
A题 公路行驶时间估计与路线优化研究
0问题概述
对于出行者来说,对公路上行驶时间的估计是一个至关重要的问题。在美国,某些六车道公路的两侧安装有检测器,在不考虑行驶车辆车道变换的情况下,可以把整条道路简化成单一的车行道进行研究,如下图所示,图中方形代表检测器。
travel direction
Detector 1 Detector 2 Detector 3 Detector 4 Detector 5
检测器可以对道路上行使的车辆进行全天观测,并以20秒为计数单位来报告平均车速而且可以将数据实时更新。A题中的表格仅提供了每两钟的后20秒的观测数据,下面结合交通工程中的交通特性指标,对这些数据进行统计分析,从而得出公路上的车辆运行特性并从中寻求规律。
1 公路上车辆行驶特性分析
根据交通工程中的车速特性分布理论,行车速度和交通量一样,也是随机变量。对车速进行统计分析,一般要借助车速分布直方图、车速频率、累计频率分布曲线。
表征车速统计分布特性的特征车速常用:
中位车速:也称50%位车速,是指在该路段上该速度一下行驶的车辆属于在该速度已上行驶的车辆数相等。
85%位车速:在该路段行驶的所有车辆中,有85%的车辆在此速度以下行驶,交通管理部门常以此速度作为某些路段的限制车速。
15%位车速:与上述类似,在高速公路和快速道路上,为了行车安全,减少阻塞排队想象,保证交通流畅通,要规定低速限制,因此15%位车速测定是非常重要的。
85%位车速与15%位车速之差反映了该路段上的车速波动幅度。
根据题目中所给的临界条件,交通拥挤与非拥挤以速度来划分,临界速度值为50英里/小时,小于此速度则认为交通流进入拥挤状态。
对表中已知观测数据进行统计分析,可得到下列图表:
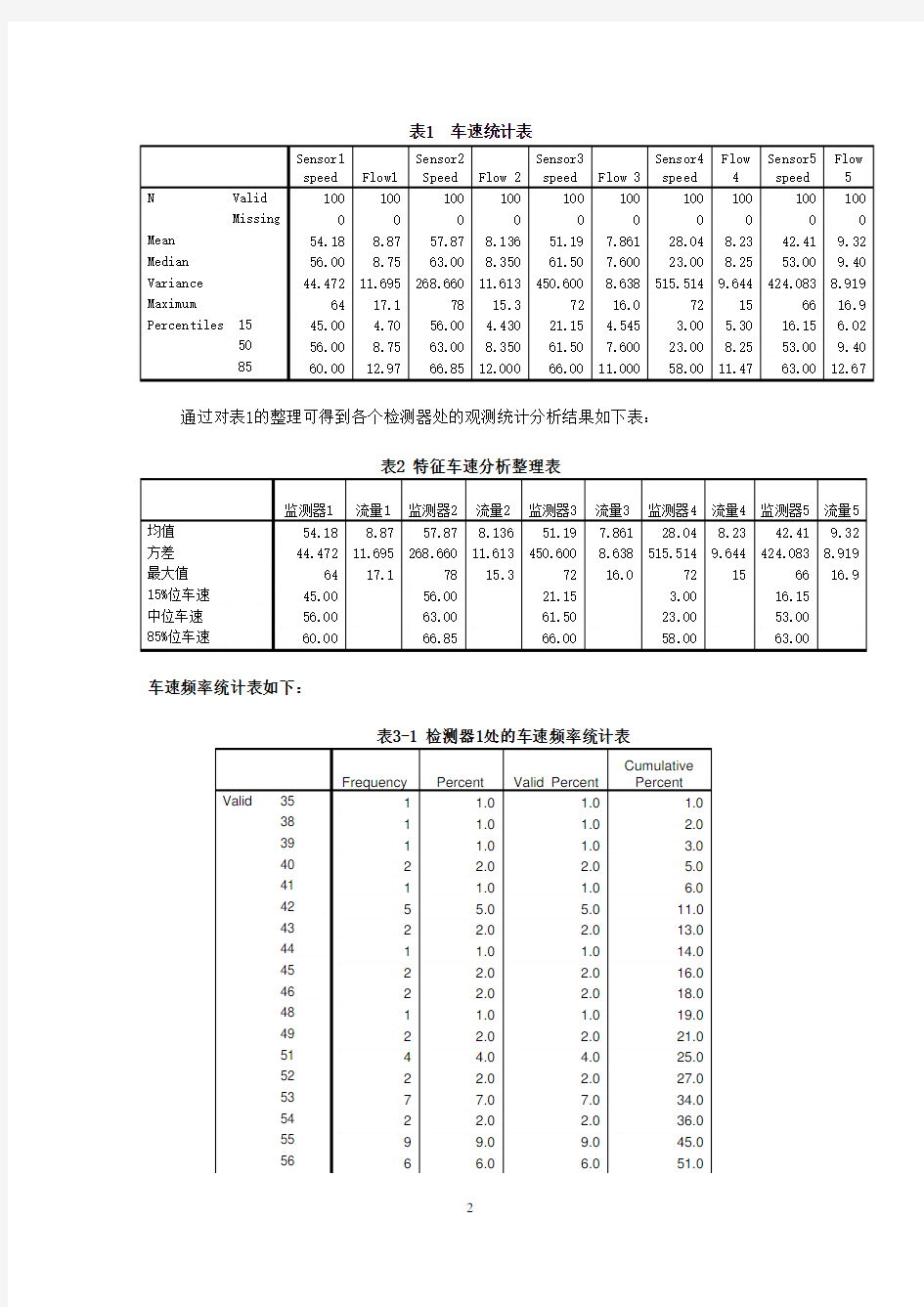
表1 车速统计表
Sensor1
speed Flow1Sensor2
Speed Flow 2
Sensor3
speed Flow 3
Sensor4
speed
Flow
4
Sensor5
speed
Flow
5
N Valid 100 100100100100100100 100 100100 Missing0 000000 0 00 Mean 54.18 8.8757.878.13651.197.86128.04 8.23 42.419.32 Median 56.00 8.7563.008.35061.507.60023.00 8.25 53.009.40 Variance 44.472 11.695268.66011.613450.6008.638515.514 9.644 424.0838.919 Maximum 64 17.17815.37216.072 15 6616.9 Percentiles 15 45.00 4.7056.00 4.43021.15 4.545 3.00 5.30 16.15 6.02
50 56.00 8.7563.008.35061.507.60023.00 8.25 53.009.40
85 60.00 12.9766.8512.00066.0011.00058.00 11.47 63.0012.67
通过对表1的整理可得到各个检测器处的观测统计分析结果如下表:
表2 特征车速分析整理表
监测器1 流量1监测器2流量2监测器3流量3监测器4 流量4 监测器5流量5均值 54.18 8.8757.878.13651.197.86128.04 8.23 42.419.32方差 44.472 11.695268.66011.613450.6008.638515.514 9.644 424.0838.919最大值 64 17.17815.37216.072 15 6616.9 15%位车速 45.00 56.0021.15 3.00 16.15
中位车速 56.00 63.0061.5023.00 53.00
85%位车速 60.00 66.8566.0058.00 63.00
车速频率统计表如下:
表3-1 检测器1处的车速频率统计表
Frequency Percent Valid Percent Cumulative Percent
35 1 1.0 1.0 1.0
38 1 1.0 1.0 2.0
39 1 1.0 1.0 3.0
40 2 2.0 2.0 5.0
41 1 1.0 1.0 6.0
42 5 5.0 5.011.0
43 2 2.0 2.013.0
44 1 1.0 1.014.0
45 2 2.0 2.016.0
46 2 2.0 2.018.0
48 1 1.0 1.019.0
49 2 2.0 2.021.0
51 4 4.0 4.025.0
52 2 2.0 2.027.0
53 77.07.034.0
54 2 2.0 2.036.0
55 99.09.045.0 Valid
56 6 6.0 6.051.0
58 1111.011.071.0
59 1313.013.084.0
60 88.08.092.0
61 3 3.0 3.095.0
62 1 1.0 1.096.0 64 4 4.0 4.0100.0 Total 100100.0100.0
表3-2 检测器2处的车速频率统计表
Frequency Percent Valid Percent Cumulative Percent
4 2 2.0 2.0 2.0
7 1 1.0 1.0 3.0
8 2 2.0 2.0 5.0
13 1 1.0 1.0 6.0
14 2 2.0 2.08.0
19 1 1.0 1.09.0
35 1 1.0 1.010.0
38 2 2.0 2.012.0
42 1 1.0 1.013.0
53 1 1.0 1.014.0
56 2 2.0 2.016.0
57 3 3.0 3.019.0
58 1 1.0 1.020.0
59 5 5.0 5.025.0
60 4 4.0 4.029.0
61 2 2.0 2.031.0
62 1515.015.046.0
63 88.08.054.0
64 1313.013.067.0
65 77.07.074.0
66 1111.011.085.0
67 1 1.0 1.086.0
68 3 3.0 3.089.0
69 6 6.0 6.095.0
70 2 2.0 2.097.0
71 2 2.0 2.099.0
78 1 1.0 1.0100.0 Valid
Total 100100.0100.0
表3-3 检测器3处的车速频率统计表
Frequency Percent Valid Percent Cumulative Percent
2 5 5.0 5.0 5.0
3 1 1.0 1.0 6.0
7 1 1.0 1.07.0
8 1 1.0 1.08.0
9 1 1.0 1.09.0 Valid
10 1 1.0 1.010.0
14 1 1.0 1.013.0
21 2 2.0 2.015.0
22 1 1.0 1.016.0
23 1 1.0 1.017.0
26 2 2.0 2.019.0
27 2 2.0 2.021.0 29 1 1.0 1.022.0
38 1 1.0 1.023.0
39 2 2.0 2.025.0 42 1 1.0 1.026.0
50 1 1.0 1.027.0
51 1 1.0 1.028.0
55 1 1.0 1.029.0
56 1 1.0 1.030.0
57 5 5.0 5.035.0
58 1 1.0 1.036.0
59 4 4.0 4.040.0
60 4 4.0 4.044.0
61 6 6.0 6.050.0
62 1212.012.062.0
63 3 3.0 3.065.0
64 1010.010.075.0
65 3 3.0 3.078.0
66 99.09.087.0
67 3 3.0 3.090.0
68 4 4.0 4.094.0
69 2 2.0 2.096.0
70 2 2.0 2.098.0 72 2 2.0 2.0100.0 Total 100100.0100.0
表3-4 检测器4处的车速频率统计表
Frequency Percent Valid Percent Cumulative Percent
1 4 4.0 4.0 4.0
2 99.09.013.0
3 6 6.0 6.019.0
4 6 6.0 6.025.0
5 5 5.0 5.030.0
6 2 2.0 2.032.0
8 1 1.0 1.033.0
9 3 3.0 3.036.0
11 1 1.0 1.037.0
12 1 1.0 1.038.0
13 1 1.0 1.039.0
15 3 3.0 3.042.0
17 1 1.0 1.043.0
20 2 2.0 2.045.0 Valid
21 2 2.0 2.047.0
23 2 2.0 2.051.0 26 1 1.0 1.052.0
28 2 2.0 2.054.0
29 1 1.0 1.055.0 34 1 1.0 1.056.0
36 3 3.0 3.059.0
37 1 1.0 1.060.0
38 1 1.0 1.061.0
39 1 1.0 1.062.0
40 5 5.0 5.067.0
44 2 2.0 2.069.0
45 5 5.0 5.074.0 47 1 1.0 1.075.0 49 1 1.0 1.076.0 52 3 3.0 3.079.0
54 1 1.0 1.080.0
55 3 3.0 3.083.0
57 1 1.0 1.084.0
58 3 3.0 3.087.0
59 2 2.0 2.089.0
61 2 2.0 2.091.0
62 3 3.0 3.094.0
63 2 2.0 2.096.0
64 3 3.0 3.099.0 72 1 1.0 1.0100.0 Total 100100.0100.0
表3-5 检测器5处的车速频率统计表
Frequency Percent Valid Percent Cumulative Percent
3 1 1.0 1.0 1.0
4 5 5.0 5.0 6.0
10 1 1.0 1.07.0
11 3 3.0 3.010.0
12 1 1.0 1.011.0
14 2 2.0 2.013.0
15 1 1.0 1.014.0
16 1 1.0 1.015.0
17 1 1.0 1.016.0
18 1 1.0 1.017.0
19 2 2.0 2.019.0
20 2 2.0 2.021.0
21 1 1.0 1.022.0
23 1 1.0 1.023.0
24 2 2.0 2.025.0
25 2 2.0 2.027.0
26 3 3.0 3.030.0
27 2 2.0 2.032.0 Valid
28 3 3.0 3.035.0
30 2 2.0 2.040.0 33 2 2.0 2.042.0 34 3 3.0 3.045.0 36 2 2.0 2.047.0 37
2 2.0 2.049.0 38 4 4.0 4.053.0 40 2 2.0 2.055.0 42 1 1.0 1.056.0 44 1 1.0 1.057.0 45 1 1.0 1.058.0 47 1 1.0 1.0
59.0 49 1 1.0 1.060.0 51 4 4.0 4.064.0 52 1 1.0 1.065.0 53 2 2.0 2.067.0 54 1 1.0 1.068.0 55 1 1.0 1.069.0 57 1 1.0 1.070.0 58 1 1.0 1.071.0 59 6 6.0 6.077.0 60 2 2.0 2.079.0 62 4 4.0 4.083.0 63 2 2.0 2.085.0 64 99.09.094.0 65 4 4.0 4.098.0 66 2 2.0 2.0100.0
Total
100
100.0
100.0
图1 各检测器处的车速分布饼图
图2 各检测器处的车速分布直方图
图3 各检测器处对应不同时段的车速分布图
根据题表和上面的图表可知,在第一个检测器附近,5:24:07 PM时平均车速降到50 mile/hr以下,以后十几分钟的时间里,车速在50 mile/hr附近波动,可知此时交通流已经不稳定,将要进入拥挤状态,后续的观测数据进一步证实了这一点。从5:38:07 PM 到6:10:07 PM,平均车速都低于50 mile/hr,交通处于拥塞状态,直到6:12:07 PM 车速超过50 mile/hr,且以后车速均大于50 mile/hr,证明6:12:07 PM左右拥塞消散。根据以上分析可见,检测器1处存在明显的交通拥塞和消散过程。从实际情况考虑,题表中的观测数据涵盖了下午的交通高峰时段,其原因是下班交通高峰造成,大约从5:40PM到6:10PM,持续半个小时左右。
同理可以分析第2、3个检测器处的交通运行特征。在第2个检测器处,5:30:07 PM左右,交通已经进入拥塞状态,一直持续到5:54:07 PM左右,后来拥挤开始消散。在第3个检测器处,5:24:07 PM左右交通进入拥塞状态,一直持续到6:18:07 PM左右,后来拥挤开始消散。
检测器4处的交通运行比较特殊,出现了多个平均车速低于50 mile/hr的时段,据此信息可以推测第4个检测器处存在着外界对交通流的干扰因素,通常可能是由于道路两侧施工或临时占用道路等原因造成。从这个问题来看,监测器还可以用于道路异常状况及事故的检测。
第5个检测器处的交通运行状况也比较特殊,其拥挤开始于4:36:07 PM 左右,而消散于6:34:07 PM左右,拥塞时间开始早、结束晚,拥挤状态时长明显超过第1、2、3检测器附近的状况,所以可以推测第5个检测器处存在交通因素以外的原因造成车辆通行不畅,通常可能是由于道路通行能力由于某种原因降低,导致上游车流到达后不能及时疏散,造成较长时间的交通拥塞状态。
下表是对5个检测器所提供的速度数据进行相关性分析所得到的相关矩阵:
表4 各检测器处的速度相关矩阵表
Correlations (data2) Marked correlations are significant at p < .05000 N=100 (Casewise
deletion of missing data)
Sensor1 Speed Sensor2 Speed Sensor3 speed Sensor4 speed Sensor5 speed Sensor1 Speed 1.0000.5950.7880.5487.4923
p= ---p=.000p=0.00p=.000p=.000 Sensor2 Speed.5950 1.0000.7729.4067.2197
p=.000 p= --- p=0.00 p=.000 p=.028 Sensor3 speed
.7880
.7729 1.0000 .5760 .4740
p=0.00
p=0.00 p= --- p=.000 p=.000 Sensor4 speed
.5487
.4067 .5760 1.0000 .4275
p=.000
p=.000 p=.000 p= --- p=.000 Sensor5 speed
.4923
.2197 .4740 .4275 1.0000
p=.000
p=.028
p=.000
p=.000
p= ---
从表中可以看出与v 的相关性较强,和的相关性较强。在95%的置信水平下, 各个监测器监测到的速度之间的相关性都是显著的,因此在考虑整个过程的行驶时间的时候,各个监测器在t 时刻监测到的速度最好是要考虑在内的。 1v 3和2v 3v
2 流量未知情况下的行驶时间估计
设t 时刻所有检测器记录的当时当地的车速分别是,以来表示五个检测器,以表示四段路程的长度。在不考虑交通流量的情况下,车辆的行驶时间与车辆的行驶速度和路程有直接关系,即。设一辆车在t 时刻通过第一个检测器,要在t 时刻给出这辆车行驶到第五个检测器所用的时间,必须要对未来一段时间内四段路上的交通情况(行
车速度)进行估计。我们可以用1v 2v 平均值12345,,,,v v v v v 12345,,,,D D D D D (,)t f v L =1234,,,L L L L 的121
(2
v v +,并)来,刻画车辆在第一段路
上的行驶速度,记为22v 车辆以这个速度行驶到2D 以这个速度作为此刻2D 到的速度,对应的此时后面各个检测器所检测到的速度为23,v v i (中3,i =21i v -和有关,我们令检测4,5)
,与2425,v ,2v 其
i v 2i v 2,1(i i v v -1
)2
=+,这样就得到了当车辆行驶到2D 时其他检测器检测到的速度的一个估计量。车辆在2D 和3之间的行驶
速度受22v 和的影响,在此我们取,23v D 33v =车辆在这段路上的行驶
速度和到达3D 处时检测器检测到的速度。
221
(2
23)v v +作为以下以此类推,我们就得到了各个路段上行驶的速度,具体表达式如下
,11,1,11,1
(),21()2
i j i j ij
i j i j v v i v v
v i -----?+
1D 5D 5
2k
k kk
L t v ==∑
(2) 其中:为与之间的路程。则:
i L i D 1i D +22334455
636417522475
t v v v v =+++
t 时刻车辆从第i 个检测器出发的这种情况,可以看作是以上过程的一部分,
则行驶到的时间很容易求出 5D 5
k k i kk
L
t v ==∑
如果能够得到每20秒的实时数据,而不是每2分钟的数据,那么本算法对行驶时间的估计将更加精确。首先,由于在实际情况下,某辆车的路段行驶速度很可能是不断变化的,基本关系式是:路程等于速度和行驶时间的乘积,路程可看作是在时间——速度坐标中,由速度曲线与时间轴所围成的面积;从积分的角度来看,把时间轴划分的份数越多,积分计算越准确。现在是在已知路程的情况下求行驶时间,道理都一样,计时间隔时段划分的越细,对真实速度的反映就越精确、越接近实际情况,从而路段行驶时间的估计结果越精确。再者,本算法通过不断更新的实时平均速度数据来估计某辆车的行驶速度,因此本算法本身也具有实时性,能将路上车流速度的变化及时地反映在路段行驶时间的计算中。检测器显示数据间隔时段越短,越接近于反映道路上车辆运行的实时情况,从而能够为计算所提供的信息就越多。
3 流量已知情况下的行驶时间估计
如题所述,检测器可以检测每20秒内的车速和流量,根据表中提供的数据,估计车辆到达第5个检测器所需的时间。
由于车流速度受交通状况和道路状况的影响,在道路状况一定的情况下,稳定交通流中的车速主要受交通流量的影响,因此已知交通量的情况下,可以提高路段行驶时间估计的合理性和准确性。而且平均速度的表达,以空间平均速度来代替时间平均速度,也将使行驶时间的计算更具有合理性和准确性。
下面给出交通工程学中时间平均车速与空间平均车速的定义:
时间平均车速t v :在单位时间内测定的通过道路某断面各车辆的点车速,这些点速度的算术平均值,即为该断面的时间平均车速,即:
1
1n
t i v n ==i v ∑ (3)
式中:
t v ——时间平均车速 (千米/小时)或(米/秒); i v ——第i 辆车的地点车速 (千米/小时)或(米/秒);
n ——单位时间内观测到的车辆总数(辆)。
空间平均车速s v :在某一特定瞬间,行驶于道路某一特定长度内的全部车辆的车速分布的平均值,当观测长度为一定时,其数值为地点车速观测值得调和平均值,即
11
111s n
n
i
i i i
ns
v t
n v ===
=
∑∑ (4)
式中:
s v ——空间平均车速 (千米/小时)或(米/秒);
s ——路段长度 (千米)或(米);
i t ——第i 辆车的行驶时间;
n ——长度为的路段上所具有的车辆数;
s i v ——第i 辆车的行驶车速 (千米/小时)或(米/秒)。
题表中给出的车速观测数据是各个20秒内的时间平均车速t v 。下面根据流量数据来计算空间平均车速s v 。
根据表中统计结果可知,20秒内的最大流量为17.1辆,即0.855辆/秒。出现在4:32:07 PM 时的检测记录中,由第一个检测器所检测到,其对应的平均行驶车速为59英里/小时。在交通管理与控制中,一般将调查得到的交通高峰时段实际流量的最大值作为道路所能通过的极大流量,题表中观测数据的时间范围在下午3:40到7:00之间,其内存在下班时间的交通高峰时段,所以可以用其观测到的流量最大值来作为值。根据交通工程学之中交通流三参数(车
速、流量、车流密度)的基本关系可以推导出所对应的行驶速度为m Q m Q m Q 1
2
f v ,其
中f v 为畅行速度,即车流密度趋于零、车辆可以畅通无阻时的平均速度。此题中可以认为f v =259?=118英里/小时,换算为52.75米/秒。又有基本关系式:
1
4
m Q =f j k v ),其中:为阻塞密度,即车流密集到所有车辆无法移动时
的车流密度。则由上式可得=0.065辆/米。
j k (0v =j k 交通工程学中,流量与车流速度有下图所示的关系: v
由公式2
(s j s f
v Q k v v =-,可求出交通流量所对应的Q s v
的值。则:
(502(502f j t j s f j t j
v k if v mile hr
k v v k if v mile h k ?+≥??=?
?
(5)
根据5个检测器所测得的流量值,就可以由上式分别求得各流量所对应的空
f
m
间平均车速。将,1,2,3,4,5si v i si v 12,,的值代入到上面流量未知情况下的算法中来代替其中相应的时间平均车速,即可求出更精确合理的路段行驶时间。这样以流量作为输入,以题表中给出的时间平均车速作为控制条件,充分利用了检测车速和流量两种数据,并相当于知道了20秒内通过检测器断面的所有车辆在实际道路上瞬间车速分布的均值,从而实现了时间数据向空间数据的转化,更趋近于表达实际车辆在道路上的分布与运行情况,因而更合理。
345,,v v v v v
4 链路行驶时间独立且随机情况下的最短路问题
由于假设任何两条链路的行驶时间相互独立,也就是说在某一条链路上行驶时不必考虑其他链路的情况,因此,此处将最优路线定义为:由出发点到目的地行驶时间最短的路线为最优路线。这样,问题就转化为求城市交通网络中任意两点间的最短路径问题。
算法描述如下图所示:
算法的实现过程:
首先是建立城市交通网络,需要输入交通节点数和任意两个节点之间的链路距离(如果某两个节点间没有直接道路相通,那么这两点间的路权为∞)。这些信息输入以后,系统将自动计算出任意两个节点中的最短路径并计算出该路径的长度。然后由司机输入起点和终点信息,系统将列出与指定的起点和终点相对应
的最短路径及其长度,并根据第I题的思想估算出此路线的行驶时间。在估算行驶时间之前,需要获得一些相关信息:
①该最短路径每个路段上处于正常工作状态的传感器的个数;
②每个处于正常工作状态的传感器上所观测到的速度值和流量值;
③各个处于正常工作状态的传感器之间的距离、该段路起点与第一个处于
正常工作状态的传感器间的距离、最后一个处于正常工作状态的传感器与该段路终点间的距离。
以上3条信息在现实情况下是不需要输入的,而是系统根据某段道路上的传感器的实际情况而获得的。但是由于该程序是一个模拟的过程,因此像这样的必要信息是需要作为输入而提供给系统的。
在计算任意两点之间的最短路径的时候用到了Floyd算法,算法描述如下:for(k=1; k<=n; k++)
for(i=1; i<=n; i++)
for(j=1; j<=n; j++)
if(A[i][k]+A[k][j] { A[i][j]=A[i][k]+A[k][j]; p[i][j]=k; } 其中A[i][j]为计算出的任意两点间的最短路径长度,二维矩阵p保存路径信息,以便能够输出该最短路径。该算法的时间复杂性为O(n3)。 上图为测试用例,首先将图中的信息(结点数、邻接矩阵)输入,然后以1为起点,3为终点。输入以上信息后,程序执行结果如下图所示: 然后分别输入1至4,4至3路段上的传感器相关信息,具体如下: 1至4路段:3个传感器 传感器1:流量10(辆/20秒),速度51km/.h; 传感器2:流量12(辆/20秒),速度49km/.h; 传感器3:流量11(辆/20秒),速度60km/.h; 各传感器将路段分成的距离分别为:60m,30m,120m,90m。 4至3路段:4个传感器 传感器1:流量10(辆/20秒),速度57km/.h; 传感器2:流量9.7(辆/20秒),速度54km/.h; 传感器3:流量10.7(辆/20秒),速度20km/.h; 传感器4:流量5.9(辆/20秒),速度58km/.h; 各传感器将路段分成的距离分别为:40m,60m,30m,30m,40m。 执行结果如下: 5 动态随机网络情况下的最短路问题研究 第Ⅱ大问题中的第2个问题,说明路段行驶时间取决于启程时间,同时又和其他路段行驶时间相关。所以,可以说路段行驶时间是与时间相关的随机变量,路段行驶时间随整个路网的交通状况呈动态变化,这种情况下寻找最短路的问题属于动态随机最短路问题。 根据上面问题描述,可以将此情境下的最优路线定义为:车辆在动态随机路网中,从起始点到目的地过程中,行程总时间的均值和方差都尽可能小的路线。 基本假设: 1、每一时段内的路段行驶时间的样本均值和相应方差和任意两段路的相关系数是可以统计获得的; 2、路段行驶时间是连续的、随时间变化的随机变量; 3、不连续时段统计到的样本均值和方差可以作为输入数据; 4、行驶时间与启程时间和到达目的地所要经过的路段(两个交叉口之间的公路)的行驶时间是相关的。 这里把每个交叉口都看作是一个节点,并以从左到右,从上到下的顺序给各个节点命名,美国德克萨斯州的San Antonio 的道路的交叉口共有q 个。假设从节点到的行驶时间服从某一分布(其中i O 1i O +i t 1,2,,i q = ) ,这一分布满足以下条件:(下面的t 均为随即变量) (1) 数学期望为i μ,其中q 1,2,,i = 表示从节点i O 到1i O +的平均行驶时间。 (2) 方差为i σ,其中q ,,表示从节点i O 到1i O 1,2,,i = +的行驶时间相对于平均行驶时间的偏离程度。 由假设可以知道i μ和i σ是可以通过统计获得的。但未来时段链路行驶时间的预测具有不确定性,未来时段链路行驶时间预测的不确定性是同平均链路行驶时间的预测误差相关的,而不是同单个驾驶员的链路行驶时间相关。从这种意义上来说,总体的不确定性或个体司机链路行驶时间预测值的方差包括两个部分:平均行驶时间预测的误差,各个车辆行驶时间的方差。 考虑到以上因素,令?i i t t ε=+,其中(0,1)N ε 为随机扰动项,由于司机个人的偏好产生。我们用来衡量行驶时间。那么实际的行驶时间为: ?i t ??()()i i i E t E t i μ εμ==+= 对应的方差为??()()()12cov(,)i i i i i D t D t D t t σε==+=++?i ε,由于随机误差项与 行驶时间之间是独立的,因此在上式中第三项为0,即()1i D t σ =+。 当车辆所要走的路程经过多个节点时,不妨设车辆从节点行驶到的行驶时间为,则有,但是,不同车辆的行驶时间存在很大差异,例如: 对于一天当中的任意时间t 来说, 某个驾驶员的车速可能会高于或低于观测到的平均链路行驶时间,某个车辆的行驶时间取决于驾驶员的自身的要求和该车辆周围的交通量。在上述情况下,单个链路的行驶时间可以表为由平均链路行驶时间和残差所决定的函数。其中,残差项刻画了司机个体的行为。上述关系可以用函数表示如下: i O l O il t l il k k i t ==∑t 我们可以把??l il k k i t t δ==+∑,作为实际的行驶时间,其中(0,1)N δ 为系统误差, 与行驶时间和个人误差项独立。则有以下的统计特征: ?il t (1) 数学期望为?il μ,其中i l <,q 1,2,,i = ,,表示从节点i O 到l O 的平均行驶时间。其数学表达式如下: ??()[()]l l l il k k k k i k i k i E t E t μ εδμ=====++=∑∑∑ (6) (2) 方差为?il σ ,其中i l <,1,2,,i q = ,表示从节点i O 到l O 的行驶时间相对于平均行驶时间的偏离程度。其数学表达式如下: ()??()[]2cov(,)(1l l l il k k k j k k i k i k i i j l i k l j k D t D t t t l i σεδσ===≤≤≤≤<==++=++-∑∑∑∑)+ (7) 实际的行驶时间会落在[]????3,3il il il il μ σμσ-+区间之内,皆为合理的。 现在考虑任意两条路段的行驶时间之间是不独立的情况,即从节点行驶到的时间与从节点行驶到的行驶时间的协方差非0的情况。这就需要设计一个车辆从节点行驶到的合理的各个路段行驶时间的协方差矩阵。 i O j O ij t k O 1O l O q O kl t 一般地,当一辆车在时刻t 进入链路a ,那么这辆车在链路上的行驶时间 可以记为a ()i a x t 。注意到单个的链路行驶时间()a x t 是一个动态随机变量,这里t 是时间,。考虑一个具体的链路a ,其上游节点记为,[0R +=∞,)t T T ∈=j 、下游节点记为1j +。如果路网上的第辆车在时刻i i y 进入节点j ,假定在节点j 没有等 待时间,那么这辆车在链路上的行驶时间为a (i a i )x y ,这个随机变量可以用() a i x y 来表示。实际上可以假定链路行驶时间取决于两个随机变量:某一车辆到达上游节点的时间和它在此链路上的行驶时间。于是,可以用(|)a x a i f x y 来表示在i y y =时a x 的条件概率函数。 这里协方差矩阵具体的设计方法和规则如下: (1) 由于协方差的统计意义反应的是两个随机变量的相关性,所以我们首先要找出影响两段路的相关性的因素。根据客观的分析我们可以知道,协方差与两个节点之间的路程和所经过的节点数,以及各个节点处所连接的道路数有关系。 (2) 根据问题我们可以知道司机想去的方向,因此,只有前方道路的状况会对现在行驶时间产生影响。而且两个节点之间的路程越长,相关性越小;所经过的节点数越多,kl O 对ij O (2,i j q <≤,2,k l q <≤)的影响越小;每个节点所连接的道路数越多,kl O 对ij O (q 2,i j <≤,2,k l q <≤)的影响也越小。由于车行方向可以知道,我们的协方差阵只有上三角。 (3) 显然,所经过的节点数为l i -,我们设整个路程的长度为il L ,节点处连接的道路数为p。考虑到在实际生活中不可能存在完全相关或者不相关的两条链路的情况,而且p 和(k-i+1)最小值为3,而且现实中肯定不会存在长度 小于9 7 米的路经,因此以下假设关系是合理的: 231 cov(,)256i j k l ij kl il n n n n t t L =+ 把上式代入到公式(7)中,就 能够得到?il σ 。 综上所述,当司机键入起点和终 点后,我们会得到两个值:所需的行驶时间和其对应的方差,通过对方差的考察来取舍路线。如果可行路段的行驶时间相差不大,那么方差非常大的路段是不可取的。 其算法如右图所示: 同前一算法的假设刚好相反,现在强调的是各段道路上的行驶时间是相互关联的。因此,我们就需要找出从起点到终点的所有可能的不同路线,并从这些可能的路线中选出一条耗时估计的均值和方差都尽可能最小的路线。在估算每段路行驶时间的过程中,需要考虑该路径上其他路段的情况对当前路段的影响,需要用 到一个反映各路段时间关联度的协方差矩阵。 该算法的实现过程主要分为两部分: ① 寻找所有可能的路径; ② 估算每条路径的行驶时间,找出最优路线。 由于在建立模型阶段对此部分已经做了比较详细的阐述,这里就不再赘叙,主要就第一部分——寻找起点到终点的所有可能路径进行说明。 首先还是输入交通结点个数和关于各个结点的邻接矩阵,建立城市交通网,然后以起点和终点作为输入,经过计算,输出所有可能的路径。 搜索路径的过程中采用的是树的先深搜索思想,对遇到的结点分以下三种情况处理: ① 所遇到的结点先前未曾经过,并且该结点不是终点: 将该结点存入路径,继续进行搜索; ② 所遇到的结点是终点: 将该结点作为终点存入路径,并将该路径作为最后结果中的一条可能的路径保存; ③ 所遇到的结点不是终点,但曾经遇到过: 这样就形成了环路,因此对此结点不作任何处理,直接返回上层结点继续搜索。 然后对于每个可能的路径,估算该路径上各路段的行驶时间,并给出该估算时间的误差,当然这里要考虑到各路段在时间上的相关度。最后比较各个路径的估算时间均值和方差,在允许误差的范围内取耗时均值和方差尽可能小的路径作为最优路线。 7 给定两点间最优路线选择与行驶时间估计 要求解第Ⅲ个问题,首先要确定期望和方差与链路长度和两端节点数的关系。由已知,车辆在各个链路上行驶时间的均值与路段长度成正比,方差与路段长度2/3次幂的倒数成正比,同时与这段路的两个端点所连接路径条数成正比。这样就可以得到关系式为: 123 2ij ij ij ij i j k L k L n n μσ-=?? ? =?? 其中分别表示链路两个端点处所连接的道路条数。 ,i j n n ij L 我们可以通过t 时刻传感器所提供的速度和流量数据,根据问题Ⅰ的解决办 法,得到每段路上的速度平均值,取他们的均值作为整个链路上的行驶速度,设 这个平均值为v ,令上面关系中的11 k v =,则能得到路程与行驶时间的具体函数 关系。并可以根据假设和已知信息设计14个节点之间的协方差矩阵。 对于链路3到14和14到3的最优行驶时间,我们可以在问题1中的监测器监测到的速度和流量的样本中,按照3到14和14到3两节点间路段上的监测器个数随机的选取样本,分别作为估计3到14和14到3行驶时间的录入数据。输入及输出结果如下: 输入起点3,终点14,从节结点3到结点14的所有路径如下: 3—〉2—〉1—〉4—〉5—〉6—〉9—〉8—〉7—〉11—〉14 3—〉2—〉1—〉4—〉5—〉6—〉9—〉81—〉12—〉11—〉14 3—〉2—〉1—〉4—〉5—〉6—〉9—〉13—〉12—〉8—〉7—〉11—〉14 3—〉6—〉9—〉13—〉12—〉11—〉14 通过计算时间得出第一条路径为最优路线,估算的时间为984.692秒,对应的方差为6.747。实际的行驶时间在[] 964.451,1004.933内,都认为估计是合理的。 从结点14到结点3的所有路径如下: 14—〉11—〉12—〉13—〉9—〉6—〉3 所以最优路线就是14—〉11—〉12—〉13—〉9—〉6—〉3,估算时间为873.347秒,对应的方差为10.885。实际的行驶时间在[] 840.692,906.002内,都认为估计是合理的。 由于路径太长,因此所涉及到的传感器的输入太多,这里无法将程序执行的原图贴出,只能打出程序执行的结果。 参考文献 [1].Shortest paths in a network with time-dependent flow speeds,Kiseok Sung a,*, Michael G.H. Bell b,1, Myeongki Seong c,2, Soondal Park c,3,European Journal of Operational Research 121 (2000) 32-39 [2].EXPECTED SHORTEST PATHS IN DYNAMIC AND STOCHASTIC TRAFFIC NETWORKS,LIPING FU,L. R. RILETT,Transpn Res.-B, V ol. 32, No. 7, pp. 499-516, 1998 [3].Genetic algorithms for rerouting shortest paths in dynamic and stochastic networks,Cedric Davies, Pawan Lingras,European Journal of Operational Research 144 (2003) 27–38 [4].Dynamic and stochastic shortest path in transportation networks with two components of travel time uncertaint,Parichart Pattanamekar , Dongjoo Park ,Laurence R. Rilett , Jeomho Lee ,Choulki Lee ,Transportation Research Part C 11 (2003) 331–354 [5].概率论与数理统计,梁之舜,邓集贤等,高等教育出版社,2001,3 [6].数学模型,姜启源,高等教育出版社,2002,1 [7].数学实验,萧树铁等,高等教育出版社,2003,8 [8].数据结构与算法基础,郭福顺,廖明宏,李莲志,大连理工大学出版社,2000,6 [9].c/c++语言入门与精通,王丽宏,苏晓红,哈尔滨工业大学出版社,1999,9 交巡警服务平台的设置与调度 摘要 由于警务资源有限,需要根据城市的实际情况与需求建立数学模型来合理地确定交巡警服务平台数目与位置、分配各平台的管辖范围、调度警务资源。设置平台的基本原则是尽量使平台出警次数均衡,缩短出警时间。用出警次数标准差衡量其均衡性,平台与节点的最短路衡量出警时间。 对问题一,首先以出警时间最短和出警次数尽量均衡为约束条件,利用无向图上任意两点最短路径模型得到平台管辖范围,并运用上下界网络流模型优化解,得到A区平台管辖范围分配方案。发现有6个路口不能在3分钟内被任意平台到达,最长出警时间为5.7分钟。 其次,利用二分图的完美匹配模型得出20个平台封锁13个路口的最佳调度方案,要完全封锁13个路口最快需要8.0分钟。 最后,以平台出警次数均衡和出警时间长短为指标对方案优劣进行评价。建立基于不同权重的平台调整评价模型,以对出警次数均衡的权重u和对最远出警距离的权重v 为参数,得到最优的增加平台方案。此模型可根据实际需求任意设定权重参数和平台增数,由此得到增加的平台位置,权重参数可反映不同的实际情况和需求。如确定增加4个平台,令u=0.6,v=0.4,则增加的平台位置位于21、27、46、64号节点处。 对问题二,首先利用各区平台出警次数的标准差和各区节点的超距比例分析评价六区现有方案的合理性,利用模糊加权分析模型以城区的面积、人口、总发案次数为因素来确定平台增加或改变数目。得出B、C区各需改变2个平台的位置,新方案与现状比较,表明新方案比现状更合理。D、E、F区分别需新增4、2、2个平台。利用问题一的基于不同权重的平台调整评价模型确定改变或新增平台的位置。 其次,先利用二分图的完美匹配模型给出80个平台对17个出入口的最优围堵方案,最长出警时间12.7分钟。在保证能够成功围堵的前提下,若考虑节省警力资源,分析全市六区交通网络与平台设置的特点,我们给出了分阶段围堵方案,方案由三阶段构成。最多需调动三组警力,前后总共需要29.2分钟可将全市路口完全封锁。此方案在保证成功围堵嫌疑人的前提下,若在前面阶段堵到罪犯,则可以减少警力资源调度,节省资源。 【关键字】:不同权重的平台调整评价模糊加权分析最短路二分图匹配 2014高教社杯全国大学生数学建模竞赛 承诺书 我们仔细阅读了《全国大学生数学建模竞赛章程》和《全国大学生数学建模竞赛参赛规则》(以下简称为“竞赛章程和参赛规则”,可从全国大学生数学建模竞赛网站下载)。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛章程和参赛规则的,如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛章程和参赛规则,以保证竞赛的公正、公平性。如有违反竞赛章程和参赛规则的行为,我们将受到严肃处理。 我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。 我们参赛选择的题号是(从A/B/C/D中选择一项填写):B 我们的报名参赛队号为(8位数字组成的编号): 所属学校(请填写完整的全名): 参赛队员(打印并签名) :1. 2. 3. 指导教师或指导教师组负责人(打印并签名): ?(论文纸质版与电子版中的以上信息必须一致,只是电子版中无需签名。以上内容请仔细核对,提交后将不再允许做任何修改。如填写错误,论文可能被取消评奖资格。) 日期: 2014 年 9 月15日 赛区评阅编号(由赛区组委会评阅前进行编号): 2014高教社杯全国大学生数学建模竞赛 编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号):赛区评阅记录(可供赛区评阅时使用): 车道被占用对城市道路通行能力的影响 摘要 随着城市化进程加快,城市车辆数的增加,致使道路的占用现象日益严重,同时也导致了更多交通事故的发生。而交通事故发生过程中,路边停车、占道施工、交通流密增大等因素直接导致车道被占用,进而影响了城市道路的通行能力。本文在视频提供的背景下通过数据采集,利用数据插值拟合、差异对比、车流波动理论等对这一影响进行了分析,具体如下: 针对问题一,首先根据视频1中交通事故前后道路通行情况的变化过程运用物理观察测量类比法、数学控制变量法提取描述变量(如事故横断面处的车流量、车流速度以及车流密度)的数据,从而通过研究各变量的变化,来分析其对通行能力的影响。而视频1中有一些时间断层,我们可根据现有的数据先用统计回归对各变量数据插值后再进行拟合,拟合过程中利用残差计算值的大小来选择较好的模型来反应各变量与事故持续时间的关系,进而更好地说明事故发生至撤离期间,事故所处横断面实际通行能力的变化过程。 针对问题二:沿用问题一中的方法,对视频2中影响通行能力的各个变量进行数据采集,同样使用matlab对时间断层处进行插值拟合处理,再将所得到的的变化图像与题一中各变量的变化趋势进行对比分析,其中考虑到两视频的时间段与两视频的事故时长不同,从而采用多种对比方式(如以事故发生前、中、后三时段比较差值、以事故相同持续时间进行对比、以整个事故时间段按比例分配时间进行对比)来更好地说明这一差异。由于小区口的位置不同、时间段是否处于车流高峰期以及1、2、3道车流比例不同等因素的影响,采用不同的数据采集方式使采集的变量数据的实用性更强,从而最后得到视频1中的道路被占用影响程度高于视频2中的影响程度,再者从差异图像的变化波动中得到验证,使其合理性更强。 针对问题三:运用问题1、2中三个变量与持续时间的关系作为纽带,再根据附件5中的信号相位确定出车流量的测量周期为一分钟,测量出上游车流量随时间的变化情况,而事故横断面实际通行能力与持续时间的关系已在1、2问中由拟合得到,所以再根据波动理论预测道路异常下车辆长度模型的结论,结合采集数据得到的函数关系建立数学模型,最后得出事故发生后,车辆排队长度与事故横断面实际通行能力、事故持续时间以及路段上游车流量这三者之间的关系式。 针对问题四:在问题3建立的模型下,利用问题4中提供的变量数据推导出其它相关变量值,然后代入模型,估算出时间长度,以此检验模型的操作性及可靠性。 关键词:通行能力车流波动理论车流量车流速度车流密度 一、基础知识 1.1 常见数学函数 如:输入x=[-4.85 -2.3 -0.2 1.3 4.56 6.75],则: ceil(x)= -4 -2 0 2 5 7 fix(x) = -4 -2 0 1 4 6 floor(x) = -5 -3 -1 1 4 6 round(x) = -5 -2 0 1 5 7 1.2 系统的在线帮助 1 help 命令: 1.当不知系统有何帮助内容时,可直接输入help以寻求帮助: >>help(回车) 2.当想了解某一主题的内容时,如输入: >> help syntax(了解Matlab的语法规定) 3.当想了解某一具体的函数或命令的帮助信息时,如输入: >> help sqrt (了解函数sqrt的相关信息) 2 lookfor命令 现需要完成某一具体操作,不知有何命令或函数可以完成,如输入: >> lookfor line (查找与直线、线性问题有关的函数) 1.3 常量与变量 系统的变量命名规则:变量名区分字母大小写;变量名必须以字母打头,其后可以是任意字母,数字,或下划线的组合。此外,系统内部预先定义了几个有特殊意 1 数值型向量(矩阵)的输入 1.任何矩阵(向量),可以直接按行方式 ...输入每个元素:同一行中的元素用逗号(,)或者用空格符来分隔;行与行之间用分号(;)分隔。所有元素处于一方括号([ ])内; 例1: >> Time = [11 12 1 2 3 4 5 6 7 8 9 10] >> X_Data = [2.32 3.43;4.37 5.98] 2 上面函数的具体用法,可以用帮助命令help得到。如:meshgrid(x,y) 输入x=[1 2 3 4]; y=[1 0 5]; [X,Y]=meshgrid(x, y),则 X = Y = 优化和评价的收费亭的数量 景区简介 由於公路出来的第一千九百三十,至今发展十分迅速在全世界逐渐成为骨架的运输系统,以其高速度,承载能力大,运输成本低,具有吸引力的旅游方便,减少交通堵塞。以下的快速传播的公路,相应的管理收费站设置支付和公路条件的改善公路和收费广场。 然而,随着越来越多的人口密度和产业基地,公路如花园州公园大道的经验严重交通挤塞收费广场在高峰时间。事实上,这是共同经历长时间的延误甚至在非赶这两小时收费广场。 在进入收费广场的车流量,球迷的较大的收费亭的数量,而当离开收费广场,川流不息的车辆需挤缩到的车道数的数量相等的车道收费广场前。因此,当交通繁忙时,拥堵现象发生在从收费广场。当交通非常拥挤,阻塞也会在进入收费广场因为所需要的时间为每个车辆付通行费。 因此,这是可取的,以尽量减少车辆烦恼限制数额收费广场引起的交通混乱。良好的设计,这些系统可以产生重大影响的有效利用的基础设施,并有助于提高居民的生活水平。通常,一个更大的收费亭的数量提供的数量比进入收费广场的道路。 事实上,高速公路收费广场和停车场出入口广场构成了一个独特的类型的运输系统,需要具体分析时,试图了解他们的工作和他们之间的互动与其他巷道组成部分。一方面,这些设施是一个最有效的手段收集用户收费或者停车服务或对道路,桥梁,隧道。另一方面,收费广场产生不利影响的吞吐量或设施的服务能力。收费广场的不利影响是特别明显时,通常是重交通。 其目标模式是保证收费广场可以处理交通流没有任何问题。车辆安全通行费广场也是一个重要的问题,如无障碍的收费广场。封锁交通流应尽量避免。 模型的目标是确定最优的收费亭的数量的基础上进行合理的优化准则。 主要原因是拥挤的 上海世博会影响力的定量评估 摘要 本文主要针对世博会对上海市的发展产生的影响力进行定量评估。 在模型一中,首先我们从上海的城市基础设施建设这一侧面定量评估世博会对上海市的发展产生的影响,而层次分析法是对社会经济系统进行系统分析的有力工具。所以我们运用层次分析法,构造成对比矩阵a,找到最大特征值 ,运用 进行一致性检验,这样对成对比矩阵a进行逐步修正,最终可以确定权向量。再运用模糊数学的综合评价法,通过组合权向量就可以得出召开世博会比没有召开世博会对上海城市基本设施建设的影响要高出40%。 在模型二中,上海世博会的影响力直接体现在GDP上,我们直接以GDP这个硬性直接指标来衡量上海世博会对上海的影响。因此我们运用线性回归的模型预测出在有无上海世博会这两者情况下的GDP的值,并将运用线性回归得到的数据与上海统计年鉴中的相关数据进行比较运算,算出误差在1.2%左右,这说明我们用线性回归得到的模型能准确地反映出世博会对上海GDP的影响。运用公式 可以计算出世博对上海GDP的影响力的大小为 。 关键词:层次分析法模糊数学线性回归城市基础建设 GDP 1 问题重述 2010年上海世博会是首次在中国举办的世界博览会。从1851年伦敦的“万国工业博览会”开始,世博会正日益成为各国人民交流历史文化、展示科技成果、体现合作精神、展望未来发展等的重要舞台。请你们选择感兴趣的某个侧面,建立数学模型,利用互联网数据,定量评估2010年上海世博会的影响力。 2 问题分析 对于模型一,为了定量评估2010年上海世博会的影响力,我们首先选取城市基础设施建设的投入这一个侧面,因为通过查找相关数据,我们发现,城市基础设施建设的投入在上海整个GDP的增长中占有很大的比重,对GDP的贡献占主体地位。而层次分析法是对社会经济系统进行系统分析的有力工具。为此,我们通过研究上海统计局的相关数据,使用层次分析法来评估世博会的召开对基础设施建设的投入的影响,目标层为世博会的召开对基础设施建设的投入的影响,准则层依次为电力建设、交通运输、邮电通信、公用事业、市政建设,方案层依次为没有召开世博时的影响、召开世博时的影响。首先我们通过层次分析法算出电力建设、交通运输、邮电通信、公用事业、市政建设的相对权重,然后应用模糊数学中的综合评价法对上海世博会对城市基础设施建设的影响作出综合的评价,应用综合评价法计算出没有召开世博和召开世博两种情况下的权重,从而得出上海世博会的召开对城市基础设施建设的影响。 对于模型二,直接以GDP这个硬性直接指标来衡量上海世博会对上海的影响。先根据上海没有申办世博会的GDP总额的相关数据,建立线性回归模型,由此预测不举办世博会情况下2010年上海市的GDP总额;再由2002年至2009年的GDP值用线性回归预测出举办世博会情况下2010年上海市的GDP总额,并将两种情况进行对比得出世博会对上海GDP的影响。 3 模型假设 3.1假设非典和奥运等重大事件对世博前的城市基础建设的投入影响很小,可以忽略。 承诺书 我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括、电子、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的 资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参 考文献中明确列出。 我们重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则 的行为,我们将受到严肃处理。 我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展 示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。 我们参赛选择的题号是(从A/B/C/D中选择一项填写): 我们的参赛报名号为(如果赛区设置报名号的话): 所属学校(请填写完整的全名): 参赛队员 (打印并签名) :1. 2. 3. 指导教师或指导教师组负责人 (打印并签名): 日期:年月日赛区评阅编号(由赛区组委会评阅前进行编号): 编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号): 全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号): 题目(黑体不加粗三号居中) 摘要(黑体不加粗四号居中) (摘要正文小4号,写法如下) (第1段)首先简要叙述所给问题的意义和要求,并分别分析每个小问题的特点(以下以三个问题为例)。根据这些特点对问题 1 用······的方法解决;对问题 2 用······的方法解决;对问题3 用······的方法解决。 (第2段)对于问题1,用······数学中的······首先建立了······ 模型I。在对······模型改进的基础上建立了······模型II。对模型进行了合理的理论证明和推导,所给出的理论证明结果大约为······,然后借助于······数学算法和······软件,对附件中所提供的数据进行了筛选,去除异常数据,对残缺数据进行适当补充,并从中随机抽取了3 组数据(每组8 个采样)对理论结果进行了数据模拟,结果显示,理论结果与数据模拟结果吻合。(方法、软件、结果都必须清晰描述,可以独立成段,不建议使用表格) (第3段)对于问题2用······ (第4段)对于问题3用······ 如果题目单问题,则至少要给出2种模型,分别给出模型的名称、思想、软 件、结果、亮点详细说明。并且一定要在摘要对两个或两个以上模型进行比较, 优势较大的放后面,这两个(模型)一定要有具体结果。 (第5段)如果在……条件下,模型可以进行适当修改,这种条件的改变可能来自你的一种猜想或建议。要注意合理性。此推广模型可以不深入研究,也可以没有具体结果。 关键词:本文使用到的模型名称、方法名称、特别是亮点一定要在关键字里出现,5~7个较合适。 注:字数700-1000 之间;摘要中必须将具体方法、结果写出来;摘要写满几乎 一页,不要超过一页。摘要是重中之重,必须严格执行!。 页码:1(底居中) 交巡警服务平台的设置与调度的数学模型 摘要 针对交巡警服务平台的设置与调度问题,本文主要考虑出警速度和各服务平台的工作量来建立合理方案。对于A区的20个交巡警服务平台分配管辖范围的问题,我们采用Dijkstra算法,分别求得在3分钟内从服务台可以到达的路口。根据就近原则,每个路口归它最近的服务台管辖。 对进出A区的13个交通要道进行快速全封锁,我们采用目标规划进行建模,运用MATLAB软件编程,先找出13个交通要道到20个服务台的所有路径。然后在保证全封锁时间最短的前提下,再考虑局部区域的封锁效率,即总封锁时间最短,封锁过程中总路程最小,从而得到一个较优的封锁方案。 为解决前面问题中3分钟内交巡警不能到达的路口问题,并减少工作量大的地区的负担,这里工作量以第一小问中20个服务台覆盖的路口发案率之和以及区域内的距离的和来衡量。对此我们计划增加四个交巡警服务台。避免有些地方出警时间过长和服务台工作量不均衡的情况。 对全市六个区交警平台设计是否合理,主要以单位服务台所管节点数,单位服务台所覆盖面积,以及单位服务台处理案件频率这些因素进行研究分析。以A 区的指标作为参考,来检验交警服务平台设置是否合理。 对于发生在P点的刑事案件,采用改进的深度搜索和树的生成相结合的方法,对逃亡的犯罪嫌疑人进行可能的逃逸路径搜索。由于警方是在案发后3分钟才接到报警,因此需知道疑犯在这3分钟内可能的路线。要想围堵嫌疑犯,服务台必须要在嫌疑犯到达某节点之前到达。用MATLAB编程,搜索出嫌疑犯可能逃跑的路线,然后调度附近的服务台对满足条件的节点进行封锁,从而实现对疑犯的围堵。 关键词:Dijkstra算法;目标规划;搜索; Haozl觉得数学建模论文格式这么样设置 版权归郝竹林所有,材料仅学习参考 版权:郝竹林 备注☆ ※§等等字符都可以作为问题重述左边的。。。。。一级标题 所有段落一级标题设置成段落前后间距13磅 二级标题设置成段落间距前0.5行后0.25行 Excel中画出的折线表字体采用默认格式宋体正文10号 图标题在图上方段落间距前0.25行后0行 表标题在表下方段落间距前0行后0.25行 行距均使用单倍行距 所有段落均把4个勾去掉 注意Excel表格插入到word的方式在Excel中复制后,粘贴,word2010粘贴选用使用目标主题嵌入当前 Dsffaf 所有软件名字第一个字母大写比如E xcel 所有公式和字母均使用MathType编写 公式编号采用MathType编号格式自己定义 公式编号在右边显示 农业化肥公司的生产与销售优化方案 摘 要 要求总分总 本文针对储油罐的变位识别与罐容表标定的计算方法问题,运用二重积分法和最小二乘法建立了储油罐的变位识别与罐容表标定的计算模型,分别对三种不同变位情况推导出的油位计所测油位高度与实际罐容量的数学模型,运用matlab 软件编程得出合理的结论,最终对模型的结果做出了误差分析。 针对问题一要求依据图4及附表1建立积分数学模型研究罐体变位后对罐容表的影响,并给出罐体变位后油位高度间隔为1cm 的罐容表标定值。我们作图分析出实验储油罐出现纵向倾斜ο14.时存在三种不同的可能情况,即储油罐中储油量较少、储油量一般、储油量较多的情况。针对于每种情况我们都利用了高等数学求容积的知识,以倾斜变位后油位计所测实际油位高度为积分变量,进行两次积分运算,运用MATLAB 软件推导出了所测油位高度与实际罐容量的关系式。并且给出了罐体倾斜变位后油位高度间隔为1cm 的罐容标定值(见表1),最后我们对倾斜变位前后的罐容标定值残差进行分析,得到样本方差为4103878.2-?,这充分说明残差波动不大。我们得出结论:罐体倾斜变位后,在同一油位条件下倾斜变位后罐容量比变位前罐容量少L 243。 表 1.1 针对问题二要求对于图1所示的实际储油罐,试建立罐体变位后标定罐容表的数学模型,即罐内储油量与油位高度及变位参数(纵向倾斜角度α和横向偏转角度β)之间的一般关系。利用罐体变位后在进/出油过程中的实际检测数据(附件2),根据所建立的数学模型确定变位参数,并给出罐体变位后油位高度间隔为10cm 的罐容表标定值。进一步利用附件2中的实际检测数据来分析检验你们模型的正确性与方法的可靠性。我们根据实际储油罐的特殊构造将实际储油罐分为三部分,左、右球冠状体与中间的圆柱体。运用积分的知识,按照实际储油罐的纵向变位后油位的三种不同情况。利用MATLAB 编程进行两次积分求得仅纵向变位时油量与油位、倾斜角α的容积表达式。然后我们通过作图分析油罐体的变位情况,将双向变位后的油位h 与仅纵向变位时的油位0h 建立关系表达式01.5(1.5)cos h h β=--,从而得到双向变位油量与油位、倾斜角α、偏转角β的容积表达式。利用附件二的数据,采用最小二乘法来确定倾斜角α、偏转角β的值,用matlab 软件求出03.3=α、04=β α=3.30,β=时总的平均相对误差达到最小,其最小值为0.0594。由此得到双向变位后油量与油位的容积表达式V ,从而确定了双向变位后的罐容表(见表2)。 本文主要应用MATLAB 软件对相关的模型进行编程求解,计算方便、快捷、准确,整篇文章采取图文并茂的效果。文章最后根据所建立的模型用附件2中的实际检测数据进行了误差分析,结果可靠,使得模型具有现实意义。 关键词:罐容表标定;积分求解;最小二乘法;MATLAB ;误差分 2014高教社杯全国大学生数学建模竞赛 承诺书 我们仔细阅读了《全国大学生数学建模竞赛章程》和《全国大学生数学建模竞赛参 赛规则》(以下简称为“竞赛章程和参赛规则”,可从全国大学生数学建模竞赛下载)。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括、电子、网上咨询等) 与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛章程和参赛规则的,如果引用别人的成果或 其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文 引用处和参考文献中明确列出。 我们重承诺,严格遵守竞赛章程和参赛规则,以保证竞赛的公正、公平性。如有违 反竞赛章程和参赛规则的行为,我们将受到严肃处理。 我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展 示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。 我们参赛选择的题号是(从A/B/C/D中选择一项填写): B 我们的报名参赛队号为(8位数字组成的编号): 所属学校(请填写完整的全名): 参赛队员 (打印并签名) :1. 2. 3. 指导教师或指导教师组负责人 (打印并签名): (论文纸质版与电子版中的以上信息必须一致,只是电子版中无需签名。以上容请仔细核对,提交后将不再允许做任何修改。如填写错误,论文可能被取消评奖资格。) 日期: 2014 年 9 月 15日赛区评阅编号(由赛区组委会评阅前进行编号): 2014高教社杯全国大学生数学建模竞赛 编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号):赛区评阅记录(可供赛区评阅时使用): 承诺书 我们仔细阅读了数学建模竞赛选拔的规则. 我们完全明白,在做题期间不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人研究、讨论与选拔题有关的问题。 我们知道,抄袭别人的成果是违反选拔规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守选拔规则,以保证选拔的公正、公平性。如有违反选拔规则的行为,我们将受到严肃处理。 我们选择的题号是(从A/B/C中选择一项填写): 队员签名:1. 2. 3. 日期:年月日 2012年河南科技大学数学建模竞赛选拔 编号专用页 评阅编号(评阅前进行编号): 评阅记录(评阅时使用): 评 阅 人 评 分 备 注 C题数学建模竞赛成绩评价与预测 一、摘要 近20 年来,CUMCM 的规模平均每年以20%以上的增长速度健康发展,是目前全国高校中规模最大的课外科技活动之一。本文对数学建模竞赛成绩的评价与预测问题进行了建模、求解和相关分析。 对于问题一,首先对广东赛区各院校2008-2011年建模奖励数据进行统计分析,将决策问题分为三个层次,建立多层次模糊综合评判模型。在该模型中,将因素集{国家一等奖,国家二等奖,省一等奖,省二等奖,省三等奖}看作准则层,将2008-2011各年建模情况看作方案层,结合实际情况,给出改进综合评判模型,解得广东金融学院、华南农业大学的总体综合评定成绩分别2.9474、2.7141,排名第一、第二。 对于问题二,首先建立单年的综合评定模型,得出广州赛区各院校2008-2011年的综合评定成绩。鉴于仅有4组数据,分别采用GM(1,1)法、回归曲线最小二乘法、移动平均法进行建模,最后结合实际情况并根据结果对比以上三种模型,确定了移动平均法方案最优,最终得出广东金融学院、华南农业大学的综合评定成绩分别为0.7369、0.6785,依旧排名第一、第二,较好地解决了问题二。 对于问题三,鉴于附件2所给数据冗杂庞大,故从中抽取2008-2011年的建模数据作为样本,分别统计出本科组和专科组在这四年中每年获得国家一等奖和国家二等奖的人数;将问题一中国家一等奖、二等奖的权重进行归一化处理,建立类似问题一的特殊综合评判模型,得出本科组哈尔滨工业大学、解放军信息工程大学的综合评定成绩分别为5.5117、4.6609;专科组海军航空工程学院、太原理工轻纺与美术学院的综合评定成绩分别为1.3931、1.3095,名列各组第一、第二,问题三得到了较好解决。 对于问题四,除全国竞赛成绩、赛区成绩外,讨论了学生的能力、参赛队数、师资力量、学校的综合实力、硬件设施等因素对建模成绩评估的影响,考虑首先对因素集进行模糊聚类分析,然后用层次分析法来进行评价,用BP神经网络结合Matlab软件来进行预测,理论上问题四能够得到较好地得到解决。 关键词: 模糊综合评判模型GM(1,1)模型移动平均法综合评定成绩 承诺书 我们仔细阅读了《全国大学生数学建模竞赛章程》和《全国大学生数学建模竞赛参赛规则》(以下简称为“竞赛章程和参赛规则”,可从全国大学生数学建模竞赛网站下载)。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛章程和参赛规则的,如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛章程和参赛规则,以保证竞赛的公正、公平性。如有违反竞赛章程和参赛规则的行为,我们将受到严肃处理。 我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。 我们参赛选择的题号是(从A/B/C/D中选择一项填写):B 我们的报名参赛队号为(8位数字组成的编号): 所属学校(请填写完整的全名): 参赛队员(打印并签名) :1. 2. 3. 指导教师或指导教师组负责人(打印并签名): (论文纸质版与电子版中的以上信息必须一致,只是电子版中无需签名。以上内容请仔细核对,提交后将不再允许做任何修改。如填写错误,论文可能被取消评奖资格。) 日期:2014 年 9 月 15日赛区评阅编号(由赛区组委会评阅前进行编号): 编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号): 全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号): 创意平板折叠桌 摘要 目前住宅空间的紧张导致越来越多的折叠家具的出现。某公司设计制作了一款折叠桌以满足市场需要。以此折叠桌为背景提出了三个问题,本文运用几何知识、非线性约束优化模型等方法成功解决了这三个问题,得到了折叠桌动态过程的描述方程以及在给定条件下怎样选择最优设计加工参数,并针对任意形状的桌面边缘线等给出了我们的设计。 针对问题一,根据木板尺寸、木条宽度,首先确定木条根数为19根,接着,根据桌子是前后左右对称的结构,我们只以桌子的四分之一为研究对象,运用空间几何的相关知识关系,推导并建立了几何模型。接着用MATLAB软件编程,绘制出折叠桌动态变化过程图。然后求出折叠桌各木条相对桌面的角度、各木条长度、各木条的开槽长度等数据,相关结果见表1。然后建立相应的三维坐标系,求出桌角各端点坐标,绘出桌角边缘线曲线图,并用MATLAB工具箱作拟合,求出桌角边缘线的函数关系式,并对拟合效果做分析(见表3)。 针对问题二,在折叠桌高度、桌面直径已知情况下,综合考虑桌子稳固性、加工方便、用材最少三个方面因素,我们运用材料力学等相关知识,对折叠桌作受力分析,确定稳固性、加工方便、用材最少三个方面因素间的相互制约关系,建立非线性优化模型。用lingo软件编程,求出对于高70 cm,桌面直径80 cm的折叠桌,平板尺寸172.24cm×80cm×3cm、钢筋位置在桌腿上距离铰链46.13cm处、各木条的开槽长度(见表3)、最长木条(桌脚)与水平面夹角71.934°。 针对问题三,对任意给出的桌面边缘线(f(x)),不妨假定曲线是对称的(否则,桌子的稳定性难以保证),将对称轴上n等份,依照等份点沿着木板较长方向平行的方向下料,则这些点即是铰接处到木板中垂线(相对于木板长方向)的距离。然后修改问题二建立的优化模型,用lingo软件编程,得到最优设计加工参数(平板尺寸、钢筋位置、开槽长度等)。最后,我们根据所建立的模型,设计了一个桌面边缘线为椭圆的折叠桌,并且给出了8个动态变化过程图(见图10)和其具体设计加工参数(见表5)。 最后,对所建立的模型和求解方法的优缺点给出了客观的评价,并指出了改进的方法。 关键字:折叠桌曲线拟合非线性优化模型受力分析 城市表层土壤重金属污染分析 摘要 本文旨在对城市土壤地质环境的重金属污染状况进行分析,建立模型对金属污染物的分布特点、污染程度、传播特征以及污染源的确定进行有效的描述、评价和定位。 对于重金属空间分布问题,首先基于克里金插值法,应用Surfer 8软件对各数据点的分布情况进行模拟,得到了直观的重金属污染空间分布图形;随后,分别用内梅罗综合污染指数以及模糊评价标准和模型对城区内不同区域重金属的污染程度进行了评判。 对于金属污染的主要原因分析问题,基于因子分析法、问题一的结果和对各个金属污染物的来源分析等因素,判断出金属污染的主要原因有:工业生产、汽车尾气排放、石油加工并推测该区域是镍矿富集区。随后讨论了污染源之间的相互关系和不同金属的污染贡献率。 针对污染源位置确定问题,我们建立了两个模型:模型一以流程图的形式出现,基于污染传播的一般规律建立模型,求取污染源范围,模型作用更倾向于确定污染源的位置;模型二基于最小二乘法原理,建立了拟合二次曲面方程,在有效确定污染源的同时也反映了其传播特征,模型更加清楚,理论性也更强。 在研究城市地质环境的演变模式问题中,我们对针对污染源位置确定问题所建模型的优缺点进行了评价,同时建立了考虑了时间,地域环境和传播媒介的污染物传播模型,从而反映了地质的演变。 综上所述,本文模型的特点是从简单的模型建立起,强更准确的数学模型发展,逐步达到目标期望。 关键词:重金属污染,克里金插值最小二乘法因子分析流程图 一、问题重述 1.1问题背景 随着城市经济的快速发展和城市人口的不断增加,人类活动对城市环境质量的影响日显突出。对城市土壤地质环境异常的查证,以及如何应用查证获得的海量数据资料开展城市环境质量评价,研究人类活动影响下城市地质环境的演变模式,日益成为人们关注的焦点。评价和研究城市土壤重金属污染程度,讨论土壤中重金属的空间分布,研究城市土壤重金属污染特征、污染来源以及在环境中迁移、转化机理,并对城市环境污染治理和城市进一步的发展规划提出科学建议,不仅有利于城市生态环境良性发展,有利于人类与自然和谐,也有利于人类社会 健康和城市可持续发展[1] 。按照功能划分,城区一般可分为生活区、工业区、山区、主干道路区及公园绿地区等,不同的区域环境受人类活动影响的程度不同。 现对某城市城区土壤地质环境进行调查。为此,将所考察的城区划分为间距1公里左右的网格子区域,按照每平方公里1个采样点对表层土(0~10 厘米深度)进行取样、编号,并用GPS 记录采样点的位置。应用专门仪器测试分析,获得了每个样本所含的多种化学元素的浓度数据。另一方面,按照2公里的间距在那些远离人群及工业活动的自然区取样,将其作为该城区表层土壤中元素的背景值。 1.2 目标任务 (1) 给出8种主要重金属元素在该城区的空间分布,并分析该城区内不同区域重金属的污染程度。 (2) 通过数据分析,说明重金属污染的主要原因。 (3) 分析重金属污染物的传播特征,由此建立模型,确定污染源的位置。 (4) 分析所建立模型的优缺点,为更好地研究城市地质环境的演变模式,分析还应收集的信息,并进一步探索怎样利用收集的信息建立模型及解决问题。 二、 模型假设 1)忽略地下矿源对污染物浓度的影响; 2)认为海拔对污染物的分布较小,故只在少数模型中讨论其作用; 3)认为题目中的采样方式是科学的,能够客观反映污染源的分布。 三、 符号说明 3.1第一问中的符号说明 i p ——污染物i 的环境污染指数 i C ——污染物i 的实测值 i S ——污染物i 的背景值 m ax (/)i i C S ——土壤污染指数的最大值 (/)i i avg C S ——土壤污染指数的平均值 论文评阅要点 一、主要标准: 1、假设的合理性; 2、建模的创造性; 3、文字表达的清晰性; 4、结果的正确性。 二、论文组成概要: 1、题目 2、摘要 3、问题重述 4、模型假设与符号 5、分析建立模型 6、模型求解 7、模型检验与推广 8、参考文献与附录 三、参考给分步骤(10分制) 1、摘要部分(论文的方法、结果、表达饿清晰度)。。。。。。。。。。。。。。3分 2、假设部分(合理性与创造性)。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。1分 3、数学模型(创造性与完整性)。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。3分 4、解题方法与结果(创造性与正确性)。。。。。。。。。。。。。。。。。。。。。。。。2分 5、模型的优缺点与推广(合理性)。。。。。。。。。。。。。。。。。。。。。。。。。。。。1分 四、评阅方法 1、每位教师把卷号、分数及主要理由记录在白纸上,以便专人统计; 2、每份论文至少要三位教师评阅过,选出获奖论文的2倍数量,对分歧大的试卷讨论给分; 3、对入选论文至少要六位教师评阅过。按分数高低排序; 4、对一、二等奖的论文要求写出30字左右的评语,与论文一起在网上发表。 五、评阅时间:5月21日(星期六) C 题:最佳广告费用及其效应 摘要:本文从经济经验上着眼,首先用回归建立了基本模型,从预期上描述了售价变化与预期销售量的关系和广告费变化与销售量增长因子的关系。其次从基本模型出发,我们构造出预期时间利润最大模型,得到了利润在预期的条件下获得最大利润116610元时的最佳广告费用33082元和售价5.9113元。 一 问题的分析与假设 (1)销售量的变化虽然是离散的,但对于大量的销售而言,可设销售量的变化随售价的增加而线性递减。 (2)销售增长因子虽然也是离散的,但当广告费逐渐增加时,可设销售增长因子也是连续变化的。 (3)要使预期利润达到最大,买进的彩漆应为模型理论上的预期最大利润时的销售量相等。 二 模型的基本假设与符号说明 (一)基本假设 1. 假设彩漆的预期销售量不受市场影响。 2. 彩漆在预期时间内不变质,并且价格在预期内不波动。 (二)符号说明 x :售价(元); y :预期销售量(千桶); : *y 回归拟合预期销售量(千桶); y :预期销售量的均值(千桶); x :售价的平均值(元) ; 0A :x 与y 的回归常数; 1A :x 与y 的回归系数; ε :x 与y 的随机变量; k :销售增长因子; m :广告费(万元); 0B :k 与m 的非线性回归系数; 1B :k 与m 的非线性回归系数; 2B :k 与m 的非线性回归常数; η :k 与m 的随机变量; Z :预期利润(元)。 三 模型的建立 (一)售价与预期销售量的模型。 根据条件(表1)描出散点图,假设售价与预期销售量为线性关系,得基本模型 ε++=x A A 10y 假定9组预期值),,(i i y x i=1,2,…,9;符合模型 基于打车软件的出租车供求匹配度模型研究与分析 摘要 目前城市“出行难”、“打车难”的社会难题导致越来越多的线上打车软件出现在市场上。“打车难”已成为社会热点。以此为背景,本文将要解决分析的三个问题应运而生。 本文运用主成分分析、定性分析等分析方法以及部分经济学理论成功解决了这三个问 题,得到了不同时空下衡量出租车资源供求匹配程度的指标与模型以及一个合适的补贴 方案政策,并对现有的各公司出租车补贴政策进行了分析。 针对问题一,根据各大城市的宏观出租车数据,绘制柱形图进行重点数据的对比分 析,首先确定适合进行分析研究的城市。之后,根据该市不同地区、时间段的不同特点 选择多个数据样本区,以数据样本区作为研究对象,进行多种数据(包括出租车分布、 出租车需求量等)的采集整理。接着,通过主成分分析法确定模型的目标函数、约束条 件等。最后运用spss软件工具对数据进行计算,求出匹配程度函数F 与指标的关系式, 并对结果进行分析。 针对问题二,在各公司出租车补贴政策部分已知的情况下,综合考虑出租车司机以 及顾客两个方面的利益,分别就理想情况与实际情况进行全方位的分析。在问题一的模 型与数据结果基础上,首先分别从给司机和乘客补贴两个角度定性分析了补贴的效果。 重点就给司机进行补贴的方式进行讨论,定量分析了目前补贴方案的效果,得出了如果 统一给每次成功的打车给予相同的补贴无法改善打车难易程度的结论,并对第三问模型 的设计提供了启示,即需要对具有不同打车难易程度和需求量的区域采取分级的补贴政 策。 针对问题三,在问题二的基础上我们设计了一种根据不同区域打车难易程度和需求 量来确定补贴等级的方法。设计了相应的量化指标,以极大化各区域打车难易程度降低 的幅度之和作为目标,建立该问题的规划模型。目的是通过优化求解该模型,使得通过 求得的优化补贴方案,能够优化调度出租车资源,使得打车难区域得到缓解。通过设计 启发式原则和计算机模拟的方法进行求解,并以具体案例分析得到,本文方法相对统一 的补贴方案而言的确可以一定程度缓解打车难的程度。 关键词:主成分分析法,供求匹配度,最优化模型,出租车流动平衡 1 2.优秀论文一具体要求:1月28日上午汇报 1)论文主要内容、具体模型和求解算法(针对摘要和全文进行概括); In the part1, we will design a schedule with fixed trip dates and types and also routes. In the part2, we design a schedule with fixed trip dates and types but unrestrained routes. In the part3, we design a schedule with fixed trip dates but unrestrained types and routes. In part 1, passengers have to travel along the rigid route set by river agency, so the problem should be to come up with the schedule to arrange for the maximum number of trips without occurrence of two different trips occupying the same campsite on the same day. In part 2, passengers have the freedom to choose which campsites to stop at, therefore the mathematical description of their actions inevitably involve randomness and probability, and we actually use a probability model. The next campsite passengers choose at a current given campsite is subject to a certain distribution, and we describe events of two trips occupying the same campsite y probability. Note in probability model it is no longer appropriate to say that two trips do not meet at a campsite with certainty; instead, we regard events as impossible if their probabilities are below an adequately small number. Then we try to find the optimal schedule. In part 3, passengers have the freedom to choose both the type and route of the trip; therefore a probability model is also necessary. We continue to adopt the probability description as in part 2 and then try to find the optimal schedule. In part 1, we find the schedule of trips with fixed dates, types (propulsion and duration) and routes (which campsites the trip stops at), and to achieve this we use a rather novel method. The key idea is to divide campsites into different “orbits”that only allows some certain trip types to travel in, therefore the problem turns into several separate small problem to allocate fewer trip types, and the discussion of orbits allowing one, two, three trip types lead to general result which can deal with any value of Y. Particularly, we let Y=150, a rather realistic number of campsites, to demonstrate a concrete schedule and the carrying capacity of the river is 2340 trips. In part 2, we find the schedule of trips with fixed dates, types but unrestrained routes. To better describe the behavior of tourists, we need to use a stochastic model(随机模型). We assume a classical probability model and also use the upper limit value of small probability to define an event as not happening. Then we use Greedy algorithm to choose the trips added and recursive algorithm together with Jordan Formula to calculate the probability of two trips simultaneously occupying the same campsites. The carrying capacity of the river by this method is 500 trips. This method can easily find the optimal schedule with X given trips, no matter these X trips are with fixed routes or not. In part 3, we find the optimal schedule of trips with fixed dates and unrestrained types and routes. This is based on the probability model developed in part 2 and we assign the choice of trip types of the tourists with a uniform distribution to describe their freedom全国数学建模竞赛一等奖论文
数学建模国家一等奖优秀论文
2013全国数学建模大赛a题优秀论文
全国数模竞赛优秀论文
美国大学生数学建模竞赛优秀论文翻译
全国数学建模优秀论文
数学建模优秀论文设计模版
2011年数学建模大赛优秀论文
数学建模优秀论文全国一等奖
2014年数学建模国家一等奖优秀论文设计
全国数学建模获奖论文
2014年数学建模国家一等奖优秀论文
2011年全国数学建模大赛A题获奖论文
数学建模大赛优秀论文
全国大学生数学建模竞赛b题全国优秀论文
美国数学建模竞赛优秀论文阅读报告
相关主题
文本预览