
https://www.doczj.com/doc/c711744925.html,
如何实现在线批量网页链接提取
在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。
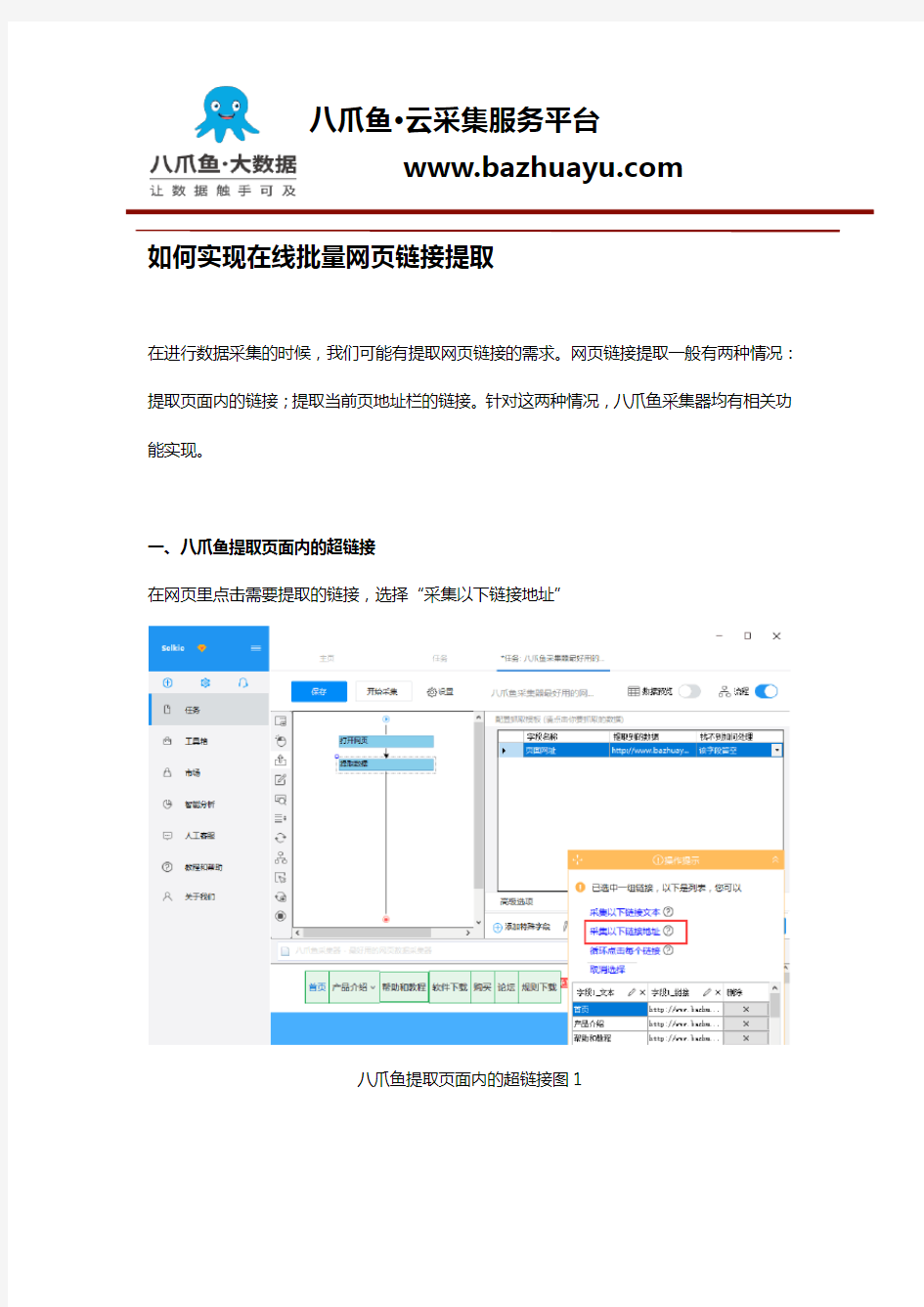
一、八爪鱼提取页面内的超链接
在网页里点击需要提取的链接,选择“采集以下链接地址”
八爪鱼提取页面内的超链接图1
https://www.doczj.com/doc/c711744925.html,
二、八爪鱼提取当前地址栏的超链接
从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
八爪鱼提取页面内的超链接图2
而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。
采集网站:
https://www.doczj.com/doc/c711744925.html,
https://https://www.doczj.com/doc/c711744925.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=suggest
步骤1:创建采集任务
1)进入主界面,选择自定义模式
八爪鱼提取页面内的超链接图3
2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/c711744925.html,
八爪鱼提取页面内的超链接图4
3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的商品url
是这次演示采集的信息
八爪鱼提取页面内的超链接图5
步骤2:创建翻页循环
https://www.doczj.com/doc/c711744925.html,
1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,
选择“循环点击下一页”
八爪鱼提取页面内的超链接图6
步骤3:商品url采集
1)如图,移动鼠标选中列表中商品的名称,右键点击,需采集的内容会变成绿色,然后点击“选中全部”
https://www.doczj.com/doc/c711744925.html,
八爪鱼提取页面内的超链接图7
2)选择“采集以下链接地址”
八爪鱼提取页面内的超链接图8
https://www.doczj.com/doc/c711744925.html, 3)点击“保存并开始采集”
八爪鱼提取页面内的超链接图9
4)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”
八爪鱼提取页面内的超链接图10
https://www.doczj.com/doc/c711744925.html,
步骤4:数据采集及导出
1)选择合适的导出方式,将采集好的数据导出
八爪鱼提取页面内的超链接图11
通过以上操作,目标网页内的商品超链接就被批量采集下来了。我们可以使用这些超链接,建立列表循环,来采集我们需要的其他字段数据,如下所示。
步骤5:创建url列表采集任务
1)重新创建一个采集任务,将导出后的商品链接复制,放到输入框中,点击“保存网址”
https://www.doczj.com/doc/c711744925.html,
八爪鱼提取页面内的超链接图12
注意:输入框中的url列表数量不要超过2W个,超过的部分可以新建任务进行采集,url 打开的页面必须是相同网站样式相近的,否则会导致数据采集缺失。
2)在页面中点击需要采集的文本数据,点击“采集数据”
八爪鱼提取页面内的超链接图13
https://www.doczj.com/doc/c711744925.html, 3)打开流程图,修改采集字段名称,点击“保存并开始采集”
八爪鱼提取页面内的超链接图14
注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
4)采集完成,点击“导出数据”
https://www.doczj.com/doc/c711744925.html,
八爪鱼提取页面内的超链接图15
5)选择合适的导出方式,将采集好的数据导出
八爪鱼提取页面内的超链接图16
https://www.doczj.com/doc/c711744925.html,
注:在八爪鱼中,要提取超链接,需要满足两个条件。
1、点击的字段在A标签,在网页源码中,A标签代表超链接,如果不是在A 标签内,八爪鱼无法判断
2、A标签内有href 属性,href 属性里的就是点击之后链接转向的地址,属性里显示什么,八爪鱼就提取什么。如果没有href属性,自然就没办法提取到。
这些都是八爪鱼自动判断的,其实看不懂也不影响操作。只是如果发现提取不到的时候,也许就是因为没满足这两个条件,要看当前网页源码的特点,根据特点找别的方式提取数据。相关采集教程:
淘宝评论采集
天猫商品信息采集
京东商品信息采集
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
https://www.doczj.com/doc/c711744925.html,
如何抓取网页数据,以抓取安居客举例 互联网时代,网页上有丰富的数据资源。我们在工作项目、学习过程或者学术研究等情况下,往往需要大量数据的支持。那么,该如何抓取这些所需的网页数据呢? 对于有编程基础的同学而言,可以写个爬虫程序,抓取网页数据。对于没有编程基础的同学而言,可以选择一款合适的爬虫工具,来抓取网页数据。 高度增长的抓取网页数据需求,推动了爬虫工具这一市场的成型与繁荣。目前,市面上有诸多爬虫工具可供选择(八爪鱼、集搜客、火车头、神箭手、造数等)。每个爬虫工具功能、定位、适宜人群不尽相同,大家可按需选择。本文使用的是操作简单、功能强大的八爪鱼采集器。以下是一个使用八爪鱼抓取网页数据的完整示例。示例中采集的是安居客-深圳-新房-全部楼盘的数据。 采集网站:https://https://www.doczj.com/doc/c711744925.html,/loupan/all/p2/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
如何抓取网页数据,以抓取安居客举例图1 2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
如何抓取网页数据,以抓取安居客举例图2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,以建立一个翻页循环
如何抓取网页数据,以抓取安居客举例图3 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里的第一个楼盘信息区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
如何抓取网页数据,以抓取安居客举例图4 2)系统会自动识别出页面中的其他同类元素,在操作提示框中,选择“选中全部”,以建立一个列表循环
https://www.doczj.com/doc/c711744925.html, 淘宝图片抓取工具使用方法 对于电商设计师来说,抓取竞品的宝贝的图片和店铺装修图片,来分析设计自己店铺的风格并做出差异化,是非常有用的方法哦。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝图片】为例,教大家如何使用八爪鱼采集软件采集淘宝图片的方法。 本文介绍使用八爪鱼7.0采集淘宝商品图片的方法:首先将淘宝商品搜索结果网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的淘宝商品图片URL,下载并保存到本地电脑中。 采集网址:淘宝商品搜索页面 比如T恤(可更换其他关键词对淘宝商品图片进行采集): https://https://www.doczj.com/doc/c711744925.html,/search?q=T%E6%81%A4&imgfile=&commend=all &search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taob ao-item.1&ie=utf8&initiative_id=tbindexz_20170306 采集数据内容:淘宝商品图片地址
https://www.doczj.com/doc/c711744925.html, 使用功能点: ●翻页设置 ●图片链接采集 步骤1:创建淘宝商品图片采集任务1)进入八爪鱼采集器主界面,选择自定义模式 淘宝商品图片采集步骤1
https://www.doczj.com/doc/c711744925.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 淘宝商品图片采集步骤2 3)如下图红色框中的淘宝商品图片即为本次要采集的内容。
https://www.doczj.com/doc/c711744925.html, 淘宝商品图片采集步骤3 步骤2:创建翻页循环 ●找到翻页按钮,设置翻页循环 ●设置ajax翻页时间 ●设置滚动页面 1)将淘宝商品搜索结果页页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
https://www.doczj.com/doc/c711744925.html, 网页链接提取方法 网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。掌握网页链接提取方法能让我们的工作事半功倍。在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。下面介绍一个网页链接提取方法。 一、八爪鱼提取页面内的超链接 在网页里点击需要提取的链接,选择“采集以下链接地址”
https://www.doczj.com/doc/c711744925.html, 网页链接提取方法1 二、八爪鱼提取当前地址栏的超链接 从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
https://www.doczj.com/doc/c711744925.html, 网页链接提取方法2 而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。 采集网站: https://https://www.doczj.com/doc/c711744925.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est
网页抓取工具如何进行http模拟请求 在使用网页抓取工具采集网页是,进行http模拟请求可以通过浏览器自动获取登录cookie、返回头信息,查看源码等。具体如何操作呢?这里分享给大家网页抓取工具火车采集器V9中的http模拟请求。许多请求工具都是仿照火车采集器中的请求工具所写,因此大家可以此为例学习一下。 http模拟请求可以设置如何发起一个http请求,包括设置请求信息,返回头信息等。并具有自动提交的功能。工具主要包含两大部分:一个MDI父窗体和请求配置窗体。 1.1请求地址:正确填写请求的链接。 1.2请求信息:常规设置和更高级设置两部分。 (1)常规设置: ①来源页:正确填写请求页来源页地址。 ②发送方式:get和post,当选择post时,请在发送数据文本框正确填写发布数据。 ③客户端:选择或粘贴浏览器类型至此处。 ④cookie值:读取本地登录信息和自定义两种选择。 高级设置:包含如图所示系列设置,当不需要以上高级设置时,点击关闭按钮即可。 ①网页压缩:选择压缩方式,可全选,对应请求头信息的Accept-Encoding。 ②网页编码:自动识别和自定义两种选择,若选中自定义,自定义后面会出现编
码选择框,在选择框选择请求的编码。 ③Keep-Alive:决定当前请求是否与internet资源建立持久性链接。 ④自动跳转:决定当前请求是否应跟随重定向响应。 ⑤基于Windows身份验证类型的表单:正确填写用户名,密码,域即可,无身份认证时不必填写。 ⑥更多发送头信息:显示发送的头信息,以列表形式显示更清晰直观的了解到请求的头信息。此处的头信息供用户选填的,若要将某一名称的头信息进行请求,勾选Header名对应的复选框即可,Header名和Header值都是可以进行编辑的。 1.3返回头信息:将详细罗列请求成功之后返回的头信息,如下图。 1.4源码:待请求完毕后,工具会自动跳转到源码选项,在此可查看请求成功之后所返回的页面源码信息。 1.5预览:可在此预览请求成功之后返回的页面。 1.6自动操作选项:可设置自动刷新/提交的时间间隔和运行次数,启用此操作后,工具会自动的按一定的时间间隔和运行次数向服务器自动请求,若想取消此操作,点击后面的停止按钮即可。 配置好上述信息后,点击“开始查看”按钮即可查看请求信息,返回头信息等,为避免填写请求信息,可以点击“粘贴外部监视HTTP请求数据”按钮粘贴请求的头信息,然后点击开始查看按钮即可。这种捷径是在粘贴的头信息格式正确的前提下,否则会弹出错误提示框。 更多有关网页抓取工具或网页采集的教程都可以从火车采集器的系列教程中学习借鉴。
https://www.doczj.com/doc/c711744925.html, 如何抓取网页数据 很多用户不懂爬虫代码,但是却对网页数据有迫切的需求。那么怎么抓取网页数据呢? 本文便教大家如何通过八爪鱼采集器来采集数据,八爪鱼是一款通用的网页数据采集器,可以在很短的时间内,轻松从各种不同的网站或者网页获取大量的规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑,规范化,摆脱对人工搜索及收集数据的依赖,从而降低获取信息的成本,提高效率。 本文示例以京东评论网站为例 京东评价采集采集数据字段:会员ID,会员级别,评价星级,评价内容,评价时间,点赞数,评论数,追评时间,追评内容,页面网址,页面标题,采集时间。 需要采集京东内容的,在网页简易模式界面里点击京东进去之后可以看到所有关于京东的规则信息,我们直接使用就可以的。
https://www.doczj.com/doc/c711744925.html, 京东评价采集步骤1 采集京东商品评论(下图所示)即打开京东主页输入关键词进行搜索,采集搜索到的内容。 1、找到京东商品评论规则然后点击立即使用
https://www.doczj.com/doc/c711744925.html, 京东评价采集步骤2 2、简易模式中京东商品评论的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为京东商品评论 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 商品评论URL列表:提供要采集的网页网址,即商品评论页的链接。每个商品的链接必须以#comment结束,这个链接可以在商品列表点评论数打开后进行复制。或者自己打开商品链接后手动添加,如果没有这个后缀可能会报错。多个商品评论输入多个商品网址即可。 将鼠标移动到?号图标可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。
国内主要信息抓取软件盘点 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展 机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相 对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具 影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序
https://www.doczj.com/doc/c711744925.html, 最全的网页图片采集方法 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.doczj.com/doc/c711744925.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.doczj.com/doc/c711744925.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集
https://www.doczj.com/doc/c711744925.html, 采集示例:百度网图片采集教程https://www.doczj.com/doc/c711744925.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.doczj.com/doc/c711744925.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.doczj.com/doc/c711744925.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
国内6大网络信息采集和页面数据抓取工具 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统(https://www.doczj.com/doc/c711744925.html,) 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 该系统主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器(https://www.doczj.com/doc/c711744925.html,) 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件(https://www.doczj.com/doc/c711744925.html,) 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器(https://www.doczj.com/doc/c711744925.html,) 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序的区别,狂人采集器分论坛采集器、CMS采集器和博客采集器三类,总计支持近40种主流建站程序的上百个版本的数据采集和发布任务,支持图片本地化,支持网站登陆采集,分页抓取,全面模拟人工登陆发布,软件运行快速安全稳定!论坛采集器还支持论坛会员无限注册,自动增加帖子查看人数,自动顶贴等。 TOP.5 网络神采(https://www.doczj.com/doc/c711744925.html,) 网络神采是一款专业的网络信息采集系统,通过灵活的规则可以从任何类型的网站采集信息,
https://www.doczj.com/doc/c711744925.html, 网络文字抓取工具使用方法 网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。 采集网站: 使用功能点: ●Ajax滚动加载设置 ●列表内容提取 步骤1:创建采集任务
https://www.doczj.com/doc/c711744925.html, 1)进入主界面选择,选择“自定义模式” 今日头条网络文字抓取工具使用步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/c711744925.html, 今日头条网络文字抓取工具使用步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
https://www.doczj.com/doc/c711744925.html, 今日头条网络文字抓取工具使用步骤3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.doczj.com/doc/c711744925.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 今日头条网络文字抓取工具使用步骤4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
https://www.doczj.com/doc/c711744925.html, 今日头条网络文字抓取工具使用步骤5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色
https://www.doczj.com/doc/c711744925.html, 网页数据抓取方法详解 互联网时代,网络上有海量的信息,有时我们需要筛选找到我们需要的信息。很多朋友对于如何简单有效获取数据毫无头绪,今天给大家详解网页数据抓取方法,希望对大家有帮助。 八爪鱼是一款通用的网页数据采集器,可实现全网数据(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等信息)的自动采集。同时八爪鱼提供单机采集和云采集两种采集方式,另外针对不同的用户还有自定义采集和简易采集等主要采集模式可供选择。
https://www.doczj.com/doc/c711744925.html, 如果想要自动抓取数据呢,八爪鱼的自动采集就派上用场了。 定时采集是八爪鱼采集器为需要持续更新网站信息的用户提供的精确到分钟的,可以设定采集时间段的功能。在设置好正确的采集规则后,八爪鱼会根据设置的时间在云服务器启动采集任务进行数据的采集。定时采集的功能必须使用云采集的时候,才会进行数据的采集,单机采集是无法进行定时采集的。 定时云采集的设置有两种方法: 方法一:任务字段配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。
https://www.doczj.com/doc/c711744925.html, 第一、如果需要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置。 第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间。所有设置完成之后,如果需要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。
https://www.doczj.com/doc/c711744925.html, 微信文章抓取工具详细使用方法 如今越来越多的优质内容发布在微信公众号中,面对这些内容,有些朋友就有采集下来的需求,下面为大家介绍使用八爪鱼抓取工具去抓取采集微信文章信息。 抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。 采集网站:https://www.doczj.com/doc/c711744925.html,/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式”
https://www.doczj.com/doc/c711744925.html, 微信文章抓取工具详细使用步骤1 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/c711744925.html, 微信文章抓取工具详细使用步骤2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”
https://www.doczj.com/doc/c711744925.html, 微信文章抓取工具详细使用步骤3 2)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮 微信文章抓取工具详细使用步骤4
https://www.doczj.com/doc/c711744925.html, 3)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 微信文章抓取工具详细使用步骤5 4)页面中出现了 “八爪鱼大数据”的文章搜索结果。将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
https://www.doczj.com/doc/c711744925.html, 微信文章抓取工具详细使用步骤6 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里第一篇文章的区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
https://www.doczj.com/doc/c711744925.html, 网页内容如何批量提取 网站上有许多优质的内容或者是文章,我们想批量采集下来慢慢研究,但内容太多,分布在不同的网站,这时如何才能高效、快速地把这些有价值的内容收集到一起呢? 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集】,以【新浪博客】为例,教大家如何使用八爪鱼采集软件采集新浪博客文章内容的方法。 采集网站: https://www.doczj.com/doc/c711744925.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集”
https://www.doczj.com/doc/c711744925.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/c711744925.html, 步骤2:创建翻页循环
https://www.doczj.com/doc/c711744925.html, 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。) 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax加载数据”,超时时间设置为5秒,点击“确定”。
https://www.doczj.com/doc/c711744925.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。 2)鼠标点击“循环点击每个链接”,列表循环就创建完成,并进入到第一个循环项的详情页面。
https://www.doczj.com/doc/c711744925.html, 大数据抓取工具推荐 大数据已经成了互联网时代最热门的词之一,采集器也成了数据行业人人都需要的工具。作为一个不会打代码的小白,如何进行数据采集呢?市面上有一些大数据抓取工具。八爪鱼和造数就是其中两款采集器,对于不会写爬虫代码的朋友来说,找到一款合适的采集器,可以达到事半功倍的效果。本文就两款采集器的优缺点做一个对比,仅供大家参考。 造数是一个基于云端爬取的智能云爬虫服务站点,通过一套网页分析的算法,分析出网页中结构化的数据,然后再爬取页面中的数据,无需编程基础,只需输入网址,选取所需的数据,就可轻松获取互联网的公开数据,并以 Excel 表格等形式下载,或使用 API 与企业内部系统深度整合。 造数有什么优缺点呢? 优点: 云端采集网页,不需要占用电脑资源下载软件 采集到数据以后可以设置数据自动推送 缺点: 1、不支持全自动网站登录采集,也不支持本地采集,采集比较容易受到限制 2、不能采集滚动页面,最多支持两个层级的采集,采集不是很灵活 然后我们看一下八爪鱼 八爪鱼是非常适合技术小白的一款采集器,技术比较成熟,功能强大,操作简单。八爪鱼采集器的各方面的功能都比较完善,云采集是它的一大特色,相比其他采集软件,云采集能够做到更加精准、高效和大规模。还有识别验证码、提供优质代理IP 、UA 自动切换等智能防封的组合功能,在采集过程都不用担心网站的限制。如果不想创建采集任务,可以到客户端直接使用简易采集模式,选择模板,设置参数马上就可以拿到数据。
https://www.doczj.com/doc/c711744925.html, 八爪鱼有什么优缺点呢? 1、功能强大。八爪鱼采集器是一款通用爬虫,可应对各种网页的复杂结构(瀑布流等)和防采集措施(登录、验证码、封IP),实现百分之九十九的网页数据抓取。 2、入门容易。7.0版本推出的简易网页采集,内置主流网站大量数据源和已经写好的采集规则。用户只需输入关键词,即可采集到大量所需数据 3、流程可视化。真正意义上实现了操作流程可视化,用户可打开流程按钮,直接可见操作流程,并对每一步骤,进行高级选项的设置(修改ajax/ xpath等)。 缺点: 1、不能提供文件托管,不能直接发布采集到的数据 2、不支持视频和app采集 相关链接: 八爪鱼使用功能点视频教程 https://www.doczj.com/doc/c711744925.html,/tutorial/videotutorial/videognd 八爪鱼爬虫软件入门准备 https://www.doczj.com/doc/c711744925.html,/tutorial/xsksrm/rmzb
1.file_get_contents获取网页内容 2.curl获取网页内容 3.fopen->fread->fclose获取网页内容
百度贴吧内容抓取工具-让你的网站一夜之间内容丰富 [hide]
var $getreplytime=1; var $showimg=1; var $showcon=1; var $showauthor=1; var $showreplytime=1; var $showsn=0; var $showhr=0; var $replylista=array(); var $pat_reply="<\/a>(.+?)
<\/td>\r\n<\/tr><\/table>"; var $pat_pagecount="尾页<\/font><\/a>"; var $pat_title="(.+?)<\/font>"; var $pat_replycon="<\/td>\r\n \r\n