
EPIDATA使用方法简介
一、建立新QES文件
第一种:在菜单中,点击“文件”(File)→“生成调查表文件QES文件”。
第二种:在工作栏的工作流程中,点击“1. 打开文件”(1.Define Data)→“建立新QES文件”。
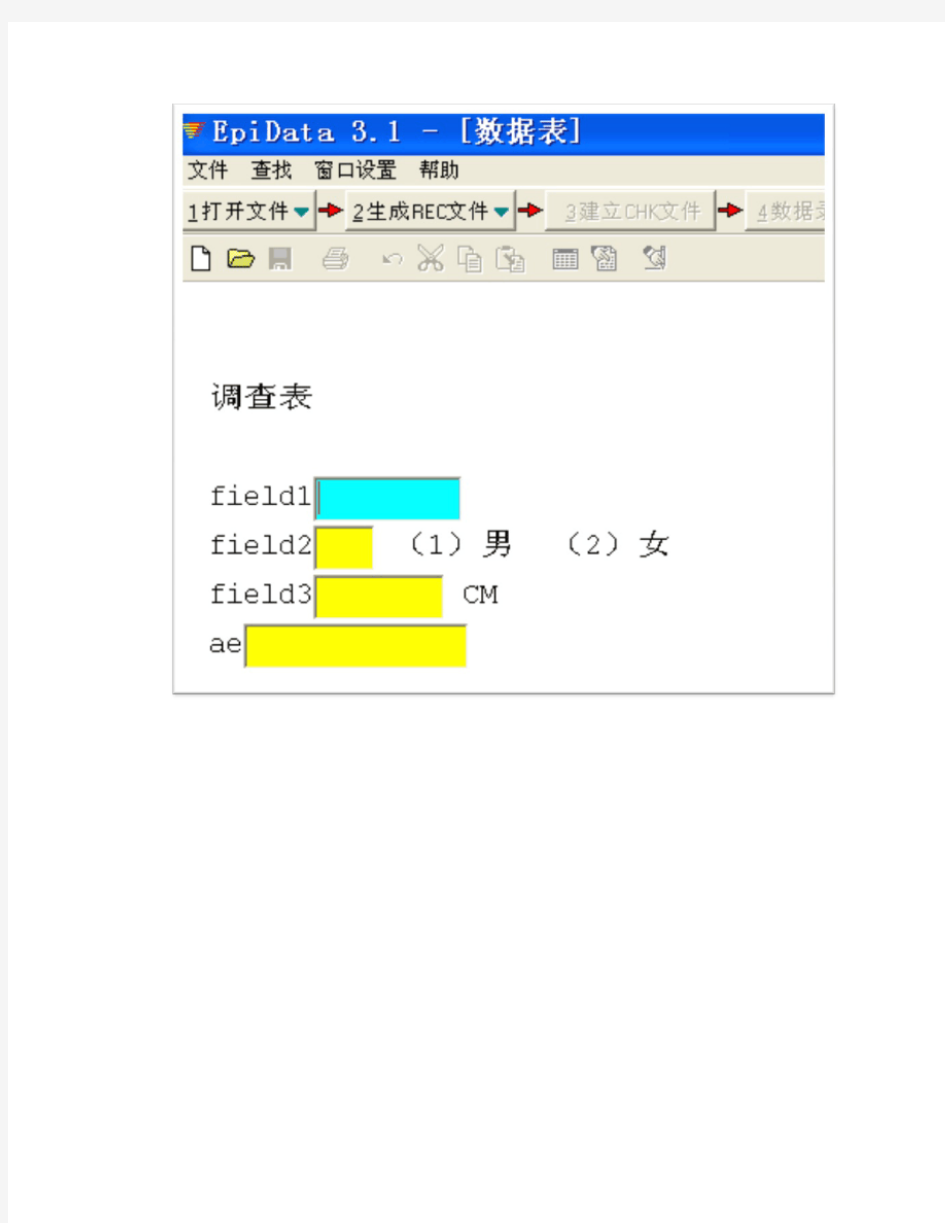
第三种:在按钮栏中,点击,这时窗口中会在工作区显示一个空白的文档,你可以在此文档中键入调查表内容和框架,编辑完成后,将调查表文件保存,文件的扩展名统一为.QES。
二、调查表书写生成
1.“文件”(File)→“选项”(Option)→“生成REC文件”(Create data file)→ 在“如何生成字段名”(How to generate field names)中选择字段的命名方式。
2.
1 如果选择:以调查表第一个词命名、更新问题为实际文件名效果。
2 如果只选择:以调查表第一个词命名,字段名为汉字显示。
3 如果只选择:使用{ }内的内容自动添加字段名,则显示{ }的内容。【①在普通文本中优先选择“{ }”括进的文本。如果问题是{my}first{field}?那末字段名将为MYFIELD;如果问题是“姓名{name}?”,产生的字段名为name。
4 ②通用常见单词不予考虑(即What?Who?If?etc.)。What did you do?产生的字段名为YOUDO。
5 ③如果字段前没有“问题”文本,字段名就取前一个字段名再加上一个数字。如果前一个字段名是dMY字段,那末下一个字段(如果没
有“问题”文本)就是dMY1。如果前一个字段是dV31,则下一个字段名就是dV32。如果不存在前一个字段名则使用隐含字段名FIELD1。
6 ④如果第一个字符是数字则在第一个字符前插入一个字母N。例如3 little mice?产生的字段名为N3LITTLE。】
3. 数值型字段:##,###.##… ;仅接受数字和空格,不输按空格
处理,分析时作缺失值处理,以“.”显示。数字位数由“#”个数决
定,小数位数由小数点右边的“#”个数确定。最长可达14位,小
数点按1个字符计算。
文本型字段:包括三种。一种是常用的文本(或下划线、或底线)型字段:________;该型字段由连续下划线来定义,长度由下划线字符个数决定,最大值为80,空白字段(字段内容空缺)时,数据管理时将按缺失值处理。另一种为大写文本型字段:。
日期型字段:包括两种。一种为常用日期字段:
自动ID号型字段:
逻辑型字段(即布尔函数型字段):
4①编写过程中及时保存文件,文件类型为.qes文件。
②系统只会根据“特殊符号”来定义一个输入字段(包括类型和长度),并根据符号前的字符给字段命名。建议在编写过程中利用“字段快速清单”插入“特殊符号”,即:选择字段类型,定义好长度后,按“插
入”图标,可避免由于“特殊符号”输入错误而不能产生有效的输入字段。
③调查表用中文编写时,可用定界符(“{}”)将字段名定义为英文字符(英文字母或英文字母+阿拉伯数字),有利于数据库的管理和其他软件的统计分析。注意:“{}”必须为半角型,而不能是全角型(“{}”)。
④尽可能把字段定义数值型,有利于统计分析。如糖尿病
史“DMHIS”可定义为数值型字段,“1”表示“有”,“0”表示“无”。
⑤调查表文件格式尽可能和原调查表一致,有利于直观录入数据。
⑥如果用其他文本编辑器编写.QES文件,在运行EPIDATA后,打开该.QES文件即可编辑。
⑦调查表文件的编写是否符合要求,可通过“数据表预览”。
3、数据文件的产生和修改
①主菜单→选择数据导入/导出菜单→“根据QES文件生成REC文件”
②在工作过程工具条按第二个按钮“生成REC文件”
③在编辑器菜单→REC文件菜单→选择“生成REC文件”
4、生成、检查核对文件
范围/合法值(Range/Legal)
跳转(Jumps)
必须输入(MustEnter)
重复输入(Repeat)
五、双人录入法:为了确保录入质量,可以采用双人录入法进行核对。
首先利用工具->复制REC文件结构,复制已建立好的数据库(包括CHK文件),另存为一新库,但已录入的数据不会被复制。如需要,可不复制字符型变量,因为家庭住址、工作单位等很少有人愿意录入两次。
两次录入的一致性检验
双轨录入完成后可进行一致检验,比较两次录入不同的地方,注意选择两数据库中的匹配字段用于比较。
双录入实时校验
先点击工具->准备双录入实时校验,指定第1 次已录入的REC文件,创建1新的REC文件,用于双录入。
EpiData数据导入导出教程 注:最好用英文的EpiData,已经证实中文版EpiData有一些莫名其妙的bug。 1.先菜单Data in/out -- Export -- Excel,把你的自己的rec数据导出成excel(以下称E1), 然后同理把他的数据导出成excel(以下称E2)。 2.复制E1中的从A2到AM211区域的所有数据(即除表头之外的所有数据),粘贴到E2 中的E2到AH211这一区域(即q1到q9对应的数据)。 3.那些地区编码、序号啥的,可以在excel用填充,直接一拖动就行,最后就整成我发给 你的“123格式”那个样子 4.然后在把q1、q2、q3、q9那几个垃圾abc的,用查找替换将123分别替换为abc,注意 选中之后再替换,不要把表头里的数字也替换了,只选中那几列的数据区域,替换之后的效果就是发给你的那个“abc格式” 5.打开那个处理好的E2,另存成一个“逗号分隔符”csv文件(直接另存,然后格式选择 成csv) 6.打开EpiData,菜单Datain/out—Import—Text,如下图所示: a)Filetoimport选择那个csv文件 b)Importtodatafile选拦截调查问卷111013.REC c)QESfile……选拦截调查问卷111013.QES d)Delimitedformat选择逗号”,”(那个下拉箭头里面),然后点 “Nofieldsareenclosedinquotes”,再点“Ignorefirstlineintextfile”,右边的Dateformat 不用管 e)然后OK,一直确定、OK
Epidata使用心得 一:建立qes文件 1、基本框架建立:可将word或excel中的调查表直接复制粘贴至“新建qes文件” 空白页面,然后进行编辑;也可直接在该页面输入要录入的内容等。(如下图) 2、字段编辑1:每一项都可以在文字说明的后面编辑一个{},大括号内为简易字母数 字组合代码(这个代码可用epidata的语言进行逻辑运算,如上图) 3、字段编辑2:编辑未来要录入数据的框,如下图所示 二:生成REC文件 编辑好了之后就要将上图这QES文件生成REC
务必要在这个“选项”框的“生成REC文件”复选框里选择“使用{}内….”然后点确定三:CHK编辑 对各个录入的框进行逻辑赋值或设定:就是建立CHK文件,如下图,单击“建立CHK文件”,然后在弹出的小窗口选择你刚建立的那个REC文件,点打开 即进入CHK文件编辑页面,如下图,可以看到鼠标每放到一个录入框处,右边有个小窗口都在 小窗口里的各项命令解释如下
若要对一个框里将要输进去的至进行逻辑限定,点击上边右图中的“编辑”会弹出这么个框(下图) 不同的框,里面的代码也不一样,有些不需要逻辑运算的就比较简单,如下图 将每一个框都定义好了之后,点击一直存在的那个窗口的“存盘”,也可以直接保存关闭。四:调试 这时再打开你刚刚创建的REC文件,录入的时候就能体会到你自己设置的各种跳转、保留、计算等,如果发现有些地方没达到你预想的设计,可以再回到CHK文件进行编辑。 五:设置颜色 最后是颜色的问题:在“选项”框里,可以调节REC和QES文件的颜色,有背景色,字的颜色和框的颜色,也可以调字体和字体的大小,如下图:
EPIDATA使用方法简介 一、建立新QES文件 第一种:在菜单中,点击“文件”(File)→“生成调查表文件QES文件”。 第二种:在工作栏的工作流程中,点击“1. 打开文件”(1.Define Data)→“建立新QES文件”。 第三种:在按钮栏中,点击,这时窗口中会在工作区显示一个空白的文档,你可以在此文档中键入调查表内容和框架,编辑完成后,将调查表文件保存,文件的扩展名统一为.QES。 二、调查表书写生成 1.“文件”(File)→“选项”(Option)→“生成REC文件”(Create data file)→ 在“如何生成字段名”(How to generate field names)中选择字段的命名方式。 2. 1 如果选择:以调查表第一个词命名、更新问题为实际文件名效果。
2 如果只选择:以调查表第一个词命名,字段名为汉字显示。 3 如果只选择:使用{ }内的内容自动添加字段名,则显示{ }的内容。【①在普通文本中优先选择“{ }”括进的文本。如果问题是{my}first{field}?那末字段名将为MYFIELD;如果问题是“姓名{name}?”,产生的字段名为name。 4 ②通用常见单词不予考虑(即What?Who?If?etc.)。What did you do?产生的字段名为YOUDO。 5 ③如果字段前没有“问题”文本,字段名就取前一个字段名再加上一个数字。如果前一个字段名是dMY字段,那末下一个字段(如果没 有“问题”文本)就是dMY1。如果前一个字段是dV31,则下一个字段名就是dV32。如果不存在前一个字段名则使用隐含字段名FIELD1。 6 ④如果第一个字符是数字则在第一个字符前插入一个字母N。例如3 little mice?产生的字段名为N3LITTLE。】 3. 数值型字段:##,###.##… ;仅接受数字和空格,不输按空格 处理,分析时作缺失值处理,以“.”显示。数字位数由“#”个数决 定,小数位数由小数点右边的“#”个数确定。最长可达14位,小 数点按1个字符计算。 文本型字段:包括三种。一种是常用的文本(或下划线、或底线)型字段:________;该型字段由连续下划线来定义,长度由下划线字符个数决定,最大值为80,空白字段(字段内容空缺)时,数据管理时将按缺失值处理。另一种为大写文本型字段:。 日期型字段:包括两种。一种为常用日期字段:
目录 一、EpiData2.0软件的安装 (3) 1.EpiData2.0软件介绍 (3) 2.EpiData2.0软件的组成 (3) 3.EpiData2.0软件的安装 (3) 4.EpiData2.0软件汉化文件的安装 (5) 5.数据文件Data的安装 (5) 6.EpiData2.0软件的启动 (5) 二、EpiData2.0软件的功能 (6) 1.工具条 (6) 2.快捷键 (7) 3.调查表文件(.qes)的制作 (7) EpiData编辑器 (7) 字段选取清单 (8) 变量符号编写器 (8) 数据表格式预览 (9) 变量命名法 (9) 自动变量命名规则 (10) 第一单词作为变量名 (11) 变量标记 (11) 自动缩进 (12) 字段输入框对齐 (12) 4.创建.REC数据文件和修改数据结构 (13) 4.1 如何创建.rec数据文件 (13) 4.2 数据文件的修改 (13) 5. .REC数据文件的追加与合并 (15) 5.1 数据文件的追加 (15) 5.2数据文件的合并 (16) 6. EpiData中的字段类型 (17) 6.1 自动编码变量 (17) 6.2 数值型变量 (17) 6.3 字符型变量 (17) 6.4 大写字符型变量 (17) 6.5 布尔变量 (17) 6.6 日期型变量 (17) 6.7 今天型日期字段 (18) Soundex型变量 (18) 6.9 隔位符 (18) 7. 编辑.CHK核查文件及核查文件命令和函数 (19) 7.1 增加/更改核对命令 (20) 7.2 使用编辑器产生核查文件 (23)
7.3 核查文件的核对命令 (24) 7.4 操作符和函数 (38) 8. 数据的录入 (43) 8.1字段间移动 (43) 8.2 记录间移动 (44) 8.3 查找记录 (44) 8.4 过滤器 (45) 8.5 数据双录入和有效性检查 (45) 8.6 关于数据文件 (46) 9. 数据输出 (47) 9.1 数据备份 (47) 9.2数据文件转成dBase III格式 (47) 9.3 数据文件转成Excel格式 (48) 9.4 数据文件转成Stata文件 (48) 9.5 将数据转成文本文件 (48) 三、EpiData 2.0软件与EpiInfo的兼容性 (49) 1.在数据文件中的不同 (49) 2.检查文件中的区别 (49) 四、结束语 (50)
临床研究数据库的建立与数据录入 ——EpiData软件的使用 一、 常见数据库软件简介 1.E xcel 大多数临床大夫和研究生常用的一种数据库软件, 优点:简单易得,界面熟悉。 缺点:数据库用简单表格列出,录入时易串行,发生录入错误;变量类型不清,允许一列内同时存在不同类型的内容(如:字符和数值),影响分析;无法进行双录入核对。 2.S PSS 常见的一种数据统计分析软件,也可利用此软件进行录入。
优点:数据库录入完成后即可统计,无需进行格式转换;可指定变量类型、长度、并设置标签。 缺点:数据库用简单表格列出,录入时易录入错误;无法进行双录入核对。 3.E piData 因大型流行病学调查需要而产生的一个数据库建立、录入、管理软件。 优点:绿色,自由软件,录入界面简单友好,可指定变量的类型、长度,可简单完成数据库双录入核查,可进行数据库追加、合并操作,数据库可转化各种数据分析软件格式。 缺点:查询功能弱,不带数据分析功能。
由丹麦欧登塞(Odense, Denmark)的一个非盈利组织,即The EpiData Association (http://www.epidata.dk)开发。EpiData 的工作原理源自DOS 版本的Epi Info 6,但是工作界面为Windows版。 翻译成各国语言:英语、中文、丹麦语、德语、西班牙语、法语、意大利语、荷兰语、挪威语、波兰语、葡萄牙语、罗马尼亚语、俄语、塞尔维亚语、斯洛文尼亚语、阿拉伯语 中文最高版本:v3.1 (2008.01更新) EpiData数据库录入、管理步骤 1. 建立调查表(QES) 2. 创建数据库(REC) 3. 建立录入规范文件(CHK) 4. 录入数据 5. 输出数据(output) 理论上,该程序对录入的记录数没有限制。而实际应用中,记录数最好不要超过200,000~300,000(曾经用250,000 测试过)。整个录入界面不能超过999行。对数值或字符串编码进行解释的文字长度最多80个字符,变量名建议控制在8个字符以内,否则可能转出到统计软件时可能出错。
EpiData manager简介(测试版) v1.06 J. Lauritsen & T. Christiansen (Translated by Shawn Kung) EpiData Project and Data Manager,简称EpiData manager,可以用来定义新的数据结构、修改既定的数据结构(而不丢失数据)以及存档或输出数据。 按照研发安排, EpiData manager将逐 步替代现存的 EpiData Entry软件。 本程序包中含有 一个样本文件,其中 包括一系列字段,章 节,并包括样本数据。 同时,这一样本文件 可以从测试站点获取, 以供用户使用。 这个样本文件含 有多种类型的文本 (用本土语言)并尽 量使用在程序中最新 加入的特性来显示如 何使用一个项目文件。 随着软件中新的特征应用的增加,软件功能将逐渐增强。软件进展的信息将在EpiData-List列表中给出,可以通过http://www.epidata.dk网站首页进行查询。 为什么转向EpiData manager? 自从1999年EpiData软件发布以来,许多特征都发生了改变。新策略的发展,有以下几大原因: l新用户们,越来越钟情于图形化界面,更注重鼠标的使用。而不理解广为人知的qes-chk-rec原则。 l多操作平台(Linux,Mac,Windows,PDA…)发展的需要。 l为了支持跨平台下兼容非拉丁字符的Unicode(UTF-8)的使用。 l我们希望将许多医学数据项目中会用到的GCP(Good Clinical Practice)进行整合,这需要在非常精细的水平对编辑进行加密和记录,以及对用户获得数据的权限进行控制。 l所有的EpiData软件都需要一个共同的引擎,例如,处理数据和元数据(数据标签等)都需要基于相同的内部程序。