
一、memcache的准备知识
memcache使用了libevent来管理事件
libevent需要注册一个事件回调函数,当事件发生时,触发回调函数libevent的稍微详细的介绍见最后的libevent介绍
二、memcache系统流程
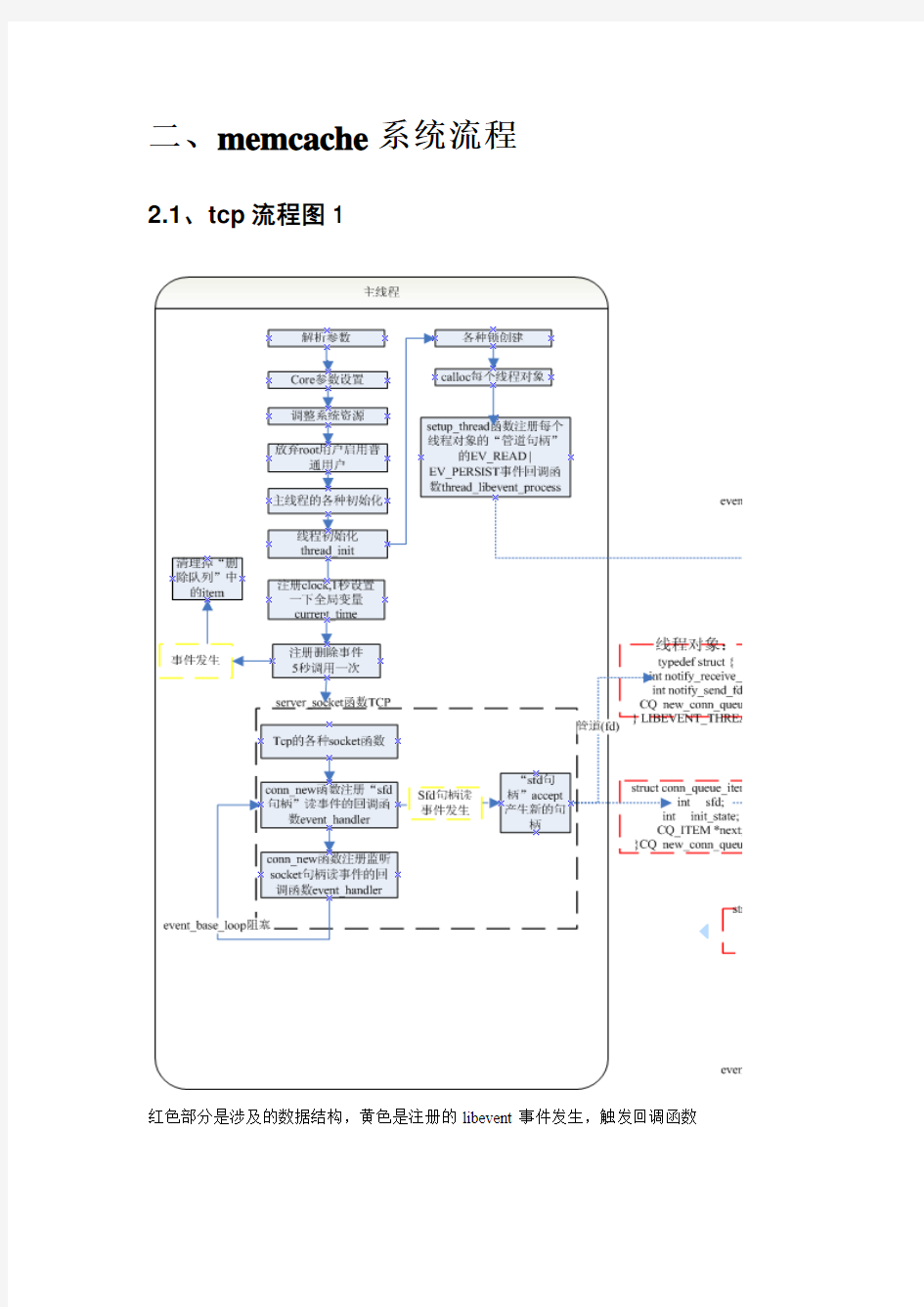
2.1、tcp流程图1
红色部分是涉及的数据结构,黄色是注册的libevent事件发生,触发回调函数
2.2、tcp流程图2
红色部分是涉及的数据结构,黄色是注册的libevent事件发生,触发回调函数
2.3、udp流程图1
红色部分是涉及的数据结构,黄色是注册的libevent事件发生,触发回调函数
2.4、udp流程图2
红色部分是涉及的数据结构,黄色是注册的libevent事件发生,触发回调函数
2.5、系统启动流程的函数说明
注册SIGINT信号-->简单的退出
signal(SIGINT, sig_handler)
初始化全局设置settings_init
|
取消标准错误输出的缓冲setbuf(stderr, NULL)
|
非常经典的解析命令行参数,覆盖默认设置(注意全局变量optarg的使用)
while( c = getopt(argc, argv, ...)){
switch(c){....} }
|
将系统资源设置到最大的
getrlimit(RLIMIT_CORE, &rlim) <==> setrlimit(RLIMIT_CORE, &rlim_new) |
创建监听socket(这里以TCP socket为例说明)
server_socket(settings.port, 0)-->第二个参数0表示这个是tcp socket
| |--->创建socket,并将它设置为非阻塞模式
| socket(...)
| if ((flags = fcntl(sfd, F_GETFL, 0)) < 0 || fcntl(sfd, F_SETFL, flags | O_NONBLOCK) < 0){...}
| 很经典的if语句^_^
| (如果使用ioctrl来设置socket为非阻塞的话{ u_long flag = 1; ioctl(sfd, FIONBIO , &flag);},即使ioctl返回成)
| 功,也不表示该socket已经设置为非阻塞模式了)
| |
| 将socket设置为地址重用,这个主要是可以在TIME_WAIT状态下马上就能绑定该端口
| setsockopt(sfd, SOL_SOCKET, SO_REUSEADDR, (void *)&flags, sizeof(flags));
| 这里总结一下SO_REUSEADDR的作用:
| 1、单进程在TIME_WAIT状态下重新绑定一个端口,IP和PORT完全相同| 2、多网卡,多IP状态下,多进程可以用不同的IP绑定同一个端口
| 3、单进程多IP可以绑定同一个端口
| 4、在UDP多播的应用中,多进程可以用相同的IP和PORT绑定相同的地址
| |
| 设置socket的选项:
| setsockopt(sfd, SOL_SOCKET, SO_KEEPALIVE, (void *)&flags, sizeof(flags));
| |
| 设置SO_KEEPALIVE选项后,如果2小时(具体时间与TCP协议栈的实现有关)内socket完全空闲,TCP将
| 发送一个主机存活探测包,这是TCP协议中必须响应的包,接受方若正常就以正
确ACK包响应,如果接收
| 方崩溃或重启,则以RST包响应,RST接收方设置错误号为ECONNREST,如果探测包接收方无任何响应,
| 源自Berkelay的TCP协议栈等待75秒再次发送一个探测包,当一共发送9个探测包仍然没有任何响应时,
| 那么发送方放弃并将发送socket的错误号设为ETIMEOUT
| |
| setsockopt(sfd, SOL_SOCKET, SO_LINGER, (void *)&ling, sizeof(ling));
| 设置socket的关闭方式,以struct linger结构调用setsocketopt
| 当参数为SO_DONTLINGER时(相当于SO_LINGER,且struct linger 为{0,0}),表示调用closesocket时强制
| 关闭socket,所有悬挂的数据将丢弃,对方recv调用将返回ECONNRESET。如果struct linger结构的
| l_onoff =1 同时l_linger != 0,当阻塞的socket调用closesocket时将一直阻塞直到悬挂的数据发送完或者超
| 时(l_linger表示超时的秒数)。当非阻塞的socket调用closesocket时将返回EWOULDBLOCK/EAGAIN错误
| |
| setsockopt(sfd, IPPROTO_TCP, TCP_NODELAY, (void *)&flags, sizeof(flags));
| 这是设置数据包的Nagle化,Nagle化是将小的数据组装为一个比较大的帧一次发送的算法,它的处理方式
| 很简单:就是在接收到前一个包的确认到来前一直缓存发送的数据(write调用),Nagle算法可以缓解网络
| 拥塞。对于一些网络应用,需要把网络数据包组装为一个最大的网络传输单元一次发送可以节省流量,这种
| 情况下可以使用TCP_CORK选项来强制socket使用MSS发送数据,不过这个选项只可以在linux平台上使用
| |
| 绑定端口并将socket转换为被动socket
| bind(sfd, (struct sockaddr *)&addr, sizeof(addr))
| listen(sfd, 1024) ;
|$ p3 l M4 }+ [
把权限降低到普通的用户(当然需要启动的用户为root)
(getuid/geteuid-->getpwnam(username)-->setgid(pw->pw_gid); setuid(pw->pw_uid)) |
当前进程进入daemon模式
daemon(maxcore, settings.verbose);关于daemon进程相关情况请参考我的另一篇blog,这里不展开了^_^.
|
初始化libevent
event_init();
|
初始化memcached的运行环境
item_init();-->将历史访问链表初始化为NULL
stats_init();-->全局状态初始化,主要是统计信息的初始化,如:命令请求、数据流量等assoc_init();-->hashtable的初始化,计算hashtable的大小-->分配空间-->初始化空间为NULL;
conn_init();-->抽象tcp连接的初始化, 分配了一个指向struct conn* 的指针数组,这个数组有200个元素
slabs_init(mem_limit, unit_factor);-->内存管理初始化
| |-->循环计算每个内存集合的内存单元大小和每个内存页所包含的内存单元数目 | 对于每个内存页的大小是与sizeof(void*)对齐的,而且内存集合的内存单元大小是以factor因子增加的
| 如果当前的内存单元的大小超过0.5M,就好停止扩展,并在最后增加一个内存单元为1M的集合
| (在memcached中内存页大小的上限是1M)
| |
| 如果编译的时候没有定义DONT_PREALLOC_SLABS而且环境变量中也没有定义T_MEMD_SLABS_ALLOC
| 那么memcached就会进行内存的预分配slabs_preallocate(power_largest)-->调用do_
三、内存结构分析
3.1、已分配的内存结构
系统的内存管理涉及3个部分:
hash链表,通过hash链表来快速的找到指定的内存块
item内存块,用户的数据都保存在item内存块里
slab内存分配器,item的分配和回收,通过slab分配器快速完成heads,tails指针:heads头保存的是最新使用的节点,tails是旧的当item内存块用光了,就要淘汰现有item
采用LRU算法,
3.2、未分配的内存结构
系统通过slab分配器来管理内存块的分配\释放等
3.3、内存操作函数说明
3.3.1、memcached的内存管理函数
内存管理都需要解决:分配、回收、碎片这几个一般性问题,memcached的处理方式是(通过宏USE_SYSTEM_MALLOC 可以控制memcached使用系统的malloc/free管理内存,这里不讨论);
分配-->预分配+ 动态2倍分配--> 减少realloc的调用
回收-->从来不释放内存--> memcached的目的就是通过内存缓存数据,没有必要释放
碎片-->固定大小分配+ 通过额外的动态指针数组保存各个分块的地址+ (增加HEAD/TAIL指针数组)LRU算法回收
--> 加快获得空闲"内存块"的获得
memcached将内存划分为不同大小的集合(通过结构体slabclass_t来维护一个集合的信息),现在看看slabclass_t结构。这里有几个概念:
内存单元:集合中维护的"逻辑内存块"的大小,它是以sizeof(void*)字节对齐的
内存页: slabclass_t分配内存的时候是以perslab个内存单元分配的,这perslab个连续的内存单元就是内存页
了解了memcached的内存管理的数据结构后,下面看看内存管理相关的几个主要函数: <1>do_slabs_newslab(class_id) 这个函数分配一个新的内存页
|-->检查内存分配是否已经超过了限制
|
检查是否需要进行内存页指针的2倍扩展
|
从操作系统中申请内存malloc(len)-->对于需要在不同的slabclass间转移数据的应用len使用的固定大小1M
| 而其他应用这里分配的是size*perslab,这里size 是sizeof(void *)对齐的
|
确认malloc成功后初时化它的值为0(memset), (我想这里可以使用calloc代替)将end_page_ptr指向新的内存页,并把它加入到内存页数组中,同时修改对应的计算变量(这个函数是memcached中唯一分配"用户可用内存"的地方, "用户可用"是指set/update/replace指令可以控制的内存)
<2>do_slabs_alloc(need_size) 这个函数功能是根据需要的大小申请内存块
|
根据需要的大小查找对应的slabclass_t结构
|
检查是否超出了设置的内存限额
检查内存单元指针数组slots是否为空,如果非空-->返回一个空的内存单元
检查是否分配了新的内存页,如果是-->返回一个"新的"内存单元(没有加入到slots中)
如果新的内存页为空,那么调用do_slabs_newslab从系统分配内存
(当然do_slabs_alloc还会修改对应的计数变量)
<3>do_slabs_free(pointer, mem_unit_size)
|
根据mem_unit_size查找对应的slabclass_t结构
|
检查是否需要进行内存单元数组slots的2倍扩展,(2倍扩展都是使用realloc完成数据转移的)
|
将释放的内存加入到内存单元数组中:
(可以看到memcached是不真正释放内存的,而且它的分配与释放操作都是很简单的指针赋值操作,
这就是memcached内存的管理,也是它快的原因之一,另外一个原因在于它的hash算法)
<4>do_slabs_reassign(src_id, des_id) 这个函数将个集合中的某一个内存页的内容复制到另一个集合的一个内存页中
|
根据id获得源集合和目标集合的slabcalss_t结构
|
检查源集合和目标集合的状态:只有在源集合没有新分配的内存页,而且存在有效的内存单元; 目标集合没有新分
| 配的内存页,并且内存页指针有空闲的空间(这个可能通过2倍扩展得到);源集合和目标集合的内存页
| 大小都是1M
|
循环源集合中每个内存单元(事实上它保存的是struct item 结构体),对于已经被"申请使用"的内存单元进行"清理":
从关联列表中(hashtable)删除该键值assoc_delete(ITEM_key(it), it->nkey)
这时还会检查item的引用计数是否为0,如果不是就会设置该忙的状态was_buse = true 从访问历史双向链表中删除对应的item,item_unlink_q(it)) c)
检查item的引用计数,当它是0时,释放该item,item_free(it)
|
循环检查源集合的内存单元数组,并从中修改指向需要"复制"的内存页中的内存块 |
如果的忙状态为true,那么就会返回-1
(从处理流程来看,这时该内存页的内存单元已经清理出了hashtable和访问历史链表。如果返回-1, 客户端就可以在稍后重新提交ressign的请求)
|
将内存分页挂到目标集合的新的分页上,并修改对应的计数变量和将item的slabs_clsid 设置为0,这个主要是要保此代码对于slabs_clsid检查的一致性
3.3.2. 名值对hashtable的管理函数
memcached使用的是hashtable来维护名值对(通过hash值和掩码计算最后的hashtable 的下标),为了降低hash值的碰撞,memcached 使用自动扩展的策略,当hashtable中保存的item数目大于它的大小的1.5倍时,memcached就会实行hashtable的扩展,并把原hanshtable中的元素会重新hash并放到新的hashtable中,而且为了降低查找的延时,这种数据迁移会分散在多次的访问中(后面我们再详细分析)。
现在我们看看相关的几个函数的实现。
<1>assoc_init()分配hashtable的所需的内存
|-->unsigned int hash_size = hashsize(hashpower) * sizeof(void*);
primary_hashtable = malloc(hash_size);
memset(primary_hashtable, 0, hash_size);
<2>assoc_find(key, key_len) 根据键寻找对应的值
|
根据key和key_len计算hash值(hash算法的细节可以参考https://www.doczj.com/doc/d81424782.html,/bob/hash/doobs.html)
|
根据hash值和掩码计算hashtable的下标
如果当前处于hashtable的扩展过程,并且下标值小于数据迁移的记录值,那么就从新的hashtable中获得该下标对应的item链表,否则就从原来的hashtable中获得item链表 |
循环对比链表中的item的key寻找对应的item
<3>assoc_insert(item) 将item加入到hashtable中
|
验证item的key不在hashtable中
|
计算hash值和需要更新的hashtable的下标和assoc_find的算法一样,根据下标和当前是否处于hashtable的扩展过程中来更新旧的hashtable或新的hashtable.
|
如果当前不是处于扩展状态,那么就检查hashtable中保存的item数是否超过其大小的1.5倍,如果是就进行2倍的容量扩展assoc_expand()
<4>assoc_expand()
|-->hashtable的2倍容量扩展
|
将hashtable中的第一个下标的item列表重新计算hash值并移到新的hashtable 中,
(这里只移动了一个下标的item链表do_assoc_move_next_bucket)
|
对于其他的元素的迁移会在用户用户请求的时候进行移动,这是把时间消耗分散的延迟处理方式
当元素迁移完成后,就会释放旧的hashtable占用的资源free
<5>assoc_delete(key, key_len) 从hashtable中删除对应key的item
|-->寻找key对应的元素的指针变量的地址
_hashitem_before
|
修改item的h_next指针,从链表中删除该元素
3.3.3. 数据保存对象struct item结构的操作函数
memcached在内部使用双向链表维护item的数据,现在我们看看item结构体和几个主要的函数:
<1>do_item_alloc(key, key_len, client_flag, expiretime, data_len) 申请足够大的内存单元
|
计算所需的内存单元大小item_make_header(key_len+1(加1表示字符串末尾的"0"), client_flag, data_len, buf, &extral_len))
|
根据所需大小查找内存单元
slabs_clsid(need_size) --> 检查是否存在内存分组
slabs_alloc(need_size) --> slabs_alloc是一个宏,对于多线程模式和单线程模式,它会映射到不同的函数
|
如果slabs_alloc失败,就从保存访问历史的全局变量tails中查找最多50次,得到一个最近最久没有使用的并且引用计数为0的item,将它从hashtable和访问历史链表中"删除"do_item_unlink(do_item_unlink调用本身并不保证item占用的内存返回到可用队列中,只有当item的引用计数变成0时才会进行真正的资源返还,由于在调用do_item_unlink前已经检查了引用计数的值,所以item占用的内存将会变成可用)
|
重新调用slabs_alloc请求内存,如果失败就直接返回NULL
|
初始化新的item的成员-->需要注意的是next/prev/h_next都会初始化为0,而且引用计算refcount会设置为1,也就是说使用方需要保证最后会将refcount减少1,这里item的状态变量it_flags也会初始化为
item_free(item*) 删除item的资源,包括hashtable、访问历史链表heads/tails/sizes, 把item占用的资源返回缓存中. u: N" Q' P, J* D) X6 J6 M1 V2 E
|
将item的状态变量设为ITEM_SLABBED,并将对应的资源返回到缓冲中
slabs_free(item*, item_total_size);
<2>item_unlink_q(item *) 从历史链表中删除对应的item
<3>item_link_q(item *) 将item加入到历史链表中
这两个函数的细节要结合一起看,item_link_q中是将item依次加入到heads的第一个元素,也就是说它是时间反向的,而tails是时间一致的,最先访问的item在tails的前面,而且tails的指针不是每次都修改的,只有在tails为空的时候才会更新,而链表的构造也是在插入到heads的时候完成了。可以看到item_unlink_q中处理(heads[class_id] == item) 和(tails[class_id] == item)的情况,它们修改的指针分别是"head = it->next"和"*tail = it->prev;"
这两个函数是不修改item的任何表示状态的变量的
<4>do_item_link(item*)
<5>do_item_unlink(item *)
这两个函数分别将item对象加入到历史链表和将item从历史链表中删除,它们首先将item加入hashtabl(或从hashtable删除),然后分别进行item_link_q/item_unlink_q 需要注意的是,对于do_item_unlink函数,还会检查refcount,当为零时,它会将释放item的资源item_free
这两个函数还会修改item的状态变量"it->it_flags |= ITEM_LINKED/it->it_flags &= ~ITEM_LINKED;
<6>do_item_update(item*)/do_item_replace(item *it, item *new_it)
这两个函数的很相似,do_item_update调用的是item_unlink_q和item_link_q,do_item_replace调用的是do_item_unlink和do_item_link,它们的代码都比较简单。
<7>do_item_get_notedeleted(key, key_len, &delete_lock) 这个函数根据key查找没有被删除的item元素
从hashtable中查找对应的item
检查item是否已经超时,这里检查主要是memcached是5秒一次检查超时的,如果在这段时间内获取item就有可能得到实际上已经超时的item, if(!item_delete_lock_over(it)){*delete_lock = false; it = NULL;}
|
检查全局设置,如果设置了统一个有效时间,并且当前时间已经超过了这个有效时间,同时item是在有效时间前设置的,那么就删除该item
检查item的超时时间,如果已经超时,就把item删除
do_item_unlink(it);
|
增加item的引用计数,并返回item指针( B)
<8>do_item_flush_expired() 这个函数是把settting.oldest_live时间后的item全部删除,这个函数的调用主要是处理memcached客户端的"flush_all"指令使用需要注意的是当client发送"flush_all"时,memcached会修改settting.oldest_live的值,这是会对do_item_get_notedeleted造成影响,因为在下一次调用do_item_get_notedeleted 的时候会对settting.oldest_live进行对比,在这个时间之前的item也会被删除,这个也是"flush_all"的分散处理时间的策略,这里也是出于性能因数作的设计。
<9>do_store_item(item* , comm) 根据comm的值(add/replace/set), 处理item的值
这个函数主要是调用其他相关的函数完成功能,需要注意的是它的处理逻辑: "add":如果存在该key对应的非删除的item(do_item_get_notedeleted得到),那么更新这个item的访问历史,对于新接收到的数据是忽略的,如果由于delete_lock不存在,那么不作任何处理,如果完全没有这个key对应的item,那么就增加这个key的item(do_item_link(it);)
"replace":如果存在该key对应的非删除的item(do_item_get_notedeleted得到),更新这个key对应的值(do_item_replace), 如果由于delete_lock不存在,那么不作任何处理,如果完全没有这个key对应的item,那么就增加这个key的item(do_item_link(it);) "set":查询key对应的item(do_item_get_nocheck,其实前面已经调用了do_item_get_notedeleted,如果发现是delete_lock,那么调用do_item_get_nocheck),如果存在那么更新key对应的ite(do_item_replace,对应的item的it_flag会被完全更新), 否则调用do_item_link将item加入到hashtable和访问历史链表中
3.4内存块struct item的保存\删除详细说明
3.4.1 struct item的保存
/*
* Generates the variable-sized part of the header for an object.
*
* key - The key
* nkey - The length of the key
* flags - key flags
* nbytes - Number of bytes to hold value and addition CRLF terminator
* suffix - Buffer for the "V ALUE" line suffix (flags, size).
* nsuffix - The length of the suffix is stored here.
*
* Returns the total size of the header.
*/
int item_make_header(char *key, uint8_t nkey, int flags, int nbytes,
char *suffix, int *nsuffix) {
*nsuffix = sprintf(suffix, " %u %u\r\n", flags, nbytes - 2);
return sizeof(item) + nkey + *nsuffix + nbytes;
}
这里的nbytes将value的长度保存起来了。因为item的key和value都不是定长的,所有必须保存它们的长度,key的长度直接保存在item的nkey中,value的长度则没有专门的变量来记录,这个suffix便是用来保存这些数据的,一是item的flag,另一个是value的长度。item_alloc函数在初始化item的后面有一句代码:memcpy(ITEM_suffix(it), suffix, nsuffix); 这样便将suffix复制到了#define ITEM_suffix(item) ((char*) &((item)->end[0]) + (item)->nkey + 1)处,这样就可以看出一个item是怎样保存的,首先放的是item,item中最后存放的是key,然后是suffix,接着才是value。这样就可以理解宏ITEM_data的定义了。
#define ITEM_data(item) ((char*) &((item)->end[0]) + (item)->nkey + 1 + (item)->nsuffix) complete_nread主要是要生成应答客户端的信息,并且调用item_link函数将item加入hash 表中,然后调用item_link_q将本item放到LRU链表的第一个位置。
分析到这里就不得不讲讲memcached怎么管理这些item了。
memcached启动时默认申请64MB的内存,memcached使用slab来管理内存
static slabclass_t slabclass[POWER_LARGEST+1];
最多可以有两百个slab,不知道为什么不使用第零个。
unsigned int size = sizeof(item) + settings.chunk_size;
默认情况下第一个slab管理的内存项大小为80字节,然后一次倍乘factor(默认值为1.25)。既然内存按固定大小分配,那么碎片也就再所难免了。每个slab首先分配1MB大小的内存,将1MB除于本slab管理固定内存块大小便是内存块的总数目了。第一个slab管理的内存块大小为:1024 * 1024 / 80 = 13107。默认情况下的启动信息如下:
slab class 1: chunk size 80 perslab 13107
slab class 2: chunk size 100 perslab 10485
slab class 3: chunk size 128 perslab 8192
slab class 4: chunk size 160 perslab 6553
slab class 5: chunk size 200 perslab 5242
slab class 6: chunk size 252 perslab 4161
slab class 7: chunk size 316 perslab 3318
slab class 8: chunk size 396 perslab 2647
slab class 9: chunk size 496 perslab 2114
slab class 10: chunk size 620 perslab 1691
slab class 11: chunk size 776 perslab 1351
slab class 12: chunk size 972 perslab 1078
slab class 13: chunk size 1216 perslab 862
slab class 14: chunk size 1520 perslab 689
slab class 15: chunk size 1900 perslab 551
slab class 16: chunk size 2376 perslab 441
slab class 17: chunk size 2972 perslab 352
slab class 18: chunk size 3716 perslab 282
slab class 19: chunk size 4648 perslab 225
slab class 20: chunk size 5812 perslab 180
slab class 21: chunk size 7268 perslab 144
slab class 22: chunk size 9088 perslab 115
slab class 23: chunk size 11360 perslab 92
slab class 24: chunk size 14200 perslab 73
slab class 25: chunk size 17752 perslab 59
slab class 26: chunk size 22192 perslab 47
slab class 27: chunk size 27740 perslab 37
slab class 28: chunk size 34676 perslab 30
slab class 29: chunk size 43348 perslab 24
slab class 30: chunk size 54188 perslab 19
slab class 31: chunk size 67736 perslab 15
slab class 32: chunk size 84672 perslab 12
slab class 33: chunk size 105840 perslab 9
slab class 34: chunk size 132300 perslab 7
slab class 35: chunk size 165376 perslab 6
slab class 36: chunk size 206720 perslab 5
slab class 37: chunk size 258400 perslab 4
slab class 38: chunk size 323000 perslab 3
slab class 39: chunk size 403752 perslab 2
slab class 40: chunk size 504692 perslab 2
<68 server listening
item都存放在其相应的slab内,然后会有两个重要的链表将它们链接起来。其中一个是单向链表,一个是双向链表。
typedef struct _stritem {
struct _stritem *next;
struct _stritem *prev;
struct _stritem *h_next; /* hash chain next */
.............................}
item结构体有上面这三个指针。其中h_next将item链接到hash表中,hash表的默认大小为65536项,如果数据项多于65536,就会产生冲突了。memcached采用拉链法来解决冲突,所有hash值相同的key将会被链接成一个单向的链表。prev,next这两个指针则用于将item 加入LRU链表中。处于相同slab id的item会被链接成一个双向的链表,heads和tails这两个数组指针分别指向这些slab LRU链表的首项和尾项。当iteam_alloc分配item时,它首先会调用slabs_alloc来申请内存,slabs_alloc有这一句有趣的一句:
if (! (p->end_page_ptr || p->sl_curr || slabs_newslab(id)))
return 0;
这里有两个或运算符,非(A或B或C)其实等价于(非A)与(非B)与(非C),这样就好理解多了。先从本slab中申请,如果没有内存的话就去slot里面找,如果还没有找到的话就要new 新的了。如果这些办法都失败了,iteam_alloc就需用动动LRU的脑筋了,它会从尾部循环50次,看看没有可以释放的item,代码如下:
for (search = tails[id]; tries>0 && search; tries--, search=search->prev) {
if (search->refcount==0) {
item_unlink(search);
break;
}
item_link_q和item_unlink_q函数专门处理item LRU,一个用于将item放到LRU链表的首位置,一个用于从LRU链表中移除本item。
这里提一下refcount这个属性,当初我一直以为这个引用计数同LRU有关系,这个值其实同LRU一点关系都没有,LRU只是通过get来更新链表。refcount用户多客户端的护持操作,当一个客户端get很多个item时,memcached在process_get_command函数中有这样一句"it->refcount++;",它使得每个item的refcount都被置成了1,这样它们就不能被删除掉了。
。memcached使用sendmsg这个函数发送数据,这个函数的实现如下:
inline int sendmsg(int s, const struct msghdr *msg, int flags)
{
DWORD dwBufferCount;
if(WSASendTo((SOCKET) s,
(LPWSABUF)msg->msg_iov,
(DWORD)msg->msg_iovlen,
&dwBufferCount,
flags,
msg->msg_name,
msg->msg_namelen,
NULL,
NULL
) == 0) {
return dwBufferCount;
}
if(WSAGetLastError() == WSAECONNRESET) return 0;
return -1;
微信公众平台开发-PHP视频教程 课程目标 1、了解微信公众平台的原理 2、根据微信公众平台所提供的开发接口来开发一个属于自己的微信 公众平台。3、开发中常用工具的使用。 适用人群 PHP爱好者,具有PHP基础及PHP面向对象相关知识的学员。 课程简介 1、微信公众平台开发者功能启用配置 2、基于新浪SAE平台开发微信公众平台 3、微信公众平台服务器及客户端交互 4、基于VPS开发微信公众平台 5、微信公众平台关注、取消关注等事件 6、微信公众平台文字、图片等消息 7、微信公众平台简单回复 8、微信公众平台机器人API 9、微信公众平台天气API 10、微信公众平台自定义菜单开发 11、微信公众平台微站开发 12、微信公众平台后台管理平台开发 备注:此课程在线服务器为Linux操作系统,开发方式为企业真实开发方式。 第一章课程介绍 1课时5分钟 1 课程介绍 [免费观看] 5分钟 本课程课程目标、课程要求及课程内容介绍。 第二章小试牛刀 4课时29分钟 2 微信公众平台介绍 [免费观看]
5分钟 介绍什么是微信公众平台,微信公众平台的分类,如何申请微信公众平台。 3 微信公众平台开发者接入 [免费观看] 10分钟 新浪SAE平台的申请,应用创建,具体使用,上传代码并进行开发者接入验证; 4 微信公众号默认消息回复 [免费观看] 7分钟 开发者中心配置,如何进行接入,开启微信默认回复。 5 微信公众号简单消息回复 [免费观看] 5分钟 对responseMsg()方法进行修改并完成简单消息回复功能! 第三章基于VPS开发微信公众平台 34课时5小时35分钟 6 VPS介绍 7分钟 什么是VPS,VPS的优点,如何购买VPS。 7 FTP工具filezilla介绍及使用 6分钟 什么是FTP,filezilla工具介绍及使用。 8
电子商务专题讲座课程论文题目:关于云 系部名称:经济管理系专业班级:营销101班 学生姓名:王丽敏学号:201004024108课程教师:王趁荣教师职称:副教授 2012年12月26日
云[1]是指停留大气层上的水滴或冰晶胶体的集合体。云是地球上庞大的水循环的有形的结果。太阳照在地球的表面,水蒸发形成水蒸气,一旦水汽过饱和,水分子就会聚集在空气中的微尘(凝结核)周围,由此产生的水滴或冰晶将阳光散射到各个方向,这就产生了云的外观。这就是在我们的生活中普遍见到的现象“云”。然而现在它却是其他的代名词,我要讲的包括阿里巴巴旗下的云计划、百度旗下的百度云以及云计算的形成和发展。 先讲一下阿里巴巴旗下的云计划,我第一次听到云计划是老师在课堂上讲阿里巴巴时提到的,当时很好奇,所以就开始慢慢了解关于云计划。我在淘宝开店时同时在阿里巴巴上注册了账号,因此可以直接进入云计划上面的生意经网站。在这之前先了解云计划的概念,发展历程以及计划。 首先,云计划的定义 云计划[2]是一个打造小企业商业智慧分享成长平台。它集合商业名家、专家学者和公众的力量,解决千万小企业的难题,助力小企业成长。由马云担任首席导师,携手由商业名家、专业机构、知名网商等组成的导师团,他们一起与小企业创业者和个人网商采取问答互动形式,进行线上交流。 第二,云计划由来 2010年5月14日,阿里巴巴店举办2010年全球股东大会。大会由阿里巴巴集团董事局主席马云及阿里巴巴公司CEO卫哲主持,吸引了包括摩根士丹利、摩根大通等国际知名投行前来。 在股东大会上,马云作为首期创业导师,启动了由他所倡导的小企业商业智慧分享平台——云计划,分享企业经营管理方面的经验和理念,帮助小企业们共同成长。 第三,“云计划”实践 2010年盛大在线推出了人才“云计划”战略。“云计划”战略由“找人计划”、“云梯计划”、“暖心计划”三大内容构成,涉及了从选人、用人到留人的管理人才三部曲。 第四,云计划的云计划 云计划是一个智慧分享的问答平台,小企业有资金、人才、管理、经营、资金等相关的问题,都可以在云计划平台上提问,云计划汇集了马云、卫哲、黄鸣、白云峰、查立等知名企业家导师,以及余庆、曾永良、柳金育、朱明、吴翔等实战经验丰富的导师,为小企业解答难题。汇聚和分享千万小企业的困
php开发主管的工作职责 php开发主管需要负责与产品需求人员沟通,完成后台架构设计、数据库设计、业务抽象、组件封装等工作。以下是小编整理的php开发主管的工作职责。 php开发主管的工作职责1 职责: 1、熟悉软件开发流程; 2、负责与需求人员接口,熟悉项目的需求规划说明; 3、负责与开发组长接口,熟悉项目的开发计划,及项目的概要设计说明数据库设计;
4、按计划完成功能模块的功能设计、代码实现, 代码编写和单元测试,并提交测试人员进行功能测试; 5、根据项目要求,判断是否需要完成《详细设计说明书》的编写; 6、严格遵守相关开发工具的编码规范; 7、参与需求和设计讨论,对项目开发各个环节进行签字确认; 8、为前端技服人员提供技术支持,解决技服过程中遇到的相关问题; 9、提交相关年、月、日计划和总结; 10、维护电子商务网站及开发工作,维护ERP系统,System Network 管理 岗位要求: 1、计算机或相关专业本科以上学历; 2、精通PHP, 编程语言,具备良好的编程风格; 3、精通网络编程,能够进行多线程开发,有实时监控系统开发经验者优先 4、具备相关行业知识或实践经验;较强的客户服务意识;
5、具备项目开发和管理经验,能良好地掌握开发速度和质量; 6、有3年以上的软件开发经验; php开发主管的工作职责2 职责: 1、负责后端各系统的架构设计、开发、重构、优化; 2、参与制定后端技术中期、短期开发计划,并带领团队完成计划; 3、解决重要项目目中的关键技术难题; 4、负责技术方案设计及关键功能的开发; 5、负责PHP开发团队的培养工作。 任职要求: 1.本科及以上学历,计算机相关专业者优先 2.有3~5年以PHP为主的中型或大型互联网产品软件的开发及维护工作经验 3.熟悉一到两种常用PHP框架(laravel、CI、Zend Framework、ThinkPHP、Yaf等)
【黑马程序员】分布式缓存技术redis学习系列----深入理解Spring Redis的使用 关于spring redis框架的使用,网上的例子很多很多。但是在自己最近一段时间的使用中,发现这些教程都是入门教程,包括很多的使用方法,与spring redis丰富的api大相径庭,真是浪费了这么优秀的一个框架。 Spring-data-redis为spring-data模块中对redis的支持部分,简称为“SDR”,提供了基于jedis 客户端API的高度封装以及与spring容器的整合,事实上jedis客户端已经足够简单和轻量级,而spring-data-redis反而具有“过度设计”的嫌疑。 jedis客户端在编程实施方面存在如下不足: 1) connection管理缺乏自动化,connection-pool的设计缺少必要的容器支持。 2) 数据操作需要关注“序列化”/“反序列化”,因为jedis的客户端API接受的数据类型为string 和byte,对结构化数据(json,xml,pojo)操作需要额外的支持。 3) 事务操作纯粹为硬编码 4) pub/sub功能,缺乏必要的设计模式支持,对于开发者而言需要关注的太多。 1. Redis使用场景 Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
我们都知道,在日常的应用中,数据库瓶颈是最容易出现的。数据量太大和频繁的查询,由于磁盘IO 性能的局限性,导致项目的性能越来越低。 这时候,基于内存的缓存框架,就能解决我们很多问题。例如Memcache ,Redis 等。将一些频繁使用的数据放入缓存读取,大大降低了数据库的负担。提升了系统的性能。其实,对于hibernate 以及Mybatis 的二级缓存,是同样的道理。利用内存高速的读写速度,来解决硬盘的瓶颈。 2. 配置使用redis 项目的整体结构如下: 在applicationContext-dao.xml 中配置如下: [AppleScript] 纯文本查看 复制代码 ? 01 02 03 04 05 06 07 0