
收稿日期:2018-03-30 修回日期:2018-07-11 网络出版时间:2018-11-15
基金项目:四川省2017年度教育科研计划项目(17ZB0059);成都理工大学工程技术学院院级基金项目(C122017024);成都理工大学工程技术
学院教研项目(2016-YY-JG06)
作者简介:杜 华(1983-),男,硕士,副教授,研究方向为网络分布式计算二最优化算法分析二计算机应用技术三
网络出版地址:https://www.doczj.com/doc/ae3830631.html, /kcms /detail /61.1450.TP.20181115.1050.074.html 云数据中心下重复数据删除技术研究
杜 华1,2,刘华春2
(1.核工业西南物理研究院,四川成都610000;
2.成都理工大学工程技术学院,四川乐山614000)
摘 要:云数据中心下企业数据量快速增长,使得数据中心面临严峻挑战三研究发现,存储系统中高达60%的数据是冗余的,因此云数据中心下的重复数据缩减受到越来越多的关注三以往单一存储结构模式下的存储性能评价指标(平均响应时间二磁盘I /O 效率和数据冗余度),不但不能完全适应云数据这种以廉价设备为分布式存储结构的新变化,而且也难以较好地满足云服务提供商向用户做出的数据高可用性二高可靠性的SLA 承诺三为此,在分析和总结云数据中心环境下数据存储的新特征之后,通过对单一存储结构下重复数据删除技术不足的剖析,提出了查询算法优化二基于SSD 改进置换效率二改进的纠删码数据容错机制三条路径,以提高云数据中心下重删系统的工作效率和工作表现三最后,通过分析云服务下不同用户对IT 资源需求的区别,有针对性地自动选择合适的去重时机,为从整体上改进云数据中心环境下重复删除系统操作效率指出了进一步研究的方向三
关键词:重复数据删除;云数据中心;指纹;SSD;纠删码
中图分类号:TP31 文献标识码:A
文章编号:1673-629X (2019)02-0157-05doi:10.3969/j.issn.1673-629X.2019.02.033Research on Deduplication of Data in Cloud Data Center
DU Hua 1,2,LIU Hua -chun 2
(1.Southwestern Institute of Physics ,Chengdu 610000,China ;2.School of Engineering and Technology ,Chengdu University of Technology ,Leshan 614000,China )
Abstract :The cloud data center is facing severe challenges with the rapid growth of the data volume from enterprises.Studies have found that up to 60%of the data in storage system is redundant ,so reducing the redundant data in the cloud data center is paid more and more attention.The storage performance evaluation index (average response time ,disk I /O efficiency and data redundancy )in the previous single storage structure mode not only fail to adapt to the new changes of cloud data completely in the distributed storage structure with cheap devices ,but also be difficult to meet SLA commitment about high availability and high reliability of the data made by the cloud service providers to users.Therefore ,we propose three paths including query algorithm optimization ,improved permutation efficiency based on SSD ,improved erasure code data tolerance mechanism after analyzing and summarizing the new features of data storage in cloud data center and shortcoming of repeat data deletion under single storage structure ,to enhance the working efficiency and performance of the system in cloud data center.Finally ,by analyzing the differences between different user ’s demands for IT resources in cloud services ,the appropriate de -duplication timing is automatically selected in a targeted way ,which points out the direction of further research for im?proving the efficiency for the deduplication system in cloud data center.
Key words :repeat data deletions ;cloud data centers ;fingerprint ;SSD ;erasure code
0 引 言
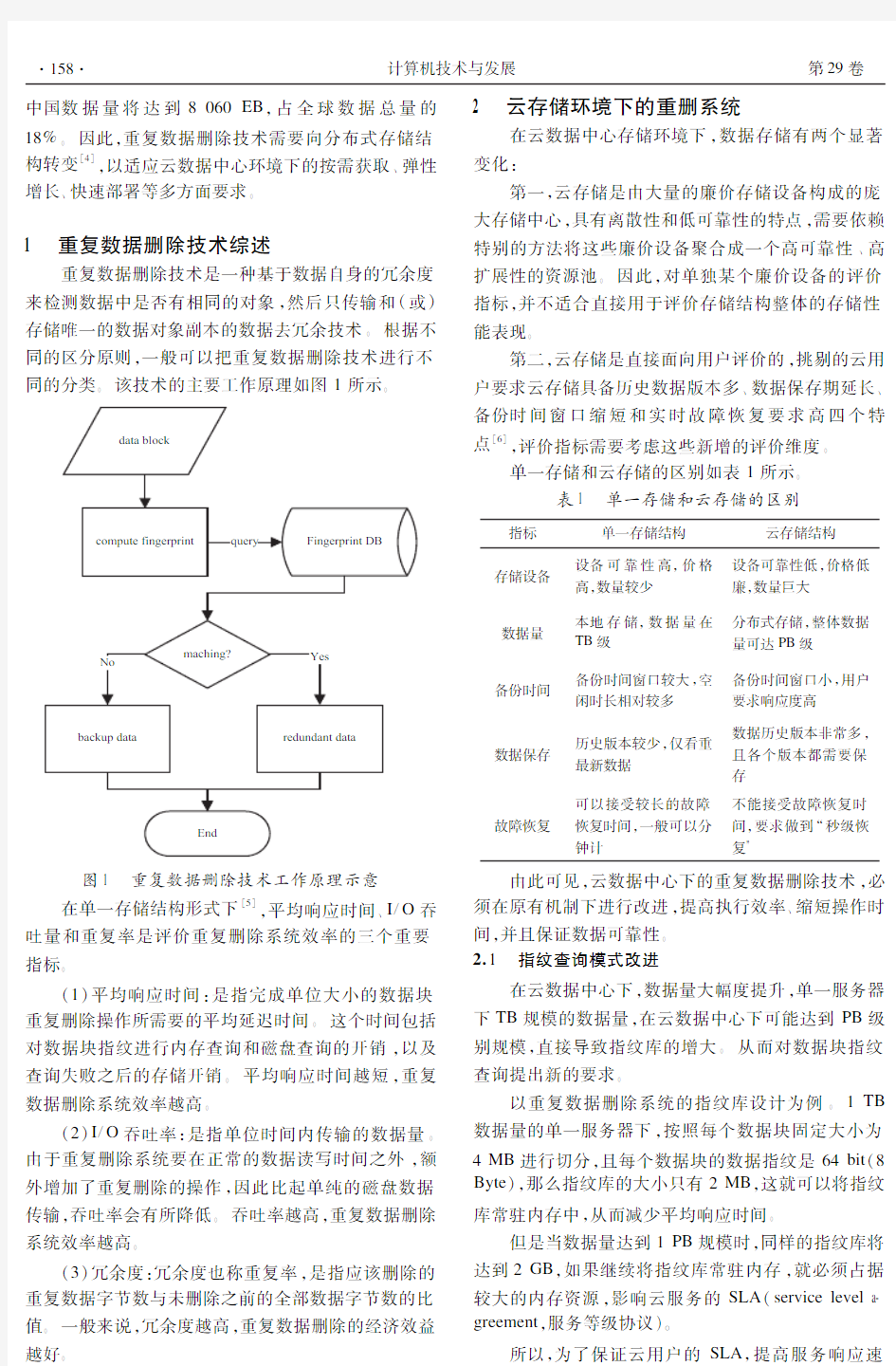
重复数据删除技术是一种数据缩减技术,常用于
基于磁盘的备份系统中,旨在减少存储系统中使用的
存储容量三以往的重复数据删除系统往往采用单服务器结构,具有配置简单二易于管理的优点[1]三近年来,随着云计算二大数据技术的发展,企业数据中心存储的需求量日益庞大[2]三据国际数据公司(IDC )统计[3],全球数据总量预计2020年达到44ZB ,第29卷 第2期2019年2月 计算机技术与发展COMPUTER TECHNOLOGY AND DEVELOPMENT
Vol.29 No.2Feb. 2019
重复数据删除(De-duplication)技术研究 文章地直址:https://www.doczj.com/doc/ae3830631.html,/liuaigui/article/details/5829083 1、Dedupe概述 De-duplication,即重复数据删除,它是一种目前主流且非常热门的存储技术,可对存储容量进行有效优化。它通过删除数据集中重复的数据,只保留其中一份,从而消除冗余数据。如下图所示。这种技术可以很大程度上减少对物理存储空间的需求,从而满足日益增长的数据存储需求。Dedupe技术可以带许多实际的利益,主要包括以下诸多方面: (1) 满足ROI(投资回报率,Return On Investment)/TCO(总持有成本,Total Cost of Ownership)需求; (2) 可以有效控制数据的急剧增长; (3) 增加有效存储空间,提高存储效率; (4) 节省存储总成本和管理成本; (5) 节省数据传输的网络带宽; (6) 节省空间、电力供应、冷却等运维成本。 Dedupe技术目前大量应用于数据备份与归档系统,因为对数据进行多次备份后,存在大量重复数据,非常适合这种技术。事实上,dedupe技术可以用于很多场合,包括在线数据、近线数据、离线数据存储系统,可以在文件系统、卷管理器、NAS、SAN中实施。Dedupe也可以用于数据容灾、数据传输与同步,作为一种数据压缩技术可用于数据打包。Dedupe技术可以帮助众多应用降低数据存储量,节省网络带宽,提高存储效率、减小备份窗口,节省成本。 Dedupe的衡量维度主要有两个,即重复数据删除率(deduplocation ratios)和性能。Dedupe性能取决于具体实现技术,而重复数据删除率则由数据自身的特征和应用模式所决定,影响因素如下表[2]所示。目前各存储厂商公布的重复数据删除率从20:1到500:1不等。
云数据中心建设 技术方案及实施、培训方案
目录 1.云数据中心建设项目设计方案 (4) 1.1.项目概述 (4) 1.1.1.深圳市城市轨道交通网络总体架构 (4) 1.1.2.深圳市轨道交通清分中心概况 (4) 1.1.3.深圳市轨道交通AFC系统线网中心(CLC)概况 (5) 1.1.4.4号线已开通线路和系统概况 (5) 1.1.5.本项目工程概况 (5) 1.1.6.本项目AFC系统概况 (6) 1.1.7.三期AFC系统需与以下系统接口: (6) 1.1.8.需求理解及分析 (7) 1.1.8.1.构建云数据中心 (7) 1.1.8.2.业务云化及运维 (8) 1.2.项目建设目标 (8) 1.2.1.建设云数据中心,提供IaaS和PaaS层云服务 (8) 1.2.2.构建云安全防护体系,满足安全等级保护三级要求 (8) 1.2.3.部署云运维管理平台,图形化展示业务运行状况 (8) 1.3.项目设计原则 (9) 1.4.方案设计总体思路 (10) 1.5.总体方案架构设计 (12) 1.5.1.港铁AFC云平台架构设计 (12) 1.5.2.新建云数据中心架构设计 (12) 1.6.详细设计方案 (15) 1.6.1.云管理平台设计方案 (15) 1.6.1.1.云管理平台架构设计 (15) 1.6.1.2.IaaS层服务设计 (21) 1.6.1.3.PaaS层服务设计 (30) 1.6.2.网络资源池设计方案 (31) 1.6.2.1.网络资源池总体架构设计 (31) 1.6.3.计算资源池设计方案 (34) 1.6.3.1.计算资源池需求 (34) 1.6.3.2.存储资源池需求 (36) 1.6.3.3.计算资源池总体架构设计 (36) 1.6.3.4.计算资源池容量规划设计 (36)
VMware私有云数据中心建设与运营 技术方案
目录 1概述 (4) 1.1项目背景 (4) 1.2现状分析 (5) 1.2.1数据中心环境现状 (5) 1.3需求分析 (8) 1.3.1数据中心基础构架分析 (8) 2VMware云计算数据中心服务调配解决方案概述 (10) 2.1方案概览 (10) 2.2功能特性 (14) 2.3典型应用场景 (16) 3云计算数据中心服务调配解决方案技术详解 (19) 3.1业务组成元素 (19) 3.1.1蓝图 (19) 3.1.2业务组和用户 (20) 3.1.3基于角色用户授权 (20) 3.1.4资源预留 (21) 3.1.5计费 (21) 3.1.6共享基础架构的管理 (22) 3.1.7机器资源的生命周期 (23) 3.2构成组件 (24) 3.3主要功能 (27) 3.3.1统一的IT服务目录 (27) 3.3.2基础架构服务调配 (28) 3.3.3应用服务调配 (40)
3.3.4XaaS–以服务的形式提供任何服务 (46) 3.4服务调配方法论与规划设计 (53) 3.4.1服务调配方法论 (53) 3.4.2服务的调配管理 (56) 3.4.3服务设计和开发管理 (59) 3.5规划设计 (63) 3.5.1基础架构服务调配规划 (63) 3.5.2应用服务调配规划 (80) 4VMware云计算数据中心运维管理解决方案概述 (82) 4.1概述82 4.2主要价值 (86) 4.3功能特性 (89) 4.4解决方案技术详解 (92) 4.4.1运维可见性与性能管理 (92) 4.4.2典型应用场景 (99) 4.4.3变更、配置与合规性管理 (119) 4.4.4性能监控、分析与告警 (122) 4.4.5应用依赖关系映射 (132) 4.4.6运维方法论与规划建议 (140) 4.4.7运维方法论 (140) 4.4.8规划建议 (154) 5VMware网络虚拟化解决方案概述 (163) 5.1方案概览 (163) 5.2主要价值 (167) 5.3典型应用场景 (168) 6VMware网络虚拟化解决方案技术详解 (170) 6.1基本组件 (170) 6.2工作原理 (173) 6.3主要功能 (175)
SQL删除重复数据 (2009-05-16 12:40:00) 转载 标签: 分类:一路辛酸---C# sql删除 重复数据 delete 执行效率 it 重复的数据可能有这样两种情况,第一种时表中只有某些字段一样,第二种是两行记录完全一样。 一、对于部分字段重复数据的删除 先来谈谈如何查询重复的数据吧。 下面语句可以查询出那些数据是重复的: select字段1,字段2,count(*) from 表名group by 字段1,字段2 having count(*) > 1 将上面的>号改为=号就可以查询出没有重复的数据了。 想要删除这些重复的数据,可以使用下面语句进行删除 delete from表名a where 字段1,字段2 in (select 字段1,字段2,count(*) from 表名group by 字段1,字段2 having count(*) > 1) 上面的语句非常简单,就是将查询到的数据删除掉。不过这种删除执行的效率非常低,对于大数据量来说,可能会将数据库吊死。所以我建议先将查询到的重复的数据插入到一个临时表中,然后对进行删除,这样,执行删除的时候就不用再进行一次查询了。如下:
CREATE TABLE临时表AS (select 字段1,字段2,count(*) from 表名group by 字段1,字段2 having count(*) > 1) 上面这句话就是建立了临时表,并将查询到的数据插入其中。 下面就可以进行这样的删除操作了: delete from 表名a where 字段1,字段2 in (select 字段1,字段2 from 临时表); 这种先建临时表再进行删除的操作要比直接用一条语句进行删除要高效得多。 这个时候,大家可能会跳出来说,什么?你叫我们执行这种语句,那不是把所有重复的全都删除吗?而我们想保留重复数据中最新的一条记录啊!大家不要急,下面我就讲一下如何进行这种操作。 在oracle中,有个隐藏了自动rowid,里面给每条记录一个唯一的rowid,我们如果想保留最新的一条记录,我们就可以利用这个字段,保留重复数据中rowid最大的一条记录就可以了。 下面是查询重复数据的一个例子: select a.rowid,a.* from表名a where a.rowid != ( select max(b.rowid) from 表名b where a.字段1 = b.字段1 and a.字段2 = b.字段2 ) 下面我就来讲解一下,上面括号中的语句是查询出重复数据中rowid最大的一条记录。 而外面就是查询出除了rowid最大之外的其他重复的数据了。 由此,我们要删除重复数据,只保留最新的一条数据,就可以这样写了: delete from 表名a where a.rowid !=
云数据中心基础环境详细设计方案
目录 第一章综合布线系统 (11) 1.1 项目需求 (11) 1.2 综合布线系统概述 (11) 1.2.1 综合布线系统发展过程 (11) 1.2.2 综合布线系统的特点 (12) 1.2.3 综合布线系统的结构 (13) 1.3 综合布线系统产品 (14) 1.3.1 选择布线产品的参考因素 (14) 1.3.2 选型标准 (15) 1.3.3 综合布线产品的经济分析 (15) 1.3.4 综合布线产品的选择 (15) 1.3.5 综合布线系统特点 (16) 1.3.6 主要产品及特点 (17) 1.4 综合布线系统设计 (23) 1.4.1 设计原则 (23) 1.4.2 设计标准 (24) 1.4.3 设计任务 (25) 1.4.5 设计目标 (26) 1.4.6 设计要领 (26) 1.4.7 设计内容 (27) 1.5 工作区子系统设计方案 (34) 1.5.1 系统介绍 (34) 1.5.2 系统设计 (35) 1.5.3 主要使用产品 (39) 1.6 水平区子系统设计方案 (40) 1.6.1 系统介绍 (40) 1.6.2 系统设计 (41) 1.6.3 主要使用产品 (46) 1.7 管理子系统设计方案 (46) 1.7.1 系统介绍 (46) 1.7.2 系统设计 (47) 1.7.3 主要使用产品 (51) 1.8 垂直干线子系统设计方案 (52)
1.8.1 系统介绍 (52) 1.8.2 系统设计 (53) 1.8.3 主要使用产品 (56) 1.9 设备室子系统设计方案 (57) 1.9.1 系统介绍 (57) 1.9.2 系统设计 (57) 1.10 综合布线系统防护设计方案 (59) 1.10.1 系统介绍 (59) 1.10.2 系统设计 (60) 1.10.3 主要使用产品 (63) 第二章强电布线系统 (64) 2.1 概述 (64) 2.2 设计原则 (64) 2.3 设计依据 (65) 2.4 需求分析 (66) 2.5 系统设计 (67) 2.6 施工安装 (69) 2.6.1 桥架施工 (69) 2.6.2 管路施工 (69) 2.6.3 电缆敷设及安装 (70) 第三章配电系统 (71) 3.1 概述 (71) 3.2 用户需求 (72) 3.3 系统设计 (72) 3.3.1 UPS输入配电柜设计 (73) 3.3.2 UPS输出配电柜设计 (73) 3.3.3 UPS维修旁路配电柜设计 (74) 3.3.4 精密空调动力配电柜设计 (74) 3.3.5 动力配电柜设计 (75) 3.3.6 机房强电列头配电柜设计 (76) 3.4 施工安装 (83) 3.4.1 桥架管线施工 (83) 3.4.2 配电柜安装 (83) 第四章精密空调系统 (85) 4.1 项目概述 (85) 4.2 设计原则 (86)
SQL中重复数据的查询与删除 ========第一篇========= 在一张表中某个字段下面有重复记录,有很多方法,但是有一个方法,是比较高效的,如下语句: select data_guid from adam_entity_datas a where a.rowid > (select min(b.rowid) from adam_entity_datas b where b.data_guid = a.data_guid) 如果表中有大量数据,但是重复数据比较少,那么可以用下面的语句提高效率 select data_guid from adam_entity_datas where data_guid in (select data_guid from adam_entity_datas group by data_guid having count(*) > 1) 此方法查询出所有重复记录了,也就是说,只要是重复的就选出来,下面的语句也许更高效select data_guid from adam_entity_datas where rowid in (select rid from (select rowid rid,row_number()over(partition by data_guid order by rowid) m from adam_entity_datas) where m <> 1) 目前只知道这三种比较有效的方法。 第一种方法比较好理解,但是最慢,第二种方法最快,但是选出来的记录是所有重复的记录,而不是一个重复记录的列表,第三种方法,我认为最好。 ========第二篇========= select usercode,count(*) from ptype group by usercode having count(*) >1 ========第三篇========= 找出重复记录的ID: select ID from ( select ID ,count(*) as Cnt from 要消除重复的表 group by ID ) T1 where https://www.doczj.com/doc/ae3830631.html,t>1 删除数据库中重复数据的几个方法 数据库的使用过程中由于程序方面的问题有时候会碰到重复数据,重复数据导致了数据库部分设置不能正确设置…… 方法一
云数据中心设计方 案
云数据中心设计方案 李万鸿 -2-25 云计算是大势所趋,选择合适的硬件和软件建立云数据中心是非常重要的,下面是一个非常详细的云数据中心设计方案。 1.云数据中心架构设计 学校云数据中心架构图 云数据中心包括Iaas、Paas、Saas三层服务,云数据中心既是一个企业云,也能够对外提供服务,学校还能够使用别的公有云如阿里云,形成混合云。 1). SaaS:提供给客户的服务是运营商运行在云计算基础设施上的应用程序,用户能够在各种设备上经过客户端界面访问,如浏览器。消费者不需要管理或控制任何云计算基础设施,包括网络、服务器、操作系统、存储等等,实现智慧校园产品及学校
现有产品等给用户使用。 2). PaaS:主要提供应用开发、测试和运行的平台,用户能够基于该平台,进行应用的快速开发、测试和部署运行,它依托于云计算基础架构,把基础架构资源变成平台环境提供给用户和应用。为业务信息系统提供软件开发和测试环境,同时能够将各业务信息系统功能纳入一个集中的SOA平台上,有效地复用和编排组织内部的应用服务构件,以便按需组织这些服务构件。典型的如门户网站平台服务,可为用户提供快速定制开发门户网站提供应用软件平台,用户只需在此平台进行少量的定制开发即可快速部署应用。提供给消费者的服务是把客户采用提供的开发语言和工具(例如Java,python, .Net等)开发的或收购的应用程序部署到供应商的云计算基础设施上去。客户不需要管理或控制底层的云基础设施,包括网络、服务器、操作系统、存储等,但客户能控制部署的应用程序,也可能控制运行应用程序的托管环境配置;能够使用Kubernetes、Docker容器完成应用系统的部署和管理。提供统一登录、权限、门户、数据中心、数据库等服务,实现容器管理、自动化部署、自动化迁移、负载均衡、弹性计算、按需分配、应用统计、性能检测、API接口、数据交换等功能。 3). IaaS:提供给消费者的服务是对所有计算基础设施的利用,包括处理CPU、内存、存储、网络和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程序。Iaas层是
重复数据删除技术的产生是有一定的渊源,那就从头说起,虽然现在存储介质的价格直线下滑,单位存储成本已经很低。但是仍然跟不上企业数据文件增长的速度。随之而来的,能源消耗、数据备份管理等等也都成了老大难问题。而且一些重复的文件也随着增多了。为此企业现在迫切需要一门技术,能够确保在存储设备中存储的是独一无二的文件。在这种背景下,重复数据删除技术就应运而生啦。重复数据删除技术的目的很简单,就是确保存储的文件不重复,从而减少数据容量。不过在实际工作中,由于种种原因用户对这个技术还存在着一些误解。消除这些误区,对于大家正确使用重复数据删除技术很关键。 误区一:后期处理重复数据删除技术的工作时机。 重复数据删除技术根据其实现的方式可以分为“联机重复数据删除技术”和“后期处理重复数据删除技术”。两个技术各有各的特点。不过由于“后期处理重复数据删除技术”这个名字起得有点其一,所以不少用户对此存在着误解。如一些人会误认为后期处理重复数据删除方式是当所有数据备份过程结束后才进行验证、删除操作的。如果大家这么认为,那么就是大错特错了。 其实后期处理重复数据删除技术通常是在虚拟的磁带介质写入备份数据后就开始进行工作了。也就是说实在等待虚拟磁带写满之后就开始。当然这中间根据需要有一定的延迟。如存储管理员可以根据不同的情况对这个延迟进行设置。可以只延迟短短的几分钟,也可以延迟几个小时。延迟时间具体为多少,主要还是根据企业的实际情况来选择。如有些管理员可能会将这个作业放在服务器比较空闲的时候进行,此时就会把这个延迟设置的比较长一点,如等到下班后进行等等。 这里需要注意的是一般情况下,为了提高数据备份的效率,会对数据备份进行分组管理。此时等待时间是从第一组备份任务传送备份数据流开始算起。当第一盘虚拟的备份磁带写满或者第一组备份数据写入结束后,重复数据删除处理就不存在延迟等待问题。这主要是因为当系统在进行前一组写入备份数据进行重复数据删除处理时,被分系统可以继续往后续虚拟磁带介质中写入第二组的备份数据。简单的说,就是重复数据处理作业与备份数据的写入作业可以独立运行。从而提高数据处理的效率。 误区二:后期处理重复数据删除方式会降低整体备份的效率。 如果光从技术上看,这个结论是成立的。一方面重复删除方式会占用服务器的资源。另一方面,重复删除方式存在着一定的延迟。但是这是一个比较孤立的观点。因为根据现在的重复数据删除技术,完全可以通过合理的配置来消除这种负面影响。 在实际工作中,如果技术人员发现后期处理重复数据删除技术降低了数据备份的效率,那么可以通过如下几种方式来消除这个不利影响。一是可以将重复数据删除技术分配到多个单独的服务器上来分担服务器的压力。一般情况下在对已写入的备份数据进行重复数据删除时,不同的处理引擎往往会访问同一磁盘阵列。不过现在的技术可以使得他们访问同一磁盘阵列的不同区域。换句话说,就是可以实现高速的并发处理。这样的话,就不会和持续写入的备份数据流产生任何的冲突,从而不会影响数据备份的效率。二是可以适当调整数据延迟的时间。如可以缩短延迟时间,或者适当延长延迟时间避开数据备份的高峰时间等等。 总之,后期处理重复数据删除技术在一定程度上确实会影响到数据备份的整体效率。但是通过合理的配置,可以将这个负面影响降低到最低的程度。至少与其优势相比,这个负面影响是可以忽略不计的。 误区三:降低备份数据流的读取速度不利于数据备份。
重复数据删除技术简介 这篇文章基于现有的SNIA材料,描述了重复数据删除流程可以进行的几个不同的地方;探讨了压缩与单实例文件以及重复数据删除之间的不同点;研究了次文件层重复数据删除执行的几个不同方式。它同时还解释了哪种类型的数据适合重复数据删除,以及哪些不适合。 介绍 重复数据删除已经成为存储行业非常热门的话题和一大类商业产品。这是因为重复数据删除可以大幅减少购置和运行成本,同时提高存储效率。随着数据量的爆炸性增长,接近一半的数据中心管理员都将数据增长评为三大挑战之一。根据最近的Gartner调查结果,重复数据删除可以减轻存储预算的压力并帮助存储管理员应对数据的增长。 虽然重复数据删除主要被视为一种容量优化技术,不过该技术也可以带来性能上的好处--随着所需存储的数据的减少,系统所需迁移的数据也减少。 重复数据删除技术可以应用在数据生命周期上的不同点上:从来源端重复数据删除,到传输中重复数据删除,一直到存储目标端重复数据删除。这些技术还可以应用在所有的存储层上:备份、归档和主存储。 重复数据删除的解释 无论使用哪种方式,重复数据删除就是一个在不同层次的粒度性上识别重复数据并将重复数据替代为指向共享复件的指针的过程,这样可以节约存储空间和迁移数据所需的带宽。 重复数据删除流程包括跟踪并识别那些被删除的重复数据,以及识别和存储那些新的和独一无二的数据。数据的终端用户完全不会感到这些数据可能已经被执行重复数据删除流程并已经在其数据生命周期中被重建许多次。 对数据进行重复数据删除操作有几种不同的方式。单实例存储(SIS)是在文件或块层次上进行重复数据删除。重复副本会被一个带着指针的实例所取代,而指针则指向原始文件或对象。 次文件层重复数据删除的操作粒度则比文件或对象更小。这种技术有两种常见的方式:固定块重复数据删除--数据被分解成固定长度的部分或块;可变长度重复数据删除--数据根据一个滑行的窗口进行重复数据删除。 数据压缩是对数据进行编码以减小它的大小;它还可以用于那些已经被重复数据删除的数据以进一步减少存储消耗。重复数据删除和数据压缩虽不同但互补--例如,数据可能重复数据删除的效率很高但是压缩的效率很低。 此外,重复数据删除数据可以在线执行;也就是说,在数据被写入目标端的时候进行重复数据删除操作;当然,重复数据删除也可以以后处理的方式执行,也就是在数据已经被写入并存储在磁盘上的时候执行。 这是一个简化的重复数据删除例子,我们有两个由块组成的对象或文件。下图显示了这些对象或文件的情况。对象或文件可以是可变的或基于窗口的部分、固定块或文件集合--可以应用同样的原则。在这个例子中,每个对象所包含的块由字母来区分。
大学数字化校 园云数据中心建设方案 精品方案 2016年 07月
目录 1项目背景4 2建设原则6 3方案设计8 3.1总体拓扑设计8 3.2总体方案描述8 3.3核心网络设计9 3.4数据中心计算资源池建设10 3.4.1需求分析10 3.4.2传统服务器建设模式弊端10 3.4.3服务器虚拟化建设方向12 3.4.4设计描述13 3.4.5服务器集群部署方案17 3.5结构化数据存储资源池建设20 3.5.1需求背景20 3.5.2需求分析20 3.5.3数据特点分析21 3.5.4统一存储系统建设22 3.5.5设计描述23 3.6非结构化大数据云存储建设23 3.6.1建设目标23 3.6.2系统组成24 3.6.3技术特点24 3.6.4分布式底层存储平台26 3.6.5数据共建与共享平台28 3.6.6一体化自动监控平台30 3.6.7数据管理统计平台32 3.7方案可靠性设计35 3.7.1服务器可靠性设计35 3.7.2存储可靠性设计36 3.7.3虚拟化可靠性37 3.7.4管理可靠性38 3.8方案特点39 3.9云平台系统建设40 3.9.1系统架构介绍40 3.9.2云管理平台解决方案特点43 3.9.3统一管理Portal45 3.9.4统一资源管理45 3.9.5物理资源管理46 3.9.6虚拟资源管理47 3.9.7监控管理48 3.9.8智能调度管理49 3.9.9组织管理51 3.9.10用户管理52 3.9.11自助服务发放53 3.9.12自动化运维55
3.9.13统计报表56 3.9.14告警管理56 3.9.15拓扑管理58 3.9.16日志管理58 3.9.17开放API59 4投资配置及预算60 4.1一期建设配置预算60 4.2二期建设配置预算60
第一章、智慧城市云数据中心建设目标 根据《国家电子政务“十二五”规划》(中办发〔2006〕18号)等文件,以智慧城市建设总体思路为指导,建设智慧城市云数据中心,实现统一建设、统一管理、统一使用,为智慧城市和全市(县、区)各部门的业务应用系统提供统一的机房空间、网络资源、存储灾备、安全保障和运维服务,实现信息基础资源互通共享,从底层来联系整个政府机构内外的异构系统、应用、数据库资源等,打通各个职能部门间的“信息孤岛”,满足社会服务与管理,共享基础数据库、协同办公、行政审批与处罚、智慧城管、智慧社区等应用以及其他职能部门之间无缝的共享和交换数据的需要,实现相关部门的资源共享,提升政府的行政效率。 1.1、建设统一云数据中心 作为电子政务统一的基础资源平台,包括:网络资源、计算资源、存储资源等,并对基础资源进行池化,使各部门各单位的用户可以灵活的共享和按需分配。 1.2、建设电子政务外网应用的云计算PAAS平台 作为全市(县、区)电子政务统一的基础资源平台,不仅需要提供IAAS层的基础设施,还能够对上层基于SOA架构的电子政务类应用进行一定的能力支撑,包括基本的数据库、中间件等通用的基础软件资源和电子政务类公共组件类的软件资源。各部门各单位不仅可以共享PAAS层资源,而且可以在PAAS平台的基础上,简单、快速的开发不同功能类的电子政务类应用。
1.3、建立统一高效的运维管理平台 建立基础资源平台的统一运维管理体系,对机房基础设施、IT设备、虚拟机、数据库以及上层应用软件等资源进行统一的检测、动态调度和自动化控制管理,简化运维管理的流程和人工操作,提高基础管理平台的运维效率,降低云数据中心运行成本。1.4、建立统一的安全保障体系 按照国家政务外网统一安全规划,参照等级保护的基本要求,建立统一的政务外网安全保障体系,加强安全管理、统一安全策略、统一标准规范,保障政务外网云数据中心和政务业务系统安全可靠运行。
文件级和块级重复数据删除技术的优缺点 https://www.doczj.com/doc/ae3830631.html, 2008年 12月 12日 11:23 https://www.doczj.com/doc/ae3830631.html, 作者:TechTarget 中国 重复数据删除技术大大提升了基于磁盘的数据保护策略、基于 WAN 的远程分公司备份整合策略、以及灾难恢复策略的价值主张。这种技术能识别重复数据,消除冗余,减少需转移和存储的数据的总体容量。 一些重复数据删除技术在文件级别上运行,另一些则更加深入地检查子文件或数据块。尽管结果存在差异, 但判断文件或块是否唯一都能带来好处。两者的差异在于减少的数据容量不同,判断重复数据所需的时间不同。 文件级重复数据删除技术 文件级重复数据删除技术通常也称为单实例存储(SIS ,根据索引检查需要备份或归档的文件的属性,并与已存储的文件进行比较。如果没有相同文件,就将其存储, 并更新索引;否则,仅存入指针,指向已存在的文件。因此,同一文件只保存了一个实例,随后的副本都以“存根”替代,而“存根”指向原始文件。 块级重复数据删除技术 块级重复数据删除技术在子文件的级别上运行。正如其名所示, 文件通常被分割成几部分——条带或块,并将这些部分与之前存储的信息予以比较,检查是否存在冗余。 最常见的检查重复数据的方法是:为数据块指定标识符, 例如, 利用散列算法产生唯一的 ID 或“足迹”,标识数据块。然后,将产生的 ID 与集中索引对比。如果 ID 已经存在, 就说明以前曾处理并存储该数据块。因此,只需存入指针,指向之前存储的数据。如果 ID 不存在,就说明数据块独一无二。此时,将 ID 添加到索引中,将数据块存储到磁盘中。
探讨重复数据删除技术在中央电台媒资备 份存储系统中应用 导读:本文探讨重复数据删除技术在中央电台媒资备份存储系统中应用,仅供参考,如果觉得很不错,欢迎点评和分享。 探讨重复数据删除技术在中央电台媒资备份存储系统中应用作者/ 刘华 一、引言 2012年初,中央电台媒资备份存储系统正式投入使用。经过一年的运行,大量的节目内容,丰富的历史资料迅速将中央电台媒资备份存储系统填满,严重掣肘了节目归档、素材入库等媒资管理工作。近期中央电台完成了媒资备份存储系统在线扩容工作。备份存储的磁盘容量由之前的20T B,增加30TB,总计达到50T B。短短一年时间,磁盘空间需求已经翻番,可以预见,中央电台媒资备份存储系统还将面临磁盘空间短缺的问题。面对日益爆炸的数据增长和由此不断上升产生的存储压力难题,如何控制和有效降低海量数据显得尤为重要。重复数据删除技术无疑是“瘦身”的一项不错选择。 二、数据冗余 目前,中央电台媒资备份存储系统中,存在大量的重复和冗余数据,造成数据冗余的原因可能是人为的: ·为了确保文件的安全性,无意中将同样的文件存储了多份;
·不同文件的部分内容重复。 冗余数据占据了大量的存储空间,降低了存储空间的利用效率。图1展示了关于媒资备份存储系统中重复数据的比例、来源和分析。 更重要的是:这些大量的冗余数据给媒资备份存储系带来了大量的问题: ·占用大量存储空间,降低存储利用效率; ·增加建设成本; ·增加额外数据管理代价。 三、重复数据删除概念 通过相关研究和对实际系统的分析发现,在海量数字存储系统中,存在大量的重复数据和相似数据。通过重复数据删除技术可以有效去除这些重复数据,对相同数据只存储一份和只存储相似数据的不同部分,可以有效利用存储空间,从而有效降低存储系统成本。 重复数据删除是一种数据缩减技术,旨在最小化文件之间的冗余和重复的无损压缩,并对存储容量进行有效优化。它通过删除数据集中重复的数据,只保留其中一份,从而达到消除冗余数据目的。 目前,绝大多数的重复数据删除算法都工作在二进制数据层次上,通常使用一些数据切分算法,如以整个文件为切分粒度,固定大小的数据切分,或者某些H A S H函数(如R a b i nFingerprinting算法),将每一个带归档的文件切分成若干相互不重叠的数据片段,并把这些数据片段作为逻辑单位进行后续处理和存储操作。在这些数据片段中,只有不重复的数据片段才真正存储到存储设备中,而其他的
云计算数据中心建设方案 2020年10月10日
目录 第一章项目概述 (1) 1.1.现状分析 (1) 1.2.工程概述说明 (2) 1.3.建设意义 (2) 第二章总体方案设计 (4) 2.1.建设原则 (4) 2.2.总体框架设计 (6) 2.2.1.总体架构设计 (6) 2.2.2.资源池逻辑架构设计 (6) 2.2.3.资源池分域设计 (8) 2.2.4.资源池分层设计 (8) 2.2.5.资源池模型设计 (10) 第三章机房硬件及服务器建设 (11) 3.1.网络方案 (11) 3.1.1.需求分析 (11) 3.1.2.网络虚拟化技术 (12) 3.1.3.网络设计 (13) 3.2.存储资源规划 (16) 3.2.1.设计需求 (16) 3.2.2.存储池化技术 (16) 3.2.3.存储设计 (20) 3.3.服务器域规划 (22) 3.3.1.服务器虚拟化技术 (23) 3.3.2.物理主机 (26) 3.4.中间件与数据库域设计 (27) 3.4.1.设计需求 (27) 3.4.2.虚拟机模板技术 (27) 3.5.安全服务域设计 (28)
3.5.1.设计需求 (28) 3.5.2.网络安全 (28) 3.5.3.主机安全 (31) 3.5.4.租户和权限隔离 (32) 3.5.5.虚拟机安全 (32) 第四章机房环境建设 (33) 4.1.装饰装修工程 (33) 4.1.1.机房的平面布局和功能室的划分 (33) 4.1.2.装修材料的选择 (33) 4.1.3.机房装饰的特殊处理 (37) 4.2.供配电系统(UPS系统) (38) 4.2.1.供配电系统设计指标 (38) 4.2.2.供配电系统技术说明 (40) 4.2.3.供配电设计 (41) 4.2.4.电池 (42) 4.3.通风系统(新风和排风) (43) 4.3.1.设计依据 (43) 4.3.2.设计目标 (43) 4.3.3.设计范围 (43) 4.3.4.新风系统 (43) 4.3.5.排烟系统 (44) 4.3.6.风幕机系统 (44) 4.4.精密空调系统 (45) 4.4.1.机房设备配置分析 (45) 4.5.防雷接地系统 (46) 4.5.1.需求分析 (46) 4.5.2.系统设计 (46) 4.6.综合布线系统 (48) 4.6.1.系统需求分析 (48)
如何用EXCEL删除重复数据 EXCEL删除重复数据在新旧版本中操作方法有所不同。 先来说说EXCEL2003吧。 这里就要用到“高级筛选”功能,不多说了。大家可以自己去了解下“高级 筛选”这个功能就知道如何弄了。呵 再来看看重点excel2007 Excel 2007设计得比较人性化,直接就增加了一个“删除重复项”功能!使 用步骤如下: 1、选择需要删除重复项的所有单元格。如果是要对所有数据进行这一操作, 可以任意选择一个单元格。 2、在工具栏中选择“数据”选项卡,再单击“排序与筛选”区中的“删除重 复项”按钮。 3、在弹出的“删除重复项”对话框选择要检查的字段,最终将只对选中的字 段进行比较。 4、最后单击“确定”按钮,多余的重复项就被删除了。 也可按以下的EXCEL删除重复数据三步法: 1、标识重复数据 打开工作表,选中可能存在重复数据或记录的区域。单击“开始”选项卡中的“条件格式”打开菜单,在“突出显示单元格规则”子菜单下选择“重复值”,打开如图1所示对话框。在左边的下拉列表中选择“重复”,在“设置为”下拉列表中选择需要设置的格式(例如“绿填充色深绿色文本”),
就可以在选中区域看到标识重复值的效果,单击“确定”按钮正式应用这种 效果。 2、筛选重复数据 如果需要进一步识别并删除重复数据,可以根据上面的标识结果将数据筛选出来:选中按上述方法标识了重复数据的待筛选区域,单击“数据”选项卡中的“筛选”按钮,使筛选区域首行的各单元格显示下拉按钮。接着单击某个下拉按钮打开菜单,选择“按颜色筛选”子菜单中的“按字体颜色排序”,即可将存在重复数据或记录的行筛选出来,这时就可以查看并手工删 除重复数据了。 3.自动删除重复数据 Excel 2007提供了名为“删除重复项”的功能,它可以快速删除工作表中的重复数据,具体操作方法是:选中可能存在重复数据或记录的区域,单击“数据”选项卡中的“删除重复项”按钮,打开如图2所示对话框。如果需要保留若干完全相同记录中的一条,然后将剩余的相同记录全部删除,必须将如图2中的列标题全部选中,点击“确定”后,会弹出对话框显示删 除结果。
厂商采纳的执行重复数据删除的基本方法有三种与及各种的优缺点。 第一种是基于散列(hash)的方法,Data Domain、飞康、昆腾的DXi 系列设备都是采用SHA-1, MD-5 等类似的算法将这些进行备份的数据流断成块并且为每个数据块生成一个散列(hash)。如果新数据块的散列(hash)与备份设备上散列索引中的一个散列匹配,表明该数据已经被备份,设备只更新它的表,以说明在这个新位置上也存在该数据。 基于散列(hash)的方法存在内置的可扩展性问题。为了快速识别一个数据块是否已经被备份,这种基于散列(hash)的方法会在内存中拥有散列(hash)索引。当被备份的数据块数量增加时,该索引也随之增长。一旦索引增长超过了设备在内存中保存它所支持的容量,性能会急速下降,同时磁盘搜索会比内存搜索更慢。因此,目前大部分基于散列(hash)的系统都是独立的,可以保持存储数据所需的内存量与磁盘空间量的平衡,这样,散列(hash)表就永远不会变得太大。 第二种方法是基于内容识别的重复删除,这种方法主要是识别记录的数据格式。它采用内嵌在备份数据中的文件系统的元数据识别文件;然后与其数据存储库中的其它版本进行逐字节地比较,找到该版本与第一个已存储的版本的不同之处并为这些不同的数据创建一个增量文件。这种方法可以避免散列(hash)冲突(请参阅下面的“不要惧怕冲突”),但是需要使用支持的备份应用设备以便设备可以提取元数据。 ExaGrid Systems的InfiniteFiler就是一个基于内容识别的重复删除设备,当备份数据时,它采用CommVault Galaxy 和Symantec Backup Exec 等通用的备份应用技术从源系统中识别文件。完成备份后,它找出已经被多次备份的文件,生成增量文件(deltas)。多个 InfiniteFilers合成一个网格,支持高达30 TB的备份数据。采用重复删除方法的ExaGrid在存储一个1GB的 .PST文件类的新信息时表现优异,但它不能为多个不同的文件消除重复的数据,例如在四个.PST文件具有相同的附件的情况下。 Sepaton 的用于它的VTL 的DeltaStor也采用内容识别方法,但是它将新文件既与相同位置上的以前的文件版本进行比较,同时也与从其它位置上备份的文件版本进行比较,因此它能够消除所有位置上的重复数据。
若水公司 2017-3-23
目录 1项目建设背景 (2) 2云数据中心潜在安全风险分析 (2) 2.1从南北到东西的安全 (2) 2.2数据传输安全 (2) 2.3数据存储安全 (3) 2.4数据审计安全 (3) 2.5云数据中心的安全风险控制策略 (3) 3数据中心云安全平台建设的原则 (3) 3.1标准性原则 (3) 3.2成熟性原则 (4) 3.3先进性原则 (4) 3.4扩展性原则 (4) 3.5可用性原则 (4) 3.6安全性原则 (4) 4数据中心云安全防护建设目标 (5) 4.1建设高性能高可靠的网络安全一体的目标 (5) 4.2建设以虚拟化为技术支撑的目标 (5) 4.3以集中的安全服务中心应对无边界的目标 (5) 4.4满足安全防护与等保合规的目标 (6) 5云安全防护平台建设应具备的功能模块 (6) 5.1防火墙功能 (6) 5.2入侵防御功能 (7) 5.3负载均衡功能 (7) 5.4病毒防护功能 (8) 5.5安全审计 (8) 6结束语 (8)
1项目建设背景 2云数据中心潜在安全风险分析 云数据中心在效率、业务敏捷性上有明显的优势。然而,应用、服务和边界都是动态的,而不是固定和预定义的,因此实现高效的安全十分具有挑战性。传统安全解决方案和策略还没有足够的准备和定位来为新型虚拟化数据中心提供高效的安全层,这是有很多原因的,总结起来,云数据中心主要的安全风险面临以下几方面: 2.1从南北到东西的安全 在传统数据中心里,防火墙、入侵防御,以及防病毒等安全解决方案主要聚焦在内外网之间边界上通过的流量,一般叫做南北向流量或客户端服务器流量。 在云数据中心里,像南北向流量一样,交互式数据中心服务和分布式应用组件之间产生的东西向流量也对访问控制和深度报文检测有刚性的需求。多租户云环境也需要租户隔离和向不同的租户应用不同的安全策略,这些租户的虚拟机往往是装在同一台物理服务器里的。 传统安全解决方案是专为物理环境设计的,不能将自己有效地插入东西向流量的环境中,所以它们往往需要东西向流量被重定向到防火墙、深度报文检测、入侵防御,以及防病毒等服务链中去。这种流量重定向和静态安全服务链的方案对于保护东西向流量是效率很低的,因为它会增加网络的延迟和制造性能瓶颈,从而导致应用响应时间的缓慢和网络掉线。 2.2数据传输安全 通常情况下,数据中心保存有大量的租户私密数据,这些数据往往代表了租户的核心竞争力,如租户的客户信息、财务信息、关键业务流程等等。在云数据中心模式下,租户将数据通过网络传递到云数据中心服务商进行处理时,面临着几个方面的问题:一是如何确保租户的数据在网络传输过程中严格加密不被窃取;二是如何保证云数据中心服务商在得到数据时不将租户绝密数据泄露出去;三是在云数据中心服务商处存储时,如何保证访问用户经过严格的权限认证并且是合法的数据访问,并保证租户在任何时候都可以安全访问到自身的数据。
Windows Server 2012重复数据删除七项注意 【文章摘要】微软公司敏锐地发现了这一需求,在其最新的服务器操作系统Windows Server 2012中,该公司增加了重复数据删除子系统的特性,它提供了一种方式,在由一个给定的Windows Server实例管理的所有卷上执行重复数据删除。它并是把重复数据删除的任务推给一个硬件或软件层,而是在OS中进行,包括块级和文件级的 - 也就是说,多种类型的数据(例如虚拟机的多个实例)都可以成功地以最小的开销进行重复数据删除。 在当前的“大数据”时代,尽管磁盘空间越来越便宜,I/O速度在提升,但重复数据删除仍是存储管理员最为关注的神奇策略之一,这项技术的存在,使得我们能够以更低的存储成本和管理成本,得到更高的存储效率。 微软公司敏锐地发现了这一需求,在其最新的服务器操作系统Windows Server 2012中,该公司增加了重复数据删除子系统的特性,它提供了一种方式,在由一个给定的Windows Server实例管理的所有卷上执行重复数据删除。它并是把重复数据删除的任务推给一个硬件或软件层,而是在OS中进行,包括块级和文件级的 - 也就是说,多种类型的数据(例如虚拟机的多个实例)都可以成功地以最小的开销进行重复数据删除。 如果您打算实施Windows Server 2012的重复数据删除技术,确保您了解以下七点: 1、重复数据删除默认情况下不启用 不要指望升级到Windows Server 2012之后,节省空间的情况会自动出现。重复数据删除被当做一项文件和存储服务的功能,而不是核心OS组件。为了达到这个目的,您必须启用它并手动配置,在服务器角色文件和存储服务文件和iSCSI服务(Server Roles File And Storage Services File and iSCSI Services)。启用之后,还需要进行基础配置。 2、重复数据删除将无系统负担 在设置重复数据删除技术,微软投入了相当的精力,所以它只要一个很小的系统占用空间,甚至可以运行在有较大的负载的服务器上。这是三条理由: 首先,存储内容只会在n天(默认情况下n为5)之后才重复数据删除,这是用户可配置的。这个时间延迟,阻止了deduplicator试图处理这样的内容:当前的和常用的,或正在被写入到磁盘上的文件(这将构成重大的性能损失)。 其次,重复数据删除受到目录或文件类型的限制。如果您要排除某些类型的文件或文件夹的重复数据删除,您可以指定自如。