高和体重列于下表 请把他们分成若干类并指出每一类的特征。这里身高以米为单位,体重以千克为单位。 2.有两种跳蚤共10只,分别测得它们四个指标值如表。 样本号甲种乙种 X3 X4 X1 X2 X3 X4 X1 X 2 1 189 245 137 163 181 305 184 209 2 192 260 132 217 158 237 13 3 188 3 217 276 141 192 18 4 300 166 231 4 221 299 142 213 171 273 162 213 5 171 239 128 158 181 297 163 224 1)用距离判别法建立判别准则。 2)问(192, 287, 141,198 和(197, 303, 170, 205 各属于哪一种? 3.考察温度x对产量y的影响,测得下列10组数据: 求y关于x的线性回归方程,检验回归效果是否显著,并预测 x=42C时产量的估值 4. 在研究化学动力学反应过程中,建立了一个反应速度和反应物 %-备 含量的数学模型,形式为y — 1 +卩2为+ P3X 2 +P4X3 其中i…,飞是未知参数,X1,X2,X3是三种反应物(氢,门戊烷, 异构戊烷)的含量,y是反应速度?今测得一组数据如表,试由此确定参数订…宀
序号反应速度y 氢X1 n戊烷X2 异构戊烷X3 1 8.55 470 300 10 2 3.79 285 80 10 3 4.82 470 300 120 4 0.02 470 80 120 5 2.75 470 80 10 6 14.39 100 190 10 7 2.54 100 80 65 8 4.35 470 190 65 9 13.00 100 300 54 10 8.50 100 300 120 11 0.05 100 80 120 12 11.32 285 300 10 13 3.13 285 190 120 5. 主成分与卡方检验已课件为主
《统计学》案例——相关回归分析 案例一质量控制中的简单线性回归分析 1、问题的提出 某石油炼厂的催化装置通过高温及催化剂对原料的作用进行反应,生成各种产品,其中液化气用途广泛、易于储存运输,所以,提高液化气收率,降低不凝气体产量,成为提高经济效益的关键问题。 通过因果分析图和排列图的观察,发现回流温度是影响液化气收率的主要原因,因此,只有确定二者之间的相关关系,寻找适当的回流温度,才能达到提高液化气收率的目的。经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化气收率比去年同期增长1个百分点的目标,即达到12.24%的液化气收率。 2、数据的收集
目标值确定之后,我们收集了某年某季度的回流温度与液化气收率的30组数据(如上表),进行简单直线回归分析。 3.方法的确立 设线性回归模型为εββ++=x y 10,估计回归方程为x b b y 10?+= 将数据输入计算机,输出散点图可见,液化气收率y 具有随着回流温度x 的提高而降低的趋势。因此,建立描述y 与x 之间关系的模型时,首选直线型是
合理的。 从线性回归的计算结果,可以知道回归系数的最小二乘估计值 b 0=21.263和b 1=-0.229,于是最小二乘直线为 x y 229.0263.21?-= 这就表明,回流温度每增加1℃,估计液化气收率将减少0.229%。 (3)残差分析 为了判别简单线性模型的假定是否有效,作出残差图,进行残差分析。
从图中可以看到,残差基本在-0.5—+0.5左右,说明建立回归模型所依赖的假定是恰当的。误差项的估计值s=0.388。 (4)回归模型检验 a.显著性检验 在90%的显著水平下,进行t 检验,拒绝域为︱t ︱=︱b 1/ s b1︱>t α/2=1.7011。 由输出数据可以找到b 1和s b1,t=b 1/ s b1=-0.229/0.022=-10.313,于是拒绝原假设,说明液化气收率与回流温度之间存在线性关系。 b.拟合度检验 判定系数r 2=0.792。这意味着液化气收率的样本变差大约有80%可以由它与回流温度的线性关系来解释。 2r r ==-0.89 这样,r 值为y 与x 之间存在中高度的负线性关系提供了进一步的证据。 由于n ≥30,我们近似确定y 的90%置信区间为: s z y )(?2 α±=21.263-0.229x ±1.282×0.388 = 21.263-0.229x ± 0.497
某农场负责人认为早稻收获量(y :单位为kg/公顷)与春季降雨(x 1:单位为mm )和春季温度(x 2:单位为℃)有一定的联系,通过7组试验获得了相关的数据。利用Excel 得到下面的回归结果(α=0.1): 方差分析表 (2)写出早稻收获量与春季降雨量、春季温度的多元线性回归方程,并解释各回归系数的意义。 (3)检验回归方程的线性关系是否显著? (4)检验各回归系数是否显著? (5)计算判定系数2 R ,并解释它的实际意义。 (6)计算估计标准误差Se ,并解释它的实际意义。 (每个空格为0.5分) -----3分 2、设总体回归模型为Y =1 2 1 2 x x αεββ+ ++ 估计回归方程为y ?=1 2 1 2 ???x x αββ++,由EXCEL 输出结果可知,y ?=120.3914.92218.45-++x x ,回归系数1 ?β 的意义指在温度不变的条件下,当降雨量每增加1mm ,早稻收获量平均增加14.92kg/公顷;回归系数 2 ?β 的意义指在降雨量不变的条件下, 当温度增加1℃,早稻收获量平均增加218.45kg/公顷。 ---5分
3、由于p 值=0.000075<α=0.05,则拒绝原假设,即表明回归方程的线性关系是显著的。 ---2分 4、由于各回归系数的P 值均小于α(0.05),所以各回归系数是显著的。 ---2分 5、 2 13878495.67 0.9914000000 = ==SSR SST R ,表示早稻收获量的总变异中有99%的部分可以由降雨量、温度的联合变动来解释。 ---4分 6、 174.29= ===e S (k 为自变量个数) ,是总体回归模型中随机扰动项ε的标准差的无偏估计量,用来衡量回归方程拟合程度的分析指标,e S 越大, 拟合程度越低;e S 越小,拟合程度越高. ---4分
数学建模常用统计方法 1.1多元回归 1、方法概述: 在研究变量之间的相互影响关系模型时候,用到这类方法,具体地说:其可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值带入回归方程可以求出因变量的估计值,从而可以进行预测等相关研究。 2、分类 分为两类:多元线性回归和非线性线性回归;其中非线性回归可以通过一定的变化转化为线性回归,比如:y=lnx 可以转化为 y=u u=lnx来解决;所以这里主要说明多元线性回归应该注意的问题。 3、注意事项 在做回归的时候,一定要注意两件事: (1) 回归方程的显著性检验(可以通过sas和spss来解决) (2) 回归系数的显著性检验(可以通过sas和spss来解决) 检验是很多学生在建模中不注意的地方,好的检验结果可以体现出你模型的优劣,是完整论文的体现,所以这点大家一定要注意。 4、使用步骤: (1)根据已知条件的数据,通过预处理得出图像的大致趋势或者数据之间的大致关系; (2)选取适当的回归方程; (3)拟合回归参数; (4)回归方程显著性检验及回归系数显著性检验 (5)进行后继研究(如:预测等)
这种模型的的特点是直观,容易理解。 这体现在:动态聚类图可以很直观地体现出来~ 当然,这只是直观的一个方面~ 2、分类 聚类有两种类型: (1) Q型聚类:即对样本聚类; (2) R型聚类:即对变量聚类; 聚类方法: (1) 最短距离法 (2) 最长距离法 (3) 中间距离法 (4) 重心法 (5) 类平均法 (6) 可变类平均法 (7) 可变法 (8) 利差平均和法 在具体做题中,适当选取方法; 3、注意事项 在样本量比较大时,要得到聚类结果就显得不是很容易,这时需要根据背景知识和 相关的其他方法辅助处理。 还需要注意的是:如果总体样本的显著性差异不是特别大的时候,使用的时候也要 注意~
企业管理 对居民消费率影响因素的探究 ---以湖北省为例改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 总消费(C:亿元) 总GDP(亿元)消费率(%) 1995 1095.97 2109.38 51.96 1997 1438.12 2856.47 50.35 2000 1594.08 3545.39 44.96 2001 1767.38 3880.53 45.54 2002 1951.54 4212.82 46.32 2003 2188.05 4757.45 45.99 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
(注:数据来自《湖北省统计年鉴》) 一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y :消费率(%) X1:总收入 (亿元) X2:人口 增长率 (‰) X3:居民 消费价格指数增长率 X4:少儿抚养系数 X5:老年 抚养系数 X6:居民 消费比重(%) 1995 51.96 1590.75 9.27 17.1 45.3 9.42 68.9 1997 50.35 2033.68 8.12 2.8 41.1 9.44 70.72 2000 44.96 2247.25 3.7 0.4 39 9.57 70.93 2004 2452.62 5633.24 43.54 2005 2785.42 6590.19 42.27 2006 3124.37 7617.47 41.02 2007 3709.69 9333.4 39.75 2008 4225.38 11328.92 37.30 2009 4456.31 12961.1 34.38 2010 5136.78 15806.09 32.50
1.1多元回归 1、方法概述: 在研究变量之间的相互影响关系模型时候, 用到这类方法, 具体地说:其可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值带入回归方程可以求出因变量的估计值,从而可以进行预测等相关研究。 2、分类 分为两类:多元线性回归和非线性线性回归; 其中非线性回归可以通过一定的变化转化为线性回归, 比如:y=lnx 可以转化为 y=u u=lnx来解决;所以这里主要说明多元线性回归应该注意的问题。 3、注意事项 在做回归的时候,一定要注意两件事: (1 回归方程的显著性检验(可以通过 sas 和 spss 来解决 (2 回归系数的显著性检验(可以通过 sas 和 spss 来解决 检验是很多学生在建模中不注意的地方, 好的检验结果可以体现出你模型的优劣, 是完整论文的体现, 所以这点大家一定要注意。 4、使用步骤: (1根据已知条件的数据,通过预处理得出图像的大致趋势或者数据之间的大致关系; (2选取适当的回归方程; (3拟合回归参数; (4回归方程显著性检验及回归系数显著性检验 (5进行后继研究(如:预测等
这种模型的的特点是直观,容易理解。 这体现在:动态聚类图可以很直观地体现出来! 当然,这只是直观的一个方面! 2、分类 聚类有两种类型: (1 Q 型聚类:即对样本聚类; (2 R 型聚类:即对变量聚类; 聚类方法: (1 最短距离法 (2 最长距离法 (3 中间距离法 (4 重心法 (5 类平均法 (6 可变类平均法 (7 可变法 (8 利差平均和法 在具体做题中,适当选取方法; 3、注意事项
在样本量比较大时,要得到聚类结果就显得不是很容易,这时需要根据背景知识和相关的其他方法辅助处理。还需要注意的是:如果总体样本的显著性差异不是特别大的时候,使用的时候也要注意! 4、方法步骤 (1首先把每个样本自成一类; 2选取适当的衡量标准,得到衡量矩阵,比如说:距离矩阵或相似性矩阵,找到矩阵中最小的元素,将该元素对应的两个类归为一类, (4重复第 2步,直到只剩下一个类; (4重复第 2步,直到只剩下一个类; 补充:聚类分析是一种无监督的分类,下面将介绍有监督的“分类” 。 我简单说明下,无监督学习和有监督学习是什么 无监督学习:发现的知识是未知的 而有监督学习:发现的知识是已知的 有监督学习是对一个已知模型做优化,而无监督学习是从数据中挖掘模型 他们在分类中应用比较广泛 (非数值分类 如果是数值分类就是预测了,这点要注意 1.3数据分类 1、方法概述
内江师范学院 中学数学建模 实验报告册 编制数学建模组审定牟廉明 专业: 班级:级班 学号: 姓名: 数学与信息科学学院 2016年3月 说明 1.学生在做实验之前必须要准备实验,主要包括预习与本次实验相关的理论知识,熟练与本次实验相关的软件操作,收集整理相关的实验参考资料,要求学生在做实验时能带上充足的参考资料;若准备不充分,则学生不得参加本次实验,不得书写实验报告; 2.要求学生要认真做实验,主要就是指不得迟到、早退与旷课,在做实验过程中要严格遵守实验室规章制度,认真完成实验内容,极积主动地向实验教师提问等;若学生无故旷课,则本次实验成绩不合格; 3.学生要认真工整地书写实验报告,实验报告的内容要紧扣实验的要求与目的,不得抄袭她人的实验报告; 4.实验成绩评定分为优秀、合格、不合格,实验只就是对学生的动手能力进
行考核,跟据所做的的情况酌情给分。根据实验准备、实验态度、实验报告的书写、实验报告的内容进行综合评定。
实验名称:数学规划模型(实验一)指导教师: 实验时数: 4 实验设备:安装了VC++、mathematica、matlab的计算机 实验日期:年月日实验地点: 实验目的: 掌握优化问题的建模思想与方法,熟悉优化问题的软件实现。 实验准备: 1.在开始本实验之前,请回顾教科书的相关内容; 2.需要一台准备安装Windows XP Professional操作系统与装有数学软件的计算机。 实验内容及要求 原料钢管每根17米,客户需求4米50根,6米20根,8米15根,如何下料最节省?若客户增加需求:5米10根,由于采用不同切割模式太多,会增加生产与管理成本,规定切割模式不能超过3种,如何下料最节省? 实验过程: 摘要:生活中我们常常遇到对原材料进行加工、切割、裁剪的问题,将原材料加工成所需大小的过程,称为原料下料问题。按工艺要求,确定下料方案,使用料最省,或利润最大就是典型的优化问题。以此次钢管下料问题我们采用数学中的线性规划模型、对模型进行了合理的理论证明与推导,然后借助于解决线性规划的专业软件Lingo 11、0对题目所提供的数据进行计算从而得出最优解。 关键词:钢管下料、线性规划、最优解 问题一 一、问题分析: (1)我们要分析应该怎样去切割才能满足客户的需要而且又能使得所用原料比较少; (2)我们要去确定应该怎样去切割才就是比较合理的,我们切割时要保证使用原料的较少 的前提下又能保证浪费得比较少; (3)由题意我们易得一根长为17米的原料钢管可以分别切割成如下6种情况(如表一): 表一:切割模式表 模式 4m钢管根数 6m钢管根数8m钢管根数余料/m 1 4 0 0 1 2 1 2 0 1 3 2 0 1 1 4 2 1 0 3 5 0 1 1 3 6 0 0 2 1
湖南城市学院 数学与计算科学学院《数学建模》实验报告 专业: 学号: 姓名: 指导教师: 成绩: 年月日
实验一 初等模型 实验目的:掌握数学建模的基本步骤,会用初等数学知识分析和解决实际问题。 实验内容:A 、B 两题选作一题,撰写实验报告,包括问题分析、模型假设、模型构建、模型求解和结果分析与解释五个步骤。 A 题 飞机的降落曲线 在研究飞机的自动着陆系统时,技术人员需要分析飞机的降落曲线。根据经验,一架水平飞行的飞机,其降落曲线是一条S 形曲线。如下图所示,已知飞机的飞行高度为h ,飞机的着陆点为原点O ,且在整个降落过程中,飞机的水平速度始终保持为常数u 。出于安全考虑,飞机垂直加速度的最大绝对值不得超过g /10,此处g 是重力加速度。 (1)若飞机从0x x 处开始下降,试确定出飞机的降落曲线; (2)求开始下降点0x 所能允许的最小值。 y 0x 一、 确定飞机降落曲线的方程
如图所示,我们假设飞机降落的曲线的方程为I d cx bx ax x f +++=23)( 由题设有 h x f f ==)(,0)0(0。 由于曲线是光滑的,所以f(x)还要满足0)(,0)0(0='='x f f ,代入f(x) 可以得到 ?? ? ? ?? ?=++='=+++==='==0 23)()(0)0(0)0(020*******c bx ax x f h d cx bx ax x f c f d f 得 ,0,0,3,22 3 ===- =d c x h b x h a 飞机的降落曲线为 )32()(2 30 2 0x x x x h x f --= 二、 找出最佳着陆点 飞机的垂直速度是关于时间t 的导数,所以 dt dx x x x x h dt dy )66(20 20--= 其中 dt dx 是飞机的水平速度, ,u dt dx = 因此 )(60 2 20x x x x hu dt dy --= 垂直加速度为 )12(6)12(6020 20202 2--=--=x x x hu dt dx x x x hu dt y d 记 ,)(22dt y d x a =则126)(0 2 02-=x x x hu x a ,[]0,0x x ∈ 因此,垂直加速度的最大绝对值为 2 26)(max x hu x a = []0,0x x ∈ 设计要求 1062 2g x hu ≤ ,所以g h u x 600?≥ (允许的最小值)
数学建模大作业
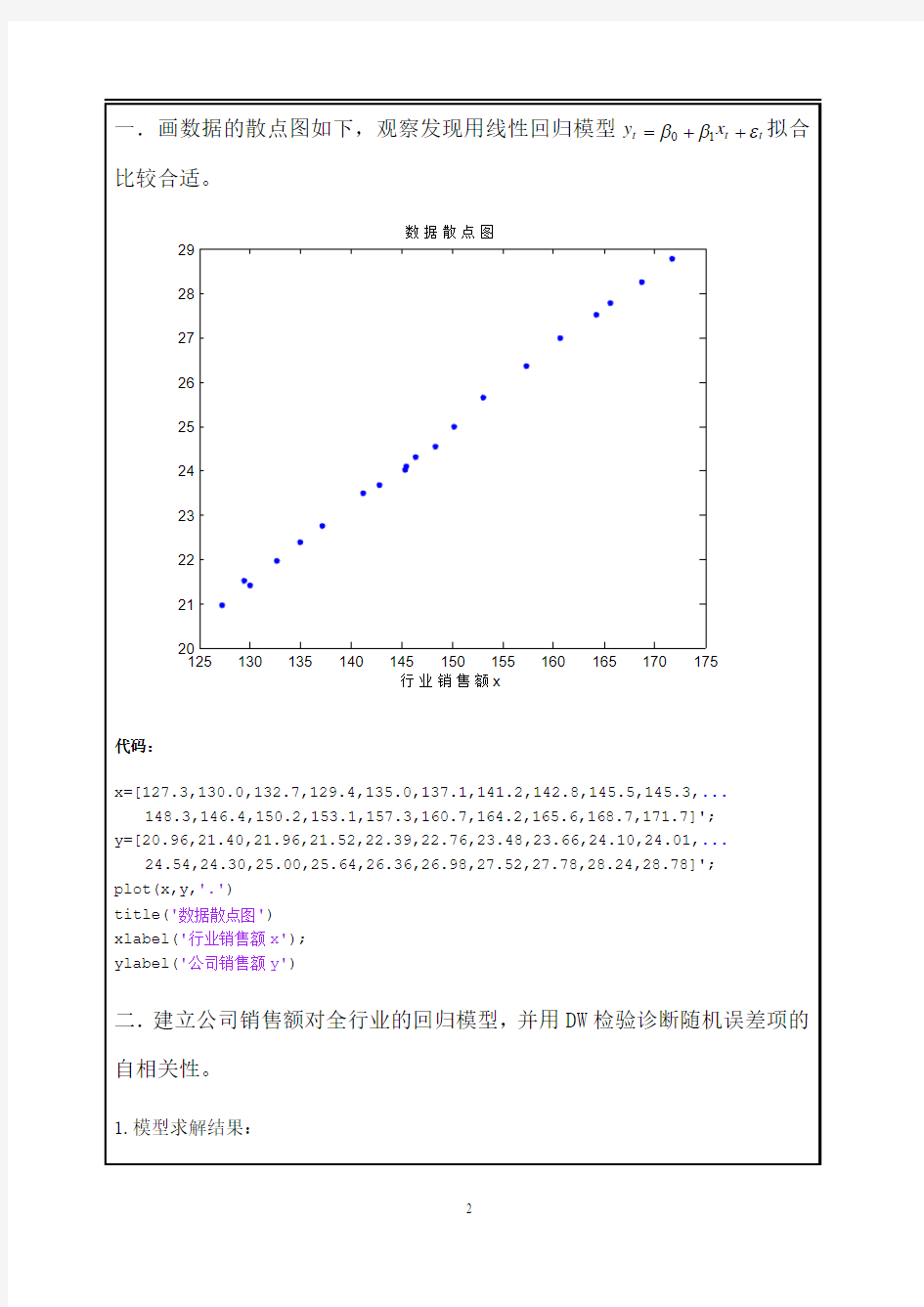
摘要 某公司想用全行业的销售额作为自变量来预测公司的销售额,题目给出了1977—1981此公司的销售额和行业销售额的分季度数据表格。通过对所给数据的简单分析,我们可以看出:此公司的销售额有随着行业销售额的增加而增加的趋势,为了更加精确的分析题目所给的数据,得出科学的结论,从而达到合理预测的目的。我们使用时间序列分析法,参照课本统计回归模型例4,做出了如下的统计回归模型。 在问题一中,我们使用MATLB数学软件,画出了数据的散点图,通过观察散点图,发现公司的销售额和行业销售额之间有很强的线性关系,于是我们用线性回归模型去拟合,发现有很好的拟合性。但是这种情况下,并没有考虑到数据的自相关性,所以我们做了下面几个问题的分析来对这个数学模型进行优化。 在问题二中,通过建立了公司销售额对全行业销售额的回归模型,并使用DW检测诊断随机误差项的自相关性。通过计算和查DW表比较后发现随即误差存在正自相关,也就是说前面的模型有一定的局限性,预测结果存在一定的偏差,还有需要改进的地方。 在问题三中,因为在问题二中得出随即误差存在正自相关,为了消除随机误差的自相关性,我们建立了一个加入自相关后的回归模型。并对其作出了分析和验证,我们发现加入自相关后的回归模型更加合理。通过使用我们建立的模型对公司的销售额进行预测,发现和实际的销售额很接近,也就是说模型效果还不错。 关键词:销售额、回归模型、自相关性 一、问题提出 某公司想用全行业的销售额作为自变量来预测公司的销售额,下表给出了1977-1981年公司销售额和行业销售额的分季度数据(单位:百万元). (1)画出数据的散点图,观察用线性回归模型拟合是否合适。 (2)监理公司销售额对全行业销售额的回归模型,并用DW检验诊断随机误差项的自相关性。