
搜索引擎索引系统概述(一)
站长之家(https://www.doczj.com/doc/9c9763054.html,)10月21日消息今日,百度站长平台Lee撰文介绍了
索引系统的相关问题概述。罗列出了如何能够在最快的速度内返回用户查找结果,从而提高用户体验度的相关信息。
搜索引擎索引系统概述(一)原文如下:
众所周知,搜索引擎的主要工作过程包括:抓取、存储、页面分析、索引、检索等几个主要过程。过去几周给大家介绍了抓取相关的简要过程。今天简要介绍一下索引系统,以亿为单位的网页库中查找特定的某些关键词犹如大海里面捞针,也许一定的时间内可以完成查找,但是用户等不起,从用户体验角度我们必须在毫秒级别给予用户满意的结果,否则用户只能流失。怎样才能达到这种要求呢?
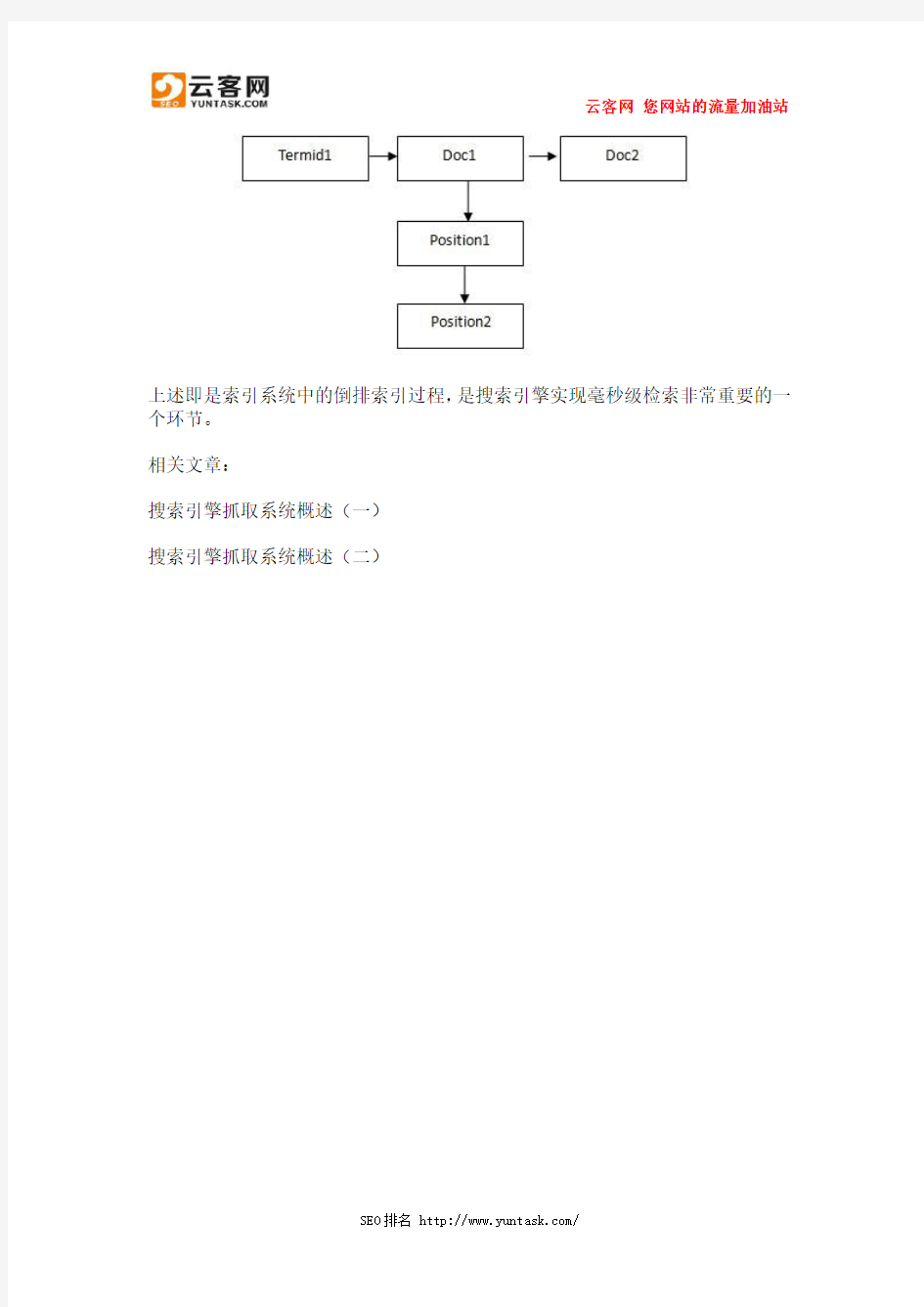
如果能知道用户查找的关键词(query切词后)都出现在哪些页面中,那么用户检索的处理过程即可以想象为包含了query中切词后不同部分的页面集合求交的过程,而检索即变成了页面名称之间的比较、求交。这样,在毫秒内以亿为单位的检索成为了可能。这就是通常所说的倒排索引及求交检索的过程。如下为建立倒排索引的基本过程:
(1)页面分析的过程实际上是将原始页面的不同部分进行识别并标记,例如:title、keywords、content、link、anchor、评论、其他非重要区域等等;
(2)分词的过程实际上包括了切词分词同义词转换同义词替换等等,以对某页面title分词为例,得到的将是这样的数据:term文本、termid、词类、词性等等;
(3)之前的准备工作完成后,接下来即是建立倒排索引,形成{termàdoc},可
以粗略的理解为如下,为什么是【term->doc】,而不是直接应用【doc->term】呢?
上述即是索引系统中的倒排索引过程,是搜索引擎实现毫秒级检索非常重要的一个环节。
相关文章:
搜索引擎抓取系统概述(一)
搜索引擎抓取系统概述(二)
搜索引擎检索技巧
搜索引擎 搜索引擎(search engine),1995年开始搜索引擎以一定的策略从网络收集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。 搜索引擎站---“网络门户”
1、搜索引擎的工作原理 信息的收集处理 信息的检索输出
2、搜索引擎的分类 搜索引擎按其工作方式主要可分为三种: 目录索引类搜索引擎(Search Index/Directory) 机器人搜索引擎(全文搜索引擎)(Full Text Search Engine)元搜索引擎(Meta Search Engine)
2、搜索引擎的分类(续) 目录式搜索引擎 目录式搜索引擎:以人工方式或半自动方式搜集信息,由编辑员查看信息之后,人工形成信息摘要,并将信息置于事先确定的分类框架中。信息大多面向网站,提供目录浏览服务和直接检索服务。 该类搜索引擎因为加入了人的智能,所以信息准确、导航质量高,缺点是需要人工介入、维护量大、信息量少、信息更新不及时。 这类搜索引擎的代表是:yahoo!、Galaxy、Open Directory……
2、搜索引擎的分类(续) 机器人搜索引擎 由一个称为蜘蛛(Spider)的机器人程序以某种策略自动地在互联网中搜集和发现信息,由索引器为搜集到的信息建立索引,由检索器根据用户的查询输入检索索引库,并将查询结果返回给用户。服务方式是面向网页的全文检索服务。 该类搜索引擎的优点是信息量大、更新及时、毋需人工干预,缺点是返回信息过多,有很多无关信息,用户必须从结果中进行筛选。 这类搜索引擎的代表是:AltaVista、Northern Light、Excite、Infoseek、Inktomi、FAST、Lycos、Google;国内代表为:百度等。
搜索引擎基本工作原理 目录 1工作原理 2搜索引擎 3目录索引 4百度谷歌 5优化核心 6SEO优化 ?网站url ? title信息 ? meta信息 ?图片alt ? flash信息 ? frame框架 1工作原理 搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。 1、抓取网页。每个独立的搜索引擎都有自己的网页抓取程序爬虫(spider)。爬虫Spider顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。 2、处理网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重
复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。 3、提供检索服务。用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。 搜索引擎基本工作原理 2搜索引擎 在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库 的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP 地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。 另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。 当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,
中外搜索引擎研究的现状与发展 夏旭李健康 (第一军医大学图书馆广州510515) 摘要: 以WWW网络搜索引擎的发展历程为基础,综述了WWW网络搜索引擎的定义、检索机制、检索规则、词表应用、分类研究、比较研究等方面取得的新进展,探讨搜索引擎发展走向与思路。同时就目前中外搜索引擎普遍存在的问题进行分析,希能对国内中文搜索引擎的开发和准确、快速、全面检索WWW网络乃至因特网信息资源有所启示。 关键词:搜索引擎研究进展综述信息资源管理 由于因特网上信息资源内容广泛、时效性强、访问快速、网络交互搜寻、动态更新,而且还提供快速访问网上信息资源的各种搜索引擎(Search Engines),用于快速搜索WWW网络乃至因特上的有用信息,使得通过WWW网络获取网络信息资源成为国内外研究的一大热点。基于网络的搜索引擎的研制与开发应用成为当前网络信息资源开发应用研究领域的热点。英文搜索引擎“GOOGLE”和中文搜索引擎“百度搜索”的推出,拉开了搜索引擎核心技术争夺战的序幕。可以预言,在今后一段相当长的时间里,搜索引擎还将有长足的发展和进步,检索功能将更趋向于集成化和更具亲和力、更显人性化。 1 搜索引擎的定义、检索机制、检索规则和词表应用 1.1 定义 搜索引擎,Search engines,又称搜索机,Web搜索器,是伴随WWW网络出现的检索网上信息资源的新工具。实质上是一种网页网址检索系统,有的提供分类和关键词检索途径,有的仅提供关键词检索途径。它根据检索规则和从其他信息服务器上得到数据并对数据进行加工处理,自动建立索引,并通过检索接口为用户提供信息查询服务,能够自动对WWW资源建立索引或进行主题分类,并通过查询语法为用户返回匹配资源的系统。搜索引擎主要是由Crawler、Spider、Worm、Robot等计算机软件程序自动在因特网上漫游,不断搜集各类新网址及网页,形成数以千万甚至上亿条记录的数据库。它是通过采集标引众多网络站点来提供全局性网络资源控制与检索机制、将全球WWW网络中所有信息资源作一完整的集合、整理和分类、方便用户查找所需信息的网络检索软件。具有检索面广、信息量大、信息更新速度快,特定主题的检索专指性强等特点。 1.1.1 常规搜索引擎和元搜索引擎 自带索引数据库的搜索引擎通常被称为常规搜索引擎或独立搜索引擎,相应地,集多种常规搜索引擎于一体的搜索引擎则称为(多)元搜索引擎。元搜索引擎是国外搜索引擎开发者新设计的一种集成型搜索引擎,与独立搜索引擎的区别在于:它是通过一个统一的用户界面帮助用户在多个独立搜索引擎中选择和利用合适的搜索引擎,甚至是同时利用多个搜索引擎来实现检索操作。元搜索引擎没有自己独立的数据库,却更多地提供统一界面,形成一个由多个搜索引擎构成的具有独立功能的虚拟逻辑体,通过元搜索引擎的功能实现对这个虚拟逻辑体中各搜索引擎数据库的查询等一切操作。由于元搜索引擎预先配置好多个搜索引擎,每条检索指令都自动通过预先配置的搜索引擎执行,免去了用户逐一记忆和单独使用每个搜索引擎的麻烦。主要的元搜索引擎有ALL-IN-ONE、CUSI、Fun City Web Search、HyperNews、Linksearch、Savvysearch、Metacrawler、Best Search、W3Search Engines、WebSearch、Profusion、Mamma、Avenuesearch、Dogpile、Kwikseek、Findspot、Bytesearch、Webferret、Bluesquirrel Webseeker等。Metacrawler (http://www. https://www.doczj.com/doc/9c9763054.html,)能同时调用6个搜索引擎;Savvysearch (http://www. https://www.doczj.com/doc/9c9763054.html,)可有选择地调用21个独立的搜索引擎,检索Web、Usenet 新闻组、软件、参考工具、技术报告等信息,每次最多并行检索5个搜索引擎的数据库。Profusion (http://www. https://www.doczj.com/doc/9c9763054.html,)最多同时调用9个独立的搜索引擎,调用方式有全部调用、系统自动选择最好的3个、系统自动选择最快的3个、用户从中选取任意个搜索引擎。最新出现的桌面型离线式搜索引擎如Webcompass、WebSeeker、WebFerret、Echosearch、Copernic98等也是元搜索引擎。 1.1.2 集中式搜索引擎和分布式搜索引擎
如何测试搜索引擎的索引量大小(前篇) 背景知识:搜索引擎的质量指标一般包括相关性(Relevance)、时效性(Freshness)、全面性(Comprehensiveness)和可用性(Usability)等四个方面,今天我们要谈的索引量就属于完整性指标的范畴。 首先需要注意的是,对于搜索引擎,网页的索引量和抓取量是不同的概念。搜索引擎的网页抓取数量一般都要远大于索引量,因为抓取的网页中包括很多内容重复或者作弊等质量不高的网页。搜索引擎需要根据算法从抓取的网页当中取其精华,去其糟粕,挑选出有价值的网页进行索引。因此,对用户而言,搜索引擎的索引量大小才更有意义。 其次,无限制增大索引量并不一定能保证搜索质量的提升。一方面,在全面性指标中,除索引量外,还需要考虑到收录网页的质量和不同类型网页的分布。另一方面,搜索引擎的质量指标体系要保证四方面的均衡发展,不是依靠单个指标的突破就可以改善的。目前包括雅虎中国在内的主流中文搜索引擎的网页索引量都在20 亿量级,基本上可以满足用户的日常查询需求。 然而,由于从外部无法直接测算出搜索引擎网页索引量的绝对值大小,很多搜索引擎服务商喜欢对外夸大自己的收录网页数,作为市场噱头。从1998年开始,Krishna Bharat和Andrei Broder就开始研究,如何通过第三方来客观比较不同搜索引擎索引量的大小。8年后,在今年5月份的WWW2006大会上,来自以色列的Ziv Bar-Yossef和Maxim Gurevich由于这方面的出色研究成果夺得了大会唯一的最佳论文奖。他们的研究算出了主流英文搜索引擎的索引量相对大小:雅虎是Google的1.28倍,Google是MSN的1.36倍。他们是如何算出这些数字的呢?下面我们将为搜索引擎爱好者介绍这个算法,以及探讨在中文搜索引擎上是如何应用的。 概述 搜索引擎的索引量或称覆盖率对搜索结果的相关性、时效性和找到率都具有深远的影响。出于市场运作的考虑,各大互联网搜索引擎不时对外公布自己索引的文档数量,然而这些数据往往不同程度地被加入了一些水份,可信度上有一个问号。因此,如何通过搜索引擎的公共接口,也就是通常所说的搜索框,比较客观、准确地测试它的索引量就成为了一个令人关注的问题。 图1 对搜索引擎的索引采样
实验一:全文搜索引擎和目录索引引擎的区别是什么? 全文搜索引擎因为依靠软件进行,所以数据库的容量非常庞大,但是,它的查询结果往往不够准确。 分类目录依靠人工收集和整理网站,能够提供更为准确的查询结果,但收集的内容却非常有限。 1搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。 2搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功;而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。 3当用于在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。 4搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。因此,分类目录型搜索引擎营销方法与技术性搜索引擎的方式有很大的不同,需要充分了解这种区别,才能充分发挥各种不同搜索引擎的作用。 实验二:百度的广告策略如何策划的。谈谈你的看法。 百度的广告策略主要是通过搜索推广、网盟推广、增值服务(百度指数、百度统计、百度推广助手、百度商桥)、其他推广服务(百度图片推广、百度品牌专区、百度火爆地带)、专业客户服务等几项来进行的。 百度推广流程是: 1. 搜索:网民在百度搜索自己关注的关键词信息 2. 推广:企业的推广信息展现在关键词对应的搜索结果页 3. 点击:用户点击推广信息进入企业网站 4. 成交:通过沟通了解,双方达成交易 百度将互联网众多内容网站整合,建立了国内最具实力的联盟体系;百度联盟囊括了24个行业类别的优质网站,加盟合作网站累计超过30万家,影响力覆盖95%以上的中国网民。 百度品牌专区是在网页搜索结果最上方为著名品牌量身定制的资讯发布平台,是为提升网民搜索体验而整合文字、图片、视频等多种展现结果的创新搜索模式。 百度火爆地带是一种针对特定关键词的网络推广方式,按时间段固定付费,出现在百度网页搜索结果第一页的右侧,不同位置价格不同。 百度图片推广是一种针对特定关键词的网络推广方式,按时间段固定付费,出现在百度图片搜索结果第一页的结果区域,不同词汇价格不同。企业购买了图片推广关键词后,就会被主动查找这些关键词的用户找到并向其展示企业推广图片,给企业带来商业机会! 实验三:各个搜索引擎对同类网站的收录情况是否相同?如果不相同,各个搜索引擎有什么特点? 各个搜索引擎对同类网站的收录情况不尽相同。百度与谷歌属于全文引擎搜索,其网页数据库的更新速度也不相同,但收录网页数与更新的速度是谷歌比百度更快,内容更丰富。而雅
搜索引擎基本原理 一.全文搜索引擎 在搜索引擎分类部分我们提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。 另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。 当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,出现的位置/频次,链接质量等——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。 二.目录索引 与全文搜索引擎相比,目录索引有许多不同之处。 首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。用户提交网站后,目录编辑人员会亲自浏览你的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,决定是否接纳你的网站。 其次,搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功。而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。
尤其象Yahoo!这样的超级索引,登录更是困难。(由于登录Yahoo!的难度最大,而它又是商家网络营销必争之地,所以我们会在后面用专门的篇幅介绍登录Yahoo雅虎的技巧) 此外,在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。 最后,搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。更有甚者,如果工作人员认为你提交网站的目录、网站信息不合适,他可以随时对其进行调整,当然事先是不会和你商量的。 目录索引,顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟搜索引擎一样,也是根据信息关联程度排列网站,只不过其中人为因素要多一些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先后顺序决定(也有例外)。 目前,搜索引擎与目录索引有相互融合渗透的趋势。原来一些纯粹的全文搜索引擎现在也提供目录搜索,如Google就借用Open Directory目录提供分类查询。而象 Yahoo! 这些老牌目录索引则通过与Google等搜索引擎合作扩大搜索范围。在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如国内搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。
.html .asp/.aspx .php .jsp Html语言变量、函数、组建、流程、循环、结构 代码结构进行优化 URL 统一资源定位符号universal resources locator 网络地址 Filetype Intitle Inurl 美萍点播系统VOD down:43 Site: 在站内进行检索 Intext: Seo搜索引擎优化-》sem搜索引擎营销-》网络营销 【项目背景介绍】 信息社会,信息以爆炸式的方式增长,网络环境下,搜索引擎是我们通往目的地的必备武器,但是在浩如烟海的网络信息里面,很多网友都只会简单的搜索,往往不能够很好的达到搜索的目的,因此也无法完成对海量信息的综合处理。作为电子商务专业学生,如何高效的完成信息检索,无论是对个人依托网络进行的学习还是今后的网络商务工作,都十分重要。 【项目工具简介和环境要求】 互联网机房 能正常访问互联网、IE插件正常 【项目延伸思考题】 搜索引擎的商用价值 各类搜索引擎通用的高级搜索命令 提高网站被检索可能性的建议 【项目教学难点】 网站备案机制 网站支付流程的合理性 网站联系信息的真实性判断 【项目实施步骤】 项目简介—快速测试—软件包传送—学生自我摸索(安装、调试、搜索等)—手把手—应用场合分析—新模式联想 随着网络技术尤其是WWW站点的快速发展和普及,人们通过Internet获取全球信息的可能性越来越大。可以说,我们所需要的信息,绝大部分都可以通过因特网获取。但是网络信息内容庞杂、分散无序,各种有价值、所需的信息资源淹没在信息的“汪洋大海”中,给人们查询和利用网络信息资源带来了极大的不便。为了更有效地开发和利用网络信息资源,人们研制了许多网络信息检索工具,其中WWW是Internet上增长最快、使用最方便灵活的多媒体信息传输与检索系统,越来越多的用户将自己的信息以WWW的方式在网上发布。WWW服务器已称为互联网上数量最大和增长最快的信息系统,因而可以检索WWW网址网页以及新闻论坛、BBS文章的检索工具——搜索引擎称为查询网络信息的最主要的检索工具。 有人说,会搜索才叫会上网,搜索引擎在我们日常生活中的地位已是举足轻重。你也许是个刚买了“猫”兴冲冲地要上网冲浪,也许已经在互联网上蛰伏了好几年,无论怎样,要想在浩如烟海的互联网信息中找到自己所需的信息,都需要一点点技巧。对于企业而言,学习搜索,提高技巧,就能找到更多的潜在客户。
一种应用于搜索引擎的索引结构研究 ① 刘 畅 张 辉 (北京航空航天大学计算机学院 北京 100083) 摘 要 索引结构是搜索引擎的核心,直接影响着搜索引擎的检索性能。 本文提出了一种新的索引结构,该结构充分利用字符串前缀个数及排列顺序的潜在规律,在查找过程中有效地重用了先前的匹配信息,提高了检索的效率。 关键词:索引结构 搜索引擎 倒排文件中图分类号:TP391.1 Study of Index Structure which Supports the High E ff iciency of Searching Liu Chang Zhang H ui (Dept.of Computer Science and Technology ,BUAA ,Beijing 100083) Abstract :Index structure is the core of a search engine ,it has an influence on the performance of whole search engine direct 2ly.In this paper ,a new index structure is presented ,which takes full advantage of the latent rules about the suffix number and the order of string ,makes full use of the match information got in searching process ,consequently improves the searching efficiency. K ey w ords :structured text ,index structure ,inverted files Class number :TP391.1 1 引言 一个良好的索引结构可以在被检索数据规模庞大的情况下保证检索操作的速度,是实现高效率检索的一个决定性因素[1]。常用的文本索引形式有三类,分别是倒排文件,后缀数组和签名文件。一个搜索引擎可以选用上述任何一种形式的索引结构,但其中应用范围最广的是倒排文件[2]。 本文在倒排文件的基础上,充分利用了字符前缀及字符串排列顺序在索引结构及查找过程中的特点,提出了一种支持高效检索的索引结构。 2 搜索引擎的总体框架 本文所描述的搜索引擎的系统框架如图1所 图1 搜索引擎的基本组成 示,主要包含以下几个主要功能模块: (1)数据预处理,对数据进行预处理,形成一定格式的结构化文本文档。 (2)词语切分,对被检索文本进行切词处理,提取有独立意义的词语。 (3)索引建立,将切分后的词语及其相关信息提交给索引器,使其以一定格式保存在索引数据库中。 (4)查询预处理,调用词法分析器将查询表达式中的词语或模式分离出来,提交检索。 (5)检索,从索引数据库中获取匹配信息。(6)组合排序,对所有匹配信息进行组合和排序处理,实现词组查询、邻近查询或布尔查询等具体处理步骤,得到最终检索结果。 由上可知,索引数据库是整个搜索引擎框架的核心部分,索引器和检索器都是在此基础上工作的,它直接关系到整个搜索引擎的性能。下一节我们将详细介绍索引结构的设计。 3 索引结构的设计 对本文所述搜索引擎,为每个参加索引的文档 分派一个唯一的文档编号,将文本中所出现有独立意义的字符串称为项。我们将数据处理成为结构 ①收到本文时间:2005年1月17日
参数,然后对相应站点进行抓取。 在这里,我要说明一下,就是针对百度来说,site的数值并非是蜘蛛已抓取你页面的数值。比 如site:https://www.doczj.com/doc/9c9763054.html,,所得出的数值并不是大家常说的百度收录数值,想查询具体的百度收录量应该在百度提供的站长工具里查询索引数量。那么site是什么?这个我会在今后的文章中为大家讲解。 那么蜘蛛如何发现新链接呢?其依靠的就是超链接。我们可以把所有的互联网看成一个有向集合的聚集体,蜘蛛由起始的URL集合A沿着网页中超链接开始不停的发现新页面。在这个过程中,每发现新的URL都会与集合A中已存的进行比对,若是新的URL,则加入集合A中,若是已在集合A中存在,则丢弃掉。蜘蛛对一个站点的遍历抓取策略分为两种,一种是深度优先,另一种就是宽度优先。但是如果是百度这类商业搜索引擎,其遍历策略则可能是某种更加复杂的规则,例如涉及到域名本身的权重系数、涉及到百度本身服务器矩阵分布等。 二.预处理。 预处理是搜索引擎最复杂的部分,基本上大部分排名算法都是在预处理这个环节生效。那么搜索引擎在预处理这个环节,针对数据主要进行以下几步处理: 1.提取关键词。 蜘蛛抓取到的页面与我们在浏览器中查看的源码是一样的,通常代码杂乱无章,而且其中还有很多与页面主要内容是无关的。由此,搜索引擎需要做三件事情:代码去噪。去除掉网页中所有的代码,仅剩下文本文字。②去除非正文关键词。例如页面上的导航栏以及其它不同页面共享的公共区域的关键词。③去除停用词。停用词是指没有具体意义的词汇,例如“的”“在”等。 当搜索引擎得到这篇网页的关键词后,会用自身的分词系统,将此文分成一个分词列表,然后储存在数据库中,并与此文的URL进行一一对应。下面我举例说明。 假如蜘蛛爬取的页面的URL是https://www.doczj.com/doc/9c9763054.html,/2.html,而搜索引擎在此页面经过上述操作后提取到的关键词集合为p,且p是由关键词p1,p2,……,pn组成,则在百度数据库中,其相互间的关系是一一对应,如下图。
web搜索引擎的设计与实现
摘要 随着网络的迅猛发展。网络成为信息的极其重要的来源地,越来越多的人从网络上获取自己所需要的信息,这就使得像Google[40],百度[39]这样的通用搜索引擎变成了人们寻找信息必不可少的工具。 本文在深入研究了通用搜索引擎基本原理、架构设计和核心技术的基础上,结合小型搜索引擎的需求,参照了天网,lucene等搜索引擎的原理,构建了一个运行稳定,性能良好而且可扩充的小型搜索引擎系统,本文不仅仅完成了对整个系统的设计,并且完成了所有的编码工作。 本文论述了搜索引擎的开发背景以及搜索引擎的历史和发展趋势,分析了小型搜索引擎的需求,对系统开发中的一些问题,都给出了解决方案,并对方案进行详细设计,编码实现。论文的主要工作及创新如下: 1.在深刻理解网络爬虫的工作原理的基础上,使用数据库的来实现爬虫部分。 2.在深刻理解了中文切词原理的基础之上,对lucene的切词算法上做出了改进的基础上设计了自己的算法,对改进后的算法实现,并进行了准确率和效率的测试,证明在效率上确实提高。 3.在理解了排序索引部分的原理之后,设计了实现索引排序部分结构,完成了详细流程图和编码实现,对完成的代码进行测试。 4.在完成搜索部分设计后,觉得效率上还不能够达到系统的要求,于是为了提高系统的搜索效率,采用了缓存搜索页面和对搜索频率较高词语结果缓存的两级缓存原则来提高系统搜索效率。 关键词:搜索引擎,网络爬虫,中文切词,排序索引
ABSTRACT With the rapidly developing of the network. Network became a vital information source, more and more people are obtaining the information that they need from the network,this making web search engine has become essential tool to people when they want to find some information from internet. In this paper, with in-depth study of the basic principles of general search engines, the design and core technology architecture, combining with the needs of small search engine and in the light of the "tianwang", lucene search engine, I build a stable, good performance and can be expanded small-scale search engine system, this article not only completed the design of the entire system, but also basically completed all the coding work. This article describle not only the background of search engines, but also the history of search engine developing and developing trends,and analyse the needs of small search engines and giving solutionsthe to the problems which was found in the development of the system ,and making a detailed program design, coding to achieve. The main thesis of the article and innovation are as follows: 1.with the deep understanding of the working principle of the network spider.I acheived network spider with using database system. 2.with the deep understanding of Chinese segmentation and segmentation algorithm of lucene system,I made my own segmentation algorithm,and give a lot of tests to my segmentation algorithm to provide that my segmentation algorithm is better. 3.with the deep understanding of sorted and index algorithm,I designed my own sorted and index algorithm with the data-struct I designed and coding it ,it was provided available after lots of tests. 4.after design of search part,I foud the efficiency of the part is not very poor,so I designed two-stage cache device to impove the efficiency of the system. Key words: search engine,net spider, Chinese segmentation,sorted and index
详细介绍常用的几类搜索引擎技术 因特网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就像大海捞针一样,搜索引擎技术恰好解决了这一难题,它可以为用户提供信息检索服务。目前,搜索引擎技术正成为计算机工业界和学术界争相研究、开发的对象。 搜索引擎(Search Engine)是随着WEB信息的迅速增加,从1995年开始逐渐发展起来的技术。 据发表在《科学》杂志1999年7月的文章《WEB信息的可访问性》估计,全球目前的网页超过8亿,有效数据超过9TB,并且仍以每4个月翻一番的速度增长。例如,Google 目前拥有10亿个网址,30亿个网页,3.9 亿张图像,Google支持66种语言接口,16种文件格式,面对如此海量的数据和如此异构的信息,用户要在里面寻找信息,必然会“大海捞针”无功而返。 搜索引擎正是为了解决这个“迷航”问题而出现的技术。搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。 目前,搜索引擎技术按信息标引的方式可以分为目录式搜索引擎、机器人搜索引擎和混合式搜索引擎;按查询方式可分为浏览式搜索引擎、关键词搜索引擎、全文搜索引擎、智能搜索引擎;按语种又分为单语种搜索引擎、多语种搜索引擎和跨语言搜索引擎等。 目录式搜索引擎 目录式搜索引擎(Directory Search Engine)是最早出现的基于WWW的搜索引擎,以雅虎为代表,我国的搜狐也属于目录式搜索引擎。 目录式搜索引擎由分类专家将网络信息按照主题分成若干个大类,每个大类再分为若干个小类,依次细分,形成了一个可浏览式等级主题索引式搜索引擎,一般的搜索引擎分类体系有五六层,有的甚至十几层。 目录式搜索引擎主要通过人工发现信息,依靠编目员的知识进行甄别和分类。由于目录式搜索引擎的信息分类和信息搜集有人的参与,因此其搜索的准确度是相当高的,但由于人工信息搜集速度较慢,不能及时地对网上信息进行实际监控,其查全率并不是很好,是一种网站级搜索引擎。 机器人搜索引擎 机器人搜索引擎通常有三大模块:信息采集、信息处理、信息查询。信息采集一般指爬行器或网络蜘蛛,是通过一个URL列表进行网页的自动分析与采集。起初的URL并不多,随着信息采集量的增加,也就是分析到网页有新的链接,就会把新的URL添加到URL列表,以便采集。
搜索引擎分析 在当今的社会,上网成为了我们大部分人每天必不可少的一部分,网络具有太多的诱惑和开发的潜力,查询资料,消遣娱乐等等,但是这些大部分都离不开搜索引擎技术的应用。今天在我的这篇论文里将会对搜索引擎进行一个分析和相关知识的概括。就如大家所知道的互联网发展早期,以雅虎为代表的网站分类目录查询非常流行。网站分类目录由人工整理维护,精选互联网上的优秀网站,并简要描述,分类放置到不同目录下。用户查询时,通过一层层的点击来查找自己想找的网站。也有人把这种基于目录的检索服务网站称为搜索引擎,但从严格意义上讲,它并不是搜索引擎。1990年,加拿大麦吉尔大学计算机学院的师生开发出Archie。当时,万维网还没有出现,人们通过FTP来共享交流资源。Archie能定期搜集并分析FTP服务器上的文件名信息,提供查找分别在各个FTP主机中的文件。用户必须输入精确的文件名进行搜索,Archie告诉用户哪个FTP服务器能下载该文件。虽然Archie搜集的信息资源不是网页,但和搜索引擎的基本工作方式是一样的:自动搜集信息资源、建立索引、提供检索服务。所以,Archie被公认为现代搜索引擎的鼻祖。 搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索
引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。百度和谷歌等是搜索引擎的代表。那么搜索引擎将来的发展方向和发展的前景又是如何?我们就先从以下的各类主流搜索引擎先进行一个大致的分析。 1.全文索引 全文搜索引擎是当今主要网络搜素时所应用的搜索引擎,在网络上也是大家所熟知的,比如google和百度都是我们平时经常使用的。它们从互联网提取各个网站的信息,建立起数据库,并能检索与用户查询条件相匹配的记录,按一定的排列顺序返回结果。根据搜索结果来源的不同,全文搜索引擎可分为两类,一类拥有自己的检索程序,俗称“蜘蛛”程序或“机器人”程序,能自建网页数据库,搜索结果直接从自身的数据库中调用,上面提到的Google 和百度就属于这种类型;另一类则是租用其他搜索引擎的数据库,并按自定的格式排列搜索结果,如Lycos搜索引擎。在搜索引擎分类部分提到过全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,就是每隔一段时间,搜索引擎就会发启“蜘蛛”程序,对一定IP 地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。而另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生很
以及其他信息。 搜索引擎基本工作原理
与全文搜索引擎相比,目录索引有许多不同之处。 首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。用户提交网站后,目录编辑人员会亲自浏览你的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,决定是否接纳你的网站。 其次,搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功。而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。尤其象Yahoo!这样的超级索引,登录更是困难。 此外,在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。 最后,搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。更有甚者,如果工作人员认为你提交网站的目录、网站信息不合适,他可以随时对其进行调整,当然事先是不会和你商量的。 目录索引,顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟搜索引擎一样,也是根据信息关联程度排列网站,只不过其中人为因素要多一些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先后顺序决定(也有例外)。 目前,搜索引擎与目录索引有相互融合渗透的趋势。原来一些纯粹的全文搜索引擎现在也提供目录搜索,如Google就借用Open Directory目录提供分类查询。而象Yahoo! 这些老牌目录索引则通过与Google等搜索引擎合作扩大搜索范围(注),在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如国内搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。 新竞争力通过对搜索引擎营销的规律深入研究认为:搜索引擎推广是基于网站内容的推广——这就是搜索引擎营销的核心思想。这句话说起来很简单,如果仔细分析会发现,这句话的确包含了搜索引擎推广的一般规律。本文作者在“网站推广策略之内容推广思想漫谈”一文中提出一个观点:“网站内容不仅是大型ICP网站的生命源泉,对于企业网站网络营销的效果同样是至关重要的”。因为网站内容本身也是一种有效的网站推广手段,只是这种推广需要借助于搜索引擎这个信息检索工具,因此网站内容推广策略实际上也就是搜索引擎推广策略的具体应用。 百度谷歌 编辑 查询处理以及分词技术 随着搜索经济的崛起,人们开始越加关注全球各大搜索引擎的性能、技术和日流量。作为企业,会根据搜索引擎的知名度以及日流量来选择是否要投放广告等;作为普通网民,会根据搜索引擎的性能和技术来选择自己喜欢的引擎查找资料;作为技术人员,会把有代表性的搜索引擎作为研究对象。搜索引擎经济的崛起,又一次向人们证明了网络所蕴藏的巨大商机。网络离开了搜索将只剩下空洞杂乱的数据,以及大量等待去费力挖掘的金矿。
一、搜索引擎引题 搜索引擎是什么? 这里有个概念需要提一下。信息检索(Information Retrieval 简称IR) 和搜索(Search) 是有区别的,信息检索是一门学科,研究信息的获取、表示、存储、组织和访问,而搜索只是信息检索的一个分支,其他的如问答系统、信息抽取、信息过滤也可以是信息检索。 本文要讲的搜索引擎,是通常意义上的全文搜索引擎、垂直搜索引擎的普遍原理,比如Google、Baidu,天猫搜索商品、口碑搜索美食、飞猪搜索酒店等。 Lucene 是非常出名且高效的全文检索工具包,ES 和Solr 底层都是使用的Lucene,本文的大部分原理和算法都会以Lucene 来举例介绍。 为什么需要搜索引擎? 看一个实际的例子:如何从一个亿级数据的商品表里,寻找名字含“秋裤”的商品。 使用SQL Like select * from item where name like '%秋裤%' 如上,大家第一能想到的实现是用like,但这无法使用上索引,会在大量数据集上做一次遍历操作,查询会非常的慢。有没有更简单的方法呢,可能会说能不能加个秋裤的分类或者标签,很好,那如果新增一个商品品类怎么办呢?要加无数个分类和标签吗?如何能更简单高效的处理全文检索呢?
使用搜索引擎 答案是搜索,会事先build 一个倒排索引,通过词法语法分析、分词、构建词典、构建倒排表、压缩优化等操作构建一个索引,查询时通过词典能快速拿到结果。这既能解决全文检索的问题,又能解决了SQL查询速度慢的问题。 那么,淘宝是如何在1毫秒从上亿个商品找到上千种秋裤的呢,谷歌如何在1毫秒从万亿个网页中找寻到与你关键字匹配的几十万个网页,如此大的数据量是怎么做到毫秒返回的。 二、搜索引擎是怎么做的? Part1. 分词 分词就是对一段文本,通过规则或者算法分出多个词,每个词作为搜索的最细粒度一个个单字或者单词。只有分词后有这个词,搜索才能搜到,分词的正确性非常重要。分词粒度太大,搜索召回率就会偏低,分词粒度太小,准确率就会降低。如何恰到好处的分词,是搜索引擎需要做的第一步。 正确性&粒度 分词正确性 “他说的确实在理”,这句话如何分词? “他-说-的确-实在-理”[错误语义] “他-说-的-确实-在理”[正确语义] 分词的粒度 “中华人民共和国宪法”,这句话如何分词?
实验五搜索引擎使用实验一、实验目的 1.了解搜索引擎的发展情况和现状;理解搜索引擎的工作原理;2.了解中英文搜索引擎的基本知识和种类; 3. 掌握中英文搜索引擎的初级检索与高级检索两种方式; 4. 分析和对比各种中英文搜索引擎的共性与区别; 5. 了解网络促销的主要方式二、实验内容: 1. 找网上的中英文搜索引擎,并列出5个中文搜索引擎和5个英文搜索引擎的名称; 2.掌握google、百度中高级搜索语法应用方法。 3. 用3个中文、2个英文搜索引擎对同一主题\同一检索词(关键词)进行检索,从检索效果分析得到的检索结果,并比较分析你所选择的搜索引擎的共性与区别。 4.了解网络促销的应用方式和网络广告促销的特点三、实验步骤 1. 搜索引擎的关键词检索(1)进入Google,熟悉并掌握以下功能:掌握Google 的网站检索功能,选取一些关键词在主页上使用“所有网页”检索网页,并通过使用运算符提高查准率;同时使用“高级检索”功能;掌握Google的图像检索功能;掌握Google的网上论坛功能;掌握Google的主题分类检索功能。(2)进入百度,熟悉并掌握Baidu各功能。搜索到至少两个专利介绍网站,并搜索一条关于手机防盗产品的专利技术,写出检索步骤并截图。 2. 搜索引擎的高级搜索语法应用(百度或谷歌) 3.浏览不同类型的网络广告。四、实验报告 1.进入Google,
搜索关键词“搜索引擎优化”,要求结果格式为Word格式;搜索关键词“电子商务”,但结果中不要出现“网络营销”字样;分别写出检索步骤并截图。 2. 精确匹配——双引号和书名号,分别加和不加双引号搜索“山东财经大学”,查看搜索结果。分别加和不加书名号搜索“围城”,查看搜索结果。 3. 搜索同时包含“山东财经大学”和“会计学院”的网页,并查看数量。 4.利用百度搜索两个专利介绍网站,并搜索一条关于手机防盗产品的专利技术,写出检索步骤并截图。 5.选择使用Google和百度,查询某商务信息(自定,如“海尔2012年销售额” )。要求写出:搜索引擎的名称、检索信息的主题、检索结果(列出前5个)。6.分析实验中所使用搜索引擎的优缺点。 7.比较说明中国和美国的网络广告发展情况。五.实验操作答案 1.(1)可以直接搜索word版的搜索引擎优化即可。如下图 (2)操作和上面差不多,看下图 2.不加引号搜索“山东财经大学”时,没有结果;而加引号时则有许多搜索结果。但是加不加引号搜索“围城”时,结果却是相同的。 3.大多为关于山东财经大学的信息,而会计学院则是属于山财的分支。 4. 1.进入