
QL Server 2000/2005 分页SQL —单条SQL语句
有关分页SQL 的资料很多,有的使用存储过程,有的使用游标。本人不喜欢使用游标,我觉得它耗资、效率低;使用存储过程是个不错的选择,因为存储过程是经过预编译的,执行效率高,也更灵活。先看看单条SQL 语句的分页SQL 吧。
方法1:
适用于SQL Server 2000/2005
SELECT TOP页大小*
FROM table1
WHERE id NOT IN
(
SELECT TOP页大小*(页数-1) id FROM table1 ORDER BY id
)
ORDER BY id
方法2:
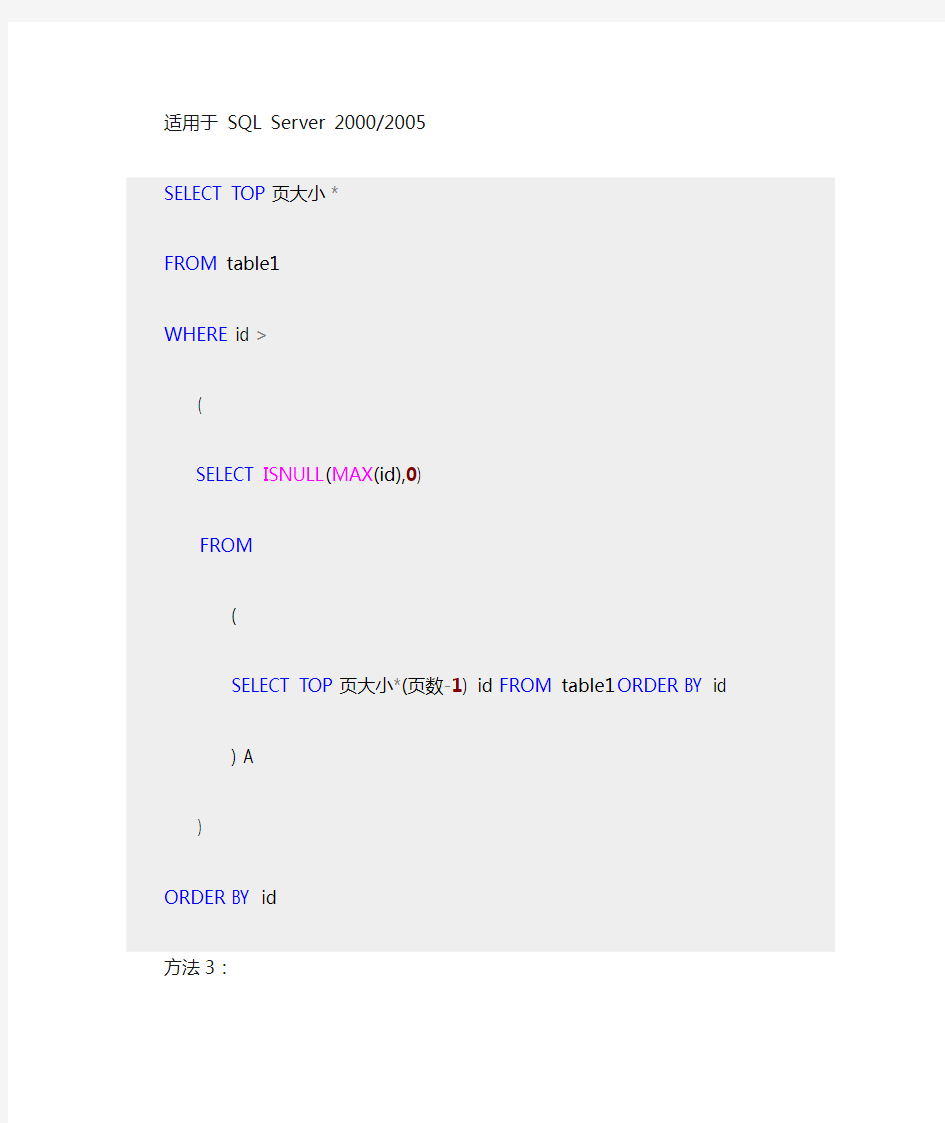
适用于SQL Server 2000/2005
SELECT TOP页大小*
FROM table1
WHERE id >
(
SELECT ISNULL(MAX(id),0)
FROM
(
SELECT TOP页大小*(页数-1) id FROM table1 ORDER BY id
) A
)
ORDER BY id
方法3:
适用于SQL Server 2005
SELECT TOP页大小*
FROM
(
SELECT ROW_NUMBER() OVER (ORDER BY id) AS RowNumber,*FROM table 1
) A
WHERE RowNumber >页大小*(页数-1)
说明,页大小:每页的行数;页数:第几页。使用时,请把“页大小”和“页大小*(页数-1)”替换成数字。
SQLServer(多语句表值函数代码) 代码如下: set ANSI_NULLS ON set QUOTED_IDENTIFIER ON go CREATE FUNCTION [dbo].[ufnGetContactInformation](@ContactID int) RETURNS @retContactInformation TABLE ( -- Columns returned by the function [ContactID] int PRIMARY KEY NOT NULL, [FirstName] [nvarchar](50) NULL, [LastName] [nvarchar](50) NULL, [JobTitle] [nvarchar](50) NULL, [ContactType] [nvarchar](50) NULL ) AS -- Returns the first name, last name, job title and contact type for the specified contact. BEGIN
DECLARE @FirstName [nvarchar](50), @LastName [nvarchar](50), @JobTitle [nvarchar](50), @ContactType [nvarchar](50); -- Get common contact information SELECT @ContactID = ContactID, @FirstName = FirstName, @LastName = LastName FROM [Person].[Contact] WHERE [ContactID] = @ContactID; SET @JobTitle = CASE -- Check for employee WHEN EXISTS(SELECT * FROM [HumanResources].[Employee] e WHERE e.[ContactID] = @ContactID) THEN (SELECT [Title] FROM [HumanResources].[Employee] WHERE [ContactID] = @ContactID) -- Check for vendor
SQLSERVER数据库操作 ******操作前,请确定SQL的服务已经开启******** 一:登录进入sql数据库 1、开始---所有程序---Microsoft SQL Server 2005---SQL Server Management Studio Express 2、此时出现“连接到服务器”的对话框, “服务器名称”设置为SQL数据库所在机器的IP地址 “身份验证”设置为SQL Server身份验证或者Windows 身份验证 填写登录名和密码后,点击“连接”按钮,即可进入到SQL数据库操作界面。 二:新建数据库 登录进去后,右击“数据库”,选择—“新建数据库” 设置数据库名称,在下面的选项卡中还可以设置数据库的初始大小,自动增长,路径。 点击确定,一个数据库就建好了。 三:如何备份的数据库文件。 登录进入后,右击相应的需要备份数据库----选择“任务” 目标下的备份到,点击“添加”按钮可以设置备份数据库保存的路径。 四:如何还原备份的数据库文件。(以本地机器为例子) 1、设置服务器名称,点击右边的下拉框的三角,选择“浏览更多…”。 此时出现查找服务器对话框,选择“本地服务器”---点开“数据库引擎”前面 的三角---选中出现的服务器名称—确定。 (注:可以在“网络服务器”选项卡中设置网络服务器) 2、设置身份验证,选择为“windows身份验证” 3、点击连接按钮,进入数据库管理页面 4、右击“数据库”,选择“还原数据库”,出现还原数据库的对话框 还原的目标----目标数据库,这里设置数据库的名字 还原的源----选择“源设备”,在弹出的对话框中点击“添加”按钮,找到所备 份的数据库文件,确定。 5、此时,在还原数据库对话框中会出现所还原的数据库的信息。在前面选中所需还 原的数据库。确定。 6、为刚刚还原的数据库设置相应的用户。 a点开“安全性”---右击“登录名”---新建登录名 b 设置登录名(假如为admin),并设置为SQL Server身份验证,输入密码,去除 “强制实施密码策略”前的勾。 C 找到导入的数据库,右击此数据库----选择“属性”,在选择页中,点击“文件” 设置所有者,点击右边的按钮,选择“浏览”,找到相应的用户(如admin)。确 定。。 7、此时重新以admin的身份进入,就可操作相应的数据库。
动态语句基本语法 1 :普通SQL语句可以用exec执行 Select * from tableName exec('select * from tableName') exec sp_executesqlN'select * from tableName' -- 请注意字符串前一定要加N 2:字段名,表名,数据库名之类作为变量时,必须用动态SQL declare @fnamevarchar(20) set @fname = 'FiledName' Select @fname from tableName -- 错误,不会提示错误,但结果为固定值FiledName,并非所要。exec('select ' + @fname + ' from tableName') -- 请注意加号前后的单引号的边上加空格 当然将字符串改成变量的形式也可 declare @fnamevarchar(20) set @fname = 'FiledName' --设置字段名 declare @s varchar(1000) set @s = 'select ' + @fname + ' from tableName' exec(@s) -- 成功 exec sp_executesql @s -- 此句会报错 declare @s Nvarchar(1000) -- 注意此处改为nvarchar(1000) set @s = 'select ' + @fname + ' from tableName' exec(@s) -- 成功 exec sp_executesql @s -- 此句正确 3. 输出参数 declare @numint, @sqlsnvarchar(4000) set @sqls='select count(*) from tableName' exec(@sqls) --如何将exec执行结果放入变量中? declare @numint, @sqlsnvarchar(4000) set @sqls='select @a=count(*) from tableName ' execsp_executesql @sqls,N'@aint output',@num output select @num 1 :普通SQL语句可以用Exec执行例: Select * from tableName Exec('select * from tableName')
SQLSERVER数据库、表的创建及SQL语句命令 SQLSERVER数据库,安装、备份、还原等问题: 一、存在已安装了sql server 2000,或2005等数据库,再次安装2008,会出现的问题 1、卸载原来的sql server 2000、2005,然后再安装sql server 2008,否则经常sql server服务启动不了 2、sql server服务启动失败,解决方法: 进入sql server configure manager,点开Sql server 网络配置(非sql native client 配置),点sqlzhh(我sqlserver 的名字)协议,将VIA协议禁用。再启动Sql Server服务,成功 如图: 二、在第一次安装SQLSERVER2008结束后,查看安装过程明细,描述中有较多项插件或程度,显示安装失败。 解决方法:
1、重新启动安装程度setup.exe,选择进行修复安装,至完成即可。 三、先创建数据库XXX,再进行还原数据库时,选择好备份文件XXX.bak,确定后进行还原,会报如下图的错误。 解决方法: 选择好备份数据库文件后,再进入“选项”中,勾选“覆盖现在数据库”即可。
四、查看数据库版本的命令:select @@version 在数据库中,点击“新建查询”,然后输入命令,执行结果如下 五、数据库定义及操作命令: 按照数据结构来组织、存储和管理数据的仓库。由表、关系以及操作对象组成,把数据存放在数据表中。 1、修改数据库密码的命令: EXEC sp_password NULL, '你的新密码', 'sa' sp_password Null,'sa','sa'
Sql Server 常用函数 1,统计函数avg, count, max, min, sum 2, 3,多数聚会不统计值为null的行。可以与distinct一起使用去掉重复的行。可以与group by 来分组4, 5, 2,数学函数 6, 7, SQRT 8, ceiling(n) 返回大于或者等于n的最小整数 9, floor(n), 返回小于或者是等于n的最大整数 10,round(m,n), 四舍五入,n是保留小数的位数 11,abs(n) 12,sign(n), 当n>0, 返回1,n=0,返回0,n<0, 返回-1 13,PI(), 3.1415.... 14,rand(),rand(n), 返回0-1之间的一个随机数 15,3,字符串函数 16, 17,ascii(), 将字符转换为ASCII码, ASCII('abc') = 97 18,char(), ASCII 码转换为字符 19,low(),upper() 20,str(a,b,c)转换数字为字符串。a,是要转换的字符串。b是转换以后的长度,c是小数位数。 str(123.456,8,2) = 123.46 21,ltrim(), rtrim() 去空格 22,left(n), right(n), substring(str, start,length) 截取字符串 23,charindex(子串,母串),查找是否包含。返回第一次出现的位置,没有返回0 24,patindex('%pattern%', expression) 功能同上,可是使用通配符 25,replicate('char', rep_time), 重复字符串 26,reverse(char),颠倒字符串 27,replace(str, strold, strnew) 替换字符串 28,space(n), 产生n个空行 29,stuff(), SELECT STUFF('abcdef', 2, 3, 'ijklmn') ='aijklmnef', 2是开始位置,3是要从原来串中删除的字符长度,ijlmn是要插入的字符串。 30,3,类型转换函数: 31, 32,cast, cast( expression as data_type), Example: 33,SELECT SUBSTRING(title, 1, 30) AS Title, ytd_sales FROM titles WHERE CAST(ytd_sales AS char(20)) LIKE '3%' 34,convert(data_type, expression) 35,4,日期函数 36, 37,day(), month(), year() 38,dateadd(datepart, number, date), datapart指定对那一部分加,number知道加多少,date指定在谁的基础上加。datepart的取值包括,
SQL SERVER函数大全 SQL SERVER命令大全 SQLServer和Oracle的常用函数对比 1.绝对值 S:select abs(-1) value O:select abs(-1) value from dual 2.取整(大) S:select ceiling(-1.001) value O:select ceil(-1.001) value from dual 3.取整(小) S:select floor(-1.001) value O:select floor(-1.001) value from dual 4.取整(截取) S:select cast(-1.002 as int) value O:select trunc(-1.002) value from dual 5.四舍五入 S:select round(1.23456,4) value 1.23460 O:select round(1.23456,4) value from dual 1.2346 6.e为底的幂 S:select Exp(1) value 2.7182818284590451 O:select Exp(1) value from dual 2.71828182 7.取e为底的对数 S:select log(2.7182818284590451) value 1 O:select ln(2.7182818284590451) value from dual; 1 8.取10为底对数 S:select log10(10) value 1 O:select log(10,10) value from dual; 1 9.取平方 S:select SQUARE(4) value 16 O:select power(4,2) value from dual 16
SQLServer语句优化 1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。 需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。 下面的表总结了何时使用聚集索引或非聚集索引(很重要): 动作描述使用聚集索引使用非聚集索引 列经常被分组排序应应 返回某范围内的数据应不应 一个或极少不同值不应不应 小数目的不同值应不应 大数目的不同值不应应 频繁更新的列不应应 外键列应应 主键列应应 频繁修改索引列不应应 事实上,我们可以通过前面聚集索引和非聚集索引的定义的例子来理解上表。如:返回某范围内的数据一项。比如您的某个表有一个时间列,恰好您把聚合索引建立在了该列,这时您查询2004年1月1日至2004年10月1日之间的全部数据时,这个速度就将是很快的,因为您的这本字典正文是按日期进行排序的,聚类索引只需要找到要检索的所有数据中的开头和结尾数据即可;而不像非聚集索引,必须先查到目录中查到每一项数据对应的页码,然后再根据页码查到具体内容。 结合实际,谈索引使用的误区 理论的目的是应用。虽然我们刚才列出了何时应使用聚集索引或非聚集索引,但在实践中以上规则却很容易被忽视或不能根据实际情况进行综合分析。下面我们将根据在实践中遇到的实际问题来谈一下索引使用的误区,以便于大家掌握索引建立的方法。 1、主键就是聚集索引 这种想法笔者认为是极端错误的,是对聚集索引的一种浪费。虽然SQL SERVER默认是在主键上建立聚集索引的。 通常,我们会在每个表中都建立一个ID列,以区分每条数据,并且这个ID列是自动增大的,步长一般为1。我们的这个办公自动化的实例中的列Gid就是如此。此时,如果我们将这个列设为主键,SQL SERVER会将此列默认为聚集索引。这样做有好处,就是可以让您的数据在数据库中按照ID进行物理排序,但笔者认为这样做意义不大。 显而易见,聚集索引的优势是很明显的,而每个表中只能有一个聚集索引的规则,这使得聚集索引变得更加珍贵。 从我们前面谈到的聚集索引的定义我们可以看出,使用聚集索引的最大好处就是能够根据查询要求,迅速缩小查询范围,避免全表扫描。在实际应用中,因为ID号是自动生成的,我们并不知道每条记录的ID号,所以我们很难在实践中用ID号来进行查询。这就使让ID号这个主键作为聚集索引成为一种资源浪费。其次,让每个ID号都不同的字段作为聚集索引也不符合“大数目的不同值情况下不应建立聚合索引”规则;当然,这种情况只是针对用户经常修改记录内容,特别是索引项的时候会
在SQL Server在线图书或者在线帮助系统中,函数的可选参数用方括号表示。在下列的CONVERT()函数例子中,数据类型的length和style参数是可选的: CONVERT (data-type [(length)], expression[,style]) 可将它简化为如下形式,因为现在不讨论如何使用数据类型: CONVERT(date_type, expression[,style]) 根据上面的定义,CONVERT()函数可接受2个或3个参数。因此,下列两个例子都是正确的: SELECT CONVERT(Varchar(20),GETDATE()) SELECT CONVERT(Varchar(20),GETDATE(), 101) 这个函数的第一个参数是数据类型Varchar(20),第2个参数是另一个函数GETDATE()。GETDATE()函数用datetime数据类型将返回当前的系统日期和时间。第2条语句中的第3个参数决定了日期的样式。这个例子中的101指以mm/dd/yyyy格式返回日期。本章后面将详细介绍GETDATE()函数。即使函数不带参数或者不需要参数,调用这个函数时也需要写上一对括号,例如GETDATE()函数。注意在书中使用函数名引用函数时,一定要包含括号,因为这是一种标准形式。 确定性函数 由于数据库引擎的内部工作机制,SQL Server必须根据所谓的确定性,将函数分成两个不同的组。这不是一种新时代的信仰,只和能否根据其输入参数或执行对函数输出结果进行预测有关。如果函数的输出只与输入参数的值相关,而与其他外部因素无关,这个函数就是确定性函数。如果函数的输出基于环境条件,或者产生随机或者依赖结果的算法,这个函数就是非确定性的。例如,GETDATE()函数是非确定性函数,因为它不会两次返回相同的值。为什么要把看起来简单的事弄得如此复杂呢?主要原因是非确定性函数与全局变量不能在一些数据库编程对象中使用(如用户自定义函数)。部分原因是SQL Server缓存与预编译可执行对象的方式。例如,即席查询可以使用任何函数,不过如果打算构建先进的、可重用的编程对象,理解这种区别很重要。 以下这些函数是确定性的: ●?AVG()(所有的聚合函数都是确定性的) ●?CAST() ●?CONVERT() ●?DATEADD() ●?DATEDIFF() ●?ASCII() ●?CHAR() ●?SUBSTRING() 以下这些函数与变量是非确定性的: ●?GETDATE()
易语言操作SQL Server 数据库全过程 最近看到很多初学者在问在易语言中如何操作SQL Serve以外部数据库,也有人提出想要个全面的操作过程,为了让大家能够尽快上手,我给大家简单介绍一下操作SQL的过程,希望能起到抛砖引玉的作用。 由于我本身工作业比较忙,就以我目前做的一个软件的部份内容列给大家简单讲讲吧,高手就不要笑话了,只是针对初学者 第步,首先需要建立一个数据库: 以建立一个员工表为例,各字段如下 3 员工ID int 4 0 0 登陆帐号nvarchar 30 1 0 密码nvarchar 15 1 0 所属部门nvarchar 30 1 0 姓名nvarchar 10 1 0 性别nvarchar 2 1 0 年龄nvarchar 10 1 0 当前职务nvarchar 10 1 0 级别nvarchar 10 1 0 出生日期nvarchar 40 1 0 专业nvarchar 10 1 0 学历nvarchar 8 1 0 婚姻状况nvarchar 4 1 0 身份证号nvarchar 17 1 0 籍贯nvarchar 50 1 0 毕业院校nvarchar 50 1 0 兴趣爱好nvarchar 600 1 0 电话nvarchar 11 1 0 家庭成员nvarchar 20 1 0 工作经历nvarchar 600 1 0 销售行业经验nvarchar 600 1 0 离职原因nvarchar 600 1 0 升迁记录nvarchar 600 1 0 调岗记录 打+ -rd nvarchar 600 1 0 特殊贡献nvarchar 600 1 0 奖励记录nvarchar 600 1 0 处罚记录nvarchar 600 1 0 同事关系nvarchar 4 1 0 企业忠诚度nvarchar 4 1 0 入司日期nvarchar 30 1 0 在职状态nvarchar 4 1 0 上级评语nvarchar 600 1 0 最后登陆时间nvarchar 20 1 0 登陆次数nvarchar 50 1 0 照片image 16 1 一般我习惯用nvarchar,因为这是可变长的的非Unicode数据,最大长度为8000个字符,您可以根
SqlServer教程:经典SQL语句集锦 SQL分类:DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) DCL—数据控制语言(GRANT,REVOKE,COMMIT,ROLLBACK) 首先,简要介绍基础语句:1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:/mssql7backup/MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表:A: create table tab_new like tab_old (使用旧表创建新表) B: create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。7、说明:添加主键: [html]view plaincopyprint? 1. Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:
序号功能语句 1创建数据库(创建之前判断该数据库是否存在)if exists (select * from sysdatabases where name='databaseName') drop database databaseName go Create DATABASE databasename 2删除数据库drop database databasename 3备份数据库USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' BACKUP DATABASE pubs TO testBack 4创建新表create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 5根据已有表创建新表1、use 原数据库名 go select * into 目的数据库名.dbo.目的表名 from 原表名(使用旧表创建新表)2、create table tab_new as select col1,col2… from tab_old definition only 6创建序列create sequence SIMON_SEQUENCE minvalue 1 -- 最小值 maxvalue 999999999999999999999999999 -- 最大值start with 1 -- 开始值 increment by 1 -- 每次加几 cache 20; 7删除新表drop table tabname 8增加一个列Alter table tabname add colname coltype alter table tablename add column_b int identity(1,1) 9删除一个列Alter table tabname drop column colname 10修改一个列ALTER TABLE 表名 ALTER COLUMN 字段名 varchar(30) NOT NULL DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 11添加主键Alter table tabname add primary key(col) 12删除主键Alter table tabname drop primary key(col) 13创建索引create [unique] index idxname on tabname(col…。)14删除索引drop index idxname on tabname 15创建视图create view viewname as select statement 16删除视图drop view viewname 17选择数据记录sql="select * from 数据表 where 字段名=字段值 order by 字段名 [desc]" sql="select * from 数据表 where 字段名 like '%字段值%' order by 字段名 [desc]" sql="select top 10 * from 数据表 where 字段名=字段值 order by 字段名 [desc]" sql="select top 10 * from 数据表 order by 字段名 [desc]" sql="select * from 数据表 where 字段名 in ('值1','值2','值3')" sql="select * from 数据表 where 字段名 between 值1 and 值2" 注:like中"%"匹配0个或多个字符;like中"_"匹配一个字符 18更新数据记录sql="update 数据表 set 字段名=字段值 where 条件表达式" sql="update 数据表 set 字段1=值1,字段2=值2 ……字段n=值n where 条件表达式" 19删除数据记录sql="delete from 数据表 where 条件表达式" sql="delete from 数据表" (将数据表所有记录删除) 20添加数据记录sql="insert into 数据表 (字段1,字段2,字段3 …) values (值1,值2,值3 …)" sql="insert into 目标数据表 select * from 源数据表" (把源数据表的记录添加到目标数据表) 21数据记录统计函数AVG(字段名) 得出一个表格栏平均值 COUNT(*;字段名) 对数据行数的统计或对某一栏有值的数据行数统计MAX(字段名) 取得一个表格栏最大的值 MIN(字段名) 取得一个表格栏最小的值 SUM(字段名) 把数据栏的值相加 引用以上函数的方法: sql="select sum(字段名) as 别名 from 数据表 where 条件表达式"set rs=conn.excute(sql) 用 rs("别名") 获取统计的值,其它函数运用同上。 22查询去除重复值select distinct * from table1 23查询数据库中含有同一这字段的表select name from sysobjects where xtype = 'u' and id in(select id from syscolumns where name = 's3') 24只复制表结构select * into a from b where 1<>1 select top 0 * into b from a 25复制内容set identity_insert aa ON insert into aa(Customer_ID, ID_Type, ID_Number) select Customer_ID, ID_Type, ID_Number from TCustomer; set identity_insert aa OFF 26UNION 运算符(使用运算词的几个查询结果行必须是一致的)UNION 运算符通过组合其他两个结果表(例如TABLE1 和TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随UNION 一起使用时(即UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自TABLE1 就是来自TABLE2。 27EXCEPT 运算符EXCEPT 运算符通过包括所有在TABLE1 中但不在TABLE2 中的行并消除所有重复行而派生出一个结果表。当ALL 随EXCEPT 一起使用时(EXCEPT ALL),不消除重复行。 SQL Server语句 1/3
查询,统计股票主要财务数据,查询Oracle正在执行的SQL语句,查询python模块的帮助文档,查询SQLServer正在执行的语句 查找/etc/passwd下bash为/bin/bash用户的数,查找两个有序数组中的中位数,查找数组中最大值最小值的另一种思路 [代码] [C/C++]代码 #include
//c#删除指定文件夹下的文件方法封装 //C#设置开机启动程序 [代码] [C/C++]代码 #include ☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆sqlserver数据库操作大全——常用语句/技巧集锦/经典语句☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆MS SQL里没有括号时,运算进行的次序将是先乘后除再模后加减 减号(-)也有两种用途:1.作为负号使用 2.从某一列中减去另一列 and or not 如果一个where子句中同时出现这三个操作符 最先评估not然后是and然后是or coalesce哪个不为空用哪个 coalesce(i.ProductID,d.ProductID) @@rowcount 返回上一条语句影响的行数 SQL判断某列中是否包含中文字符或者英文字符 select*from表名where某列like'%[吖-座]%' select*from表名where某列like'%[a-z]%' --数据操作,中英文对照 select--从数据库表中检索数据行和列 insert--向数据库表添加新数据行 delete--从数据库表中删除数据行 update--更新数据库表中的数据 --数据定义 create table--创建一个数据库表 drop table--从数据库中删除表 alter table--修改数据库表结构 create view--创建一个视图 drop view--从数据库中删除视图 create index--为数据库表创建一个索引 drop index--从数据库中删除索引 create proceduer--创建一个存储过程 drop proceduer--从数据库中删除存储过程 create trigger--创建一个触发器 drop trigger--从数据库中删除触发器 create schema--向数据库添加一个新模式 drop schema--从数据库中删除一个模式 create domain--创建一个数据值域 alter domain--改变域定义 drop domain--从数据库中删除一个域 --数据控制 grant--授予用户访问权限 deny--拒绝用户访问 revoke--解除用户访问权限 --事务控制 commit--结束当前事务 rollback--中止当前事务 set transaction--定义当前事务数据访问特征 --程序化SQL declare--为查询设定游标 explan--为查询描述数据访问计划 open--检索查询结果打开一个游标 fetch--检索一行查询结果 close--关闭游标 prepare--为动态执行准备SQL语句 execute--动态地执行SQL语句 describe--描述准备好的查询 ------------------SQL中插入数据的技巧-----------------插入少量数据时可以用: C#数据库连接操作大全+sql语句大全 下面是c#与数据库的连接及增删改除的各种操作,全部经过上机验证。学习软件的过程中,数据库起着至关重要的作用。软件行业里面有句老话,不会数据库就没有入门。软件思想可以慢慢培养,但是数据库的链接是一定要学会的。增删改查各种都不能少。 创建数据库 创建之前判断该数据库是否存在if exists (select * from sysdatabases where name='databaseName') drop database 'databaseName' go Create DATABASE database-name 删除数据库 drop database dbname 备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表:A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 删除新表 drop table tabname 增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 添加主键 Alter table tabname add primary key(col) 说明:删除主键:Alter table tabname drop primary key(col) 创建索引 create [unique] index idxname on tabname(col….) 删除索引:drop index idxname on tabname 注:索引是不可更改的,想更改必须删除重新建。 创建视图 create view viewname as select statement 删除视图:drop view viewname 几个简单的基本的sql语句 选择:select * from table1 where 范围插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围更新:update table1 set field1=value1 where 范围查找:select * from table1 where field1 like ?%value1%? (所有包含…value1?这个模式的字符串)---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count(*) as totalcount from table1 求和:select sum(field1) as sumvalue from SQLSERVER存储过程使用说明书 引言 首先介绍一下什么是存储过程:存储过程就是将常用的或很复杂的工作,预先用SQL语句写好并用一个指定的名称存储起来,并且这样的语句是放在数据库中的,还可以根据条件执行不同SQL语句,那么以后要叫数据库提供与已定义好的存储过程的功能相同的服务时,只需调用execute,即可自动完成命令。 请大家先看一个小例子: create proc query_book as select * from book go --调用存储过程 exec query_book 请大家来了解一下存储过程的语法。 Create PROC [ EDURE ] procedure_name [ ; number ] [ { @parameter data_type } [ VARYING ] [ = default ] [ OUTPUT ] ] [ ,...n ] [ WITH { RECOMPILE | ENCRYPTION | RECOMPILE , ENCRYPTION } ] [ FOR REPLICATION ] AS sql_statement [ ...n ] 一、参数简介 1、procedure_name 新存储过程的名称。过程名必须符合标识符规则,且对于数据库及其所有者必须唯一。 要创建局部临时过程,可以在 procedure_name 前面加一个编号 符 (#procedure_name),要创建全局临时过程,可以在 procedure_name 前面加两个编号符 (##procedure_name)。完整的名称(包括 # 或 ##)不能超过 128 个字符。指定过程所有者的名称是可选的。 2、;number 是可选的整数,用来对同名的过程分组,以便用一条 Drop PROCEDURE 语句即可将同组的过程一起除去。例如,名为 orders 的应用程序使用的过程可以命名为 orderproc;1、orderproc;2 等。Drop PROCEDURE orderproc 语句将除去整个组。如果名称中包含定界标识符,则数字不应包含在标识符中,只应 在 procedure_name 前后使用适当的定界符。 3、@parameter 过程中的参数。在 Create PROCEDURE 语句中可以声明一个或多个参数。用户必须在执行过程时提供每个所声明参数的值(除非定义了该参数的默认值)。存储过程最多可以有 2100 个参数。 使用@符号作为第一个字符来指定参数名称。参数名称必须符合标识符的规则。每个过程的参数仅用于该过程本身;相同的参数名称可以用在其它过程中。默认情况下,参数只能代替常量,而不能用于代替表名、列名或其它数据库对象的名称。 4、data_type 参数的数据类型。所有数据类型(包括 text、ntext 和 image)均可以用作存 易语言操作SQL Server数据库全过程 第一步,首先需要建立一个数据库: 以建立一个员工表为例,各字段如下: 3 员工ID int 4 0 0 登陆帐号 nvarchar 30 1 0 密码 nvarchar 15 1 0 所属部门 nvarchar 30 1 0 姓名 nvarchar 10 1 0 性别 nvarchar 2 1 0 年龄 nvarchar 10 1 0 当前职务 nvarchar 10 1 0 级别 nvarchar 10 1 0 专业 nvarchar 10 1 0 学历 nvarchar 8 1 0 婚姻状况 nvarchar 4 1 0 身份证号 nvarchar 17 1 0 籍贯 nvarchar 50 1 0 毕业院校 nvarchar 50 1 0 兴趣爱好 nvarchar 600 1 0 电话 nvarchar 11 1 0 家庭成员 nvarchar 20 1 0 工作经历 nvarchar 600 1 0 销售行业经验nvarchar 600 1 0 升迁记录 nvarchar 600 1 0 调岗记录 nvarchar 600 1 0 特殊贡献 nvarchar 600 1 0 奖励记录 nvarchar 600 1 0 处罚记录 nvarchar 600 1 0 同事关系 nvarchar 4 1 0 企业忠诚度 nvarchar 4 1 0 入司日期 nvarchar 30 1 0 在职状态 nvarchar 4 1 0 上级评语 nvarchar 600 1 0 最后登陆时间 nvarchar 20 1sqlserver数据库操作语句集锦
C#与sqlserver数据库操作_附实例说明及sql语句大全
SQLSERVER存储过程大总结
易语言操作SQLServer数据库全过程
相关主题
文本预览