一.研究目的:为了研究农民收入,我们选取了其中7种主要影响因素,包括财政用于农业的支出的比重(%),第二、三产业从业人数占全社会从业人数的比重(%),非农村人口比重,乡村从业人员占农村人口的比重(%),农业总产值占农林牧总产值的比重(%),农作物播种面积(千公顷),农村用电量(亿千瓦时)。(数据见最后一页)
二.研究变量:在经济生活中,根据以上分析,我们在影响农民收入因素中引入7个变量。即设置变量:x1-财政用于农业的支出的比重,x2-第二、三产业从业人数占全社会从业人数的比重,x3-非农村人口比重,x4-乡村从业人员占农村人口的比重,x5-农业总产值占农林牧总产值的比重,x6-农作物播种面积,x7
—农村用电量。
一、研究方法:SPSS中的因子分析。
具体操作步骤
(1)定义变量:x1-财政用于农业的支出的比重,x2-第二、三产业从业人数占全社会从业人数的比重,x3-非农村人口比重,x4-乡村从业人员占农村人口的
农村用比重,x5-农业总产值占农林牧总产值的比重,x6-农作物播种面积,x7
—
电量。
(2)导入数据:
file-open-data
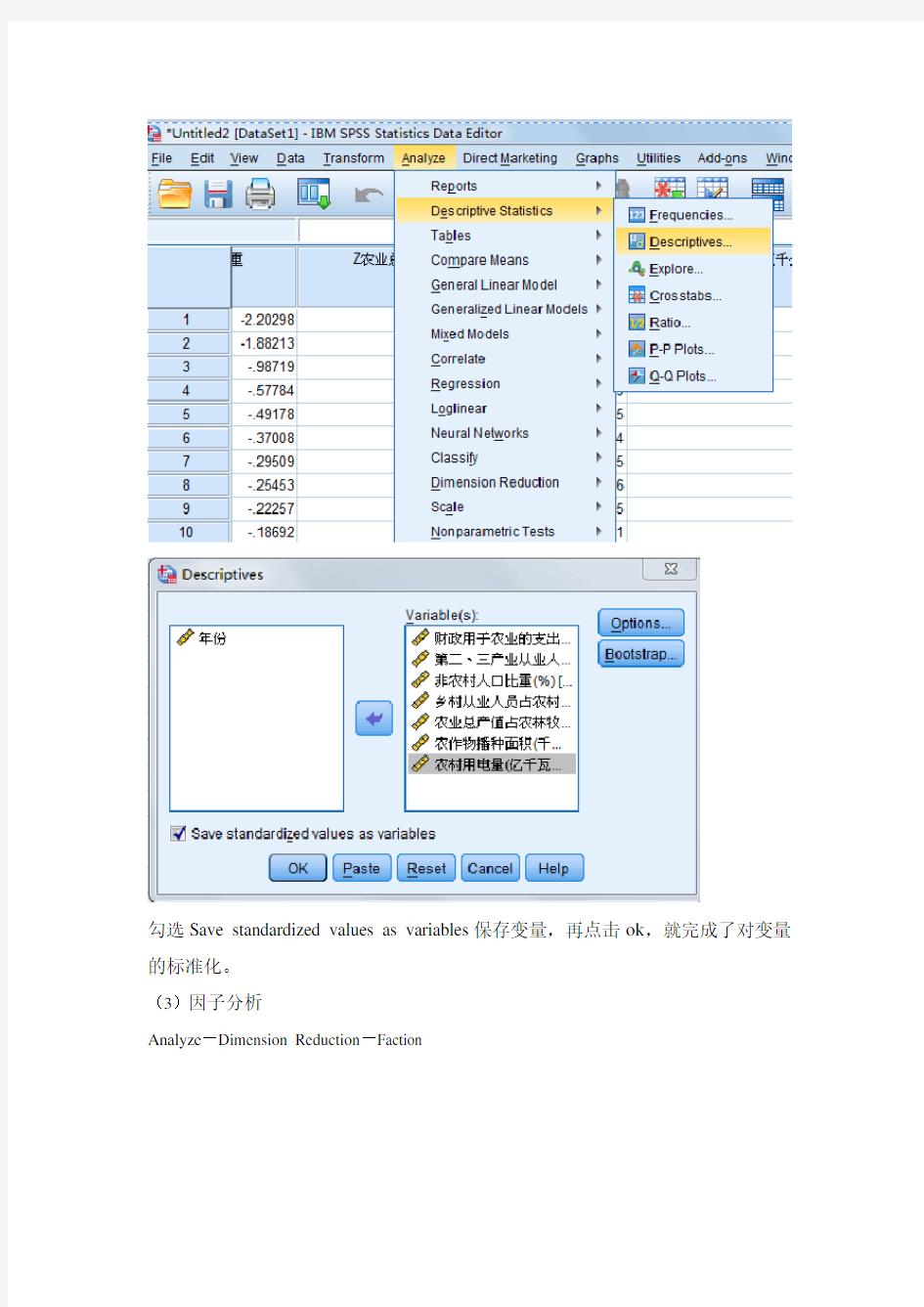
(3)变量标准化Analyze-Descriptive Statistics-Descriptives
勾选Save standardized values as variables保存变量,再点击ok,就完成了对变量的标准化。
(3)因子分析
Analyze—Dimension Reduction—Faction
点击右侧的Description选项,选择Statistics选项组中的initial solution,勾选Correlation Matrix 选项组中的Coefficients和KMO and Bartlelts test of sphericity,点击Continue。
点击右侧Extraction选项,其中Method选Principal components,Analyze选择Correlation matrix,Display中选择Unrotated factor solution,Extract如图,点击Continue.
点击右侧Rotation选项,勾选Method选项组中的Varimax,Display中的两个选项都勾选,点击Continue。
点击右侧Scores,如图勾选,点击点击Continue。
最后点击options,默认
(4)结果分析
1.KMO and Bartlett's的检验结果图
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .725
Bartlett's Test of Sphericity Approx. Chi-Square 255.159
df 21
Sig. .000
可以从此表中看出KMO统计量为0.725,大于最低标准,说明适合做因子分析,Bartlet球形检验,p<0.001,适合做因子分析。
2.主成分列表
Total Variance Explained
Compon ent
Initial Eigenvalues
Extraction Sums of
Squared Loadings Rotation Sums of Squared Loadings Total
% of
Varian
ce
Cumulative
% Total
% of
Varianc
e
Cumulat
ive % Total
% of
Variance
Cumulativ
e %
1 5.920 84.57
2
84.572 5.920 84.572 84.572 3.308 47.261 47.261
2 .65
3 9.330 93.902 .653 9.330 93.902 3.265 46.641 93.902
3 .249 3.559 97.462
4 .126 1.798 99.259
5 .042 .595 99.854
6 .008 .108 99.962
7 .003 .038 100.000
Extraction Method: Principal Component Analysis.
可以从此表中看出前2个主成分特征值较大,它们的累积贡献率达到了93.902%,故选择前
2个公共因子。
3.公因子方差比结果图
Communalities
Initial Extraction
Zscore(财政用于农业的支出
的比重)
1.000 .906
Zscore: 第二、三产业从业
人数占全社会从业人数的比
重(%)
1.000 .940
Zscore: 非农村人口比重
(%)
1.000 .979
Zscore(乡村从业人员占农村
人口的比重)
1.000 .977
Zscore(农业总产值占农林牧
总产值的比重)
1.000 .943
Zscore: 农作物播种面积(千
公顷)
1.000 .909
Zscore: 农村用电量(亿千瓦
时)
1.000 .918
Extraction Method: Principal Component Analysis.
结果显示,每一个指标变量的共性方差都在0.9以上,说明这2个公共因子能够很好地反应
原始各项指标变量的绝大部分内容。
4.载荷散点图
从载荷散点图可以看出,第一公共因子能很好解释变量x1-财政用于农业的支出的比重,变量x5-农业总产值占农林牧总产值的比重,第二公共因子能很好地解释变量x2-第二、三产业从业人数占全社会从业人数的比重,x3-非农村人口比重,
农村用电量。
x4-乡村从业人员占农村人口的比重,x6-农作物播种面积,x7
—
5.旋转后的因子载荷图
Component Score Coefficient Matrix
Component
1 2
Zscore(财政用于农业的支出
.507 -.697
的比重)
Zscore: 第二、三产业从业
.120 .112
人数占全社会从业人数的比
重(%)
Zscore: 非农村人口比重
.170 .066
(%)
Zscore(乡村从业人员占农村
.072 .164
人口的比重)
Zscore(农业总产值占农林牧
.026 -.257
总产值的比重)
Zscore: 农作物播种面积(千
.691 -.510
公顷)
Zscore: 农村用电量(亿千瓦
.247 -.022
时)
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
Component Scores.
经过旋转后,农作物播种面积(千公顷)、农村用电量(亿千瓦时)在因子一上有较大载荷,财政用于农业的支出的比重、农业总产值占农林牧总产值的比重咋因子二上有较大载荷。故因子一可称为农业基本发展条件,因子二可称为政府支持情况。
6.历年农民收入总得分降序表
其中F=f1*84.572/93.902+f2*9.330/93.902
年份f1 f2 总分F
2004 1.46067 0.23231 1.338621494
2005 1.24137 1.08005 1.225341421
1998 1.44755 -1.0258 1.20180065
1999 0.88995 -0.04301 0.797252115
2000 0.83304 0.28099 0.778188916
2001 0.79886 0.42652 0.761864705
2002 0.56754 0.85163 0.595766872
2003 0.29613 1.3662 0.402450985 1997 0.35599 0.15899 0.336416295 1996 0.141 0.023 0.129275649 1986 0.0712 -2.97824 -0.231789023 1991 -0.35654 -0.496 -0.370396593 1995 -0.53681 0.53338 -0.430477092 1992 -0.46086 -0.24669 -0.439580303 1994 -0.68793 0.39726 -0.580106709 1990 -0.70907 -0.29782 -0.66820865 1993 -0.78235 0.24344 -0.680428628 1987 -0.88133 -1.73639 -0.966287826 1989 -1.23195 0.22253 -1.087434458 1988 -2.45646 1.00764 -2.112270813
数据:
年份财政用于农业的
支出的比重
第二、三产业从业
人数占全社会从
业人数的比重(%)
非农村人口比重(%)
乡村从业人员占农
村人口的比重
农业总产值占农林牧
总产值的比重
农作物播种面积
(千公顷)
农村用电量(亿
千瓦时)
1986 13.43 29.5 17.92 36.01 79.99 150104.07 253.1 1987 12.2 31.3 19.39 38.62 75.63 146379.53 320.8 1988 7.66 37.6 23.71 45.9 69.25 143625.87 508.9 1989 9.42 39.9 26.21 49.23 62.75 146553.93 790.5 1990 9.98 39.9 26.41 49.93 64.66 148362.27 844.5 1991 10.26 40.3 26.94 50.92 63.09 149585.8 963.2 1992 10.05 41.5 27.46 51.53 61.51 149007.1 1106.9 1993 9.49 43.6 27.99 51.86 60.07 147740.7 1244.9 1994 9.2 45.7 28.51 52.12 58.22 148240.6 1473.9 1995 8.43 47.8 29.04 52.41 58.43 149879.3 1655.7 1996 8.82 49.5 30.48 53.23 60.57 152380.6 1812.7 1997 8.3 50.1 31.91 54.93 58.23 153969.2 1980.1 1998 10.69 50.2 33.35 55.84 58.03 155705.7 2042.2 1999 8.23 49.9 34.78 57.16 57.53 156372.81 2173.45 2000 7.75 50 36.22 59.33 55.68 156299.85 2421.3 2001 7.71 50 37.66 60.62 55.24 155707.86 2610.78 2002 7.17 50 39.09 62.02 54.51 154635.51 2993.4 2003 7.12 50.9 40.53 63.72 50.08 152414.96 3432.92 2004 9.67 53.1 41.76 65.64 50.05 153552.55 3933.03
2005 7.22 55.2 42.99 67.59 49.72 155487.
73
4375.7
企业管理 对居民消费率影响因素的探究 ---以湖北省为例 改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总 收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y:消费率(%)X1:总收入 (亿元) X2:人口增 长率(‰) X3:居民消 费价格指 数增长率 X4:少儿抚 养系数 X5:老年抚 养系数 X6:居民消 费比重(%) 1995 1997 200039 2001 2002 2003 2004 2005 2006 2007 2008 2009
SPSS因子分析(因素分析)——实例分析 提起因子分析那是老生常谈,分析人士大都喜欢讨论主成分与因子分析。我也凑个热闹,顺便温习温习,时间长了就会很模糊。 一、概念 探讨存在相关关系的变量之间,是否存在不能直接观察到的但对可观测变量的变化其支配作用的潜在因子的分析方法就是因子分析,也叫因素分析。通俗点:原始变量是共性因子的线性组合。 二、简单实例 现在有12个地区的5个经济指标调查数据(总人口、学校校龄、总雇员、专业服务、中等房价),为对这12个地区进行综合评价,请确定出这12 个地区的综合评价指标。点击下载 三、解决方案 1、不同地区的不同指标不同,这导致目前我们拥有的5个指标数据很难对这12个地区给一个明确的评价。所以,有必要确定综合评价指标,便于对比。因子分析是一种选择,当然还有其他的方法。5个指标即为我们分析的对象,直接选入。
2、描述统计选项卡。我们要对比因子提取前后的方差变化,所以选定“初始分析结果”;现在是基于相关矩阵提取因子,所以,选定相关矩阵的“系数”;比较重要的还有KMO和球形检验,它告诉我们数据是不是适合做因子分析。选定。其他选择自定。 3、抽取选项卡。提取因子的方法有很多,最常用的就是主成分法。这里选主成分。关于特征值,不想解释太多,这和显著性水平一样,都是统计学的一个基本概念。因为参与分析的变量测度单位不同,所以选择“相关矩阵”,如果参与分析的变量测度单位相同,则考虑选用协方差矩阵。
4、是否需要旋转?因子分析要求对因子给予命名和解释,对因子旋转与否取决于因子的解释。如果不经旋转因子已经很好解释,那么没有必要旋转,否则,应该旋转。这里直接旋转,便于解释。至于旋转就是坐标变换,使得因子系数向1和0靠近,对公因子的命名和解释更加容易。 5、要计算因子得分,就必须先写出因子的表达式。而因子是不能直接观察到的,是潜在的。但是可以通过可观测到的变量获得。前面说到,因子分析模型是原始变量为因子的线性组合,现在我们可以根据回归的方法将模型倒过来,用
SPSS皮尔逊相关分析实例操作步骤 选题: 对某地29名13岁男童的身高(cm)、体重(kg),运用相关分析法来分析其身高与体重是否相关。 实验目的: 任何事物的存在都不是孤立的,而是相互联系、相互制约的。相关分析可对变量进行相关关系的分析,计算29名13岁男童的身高(cm)、体重(kg),以判断两个变量之间相互关系的密切程度。 实验变量: 编号Number,身高height(cm),体重weight(kg) 原始数据: 实验方法: 皮 尔 逊 相 关 分 析 法 软件: 操作过程与结果分析:
第一步:导入Excel 数据文件 1.open data document ——open data ——open ; 2. Opening excel data source ——OK. 第二步:分析身高(cm )与体重(kg )是否具有相关性 1. 在最上面菜单里面选中Analyze ——correlate ——bivariate ,首先使用Pearson ,two-tailed ,勾选flag significant correlations 进入如下界面: 2. 点击右侧options ,勾选Statistics ,默认Missing Values ,点击Continue 输出结果: 图为基本的描述性统计量的输 出表格,其中身高的均值(mean ) 为、标准差(standard deviation ) 为、样本容量(number of cases ) 为29;体重的均值为、标准差为、 样本容量为29。两者的平均值和标准差值得差距不显着。 图为相关分析结果表,从表中可以看出体重和身高之间的皮尔逊相关系数为,即 |r|=,表示体重与身高呈正相关关系,且两变量是显着相关的。另外, 两者之间不相关的双侧检验值为,图中的双星号标 记的相关系数是在显着性水平为以下,认为标记的相关系数是显着的,验证了两者显着相关的关系。所以可以得出结论:学生的体重与身高存在显着的 Descriptive Statistics Mean Std. Deviation N 身高(cm ) 29 体重(kg) 29 Correlations 身高(cm ) 体重(kg) 身高(cm ) Pearson Correlation 1 .719** Sig. (2-tailed) .000 Sum of Squares and Cross-products Covariance N 29 29 体重(kg) Pearson Correlation .719** 1 Sig. (2-tailed) .000 Sum of Squares and Cross-products Covariance N 29 29 **. Correlation is significant at the level (2-tailed).
一.研究目的:为了研究农民收入,我们选取了其中7种主要影响因素,包括财政用于农业的支出的比重(%),第二、三产业从业人数占全社会从业人数的比重(%),非农村人口比重,乡村从业人员占农村人口的比重(%),农业总产值占农林牧总产值的比重(%),农作物播种面积(千公顷),农村用电量(亿千瓦时)。(数据见最后一页) 二.研究变量:在经济生活中,根据以上分析,我们在影响农民收入因素中引入7个变量。即设置变量:x1-财政用于农业的支出的比重,x2-第二、三产业从业人数占全社会从业人数的比重,x3-非农村人口比重,x4-乡村从业人员占农村人 农村口的比重,x5-农业总产值占农林牧总产值的比重,x6-农作物播种面积,x7 — 用电量。 一、研究方法:SPSS中的因子分析。 具体操作步骤 (1)定义变量:x1-财政用于农业的支出的比重,x2-第二、三产业从业人数占全社会从业人数的比重,x3-非农村人口比重,x4-乡村从业人员占农村人口的 农村用电比重,x5-农业总产值占农林牧总产值的比重,x6-农作物播种面积,x7 — 量。 (2)导入数据: file-open-data (3)变量标准化Analyze-Descriptive Statistics-Descriptives
" 勾选Save standardized values as variables保存变量,再点击ok,就完成了对变量的标准化。 (3)因子分析 Analyze—Dimension Reduction—Faction
点击右侧的Description选项,选择Statistics选项组中的initial solution,勾选Correlation Matrix 选项组中的Coefficients和KMO and Bartlelts test of sphericity,点击Continue。 点击右侧Extraction选项,其中Method选Principal components,Analyze选择Correlation matrix,Display中选择Unrotated factor solution,Extract如图,点击Continue.
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: (
2010年中国各地区城市居民人均年消费支出和可支配收入
} 数据来源:《中国统计年鉴》2010年 2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 模型… R R方调整R方标准估计的误差 1.965a.93 2.930 a.预测变量:(常量),可支配收入X(元)。 b.因变量:消费性支出Y(元) ~ 表3 相关性 消费性支出Y (元) 可支配收入X(元) Pearson相关 性消费性支出 Y(元) .965 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
SPSS因子分析实例操作步骤 实验目的: 引入2003~2013年全国的农、林、牧、渔业,采矿业,制造业电力、热力、燃气及水生产与供应业,建筑业,批发与零售业,交通运输、仓储与邮政业7个产业的投资值作为变量,来研究其对全国总固定投资的影响。 实验变量: 以年份,合计(单位:千亿元),农、林、牧、渔业,采矿业,制造业电力、热力、燃气及水生产与供应业,建筑业,批发与零售业,交通运输、仓储与邮政业作为变量。 实验方法:因子分析法 软件:spss19、0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2、 Opening excel data source——OK、
第二步: 1、数据标准化:在最上面菜单里面选中Analyze——Descriptive Statistics——OK (变量选择除年份、合计以外的所有变量)、 2.降维:在最上面菜单里面选中Analyze——Dimension Reduction—— Factor ,变量选择标准化后的数据、
3.点击右侧Descriptive,勾选Correlation Matrix选项组中的 Coefficients与KMO and Bartlett’s text of sphericity,点击 Continue、 4、点击右侧Extraction,勾选Scree Plot与fixed number with factors,默认3个,点击Continue、
5、点击右侧Rotation,勾选Method选项组中的Varimax;勾选Display选项组中的Loding Plot(s);点击Continue、 6、点击右侧Scores,勾选Method选项组中的Regression;勾选Display factor score coefficient matrix;点击Continue、
典型相关分析 典型相关分析(Canonical correlation )又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关, 而不是 两个变量组个别变量之间的相关。 典型相关与主成分相关有类似, 不过主成分考虑的是一组变量,而典型相关考虑的是两 组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的 成分使之与另一组的成分具有最大的线性关系。 典型相关模型的基本假设: 两组变量间是线性关系, 每对典型变量之间是线性关系,每 个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共 线性。典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因 变量。 典型相关会找出一组变量的线性组合 * *= i i j j X a x Y b y 与,称为典型变量;以 使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。 i a 和j b 称为典型系数。如果对变量进行标准化后再进行上述操作,得到的是标准化的典型系数。 典型变量的性质 每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关; 原来所有 变量的总方差通过典型变量而成为几个相互独立的维度。一个典型相关系数只是两个典型变 量之间的相关,不能代表两个变量组的相关;各对典型变量构成的多维典型相关, 共同代表 两组变量间的整体相关。 典型负荷系数和交叉负荷系数典型负荷系数也称结构相关系数, 指的是一个典型变量与本组所有变量的简单相关系数,
SPSS因子分析实例操作步骤 实验目的: 引入2003~2013年全国的农、林、牧、渔业,采矿业,制造业电力、热力、燃气及水生产和供应业,建筑业,批发和零售业,交通运输、仓储和邮政业7个产业的投资值作为变量,来研究其对全国总固定投资的影响。 实验变量: 以年份,合计(单位:千亿元),农、林、牧、渔业,采矿业,制造业电力、热力、燃气及水生产和供应业,建筑业,批发和零售业,交通运输、仓储和邮政业作为变量。 实验方法:因子分析法 软件: 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK. 第二步: 1.数据标准化:在最上面菜单里面选中Analyze——Descriptive Statistics——OK (变量选择除年份、合计以外的所有变量). 2.降维:在最上面菜单里面选中Analyze——Dimension Reduction——Factor ,变量选择标准化后的数据. 3.点击右侧Descriptive,勾选Correlation Matrix选项组中的 Coefficients和KMO and Bartlett’s text of sphericity,点击 Continue.
4.点击右侧Extraction,勾选Scree Plot和fixed number with factors,默认3个,点击Continue. 5.点击右侧Rotation,勾选Method选项组中的Varimax;勾选Display选项组中的Loding Plot(s);点击Continue. 6.点击右侧Scores,勾选Method选项组中的Regression;勾选Display factor score coefficient matrix;点击Continue. 7.点击右侧Options,勾选Coefficient Display Format选项组中所有选项,将Absolute value blow改为,点击Continue. 8.返回主对话框,单击OK. 输出结果分析:
相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 ①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。 ②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。 ③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。如果r=1或–1,则表示两个现象完全直线性相关。如果=0,则表示两个现象完全不相关(不是直线相关)。 ④3.0 因子分析 ? 因子分析(Factor analysis ):用少数几个因子来描述许多指标或因素之间的联系,以较少几个因子来反映原资料的大部分信息的统计学分析方法。从数学角度来看,主成分分析是一种化繁为简的降维处理技术。 主成分分析(Principal component analysis ):是因子分析一个特例,是使用最多的因子提取方法。它通过坐标变换手段,将原有的多个相关变量,做线性变化,转换为另外一组不相关的变量。选取前面几个方差最大的主成分,这样达到了因子分析较少变量个数的目的,同时又能与较少的变量反映原有变量的绝大部分的信息。 两者关系:主成分分析(PCA )和因子分析(FA )是两种把变量维数降低以便于描述、理解和分析的方法。 ? 特点 (1)因子变量的数量远少于原有的指标变量的数量,因而对因子变量的分析能够减少分析中的工作量。 (2)因子变量不是对原始变量的取舍,而是根据原始变量的信息进行重新组构,它能够反映原有变量大部分的信息。 (3)因子变量之间不存在显著的线性相关关系,对变量的分析比较方便,但原始部分变量之间多存在较显著的相关关系。 (4)因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。 在保证数据信息丢失最少的原则下,对高维变量空间进行降维处理(即通过因子分析或主成分分析)。显然,在一个低维空间解释系统要比在高维系统容易的多。 ? 类型 根据研究对象的不同,把因子分析分为R 型和Q 型两种。 当研究对象是变量时,属于R 型因子分析; 当研究对象是样品时,属于Q 型因子分析。 但有的因子分析方法兼有R 型和Q 型因子分析的一些特点,如因子分析中的对应分析方法,有的学者称之为双重型因子分析,以示与其他两类的区别。 ? 分析原理 假定:有n 个地理样本,每个样本共有p 个变量,构成一个n ×p 阶的地理数据矩阵 : 当p 较大时,在p 维空间中考察问题比较麻烦。这就需要进行降维处理,即用较少几个综合指标代替原来指标,而且使这些综合指标既能尽量多地反映原来指标所反映的信息,同时它们之间又是彼此独立的。 线性组合:记x1,x2,…,xP 为原变量指标,z1,z2,…,zm (m ≤p )为??????????????=np n n p p x x x x x x x x x X 212222111211 SPSS因子分析经典案例 因子分析已经被各行业广泛应用,各种案例琳琅满目,以前在百度空间发表过相关文章,是以每到4至6月,这些文章总会被高校毕业生扒拉一遍,也总能收到各种魅惑的留言,因此,有必要再次发布这经典案例以飨读者。 什么是因子分析? 因子分析又称因素分析,传统的因子分析是探索性的因子分析,即因子分析是基于相关关系而进行的数据分析技术,是一种建立在众多的观测数据的基础上的降维处理方法。其主要目的是探索隐藏在大量观测数据背后的某种结构,寻找一组变量变化的共同因子。 因子分析能做什么? 人的心理结构具有层次性,即分为外显和内隐。但是作为具有同一性的个体来说,内隐的方面总是和外显的方面相互作用,内隐方面制约着外显特征。所以我们经常说,一个人的内在自我会在相当程度上决定他的外在行为特征,表现为某些行为倾向具有高度的一致性或相关性。 反过来说,我们可以通过对个体进行系统的观察和测量,从一组高度相关的行为倾向(可观测)中,探索到某种稳定的内在心理结构(潜存在),这就是因子分析所能做的。 具体来说主要应用于: (1)个体的综合评价:按照综合因子得分对case进行排序; (2)调查问卷效度分析:问卷所列问题作为输入变量,通过KMO、因子特征值贡献率、因子命名等判断调查问卷架构质量; (3)降维处理,结果再利用:因子得分作为变量,进行聚类或其他分析。 案例描述: 高中大家都读过吧,那是一个以成绩论英雄的时代,理科王子、文科小生是时代标签。为什么我们会将数学、物理、化学归并为理科,其他的归并为文科,有没有数据支持?今天我们将用科学的方法找到答案。 100个学生数学、物理、化学、语文、历史、英语成绩如下表(部分),请你来评价他们。 SPSS统计分析案例 一、我国城镇居民现状 近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。 二、我国居民消费结构的横向分析 第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。随着收入的增加,衣着支出比重呈现先上升后下降的走势。事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动内需,促进我国的经济发展方面有着重大的现实意义。 三、我国居民消费结构的纵向分析 进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费 S P S S因子分析实例操作步骤 实验目的: 引入2003~2013年全国的农、林、牧、渔业,采矿业,制造业电力、热力、燃气及水生产和供应业,建筑业,批发和零售业,交通运输、仓储和邮政业7个产业的投资值作为变量,来研究其对全国总固定投资的影响。 实验变量: 以年份,合计(单位:千亿元),农、林、牧、渔业,采矿业,制造业电力、热力、燃气及水生产和供应业,建筑业,批发和零售业,交通运输、仓储和邮政业作为变量。 实验方法:因子分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件??? 1.opendatadocument——opendata——open; 2.Openingexceldatasource——OK. 第二步: 1.数据标准化:在最上面菜单里面选中Analyze——DescriptiveStatistics——OK?(变量选择除年份、合计以外的所有变量). 2.降维:在最上面菜单里面选中 Analyze——DimensionReduction——Factor?,变量选择标准化后的数据. 3.点击右侧Descriptive,勾选CorrelationMatrix选项组中的 Coefficients和KMOandBartlett’stextofsphericity,点击Continue. 4.点击右侧Extraction,勾选ScreePlot和fixednumberwithfactors,默认3个,点击Continue. 5.点击右侧Rotation,勾选Method选项组中的Varimax;勾选Display选项组中的LodingPlot(s);点击Continue. 6.点击右侧Scores,勾选Method选项组中的Regression;勾选Displayfactorscorecoefficientmatrix;点击Continue. 7.点击右侧Options,勾选CoefficientDisplayFormat选项组中所有选项,将Absolutevalueblow改为0.60,点击Continue. 8.返回主对话框,单击OK. 输出结果分析: 1.描述性统计量 本次实验采用2005年东部、中部和西部各地区省份城镇居民月平均消费类型划分的数据(课本139页),将东部、中部和西部看作三个不同总体,31个数据分别来自于这三个总体。本人对这三个不同地区的城镇居民月平均消费水平进行比较,并选取人均粮食支出、副食支出、烟酒及饮料支出、其他副食支出、衣着支出、日用杂品支出、水电燃料支出和其他非商品支出八个指标来衡量城镇居民月平均消费情况。 在进行比较分析之前,首先对个数据是否服从多元正态分布进行检验,输出结果为: 表一 如表一,因为该例中样本数n=31<2000,所以此处选用Shapiro-Wilk统计量。由正态性检验结果的sig.值可以看到,人均粮食支出、烟酒及饮料支出、其他副食支出、水电燃料支出和其他非商品支出均明显不遵从正态分布(Sig.值小于,拒绝服从正态分布的原假设),因此,在下面分析中,只对人均副食支出、衣着支出和日用杂品支出三项指标进行比较,并认为这三个变量组成的向量都遵从正态分布,并对城镇居民月平均消费状况做出近似的度量。另外,正态性的检验还可以通过Q-Q图来实现,此时应判别数据点是否与已知直线拟合得好。如果数据点均落在直线附近,说明拟合得好,服从正态分布,反之,不服从。具体情况这里 不再赘述。 下面进行多因素方差分析: 一、多变量检验 表二 由地区一栏的(即第二栏)所列几个统计量的Sig.值可以看到,无论从那个统计量来看,三个地区的城镇居民月平均消费水平都是有显著差别的(Sig.值小于,拒绝地区取值不同,对Y,即城镇居民月平均消费水平的取值没有显著影响的原假设)。 二、主体间效应检验 如表三,可以看到三个指标地区一栏的(即第三栏)Sig.值分别为、、,说明三个地区在人均衣着支出指标上没有明显的差别(Sig.值大于,不拒绝地区取值不同,对指标的取值没有显著影响的原假设),反之,而在人均副食支出和日用杂品支出指标上有显著差别。 三、多重比较 因子分析作业: 全国30个省市的8项经济指标如下: 要求:先对数据做标准化处理,然后基于标准化数据进行以下操作 1、给出原始变量的相关系数矩阵; 2、用主成分法求公因子,公因子的提取按照默认提取(即特征值大于1),给出公因子的方差贡献度表; 3、给出共同度表,并进行解释; 4、给出因子载荷矩阵,据之分析提取的公因子的实际意义。如果不好解释,请用因子旋转(采用正交旋转中最大方差法)给出旋转后的因子载荷矩阵,然后分析旋转之后的公因子,要求给各个公因子赋予实际含义; 5、先利用提取的每个公因子分别对各省市进行排名并作简单分析。最后构造一个综合因子,计算各省市的综合因子的分值,并进行排序并作简单分析。 1、输入数据,依次点选分析描述统计描述,将变量x1到x8选入右边变量下面,点选“将标 准化得分另存为变量”,点确定即可的标准化的数据。 依次点选分析降维因子分析,打开因子分析窗口,将标准化的8个变量选入右边变量下面,点选描述相关矩阵下选中系数及KMO和Bartlett的检验,点继续,确定,就可得出8个变量的相关系数矩阵如下图。 由表中数据可以看出大部分数据的绝对值都在以上,说明变量间有较强的相关性。 KMO 和 Bartlett 的检验 取样足够度的 Kaiser-Meyer-Olkin 度量。.621 Bartlett 的球形度检验近似卡方 df28 Sig..000 由上图看出,sig.值为0,所以拒绝相关系数为0(变量相互独立)的原假设,即说明变量间存 在相关性。 2、依次点选在因子分析窗口点选抽取方法:主成分;分析:相关性矩阵;输出:未旋转的因子解,碎石图;抽取:基于特征值(特征值大于1);继续,确定,输出结果如下3个图。 解释的总方差 成份 初始特征值提取平方和载入 合计方差的 %累积 %合计方差的 %累积 % 1 2 3 4.403 因子分析与主成分分析 一、问题概述 现希望对30个省市自治区经济发展基本情况的八项指标进行分析。具体采用的指标只有:GDP、居民消费水平、固定资产投资、职工平均工资、货物周转量、居民消费价格指数、商品零售价格指数、工业总产值。这是一个综合分析问题,八项指标较多,用主成分分析法进行综合。 二、数据处理与分析 1.因子分析 打开数据后,在SPSS中进行因子分析的步骤如下: 选择“分析---降维---因子分析”,在弹出的对话框里 (1)描述---系数、KMO与Bartlett的球形度检验 (2)抽取---碎石图、未旋转的因子解 (3)旋转---最大方差法、旋转解、载荷图 (4)得分---保存为变量、显示因子得分系数矩阵 (5)选项---按大小排序 点击确定得到如下各图: 图3-1 图3-2 KMO 和 Bartlett 的检验 取样足够度的 Kaiser-Meyer-Olkin 度量。.620 Bartlett 的球形度检验近似卡方231.285 df 28 Sig. .000 图3-3 公因子方差 图3-6 成份矩阵a 图3-9 (2)因子模型中各统计量的意义 A)因子载荷错误!未找到引用源。:因子载荷错误!未找到引用源。为第i个变量在第j个因子上的载荷,实际上就是错误!未找到引用源。与错误!未找到引用源。的相关系数,表示变量错误!未找到引用源。依赖因子错误!未找到引用源。的程度,反应了第i个变量错误!未找到引用源。对于第j个因子错误!未找到引用源。的重要性。 B)变量错误!未找到引用源。的变量共同度:k个公因子对第i个变量方差的贡献,也称为公因子方差比,记为错误!未找到引用源。,公式为:错误!未找到引用源。=错误!未找到引用源。(j=1,2,….,k) 因子分析的基本概念和步骤 一、因子分析的意义 在研究实际问题时往往希望尽可能多地收集相关变量,以期望能对问题有比较全面、完整的把握和认识。例如,对高等学校科研状况的评价研究,可能会搜集诸如投入科研活动的人数、立项课题数、项目经费、经费支出、结项课题数、发表论文数、发表专著数、获得奖励数等多项指标;再例如,学生综合评价研究中,可能会搜集诸如基础课成绩、专业基础课成绩、专业课成绩、体育等各类课程的成绩以及累计获得各项奖学金的次数等。虽然收集这些数据需要投入许多精力,虽然它们能够较为全面精确地描述事物,但在实际数据建模时,这些变量未必能真正发挥预期的作用,“投入”和“产出”并非呈合理的正比,反而会给统计分析带来很多问题,可以表现在: 计算量的问题 由于收集的变量较多,如果这些变量都参与数据建模,无疑会增加分析过程中的计算工作量。虽然,现在的计算技术已得到了迅猛发展,但高维变量和海量数据仍是不容忽视的。 变量间的相关性问题 收集到的诸多变量之间通常都会存在或多或少的相关性。例如,高校科研状况评价中的立项课题数与项目经费、经费支出等之间会存在较高的相关性;学生综合评价研究中的专业基础课成绩与专业课成绩、获奖学金次数等之间也会存在较高的相关性。而变量之间信息的高度重叠和高度相关会给统计方法的应用带来许多障碍。例如,多元线性回归分析中,如果众多解释变量之间存在较强的相关性,即存在高度的多重共线性,那么会给回归方程的参数估计带来许多麻烦,致使回归方程参数不准确甚至模型不可用等。类似的问题还有很多。 为了解决这些问题,最简单和最直接的解决方案是削减变量的个数,但这必然又会导致信息丢失和信息不完整等问题的产生。为此,人们希望探索一种更为有效的解决方法,它既能大大减少参与数据建模的变量个数,同时也不会造成信息的大量丢失。因子分析正式这样一种能够有效降低变量维数,并已得到广泛应用的分析方法。 因子分析的概念起源于20世纪初Karl Pearson和Charles Spearmen等人关于智力测验的统计分析。目前,因子分析已成功应用于心理学、医学、气象、地址、经济学等领域,并因此促进了理论的不断丰富和完善。 因子分析以最少的信息丢失为前提,将众多的原有变量综合成较少几个综合指标,名为因子。通常,因子有以下几个特点: ↓因子个数远远少于原有变量的个数 原有变量综合成少数几个因子之后,因子将可以替代原有变量参与数据建模,这将大大减少分析过程中的计算工作量。 ↓因子能够反映原有变量的绝大部分信息 因子并不是原有变量的简单取舍,而是原有变量重组后的结果,因此不会造成原有变量信息的大量丢失,并能够代表原有变量的绝大部分信息。 ↓因子之间的线性关系并不显著 由原有变量重组出来的因子之间的线性关系较弱,因子参与数据建模能够有效地解决变量多重共线性等给分析应用带来的诸多问题。 ↓因子具有命名解释性 通常,因子分析产生的因子能够通过各种方式最终获得命名解释性。因子的命名解 本科教学实验报告 (实验)课程名称:数据分析技术系列实验 实验报告 学生姓名: 一、实验室名称: 二、实验项目名称:相关分析 三、实验原理 相关关系是不完全确定的随机关系。在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。 按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall 秩相关系数测定;定类变量的相关分析要使用列连表分析法。 四、实验目的 理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。 五、实验内容及步骤 实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。 1)分析性别与工资之间是否存在相关关系。 2)分析教育程度与工资之间是否存在相关关系。 实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。 1.分析性别与工资之间是否存在相关关系。 分析:性别属于定类变量,是离散值,因使用卡方检验。 Step1.操作为Analyze\DescriptiveStatistics\Crosstabs Step2.将性别(Gender)和收入(CurrentSalary)分别移入Rows列表框和Columns 列表框。 Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。退回到主对话框,单击ok。 2.分析教育程度与工资之间是否存在相关关系。 分析:教育程度为定序变量,工资为连续变量,可使用Spearman和Kendall秩相关系数检验。 Step1.用散点图初步判断二变量的相关性,操作为Graphs/LegacyDialogs/Scatter,选择SimpleScatter,教育程度为自变量,工资为因变量,做散点图。 散点图结果如图示,二者存在线性相关关系。只有线性相关的关系确定后才能继续进行下一步分析。因此,在进行相关分析之前的预分析过程也是十分重要的。 Step2.两变量相关分析,操作为Analyze/Correlate/Bivariate,选择Kendall和Spearman 相关系数。 六、实验器材(设备、元器件): 计算机、打印机、硒鼓、碳粉、纸张 七、实验数据及结果分析 1.分析性别与工资之间是否存在相关关系。 卡方检验结果为 显着性水平为,即至少有%的把握认为性别和工资之间存在显着的相关系。 SPSS探索性因子分析的过程 现要对远程学习者对教育技术资源和使用情况进行了解,设计一个李克特量表,如下图所示: 一. 因子分析的定义 在现实研究过程中,往往需要对所反映事物、现象从多个角度进行观测。因此研究者往往设计出多个观测变量,从多个变量收集大量数据以便进行分析寻找规律。多变量大样本虽然会为我们的科学研究提供丰富的信息,但却增加了数据采集和处理的难度。更重要的是许多变量之间存在一定的相关关系,导致了信息的重叠现象,从而增加了问题分析的复杂性。 因子分析是将现实生活中众多相关、重叠的信息进行合并和综合,将原始的多个变量和指标变成较少的几个综合变量和综合指标,以利于分析判定。用较少的综合指标分析存在于各变量中的各类信息,而各综合指标之间彼此是不相关的,代表各类信息的综合指标成为因子。因子分析就是用少数几个因子来描述许多指标之间的联系,以较少几个因子反应原资料的大部分信息的统计方法。 二. 数学模型 Z i i1F1 i2^ i3F3 …im F m U i 乙为第i个变量的标准化分数;(标准分是一种由原始分推导出来的相对地位量数,它是用来说明原始分在所属的那批分数中的相对位置的。) F m为共同因子; m为所有变量共同因子的数目; U为变量Z的唯一因素; i个变量与第im为因子负荷。(也叫因子载荷,统计意义就是第 m个公共因子的相关系数,它反映了第i个变量在第m个公共因子上的相对重要性也就是第m个共同因子对第i个变量的解释程 度。) 因子分析的理想情况,在于个别因子负荷im不是很大就是很小,这样每个变量才能与较少的共同因子产生密切关联,如果想要以最少的共同因素数来解释变量间的关系程度,则U彼此间不能有关联存在。 所谓的因子负荷就是因子结构中原始变量与因子分析时抽取出共同因子的相关,即在各个因子变量不相关的情况下,因子负荷.就是第i个原有变量和第m个因子变量间的相关系数,也就是Z在第m个共同因子变量上的相对重要性,因此,.绝对值越大则公共因子和原有变量关系越强。在因子分析中有两个重要指针:一为“共同性”,二为“特征值”。 所为共同性,也称变量共同度或者公共方差,就是每个变量在每个共同因子的负荷量的平方总和(一横列中所有因子负荷的的平方和),也就是个别变量可以被共同因子解释的变异量百分比,这个值是个别变量与共同因子间多元相关的平方。从共同性的大小可以判断这个原始变量与共同因子间的关系程度。如果大部分变量的共同度都高于0.8,则说明提取出的共同因子已经基本反映了各原始变量80%以上的信息,仅有较少的信息丢失,因子分析效果较好。而各变量的唯一因素就是1减掉该变量共同性的值,就是原有变量不能 [例11-1]下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行因子分析。 图 ???对话框(图框。 图 钮返回 图11.3?描述性指标选择对话框 ???点击Extraction...钮,弹出FactorAnalysis:Extraction对话框(图11.4),系统提供如下因子提取方法: 图11.4?因子提取方法选择对话框 ???Principalcomponents:主成分分析法; ???Unweightedleastsquares:未加权最小平方法; ???Generalizedleastsquares:综合最小平方法; ???Maximumlikelihood:极大似然估计法; ???Principalaxisfactoring:主轴因子法; ???Alphafactoring:α因子法; ???对话框。 ???5种因图 ???旋转的目的是为了获得简单结构,以帮助我们解释因子。本例选正交旋转法,之后点击Continue钮返回FactorAnalysis对话框。 ???点击Scores...钮,弹出弹出FactorAnalysis:Scores对话框(图11.6),系统提供3种估计因子得分系数的方法,本例选Regression(回归因子得分),之后点击Continue钮返回FactorAnalysis对话框,再点击OK钮即完成分析。 图11.6?估计因子分方法对话框? ?11.2.3?结果解释 ??在输出结果窗口中将看到如下统计数据: ??系统首先输出各变量的均数(Mean)与标准差(StdDev),并显示共有25例观察单位进入分析;接着输出相关系数矩阵(CorrelationMatrix),经Bartlett检验表明:Bartlett值=326.28484,P<0.0001,即相关矩阵不是一个单位矩阵,故考虑进行因子分析。 好。今KMO值 NumberofCases?=?????25 CorrelationMatrix: X1???????X2???????X3???????X4???????X5???????X6???????X7 X1????????1.00000 X2?????????.58026??1.00000SPSS因子分析法
SPSS因子分析经典案例
SPSS统计分析分析案例
SPSS因子分析实例操作步骤
spss相关分析案例多因素方差分析
因子分析SPSS操作
应用统计学因子分析与主成分分析案例解析_SPSS操作分析
(完整版)SPSS因子分析法-例子解释
SPSS相关分析实验报告精选
SPSS探索性因子分析的过程
【精品管理学】spss因子分析案例 共(13页)
相关主题
文本预览