Semantic Workflow Management
- 格式:pdf
- 大小:106.04 KB
- 文档页数:2

英文文本预处理流程English text preprocessing is a critical step in natural language processing (NLP) and text mining tasks. It involves a series of steps to clean, transform, and prepare the raw text data for further analysis and modeling. This process is essential for improving the accuracy and effectiveness of various NLP applications, such as sentiment analysis, text classification, and language generation. In this essay, we will explore the common steps involved in the English text preprocessing workflow.1. Data Acquisition:The first step in the text preprocessing workflow is to acquire the raw text data. This can be obtained from a variety of sources, such as websites, social media platforms, databases, or custom-built datasets. The data may come in different formats, such as plain text, HTML, PDF, or spreadsheets, and may require some initial processing to extract the relevant text content.2. Text Cleaning:Once the raw text data is obtained, the next step is to clean the text.This involves removing any unwanted or irrelevant information, such as HTML tags, URLs, email addresses, special characters, numbers, and punctuation marks. This step helps to remove noise and ensure that the text is in a format that can be easily processed by the subsequent steps.3. Tokenization:Tokenization is the process of breaking down the text into smaller units called tokens, which are typically individual words or phrases. This step is crucial for many NLP tasks, as it helps to identify the basic building blocks of the text. Tokenization can be done using various techniques, such as white space separation, regular expressions, or more advanced methods like sentence boundary detection.4. Stopword Removal:Stopwords are common words that do not carry much semantic meaning, such as "the," "a," "and," "is," and "to." These words are often removed from the text during the preprocessing stage, as they can introduce noise and reduce the effectiveness of subsequent analysis tasks. Stopword removal can be done using predefined lists of stopwords or by applying more advanced techniques, such as term frequency-inverse document frequency (TF-IDF) analysis.5. Lemmatization and Stemming:Lemmatization and stemming are techniques used to reduce words to their base or root form, known as the lemma or stem, respectively. Lemmatization uses a vocabulary and morphological analysis to convert words to their base forms, while stemming uses a simpler rule-based approach to remove suffixes and prefixes. These techniques help to reduce the dimensionality of the text data and improve the performance of various NLP models.6. Text Normalization:Text normalization is the process of converting the text to a consistent format, such as converting all characters to lowercase or uppercase, handling abbreviations and contractions, or standardizing the spelling of words. This step helps to ensure that the text is in a format that can be easily processed by the subsequent steps.7. Feature Extraction:Once the text has been cleaned, tokenized, and normalized, the next step is to extract relevant features from the text. This can involve techniques such as bag-of-words, n-grams, or more advanced methods like word embeddings. The choice of feature extraction technique depends on the specific NLP task and the characteristics of the text data.8. Data Augmentation:In some cases, the available text data may be limited or imbalanced,which can affect the performance of NLP models. Data augmentation is a technique used to generate additional synthetic data by applying various transformations to the existing text, such as paraphrasing, back-translation, or synonym replacement. This can help to improve the robustness and generalization of the NLP models.9. Model Training and Evaluation:The final step in the text preprocessing workflow is to train and evaluate the NLP models using the preprocessed text data. This may involve tasks such as text classification, sentiment analysis, named entity recognition, or language modeling, depending on the specific application. The performance of the models can be evaluated using various metrics, such as accuracy, precision, recall, or F1-score, and the results can be used to fine-tune the preprocessing steps or the model architecture.In conclusion, the English text preprocessing workflow is a crucial step in the NLP pipeline, as it helps to transform the raw text data into a format that can be effectively processed by various NLP models. By following the steps outlined in this essay, researchers and practitioners can improve the accuracy and performance of their NLP applications, leading to better insights and more effective decision-making.。


浅谈基于语义网的知识管理摘要随着知识型企业的出现,知识己逐渐成为企业首要的生产要素。
企业如何通过对知识实施有效管理来效益最大化,增强竞争能力,已经引起人们的普遍重视。
本文从知识管理目前存在的问题出发,提出了语义网相关技术在知识管理中的作用,给出基于语义网的知识管理方法。
关键词语义Web;知识管理;信息查询在人类社会进入新世纪的同时,人类也进入了一个全新的时代——知识经济时代。
随着知识型企业的出现,知识逐渐成为首要的生产要素。
企业如何通过对知识实施有效管理来效益最大化,增强竞争能力,已经引起人们的普遍重视。
企业知识管理已成为当今管理学界和企业管理者们最为关注的课题之一。
1 知识管理1.1 知识管理的出现所谓“知识经济”,就是“以知识为基础的经济”,这个术语于对知识和技术在经济增长中所起作用的充分了解,体现了人力资本和技术中的知识是经济发展的核心,强调了知识作为一种资源在新的经济社会形态中所具有的基础特征。
就企业管理来讲,知识管理 __主要有四个方面:(1)经济全球化给组织(企业)产生了巨大压力。
(2)知识密集型产业成为现代经济增长的主导力量。
对传统产业来说“知识化”将是其维持现有地位或实现创新的惟一出路。
(3)知识作为一种独立的生产要素在各种要素投入中占据主导地位,与此相应地“知识工人”在企业中的地位不断强化。
(4)信息技术的飞速发展和信息基础设施的极大改善为组织运作提供了与工业化时代在本质上不同的基本环境。
在上述背景下,管理学家和企业管理者们日益认识到,知识及其学习代表着企业(组织)竞争优势的重要源泉,“企业知识管理”便由此应运而生。
1.2 目前存在的问题在互连网上有数以百亿计的文档被超过上亿的用户使用,这些文档中有很多是在企业或组织内部的Intra上。
随着网络的不断发展,这些为企业服务的文档会越来越多地出现在网络上,所以我们有理由相信未来企业对于信息和知识的管理都会偏向于网络。
但是目前基于网络知识管理系统都存在着明显的不足:1) 信息检索目前的信息检索方式主要是基于关键词的检索而并非语义。

HARVEY SPENCER ASSOCIATES ______________________________________________________________________________Executive SummaryMany organizations have invested in Capture softwareand technologies to transform paper documents into digital artifacts, but a strategy that focuses on capture as a standalone solution is tactical and limiting. Today’s Capture software has evolved so that it can hand off captured data from paper or electronic media to any repository or line of business application and initiate processes. Capture software understands the process inputs and, via execution of business rules, delivers appropriate data to these processes with limited or no human intervention. The emergence of agile rapid development and deployment models, along with Capture Services, means capture workflows can be created and implemented faster. Interoperability and improved connections to business systems, social and collaboration platforms, and content management repositories mean that capture technology serves as the critical on-ramp to business applications supporting transactional processes, customer-facing activities and real-time decision making. Organizations that consider Capture as a key element of an overall information management strategy can meet cost reduction and efficiency goals.IntroductionOrganizations require information to execute business processes and to meet and maintain regulatory compliance. If that information is contained in paper documents, it cannot be easily accessed and thus slows down the process. Many organizations have implemented Capture software to convert their paper documents into digital images, but simply creating a digital image still leads to inefficiencies and increased Capture 2.0: Delivering Content IntelligenceCapture 2.0 consists of services that enable organizations to interpret and understand incoming multichannel (paper or electronic) data and thus transforming them into information. Input media can be on the form of images (document, photographic) voice, video, text messages (SMS/Chat/Social Media. Capture 2.0 technologies include: OCR/ICR, image recognition, object recognition, voice recognition, Natural Language Processing (NLP), semantic understanding, sentiment analysis, and more. In short, Capture’s next generation of capabilities make content intelligent. Traditionally a Batch Oriented Process, Capture is now becoming services based and integrated with© 2018 – Harvey Spencer Associates Inc.labor costs from manual data entry. The volume of data available to the organization is also increasing and coming from a variety of sources and in a variety of formats.Today’s Capture software has evolved into a set of software tools that are applied to interpret, understand, extract and validate data from a variety of information types. Harvey Spencer Associates (HSA) defines this next -generation of capture as “Capture 2.0” (see Figure 1. Capture 2.0 Framework).Figure 1. Capture 2.0 FrameworkSource: Harvey Spencer Associates Inc.Enterprise Challenges to Efficient Processes and Information Management Organizations and industries face digital disruption with business being transacted at ever increasing speeds. To compete, business must understand incoming information faster and more accurately. Informationmust get converted to usable data quickly and routed to the appropriatepeople or applications, so actions can be taken.© 2018 – Harvey Spencer Associates Inc.Organizations undergoing digital transformation face challenges regarding business processes and the unstructured information required to make them more streamlined and efficient. These include the following:•Changing service expectations: As businesses become attuned to digital transaction, expectations for immediacy heighten. Serviceexpectations are compressed with customers expecting answers ordecisions in minutes now. Content needs to get to right person at the right time and in the context of the moment. Capturing informationclose to the data source is essential.•Data quality: Critical data remains locked in unstructured and semi-structured content. Document images are often simply “dumb” staticimages with poor or missing metadata. Manual key entry can introduce errors.•Manual and multiple touchpoints: Document preparation, indexing/ validation, quality control and exception processing are labor intensive activities. Organizations must reduce touch points and eliminatemanual roadblocks to document throughput.•New content types: Data now needs to be gleaned from multiple media, including documents, images, voice transcriptions, socialmedia, and video. Business applications also need to understand when the data is really a case of “same info, different content type.” Forexample, an eForm, a PDF and a scanned image may just be replicasof the same single piece of information.•New input streams and multiple endpoints: Content is created, accessed and submitted into a process from e-mail, mobile devices, or cloud applications. Business applications must use data that isgenerated in field offices, customer facing encounters or eveninformation that comes from customers. Capture has to be integrated at multiple points in a process and accommodate multiple end points. Capture BenefitsOpportunities remain for reducing operational costs and optimizing processes by taking paper out of the equation, but new uses are emerging where capture and related capabilities can be further leveraged to interpret, classify and understand multichannel data. Capture Services classify and extract accurate relevant transactional data, which is then integrated with© 2018 – Harvey Spencer Associates Inc.the business process. Capture transforms business by enabling increased revenue through better sales efficiency, faster access to data, more accurate new account on-boarding, enhanced claims and inquiry processing, and improved customer acquisition and retention.Capture software has improved, getting smarter at interpreting, classifying, and understanding data. From its roots as centralized batch capture of paper, Capture has evolved into a decentralized solution capable of handling multichannel inputs and multimedia content. Smarter Capture software reduces the need for human intervention and enables automated routing of information to the appropriate person, location or application. For example, an invoice that never changes should not have to be touched by humans. With classification, data extraction and process integration, the invoice can automatically be routed to where it needs to go. Integration and Connectivity enable Capture to serve as an on-ramp to processes, content management and collaboration applications, and Line of Business (LOB) applications (e.g., ERP, CRM, EMR, HRIMS).Capture is as much about business processes and business rules as it is about technology. Application developers can now build an integrated Capture capability as a component of a business workflow much more easily thanks to advances in Capture services. The technology components are designed to understand the process inputs and via execution of business rules, deliver appropriate data to these processes with limited or no human intervention. Business Rules Processing determines what actions are needed, drives dynamic workflow and decides how best to route information to the proper business application. Capture Services can be called at each workflow decision point and where a human is involved, Artificial Intelligence (AI) will learn the process decision, which gets incorporated into the rules set.The overall Capture Software valueproposition will stem from enhancedclassification, interpretation, identification,extraction and routing of information thatis key to the business process. –HSA, Inc.Worldwide Capture Software MarketReport, 2017-2018© 2018 – Harvey Spencer Associates Inc.© 2018 – Harvey Spencer Associates Inc.Capture in the Real WorldAs Capture software becomes more deeply integrated into business processes, it is being optimized and packaged to address the needs of specific vertical industries and horizontal applications. Figure 2. Vertical Markets for Capture shows the top industries with continued opportunities for Capture software and services. Along with traditional back-officeapplications, solutions now address customer-facing applications where the real time understanding of various forms of digital content is critical.Interoperability and improved connections to business systems, collaboration platforms, and content management repositories mean that capturetechnology serves as the critical on-ramp to business applications supporting transactional processes, customer-facing activities and real-time decision making.Figure 2. Vertical Markets for CaptureSource: Harvey Spencer Associates Inc. The 2017-2018 Worldwide Capture Software Market ReportWhile paper processing has value, Capture software’s process integrationcapabilities can positively impact customers and help an organization meetits strategic goals. Use cases include onboarding, new account opening, and financial processes such as payments and invoices.•Onboarding: Consider a real-time or automated client onboarding scenario in which the capture solution processes and identifiesinformation related to routing, thus allowing for greater straightthrough processing. A client-centric South African bank(https:///customer-stories/customer-story-detail?id=1345) embarked on a digital strategy to improve clientinteractions and enable a more streamlined, real-time onboardingprocess. The bank used OpenText Captiva with advanced recognitionto capture customer documents right in the branch, providing real-time validation and processing. OpenText Captiva is integrated withOpenText Documentum and OpenText xCP for process automation.OpenText xPression generates all necessary agreements requiring asignature. The client signs agreements electronically and files arestored in the Documentum repository. The bank was able to reducethe time spent on client interactions, reducing costs and improvingcustomer satisfaction.•New Account Opening: Many financial service companies have streamlined the process of opening a new account with batch Capture and content management technologies, saving money and increasing the volume of accounts. In the digital age, opening a new bank orinvestment account requires accommodating a variety of inputchannels. It is critical that banks scan and process these documents at the point of interaction with the customer. Capture solutions designed for distributed deployment, such as mobile capture applications,support on-demand document gathering, classification, validation and interpretation.Conclusion: Take ActionA strategy that focuses on Capture as a standalone solution is tactical and limiting. Organizations should consider Capture technologies and services as the critical on-ramp for enterprise information management and focus on process and application integration. Doing so will enable them to meet cost reduction and efficiency goals, increase revenue through such activities as better sales efficiency, faster access to data, more accurate new account on-© 2018 – Harvey Spencer Associates Inc.boarding, enhanced claims and inquiry, and improved customer acquisition and retention. Specific actions include the following:•Consider ways to improve data quality at the point of capture. Basing document classification/ metadata on existing organizationalknowledge may be desirable.•Determine what information needs to be captured and acted upon versus simply being historical/archival. Determine the value of capture with process/routing mapping.•Streamline the flow of information by connecting your Capture solution to back-end systems, repositories and processes.About HSA, Inc. (Harvey Spencer Associates):Since 1989, HSA, Inc. has specialized in electronic information capture technologies used to create, understand and extract meaningful information from semi structured and unstructured data to improve business process efficiencies. HSA assists organizations and vendors that support them with market support, insight and future direction.About OpenText:OpenText, The Information Company™, enables organizations to gain insight through market leading information management solutions, on-premises or in the cloud.© 2018 – Harvey Spencer Associates Inc.。

D2.3.3.v1SemVersion–Versioning RDF and Ontologies Max V¨o lkel(University of Karlsruhe)with contributions from:Carlos F.Enguix(National University of Ireland,Galway,Ireland)Sebastian Ryszard Kruk(DERI)Anna V.Zhdanova(DERI)Robert Stevens(U Manchester)York Sure(AIFB)Abstract.EU-IST Network of Excellence(NoE)IST-2004-507482KWEBDeliverable D2.3.3.v1(WP2.3)This papers describes the requirements for a semantic versioning system.The design,implementation and usage of SemVersion are described.KWEB/2004/D2.3.3.a/v1.0Document Identi-fierProject KWEB EU-IST-2004-507482Version v1.0Date June6th,2005StatefinalDistribution internalKnowledge Web ConsortiumThis document is part of a research project funded by the IST Programme of the Commission of the European Communities as project number IST-2004-507482.University of Innsbruck(UIBK)-CoordinatorInstitute of Computer Science Technikerstrasse13A-6020InnsbruckAustriaFax:+43(0)5125079872,Phone:+43(0)5125076485/88Contact person:Dieter FenselE-mail address:dieter.fensel@uibk.ac.at `Ecole Polythechnique F´e d´e rale de Lausanne (EPFL)Computer Science DepartmentSwiss Federal Institute of TechnologyIN(Ecublens),CH-1015LausanneSwitzerlandFax:+41216935225,Phone:+41216932738 Contact person:Boi FaltingsE-mail address:boi.faltings@epfl.chFrance Telecom(FT)4Rue du Clos Courtel35512Cesson S´e vign´eFrance.PO Box91226Fax:+33299124098,Phone:+33299124223 Contact person:Alain LegerE-mail address:alain.leger@ Freie Universit¨a t Berlin(FU Berlin) Takustrasse914195BerlinGermanyFax:+493083875220,Phone:+493083875223 Contact person:Robert TolksdorfE-mail address:tolk@inf.fu-berlin.deFree University of Bozen-Bolzano(FUB) Piazza Domenicani339100BolzanoItalyFax:+390471315649,Phone:+390471315642 Contact person:Enrico FranconiE-mail address:franconi@inf.unibz.it Institut National de Recherche en Informatique et en Automatique(INRIA) ZIRST-655avenue de l’Europe-Montbonnot Saint Martin38334Saint-IsmierFranceFax:+33476615207,Phone:+33476615366 Contact person:J´e rˆo me EuzenatE-mail address:Jerome.Euzenat@inrialpes.frCentre for Research and Technology Hellas/ Informatics and Telematics Institute(ITI-CERTH)1st km Thermi-Panorama road57001Thermi-ThessalonikiGreece.Po Box361Fax:+30-2310-464164,Phone:+30-2310-464160 Contact person:Michael G.StrintzisE-mail address:strintzi@iti.gr Learning Lab Lower Saxony(L3S)Expo Plaza130539HannoverGermanyFax:+49-511-7629779,Phone:+49-511-76219711 Contact person:Wolfgang NejdlE-mail address:nejdl@learninglab.deNational University of Ireland Galway (NUIG)National University of IrelandScience and Technology BuildingUniversity RoadGalwayIrelandFax:+35391526388,Phone:+353876826940 Contact person:Christoph BusslerE-mail address:chris.bussler@deri.ie The Open University(OU)Knowledge Media InstituteThe Open UniversityMilton Keynes,MK76AAUnited KingdomFax:+441908653169,Phone:+441908653506 Contact person:Enrico MottaE-mail address:e.motta@Universidad Polit´e cnica de Madrid(UPM) Campus de Montegancedo sn28660Boadilla del MonteSpainFax:+34-913524819,Phone:+34-913367439 Contact person:Asunci´o n G´o mez P´e rezE-mail address:asun@fi.upm.es University of Karlsruhe(UKARL)Institut f¨u r Angewandte Informatik und Formale Beschreibungsverfahren-AIFBUniversit¨a t KarlsruheD-76128KarlsruheGermanyFax:+497216086580,Phone:+497216083923 Contact person:Rudi StuderE-mail address:studer@aifb.uni-karlsruhe.deUniversity of Liverpool(UniLiv) Chadwick Building,Peach StreetL697ZF LiverpoolUnited KingdomFax:+44(151)7943715,Phone:+44(151)7943667 Contact person:Michael WooldridgeE-mail address:M.J.Wooldridge@ University of Manchester(UoM)Room2.32.Kilburn Building,Department of Computer Science,University of Manchester, Oxford RoadManchester,M139PLUnited KingdomFax:+441612756204,Phone:+441612756248 Contact person:Carole GobleE-mail address:carole@University of Sheffield(USFD)Regent Court,211Portobello streetS14DP SheffieldUnited KingdomFax:+441142221810,Phone:+441142221891 Contact person:Hamish CunninghamE-mail address:hamish@ University of Trento(UniTn)Via Sommarive1438050TrentoItalyFax:+390461882093,Phone:+390461881533 Contact person:Fausto GiunchigliaE-mail address:fausto@dit.unitn.itVrije Universiteit Amsterdam(VUA) De Boelelaan1081a1081HV.AmsterdamThe NetherlandsFax:+31842214294,Phone:+31204447731 Contact person:Frank van HarmelenE-mail address:Frank.van.Harmelen@cs.vu.nl Vrije Universiteit Brussel(VUB) Pleinlaan2,Building G101050BrusselsBelgiumFax:+3226293308,Phone:+3226293308 Contact person:Robert MeersmanE-mail address:robert.meersman@vub.ac.beExecutive SummaryChange management for ontologies becomes a crucial aspect for any kind of on-tology management environment,as engineering of ontologies often takes place in distributed settings where multiple independent users have to interact.There is also a variety of ontology languages used.Although RDF Schema and OWL are gaining more and more popularity,a lot of semantic data still resides in other formats,as it is the case in the biology domain(c.f.Sec.1.2.3).Until now,no standard version-ing system or methodology has arisen,that can provide a common way to handle versioning issues.This deliverable describes the RDF-centric versioning approach and implementa-tion SemVersion.It provides structural(purely triple based)and semantic(ontology language based,like RDFS,OWL and OBOL)versioning.It separates language-neutral features for data management from language-specific features like semantic diffs in design and implementation.This way SemVersion offers a common approach for already widely used RDF models and a wide range of ontology languages.The requirements for our system are derived from a set of practical scenarios, which are documented in detail in this deliverable.The project experienced a shift in requirements,when Robert Stevens from Uni-versity of Manchester joined the group in May2005.WP2.3decided to tackle the problem of versioning the Gene Ontology.In[1]we suggested reification for data storage.As we now face the large volume of the Gene Ontology data(see1.2.3),we need more powerful storage solutions than for the other use cases.Addressing triple sets(models)is another challenge.In[1] we argued to use reification,which would make models four times as large.To avoid this,we now use native quad stores,which provide a context URI for each triple. We use the context URI to address models more efficiently.A sub-project,Rdf2Go,has been created to deal with various model abstrac-tions and serves as a unifying triple(and quad)store entry point.Rdf2Go is described in Chapter2.A second sub-project of SemVersion,RdfReactor,facilitates the usage of RDF Schema based data in Java significantly.It’s latest version is based on Rdf2Go.In fact,RDFReactor has been designed for SemVersion in thefirst place.RDFReactor is described in Sec.1.5.4.Contents1SemVersion–An RDF Versioning System11.1Introduction (1)1.1.1Term Definitions (3)1.2Requirements for an ontology versioning system (3)1.2.1Use Case1:MarcOnt Collaborative Ontology Development..31.2.2Use Case2:The People’s Portal for Community OntologyDevelopment (6)1.2.3Use Case3:Versioning the Gene Ontology (7)1.2.4Use Case4:Versioning in a Semantic Wiki (10)1.2.5Use Case5:Analysis of Wikipedia (10)1.2.6Requirements Summary (11)1.3Data Management Design (12)1.3.1RDF as the structural core of ontology languages (12)1.3.2Version Data Management (13)1.4Versioning Functionality Design (14)1.4.1Structural Diff (14)1.4.2Semantic Diff (15)1.4.3Blank Nodes and the Diff (16)1.4.4Branch and Merge (17)1.4.5Conflict Detection (18)1.4.6Query Language Extension (18)1.5Implementation (18)1.5.1Storage Layer Access (19)1.5.2Handling Commits (20)1.5.3Generating globally unique URIs (20)1.5.4RDFReactor (20)2RDF2Go222.1What is RDF2Go? (22)2.2Working Example:Simple FOAF via RDF2Go (24)2.3Architecture (26)2.4The API (26)2.4.1Model and ContextModel (26)iiD2.3.3.v1SemVersion–Versioning RDF and Ontologies IST Project IST-2004-5074822.4.2Queries (29)2.5How to get started (30)3Using and Extending SemVersion313.1Using SemVersion (31)3.1.1Typical Actions (32)3.1.2Administration (33)3.1.3Usage and Implementation Notes (34)3.1.4SemVersion Usage Examples (34)3.2Extending SemVersion (34)4Conclusions and Outlook36 KWEB/2004/D2.3.3.a/v1.0June6th,2005iiiChapter 1SemVersion –An RDF Versioning System1.1IntroductionAs outlined in the Knowledge Web Deliverable D2.3.1”Specification of a method-ology for syntactic and semantic versioning”[1],there is a clear need for RDF data and ontology versioning.This deliverable is a follow-up of D2.3.1,which explains the underlying concepts in detail.Here we focus on the concrete approach and implementation.Change management for ontologies becomes a crucial aspect for any kind of ontology management environment,as engineering of ontologies often takes place in distributed settings where multiple independent users have to interact.There is also a variety of ontology languages used.Although RDF Schema and OWL are gaining more and more popularity,a lot of semantic data still resides in other formats,as it is the case in the biology domain (c.f.Sec. 1.2.3).Until now,no standard versioning system or methodology has arisen,that can provide a common way to handle versioning issues.This deliverable describes the RDF-centric versioning approach and implementa-tion SemVersion 1.It provides structural (purely triple based)and semantic (ontol-ogy language based,like RDFS,OWL and OBOL)versioning.It separates language-neutral features for data management from language-specific features like semantic diffs in design and implementation.This way SemVersion offers a common approach for already widely used RDF models and a wide range of ontology languages.SemVersion is published as an open-source software project on the site OntoWare.The current version of the project homepage is depicted in Fig.1.1.1The name resembles the upcoming de-facto standard subversion ( )and is also a short form of ”Semantic Versioning”11.SEMVERSION–AN RDF VERSIONING SYSTEMFigure1.1:Homepage of the SemVersion project2June6th,2005KWEB/2004/D2.3.3.a/v1.0D2.3.3.v1SemVersion–Versioning RDF and Ontologies IST Project IST-2004-507482 Our approach is inspired by the classical CVS system for version management of textual documents(e.g.Java code).Core element of our approach is the sepa-ration of language-specific features(the semantic diff)from general features(such as structural diff,branch and merge,management of projects and metadata).A speciality of RDF is the usage of so-called blank nodes.As part of our approach we present a method for blank node enrichment which helps in versioning of such blank nodes.1.1.1Term DefinitionsRDF is a data model with the types URI,blank node,plain literal,language tagged literal and data typed literal.It consists of triples(also called state-ments).A set of triples is called model(or triple set).An ontology is a model, in which semantics have been assigned to certain URIs and/or triple constructs, according to an ontology language.We use the term concept to denote things ontologies talk about:classes,properties and instances.In an RDF context,every-thing that is addressable by URI or by blank node is considered a concept.SemVersion versions models.A model under version control is named a ver-sioned model.A versioned model has a root model,which is a version.A version is a model plus versioning metadata.Versions in SemVersion never change. Instead,every operation that changes the state of a versioned model(commit,merge, ...)results in the creation of a new version.More details about SemVersion’s con-ceptual data model can be found in Sec.1.3.2.1.2Requirements for an ontology versioning sys-temWe gathered different requirements from Knowledge Web partners in order to create a more general design.We tried to gather as concrete usage requirements as possible to obtain a usable(and hence testable)design and implementation.In this section we present the different usage requirements.For each use case we name the stakeholder and provide a use case description, characteristics of the data set,and derived versioning requirements.1.2.1Use Case1:MarcOnt Collaborative Ontology Devel-opmentStakeholder:Sebastian Ryszard Kruk(DERI),sebastian.kruk@KWEB/2004/D2.3.3.a/v1.0June6th,200531.SEMVERSION–AN RDF VERSIONING SYSTEMThe MarcOnt2scenario served as thefirst source of inspiration for SemVersion. MarcOnt is a project to create an ontology for library data exchange.One of the most commonly used bibliographic description format is MARC21. Though it is capable of describing most of the features of the library resources, its semantic content is low.It means that while searching for a resource,one has to look for particular keywords in the resource’s descriptionfields,but one cannot carry out a search be meaning or concept.This can often result in large sets of results.Also the data communication between library systems is very hard to extend. On of the earliest shared vocabularies is the Dublin Core Metadata standard for library resource description.Besides the fact that most of the information covered by MARC21is lost,the full potential of the Semantic Web is not being used.The project aims at creating the MarcOnt ontology,based on a social agreement that will combine descriptions from MARC21together with DublinCore and makes use of the full potential of the Semantic Web technologies.This will include transla-tions to/from other ontologies,more efficient searching for resources(ers may have impact on the searching process).The MarcOnt initiative is strongly connected to the Jerome Digital Library project(e-library with semantics,formerly ElvisDL)-which implements a simple library ontology and can be used as a starting point for further work.MarcOnt also assumed that JeromeDL will be a testing platform for an experimental results from the MarcOnt initiative.Data Set Currently there exists only one version of the MarcOnt ontology,which can be downloaded at /index.php?option=com_content&task=view&id=13&Itemid=27.Versioning Requirements The MarcOnt project has a clear view on the process of ontology evolution.It starts with a current main version.Now people can suggest (multiple,independent)changes.Then the community discusses about the proposed changes and selects some.The changes are applied and a new main version is created. The process is illustrated in Fig.1.2.The ontology builder of the MarcOnt portal requires not only a GUI for building the ontology through submitting changes.It also needs the ability to:•Manage a main trunk of the ontology(R1.1)3•Manage versions of suggestions(R1.2)•Generate snapshots of the main ontology with some suggestions applied(R1.3) 2/3Requirements are numbered by”use case number”/”.”/running number4June6th,2005KWEB/2004/D2.3.3.a/v1.0Figure1.2:Versions and suggestions in the MarcOnt use caseKWEB/2004/D2.3.3.a/v1.0June6th,20055•Detect and resolve conflicts(R1.4)•Add suggestions to the main trunk(R1.5)•Attach mapping/translation rules(R1.6)•Be able to check out arbitrary versions by HTTP GET with a specific URL (R1.7)1.2.2Use Case2:The People’s Portal for Community On-tology DevelopmentStakeholder:Anna V.Zhdanova(DERI),anna.zhdanova@deri.at People’s portal[2]is an implementation of a human-Semantic Web interactive environment.The environment is named The People’s Portal and it is implemented employing Java,Jena and Tomcat.The basic idea of the People’s portal is to marry a community Semantic Web portal technology with collaborative ontology manage-ment functionalities in order to bring the Semantic Web to masses and overcome limitations of the existing community web portals.Use cases:The People’s portal environment is applied to DERI and used to produce part of the DERI web site.DERI members can login here to enter the environment.DERI web site managers can login here to manage the data in a centralized fashion.Versioning Requirements The system uses a subset of RDF ers of the portal can introduce new classes and properties on thefly.Consensus is partly reached by usage.Properties that are often used and classes that have many instances are considered useful for the community.Hence it is necessary to ask the versioning system:•How many instance does this class have now?Last week?Generalised:How many instances does a concept(rdfs:Class or rdfs:Property)has at a specific point in time?(R2.1)•When has this classfirst been instantiated?(R2.2)•How many properties are attached to this class?Since when?(R2.3)number of instances of class,properties NOW(specific point in time also)•Who added this ontology item?(R2.4)•Store new versions and return diffs between arbitrary points in time.(R2.5)•Return predecessor of an ontology item(class,property)in time(R2.6)6June6th,2005KWEB/2004/D2.3.3.a/v1.0•Support the evolution primitives:”add”,”remove”and ”replace”on concept definitions.(R2.7)•Return number of changed instance items (also properties,classes)and show which items changed.(R2.8)•Which concepts appeared within a given time interval?(R2.9)•Queries across change log/activity log:For each attribute,when was it instan-tiated and when have instances been created?(R2.10)•What are hot attributes?Those instantiated or changed often recently.Which are these?(R2.11)1.2.3Use Case 3:Versioning the Gene OntologyStakeholder:Robert Stevens (U Manchester),robert.stevens@ Background An important step was the phone conference on 12.07.2005,in which common goals were identified 4.Robert Stevens from Manchester University has be-come an active member of the work package.Robert is a biologist who is also a doctor in Computer Science.Robert is a Bioinformatics Lecturer in the BioHealth Informatics Group at the University of Manchester.He has around 80publications in international conferences,workshops,journals and so on.He was involved in the TAMBIS project for transparent access and integration of biological databases.Now one of his main interests is in the definition of formal biological ontologies.He is involved in the transformation of the Gene Ontology controlled vocabulary into a description-logics OWL based ontology.He is interested in contributing to the devel-opment of an ontology-based versioning system to the Gene Ontology which is part of the Open Biological Ontologies.Also he want’s to study how conceptualisations change over time,hence the need for data analysis.Use case description The gene ontology 5community is where collaborative on-tology construction is practiced a long time comparing to other communities.The GO community showed that involvement of multiple parties is a must for a compre-hensive ontology as a result.The GO community is far ahead of other communities constructing ontologies [3].Hence they are the ideal subject to study real-world change operations.”The goal of the Gene Ontology (GO)consortium is to produce a controlled vocabulary that can be applied to all organisms even as knowledge of gene and 4/wiki/KnowledgeWeb/WP23/MeetingAgenda12July20055KWEB/2004/D2.3.3.a/v1.0June 6th,20057protein roles in cells is accumulating and changing.GO provides three structured networks of defined terms to describe gene product attributes.”6Current Gene Ontology versions are maintained by CVS repositories which han-dle only syntactic differences among ontologies.In other words CVS is not able to differentiate class versions for instance,being able only to differentiate text/file differences.Versioning Requirements Essentially,here SemVersion is used for data analysis.In order to study ontology change operations,SemVersion must cope with multiple versions of the Gene Ontology (GO).The GO is authored in Open Biology Language 7(OBOL),for which usable OWL exports exist.The GO has about 19.000concepts.Assuming about 10statements per concept we estimate a size of roughly 100.000statements –per version.The researchers who study the ontology change patterns (Robert Stevens and his team)would like to use a monthly snapshot for a period of 6years.This amounts to 6years ×12month =72versions.Thus the underlying triple store must be able to handle up to 7million triples and search (maybe even reason)over them.The requirements in short form are thus•Store up to 7million triples (R3.1)•Allow meta-data queries over the 72versions (R3.2)•Allow data queries over all versions (7million triples)(R3.3)•OBOL semantic diff(R3.4)•OBOL to RDF converter (R3.5)•A Java interface (R3.6)Data Set The Gene Ontology ”per se”is not an Ontology in the formal sense,it is rather a cross-species controlled biological vocabulary as previously indicated above.The Gene Ontology is divided in three disjoint sub-ontologies,currently stored in big flat files or also stored in persistent repositories such as a relational database (MySQL database).The three sub-ontologies are divided into vocabularies that describe gene products in terms of:Molecular functions,associated biological processes and cellular components.The GO ontology permits to associate biological relationships among molecular functions,the involvement of molecular functions in biological processes and the 6Extracted from the OBO site /7/8June 6th,2005KWEB/2004/D2.3.3.a/v1.0occurrence of biological processes at a given time and space in cells [4].Whereas the molecular function defines what a gene product does at the biochemical level,the bi-ological process normally indicates a transformation process triggered or contributed by a gene product involving multiple molecular functions.Finally the cellular com-ponent indicates the cell structure a gene product is part of.The Gene Ontology contains around 20.000concepts which are convertible to OWL.The latest statistics about the GO could be found at the GO site 8:Current term counts (as of June 20,2005at 6:00Pacific time):•17946terms,94.2%with definitions.•6984(38.9%)Molecular functions•9410(52.4%)Biological processes•1552(8.6%)Cellular components•There are 998obsolete terms not included in the above statistics(Total Terms=18944)Further complexity assessments can be found at /~cjm/obol/doc/go-complexity.html .According to [5]the GO is a handcrafted ontology accepting only ”is-a”and ”part-of”relationships.The hierarchical organization is represented via a directed-acyclic-graph (DAG)structure similar to the representation of Web pages or hypertext systems.Members of the Consortium group contribute to updates and revisions of the GO.The Go is maintained by editors and scientific curators who notify GO users of ontology changes via email,or at the GO site by monthly reports 9.Please note that ontology creation and annotation of GO terms in databases (association of GO terms with gene products)are two different operations.Each annotation should include its data provenance or source(a cross database reference,a literature reference,etc).Technically,there are two different data sets,available via public CVS stores.Set I ranges from 1999to 2001and has a snapshot of the GO for each month in GO syntax.The second set runs from 2001up to now and contains for each month a Go snapshot in OBO syntax.As OBO is the newer syntax,we assume the existence of a converter from GO syntax to OBO syntax available from the GO community.In order to use the data sets,one has to decide for a format.There are three options:(a)RDF,(b)OWL generated from DAG-Edit 10or (c)nice OWL generated by Prot´e g´e -Plugin.Whatever choice is made,the exported data should contain the provenance8/GO.downloads.shtml#ont9/MonthlyReports/10/dev/java/dagedit/docs/index.html KWEB/2004/D2.3.3.a/v1.0June 6th,20059information of the source file and the conversion process used.SemVersion offers ways to store such provenance information.1.2.4Use Case 4:Versioning in a Semantic WikiStakeholder:Max V ¨o lkel (U Karl),mvo@aifb.uni-karlsruhe.deA wiki is a browser-based environment to author networked,structured notes,often in a collaborative way.The project SemWiki 11aims at creating a semantic wiki for personal note management.SemWiki extends the wiki syntax with means to enter statements about resources,much like in RDF.In a traditional wiki,users are accustomed to see and compare different versions of a page.In the semantic wiki ”SemWiki”12pages are just a special kind of resource and some attached properties.Hence,a semantic diffhas to be calculated ”by hand”.Data Set A typical personal wiki has up to 3000pages with approximately 10versions per page.Each page consists roughly of 50statements.This leads to approximately 1.5million triples for a snapshot-based versioning system.Versioning Requirements SemWiki users need ways to request a semantic diffbetween two page-versions.As pages partly consist of ”background statements”,which do not belong to a particular page,SemWiki needs a model-based versioning approach (R4.1).Sometimes users want to roll-back page changes,thus we need the ability to revert to old states (R4.2).Additionally,users want to track each statement:Who authored it,when has it been introduced,etc.(R4.3).1.2.5Use Case 5:Analysis of WikipediaStakeholder:Denny Vrandecic,Markus Kr ¨o tzsch,Max V ¨o lkel (U Karl){dvr,mkr,mvo}@aifb.uni-karlsruhe.deAn emerging research topic at AIFB is the analysis of changes in the Wikipedia 13.This use case is mostly similar to ”Versioning the Gene Ontology”.Data Set The Wikipedia contains roughly 1.500.000articles across all language versions.11 121310June 6th,2005KWEB/2004/D2.3.3.a/v1.0Versioning Requirements There are no obvious requirements beyond those al-ready mentioned in use case 3.1.2.6Requirements SummaryWe can distinguish rather data management related requirements and rather ontol-ogy language specific features.Data Management Requirements•Store and retrieve versions;store up to 7million triples•Retrieve versions via HTTP or Java function calls;address versions unambigu-ously via URIs and user-friendly via labels•Rich meta data per model /statement:provenance,author,valid time,transaction time•Model based versioning and additionally concept-oriented queries•Queries across versions concerning meta data•Each version can have a number of attached ”suggestions”;ability turn sug-gestions into official versionsOntology Language Requirements•Queries across versions concerning the content•return diffs between arbitrary versions•OBOL semantic diff•OBOL to RDF converter•RDFS semantic diff•OWL semantic diff•Semantic Wiki semantic diff•Conflict detection in OWLKWEB/2004/D2.3.3.a/v1.0June 6th,2005111.3Data Management DesignA versioning system has generally two main parts.One deals with general data management issues,the other part with versioning specific functionality such as cal-culating the difference between two versions.Wefirst present the data management parts and then the ontology specific versioning functions.The data management parts can be used no matter which ontology language is used–as long as the data model is encoded as RDF.RDF encoding of data is crucial in order to have a significant re-use of software across ontology languages.We now present some arguments for this claim.A more detailed discussion can be found in the Knowledge Web Deliverable D2.3.1[1].1.3.1RDF as the structural core of ontology languagesThe most elementary modelling primitive that is needed to model a shared con-ceptualisation of some domain is a way to denote entities and to unambiguously reference them.For this purpose RDF uses URIs,identifiers for resources,that are supposed to be globally unique.Every ontology language needs to provide means to denote entities.For global systems the identifier should be globally unique.Hav-ing entities,that can be referenced,the next step is to describe relations between them.As relations are semantic core elements,they should also be unambiguously addressable.Properties in RDF can be seen as binary relations.This is the very basic type of relations between two entities.More complex types of relations can be modelled by defining a special vocabulary for this purpose on top of RDF,like it has been done in OWL.The two core elements for semantic modelling,mechanisms to identify entities and to identify and state relationships between them,are provided by RDF.Ontol-ogy languages that build upon RDF use these mechanisms and define the semantics of certain relationships,entities,and combinations of relationships and entities.So RDF provides the structure in which the semantic primitives of the ontology lan-guages are embedded.That means we can distinguish three layers here:syntactic layer(e.g.XML),structural layer(RDF),semantic layer(ontology languages).The various ontology languages differ in their vocabulary,their logical founda-tions,and epistemological elements,but they have in common that they describe structures of entities and their relations.Therefore RDF is the largest common de-nominator of all ontology languages.RDF is not only a way to encode the ontology languages or just an arbitrary data model,but it is a structured data model that matches exactly the structure of ontology languages.12June6th,2005KWEB/2004/D2.3.3.a/v1.0。
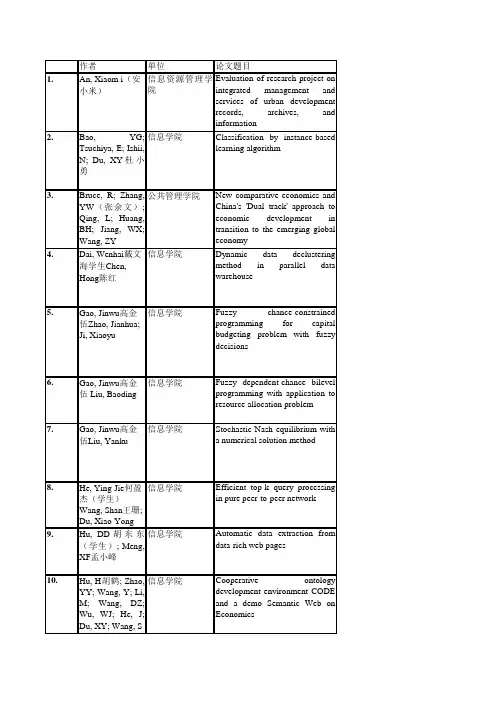
作者单位论文题目1.An, Xiaom i(安小米)信息资源管理学院Evaluation of research project onintegrated management andservices of urban developmentrecords, archives, and information2.Bao,YG;Tsuchiya,E;Ishii,N; Du, XY杜小勇信息学院Classification by instance-basedlearning algorithm3.Bruce,R;Zhang,YW(张余文);Qing,L;Huang,BH;Jiang,WX;Wang, ZY 公共管理学院New comparative economics andChina's'Dual track'approach toeconomic development intransition to the emerging globaleconomy4.Dai, Wenhai戴文海学生Chen,Hong陈红信息学院Dynamic data declustering methodin parallel data warehouse5.Gao, Jinwu高金伍Zhao, Jianhua;Ji, Xiaoyu 信息学院Fuzzy chance-constrainedprogramming for capitalbudgeting problem with fuzzydecisions6.Gao, Jinwu高金伍 Liu, Baoding 信息学院Fuzzy dependent-chance bilevelprogramming with application toresource allocation problem7.Gao, Jinwu高金伍Liu, Yanku 信息学院Stochastic Nash equilibrium witha numerical solution method8.He, Ying-Jie何盈杰(学生)Wang, Shan王珊;Du, Xiao-Yong 信息学院Efficient top-k query processing inpure peer-to-peer network9.Hu,DD胡东东(学生);Meng,XF孟小峰信息学院Automatic data extraction fromdata-rich web pages10.Hu,H胡鹤;Zhao,YY;Wang,Y;Li,M;Wang,DZ;Wu,WJ;He,J;Du, XY; Wang, S 信息学院Cooperative ontologydevelopment environment CODEand a demo Semantic Web onEconomics11.Hu, He胡鹤Du,Xiaoyong 信息学院Description logics based oninterval fuzzy theory12.Hu, He胡鹤Liu,Dayou; Zhan, Kai 信息学院Ontology middleware in the ESplatform13.Hu, He胡鹤Liu,Dayou; Hu,Zhiyong 信息学院Spatio-temporal ontologyconstruction based on logicmapping14.Hu, He胡鹤Liu,Dayou; Hu,Zhiyong 信息学院Web ontology server and its queryinterface15.Huang,YF(黄燕芬)公共管理学院Poverty and the minimum livingguarantee in China16.Huang, Zhiyong黄志勇Jiang,Yunping; Wang,Yuefei 信息学院On conformal measures forinfinitely renormalizablequadratic polynomials17.Li,C林灿学生;Qian,Z;Meng,XF孟小峰;Liu,WY 信息学院Postal address detection from webdocuments18.Li,M;李曼(学生) Du, XY杜小勇; Wang, S 信息学院A semi-automatic ontologyacquisition method for theSemantic Web19.Li,M李曼(学生);Wang,DZ;Du,XY杜小勇;Wang, S 信息学院Ontology construction forsemantic web:A role-basedcollaborative development method20.Li, Man李曼(学生)Wang, Da-Zhi; Du, Xiao-Yong杜小勇;Wang, Shan 信息学院Dynamic composition of webservices based on domainontology21.Li, Man李曼(学生)Du, Xiao-Yong杜小勇;Wang, Shan 信息学院Learning ontology from relationaldatabase22.Li,Man李曼(学生)Wang,Yan;Zhao,Yiyu;Du,Xiaoyong;Wang,Shan 信息学院Study on storage schema of largescale ontology based on relationaldatabase23.Li, Q李青公共管理学院Case study of institutionaleconomics-China's reform in thenatural monopoly of publicutilities24.Li, Sheng-En李盛恩(学生)Wang, Shan王珊信息学院Multidimensional data model ER([script H] )25. Liang, K Margarita as symbol of eternalfemininity: A religiousinterpretation of 'The Master andMargarita'26.Liu, Qing刘青Zhou, Peng 信息学院Data analysis of cosmicallymicroarray gene expression basedon neural networks with enhancedgeneralization27.Lu, Yanmin卢燕敏学生Chen,Hong陈红信息学院Markov model prediction basedcache management policy28.Luo, Dao-Feng罗道锋(学生)Meng, Xiao-Feng;孟小峰 Jiang, Yu 信息学院Updating of extended preordernumbering scheme on XML29.Ma,YW;Yan,F;Zhu, J; Kou, W Timing asteroid occultations by photometry30.Mao,JY毛基业;Vredenburg,K;Smith,PW;Carey, T 商学院The state of user-centered designpractice-UCD is gaining industryacceptance-but its currentpractice needs fine-tuning.31.Mao,W(毛薇);Zheng,FT(郑风田);Mao, J 农业与农村发展学院The researches on food safetysystem from the perspective ofpublic administration32.Song, YF宋雅范图书馆Continuing education in Chineseuniversity libraries:Issues andapproaches33.Tang, YJ A study on durability andpreservation of imaging discs34.Wang,CY汪昌云?财政金融学院Ownership and operatingperformance of Chinese IPOs35.Wang,HC;Yin,MQ Stock return and systematic risk: An empirical study on Shanghai stock market36.Wang, Jing王静(学生)Meng,Xiao-Feng; Wang,Yu; Wang, Shan 信息学院Target node aimed pathexpression processing for XMLdata37.Wang, Shan王珊Zhang, Kun-Long 信息学院Searching databases withkeywords38.Wei, Y(袁卫)统计学院The statistical profession in China39.Wen, Ji-Jun文继军(学生)Wang, Shan 信息学院SEEKER:Keyword-basedinformation retrieval overrelational databases40.Yang, Nan杨楠Gong, Danzhi; Li,Xian; Meng,Xiaofeng 信息学院Survey of Web communitiesidentification41.Ye,XM;Fan,SR;Liang, J Domestic e-shop comprehensive evaluation research42.Yong,L林勇;Kai, W 信息学院ARFIMA model and the nonlinearanalysis of the Chinese securitiesmarkets43.Yu, Li余力Liu,Lu; Li, Xuefeng 信息学院A hybrid collaborative filteringmethod for multiple-interests andmultiple-content recommendationin E-Commerce44.Yu, Li余力 Di,Yan; Wang, Jun;Cao, Shujuan 信息学院Exploration of budgeting for landconsolidation project45.Yu,SY(于澍燕);Li,SH;Huang,HP;Zhang,ZX;Jiao,Q;Shen,H;Hu,XX; Huang, H 化学系Molecular self-assembly withmodularization and directionality:Vector-manipulation at metalcenters46.Zha,DJ(查道炯)国际关系学院Comment: can China rise?47.Zhan, Jiang占江学生 Feng, Yueli;Wang, Shan王珊信息学院Research and implementation offull text index on Chinese inPostgreSQL48.Zhang,H(张晗);Xu,EM(徐二明);Xu,W 商学院The research of strategiccorporate governance based on thecorrelativity analysis49.Zhang,KL张坤龙(学生);Wang,S王珊信息学院LinkNet:A new approach forsearching in a large peer-to-peersystem50.Zhang,Y;Yang,B; Chen, PF Flowstep:A web-based distributed workflow management system51.Zhang, Zhanlu张占录Yang,Qingyuan 公共管理学院Driving force analysis of theconsolidation of countryresidential areas in Shunyi district52.Zhang, Zhengfeng张正峰 Chen,Baiming 公共管理学院Land consolidation sub-zoning:Acase study of Daxing district ofBeijing53.Xu, GQ许光清环境学院The system dynamics-an effectiveway to address sustainability54.Zhao,XJ(赵锡军);Chen,QQ;Wei, GY 财政金融学院Monetary and financialcooperation in Asia:Retrospectand future proposal55.Liyue Study on the financial function onindustrial technical progress:Theory and the practice of China56.Zhao,XJ(赵锡军); Chen, QQ 财政金融学院Research on Asian stock marketintegration57.Yang,QJ;Chen,C; Qi, ZQ Rough approximations in complete Boolean lattice58.Zhang,YS张越松; Li, GJ 公共管理学院Diagnosis and optimization ofDEA ineffectiveness of theconstruction projects59.Tao, CG Research on the growth of estateconstruction enterprises in China60.Xie,ZJ;Hong,C;Wang, L Subnets based distributed data-centric hierarchical ant routing for sensor networks61.Sun,CH;Shiu,SCK; Wang, XZ Organizing large case library by linear programming62.Yang,B;Fu,HJ;Zuo, MY 经济学院?杨斌The integration mechanism of IToutsourcing partnership63.Yu,MX(俞明轩);Yang,JY;Zhang, L 商学院Study on distribution ofconversion income of collectivebuilding land64.Yu,MX(俞明轩); Yang, QY 商学院A study on position evaluationsystem in real estate appraisalfirm发表刊物地址Reprint Address:Tsinghua Science and Technology,v10,n SUPPL., December, 2005, p 852-858School of Information Resources Management, Renmin University of ChinaINTELLIGENT DATA ENGINEERING AND AUTOMATED LEARNING IDEAL 2005, PROCEEDINGS, 3578: 133-140 2005Renmin Univ China,SchInformat,Beijing,PeoplesR Chinabaoyg@;eisuke@hm.aitai.ne.jp;ishii@in.aitech.ac.jp;duyong@PROCEEDINGS OF2005 INTERNATIONAL CONFERENCE ON PUBLIC ADMINISTRATION 50-68, 2005Renmin Univ China,Sch Publ Adm,Beijing, 100000 Peoples R ChinaHuazhong Keji Daxue Xuebao(Ziran Kexue Ban)/Journal of Huazhong University of Science and Technology(Natural Science Edition),v33,n SUPPL.,December,2005,p 239-242 Language: Chinese School of Information, Renmin University of ChinaLecture Notes in Artificial Intelligence (Subseries of Lecture Notes in Computer Science),v3613,n PART I,Fuzzy Systems and Knowledge Discovery:Second International Conference,FSKD2005. Proceedings, 2005, p 304-311School of Information, Renmin University of ChinaIEEE International Conference on Fuzzy Systems,Proceedings of the IEEE International Conference on Fuzzy Systems, FUZZ-IEEE 2005, 2005, p 541-545Uncertain Systems Laboratory,Department of Mathematics,Renmin University of ChinaLecture Notes in Computer Science,v3496, n I,Advances in Neural Networks-ISSN 2005:Second International Symposium on Neural Networks.Proceedings,2005,p811-816Uncertain Systems Laboratory,School of Information,Renmin University of ChinaRuan Jian Xue Bao/Journal of Software,v 16,n4,April,2005,p540-552Language: Chinese Info.Sch.,Renmin Univ. of ChinaDATABASE SYSTEMS FOR ADVANCED APPLICATIONS,PROCEEDINGS828-839, 2005Renmin Univ China,SchInformat,Beijing,PeoplesR ChinaHu,DD,Renmin UnivChina,Sch Informat,Beijing,Peoples RChina.WEB TECHNOLOGIES RESEARCH AND DEVELOPMENT-APWEB20051049-1052, 2005Renmin Univ China,SchInformat,Beijing,100872Peoples R ChinaHu,H,Renmin UnivChina,Sch Informat,Beijing,100872PeoplesR ChinaHuazhong Keji Daxue Xuebao(Ziran Kexue Ban)/Journal of Huazhong University of Science and Technology(Natural Science Edition),v33,n SUPPL.,December,2005,p 275-277 Language: Chinese Information School, Renmin Univ. of ChinaJisuanji Gongcheng/Computer Engineering,v 31,n5,Mar5,2005,p51-52+108 Language: Chinese Coll.of Info.,Renmin Univ. of ChinaJisuanji Gongcheng/Computer Engineering,v 31,n10,May20,2005,p139-141 Language: Chinese Information College, Renmin University of ChinaJisuanji Gongcheng/Computer Engineering,v 31, n 9, May 5, 2005, p 43-45Information College, Renmin University of ChinaPROCEEDINGS OF2005 INTERNATIONAL CONFERENCE ON PUBLIC ADMINISTRATION966-981, 2005Renmin Univ China,Sch Publ Adm,Beijing, Peoples R China.Science in China,Series A:Mathematics,v 48, n 10, October, 2005, p 1411-1420School of Information, Renmin University of ChinaINTERNATIONAL WORKSHOP ON CHALLENGES IN WEB INFORMATION RETRIEVAL AND INTEGRATION, PROCEEDINGS 40-45, 2005Renmin Univ,SchInformat,Beijing,100872Peoples R China.Li,C,Renmin Univ,SchInformat,Beijing,100872Peoples RChina.ADVANCES IN WEB-AGE INFORMATION MANAGEMENT, PROCEEDINGS 209-220, 2005Renmin Univ China,SchInformat,Beijing,100872Peoples R China.Li,M,Renmin UnivChina,Sch Informat,Beijing,100872PeoplesR ChinaWEB TECHNOLOGIES RESEARCH AND DEVELOPMENT-APWEB2005,3399: 609-619 2005Renmin Univ,SchInformat,Beijing100872,Peoples R China;ChineseAcad Sci,Chengdu InstComp Applicat,Chengdu610041, Peoples R ChinaLi,M,Renmin Univ,SchInformat,Beijing100872,Peoples RChina.Jisuanji Xuebao/Chinese Journal of Computers,v28,n4,April,2005,p643-650 Language: Chinese Sch.of Info.,Renmin Univ. of China2005International Conference on Machine Learning and Cybernetics,ICMLC2005, 2005International Conference on Machine Learning and Cybernetics,ICMLC2005, 2005, p 3410-3415School of Information, Renmin University of ChinaSchool of Information,Renmin University of China Language: Chinese Huazhong Keji Daxue Xuebao(Ziran Kexue Ban)/Journal of Huazhong University of Science and Technology(Natural Science Edition),v33,n SUPPL., December, 2005, p217-220Language: ChinesePROCEEDINGS OF2005 INTERNATIONAL CONFERENCE ON PUBLIC ADMINISTRATION 69-77, 2005Renmin Univ China,Sch Publ Adm,Beijing, 100872 Peoples R China.Jisuanji Xuebao/Chinese Journal of Computers,v28,n12,December,2005,p 2059-2067 Language: Chinese School of Information, Renmin University of ChinaFOREIGN LITERATURE STUDIES,(6): 118-+ DEC 2005Renmin Univ,CollLiberal Arts China,Beijing, Peoples R ChinaLiang,K,Renmin Univ,Coll Liberal Arts China,Beijing,Peoples RChina.Jisuanji Gongcheng/Computer Engineering,v 31,n3,Feb5,2005,p189-191Language: Chinese Sch.of Info.,Renmin Univ. of ChinaHuazhong Keji Daxue Xuebao(Ziran Kexue Ban)/Journal of Huazhong University of Science and Technology(Natural Science Edition),v33,n SUPPL.,December,2005,p 261-264 Language: Chinese School of Information, Renmin University of ChinaRuan Jian Xue Bao/Journal of Software,v 16,n5,May,2005,p810-818Language: Chinese Information School, Renmin UniversityICARUS, 178 (1): 284-288 NOV 1 2005Renmin Univ China,HighSch,Beijing100080,Peoples R China;BeijingPlannetarium,Beijing100044,Peoples R ChinaReprint Address:Yan,F,Renmin Univ China,HighSch,37ZhongguancunRd,Beijing100080,Peoples R China.frankyanfeng@COMMUNICATIONS OF THE ACM,48 (3): 105-109 MAR 2005Renmin Univ China,Beijing,Peoples R China;Univ Waterloo,Waterloo,ON N2L3G1,Canada;IBM Corp User CtrDesign&User Engn,Toronto,ON,Canada;IBM Ctr Adv Studies,Toronto, ON, CanadaMao,JY,Renmin UnivChina,Beijing,PeoplesR China.E-mailAddress:jymao@;PROCEEDINGS OF2005 INTERNATIONAL CONFERENCE ON PUBLIC ADMINISTRATION219-222, 2005Renmin Univ,Sch Agr Econ&Rural Dev, Beijing,100872Peoples R China.LIBRI, 55 (1): 21-30 MAR 2005Renmin Univ China,Lib,Beijing100872,PeoplesR China Song, YF, Renmin Univ China, Lib, 59 Zhongguancun St, Beijing 100872, Peoples R China. E-mail Address:songyafan1@2005BEIJING INTERNATIONAL CONFERENCE ON IMAGING: TECHNOLOGY AND APPLICATIONS FOR THE 21ST CENTURY 206-207, 2005Renmin Univ China,SchInformat ResourceManagement,Beijing,Peoples R China.Tang,YJ,Renmin UnivChina,Sch InformatResource Management,Beijing,Peoples RChina.JOURNAL OF BANKING&FINANCE,29 (7): 1835-1856 JUL 2005Renmin Univ China,SchFinance,Beijing100872,Peoples R China;NatlUniv Singapore,SchBusiness,Dept Finance&Accounting,Singapore119260, SingaporeWang,CY,RenminUniv China,SchFinance, Beijing 100872,Peoples R China.E-mailAddress:bizwcy@.sgPROCEEDINGS OF THE2005 INTERNATIONAL CONFERENCE ON MANAGEMENT SCIENCE& ENGINEERING(12TH),VOLS1-31727-1731, 2005Renmin Univ China,Sch Business,Beijing,100872 Peoples R ChinaRuan Jian Xue Bao/Journal of Software,v 16,n5,May,2005,p827-837Language: Chinese Information School, Renmin University of ChinaJournal of Computer Science and Technology,v20,n1,January,2005,p55-62School of Information, Renmin University of ChinaINTERNATIONAL STATISTICAL REVIEW 73 (2): 277-278 AUG 2005Renmin Univ China,Beijing, Peoples R ChinaWei,Y,Renmin UnivChina,Beijing,PeoplesR China.Ruan Jian Xue Bao/Journal of Software,v 16,n7,July,2005,p1270-1281Language: Chinese Information School, Renmin University of ChinaJisuanji Yanjiu yu Fazhan/Computer Research and Development,v42,n3,March, 2005, p 439-447 Language: Chinese Sch.of Information, Renmin Univ. of China2005INTERNATIONAL CONFERENCE ON SERVICES SYSTEMS AND SERVICES MANAGEMENT,VOLS1 AND2,PROCEEDINGS1446-1450,2004(请核对论文集是哪年发表?)RenMin Univ,Beijing,100872 Peoples R ChinaYe,XM,RenMin Univ,Beijing,100872PeoplesR ChinaWAVELET ANALYSIS AND ACTIVE MEDIA TECHNOLOGY VOLS1-31451-1456, 2005Renmin Univ China,Informat Sch,Beijing,100872 Peoples R China.Yong,L,Renmin UnivChina,Informat Sch,Beijing,100872PeoplesR ChinaExpert Systems with Applications,v28,n1, January, 2005, p 67-77School of Information, Renmin University of ChinaNongye Gongcheng Xuebao/Transactions of the Chinese Society of Agricultural Engineering,v21,n SUPPL.,February, 2005, p 119-122 Language: Chinese Department of Agricultural Economy, Renmin University of ChinaCURRENT ORGANIC CHEMISTRY,9 (6): 555-563 APR 2005Renmin Univ China,DeptChem,Beijing100872,Peoples R China;ChineseAcad Sci,State Key LabPolymer Phys&Chem,Inst Chem,Beijing100080,Peoples R China;Chinese Acad Sci,GradSch,Beijing100080,Peoples R China;ChineseAcad Sci,Fujian Inst ResStruct Matter,State KeyLab Struct Chem,Fuzhou350002,Peoples R China;Lanzhou Univ,State KeyLab Appl Organ Chem,Lanzhou100080,PeoplesR ChinaYu,SY,Renmin UnivChina,Dept Chem,Beijing100872,PeoplesR China.REVIEW OF INTERNATIONAL STUDIES, 31 (4): 775-785 OCT 2005Renmin Univ China,SchInt Studies,Beijing,Peoples R ChinaZha,DJ,Renmin UnivChina,Sch Int Studies,Beijing, Peoples R ChinaHuazhong Keji Daxue Xuebao(Ziran Kexue Ban)/Journal of Huazhong University of Science and Technology(Natural Science Edition),v33,n SUPPL.,December,2005,p 213-216 Language: Chinese School of Information, Renmin University of ChinaPROCEEDINGS OF THE2005 INTERNATIONAL CONFERENCE ON MANAGEMENT SCIENCE& ENGINEERING(12TH),VOLS1-3949-953, 2005Renmin Univ China,Sch Business,Beijing,100872 Peoples R China.WEB TECHNOLOGIES RESEARCH AND DEVELOPMENT-APWEB2005,3399: 241-246 2005Renmin Univ China,SchInformat,Beijing100872,Peoples R ChinaZhang,KL,RenminUniv China,SchInformat,Beijing100872,Peoples RChinaFOURTH WUHAN INTERNATIONAL CONFERENCE ON E-BUSINESS:THE INTERNET ERA&THE GLOBAL ENTERPRISE,VOLS1AND2599-609, 2005Renmin Univ China, Informat Sch,Beijing, Peoples R China.Nongye Gongcheng Xuebao/Transactions of the Chinese Society of Agricultural Engineering,v21,n11,November,2005,p 49-53 Language: Chinese College of Public Administration,Renmin University of ChinaNongye Gongcheng Xuebao/Transactions of the Chinese Society of Agricultural Engineering,v21,n SUPPL.,February, 2005, p 123-126 Language: Chinese Land Management Department,Renmin University of ChinaPROCEEDINGS OF THE2005 CONFERENCE OF SYSTEM DYNAMICS AND MANAGEMENT SCIENCE,VOL1-SUSTAINABLE DEVELOPMENT OF ASIA PACIFIC 166-173, 2005Renmin Univ China,Sch Environm&Nat Resources,Beijing, Peoples R China.PROCEEDINGS OF THE2005 INTERNATIONAL CONFERENCE ON MANAGEMENT SCIENCE AND ENGINEERING-PROCEEDINGS OF 2005INTERNATIONAL CONFERENCE ON MANAGEMENT SCIENCE AND ENGINEERING 899-904, 2005Renmin Univ China,Sch Finance,Beijing,100872 Peoples R ChinaPROCEEDINGS OF THE2005 INTERNATIONAL CONFERENCE ON MANAGEMENT SCIENCE AND ENGINEERING-PROCEEDINGS OF 2005INTERNATIONAL CONFERENCE ON MANAGEMENT SCIENCE AND ENGINEERING 905-910, 2005Renmin Univ China, Finance&Secur Inst, Beijing,100872Peoples R ChinaINTERNATIONAL CONFERENCE ON MANAGEMENT SCIENCE AND ENGINEERING-PROCEEDINGS OF 2005INTERNATIONAL CONFERENCE ON MANAGEMENT SCIENCE AND ENGINEERING 927-932, 2005Finance,Beijing,100872 Peoples R China.PROCEEDINGS OF THE2005IEEE INTERNATIONAL CONFERENCE ON NATURAL LANGUAGE PROCESSING AND KNOWLEDGE ENGINEERING (IEEE NLP-KE'05) 791-795, 2005Renmin Univ China,SchInformat,Beijing,100872Peoples R China.Yang,QJ,Renmin UnivChina,Sch Informat,Beijing,100872PeoplesR China.PROCEEDINGS OF2005 INTERNATIONAL CONFERENCE ON CONSTRUCTION&REAL ESTATE MANAGEMENT,VOLS1AND2-CHALLENGE OF INNOVATION IN CONSTRUCTION AND REAL ESTATE 243-245, 2005Renmin Univ China, Beijing,100872Peoples R China.PROCEEDINGS OF2005 INTERNATIONAL CONFERENCE ON CONSTRUCTION&REAL ESTATE MANAGEMENT,VOLS1AND2-CHALLENGE OF INNOVATION IN CONSTRUCTION AND REAL ESTATE 1024-1027, 2005Renmin Univ China,Sch Finance,Beijing,Peoples R China2005INTERNATIONAL CONFERENCE ON WIRELESS COMMUNICATIONS, NETWORKING AND MOBILE COMPUTING P ROCEEDINGS,VOLS1 AND 2 895-900, 2005RenMin Univ,SchInformat,Beijing,100872Peoples R China.Xie,ZJ,RenMin Univ,Sch Informat,Beijing,100872 Peoples R ChinaMICAI2005:ADVANCES IN ARTIFICIAL INTELLIGENCE 554-564, 2005Renmin Univ China,Informat Sch,Beijing,100872 Peoples R China.Sun,CH,Renmin UnivChina,Informat Sch,Beijing,100872PeoplesR China.SEVENTH INTERNATIONAL CONFERENCE ON ELECTRONIC COMMERCE,VOLS1AND2, SELECTED PROCEEDINGS801-803, 2004(会议时间是05?)Renmin Univ China,Informat Sch,Beijing,100872 Peoples R China.Renmin Univ China,Informat Sch,Beijing,100872Peoples RChina.PROCEEDINGS OF CRIOCM2005 INTERNATIONAL RESEARCH SYMPOSIUM ON ADVANCEMENT OF CONSTRUCTION MANAGEMENT AND REAL ESTATE 325-329, 2005Renmin Univ China,Sch Business,Beijing,100872 Peoples R China.INTERNATIONAL RESEARCH SYMPOSIUM ON ADVANCEMENT OF CONSTRUCTION MANAGEMENT AND REAL ESTATE 448-454, 2005Business,Beijing,100872 Peoples R China.EISCI、ISTP ISSHPEIEI 、ISTP、SCI EI、ISTPEI、ISTP、SCI EIISTP、SCI ISTP、EI、SCIEIEIEIISSHPEIISTPISTP、SCI ISTP、SCI、EIEIEI、ISTPISSHP EIA&HCI EIEIEI SCIEI 、SCIISSHPSSCIISTPSSCIISTP 、ISSHP EIEI 、SCI ISTP 、SCIEIISTP、 ISSHP ISTPEIEISCISSCIISTP、ISSHP SCI、ISTP、EIISTP、ISSHPEIEIISTP、ISSHP ISTP、ISSHP ISTP、ISSHPISTP、ISSHP ISTPISTP、ISSHP ISTP、ISSHP ISTPISTP、SCI ISSHP ISSHP。

WPDL中的JOIN语义问题和分区解决方案*郝克刚①,③王斌君①,② 安贵③①西北大学软件工程研究所,西安 710069;②中国人民公安大学科技系,北京 102614③西安协同数码股份有限公司西安 710075摘要:本文分析并研究了工作流过程定义语言WPDL中的JOIN语义,指出了其中AND-JOIN定义存在的问题。
为了解决这个问题,我们在信牌驱动计算模型中,形式地定义了AND-JOIN的同步语义,提出了同步区与非同步区的概念,以及在同步区使用真假信牌规则,在非同步区使用真信牌规则的分区解决方案,并对由此而引出的许多问题进行了全面、系统地研究,给出了各种控制结构在同步区和非同步区中使用的限制,提出了相应的解决办法。
最后给出了计算聚焦点和同步区的算法。
关键字:工作流过程定义语言、WPDL、信牌驱动模型、同步区、聚焦点、真假信牌、Petri网The JOIN Semantic Issue in WPDL and theSynchronized Area SolutionHao Kegang①,③ Wang Binjun①,② An Gui③① Software Engineering Institute, Northwest University, Xi’an 710069② Department of Science and Technology, the Public Security University, Beijing 102614③ Xi’an Synchrobit Co., Ltd., Xi’an 710075Abstract: The semantic of JOIN in workflow process definition language WPDL is analyzed and studied. It is point out that there is a problem about AND-JOIN. To solve the problem, the synchronized semantic of AND-JOIN in extended Xinpai-driven model is defined formally. It is put forward the concepts of synchronized area and asynchronized area. it gives the solution of true-and-false token rules in synchronized area and true token rules in asychronized area, and some other issues arisen from the solution are studied systematically and completely. The constrain issues of control structures in synchronized area and asynchronized area is discussed, and its solution is put forward. Finally, the algorithm of how to find the focus point and synchronized area are given.Keyword: workflow process definition language, WPDL, Xinpai-driven model, synchronized area, true-and-false token, focus point, petri net*本文受国家“十五”重点科技攻关项目资助(项目编号:2001BA107C)。



L E S Z E K (L E H – s h e k) T. L I L I E NDepartment of Computer ScienceWestern Michigan UniversityKalamazoo, Michigan 49008-5466llilien@/~llilienSUMMARYU.S.Citizen.Ph.D.in Computer Science,University of Pittsburgh. Research at Western Michigan University(WMU),Purdue University,and University of Illinois at Chicago(UIC). Teaching at WMU and UIC. Tutorial instructor for IEEE Computer Society.Diversified R&D experience at AT&T/Lucent Bell Labs.Consultant for academic and business projects.Entrepreneurial experience in the United States and Poland.Research focus on privacy,trusted computing,and security in large,open,and dynamic computing systems,including health information systems.Co-PI for an NSF Cyber Trust grant.Experience in research on decentralized control,distributed computing systems,database systems,reliability,fault tolerance, recovery, and semantic integrity.Senior Member of the Institute of Electrical and Electronics Engineers(IEEE)and IEEE Computer Society.Affiliated with the Center for Education and Research in Information Assurance and Security(CERIAS)and the Regenstrief Center for Healthcare Engineering(RCHE),both at Purdue University.EDUCATION1978 - 1983, Ph.D., Computer ScienceDepartment of Computer Science, University of Pittsburgh, Pittsburgh, PennsylvaniaPh.D. Dissertation: "Integrity in Database Systems," March 19831978 - 1979, M.S., Computer ScienceDepartment of Computer Science, University of Pittsburgh, Pittsburgh, Pennsylvania1976 - 1978, Doctoral StudentłłUniversity of Technology(Politechnika Wroc awska), Institute of Engineering Cybernetics,Wroc awłWroc aw, Poland1971 - 1976, M.S. (żmagister in ynier) Summa Cum Laude, ElectronicsłłWroc aw, Faculty of Electronics,Wroc awłUniversity of Technology(Politechnika Wroc awska), PolandM.S.Thesis:"A Test in the Application of Class Theory to the Description of the Engineering Design System," June 1976EMPLOYMENT2005 – present, Assistant ProfessorDepartment of Computer ScienceWestern Michigan University, Kalamazoo, MichiganResearch on privacy,trusted computing,and security in large,open,and dynamic computing systems.•Current projects include:vulnerability analysis and threat assessment/avoidance for database systems;privacy-preserving data dissemination;authentication and privacy in health care;investigating the tradeoffs between privacy and trust;the role of trust in open computing environments;modeling computer fraud;opportunistic sensor networks;security and privacy in pervasive systems, including sensor networks, ad hoc networks, and embedded networks.Graduate and undergraduate teaching and project supervision.•Teaching CS5950/6030—Network Security in Fall2005,and CS5950/6030—Computer Security and Information Assurance in Spring 2006 (both crosslisted as undergraduate/graduate courses).•Supervising graduate and undergraduate projects in the areas of computer security and privacy, and sensor networks.2002 – 2005, Post Doctoral Research AssociateDepartment of Computer SciencesPurdue University, West Lafayette, IndianaResearch on trusted computing,security,and privacy in large,open,and dynamic computing systems.•Focus on vulnerability analysis and threat assessment/avoidance for database systems;privacy-preserving data dissemination;authentication and privacy in health care;analysis of computer security paradigms;modeling computer fraud;investigating the tradeoffs between privacy and trust; and security issues in sensor networks.Consulting:“Evaluations and Recommendations for the Third Authentication‘Token’for the IHIE Provider Network,” Indiana Health Information Exchange (IHIE), Indianapolis, Indiana, 2005.1998, Telecommunications ConsultantLucent Technologies, The Hague, NetherlandsTested different implementations of the SS7signaling protocol for reliability and compatibility in an intelligent telephony network.Testing resulted in uncovering software bugs, subsequently fixed by the manufacturer.Awarded Certificate of Appreciation.1995 - 2002, Founder/PrincipalLTLA, Wheaton, Illinois, and Signus, Kraków (Cracow), PolandWorked on design of a system for the proton therapy of eye cancers.Design objectives included high levels of safety and security. In cooperation with the Nuclear Physics Institute, Kraków, Poland.Involved in design, prototyping, building, and marketing of unique electronic devices for monitoring, measuring, and control.Worked on design,prototyping,and marketing of an off-the-shelf research instrument for non-invasively estimating body composition of small animals.Distinctive features included reliability-oriented and modular design,both autonomous and PC-based control software,and use of a patented method for the electromagnetic measurement chamber.Worked on establishing a software development business,and setting up a nationwide dealership for company developing software for the construction industry.1988 - 1995, Member of Technical StaffAT&T Bell Labs/Lucent Technologies Bell Labs, Naperville, IllinoisLed the design team for the SPARTAN project:a system for data design and for tracking data development for the 5ESS® Switch (telephony).Use of SPARTAN resulted in significant improvements in accuracy and speed of data design.•Co-designed the high-level system structure.Design objectives included high system reliability and availability.The basic functions included:computer-aided data design,an automated tracking of data development, and an on-line information source.•Investigated,evaluated,and integrated many software tool packages for use in SPARTAN(in its UNIX operating system environment).The tools included object-oriented and relational database management systems,project management tools,hypertext systems,spreadsheets,toolkits for integration of independently developed tools, and application generators.•Implemented a number of proprietary system components,including database schemas and “canned”queries;a menu-based user interface;programs using specialized statistical and string-processing languages, and the Korn Shell command language.Designed, developed, and tested software for miscellaneous AT&T/Lucent products.•Worked on applications for a customized workflow management system for the5ESS project management(written in C and the fourth-generation languages SQL and ESQL on top of the Ingres database management system,in the UNIX environment).Performed Database Administrator functions.•Developed software for and tested A-I-Net, an advanced intelligent (telephone) network.•Designed and optimized physical data structures for the pseudo-relational,embedded,memory-resident database for the 5ESS Switch (in the UNIX environment).Taught (as a "co-trainer") the "Kelley-Caplan Productivity Enhancement Group" seminar (2 groups).Received excellent teaching evaluations from the participants and an award from organizers of the seminar.1983 - 1988, Assistant ProfessorDepartment of Electrical Engineering and Computer ScienceUniversity of Illinois at Chicago, Chicago, IllinoisResearch focused on database systems and distributed computing systems.Results published in book chapters, journal papers, refereed conference papers, and invited papers.•Research areas included:semantic integrity in databases;database reliability,fault tolerance,and recovery;concurrency control in database systems;federated and heterogeneous database systems;logical and physical database design;decentralized control in distributed computing systems; and recovery in distributed computing systems.Graduate teaching and M.S. thesis/project supervision.Record-breaking course enrollments and excellent teaching evaluations.•Taught courses:a) “Database Management Systems” (developed as a new offering of the Department);b) “Distributed Computing Systems” (developed as a new offerings of the Department);•Updated contents of the course: “Advanced Database Systems.”•Supervised M.S.and other graduate projects in the areas of database management systems and distributed computing systems, including 4 M.S. Theses and 16 M.S. Projects.Undergraduate teaching and project supervision.A wide range of courses and projects.•Taught courses:a) “Database Systems;”b) “File and Communication Systems;”c) “Computer Graphics I;”d) “Data Structures;”e) “Digital System Design;”f) “Microprocessors.”•Updated contents of the course: “Introduction to Programming Languages.”•Supervised numerous undergraduate projects in diverse areas of computer science and engineering.1986 - 1988, Consultant (part-time, concurrent with the university employment)RAID Project, Department of Computer Sciences, Purdue University, West Lafayette, Indiana Sperry Corporation, Roseville, MinnesotaSKS Technologies, Des Plaines, IllinoisKineticSystems Corporation and the Fermi National Accelerator Laboratory, Batavia, IllinoisConsulted on semantic integrity in database systems,object-oriented database systems,recovery in distributed computing systems, transaction processing, and database management.1984 - 1986, Tutorial Instructor (part-time, concurrent with the university employment)IEEE Computer Society, Washington, D.C.Prepared and presented tutorials on reliability and performance of distributed database systems in Silver Spring,Maryland,October1984;Arlington,Virginia,November1985;and Orlando,Florida, April 1986.PUBLICATIONSBook Chapters1. B.Bhargava and L.Lilien,"Expert Systems for Fault Tolerant Distributed Database Systems,"pp.41-182in:Essays in Computer Vision and Other Topics,ed.J.Tou(dedicated to Prof.K.S.Fu),Academia Sinica, Republic of China, 1990.2. B.Bhargava and L.Lilien,"A Review of Concurrency and Reliability Issues in Distributed DatabaseSystems,"pp.1-84in:Concurrency Control and Reliability in Distributed Systems,ed.B.Bhargava,Van Nostrand Reinhold, New York, New York, 1987.Journal Papers1.L.Lilien and B.Bhargava,”A Scheme for Privacy-preserving Data Dissemination,”IEEE Transactionson Systems, Man and Cybernetics (to appear).2. B.Bhargava,L.Lilien,A.Rosenthal,and M.Winslett,"Pervasive Trust,"IEEE Intelligent Systems,vol.19(5), September/October 2004, pp. 74-77 (magazine).3.L.Lilien,S.M.Shatz,and S.Damerla,"Redistribution of Hierarchically Structured Software inResponse to Distributed System Site Crashes,"International Journal of Computer Systems Science and Engineering, Vol. 10 (3), July 1995, pp. 144-155.4.W.Kozaczynski,L.Lilien,and C.Yu,"An Adaptive Mixed Relation Decomposition Algorithm forConjunctive Retrieval Queries," Information Sciences, Vol. 53 (1-2), January 1991, pp. 35-60.5.L.Lilien and T.M.Chung,"Pessimistic Quasipartitioning Protocols for Distributed DatabaseSystems," IEEE Journal on Selected Areas in Communications, Vol. 7 (3), April 1989, pp. 341-353.6. B.Bhargava and L.Lilien,"Enforcement of Data Consistency in Database Systems,"Sadhana–Academy Proceedings in Engineering,Vol.11,Parts1and2,Proceedings of the Indian Academy of Sciences(special issue on Reliability and Fault-tolerance Issues in Real-time Systems),October1987, pp. 1149-1180.7.L.Lilien and B.Bhargava,"Database Integrity Block Construct:Concepts and Design Issues,"IEEETransactions on Software Engineering, Vol. SE-11 (9), September 1985, pp. 865-885.8.L.Lilien and B.Bhargava,"A Scheme for Batch Verification of Integrity Assertions in a DatabaseSystem," IEEE Transactions on Software Engineering, Vol. SE-10 (6), November 1984, pp. 664-680.9. B.Bhargava and L.Lilien,"On Optimal Scheduling of Integrity Assertions in a TransactionProcessing System,"International Journal of Computer and Information Sciences,Vol.10(5),October 1981, pp. 315-330.10.L.Lilien,"A Test in the Application of the Class Theory for the Description of the Technical DesignSystem,"Postepy Cybernetyki,Vol.1(1),Press of the Polish Academy of Sciences,Warsaw,Poland, 1978, pp. 41-51 (in Polish).Papers in Refereed Conferences1.V.Bhuse,A.Gupta,and L.Lilien,“DPDSN:Detection of packet-dropping attacks for wireless sensornetworks,”Proc.4th International Trusted Internet Workshop(TIW),Goa,India,December2005(to appear).2. B.Bhargava and L.Lilien,"Vulnerabilities and Threats in Distributed Systems,"in:DistributedComputing and Internet Technology:First International Conference,ICDCIT2004,Bhubaneswar,India, December2004(Springer-Verlag Lecture Notes in Computer Science Vol. 3347),pp.146-157(invited paper).3. B.Bhargava and L.Lilien,"Private and Trusted Collaborations,"Proc.Secure Knowledge Management(SKM 2004): A Workshop, Amherst, NY, September 2004 (invited paper).4.M.Jenamani,L.Lilien,and B.Bhargava,"Anonymizing Web Services Through a Club Mechanismwith Economic Incentives,"Proc.International Conference on Web Services(ICWS 2004),San Diego, California, July 2004, pp. 792-795.5.L.Lilien,"Developing Pervasive Trust Paradigm for Authentication and Authorization,"Proc.ThirdCracow Grid Workshop (CGW’03), Kraków (Cracow), Poland, October 2003, pp. 42-49, (invited paper).6.L.Lilien and A.Bhargava,"From Vulnerabilities to Trust:A Road to Trusted Computing,"Proc.International Conference on Advances in Internet,Processing,Systems,and Interdisciplinary Research(IPSI-2003), Sv. Stefan, Serbia and Montenegro, October 2003.7.I.Chung,B.Bhargava,M.Mahoui,and L.Lilien,"Autonomous Transaction Processing Using DataDependency in Mobile Environments,"Proc.The Ninth IEEE Workshop on Future Trends of Distributed Computing Systems (FTDCS '2003), San Juan, Puerto Rico, May 2003, p. 138-144.8.L.Lilien,"Quasi-partitioning:A New Paradigm for Transaction Execution in Distributed DatabaseSystems,"Proc.IEEE Fifth International Conference on Data Engineering,Los Angeles,California, February 1989, pp. 546-553.9.L.Lilien and T.M.Chung,"Pessimistic Protocols for Quasi-partitioned Distributed DatabaseSystems,"Proc.IEEE Seventh Symposium on Reliable Distributed Systems,Columbus,Ohio,October 1988, pp. 35-43.10.C.Orji,J.Hyziak,and L.Lilien,"A Performance Analysis of an Optimistic and a Basic Timestamp-ordering Concurrency Control Algorithms for Centralized Database Systems,"Proc.IEEE Fourth International Conference on Data Engineering, Los Angeles, California, February 1988, pp. 64-71.11.W.Kozaczynski and L.Lilien,"An Extended Entity-Relationship(E2R)Database Specification and itsAutomatic Verification and Transformation into the Relational Logical Design,"Proc.Sixth International Conference on Entity-Relationship Approach,New York,New York,November1987,pp.497-513.12.L.Lilien,W.Zhang,S.Huo,and K.Tan,"An Abstract Model of Concurrency Control Algorithms inDistributed Database Systems,"Proc.IFIP Working Conference on Distributed Processing,Amsterdam, Netherlands, October 1987, pp. 563-575.13.J.Xu and L.Lilien,"A Survey of Methods for System-Level Fault Diagnosis,"Proc.ACM-IEEEComputer Society 1987 Fall Joint Computer Conference, Dallas, Texas, October 1987, pp. 534-540.14.Z.U.Bhatti,L.Lilien,M.Panjwani,and D.Srdjevic,"Degrees of Concurrency in DistributedComputing Systems,"Proc.IEEE Seventh International Conference on Computer Science,Santiago,Chile, August 1987, pp. 47-56.15.R.W.Lee and L.Lilien,"Optimistic Algorithms in Distributed Systems,"Proc.Second InternationalConference on Computers and Applications,Beijing(Peking),People's Republic of China,June1987,pp.699-705.16.L.Lilien and S.M.Shatz,"Software Redistribution in Distributed Mission-Oriented Systems after SiteCrashes and Network Partitionings,"Proc.Second International Conference on Supercomputing,Vol.III, Santa Clara, California, May 1987, pp. 106-114.17.S.V.Pillai,R.Gudipati,and L.Lilien,"Design Issues and an Architecture for a HeterogeneousMultidatabase System,"Proc.ACM Computer Science Conference,St.Louis,Missouri,February1987, pp. 74-79.18.W. Kozaczynski, L. Lilien, and C. Yu, "A Method for Adaptive Mixed Relation Decomposition," Proc.International Computer Symposium'86,Tainan,Taiwan,Republic of China,December1986,pp.1615-1623.19.L.Lilien,"Outline of an Architecture for a Highly Fault-Tolerant Database System,"Proc.AAAAutomation'86-High Technology Computer Conference,Houston,Texas,March1986,pp.139-142, (invited paper).20.C.Yu,L.Lilien,K.Guh,M.Templeton,D.Brill,and A.Chen,"Adaptive Techniques for DistributedQuery Optimization,"Proc.IEEE Second International Conference on Data Engineering,Los Angeles, California, February 1986, pp. 86-93.21.B.Bhargava and L.Lilien,"Cost Analysis of Selected Database Restoration Techniques,"in Entity-Relationship Approach to Software Engineering(Proc.Third International Conference on Entity-Relationship Approach,Anaheim,California,October1983),ed.C.G.Davis et al.,North-Holland,New York,New York 1983, pp. 783-805.22.B.Bhargava and L.Lilien,"Time Complexity of Database Verification and Recovery,"Proc.International Computer Symposium'82,Taichung,Taiwan,Republic of China,December1982,Vol.I, pp. 229-238.23.L.Lilien and B.Bhargava,"A Scheme for Verification of Integrity Assertions in a TransactionProcessing System,"Proc.IEEE Computer Society's Sixth International Computer Software and Applications Conference COMPSAC 82, Chicago, Illinois, November 1982, pp. 139-148.24.B.Bhargava and L.Lilien,"Feature Analysis of Selected Database Recovery Techniques,"Proc.AFIPSNational Computer Conference, Chicago, Illinois, May 1981, pp. 543-554.25.L.Lilien,"On the Criteria of the Design Process Optimization,"Proc.National Conference"Design III.łPoland,łUniversity of Technology,Wroc aw, Research-Education-Practice,"Press of the Wroc awSeptember 1978, pp. 91-100.26.L.Lilien,"A Test in the Application of the Class Theory for the Description of the Technical DesignłProcess,"Proc.Conference“Design Methodology and Computer-Aided Design,”Press of the Wroc awłUniversity of Technology, Wroc aw, Poland, September 1976, pp. 157-163 (in Polish).Other Publications1.M.Jenamani,L.Lilien,and B.Bhargava,“A Club Mechanism with Economic Incentives forAnonymizing Web Services,”Technical Report CSD-TR04-008,Department of Computer Sciences, Purdue University, West Lafayette, Indiana, February 2004.2.L.Lilien,T.Morris,A.Savoy,and B.Bhargava,"An Analysis of Security Breaches in MS Access andOracle Database Systems,"Working Paper,Department of Computer Sciences,Purdue University, West Lafayette, Indiana, February 2004.3. B.Bhargava,C.Farkas,L.Lilien,and F.Makedon,"Trust,Privacy,and Security.Summary of aWorkshop Breakout Session at the National Science Foundation Information and Data Management (IDM)Workshop held in Seattle,Washington,September14-16,2003,"CERIAS Tech Report2003-34,Center for Education and Research in Information Assurance and Security,Purdue University, West Lafayette, Indiana, December 2003.4.M.Khan, B.Bhargava,and L.Lilien,"Self-configuring Clusters,Data Aggregation,andAuthentication in Microsensor Networks,"Technical Report CSD-TR03-005,Department of Computer Sciences, Purdue University, West Lafayette, Indiana, August 2003 (revised).5. B.Bhargava,I.Chung,and L.Lilien,"A Protocol for Transaction Processing in Mobile Multilevel-Security Database Systems"(a reviewed extended abstract),Proc.Sixth International Conference on Soft Computing and Distributed Processing, Rzeszow, Poland, June 2002.6.L.Lilien and K.Venkatraman,"A Paradigm of Modern Mixed Economy for Decentralized Control inMassive Distributed Computing Systems,"Working Paper,Department of Electrical Engineering and Computer Science,University of Illinois at Chicago,Chicago,Illinois,December1988.(Related M.S.Project:K.Venkatraman,"Free Enterprise Paradigm for Decentralized Control of Distributed Computing Systems,"Department of Electrical Engineering and Computer Science,University of Illinois at Chicago, Chicago, Illinois, November 1988.)7.L.Lilien,"Partitioning and Quasi-partitioning in Distributed Database Systems,"IEEE DistributedProcessing Technical Committee Newsletter, Vol. 10 (2), November 1988, pp. 63-72.8.T.Hyziak and L.Lilien,“An Architecture for an Adaptive File Management System,”TechnicalReport UIC-EECS-88-12,Department of Electrical Engineering and Computer Science,University of Illinois at Chicago, Chicago, Illinois, August 1988.9.W.-M.Au,S.Elliot,L.Fu,B.C.Lee,B.Nicholson,and L.Lilien“An Overview of Naming Schemes inDistributed Computer Systems,”Technical Report UIC-EECS-88-11,Department of Electrical Engineering and Computer Science, University of Illinois at Chicago, Chicago, Illinois, August 1988.10.S.Gargeya and L.Lilien,“Improving Availability and Performance of Distributed ComputingSystems via Resource Replication - An Overview,” Technical Report UIC-EECS-88-10,Department of Electrical Engineering and Computer Science,University of Illinois at Chicago,Chicago,Illinois,July 1988.11.M.A.Blackwell and L.Lilien,“An Abstract Model and a Comparison of Concurrency ControlAlgorithms in Distributed Database Systems,”Technical Report UIC-EECS-88-9,Department ofElectrical Engineering and Computer Science,University of Illinois at Chicago,Chicago,Illinois,July 1988.12.L.Lilien and W.Kozaczynski,“An Information Architecture for Federated Databases,”TechnicalReport UIC-EECS-88-7,Department of Electrical Engineering and Computer Science,University of Illinois at Chicago, Chicago, Illinois, May 1988.13.C.T.Yu,L.Lilien,K.C.Guh,and E.Wu,“A Graphic Interface for Learning in Distributed QueryProcessing,”Technical Report UIC-EECS-88-6,Department of Electrical Engineering and Computer Science, University of Illinois at Chicago, Chicago, Illinois, May 1988.14.K.-Y.Fang,J.T.Ibrahim,L.Lilien,and J.P.Tsai,"FASTBUS Overview and Implementation of BasicFASTBUS Software,"Report for KineticSystems Corp.and the Fermi National Accelerator Laboratory, Chicago, Illinois, May 1988.15.L.Lilien and T.M.Chung,"Pessimistic Protocols for Quasi-partitioned Distributed DatabaseSystems,"Technical Report UIC-EECS-88-5,Department of Electrical Engineering and Computer Science, University of Illinois at Chicago, Chicago, Illinois, April 1988.16.W.Kozaczynski,L.Lilien,and C.T.Yu,"An Adaptive Mixed Relation Decomposition Algorithm forConjunctive Retrieval Queries,"Technical Report UIC-EECS-88-4,Department of Electrical Engineering and Computer Science, University of Illinois at Chicago, Chicago, Illinois, April 1988. 17.K.-Y.Fang,L.Lilien,and J.P.Tsai,"FASTBUS and its Potential Applications-A Preliminary Report,"Report for KineticSystems Corp.and the Fermi National Accelerator Laboratory,Chicago,Illinois, January 1988.18.L.Lilien,"Feasibility Analysis for the SKS Product,"Report for SKS Technologies,Chicago,Illinois,May 1987.19.L.Lilien,"On-line Transaction Processing Applications for the SKS Product,"Report for SKSTechnologies, Chicago, Illinois, April 1987.20.L.Lilien,C.Hua,and B.Bhargava,"Maintaining Integrity of En-Route Air Traffic Control Systems'Database," Report for Federal Aviation Administration, Pittsburgh, Pennsylvania, August 1983. 21.L.Lilien,"Integrity in Database Systems,"Department of Computer Science,University ofPittsburgh,Pittsburgh,Pennsylvania,April1983(Ph.D.dissertation).Available from University Microfilms International, Ann Arbor, Michigan 48106.22.B.Bhargava and L.Lilien,"Reliability in Distributed Database Systems,"Technical Report82-1,Department of Computer Science,University of Pittsburgh,Pittsburgh,Pennsylvania,September 1982.23.C.Hua,L.Lilien,and B.Bhargava,"Analysis of Selected Failures in En Route Air Traffic ControlSystem,"Research Report for the Federal Aviation Administration,Pittsburgh,Pennsylvania, December 1981.24.L.Lilien,"Cost Analysis of Selected Database Recovery Techniques",Proc.ACM Computer ScienceConference, St. Louis, Missouri, February 1981, p. 30 (abstract only).25.B.Bhargava,H.Chuang,C.Hua,L.Lilien,and T.Altman,"Software and Processing Structures withPerformance Requirements of En Route Air Traffic Control System,"Research Report for the Federal Aviation Administration, Pittsburgh, Pennsylvania, December 1980.B.Bhargava,H.Chuang,C.Hua,L.Lilien,et al.,"Software Reliability in En Route Air Traffic ControlSystem,"Research Report for the Federal Aviation Administration,Pittsburgh,Pennsylvania,August 1980.RESEARCH GRANTS AND RELATED ACTIVITIESGrantsB.Bhargava(PI)and L.Lilien(co-PI),Vulnerability Analysis and Threat Assessment/Avoidance.Submitted to the National Science Foundation (NSF) in August 2002. Awarded $212,000, 2003-2006.Participation in NSF Principal Investigator WorkshopsNational Science Foundation Information and Data Management(IDM)Workshop,Boston,Massachusetts, October 10-12, 2004.•L.Lilien,"Trust,Privacy,and Security,”Summary of a Workshop Breakout Session presented at the Plenary Session, October 12, 2004.National Science Foundation Cyber Trust Principal Investigators Meeting,Carnegie Mellon University, Pittsburgh, Pennsylvania, August 18-20, 2004.National Science Foundation Information and Data Management(IDM)Workshop,Seattle, Washington, September 14 - 16, 2003.• C.Farkas and L.Lilien,"Trust,Privacy,and Security,”Summary of a Workshop Breakout Session presented at the Plenary Session, September 16, 2004.National Science Foundation Inaugural Cyber Trust Principal Investigators Meeting and Research Directions Workshop, Johns Hopkins University, Baltimore, Maryland, August 13 - 15, 2003.HONORS AND AWARDSSenior Member of the Institute of Electrical and Electronics Engineers (IEEE), February 2005.Certificate of Appreciation(for SS7testing at PTT),Veritel Group and Lucent Technologies,The Hague, The Netherlands, February 23, 1998.Teaching award for the"Kelley-Caplan Productivity Enhancement Group"seminar(2groups), AT&T Bell Labs, Naperville, Illinois, 1993.The paper"Pessimistic Quasipartitioning Protocols for Distributed Database Systems"(co-authored by T.M.Chung),presented at IEEE Seventh Symposium on Reliable Distributed Systems,Columbus, Ohio,October1988,selected as one of the best for publication in IEEE Journal on Selected Areas in Communications.The paper"A Scheme for Verification of Integrity Assertions in a Transaction Processing System"(co-authored by B.Bhargava)selected as one of the best at the IEEE Computer Society's Sixth International Computer Software and Applications Conference COMPSAC 82, Chicago, November 1982.łUniversity of Magisterżin ynier(M.S.)Summa Cum Laude,Department of Electronics,Wroc awłTechnology, Wroc aw, Poland, June 1976.łUniversity Awarded a special individual study plan.Institute of Engineering Cybernetics,Wroc awłof Technology, Wroc aw, Poland, 1974 - 1976.。

利用点云构建bim模型的流程## Point Cloud to BIM Modeling Workflow.### Workflow Overview.The following steps provide a comprehensive workflow for utilizing point cloud data to construct a Building Information Model (BIM):1. Data Acquisition: Capture the existing structure using a laser scanner or other data acquisition method.2. Data Registration: Align and stitch multiple scans to create a complete and accurate representation of the building.3. Point Cloud Processing: Remove noise, outliers, and unneeded data from the point cloud.4. Feature Extraction: Identify and extract relevantbuilding features such as walls, floors, and ceilings from the processed point cloud.5. Geometric Modeling: Create 3D models of the extracted features using parametric or NURBS modeling techniques.6. Semantic Labeling: Assign appropriate materials, properties, and other semantic information to the geometric models.7. BIM Integration: Import the labeled models into a BIM platform to create a comprehensive and information-rich BIM representation of the structure.### Detailed Workflow.1. Data Acquisition.Utilize a laser scanner or other technology to capture a dense and accurate point cloud representation of the existing structure.Ensure proper calibration and setup of the data acquisition equipment to minimize errors.2. Data Registration.Align and register multiple scans using software tools to create a seamless and complete point cloud dataset.Utilize techniques such as ICP (Iterative Closest Point) or other registration algorithms.3. Point Cloud Processing.Remove noise and outliers from the point cloud using filtering algorithms.Segment the point cloud into different categories or clusters based on geometric properties.4. Feature Extraction.Identify and extract building features by applying geometric analysis techniques to the processed point cloud.Utilize edge detection, region growing, or pattern recognition algorithms to identify walls, floors, ceilings, and other structural elements.5. Geometric Modeling.Create 3D models of the extracted features using parametric or NURBS modeling techniques.Parametric modeling allows for automated feature creation based on defined parameters.NURBS modeling enables the generation of smooth and accurate surface representations.6. Semantic Labeling.Assign appropriate materials, properties, and other semantic information to the geometric models.Utilize a BIM classification system or industry standards to define material types, structural properties, and other relevant attributes.7. BIM Integration.Import the labeled models into a BIM platform such as Revit, ArchiCAD, or Bentley AECOsim.Create a comprehensive BIM representation of the structure that includes geometry, semantic data, and related documentation.## 中文回答:点云构建 BIM 模型流程。
npm英文规格书NPM English Specification BookIntroductionThe NPM (Node Package Manager) is a popular tool used by developers worldwide to manage and share reusable JavaScript code modules. This English specification book aims to provide a comprehensive guide on the functionalities and features of NPM, enabling users to effectively use and contribute to the NPM ecosystem.1. Overview of NPM1.1 DefinitionNPM is a package manager for JavaScript that allows developers to install, publish, and manage dependencies for their projects. It simplifies the process of integrating third-party libraries and ensures the easy sharing and reuse of code modules.1.2 Key Features- Dependency Management: NPM provides a centralized system for managing project dependencies, ensuring seamless integration of external code modules.- Version Control: NPM allows developers to specify version requirements for dependencies, ensuring code stability and preventing version conflicts.- Scripts: NPM enables the execution of custom-defined scripts, automating various tasks during the development process.- Registry: NPM maintains a registry that serves as a repository for thousands of publicly available JavaScript packages.- Collaboration: NPM facilitates collaboration by allowing developers to publish and share their own packages with the community.2. Installation and Setup2.1 InstallationTo start using NPM, you need to have Node.js installed on your machine. Node.js includes NPM by default. Detailed installation instructions for various platforms can be found on the official Node.js website.2.2 Project InitializationTo initialize a new project with NPM, navigate to the project directory in the terminal and run the following command:```npm init```This command will prompt you to enter relevant information about your project and generate a package.json file, which serves as a manifest for your project dependencies.3. Managing Dependencies3.1 Installing DependenciesTo install dependencies for your project, use the following command:```npm install [package-name]```This will download and install the specified package and add it to the project's dependencies.3.2 Updating DependenciesTo update dependencies to their latest versions, run:```npm update [package-name]```This command will check for new versions and update the package.json file accordingly.3.3 Removing DependenciesIf you no longer require a particular dependency, you can remove it from your project using the following command:```npm uninstall [package-name]```This will remove the package from your project's dependencies.4. Publishing Packages4.1 Creating a PackageTo publish your own package on the NPM registry, you need to create a package.json file in your project directory. This file should contain relevant metadata and configuration details.4.2 Publishing ProcessOnce your package.json file is set up, run the following command to publish your package:```npm publish```This command will upload your package to the NPM registry, making it accessible to other developers.4.3 VersioningNPM follows semantic versioning for packages. It is recommended to follow the versioning guidelines when updating your package to ensure compatibility and avoid breaking changes.5. Advanced Features5.1 ScopesNPM supports scoped packages, which allow developers to logically group related packages together. Scoped packages are useful for organizations and provide additional control over package visibility and access.5.2 Custom ScriptsThe package.json file allows you to define custom scripts that can be executed using the `npm run` command. Custom scripts are ideal for automating tasks such as building, testing, and deployment.5.3 Private PackagesIn addition to public packages, NPM also supports private packages. Private packages are only accessible to specified users or organizations, providing an additional layer of security and control.ConclusionThis NPM English specification book has provided a comprehensive overview of NPM, its key features, installation process, dependency management, package publishing, and advanced features. By following this guide, developers can harness the power of NPM to effectively manage dependencies, collaborate with the community, and streamline their JavaScript development workflow.。
Semantic Workflow Management Edoardo Pignotti Dept. of Computing Science University of Aberdeen Aberdeen, AB24 3UE, Scotland epignott@csd.abdn.ac.uk
ABSTRACT In the e-Science context, workflow technologies provide a problem-solving environment for scientists by facilitating the creation and execution of experiments from a pool of available data and computation services. We argue that in order to characterise scientific analysis we need to go beyond low-level service composition and execution details by capturing higher-level description of the scientific process. The aim here is to make the experimental conditions and goals of the experiment transparent. Current workflow technologies do not incorporate any representation of these goals and conditions, which we call the scientist’s intent. Our hypothesis is that by extending workflow representation in this way, scientists (including social scientists) would be able to analyse, verify, execute, monitor and re-use workflows more efficiently.
Categories and Subject Descriptors H.4.1 [Office Automation]: Workflow management. D.2.6 [Programming Environments]: Integrated environments.
General Terms Management, Design, Experimentation, Human Factors.
Keywords Semantic workflow, scientist’s intent.
1. OVERVIEW In the e-Science context, workflow technologies provide a problem-solving environment for researchers by facilitating the creation and execution of experiments from a pool of available data and computation services. We argue that in order to characterize such analysis we need to go beyond low-level service composition and execution by capturing a higher-level description of the experimental process. The aim here is to make the conditions and goals of the experiment transparent. Current workflow technologies do not incorporate any representation of these goals and conditions, which we describe as the scientist’s intent. Early in our work we identified a number of scenarios through interactions with collaborators from the social simulation community. We now present a simulation case study using a virus model developed in NetLogo1; the model is an agent-based simulation of the transmission and perpetuation of a virus in a human population. An experiment using this model might involve studying the differences between different types of virus in a specific environment. A researcher wishing to test the hypothesis 1 http://ccl.northwestern.edu/netlogo/ ‘Smallpox is more infectious than Bird Flu in environment A’ might run a set of simulations using different random seeds. If in this set of simulations, Smallpox outperformed Bird Flu in a significant number of simulation runs, the experimental results could be used to support the hypothesis. Figure 1 shows a workflow built using the Kepler editor tool (Ludäscher et al., 2005) that uses available services to perform the experiment described above. The VirusSimulationModel generates simulation results based on a set of parameters loaded as input from a data repository; the experiment definition is selected by Experiment ID. These simulation results are aggregated and fed into the Significance Test component which outputs the results of the test. The hypothesis is tested by looking at the result of the significance test; if the virus that we are considering (e.g. Smallpox) outperforms others in a significant way, we can use this result to support our hypothesis. Figure 1 - Simulation Workflow Example. However, the experimental workflow defined in Figure 1 has some limitations as it is not able to capture the scientist’s goals and conditions (scientist’s intent). For example, the goal of this experiment is to obtain a significant number of simulation results that support the hypothesis. Imagine that the scientist knows that the simulation model could generate out-of-bound results and these results cannot be used in the significance test as they will affect the experiment. For this reason, we don't know a priori how many simulation runs per comparison we need to do in order to have a significant number of results. There may also be constraints associated with the workflow (or specific activities within the workflow) depending upon the intent of the scientist. For example, a researcher may be concerned about floating point support on different operating systems; if the Significance Test activity runs on a platform not compatible with IEEE 754 specifications, the results of the simulation could be compromised. Existing workflow languages are unable to explicitly associate such information with their workflow descriptions.