
数据库容灾解决方案
2006-12-02 10:31:42第一章企业面临的挑战以及发展趋势
1.1前言
1958年,Bill Gore 和他的太太Vieve Gore在美国特拉华州Newark市,自己家里的地下室成立了Gore公司。1969年,Gore公司研制成功独特的,具有防风、防水、透气功能的GORE-TEX面料并广泛应用于生产具有功能性、保护性和时尚感的服装和鞋类产品。目前,Gore公司已成为一家在全球拥有6000多名员工、40多间加工厂的跨国公司,并在氟材料的技术研究和应用领域始终占据世界领先地位。
对于Gore这样的以研发新型材料作为企业动力的公司而言,材料的研发过程记录、研发历史数据、研发结果数据是企业最可宝贵的财富。请假设这样一种情况,如果这些数据在一次事故中全部丢失,Gore公司会蒙受多么大的损失?
1983年,当个人电脑还处于萌芽期的时候,美国青年戴尔成立了自己的个人电脑公司,主要销售IBM的旧电脑和自己组装的品牌电脑。那是一个电脑群雄激烈厮杀的年代,当行业的领导者们争相以引人注目的技术推出计算机时,戴尔注意到了平凡的供应链。戴尔公司利用信息技术全面管理公司生产过程。通过互联网,戴尔公司和其上游的配件制造商能够对客户的定单迅速地做出反应:当定单传至戴尔的控制中心时,控制中心把定单分解为一个个子任务,并通过网络分派给各独立配件制造商进行生产。各制造商按照戴尔的电子定单进行生产组装,并按照戴尔控制中心的时间表来供货。戴尔所需要做的只是在成品车间完成组装和系统测试,剩下的就是客户服务中心的事情了。“经过优化后,戴尔供应链每20秒钟汇集一次定单”,“平均库存时间仅有7小时”。虽然没有傲视群雄的杰出技术,现在的戴尔公司却已成长为一个年销售额达410亿美金的企业。
对戴尔公司来说,市场信息的获取、物流信息的传递以及合作伙伴的信息交换,这些共同构成了拉动企业正常运转的信息链。如果有一天,一场意外的事故导致供应链的崩裂,戴尔该如何面对客户恼怒的面容和企业直线下滑的利润?
信息,作为企业宝贵的资源,其重要性已经得到了人们的充分认识。但是我们该如何保护这一资源?假设您就是某企业的一位高级管理人员,当您的企业遭遇以下事故时,您将如何去面对:
1.某一天,证券公司的交易数据因操作失误而损坏;
2.某一天,保险公司的所有保单数据因电源故障而丢失;
3.石油勘探公司辛苦一年获取的地质数据因人为的恶意操作而丢失;
4.医院保存的所有病历因为磁带的损坏而无法使用;
……
这样的例子还有很多很多。
那么这样的事故所带来的后果是什么?至少,很难想象这个不幸的企业还能毫发无损的健康生存。因为,对于信息时代的企业而言,健全的信息往往是维持其运转所必须的基本条件。所以,如何保护企业的信息资源,如何使企业免遭信息灾难,已经成为企业所必须考虑的沉重问题。
第二章容灾概述
2.1 概述
常言道,“知己知彼,百战不殆”。要实现容灾,首先要了解我们的“敌人”-灾难。
那么,哪些事件可以定义为灾难呢?典型的灾难事件是自然灾难,如火灾、洪水、地震、飓风、龙卷风、台风等,还有其它如原先提供给业务运营所需的服务中断,如设备故障、软件错误、电信网络中断和电力故障等等。此外,人为的因素往往也会酿成大祸,如操作员错误、破坏、植入有害代码和恐怖袭击。现阶段,由于我国很多行业正处在高速发展的阶段,很多生产流程和制度仍不完善,加之缺乏经验,这方面的损失屡见不鲜。事实上,我国2003年遭遇的“非典”,某种意义上也是灾难。对此,我们认为需要做到两点:一是建立切实可行的应急机制,这主要包含一套基于充分且清楚地将风险予以分类定义的业务持续计划,二是在危机突然降临时,此计划能被有效执行。
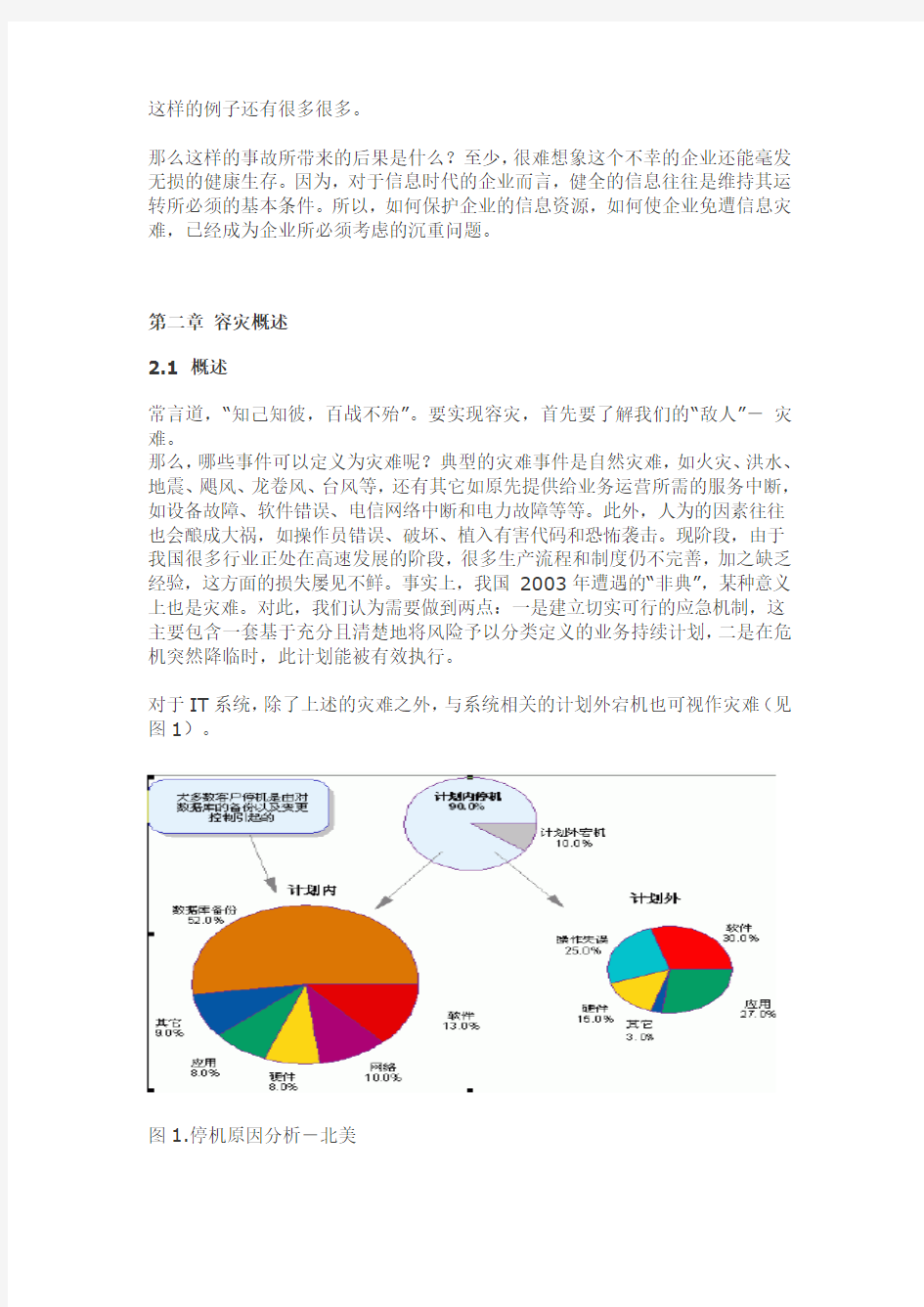
对于IT系统,除了上述的灾难之外,与系统相关的计划外宕机也可视作灾难(见图1)。
图1.停机原因分析-北美
自“9.11”之后,全球各企业均认识到灾难防范保护的重要性。某些大型金融机构之所以能够在两天内恢复营业,其主要原因是它们不仅象一般公司那样在内部进行数据备份,而且在数英里外的数据备份中心也保留着数据备份。这些备份都是通过数据备份软件和数据复制软件进行的。采取了这种措施后,一旦工作现场发生意外,企业就可以立即使用另一套数据。华尔街的金融机构重新对灾难恢复的步骤做了评估,并认识到灾难恢复只是技术手段之一,它们开始强调Business Continuity - 业务连续性而不仅仅是Disaster Recovery - "灾难"恢复。因为过去的"灾难"恢复计划并没有强调全局性及对整个市场的影响,而如何维持业务的连续运作将成为企业运营风险评估中至关重要的一环。事实证明,只有对数据存储备份制定完备、持续且可执行的容灾计划,特别是业务连续计划,才能为人们提供万无一失的数据安全保护。
严格的说,容灾计划包括一系列应急计划,如业务持续计划(BCP-Business Continuity Plan),业务恢复计划(ERP-Business Recovery Plan),运行连续性计划(COOP-Continuity of Operations Plan),事件响应计划(IRP-Incident Response Plan),场所紧急计划(OEP-Occupant Emergency Plan),危机通信计划(CCP-Crisis Communication Plan),灾难恢复计划(DRP-Disaster Recovery Plan)等等。
业务持续计划(BCP)
它是一套用来降低组织的重要营运功能遭受未料的中断风险的作业程序,它可能是人工的或系统自动的。业务持续计划是高层管理人员的首要职责,因为他们被委任于保护公司的资产及公司的生存。业务持续计划的目的是使得一个组织及其信息系统在灾难事件发生时仍可以继续运作。为了能对灾难事件有适当的对策,严密的计划及相关资源的投入是必须的。
业务恢复计划(BRP)
它也叫业务继续计划,涉及紧急事件后对业务处理的恢复,但与BCP不同,它在整个紧急事件或中断过程中缺乏确保关键处理的连续性的规程。BRP的制定应该与灾难恢复计划及BCP进行协调。BRP应该附加在BCP之后。
操作连续性计划(COOP)
COOP 关注位于机构(通常是总部单位)备用站点的关键功能以及这些功能在恢复到正常操作状态之前最多30天的运行。由于COOP涉及到总部级的问题,它和BCP是互相独立制定和执行的。COOP的标准要素包括职权条款、连续性的顺序和关键记录和数据库。由于COOP强调机构在备用站点恢复运行中的能力,所以该计划通常不包括IT运行方面的内容。另外,它不涉及无需重新配置到备用站点的小型危害。但是COOP可以将BCP、BRP和灾难恢复计划作为附录。
危机通信计划(CCP)
机构应该在灾难之前做好其内部和外部通信规程的准备工作。危机通信计划通常由负责公共联络的机构制定。危机通信计划规程应该和所有其它计划协调,以确保只有受到批准的内容公之于众,它应该作为附录包含在BCP中。通信计划通
常指定特定的人员作为在灾难反应中回答公众问题的唯一发言人。它还可以包括向个人和公众散发状态报告的规程,例如记者招待会的模板。
计划(IRP)
事件响应计划建立了处理针对机构的IT系统攻击的规程。这些规程用来协助安全人员对有害的计算机事件进行识别、消减并进行恢复,这些事件的例子包括:对系统或数据的非法访问、拒绝服务攻击、或对硬件、软件、数据的非法更改(如有害逻辑:病毒、蠕虫或木马等)。本计划可以包含在BCP的附录中。
灾难恢复计划(DRP)
正如其名字所表示的,DRP应用于重大的、通常是灾难性的、造成长时间无法对正常设施进行访问的事件。通常,DRP指用于紧急事件后在备用站点恢复目标系统、应用或计算机设施运行的IT计划。DRP的范围可能与IT应急计划重叠,但是DRP的范围比较狭窄,它不涉及无需重新配置的小型危害。根据机构的需要,可能会有多个DRP附加在BCP之后。
场所紧急计划(OEP)
OEP在可能对人员的安全健康、环境或财产构成威胁的事件发生时,为设施中的人员提供反应规程。OEP在设施级别进行制定,与特定的地理位置和建筑结构有关。设施OEP可以附加在BCP之后,但是独立执行。
BCP关注在中断期间和之后维持机构的业务功能。业务功能的一个可能的例子是工资的支付处理或客户的信息处理。BCP可以专门为某个特定的业务处理编写也可以涉及到所有关键的业务处理。IT系统在BCP中被认为是对于业务处理的支持。在某些情况下,BCP可能没有涉及到对过程的长期恢复并使其回到正常运行状态,而只是包含过渡的业务连续性需求。灾难恢复计划、业务继续计划和场所紧急计划可以附加在BCP之后。在BCP中设定的职责和优先顺序应该和其在操作连续性计划(COOP)中的一致以消除可能的冲突。
按一般惯例,备用站点维持机构(通常是总部)要支持长达30天的运行,直到整个系统恢复到正常状态,COOP正是为了达到这个要求而制定的。BCP涉及到在重大中断期间和之后维持业务处理所需的业务功能和IT系统。BRP记录了机构在备用站点进行业务处理的持续规程。与BCP不同,BRP不涉及在紧急事件期间对关键处理的连续性维持。DRP是指设计用于重大和通常是毁灭性灾难之后的目标系统、应用程序或计算机设施的恢复,它是以IT为主的计划。两个计划都提供了IT系统的恢复和继续规程。由于包括了对无需重新部署到备用站点的小型中断进行系统恢复的规程,所以这类计划比DRP的范围更广泛。计算机事件响应计划建立了使安全人员可以确定、防止和恢复针对机构IT系统进行的计算机攻击的规程。OEP则提供了在人员的健康和安全以及环境或财产等受到威胁的紧急情况下,设施工作人员所遵循的指导方针。计划的制定者之间必须进行协调以确保各自的策略和规程能够互为补充,必须将所有有关计划、系统和处理的变化情况反馈给系统和相应处理计划的制定者。
第三章容灾方案分析
在现代企业的IT系统管理过程中,常常会遇到各种有关灾难备份范畴的需求,例如:
“无论发生任何问题,业务系统必须在最短的时间内恢复!”;
“无论发生任何问题,数据绝对不能丢失!”
……
针对这些问题,有经验的管理人员可能会考虑到一系列由此引发的问题:
“究竟有些什么因素可能导致业务中断?”
“究竟最短的时间是多长?”
“是否所有的应用系统数据都不能丢失?”
“这些恢复目标是否合理?”
“目前的IT架构是否能够满足所要求的恢复目标?”
“是否IT系统得到恢复,就意味着业务部门可以对客户进行服务?”
“如何衡量灾难备份方案的投入产出比?”
……
回答以上这些问题的过程,就是考虑企业业务连续性的过程。事实上,随着IT 系统在企业内部应用的深入,灾难备份在企业中已不是IT一个部门的问题,而是整个企业各业务部门与IT部门紧密合作的问题。其内容也不仅局限于数据的备份和应用的接管,还包含了网络的冗余、人员与组织架构的整理、恢复流程的设计等一系列技术以外的范畴。目的在于保证在灾难环境下,企业真正从业务的角度得到保护,而不仅仅是IT环境的恢复。
3.1业务连续性开发模式
各行各业的用户,需要针对自身情况,设立可行的业务恢复目标,并制订出切合实际、投资合理、可靠的业务连续性及技术方案。这种业务连续性开发模式,体现在业务连续性或灾难备份的项目中,就是灾难备份项目实施的步骤:
1. 灾难类型分析
2. 业务冲击分析
3. 当前业务环境及恢复能力分析
4. 容灾策略制订
5. 容灾方案设计
6. 业务连续性流程设计
7. 业务连续性流程及容灾方案管理和测试
其过程如下图所示,是一个周而复始的过程,随着企业内部环境的变化随时灵活变化:
图一. 灾难备份项目实施过程
3.1.1阶段一、灾难类型分析(风险分析)
在本阶段,需要进行详细而量化的风险分析,以确定当前IT环境之中存在哪些无法接受的物理威胁或者可能发生的灾难,并对灾难发生的可能性、目前可能的防护措施的有效性和该灾难所威胁的资产价值进行分析,最终得到带有优先级别的需要防护的灾难列表,并制订可能的处理方法,如接受该灾难发生的风险而不进行防护、自行制订该灾难的防护方法或者采取购买保险等风险转嫁策略。其结果可以由下图表示:
在该图中,横坐标为风险发生的可能性,纵坐标为风险发生所造成的损失。在某一风险发生的可能性极小时,即使造成的损失极大,也可能属于可接受的风险范畴,例如美国的“9?11”事件。但该接受程度是与时俱进的,在“9?11”事件发生
后,事实是大部分没有考虑这种大范围灾难性事件的企业基本没有得到恢复的机会。目前业界也已经将低概率事件逐渐纳入防护的范围。
3.1.2阶段二、业务冲击分析
在本阶段,应该针对各种业务流程进行分析,通过走访各业务部门的相关人员,了解各种业务流程本身对该企业的重要程度。(例如在银行业里,储蓄和单据、网上支付、电话银行等业务就具有不同的优先等级。)同时根据一定的评判原则,得出在核心流程由于灾难的发生而无法正常进行时对企业本身的损失情况。这种损失可能是可以量化的,例如单据的丢失、计算的错误而导致的直接损失;也可以是无形的损失,例如客户满意度及竞争优势的丢失。通过对可量化和不可量化损失的综合考虑,得出各种核心业务流程由于灾难受损的可容忍程度及损失的决策依据。体现在IT系统上,是三个指标:
数据恢复点目标(RECOVERY POINT OBJECTIVE):体现为该流程在灾难发生后,恢复运转时数据丢失的可容忍程度;
恢复时间目标(RECOVERY TIME OBJECTIE):体现为该流程在灾难发生后,需要恢复的紧迫性也即多久能够得到恢复的问题;
网络恢复目标(NETWORK RECOVERY OBJECTIVE):即营业网点什么时候才能通过备份网络与数据中心重新恢复通信的指标;
对于不同的业务流程,这三个指标可能相差非常之大,各个流程本身对这三个目标的优先程度也是不一样的,有的流程可能要求数据丢失的程度较小,但恢复时间可以较长,而另一些流程可能要求短时间内恢复,但数据的丢失程度可以放大一些。这三个指标直接影响所使用的容灾策略及技术方案,并指导企业的投入成本。可以用下图表示:
图3. 业务冲击分析曲线
在该图中,横坐标为灾难持续时间,纵坐标为灾难损失,在某一程度以下属于可接受的程度,即横虚线所示。这种可接受决策应该由负责该流程的业务部门综合考虑后做出。
3.1.3阶段三、企业容灾环境分析
本阶段主要针对业务冲击分析的结果,对目前的内部环境进行评估,得出与恢复目标之间的差距。分析的对象为业务流程需要的资源,如IT环境等。通过本阶段的工作,得出各业务流程所牵涉的企业资产及资源(人力资源、IT架构、技术储备、技术使用程度、网络环境等),并分析得出目前的业务环境对容灾需求、冗余程度、可能造成的数据损失是否能够支持等方面的报告。用下图表示:
图4. 容灾环境分析
图中右边红线为目前环境所支持的容灾能力,左边红线为经过业务冲击分析所得到的需要达到的恢复能力,在灾难恢复时间和灾难造成损失两个方面都需要得到降低。
3.1.4阶段四、容灾策略制订
在本阶段,结合以上各阶段的分析成果,以及企业本身在容灾上的投入能力,制订企业短期、长期范围内的容灾策略和目标,并有意识地将企业本身的人员组成和组织架构做出调整以适应策略要求。最重要的是制订出容灾实施步骤,优先解决最为重点的问题。如下图所示:
3.1.5阶段五、容灾方案设计
容灾方案可供选择的范围很大,但所有的容灾方案都必须考虑的因素包括恢复时间、实施与维护容灾策略所需的投入等。容灾恢复时间的需求越短,所需的实施成本就越大,实施难度也就越高。恢复时间与投入的比值可以用以下这张曲线图加以说明:
图6. 容灾方案层次
图中的各种层次方案可以分别满足不同的数据恢复目标和恢复时间目标,需要根据业务冲击分析的结果,针对每一种业务流程,综合选择能够满足容灾目标的方案。
3.1.6 阶段六、业务连续性流程设计
有了IT系统的恢复方案,只能够保证在灾难环境下,IT系统的恢复能够保证业务冲击分析的目标,但是业务的连续性并不只是IT系统的恢复,还包括办公场地、办公设备、紧急流程、指挥架构、人员调度等等多方面、各部门的综合考虑。只有业务流程执行过程的每一个环节都达到容灾目标的要求,才能够认为业务冲击分析的目标得到了满足。一般来说,每个企业都应该设立一个由领导挂帅,各业务部门和IT部门联合组成的一个容灾指挥小组:
由该小组指挥,IT部门和业务部门分别执行,IT恢复计划和业务连续性计划才能得到同步,从而达到容灾设计的目标。
3.1.7阶段七、业务连续性流程及容灾方案管理和测试
任何制订的计划,都必须经过不断的测试和修正,才能满足企业不断发展的需求。同时,通过测试过程,也能够使企业内部各部门及人员熟悉自己在业务连续性计划中所扮演的角色,做到胸有成竹,才能够在灾难真正发生的时刻有条不紊地开展恢复的过程。
测试的过程可以分为“纸上谈兵”和实地演习两种方式,根据企业需要及对业务影响的不同分别采用。
需要注意的是,无论平时的测试如何完善,也没有办法预测可能发生的灾难情况。关键人员的损失或者关键文档的丢失,都有可能对灾难恢复计划的执行造成巨大影响。因此,在灾难演练过程中要注意到人员的交叉备份情况,除了每个人自己所担负的责任外,尽量做到关键步骤有后备人选作为应变。
第四章容灾系统的设计过程
容灾方案的制定是一个系统的过程,包含一系列的工作及计划的制订,包括Business Continuity Planning (BCP),Business Recovery Plan (BRP),Continuity of Operations Plan (COOP),Incident Response Plan (IRP),Occupant Emergency Plan (OEP),Disaster Recovery Plan (DRP)等计划,在此我们主要介绍灾难恢复计划(Disaster Recovery Plan 或DRP)的制订过程及方法
相比于其它机构和领域,IT系统更容易受到各种灾难的伤害而导致中断,特别是在许多情况下,关键资源可能属于不可控范围(如电力和电信),于是有效的灾难恢复计划、履行计划和对计划进行有效地测试对于削减系统风险与各种服务的不可用性就显得非常重要了。为了保证灾难恢复计划的成功,管理者应该做到以下几点:
1. 理解灾难恢复计划的全部过程及其在整个运行连续性计划和业务连续性计划过程中的地位。
2. 制定或复查其应急策略及计划过程并运用计划周期要素,包括预备计划、业务影响分析、备用站点选择和恢复策略。
3. 制定和复查其灾难恢复计划策略,重点在于计划的维护、培训以及对应急计划的演练。
4.1灾难恢复计划描述
简单地讲,灾难恢复计划的重点在于IT的恢复,如系统、应用、数据和相关的设施(如网络等)。灾备的主要目标是在事件发生时,能够保证全部或部分计算机服务的持续可用。灾难恢复计划就是指,在灾难发生时需要采取的响应步骤的详细过程。
灾难恢复计划包含了一系列灾难发生前、过程中和灾难发生后所采取的动作,灾备方案计划书应该文档化,并经过充分的测试,以保证灾难处理过程中各种操作的连续性和关键资源的可用性。
根据灾难发生的时段或业务中断的严重程度的不同,一个企业的生存能力也依赖于管理层重建其关键业务的能力。一般来讲,这些业务功能的重建需要几年的时间。但是,对于管理层,必须在几个小时或几天的时间内重建,确实是一个难题。重建复杂的商业环境要求有一个经过慎重考虑且具体的计划,以备在灾难发生时执行。从这份计划中我们可以看到,为恢复初始环境,在重建过程中应该采取的步骤。
在一个组织中,灾难的发生是不可预测的。对客户而言,最想知道的事情是灾难什么时候发生。系统和工作人员可以应对灾难,并对可预知的灾难进行反应是最终的目标。换句话说,灾难发生时,不需要等待,而只需要确定你的计划是否可行。
灾难发生时,客户、供应商和员工通常会关心中央处理设备的停机时间。在这种情况下,这些人都没有什么过分的要求,只关心停机的等待时间,而停机时间的多少则依赖于灾难恢复方案。通常,这种停机时间可以分为以下两个部分:
a) 服务丢失
表示从灾难发生到系统恢复正常所损失的时间。
b) 数据丢失
表示用户数据的丢失,也就是说,系统恢复到灾难发生前的数据层面,要花费多少时间可以重新工作。
一个组织的大部分收入,如果过分的依赖于生产系统,一旦应用和网络停机,则将会造成巨额收入的损失。在不同的行业,如果以小时为单位计算收入损失,因灾难而造成的收入减少也是不同的,如能源、电信、制造行业和金融部门,造成巨额收入的损失并不惊奇。另外,实际收入损失所占的百分比也和运营的关键业务有关系
总之,灾备计划就是要保证灾难发生后,能及时地按照一定的策略、过程和技术等方法迅速恢复IT系统、操作和数据。
第五章典型方案介绍
5.1 基于软件的数据备份技术
在应用软件进行灾难备份的解决方案中,应从下面三个层次考虑:
用户应用程序
客户机软件
数据库引擎
其中用户应用程序和客户机软件一般不包含关键数据,几乎所有数据都由数据库引擎管理并放置在数据库服务器中。在这三者之中,数据库中的数据保护最为重要。
一般情况下,用户应用程序和客户机软件只需要将其执行代码和参数配置文件做以备份,当灾难发生时,可以通过这些备份重新安装和配置用户应用程序和客户机软件。
对数据库的备份,如果采用硬件级灾难备份有两种方法:一是采用备份的方法,即定期地将数据备份到硬盘和磁带/磁带库上,这些磁带可以通过运输的方式运到远程,以防磁带在本地的灾难中发生毁坏。这种方法的缺陷是实时性较差,恢复时间较长;另一种做法就是硬件镜像的做法,这种做法在硬件的投资上较大,对两点间的网络带宽有较大的要求。那么,有没有一种两者兼顾的解决方案呢?数据库产品提供的数据库复制技术就是一种两者兼顾的灾难备份解决方案。在前面提到的灾难恢复方案的7个层次中属于第5或第6层次。
数据库复制技术在数据库级别的灾难备份解决方案中可以实现远程容灾。目前已有的产品有DSG Realsync、IBM DB2 HADR、IBM INFORMIX HDR以及ORACLE DATA GUARD。
IBM DB2 HADR是High Availability Disaster Recovery 的缩写,HADR 将HA(高可用性)和INFORMIX DR的技术紧密结合起来。INFORMIX HDR是High Availability Data Replication的缩写。
HDR的工作原理是通过将主数据库服务器(简称为A)的逻辑日志缓冲区复制到备份数据库服务器(简称为B),而且能在主数据库服务器操作失败时自动切换到备份数据库服务器。复制方式有同步方式和异步方式两种。我们将在下面详细介绍HDR的工作原理以及同步方式和异步方式。
正常状态下,主数据库服务器做数据库的读写操作,备份数据库服务器为只读方式。当主数据库服务器失败时,备份数据库服务器会自动接管主数据库服务器的事务处理。此时,备份数据库服务器作为主数据库服务器进行数据库的读写操作。当主数据库服务器被修复后,主数据库服务器作为新的备份数据库服务器。
此时备份数据库服务器虽为只读方式,但并不是空闲的。它可以分担主数据库服务器的负载,例如执行查询、出报表等任务。
数据库复制对硬件的要求相对较低,只要主数据库服务器和备份数据库服务器的硬件配置相同即可,不是必须使用高端存储设备,例如IBM ESS等。主数据库服务器和备份数据库服务器的距离不受限制,而且对网络的压力并不大,但需要更强的数据库管理能力。
下面介绍一下HDR的工作原理。如下图所示:
在逻辑日志缓冲区(Logical Log buffer)刷新之前,它里面所有的交易(Transaction )将拷贝到数据复制缓冲区(Data Replication Buffer)。数据复制缓冲区的大小和逻辑日志缓冲区相同。数据复制缓冲区通过TCP/IP网络将数据发送到备份数据库服务器的数据复制缓冲区中。在备份数据库服务器端,一个数据复制线程接收数据复制缓冲区的数据并把他们放入到恢复缓冲区(Recovery Buffer). 另一个数据复制线程(或一些线程)记录数据库日志信息。主数据库服务器和备份数据库服务器都有一个“Ping”线程在运行,它会定时唤醒并且检查两个数据库服务器的连接。如果任何一台服务器上的“Ping”线程检测到连接中断,都会发一条出错信息到消息日志中。
HDR有两种复制方式:同步方式(Synchronous)和异步方式(Asynchronous)
在同步复制的方式下,主数据库服务器的逻辑日志缓冲区只有在下面的过程完成后才可以刷新:
1. Copy: 逻辑日志缓冲区数据拷贝到数据复制缓冲区;
2. Send: 数据从主数据库服务器的数据复制缓冲区通过网络传送到备份数据库服务器;
3. Acknowledge:当备份数据库服务器接收到数据后发回确认信息;
4. Flush: 此时,主数据库服务器才可以刷新其逻辑日志缓冲区的数据。
采用同步方式的优点是两边数据库服务器的数据一致,但是由于每笔在主数据库服务期提交的交易需要发送到备份数据库服务器而且得到确认后才算真正成功完成,由此而产生的时间延迟会使性能受到一定的影响。
如果采用异步复制方式,主数据库服务器的逻辑日志缓冲区只要在逻辑日志缓冲区的数据拷贝到数据复制缓冲区之后就可以进行刷新了。这样做的缺点是在某些系统失败的情况下,可能会有一些数据还没有来得及通过网络传送到备份数据库服务器;优点是主数据库服务器的性能不受影响。
对于Oracle DATA GUARD的工作原理,大致上与IBM HADR 和INFORMIX
HDR的工作原理类似。
Oracle9i DATA GUARD 通过使用称为备份的数据库来防止数据灾难的出现。它通过将源数据库的重做日志传输并应用到备份数据库中,来使备份数据库与源数据库同步:
可以将重做日志直接从源数据库同步的写到备份数据库,来完成零数据损失的灾难保护,这会给源数据库的性能带来一定的性能损失。
可以将归档的重做日志从源数据库异步的写到备份数据库,来使源数据库在极少的损失性能的前提下,最小化地减少数据的丢失。
如果重做日志数据到达备份数据库后就快速应用到备份数据库,则在源数据库出现问题时便可以快速地切换到备份数据库。然而,如果延缓一定时间后再应用重做日志数据,就可以避免源数据库的错误快速地传播到备份数据库。
DATA GUARD同样也有同步和异步复制两种方式可以选择。
附录A.容灾方案演示环境
6.1基于磁盘系统的PPRC数据级灾难备份解决方案典型应用环境
.图:基于磁盘系统的PPRC数据级灾难备份解决方案典型应用环境拓扑图
6.1.1应用环境基本需求
1. 硬件环境配置
本地生产中心:
IBM xSeries 445(4 CPU, 2GB内存) 1 台
Qlogic 2310光纤通道卡2 块
IBM 2109-F16光纤交换机2 台
IBM ESS800 企业级存储服务器1 台
客户端PC机若干
远程备份中心:
IBM xSeries 445(4 CPU, 2GB内存) 1 台
Qlogic 2310光纤通道卡2 块
IBM 2109-F16光纤交换机2 台
IBM ESS800 企业级存储服务器1 台
客户端PC机若干
软件环境配置
Microsoft Windows Advanced Server(Service Pack 3)
Qlogic 2310: Bios level 1.35 驱动程序8.2.2.61
ESS SDD 1.5.0.1
ESS 800 微码版本: 2.3.1.124
ESS Flashcopy 版本2
ESS PPRC 版本2
IBM 2109-F16固件版本:3.0.2f
3. 网络环境配置
本环境中的网络部分由两部分组成:
第一部分为公网部分,主要承担应用环境中,服务器与服务器之间,服务器与客户机之间的网络通讯;该部分使用10.1.1.X网段,子网掩码为255.255.255.0。
第二部分为管理网段,主要承担应用环境中存储服务器ESS800、光纤交换机的通讯,这里我们命名为ESSNet。该部分使用172.31.1.X网段,子网掩码为255.255.255.0。
4. SAN环境配置
本环境中在本地生产中心和远程备份中心各配置有独立且冗余的光纤交换机。本地生产中心和远程备份中心的每台服务器都至少配置有两块光纤通道卡。本地生产中心和远程备份中心的存储服务器IBM ESS800配置有4块光纤卡,其中两块光纤卡用于服务器与ESS800的连接;另外两块光纤卡分别应用于本地生产中心和远程备份中心的ESS800之间的专用光纤数据链路。本地生产中心和远程备份中心的光纤卡都通过冗余的方式连接到光纤交换机上。本地生产中心和远程备份中心的光纤交换机采用光纤电缆级联起来,构成一个统一的光纤网络。
6.1.2基于磁盘系统的PPRC数据容灾及恢复过程
利用上述典型应用环境,可以实现对相应的生产系统数据进行容灾备份。PPRC进行数据恢复非常简单,由于数据在远程同步保存着同样的数据,因此主
机部分的容灾操作仅需要在远程重新启动主机,而恢复过程则可以反向执行初始化操作。具体过程如下(只考虑主机、存储部分)
a. 灾难发生
(1) 确认灾难,如果需要切换则执行下一步(可自动,但最好由人工控制);
(2) 在远程备份中心停止复制操作(数据复制已经停止,只是释放此数据卷);
(3) 启动远程备份中心主机,主机、数据恢复过程完成。
b. 灾难恢复
(1) 确认原生产中心正常;
(2) 反向建立数据复制对;
(3) 开始同步数据;
(4) 暂停容灾中心业务,然后停止同步过程;
(5) 在生产中心重新启动业务,切换网络,业务恢复;
(6) 建立正向数据同步复制对,容灾业务恢复。
附录B.术语
中文英文
活动状态的备份中心Active Secondary Center
高级对等网络APPN,Advanced Peer to Peer Networking
美国电话电报公司AT&T, American Telephone and Telegraph
异步传输模式ATM,Asynchronous Transfer Mode
业务连续计划BCP, Business Continuity Plan
边界网关协议版本 4 BGP-4,Border Gateway Protocol - 4
基本输入输出系统BIOS,Basic Input/Output System
底线Bottom Line
业务恢复计划BRP, Business Recovery Plan
业务连续性Business Continuity
业务影响分析Business Impact Analysis
层叠PPRC Cascading PPRC
危机通信计划CCP, Crisis Communication Plan
首席信息官CIO,Chief Information Officer
命令行接口Command Line Interface
运行连续性计划COOP, Continuity of Operations Plan
信用事件Credit event
客户关系管理(软件)CRM, Customer Relationship Management
数字数据网DDN,Digital Data Network
"灾难"恢复Disaster Recover
降级操作DOO, Degraded Operations Object
灾难恢复计划DRP, Disaster Recovery Plan
增强版内部网关路由协议EIGRP,Enhanced Interior Gateway Routing Protocol
电子链接Electronic Vaulting
电子链接Electronic vaulting
企业系统连接ESCON,Enterprise System Connection
企业级存储服务器ESS, Enterprise Storage Server
故障切换Failover
光纤连接FICON,Fiber Connection
地理分布并行系统GDPS,Geographically Dispersed Parallel Sysplex
高可用性集群多处理软件HACMP, High Availability Cluster Multi-Processing
高可用性灾难恢复HADR, High Availability Disaster Recovery
IBM的一种灾备软件HAGEO,High Availability Geography
热交换中心Hot Center
国际数据中心IDC,International Data Center
事件响应计划IRP, Incident Response Plan
管理信息系统MIS,Management Information Systems
没有异地数据No off-site Data
网络恢复目标NRO, Network Recovery Object
场所紧急计划OEP, Occupant Emergency Plan
开放最短路由优先协议OSPF,Open Shortest Path First
PTAM卡车运送访问方式 Pickup Truck Access Method
快照Point-in-time Copies
PPRC镜像对PPRC Pairs
对等远程拷贝PPRC, Peer-to-Peer Remote Copy
距离扩展的对等远程拷贝PPRC/XD, Peer-to-Peer Remote Copy/Extended Distance
应用版本的一致性PTF
磁盘冗余阵列RAID,Redundant Array of Disks
恢复时间点RPO, Recovery Point Object
一种串行通信端口RS232
恢复时间RTO, Recovery Time Object
存储区域网络SAN, Storage Area Network
小型计算机系统接口SCSI,Small Computer
System Interface
一家商用软件供应商Siebel
系统网络结构协议SNA,System Network Architectur e
光谱共同基金Spectra mutual fund
备用服务器Standby Server
存储系统级别Storage Device Level
子系统设备驱动程序Subsystem Device Driver
外宕机System down
层次Tier
两数据中心,两个阶段的数据传输承诺Two-Si te Two-Phase Commit
虚拟磁带服务器 VTS, Virtual Tape Server
0数据丢失Zero Data Loss
数据中心容灾备份方案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
数据保护系统 医院备份、容灾及归档数据容灾 解决方案 1、前言 在医院信息化建设中,HIS、PACS、RIS、LIS 等临床信息系统得到广泛应用。医院信息化 HIS、LIS 和 PACS 等系统是目前各个医院的核心业务系统,承担了病人诊疗信息、行政管理信息、检验信息的录入、查询及监控等工作,任何的系统停机或数据丢失轻则降低患者的满意度、医院的信誉丢失,重则引起医患纠纷、法律问题或社会问题。为了保证各业务系统的高可用性,必须针对核心系统建立数据安全保护,做到“不停、不丢、可追查”,以确保核心业务系统得到全面保护。 随着电子病历新规在 4 月 1 日的正式施行,《电子病历应用管理规范(试行)》要求电子病历的书写、存储、使用和封存等均需按相关规定进行,根据规范,门(急)诊电子病历由医疗机构保管的,保存时间自患者最后一次就诊之日起不少于15 年;住院电子病历保存时间自患者最后一次出院之日起不少于 30 年。
2、医院备份、容灾及归档解决方案 针对医疗卫生行业的特点和医院信息化建设中的主要应用,包括:HIS、PACS、RIS、LIS 等,本公司推出基于数据保护系统的多种解决方案,以达到对医院信息化系统提供全面的保护以及核心应用系统的异地备份容灾 数据备份解决方案 针对于医院的 HIS、PACS、LIS 等服务器进行数据备份时,数据保护系统的备份架构采用三层构架。 备份软件主控层(内置一体机):负责管理制定全域内的备份策略和跟踪客户端的备份,能够管理磁盘空间和磁带库库及光盘库,实现多个客户端的数据备份。备份软件主服务器是备份域内集中管理的核心。 客户端层(数据库和操作系统客户端):其他应用服务器和数据库服务器安装备份软件标准客户端,通过这个客户端完成每台服务器的 LAN 或 LAN-FREE 备份工作。另外,为包含数据库的客户端安装数据库代理程序,从而保证数据库的在线热备份。 备份介质层(内置虚拟带库):主流备份介质有备份存储或虚拟带库等磁盘介质、物理磁带库等,一般建议将备份存储或虚拟带库等磁盘介质作为一级备份介质,用于近期的备份数据存放,将物理磁带库或者光盘库作为二级备份介质,用于长期的备份数据存放。
系统容灾解决方案 容灾基本概念 容灾是一个范畴比较广泛的概念,广义上,我们可以把所有与业务连续性相关的内容都纳入容灾。容灾是一个系统工程,它包括支持用户业务的方方面面。而容灾对于IT而言,就是提供一个能防止用户业务系统遭受各种灾难影响及破坏的计算机系统。容灾还表现为一种未雨绸缪的主动性,而不是在灾难发生后的“亡羊补牢”。 从狭义的角度,我们平常所谈论的容灾是指:除了生产站点以外,用户另外建立的冗余站点,当灾难发生,生产站点受到破坏时,冗余站点可以接管用户正常的业务,达到业务不间断的目的。为了达到更高的可用性,许多用户甚至建立多个冗余站点。 容灾系统是指在相隔较远的异地,建立两套或多套功能相同的IT系统,互相之间可以进行健康状态监视和功能切换,当一处系统因意外(如火灾、地震等)停止工作时,整个应用系统可以切换到另一处,使得该系统功能可以继续正常工作。容灾技术是系统的高可用性技术的一个组成部分,容灾系统更加强调处理外界环境对系统的影响,特别是灾难性事件对整个IT节点的影响,提供节点级别的系统恢复功能。 要实现容灾,首先要了解哪些事件可以定义为灾难?典型的灾难事件是自然灾难,如火灾、洪水、地震、飓风、龙卷风、台风等;还有其它如原提供给业务运营所需的服务中断,出现设备故障、软件错误、网络中断和电力故障等等;此外,人为的因素往往也会酿成大祸,如操作员错误、破坏、植入有害代码和病毒袭击等。现阶段,由于信息技术正处在高速发展的阶段,很多生产流程和制度仍不完善,加之缺乏经验,这方面的损失屡见不鲜。 容灾的七个层次 等级1: 被定义为没有信息存储的需求,没有建立备援硬件平台的需求,也没有发展应急计划的需求,数据仅在本地进行备份恢复,没有数据送往异地。这种方式是成本最低的灾难恢复解决方案,但事实上这种恢复并没有真正达到灾难恢复的能力。 一种典型等级1方式就是采用本地磁带库自动备份方案,通过制定相关的备份策略,可以实现系统等级1备份。 等级2: 是一种为许多站点采用的备份标准方式。数据在完成写操作之后,将会送到远离本地的地方,同时具备有数据恢复的程序。在灾难发生后,在一台未启动的计算机上重新完成。系统和数据将被恢复并重新与网络相连。这种灾难恢复方案相对来说成本较低,但同时有难以管理的问题,即很难知道什么样的数据在什么样的地方。这种情况下,恢复时间长短依赖于何时硬件平台能够被提供和准备好。
容灾项目方案设计
目录
容灾技术规范 作为风险防范系统,灾备系统建设本身在总体规划、方案选择和投产实施后的管理运行,以及真正面对灾难时的切换操作等方面也存在着潜在的风险。 计算机信息系统实现数据大集、应用大集中后,系统的运行安全成为风险控制的焦点。目前,已经有多系统开始或准备进行灾备系统的建设,灾备系统建设的目标是减灾容灾,使计算机信息系统和数据能够最大限度地防范和化解各种意外和灾害所带来的风险。然而,与大多数工程一样,灾备系统建设本身在总体规划、方案选择和投产实施后的管理运行,以及真正面对灾难时的切换操作等方面也存在着潜在的风险。 可以说,风险防范系统本身也存在风险点,需要小心应对。 灾备系统建设中所涉及的潜在风险大致可分为技术风险、管理风险和投资风险,其中尤以技术选择风险最大,技术方案选择优越,可以规避一定的管理风险和投资风险。而这三者也存在内在的相互关联,不同灾备级别对应的建设投资规模、所采用的技术以及实施和管理的复杂度也不同,应考虑保护计算机系统的原有投资并提高灾备系统建设投资的利用率。 1.1 容灾的总体规划 1.2 真正的容灾是数据被不间断的一致性访问! 在灾难备份的世界里,是有等级观念的,级别不同,灾备系统所采用的技术和达到的功能是不同的,在系统建设资金投入方面的差距也很巨大。所以,对用户来说,明确灾备系统建设的总体规划十分必要。 1.2.1 技术指标RPO、RTO 衡量容灾技术的两个技术指标RPO、RTO RPO(Recovery Point Objective): 以数据为出发点,主要指的是业务系统所能容忍的数据丢失量。及在发生灾难,容灾系统接替原生产系统运行时,容灾系统与原
2 CMB 分行 MirrorView 演练方案 2008年12月5日 易安信电脑系统(中国)有限公司广州分公司 技术解决方案部 广州市天河北路233号中信广场7401室 电话:(86-20) 38771938 EMC Technical Solution Group
文档信息 项目名称:招商银行分行容灾项目文档版本号: 1.5 文档作者:方天舒生成日期:2008年9月8日文档审核者:审核日期: 文档维护记录 版本号维护日期作者/维护人描述 1.0 2008年9月10日方天舒创建 1.1 2008年11月21日方天舒完善文档内容 1.2 2008年11月27日方天舒完善文档内容 1.3 2008年12月05日方天舒完善文档内容 1.4 2009年2月3日樊军修改文档为通用版本 1.5 2009年2月4日韩震调整格式 版权说明 本文件中出现的任何文字叙述、文档格式、插图、照片、方法、过程等内容,除另有特别注明,版权均属广东发展银行和美国EMC公司所有,受到有关产权 及版权法保护。任何个人、机构未经广东发展银行和美国EMC公司的书面授权许可,不得复制、引用或传播本文件的任何片断,无论通过电子形式或非电子形式。
CMB分行MirrorView/S演练方案 目录 1 前言 (4) 2 MirrorView灾备切换演练步骤 (5) 2.1 演练前的环境准备 (5) 2.2 计划性(planned)的灾备切换演练 (5) 2.3 非计划性(unplanned)的容灾切换演练 (6) 3 MirrorView/S灾备切换演练详细步骤示例(武汉分行) (8) 3.1 演练前的环境准备 (8) 3.1.1 主机环境准备 (8) 3.1.2 应用系统数据备份 (8) 3.1.3 VG信息保存 (9) 3.1.4 LV裸设备的用户权限设置保存 (9) 3.1.5 数据库关键表的记录总数和表占用空间记录 (9) 3.1.6 备份操作系统 (11) 3.1.7 主机系统环境要求 (11) 3.1.8 SAN Switch环境准备 (12) 3.1.9 存储环境准备 (12) 3.2 计划性(planned)的灾备切换演练 (12) 3.2.1 演练前的系统环境检查 (12) 3.2.2 在生产端主机(mbfe)上停止应用系统 (13) 3.2.3 将生产数据由生产端切换到容灾端 (14) 3.2.4 检查容灾端的数据的可用性和完整性 (14) 3.2.5 在容灾端主机(mbfe)上停止应用系统 (16) 3.2.6 将生产数据由容灾端切换到生产端 (16) 3.2.7 检查生产端的数据的可用性和完整性,恢复生产环境 (17) 3.3 非计划性(unplanned)的容灾切换演练 (20) 3.3.1 演练前的系统环境检查 (20) 3.3.2 灾难发生模拟 (21) 3.3.3 在生产端主机(mbfe)上恢复演练环境 (21) 3.3.4 将生产数据由生产端切换到容灾端 (21) 3.3.5 检查容灾端的数据的可用性和完整性 (22) 3.3.6 删除容灾端存储系统(SECONDARY ARRAY)上的MirrorView/S配置 (24) 3.3.7 删除生产端存储系统(PRIMARY ARRAY)上的MirrorView/S配置 (24) 3.3.8 灾难解除模拟 (25) 3.3.9 在容灾端存储系统(SECONDARY ARRAY)重新创建MirrorView/S配置 (25) 3.3.10 在容灾端主机(mbfe)上停止应用系统 (26) 3.3.11 将生产数据由容灾端切换到生产端 (27) 3.3.12 检查生产端的数据的可用性和完整性,恢复生产环境 (27) 3.4 异常处理步骤 (29) 3.4.1 数据库数据恢复 (29) 3.4.2 手工启动应用系统 (30) 第3页
数据保护系统 医院备份、容灾及归档数据容灾 解决方案
1、前言 在医院信息化建设中,HIS、PACS、RIS、LIS 等临床信息系统得到广泛应用。医院信息化HIS、LIS 和PACS 等系统是目前各个医院的核心业务系统,承担了 病人诊疗信息、行政管理信息、检验信息的录入、查询及监控等工作,任何的系统停机或数据丢失轻则降低患者的满意度、医院的信誉丢失,重则引起医患纠纷、法律问题或社会问题。为了保证各业务系统的高可用性,必须针对核心系统建立数据安全保护,做到“不停、不丢、可追查”,以确保核心业务系统得到全面保护。 随着电子病历新规在 4 月 1 日的正式施行,《电子病历应用管理规范(试行)》要求电子病历的书写、存储、使用和封存等均需按相关规定进行,根据规范,门(急)诊电子病历由医疗机构保管的,保存时间自患者最后一次就诊之日起不少于15 年;住院电子病历保存时间自患者最后一次出院之日起不少于30 年。
2、医院备份、容灾及归档解决方案 针对医疗卫生行业的特点和医院信息化建设中的主要应用,包括:HIS、PACS、RIS、LIS 等,本公司推出基于数据保护系统的多种解决方案,以达到对医院信息化系统提供全面的保护以及核心应用系统的异地备份容灾 2.1 数据备份解决方案 针对于医院的HIS、PACS、LIS 等服务器进行数据备份时,数据保护系统的备份架构采用三层构架。 备份软件主控层(内置一体机):负责管理制定全域内的备份策略和跟踪客户端的备份,能够管理磁盘空间和磁带库库及光盘库,实现多个客户端的数据备份。备份软件主服务器是备份域内集中管理的核心。 客户端层(数据库和操作系统客户端):其他应用服务器和数据库服务器安装备份软件标准客户端,通过这个客户端完成每台服务器的LAN 或LAN-FREE 备份工作。另外,为包含数据库的客户端安装数据库代理程序,从而保证数据库的在线热备份。
DSG SuperSync平台容灾演练方案
目录 第一章文档介绍 (3) 1.1摘要 (3) 1.2客户的受益 (3) 1.3责任人............................................................................................................................ 错误!未定义书签。第二章灾备前搭建测试环境进行演练 (4) 第三章灾备演练计划和安排 (6) 2
第一章文档介绍 1.1 摘要 此文档主要阐述了本次软件灾备演练的目的、计划、步骤、分工,以及评测方法,便于医院信息管理部各位领导了解整个演练进程,并做相应检验。 本次在医院处进行的灾备演练评测,是希望通过在实际生产环境中的部署与试用,使医院信息管理部各位领导和专家能够全面了解并评估DSG公司的SuperSync数据库复制软件及其应用技术,为医院未来的企业业务容灾系统建设提供有益的探索。我们精心设计了整个演练过程,力求以医院业务应用的视角来评测该软件。 1.2 客户的受益 通过此文档,客户方信息管理部相关人员将能够更加清晰地了解测试的全部细节,从而便于安排相关检测。 3
第二章灾备前搭建测试环境进行演练 本次评测在医院搭建的测试拓扑图如下 具体模拟灾备测试环境的相关参数列表如下(实际灾备演练过程和此次测试过程一致): 4
目标端软件测试情况: 测试用DSG用户在源端和目标端分别做了insert,update,delete测试,数据均完全一致,两边可以随意切换。下面就是联系应用和用户确定方案和时间,做正式灾备演练测试。 5
财政灾备中心数据容灾解决方案 上海浪擎科技有限公司售前咨询部2012年8月25日
目录 1. 统一统筹,责任分明................................... 错误!未定义书签。2.浪擎灾备中心设计 (3) 2.1 灾备中心网络设计 (3) 2.2 两级监管的优势 (4) 2.3 横向扩展—支撑更多的用户 (5) 2.4 浪擎灾备软件的容灾优势 5 3.附件: (10) 2.4 附件1:部分案例介绍 (10) 1.统一统筹,分级管理
众所周知,集中建设备份中心的目的很明确,就是要本着少花钱多办事的原则,为全区域的各政府部门建立起一个共享的灾备平台,统一规划,节省投资。灾备中心共享化的确是一种符合政府信息化需求特点的建设趋势,即建成后将用一个灾备中心同时满足多个政府部门的数据备份保护需求。同时,灾备是一项长效的、专业的系统工程,只有专业的管理和服务才能将产品、技术、运维、演练有机结合,才能真正将灾备落到实处。然而各政府部门用户普遍“人少事多”,在规划和建设灾难备份和恢复系统时,经常面临着许多同样的困惑,例如对灾难恢复建设不熟悉、没经验,管理、技术、运维都面临调整、垂直行业无标准或标准混乱;投资保护和长远规划难于兼顾等等。因此,集中建立一个共享的灾备平台,实现专业人员集中管理,将灾备作为一种既统一管理、又可自主选择灾备级别的服务提供给各委办局使用,能从根本上避免“建而不管,备未无患”的尴尬,同时因为采用共享式灾备,可以极大的节约灾备中心的软硬件投入。 可见,建立集中的政府灾备中心,确实是一件有很大价值的好事儿。 但另一方面,随着部份地区的探索和实践,也发现政府异地灾备份中心与普遍意义的数据(灾备)中心在建设上存在着较大差异,建设和管理还存在很多难处。由区域政府牵头来建设灾备份中心,其核心难度在于:各条块、各委办局IT系统建设程度不一,数据存储形式复杂。因此如何搭建起一个同时满足各种不同复杂需求的统一灾备中心,并如何将灾备作为一种统一的、可选择的服务提供给各委办局使用,的确是一件非常“棘手”的任务。 结合多年的实际经验,浪擎科技对政府异地备份建设进行了一个小小的总结: 政府异地备份一般由灾备中心、委办局单位、备份系统、管理制度等组成。浪擎科技的建设经验证明,由于多家单位牵涉其中,在灾备系统建设之初就应理顺各方关系,协调好责任与义务。 上海浪擎信息科技有限公司是一家专注于存储、备份与容灾领域解决方案研发的公司,建设了多个大型的政府异地备份系统结合多年的实际经验,浪擎科技对政府异地备份建设进行了一个小小的总结: 政府异地备份一般由灾备中心、委办局单位、备份系统、管理制度等组成。浪擎科技的建设经验证明,由于多家单位牵涉其中,在灾备系统建设之初就应理顺各方关系,协调好责任与义务。 2.浪擎灾备中心设计 2.1灾备中心网络设计 目前政府电子政务网络由政务内网和政务外网构成。政府灾备可以选择电子政务网络作为灾备的基础网络,对于涉密的系统可经由政务内网传输;对于非涉密的系统可经由政务外网传输。数据量特别大的单位可架设专网接入灾备中心。
Oracle数据库异地容灾方案介绍 2008年11月
目录 第一章需求分析 (4) 1.1 序言 (4) 1.2 用户现状 (4) 1.2.1 系统平台 (4) 1.2.2 数据库平台 (6) 1.3 用户需求 (7) 1.3.1 日常功能 (7) 1.3.2 故障切换 (7) 1.3.3 基本要求 (7) 1.3.4 性能要求 (8) 1.3.5 数据一致性 (9) 1.3.6 系统兼容性 (9) 1.3.7 高可用性 (10) 1.3.8 健壮性要求 (10) 1.3.9 设备无关性 (10) 1.3.10 管理监控功能 (11) 第二章Oracle Data Guard介绍 (12) 2.1 Data Guard实现原理 (12) 2.2 Oracle Data Guard 优势 (15) 2.3 Data Guard提供的保护模式 (16) 2.4 Data Guard实现方式以及对系统的限制要求 (17) 2.5 切换方式 (17) 第三章系统建议方案 (19) 3.1 Data Guard优势 (19) 3.2 Data Guard运行模式 (19) 3.3 Data Guard保护模式 (20)
3.4 Data Guard初始安装步骤 (20) 3.5 用户需求点对点应答 (21) 3.5.1 日常功能 (21) 3.5.2 故障切换 (22) 3.5.3 基本要求 (23) 3.5.4 性能要求 (23) 3.5.5 数据一致性 (25) 3.5.6 系统兼容性 (26) 3.5.7 高可用性 (26) 3.5.8 健壮性要求 (27) 3.5.9 设备无关性 (27) 3.5.10 管理监控功能 (28)
EMC异地容灾方案 大家都知道NAS具有低TCO、扩充性、跨平台、高可用性、高速度、方便的安装、维护、使用等特点,但是廉价的NAS系统采用了以软件构建RAID的方式,当系统负荷较重的时候,NAS系统中的处理器性能瓶颈也会引发传输速率的明显下降,正因为这样许多企业在选购NAS的同时使用更加安全有效地存储备份方法,从而有效保证了数据的安全性。 什么是数据备份? 数据备份顾名思义就是将原有的资料重新复制进行保留,以便在特殊情况下可以重新利用。数据备份就像我们生活中的汽车备胎,一旦出现故障我们只要将备胎换上去就可以重新使用了。除了汽车备胎我们在生活中所使用的钥匙也都是备份思想的体现。我们要记住数据备份是最基础的,没有它一切先进的技术也都没有意义了。 数据备份的目的 很多人对数据备份有着错误的理解,认为只要将数据备份到本地就可以万事大吉了。肯定地说存在这种想法的人有很多,在实际生活中有很多案例证明了数据丢失后而不能正常恢复,这种灾难性后果可能会对金融及电信行业带来无法估量的损失。进行数据备份目的是将原有数据重新利用,但是在绝大部分情况下备份的数据是没有任何作用的。在实际工程中经常会遇到一些系统集成商向客户介绍他们的产品是如何的方便、可靠,但光有数据备份还不行,一旦出现故障必须将数据恢复才可以,一个不能恢复的备份对任何企业来说都是没有意义的。因此只有安全、可靠、高效地恢复数据,才是系统备份的真正目的。 数据备份在存储领域的地位 在SAN和NAS这些新的存储系统结构中,传统的备份技术在结构上也得到了长足的发展。数据备份作为存储领域的一个重点,其在存储系统中的地位和作用都是不可替代的。从LAN Free备份到无服务器备份,这些备份领域里的新兴技术正在日渐成熟和完善。对一个完整的IT系统而言,备份工作是其中必不可少的组成部分。之所以备份工作具有很大的意义,是因为它更像是我们为了留住美好时光而拍摄的照片或影片,把这些数据通过刻录等方式永久的保存了下来,供我们怀旧和欣赏。显然当然我们看到一张儿时的照片就回到从前的可能性根本没
xxxxxxxxxxxxxxxxxxxxxxxx项目 容 灾 演 练 方 案
目录 第一章、总拓扑图 (4) 第二章、网络容灾演练方案 (5) 2.1 核心交换机 (5) 2.1.1 参加演练人员 (6) 2.1.2 演练流程 (6) 2.1.3 准备工作 (6) 2.1.4 演练步骤 (8) 2.1.5 预期演练结果 (9) 2.2 radware负载均衡器 (9) 2.2.1 参加演练人员 (9) 2.2.2 演练流程 (10) 2.2.3 准备工作 (10) 2.2.4 演练步骤 (13) 2.2.5 预期演练结果 (14) 第三章、应用服务器容灾演练方案 (14) 3.1 Vmware HA (14) 3.1.1 参加演练人员 (15) 3.1.2 演练流程 (15) 3.1.3 准备工作 (15) 3.1.4 模拟JJESX1故障 (16) 3.1.5 模拟JJESX2故障 (17) 3.1.6 预期演练结果 (17) 3.2 websphere (18) 3.2.1 参加演练人员 (18) 3.2.2 演练流程 (19) 3.2.3 准备工作 (20) 3.2.4 WAS故障 (24) 3.2.5 DMGR故障 (24)
3.2.6 ODR故障 (25) 3.2.7 WVE故障 (25) 3.2.8 预期演练结果 (25) 第四章、数据库系统容灾演练方案 (26) 4.1小型机故障切换 (26) 4.1.1 参加演练人员 (26) 4.1.2 演练流程 (26) 4.1.3 准备工作 (27) 4.1.4 演练步骤 (32) 4.1.5 预期演练结果 (32) 4.2生产端数据库平台整体故障切换 (33) 4.2.1 参加演练人员 (33) 4.2.2 切换流程 (34) 4.2.3 演练步骤 (35) 4.2.4 还原流程 (42) 4.2.5 演练步骤 (43) 4.2.6 预期演练结果 (46)
六种数据库容灾方案 1、经典方案,即双机ha,单盘阵的环境。 简单的说,双机热备就是用两台机器,一台处于工作状态,一台处于备用状态,但备用状态下,也是开机状态,只是开机后没有进行其他的操作。打个比方来说,在网关处架上两台频宽管理设备,将两台的配置设定为一致,只是以一台的状态为主,一台为次。主状态下的频宽管理设备工作,处理事件,次状态下的频宽管理设备处于休眠,一旦主机出现故障,备用频宽管理设备将自动转为工作状态,代替原来的主机。这就是“双机热备”。 2、单机双盘阵(os层镜像)。针对某些用户的双盘阵冗余的需求,我提出了在os层安装卷管理软件,用软件对两台盘阵做镜像的方案,但只有单机工作,一台盘阵挂了,因为os层的软raid的作用,系统仍然可以工作。 3、双机双柜(os层镜像)方案,这个方案,仍然是用os层做镜像,但是用了双机ha,这种方式有个尚未确认的风险,非纯软方式的ha要求主机有共享的存储系统。一台机器对盘阵lun做的镜像虚拟卷,是否也适用另一台主机,也就是说,a主机做的镜像,b主机接管后,是否会透明的认出a机做镜像之后的逻辑虚拟卷,如果ab两主机互相都能认,那么就是成功的方案!! 4、双机双柜(底层镜像)。这种方案,虽然共享的lun不是在一台物理盘阵上,但是被底层存储远程镜像到另一台盘阵上,能保持数据的一致性
5、双机双柜纯软方式HA。这种方案,主机装纯软HA软件,虽然纯软不需要外接盘阵,但是接了盘阵,照样可行。 6、双机双柜(hacmp geo),其实geo大体上就是个类似于纯软HA的软件。
数据库安全 (一)数据库安全的定义 数据库安全包含两层含义:第一层是指系统运行安全,系统运行安全通常受到的威胁如下,一些网络不法分子通过网络,局域网等途径通过入侵电脑使系统无法正常启动,或超负荷让机子运行大量算法,并关闭cpu风扇,使cpu过热烧坏等破坏性活动;第二层是指系统信息安全,系统安全通常受到的威胁如下,黑客对数据库入侵,并盗取想要的资料。 编辑本段 (二)数据库安全的特征 数据库系统的安全特性主要是针对数据而言的,包括数据独立性、数据安全性、数据完整性、并发控制、故障恢复等几个方面。下面分别对其进行介绍 1.数据独立性 数据独立性包括物理独立性和逻辑独立性两个方面。物理独立性是指用户的应用程序与存储在磁盘上的数据库中的数据是相互独立的;逻辑独立性是指用户的应用程序与数据库的逻辑结构是相互独立的。 2.数据安全性 操作系统中的对象一般情况下是文件,而数据库支持的应用要求更为精细。通常比较完整的数据库对数据安全性采取以下措施: (1)将数据库中需要保护的部分与其他部分相隔。 (2)采用授权规则,如账户、口令和权限控制等访问控制方法。 (3)对数据进行加密后存储于数据库。 3.数据完整性 数据完整性包括数据的正确性、有效性和一致性。正确性是指数据的输入值与数据表对应域的类型一样;有效性是指数据库中的理论数值满足现实应用中对该数值段的约束;一致性是指不同用户使用的同一数据应该是一样的。保证数据的完整性,需要防止合法用户使用数据库时向数据库中加入不合语义的数据 4.并发控制 如果数据库应用要实现多用户共享数据,就可能在同一时刻多个用户要存取数据,这种事件叫做并发事件。当一个用户取出数据进行修改,在修改存入数据库之前如有其它用户再取此数据,那么读出的数据就是不正确的。这时就需要对这种并发操作施行控制,排除和避免这种错误的发生,保证数据的正确性。 5.故障恢复 由数据库管理系统提供一套方法,可及时发现故障和修复故障,从而防止数据被破坏。数据库系统能尽快恢复数据库系统运行时出现的故障,可能是物理上或是逻辑上的错误。比如对系统的误操作造成的数据错误等。 SQL server数据库安全策略 SQL Server2000[1]的安全配置在进行SQL Server2000数据库的安全配置之前,首先必须对操作系统进行安全配置,保证操作系统处于安全状态。然后对要使用的操作数据库软件(程序)进行必要的安全审核,比如对ASP、PHP等脚本,这是很多基于数据库的Web应用常出现的安全隐患,对于脚本主要是一个过滤问题,需要过滤一些类似“,;@/”等字符,防止破坏者构造恶意的SQL语句。接着,安装SQL Server2000后请打上最新SQL补丁SP3。 SQL Server的安全配置 1.使用安全的密码策略 我们把密码策略摆在所有安全配置的第一步,请注意,很多数据库账号的密码过于简单,这跟系统密码过于简单是一个道理。对于sa更应该注意,同时不要让sa账号的密码写于应用程序或者脚本中。健壮的密码是安全的第一步,建议密码含有多种数字字母组合并9位以上。SQL Server2000安装的时候,如果是使用混合模式,那么就需要输入sa的密码,除非您确认必须使用空密码,这比以前的版本有所改进。同时养成定期修改密码的好习惯,数据库管理员应该定期查看是否有不符合密码要求的账号。 2.使用安全的账号策略 由于SQL Server不能更改sa用户名称,也不能删除这个超级用户,所以,我们必须对这个账号进行最强的保
某公司软件容灾方案 1容灾软件 Symantec 的存储管理软件VERITAS Storage Foundation(简称SF)适用于企业存储管理的标准化平台,它不仅提供比操作系统本身逻辑卷管理器更加强大的在线卷管理功能,还提供许多高级的存储管理功能,其中包括用于容灾的数据镜像、数据复制等功能。是目前市场上广泛使用的容灾软件。 Symantec VERITAS Cluster Server(简称VCS)是一个用于容灾演练、应用级容灾的软件。它是在基本的HA软件功能的基础上发展而来的。 Veritas Storage Foundation 软件可以根据企业不同需求,提供不同的容灾解决方案,小到同城数据镜像,大到两地三中心数据容灾。SF与VCS紧密集成,可以提供完整的、从数据到应用、并自动实时演练的企业容灾方案。 铁道部高铁指挥实验系统采用了SF/VCS实现了容灾。
2数据同城镜像方式 利用灾备中信和主中心之间或者同机房内的裸光纤线路构成SAN环境,直接采用Storage Foundation在两个存储之间实现存储镜像。即所有数据都将同时写入两边的磁盘整列中。 如上图所示,主中心的服务器将应用的每个写i/o数据同时写入到两个中心的存储中。由于镜像的实现是依托于底层的Volume,所有数据存取的过程对于应用来说都是透明的。我们可以通过设臵Volume Manager的读取策略来指定主中心的服务器从本地的磁盘阵列上读取数据,加快数据查询的速度。 在这个场景中,数据发生物理错误的可能性基本上分为两种,生产中心的存储系统出现物理错误,如硬盘问题、光纤卡问题、光纤连接问题或光纤交换机问题等,另外一种就是整个数据中心出现故障。
双机容灾系统建设方案建议书
第一章纯软方式双机热备系统建设方案提示:因为纯软双机只支持Windows平台,如不改变现有服务器的Linux操作系统,请跳过本章 由于上述的建设双机系统的必要性和双机系统数据的重要性,就需要搭建一个非常适合双机系统运行和数据存储的平台,以此来保障双机系统安全、高效的运行。只有这样,才能充分发挥双机系统在企业的核心作用,从而全面提升企业的竞争力和生产力。 结合贵方的需求和现状,我们设计一款纯软方式的解决方案,以供参考。 图4.1 拓扑结构图 1.1方案描述 使用用户原有得两台业务服务器,构成一对双机。因为纯软双朵只支持Windows平台,所以需要将两台服务器全部改成Windows 系列操作系统,将原Oralce 9i数据库改成Windows平台版本Oracle数据库。两台服务器通过双机软件组成双机热备系统,双机中任何一台机器发生故障的情况下,由备机接管相应的IP地址、主机名、数据库服务及业务应用。 硬件要求:两台服务器的配置相同(CPU、内存和磁盘分区的类型、大小),
同时配置双网卡 网络环境要求:两台服务器安装相同的操作系统、数据库、应用程序及服务将两台服务器部署到企业的以太网中,分别将两台服务器中的一块网卡设为业务网卡,并分配固定的物理IP地址。将两台服务器的另一块网卡作为心跳网卡,通过一条心跳线相连。两台服务为一主一从的关系,主机为当前业务服务器,从机为灾备业务服务器。主机上的业务数据会被双机软件通过心跳线同步到从机。 通过双机软件虚拟一个业务IP地址,对外提供服务。绑定在主机IP址上,当主机发生故障时,再自动切换到从机物理IP地址上进行绑定。同时,接管数据库服务,应用程序服务等相关业务服务。双机软件以一定时间频率通过心跳线从主机发送验证信息到从机,检验主机是否运行正常,当主机的IP地址,数据库服务,数据存储区三者之一发生问题,双机软件会认为主机业务已停止,需要从机进行业务接管。同时停止主机的服务,开启从机服务。 当主机需要进行系统维护,系统升级,硬件安装等操作时,可手动将业务切换到从机上。当操作完成时,再将数据同步回主机并将业务切换到主机上。 1.2本方案采用双机软件的特性 ●双机软件的产品和服务能够使信息不间断,它通过一个接近无缝的 处理来管理和保护贯穿一个企业的数据。 ●基于双机软件的高可用性和高可靠性,我们选择它作为核心信息系 统和数据库服务器的双机切换软件。
河池XX县人民医院存储容灾演练方案 2011年11月
目录 第1章实施步骤、效果说明和测试方案 (2) 1.1整个EMC Recoverpoint实施步骤和时间预估 (2) 1.2效果说明 (2) 1.3测试目的 (2) 1.4测试环境说明 (3) 1.5服务器系统 (4) 3.5.1常见系统故障 (4) 3.5.2常见系统维护 (4) 1.6测试项目设置 (5) 1.7具体测试内容 (6) 3.7.1数据一致性测试 (8) 3.7.2数据容灾故障恢复测试 (9) 3.7.3容灾:任意时间点回滚测试 (10) 3.7.4容灾: 容灾存储恢复至主存储数据测试 (11) 3.7.5容灾:主存储误操作数据恢复测试 (11)
第1章实施步骤、效果说明和测试方案 1.1 整个EMC Recoverpoint实施步骤和时间预估 1.2 效果说明 1,实现存储间的数据互联互通、相互流动的功能。 2,实现主备存储间数据实时同步,主备存储的数据一致、高可用的功能。 3,实现当主存储发生逻辑错误后,可以通过备用存储对主存储的数据追回、不丢失数据的功能。 4,实现存储上的数据任意时间点回滚功能,有效地避免主数据库的逻辑错误或突然断电导致数据库无法正常运行的故障。并将数据丢失率降低至最小。 5,实现备用存储的在线使用功能,当备用存储的数据修改后,能够直接恢复到主存储。该功能可以在备用存储上打开数据库,实现报表、测试、升级、培训 等操作,分流用户的业务,降低生产系统的负载。 6,完成备用存储的报表、测试、升级、培训功能后,可以通过主存储将其变化的数据继续同步到备用存储,恢复存储间的数据实时同步,保持数据一致、高 可用状态。 1.3 测试目的 为了检验是否可以达到客户的要求,在首次完成recoverpoint后,需要按
数据容灾备份设计方案 1.1数据备份的主要方式 目前比较实用的的数据备份方式可分为本地备份异地保存、远程磁带库与光盘库、远程关键数据+定期备份、远程数据库复制、网络数据镜像、远程镜像磁盘等六种。 (1)本地备份异地保存 是指按一定的时间间隔(如一天)将系统某一时刻的数据备份到磁带、磁盘、光盘等介质上,然后及时地传递到远离运行中心的、安全的地方保存起来。 (2)远程磁带库、光盘库 是指通过网络将数据传送到远离生产中心的磁带库或光盘库系统。本方式要求在生产系统与磁带库或光盘库系统之间建立通信线路。 — (3)远程关键数据+定期备份 本方式定期备份全部数据,同时生产系统实时向备份系统传送数据库日志或应用系统交易流水等关键数据。 (4)远程数据库复制 生产系统相分离的备份系统上建立生产系统上重要数据库的一个镜像拷贝,通过通信线路将生产系统的数据库日志传送到备份系统,使备份系统的数据库与生产系统的数据库数据变化保持同步。 (5)网络数据镜像 是指对生产系统的数据库数据和重要的数据与目标文件进行监控与跟踪,并将对这些数据及目标文件的操作日志通过网络实时传送到备份系统,备份系统则根据操作日志对磁盘中数据进行更新,以保证生产系统与备份系统数据同步。 (6)远程镜像磁盘 利用高速光纤通信线路和特殊的磁盘控制技术将镜像磁盘安放到远 …
离生产系统的地方,镜像磁盘的数据与主磁盘数据以实时同步或实时异步方式保持一致。磁盘镜像可备份所有类型的数据。备份拓扑网络结构1.2(即东风东路院区中心机广州市第八人民医院具有两个不同地点的中心机房房和嘉禾院区中心机房),在这基础上是可以构建一个异地容灾的数据备份系统,以确保本单位的系统正常运营及对关键业务数据进行有效地保护,以下设计方案仅提供参考。嘉禾院区数据中心东风东院区数据中心 本方案中,我们采用EMC的CDP保护技术来实现数据的连续保护和容灾系统。 1.在东风东院区数据中心部署一台EMC 480统一存储平台,配置一个大容量光纤磁盘存储设备,作为整个系统数据集中存储平台。 2.在嘉禾院区数据中心部署一台EMC 480统一存储系统,配置一个大容量光纤磁盘存储设备,作为整个平台的灾备存储平台。 ) 3.两地各部署两台EMC RecoverPoint/SE RPA,采用CLR技术,即CDP(持续数据保护)+CRR(持续远程复制),实现并发的本地和远程数据保护。 4.在东风东院区数据中心本地采用EMC RecoverPoint/SE CDP(持续数据保护)技术实现本地的数据保护。. 5.两地采用EMC RecoverPoint/SE CRR(持续远程复制)技术,实现远程的数据保护。由于两地之间专线的带宽有限,可以采用EMC Recoverpoint/SE异步复制技术,将东风东院区数据中心EMC480上的数据定时复制到嘉禾院区数据中心。根据带宽的大小,如果后期专线带宽有所增加,RecoverPoint会自动切换同步、异步、快照时间点三种复制方式,尽最大可能保证数据的零丢失。 1.3本地数据数据保护(CDP)设计
XXXX公司Oracle数据库异地容灾方案 2011年08月29日
1、公司简介 XXXX公司。 2、项目背景 ●XXXX有两个数据中心。 ●两个基地之间使用TCP/IP网络进行连接。 ●生产业务系统的后台数据库为Oracle。 ●数据库服务器操作系统为Windows。 ●数据库目前总体数据量约为2.4T。 ●生产系统为双机容错架构。 ●希望远程数据中心成为容灾中心。 3、解决方案 3.1方案原理 这是一个很典型的应用场景,用户对RPO、RTO的要求比较高,用户希望数据丢失尽可能少,恢复尽可能快。可是,要实现这一愿望,传统的容灾方案都是采用昂贵的存储设备或卷管理软件来实现,投入相当惊人,用户很难接受!CommVault的CDR连续数据复制是一个性价比很高的解决方案,工作原理如下图所示:
这个Oracle远程容灾方案的设计思想是:在容灾系统初始化时或备份系统被破坏时,利用备份和恢复来传送数据库的DBF文件;在数据库日常工作时,利用CDR来时复制数据库日志文件,并将日志回滚到备份数据中(对于双机架构来说,原理相同,所需模块相同, 如图生产主机可为双机或集群架构)。系统的数据流如下图所示:
3.2实施过程 在这个方案中,我们采用了CommVault的备份技术和CDR技术,数据共有4份冗余,除了生产数据外,还有容灾数据,本地备份和异地备份数据;这里需要注意的是,在两个数据中心的数据库都是使用本地数据为业务系统提供服务,并且将数据在两个数据中心之间相互复制,以便达到两个数据中心互为容灾中心的目的。整个容灾系统的建立共分4个阶段: ●初始化阶段:通过备份+恢复方式,在容灾站点生成初始化数据 ●容灾复制阶段: 1.通过CDR复制交易日志 2.自动回滚日志实现数据库容灾 3.每天做异地数据库的冷备份 4.每天做本地数据库的热备份 ●灾难重建阶段: 如果数据崩溃,由于本地和异地都有灾备数据,通过本地的直接恢复实现本地网络 的灾难数据重建,避免在远程网络上传送大量的初始化数据 ●容灾演练阶段: 将容灾站点的数据库打开,就可以使用了。恢复正常工作方式,只要将灾备的数据 恢复,然后回滚以前的日志数据,就能恢复容灾复制阶段。 4、技术要点 在这4个阶段中,充分利用了CommVault的独特技术: ●CDR复制:连续数据复制,复制数据库交易日志。 ●断点续传:支持从中断点继续传送。 ●GridStor:支持多个介质服务器使用不同地区的数据源,这样就不需要通过网络来 回传送大量的数据。 ●自动恢复和回滚:支持以时间或者自动的方式,恢复和回滚日志或其它数据,而不 需要手工执行。 ●辅助拷贝:支持将本地的备份数据复制到异地,实现异地的灾备。
竭诚为您提供优质文档/双击可除容灾备份系统方案建议书 篇一:容灾备份系统方案建议书 xxx容灾备份系统 方案建议书 华为技术有限公司 20XX-10-18 目录 1 1.1 1.2 1.3 2 3 3.1 3.2 4 4.1
4.2备份容灾系统概述................................................. ................................................... .....................3容灾概念................................................. ................................................... ...................................3容灾与备份的关系................................................. ................................................... ...................3容灾的等级................................................. ................................................... ...............................4xxx项目背景................................................. ................................................... ...........................5xxx网络现状................................................. ................................................... ...........................6现网络设备拓扑图................................................. ................................................... ...................6建设目
XX市商业银行 灾难备份系统 切换演练总体方案 XX市商业银行 2016年1月
目录 一、本次演练目的和原则 (1) 1. 演练目的 (1) 2. 演练要求 (1) 二、演练时间及参演部门 (3) 三、演练组织架构及名单 (4) 四、演练方案 (7) 1. 演练内容 (7) 2. 演练总体安排 (7) 3. 本次演练涉及的主要服务器 (8) 4. 演练步骤 (8) 五、演练风险控制 (10) 六、演练后的总结及修订情况 (11)
一、本次演练目的和原则 1.演练目的 为保障XX市商业银行信息系统安全、可靠、稳定运行,提高应对各类信息系统突发事件对能力,有效防范重要信息系统风险,根据中国银监会关于《银行业重要信息系统突发事件应急管理规范》对通知,结合我行自身情况,特制定本次灾备切换演练计划。 本次灾备切换演练主要目的: ●论证我行重要信息系统突发事件应急预案对可行性; ●验证核心系统切换到灾备中心后,灾备核心系统接管生产的可用 性; ●验证灾备中心DELL SharePlex数据库同步的可用性; ●检验系统切换手册和文档的可用性,并在演练过程中发现信息系 统应急管理体系存在的问题和不足,以便演练后进行改进和完善; ●验证网点接入灾备中心网络能力; ●使参演人员熟悉应急管理和灾难恢复/切换的流程; ●提高参演人员的应急处理能力和系统的风险防控能力。 2.演练要求 1.切换演练实施前按照监管单位要求,向上级报备; 2.切换演练中要做好回退方案,防范切换演练过程中对风险;
3.演练后不影响生产系统数据和对外服务; 4.演练后不影响全行生产环境其它各系统的正常运行; 5.演练后不影响灾备中心数据复制的正常运行; 6.演练后不影响灾备中心接管生产系统能力; 7.演练后向上级单位汇报演练情况。